
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The current advanced neural network models are expanding in size and complexity to achieve improved detection accuracy. This study designs a lightweight fabric defect detection algorithm based on YOLOv7-tiny, called YOLOv7-tiny-MGCK. Its objectives are to improve the performance of fabric defect detection against complex backgrounds and to find a balance between the algorithm’s lightweight nature and its accuracy. The algorithm utilizes the Mish activation function, known for its superior nonlinear performance capability and smoother curve, enabling the neural network to manage more complex challenges. The Ghost convolution module is also incorporated to reduce computation and model parameters. The lightweight upsampling technique CARAFE facilitates the flexible extraction of deep features, coupled with their integration with shallow features. In addition, an improved K-Means clustering algorithm, KMMP, is employed to select appropriate anchor box for fabric defects. The experimental results show: a reduction in the number of parameters by 45.5% and computational volume by 41.0%, along with increases in precision by 3.9%, recall by 7.0%, and mAP by 3.0%. These results indicated that the improved algorithm achieves a more effective balance between detection performance and the requirement for a lightweight solution.
摘要
目前先进的神经网络模型在规模和复杂度上都在扩展,以提高检测精度. 本研究设计了一种基于YOLOv7-tiny 的轻量级织物缺陷检测算法,称为YOLOv7-tiny-MGCK.其目标是提高织物缺陷检测在复杂背景下的性能,并在算法的轻量级和准确性之间找到平衡. 该算法利用了Mish激活函数,该函数以其卓越的非线性性能和更平滑的曲线而闻名,使神经网络能够应对更复杂的挑战. 还加入了鬼卷积模块,以减少计算和模型参数. 轻量级的上采样技术CARAFE有助于灵活提取深层特征,并将其与浅层特征相结合. 此外,还采用改进的K-Means聚类算法KMMP来选择合适的锚盒来解决织物缺陷. 实验结果表明:参数数量减少了45.5%,计算量减少了41.0%,精度提高了3.9%,召回率提高了7.0%,mAP提高了3.0%. 这些结果表明,改进的算法在检测性能和对轻量级解决方案的要求之间实现了更有效的平衡.
Introduction
For various factors, such as machine fault and yarn breaks, there are inevitably some defects in the production of textiles. Therefore, defect detection is required to ensure the product’s quality (Zhan, Zhou, and Xu Citation2022). Due to the complexity and diversity of fabric defects, which come in various shapes, the existing worker detection method is highly unstable and sensitive to human subjective influence. There are also problems with manual detection such as low efficiency, missed and false detection, heavy workload and detrimental to the employees’ vision. With the advancement of artificial intelligence in recent years, target detection in industrial quality control scenarios has proven successful. The textile industry desperately needs this cutting-edge technology to achieve intelligent defect identification, reduce reliance on a high volume of manual labor, lower the risk of missed and false detection, and enhance product quality (Ngan, Pang, and Yung Citation2011).
The field of fabric inspection is currently divided into several areas, including structure-based defect detection methods, statistically-based methods, spectral methods, model-based methods (Mo et al. Citation2020), and deep learning-based methods (Zhao et al. Citation2023). As computer processing power increases, high-efficiency and accurate deep-learning target identification techniques are becoming increasingly popular.
Based on its algorithmic process, deep learning target detection can be classified into Two-Stage and One-Stage algorithms. The Two-Stage algorithm separates the detection process into two phases: generating candidate anchor box initially and then using these anchor box to identify the detection target and adjust the anchor box size. Examples include Faster R-CNN algorithms. The One-Stage method achieves faster detection by extracting the target directly from the image and modifying the anchor size. The YOLO series are representative algorithms.
Related work
X. Zhang et al. (Citation2018) employed YOLOv2 to detect yarn-dyed fabric defects. By fine-tuning the hyperparameters, the detection accuracy is increased; however, detection is slow and performance in detecting fabrics with complex features is subpar. Chen-Ming and Rong-Gang (Citation2020) utilized GIoU loss as the bounding box loss function of YOLOv3 to improve the ability to detect small targets and achieve more accurate bounding box localization. However, the excessive number of model parameters and the computation required limit its use in application scenarios where computational resources are constrained. By embedding optimized Gabor layer, Chen et al. (Citation2022) can greatly improve the accuracy of the Faster R-CNN model in terms of hole and stain defects. However, the scope of application of the model is small, the model size is large, and the detection speed is slow. In conclusion, all of the above models suffer from excessive model size, slow detection speed, and are not suitable for real-time detection Streamlining neural networks to meet the requirements of mobile devices, such as embedded systems, is crucial. Zhang et al. (Citation2022) achieved this streamlining while only experiencing a slight decline in the model’s detection capability by simplifying the YOLOv3 structure and integrating the RFB module. In addition, the Google team introduced Mobilenet (Howard et al. Citation2017; Sandler et al. Citation2018), a lightweight convolutional neural network designed for mobile devices. Its primary objective is to minimize the computational effort on neural networks by simplifying their convolution kernel. Depthwise separable convolution at the heart of Mobilenet Inspired by this, Kuangxiang Technology developed the Shufflenet series of lightweight neural network models (N. Ma et al. Citation2018; H.-W. Zhang et al. Citation2018), which shares the same core principle as Mobilenet. Its unique feature is the channel shuffle method, which reduces computation through pointwise group convolution followed by a channel shuffle to complete feature fusion between the convolution kernels. The technique of depthwise separable convolution has gained popularity due to its effectiveness in reducing model size.
Cheng et al. (Citation2022) incorporated depthwise separable convolution into YOLOv4, significantly reducing the model’s parameters with only a minor decrease in detection capability. By applying depthwise separable convolution, Ma et al. (Citation2023) (A. A.-H. Ma et al. Citation2023) reduce the YOLOv5 network’s parameter count. In addition, they utilized the Attention Mechanism. Experimental results showed that diminishing the number of parameters in the neural network model slightly reduces detection accuracy. However, enhancing the network’s feature extraction capability through the attention mechanism slightly improves the final detection accuracy, meeting the requirements for fabric defect detection. Zhang et al. (Citation2023) use EfficientNetV2 as the backbone network, and the core is a lightweight model using deeply separable convolution. An improved feature pyramid network enhances feature fusion and uses an attention mechanism to enhance the model’s focus on defect. Cheng et al. (Citation2023) used depth-separable convolution to lighten UNet, and the improved model parameter count is only 4.27 M. The use of cross-parallel ratio loss function accelerates the model convergence and improves the detection accuracy. The experimental results show that the accuracy can reach 98%. However, the robustness of the model is poor because it only uses gray scale images and the textiles in real life have different colors.
In conclusion, advanced neural network models improve the detection accuracy of neural networks by scaling up the model size and complexity, whereas the use of lightweight models leads to a decrease in detection accuracy. Balancing neural network model size and detection accuracy has become the focus of current research.
Accordingly, fabric defect detection faces challenges such as a high number of model parameters, reduced detection accuracy following lightweighting, and a low degree of bounding box matching. YOLOv7 (C.-Y. Wang, Bochkovskiy, and Mark Liao Citation2023), an improved version of YOLOv5, is increasingly used in target detection within deep learning due to its high detection accuracy and rapid detection speed.
To address the challenges above, we developed a lightweight network based on yolov7-tiny network. This network improves fabric detection accuracy while reducing the number of parameters and computation.
The main contributions are summarized as follows.
Compared with the mainstream lightweighting methods, the lightweighting method in this paper has the least impact on the detection accuracy of the fabric defect detection model.
The K-means clustering approach was improved to obtain anchor that more accurately matches fabric defect.
The detection performance of the neural network model in this paper is compared with several common neural networks. The experimental results show that the model in this paper has the best detection performance. The number of parameters and computation of the model are smaller, and the detection speed is faster, which is more suitable for the automatic detection of textile industry scenarios.
Methods
Limitations of the original YOLOv7-tiny algorithm
Alexey Bochkovskiys team released the YOLOv7 series of models on July 7, 2022. YOLOv7 is available in three variations: YOLOv7-tiny, YOLOv7, and YOLOv7×. The primary differences among these versions relate to the size, complexity, and breadth of each model’s modules. illustrates the network structure of the YOLOv7-tiny algorithm. As the simplest version, YOLOv7-tiny is a lightweight network model suitable for edge computing scenarios.
Figure 1. The YOLOv7-tiny network structure.
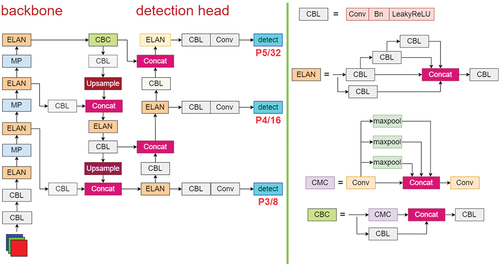
YOLOv7-tiny, a target detection method proposed for the COCO dataset, exhibits certain limitations in the context of fabric defect identification. These include (1) a high number of model parameters and a significant weight file, making it impractical for mobile devices such as embedded systems; (2) the use of nearest-neighbor interpolation for upsampling, despite being computationally simple, offers poor information sensitivity; and (3) the design of its anchor box based on clustering techniques applied to the COCO dataset, leading to a mismatch in size and relevance when detecting fabric defects due to the significant differences between the COCO and fabric defects datasets.
Improved algorithms
This study proposes several enhancement strategies to overcome these challenges. Firstly, it recommends the extensive use of the Mish activation function. Despite its higher computational demand than traditional activation functions, Mish offers infinite order continuity, smoothness, and enhanced nonlinear capabilities, thus improving model performance. Secondly, introducing the Ghost convolution module aims to simplify the network structure by exploiting the redundancy in neural networks’ feature maps. This module reduces computational demands and parameter counts by generating primary feature maps with fewer convolution kernels and employing low-cost linear operations to capture redundant feature maps. Thirdly, the CARAFE upsampling module is utilized in the feature fusion stage to enhance the detection of small targets by preserving deep neural network semantic information through reconfiguring the convolution kernel. Lastly, considering the unique characteristics of the textile industry, we improve the shortcomings of the K-means clustering algorithm to better align the model’s anchor box with these specific traits.
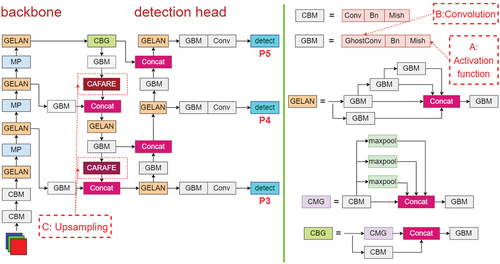
This study introduces a novel approach termed the YOLOv7-tiny-Mish-Ghost-CARAFE-KMMP algorithm (YOLOv7-tiny-MGCK algorithm), incorporating the Mish activation function, Ghost convolutional module, CARAFE upsampling, and the KMMP clustering algorithm. illustrates its network structure. Within this structure, the red dashed box labeled A indicates the position of the replacement activation function, B marks the position of the replacement convolution module, and C identifies the position of the replacement upsampling.
Figure 2. YOLOv7-tiny-MGCK network structure diagram.
Mish activation function
The activation function is a fundamental neural network component aiming to enhance the model’s representational capacity. The model can handle complex scenarios by introducing nonlinear elements through the activation function, diversifying its intermediate outputs. Without the activation function, the models response to input data will be linear, significantly weakening the neural networks ability to address complex real-world challenges. The Mish activation function (Misra Citation2019) possesses distinctive features:
No upper bound with a lower bound: the activation function must have this property to prevent gradient saturation. In specific ways, having a lower constraint helps to regularize the data by preventing the model from overfitting.
Non-Monotonic Functions: These functions improve network information flow by allowing relatively tiny negative gradients in the network model.
Continuity, infinite order, and smoothness: improved Mish smoothness, generalization, and model fit.
Ghost convolution
The specific application of Ghost convolution in neural network models is shown in . In order to minimize the negative impact of the Ghost convolution on the detection accuracy of the neural network, the traditional convolution will not be fully replaced by the Ghost convolution. As in , at the input side, two traditional convolutions are not replaced in order to ensure the integrity of the image information. On the output side, in order to ensure the detection accuracy, the three detect heads also use the traditional convolution.
The lightweight convolution kernel, known as Ghost convolution, serves as the foundation of GhostNet (Han et al. Citation2020). The primary goal of Ghost convolution is to use low-cost linear operations to reduce the number of convolution kernels required to produce the same number of output channels as traditional convolution, as displayed in .
Figure 3. Conventional convolution module and ghost convolution module.
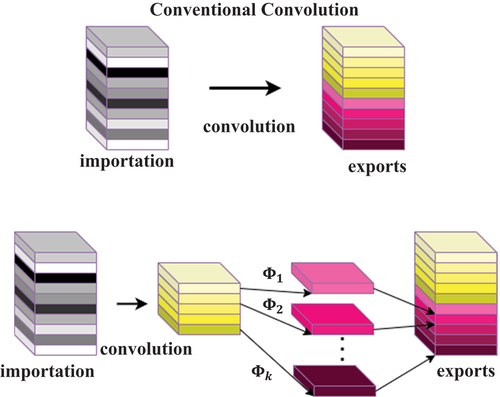
Conventional convolution feature maps for n channels are produced using n convolution filters. The FLOPs(Floating Point Operations Per Second) often reach hundreds of thousands, as convolution kernels (n) and channels (c) are typically immense. As a result, Ghost convolution reduces the number of parameters and computational requirements using fewer convolution kernels. The output feature maps consists of ghost feature maps obtained by inexpensive linear operations, and ordinary feature maps obtained by a convolution kernel. This approach significantly decreases model computation, as the low-cost linear operations require far less computing power than convolution.
CARAFE upsampling module
Upsampling is the process of enlarging an image. In a convolutional neural network, the output feature maps often shrink after the input feature maps are convolved. Upsampling is sometimes necessary to enlarge the image for subsequent computations. Common upsampling techniques for target detection include bilinear interpolation and nearest-neighbor interpolation, with the latter being the default approach in YOLOv7-tiny. Bilinear interpolation offers superior image quality but requires more computing power and operates more slowly than nearest-neighbor interpolation, which is less computationally intensive and faster but produces lower-quality images.
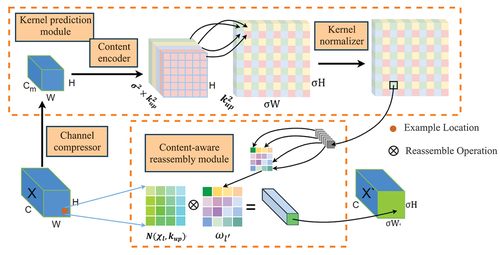
This study introduces the CARAFE upsampling module () (J. Wang et al. Citation2019), which possesses the following qualities: (1) a wide field of senses, utilizing feature information over a broad range when creating rearrangement kernels; (2) content awareness, dynamically developing adaptable kernels based on the deep feature maps at various locations, rather than employing a static kernel; and (3) efficiency in computation and lightweight design, employing point-by-point convolution to reduce the number of channels in the input feature map without sacrificing performance, thus lowering the parameter and computational expenses in later stages.
Figure 4. CARAFE upsampling module.
KMMP clustering algorithm
The target bounding box, which detects the target, is real, and the anchor box, which predicts the real bounding box, is the candidate bounding box. Thus, the closer the dimensions of the anchor box match those of the target bounding box, the faster the neural network model will converge and the more accurate the target detection will be.
This study makes the following improvements to the commonly used K-Means clustering method: (1) The initial clustering centroids are selected to be as far away from each other as possible. (2) The clustering center point is determined by the sample point closest to the sample mean. The conventional clustering technique uses the Euclidean distance, which represents the absolute difference in values, to determine the distance between samples. However, this distance measure is impractical for clustering the bounding box’s dimensions based on their overlap. In this study, we adopt the bounding box loss concept and replace the Euclidean distance with the 1-IOU distance. The clustering effect is superior, as it represents the relative value of the bounding box change. The new, enhanced technique is called the KMMP clustering algorithm, which improves the shortcomings of the previous algorithms. lists the specific steps of the KMMP clustering algorithm:
Table 1. Calculation steps of the KMMP clustering algorithm.
is determined as follows:
Experimental
Experimental data set preparation
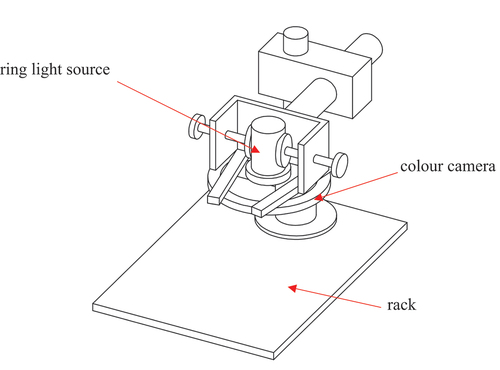
The dataset used in this paper is collected by the authors on site at a textile factory in Zhejiang. Since the factory inspection process takes a long time for a defect to appear, defective fabrics are regularly cut and collected by the factory and sent to the laboratory. A fabric defect data set is created by means of a simple collection device with a fixed machine position. The schematic is shown in and includes a rack, color camera, ring light source, etc. Considering the cost and portability factors, the camera uses Daheng MER-1520-7GC type face array camera and the light source is JL-AR125045W type ring light source. The pixel size of the captured image in the shooting area is 4608 × 3288. The image size is too large and there is too much background interference information. In order to ensure that the proportion of positive and negative samples for defect detection is coordinated, and to speed up the processing speed of the algorithm, the image needs to be cropped.
Figure 5. Schematic diagram of image acquisition device.
In order to improve the speed of image processing, a semi-automatic interception tool was developed based on python. The specific process is: use the mouse to click on the fabric defect image to generate a rectangular box. The rectangular box to the mouse click as the center of the outward generation, width and height can be selected according to need, the default is 512 × 512. Different samples were generated by clicking on different locations based on the two principles of including the main background and including the main defect.
The dataset contains 2407 images of woven fabrics. Six categories of flaws were identified: shedding yarn, slub yarn, broken yarn, cotton balls, holes, and stains. Each image measures 512 × 512 pixels. The source image is displayed in .
Figure 6. Fabric defect samples in the dataset.

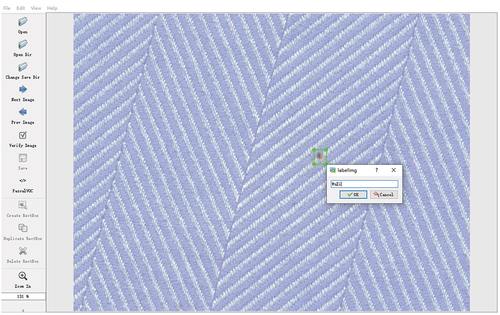
As shown in , the dataset images were tagged using the free and open-source program LabelImg. An XML format file containing the labeled information was saved. A 7:2:1 ratio was employed to randomly divide the labeled dataset into training, validation, and test sets. Data enhancement techniques such as HSV transformation, random rotation, translation, scaling, cropping, miscutting, perspective transformation, flipping, and four-image splicing were applied to the training and validation sets before network training. After data augmentation, a total of 7,221 fabric image samples were obtained; of these, 1,266 had defects involving slub yarn, 1131 featured broken yarn faults, 750 exhibited cotton ball defects, 807 had holes, 2,001 presented with shedding yarn, and 1,266 showed stains.
Figure 7. LabelImag annotation example.
Experimental environment and parameter settings
The experimental environment is outlined in , while the settings for the training section are listed in .
Table 2. Experimental environment information table.
Table 3. Parameter setting.
Identification of evaluation indicators
Precision(P); Recall(R); F1; Multi-category Average Precision(IOU = 0.5)([email protected]); Parameters (Params); Calculation (FLOPs); Detection speed, and others are the assessment indices of the detection effectiveness of the model in this study.
The concept of the F1 score is introduced based on precision and recall to evaluate their combined effectiveness. This approach is adopted because relying solely on either precision or recall is inadequate for a comprehensive evaluation of the model, enabling an assessment of the strengths and weaknesses of various algorithms. Precision and recall are computed using EquationEquations (2)(2)
(2) and (Equation3
(3)
(3) ), respectively, while the F1 score is calculated using EquationEquation (4)
(4)
(4) . Subsequently, the precision-recall (PR) curve is constructed based on precision and recall values. The Average Precision (AP) for a category is calculated by determining the area under the PR curve using EquationEquation (5)
(5)
(5) , and the mean Average Precision (mAP) is derived by averaging the AP across multiple categories. The model’s average detection speed per image is calculated by averaging the detection speeds across different categories on the validation set, with a batch size of one. The specific equation is provided as follows:
Where FP is negative samples that are mistakenly labeled as positive samples; TP is positive samples that are correctly classified; FN is the number of positive samples that are mistakenly classified as negative samples; AP(i) is the area under the PR curve of the class inside all images, where
is the number of detection categories and recall and precision are the horizontal and vertical axes, respectively. EquationEquation (6)
(6)
(6) displays the formula employed by AP to compute.
Results and analysis
Analysis of the experimental results of the substitution activation function
This section compares the original activation function and LeakyReLU to activation functions such as Mish, SiLU, and HardSwish to validate the effectiveness of the Mish activation function. The replacement locations are illustrated in , and the experiments are based on the YOLOv7-tiny model. lists the outcomes of these experiments.
Table 4. Experimental results of different activation functions.
shows that the Mish activation function outperforms others in terms of precision, recall, F1 score, and [email protected]. The original activation function yields the lowest performance metrics among all tested functions. Utilizing the Mish activation function, as opposed to the original one, results in a 2.6% increase in [email protected], a 2.4% increase in precision, and a 5.2% increase in recall. Consequently, all evaluation metrics reached their optimal levels when the Mish activation function was employed, establishing it as the selected activation function for further analyses.
Analysis of experimental results of ghost module
The model’s lightweighting focuses on the Ghost convolution module. Previous lightweighting research methods have used either the mobilenet model or the shufflenet model as the backbone network. This study evaluates the effectiveness of the Ghost module by comparing these three lightweighting methods. The results, presented in , confirm the experiment’s outcomes.
Table 5. Experimental results of different lightweighting methods.
reveals that integrating the Ghost convolution module substantially reduces the computational FLOPs and the number of model parameters, resulting in a 45.9% decrease in model parameters and a 41.0% reduction in computational volume. Although the lightweighting process reduces precision, it improves recall, reflecting the Ghost module’s regularization effects. Comparing the three lightweighting methods, the lightweighting method in this paper performs optimally on both F1 and [email protected] with similar lightweighting scales.
Analysis of experimental results of sampling module on CARAFE
The effectiveness of the CARAFE upsampling module is examined through the manipulation of two hyperparameters . This section selects specific combinations of these hyperparameters, informed by the study, and compares them against the upsampling modules of the original model. displays the new CARAFE upsampling module, with summarizing the experimental results.
Table 6. Experimental results of different upsampling modules.
illustrates that the parameters (1,3) and (1,5) each offer benefits when combined, demonstrating that the default parameters (3,5) from the original paper are not suitable for the model discussed in this study. The model’s accuracy improves when a parameter (1,3) is prioritized. Similarly, prioritizing parameter (1,5) enhances model recall. mAP is preferred for comparison as it represents the average value of identifying distinct targets. The parameters (1,3) and (1,5) were selected by comparing mAP. Compared to the original model, its MAP improves by 1.5% and another 2.8% for F1 Hence, the CARAFE upsampling module markedly enhances the model’s precision and increases the number of model parameters, which proves beneficial for detecting defects in complex backgrounds.
Analysis of experimental results of the KMMP clustering algorithm
Nine sets of anchor box with sizes {10, 13, 16, 30, 33, 23}, {30, 61, 62, 45, 59, 119}, and {116, 90, 156, 198, 373, 326} were utilized in the original YOLOv7-tiny network. After applying it to the dataset, the Best Possible Recall (BPR) (Tian et al. Citation2019) was recorded as 0.9828. The initial anchor box of the network model are deemed unsuitable due to the unique characteristics of the textile industry. Employing the new clustering method, KMMP, the following anchor box were identified for the fabric defects dataset: {59, 55, 85, 90, 128, 110}, {175, 175, 830, 69, 85, 556}, {588, 107, 299, 246, 135, 597}. Upon application to the dataset, the BPR reached 1.0000. A comparison of the bounding box loss between the original technique and the clustering using the KMMP clustering algorithm is depicted in .
Figure 8. Comparison of bounding box loss using KMMP clustering algorithm and original algorithm.
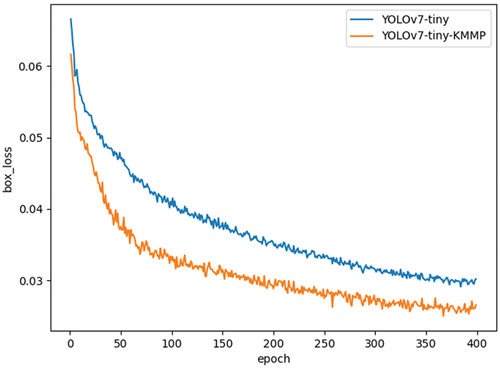
indicates that applying the KMMP clustering algorithm reduces the network’s bounding box loss value and speeds up the convergence, resulting in faster and more accurate anchor box localization. This approach effectively addresses the shortcomings of the K-Means algorithm, which is highly unstable and heavily dependent on the initial values. It yields a more suitable anchor box value for fabric defects, enabling more precise localization of blemishes.
YOLOv7-tiny-MGCK model ablation experiments
The Mish activation function, Ghost module, CARAFE upsampling module, and KMMP module are validated tools for ablation experiments to confirm the efficacy of the revised algorithm on the detection effect. displays the findings of the experiment. Data from the table show that the model [email protected] is enhanced by each of the four modifications, with the Mish activation function showing the largest enhancement effect on the original model. The Ghost module significantly decreases the computation and parameter count of the original model. The precision of the original model is mainly increased by 4.4% due to the CARAFE upsampling module. The KMMP clustering approach primarily increases the model’s recall by reducing the bounding box loss, having the least positive impact on the original model.
Table 7. YOLOv7-tiny-MGCK model ablation experiment results.
The YOLOv7-tiny-MGCK algorithm model outperforms the previous model in terms of precision (up by 3.9%), recall (up by 7.0%), F1 score (up by 5.5%), and [email protected] (up by 3.7%). In addition, the model requires 45.5% fewer parameters and 41.0% less computation. Therefore, the experimental results prove the effectiveness of the improved algorithm.
Fabric flaw detection employs the original and modified approaches; the results of the detection part are displayed in . A comparison of shows that the improved bounding box more accurately matches the fabric faults. A comparison of revealed that the former algorithm struggled with missed detection, incorrect detections, and similar issues. The enhanced model boasts increased detection confidence and is more reliable in identifying defects, experiencing fewer instances of missed detection and incorrect detections.
Figure 9. YOLOv7-tiny detection results.

Figure 10. YOLOv7-tiny-MGCK detection results.

Performance comparison of different algorithms
This section compares the YOLOv7-tiny-MGCK detection algorithm to other algorithms, including the Two-Stage detection algorithm Faster R-CNN, the single-stage detection algorithm SSD, the larger models YOLOv3 and YOLOv5l, and the lightweight models YOLOv3-tiny, YOLOv5s, and YOLOv7-tiny. This comparison aims to demonstrate the superiority of the YOLOv7-tiny-MGCK detection algorithm. The experimental results are displayed in .
Table 8. Performance comparison of different algorithms.
Among them, Faster R-CNN with SSD data from Zhou et al. (Citation2023). illustrates the comparison of the proposed algorithm to large model algorithms (YOLOv3, YOLOv5l) and similar-level algorithms (YOLOv3-tiny, YOLOv5s, YOLOv7-tiny). The improved model, YOLOv7-tiny-MGCK, achieves the highest F1 value and [email protected] and has the fewest model parameters and weights. This satisfies the dual objectives of enhancing model detection accuracy while maintaining a lightweight design, thus meeting the requirements for embedded and other mobile devices. The YOLOv7-tiny-MGCK network excels in fabric blemish detection.
Conclusion
This study proposes a lightweight neural network fabric detection algorithm model, YOLOv7-tiny-MGCK, to improve the performance of fabric defect detection against complex backgrounds. This model balances accuracy and lightweight characteristics for mobile devices, such as embedded devices. Based on the YOLOv7-tiny, it boosts the model’s nonlinear expressive capacity by incorporating an improved smoothness and a non-monotonic activation function, Mish. This enhances the model’s nonlinear representation. Traditional convolution is replaced with the Ghost lightweight convolution module, which reduces the number of model parameters and the computation amount. This adaptation meets the needs of mobile devices and achieves comparable effectiveness with fewer convolution kernels and cost-efficient linear operations. The upsampling technique is then improved by utilizing an adaptive reassembly kernel, which effectively combines the semantic content of deep features with shallow features to enhance model detection accuracy. Finally, the study applied an improved clustering technique, KMMP, to more accurately match anchor box with fabric defects. The proposed algorithm demonstrates a better detection effect than other algorithms with fewer resources, showing its high practical value in fabric defect detection after a comprehensive comparison and analysis of experimental results from various target detection algorithms.
Highlight
The relationship between the activation function, the upsampling module, the convolution module, and the clustering algorithm in the YOLO algorithm and the performance improvement of fabric defect detection is investigated.
Factors affecting the improvement of fabric defect detection performance and significant factors affecting the model size for fabric defect detection are found.
A new lightweight YOLOv7-tiny-based detection algorithm is proposed to reduce the model size while improving the model detection performance.
This study provides a software basis for fabric defect detection and promotes the automation and intelligent development of the textile industry, which is of great practical significance.
Acknowledgments
This work was supported by The National Key Research and Development Program, and Innovation Base (SQ2023YFB4600241, 111HTE2022002).
Disclosure statement
All authors are informed and agree to publish the paper.
Additional information
Funding
References
- Cheng, S., D. Jin-Tao, Y. Hong-Gang, and C. Yun-Xia. 2022. “Weld Seam Image Detection and Recognition Based on Improved YOLOv4.” Advances in Lasers and Optoelectronics 59 (16): 105–16.
- Cheng, L., J. Yi, A. Chen, and Y. Zhang. 2023. “Fabric Defect Detection Based on Separate Convolutional UNet.” Multimedia Tools & Applications 82 (2): 3101–3122.
- Chen-Ming, Z., and X. Rong-Gang. 2020. “YOLOv3 Target Detection Algorithm Incorporating GioU and Focal Loss.” Computer Engineering and Applications 56 (24): 214–222.
- Chen, M., L. Yu, C. Zhi, R. Sun, S. Zhu, Z. Gao, Z. Ke, M. Zhu, and Y. Zhang. 2022. “Improved Faster R-CNN for Fabric Defect Detection Based on Gabor Filter with Genetic Algorithm Optimization.” Computers in Industry 134:103551. https://doi.org/10.1016/j.compind.2021.103551.
- Han, K., Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu. 2020. “Ghostnet: More Features from Cheap Operations.” Paper presented at the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, June 13–19, 2020, Seattle, WA, USA.
- Howard, A. G., M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. 2017. “Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” arXiv preprint arXiv:1704.04861.
- Ma, A.-H., Z. Shuang-Wu, L. Chou-Dan, M. Xiao-Tong, and W. Shi-Hao. 2023. “Improvement of Fabric Defect Detection Algorithm in YOLOv5.” Computer Engineering and Applications 59 (10): 244–252.
- Ma, N., X. Zhang, H.-T. Zheng, and J. Sun. 2018. “Shufflenet v2: Practical guidelines for efficient cnn architecture design.” Paper presented at the Proceedings of the European conference on computer vision (ECCV), Munich, Germany.
- Misra, D. 2019. “Mish: A Self Regularized Non-Monotonic Activation Function.” arXiv preprint arXiv:1908.08681.
- Mo, D., W. Keung Wong, Z. Lai, and J. Zhou. 2020. “Weighted Double-Low-Rank Decomposition with Application to Fabric Defect Detection.” IEEE Transactions on Automation Science and Engineering 18 (3): 1170–1190.
- Ngan, H. Y., G. K. Pang, and N. H. Yung. 2011. “Automated Fabric Defect Detection—A Review.” Image and Vision Computing 29 (7): 442–458.
- Sandler, M., A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. 2018. “Mobilenetv2: Inverted Residuals and Linear Bottlenecks.” Paper presented at the Proceedings of the IEEE conference on computer vision and pattern recognition, June 18–23, 2018, Salt Lake City, UT, USA.
- Tian, Z., C. Shen, H. Chen, and T. He. 2019. “FCOS: Fully Convolutional One-Stage Object Detection.” arXiv 2019. arXiv preprint arXiv:1904.01355.
- Wang, C.-Y., A. Bochkovskiy, and H.-Y. Mark Liao. 2023. “YOLOv7: Trainable Bag-Of-Freebies Sets New State-Of-The-Art for Real-Time Object Detectors.” Paper presented at the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, June 17–24, 2023, Vancouver, BC, Canada.
- Wang, J., K. Chen, R. Xu, Z. Liu, C. Change Loy, and D. Lin. 2019. “Carafe: Content-Aware Reassembly of Features.” Paper presented at the Proceedings of the IEEE/CVF international conference on computer vision, Long Beach, CA, USA.
- Zhang, H., G. Qiao, S. Lu, L. Yao, and X. Chen. 2023. “Attention-Based Feature Fusion Generative Adversarial Network for Yarn-Dyed Fabric Defect Detection.” Textile Research Journal 93 (5–6): 1178–1195.
- Zhang, G.-R., C. Xiang, Z. Yu, W. Jian-Jun, and Y. Guo-Biao. 2022. “Lightweight YOLOv3 Algorithm for Small Target Detection.” Advances in Lasers and Optoelectronics 59 (16): 152–160.
- Zhang, H.-W., L.-J. Zhang, P.-F. Li, and D. Gu. 2018. “Yarn-Dyed Fabric Defect Detection with YOLOV2 Based on Deep Convolution Neural Networks.” Paper presented at the 2018 IEEE 7th data driven control and learning systems conference (DDCLS), Enshi, Hubei Province, China.
- Zhang, X., X. Zhou, M. Lin, and J. Sun. 2018. “Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices.” Paper presented at the Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA.
- Zhan, Z., J. Zhou, and B. Xu. 2022. “Fabric Defect Classification Using Prototypical Network of Few-Shot Learning Algorithm.” Computers in Industry 138:103628. https://doi.org/10.1016/j.compind.2022.103628.
- Zhao, S., R. Y. Zhong, J. Wang, C. Xu, and J. Zhang. 2023. “Unsupervised Fabric Defects Detection Based on Spatial Domain Saliency and Features Clustering.” Computers & Industrial Engineering 185:109681. https://doi.org/10.1016/j.cie.2023.109681.
- Zhou, S., J. Zhao, Y. Shan Shi, Y. Fan Wang, and S. Qi Mei. 2023. “Research on Improving YOLOv5s Algorithm for Fabric Defect Detection.” International Journal of Clothing Science and Technology 35 (1): 88–106.