
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The problem of appropriately matching items subject to compatibility constraints arises in a number of important applications. While most of the literature on matching theory focuses on a static setting with a fixed number of items, several recent works incorporated time by considering a stochastic model in which items of different classes arrive according to independent Poisson processes and assignment constraints are described by an undirected non-bipartite graph on the classes. In this paper, we prove that the Markov process associated with this model has the same transition diagram as in a product-form queueing model called an order-independent loss queue. This allows us to adapt existing results on order-independent (loss) queues to stochastic matching models and, in particular, to derive closed-form expressions for several performance metrics, like the waiting probability or the mean matching time, that can be implemented using dynamic programming. Both these formulas and the numerical results that they allow us to derive are used to gain insight into the impact of parameters on performance. In particular, we characterize performance in a so-called heavy-traffic regime in which the number of items of a subset of the classes goes to infinity while items of other classes become scarce.
1. Introduction
Matching items with one another in such a way that an individual item’s preferences are met is a well-known problem in mathematics, computer science, and economics. Classical applications include assigning users to servers in distributed computing systems, joining components in assembly systems, matching passengers to drivers in ride-sharing applications, and assigning questions to experts in question-and-answer websites.
While most of the literature on matching theory focuses on a static setting in which a fixed set of items has to be matched, applications to modern large-scale service systems require that we also consider the time dimension. In assembly systems for instance, components of different types arrive at random instants as they are manufactured, and the primary objective is to have sufficient balance between components to maximize throughput while also minimizing the number of components to be stored. This observation gave rise to models that can be seen as stochastic generalizations of classical matching problems. In these stochastic matching models, items of different classes arrive according to independent Poisson processes. Compatibility constraints between items are described by an undirected graph on the classes, so that there is an edge between two classes if items of these classes can be matched with one another. In the example of , class-3 items can be matched with items of classes 1, 2 and 4, and items of classes 1 and 2 can also be matched with one another. A matching policy is a decision rule that specifies, whenever an item arrives, to which compatible waiting unmatched item, if any, it is matched. The primary objective of a matching policy is to make the system stable in the sense that the stochastic process describing the evolution of the number of unmatched items over time is ergodic. The secondary objective is to optimize performance metrics like the mean matching time, defined as the average amount of time between the arrival of an item and its matching with another item.
Figure 1. An undirected non-bipartite compatibility graph.
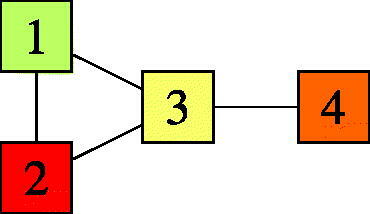
Two variants of the stochastic matching model have been studied in the literature. The stochastic bipartite matching model was introduced in Ref. [Citation11] and further studied in Refs. [Citation1–3, Citation9]. As the name suggests, this model assumes that the compatibility graph is bipartite. One can verify that such a model is always unstable if items arrive one by one at random instants (as the corresponding Markov process is either transient or null recurrent). Stability in this model is made possible by imposing that items always arrive in pairs, so that the classes of items in a pair belong to the two parts of the graph. The stochastic non-bipartite matching model, which we consider in this paper, was introduced in Ref. [Citation20] and further studied in Refs. [Citation4, Citation10, Citation21]. In this model, items arrive one at a time, and stability is made possible by imposing the presence of odd cycles in the compatibility graph. Mairesse and Moyal [Citation20] consider matching policies that are admissible in the sense that the matching decision is based solely on the class of the incoming item and the sequence, in order of arrival, of classes of unmatched items. This work characterizes the maximum stability region, that is, the set of vectors of per-class arrival rates under which there exists an admissible policy that makes the system stable. The focus of Refs. [Citation4, Citation10, Citation21] is on an admissible policy called first-come-first-matched; this is also our focus. As the name suggests, each incoming item is matched with the compatible item that has been waiting the longest, if any. In addition to being perceived as fair, this policy has the advantage of maximizing the stability region and leading to tractable results, as we will develop in this paper. The rationale behind this policy, which gives an intuition for its maximum stability, is as follows: if an item has been waiting longer than another, it is likely that this item is compatible with classes that are relatively scarcer, so that matching this item if an opportunity arises is a good heuristic to preserve stability. It is shown in Ref. [Citation21] that this matching policy is indeed maximally stable and leads to a product-form stationary distribution. This work also derives a closed-form expression for the normalization constant of this stationary distribution. A similar closed-form expression for the mean matching time is proposed in Ref. [Citation10], which applies this result to study the impact of the compatibility graph on performance. The authors observe that adding edges sometimes has a negative impact on performance, which is akin to Braess’s paradox in road networks. Lastly, the recent work [Citation4] adapts some of the above results to a variant of the model in which the items of a given class can also be matched with one another.
Several recent papers [Citation1–3, Citation16] have pointed out the similarity between the stationary distribution of stochastic matching models under this first-come-first-matched policy and that of order-independent queues[Citation5], a product-form queueing model that recently gained momentum in the queueing-theory community. Our first main contribution consists of formally proving that a stochastic non-bipartite matching model is an order-independent loss queue, a loss variant of order-independent queues introduced in Ref. [Citation6]. This allows us to adapt known results on order-independent queues to stochastic non-bipartite matching models, and in particular to provide simpler proofs for the product-form and stability results derived in Ref. [Citation21]. The relation with order-independent loss queues also allows us to extend these results to several variants of the model, some of which were already considered in the literature. Our second main contribution consists of closed-form expressions for several performance metrics like the waiting probability and the mean matching time. Some of these expressions can be seen as recursive variants of those derived in Refs. [Citation10, Citation21], and are adapted from the works [Citation12, Citation14, Citation22] which focus on order-independent queues and related queueing models. The recursive form of these expressions allows us to avoid duplicate calculations by using dynamic programming, which significantly reduces the complexity of the calculations. In addition to their numerical applications, these formulas allow us to gain intuition on the impact of the parameters on performance, and in particular to formalize what it means to have a balanced system. Along the same lines, our third and last contribution is a performance analysis in a scaling regime, called heavy traffic by analogy with the scaling regime of the same name in queueing theory, in which the vector of per-class arrival rates tends to a boundary of the stability region. This result can be seen as a generalization of the heavy-traffic result of Ref. [Citation12], which focuses on order-independent queues, although the conclusion is different and illustrates the subtle difference between stochastic matching models and conventional queueing models.
The paper is organized as follows. Section 2 describes a continuous-time variant of the stochastic non-bipartite matching model proposed in Ref. [Citation20] and introduces useful notation. In Section 3.1, we prove that this stochastic matching model is an order-independent loss queue. This result is applied in the rest of Section 3 and in Section 4 to translate known results for order-independent queues to the stochastic matching model and to generalize them. In particular, Sections 3.2 and 3.3 give simpler proofs of the product-form result and stability condition of Ref. [Citation21], while in Section 4 we derive closed-form expressions for several performance metrics. These results are applied in Section 5 to gain insight into the impact of parameters on performance. More specifically, we propose several heuristics to minimize the mean matching time and study what happens when part of the system becomes unstable. Numerical results in Section 6 allow us to gain further insight into the dynamics of stochastic matching models. Section 7 concludes the paper.
2. Stochastic non-bipartite matching model
We first define a continuous-time variant of the stochastic non-bipartite matching model introduced in Ref. [Citation20].
2.1. Continuous-time model
Let denote a finite set of item classes and consider an undirected connected non-bipartite graph without loops with vertex set
This graph will be called the compatibility graph of the matching model because it will eventually describe the matching compatibilities between items. An example is shown in . For each
we write
if there is an edge between classes i and j in the compatibility graph and
otherwise. For each
we also let
denote the set of neighbors of class i in the compatibility graph. With a slight abuse of notation, for each set
of classes, we also let
denote the set of classes that are neighbors of at least one class in
Our assumption that the compatibility graph is non-bipartite is not necessary for the soundness of the model, but we will see in Section 3.3 that it is required for stability.
For each class-i items enter the system according to an independent Poisson process with rate
As we will see in Section 3.2, we can (and will) assume without loss of generality that the vector
is normalized in the sense that
For each subset
of classes, we also let
denote the overall arrival rate of the classes in
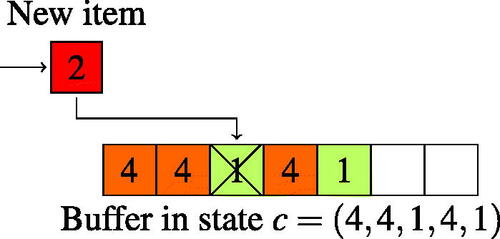
All unmatched items are queued in a buffer in their arrival order. In for instance, unmatched items are ordered from the oldest on the left to the newest on the right, and the number written on each item represents its class. Each incoming item is matched with an item of a compatible class present in the buffer, if any, in which case both items disappear immediately; otherwise, the incoming item is added at the end of the buffer. If an incoming item finds several compatible items in the buffer, it is matched with the compatible item that has been in the buffer the longest. This matching policy is called first-come-first-matched and was studied in Refs. [Citation4, Citation10, Citation20, Citation21]. Note that this matching policy can be applied with a more decentralized approach in which each item is only aware of the arrival order of its compatible items. Such a decentralized approach leads to the same dynamics and therefore to the same performance measures.
Figure 2. Unmatched items are ordered in the buffer from the oldest item on the left to the newest on the right. In particular, in the state depicted in the picture, the oldest item is of class 4 and the newest is of class 1. With the compatibility graph of , if a class-2 item arrives while the system is in this state, this item scans the buffer from left to right until it finds a compatible item, and is therefore matched with the oldest class-1 item. The new system state after this transition is
2.2. Markov process
We now define a Markov process that describes the evolution of the continuous-time stochastic matching model that we have just introduced.
2.2.1. Markovian state
We describe the system state with the sequence of unmatched item classes present in the buffer. More specifically, we consider the sequence where n is the number of items in the buffer and cp is the class of the p-th oldest item, for each
In particular, c1 is the class of the item that has been in the buffer the longest. shows a possible buffer state associated with the compatibility graph of , with the newest items on the left. The corresponding state descriptor is
We assume that the state is initially empty, with n = 0, in which case we write
The assumption that each class of items arrives according to an independent Poisson process guarantees that the stochastic process defined by the evolution of this state descriptor over time has the Markov property. When the system is in state
and a class-i item arrives, the new system state is
if
for each
and
where
otherwise. The overall departure rate from each state is
2.2.2. State space
The system state belongs to the set
made of the finite sequences over the alphabet
but the matching policy imposes additional restrictions on the form of this sequence. More specifically, the buffer cannot contain customers of classes
such that
as the newest of the two items would necessarily have been matched with the oldest (or with an older compatible item) upon arrival. In for instance, an incoming class-2 item would be matched with the oldest class-1 item, so that items of classes 1 and 2 cannot be in the buffer at the same time. Therefore, in general, the state space of the Markov process defined by the system state is a strict subset of
which we denote by
To better describe the structure of this state space, additional notation is introduced in the next paragraph.
A nonempty set is called an independent set (of the compatibility graph) if
for each
In other words, the set
is independent if the intersection of this set with the set
of its neighbors is empty. The set of all independent sets is denoted by
As an example, the set of independent sets of the compatibility graph of is
In general, if a set
is an independent set, then any nonempty subset of
is also an independent set. For convenience, we also let
denote the set of independent sets completed with the empty set.
For each we let
denote the set of words in
that contain exactly the classes in
Equivalently, if
denotes the set of item classes present in the word
we have
if and only if
Observe that
is a strict subset of
in general, as words in
need not contain all classes in
In the special case where
the set
contains only the empty state
With this notation, the state space of the Markov process defined in the previous paragraph can be partitioned as follows:
(1)
(1)
In particular, the set of item classes present in a feasible state of the matching model is an independent set.
Remark.
The stochastic non-bipartite matching model of Refs. [Citation4, Citation10, Citation20, Citation21] works in the same way as the one presented above, except that time is slotted and there is exactly one arrival during each time slot. More specifically, the classes of incoming items during different time slots are independent and identically distributed and, for each αi is the probability that an incoming item is of class i. One can verify that the (discrete-time) Markov chain associated with the state of this discrete-time stochastic matching model is the jump chain of the Markov process defined above. Since the departure rate from each state in the Markov process is
inspection of the balance equations reveals that the Markov chain and the Markov process have the same stationary measures. Consequently, the results in Ref. [Citation21, Theorem 1], derived for the discrete-time stochastic matching model, also apply to the continuous-time stochastic matching model defined above. These results will be recalled in Sections 3.2 and 3.3. For simplicity, the continuous-time stochastic non-bipartite matching model introduced in Section 2.1 will be called the stochastic matching model in the remainder.
3. Product-form queueing model
In Section 3.1, we prove that the stochastic matching model of Section 2.1 is an instance of a queueing model, called an order-independent loss queue[Citation6], that is known to have a product-form stationary distribution. We then identify several extensions of the stochastic matching model that can also be cast as order-independent loss queues. In Sections 3.2 and 3.3, we use this observation to provide simpler proofs for two results from the literature on stochastic matching models. The reader who is more interested in understanding the long-term performance of the stochastic matching model can skip Section 3.1 and move directly to Section 3.2.
3.1. Order-independent loss queue
Our definition of order-independent loss queues, given in Definition 1 below, differs in spirit from that of Ref. [Citation6, Section 1] in that conditions are given directly in terms of the associated Markov process, rather than in terms of the queueing system itself. In particular, although the name loss usually entails rejecting customers, here this manifests itself via the fact that the state space may be a strict subset of
This definition happens to be more convenient to show the connection with the stochastic matching model of Section 2.1, and preserves all the properties of the order-independent loss queues defined in Ref. [Citation6]. We also make a few restrictions (such as imposing constant arrival rates) compared to Ref. [Citation6] to avoid introducing superfluous notation.
Definition 1.
Consider a queueing system with a set of customer classes. This queueing system is called an order-independent loss queue with state space
arrival-rate vector
and departure-rate function
if the following conditions are satisfied:
The evolution over time of the sequence
of classes of present customers, ordered by arrival, defines a Markov process such that:
The state space of this Markov process is
The transitions from each state
For each class
For each position
The state space
if
if
The departure-rate function μ satisfies the following conditions:
Proposition 2 below is our first main contribution. It proves that the stochastic matching model is an order-independent loss queue. Note the form of the state space defined by Equation(1)
(1)
(1) , which differs from classic applications of loss queueing models in that the number of items of each class can be arbitrarily large when it is not zero. Once Proposition 2 is verified, applying Ref. [Citation6, Theorem 1] suffices to prove that the stationary measures of the Markov process defined in Section 2.2 have the product form derived in Ref. [Citation21, Theorem 1]. Both the result and its proof will be recalled in Section 3.2 for completeness.
Proposition 2.
The stochastic matching model defined in Section 2.1 is an order-independent loss queue, in the sense of Definition 1, with the state space defined by Equation(1)
(1)
(1) , the arrival-rate vector
, and the departure-rate function
defined by
Proof.
The details of checking the conditions of Definition 1 are left to the reader. We simply make two remarks regarding the transitions of the Markov process defined in Section 2.2. First, for each state and class
we have
if and only if
that is, if and only if class i cannot be matched with any class present in state c. Second, if the function
is as defined in the proposition, then for each state
and position
the difference
gives the arrival rate of the classes that can be matched with class cp but not with the classes present in
□
Remark.
The versatility of the order-independent framework allows us to generalize the stochastic matching model introduced in Section 2.1 in several directions while preserving its product-form nature. For instance, we again obtain an order-independent loss queue if items of a given class can be matched with one another. The main difference with the original model is that the state space is reduced, as the buffer can contain at most one customer of such a class at a time. We note that this extension was considered in the recent work [Citation4], and that the proofs of Theorems 3 and Equation4(1)
(1) in Sections 3.2 and 3.3 can be adapted to provide a simpler proof of Ref. [Citation4, Theorem 1]. Another extension, which again leads to an order-independent loss queue, consists of describing compatibilities with a directed graph (instead of an undirected graph), so that there is an edge from class i to class j if incoming class-i items can be matched with class-j items (which does not imply that incoming class-j items can be matched with class-i items). Yet another extension consists of allowing for item abandonment[Citation23], meaning that an item may leave the system without being matched. The stability region and product-form stationary distribution of these extensions can be characterized by following a similar approach as in the proofs of Theorems 3 and 4, or by applying known results on order-independent queues and quasi-reversible queues, a more general class of queueing models studied in Refs. [Citation18, Chapter 3] and [Citation13]. A last extension consists of imposing an upper bound on the number of unmatched items (either of each class or in total), or any other rejection rule that again leads to an order-independent loss queue. In this case, the stationary distribution is the restriction of that recalled in Theorem 3 to the set of reachable states (after renormalization), and no stability condition is needed.
Remark.
The usefulness of the equivalence between stochastic matching models and conventional queueing models is particularly evident under the first-come-first-matched policy, as the corresponding queueing model is known to have a product-form stationary distribution. However, this equivalence may also prove useful to transpose existing scheduling policies into matching policies, as was done in Refs. [Citation4, Citation9, Citation20], or to adapt exact or approximate analysis methods.
3.2. Product-form stationary distribution
The Markov process defined in Section 2.2 is irreducible. Indeed, for each state and each state
we can first go from state c to state
via n transitions corresponding to arrivals of items compatible with the items in state c, and then from state
to state d via m transitions corresponding to arrivals of the items present in state d. Note that the first n transitions occur with a positive probability because the compatibility graph contains no isolated node; additionally, the latter m transitions indeed lead to state d because the set of classes in d is an independent set by definition of
Theorem 3 below recalls the form of the stationary measures of the Markov process defined in Section 2.2. As observed before, this theorem is analogous to Ref. [Citation21, Theorem 1], which was stated for the discrete-time variant of the stochastic matching model. Thanks to the relation with order-independent loss queues proved in Proposition 2, we propose a simpler proof that consists of explicitly writing the (partial) balance equations of the Markov process. This proof, which is a special case of that of Ref. [Citation6, Theorem 1], is sketched below for completeness.
Theorem 3.
The stationary measures of the Markov process associated with the system state are of the form
(2)
(2)
where
is a normalization constant. The system is stable, in the sense that this Markov process is ergodic, if and only if
(3)
(3)
in which case the stationary distribution of the Markov process is given by Equation(2)
(2)
(2) with the normalization constant
(4)
(4)
Sketch of proof. We will prove that any measure π of the form Equation(2)(2)
(2) satisfies the following partial balance equations in each state
:
Equalize the flow out of state c due to the arrival of an item that can be matched with a present item and the flow into state c due to the arrival of an item that cannot be matched with a present item (if
Equalize the flow out of state c due to the arrival of an item of a class
Proving that a measure π satisfies Equation(5)(5)
(5) and Equation(6)
(6)
(6) is sufficient to prove that π is a stationary measure of the Markov process defined by the system state, as summing these partial balance equations yields the balance equations of the Markov process. We can easily verify that any measure π of the form Equation(2)
(2)
(2) satisfies Equation(5)
(5)
(5) . That this measure also satisfies Equation(6)
(6)
(6) can be proved by induction over the buffer length n, in a similar way as in Ref. [Citation5, Theorem 1].
The stability condition Equation(3)(3)
(3) means that there exists a stationary measure whose sum is finite, which is indeed necessary and sufficient for ergodicity of the Markov process. Lastly, the constant
given by Equation(4)
(4)
(4) is chosen such that the stationary distribution sums to one. □
Multiplying all arrival rates αi for by the same positive constant does not modify the form of the stationary measures Equation(2)
(2)
(2) . Indeed, this amounts to rescaling time without modifying the relative importance of the states. In particular, as already stated in Section 2.1, we can assume without loss of generality that
so that αi is also the fraction of arrivals that are of class i. In the remainder, it will also be more convenient to define the stationary measures Equation(2)
(2)
(2) with the following recursion:
(7)
(7)
3.3. Stability condition
We now recall the stability condition derived in Ref. [Citation21, Theorem 1] and again provide a simpler proof based on the relation with order-independent loss queues.
Theorem 4.
The stochastic matching model is stable, in the sense that the associated Markov process is ergodic, if and only if
(8)
(8)
Sketch of proof. The proof consists of showing that Equation(3)(3)
(3) is satisfied if and only if the arrival rates satisfy Equation(8)
(8)
(8) . The key idea is to observe that the denominators in Equation(3)
(3)
(3) only depend on the set of classes in the sequence
Guided by this observation, we can define a new partition of the state space
that is a refinement of the partition
such that the restriction of the sum in Equation(3)
(3)
(3) to each part of this new partition can be written as a finite product of geometric series that are convergent if and only if the conditions Equation(8)
(8)
(8) are satisfied. The details of the proof follow along the same lines as in the proof of Theorem 1 in the appendix of Ref. [Citation7]. The only difference is that the set of customer classes that can be in the queue at the same time is an independent set, so that the stability condition is also restricted to independent sets. □
The stability condition Equation(8)(8)
(8) means that, for each independent set
there are enough items that can be matched with the classes in
to prevent items of these classes from building up in the buffer. As proved in Ref. [Citation20], no matching policy can make the system stable if the arrival rates do not satisfy the stability condition Equation(8)
(8)
(8) (in particular, first-come-first-matched is maximally stable). It is also shown in Ref. [Citation20] that we would not be able to find arrival rates that satisfy this stability condition if the compatibility graph were bipartite. To better understand why the presence of odd cycles is necessary, we examine two toy examples. First consider a stochastic matching model similar to that of Section 2.1, except that the graph is bipartite and consists of only two classes connected by an edge. The stability condition Equation(8)
(8)
(8) becomes
and
and can therefore not be satisfied. Consistently, if we examine the associated Markov process, we obtain a two-sided infinite birth-and-death process, with transition rate α1 in one direction and α2 in the other, that is either transient (if
) or null recurrent (if
), but cannot be positive recurrent. Now, if we instead consider a stochastic matching model with three classes that are all compatible, the stability condition Equation(8)
(8)
(8) becomes
and
and is satisfied for instance when
If we examine the associated Markov process, we obtain a three-sided infinite birth-and-death process that is positive recurrent under the above conditions. In the remainder, we will assume that the stability condition Equation(8)
(8)
(8) is satisfied and let π denote the stationary distribution of the Markov process.
4. Performance metrics
Another consequence of Proposition 2 is that we can adapt numerical methods originally developed for order-independent queues[Citation12, Citation14, Citation22] to stochastic matching models. Note that calculating average performance metrics associated with loss product-form queueing models is considered a hard problem in the queueing literature[Citation19]. Our task here is simplified by the fact that the number of items of a given class can be arbitrarily large if it is not zero, so that we can apply methods developed for open queues. Also, since we established that the continuous-time stochastic matching model and its discrete-time counterpart have the same stationary distribution, the formulas derived in this section can be applied without change to the discrete-time variant of the model.
4.1. Probability of an empty system
We first propose a new formula to compute the normalization constant of the stationary distribution of the stochastic matching model. With a slight abuse of notation, for each we let
denote the stationary probability that the set of unmatched item classes is
that is,
(9)
(9)
EquationEquation (1)
(1)
(1) guarantees that
The following proposition gives a recursive formula for
each
We will see later that this recursive formula also gives a closed-form expression for the normalization constant
The proof technique is similar to that of Ref. [Citation14, Theorem 5.1], which was itself inspired from Ref. [Citation22, Theorem 4], but the proof is more straightforward because we skip the intermediary state aggregation considered in these two works.
Proposition 5.
The stationary distribution of the set of unmatched item classes satisfies the recursion
(10)
(10)
Proof.
Let The proof of Equation(10)
(10)
(10) relies on the following partition of the set
(11)
(11)
where the unions are disjoint and, for each
and
we write
We first apply Equation(7)
(7)
(7) and Equation(9)
(9)
(9) to rewrite
as follows:
Then applying Equation(11)(11)
(11) yields
Rearranging the terms yields Equation(10)(10)
(10) . □
Proposition 5 gives a closed-form expression for the normalization constant It suffices to observe that the unnormalized stationary measure
also satisfies recursion Equation(10)
(10)
(10) . Therefore, we can first compute
for each
by applying recursion Equation(10)
(10)
(10) with the base case
and then derive
by normalization, that is,
Since there is a finite number of independent sets, this provides us with a closed-form expression for the normalization constant. Note that the denominator in Equation(10)
(10)
(10) is always positive thanks to the stability condition Equation(8)
(8)
(8) .
One can verify that unfolding the above recursion yields the closed-form expression derived in Ref. [Citation21, EquationEquation (5)(5)
(5) ]. The advantage of the above recursion is that it avoids duplicate calculations. More specifically, the overall complexity to evaluate the normalization constant using Equation(10)
(10)
(10) with dynamic programming is O(MN), where
is the number of independent sets and
is the number of item classes. By comparison, if we naively apply Ref. [Citation21, EquationEquation (5)
(5)
(5) ], the complexity is
where P is the independence number of the compatibility graph, that is, the cardinality of a maximum independent set in this graph. In both cases however, we need to enumerate all independent sets of the compatibility graph, which is an NP-hard optimization problem in general. Consequently, both formulas can be applied to make calculations only when there are few classes, when symmetries between classes can be exploited to reduce complexity (see for instance Ref. [Citation8]), or when the graph structure guarantees that the number of independent sets is small. The same remark holds for the formulas derived in Propositions 6 to 10 below. However, we will see in Section 5 that, even when these conditions are not meet, these formulas can be used to gain insight into the impact of parameters on performance.
4.2. Waiting probability
The result of Proposition 5 gives us directly a closed-form expression for the waiting probability of the items of each class. Indeed, it follows from the PASTA property that, for each the waiting probability of class-i items is given by
(12)
(12)
Upon recalling that Proposition 6 below shows that the average waiting probability is simply given by
This result is not surprising. Indeed, each matching occurs between two items, one of that has just arrived (and therefore does not wait) and another that was waiting. However, this result highlights that improving the performance of one class (in terms of the waiting probability) necessarily comes at the expense of another class.
Proposition 6.
The average waiting probability is given by
Proof.
We will verify that the per-class waiting probabilities satisfy the following conservation equation:
(13)
(13)
after which the result follows by rearranging the terms. We have successively:
where the first equality follows from the definition of ωi, the second by exchanging the two sums, and the third from the definition of
Applying Equation(10)
(10)
(10) to the last member of this equality yields
where the second equality follows by exchanging the sums. EquationEquation (13)
(13)
(13) follows by observing that, for each
we have
where the first equality follows from a change of variable and the second by definition of ωi. □
4.3. Mean number of unmatched items and mean matching time
Consider a random vector distributed as the vector of numbers of unmatched items of each class in the stationary regime in the stochastic matching model of Section 2.1. For now, we focus on the means
for each
and we also let
be the mean number of unmatched items, all classes included. Propositions 7 and 8 below give a closed-form expression for these quantities by using a similar aggregation technique as in the proof of Proposition 5. As observed in Ref. [Citation21, Section 3.4], these can be used to calculate the mean matching time of items, that is, the mean time between the arrival of an item and its matching with another item. Indeed, according to Little’s law, the mean matching time of class-i items is
for each
and the overall mean matching time is given by
(since we assumed that
).
Proposition 7.
For each , the mean number of unmatched class-i items is given by
where
is the mean number of unmatched class-i items given that the set of unmatched items is
, and is given by the recursion
(14)
(14)
with the base case
for each
such that
.
Proof.
The proof follows similar steps as that of Proposition 5, with some technical complications. Let We have
where, for each
is the mean number of unmatched class-i items given that the set of unmatched item classes is
We have directly that
if
If
we have
where
is the number of unmatched class-i items in state c, for each
and the second equality follows from Equation(7)
(7)
(7) . Applying partition Equation(11)
(11)
(11) yields
This, in turn, can be rewritten as
Rearranging the terms yields Equation(14)(14)
(14) . □
To the best of our knowledge, no previous work obtained the above formula for the stochastic matching model (either in recursive or in non-recursive form). We now provide an analogous formula to directly calculate the mean number of unmatched items, all classes included, without needing to calculate the mean number of unmatched items of each class.
Proposition 8.
The mean number of unmatched items is given by
where
is the mean number of unmatched items given that the set of unmatched items is
, and is given by the recursion
(15)
(15)
with the base case
Proof.
The result follows by applying Equation(14)(14)
(14) to
and simplifying the expression with Equation(10)
(10)
(10) . □
Unfolding recursion Equation(15)(15)
(15) yields the formula given in Ref. [Citation10, Proposition 4] but, as for the normalization constant, applying dynamic programming leads to a significant reduction of complexity compared to a naive application of this proposition. More specifically, the time complexity to compute Li for some
or L is O(MN) if we use our approach, while the time complexity to compute L is
if we naively apply the formula of Ref. [Citation10, Proposition 4].
4.4. Distribution of the number of unmatched items
As before, let be a random vector distributed like the vector of numbers of unmatched items of each class in stationary regime in the stochastic matching model of Section 2.1. A closed-form expression for the joint probability distribution of the vector X can be derived in the same way as in Ref. [Citation14, Theorem 3.2, Equation (3.1)]. Here, we are instead interested in the probability generating function gX of this vector, defined as
(16)
(16)
where
One can show that this generating series converges whenever
The following notation will be useful to state Proposition 9 below. First, for each
we write
for each
Also, given two vectors
and
we let
denote their elementwise product. We are now in position to give a closed-form expression for the probability generating function of the vector X. Both this result and its proof are adapted from Ref. [Citation12, Proposition 3.1].
Proposition 9.
The probability generating function of the numbers of unmatched items of each class in the buffer is given by
(17)
(17)
where, for each
and
such that
for each
, the set function
is defined by the recursion
(18)
(18)
with the base case
Proof.
It suffices to observe that, according to Equation(2)(2)
(2) , Equation(4)
(4)
(4) , and Equation(16)
(16)
(16) ,
can be rewritten as
where, for each and
such that
for each
we have
The recursive expression Equation(18)(18)
(18) follows from a similar argument as in the proof of Proposition 5. □
Taking in Equation(18)
(18)
(18) yields (Equation10
(10)
(10) ), so that in particular the denominator in Equation(17)
(17)
(17) is the normalization constant of the stationary distribution Equation(2)
(2)
(2) . Referring back to the order-independent loss queue introduced in Section 3.1, the vector
in Equation(18)
(18)
(18) can be seen as the arrival rates of the customer classes, while the vector
could be seen as service rates.
4.5. Distribution of the matching time
Let denote a vector distributed like the vector of matching times of each class in the stationary regime in the stochastic matching model of Section 2.1. For each
the Laplace-Stieltjes transform of the stationary matching time Ti is defined as
(19)
(19)
One can show that this expectation is finite whenever but we will be especially interested in the range
Proposition 10 below gives a closed-form expression for this Laplace-Stieltjes transform by applying the distributional form of Little’s law, in a similar way as in Ref. [Citation12, Corollary 3.2].
Proposition 10.
For each , the Laplace-Stieltjes transform of the matching time of class i is given by
(20)
(20)
where the function gX is defined on
by (Equation17
(17)
(17) ) and the vector
is given by
Proof.
Let The main argument consists of observing that class i satisfies the assumptions of the following theorem, proved in Ref. [Citation17, Theorem 1]:
Theorem 11
(Distributional form of Little’s law). Let an ergodic queueing system be such that, for a given class i of customers:
arrivals form a Poisson process with rate αi;
all arriving customers enter the system, and remain in the system until served, i.e. there is no blocking, balking, or reneging;
the customers leave the system one at a time in order of arrival;
for any time t, the arrival process after time t and the time in the system of any customer arriving before t are independent.
Then the moment generating function of the ergodic number Xi of customers of this class in the system and the Laplace-Stieltjes transform
of the ergodic time Ti spent in the system by a customer of this class satisfy
The distributional form of Little’s law therefore implies that
where
is the probability generating function of the stationary number Xi of unmatched class-i items. We conclude by observing that, for each
we have
where
is the N-dimensional vector with zi in component i and 1 elsewhere. □
5. Impact of load on performance
Performance in a stochastic matching model is the result of an intricate interaction between arrival rates and matching compatibilities. Even finding arrival rates that stabilize the matching model associated with a given compatibility graph is non-trivial a priori. More subtly, it was observed in Ref. [Citation10] that, given a compatibility graph and a set of arrival rates that make the system stable, adding more edges to the compatibility graph may hurt performance (even if Equation(8)(8)
(8) guarantees that the system will remain stable). Furthermore, applying the results of Sections 3 and 4 to derive performance in a real-world matching problem will often be impossible due to the complexity of the formulas. In this section, we show that these results are also useful to gain intuition about the choices of parameters that optimize performance or at least make the system stable. By analogy with queueing theory, we define the loads of the independent sets as
(21)
(21)
These loads will be key to analyze performance, as for instance the stability condition Equation(8)(8)
(8) can be rewritten as
for each
Although this definition is inspired from the analogy with queueing theory, there is a fundamental difference between Equation(21)
(21)
(21) and the regular definition of load in a queue, namely in Equation(21)
(21)
(21) the arrival rates appear both in the numerator and denominator. This implies in particular that the loads are not increasing functions of the arrival rates.
5.1. Heuristics to optimize performance
Given the conclusions of Ref. [Citation10], one may wonder, for a given vector of arrival rates and a given compatibility graph that lead to a stable stochastic matching model, whether or not removing edges from the compatibility graph may improve performance, and in this case which edge(s) should be removed. This discrete optimization problem is difficult in general, as the number of configurations is exponential in the number of classes. To gain insight into this question, we consider a related problem that consists of finding arrival rates that stabilize the system and minimize the mean matching time for a given compatibility graph. Solving this optimization problem exactly with the formulas of Section 4 is practically unfeasible when the number of classes is large, but we propose two heuristics that yield acceptable performance in practice.
5.1.1. Degree proportional
It was shown in Ref. [Citation20, Theorem 1] that there exists a vector of arrival rates that stabilizes the system if and only if the compatibility graph is non-bipartite (which we assumed in Section 2.1), but exhibiting such arrival rates is not trivial a priori. Lemma 12 below gives a simple method to generate (an infinite number of) such arrival rates.
Lemma 12.
Let denote a symmetric matrix such that
if and only if nodes i and j are neighbors in the compatibility graph. For each
, the weight of class i is defined as
. The matching model is stable if the arrival rates are chosen to be proportional to the weights, that is,
(22)
(22)
Proof.
Assume that the arrival rates are given by Equation(22)(22)
(22) for some matrix A that satisfies the assumptions of the proposition, and let
We will prove that these arrival rates satisfy the stability condition Equation(8)
(8)
(8) . Consider an independent set
We have successively
To prove that the above inequality is indeed strict, it suffices to show that we cannot find an independent set such that
We can prove this by contradiction. Indeed, if there were such an independent set
this would imply that
(because the compatibility graph is connected) and that
is also an independent set, which would contradict our assumption that the compatibility graph is non-bipartite. □
The matrix A can be interpreted as the adjacency matrix of a weighted variant of the compatibility graph. As a special case, if A is the adjacency matrix of the compatibility graph, then di is the degree of class i, in which case the arrival rates defined by Equation(22)(22)
(22) are called degree proportional. For example, in the graph of , the degree-proportional arrival rates are
and
choosing these arrival rates yields approximately a probability 0.17 that the system is empty and a mean matching time of 2.25 time units. In general, if the number of classes is sufficiently small so that all independent sets can be enumerated, this degree-proportional solution can also be used to initialize an optimization algorithm that searches for arrival rates that minimize the mean matching time by applying Proposition 8.
5.1.2. Load minimization
The loads defined in Equation(21)(21)
(21) also play an instrumental role in better understanding which arrival rates yield acceptable performance. To understand this, let us first focus on the probability that the system is empty, which is the inverse of the normalization constant and is given by Proposition 5. First observe that Equation(10)
(10)
(10) can be rewritten as
(23)
(23)
where the loads for
are given by Equation(21)
(21)
(21) . Expanding the recursion yields
where
is the set of permutations of the set
interpreted as the set of all sequences
in which each element of
appears exactly once. The first product may tend to infinity if the load
of any set
tends to one, while the second product is always between zero and one. By applying the normalization condition, we obtain that
is a linear combination of products of the form
Similarly, we can rewrite Equation(15)(15)
(15) as follows:
(24)
(24)
In both cases, the variations of the function on (0, 1) suggest that solving the following optimization problem is a good heuristic to maximize the probability that the system is empty and minimize the mean matching time:
(25)
(25)
One can verify that a solution of this optimization problem satisfies the stability condition Equation(8)(8)
(8) . In the example of , the objective function of the optimization problem Equation(25)
(25)
(25) can be rewritten as
and the unique solution is
and
These arrival rates happen to be a global maximum for the probability that the system is empty, with maximum value 0.25, and a local minimum for the mean matching time, with minimum value 1.5 time unitsFootnote1.
In general, calculating a solution of the optimization problem Equation(25)(25)
(25) requires enumerating all independent sets, which is precisely why we may not be able to apply the results of Section 4 on the first place. This issue can be mitigated by focusing on the independent sets with cardinality at most n for some
or on the independent sets containing the most central nodes (under an appropriate definition of centrality), but the obtained solution may not be stable. To further stress the importance of minimizing the loads, we now consider a scaling regime in which the load of a (subset of) class(es) becomes close to one, thus making the system unstable.
5.3. Heavy-traffic regime
We consider a scaling regime called heavy traffic by analogy with the regime of the same name studied in queueing theory. In a nutshell, the stability condition associated with a maximal independent set becomes violated in Equation(8)(8)
(8) , so that items of these classes accumulate in the buffer (while items of other classes become scarce); our result describes the corresponding limiting distributions and performance metrics. The analysis relies on the closed-form expressions derived in Section 4. The proof technique and the results generalize those of Ref. [Citation12, Theorem 3.1] but, as announced in the introduction, the conclusions are different and illustrate the fundamental difference between stochastic matching models and conventional queueing models.
5.3.1. Scaling regime
Fix an independent set that is maximal with respect to the inclusion relation. We have in particular that
and
We consider a scaling regime where, for each
(26)
(26)
with
and
In this way,
is the ratio of the arrival rate of the classes in
to the arrival rate of their compatible classes, that is, the load of set
We will show that, under some technical assumptions, as
the buffer becomes saturated with items of the classes in
while running out of items of the classes in
That the classes in
become saturated is a consequence of Equation(26)
(26)
(26) , as we have
(27)
(27)
The following technical assumption guarantees that the set is the only one that becomes saturated.
Assumption 13.
There exists such that the stability conditions Equation(8)
(8)
(8) are satisfied by the measures α defined by Equation(26)
(26)
(26) for each
and
5.3.2. Asymptotic distribution
Proposition 14 below shows that, under the above technical assumption, the mean number of items of the classes in goes to infinity like
as
while the mean number of items of the classes in
goes to zero. Furthermore, the distribution of items of the classes in
depends on their respective arrival rates but not on their compatibility constraints with the classes in
Similarly, as intuition suggests, the waiting probability of the classes in
tends to one as
while the waiting probability of the classes in
tends to zero. In this way, despite the structural differences between the stochastic matching model and a more conventional queueing model, the classes in
experience the same performance as in an M/M/1 multi-class queue in which the load ρ tends to one while, for each
the relative arrival rate of class i is kept constant equal to pi. The fundamental difference with an M/M/1 multi-class queue, discussed in the remark below, is that the number of items of the classes in
tends to zero. Given
and two functions f and g, defined on
such that
for each
we write
if
Proposition 14.
If Assumption 13 is satisfied, then the following limiting results hold:
(14-a) The stationary distribution of the set of unmatched item classes satisfies:
(14-b) The waiting probability of each item class satisfies:
(14-c) The mean number of unmatched items of each class satisfies:
In particular, the limiting mean number of unmatched items (over all classes) satisfies
(14-d) The number of unmatched items of each class has the following limit in distribution:
where
(14-e) The mean matching time of each class satisfies:
where
Sketch of proof. The proof of each property relies on the corresponding expression derived in Section 4. Each proof follows the same pattern: the expression for which we want to calculate the limit is a fraction whose numerator and denominator are sums of terms given by recursive expressions; we first use the recursive expressions to identify the dominating term in each sum, and then we simplify the dominating terms to derive the limit. The complete proof is given in the appendix. □
Remark.
The analysis is simplified by our choice of a maximal independent set and by Assumption 13. Indeed, these two assumptions guarantee that is the only independent set that becomes saturated as
and that all other classes are absorbed by the surplus of items in the classes in
We could also consider a scaling regime where these assumptions are not satisfied. For instance, we could choose an independent set
that is not maximal with respect to the inclusion relation. Under some technical assumptions, we would obtain a scaling regime where the buffer becomes saturated with items of the classes in
and runs out of items of the classes in
while containing a positive but finite number of items of the classes in
This intermediary scaling regime becomes apparent in the numerical results of Section 6.
Remark.
The above-defined heavy-traffic regime is actually closer to a light-traffic regime for the classes in as Proposition 14 shows that the number of items of these classes tends to zero. Yet, one can verify that the loads of the classes of this set do not tend to zero. These two observations may seem paradoxical, especially with conventional queueing models, like the M/M/1 queue, in mind. This apparent paradox can be explained by recalling that the arrival of an item can either increase or decrease the number of present items. This is different from conventional queueing models, in which the arrival of a customer always increases the number of present customers. Intuitively, in the scaling regime studied in this section, the arrival of an item of a class in
will (almost) always increase the number of unmatched items, while the arrival of an item of a class in
will (almost) always decrease the number of unmatched items.
6. Numerical results
In this section, we study the toy examples of and evaluate two performance metrics, the waiting probability and the mean matching time, defined in Sections 4.2 and 4.3. All numerical results are computed using the closed-form expressions derived in these two sections. As before, we impose that so that αi is the long-term fraction of items that belong to class i, for each
More specifically, in each case, we impose that
and let the arrival rate α1 of class 1 vary such that its load
belongs to the interval (0, 1). This allows us to gain insight into the impact of varying the load of one class on performance and to illustrate the heavy-traffic result of Section 5.1.1.
Figure 3. Toy examples with N = 9 classes.
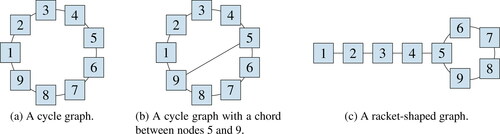
6.1. Cycle graph
We first consider a stochastic matching model with a simple yet insightful compatibility graph, namely a cycle graph with an odd number of nodes. More specifically, we let denote the number of classes, where
and we assume that, for each
items of classes i and i + 1 can be matched with one another (with the convention that
if i = N). An example of a cycle graph with N = 9 nodes is shown in . The dynamics in a matching model with a cycle graph are representative of the dynamics obtained with more complex compatibility graphs. Indeed, as recalled in Section 3.3, a stochastic matching model can be stabilized if and only if its compatibility graph is non-bipartite, which means that it contains at least one odd cycle. The arrival rates are given by
(28)
(28)
so that ρ is the load of class 1. One can show by a direct reasoningFootnote2 that
for each
which is sufficient to prove that, under the arrival rates Equation(28)
(28)
(28) , the system is stable for each
In what follows, we focus on the case N = 9 for simplicity of exposition, but the results for
(not shown here) are similar. To illustrate the performance gain permitted by the recursive expressions of Section 4 compared to existing expressions, we observe that, again with N = 9, the number of terms to sum to derive each metric is equal to 75 using dynamic programming and to 459 if we naively apply the formulas of Ref. [Citation21, EquationEquation (5)
(5)
(5) ] and Ref. [Citation10, Proposition 4], giving a ratio of
with N = 15 classes, the numbers of terms to sum are 1,363 and 234,405, respectively, giving a ratio of
The waiting probability and mean matching time are shown in . Because of the symmetry of the model, the performance of a class only depends on its distance to class 1, so that classes i + 1 and have the same performance for each
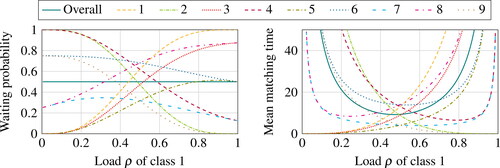
Focusing on the waiting probability, we can partition classes into two categories, those at an odd distance from class 1 (namely, classes 2, 4, 7, and 9) and those at an even distance from class 1 (namely, classes 1, 3, 5, 6, and 8). Indeed, as the load of class 1 increases, the waiting probability of the former set of classes decreases while that of the latter set of classes increases. The only exception is the waiting probability of classes 5 and 6, which first increases and then decreases; we will mention this again at the end of this paragraph. Intuitively, increasing the load of class 1 has the following cascading effect. To preserve the system stability, the additional class-1 items need be matched with items of classes 2 and 9, so that the waiting probability of these two classes decreases. The side effect is that there are fewer items of classes 2 and 9 to be matched with items of classes 3 and 8, so that the waiting probability of classes 3 and 8 increases. In turn, surplus items of classes 3 and 8 need be matched with items of classes 4 and 7 to preserve stability, so that the waiting probability of classes 4 and 7 decreases, and so on. The only exception is classes 5 and 6, whose waiting probability is first increasing and then decreasing. Focusing on class 5 for instance, the non-monotonic evolution of the waiting probability is the result of two conflicting effects. On the one hand, the even path 1–2–3–4–5 suggests that increasing the load of class 1 tends to increase the waiting probability of class 5. On the other hand, the odd path 1–9–8–7–6–5 suggests that increasing the load of class 1 tends to decrease the waiting probability of class 5.
Figure 4. Performance (overall and per class) in a cycle with N = 9 classes.
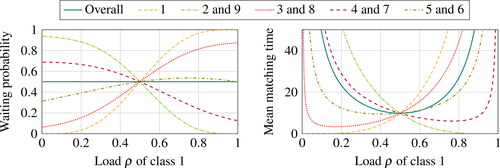
Considering the mean matching time allows us to refine the above discussion. Indeed, we can observe that, except for classes 1, 2, and 9, the mean matching time of all classes tends to infinity both when ρ tends to zero and when ρ tends to one. This suggests that not only the performance of classes 5 and 6 but also those of other classes are the result of two opposite effects, one that is conveyed by the odd-length path from class 1 and the other by the even-length path from class 1.
To better understand the speeds at which the mean matching times of classes tend to infinity, let us start with (meaning that all arrival rates are equal) and consider the chain reaction on the path 1–2–3–
-8–9 as the load ρ decreases and tends to 1. The first class to be impacted is class 2, as this class needs the presence of class 1 to remain stable, and indeed the mean matching time of class 2 tends to infinity the fastest. The side effect is that class-3 items are matched more frequently with class-2 items, so that the mean matching time of class 3 decreases. This implies that class-3 items are less available for class 4, so that the mean matching time of class 4 is the next to tend to infinity. By repeating this reasoning, we obtain that the mean matching time of class 6 is the next to tend to infinity, followed by the mean matching time of class 8. A similar phenomenon occurs on the path 1–9–8–
–3–2, so that the mean matching times of classes 9, 7, 5, and 3 also tend to infinity one after the other.
6.2. Cycle graph with a chord
To complement our observations, we break the model symmetry by adding a chord between classes 5 and 9. The arrival rates are still given by (Equation28(28)
(28) ). It follows from (Equation8
(8)
(8) ) that adding an edge to the compatibility graph cannot reduce the stability region of the corresponding stochastic matching model, so that the model is still stable for each
We again focus on a model with N = 9 classes. We have verified that the reasoning we develop below generalizes to other numbers of classes and other placements of the chord relative to class 1, although the results vary qualitatively.
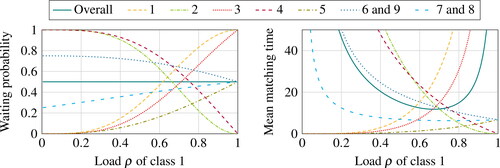
The results are shown in . Adding a chord breaks the symmetry between classes, but we can still divide classes into several categories depending on the limiting behavior of their waiting probability and mean matching time as the load ρ tends to either zero or one. Let us first focus on the limiting regime where the load ρ tends to zero. In view of the mean matching times, the first class to become unstable is class 2, which is natural because the supply rate of class 3 items is not sufficient to maintain its stability. The main difference with the previous scenario is that the stability of class 9 is temporarily preserved by its compatibility with classes 8 and 5. The overabundance of class 2 leads to the exhaustion of class 3, which in turn leads to the overabundance of class 4, which in turn leads to the exhaustion of class 5. Once class 5 is exhausted, the next classes to become unstable are its neighbors, classes 6 and 9, which eventually leads to the overabundance of classes 7 and 8 as well. The limiting behavior as the load ρ tends to one is close to that observed for the cycle without chord. The reason is that the first immediate impact of increasing the load of class 1 is the exhaustion of class 9 (as well as class 2), rendering the presence of the chord useless, so that then we are back to the scenario of Section 6.1.
Figure 5. Performance (overall and per class) in a cycle with N = 9 classes supplemented with a chord between classes 5 and 9.
6.3. Racket-shaped graph
We finally consider the racket-shaped graph of . Although a line alone cannot be stabilized because it forms a bipartite graph, this example gives us an idea of the dynamics that may arise in such a graph. One can also think of this graph as being obtained by removing the edge between nodes 1 and 9 in the cycle graph with a chord of . The arrival rates of classes are given by
so that ρ is again the load of class 1. One can do a similar reasoning as for the cycle to show that this system is stable whenever
We again focus on a scenario with N = 9 nodes in total, 4 of which belong to the line part and 5 to the cycle part. In general, we observed that the qualitative behavior of the results depends mainly on the parity of the numbers of classes on the line part and on the circle part of the graph, and we may again adapt the reasoning below to explain this qualitative behavior.
The results for the racket-shaped graph of are shown in . Along the line part of the graph, the impact of increasing or decreasing the load ρ of class 1 is as one could expect. For instance, as ρ tends to one, class-2 items become scarce, which leads to the instability of class 3, which in turn leads to the scarcity of class 4. Compared to the cycle with a chord, the most striking observation is that classes 5, 6, 7, 8, and 9 remain stable as the load ρ tends to one, and that these classes have the same asymptotic waiting probability and mean matching time. The reason is that, asymptotically, the model restricted to classes 5 to 9 evolves like a cycle with five classes that all have the same arrival rate, and this model is stable.
Figure 6. Performance (overall and per class) in the racket-shaped graph with N = 9 classes shown in .
If we again focus on the asymptotic regime where the load ρ tends to one, it seems that the overall mean matching time is lower in the racket-shaped graph than in the cycle with a chord, which may seem counterintuitive after observing that the former is obtained by removing an edge from the latter. This observation is however consistent with the discussion of Ref. [Citation10], which compared this phenomenon with Braess’s paradox in road networks.
7. Conclusion
In this paper, we proved that a stochastic non-bipartite matching model is an order-independent loss queue. This equivalence allowed us to propose simpler proofs for existing results and to derive new results regarding stochastic matching models. In particular, we used the order-independent queue framework to give alternative proofs for the product-form stationary distribution and the stability condition derived in Ref. [Citation21, Theorem 1]. By adapting numerical methods developed in Ref. [Citation12,Citation14,Citation22], we also derived new closed-form expressions for the normalization constant, the mean matching time, and other performance metrics. In turn, these formulas were applied to gain insight into the impact of parameters on performance. By analogy with queueing theory, we highlighted the importance of the so-called load parameters and studied the system behavior in the heavy-traffic regime, in which the load of a subset of classes becomes critical. The obtained formulas were also put in practice with numerical results.
For future works, we would like to derive simpler formulas for the performance metrics. Indeed, even though our recursive formulas allow for a dynamic-programming approach, complexity remains exponential in the number of classes in general, which limits their applicability to models with only a few classes. In parallel, we would like to understand if and how these results can be adapted to analyze the performance of stochastic matching models with a bipartite compatibility graph, like the one studied in Ref. [Citation1–3,Citation9,Citation11], in which items arrive in pairs. Lastly, as mentioned before, we would like to explore the generalizations of the stochastic matching model made possible by the equivalence with order-independent loss queues. Yet another avenue for future work, which goes beyond the scope of stochastic matching models, consists of extending the heavy-traffic result proved for multi-class multi-server queues in Ref. [Citation12] to other order-independent (loss) queues, like those considered in [14, Section 4.3].
Acknowledgement
The author is grateful to Sem Borst for his valuable comments on an earlier draft of this paper and to Ellen Cardinaels for mentioning the reference [Citation4]. The author thanks both of them for helpful discussions on the related work [Citation12]. The author is also grateful to the anonymous editor and reviewer for their valuable suggestions on the contents and exposition of the paper, and in particular for suggesting a simplification in Section 3.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Notes
1 Although numerical evaluations suggest that this is also a global minimum, proving this conjecture is complicated by the structure of Equation(15)(15)
(15) . Better understanding the properties of the mean matching time seen as a function of the arrival rates and/or the graph structure would be an interesting topic for future work.
2 Let The sets
and
(again with the convention that
if i = N and
if
) both contain
nodes and are included into
It suffices to show that at least one of these two sets contains an element that the other does not. In turn, to prove this, it suffices to observe that an independent set
contains at most K nodes, so that at least two of these nodes are separated by at least two nodes that do not belong to
References
- Adan, I.; Bušić, A.; Mairesse, J.; Weiss, G. Reversibility and further properties of FCFS infinite bipartite matching. Math. Oper. Res. 2018, 43, 598–621. DOI: https://doi.org/10.1287/moor.2017.0874.
- Adan, I.; Kleiner, I.; Righter, R.; Weiss, G. FCFS parallel service systems and matching models. Perform. Eval. 2018, 127-128, 253–272. DOI: https://doi.org/10.1016/j.peva.2018.10.005.
- Adan, I.; Weiss, G. Exact FCFS matching rates for two infinite multitype sequences. Oper. Res. 2012, 60, 475–489. DOI: https://doi.org/10.1287/opre.1110.1027.
- Begeot, J.; Marcovici, I.; Moyal, P.; Rahme, Y. A general stochastic matching model on multigraphs. arXiv:2011.05169 [math], 2020.
- Berezner, S. A.; Kriel, C. F.; Krzesinski, A. E. Quasi-reversible multiclass queues with order independent departure rates. Queue. Syst. 1995, 19, 345–359. DOI: https://doi.org/10.1007/BF01151928.
- Berezner, S. A.; Krzesinski, A. E. Order independent loss queues. Queue. Syst. 1996, 23, 331–335. DOI: https://doi.org/10.1007/BF01206565.
- Bonald, T.; Comte, C. Balanced fair resource sharing in computer clusters. Perform. Eval. 2017, 116, 70–83. DOI: https://doi.org/10.1016/j.peva.2017.08.006.
- Bonald, T.; Comte, C.; Shah, V.; de Veciana, G. Poly-symmetry in processor-sharing systems. Queue. Syst. 2017, 86, 327–359. DOI: https://doi.org/10.1007/s11134-017-9525-2.
- Bušić, A.; Gupta, V.; Mairesse, J. Stability of the bipartite matching model. Adv. Appl. Probab. 2013, 45, 351–378. DOI: https://doi.org/10.1239/aap/1370870122.
- Cadas, A.; Doncel, J.; Fourneau, J.-M.; Bušić, A. Flexibility can hurt dynamic matching system performance. arXiv:2009.10009 [cs, math], 2020.
- Caldentey, R.; Kaplan, E. H.; Weiss, G. FCFS Infinite Bipartite Matching of Servers and Customers. Adv. Appl. Probab. 2009, 41, 695–730. DOI: https://doi.org/10.1239/aap/1253281061.
- Cardinaels, E.; Borst, S.; van Leeuwaarden, J. S. H. Heavy-traffic universality of redundancy systems with data locality constraints. arXiv:2005.14566 [math], 2021.
- Chao, X. Networks with customers, signals, and product form solution. In Queueing Networks: A Fundamental Approach, International Series in Operations Research & Management Science; R. J. Boucherie and N. M. van Dijk, Eds.; Springer: US, 2011; 217–267.
- Comte, C. Resource management in computer clusters: algorithm design and performance analysis. PhD thesis, Institut Polytechnique de Paris, 2019.
- Feller, W. An Introduction to Probability Theory and Its Applications, Volume 2; John Wiley & Sons, Inc., 1966, 826 pp.
- Gardner, K.; Righter, R. Product forms for FCFS queueing models with arbitrary server-job compatibilities: An overview. Queue. Syst. 2020, 96, 3–51. DOI: https://doi.org/10.1007/s11134-020-09668-6.
- Keilson, J.; Servi, L. D. A distributional form of little’s law. Oper. Res. Lett. 1988, 7, 223–227. DOI: https://doi.org/10.1016/0167-6377(88)90035-1.
- Kelly, F. P. Reversibility and Stochastic Networks; Cambridge University Press: New York, NY, USA, 2011.
- Louth, G.; Mitzenmacher, M.; Kelly, F. Computational complexity of loss networks. Theor. Comput. Sci. 1994, 125, 45–59. DOI: https://doi.org/10.1016/0304-3975(94)90293-3.
- Mairesse, J.; Moyal, P. Stability of the stochastic matching model. J. Appl. Probab. 2016, 53, 1064–1077. DOI: https://doi.org/10.1017/jpr.2016.65.
- Moyal, P.; Bušić, A.; Mairesse, J. A product form for the general stochastic matching model. J. Appl. Probab. 2021, 58, 449–468. DOI: https://doi.org/10.1017/jpr.2020.100.
- Shah, V.; de Veciana, G. High-performance centralized content delivery infrastructure: Models and asymptotics. IEEE/ACM Trans. Netw. 2015, 23, 1674–1687. DOI: https://doi.org/10.1109/TNET.2015.2461132.
- Thi, T. H. D.; Fourneau, J.; Tran, M. A. Networks of order independent queues with signals. In 2013 IEEE 21st International Symposium on Modelling, Analysis and Simulation of Computer and Telecommunication Systems; 2013, 131–140.
Appendix
Proof of Proposition 14
As announced, the proof of each property relies on the corresponding expression derived in Section 4. The key argument consists of observing that EquationEquation (27)(27)
(27) and Assumption 13 can be reformulated as follows: as
tends to one if
(as we have
) and to a constant strictly less than one if
Proof of Property (14-a). According to Proposition 5 and EquationEquation (23)(23)
(23) , the stationary distribution of the set of unmatched classes can be rewritten as
(29)
(29)
where is given by
and
Since tends to one if
and to a constant strictly less than one if
it follows that
tends to infinity if
and to a finite constant if
We conclude by inserting this into Equation(29)
(29)
(29) . □
Proof of Property (Equation14-b). The result for the classes in
follows by inserting Property (14-a) into (Equation12
(12)
(12) ). The result for the classes in
is then a consequence of Equation(13)
(13)
(13) and Equation(27)
(27)
(27) . □
Proof of Property (Equation14-c) and (Equation14-e
). Consider a class
According to Proposition 7 and EquationEquation (29)
(29)
(29) , the expected number of class-i items can be rewritten as
(30)
(30)
where
is given by
if
and
if
By following a similar reasoning as in the proof of Property Equation(14-a)
(28)
(28) and recalling that
tends to one if
and to a constant strictly less than one if
we obtain
After simplification, we conclude by observing that Equation(26)(26)
(26) implies
If we consider instead
a similar reasoning shows that all terms in the numerator of Equation(30)
(30)
(30) have a finite limit, while its denominator still tends to infinity, so that Li tends to zero as
The limiting result for L follows by summation, and that for
follows by applying Little’s law and simplifying the result. □
Proof of Property (Equation14-d). Consider the random vector
defined by
The Laplace-Stieltjes transform of this random vector is defined, for each by
where the vector
is given by
for
and
for
We will use Proposition 9 to show that this Laplace-Stieltjes transform satisfies
(31)
(31)
One can verify that this is also the Laplace-Stieltjes transform of a random vector such that
for each
and
for each
According to Ref. [Citation15, Section 13.1, Theorem 2], this suffices to conclude that S weakly converges to
as
By following a similar approach as in the proof of Properties (14-a) and (Equation14-c) and recalling that
if
and
if
we obtain
Using Equation(18)(18)
(18) , we can rewrite the right-hand side of this equivalence as
(32)
(32)
As the first factor tends to 1 because
for each
while we can show with a Taylor series expansion that the second factor tends to
This proves Equation(31)
(31)
(31) and completes the proof. □
Proof of Property (Equation14-f). We will show that, for each
we have
(33)
(33)
We recognize the Laplace-Stieltjes transform of an exponentially-distributed random variable with rate for
and the degenerate Laplace-Stieltjes transform of a constant random variable equal to 0 for
The conclusion of the proposition then again follows from Ref. [Citation15, Section 13.1, Theorem 2].
First let According to Proposition 10, we have
where
is given by
and zj = 1 for each
Since
as
and by following a similar reasoning as in the proof of Property (14-d), we obtain
The right-hand side of this equivalence is again given by (32). By using the definition of z, we can show that the second factor in Equation(32)(32)
(32) simplifies to
which tends to
according to Equation(33)
(33)
(33) . Since we also know that the first factor in (Equation32
(32)
(32) ) tends to 1, this proves Equation(33)
(33)
(33) . The proof for
is similar, the main difference being that we have directly
because
□