
Abstract
The application of artificial intelligence and machine learning (ML) technologies in healthcare have immense potential to improve the care of patients. While there are some emerging practices surrounding responsible ML as well as regulatory frameworks, the traditional role of research ethics oversight has been relatively unexplored regarding its relevance for clinical ML. In this paper, we provide a comprehensive research ethics framework that can apply to the systematic inquiry of ML research across its development cycle. The pathway consists of three stages: (1) exploratory, hypothesis-generating data access; (2) silent period evaluation; (3) prospective clinical evaluation. We connect each stage to its literature and ethical justification and suggest adaptations to traditional paradigms to suit ML while maintaining ethical rigor and the protection of individuals. This pathway can accommodate a multitude of research designs from observational to controlled trials, and the stages can apply individually to a variety of ML applications.
INTRODUCTION
Machine learning (ML) is the most widely applied branch of artificial intelligence (AI)Footnote1 and has the potential to dramatically augment healthcare (Hinton Citation2018; Naylor Citation2018). Applying ML at point-of-care may help to reduce arbitrary variation, minimize medical errors, and provide information to support clinical decision-making. A major goal of current work in health ML is toward translating the ability to make predictions into clinically useful information that can be mobilized to improve patient health outcomes.
The well-recognized “AI chasm” describes the current gap between the development of a robust algorithm and its clinically meaningful application (Keane and Topol Citation2018). The problem has been variably formulated as technical (e.g., challenges related to limitations inherent to the science of ML), logistical (e.g., challenges related to integration with hospital data infrastructures), and human (e.g., challenges related to human factors) (Kelly et al. Citation2019). The disagreement about how to responsibly evaluate ML to justify implementation has contributed to the use of pathways based on ease and access rather than substantive ethical foundations (Vayena and Blasimme Citation2018). In this paper, we argue that the AI chasm is also epistemic (methodological) and ethical, generated by a clash between the (epistemic and ethical) cultures of computer science and clinical science (Wongvibulsin and Zeger Citation2020). If AI is to be translated successfully into the clinic, the values and methods of these disparate cultures must be reconciled.
On the epistemic or methodological side, we argue that closing the AI chasm requires an evaluative paradigm that reflects the existing norms of evidence-based medicine (EBM) and clinical research methods, reflecting the particularities and increased complexities of AI methodologies. A comprehensive evaluation of an AI system’s performance must provide a means to confidently establish its ability to accomplish a particular task in a real-world clinical workflow. Furthermore, given that the ultimate goal of many ML tools in healthcare is the improvement of the health outcomes of patients, methods suited to the evaluation of patient-related outcomes (i.e., the methods of clinical research) are necessary.
On the ethical side, we argue that closing the AI chasm requires a unification of ML and the ethical norms of human subjects research. Elsewhere (McCradden, Stephenson, and Anderson Citation2020), we described a process for research ethics oversight of clinical AI. In the current paper, we elaborate specifically on the ethical underpinnings of this process and particularly explore the considerations for the silent period and prospective clinical evaluation.
BACKGROUND
Healthcare ML, like evidence-based medicine (EBM) before it, aims to integrate new methods of inquiry into clinical care in order to improve the care of patients. During the early years of EBM, David Sackett described receiving criticism ranging from accusations that EBM was “old hat to it being a dangerous innovation, perpetrated by the arrogant to serve cost cutters and suppress clinical freedom” (Sackett et al. Citation1996). The parallels with criticisms of the contemporary healthcare ML movement are striking. The data-driven shift from a science of populations to that of individuals has created a “clash of cultures” culminating in both epistemic and ethical challenges with evidence-based clinical translation (Wongvibulsin and Zeger Citation2020).
Evidence
On the epistemic side, the culture clash between ML and clinical science is driven primarily by differences in method. Computational methodology itself is the primary focus of ML research. Scientific inquiry in ML focuses on the validation of models as functional mapping of inputs to outputs within historical datasets, often, without the application of experimental/quasi-experimental methods to validate models. Furthermore, ML typically uses data that was originally collected for other purposes. This practice is not unfamiliar to clinical researchers, e.g., secondary use of data (more on this below), but has been used in clinical research primarily for hypothesis generation, not hypothesis testing.
As noted in the introduction, it is now widely acknowledged that validation in a historical data set is not sufficient for morally justified deployment in healthcare (or elsewhere, perhaps). ML models are complex sociotechnical interventions; their success in a clinical environment is dependent on more than technical performance alone (Elish Citation2018). Yet, most research in ML focuses heavily on performance metrics and technical validation (Birhane et al. Citation2021), with limited attention to experimental methodology as the foundation for justified empirical claims. Practices of responsible ML (e.g., see Wiens et al. Citation2019) are increasingly adopted, recognizing these as essential precursors to good model development. However, responsible algorithmic (technical) validation does not provide the kind of information that establishes knowledge about the model’s impact on true clinical outcomes. More broadly in healthcare, van Calster et al. (Citation2021) note that inadequate methodology underlying clinical evaluation can constitute research waste and lead to urgent ethical concerns. To align ML-enabled care with the standards by which we currently evaluate health technologies we must operationalize our commitment to patients’ best interests by establishing the appropriate empirical basis for their use.
Regulators have a role to play in this process by establishing appropriate evidential norms for licensure. For example, AI products are being incorporated into frameworks regulating software as a medical device (SaMD) in the USA, Canada, the UK, and Australia. The role of regulatory bodies responsible for evaluation under these frameworks is to ensure the basic level of safety and efficacy required for licensing and market entry (Harvey and Gowda Citation2020). Achieving these standards, however, does not ensure that AI actually benefits patients, clinicians, or healthcare systems (Topol Citation2020). Furthermore, it is important to recognize that regulatory bodies do not currently provide normative guidance as to what kind of evidence constitutes sufficient demonstration of safety and efficacy of AI, leading to concerns for patient safety when algorithms are deployed at scale (Wu et al. Citation2021; Hernandez-Boussard, Lundgren, and Shah Citation2021). Wu et al. note in a recent review that nearly all (126 of 130) FDA-approved AI devices relied only on retrospective studies, and of the 54 high-risk devices none had prospective studies supporting their safety and efficacy. The exemption of some AI-enabled devices from premarket review has been flagged by some scholars as a potential risk of harm to patients—particularly marginalized ones (Ferryman Citation2020)—and poses a concern regarding the long-term trust and viability of AI in healthcare (Hernandez-Boussard, Lundgren, and Shah Citation2021; Zou and Schiebinger Citation2021).
The efforts of regulators notwithstanding, therefore, a comprehensive approach to evidence generation for clinical AI is urgently needed to ensure that individual tools reliably and demonstrably augment the health of patients and the efficacy of the healthcare system beyond the demonstration of good technical performance (Park et al. Citation2020).
Historically, as noted above, the evidence for putatively successful ML models has derived largely from a purely “algorithmic” approach to validation. This reality led to calls for increased rigor in methodology, study design, and reporting of trials evaluating ML (Faes et al. Citation2020; Liu et al. Citation2019; Nagendran et al. Citation2020; Watkinson et al. Citation2021). To date, however, few prospective, controlled studies of clinical ML models have been conducted—though, promisingly, the number is steadily rising. Moving forward, responsible evaluation, validation, and clinical integration of clinical ML require the same stepwise approach, and sound research methods, seen in other areas of clinical research—adapted for ML approaches.
Ethics
On the ethics side, the culture clash between ML and clinical science has been driven by a number of factors. Historically, the development of modern ML methods has involved the use of large, open datasets, at times without participant consent. The ethical and legal norms associated with access to the personal health data required for healthcare ML could not be more different. The acculturation within the ML community to open access and data availability has led to frustration with the relatively protectionist policies surrounding access to health data. The lack of data availability has undoubtedly been an impediment to progress in ML research, which has struggled to find a practicable way of leveraging the valuable insights that a more systematic approach to data-driven research might offer. The tension between enabling access to data while protecting participants’ rights has escalated a debate about the value and operationalization of informed consent (reviewed in Mittelstadt and Floridi Citation2016). Questions about the reasonable bounds between research and practice, level of risk, and how to obtain consent are all active areas of ethical inquiry.
The history of clinical research more generally is also salient here. The development of research ethics was driven by a long history of sometimes horrific ethical failure. From the gruesome experiments conducted on prisoners by Nazi physicians during the Second World War, to the U.S. Public Health Services Tuskegee Syphilis Study conducted without participant consent, to present-day concerns about distributive inequities and the underrepresentation of racialized persons in clinical research, clinical science and medicine long grappled with the ethical challenges associated with clinical research. National and International guidelines and regulations committed to respect for persons, beneficence, non-maleficence, and justice (e.g., The Nuremberg Code, 1947; The Declaration of Helsinki, 1964; The Belmont Report, 1979), and the institutional structures required to operationalize these commitments, have been developing since the middle of the 20th century. Several scholars have noted that big data research subjects are in need of even more robust protections in light of the novel risks of ML/big data methods (Ferretti et al. Citation2021; Metcalf and Crawford Citation2016; Sula Citation2016).
As ML researchers increasingly grapple with the ethical implications of their methodology and practices, it is essential that we move forward with a strong grasp of the past and its relevance to current practice (Ferretti et al. Citation2021; Vayena et al. Citation2016). Looking at historical practices in healthcare research highlights the risks of reducing oversight for the sake of efficiency and innovation. What is required is a solution that fits the novel methodology of ML while upholding the ethical principles that underlie modern research ethics (Emanuel, Wendler, and Grady Citation2000). For example, Ferretti et al. (Citation2021) provide an informative overview of research ethics oversight with respect to big data, identifying aspects that require improvement in light of the novel risks posed. We apply a similar approach to the oversight and development of healthcare ML in this paper.
The basic ethical challenge in the clinical context is that the addition of an ML model to an extant clinical workflow may involve significant departures from the standard of care, with attendant risks. By contrast, quality improvement (QI) is typically undertaken to improve a process or intervention that is already known to be beneficial to patients (Lynn Citation2004). The relatively minimal oversight of QI is therefore predicated on the assumption that the benefits and risks of the interventions under study are already known and empirical support justifies its use inpatient care (Baily et al. Citation2006). We now know that ML interventions are subject to automation bias, fairness issues, and other unintended secondary effects (e.g., over-reliance, automation bias; Tschandl et al. Citation2020) that may exacerbate these risks. There is also the accepted fact that models will inevitably be imperfect, and knowing precisely under what circumstances they ought to be considered authoritative is an empirical question that requires robust evidence, particularly when model outputs may override clinical judgment.
Fulsome evaluation of the model’s performance is, therefore, of utmost importance to patient safety, clinical, medicolegal and institutional accountability. Generally, the rationale for undertaking prospective clinical research is to systematically establish the causal influence of an intervention on a particular outcome. Randomization traditionally provides the best means for controlling for confounders to accurately measure this effect in the complex causal web of healthcare (Hernán, Hsu, and Healy Citation2019). Compared with observational studies, controlled experiments (meaning here quasi-interventional and interventional studies) are less likely to commit type I (false negative) and type II (false positive) errors, and more likely to produce reliable quantification of risks or harms. Fulsome evaluation, therefore, involves strong methodological paradigms to control for biases and support valid inferences about the model’s effects on clinically relevant outcomes.
In short, prospective clinical research is necessary for both scientific and ethical reasons to justify the clinical translation of ML to the bedside. Patients will ultimately bear the risks of participation in ML research and for this reason, the process requires oversight. But a de novo system of oversight is not necessary; the longstanding system of institutional ethics oversight for clinical research can be adapted to health care ML.
Scope
It is important to acknowledge that the arguments of this paper, and the pathway we describe here, are intended to focus on a subset of all potential activities underlying the evaluation of healthcare ML. There is a wide array of potential applications of AI in healthcare, from administrative to a full-scale randomized clinical trial, not all of which require research ethics oversight. In brief, we are concerned with clinical ML research involving human subjects (and/or their data) It is beyond the scope of this paper to provide a precise account of the distinction between “clinical” and “non-clinical,” or “research” and “non-research,” precisely because these distinctions are complex and, to some extent, challenged by the methods of ML (refer to Box 1). Paradigmatically (not precisely or exhaustively), by “clinical” ML we mean models that are directed toward “the observation and treatment of actual patients rather than theoretical or laboratory studies” (Oxford Dictionary). Purely administrative applications of ML, e.g., algorithms for assigning billing codes to clinical encounters, are not obviously clinical in this sense and would, therefore, be exempt from research ethics review. By “research,” as the above suggests, we mean (again, paradigmatically—not precisely or exhaustively) the evaluation of ML models intended to influence care management for patients, where the benefits and risks of the intervention are unknown.
Box 1 Definitions of Human Subject Research.
The Belmont Report 1979: “An activity designed to test a hypothesis, permit conclusions to be drawn, and thereby to develop or contribute to generalizable knowledge (expressed, for example, in theories, principles, and statements of relationships). Research is usually described in a formal protocol that sets forth an objective and a set of procedures designed to reach that objective.”
Federal Policy for the Protection of Human Subjects 2018 (§46.102(l)): “Research means a systematic investigation, including research development, testing, and evaluation, designed to develop or contribute to generalizable knowledge.”
Tri-Council Policy Statement-2, 2018 (Article 2.1): “‘Research’ is defined as an undertaking intended to extend knowledge through a disciplined inquiry and/or systematic investigation. The term “disciplined inquiry” refers to an inquiry that is conducted with the expectation that the method, results and conclusions will be able to withstand the scrutiny of the relevant research community.”
Some examples of investigations that may be exempt from ethics review include quality improvement or quality assurance studies like program evaluation activities, reviews or testing within the usual educational requirements, and some secondary research (TCPS2, Article 2.5; CFR §46.104).
Finally, it is important to acknowledge that legally, only publicly funded human subjects research is required to undergo research ethics review. Since a large share of ML products are developed in the private sector, many of these products can and may be developed in the absence of research ethics oversight—a gap that some have highlighted as an ethical vulnerability (Vayena and Blasimme Citation2018). Though the scope of research ethics (in the US) has always been legally delimited in this way, it has nonetheless functioned to protect the interests of research participants in publicly funded research. Furthermore, the credibility of novel clinical ML applications will likely turn on the publication of well-designed studies in peer-reviewed medical journals. Most medical journals require evidence of research ethics review as a condition of publication, whatever the funding source. Ultimately, the success of clinical ML will likely depend on the close collaboration of computer scientists with clinicians and clinical researchers in actual clinical contexts. Entry into these contexts by ML researchers (funded publicly or privately) will necessitate the acceptance of the norms of evidence and ethics that prevail in those contexts (with some adaptation on both sides).
A RESEARCH ETHICS FRAMEWORK ENABLING CLINICAL TRANSLATION OF ML
Having previously described our translation pipeline (McCradden, Stephenson, and Anderson Citation2020), we herein describe the ethical analysis supporting the framework. The pipeline describes the research oversight of the initial development and evaluation of ML systems and involves three stages: (1) exploratory ML research; (2) silent period evaluation; and (3) prospective clinical evaluation (). These steps are not necessarily sequential—they may be iterative and overlapping, as stage 1 can lead to several different models proceeding through the silent trial and prospective clinical evaluations stages. We grant that individual institutions hold varied practices regarding the procedures for institutional review board (IRB)/research ethics board (REB) applications. This pathway is not intended to proscribe a method of application, merely to identify the salient issues from a research ethics perspective ().
Figure 1. An evidentiary hierarchy for healthcare ML research.
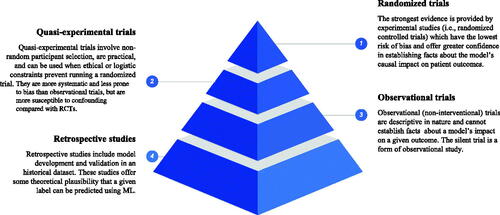
Table 1: Scientific objective, methods, and core ethical principles of research in the ML pipeline
Phase 1: Exploratory ML Research
Developing an AI intervention for a healthcare involves a hypothesis-generating exploration of historical data to identify patterns in data that are relevant to health outcomes which may be mapped with an ML approach. These data sources are clinical since it is now widely recognized that administrative datasets offer little possibility of enabling the development of point-of-care models that are sufficiently personalized. Model development begins with exploring and understanding the data with which one will work and, in conjunction with clinicians, identifying relationships therein to develop clinically actionable models.
In practice, model development consists of obtaining and cleaning data, the application of pre-processing methodologies, and the training of the model on a portion of the dataset. This training phase establishes the initial model (a mathematical function describing the mapping of inputs to outputs) which is then tested on the unseen portion of the original dataset or an external dataset. Controlling for “dataset shift”—testing for the ability to generalize beyond the initial training data—necessitates multiple batches of data, and potential external validation as well.
In line with previous commentators (Larson et al. Citation2020), we suggest that this computational work is consistent with the secondary use of health data stipulations afforded by most research ethics guidelines and have proposed the use of data access protocols for these purposes. Some modifications are required for practical purposes and to facilitate a proportionate review of exploratory ML research. The benefit of this approach is that it is feasible for healthcare institutions and independent groups to utilize healthcare data sources in the absence of a more robust data storage and retrieval infrastructure. While many institutions are considered learning health care systems with embedded, systematic data access for research purposes, this is not the case for all.
Big data access protocols can be adapted to facilitate health data research while still maintaining a high standard of accountability, data privacy and confidentiality (Vayena and Blasimme Citation2018). Data governance rather than project-specific application allows for the flexibility and breadth required for effective clinical ML work. These protocols are similar to those governing other retrospective health data research in terms of privacy protections, de-identification processes, and data retention practices, but with a number of differences specific to ML projects. First, data sources will be clinical data repositories such as electronic health record databases, imaging databases, and others. Second, data drawn from these repositories will be routine and frequent. Replenishing data enhances the model overall, but also allows for continuous updating in response to changing trends, policies, or other dynamic local factors, thus mimicking the clinical scenario in which the model will function if successful. Third, the methodology and hypotheses will not be specified at the outset (elaboration below).
Exploratory data science projects have colloquially been referred to as “fishing expeditions.” This characterization reflects the appearance that ML researchers are simply looking through the data to find some functional mapping they can characterize in a meaningful way without declaring a hypothesis up front. Data science projects do not always focus on determining a priori what the research question will be, and what methodology will be used (beyond simply the use of ML). For ML applications, this approach avoids making assumptions about the data, the relationships between variables, and the possible tasks that can be predicted to preserve the integrity of the relationships within the data, avoiding a priori assumptions that could bias model development. ML researchers also ideally refrain from assuming certain outcomes can be predicted, given that concerns about data quality, completeness, and/or validity may prevent the development of a good model (Wiens et al. Citation2019). Such assumptions can result in motivational bias, where the researcher continues to modify a model to maximize accuracy, which may end up “over-fitting” (learning idiosyncratic noise specific to a dataset rather than a fundamental signal) or lose its scalability and representativeness. As such, a common method is that the research team works with the data that is available and tests different approaches to generate hypotheses and the corresponding predictive models, whether or not it has value to clinicians, and is clinically actionable. A collaborative, iterative approach supports an exploration that is goal-oriented (benefiting patients), clinically actionable, and feasible for implementation.
An ethical challenge here is that secondary use often involves an obligation to minimize the amount of PHI collected to minimize privacy infringement (Larson et al. Citation2020). Traditionally, researchers specify the fields they want to extract, and each form of PHI must be justified for extraction. ML researchers can do this as well, but it is problematic given that they do not know what will be relevant for the model to maximize its accuracy and actionability. For example, a desire to avoid visit dates in the dataset and the assumption that these will not be relevant can prevent ML researchers from uncovering trends related to practice changes, policy implementation, and even change in personnel that impact task prediction.
A second challenge to the secondary use characterization is that the secondary use framework was not intended to address a prospective approach to research with clinical data. To adopt the above justification and at an institutional level is somewhat out of keeping with the original intent of the guidelines, which was for retrospective secondary use of data collected for other purposes. Prospectively, consent for use of health data for research purposes is both feasible and practical (though some questions remain; Vayena and Blasimme Citation2018). Whether consent should be required for research involving health data is a matter of substantial debate, and we do not take a particular position in this paper. The secondary use approach can apply in the absence of a means of socially licensed, prospective legal or institutional guidelines for the routine utilization of health data, and may be well-suited to institutions lacking an institutional approach to data access. These considerations may additionally be modified given an institution’s ability to utilize privacy-preserving practices (Scheibner et al. Citation2021).
Reassuringly, quantitative and qualitative research worldwide has demonstrated that a significant majority of the general public support the use of their health data for research purposes, under specific conditions (McCradden et al. Citation2020a,Citationb). These conditions are typically: (1) that their data does not leave the institute or affiliated research centers; (2) that it is not sold; (3) that patients are approached and asked should any unforeseen uses arise (e.g., commercialization of data). Violating these conditions can lead to long-term damage to the trust of healthcare institutions (Emanuel, Wendler, and Grady Citation2000; McCoy, Joffe, and Emanuel Citation2020; Ploug Citation2020). We suggest that, at a minimum, transparent disclosure to patients should be required regarding the use of health data for research. As noted by Vayena and Blasimme (Citation2018), ethical obligations to data subjects extend beyond being granted access to data. The extension of ethical and legal guidance with respect to the use and protection of data collected for clinical purposes is urgently needed to ensure consistency and clear expectations from the public as to the uses of their health information.
Phase 2: The Silent Evaluation
As noted previously in the background section of this paper, the well-recognized gap between a model developed on historical data and its real-world performance has made it apparent that additional validation is needed prior to clinical implementation. The silent period (also referred to as a shadow evaluation) bridges this gap by allowing the model to be tested in a live environment without directly informing the care of patients prior to demonstrating validity (Wiens et al. Citation2019). In this section, we consider how silent evaluations may fit under a research paradigm and how this may be handled procedurally.
Similar to preclinical testing in biomedical research, the silent period is analogous to a prospective non-interventional trial, testing whether the model can predict trends or events for patients in real-time. To answer this question may require: (1) a technical indicator of performance (model validity); (2) a real-world/on-the-ground indicator of performance (ecological validity). Even the most robust models may experience a drop in performance in the deployment environment, and predictions at this stage are masked (akin to blinding) to the clinical or treating team to prevent biasing the care of the patient. A research team assesses predictions against a given reference standard or other real-world biomarkers (e.g., human annotation, confirmatory testing, future true outcome; Channa et al. Citation2021) to establish clinical accuracy and other values (e.g., positive and negative predictive accuracy, false positives and negatives, etc). The model undergoes calibration and additional validation steps to ensure technical quality required to establish the ecological validity of the model. For example, Park et al. (Citation2020) identify the importance of proof-of-concept testing, potential harm identification, usability testing, and ethnographic methods which may fall under the scope of a silent evaluation.
While a silent period will be utilized for nearly all ML models applied in healthcare, not all silent evaluations fit the definition of “research” per se. We utilize the term “silent trial” to refer to silent evaluations which will fit the definition of research in this regard (See Box 1). Many applications of technology in medicine are validated without research ethics oversight (e.g., technical validation of lab tests, administrative algorithms). Notably, however, this is generally reserved for technologies that have already been approved for routine use on the basis of some demonstration of validity. The distinguishing feature that differentiates many of these applications from the silent trials is that the latter are attempting to capture on-the-ground/clinical validation (not just technical validation). Technical validation alone is a goal that is readily accomplished under Phase 1 through a data governance framework and would not require a novel step in the pathway.
Procedurally, from an ethics review perspective, some trials may involve identical parameters to the data governance phase. When this occurs, it may be reasonable to consider the silent trial as an extension of the data governance phrase, which includes the validation and development of models. In this case, silent evaluation may be a component of this validation process and would not constitute a new research project requiring its own application for ethics review. In other cases, a silent trial may involve exploration of qualitative and quantitative factors surrounding the implementation-related goals of the trial (e.g., human factors, workflow evaluation, clinical acceptability and ease of use). Where silent evaluations may require recruiting participants, expanding to new data sources, or presenting novel risks beyond those articulated in Phase 1, they may require independent ethics review. This decision will be at the discretion of the ethics review boards.
ML models are complex sociotechnical interventions; their success in a clinical environment is dependent on more than technical performance alone (Elish Citation2018). The assessment of a model’s utility may include testing different interfaces, processes and guidelines for use, and refinement of the patient cohort for which it is used. Failure to account for the interdependent factors which hamper an intervention’s success can both result in negative and positive trials without a strong understanding of why and how this result was obtained (Campbell et al. Citation2007). A less comprehensive evaluation during the silent stage may increase the risk of a negative trial result, having insufficiently mapped out the considerations relevant to prospective clinical evaluation. Campbell and colleagues (Citation2007) offer a preclinical evaluative framework which helps researchers determine the appropriate form of prospective evaluation and the combination of environmental factors, processes, and parameters that support the proposed intervention. Procedurally, a silent trial protocol should allow for some iteration and flexibility in the silent period to identify the optimal combination of factors that will support prospective evaluation.
We have previously suggested that the ethical goal of the silent period is to establish clinical equipoise. Clinical equipoise is widely regarded as the moral foundation of the randomized controlled trial (RCT). Absent equipoise, RCTs create an ethical dilemma for clinicians, a conflict between their commitment to research and their commitment to providing care in the best interests of their patients. Since care is randomly assigned in an RCT, offering enrollment appears to be inconsistent with their duty of care. Equipoise resolves this tension by insisting that a trial is morally justified only if there is honest disagreement in the expert community about which of the interventions under study is preferable. Under these conditions, an offer of enrollment is consistent with the clinician’s duty of care (Freedman, Citation1987).
Though the RCT dilemma is specific to the RCT, a similar dilemma arises for clinicians whenever a novel intervention is studied in/on their patients and the criteria for an assignment are not based on individual patient characteristics. Under such circumstances, responsible clinicians must assure themselves that they are not disadvantaging their patients by offering enrollment in the study. In order for clinical equipoise to arise, there must be evidence that the novel intervention is as good as or better than the status quo. This is a key point for healthcare ML. There is an ethical imperative to remain epistemologically and practically consistent with clinical evidentiary standards (Chin-Yee and Upshur Citation2019) and those with successful ML-based clinical decision support tools have noted this as a key facilitator of successful translation (Drysdale et al. Citation2020). Particularly where equipoise is concerned, beliefs about ML’s superiority must be grounded in clinical evidence. Running the model in a silent period is the first step in this (empirical) process. If and when this evidence generates clinical equipoise (i.e., genuine uncertainty in the expert community about the preferability of unassisted care), model validation may proceed to the final phase of validation: prospective clinical evaluation.
As noted by others (Campbell et al. Citation2007), there is an additional possibility that the evidence for a given intervention is so strong that randomization is not ethically supported, and equipoise is surpassed. This determination will only be possible by complying with a rigorous empirical evaluation during the silent trial. The strength of evidence generated through the silent trial can also inform IRB/REB determinations of the requirements (or waiver) for informed consent, disclosure to participants, and whether the design is ethically justified (e.g., randomization).
Additional Applications of the Silent Period
Many applications are developed outside of healthcare institutions where research ethics compliance is not required (Nebeker, Torous, and Bartlett Ellis Citation2019). We have described the importance of the local context for ML models and the inevitable performance discrepancy that will result from the model’s application outside of its home environment. This reality poses a challenge for institutions planning to implement a system that has been developed and validated elsewhere. A silent trial may offer a means to verify the retention of ecological validity in the new setting.
Proceeding down the ML pipeline anew is likely not necessary, but institutions may want to run the model in silent mode prior to committing to its use in clinical practice. This stopgap can ensure the model will perform adequately in this new population, be feasible within the clinical workflow, and attain a comparable performance to that described in trials elsewhere. This measure is particularly important as there is variable regulation of ML products, and best practices are not fully established within the community. Further, even well-validated models may suffer from “dataset shift” when the population characteristics differ more significantly from the conditions under which the model has been previously validated (Finlayson et al. Citation2021). We suggest that institutions take this step to protect patients from unintended harms as well as protect their institutional reputation. Ethics review can prioritize a focus on the protection of research subjects and may or may not decide to waive informed consent requirements, informed by prior evidence where available.
Stage 3: Prospective Clinical Evaluation
Once equipoise is established and there is genuine uncertainty among the relevant community as to whether the model’s use could be superior to the status quo, prospective clinical evaluation should be initiated. This step is necessary because, by definition, a model’s impact on the patient is not being evaluated during the silent trial. The initiation of prospective studies (observational, quasi-interventional, and interventional) should be predicated on sufficient performance and destabilization of our confidence in the current standard. The central research question is whether the model, as a healthcare intervention, can independently influence patient outcomes. The comparisons between the model’s predictions and how it might have affected care management are hypothetical and require formal testing to provide evidence of the model’s effect on patient outcomes. The empirical rigor offered by conducting these trials allows for a thorough collection of information necessary to make evidence-based decisions to maximize the benefits of the implementation while offsetting potential downstream effects.
Trial Methodologies and Empirical Rigour
Significant concerns have been raised about the level of rigor in methodology, study design, and reporting of trials evaluating ML thus far (Faes et al. Citation2020; Liu et al. Citation2019; Nagendran et al. Citation2020). The recently published standardized reporting guidelines for clinical trials evaluating an ML/AI intervention’s impact on patient outcomes are essential to advancing the field (Cruz Rivera et al. Citation2020; Liu et al. Citation2020). Several authors advocate for the use of RCTs to evaluate ML (Topol Citation2020; Angus Citation2020; Harvey and Oakden-Rayner Citation2020). We suggest that the type of trial design should be selected to maximize the strength of evidence by which one can determine the effect of the ML intervention on a given outcome, and adjusted for practical and ethical constraints. The traditional hierarchy of evidence-based medicine (EBM) describes the strength of evidence according to trial design. In we share an analogous hierarchy of evaluative paradigms for evidence supporting clinical ML applications. The Grading of Recommendations Assessment, Development and Evaluation (GRADE) system was developed to standardize the reporting of trial outcomes to promote transparent, consistent conclusions made on the basis of evidence (Atkins et al. Citation2004). The importance of attending to the quality of evidence is essential both to prevent significant harm to patients and to ensure rapid translation of beneficial tools. There is no obligation to do any particular kind of clinical trial for ML interventions, but the strength of one’s conclusions regarding the impact of the model must be related to the methodology one used and the research question being tested. The methodology and quality of prospective evaluation determine the justified claims one can make about the impact of the intervention being evaluated.
Critiques of the EBM pyramid often highlight that RCTs are not appropriate in many contexts, and, clearly, this may be the case for ML as well. We stress that design choice should be driven by consideration of both the kind of evidence one needs (or the questions one is asking) and the constraints of the environment. While specific recommendations regarding trial design according to intervention type are beyond the scope of this paper, here we highlight the variety of potential prospective validation at researchers’ disposal to demonstrate evidence of efficacy with respect to patient outcomes.
Again, the reason for prospective, controlled evaluation of ML interventions is to establish their independent influence on a particular patient outcome. RCTs provide the strongest evidence for drawing conclusions about the efficacy of an intervention. As noted above, however, RCTs can be unfeasible and even unethical in some circumstances. In some cases, they are simply not the best design to test the relevant hypothesis of interest.
Prospective observational trials offer a valid alternative to the RCT when the latter is inappropriate. Justified causal inference can be made on the basis of observational data, given robust, rigorous, and replicable analyses (Franklin et al. Citation2021; VanderWeele Citation2020). Some argue that well-designed longitudinal studies, when properly conducted, can provide robust evidence for elucidating causal relationships (VanderWeele Citation2020). Others offer a set of suggestions for valid inference where nonrandomization is used in a study on medical treatment (Franklin et al. Citation2021). Many ML models may be reasonably evaluated under observational paradigms to establish certain facts about their ability to predict real-world events reliably, and the bounds of these predictions. Moreover, the cost and feasibility of clinical trials is a notable barrier to such evaluation in many contexts (Morse, Bagley, and Shah Citation2020). Standardized reporting is even more important here to promote replicability and reproducibility of research, enhancing the overall level of confidence in a particular ML system through a convergence of studies evaluating their clinical utility.
Rigorous testing of a model’s clinical impact is essential to inform the risk-benefit profile of the intervention both at the patient care level and at a systems level. Furthermore, securing this level of evidence may be essential for medical-legal accountability. Many models enable early intervention, which is often presumed an unequivocal “good,” and yet the evidence does not always bear this out. For example, advanced cancer screening has proven controversial despite its technical accuracy; at a population level, it has often contributed to needless anxiety, increased healthcare costs, and provided little value to no value to patients and loved ones (Shieh et al. Citation2016). More recently, a presumed low-risk study assessing an e-alert intervention for treating kidney disease found the intervention arm had a higher rate of mortality than the control arm (Wilson et al. Citation2021; Wilson Citation2021). An additional motivation for prospective clinical evaluation is the responsible use of healthcare dollars. Morse et al. (Citation2020) note the substantial cost of implementing ML and suggest careful consideration of the impact to workflow should guide decisions to avoid unjustified costs that provide no clinical benefit or value.
ML and Risks
ML models may introduce novel risks compared with the status quo by changing the clinical decision-making process, particularly with respect to the potential for over-reliance and automation bias (Bond et al. Citation2018; Goddard et al. Citation2012; Jacobs et al. Citation2021; Lakkaraju and Bastani Citation2020; Tschandl et al. Citation2020). While there is certainly not a paucity of biases in standard care, we are ethically obligated to do all we can to minimize or prevent new biases that arise with novel technologies. In some cases, there may be secondary, unintended effects. For example, one algorithm designed to reduce primary inpatient admissions for UTIs did just that, but increased secondary admissions twofold (Stalenhoef et al. Citation2017). There is widespread recognition that they may also present challenges to fairness with respect to minoritized groups which poses a threat to equitable ML-enabled healthcare (Benjamin Citation2019; Chen et al. Citation2020; McCradden et al. Citation2020; Obermeyer et al. Citation2019). Correcting for discrepancies in outputs will not necessarily lead to better clinical outcomes for disadvantaged patients and prospective clinical evaluation provides the best means to evaluate the true impact on patients.
Importantly, review boards should recognize that ML-related risks will not be evenly distributed; neither, however, should the status quo or reference standard be assumed to be neutral (Vyas, Eisenstein, and Jones Citation2020). Risk, from a research ethics perspective, relates to the probability and severity of harm that may occur pursuant to a research project (Kimmelman Citation2004). Clinical ML has opened a window into risks that were not previously systematically characterized. One example is that of pernicious bias, which refers generally to when patterns of social inequality influence ML outputs in a non-causal manner that potentially exacerbates the relative disadvantage of these patients. Numerous examples now exist and the problem has been well-characterized in the “Fair ML” literature from a technical perspective. To illustrate the stakes, Ziad Obermeyer et al. (Citation2019) uncovered how a commonly used algorithm that allocates patients to a beneficial complex care management program was racially biased. The algorithm systematically disadvantaged Black patients, exacerbating existing inequities and effectively resulting in racial discrimination (Benjamin Citation2019). The recent attention to the plethora of “race corrections” in medicine (Vyas, Eisenstein, and Jones Citation2020) highlights the crossroads we face in medicine: the status quo in many contexts may itself be unfair, and for ML to improve care we must pay specific attention to how it will impact those most at risk of unfairness. Given that widespread inequalities exist within healthcare systems, some of which are medically relevant differences (e.g., patterns of genetic condition prevalence among particular ethnic groups), while others are bona fide inequities, a one size fits all approach to these issues is not likely possible.
From a research ethics perspective, two particular points should be noted to address the issue of risk: (1) IRB/REBs can add equity-based practices to their review process; (2) IRB/REBs can signal when external consultation is necessary to inform their risk assessment. Kadija Ferryman (Citation2020) advocates for an equity assessment as a core component of regulatory approval of ML models; we further suggest that researchers in healthcare adopt this as a best practice. A core component of these guidelines would include a positive duty on researchers to report on features such as representativeness of training data, model performance divided by subgroups, stakeholder involvement to support the algorithm development, data missingness, internal and external validation, and error analysis. IRBs/REBs evaluating ML protocols can require such reporting metrics (or justification of why they are not included) in their review process to assess potential risks and limitations. This addition would promote scientific consistency and inform the appropriateness of a model’s potential clinical integration. Boards should suggest to researchers when they need additional perspectives (e.g., social scientists, representatives from marginalized groups, under-served patient navigators and representatives) to better inform the project design and mitigate potential unforeseen risks (Mello & Wolf, Citation2010). IRB/REBs should aim for representation within their own board or among protocol reviewers to seek the advice of those with specific knowledge about equity (e.g., health equity researchers, ethicists, social scientists, etc). There is an added importance to attend to equity-based considerations, particularly when third parties may have access to data or when commodification is possible (Fox Citation2020).
An additional, note-worthy consideration for review boards is demonstrated by the National Institute of Health (NIH)’s All Of Us research initiative for precision medicine’s approach to broadening the review process to incorporate considerations of stigmatizing research (2010). Some ML work has received significant criticism in relation to the disproportionate implications for oppressed and disempowered groups. For example, facial image recognition has generated substantial controversy outside of healthcare, with groups like the Academy of Computing Machinery calling for an outright ban on this work (ACM U.S. Technology Policy Committee Citation2020; Raji et al. Citation2020). Yet, ML-enabled processing of facial images can have beneficial applications in the context of certain clinical tasks (McCradden, Patel, and Chad Citation2021). An ethics review process could seek to balance the risks and implications identified by the technology in general to justify the use of the same technology in a research endeavor.
Informed Consent
For the reasons outlined above, we take it as a given that informed consent to participate in a study involving prospective clinical evaluation of ML tools would be prima facie required. Notably, IRB/REBs may elect to waive informed consent under specific circumstances or in relation to particular activities. For example, Faden et al. (Citation2013) argue that informed consent is not always a necessary condition for low-risk interventional research. It is important to recognize that despite a relatively ubiquitous characterization of ML being low risk, even “low-risk” interventions can entail higher mortality in the intervention group (Wilson Citation2021). There are a plethora of consent models advocated within the literature, and none of which could plausibly apply to all the ML models evaluated through the process we articulate in this paper. As such, we do not advocate for a particular approach to consent in this article, but instead advocate for the involvement of the group most expert in determining consent models—namely, the IRB/REB—and would welcome peer commentary on this account. We note, however, that many notions of risk consider it to be uniform across all participants – yet, as indicated above, this is not the case for many ML models, nor for exploratory research. For some excellent reviews and commentaries on the topic, the reader is referred to Mittelstadt and Floridi (Citation2016), Grady et al. (Citation2015), Ploug and Holm (Citation2017), and Vayena and Blasimme (Citation2018).
CONCLUSION
This paper has proposed and justified a process by which evaluation and translation of ML models may be conducted using existing research ethics guidelines and associated privacy protections. We outline how the adapted process can still serve the fundamental ethical principles that underlie evidence-based research conduct. We consider this process an evolving one that will continue to adapt to the needs of this developing science and emerging institutional and legal guidelines that will emerge to accommodate novel technologies like healthcare machine learning. We look forward to commentary from our peers to share practices, insights, and learnings to enable a robust, trustworthy foundation for the clinical translation of ML systems grounded in clinical evidence.
The key challenge for the medical, clinical ethics, research ethics, legal, and scientific communities collectively is to explore the evidential and epistemic bases for integrating ML-based interventions into the healthcare workflow. As best practices evolve and reporting standards emerge that are specific to ML methodologies and AI interventions, it is incumbent upon researchers and ethics review boards to collaborate to ensure the necessary collective expertise informs the evaluation of ML research. Ultimately, all parties share the goal of bringing safe, efficient, and beneficial interventions to the bedside. To realize these goals, we cannot neglect the importance of grounding such claims in clinical evidence.
AUTHOR CONTRIBUTORS
MDM and JAA conducted the ethical analysis underpinning this framework and collaborated to conceptualize, develop, and write-up the first draft of this manuscript. LE, ED, and AG were involved in trialing the pathway at our institution. Their insights and experiences are reflected throughout this work and all provided important editorial contributions to the manuscript. EAS as the REB Chair led the implementation of the pathway and was accountable for establishing its alignment with current research ethics and institutional standards. RZS provided important ethical oversight and leadership to the planning and execution of this pathway and reviewed the manuscript for important editorial content.
ACKNOWLEDGEMENTS
The authors wish to acknowledge the involvement and support of Rose Gaiteiro, Andrea McCormack, Kathy Boutis, Mandy Rikard, Armando Lorenzo, Mjaye Mazwi, David Kenney, and Ian Stedman.
DISCLOSURE STATEMENT
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 In this paper, we will use the terms machine learning (ML) and artificial intelligence (AI) interchangeably, although ML will have the priority when referring to actual models or algorithms.
REFERENCES
- ACM U.S. Technology Policy Committee. 2020. Statement on principles and prerequisites for the development, evaluation and use of unbiased facial recognition technologies. Accessed June 30, 4 July 2020. https://www.acm.org/binaries/content/assets/public-policy/ustpc-facial-recognition-tech-statement.pdf.
- All of Us Research Program. 2020. Policy on stigmatizing research. Accessed December 5 2020. https://www.researchallofus.org/wp-content/themes/research-hub-wordpress-theme/media/2020/05/AoU_Policy_Stigmatizing_Research_508.pdf.
- Angus, D. C. 2020. Randomized clinical trials of artificial intelligence. JAMA 323(11):1043–5. doi: 10.1001/jama.2020.1039.
- Atkins, D., M. Eccles, S. Flottorp, G. H. Guyatt, D. Henry, S. Hill, A. Liberati, D. O'Connell, A. D. Oxman, B. Phillips, et al. 2004. Systems for grading the quality of evidence and the strength of recommendations I: Critical appraisal of existing approaches the GRADE Working Group. BMC Health Services Research 4(1):38. doi: 10.1186/1472-6963-4-38.
- Baily, M. A., M. M. Bottrell, J. Lynn, and B. Jennings. 2006. Special report: The ethics of using QI methods to improve health care quality and safety. Hastings Center Report 36(4)2006):S1–S40. doi: 10.1353/hcr.2006.0054.
- Benjamin, R. 2019. Assessing risk, automating racism. Science 366(6464):421–2. doi: 10.1126/science.aaz3873.
- Birhane, A., P. Kalluri, D. Card, W. Agnew, R. Dotan, and M. Bao. 2021. The Values Encoded in Machine Learning Research. arXiv preprint arXiv:2106.15590.
- Bond, R. R., T. Novotny, I. Andrsova, L. Koc, M. Sisakova, D. Finlay, D. Guldenring, J. McLaughlin, A. Peace, V. McGilligan, et al. 2018. Automation bias in medicine: The influence of automated diagnoses on interpreter accuracy and uncertainty when reading electrocardiograms. Journal of Electrocardiology 51(6):S6–S1. doi: 10.1016/j.jelectrocard.2018.08.007.
- Campbell, N. C., E. Murray, J. Darbyshire, J. Emery, A. Farmer, F. Griffiths, B. Guthrie, H. Lester, P. Wilson, A. L. Kinmonth, et al. 2007. Designing and evaluating complex interventions to improve health care. BMJ 334(7591):455–9. doi: 10.1136/bmj.39108.379965.BE.
- Channa, R., R. Wolf, and M. D. Abramoff. 2021. Autonomous artificial intelligence in diabetic retinopathy: From algorithm to clinical application. Journal of Diabetes Science and Technology 15(3):695–8. doi: 10.1177/1932296820909900.
- Chen, I. Y., E. Pierson, S. Rose, S. Joshi, K. Ferryman, and M. Ghassemi. 2020. Ethical machine learning in health. arXiv preprint arXiv:2009.10576.
- Chin-Yee, B., and R. Upshur. 2019. Three problems with big data and artificial intelligence in medicine. Perspectives in Biology and Medicine 62(2):237–56. doi: 10.1353/pbm.2019.0012.
- Cruz Rivera, S., X. Liu, A.-W. Chan, A. K. Denniston, and M. J. Calvert. 2020. Guidelines for clinical trial protocols for interventions involving artificial intelligence: The SPIRIT-AI extension. British Medical Journal 370: m3210. doi: 10.1136/bmj.m3210.
- Drysdale, E., E. Dolatabadi, C. Chivers, et al. 2020. White paper: Implementing AI in healthcare. Available: https://vectorinstitute.ai/wp-content/uploads/2020/03/implementing-ai-in-healthcare.pdf.
- Elish, M. C. 2018. The stakes of uncertainty: Developing and integrating machine learning in clinical care. Ethnographic Praxis in Industry Conference Proceedings 2018(1):364–80. doi: 10.1111/1559-8918.2018.01213.
- Emanuel, E. J., D. Wendler, and C. Grady. 2000. What makes clinical research ethical? JAMA 283(20):2701–11. doi: 10.1001/jama.283.20.2701.
- Faden, R. R., N. E. Kass, S. N. Goodman, P. Pronovost, S. Tunis, and T. L. Beauchamp. 2013. An ethics framework for a learning health care system: A departure from traditional research ethics and clinical ethics. Hastings Center Report 43(s1):S16–S27. doi: 10.1002/hast.134.
- Faes, L., X. Liu, S. K. Wagner, D. J. Fu, K. Balaskas, D. A. Sim, L. M. Bachmann, P. A. Keane, and A. K. Denniston. 2020. A clinician's guide to artificial intelligence: How to critically appraise machine learning studies. Translational Vision Science & Technology 9(2):7. doi: 10.1167/tvst.9.2.7.
- Ferretti, A., M. Ienca, M. Sheehan, A. Blasimme, E. S. Dove, B. Farsides, P. Friesen, J. Kahn, W. Karlen, P. Kleist, et al. 2021. Ethics review of big data research: What should stay and what should be reformed? BMC Medical Ethics 22(1):1–3. doi: 10.1186/s12910-021-00616-4.
- Ferryman, K. 2020. Addressing health disparities in the food and drug administration’s artificial intelligence and machine learning regulatory framework. Journal of the American Medical Informatics Association 27(12):2016–2019. doi: 10.1093/jamia/ocaa133.
- Finlayson, S. G., A. Subbaswamy, K. Singh, J. Bowers, A. Kupke, J. Zittrain, I. S. Kohane, and S. Saria. 2021. The clinician and dataset shift in artificial intelligence. The New England Journal of Medicine 385(3):283–286. doi: 10.1056/NEJMc2104626.
- Fox, K. 2020. The illusion of inclusion – the “All of Us” research program and indigenous peoples' DNA. The New England Journal of Medicine 383(5):411–413. doi: 10.1056/NEJMp1915987.
- Franklin, J. M., R. Platt, N. A. Dreyer, A. J. London, G. E. Simon, J. H. Watanabe, M. Horberg, A. Hernandez, and R. M. Califf. 2021. When can nonrandomized studies support valid inference regarding effectiveness or safety of new medical treatments? Clinical Pharmacology & Therapeutics. Published Online 7 April 2021. doi: 10.1002/cpt.2255.
- Freedman, B. (1987). Equipoise and the ethics of clinical research. New England Journal of Medicine 317;141–5.
- Goddard, K., A. Roudsari, and J. C. Wyatt. 2012. Automation bias: A systematic review of frequency, effect mediators, and mitigators. Journal of the American Medical Informatics Association 19(1):121–127. doi: 10.1136/amiajnl-2011-000089.
- Grady, C., S. R. Cummings, M. C. Rowbotham, M. V. McConnell, E. A. Ashley, and G. Kang. 2015. Informed consent. New England Journal of Medicine 372(9):855–862. doi: 10.1056/NEJMra1411250.
- Harvey, B. H., and V. Gowda. 2020. How the FDA regulates AI. Academic Radiology 27(1):58–61. doi: 10.1016/j.acra.2019.09.017.
- Harvey, H., and L. Oakden-Rayner. 2020. Guidance for interventional trials involving artificial intelligence. Radiology. Artificial Intelligence 2(6):e200228. doi: 10.1148/ryai.2020200228.
- Hernán, M. A., J. Hsu, and B. Healy. 2019. A second chance to get causal inference right: A classification of data science tasks. Chance 32(1):42–49. doi: 10.1080/09332480.2019.1579578.
- Hernandez-Boussard, T., M. P. Lundgren, and N. Shah. 2021. Conflicting information from the Food and Drug Administration: Missed opportunity to lead standards for safe and effective medical artificial intelligence solutions. Journal of the American Medical Informatics Association 28(6):1353–5. doi: 10.1093/jamia/ocab035.
- Hinton, G. 2018. Deep learning-a technology with the potential to transform health care. JAMA 320(11):1101–2. doi: 10.1001/jama.2018.11100.
- Jacobs, M., M. F. Pradier, T. H. McCoy, R. H. Perlis, F. Doshi-Velez, and K. Z. Gajos. 2021. How machine-learning recommendations influence clinician treatment selections: The example of the antidepressant selection. Translational Psychiatry 11(1):1–9. doi: 10.1038/s41398-021-01224-x.
- Keane, P. A., and E. J. Topol. E. J. 2018. With an eye to AI and autonomous diagnosis. NPJ Digital Medicine 1:40. doi: 10.1038/s41746-018-0048-y.
- Kelly, C. J., A. Karthikesalingam, M. Suleyman, G. Corrado, and D. King. 2019. Key challenges for delivering clinical impact with artificial intelligence. BMC Medicine 17(1):1–9. doi: 10.1186/s12916-019-1426-2.
- Kimmelman, J. 2004. Valuing risk: The ethical review of clinical trial safety. Kennedy Institute of Ethics Journal 14(4):369–93. doi: 10.1353/ken.2004.0041.
- Lakkaraju, H., and O. Bastani. 2020. “How do I fool you?” Manipulating User Trust via Misleading Black Box Explanations. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society 79–85.
- Larson, D. B., D. C. Magnus, M. P. Lungren, N. H. Shah, and C. P. Langlotz. 2020. Ethics of using and sharing clinical imaging data for artificial intelligence: A proposed framework. Radiology 295(3):675–682. doi: 10.1148/radiol.2020192536.
- Liu, X., L. Faes, A. U. Kale, S. K. Wagner, D. J. Fu, A. Bruynseels, T. Mahendiran, G. Moraes, M. Shamdas, C. Kern, et al. 2019. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. The Lancet. Digital Health 1(6):e271–97. doi: 10.1016/S2589-7500(19)30123-2.
- Liu, X., S. C. Rivera, D. Moher, M. J. Calvert, and A. K. Denniston. 2020. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: The CONSORT-AI extension. British Medical Journal 370: m3164.
- Lynn, J. 2004. When does quality improvement count as research? Human subject protection and theories of knowledge. Quality & Safety in Health Care 13(1):67–70. doi: 10.1136/qshc.2002.002436.
- McCoy, M. S., S. Joffe, and E. J. Emanuel. 2020. Sharing patient data without exploiting patients. JAMA 323(6):505–6. doi: 10.1001/jama.2019.22354.
- McCradden, M. D., A. Baba, A. Saha, S. Ahmad, K. Boparai, P. Fadaiefard, and M. D. Cusimano. 2020a. Ethical concerns around use of artificial intelligence in health care research from the perspective of patients with meningioma, caregivers and health care providers: A qualitative study. CMAJ Open 8(1):E90–5. doi: 10.9778/cmajo.20190151.
- McCradden, M. D., S. Joshi, M. Mazwi, and J. A. Anderson. 2020. Ethical limitations of algorithmic fairness solutions in health care machine learning. The Lancet. Digital Health 2(5):e221–3. doi: 10.1016/S2589-7500(20)30065-0.
- McCradden, M. D., E. Patel, and L. Chad. 2021. The point-of-care use of a facial phenotyping tool in the genetics clinic: An ethics tête-a-tête. American Journal of Medical Genetics. Part A 185(2):658–660. doi: 10.1002/ajmg.a.61985.
- McCradden, M. D., Sarker, T., and P. Paprica, A. 2020b. Conditionally positive: A qualitative study of public perceptions about using health data for artificial intelligence research. BMJ Open 10(10):e039798. doi: 10.1136/bmjopen-2020-039798.
- McCradden, M. D., E. A. Stephenson, and J. A. Anderson. 2020. Clinical research underlies ethical integration of healthcare artificial intelligence. Nature Medicine 26(9):1325–1326. doi: 10.1038/s41591-020-1035-9.
- Mello, M. M., and L. E. Wolf. 2010. The Havasupai Indian tribe case-lessons for research involving stored biologic samples. The New England Journal of Medicine 363(3):204–7. doi: 10.1056/NEJMp1005203.
- Metcalf, J., and K. Crawford. 2016. Where are human subjects in big data research? The emerging ethics divide. Big Data & Society 3(1): 2053951716650211.
- Mittelstadt, B. D., and L. Floridi. 2016. The ethics of big data: Current and foreseeable issues in biomedical contexts. Science and Engineering Ethics 22(2):303–41. doi: 10.1007/s11948-015-9652-2. Epub 2015 May 23. PMID: 26002496.
- Morse, K. E., S. C. Bagley, and N. H. Shah. 2020. Estimate the hidden deployment cost of predictive models to improve patient care. Nature Medicine 26(1):18–9. doi: 10.1038/s41591-019-0651-8.
- Nagendran, M., Y. Chen, C. A. Lovejoy, A. C. Gordon, M. Komorowski, H. Harvey, E. J. Topol, J. P. A. Ioannidis, G. S. Collins, and M. Maruthappu. 2020. Artificial intelligence versus clinicians: Systematic review of design, reporting standards, and claims of deep learning studies. BMJ 368: M 689. doi: 10.1136/bmj.m689.
- Naylor, D. C. 2018. On the prospects for a (deep) learning health care system. JAMA 320(11):1099–100. doi: 10.1001/jama.2018.11103.
- Nebeker, C., T. Torous, and R. J. Bartlett Ellis. 2019. Building the case for actionable ethics in digital health research supported by artificial intelligence. BMC Medicine 17(1):137. doi: 10.1186/s12916-019-1377-7.
- Obermeyer, Z., B. Powers, C. Vogeli, and S. Mullainathan. 2019. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366(6464):447–53. doi: 10.1126/science.aax2342.
- Park, Y., G. P. Jackson, M. A. Foreman, D. Gruen, J. Hu, and A. K. Das. 2020. Evaluating artificial intelligence in medicine: Phases of clinical research. JAMIA Open 3(3):326–31. doi: 10.1093/jamiaopen/ooaa033.
- Ploug, T. 2020. In Defence of informed consent for health record research-why arguments from ‘easy rescue. BMC Medical Ethics 21(1):1–3. doi: 10.1186/s12910-020-00519-w.
- Ploug, T., and S. Holm. 2017. Informed consent and registry-based research-the case of the Danish circumcision registry. BMC Medical Ethics 18(1):1–10. doi: 10.1186/s12910-017-0212-y.
- Raji, D. I., T. Gebru, M. Mitchell, J. Buolamwini, J. Lee, and E. Denton. 2020. Saving face: Investigating the ethical concerns of facial recognition auditing. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society 145–151.
- Sackett, D. L., W. M. Rosenberg, J. A. Gray, R. B. Haynes, and W. S. Richardson. 1996. Evidence based medicine: What it is and what it isn't. BMJ 312(7023):71–2. doi: 10.1136/bmj.312.7023.71.
- Scheibner, J., J. L. Raisaro, J. R. Troncoso-Pastoriza, M. Ienca, J. Fellay, E. Vayena, and J. P. Hubaux. 2021. Revolutionizing medical data sharing using advanced privacy-enhancing technologies: technical, legal, and ethical synthesis. Journal of Medical Internet Research 23(2):e25120. doi: 10.2196/25120.
- Shieh, Y., M. Eklund, G. F. Sawaya, W. C. Black, B. S. Kramer, and L. J. Esserman. 2016. Population-based screening for cancer: hope and hype. Nature Reviews. Clinical Oncology 13(9):550–65. doi: 10.1038/nrclinonc.2016.50.
- Stalenhoef, J. E., W. E. van der Starre, A. M. Vollaard, E. W. Steyerberg, N. M. Delfos, E. M. S. Leyten, T. Koster, H. C. Ablij, J. W. van’t Wout, J. T. van Dissel, et al. 2017. Hospitalization for community-acquired febrile urinary tract infection: validation and impact assessment of a clinical prediction rule. BMC Infectious Diseases 17(1):400. doi: 10.1186/s12879-017-2509-3.
- Sula, C. A. 2016. Research ethics in an age of big data. Bulletin of the Association for Information Science and Technology 42(2):17–21. doi: 10.1002/bul2.2016.1720420207.
- Topol, E. J. 2020. Welcoming new guidelines for AI clinical research. Nature Medicine 26(9):1318–20. doi: 10.1038/s41591-020-1042-x.
- Tschandl, P., C. Rinner, Z. Apalla, G. Argenziano, N. Codella, A. Halpern, M. Janda, A. Lallas, C. Longo, J. Malvehy, et al. 2020. Human-computer collaboration for skin cancer recognition. Nature Medicine 26(8):1229–1234. doi: 10.1038/s41591-020-0942-0.
- Van Calster, B., L. Wynants, R. D. Riley, M. van Smeden, and G. S. Collins. 2021. Methodology over metrics: Current scientific standards are a disservice to patients and society. Journal of Clinical Epidemiology 138:219–226. doi: 10.1016/j.jclinepi.2021.05.018.
- VanderWeele . 2020. Can sophisticated study designs with regression analyses of observational data provide causal inferences? JAMA Psychiatry 78(3):244. doi: 10.1001/jamapsychiatry.2020.2588.
- Vayena, E., and A. Blasimme. 2018. Health research with big data: Time for systemic oversight. The Journal of Law, Medicine & Ethics 46(1):119–29. doi: 10.1177/1073110518766026.
- Vayena, E., U. Gasser, A. B. Wood, D. O'Brien, and M. Altman. 2016. Elements of a new ethical framework for big data research. Washington and Lee Law Review Online 72(3): 420–441.
- Vyas, D. A., L. G. Eisenstein, and D. S. Jones. 2020. Hidden in plain sight – reconsidering the use of race correction in clinical algorithms. The New England Journal of Medicine 383(9):874–882. 2020. doi: 10.1056/NEJMms2004740.
- Watkinson, P., D. Clifton, G. Collins, P. McCulloch, and L. Morgan. 2021. DECIDE-AI: New reporting guidelines to bridge the development-to-implementation gap in clinical artificial intelligence. Nature Medicine. 27: 186–187
- Wiens, J., S. Saria, M. Sendak, M. Ghassemi, V. X. Liu, F. Doshi-Velez, K. Jung, K. Heller, D. Kale, M. Saeed, et al. 2019. Do no harm: A roadmap for responsible machine learning for health care. Nature Medicine 25(9):1337–40. doi: 10.1038/s41591-019-0548-6.
- Wilson, F. P. 2021. The challenge of minimal risk in e-alert trials. BMJ Blog, (2021). Available from: https://blogs.bmj.com/bmj/2021/01/18/the-challenge-of-minimal-risk-in-e-alert-trials/.
- Wilson, F. P., M. Martin, Y. Yamamoto, C. Partridge, E. Moreira, T. Arora, A. Biswas, H. Feldman, A. X. Garg, J. H. Greenberg, et al. 2021. Electronic health record alerts for acute kidney injury: Multicenter, randomized clinical trial. BMJ 372:m4786.
- Wongvibulsin, S., and S. L. Zeger. 2020. Enabling individualised health in learning healthcare systems. BMJ Evidence-Based Medicine 25(4):125–29. doi: 10.1136/bmjebm-2019-111190.
- Wu, E., K. Wu, R. Daneshjou, D. Ouyang, D. E. Ho, and J. Zou. 2021. How medical AI devices are evaluated: Limitations and recommendations from an analysis of FDA approvals. Nature Medicine 27(4):582–584. doi: 10.1038/s41591-021-01312-x.
- Zou, J., and L. Schiebinger. 2021. Ensuring that biomedical AI benefits diverse populations. Ebiomedicine 67:103358. doi: 10.1016/j.ebiom.2021.103358.