
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper we analyze a continuous review finite capacity production-inventory system with two products in inventory. With stochastic order quantities and time between orders, the model reflects a supply chain that operates in an environment with high levels of volatility. The inventory is replenished using an independent order-up-to (s, S) policy or a can-order (s, c, S) joint replenishment policy in which the endogenously determined lead times drive the parameters of the replenishment policy. The production facility is modeled as a multi-type MMAP[K]/PH[K]/1 queue in which there are K possible inventory positions when the order is placed and the age process of the busy queue has matrix-exponential distribution. We characterize the system and determine the steady state distribution using matrix analytic methods. Using numerical methods we obtain the inventory parameters that minimize the total ordering and inventory related costs. We present numerical comparisons of independent and joint replenishment policies with varying lead times, order quantities, and cost reductions. We further demonstrate the interplay between the two products in terms of lead times, order quantities and costs.
1. Introduction
Inventory management has been studied for decades, but volatile market conditions have increased the complexity of modeling and analysis, as supply chain factors such as production rate, demand rate, and lead time become more variable. While much of the research in inventory management deals with single product analysis, companies need to make decisions on many aspects of inventory management, and the replenishment of multiple items is a common operational concern[Citation6].
We study a continuous review production-inventory system with a single production line, two products in inventory, stochastic order quantities, stochastic time between orders, and where the objective is to determine the parameters of the inventory policy for each product that minimizes the total ordering and inventory related costs for both products.
We consider two policies of replenishing each product’s inventory: an order-up-to (s, S) policy in which each product is replenished independently[Citation1]; and a can-order joint replenishment (s, c, S) policy[Citation5], where if the inventory position of one product reaches its reorder point s or below, all other products whose inventory position is below their can-order level c, are included in the same replenishment order and any order placed raises the inventory position of that product to the order-up-to level S. Considerable savings may be realized by such coordinated replenishments[Citation8] and an important factor making this approach cost effective is the joint set-up cost structure. However, the interaction between items makes determination of optimal parameters a difficult task.
The lead time is the time between the moment an order is placed and the moment it is received in inventory and thus consists of a waiting time in queue (if the system is busy), a setup time and a production time. The lead time depends on the way orders are placed and the production process, and influences inventory levels and inventory related costs.
Much of the inventory literature treats lead times as a fixed constant or as an exogenous variable with a given probability distribution, which means that the time required to deliver an order is assumed to be independent of the size of the current order and independent of the lead time of previous orders[Citation22,Citation40]. This approach is justified when both production and inventory are decoupled through a large inventory at the production; if the owner of the production system guarantees a fixed delivery date; or if transportation lead times are much longer than production lead times, as in these scenarios the inventory policy does not impact significantly on lead times.
When multiple products are produced on the same production line, the order process of each individual product loading the production queue, impacts the lead times for all products ordered and all inventory levels are affected. Ignoring this impact may lead to suboptimal inventory parameters and higher costs. For example, in the context of a fixed order period (r, S) policy, it was shown that relying on exogenous lead times can result in a severe underestimation of the required inventory on hand[Citation39].
In an integrated production-inventory setting, the interaction between the inventory control system and the production system is explicitly modeled: inventory influences production by initiating orders, and production influences inventory by completing and delivering orders to inventory. Accordingly, the lead times are endogenously determined by the production system: as the orders of each product load the production line, they determine the lead times, hence influence the time to replenish each product in inventory, and impact the holding and backlogging costs. Thus there is correlation between demand and lead times: high demand depletes inventory more, creating a larger order to replenish inventory, which in turn takes longer to produce. In order to characterize the retailer’s inventory behavior in a production-inventory system in an exact way, we include this correlation in our analysis.
Much queueing theory literature assumes the arrival processes of customers are independent processes. The introduction of the Markov arrival process with marked transitions, MMAP[K][Citation17], allowed modeling of complicated queues with multiple types of customers and correlated arrival times[Citation2]. Further, the application of standard matrix analytic methods has allowed the development of efficient algorithms for computing relevant performance measures[Citation15,Citation18].
In this paper, the production facility is modeled as a MMAP[K]/PH[K]/1 queue[Citation16,Citation38]. Queues of this type have a single server, correlated interarrival times and K types of customers, where each customer type may have a different phase-type service requirement. In our case, the customer types correspond to the possible inventory positions when the order is placed.
The state space for the process records information on the type of order, the inventory position when the order was placed, and the current state of production or setup. The age process that observes this queue during the busy period keeps track of the age of the order in production, the current production phase and has matrix-exponential distribution[Citation31,Citation32]. To enable efficient computation of the inventory level distribution, we construct a fluid queue to enable computation of required matrices[Citation13] and from these we can determine the cost-minimizing order quantity of the replenishment orders.
In our model the setup, change-over and production times are stochastic and follow a phase-type distribution[Citation24]. The advantage of a phase-type distribution is that its Markovian nature allows for an exact analysis and performance evaluation.
The contribution of this work is to construct an exact evaluation for the can-order joint replenishment policy while taking endogenous lead times into account, and hence to study the complex interplay between mutually dependent product inventory levels. We provide illustrations of the interaction between the inventory properties for the two product case, in terms of lead times, order quantities, and cost reductions from a can-order joint replenishment policy as compared with an independent order-up-to policy. The analysis is applicable to more products but leads to state space explosion.
The structure of this paper is as follows: in Section 3 we define the production-inventory model and then, in Section 4, define the associated Markov process characterizing the production-inventory system. From the matrix exponential form of the steady state distribution, we construct the associated fluid process in Section 5. In Section 6 we present results required for the computation of the expected costs, outline the numerical method, and present some individual and joint replenishment outcomes, illustrating the impact of different parameter values. Concluding remarks are given in Section 7.
2. Background
Inventory analyses are generally aimed at minimizing ordering and holding costs while satisfying demand and there is a vast literature addressing differing assumptions on how customer orders and production systems are managed. We mention just a few variations. For example, inventory control policies assuming independent and identically distributed inter-event times have received most attention, but a recent study of production policies to minimize expected holding and backlog costs, while considering correlated inter-arrival and processing times, showed that effective production control policies should take correlations in service and demand into account[Citation12]. We use a model that assumes customer orders are held until the item is produced. Much research seeks ordering policies to maintain the inventory position at a constant level, but a recent analysis illustrates opportunities for performance improvement by using the current inventory level to set a dynamic target for inventory-in-transit, and to place orders that follow this target[Citation36]. Other work considers situations where a customer may have a ready alternative source and sales are lost[Citation14], and situations where the supplier has access to an emergency supply to raise the inventory level[Citation7].
In the context of an inventory managing multiple items, the joint replenishment problem deals with the prospect of saving resources through coordinated replenishments, by considering interdependencies amongst product orders involving a single supplier. Studies of joint replenishment have led to many models, solution methods and applications[Citation8]. As the complexity of many variations of the joint replenishment problem has been determined to be NP-hard[Citation11], studies focus on approximate and heuristic methods.
Replenishment models cover both deterministic demand types, for examples, see Bastos et al.[Citation8], and stochastic demand types, for example, see Barron[Citation6], Krishnamurthy and Seethapathy[Citation21], and Kulkarni and Yan[Citation22]. With the stochastic demand models, there are two main replenishment policies: (i) the periodic replenishment policy, in which all products follow the same replenishment periodic interval, and each one is replaced to a pre-determined inventory level[Citation4]. (ii) the continuous review can-order policy, in which if any item reaches a must-order point, a replenishment order is made, and if the other items have inventory levels below a can-order point, they are included in the same order[Citation5,Citation20,Citation30]. On stochastic demand models based on the can-order policy, solution methods have focused mostly on determining optimal values for re-order and can-order parameters in relation to the selected policy[Citation8].
Markov processes are valuable as approximate processes, due to their versatility in matching key statistical properties of the demand process[Citation10,Citation26]. Phase-type distributions[Citation27] are often used, and in which their matrix structure supports efficient computational implementation[Citation7]. When general distributions are appropriate for modeling the demand, phase-type distributions can be taken into account in a natural way, as any non-negative continuous distribution of the probability can be approximated with a phase-type distribution[Citation3].
Prior studies of models incorporating endogeneous lead times include: early work on assemble-to-order production-inventory systems with stochastic lead times, in which one must allow for correlated demands by jointly managing inventories and production capacities across several items—that work used matrix geometric methods for exact analysis to evaluate order-fulfilment performance measures[Citation34]; performance analysis of a single product production-inventory system with periodic demands[Citation9]; and more recent work studying a single product dual-source inventory system where the lead times at both sources are stochastic and endogeneous, namely sojourn times in a queueing system—where the authors establish a new approach to finding an optimal policy[Citation35], in part drawing on results on endogeneous stochastic supply networks[Citation33].
A key element influencing the complexity and usefulness of any Markov model is the choice of the state space and transition function. In our model, the state representation records information on the type of order, the inventory position when the order was placed, and the current state of production or setup, and the analysis takes advantage of matrix analytic and fluid queue results applicable to the associated age process. An approach similar to ours was used by Noblesse et al.[Citation28] for the single item problem, but the analysis in the current paper allows for systems with batch demand arrivals, variable order quantities, and non-exponential production times. Related approaches in less complex settings than that studied here have been used by Horvath and Van Houdt[Citation19], Otten et al.[Citation29], Van Houdt[Citation37].
3. Model description
Consider a production-inventory system with products, where demands arrive according to a compound Poisson process with rate
The sizes of the batch demands are i.i.d. and follow a general discrete distribution with maximum demand size mj. Let
denote the probability of a demand of size x for product j. If inventory is insufficient to fulfill demand, unmet demand is backlogged.
The inventory of product j is replenished according to a policy, where
if the inventory position of product j reaches its reorder point sj, product
will also place an order if its inventory position is at or below the can-order level
otherwise it will not join the order. Setting cj = sj, the
policy reduces to an (sj, Sj) policy, therefore our analysis holds for both joint and independent replenishment policies. The maximum order size is
Orders are sent to the production queue and produced on a first-come-first-served basis by a single machine which produces the units of each order sequentially. Each order requires a major setup time and a production time per unit. If a joint order is placed, only one major setup time is required and an additional minor change-over time. Typically, the minor change-over time will be smaller than the major setup time, although the model does not require this assumption.
When both the setup is complete and the last unit of the order is produced, the order is replenished in inventory. If a joint order is placed, the order is only delivered in inventory when the production for both products is completed. We assume the unit production time is identical for both products and follows phase-type distribution that is, with subgenerator matrix Up and initial probability vector γp of order np. The major setup time and minor change-over time are assumed to both follow phase-type distributions with
of order
and
of order
respectively.
Denote by ηj the expected number of orders placed per unit time of only product j and the expected number of joint orders per unit time initiated by product j. An inventory holding cost hj is incurred per unit per time and
is the expected number of units in inventory of product j at a random point in time. A backlogging cost pj is incurred per unit per time and
denotes the expected number of units of product j backlogged at a random point in time. The expected total cost per unit of time for both products is
(1)
(1)
where a major fixed order cost
is incurred per order placed and a minor fixed order cost kj if product j is included in the order. For ease of reference, a summary of key notation is provided in .
Table 1. Summary of key notation.
The objective is to determine the inventory parameters that minimize
We next describe the Markov process of the underlying model, and key theoretical results are set out in the following two sections, enabling the iterative procedure used for the numerical solutions discussed in Section 6.3.
4. Markov process of the two product system
Below we describe the state representation and transitions (Section 4.1). For the busy process we use a state space construct similar to that in He[Citation15] and Noblesse et al.[Citation28]. Then we present the transition rate and density matrices (Sections 4.2 and 4.3), and introduce the product utilization rate, ρp (Section 4.4) that is used in the inventory level distribution that is derived in Section 5.3.
4.1. Process description
When the server is idle, we use as state space where each element of
characterizes an inventory position. Clearly
has dimension
A Markov process
then records the inventory depletions due to arrivals of demands.
When the server is busy, we represent the system using the Markov process The first component
represents the age, i.e., the elapsed time since the order in service was placed, and the second component
represents the state of the order in service at time t. This busy process describes the transitions in the MMAP[K]/PH[K]/1 queue that models the production facility[Citation17].
For an order in production, the state space is defined as
where the states in
describe the order when initiated by product j, i.e., the product that reached its reorder point, and we set
partitioned according to whether the order in production is an individual or joint order.
For an order initiated by product 1, define
where ij represents the inventory position of product j when the order in production at time t was placed, i.e., at time
and the third component, z, represents the progress of the production: i.e., it is either in major setup (in a state in
), or in production with r − 1 remaining items to be produced to complete the order and the server is currently in state
So
Accordingly,
Define
where
In contrast to here we do not need to keep track of the inventory position i2 as it will increase to S2 irrespective of the value of i2. We note that the range of z is now larger as the order also involves at most
items of product 2 and the server can also be in one of the states of the minor change-over time. If
the server is in state z of the minor change-over time, if
a major setup is ongoing and the remaining z values correspond to the production of an item.
When the inventory position of product 1, exceeds c1, the order only includes product 2, while for inventory positions up to c1, the order is joint with product 1. So, for an order initiated by product 2, define
where
and
where
We have defined the model from the perspective of product 1 and thus the sets and
are structurally different. This representation provides sufficient information to derive the inventory distributions, but enables smaller matrix calculations than if we retained the same structure for
as
We also note that to obtain a Markov process it is not necessary to keep track of the inventory position, i1 of product 1 (as the inventory position increases to S1 irrespective of the value of i1), but we have included this in the representation as it can then be used in deriving the inventory level distribution of product 1 in Section 5.3, which in turn is used in our iterative procedure to compute the expected cost in Section 6.3.
The process evolves as follows: as the production of an order continues, Xt increases linearly over time and a downward jump in Xt occurs when an order completes service. Three types of transitions can occur from state
A transition to state (x, j) for
when the state of production/change-over/setup changes but the same order remains in service. Denote by
A transition to a state (y, j) with
A transition to state
Figure 1. Sample path of Xt. Upon production completion of the nth order at age x, the subsequent order in service has already spent at least x – u time units in the system.
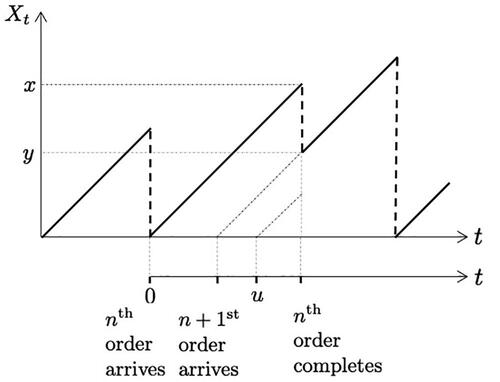
The matrices A0 and dA(u) are described in the next sections.
4.2. Transition rate matrix A0
Define
(2)
(2)
where
is an order
matrix that contains the rates when the order was initiated by product j. Then
(3)
(3)
where
records the inventory position of product 1 the moment the order was placed, the matrices
and
describe the joint and individual orders initiated by product 1, respectively, and ⊗ denotes the Kronecker product. Then,
(4)
(4)
is an order
matrix and describes the transitions in production and setup phases and where the vectors
and
denote the completion rates of the unit production and the major setup time, respectively. Define,
(5)
(5)
an order
matrix. Since there is no minor setup time, we record the inventory position of product 2 with
the moment the order was placed. Then we obtain a zero matrix, except for the
sub-matrices on the diagonal where each of sub-matrix defines the transitions in production and setup and specifying i2. Similarly, define
(6)
(6)
where
(7)
(7)
is of order
and
(8)
(8)
is of order
In both joint and individual orders, we keep track of the inventory position of product 1 at the moment the order was placed.
4.3. Density matrix dA(u)
The density function of the rate matrix A(u) can be expressed as
(9)
(9)
where
describes the transitions from the states in
prior to service completion to the inventory positions of both products immediately after the order was placed. The matrix exponential
gives the density of the inter-arrival time of u, where
describes the evolution of the inventory position until the subsequent order is placed. The matrix
describes the transitions to the initial production state of the subsequent order beginning at
4.3.1. Production completion of the order in service ()
Denote by αj the vector of the steady state probabilities of the inventory position immediately after a replenishment, then with length
Let
(10)
(10)
where
describes the transitions when the order was initiated by j. Recalling that completion occurs after a major setup time in an individual order, or after a minor change over time of a joint order, we have
(11)
(11)
with dimensions
and where
is a vector of length
and
a vector of length
where
denotes the transpose of
The vector
records the inventory level of product 1 during production as a new order is about to begin. The upper sub-matrix in EquationEquation (11)
(11)
(11) describes an individual order of product 1, then the inventory position of product 1 is raised to S1 and we record the inventory position of product 2 with
The lower sub-matrix describes a joint order, in which case the inventory positions of both products are raised to their respective Sj. Similarly,
(12)
(12)
where
is used to keep track of the inventory position of product 1 when only product 2 is replenished, and
records the inventory position of product 1 in a joint order.
4.3.2. Inventory position until subsequent order ()
The matrix is of order
and describes the transition rates in the inventory positions of both products due to demand arrivals until the reorder point of one of the products is reached. Then
(13)
(13)
The time u between subsequent orders is then equivalent to the time it takes for the process to decrease from the inventory positions just after an order was placed until absorption in one of the reorder points (or below), thus its density is given by
4.3.3. Start of production of the subsequent order ()
Let where
records the transitions when the order was initiated by product j and which has dimension
Then
(14)
(14)
where
(15)
(15)
is a column vector
of length
and contains the rates of demand arrivals for product 1 which result in an order of size
The matrix
determines the state in which production starts if the order size of product 1 equals
and if the inventory position of product 2 is
at the moment when product 1 initiates an order, for
If only product 1 is replenished,
also records the inventory position of product 2, i2. Thus
is an
matrix with all its entries equal to zero, except for np entries given by γp. For
the inventory position of product 2 remains above c2 and the np nonzero entries of row i2 of
are on the columns corresponding to the states
with
to
For
we have a joint order and the np nonzero entries on row i2 of
are on the columns corresponding to the states
of
with
to
as the joint order has size
Similarly, defines the transition rates when product 2 reaches its reorder point,
(16)
(16)
with
an
matrix with all its entries equal to zero, except that each row contains np entries equal to γp. More specifically, the non-zero entries on row
appear on the columns corresponding to the states
with
to
For
the columns corresponding to the states
of
with
to
holds the entries of γp.
4.4. Utilization of the production system
Define ρp as the production utilization rate, that is, excluding the setup times, then
(17)
(17)
where
is the mean unit production time and
is the mean demand size for product j. The overall utilization ρ is then determined by the number of orders placed,
(18)
(18)
where
and
are the mean major setup and minor change-over times, respectively.
5. Steady-state analysis
We consider the form of steady state of the Markov process in Section 5.1 and construct the associated fluid queue in Section 5.2. In Section 5.3 we obtain an expression for the inventory position and the number of demand arrivals since an order was placed and combine the results to determine the inventory level distribution.
5.1. Preliminaries
For x > 0, denote the steady-state density of (Xt, Lt) as
(19)
(19)
and the corresponding vector
If
the process (Xt, Lt) has matrix exponential form[Citation31,Citation32] and there exists a matrix T of order
such that
(20)
(20)
where the matrix T is the smallest non-negative solution to
(21)
(21)
and
where θ is the stationary vector of
(22)
(22)
See Van Houdt[Citation37] for details.
Using the matrices A0 and dA(x), the matrix T can be computed iteratively, with
[Citation31]. As this method results in linear convergence and is therefore impractical under high loads, in the next section we present a more efficient approach.
5.2. Reduction to a fluid queue
To employ a method for computing T that converges quadratically we construct a fluid queue[Citation13]. In order to obtain a fluid queue, the fluid process must be skip-free in both directions so we replace the immediate downward jumps in Xt by intervals of the appropriate length during which the level decreases linearly. Then there are phases in which the fluid increases and
artificial phases in which the fluid decreases and the rate matrix of the underlying continuous-time Markov chain is
(23)
(23)
The matrix contains the rates at which the phase changes while the fluid increases (the same order remains in service),
contains the transitions from an increase to a decrease in fluid (a service completion occurs),
contains the transitions from a decrease to an increase in fluid (a new order enters service) and
contains the transition rates while the fluid decreases (demands arrive depleting the inventory, but no product has reached its order point).
When the fluid queue hits level zero the phase continues to evolve according to until an event part of
occurs and the fluid level becomes positive again. Censoring the queue only on the periods where the level increases we obtain the Markov process of Section 4, in which the age always increases, unless there is a downward jump. Due to EquationEquation (9)
(9)
(9) , a downward jump to level zero occurs with rate
where the part
captures the evolution of the phase of the fluid queue at zero.
If we take the expression for the steady state of a fluid queue[Citation23] and observe the queue only when the level is increasing, the steady state has the form given in EquationEquation (20)(20)
(20) with
(24)
(24)
and
where θ is the stationary vector of
and matrix
the first return probabilities to the initial level, is the minimal non-negative solution to an algebraic Riccati equation
(25)
(25)
To reduce the computation time of θ, we employ the power method[Citation39]. Further, as has block diagonal form, we can apply the algorithm of Meini[Citation25], which exploits this structure to reduce the memory and time complexity.
Observing the phase process only during the intervals of time in which the fluid level is decreasing, that is, when the production facility is idle, the rate matrix is
(26)
(26)
from which we obtain the steady state probabilities of the idle production facility,
such that
5.3. Inventory level distribution of product 1
For denote by
the probability the inventory level is
To derive this distribution, we separately consider the situations in which the server is busy and where it is idle.
Firstly when the server is busy, define as the probability that the inventory position of product 1 was
at the moment when the order in production was placed and n demand arrivals of product 1 have depleted inventory since. The corresponding vector
is partitioned such that
(27)
(27)
where the entries refer to individual orders placed by product 2, joint orders initiated by product 2, and orders initiated by product 1 (joint or individual), respectively. During the time x this order has spent in the system, the probability that the inventory is further depleted by the arrival of n demands for product 1 is
Let
(28)
(28)
then
We can then write
(29)
(29)
where
is the probability of a idle server in which the inventory level of product 1 is at least
and the idle probabilities gi are given by
(30)
(30)
where
is derived from the fluid queue construction in EquationEquation (26)
(26)
(26) and where
if A is true and
otherwise.
When the server is busy, with probability ρ, is obtained by
and the n-fold convolution of the demand size distribution,
(31)
(31)
Then the expected number of units in inventory and expected number of units backlogged are
(32)
(32)
Denote by L the lead time and define as its steady state density,
(33)
(33)
where
and with corresponding distribution function
(34)
(34)
then the expected lead time of a random order is
Conditioning on the order if product 1 is included, the product dependent expected lead time is
(35)
(35)
where
(36)
(36)
using the expression for
in EquationEquation (12)
(12)
(12) , and where
denotes the Hadamard product.
6. Expected total cost
For the computation of the expected total cost, we need to characterize the time between orders. In Section 6.1 we consider the time, ηj, between individual orders, and similarly in Section 6.2 for the time, between joint orders. In Section 6.3 we present the iterative procedure employed to derive the policy parameters for both products and give numerical illustrations.
6.1. Expected number of individual orders per unit time
The time between two subsequent individual orders has distribution of order
and the time to place the subsequent order is equivalent to the time to reach absorption. The expected time between subsequent individual orders of product j is given by
Define
(37)
(37)
The matrix records the transitions in inventory position until the subsequent replenishment, thus only a decrease in inventory positions is possible. However in
an increase in inventory positions is possible when product
places an order. Then for j = 1,
(38)
(38)
where the second term refers to an increase in inventory positions due to a joint order initiated by product 1, and the third term refers to a (joint or individual) order placed for product 2. The vector
contains the probabilities of starting in a given state following an individual order of product 1 and is the stationary distribution of
as an individual order for product 1 can only occur if the inventory position of product 2 is at least
Similarly,
(39)
(39)
and
is the stationary distribution of
6.2. Expected number of joint orders per unit time
The time between two subsequent joint orders initiated by product 1 has distribution then
As the inventory position of both products after placing a joint order is
the initial state vector is
and
(40)
(40)
where the second term accounts for the individual orders placed of product 1, and the third term refers for the orders placed by product 2. The time between two subsequent joint orders initiated by product 2 is
with
where
(41)
(41)
6.3. Iterative solution and numerical examples
To obtain the inventory parameters that minimize in EquationEquation (1)
(1)
(1) , we use an iterative procedure to obtain successive approximations for both products using neighbor search and steepest descent algorithms. Given a set of initial inventory parameters for product 1, we determine the optimal inventory parameters for product 2. Then given this inventory policy for product 2, we determine the inventory parameters for product 1 that minimize
and repeat until convergence is reached. We note that to compute the cost for both products simultaneously would involve matrices with significantly larger dimensions and hence be less tractable.
We present results for six experiments for different values of the ordering costs and minor change-over times, as these drive the order quantities, and
The parameter values are chosen to highlight the impact of changing the key replenishment drivers and costs, being the ordering costs and setup times. The holding and backlogging costs represent a service level of 90%. Parameter values common to all experiments are listed in and the different values are listed in . The unit production time, major setup and minor change-over times are each exponentially distributed and the demand size distribution is zero-truncated binomial.
Table 2. Parameter values common to all numerical experiments.
Table 3. Ordering costs and setup times for each experiment.
We demonstrate the iterative procedure for deriving parameters for the case of an independent replenishment policy and discuss the interplay between the quantities of interest. We then illustrate the cost reduction by using a joint replenishment policy compared to independent policy.
Obtaining cost minimizing parameters for individual replenishment. For Experiment 1, we outline the solution for The iterations are listed in with an initial guess of
from which we obtain
and
Table 4. Parameters obtained for the iterative procedure in Experiment 1 for
To understand how the quantities of interest change throughout the iteration, illustrate how ρ, and sj evolve.
Figure 2. Order quantity vs. utilization rate ρ.
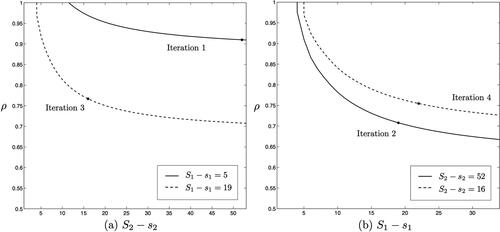
Figure 3. Order quantity vs. reorder points
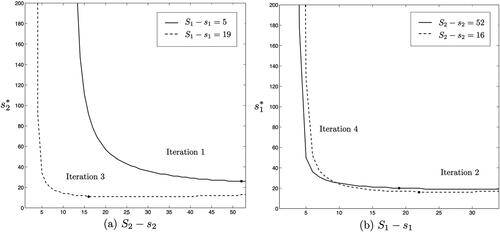
Figure 4. Order quantity vs. expected total cost
![Figure 4. Order quantity (Sj−sj) vs. expected total cost E[C].](/cms/asset/c61571de-d079-4746-a7d8-e471005cbf1a/lstm_a_2049822_f0004_b.jpg)
Iteration 1. For the initial order quantity the small size leads to multiple setups, congested production, long lead times and high costs. The solid line illustrates how ρ decreases as the order quantity of product 2 increases. The cost-minimizing reorder point s2 as a function of the order quantity is illustrated in and Citation4(a) illustrates the impact on
Due to the small order of product 1, a large order of product 2 is optimal, as this tempers the utilization rate and lead times.
Iteration 2. Given the solid lines of (b) illustrate the impact of the order quantity of product 1 on the utilization rate ρ, optimal reorder point s1 and expected total costs
respectively. Increasing the order quantity of product 1 from 5 to 19, leads to more favorable lead times (due to a reduction in setups) and lower total system costs.
Iteration 3. Given the dashed lines of (a) illustrate how
impacts ρ,
and
respectively. Compared to the scenario in Iteration 1, the order quantity of 1 is larger, thus the order quantity of 2 can be reduced to 16 units while
is also reduced.
Iterations 4 and 5. Given the dashed lines in (b) illustrate quantities for iteration 4. We obtain
with
and
Proceeding to the next iteration with
we find
thus the procedure ends and the optimal inventory parameters are
and
The results for the all experiments are listed in . As expected, the minor change-over time has no impact as no joint orders are placed. Different values of and kj have no impact as long as
remains the same for product j, which explains why the result of experiments
are the same for the (sj, Sj) policy. In experiments 5 and 6
and the optimal order quantities are only slightly smaller compared to experiments
due to the impact of the order quantities on setup times and lead times.
Table 5. Optimal replenishment parameters for each experiment.
Comparison of independent and joint replenishments. Following a similar iterative procedure, we present the solutions for in . In , we give the cost reductions of (s, c, S) compared to the (s, S) policy, listed alongside the ratios of the fixed ordering costs
and the mean setup time vs. the mean change-over time. As expected,
is lower in the joint replenishment scenarios.
Table 6. Ratio of ordering costs and setup times.
In Experiment 6, due to the small change-over time, we find the highest gains with a cost reduction of 10.73%, in which the benefit is mostly seen from the reduction in setup time by placing joint orders. We see the benefit of joint replenishment is not only influenced by the ratio of but also by the ratio of the joint major setup time and the changeover time. Comparing the individual and joint policies we find that the mean number of orders placed reduces in our set of experiments by more than 14%.
We demonstrate that this cost discrepancy increases in the ratio of and kj and in the ratio of the major setup time and the minor change-over time. The impact of a can order policy on lead times is unclear. Although the number of setups reduces, lead times may not necessarily go down due to a batching time, i.e., waiting time after production until the joint order is completed.
7. Concluding remarks
The analysis of sufficiently detailed production-inventory models is challenging when accounting for the number of variable quantities in the supply-chain process. We consider a continuous review finite capacity production-inventory system with two products in inventory. As the order process of each individual product impacts the utilization rate of the production system and thus the lead times for all products, the inventory levels are mutually dependent.
The contribution of this work is to construct an exact evaluation for the can-order joint replenishment policy while taking endogenous lead times into account and hence, using numerical examples, to study the complex interplay between product inventory levels, adding to the relatively limited studies of multi-item inventory analysis. The analysis in the current paper allows for systems with batch demand arrivals, variable order quantities, and non-exponential production times. Modeling the production facility as a multi-type queue, with correlated arrivals and type dependent service, the matrix exponential form of the age process of the busy queue is used to compute the inventory level distribution. For a given set of input values, our analysis generates parameters to specify a minimal cost can-order policy, a well-known heuristic for the joint replenishment problem.
We use numerical methods to obtain inventory parameters that minimize total ordering and holding costs and provide examples of the interaction between the inventory properties for the two product case, in terms of lead times, order quantities, and cost reductions from a can-order joint replenishment policy as compared with an independent order-up-to policy. We demonstrate scenarios where there is decreased cost of a can-order (s, c, S) joint replenishment policy as compared with an independent order-up-to (s, S) policy. Our analysis also can apply to a setting with multiple retailers of a single product that is produced on the same production line[41] and joint replenishment in transport applications[Citation30]. A limitation is the computation time, which grows rapidly with the number of products, the maximum demand size or the order quantity. The analysis is applicable to more products but further work includes establishing optimality of the solution obtained numerically, and development of heuristics to manage combinatorial state space explosion. The analysis can be extended to a system with MAP arrival processes, however, this will increase the dimension of the matrices involved (by a factor equal to the product of the number of states of both MAPs).
Additional information
Funding
References
- Arrow, K.; Harris, T.; Marschak, J. Optimal inventory policy. Economet: J. Economet. Soc. 1951, 19, 250–272. pages DOI: https://doi.org/10.2307/1906813.
- Artalejo, J.; Gómez-Corral, A.; He, Q. Markovian arrivals in stochastic modelling: A survey and some new results. Stat. Oper. Res.Trans. 2010, 34, 101–144.
- Asmussen, S.; Kella, O. A multi-dimensional martingale for Markov additive processes and its applications. Adv. Appl. Probab. 2000, 32, 376–393. DOI: https://doi.org/10.1239/aap/1013540169.
- Atkins, D.; Iyogun, P. Periodic versus can-order policies for coordinated multi-item inventory systems. Manage. Sci. 1988, 34, 791–796. DOI: https://doi.org/10.1287/mnsc.34.6.791.
- Balintfy, J. On a basic class of multi-item inventory problems. Manage. Sci. 1964, 10, 287–297. DOI: https://doi.org/10.1287/mnsc.10.2.287.
- Barron, Y. Critical level policy for a production-inventory model with lost sales. Int. J. Prod. Res. 2019, 57, 1685–1705. DOI: https://doi.org/10.1080/00207543.2018.1504243.
- Barron, Y. The continuous (S, s, Se) inventory model with dual sourcing and emergency orders. Eur. J. Oper. Res. 2021, 1–21. DOI: https://doi.org/10.1016/j.ejor.2021.09.021.
- Bastos, L.; Mendes, M.; Nunes, D.; Melo, A.; Carneiro, M. A systematic literature review on the joint replenishment problem solutions: 2006–2015. Production 2017, 27, 1–11. DOI: https://doi.org/10.1590/0103-6513.222916.
- Boute, R.; Lambrecht, M.; Van Houdt, B. Performance evaluation of a production/inventory system with periodic review and endogenous lead times. Naval Res. Logist. 2007, 54, 462–473. DOI: https://doi.org/10.1002/nav.20222.
- Chakravarthy, S.; Rao, B. Queuing-inventory models with MAP demands and random replenishment opportunities. Mathematics 2021, 9, 1092. DOI: https://doi.org/10.3390/math9101092.
- Cohen-Hillel, T.; Yedidsion, L. The periodic joint replenishment problem is strongly NP-hard. Math. Oper. Res. 2018, 43, 1269–1289. DOI: https://doi.org/10.1287/moor.2017.0904.
- Dizbin, N.; Tan, B. Optimal control of production-inventory systems with correlated demand inter-arrival and processing times. Int. J. Prod. Econ. 2020, 228, 107692. DOI: https://doi.org/10.1016/j.ijpe.2020.107692.
- Dzial, T.; Breuer, L.; da Silva Soares, A.; Latouche, G.; Remiche, M. Fluid queues to solve jump processes. Perform. Eval. 2005, 62, 132–146. DOI: https://doi.org/10.1016/j.peva.2005.07.013.
- Faaland, B.; McKay, M.; Schmitt, T. A fixed rate production problem with poisson demand and lost sales penalties. Prod. Oper. Manage. 2019, 28, 516–534. DOI: https://doi.org/10.1111/poms.12931.
- He, Q. Age process, workload process, sojourn times, and waiting times in a discrete time SM[K]/PH[K]/1/FCFS Queue. Queueing Syst. 2005, 49, 363–403. ( DOI: https://doi.org/10.1007/s11134-005-6972-y.
- He, Q.; Alfa, A. The MMAP[K]/PH[K]/1 queues with a last-come-first-served preemptive service discipline. Queueing Syst. 1998, 29, 269–291. DOI: https://doi.org/10.1023/A:1019140332008.
- He, Q.; Neuts, M. Markov chains with marked transitions. Stoch. Process. Appl. 1998, 74, 37–52. DOI: https://doi.org/10.1016/S0304-4149(97)00109-9.
- Horvath, G. Efficient analysis of the MMAP[K]/PH[K]/1 priority queue. Eur. J. Oper. Res. 2015, 246, 128–139. DOI: https://doi.org/10.1016/j.ejor.2015.03.004.
- Horvath, G.; Van Houdt, B. A multi-layer fluid queue with boundary phase transitions and its application to the analysis of multi-type queues with general customer impatience. In Proceedings of the 2012 Ninth International Conference on Quantitative Evaluation of Systems. IEEE Computer Society, 2012; 23–32.
- Kayi, E.; Bilgi, T.; Karabulut, D. A note on the can-order policy for the two-item stochastic joint-replenishment problem. IIE Trans. 2008, 40, 84–92.
- Krishnamurthy, A.; Seethapathy, D. Production inventory models for a multi-product batch production system. In Rapid Modelling and Quick Response; Springer: London, 2010; 47–59.
- Kulkarni, V.; Yan, K. Production-inventory systems in stochastic environment and stochastic lead times. Queueing Syst. 2012, 70, 207–231. DOI: https://doi.org/10.1007/s11134-011-9272-8.
- Latouche, G. Structured Markov Chains in Applied Probability and Numerical Analysis. In MAM 2006: Markov Anniversary Meeting; C&M Online Media, Inc.: North Carolina, USA, 2006; 69–78.
- Latouche, G.; Ramaswami, V. Introduction to Matrix Analytic Methods in Stochastic Modeling. ASA-SIAM Series on Statistics and Applied Probability. Society for Industrial and Applied Mathematics: USA, 1999.
- Meini, B. On the numerical solution of a structured nonsymmetric algebraic Riccati equation. Perform. Eval. 2013, 70, 682–690. DOI: https://doi.org/10.1016/j.peva.2013.04.001.
- Nasr, W. Inventory systems with stochastic and batch demand: computational approaches. Ann. Oper. Res. 2022, 309, 163–125. DOI: https://doi.org/10.1007/s10479-021-04186-x.
- Neuts, M. F. Matrix-Geometric Solutions for Stochastic Models. John Hopkins University Press: Baltimore, 1994.
- Noblesse, A.; Boute, R.; Lambrecht, M.; Van Houdt, B. Lot sizing and lead time decisions in production/inventory systems. Int. J. Prod. Econ. 2014, 155, 351–360. DOI: https://doi.org/10.1016/j.ijpe.2014.04.027.
- Otten, S.; Krenzler, R.; Daduna, H. Separable models for interconnected production-inventory systems. Stoch. Models 2020, 36, 48–93. DOI: https://doi.org/10.1080/15326349.2019.1692667.
- Padilla Tinoco, S.; Creemers, S.; Boute, R. Collaborative shipping under different cost-sharing agreements. Eur. J. Oper. Res. 2017, 263, 827–837. DOI: https://doi.org/10.1016/j.ejor.2017.05.013.
- Sengupta, B. Markov processes whose steady state distribution is matrix-exponential with an application to the GI/PH/1 queue. Adv. Appl. Probab. 1989, 21, 159–180. pages DOI: https://doi.org/10.2307/1427202.
- Sengupta, B. The semi-Markovian queue: Theory and applications. Stoch. Models 1990, 6, 383–413. DOI: https://doi.org/10.1080/15326349908807154.
- Song, J.; Zipkin, P. Inventories with multiple supply sources and networks of queues with overflow bypasses. Manage. Sci. 2009, 55, 362–372. DOI: https://doi.org/10.1287/mnsc.1080.0941.
- Song, J.; Xu, S.; Liu, B. Order-fulfillment performance measures in an assemble-to-order system with stochastic leadtimes. Oper. Res. 1999, 47, 131–149. DOI: https://doi.org/10.1287/opre.47.1.131.
- Song, J.; Xiao, L.; Zhang, H.; Zipkin, P. Optimal policies for a dual-sourcing inventory problem with endogenous stochastic lead times. Oper. Res. 2017, 65, 379–395. DOI: https://doi.org/10.1287/opre.2016.1557.
- Stolyar, A.; Wang, Q. Exploiting random lead times for significant inventory cost savings. Oper. Res. 2021. DOI: https://doi.org/10.1287/opre.2021.2129.
- Van Houdt, B. A matrix geometric representation for the queue length distribution of multitype semi-Markovian queues. Perform. Eval. 2012, 69, 299–314. DOI: https://doi.org/10.1016/j.peva.2012.01.001.
- Van Houdt, B.; Blondia, C. The waiting time distribution of a type k customer in a discrete-time MMAP[K]/PH[K]/c (c = 1, 2) queue using QBDs. Stoch. Models 2004, 20, 55–69. DOI: https://doi.org/10.1081/STM-120028391.
- Van Houdt, B.; Pérez, J. Impact of dampening demand variability in a production/inventory system with multiple retailers. In Matrix-Analytic Methods in Stochastic Models; Springer: New York, 2013; 227–250.
- Zipkin, P. Stochastic leadtimes in continuous time inventory models. Naval Research Logistics 1986, 33, 763–774. November DOI: https://doi.org/10.1002/nav.3800330419.
- Zipkin, P. Performance analysis of a multi-item production-inventory system under alternative policies. Manage. Sci. 1995, 41, 690–703. DOI: https://doi.org/10.1287/mnsc.41.4.690.