
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper presents a new dictionary-based interpolation technique to improve text quality when the resolution of an image is increased, so that the text can be displayed on a high-resolution display device. The proposed algorithm analyzes an image and extracts the shape of the text from the image. Further, it encodes and decodes the pattern of the text, and enhances the legibility of the text using a pre-trained code dictionary. Therefore, the proposed method improves text quality in terms of sharpness. In the experiments, the proposed algorithm outperformed benchmark methods for all test images. Specifically, the proposed method reduced the blur index by up to 0.112.
I. Introduction
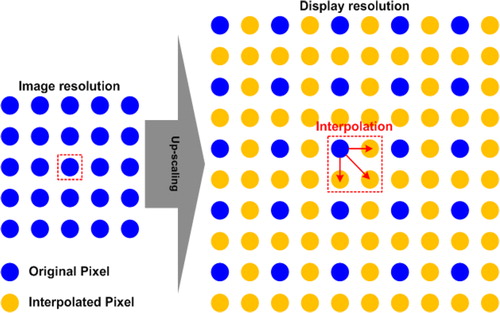
The resolution of displays, such as the liquid crystal display (LCD) and the organic light emitting diode (OLED) display, has been increasing in response to demands for clearer and more vivid images. High resolution is now possible because of the improvement of electronic devices and display manufacturing processes. For example, the improvement of television systems has led to an increase in their resolution from high definition (HD) to full high definition (FHD), and recently, to ultra-high definition (UHD). However, even if a display device has a UHD resolution, the increase in the resolution of the image contents requires the replacement of broadcasting equipment and an increase in the transmission bandwidth. To solve this problem, image up-scaling, a technique that increases the resolution of an image using two-dimensional interpolation, is used. Figure shows an example of two-dimensional interpolation in a case wherein the resolution of the display device is twice higher than that of the image content. In this case, new pixels are generated using an interpolation technique based on either the current pixel or the current and neighboring pixels. The performance of the up-scaling system depends greatly on the interpolation performance.
Figure 1. An example of up-scaling using interpolation, wherein the resolution of an input image is increased by a factor of two.
The basic interpolation techniques are bilinear and bicubic interpolations [Citation1–4]. These methods use linear interpolation, and hence, require little computation. However, they do not exactly produce the interpolated pixel in the edge area, where the luminance changes nonlinearly, because a new pixel is generated by linearly connected pixels. To solve this problem, several interpolation techniques have been proposed. The methods used in [Citation5] and [Citation6] are based on fitting local fifth-order polynomials. They consider a small number of neighboring pixels, and hence, have low computational complexity. The method in [Citation7] uses the raised cosine pulse for interpolation. It has several advantages, such as fast implementation using the fast Fourier transform (FFT) and simple hardware architecture using a finite impulse response (FIR) filter. The methods in [Citation8] and [Citation9] use polynomials matched by the values of the function at various points and those of the first-order derivatives, thus achieving a higher degree of continuity. Conventional interpolation methods focus on improving the smoothness among neighboring pixels for generating an interpolated pixel. However, if these methods are used to increase the resolution of a text image, a blurring artifact at the boundary of the text occurs. When the width of a text string is thin and the background color is uniform, such as in web pages, the legibility of text can be seriously degraded.
In this paper, a dictionary-based interpolation technique is proposed to improve the text quality when the width of a text string is thin and the background color is uniform, such as in web pages. The proposed method separates the text from the background of the image. Specifically, it analyzes the shape of the text and changes such shape to enhance the legibility of the text using the pre-trained dictionary. This paper is organized as follows. In section II, the proposed dictionary-based interpolation algorithm is described in detail. Section III presents the experimental results and evaluates the performance of the proposed algorithm in terms of blur assessment for text quality. Finally, section IV concludes the paper.
II. Proposed method
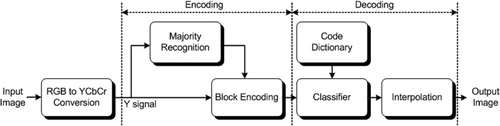
Figure shows the entire architecture of the proposed up-scaling system. First, the RGB input image is converted to a YCbCr image. Next, Y signals are encoded into serial bits by blocks using the majority recognition module and the block encoding module. Based on the pre-processed code, the input code is classified and the most suitable match in the dictionary is selected. Finally, interpolation is performed after the selected bits are decoded.
Figure 2. Process of the proposed dictionary-based interpolation algorithm.
A. Encoding stage
In this stage, the shape of the text is encoded after the text image is extracted from an input image. Specifically, using the Y signal as an input, a luminance histogram is generated for pixels in the current and neighboring blocks (as shown in Figure ), and the highest majority, i.e. the background luminance, which is defined in (1), is extracted.
(1)
(1) where li denotes the luminance of the i-th pixel and lmaj denotes the luminance of the majority of the pixels, i.e. the background luminance. N stands for the number of bits used to represent the pixel luminance. In this case, eight bits were used.
Figure 3. An example of extracting the highest majority using majority recognition.
Based on the luminance of the background, the shape of the text for a current block is encoded as shown in Figure according to (2).
(2)
(2) where lin denotes the luminance of an input pixel and M denotes the acceptable margin between which the luminance may fluctuate due to noise. M is set experimentally to eight. C stands for the one-bit code.
Using (2), the the nine-bit code (Codein) is extracted for the 3 × 3 block, as shown in Figure (a). For example, in Figure , the luminance of the background and the luminance of the text are white and gray, respectively. Hence, lmaj and ltext are 255 and 100, respectively. Therefore, in the case of the text, the difference between its luminance and the background luminance is higher than M, and the one-bit code is 1. In the case of the background, the difference between its luminance and the luminance of the text is lower than M, and the one-bit code is 0. For the 3 × 3 block, encoding is performed from the top-left to the bottom-right, and 100 010 001 is extracted, as shown in Figure . Subsequently, this code and the luminance of the text enter the decoding stage.
Figure 4. Encoding and decoding in the proposed method for the current block in Figure : (a) the input code and the image with a low resolution, (b) the code dictionary, and (c) the output code and the image with a high resolution.
B. Decoding stage
In the decoding stage, the input code is analyzed and the legibility of the text is improved by changing its shape. For this, a code dictionary that contains pre-trained codes is used. Specifically, in the code dictionary, an image with a low resolution (LR) is paired with an image with a high resolution (HR), as shown in Figure (b). The pairing of the LR and HR images in the dictionary is defined by a user to improve the text legibility. If the code dictionary receives the input code (codein), as shown in Figure , the same code is searched for in the dictionary and the code (codeout) for the HR image is selected.
Next, the interpolation module converts the code for the HR image into the luminance of the output image, as shown in (3).
(3)
(3) where ltext and lout denote the luminance of the pixel of the text and the final luminance of the output image, respectively. For example, in Figure , when codein is 100 010 001, the same code is searched for and codeout, which is 110000 111000 011100 001110 000111 000011, is outputted. Next, the interpolation module decodes this code into the luminance, and accordingly, the boundary of a diagonal line is improved, as shown in Figure (c).
III. Experiment results
The performance of the proposed method was evaluated subjectively and objectively. First, the text qualities of sample text images constructed using the proposed and benchmark methods were visually compared. Second, the text qualities of the proposed and benchmark methods were assessed in terms of their blur, using a perceptual blur metric [Citation10]. Third, the computation times of the proposed and benchmark methods were calculated. The interpolation algorithms in [Citation5] (method 1), [Citation7] (method 2), [Citation9] (method 3), and [Citation4] (method 4) were used as the benchmark methods. For the test images, sample text images in several languages, i.e. English, Japanese, Chinese, German, and Korean, were used. Each language category consisted of 20 images. Images with an HD resolution (1280 × 720) were used, and their resolutions were converted to WQHD (2560 × 1440).
For the subjective evaluation, Figure shows samples of the English and Japanese text images. The benchmark methods (methods 1, 2, 3, and 4) used neighboring pixels to enhance smoothness in the boundaries, and hence, blurred the boundaries of the text. Methods 3 and 4 used a large number of neighboring pixels, and the blur is more marked than that in methods 1 and 2, as shown in Figure . On the other hand, the proposed dictionary-based interpolation method considered not only the smoothness but also the sharpness of the boundaries. Therefore, the blur was significantly reduced, unlike in the benchmark methods. Additionally, Figure shows that the staircase effect of the text was reduced, unlike in the benchmark methods. This is because the proposed method, using the pre-trained code dictionary, performed interpolation only when the boundaries had to be improved.
Figure 5. Comparison of the subjective qualities of the sample test images of English (top) and Japanese (bottom) text using (a) method 1, (b) method 2, (c) method 3, (d) method 4, and (e) the proposed method.
For the objective evaluation, the blur indexes of the proposed and benchmark methods were assessed over the blur index of all the test images. The blur indexes ranged from 0 to 1, where a higher index indicates poorer image quality with respect to blur. Figure shows graphs of the blur indexes of all the test images. The blur index of the proposed dictionary-based interpolation is lower than the blur indexes of the conventional methods for all the test images. In the case of the languages with many strokes, i.e. Chinese, Japanese, and Korean, the blur reduction effect was enhanced in the proposed method. Table lists the average blur indexes of the proposed and benchmark methods. The average blur indexes of methods 1, 2, 3, and 4 were 0.072, 0.069, 0.114, and 0.162, respectively. On the other hand, the blur index of the proposed method was 0.058. Specifically, the average blur indexes of the proposed method were up to 0.021, 0.017, 0.067, and 0.112, which are lower than those of methods 1, 2, 3, and 4, respectively. This is because the proposed method could maintain the sharpness of the text boundaries by adaptively controlling the interpolation based on the pre-trained code dictionary. Table lists the computation times of the proposed and benchmark methods. To measure the computation times, all the simulations were performed using MATLAB on a PC with an Intel Core i3-2120 processor at 3.30 GHz. The computation times of the proposed method were 14.77, 3.87, and 37.77 ms lower than those of methods 1, 2, and 3, respectively. Even though the computation time of the proposed method was slightly higher than that of method 4, which involves linear interpolation, this drawback was significantly compensated for by the improved image quality in the proposed method.
Figure 6. Blur indexes of the proposed and benchmark methods for the sample test images of: (a) English text, (b) Chinese text, (c) Japanese text, and (d) Korean text.
Table I. Blur indexes of the proposed and benchmark methods.
Table II. Computation times of the proposed and benchmark methods.
IV. Conclusion
In this paper, a proposal was presented for a dictionary-based interpolation for text quality enhancement when low-resolution image content is up-scaled to a high-resolution display device. The proposed algorithm extracts the shape of the text and the background luminance from an image, and then adaptively applies interpolation to improve the text legibility using a pre-trained code dictionary. The proposed method improves the text quality in terms of sharpness, which was experimentally validated using various test images. In these experiments, the proposed method reduced the blur index by up to 0.112, higher than did the benchmark methods.
Acknowledgment
This research was supported by the Ministry of Science and ICT (MSIT) of Korea under the Information Technology Research Center support program (IITP-2020-2018-0-01421) and supervised by the Institute of Information & Communications Technology Planning & Evaluation (IITP) and the National Research Foundation of Korea grant funded by the Korean government (MSIT) (No. 2020M3H4A1A02084899). Suk-Ju Kang received a B.S. degree in Electronic Engineering from Sogang University, Republic of Korea, in 2006, and a Ph.D. degree in Electrical and Computer Engineering from Pohang University of Science and Technology in 2011. From 2011 to 2012, he was a Senior Researcher at LG Display, where he was also a project leader for resolution enhancement and multi-view 3D system projects. Then, from 2012 to 2015, he was an Assistant Professor of Electrical Engineering at the Dong-A University, Busan. He is currently an Associate Professor of Electronic Engineering at Sogang University. His current research interests include image analysis and enhancement, video processing, multimedia signal processing, circuit design for display systems, and deep learning systems.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors

Sung In Cho
Sung In Cho (member, IEEE) received a B.S. degree in Electronic Engineering from Sogang University, South Korea in 2010, and a Ph.D. degree in Electrical and Computer Engineering from Pohang University of Science and Technology in 2015. From 2015 to 2017, he was a Senior Researcher at LG Display; and from 2017 to 2019, an Assistant Professor of Electronic Engineering at Daegu University. He is currently an Assistant Professor of Multimedia Engineering at Dongguk University, Seoul. His research interests include image analysis and enhancement, video processing, multimedia signal processing, and circuit design for LCD and OLED systems.

Suk-Ju Kang
Suk-Ju Kang (member, IEEE) received a B.S. degree in Electronic Engineering from Sogang University, South Korea in 2006, and a Ph.D. degree in Electrical and Computer Engineering from Pohang University of Science and Technology in 2011. From 2011 to 2012, he was a Senior Researcher and a Project Leader for resolution enhancement and multi-view 3D system projects at LG Display; and from 2012 to 2015, an Assistant Professor of Electrical Engineering at Dong-A University, Busan. He is currently an Associate Professor of Electronic Engineering at Sogang University. In 2019, he received the Young IT Engineer of the Year Joint Award from IEIE/IEEE. His research interests include image analysis and enhancement, video processing, multimedia signal processing, circuit design for display systems, and deep learning systems.
References
- J. Allebach, and P.W. Wong, Edge-Directed Interpolation, Proc. IEEE Int. Conf. Image Process. 3, 707–710 (1996). doi: 10.1109/ICIP.1996.560768
- J.W. Hwang, and H.S. Lee, Adaptive Image Interpolation Based on Local Gradient Features, IEEE Signal Process. Lett. 11 (3), 359–362 (March 2004). doi: 10.1109/LSP.2003.821718
- T.M. Lehmann, C. Gonner, and K. Spitzer, Survey: Interpolation Methods in Medical Image Processing, IEEE Trans. Med. Imaging 18 (11), 1049–1075 (Nov. 1999). doi: 10.1109/42.816070
- M.A. Nuno-Maganda, and M.O. Arias-Estrada, Real-Time FPGA-Based Architecture for Bicubic Interpolation: An Application for Digital Image Scaling, Proc. IEEE Int. Conf. Reconfig. Comput. FPGAs, 8 (2005).
- M. Hahn, L. Kruger, and C. Wohler, 3D Action Recognition and Long-Term Prediction of Human Motion, Computer Vision Syst. 5008, 23–32 (2008). doi: 10.1007/978-3-540-79547-6_3
- D. Unat, T. Hromadka, and S.B. Baden, An Adaptive Sub-Sampling Method for In-Memory Compression of Scientific Data, Data Compression Conf., 262–271 (March 2009).
- A. Roy, and J.F. Doherty, Raised Cosine Filter-Based Empirical Mode Decomposition, IET Signal Process. 5 (2), 121–129 (Apr. 2011). doi: 10.1049/iet-spr.2009.0207
- G. Petrazzuoli, M. Cagnazzo, F. Dufaux, and B. Pesquet-Popescu, Wyner-Ziv Coding for Depth Maps in Multiview Video-Plus-Depth, IEEE Inter. Conf. Image Process., 1817–1820 (Sept. 2011).
- C.C. Tseng, and S.L. Lee, Design of Fractional Delay Filter Using the Hermite Interpolation Method, IEEE Trans. Circuits. Syst. I 59 (7), 1458–1471 (July 2012). doi: 10.1109/TCSI.2011.2177136
- F. Crete, T. Dolmiere, P. Ladret, and M. Nicolas, The Blur Effect: Perception and Estimation with a New No-Reference Perceptual Blur Metric, Proc. SPIE Conf. Hum. Vision Electron. Imaging 6492 (Feb. 2007).