
ABSTRACT
This study applies social contract theory to examine whether perceptions of a social contract explains adaptive behavior to safeguard online privacy. We (1) identify and (2) estimate the prevalence of subgroups that differ in their perceived “social contract” (based on privacy concerns, trust, and risk), and (3) measure how this perceived social contract affects adaptive online behavior. Using a representative two-wave panel survey (N = 1,222), we distinguished five subgroups of internet users; the highly-concerned, wary, ambivalent, neutral (the largest group), and carefree users. The former three were more likely to adapt their behavior than the latter two subgroups. We argue that the implied social contract represents an important construct that helps to identify whether individuals engage in privacy protection behavior.
Privacy is one of the most pivotal issues in the digital age of information and communication (Acquisti, Brandimarte, & Loewenstein, Citation2015; Baruh, Secinti, & Cemalcilar, Citation2017; Trepte & Reinecke, Citation2011). Individuals leave a trail of personal information online by searching for information, using social media, and releasing of personal information via online forms. This information may be collected and used by online entities, such as advertisers and social media platforms, to show internet users targeted messages (e.g., advertisements) or to adapt the website to the users’ needs. As a result, many people report to be concerned about their privacy online (Antón, Earp, & Young, Citation2010) and distrust, for instance, major advertisers (Turow & Hennessy, Citation2007). However, it has been argued that in many cases, people’s online behavior does not mirror their privacy concerns (Taddicken, Citation2014, p. 248). This is coined the “privacy paradox” (e.g., Norberg, Horne, & Horne, Citation2007); the discrepancy between people’s claim to care about their privacy and their actual online behavior that does not reflect these concerns (Taddicken, Citation2014). More specifically, the claim is that concerned individuals continue to share personal information and do not engage in behavior to protect their privacy.
When it comes to protecting one’s privacy online, individual differences are profound. We argue that an important underlying construct – the implied social contract people have with online entities when exchanging information online – plays a crucial role in explaining which people do not engage in behavior to safeguard their privacy. The social contract, in the context of online communication, is a hypothetical contract that people feel they have when they share their personal information to online businesses. Based on social contract theory (Fogel & Nehmad, Citation2009), we argue that when people trust an online business to handle their personal information safely, and thus perceive the social contract as more reliable (i.e., have more confidence in the implied contract), they are more likely to share their personal data with online businesses. However, when people are concerned and perceive the social contract as less reliable, they might decide to safeguard their privacy by adapting their behavior, for instance, by not sharing their personal data with online businesses (for behavior regarding social media platforms, see Wang, Min, & Han, Citation2016). Therefore, this paper examines whether people’s perceptions of the social contract explains privacy protection behavior using a longitudinal data approach. Research applying social contract theory in the realm of communication research is remarkably scarce (Martin, Citation2012). Most studies regarding online privacy focus on researching cost-benefit tradeoffs people make online using privacy calculus theory (e.g., Dienlin & Metzger, Citation2016; Jiang, Heng, & Choi, Citation2013) or use privacy concerns as an important predictor of behavior (for an overview of the literature, see Baruh et al., Citation2017). Privacy protective behavior in this paper is operationalized as adaptive behavioral responses to safeguard privacy when sharing personal information online (Milne, Labrecque, & Cromer, Citation2009).
This paper advances previous work in three distinct ways. First, it examines how people differ in their perceptions toward the social contract. Some people might be more concerned that online businesses honor the social contract and handle their data safely, while others are less concerned (Li, Citation2012). Because individuals’ feeling of a shared social contract is a complex construct (a latent variable) that is difficult to measure directly (Kongsted & Nielsen, Citation2017), we use a latent class analysis (LCA, Oberski, Citation2016). Such a method acknowledges the complexity of the social contract construct, and enables us to identify different subgroups that have different perceptions toward the social contract and estimate the prevalence of these groups (Kongsted & Nielsen, Citation2017). Hence, conducting an LCA leads to a conceptual and empirical breakdown of people’s feelings toward privacy (resulting in a typology which adds to previous work, e.g., Sheehan, Citation2002). To perform the LCA, we use three (observable) measures that form the foundation of the social contract with regard to online information exchange; individual privacy concerns, risk, and trust perceptions. While trust, risk, and privacy concerns have been linked to privacy protective behaviors in previous work (see e.g., Zimmer, Arsal, Al-Marzouq, & Grover, Citation2010), they have not been measured in such a way that they form the foundation of the social contract (i.e., using a LCA). We believe that the combined influence of these three concepts play a fundamental role in understanding the social contract.
Second, once we have identified these groups we can assess why some individuals adapt their behavior to protect their privacy, while others do not. We argue that those who perceive the social contract between them and the online business as more reliable (e.g., are less concerned, feel less risks, and have more trust) are less likely to adapt their behavior. We predict that only those who believe the social contract is less reliable are more likely to adjust their behavior.
Lastly, current work on privacy concerns, online tracking, and privacy protective behavior has often been restricted to the use of cross-sectional data while empirical evidence using longitudinal data is scarce. By deploying data from two waves of a panel survey, which was distributed among a representative sample of the Dutch population, we enhance our understanding about a possible causal relationship between individual perceptions and their privacy related behavior.
Theoretical perspectives and evidence on social contract theory
Historically, SCT is used to explain why people maintain in a social order and give up their freedom to be governed in a nation (Okazaki, Li, & Hirose, Citation2009). In marketing and business studies, SCT assumes a similar social contract between an internet user and a business when exchanging personal information (Fogel & Nehmad, Citation2009; Martin, Citation2016; Pan & Zinkhan, Citation2006): “the social contract [is] defined as the commonly understood obligations or social norms for the parties involved” (Li, Citation2012, p. 474). More concretely, the social contract is a hypothetical contract that people feel they have with online businesses when sharing personal information and privacy sensitive data.
Recently, researchers have shown an increased interest in social contract theory (SCT) in the context of online targeting (Fogel & Nehmad, Citation2009; Martin, Citation2016). People share their personal information with online businesses and trust the business that they handle their data safely because they have the moral obligation to protect it according to the internet user (i.e., the implied social contract). In other words, people believe that their rights with regard to their personal information are “respected by users of that information” and that “the use of this information will not go beyond mutually accepted purposes” (Okazaki et al., Citation2009, p. 64). This belief reflects the confidence in the implied social contract. People may vary in their perceptions toward the implied social contract, which we operationalize in this study as “the reliability of the social contract”. When people perceive the implied contract as more reliable, and thus have more confidence in it, they are more likely to share personal information. However, when the user perceives that the social contract is less reliable, either because the collection or use of personal information by the online business is perceived to be dishonored, unfair, or creepy, this can negatively influence their online behavior. Thus, when an internet user perceives the social contract as less reliable, they may adapt their behavior to safeguard their privacy (Martin, Citation2016; Pan & Zinkhan, Citation2006).
In addition, some studies focus on the social contract in a more specific and contextual dependent setup (i.e., micro level such as privacy perceptions on social media or on a specific website; Martin, Citation2016). When focusing on a micro level, an internet user may feel that the online business has the moral obligation to respect privacy norms within a specific context. For instance, when internet users shop online and give their personal information to buy a product. We follow a macro approach and note that the social contract also applies to a more general feeling of agreement on social privacy norms between the internet user and the online business. Hence, internet users expect a general protection of personal information when providing personal information online, because they feel that websites have the moral obligation to protect their personal data or because they feel protected by the government. However, because many internet users poorly understand who collects and uses their personal data online (e.g., McDonald & Cranor, Citation2010; Smit, Van Noort, & Voorveld, Citation2014; Ur, Leon, Cranor, Shay, & Wang, Citation2012), the social contract is a general perception, or an intuition, on which people base their decision. When people perceive the social contract when using the internet as more reliable, people will not actively engage in privacy protection behaviors online. But when people perceive the social contract as less reliable, they will engage in privacy protective behavior. These considerations also shape the social contract in this study. We define the social contract as a general normative and hypothetical social contract between the internet user and online businesses (Donaldson & Dunfee, Citation1994; Gilbert & Behnam, Citation2009). More specifically, we examine the perspective of the internet user, and therefore we focus on the social contract from their perspective.
It has become obvious in the previous section that the social contract is a complex concept that is difficult to examine directly. Many studies use substitute measures to examine the social contract (Fogel & Nehmad, Citation2009). Generally, studies that focus on SCT do not provide “readily applicable frameworks for empirical research” (Li, Citation2012, p. 474). SCT is often used as a basis for other theoretical frameworks to understand and explain the different dimensions of privacy concerns (Malhotra, Kim, & Agarwal, Citation2004) or other privacy related behaviors, such as why some people disclose information online (Bansal, Zahedi, & Gefen, Citation2010) or engage in privacy protection behaviors (Youn, Citation2009).
To give two concrete examples, Pan and Zinkhan (Citation2006) found support for SCT in the context of e-commerce. They demonstrated that privacy disclosures on websites positively affect internet users’ trust in the online store. The privacy disclosures suggest that the online business can be trusted, which is an indicator of the social contract. Additionally, they found that internet users who perceive a high level of privacy risk, are more likely to read privacy disclosures carefully. Pan and Zinkhan (Citation2006) therefore suggest “that consumers view the exchange of personal information as an implied social contract” (p. 336). Another example is a study by Okazaki et al. (Citation2009), who focused on SCT in the context of mobile advertising. They found that people with more privacy concerns and higher perceived risks favor stricter regulatory controls with regard to mobile advertising. The notion that perceived trust, however, influences the preference for more regulatory controls was not supported.
Based on the latter two studies and other work that applies SCT, we argue that observable (or manifest) variables measuring trust and risk perceptions, and privacy concerns regarding the collection and use of personal information reflect these definitions and therefore play an important role in SCT. First, and foremost, “[t]rust provides the foundation for a social contract” (Okazaki et al., Citation2009, p. 66). Individual internet users’ trust perceptions toward online companies is an important factor in the social contract, because “[w]hen parties engage in a contractual relationship, one party must assume that the other will take responsibility for its promises” (Okazaki et al., Citation2009, p. 66). Specifically, when internet users trust online companies to handle their data safely (i.e., internet users have the perception that online businesses take responsibility for the data collection and use), the internet user perceives the social contract as more reliable. In this study, trust perceptions refer to individuals’ beliefs that the online business or websites are able to protect the personal information of individuals (Malhotra et al., Citation2004).
Furthermore, if internet users do not think that online companies handle their data safely, they perceive many risks when providing their personal information to online businesses (Dinev, Xu, Smith, & Hart, Citation2013). When people perceive that there are many risks involved with providing information to online businesses, for instance because it is unclear what happens with the data in the future (Okazaki et al., Citation2009), there is no basis to perceive the social contract as more reliable. When internet users are uncertain about the safety of their personal data, and thus perceive more risks when exchanging information online, people are more likely to perceive the social contract as less reliable. Thus, risk perceptions are important in the social contract and it refers to individuals’ beliefs that there might be a high prospective of loss when giving or providing personal information (Malhotra et al., Citation2004).
Lastly, privacy concerns play a pivotal role in the social contract because concerns about privacy are closely related to the consequences of the social contract. Privacy concerns are beliefs about the possible undesirable consequences of the collection and sharing of personal information by online companies (Baruh et al., Citation2017; Okazaki et al., Citation2009). The basis of the social contract is that information is respected by users and will not be used for other purposes (Okazaki et al., Citation2009). When people are concerned about their privacy, this indicates that they are concerned that their information is not respected and not kept safe. Thus, we argue that people with high levels of privacy concerns perceive the social contract as less reliable, while people with lower levels of privacy concerns perceive the social contract as more reliable.
Taken together, we propose that trust, risk perceptions, and privacy concerns form the foundation of the latent construct; the social contract. We predict that people who have a higher level of trust in online businesses, experience fewer risks when providing personal information, and are less concerned about their privacy online, perceive the social contract as more reliable (i.e., they have more confidence in the implied contract). Contrariwise, people who have a low level of trust in online businesses, experience more risks when providing personal information, and are more concerned about their privacy, perceive the social contract as less reliable. Using a LCA, we combine these three variables to examine the complex construct of the implied social contract. We thereby identify distinct subgroups of individuals who are expected to score differently with respect to their perceptions of risk and trust, and their privacy concerns. In other words, we identify people’s perceptions toward the social contract by classifying which people are more likely perceive the social contract as more reliable and those who perceive it as less reliable. We also examine the prevalence of these classes (or subgroups). Because this is an explorative question, as we do not know which groups of people will be found, we propose a research question:
RQ1: (a) Which different subgroups of individuals can be distinguished on the basis of trust perceptions, risk perceptions, and privacy concerns, and (b) what is the prevalence of these subgroups?
Predicting privacy behavior
Since earlier studies did not measure the social contract directly, it is difficult to develop specific expectations about the consequences of the social contract once it is perceived to be “less reliable.” In other words, we are unsure how people who perceive the social contract as less reliable behave. Because we measure a latent construct, the reliability of the social contract, we base our hypothesis on previous work that focused on the relationship between the observable variables privacy concerns, trust, and risk perceptions on the one hand, and people’s adaptive behavior to safeguard their privacy on the other hand.
With regard to privacy concerns, the results point toward one clear direction. A recent meta-analysis found that people with higher levels of privacy concerns shared less information online, were less likely to use services online, and were more likely to protect their privacy (Baruh et al., Citation2017). Privacy concerns are thus associated with privacy related behavior (for an overview of the specific results, see Baruh et al., Citation2017).
Furthermore, another meta-analysis examining the effects of trust and risk perceptions on behavior toward social networking sites (SNSs, Wang et al., Citation2016), found that trust and risk perceptions are both related to behavior on SNSs (i.e., adoption of SNSs, purchase on SNSs, and sharing behavior), with trust as a seemingly strong predictor of SNSs behavior. Others have examined the influence of trust and risk on other types of behaviors and preferences for more control. For instance, Kim, Ferrin, and Rao (Citation2008) found that trust and risk perceptions have a positive effect on consumer’s online purchasing decisions. Metzger (Citation2004) discovered that trust is a key antecedent of disclosing personal information to a website. In the context of mobile advertising, Okazaki et al. (Citation2009) observed that an increased perceived risk among mobile phone users led to a greater preference for regulatory control in advertising on mobile phone. For trust, such a relationship was not found in this particular study. Xu, Teo, and Tan (Citation2005) examined the extent to which trust and risk perceptions affect the adoption of location-based services. They found that both risk and trust perceptions had a positive effect on behavioral intentions (i.e., disclose personal information to a location-based service). Thus, in sum, these results indicate that both risk and trust (i.e., the trust-risk dimension) play a pivotal role in predicting different privacy related behaviors.
Taken together, based on these results that uncovered a positive relationship between the three observable variables and behavior, we predict that people with higher levels of trust, lower levels of risk perceptions, and more privacy concerns are more likely to adapt their behavior to safeguard their privacy. In other words, those people perceive the social contract as less reliable, are more likely to adapt their privacy protective behavior. It should be noted that because the first research question is explorative in nature, we do not know yet which subgroups of people we will discover. As a consequence, it is more difficult to form specific hypotheses. For that reason, we developed the following research question:
RQ2: To what extent do individuals, who perceive the social contract as less reliable (i.e., those who are segmented into types that have high levels of perceived risks, less trust, and more privacy concerns), adapt their behavior to safeguard their privacy online?
Method
Sample
We rely on data from two waves of a panel survey (N = 1,222), which was distributed among a representative sample of the Dutch population. The two waves are part of a larger study, in which more data about personalized communication is systematically collected; see personalised-communication.net. The survey was carried out in April 2016 (first wave) and November 2016 (second wave). Data were collected using an online questionnaire. For the first wave, 1,523 respondents were selected for the study. In total, 1,222 respondents answered the questions; 1,060 respondents completed the survey in the second wave. The final sample consisted of respondents with the following characteristics (based on Wave 1); 51.9% was female, the average age was 53.95 (SDage = 16.89), the average real disposable household income per month is 2,894.27 euro (SDincome = 1,522.77) the average educational level was measured on a six-point scale ranging from low to high (Meducational level = 3.64; SDeducational level = 1.51; 32.30% had a low, 33.11% had a medium, and 34.59% had a high educational level). The sample is largely representative for the Dutch population, as data was collected by CentERdata who monitors the panel to make sure that the panel is a representative reflection of the Dutch population.
Measures
Dependent variables
Adaptive privacy behavior
Behavior regarding privacy, or information privacy-protective responses, have been measured in various ways, for instance refusing to disclose personal information, negative word-of-mouth about their experiences online (Son & Kim, Citation2008), refraining from visiting a website because it is only accessible when you accept cookies (Boerman, Kruikemeier, & Borgesius, Citation2018), or providing false information (Sannon, Bazarova, & Cosley, Citation2018). We assessed adaptive behavior to safeguard one’s privacy using five items derived from two scales that measured maladaptive and adaptive behavior (Milne et al., Citation2009). They note that “[a]daptive behaviors are actions taken with an online business to keep information safe. Maladaptive behaviors are avoidance responses that are driven by a more general fear of online shopping” (p. 450). In our study, we combined the two measures into one measure. As a consequence, we operationalize adaptive behavior as actions and avoidance responses to keep personal information safe online. Most of the items relate to the online shopping sphere, because we expect that this is something where many people have experience with. All items (e.g., “In the past year [second wave: in the past six months], how often … did you refuse to give information to an online company, because it was too personal?”)Footnote1 were measured on a 5-point Likert scale ranging from 1 (never) to 5 (very often). The items were averaged and higher scores indicated that the respondent adapted his or her privacy behavior (Eigen Valuewave 1 = 3.17, Explained Variancewave 1 = 63.3%, Cronbach’s αwave 1 = 0.85, Mwave 1 = 2.28, SDwave 1 = 0.94, Eigen Valuewave 2 = 3.17, Explained Variancewave 2 = 63.3%, Cronbach’s αwave 2 = 0.85, Mwave 2 = 2.11, SDwave 2 = 0.94).
Independent variables
Participants answered all items on privacy concerns, trust perceptions, and risk perceptions on a 7-point scale ranging from 1 (strongly disagree) to 7 (strongly agree). Factor validity was tested via confirmatory factor analyses (CFAs) by computing an overall model analyzing the three variables together. Referring to common fit criteria (e.g., Kline, Citation2016), all measures showed good model fit and reliability: χ2 (34) = 546.14, p < .001, TLI = 0.956, CFI = 0.964, RMSEA = .066, SRMR = .070. To explore discriminant validity, we conducted two tests. First, we compared the amount of the variance captured by the construct (average variance extracted: AVE) with the shared variance with other constructs (zero-order correlations). According to the criterion of Fornell and Larcker (Citation1981), the levels of the square root of the AVE for each construct should be greater than the zero-order correlations involving the constructs. Second, we conducted a CFA where we constrained the covariance path between privacy concerns and risk perceptions to zero, to test whether a model where these two constructs could be seen as one would not significantly deteriorate the model fit. When assuming privacy concerns and risk perceptions to be one dimension, CFA showed a worse model fit, χ2 (33) = 1043.86, p < .001, TLI = 0.909, CFI = 0.925, RMSEA = .095, SRMR = .210, which presented a significant decrease in model fit, χ2 (1) = 497.73, p < .001.
Overall, discriminant validity can be accepted for our measurement model and supports the discriminant validity between the constructs privacy concerns, trust perceptions, and risk perceptions (see for zero-order correlations between constructs and the AVE for each construct).
Table 1. Average Variance Extracted (AVE), the square root of the AVE (Diagonal in Bold) and zero-order correlations between constructs (Off-Diagonal).
Privacy concerns
Questions that measured respondents’ concerns regarding their privacy were based on a modified and shorter version of a scale previously used by Baek and Morimoto (Citation2012). We included five items, such as ‘I am concerned that my personal data (such as my surf and search behavior, name, and location) are misused by others’Footnote2. The five items were averaged and higher scores indicated that the respondent has more privacy concerns (Cronbach’s αwave 1 = 0.93, Mwave 1 = 4.67, SDwave 1 = 1.46).
Trust perceptions
Five questions were asked that measured respondents’ trust in online companies (Jarvenpaa, Tractinsky, & Saarinen, Citation1999; based upon, Malhotra et al., Citation2004). The items were measured on a 7-point Likert scale ranging from 1 (totally disagree) to 7 (totally agree; e.g., “Online companies are committed to protect my personal information”)Footnote3. The five items were averaged and higher scores indicated that the respondent had more trust in online entities, and also in the government, that their personal information is kept safe (Cronbach’s αwave 1 = 0.88, Mwave 1 = 3.29, SDwave 1 = 1.21).
Risk perceptions
We included five questions that asked the extent to which people perceive it as risky to disclose personal information online. The items are based upon other studies and were slightly modified for this study (Malhotra et al., Citation2004). The items were measured on a 7-point Likert scale ranging from 1 (totally disagree) to 7 (totally agree; e.g., “It is risky to give your personal data [such as your name, address, and age] to online businesses.”)Footnote4. The five items were averaged and higher scores indicated that the respondent thinks it is more risky to give personal information to online businesses (Cronbach’s αwave 1 = 0.80, Mwave 1 = 5.03, SDwave 1 = 1.13).
Control variables
Knowledge
We also measured respondents’ knowledge regarding online behavioral tracking in Wave 1. Previous work has shown that knowledge levels about behavioral advertising vary (Smit et al., Citation2014). It has been voiced that people with more awareness and knowledge about advertising techniques (i.e., persuasion knowledge) are better at coping with advertising practices (Friestad & Wright, Citation1994; Wright, Friestad, & Boush, Citation2005). Therefore, we expect that knowledge is also an important predictor of adaptive behavior. In the survey, we exposed respondents to a short description in which we explain the practice of online behavioral advertising. After reading the description, respondents could indicate whether or not they were familiar with this phenomenon (68.25% filled out that there were familiar with it and 31.75% were not).
Online buying habits
We measured respondents’ online buying habits by asking them how often they bought products online. We expect that those people who have more experience online – in online shopping –, and thus make more use of the internet, are more likely to be positive about the social contract. Therefore, we asked respondents: “How often do you buy online products in general?” The item was measured on a Likert scale ranging from 1 (several times a week) to 7 (never). The item was reversely coded, which indicates that a higher score showed that an individual shops more often online (Mwave 1 = 3.17, SDwave 1 = 1.37).
Analytic method
To analyze (a) which different subgroups of individuals can be distinguished on the basis of trust perceptions, risk perceptions, and privacy concerns and (b) how prevalent these subgroups are, we performed LCA based on the following clustering variables derived from SCT: privacy concerns, trust perceptions, and risk perceptions. LCA is a statistical method that uses a mixture of distributions to identify the most likely model describing the heterogeneity of data as a finite number of classes (subgroups). When using continuous variables for clustering, LCA is also often referred to as latent profile analysis (LPA, see also Masyn, Citation2013; Wang & Wang, Citation2012) or latent class cluster analysis (LCCA, see also Masyn, Citation2013). The purpose of LCA is to identify a number of subgroups that describe the underlying scoring patterns in the data, estimate the prevalence of the subgroups, and estimate each individual’s probability of belonging to each subgroup (Kongsted & Nielsen, Citation2017). LCA differs from other techniques, such as principal component analysis or cluster analysis, by fitting “a model to the data rather than providing an ad hoc classification of the given data” (Van de Pol, Holleman, Kamoen, Krouwel, & De Vreese, Citation2014, p. 402). We performed the LCA six times to see which cluster solution fits the data best using Mplus software (version 8). There are many different ways to assess the fit of a model (see e.g., Oberski, Citation2016), but for this study we included the most commonly used ones (see ). We used the log likelihood (LL) and the Bayesian Information Criterion (BIC), the Lo-Mendell-Rubin Adjusted LRT Test and the entropy score. Lower values the LL and BIC indicate better fit (Oberski, Citation2016). The LRT test compares the fit of a model with the previous one (e.g., compares the solution with five to the solution with four classes) and gives a p-value which shows whether one model (e.g., five classes) has a significant better fit over the other one (e.g., four classes, Nylund, Asparouhov, & Muthén, Citation2007). In other words, the LRT compares whether a model with K classes is significantly better than a model with K-1 classes with a significant p-value indicating a better model fit. The last measure we use to assess the fit is the entropy score (Celeux & Soromenho, Citation1996). Specifically, the entropy score indicates how well the cluster variables predict membership of the latent classes, with a value closer to 1 means better fit (Hagenaars & McCutcheon, Citation2002). For the most optimal class solution, we reported the class count, proportions, and average latent class probabilities for most likely membership for each class. Based on the latter information, a new variable was put in the dataset that indicated the most likely class membership for each individual case in the dataset.
To examine the specific characteristics of each subgroup, we conducted a multinomial logistic regression. We included several predictors; gender, age, educational level, knowledge about targeting, and online shopping habits. Lastly, to examine our second research question, we performed a regression analysis, deploying bootstrapping (with 5,000 bootstrap samples). In this analysis, we used adaptive behavior measured in Wave 2 as dependent variable, adaptive behavior measured in Wave 1 as lagged variable, the membership of the classes as independent variables, and lastly, the control variables and socio-demographics as predictors. Such a model is important here as it makes it possible to make stronger causal inferences. By including the lagged dependent variable (i.e., adoptive behavior at Wave 1), we capture how the independent variables (i.e., class membership and the control variables) are related to changes in adoptive behavior.
Results
Latent class analysis
We first conducted an LCA to measure the extent to which people perceive the “social contract” as more reliable, using the concerns, trust, and risk items (see RQ1). We ran the model successively until an appropriate fit was found. In this study, it appeared that the six-class solution was not significantly better than the five-class solution (p = .515), while the five-class solution was significantly better than the four-class solution (p = .027). Another measure to assess the fit is the entropy value (Celeux & Soromenho, Citation1996), a higher value indicates better fit. The 4-class solution showed a higher entropy value, which indicated good fit, but since the LMR test showed a significant better fit for the 5-class solution, we focused on the 5-class solution. shows the common fit indices for 1-, 2-, 3-, 4-, 5-, and 6-class solutions. reports the class count, proportions, and average latent class probabilities for most likely membership for each class.
Table 2. LCA results with different fit indices.
Table 3. Class count, proportions, and average latent class probabilities for most likely membership (Row) by Class (Column).
Based on the analyses, we found that five different types of people can be distinguished that differ on the social contract dimensions of privacy concerns, F(4, 1217) = 596.90, p < .001, risk perceptions, F(4, 1217) = 1380.99, p < .001, and trust perceptions, F(4, 1217) = 135.55, p < .001 (see and ). shows the mean scores, standard errors, and confidence intervals for privacy concerns, trust perceptions, and risk perceptions for each type. visualizes the mean scores on these constructs for each type.
Table 4. Estimated means, standard errors, and confidence intervals for privacy concerns, trust perceptions, and risk perceptions for the five-class solution.
Figure 1. Estimated means of privacy concerns, trust and risk for each type.
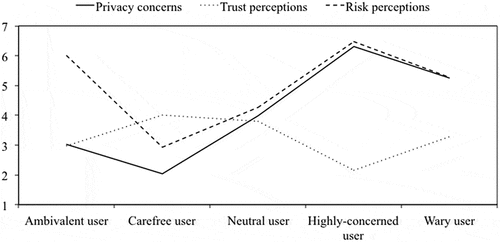
shows the results of a multinomial logistic regression analysis examining the characteristics (i.e., socio-demographics, knowledge, and online shopping behavior) of the different types. This is important, as it provides insightFootnote5 into the question who these different types are and it might help to compare the outcome of this work to other studies that investigate typologies. The first type that can be distinguished is the “neutral user”. These users seem to be neutral and do not hold strong negative nor positive attitudes toward the collection and use of personal information. This is also the largest groups (41.98%), and consists of people who score rather in the middle of the scales of privacy concerns (M = 3.94, SE = .04), trust (M = 3.82, SE = .04), and risk (M = 4.22, SE = .02). This group does not perceive the social contract as more reliable, but also not as completely unreliable. This group is used as the reference category in the multinomial regression analysis (see ).
Table 5. Multinomial regression predicting membership of the classes using socio-demographics, knowledge, and online buying habits.
The second type is the “carefree user” (4.75%). This rather small group consists of people who are less concerned about their privacy (M = 1.96, SE = .11), have an average level of trust in online companies and the government (M = 4.03, SE = .22), and do not perceive many risks to share personal information (M = 2.83, SE = .08). It seems that this user is more likely to perceive the social contract as more reliable. Compared to the neutral user, this type is less likely to shop online.
The third type that can be distinguished is the “highly-concerned user”. This group is moderately large (20.62%), and consists of people who are highly-concerned about their privacy (M = 6.32, SE = .05), have less trust (M = 2.07, SE = .07), and feel relatively more risks online (M = 6.52, SE = .03). Highly-concerned users (compared to the neutral users) are often older, have more knowledge about tracking, and shop less often online. This group can be identified as perceiving the social contract as particularly less reliable.
The fourth type is the “wary user”. This group is wary toward the safety of their personal information; they are suspicious about the social contract. This is also a relatively large group (27.99%), and consists of people who are similar to the highly-concerned user, but score less extreme on the three variables (see ). This group is thus concerned (M = 5.30, SE = .05), feels it is risky to give information to online companies (M = 5.32, SE = .02), and has less trust (M = 3.32, SE = .06), but they are significantly less alarmed than the highly-concerned user. Wary users (compared to the neutral users) are also often older, have more knowledge about tracking, and shop less often online.
The last type consists of users who are ambivalent about the social contract, therefore, we named this group the “ambivalent user”. This is a relatively small group (4.66%). This type of user has lower levels of privacy concerns (M = 2.81, SE = .12), but has surprisingly less trust in online companies (M = 3.07, SE = .16), and they feel it is riskier to share personal information with online companies (M = 6.12, SE = .07). This ambiguous user has contradictory expectations regarding the reliability of the social contractFootnote6. Compared to the neutral users, the ambivalent user shops less often online and is older (this latter predictor is marginally significant).
In the next step, we investigate which type is more likely to adapt its behavior to safeguard privacy (RQ2). shows the regression analysis that measures the change in individual behavior. The results show that the highly-concerned user, compared to the neutral user, is more likely to adapt its privacy behavior (unstandardized b-coefficient = .21, p = .003). This effect is also found when the highly-concerned user is compared to the carefree user (not displayed). Respondents that are highly-concerned, have less trust, and perceive more risks, are very likely to engage more often in privacy behavior. This indicates that when internet users perceive the social contract as less reliable, people are more likely to adapt their behavior to protect their privacy when shopping online. At the same time, those people who are more neutral or carefree about the reliability of the social contract are less likely to adapt their behavior. Interestingly, although marginally significant, the ambivalent user is more likely to adapt its privacy behavior (b = .28, p = .071) compared to the neutral user. This effect was also significant when the ambivalent user is compared to the carefree user (not displayed). This indicates that respondents that have low privacy concerns are still likely to adapt their privacy behavior when shopping online, because they have less trust and feel more risk online. This suggests that the trust-risk dimension might be important in the social contract and may even by itself predict adaptive behavior. Lastly, although only marginally significant, we also found that the wary user, compared to the neutral user, is more likely to adapt its privacy behavior (b = .10, p = .089). Thus, perceiving the social contract as a bit less reliable may also lead to a change in behavior when shopping online. In sum, these findings seem to indicate that when people perceive the contract as less reliable, they are more likely to adapt their behavior by safeguarding their privacy (RQ2).
Table 6. Predicting change in adaptive behavior to safeguard privacy.
Robustness checks
We examined the relationship between probability of class membership, instead of the “most likely” cluster membership of each respondent, and adaptive behavior. Results show similar results and indicates again that the highly-concerned users are more likely to adapt their behavior, compared to the carefree and the neutral user (analysis not displayed). Other relationships did not appear to be significant, confirming the robust effect of highly-concerned users on adaptive behavior.
Lastly, we examined the direct relationship between the separate constructs – trust, risks, concerns – and adaptive behavior. A regression analyses including these results as separate predictors shows a significant relationship between concerns and behavior, but not between trust and risks. This indicates that taking into account the main effects of the separate observable (manifest) variables offer some insight. But, testing only for the direct effect is over-simplified, as it does not show the complex feelings individuals have toward online privacy (i.e., the social contract) and the effects it has on individuals’ behavior.
Discussion and conclusion
This paper examined the extent to which individuals’ perceptions of a more or less reliable implied social contract (Fogel & Nehmad, Citation2009; Martin, Citation2016) explains adaptive behavior to safeguard privacy when shopping online. This is important as social contract theory has been often overlooked in the realm of communication research (Martin, Citation2012). This is surprising as the social contract between internet users and online entities become more and more important in the digital communication age, and because it helps to understand why people may or may not adapt their behavior to safeguard their privacy online. We relied on data from a two-wave panel survey which offers the opportunity to examine the relationship between the social contract and adaptive behavior over time and thus examine change in behavior using a representative sample.
First, the results indicate that people differ regarding the perceived reliability of the social contract, which is in line with other typologies (see e.g., Dupree, Devries, Berry, & Lank, Citation2016; Sheehan, Citation2002; Westin, Citation2000). More specifically, with regard to our findings, a large proportion of society, albeit still a minority, seems to perceive the social contract as less reliable. When we uncovered different subgroups of people’s perceptions toward the social contract, we found that a moderately large group of people (20.62%) were labeled the highly-concerned users. These people do not trust online companies, have high levels of risk perceptions, and are concerned about their privacy. Hence, for these people the social contract is less reliable. Another interesting group is the people who are suspicious about the social contract; the wary users. This is also a relatively large group (27.99%) and consists of people who are similar to the highly-concerned user, but score less extreme on the three variables. It is difficult to compare these results with other typologies, especially as different methods are applied. However, when the highly-concerned and the wary user groups are combined, this finding is somewhat similar to (Sheehan, Citation2002). Sheehan (Citation2002) found four types, and among these the alarmed internet users (3% in their study) and the wary internet users (43%). It could thus be argued that in society, almost half of the people perceive the social contract as less reliable and those people do not have the confidence that online businesses keep their data safe. This is also in line with others that found that the majority of European citizens perceive the privacy of personal information very important (Eurobarometer, Citation2016). Also many Americans distrust organizations (both public and private) in protecting their personal information when collected online (Rainie, Citation2016).
Interestingly, only a very small proportion of people in society seem to perceive the social contract online as more reliable (4.75%). These carefree users have trust in online companies, experience little risk, and do not have much privacy concerns. Moreover, the largest group of people, are people that are more neutral. The largest group (41.98%) in our data does not seem to hold strong opinions regarding the collection and use of personal information. This is an interesting finding in light of the privacy paradox. In our data, we found that many people have a more neutral stance toward privacy; they are not completely anxious, yet people are not unconcerned as well. They perceive the social contract not as more or less reliable. This might explain why a lot of people do not act upon their feelings toward privacy. There are some concerns, but these are not heightened enough to be acted upon.
Second, the results indicate that when people perceive the social contract as less reliable, they adapt their online behavior to protect their privacy. This demonstrates, at least to some extent, that the combination of key concepts of the social contract (i.e., privacy concerns, trust, and risk perceptions) seems to play an important role in the change of privacy behavior. Simultaneously, we found that users that are neutral or carefree about the social contract are less likely to adapt their behavior online. With that result, we offer new insights, especially regarding the privacy paradox (Norberg et al., Citation2007; Taddicken, Citation2014). Simply put, the privacy paradox notes that despite the fact that people report that they are concerned, people do not adapt their behavior. Baruh et al. (Citation2017) already noted that privacy concerns are a predictor of actual behavior, yet often “with typically small or moderate effect sizes” (p. 20). And also others already noted that “[t]he privacy paradox can be considered a relic of the past” (Dienlin & Trepte, Citation2015, p. 295). Although people still disclose personal information online, for instance on Facebook, despite their concerns, they do also act upon their concerns by engaging in specific privacy protection strategies (Young & Quan-Haase, Citation2013). Our results add to this notion and suggest that privacy concerns are indeed only part of the story. The social contract, and especially when people perceive it as less reliable, is an important predictor of privacy related behavior online. This finding offers a starting point for future work that focuses on privacy behavior in the digital age. It offers an alternative explanation why only those with high concerns, low trust, and high risk perceptions are likely to alter their behavior, and why still a majority of people do not act upon their concerns. The answer, according to our results, seems to lie in the fact that those people do not have a sufficient amount of confidence in online companies, or the authorities, that their personal information is protected.
Practical and theoretical implications
This study adds to previous work by showing that perceptions toward online privacy are complex and that these individual perceptions play an important role in predicting who is more likely to protect or share personal information (Acquisti & Grossklags, Citation2008). Moreover, the implied social contract represents an alternative explanation that helps to identify why some individuals engage in privacy protection behavior online, while others do not. In this way, this study adds to work (Malhotra et al., Citation2004), and the APCO framework (Smith, Dinev, & Xu, Citation2011), that focuses on privacy related behavior in the digital information age. It also adds new insights into existing theories that are applied in online privacy research (Li, Citation2012). More specifically, our study found evidence which points to differences in people’s perceptions toward the reliability of the social contract. However, for some groups, the implications are more obvious compared to others. Results are more clear-cut for people who do not perceive the social contract as very reliable (i.e., highly-concerned users) and those who perceive the social contract as more reliable (i.e., carefree users). However, we also observed three other, more “ambiguous” groups. They do not fit in the two dual groups – but these groups are finding middle ground; they do not perceive the social contract completely unreliable but they have some concerns. This adds to the notion that privacy feelings are complex and future work should focus on these specific “alternative” groups as well. These groups have particular characteristics (e.g., being more neutral), which have not been observed in previous work.
Secondly, we followed a macro approach, in the sense that we operationalized the social contract as a general feeling of agreement on social privacy norms between the internet user and the online business. Future work might explore the social contract on a micro level (Martin, Citation2016). This offers a more nuanced understanding into the origins of the individual perceptions of the social contract (i.e., when was the contract breached, in which context, and what was the reason) using for instance a qualitative approach. A future study could also assess, using experimental methods, which determinants affect perceptions of the social contract in specific contexts (e.g., on social media). For instance, people might have a different set of “rules” in every specific situation. As a consequence, this could affect their privacy protection strategies when using the Internet for different purposes (Poddar, Mosteller, & Ellen, Citation2009). Another limitation lies in the fact that more work needs to be done to determine whether other observable variables also play a role in the perceived reliability of the social contract, such as previous negative experiences or having more privacy knowledge. Thus, future work should not only examine which people change their behavior, but also why people change their behavior (e.g., due to exposure to news about privacy issues, experience with online shopping).
The results of our research have a number of implications for future practice. First, it shows that the individual differences matter when explaining why some people adapt their behavior by protecting their privacy. It is an interesting result that many people are not likely to adapt their behavior because they are having a lot of confidence in online businesses. It is unclear whether or not this increased level of confidence in online businesses is justified, which makes these people, in some cases, also vulnerable. Trusting online companies might be, in particular cases, naïve and therefore policies could be developed to protect these more vulnerable people (Acquisti et al., Citation2015). Moreover, to capture trust in online companies, future work should also examine trust more closely. Trust can be conceptualized in many different ways. Second, on the other end of that spectrum, some people also perceive the social contract as less reliable (i.e., the highly-concerned users). The fact that these people adapt their behavior as a consequence is quite important. If the amount of people who perceive the social contract as less reliable (potentially) grows in the future. This might be negative for online businesses as well. They could miss out on profits, which negatively affects the digital economy. So, once a social contract is “breached”, or more nuanced, is perceived to be less reliable, online businesses should make an effort in restoring trust, for instance by giving people more control over their personal data or inform people about the use of personal information. In that sense, the ball also lies with online businesses. If more businesses continue to handle data safely, more people will believe the social contract is reliable.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1. Other items were: “…did you decide not to shop online because you were worried about online companies not handling your personal information well”, “…did you decide not to shop online because it was unclear how online companies were handling your personal data”, “…did you encouraged other people not to shop online, because you were worried that online companies were not handling other people’s personal information well”, and “…did you decide to shop in an actual brick store, instead of an online shop, because this was less risky?”.
2. Other items were: “When I am online, I feel that others keep track of my clicks and online surfing behavior”, “I am afraid that the personal data that I share online are not safely stored”, “I am concerned that my personal data on the Internet are further distributed to other companies”, and “I am concerned that people that I do not know see my personal information on the Internet.”
3. Other items were: “I trust online businesses with handling my personal data”, “Online businesses are always honest to me about their use of my data”, “Online businesses protect the personal data I share with them”, and “The Dutch government ensures that my personal data is protected.”
4. Other items were: “Giving personal data to online businesses can lead to unexpected problems”, “It is safe to give personal data to online businesses (R)”, “Personal data that is collected online may be available to others without my knowledge”, and “Personal data that is collected online may be misused.”
5. The Nagelkerke R-square is rather low, which indicates that other predictors that were not included in this study may be more strongly related to membership of the classes.
6. We observed that the five-class solution has two smaller classes. Because these classes are very distinct and offer additional insight into the contract, we believe the five-class solution is the best fit. Specifically, the carefree user believes the contract is more reliable, yet the ambivalent users has mixed feelings. Both are very different from the other larger groups, who are either neutral or perceived the contract as less reliable. Because the smaller groups are also conceptually different, we believe that the five-class solution is the optimal solution.
Related Research Data
References
- Acquisti, A., & Grossklags, J. (2008). What can behavioral economics teach us about privacy. In A. Acquisti, S. Gritzalis, C. Lambrinoudakis, & S. Di Vimercati (Eds.), Digital privacy: Theory, technologies, and practices (pp. 363–377). Boca Ration, Florida: Auerbach Publications.
- Acquisti, A., Brandimarte, L., & Loewenstein, G. (2015). Privacy and human behavior in the age of information. Science, 347, 509–514. doi:10.1126/science.aaa1465
- Antón, A. I., Earp, J. B., & Young, J. D. (2010). How internet users’ privacy concerns have evolved since 2002. IEEE Security & Privacy, 8, 21–27. doi:10.1109/MSP.2010.38
- Baek, T. H., & Morimoto, M. (2012). Stay away from me. Journal of Advertising, 41, 59–76. doi:10.2753/JOA0091-3367410105
- Bansal, G., Zahedi, F. M., & Gefen, D. (2010). The impact of personal dispositions on information sensitivity, privacy concern and trust in disclosing health information online. Decision Support Systems, 49, 138–150. doi:10.1016/j.dss.2010.01.010
- Baruh, L., Secinti, E., & Cemalcilar, Z. (2017). Online privacy concerns and privacy management: A meta-analytical review. Journal of Communication, 67, 26–53. doi:10.1111/jcom.12276
- Boerman, S. C., Kruikemeier, S., & Zuiderveen Borgesius, F. J. (2018). Exploring motivations for online privacy protection behavior: insights from panel data. Communication Research. doi: 10.1177/0093650218800915
- Celeux, G., & Soromenho, G. (1996). An entropy criterion for assessing the number of clusters in a mixture model. Journal of Classification, 13, 195–212. doi:10.1007/BF01246098
- Dienlin, T., & Metzger, M. J. (2016). An extended privacy calculus model for SNSs: Analyzing Self-Disclosure and Self-Withdrawal in a representative US sample. Journal of Computer‐Mediated Communication, 21, 368–383. doi:10.1111/jcc4.12163
- Dienlin, T., & Trepte, S. (2015). Is the privacy paradox a relic of the past? An in‐depth analysis of privacy attitudes and privacy behaviors. European Journal of Social Psychology, 45(3), 285–297. doi:10.1002/ejsp.2049
- Dinev, T., Xu, H., Smith, J. H., & Hart, P. (2013). Information privacy and correlates: An empirical attempt to bridge and distinguish privacy-related concepts. European Journal of Information Systems, 22(3), 295–316. doi:10.1057/ejis.2012.23
- Donaldson, T., & Dunfee, T. W. (1994). Toward a unified conception of business ethics: Integrative social contracts theory. Academy of Management Review, 19, 252–284. doi:10.5465/AMR.1994.9410210749
- Dupree, J., Devries, R., Berry, D., & Lank, E. (2016). Privacy personas. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 5228–5239). New York, NY: ACM.
- Eurobarometer. (2016). E-privacy (No. 2016.7036). European Commission. doi:10.2759/249540
- Fogel, J., & Nehmad, E. (2009). Internet social network communities: Risk taking, trust, and privacy concerns. Computers in Human Behavior, 25, 153–160. doi:10.1016/j.chb.2008.08.006
- Fornell, C., & Larcker, D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 39–50. Retrieved from www.jstor.org/stable/3151312
- Friestad, M., & Wright, P. (1994). The persuasion knowledge model: How people cope with persuasion attempts. Journal of Consumer Research, 21, 1–31. doi:10.1086/209380
- Gilbert, D. U., & Behnam, M. (2009). Advancing integrative social contracts theory: A habermasian perspective. Journal of Business Ethics, 89, 215–234. doi:10.1007/s10551-008-9995-6
- Hagenaars, J. A., & McCutcheon, A. L. (2002). Applied latent class analysis. New York, NY: Cambridge University Press.
- Jarvenpaa, S. L., Tractinsky, N., & Saarinen, L. (1999). Consumer trust in an internet store: A cross-cultural validation. Journal of Computer-Mediated Communication, 5(2). doi:10.1111/j.1083-6101.1999.tb00337.x
- Jiang, Z., Heng, C. S., & Choi, B. C. (2013). Research note—Privacy concerns and privacy-protective behavior in synchronous online social interactions. Information Systems Research, 24(3), 579–595. doi:10.1287/isre.1120.0441
- Kim, D. J., Ferrin, D. L., & Rao, H. R. (2008). A trust-based consumer decision-making model in electronic commerce: The role of trust, perceived risk, and their antecedents. Decision Support Systems, 44, 544–564. doi:10.1016/j.dss.2007.07.001
- Kline, R. B. (2016). Principles and practice of structural equation modeling (4th ed.). New York, NY: The Guilford Press.
- Kongsted, A., & Nielsen, A. M. (2017). Latent class analysis in health research. Journal of Physiotherapy, 63, 55–58. doi:10.1016/j.jphys.2016.05.018
- Li, Y. (2012). Theories in online information privacy research: A critical review and an integrated framework. Decision Support Systems, 54, 471–481. doi:10.1016/j.dss.2012.06.010
- Malhotra, N. K., Kim, S. S., & Agarwal, J. (2004). Internet users’ information privacy concerns (IUIPC): The construct, the scale, and a causal model. Information Systems Research, 15, 336–355. doi:10.1287/isre.1040.0032
- Martin, K. E. (2012). Diminished or just different? A factorial vignette study of privacy as a social contract. Journal of Business Ethics, 111, 519–539. doi:10.1007/s10551-012-1215-8
- Martin, K. E. (2016). Understanding privacy online: Development of a social contract approach to privacy. Journal of Business Ethics, 137, 551–569. doi:10.1007/s10551-015-2565-9
- Masyn, K. E. (2013). Latent class analysis and finite mixture modeling. In T. D. Little (Ed.), Oxford library of psychology. The Oxford handbook of quantitative methods: Statistical analysis (pp. 551–611). New York, NY: Oxford University Press.
- McDonald, A., & Cranor, L. F. (2010). Beliefs and behaviors: Internet users’ understanding of behavioral advertising. TPRC 2010. Retrieved from https://ssrn.com/abstract=1989092
- Metzger, M. J. (2004). Privacy, trust, and disclosure: Exploring barriers to electronic commerce. Journal of Computer-Mediated Communication, 9(4). doi:10.1111/j.1083-6101.2004.tb00292.x
- Milne, G. R., Labrecque, L. I., & Cromer, C. (2009). Toward an understanding of the online consumer’s risky behavior and protection practices. Journal of Consumer Affairs, 43, 449–473. doi:10.1111/j.1745-6606.2009.01148.x
- Norberg, P. A., Horne, D. R., & Horne, D. A. (2007). The privacy paradox: Personal information disclosure intentions versus behaviors. Journal of Consumer Affairs, 41, 100–126. doi:10.1111/j.1745-6606.2006.00070.x
- Nylund, K. L., Asparouhov, T., & Muthén, B. O. (2007). Deciding on the number of classes in latent class analysis and growth mixture modeling: A monte carlo simulation study. Structural Equation Modeling, 14, 535–569. doi:10.1080/10705510701575396
- Oberski, D. (2016). Mixture models: Latent profile and latent class analysis. In J. Robertson & M. Kaptein (Eds.), Modern statistical methods for HCI (pp. 275–287). Cham, Switzerland: Springer International Publishing. doi:10.1007/978-3-319-26633-6_12
- Okazaki, S., Li, H., & Hirose, M. (2009). Consumer privacy concerns and preference for degree of regulatory control. Journal of Advertising, 38(4), 63–77. doi:10.2753/JOA0091-3367380405
- Pan, Y., & Zinkhan, G. M. (2006). Exploring the impact of online privacy disclosures on consumer trust. Journal of Retailing, 82, 331–338. doi:10.1016/j.jretai.2006.08.006
- Poddar, A., Mosteller, J., & Ellen, P. S. (2009). Consumers’ rules of engagement in online information exchanges. Journal of Consumer Affairs, 43(3), 419–448. doi:10.1111/j.1745-6606.2009.01147.x
- Rainie, L. (2016, September 21). The state of privacy in post-snowden America. Retrieved from http://www.pewresearch.org/fact-tank/2016/09/21/the-state-of-privacy-in-america/
- Sannon, S., Bazarova, N. N., & Cosley, D. (2018, April). Privacy lies: Understanding how, when, and why people lie to protect their privacy in multiple online contexts. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal QC, Canada (pp. 52). ACM.
- Sheehan, K. B. (2002). Toward a typology of Internet users and online privacy concerns. The Information Society, 18(1), 21–32. doi:10.1080/01972240252818207
- Smit, E. G., Van Noort, G., & Voorveld, H. A. M. (2014). Understanding online behavioural advertising: User knowledge, privacy concerns and online coping behaviour in Europe. Computers in Human Behavior, 32, 15–22. doi:10.1016/j.chb.2013.11.008
- Smith, H. J., Dinev, T., & Xu, H. (2011). Information privacy research: An interdisciplinary review. MIS Quarterly, 35(4), 989–1016. Retrieved from www.jstor.org/stable/41409970
- Son, J. Y., & Kim, S. S. (2008). Internet users’ information privacy-protective responses: A taxonomy and a nomological model. MIS Quarterly, 503–529. Retrieved from www.jstor.org/stable/25148854
- Taddicken, M. (2014). The ‘Privacy paradox’ in the social web: The impact of privacy concerns, individual characteristics, and the perceived social relevance on different forms of self-disclosure. Journal of Computer-Mediated Communication, 19, 248–273. doi:10.1111/jcc4.12052
- Trepte, S., & Reinecke, L. (2011). Privacy online: Perspectives on privacy and self-disclosure in the social web. Heidelberg, Germany: Springer.
- Turow, J., & Hennessy, M. (2007). Internet privacy and institutional trust: Insights from a national survey. New Media & Society, 9(2), 300–318. doi:10.1177/1461444807072219
- Ur, B., Leon, P. G., Cranor, L. F., Shay, R., & Wang, Y. (2012). Smart, useful, scary, creepy: Perceptions of online behavioral advertising. Proceedings of the Eighth Symposium on Usable Privacy and Security, art. 4, Washington, D.C., USA. doi:10.1145/2335356.2335362
- Van de Pol, J., Holleman, B., Kamoen, N., Krouwel, A., & De Vreese, C. (2014). Beyond young, highly educated males: A typology of VAA users. Journal of Information Technology & Politics, 11, 397–411. doi:10.1080/19331681.2014.958794
- Wang, J., & Wang, X. (2012). Structural equation modeling: Applications using Mplus. Chichester, UK: Wiley.
- Wang, Y., Min, Q., & Han, S. (2016). Understanding the effects of trust and risk on individual behavior toward social media platforms: A meta-analysis of the empirical evidence. Computers in Human Behavior, 56, 34–44. doi:10.1016/j.chb.2015.11.011
- Westin, A. F. (2000). Intrusions. Public Perspective, 11(6), 8–11.
- Wright, P., Friestad, M., & Boush, D. M. (2005). The development of marketplace persuasion knowledge in children, adolescents, and young adults. Journal of Public Policy & Marketing, 24, 222–233. doi:10.1509/jppm.2005.24.2.222
- Xu, H., Teo, H., & Tan, B. (2005, December). Predicting the adoption of location-based services: The role of trust and perceived privacy risk. International Conference on Information Systems (ICIS), Las Vegas, NV, USA (pp. 71).
- Youn, S. (2009). Determinants of online privacy concern and its influence on privacy protection behaviors among young adolescents. Journal of Consumer Affairs, 43, 389–418. doi:10.1111/j.1745-6606.2009.01146.x
- Young, A. L., & Quan-Haase, A. (2013). Privacy protection strategies on Facebook: The internet privacy paradox revisited. Information, Communication & Society, 16(4), 479–500. doi:10.1080/1369118X.2013.777757
- Zimmer, J. C., Arsal, R. E., Al-Marzouq, M., & Grover, V. (2010). Investigating online information disclosure: Effects of information relevance, trust and risk. Information & Management, 47(2), 115–123. doi:10.1016/j.im.2009.12.003