
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper presents a system and model for data acquisition and augmentation in OLED panel defect detection to improve detection efficiency. It addresses the challenges of data scarcity, data acquisition difficulties, and classification of different defect types. The proposed system acquires a hypothetical base dataset and employs an image generation model for data augmentation. While image generation models have been instrumental in overcoming data scarcity, time and cost constraints in various fields, they still pose limitations in generating images with regular patterns and detecting defects within such data. Even when datasets are available, the precise definition and classification of different defect types becomes imperative. In this paper, we investigate the feasibility of using an image generation model to generate pattern images for OLED panel defect detection and apply it for data augmentation. In addition, we introduce an OLED panel defect data acquisition system, improve the limitations of data augmentation, and address the challenges of defect detection data augmentation using image generation models.
1. Introduction
With the increasing demand for Organic Light Emitting Diode (OLED) technology in various industries, the efficiency of OLED panel defect detection has become a critical concern [Citation1]. However, the acquisition of reliable OLED panel defect data presents a formidable challenge [Citation2]. The scarcity of real-world data, coupled with the diverse nature of defect types and the precision required in the acquisition process, contributes to the complexities associated with obtaining a robust dataset. Traditional defect detection systems in OLED manufacturing rely on vision-based technologies that capture physical images of OLED panels to identify defects. These systems generally achieve detection rates above 98%, but their heavy dependence on specific systems and panel types is a significant drawback. Additionally, they lack flexibility because changing panel types or addressing errors requires complete system reconfigurations and hardware resets, leading to both time-consuming and costly adjustments. There is an urgent need to explore innovative approaches to approach these challenges. The application of deep learning-based object detection networks, which are widely used in various domains, is one promising avenue [Citation3]. There is potential to improve the efficiency and accuracy of OLED panel defect detection by exploiting the capabilities of artificial intelligence, in particular deep learning.
This paper presents a solution to address gaps in OLED data collection by incorporating artificial data [Citation4–10]. The rationale behind this approach is explored, highlighting the importance of synthetic data in overcoming the limitations associated with real-world data scarcity and precision requirements [Citation11–14]. We also propose to complement this strategy with the use of diffusion models to address the inherent limitations of artificially generated data. By applying deep learning object detection networks and integrating generation models, we aim to not only mitigate the challenges, but also improve the overall effectiveness of OLED panel defect detection. In the following sections, we discuss the proposed system, delve into the integration of deep learning models, and present the results of experiments conducted to validate the efficacy of our approach. This research aims to make a significant contribution to the advancement of OLED panel defect detection methods, paving the way for more robust and cost-effective solutions in the evolving landscape of display technology.
2. Related studies
2.1. Object detection and segmentation
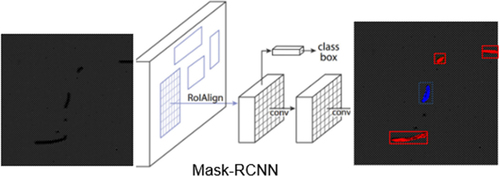
Object detection networks are primarily used to identify and classify the location of specific objects in an image or video. The use of deep neural networks significantly improves accuracy and performance over traditional methods. Typical architectures include region-based convolutional neural networks (R-CNN) and look-only-once (YOLO). R-CNN uses the strategy of generating candidate regions and classifying each region independently [Citation15–20]. YOLO, on the other hand, divides the image into a grid and directly predicts the bounding box and class for each grid cell. R-CNN and YOLO have their own advantages. YOLO is suitable for real-time processing, while R-CNN offers high precision in detecting intricate objects. Both methods are adequate for real-time processing in this study. However, due to the highly intricate nature of defects in OLED panels with various sizes and complex patterns, R-CNN, as depicted in Figure , was chosen for its precision. Research is currently being conducted on the application of these networks in various domains. In this study, R-CNN is applied to OLED panel defect detection to increase the efficiency and accuracy of data collection.
Figure 1. RCNN-based segmentation.
2.2. Diffusion model
Synthetic data pose various limitations. Firstly, it often fails to fully capture realistic and diverse scenarios due to imperfect representation. Secondly, a lack of diversity in the generated data can hinder the model's ability to handle different patterns or types that are not present in the training dataset. To address these limitations, we introduce the concept of ‘diffusion models’. Diffusion models revolutionized image generation by progressively diffusing noise throughout the generation process, consequently improving detail and overall image quality [Citation21–23]. These models excel at realistically representing patterns and intricate details in images [Citation24,Citation25]. In this paper, we propose the integration of diffusion models to augment the limitations of synthetic data. With the diffusion model, we aim to improve the quality of image generation and provide a more robust and realistic dataset for various applications.
3. Data acquisition system
3.1. Devices
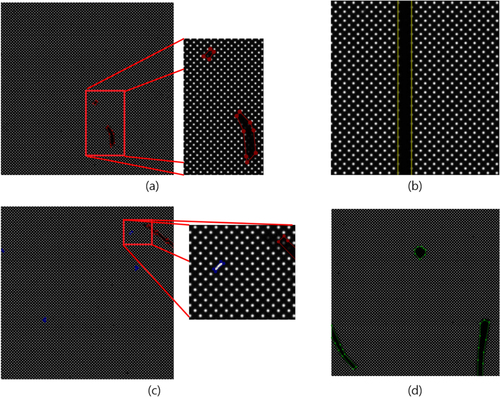
Since it is costly to generate a data set using real OLED panels, the focus has shifted to generating artificial data. First, artificial defect images are yielded onto OLED panels as depicted in Figure (a). Artificial defects occurring in panel modules are captured using high-resolution cameras and frame grabbers in Figure (b,c). Specifically, we utilize the IMX411-VC-151MX camera sensor model, which can acquire panel images with a resolution of 14,192 × 10,640 pixels. This resolution is approximately 50 times higher than the panel output (1080 × 2400), so it includes information from every pixel within the panel. This process allows us to effectively obtain and integrate virtual defects into the dataset, which are important for training image generation models. The integration of high-resolution cameras and frame grabbers plays a key role in capturing detailed pixel information and setting the stage for robust training and subsequent defect detection.
Figure 2. (a) Artificial defect source image example; (b) Output device and (c) Camera sensors and mounts; (d) Acquired raw image (14,192 × 10,640).

3.2. Definition of defect classification
As highlighted earlier, fine-grained classification of defects within the acquired image poses a challenge. This classification task is complicated by the fact that the original defect images contain over 100 million pixels of pixel-by-pixel detail of OLED panel defects, making them unsuitable for direct application in object detection through learning. To overcome this problem, a series of pre-processing steps are performed. First, the acquired defect images, which are rich in pixel-level information, are converted to PNG format. A normalization process is subsequently applied, after which the image is cropped to a standardized size of 1024 × 1024 pixels. This cropping process maintains the resolution of the original image while enabling application to the learning model. Each cropped image contains precise pixel information at a resolution 50 times higher than the actual panel. In this system, the generated virtual defects were classified into different categories in Figure : missing pixels (Open), connected pixels (Short), missing lines (Line out) and foreign bodies (Foreign body). Each category represents a specific type of defect and forms the basis for effective training and subsequent detection using the image generation model. ‘Open’ is a defect where specific pixels on the panel are missing, indicating an open state of the pixels. It is detected as a pixel ‘Open’ defect when three or more adjacent pixels are missing within the panel. ‘Short’ refers to defects caused by pixel short-circuiting between panel pixels or panel light leakage. Line out occurs due to mask defects during OLED panel deposition. Lastly, defects involving foreign bodies are assumed when inspecting irregular patterns or shapes spanning 4–5 pixels or more on the panel surface. This classification of defect is fundamental to improving the precision and accuracy of the defect detection model.
Figure 3. Example of a defined defect classification; (a) Open (b) Line out (c) Short (d) Foreign bodies.
4. Defect detection with system-acquired data
The dataset was divided into 240 images, with 204 used for training and 36 for testing. Each image contains between 10–100 defect objects, providing a rich dataset for training the model. This abundance of defect instances within each image ensures that the model can learn effectively from a diverse set of defect types and scenarios. Using Faster R-CNN, a box-based object detection algorithm, we integrated a mask-branching extension to the Region of Interest (RoI) recommended by the Region Proposal Network (RPN). This addition allowed precise pixel-level estimation of defect information within defined regions. During network training, the mask threshold was adjusted from the default value of 0.7 to the optimized value of 0.5. Despite the traditionally high performance of the ResNet-101-based network, performance and processing speed degraded as the network layers deepened while processing high-quality images with simple patterns. Defect detection rate was assessed by comparing the model's defect detections with actual defect objects in the images. There was only one false positive for open defects, while other defects were mostly false negatives (Figure ). Overall, as shown in Table , the detection rate was 98.4% based on a total of 375 defect objects.
Figure 4. Result of the defect detection, row 1 is the 1024 × 1024 output data and row 2 is the zoomed-in image.
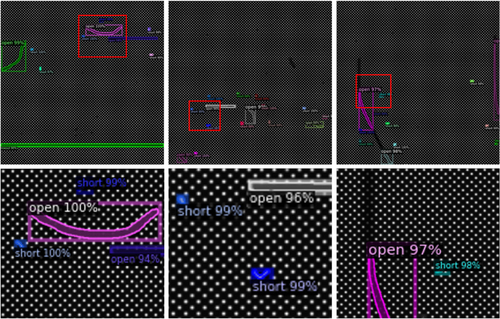
Table 1. Detection rate by defined defect type.
5. Data augmentation with diffusion model
5.1. Issues with diffusion model in the OLED panel data
Most OLED defects fall into four predefined classes. However, unexpected defects can occur. The data generated by the system described in Section 3 may be biased toward these defects. To mitigate this, an attempt was made to augment the data using a diffusion model to minimize the bias and to improve the ability to detect unexpected defects. The diffusion process can be mathematically represented as follows:
where
is the image at time step
is the original image,
is a constant factor controlling the amount of noise, and
is the Gaussian noise added at each step. In images obtained by data augmentation using the diffusion model, the noise parameter is used as an indicator of pixel information loss in OLED panels, with lower values of the noise parameter preserving more original information. It has been observed that the denoising stage of the diffusion model can cause distortion or loss of OLED information. This is because OLED data is an image with a specific pattern, and the denoising stage of the diffusion model loses important information [Citation25–27]. This means data augmentation using a simple diffusion model cannot be applied to OLED defect data. Figure shows the progressive changes in an image as noise is diffused and then reduced, illustrating the loss of OLED pattern information through the diffusion process.
Figure 5. Source data on the left, diffusion model on the right 3 images, OLED pattern information lost as the network process.

5.2. Data augmentation with diffusion models
The proposed method generates unclassified defect data by leveraging the inherent properties of diffusion models in deep learning. While most OLED panel defects can be classified into four predefined classes, unexpected defects can occur. To improve the generality of the detection model, a partial application of the diffusion model to images is proposed to artificially generate OLED defects. This method utilizes the propensity of the diffusion model to lose or distort pattern information. Direct application of the diffusion model for data augmentation is not feasible, but its partial application within images facilitates the dataset's versatility through unpredictable image transformations (Figure ). This approach not only maintains the generality of the data but also minimizes the loss of OLED pattern information, thereby increasing the model’s performance (Table ).
Figure 6. Generate OLED panel unclassified defect images with a partial diffusion model.

Table 2. Detecting unclassified defects in partial application models of diffusion models.
Evaluation of the approach in terms of model performance showed that the model trained on system-acquired classified data achieved a detection rate of 98.4% for predefined defect detection. In contrast, the model trained on data augmented by partial application of the diffusion model showed a slightly improved detection rate of 98.6%. In the unclassified defect detection test, the model trained on system-acquired data detected 44 out of 70 instances, resulting in a detection rate of 62.8%. However, when trained on the generated unclassified images and augmented by partial application of the diffusion model, the detection rate increased significantly to 92.85%, detecting 65 out of 70 instances. This significant improvement in the detection of unclassified defects underscores the effectiveness of using data generated from unclassified images for training, consequently improving the model’s overall performance. While the noise-added features do not correspond directly to observed physical defects, they effectively enhance the model's ability to detect unexpected, unclassified defects that were previously undetectable by conventional systems. The newly generated images with partial application of the diffusion model do not directly correspond to specific physical defects. However, they can be loosely associated with defects caused by light refraction due to foreign objects. This illustrates the potential for the diffusion model to create diverse and unpredictable defect patterns that improve the model's robustness.
6. Conclusion
Considering the development of a data acquisition system aimed at reducing the cost and increasing the effectiveness of OLED panel defect detection, the 98.4% performance was achieved in terms of defect detection rates based on the obtained dataset. However, inherent limitations were observed where the generated dataset showed high performance only in the identified defect classifications, showing a bias toward defined categories. To reduce this bias, we used the diffusion model to generate unclassified defect images. This approach proved effective not only in conventional defect detection, but also in the detection of unpredictable unclassified defects. It is expected that application of the proposed method can be extended beyond OLED panels, improving defect detection in various precision-driven devices and panels.
Acknowledgment
This research was supported by the Technology Development Program (1425166398) funded by the Ministry of SMEs and Startups (MSS, Korea), and Future Research Program by Sogang University (202319069.01).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors

Byungjoon Kim
Byungjoon Kim received his Bachelor's degree in Electrical Engineering from Sogang University in 2015. He then went on to complete his Master's degree in Visual Engineering from Sogang University in 2019. Byungjoon is currently pursuing a Ph.D. in Art and Technology Media Engineering at Sogang University, a program that he began also in 2019. His research interests include data augmentation, object detection, computer vision, and generative models.

Yongduek Seo
Yongdeuk Seo received his Bachelor's degree in Electrical Engineering from Kyungpook National University in 1992. He then pursued his Master's degree in Electrical Engineering from POSTECH (Pohang University of Science and Technology) in 1994, followed by a Ph.D. in Electrical Engineering from POSTECH in 2000. Yongdeuk Seo has served as a professor at Sogang University since 2003. His research interests include computer vision, augmented reality (AR), and deep learning.
References
- Y. Huang, E.L. Hsiang, M.Y. Deng, and S.T. Wu, Mini-LED, Micro-LED and OLED displays: present status and future perspectives, Light Sci. Appl. 9, 105 (2020). doi:10.1038/s41377-020-0341-9
- V.A. Sindagi and S. Srivastava, OLED panel defect detection using local inlier-outlier ratios and modified LBP, in 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan (2015), pp. 214–217.
- Z.-Q. Zhao, P. Zheng, S.-T. Xu, and X. Wu, Object detection with deep learning: a review, IEEE Trans. Neural Networks Learn. Syst. 30 (11), 3212–3232 (2019).
- K. He, X. Zhang, S. Ren, and J. Sun, Spatial pyramid pooling in deep convolutional networks for visual recognition, in ECCV, edited by D. Fleet, T. Pajdla, and B. Schiele (Springer, Cham, 2014). pp. 346–361.
- K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, Show, attend and tell: neural image caption generation with visual attention, in ICML, edited by F. Bach. and D. Blei. (International Machine Learning Society(IMLS), Lille, France, 2015), pp. 2048–2057.
- R. Girshick, J. Donahue, T. Darrell, and J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in CVPR (IEEE, 2014), pp. 580–587.
- J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, You only look once: unified, real-time object detection, in CVPR (IEEE, 2016), pp. 779–788.
- J. Redmon and A. Farhadi, Yolov3: An incremental improvement, arXiv preprint arXiv:1804.02767 (2018).
- W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, Ssd: Single shot multibox detector, in ECCV (Springer, Cham, 2016), pp. 21–37.
- A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, arXiv preprint arXiv:2004.10934 (2020).
- S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li, Single shot refinement neural network for object detection, in CVPR (2018).
- H. Law, and J. Deng, Cornernet: Detecting objects as paired keypoints, in Proceedings of the European Conference on Computer Vision (ECCV) (Springer, Cham, 2018), pp. 734–750.
- Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, Distance-IoU loss: faster and better learning for bounding box regression, Proc. AAAI Conf. Artif. Intell. 34 (07), 12993–13000 (2020). doi:10.1609/aaai.v34i07.6999
- N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, End-to-end object detection with transformers, in European Conference on Computer Vision, edited by A. Vedaldi, H. Bischof, and J. Frahm (Springer, Cham, 2020), pp. 213–229.
- R. Girshick, Fast r-cnn, in ICCV (IEEE, Santiago, Chile, 2015), pp. 1440–1448.
- S. Ren, K. He, R. Girshick, and J. Sun, Faster RCNN: towards real-time object detection with region proposal networks, in Advances in Neural Information Processing Systems, edited by C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett (MIT Press, Cambridge, MA, 2015), pp. 91–99.
- K. He, G. Gkioxari, P. Dollar, and R. Girshick, Mask ´r-cnn, in ICCV (IEEE, Venice, Italy, 2017), pp. 2980–2988.
- T.-Y. Lin, P. Dollar, R.B. Girshick, K. He, B. Hariharan, and S.J. Belongie, Feature pyramid networks for object detection, CVPR, 936–944 (2017).
- T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, Focal loss for dense object detection, IEEE Trans. Pattern Anal. Mach. Intell. 42 (2), 318–327 (2018).
- Z. Cai, and N. Vasconcelos, Cascade r-cnn: Delving into high quality object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (IEEE, Salt Lake City, UT, 2018), pp. 6154–6162.
- P. Dhariwal and A. Nichol. Diffusion models beat GANs on image synthesis, arXiv:2105.05233 (2021).
- T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion-based generative models. arXiv:2206.00364 (2022).
- NovelAI. Novel ai improvements on stable diffusion (2023). https://blog.novelai.net/ novelai-improvements-on-stable-diffusion-e10d38db82ac.
- W. Feng, X. He, T. Fu, V. Jampani, A. Akula, P. Narayana, S. Basu, X.E. Wang, and W.Y. Wang. Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv:2212.05032 (2023).
- Nicholas Guttenberg and CrossLabs. Diffusion with offset noise (2023). https://www.crosslabs. org/blog/diffusion-with-offset-noise.
- S. Lin, B. Liu, J. Li, and X. Yang. Common diffusion noise schedules and sample steps are flawed. arXiv:2305.08891 (2023).
- D. Berthelot, A. Autef, J. Lin, D. A. Yap, S. Zhai, S. Hu, D. Zheng, W. Talbot, and E. Gu. TRACT: denoising diffusion models with transitive closure time-distillation. arXiv:2303.04248 (2023).