
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
To further improve the computational performance of the diffractive deep neural network (D2NN) model, we use the ReLU function to limit the phase parameters, which effectively solves the problem of vanishing gradient that occurs in the mitigation model. We add various commonly used nonlinear activation functions to the hidden layer of the model and establish the ReLU phase-limit nonlinear diffractive deep neural network (ReLU phase-limit N-D2NN) model. We evaluate the model by comparing the performance of various nonlinear activation functions, where confusion matrix and accuracy are used as evaluation methods. The numerical simulation results show that the model achieves better classification performance on the MNIST and Fashion-MNIST datasets, respectively. In particular, the highest classification performance is obtained by the ReLU phase-limit N-D2NN model, in which the hidden layer uses PReLU, with 98.38% and 90.14%, respectively. This paper provides a theoretical basis for applying the nonlinear D2NN systems in natural scenes.
1. Introduction
Diffractive deep neural network (D2NN)[Citation1] is a relatively new approach to optical neural networks (ONN), which first came from a publication in 2018 by Lin et al. The team used a terahertz light source as input, and they first built an all-optical diffractive deep neural network (D2NN) model using Rayleigh-Sommerfeld diffraction theory. Next, they optimized the model parameters using a stochastic gradient descent algorithm, and then the team fabricated diffraction elements using 3D printing technology and constructed the D2NN system, which can classify images of handwritten figures and fashion products. D2NN has the following advantages, (1) The whole system adopts passive devices, so the power consumption of the system is low. (2) The system adopts the principle of optical diffraction. D2NN connects hundreds of millions of neurons hundreds of billions of times in a fully connected neural network, so the system runs at the speed of light. Since the original D2NN was proposed, many scholars have carried out a lot of research on improving computing performance and application scenarios of D2NN. For example, D2NN can be applied in scenarios such as beam conversion,[Citation2] frequency control,[Citation3] and mode differentiation.[Citation4] In particular, we describe in detail a series of related works on improving the performance of D2NN computation in Section 2, these include adding activation functions to the hidden layer of the model, and using nonlinear optical materials to make diffraction gratings for the D2NN framework. With the help of the D2NN framework, researchers can apply it to tasks such as image analysis, feature detection and object classification.
In previous studies, the original D2NN model used the Sigmoid function to constrain the phase, which has the vanishing gradient problem during error back propagation. To solve this problem, we propose a ReLU phase-limit N-D2NN model in this paper. We use the ReLU function to limit the phase factor in the model and verify the effectiveness of the ReLU phase-limited N-D2NN model by numerical simulation, in which the hidden layer incorporates various common activation functions. Because ReLU has a constant gradient of 1 in the positive interval compared to Sigmoid, it can better update the parameters of the D2NN model. The ReLU function is not an exponential function, so the derivative computation will be much saved when back propagation error transfer is performed. We detail the advantages of choosing the ReLU function to limit the phase factor in Section 3.1. Interestingly, the proposed method further improves the computational performance of D2NN. The ReLU phase-limit N-D2NN achieves 98.38% accuracy on the MNIST dataset, and 90.14% accuracy on the Fashion-MNIST dataset, which is the highest accuracy known for the D2NN framework. In summary, this study proposes an approach to alleviate vanishing gradient the N-D2NN model, and evaluates the inference performance of ReLU phase limited N-D2NN model, where various nonlinear activation functions are added to the hidden layer of the model.
The rest of this paper is organized as follows. In Section 2, we report on related work to D2NN. In Section 3, we describe the principle of the method of alleviating vanishing gradient, the ReLU phase-limit N-D2NN model, and the nonlinear activation function of the model. In Section 4, we present the numerical experiment results of the ReLU phase-limit N-D2NN model with a nonlinear activation function, including the introduction of the dataset, evaluation method, and selection of hyperparameters, and compare the computational performance with other nonlinear D2NN models. In Section 5, we state the conclusion.
2. Related works
2.1. Nonlinear study of D2NN
The study of optical nonlinearities has been an important part of D2NN. A core unit of neural network design is a nonlinear activation function, which endows neurons with the ability to self-learn and adapt. Additionally, activation functions normalize execution data, limit the expansion of data, and prevent overflow risks caused by excessive data. Neural networks with an activation function can complete the nonlinear transformation of data, solve the linear model expression, and classification problems. In previous studies, Wei et al. and Mengu et al. have previously discussed the nonlinearity of D2NN in a series of studies.[Citation5,Citation6] Later, many researchers continued to explore and apply the nonlinearity of D2NN. In July 2019, Yan et al. introduced the Fourier spatial diffraction deep neural network (F-D2NN) that uses diffraction layer modulation through the Fourier transform in the optical system. The nonlinear optics use a ferroelectric film, and the method is effective for high-precision visual saliency detection and target classification.[Citation7] In June 2020, Zhou et al. proposed an optical error backpropagation framework for field training of linear and nonlinear D2NN, which could accelerate the training speed and improve energy efficiency.[Citation8] In February 2021, our research team proposed a miniaturized nonlinear all-optical diffractive deep neural network (N-D2NN) model using ReLU family functions as nonlinear activation functions.[Citation9] In January 2021, Kulce et al. investigated the dimensions of the all-optical solution space covered by the D2NN design, and increasing the number of trainable neurons could enhance the reasoning ability of D2NN.[Citation10] In July 2021, Luo et al. proposed a metasurface-based diffractive neural network (MDNN) framework based on polarization multiplexing, which can extend the channel of the neural network.[Citation11] In January 2022, our research team proposed an all-optical diffractive neural network based on the nonlinear optical materials (DNN-NOM) model, the optical limiting effect function is taken as the nonlinear activation function of the neural network.[Citation12] At the same time, Ighodalo et al. proposed an algorithm for the reverse design of the D2NN using the (DNA)2 optimization program. These studies show the potential of D2NN in all-optical imaging and signal processing, and provide new insights for further research.[Citation13]
2.2. Other improvements to D2NN
In addition to the use of optical nonlinear properties, there are other research methods currently available to improve D2NN performance. In December 2019, Chen et al. proposed using multi-frequency channel D2NN to improve classification accuracy by combining light waves of different frequencies.[Citation14] In January 2020, Mengu et al. improved D2NN by changing the loss function and using a complex-valued neural network to modulate phase and amplitude.[Citation15] In May 2020, Dou et al. proposed Residual D2NN (Res-D2NN) to solve the problem of vanishing gradientby constructing diffraction residual learning blocks.[Citation16] In July 2020, Mengu et al. proposed vaccinated D2NN (V-D2NN) to significantly improve the tolerance margin of D2NN by modeling undesirable system changes as continuous random variables.[Citation17] In December 2020, Mengu et al. proposed a method to quantify sensitivity to overcome D2NN's sensitivity to spatial scaling, translation, and rotation of input objects.[Citation18] Meanwhile, Su et al. proposed multiwave optical diffractive network (MWDN) that performed different tasks using optical diffraction and laser wavelengths. These methods significantly improved the robustness of D2NN and its ability to adapt to changes in undesired target fields.[Citation19] In December 2020, Shi et al. proposed the strong robustness active neural network (SRNN) model, called D2NN, to design an intelligent imaging detector array. The model reduced the impact of structure error and optical wave frequency shift on D2NN output.[Citation20] In the training process, they simulated the error distribution of the solid phase mask by adding Gaussian noise into weights. In January 2021, Rahman et al. trained 1252 D2NNs with different designs of passive input filters and proposed an iterative pruning algorithm to optimize D2NN, which improved the classification accuracy and generalization ability of the model.[Citation21] In March 2021, Li et al. proposed a D2NN system for optical classification using a single-pixel spectral detector that used an array of diffractive modulation layers to encode spatial information into the power spectrum of the diffracted light.[Citation22] In October 2021, Xiao et al. proposed a concept of optical random phase difference to improve the generalization ability of D2NN model by using complex conjugate factors and compatibility conditions.[Citation23] In July 2021, Shi et al. proposed a multiple-view D2NNs array (MDA) system that combined the information of multiple views of 3D objects with a hybrid photoelectric structure to improve the classification accuracy of 3D objects.[Citation24] In January 2022, Panda et al. proposed a fault-tolerant optical neural network with anti-noise performance using regularization in simulation.[Citation25] In January 2023, Dong et al. proposed an OReLU function using optoelectronic devices to increase sparsity and classification accuracy. By optimizing the threshold factor, they achieved high accuracy on the MNIST and Fashion-MNIST datasets with genetic algorithms.[Citation26] In February 2023, Zhou et al. proposed a novel framework by incorporating a highway network and a wavelet-like phase modulation pattern (WPMP) technique into D2NN. The researchers demonstrated that WPMP can significantly reduce the parameters of the network layer by modulating the phase of the incident light.[Citation27]
3. Methods
3.1. Methods to mitigate vanishing gradient
In N-D2NN, the error backpropagation is used to update the network parameters, which involves computing the error between the network output and the true value, and propagating it backwards through the network. Gradient is a very critical concept in the error backpropagation process, which represents the rate of change of the error with respect to N-D2NN parameters, and it is the basis of the optimization algorithm. However, when the number of N-D2NN layers is large, the error will gradually become smaller after several times of back-propagation, which leads to the gradient also becoming smaller or even disappearing. That is, the vanishing gradient problem. Vanishing gradient can cause the network parameters to fail to update, thus affecting the training effect of N-D2NN. In the original N-D2NN model, each neuron contains a complex neuron modulation function In the previous study on N-D2NN, the phase
in network training is represented by a potential variable
namely:[Citation15]
(1)
(1)
In EquationEquation (1)(1)
(1) , the Sigmoid function acts as an auxiliary variable rather than information flowing through the network, and the Sigmoid function limits
to the interval (0, 2π). However, using the sigmoid function to limit the phase has the following shortcomings. Sigmoid function can saturate, when it takes very large positive (negative) values in phase in absolute terms. This means that the function becomes insensitive to small changes in the input. Moreover, in the original N-D2NN model for backpropagation, the weights are basically not updated when the gradient is close to 0, and the gradient can easily disappear, so the training of N-D2NN cannot be done effectively. the output of the Sigmoid function is not zero-centered. This will lead to the input of non- zero-centered signals to the neurons in the later layers, which will have an impact on the gradient. Because the Sigmoid function is in exponential form, the computational complexity is high. To solve the above problem, EquationEquation (2)
(2)
(2) is used to alleviate such problems:
(2)
(2)
EquationEquation (2)(2)
(2) shows that the phase
of each neuron becomes unbounded. However, because the
term is periodic and bounded to
the error backpropagation algorithm can solve it. Compared with the Sigmoid function, the ReLU function will make some of the neurons zero, which causes the sparsity of the network and reduces the interdependence of the parameters, alleviating the overfitting problem. Therefore, in this paper, we use the ReLU function to limit the phase, so as to alleviate the problem of vanishing gradient the ReLU phase-limit N-D2NN model training.
3.2. ReLU phase-limit N-D2NN model principle
The ReLU phase-limit N-D2NN model can be found in our previous work, which includes the establishment of N-D2NN[Citation9] and the complex neural network.[Citation28] represents the schematic diagram of the ReLU phase-limit N-D2NN structure. The neurons in each layer of the ReLU phase-limit N-D2NN model can be calculated by the secondary wave source equation, which is as follows:
(3)
(3)
where
represents the
-th layer of the network,
describes the
-th neuron of the
-th layer,
represents the Euclidean distance between the
-th neuron of the
-th layer and the neuron of the
-th layer,
represents the incident wavelength, and the input plane is the 0-th layer, then corresponding to the
-th layer, the output field can be expressed as:
(4)
(4)
where
represents the output of
the
-th neuron at layer
-th of
is the relative amplitude of the second wave,
is the phase delay increased by input wave
and complex neuron modulation function
on each neuron, and
is the multiple modulations, namely:
(5)
(5)
Figure 1. Schematic diagram of ReLU phase-limit N-D2NN structure. (a) Using MNIST as a dataset to train the model. (b) Using Fashion-MNIST as a dataset to train the model.
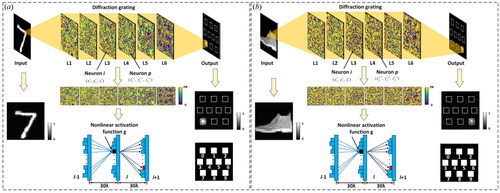
To simplify the representation of EquationEquations (3)(3)
(3) , Equation(4), and (5)
(5)
(5) , it can be rewritten as the formula of the forward propagation model:
(6)
(6)
where
represents the
-th neuron in the
-th layer,
represents the
neuron in the
-th layer, and the neurons between each layer are fully connected through diffraction. All the output neurons of layer
are added together to the
-th neuron
of layer
The neuron is transmitted to the
-th neuron
in layer
by modulation of the nonlinear unit. Each neuron in each layer propagates as described above.
represents the output of the nonlinear activation function in ReLU phase-limit N-D2NN, its function is to transmit modulated secondary wave neurons to the next layer through nonlinear cells. Monolayer perceptron can only solve linearly separable problems, so its learning ability is minimal. Deep feedforward neural networks introduce activation functions into hidden layer neurons, enabling them to learn more complex functional relationships, thus improving the learning ability and accuracy of the model.
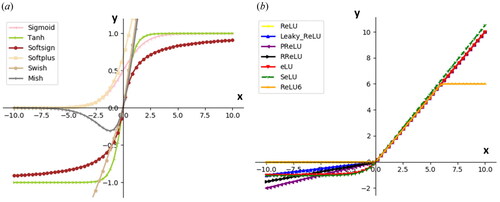
In our previous work, we used the ReLU family function as the nonlinear activation function for the hidden layer in the original N-D2NN model. To make this work more detailed and informative, in this paper we use Tanh, Softsign, Swish,[Citation29] Mish,[Citation30] ReLU,[Citation31,Citation32] Leaky-ReLU, Parametric-ReLU (PReLU),[Citation33] Randomized-ReLU (RReLU), eLU,[Citation34] self-normalizing neural networks (SeLU),[Citation35] and ReLU6 functions as activation functions of the hidden layer in the ReLU phase-limit N-D2NN model. The mathematical model of the activation function above is shown in .
Figure 2. Mathematical models of various activation functions. (a) Sigmoid, Tanh, Softsign, Softplus, Swish and Mish. (b) ReLU, Leaky- ReLU, PReLU, RReLU, eLU, SeLU and ReLU6.
4. Results
4.1. MNIST and fashion-MNIST datasets
The ReLU phase-limit N-D2NN model uses MNIST and Fashion-MNIST as datasets. MNIST (Modified National Institute of Standards and Technology)[Citation36] is a large dataset of handwritten numbers, commonly used to train various image processing systems. The images on the MNIST dataset are 28 × 28 pixel grayscale images. The MNIST dataset contains 60,000 training images and 10,000 test images. Fashion-MNIST[Citation37] is a ten-category clothing dataset, the pixel size, format, training set, and test set division of Fashion-MNIST are entirely consistent with the original MNIST. Each training sample and test sample in the MNIST and Fashion-MNIST datasets was labeled in ten categories according to labels 0–9, number 0, number 1, number 2, number 3, number 4, number 5, number 6, number 7, number 8, number 9 and shirt, trousers, pullover, dress, coat, sandal, shirt, sneaker, bag, ankle boot, respectively. The MNIST and Fashion-MNIST datasets are publicly available on the following websites, respectively:
MNIST dataset: https://github.com/amplab/datascience-sp14/raw/master/lab7/mldata/mnist-original.mat
Fashion-MNIST dataset: https://github.com/zalandoresearch/fashion-mnist
4.2. The model calculates performance evaluation indicators
In this paper, confusion matrix and classification accuracy are used as evaluation methods and indexes of the ReLU phase-limit N-D2NN model. The confusion matrix is a standard format for precision evaluation. shows the confusion matrix of ten categories.[Citation38]
Table 1. The confusion matrix of ten classifiers.
The accuracy rate represents the percentage of the total sample in which the predicted results are correct. In this paper, we need to calculate the confusion matrix (i = 0–9). For every single class, the evaluation is defined by
Therefore, the accuracy rate of the classifier can be expressed as:
(7)
(7)
where
represents the true value in
and the quantity predicted by the model.
is the total number of samples per test.
4.3. Model hyperparameter selection
The hyperparameters in the ReLU phase-limit N-D2NN model include diffraction grating physical parameters and neural network training parameters, which are represented by and , respectively.
Table 2. Physical parameters of grating in ReLU phase-limit N-D2NN.
Table 3. Training parameters in ReLU phase-limit N-D2NN.
In this paper, ReLU phase-limit N-D2NNs were simulated using Python (v3.6.8) and TensorFlow (v1.14.0, Google Inc.) framework. ReLU phase-limit N-D2NNs were trained for 50 epochs using a desktop computer with a GeForce GTX TITAN V Graphical Processing Unit, GPU, and Intel(R) Core (TM) i7-8700K CPU @3.37 GHz and 64GB of RAM, running Windows 10 operating system (Microsoft).
4.4. Simulation experiment results
In the ReLU phase-limit N-D2NN model based on 10.6 µm wavelength, After using the activation function in Section 3.2 as the activation function of the hidden layer of the model for training. shows the correspondence between epoch and accuracy at training time for different ReLU phase-limit N-D2NN models. From the training model in , it can be seen that the model with the hidden layer as the ReLU family activation function still has a better inference performance, especially PReLU.
Figure 3. Correspondence between epoch and accuracy at training time for different ReLU phase-limit N-D2NN models. (a) Using MNIST as a dataset to train the model. (b) Using Fashion-MNIST as a dataset to train the model.
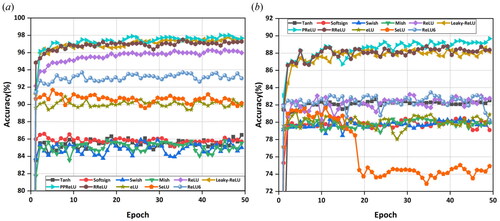
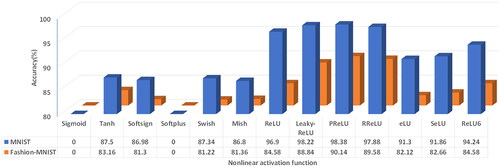
represents the classification performance obtained by different the ReLU phase-limit N-D2NN on the two datasets. As can be seen from , the ReLU phase-limit N-D2NN with the hidden layer as PReLU function obtained the highest accuracy of 98.38% and 90.14% on the MNIST and Fashion-MNIST datasets, respectively. The recognition accuracy of the MNIST and Fashion-MNIST datasets is increased by 0.57%, and 0.82%, respectively, which theoretically proves the correctness of the model. However, when Sigmoid and Softplus are chosen as activation functions for the hidden layer of the model, the ReLU phase-limit N-D2NN has the vanishing gradient problem. This may be because the Sigmoid function changes very little when it tends to infinity, which is not conducive to the feedback transmission of the ReLU phase-limit N-D2NN model and easy to cause the vanishing of the gradient. In training of the ReLU phase-limit N-D2NN model, the Softplus function is prone to the phenomenon of vanishing gradient, or some neurons in the neural network may be “necrotic” due to excessive learning rate. Figures S1 and S2 show the confusion matrix images of the ReLU phase-limit N-D2NN model on the MNIST and Fashion-MNIST datasets, respectively, where different activation functions are chosen for the hidden layer. As can be seen from the confusion matrix images in Figure S1, except for the hidden layer of RReLU function, the rest of the models have a classification accuracy of more than 70% on each label of the MNIST dataset. The models with hidden layers Leaky-ReLU and PReLU functions are even more significant than 94%. Among them, the ReLU phase-limit N-D2NN model obtained the highest classification accuracy on the MNIST dataset with label 0 (number 0) and label 1 (number 1). In particular, the classification accuracy of the model is 100% for both labels, where it is the hidden layer chosen for PReLU. According to Figure S2, the ReLU phase-limit N-D2NN obtains the highest classification accuracy for label 1 (picture type is trousers) and label 8 (picture type is bag) in the Fashion-MNIST dataset, where various activation functions are chosen for the hidden layer. The models with hidden layers Leaky-ReLU and PReLU can achieve the highest 97% and 97% on label 1, and 98% and 97% on label 8.
Figure 4. Classification performance obtained by different the ReLU phase-limit N-D2NN on the the MNIST and Fashion-MNIST datasets.
4.5. Calculation performance comparison with other D2NN models
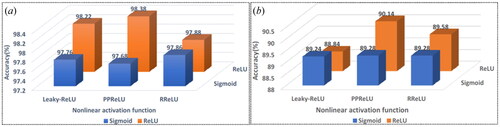
represents the classification accuracy of the Sigmoid phase-limit[Citation9] and ReLU phase-limit N-D2NN models on the MNIST dataset and the Fashion-MNIST dataset, respectively. It can be seen from that ReLU phase-limit N-D2NN has higher accuracy compared to Sigmoid phase-limit N-D2NN on the MNIST and Fashion-MNIST datasets. As shown in , Except for the model with Leaky-ReLU function in the hidden layer, the recognition accuracy of the ReLU-limited phase N-D2NN model is higher than that of the Sigmoid-limited phase. It is proved that using the ReLU function to limit the phase can improve the calculation performance of N-D2NN.
Figure 5. Two kinds of functions are used to limit the classification accuracy of N-D2NN with phase on datasets. (a) MNIST. (b) Fashion-MNIST.
shows the computational performance of different D2NN models. It can be seen from that the ReLU phase-limit N-D2NN has good computational performance. Besides the Res-D2NN model (98.40%),[Citation16] our model has the highest accuracy rate (98.38%) in the MNIST dataset classification. However, compared to the 20 hidden layers used in the Res-D2NN model, our proposed model requires only 6 hidden layers, and the accuracy obtained on the MNIST dataset is almost the same, while our model is less computationally intensive and takes less time for training and testing. In addition, among many models, our model has the highest accuracy rate (90.14%) in the category of the Fashion-MNIST dataset, which is the highest accuracy rate obtained by the known D2NN-derived model in the Fashion-MNIST dataset.
Table 4. Computational performance of different D2NN models.
5. Conclusions
This paper proposes a method to improve the computational performance of the N-D2NN model. First, we introduce the role of error back-propagation for the N-D2NN model and the use of the ReLU function to mitigate the problem of vanishing gradient in the model. Next, we build the ReLU phase-limit model using a deep feed-forward neural network, the Rayleigh-Sommerfeld diffraction equation, and the ReLU limiting phase factor. Then, we judge the classification performance of the model on the MNIST and Fashion MNIST datasets by confusion matrix and accuracy. This ReLU phase-limit N-D2NN achieves higher accuracy. The ReLU phase-limit N-D2NN model with PReLU in the hidden layer achieves the highest accuracy of 98.38% (90.14%) on the MNIST (Fashion-MNIST) dataset. Finally, compared with other D2NN derived models, the ReLU phase-limit N-D2NN model has one of the highest computational performance models. The performance of our model on the Fashion-MNIST dataset is higher than all the currently proposed D2NN. The accuracy obtained by our proposed model on the MNIST dataset is only smaller than that of the Res-D2NN model. However, we obtain higher computational performance by using fewer diffraction layers. This study provides a theoretical basis and methodological guarantee for the realization of physical systems and devices based on a 10.6 µm wavelength nonlinear all-optical diffractive neural network.
Supplemental Material
Download MS Word (1.2 MB)Disclosure statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability statement
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.
Additional information
Funding
References
- Lin, X.; Rivenson, Y.; Yardimci, N.T.; Veli, M.; Luo, Y.; Jarrahi, M.; Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science 2018, 361, 1004–1008+. DOI: 10.1126/science.aat8084.
- Shi, J.; Chen, Y.; Zhang, X. Broad-spectrum diffractive network via ensemble learning. Opt. Lett. 2022, 47, 605–608. DOI: 10.1364/OL.440421.
- Luo, Y.; Mengu, D.; Yardimci, N.T.; Rivenson, Y.; Veli, M.; Jarrahi, M.; Ozcan, A. Design of task-specific optical systems using broadband diffractive neural networks. Light. Sci. Appl. 2019, 8, 112. DOI: 10.1038/s41377-019-0223-1.
- Huang, Z.; Wang, P.; Liu, J.; Xiong, W.; He, Y.; Xiao, J.; Ye, H.; Li, Y.; Chen, S.; Fan, D. All-optical signal processing of vortex beams with diffractive deep neural networks. Phys. Rev. Appl. 2021, 15, 014037. DOI: 10.1103/PhysRevApplied.15.014037.
- Mengu, D.; Luo, Y.; Rivenson, Y.; Lin, X.; Veli, M.; Ozcan, A. Response to comment on “All-optical machine learning using diffractive deep neural networks". arXiv preprint arXiv:1810.04384, 2018.
- Wei, H.; Huang, G.; Wei, X.; Sun, Y.; Wang, H. Comment on” All-optical machine learning using diffractive deep neural networks". arXiv preprint arXiv:1809.08360, 2018.
- Yan, T.; Wu, J.; Zhou, T.; Xie, H.; Xu, F.; Fan, J.; Fang, L.; Lin, X.; Dai, Q. Fourier-space diffractive deep neural network. Phys. Rev. Lett. 2019, 123, 023901. DOI: 10.1103/PhysRevLett.123.023901.
- Zhou, T.; Fang, L.; Yan, T.; Wu, J.; Li, Y.; Fan, J.; Wu, H.; Lin, X.; Dai, Q. In situ optical backpropagation training of diffractive optical neural networks. Photon. Res. 2020, 8, 940–953. DOI: 10.1364/PRJ.389553.
- Sun, Y.; Dong, M.; Yu, M.; Xia, J.; Zhang, X.; Bai, Y.; Lu, L.; Zhu, L. Nonlinear all-optical diffractive deep neural network with 10.6 µm wavelength for image classification. Int. J. Opt. 2021, 2021, 1–16.
- Kulce, O.; Mengu, D.; Rivenson, Y.; Ozcan, A. All-optical information-processing capacity of diffractive surfaces. Light. Sci. Appl. 2021, 10, 25. DOI: 10.1038/s41377-020-00439-9.
- Luo, X.; Hu, Y.; Ou, X.; Li, X.; Lai, J.; Liu, N.; Cheng, X.; Pan, A.; Duan, H. Metasurface-enabled on-chip multiplexed diffractive neural networks in the visible. Light. Sci. Appl. 2022, 11, 158. DOI: 10.1038/s41377-022-00844-2.
- Sun, Y.; Dong, M.; Yu, M.; Lu, L.; Liang, S.; Xia, J.; Zhu, L. Modeling and simulation of all-optical diffractive neural network based on nonlinear optical materials. Opt. Lett. 2022, 47, 126–129. DOI: 10.1364/OL.442970.
- Idehenre, I.U.; Harper, E.S.; Mills, M.S. Diffractive deep neural network adjoint assist or (DNA) 2: A fast and efficient nonlinear diffractive neural network implementation. Opt. Express. 2022, 30, 7441–7456. DOI: 10.1364/OE.449415.
- Chen, Y.; Zhu, J. An optical diffractive deep neural network with multiple frequency-channels. arXiv preprint arXiv:1912.10730, 2019.
- Mengu, D.; Luo, Y.; Rivenson, Y.; Ozcan, A. Analysis of diffractive optical neural networks and their integration with electronic neural networks. IEEE J. Select. Topics Quantum Electron. 2020, 26, 1–14. DOI: 10.1109/JSTQE.2019.2921376.
- Dou, H.; Deng, Y.; Yan, T.; Wu, H.; Lin, X.; Dai, Q. Residual D 2 NN: Training diffractive deep neural networks via learnable light shortcuts. Opt. Lett. 2020, 45, 2688–2691. DOI: 10.1364/OL.389696.
- Mengu, D.; Zhao, Y.; Yardimci, N.T.; Rivenson, Y.; Jarrahi, M.; Ozcan, A. Misalignment resilient diffractive optical networks. Nanophotonics 2020, 9, 4207–4219. DOI: 10.1515/nanoph-2020-0291.
- Mengu, D.; Rivenson, Y.; Ozcan, A. Scale-, shift-, and rotation-invariant diffractive optical networks. ACS Photonics 2021, 8, 324–334. DOI: 10.1021/acsphotonics.0c01583.
- Su, J.; Yuan, Y.; Liu, C.; Li, J. Multitask learning by multiwave optical diffractive network. Math. Prob. Eng. 2020, 2020, 1–7. DOI: 10.1155/2020/9748380.
- Shi, J.; Chen, M.; Wei, D.; Hu, C.; Luo, J.; Wang, H.; Zhang, X.; Xie, C. Anti-noise diffractive neural network for constructing an intelligent imaging detector array. Opt. Express. 2020, 28, 37686–37699. DOI: 10.1364/OE.405798.
- Rahman, M.S.S.; Li, J.; Mengu, D.; Rivenson, Y.; Ozcan, A. Ensemble learning of diffractive optical networks. Light. Sci. Appl. 2021, 10, 14. DOI: 10.1038/s41377-020-00446-w.
- Li, J.; Mengu, D.; Yardimci, N.T.; Luo, Y.; Li, X.; Veli, M.; Rivenson, Y.; Jarrahi, M.; Ozcan, A. Spectrally encoded single-pixel machine vision using diffractive networks. Sci. Adv. 2021, 7, eabd7690. DOI: 10.1126/sciadv.abd7690.
- Xiao, Y.-L.; Li, S.; Situ, G.; You, Z. Optical random phase dropout in a diffractive deep neural network. Opt. Lett. 2021, 46, 5260–5263. DOI: 10.1364/OL.428761.
- Shi, J.; Zhou, L.; Liu, T.; Hu, C.; Liu, K.; Luo, J.; Wang, H.; Xie, C.; Zhang, X. Multiple-view D 2 NNs array: Realizing robust 3D object recognition. Opt. Lett. 2021, 46, 3388–3391. DOI: 10.1364/OL.432309.
- Panda, S.S.; Hegde, R.S. Fault tolerance and noise immunity in freespace diffractive optical neural networks. Eng. Res. Express. 2022, 4, 011301. DOI: 10.1088/2631-8695/ac4832.
- Dong, C.; Cai, Y.; Dai, S.; Wu, J.; Tong, G.; Wang, W.; Wu, Z.; Zhang, H.; Xia, J. An optimized optical diffractive deep neural network with OReLU function based on genetic algorithm. Opt. Laser Technol. 2023, 160, 109104. DOI: 10.1016/j.optlastec.2022.109104.
- Zhou, Y.; Shui, S.; Cai, Y.; Chen, C.; Chen, Y.; Abdi-Ghaleh, R. An improved all-optical diffractive deep neural network with less parameters for gesture recognition. J. Vis. Commun. Image Represent. 2023, 90, 103688. DOI: 10.1016/j.jvcir.2022.103688.
- Mönning, N.; Manandhar, S. Evaluation of complex-valued neural networks on real-valued classification tasks. arXiv preprint arXiv:1811.12351, 2018.
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv preprint arXiv:1710.05941, 2017.
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv preprint arXiv:1908.08681, 2019.
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010.
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
- He, K.; Zhang, X.; Ren, A.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, 2015.
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. Adv. Neural Inform. Process. Syst. 2017, 30. arXiv preprint arXiv:1706.02515, 2017.
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. DOI: 10.1109/5.726791.
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv preprint arXiv:2010.16061, 2020.
- Chen, H.; Feng, J.; Jiang, M.; Wang, Y.; Lin, J.; Tan, J.; Jin, P. Diffractive deep neural networks at visible wavelengths. Engineering 2021, 7, 1483–1491. DOI: 10.1016/j.eng.2020.07.032.