
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper presents matrix-exponential (ME) distributions, whose squared coefficient of variation (SCV) is very low. Currently, there is no symbolic construction available to obtain the most concentrated ME distributions, and the numerical optimization-based approaches to construct them have many pitfalls. We present a numerical optimization-based procedure which avoids numerical issues.
1. Introduction
Highly concentrated matrix-exponential functions play an important role in many research fields, for example, they turned out to be essential for numerical inverse Laplace transform methods as well.[Citation8]
The least varying phase type (PH) distribution of order N is known to be the Erlang distribution[Citation1] with SCV= (defined as
where
are the moments of the distribution). Much less is known about the least varying ME distribution for order N. It is known that for order 2 the class of ME distributions is identical to the class of PH distributions, and it is also known that there exists an order 3 ME distribution with SCV =
but it is still only a conjecture that this is the least varying order 3 ME distribution. Concentrated ME distributions are provided in Éltető et al.[Citation4] up to order 17 and in Horváth et al.[Citation7] up to order 47. These preliminary results indicate that, as N increases, the minimal SCV of order N ME distributions tends to be less than
for odd N, and for even N, the minimal SCV is close to the minimal SCV of order N – 1 ME distributions. In this paper, we propose numerical procedures by which much higher odd order concentrated ME distributions can be computed, and based on that, we refine the dependence of the minimal SCV on the order.
The rest of the paper is organized as follows. In Section 2, we provide the basic definition of the considered set of functions and the SCV. Section 3 presents an algorithm for efficient SCV computation of exponential cosine-square functions, while Section 4 introduces the numerical optimization procedure to obtain ME functions with low SCV. A heuristic approach with only 3 parameters is proposed in Section 5 and Section 6 concludes the paper.
2. Concentrated ME distributions
In this paper, we focus on real functions and a distribution on
Definition 2.1.
Order N ME functions (referred to as ME(N)) are given by
(1)
(1)
where
is a real row vector of size N, A is a real matrix of size N × N and
is the column vector of ones of size N,
is such that
and
for
According to Equation(1)(1)
(1) , vector
and matrix A define the ME function. We refer to the pair
as a matrix representation in the sequel. The matrix representation is not unique. Applying a similarity transformation with a nonsingular matrix T, for which
holds, we obtain vector
and matrix
that define the same ME function, since
(2)
(2)
Definition 2.2.
The SCV of the real function f(t) is defined as
(3)
(3)
where
for
According to Definition 2.2, the SCV is insensitive to multiplication and scaling, because and
(4)
(4)
Definition 2.3.
[Asmussen and Bladt[Citation2] and Asmussen and O’Cinneide[Citation3]] The probability density function of an order N ME distribution is an ME(N) function with the following properties: for
and
If f(t) is a density function of an ME distribution, then μi denotes the ith moment and the squared coefficient of variation (SCV) of the ME distribution. An ME distribution with density function f(t) is said to be concentrated if
is low.
Although ME functions have been used for many decades, there are still many questions open regarding their properties. Such an important question is how to decide efficiently if an ME function is non-negative for all t > 0. In general, does not hold for given
matrix representation for all t > 0, unless it has been constructed to be non-negative. In this paper, we are going to restrict our attention to such a special construction, the exponential-cosine square functions.
For the least varying ME(N) distributions only conjectures are available for [Citation4] According to the current conjecture, for odd N, the density function of the most concentrated ME(N) distribution belongs to a special class characterized by
where c1 and c2 are positive constants and
is an exponential cosine-square function defined below.
Definition 2.4.
The set of exponential cosine-square functions of order n has the form
(5)
(5)
where
and
for
Since the SCV is insensitive to multiplication and scaling, in the rest of the paper we focus on with
as defined in Equation(5)
(5)
(5) (that is, without normalization and scaling).
An exponential cosine-square function is defined by n + 1 parameters: ω and for
is an ME(
) function. Although the representation in Equation(5)
(5)
(5) , which we refer to as the cosine-square representation, is not a matrix representation, [Horváth et al.,[Citation7] Appendix A] presents the associated matrix representation of size
Consequently, the set of exponential cosine-square functions of order n define a special subset of ME(
) since
by construction, is non-negative. The SCV of
is a complicated function of the parameters, whose minimum does not exhibit a closed analytic form. That is why we have resorted to the following numerical problem. For a given odd order
we are looking for efficient numerical methods for finding the ω and
(
) parameters which result in a low
For efficient numerical minimization of the SCV for N > 47 (i.e., n > 23) we need
an accurate computation of the SCV based on the parameters with low computational cost and
an efficient optimization procedure with low computational cost.
In this paper we present a method that addresses i) in Section 3, and one that addresses ii) in Section 4.
3. Efficient computation of the squared coefficient of variation
To evaluate the objective function of the optimization problem, namely the SCV, we need efficient methods to compute μ0, μ1 and μ2. Deriving the μi parameters based on Equation(5)(5)
(5) is difficult for large N. Hence we propose to compute them based on a different representation.
3.1. The hyper-trigonometric representation
The following theorem defines the hyper-trigonometric form of the exponential cosine-square functions and provides a recursive procedure to obtain its parameters from ω and
Theorem 3.1.
An order exponential cosine-square function can be transformed to a hyper-trigonometric representation of form
(6)
(6)
where
and the coefficients
are calculated recursively:
for n = 1:
(7)
for
for
Proof.
The theorem is proved by induction. For the order cosine-square function we introduce the notation
For n = 1,
and the theorem holds. Assuming that the theorem holds for n – 1, we are going to show that it holds for n as well. We have that
Using the identities
and collecting the coefficients corresponding to
and
provides Equation(10)
(10)
(10) and Equation(11)
(11)
(11) . Terms from
at k = 1 contribute to
leading to
The relations for the boundaries can be obtained in a similar manner. □
The hyper-trigonometric representation makes it possible to express the Laplace transform (LT) and the μi moments for in a simple and compact way.
Corollary 3.2.
The LT and the moments of the exponential cosine-square function, for
, are given by
(12)
(12)
and
(13)
(13)
Proof.
Since Equation(6)(6)
(6) is linear, it can be Laplace transformed term-by-term using the relations
Based on the μi moments can be computed using the LT moment relation
In order to compute the matrix representation of the exponential cosine-square function, we introduce one more representation, and the associated transformation.
3.2. The spectral representation
The hyper-trigonometric representation makes it easy to obtain the spectral form of as
(14)
(14)
where
denotes the imaginary unit. We refer to Equation(14)
(14)
(14) as the spectral representation because these exponential coefficients are the eigenvalues of matrix A in the matrix representation.
3.3. The matrix representation
Corollary 3.3.
The function has a size
matrix representation
, where the row vector
is composed by the elements
(15)
(15)
(16)
(16)
(17)
(17)
and the matrix A is given by
(18)
(18)
where
, for
Proof.
According to Equation(18)(18)
(18) ,
(19)
(19)
where
(20)
(20)
Based on Equation(19)(19)
(19) and Equation(20)
(20)
(20) , we can write
(21)
(21)
which is identical with Equation(6)(6)
(6) . □
3.4. Numerical computation of the moments
Theorem 3.1 together with Corollary 3.2 provides a very efficient explicit method to compute the SCV based on the parameters
There is one numerical issue that has to be taken care of when applying this numerical procedure with floating point arithmetic for large values of n. To evaluate the SCV, coefficients need to be obtained from the ω and
parameters. The recursion defined in Theorem 3.1 involves multiplications between bounded numbers (sine and cosine always fall into
), which is beneficial from the numerical stability point of view, but subtractions are unfortunately also present, leading to a loss of precision. To overcome this loss of precision, we introduce increased precision floating point arithmetic both in our Mathematica and C++ implementations1.[Citation9,Citation10] Mathematica can quantify the precision loss, enabling us to investigate this issue experimentally. According to , the number of accurate decimal digits lost when evaluating the SCV from the
parameters (computed by the Precision function of Mathematica), denoted by Ln, is nearly linear and can be approximated by
(22)
(22)
Figure 1. The precision loss while computing the SCV.
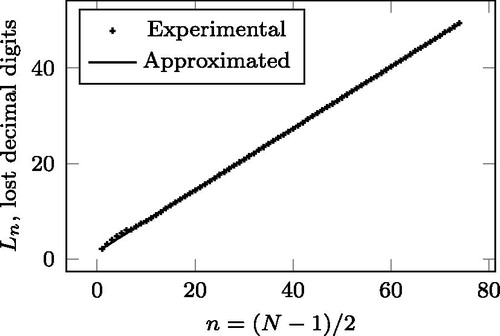
In the forthcoming numerical experiments we have set the floating point precision to decimal digits to obtain an accuracy of results up to 16 decimal digits, and this precision setting eliminated all numerical issues.
It is important to note that the high precision is needed only to calculate the coefficients and the SCV itself. Representing parameters
themselves does not need extra precision, and the resulting exponential cosine-square function
can be evaluated with machine precision as well (in the range of our interest,
).
A basic pseudo-code of the computation of the SCV with the indications where high precision is needed is provided by Algorithm 1.
Algorithm 1.
Pseudo-code for the computation of the SCV
procedure ComputeSCV(
Compute the required precision, Ln, from Equation(22)
Convert
Calculate
Calculate moments
Calculate
return SCV
end procedure
4. Minimizing the squared coefficient of variation
Given the size of the representation the
function providing the minimal SCV is obtained by minimizing Equation(3)
(3)
(3) subject to ω and
The form of the SCV does not allow a symbolic solution, and its numerical optimization is challenging, too. The surface to optimize has many local optima, hence simple gradient descent procedures failed to find the global optimum and are sensitive to the initial guess.
4.1. Optimizing the parameters
In the numerical optimization of the parameters, we had success with evolutionary optimization methods, in particular with evolution strategies. The results introduced in Horváth et al.[Citation7] were obtained by one of the simplest evolution strategies, the Rechenberg method.[Citation11]. In Horváth et al.,[Citation7] it was the high computational demand of the numerical integration needed to obtain the SCV and its reduced accuracy that prevented the optimization for N > 47 (n > 23).
However, computing the SCV based on the hyper-trigonometric representation using the results of Section 3.1 allows us to evaluate the moments orders of magnitudes faster and more accurately, enabling the optimization for higher n values. With the Rechenberg method (Rechenberg[Citation11], also referred to as (1 + 1)-ES in the literature) it is possible to obtain low SCV values relatively quickly for orders as high as n = 125, but these values are suboptimal in the majority of cases.
With more advanced evolution strategies the optimal SCV can be approached better. Our implementation[Citation9] supports the covariance matrix adoption evolution strategy (CMA-ES[Citation5]), and one of its variants, the BIPOP-CMA-ES with restarts.[Citation6]. Starting from a random initial guess, we got very low SCV values much quicker with the CMA-ES than with the (1 + 1)-ES with similar suboptimal minimum values (cf. ). The limit of applicability of CMA-ES is about n = 180. The best solution (lowest SCV for the given order), however, was always provided by the BIPOP-CMA-ES method, although it was by far the slowest among the three methods we studied. In fact, we believe that BIPOP-CMA-ES returned the global optimum for and we investigate the properties of those solutions in the next sections. For n > 74, we can still compute low SCV functions with the BIPOP-CMA-ES method, but its computation time gets to be prohibitive, and we are less confident about the global minimality of the results.
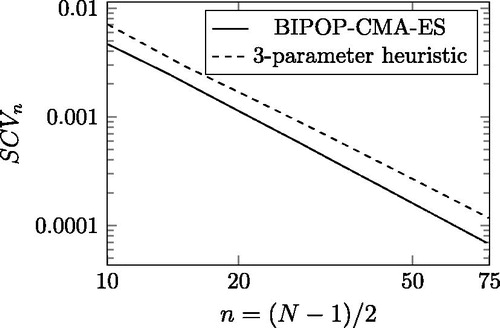
Figure 2. The minimal and the heuristic SCV as a function of order n in log-log scale.
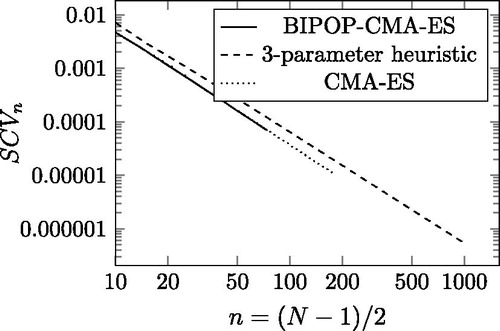
For our particular problem, the running time, T, and the quality of the minimum, Q (how low the SCV is), obtained by the different optimization methods can be summarized as follows
4.2. Properties of the minimal SCV solutions
The minimal SCV values obtained by the BIPOP-CMA-ES optimization, which we conjecture to be optimal for are depicted in . Apart from the minimal SCV values of the exponential cosine-square functions, also plots
and
for comparison. The
is known to be the minimal SCV value for PH distributions of order N,[Citation1] which form a subset in the set of order N ME distributions.[Citation2] The
curve is reported to be the approximate decay rate in Horváth[Citation7], up to n = 23 (N = 47).
Figure 3. The minimal SCV of the exponential cosine-square functions as the function of n in log-log scale.
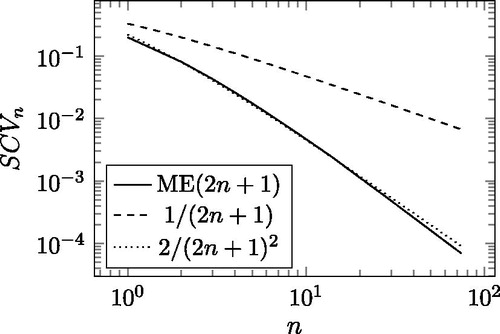
indicates that the SCV decreases much faster than and a bit faster than
Indeed,
is a good approximation up to n = 23, but the decay seems to decrease below
for n > 23.
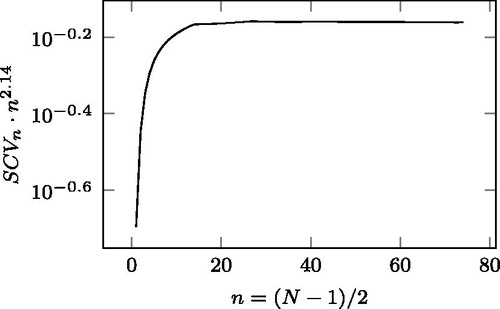
We suspect that the decrease is asymptotically polynomial (at ), that we checked by plotting the
function in . While the exponent is determined empirically and might be slightly off, it is visible that the convergence is faster than
for the examined range (n < 1000).
Figure 4. The function with logarithmic y axis.
4.3. The parameters providing the minimal SCV
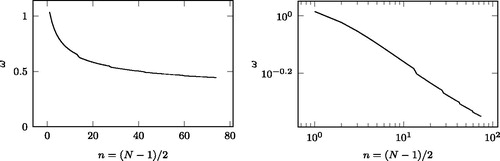
In this section, we investigate the parameters corresponding to the minimal SCV and provide an intuitive explanation for the observed behavior. depicts the optimal ω parameter as a function of n. It shows a slow decrease with some inhomogeneity around suggests that ω tends to 0 as
and the inhomogeneity is related to the behavior of the
parameters, as it is detailed below.
Figure 5. The ω parameter providing the minimal SCV in lin-lin and log-log scales.
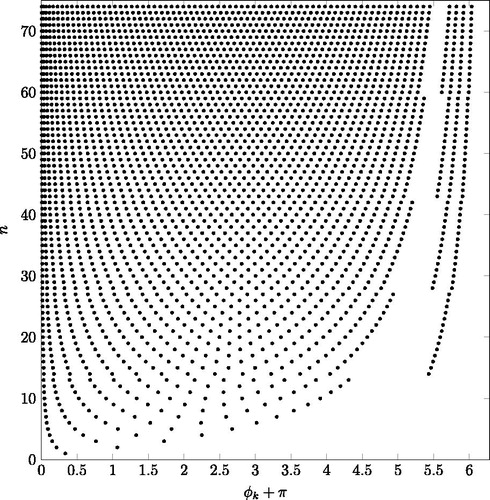
The visual appearance of the optimal parameters in reveals many more interesting properties. First, since the period of the cosine-square function is π, the
parameters in Equation(5)
(5)
(5) are
periodic. That is, adding an integer times
to any of the
parameters does not change the
function. In we transformed all
parameters to the
range and depicted
instead of
because
indicates the location where the cosine-square term with
is zero in the
cycle, which is the
interval of
The nth row in depicts n points, which are the optimal
values for
In these n points of the
cycle
equals zero. In between these zeros
has humps.
Figure 6. The location of the parameters providing the minimal SCV.
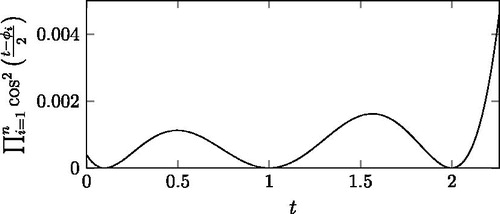
and demonstrate the effect of on
for ω = 1, n = 3,
for
In the
interval, both,
and
have zeros at 0.1, 1 and 2. depicts
with the exponential attenuation, while depicts
without the exponential attenuation. In the sizes of the humps depend on the distance of the neighboring zeros. The hump between 0.1 and 1 is smaller than the one between 1 and 2, which indicates that the closer the neighboring zeros are the smaller the humps are. In , the exponential attenuation also affects the sizes of the humps. With the exponential attenuation the hump between 0.1 and 1 is larger than the one between 1 and 2. Additionally, the SCV is more sensitive to the humps further from the main peak, which motivates the fact that the
parameters are more concentrated around 0 to make the function as flat as possible near t = 0, where the exponential attenuation is rather weak. In , right of the main peak,
is suppressed by the exponential attenuation, while left of the peak the zeros of the cosine square terms keep the function low (c.f. ).
Figure 7. with ω = 1, n = 3,
for
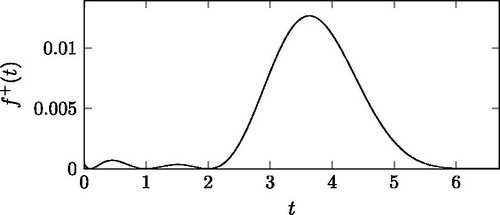
Figure 8. The initial part of (without exponential attenuation), with ω = 1, n = 3,
for
In , for n < 14, the zeros are located between 0 and 5, which means that in this range of is kept close to zero by the cosine-square functions in the interval (0, 5). It has a peak between 5 and
and the next cycles are suppressed by the exponential attenuation.
For there is a gap in the sequence of
parameters, indicating the location of a spike of
It means that the exponential attenuation is not strong enough for suppressing
right after the spike, and the minimal SCV is obtained when some cosine-square terms are used to enforce the suppression beyond the spike.
The number of cosine-square terms used to suppress beyond the spike changes at
These changes result in the small inhomogeneity in the ω values at
in .
According to our intuitive understanding ω tends to 0 as because the cosine squared terms are more efficient in suppressing
than the exponential attenuation, and for large n, the cosine squared terms create a sharp spike inside the
cycle (which is the
interval), such that the zeros are located on both sides of the spike. The cosine squared terms are
periodic and consequently, there is a spike also in the
interval which is suppressed by exponential attenuation. The exponential attenuation in a
long interval is
In order to efficiently suppress the spike in the
interval, ω has to be small.
5. Heuristic optimization with 3 parameters
According to the previously discussed approach the number of parameters to optimize increases with n. This drawback limits the applicability of the general optimization procedures to about in the case of BIPOP-CMA-ES and about
in the case of the basic CMA-ES. Using these n values the optimization procedure takes several days to terminate on an average PC clocked at 3.4 GHz.
While the function obtained this way for n = 180 has an extremely low SCV (
) already, some applications might benefit from ME distributions with even lower SCV. To overcome this limitation we developed a suboptimal heuristic procedure, that aims to obtain low SCV for a given large order n.
Our heuristic procedure has to optimize only three parameters, independent of the order n. The procedure is based on the assumption that the location of the spike in the cycle of the cosine-squared function plays the most important role in the SCV, and the exact values of the
parameters are less important, the only important feature is that the cosine-squared terms characterized by the
parameters should suppress
uniformly in the
cycle – apart from the spike (cf. ). In case of ME distributions, the spike is the dominant mode of the density function.
Figure 9. The spike and the zeros of
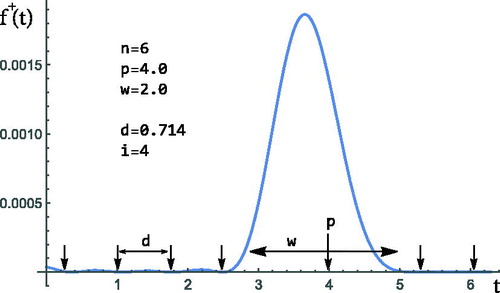
Based on this assumption we set the parameters of the cosine-squared terms equidistantly. This way the position of the spike (denoted by p) and its width (w) inside the
interval completely define the
values for a given order n.
The distance of the parameters (d) and the number of
parameters before the spike (i) can be computed from p and w by
(23)
(23)
and for
the
parameters are
(24)
(24)
The obtained heuristic procedure has only 3 parameters to optimize: ω, p and w (see Algorithm 2). The SCV values computed by this heuristic optimization procedure are depicted in for The figure indicates that for small n (n < 15) the procedure is inaccurate, but it is not a problem because the minimal SCV can be computed quickly in these cases. For larger n (
) the SCV provided by the heuristic procedure is less than twice the minimal SCV in the given range. Assuming that this ratio to the optimal SCV remains valid also for n > 74 the heuristic procedure which is applicable up to n = 1000, is an efficient tool to compute highly concentrated ME distributions for large order n values.
Figure 10. The minimal and the heuristic SCV as a function of order n in log-log scale.
Algorithm 2.
The objective function of the heuristic method
procedure ComputeSCV-heuristic(
Obtain the distance of zeros, d, and threshold i by Equation(23)
Obtain
Compute SCV by Algorithm 1
return SCV
end procedure
depicts the SCV obtained by the heuristic procedure for large n values, compared with the outputs of the highly accurate BIPOP-CMA-ES and the faster CMA-ES optimization procedures. suggests that the heuristic optimization remains very close to the minimum also for larger n values and the SCV obtained by the heuristic optimization maintains its polynomial decay between and
5.1. Implementation notes
The reader can validate the results of the paper based on the parameters we computed for a representative set of n values between 1 and 1000 and made available at https://github.com/ghorvath78/iltcme.[Citation10] The file itccme.json contains (among other parameters) the parameters for the computed set of n values from which
can be plotted using Equation(14)
(14)
(14) (to check the non-negativity of
), and the SCV can be computed using Equation(13)
(13)
(13) in any general mathematical programing environments. Some related functions processing the parameters in itccme.json are also available at https://github.com/ghorvath78/iltcme[Citation10] in various programing environments. Additionally, the implementation of the optimization procedure at https://github.com/ghorvath78/cmefinder[Citation9] allows the reader to reproduce the parameters of the CME distributions presented in itccme.json.
The parameter setting of the code in https://github.com/ghorvath78/cmefinder[Citation9] resulted from the trends of the parameters depicted in and , which can also be projected to unexplored orders with some confidence. Our numerical experiments suggest that there are several local optima with similar SCV in the range of initial guesses and outside that range the obtained SCV is several orders of magnitude larger. That is, the optimization is sensitive to the initial guess, but with a proper initial guess it is insensitive to implementation details like the stopping criteria.
6. Conclusion
The paper presents a method to generate ME distributions with very low SCV. The hyper-trigonometric representation of the subset of ME distributions with exponential cosine-squared density function enables the efficient, explicit computation of the squared coefficient of variation. By selecting the appropriate numerical precision and a suitable numerical optimization method, we managed to create ME functions up to order n = 1000 with very low SCV ( for n = 1000). Such non-negative, low-SCV matrix exponential functions are important ingredients in several numerical procedures, including the numerical inverse Laplace transform and representing deterministic delay in stochastic models.
Note
Additional information
Funding
Notes
1 In C++ we used the mpfr library for multi-precision computations.
References
- Aldous, D.; Shepp, L. The least variable phase type distribution is Erlang. Stoch. Models 1987, 3, 467–473.
- Asmussen, S.; Bladt, M. Renewal theory and queueing algorithms for matrix-exponential distributions. In Matrix-Analytic Methods in Stochastic Models. Volume 183 of Lecture Notes in Pure and Applied Mathematics; Alfa, A. S., Chakravarthy, S. R., Eds.; New York: Marcel Dekker, 1996; pp 313–341.
- Asmussen, S.; O’Cinneide, C. A. Matrix-exponential distributions – Distributions with a rational Laplace transform. In Encyclopedia of Statistical Sciences; Kotz, S.; Read, C., Eds.; John Wiley & Sons: New York, 1997; pp 435–440.
- Éltető, T.; Rácz, S.; Telek, M. Minimal coefficient of variation of matrix exponential distributions. Presented at 2nd Madrid Conference on Queueing Theory, Madrid, Spain, Jul 2006.
- Hansen, N. The CMA evolution strategy: A comparing review. In Towards a New Evolutionary Computation; Lozano, J. A., Larrañaga, P., Inza, I., Bengoetxea, E., Eds.; Springer: Berlin, Heidelberg, 2006; pp 75–102.
- Hansen, N. Benchmarking a BI-population CMA-ES on the BBOB-2009 function testbed. Presented at Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, ACM, Montreal, Québec, Canada, July 8–12, 2009, pp 2389–2396.
- Horváth, I.; Sáfár, O.; Telek, M.; Zámbó, B. Concentrated matrix exponential distributions. In European Workshop on Performance Engineering; Fiems, D., Paolieri, M., Platis, A. N., Eds.; Cham, Switzerland: Springer, 2016; pp 18–31.
- Horváth, I.; Talyigás, Z.; Telek, M. An optimal inverse Laplace transform method without positive and negative overshoot – An integral based interpretation. Electron. Notes Theor. Comput. Sci. 2018, 337, 87–104. DOI: 10.1016/j.entcs.2018.03.035.
- Optimization procedure for finding ME(n) with low SCV. https://github.com/ghorvath78/cmefinder [accessed Sep 22, 2019].
- Parameters of ME(n) distributions with low SCV. https://github.com/ghorvath78/iltcme [accessed Sep 22, 2019].
- Rechenberg, I. Evolutionsstrategien. In Simulationsmethoden in der Medizin und Biologie; Schneider, B., Ranft, U., Eds.; Springer-Verlag: Berlin, Heidelberg, 1978; pp 83–114.