
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper introduces a computationally efficient data assimilation scheme based on Gaussian quadrature filtering that potentially outperforms current methods in data assimilation for moderately nonlinear systems. Moderately nonlinear systems, in this case, are systems with numerical models with small fourth and higher derivative terms. Gaussian quadrature filters are a family of filters that make simplifying Gaussian assumptions about filtering pdfs in order to numerically evaluate the integrals found in Bayesian data assimilation. These filters are differentiated by the varying quadrature rules to evaluate the arising integrals. The approach we present, denoted by Assumed Gaussian Reduced (AGR) filter, uses a reduced order version of the polynomial quadrature first proposed in Ito and Xiong [Citation2000. Gaussian filters for nonlinear filtering problems. IEEE Trans. Automat. Control. 45, 910–927]. This quadrature uses the properties of Gaussian distributions to form an effectively higher order method increasing its efficiency. To construct the AGR filter, this quadrature is used to form a reduced order square-root filter, which will reduce computational costs and improve numerical robustness. For cases of sufficiently small fourth derivatives of the nonlinear model, we demonstrate that the AGR filter outperforms ensemble Kalman filters (EnKFs) for a Korteweg-de Vries model and a Boussinesq model.
1. Introduction
Data assimilation is the process of estimating the system state given previous information and current observational information. The methods typically used for data assimilation in the ocean and atmosphere are variational schemes (Talagrand and Courtier, Citation1987; Daley, Citation1991; Courtier et al., Citation1998) and ensemble Kalman filters (EnKFs) (Evensen, Citation2003; Bishop et al., Citation2001). Both methods are built on linear hypotheses and have led to useful results in quasi-nonlinear situations. These methods are optimal for the case where the observations and model error are Gaussian. These methods have been successful in numerical weather prediction (NWP) (Buehner et al., Citation2010; Kuhl et al., Citation2013) but are suboptimal for nonlinear model dynamics as the Fokker-Plank equations that govern the evolution of a pdf may only be solved exactly for certain cases. This sub-optimality has led to a proliferation of methods to perform data assimilation each with their own advantages (see, for example, Daley, Citation1991; Anderson, Citation2001; Bishop et al., Citation2001; Sondergaard and Lermusiaux, Citation2013; Poterjoy, Citation2016).
While it is well known that atmospheric and oceanic models may have non-Gaussian statistics (Morzfeld and Hodyss, Citation2019), computational resources limit our ability to fully resolve the data assimilation problem. It was shown in Miyoshi et al., (2014) that ensembles need to have on the order of a thousand members to represent non-Gaussian prior pdfs in an EnKF for a general circulation model, however, typical ensemble sizes are on the order of a hundred (Houtekamer et al., Citation2014). Additionally, computational constraints lead to data assimilation systems using lower resolutions than the forecasting model and are therefore more linear. In targeting this specific application, algorithmic efficiencies may be found.
Gaussian quadrature filters explicitly assume conditional pdfs are Gaussian in the Bayesian filtering equations. Then powerful numerical integration techniques are used, e.g. Gaussian quadrature and cubature, to evaluate the resulting integral equations. The first of these types of filters appeared in the early 2000s with Ito and Xiong (Citation2000) and Wu et al. (Citation2006) but it was not until the cubature Kalman filter (Arasaratnam and Haykin, Citation2009) that Gaussain quadrature filters became popular. Since then, they have seen extensive use in radar tracking (Haykin et al., Citation2011), traffic flow (Liu et al., Citation2017), power systems (Sharma et al., Citation2017), etc.; however, they have not enjoyed the same popularity in atmospheric and oceanographic sciences. This is likely due to their expense as quadrature rules require many evaluations of the nonlinear model. The central difference filter (CDF) (Ito and Xiong, Citation2000) uses low-order polynomial quadrature requiring twice the number of model evaluations as the size of the state space. Higher order quadrature methods require even more model evaluations. The CDF has successfully outperformed Extended Kalman Filter (EKF) (Ito and Xiong, Citation2000), unscented Kalman filter (UKF) (Ito and Xiong, Citation2000), and 4 D-Var (King et al., Citation2016) for low dimensional problems. The nonlinear filter presented here, the Assumed Gaussian Reduced (AGR) filter, is essentially a square root version of the CDF with dynamical sampling.
The AGR filter uses low-order polynomial quadrature that takes advantage of the properties of Gaussian distributions to achieve an effective higher order of accuracy. To further reduce the computational costs of the filter, singular value sampling is used. These two techniques make the AGR filter efficient in terms of nonlinear model evaluations giving it potential for atmospheric and oceanic applications. The algorithm for the AGR filter is similar to that of a square-root EnKF but with a different prediction step. This prediction step will cost more computationally to perform than a typical EnKF prediction step in terms of matrix and vector operations. However, the AGR filter formulation of this prediction step will be more accurate for numerical models with small fourth order derivatives, i.e., moderately nonlinear systems.
This manuscript is organized as follows: Section 2 begins with a brief review of Bayesian filtering followed by details regarding assumptions about the associated pdfs to arrive at a discrete filter in terms of Gaussian integrals. The evaluation of these Gaussian integrals is discussed in Section 3 in terms of low-rank polynomial quadrature for scalar and multi-dimensional problems. Results are presented relating to the performance of this quadrature to help to define the scenarios in which this filter should be used. The algorithm for the full AGR filter is presented in Section 4. Section 5 uses a one-dimensional Korteweg-de Vries model and a two-dimensional Boussinesq model to compare the performance of the AGR filter versus a square root EnKF filter. Final remarks are in Section 6. The appendix contains the formulas used in Sections 2 and 3.
2. Linking Bayesian filtering to Gaussian quadrature filters
We begin our discussion with a review of Bayesian filtering in order to highlight the differences between common types of nonlinear filters. The aim of Bayesian filtering is to estimate the pdf where xt is the current state at time t and
contains the previous observations up to time t. The Bayesian filter is most commonly developed as a recursive filter formed by first applying Bayes’ rule to
and then applying the Markovian properties of the observations, i.e. the property that observations depend only on the current state. The filter was first described in Ho and Lee (Citation1964) and is discussed detail in Särkkä (Citation2013) and Chen (2003). This filter is typically divided into two steps: the first step, which we will refer to as the prediction step, computes the prior distribution using preliminary information given by the Chapman–Kolmogorov equation
(2.1)
(2.1)
The second step, which we will refer to as the correction step, computes the posterior distribution
(2.2)
(2.2)
where
is the normalization constant. The exact solutions of Equation(2.1)
(2.1)
(2.1) and Equation(2.2)
(2.2)
(2.2) are unknown except in special cases. In particular, for linear state dynamics where the prior pdf
is Gaussian and the measurement likelihood
is Gaussian, the filter Equation(2.2)
(2.2)
(2.2) has an exact solution given by the Kalman filter (Kalman, Citation1960). Otherwise Equation(2.2)
(2.2)
(2.2) may be approximated using a particle filter (Särkkä, Citation2013; Poterjoy, Citation2016). In practice, the full pdf
is not used and instead only its first two moments, the mean and covariance, are used. Under Gaussian assumptions this leads to what are referred to as Kalman-type filters.
To summarize the relationship between the Bayesian filter in Equation(2.1)(2.1)
(2.1) and Equation(2.2)
(2.2)
(2.2) and Kalman-type filters we begin by considering the system given by
(2.3)
(2.3)
with the observation process
(2.4)
(2.4)
where
f is the model, H is the linear map between the state space and the observation space, w is the Gaussian model error with covariance Q, and v is the Gaussian observation error with covariance R. At time t, the mean of the predictive distribution Equation(2.1)
(2.1)
(2.1) is given by
(2.5)
(2.5)
(2.6)
(2.6)
(2.7)
(2.7)
where b in
indicates that x is the background estimate of the mean at time t. EquationEquation (2
(2.1)
(2.1) .7) is computed using Equation(A.3)
(A.3)
(A.3) from Appendix A where
is the expectation.
Similarly, the covariance of Equation(2.1)(2.1)
(2.1) is given by
(2.8)
(2.8)
(2.9)
(2.9)
(2.10)
(2.10)
using Equation(A.6)
(A.6)
(A.6) . The equations for the prediction step, Equation(2.7) and (2.10)
(2.10)
(2.10) , are both a consequence of the model error w being Gaussian. To approximate the correction step, it is first assumed that the joint distribution of
is Gaussian, more specifically,
(2.11)
(2.11)
(2.12)
(2.12)
(2.13)
(2.13)
where
is the estimated observations computed via Equation(2.4)
(2.4)
(2.4) using
is the cross-covariance between
and
and
is the covariance of
The observation process
and
are computed similar to Equation(2.7)
(2.7)
(2.7) and Equation(2.10)
(2.10)
(2.10) . The computation of the cross covariance
Equation(2.13)
(2.13)
(2.13) may be found in the appendix (Equation (A.12)). Then it follows from Equation(2.13)
(2.13)
(2.13) that the conditional distribution of xt given yt in Equation(2.2)
(2.2)
(2.2) is approximated in terms of the mean
and covariance
where the mean and covariance are given by the Kalman equations
(2.14)
(2.14)
(2.15)
(2.15)
(2.16)
(2.16)
where
is the mean at the analysis (denoted by the a) at time t, y are the observations, and Kt is the Kalman gain. Note that in the above Kalman-type filter framework we have assumed the observation operator H is linear, however, this need not be the case (Ito and Xiong, Citation2000; Särkkä, Citation2013). In general, solving Equation(2.7) and (2.10)
(2.10)
(2.10) explicitly is intractable for large problems, including the large problems found in geosciences. One strategy for approximating Equation(2.7) and (2.10)
(2.10)
(2.10) is to use sampling which leads to the expressions for the sample mean and covariance used in EnKFs. Another strategy is to make the further simplifying assumption that
is Gaussian, arriving at a particular type of assumed density filter referred to as a Gaussian filter in literature. Since EnKF filters also contain Gaussian assumptions, to differentiate these filters we will refer to Gaussian filters as Gaussian quadrature filters.
To form the basis for Gaussian quadrature filters, we will make the additional simplifying assumption
(2.17)
(2.17)
i.e., that our prior distribution is Gaussian. With this additional assumption, Equations Equation(2.7) and (2.10)
(2.10)
(2.10) simplify and we arrive at the algorithm
(1) Prediction step:
(2.18)
(2.18)
(2.19)
(2.19)
(2) Correction step:
With this formulation it is easily verified that for a linear f(x) in Equation(2.3)(2.3)
(2.3) , we arrive at the Kalman filter equations exactly. In this regard, the Gaussian quadrature filters can be seen as a nonlinear extension of the Kalman filter. Other nonlinear filters such as the extended Kalman filter or UKF (Julier et al., Citation2000) may also be formulated using this framework (Särkkä, Citation2013).
3. Gaussian integration
The distinct feature of Gaussian quadrature filters is the evaluation of the Gaussian integrals Equation(2.18) and (2.19)(2.19)
(2.19) which are multidimensional integrals of the form
(3.1)
(3.1)
where
is a general function and
is equivalent to
These types of filters are differentiated by the type of quadrature they use, for example, the Gauss-Hermite Kalman filter (Ito and Xiong, Citation2000; Wu et al., Citation2006), the cubature Kalman filter (Arasaratnam and Haykin, Citation2009), and the central difference filter (Ito and Xiong, Citation2000). The quadrature rules in these methods entail model evaluations and the computation of weights requiring a trade-off between cost and performance. Higher order methods provide greater numerical accuracy but require substantially more model evaluations which may be cost prohibitive. We will use low-order polynomial quadrature to balance computational cost and performance.
3.1. Gaussian pdf integration: scalar case
To discuss the evaluation of the Gaussian integrals of the form Equation(3.1)(3.1)
(3.1) , we begin with the scalar case given by
Using the change of variables where
is the square root of
we arrive at the integral in standard form given by
where
This form of the Gaussian integral allows for the development of explicit formulas to evaluate it. We approximate
by a second-degree polynomial
given by
(3.2)
(3.2)
where
(3.3)
(3.3)
where d > 0 is the step size. Note that because of the change in variables the first and second derivatives, a1 and a2, are in the direction of
Then using Equation(3.2)
(3.2)
(3.2) in Equation(2.18)
(2.18)
(2.18) , the prior mean estimate is given by
(3.4)
(3.4)
(3.5)
(3.5)
(3.6)
(3.6)
The odd term in Equation(3.5)(3.5)
(3.5) zeros out and the mean estimate is now the previous mean propagated forward with a second-order correction term. Similarly, using Equation(3.2) and (3.6)
(3.6)
(3.6) , we may compute the prior covariance prediction Equation(2.19)
(2.19)
(2.19) as
(3.7)
(3.7)
(3.8)
(3.8)
(3.9)
(3.9)
The variance is now in terms of the first and second derivatives of the model. The primary cost of evaluating Equation(3.6) and (3.9)(3.9)
(3.9) comes from computing a1 and a2 via Equation(3.3)
(3.3)
(3.3) which requires three evaluations of the model Equation(2.3)
(2.3)
(2.3) :
and
One of the reasons this method is effective is that the quadrature error of the mean estimation in (3.6) is based on the fourth derivative of the model f even though we are using a second-order polynomial approximation, see Equation(B.3)(B.3)
(B.3) in Appendix B. This is due to the fact that odd terms drop out in Gaussian polynomial integration. Meanwhile, the quadrature error in the estimation of the covariance, see Equation(B.6)
(B.6)
(B.6) , is related to the size of the third derivative of f.
3.2. Non-Gaussian pdf integration
For comparison, we now consider the case of Equation(2.7) and (2.10)(2.10)
(2.10) without making a Gaussian assumption. To simplify our notation, we will denote
the prior pdf by
Assume at time t we have
sampled from
we may then determine the expected error in the mean and variance at time t by propagating samples drawn from
forward, and determining their error (see Section 3.3). As in the previous case where
is Gaussian, we will relate the error to the moments of
This is most conveniently done through a Taylor-series expansion of Equation(2.3)
(2.3)
(2.3) . To this end, note that
(3.10)
(3.10)
where
is the true mean of
Applying Equation(3.10)
(3.10)
(3.10) to the expectation of xt gives
(3.11)
(3.11)
(3.12)
(3.12)
(3.13)
(3.13)
where
is the variance derived from
Similarly, subtracting Equation(3.13)
(3.13)
(3.13) from Equation(3.10)
(3.10)
(3.10) , squaring the result, and applying the expectation one obtains
(3.14)
(3.14)
where
and
are the third and fourth moments of
respectively. Without the simplifying assumptions used in the Gaussian pdf case, we arrive at these infinite sums for the mean and covariance.
3.3. EnKF framework
To evaluate integrals of the form Equation(2.7) and (2.10)(2.10)
(2.10) , or the expressions in Equation(3.13) and (3.14)
(3.14)
(3.14) , in an EnKF framework, statistical sampling is used. The sample mean and variance at time t are
(3.15)
(3.15)
(3.16)
(3.16)
where k is the number of samples. The error in these estimates is well-known form central limit theorem-type arguments (for example, see Hodyss et al., Citation2016). The error may be quantified by calculating the squared deviation about the true mean and variance:
(3.17)
(3.17)
(3.18)
(3.18)
The AGR filter update EquationEquations (3.6)(3.6)
(3.6) and Equation(3.9)
(3.9)
(3.9) are only approximating the first few terms in Equation(3.13) and (3.14)
(3.14)
(3.14) assuming the pdf
is Gaussian. In contrast, the sample mean Equation(3.15)
(3.15)
(3.15) and sample covariance Equation(3.16)
(3.16)
(3.16) are attempting to approximate the full sums in Equation(3.13) and (3.14)
(3.14)
(3.14) without knowledge of
which is a more difficult task.
3.4. Scalar example
In this example, we explore the differences in the predicted mean and covariance estimates used by the AGR filter and EnKF filters. In the scalar case, the AGR filter is full rank allowing for comparison between the error caused by the low-order polynomial approximation Equation(3.2)(3.2)
(3.2) versus the sampling error in an EnKF estimate. Consider the scalar model given by
(3.19)
(3.19)
with
Gaussian and
This implies from Equation(3.13) and (3.14)
(3.14)
(3.14) that the true mean and variance are given by
(3.20)
(3.20)
(3.21)
(3.21)
In this example, and the following examples, we are not considering model error. For the EnKF case, where we approximate Equation(3.20) and (3.21)(3.21)
(3.21) , the mean and covariance depend on c1 and c2. We set the variance P = 1 and
and let
and
We define the true solution to this problem to be given by Equation(3.15)
(3.15)
(3.15) with k = 50,000. In this case, we perform a random draw from P to form the ensembles. We propagate the mean estimate for the AGR filter and the ensemble for the EnKF using Equation(3.19)
(3.19)
(3.19) and compute the error in the predicted means and covariances. The error map of the mean estimates of Equation(3.6) and (3.15)
(3.15)
(3.15) for the different values of c2, c4 and ensemble sizes k = 5, 10, 100 for the EnKF are shown in . Note for this example the AGR filter only requires 3 model evaluations as described in Section 3.1 whereas the EnKF requires the same number of model evaluations as the ensemble size.
Fig. 1. The L2 error in the estimated (a) EnKF mean (3.15) for k = 5, (b) EnKF mean for k = 10, (c) EnKF mean for k = 100, and (d) AGR filter mean (3.6) for increasing values of c2 (horizontal axis) and c4 (vertical axis). Note that the color scales are different between the first two plots (a) & (b) and the second two (c) & (d).
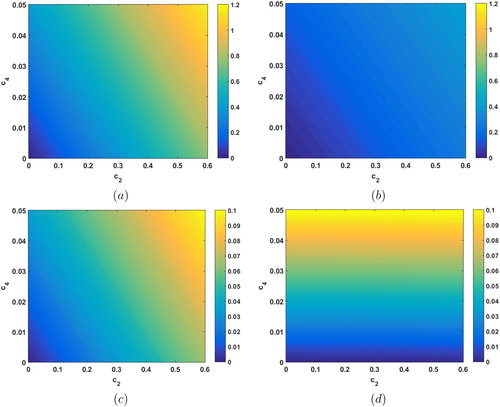
In and (), for a similar number of model evaluations to the AGR filter, the sampling error in the EnKF estimates are quite large. Note that the color bars in (a) and (b) are the same and are of a different order than the color bars used in (c) and (d). In panels (c) and (d), the amount error in the EnKF estimate with k = 100 and the AGR filter is comparable. The AGR filter quadrature error is invariant with respect to changes in c2, whereas the EnKF estimation error depends on both c2 and c4 as expected given Equation(3.20)(3.20)
(3.20) . If c4, which the fourth derivative depends on, is sufficiently small we expect better performance from the AGR filter estimated mean (3.6) regardless of the size of c2.
In the prior covariance estimates in , we see in (a) that the error in the EnKF covariance estimate with k = 100 grows with increases in c2 and c4. By comparison, the error in the AGR filter covariance in (b) is small when c4 is small and grows as the fourth-order derivative grows as expected since the error depends on The AGR filter covariance estimation is equal to or better than the EnKF estimate for small c4. For larger c4, the EnKF covariance estimate performs better. Note for this example we do not have a c3 term which the error in the AGR filter and EnKF depends on as well.
Fig. 2. The L2 error in (a) EnKF prior covariance estimate for k = 100 and (b) the error in the AGR filter prior covariance estimate for increasing values of c2 (horizontal axis) and c4 (vertical axis).
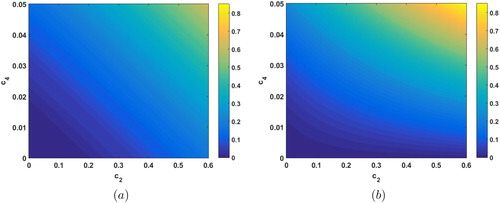
This example demonstrates the types of scenarios where one might choose one type of filter over another. For small ensemble sizes, the AGR filter may be the preferable choice as well as for the case where the model is moderately nonlinear, i.e. small magnitude higher order terms. For a large ensemble with large model fourth derivatives, the EnKF may provide a better estimate of the predicted mean.
3.5. Gaussian pdf integration: multi-dimensional case
We will now extend the results in Section 3.1 to higher dimensions. To evaluate integrals of the form (3.1), we begin by first applying the coordinate transform where S is the square root of the covariance
such that
Using this change of coordinates, we can convert (3.1) to the standard form with N(0, I), where I is the identity matrix. Then
(3.22)
(3.22)
where
(3.23)
(3.23)
Using Equation(3.22)(3.22)
(3.22) we can develop formulas to evaluate Equation(2.18) and (2.19)
(2.19)
(2.19) explicitly based on polynomial quadrature. In Ito and Xiong (Citation2000),
is approximated by the function
such that
for points
in
The multivariate polynomial
is given by
(3.24)
(3.24)
where
is the ith column of a, the first-order variation or Jacobian, si is the ith column of S, and bi is the ith column approximation of the second-order variation, or Hessian. The coefficients a and b may be determined using centered differencing, similar to the scalar case, via
(3.25)
(3.25)
where
are unit vectors and d > 0. We approximate bi via
(3.26)
(3.26)
Evaluating a and b requires model evaluations. Note that we do not use cross derivative terms in the Hessian which would require an additional
model evaluations to compute.
Using the polynomial in Equation(3.24)(3.24)
(3.24) , we can write the integral Equation(3.22)
(3.22)
(3.22) as
(3.27)
(3.27)
and create explicit formulas for the mean and covariance:
(3.28)
(3.28)
(3.29)
(3.29)
(3.30)
(3.30)
and
(3.31)
(3.31)
(3.32)
(3.32)
(3.33)
(3.33)
(3.34)
(3.34)
To summarize, a change of coordinates is used to transform the Gaussian integrals into standard form. We then approximate by a quadratic polynomial. Using this approximation, we create self-contained formulas for the predicted mean and covariance.
Similar to the scalar case, odd polynomial terms drop out in the polynomial quadrature. This results in the quadrature error in estimating the mean Equation(3.30)(3.30)
(3.30) on the order of the fourth derivative of the nonlinear model (see Equation(B.8)
(B.8)
(B.8) in the appendix) even though our polynomial approximation Equation(3.24)
(3.24)
(3.24) is only second order. We do not see as much benefit in the computation of the covariance as the error given by Equation(B.11)
(B.11)
(B.11) is related to the cross terms in the Hessian approximation that were dropped in Equation(3.24)
(3.24)
(3.24) . Overall, the contribution to the filter error from the low-order polynomial quadrature is minimized for moderately nonlinear systems.
3.5.1 Multidimensional example
For this example, we will again look at the effects of nonlinearity versus sampling in the AGR filter and the EnKF. We consider a variable coefficient Korteweg-de Vries (KdV) model that governs the evolution of Rossby waves in a jet flow (Hodyss and Nathan, Citation2002). This may be written as
(3.35)
(3.35)
where
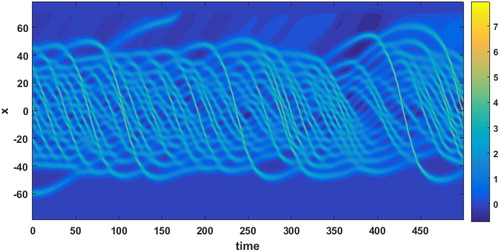
and a = 0.0005. The derivatives are vanishing on the boundary, the initial condition is given by a solitary Rossby wave, and we use 512 model computational nodes. A contour plot of the true solution in time is shown in .
Fig. 3. Contour plot of the wave amplitude over the domain (vertical axis) of the KdV equation over time (horizontal axis).
We begin by creating a 35,000 member ensemble that will be used as the true solution in our experiments. This ensemble was created by drawing the members from climatology then using an EnKF to perform three system cycles using observations created from an ensemble member. This was done to improve the quality of the ensemble. The resulting covariance of this ensemble has eigenvalues plotted in .
Fig. 4. The 512 sorted eigenvalues of the initial background error covariance created from a 35000 member climatological ensemble. The horizontal axis is the eigenvalue number and the vertical axis is the magnitude of each eigenvalue.
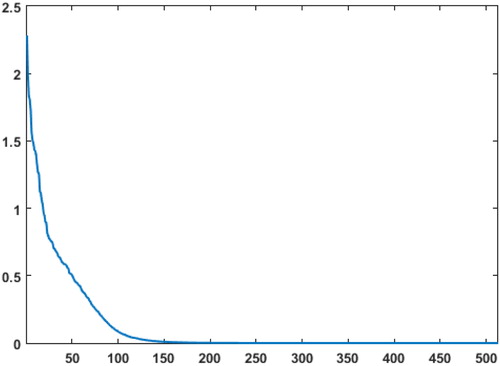
The eigenvalues of and their corresponding eigenvectors will be used to form
needed by the AGR filter. Additionally, members for smaller ensemble sizes will be drawn randomly from the 35,000-member ensemble. Since
has near-zero eigenvalues, we will consider only the first 250 eigen-directions thus
where Σm is a truncated matrix with the first 250 eigenvalues of
along the diagonal and Um is composed of the corresponding eigenvectors. The square root of
is then given by
which is used in the coordinate transform Equation(3.23)
(3.23)
(3.23) . In this example, 501 model evaluations are used to compute Equation(3.30) and (3.34)
(3.34)
(3.34) , thus the solution will be compared to an ensemble with 500 members for fairness. Similar to the one-dimensional example, the error in the prior mean estimates of the AGR filter and the EnKF is examined as nonlinearity is increased. The nonlinearity is further developed by increasing the amount of time (t0) the model is integrated forward.
One way to observe the impact of the increased nonlinearity is to look at the influence of b in (3.24). For comparison we consider the filter without the second-order correction term which uses the first-order polynomial quadrature as AGR1, and with b which uses the second-order polynomial quadrature as AGR2.
Both filters are initialized using the mean of the 35,000 member ensemble, which we consider to be the true mean. The perturbations for the 500 member ensemble are drawn from the 35,000 member ensemble and then re-centered on the true mean. The S for the AGR filters is described above. All methods are integrated forward to t0 and the prior means and covariances are computed. compares the L2 error in the EnKF prior mean solution with K = 500 and the AGR filter solutions with m = 250. The AGR2 filter significantly outperforms the AGR1 filter, demonstrating the importance of the second-order correction term. The AGR2 filter outperforms the EnKF until about or 5501 model time steps. The AGR2 filter performs well prior to this point having half the error of the EnKF at
or 2501 model time steps. compares the covariances of the EnKF and AGR filter using the Frobenius norm given by
Fig. 5. (a) The L2 error (vertical axis) in the estimate of the prior mean for the EnKF with k = 500, the AGR1 with m = 250, and AGR2 with m = 250 for time step length t0 (horizontal axis). (b)The error in the Frobenius norm of the corresponding covariance estimates.
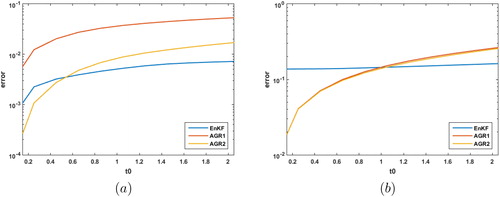
The AGR1 and AGR2 filters have about the same error in their covariances and outperform the EnKF until about For model regimes which do not have overly large higher order terms, the AGR2 may provide better estimation.
For large n, evaluating Equation(3.30) and (3.34)(3.34)
(3.34) is prohibitively expensive since it requires
model evaluations where ne is the number of nonzero eigenvalues. To reduce the computational cost, we consider the case where only the leading m eigenvalues are kept. Ideally, m would be chosen so that the singular values capture the essential dynamics, however, in atmospheric applications this is may not be possible due to computational constraints. The truncation error in the estimation of the square root Sm of
is given by
(3.36)
(3.36)
If has n–m eigenvalues approaching zero this estimation is very accurate. In other words, the extent of the correlations in
determines the accuracy of this truncation. The error in evaluating Equation(3.30) and (3.34)
(3.34)
(3.34) now comes from both quadrature and this truncation.
We repeat the previous experiment with K = 40 introducing undersampling for the EnKF estimate and m = 20 for the AGR estimates. Again we see the importance of the second-order correction term when comparing AGR1 and AGR2 in . In (a) the AGR2 filter again has half the error of the EnKF at However, due to the presence of sampling error in both of the prior mean estimates, the AGR2 continues to outperform the EnKF until about
or 15,501 model time steps after which time the EnKF has a slight edge in performance. In (b) both the AGR1 and AGR2 estimates outperform the EnKF covariance estimates for various values of t0.
Fig. 6. (a) The L2 error (vertical axis) in the estimate of the prior mean for the EnKF with k = 40, the AGR1 with m = 20, and AGR2 with m = 20 for time step length t0 (horizontal axis). (b) The corresponding error in the Forbenius norm for the prior covariance estimates.
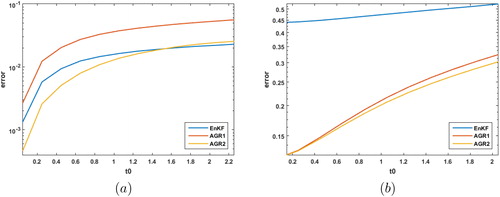
In both the cases with undersampling and without undersampling the AGR2 consistently outperformed AGR1 due to the inclusion of the second-order correction term b. Additionally, in both cases, there was a moderately nonlinear regime in which the AGR2 filter outperformed the EnKF. Similar to the scalar case, the AGR2 filter was found to be more sensitive to increased nonlinearity than the EnKF; however, the EnKF proved to be more sensitive to undersampling. This broadened the regime in which the AGR2 filter outperformed the EnKF.
3.5.2 A note on 
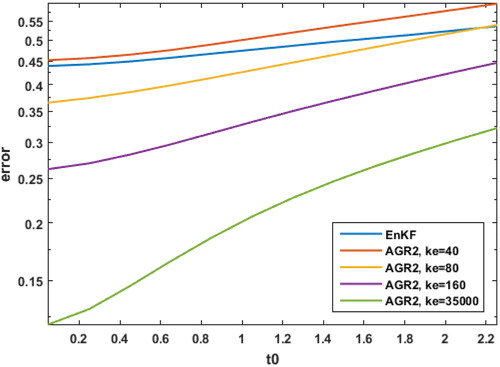
For this example, Sm was computed from for the AGR filters. This
was created using a 35,000 member climatological ensemble. Using fewer ensemble members to create
introduces another source of error at the starting time. For example, if
is constructed with
ensemble members, then the accuracy of the AGR2 filter for m = 20 decreases accordingly for computing the prior covariance estimates as in . For convenience, we have included the error estimate for the EnKF in this plot. Note that the ensemble of the 40 member EnKF is drawn from the 35,000 member climatological ensemble. There are numerous strategies to develop a more accurate and higher rank
(Clayton et al., 2013; Derber and Bouttier, Citation1999) which are beyond the scope of this paper.
Fig. 7. The error in the Frobenius norm (vertical axis) of the prior covariance estimates in the AGR2 filter for m = 20 with computed using
ensemble members for time step length t0 (horizontal axis).
4 AGR filters
In order to utilize the mean Equation(3.30)(3.30)
(3.30) and covariance Equation(3.34)
(3.34)
(3.34) updates, we develop an algorithm in the same vein as the ensemble square root filters (Whitaker and Hamill, Citation2002), i.e. we will update Sm keeping Pb in factored form. To begin with we note that after some algebraic manipulation and dropping Q, we may rewrite Equation(3.34)
(3.34)
(3.34) as
(4.1)
(4.1)
where
and
are computed using the centered differencing scheme
(4.2)
(4.2)
and we approximate bi via
(4.3)
(4.3)
The above equations are the same as Equation(3.25) and (3.26)(3.26)
(3.26) but with the truncated S = Sm. Letting
where
is the Moore-Penrose pseudo inverse, and using Equation(4.1)
(4.1)
(4.1) , then
where
(4.4)
(4.4)
Note that so the expression in Equation(4.4)
(4.4)
(4.4) may not be overly expensive to compute. To form the filter, we use the Potter method (Potter, Citation1963) for the Kalman square root update in reduced order form. This will improve the numerical robustness by ensuring
is symmetric and reducing the amount of storage required by the AGR filter by only storing the square root S. To form the filter, let
(4.5)
(4.5)
then
(4.6)
(4.6)
Thus,
Letting then we update S by
where
is a tunable parameter. We have chosen to form a regularized S which will help with the conditioning of the matrix and decrease dispersion. Other inflation methods such as multiplicative covariance inflation may also be used. To summarize, the algorithm for the AGR2 filter is as follows:
Given
Compute
Let
where
and
Decompose η such that
The algorithm itself is readily implemented and requires minimal tuning of the parameter d from EquationEquations (4.2)(4.2)
(4.2) and Equation(4.3)
(4.3)
(4.3) . For quasi-linear systems, the second-order correction term b may be dropped giving the AGR1 filter. In this case, we may further reduce computational cost by using finite differencing instead of centered differencing. Then to evaluate Equation(3.30) and (3.34)
(3.34)
(3.34) , we use the finite differencing scheme to approximate the
i.e.,
(4.7)
(4.7)
after the coordinate change where d > 0 is the step size. The benefit of computing ai in this manner is that this only requires m + 1 model evaluations. Note that the expression Equation(4.7)
(4.7)
(4.7) amounts to a directional derivative determined by the truncated S. In using S the derivative is computed in the direction of the largest change in the dynamics. Meanwhile, the parameter d restricts the search direction to a constrained set. This is a generalization of the standard derivative, in fact it is a numerical approximation of the Jacobian under a coordinate transformation. In this way, the AGR1 may be viewed as a form of an extended Kalman filter.
5. Data assimilation
In this section, we present data assimilation comparisons between the AGR2 filter, described in the previous section, and the ensemble square root filter (Tippett et al., Citation2003) as the example EnKF method. We use this particular filter as the correction step as it is most similar to the AGR filter while having an ensemble estimate for the mean and covariance.
5.1. 1 D Example
We return to the KdV model given by Equation(3.35)(3.35)
(3.35) . As before we will use k = 40 ensemble members drawn from the 35,000 member ensemble for the EnKF and the AGR2 filter with m = 20. This time the initial
for the AGR2 filter will be the mean of the k = 40 EnKF ensemble. Both the EnKF and AGR2 filter will use the same 32 observations at assimilation time. We use localization and multiplicative inflation wherein the correlation length scale used in the localization and the inflation factor were tuned so that the ensemble variance correspond to the true error variance. We again consider different values of t0, the time the model is integrated forward before assimilation, to see how increasing the nonlinearity affects these two filtering algorithms. To reduce the influence of the initial conditions, we will only consider assimilation cycles 200–450.
is a plot of the average error across a data assimilation window for various t0. For smaller t0 the model integration is less nonlinear and we can see that the AGR2 filter has about 30% less error than the EnKF. As t0 gets larger, the model integration is more nonlinear and the error in the solution of the AGR2 grows more rapidly than the EnKF and by or 20001 model time steps the AGR2 error is about 24% less than the EnKF.
Fig. 8. The L2 error (vertical axis) averaged over the assimilation window for increasing t0 (horizontal axis), the time between cycles, for the EnKF and the AGR2 filter.
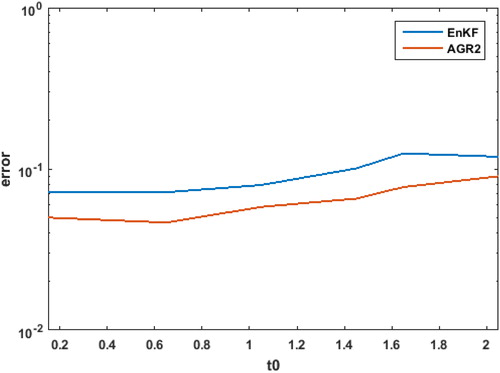
This cycling experiment result demonstrates that the improvement in the predicted mean and covariance estimates seen in leads to an improvement in the data assimilation state estimation or analysis. Also it demonstrates that increasing the nonlinearity has more of an impact on the quality of the AGR2 solution versus the EnKF solution.
5.2. 2 D Example
We will now investigate the performance of the proposed AGR filter using a two-dimensional Boussinesq model that develops Kelvin-Helmhotz waves, specifically, we use the model developed in (Hodyss et al., Citation2013). The governing equations given by
(5.1)
(5.1)
where
is the Laplacian operator, u and w are zonal and vertical winds, respectively, θ is the potential temperature, and ζ is the vorticity. The vorticity source F and the heat source H both have sub-grid scale parameterizations, more details may be found in Hodyss et al. (Citation2013). The buoyancy frequency of the reference state
is given by the background potential temperature:
And
is the reference state for the zonal wind with
μ = 8, L = 1 km, and
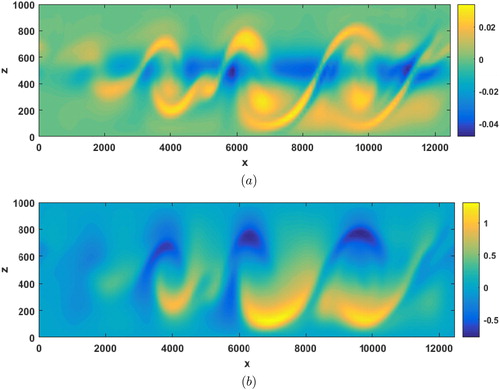
km. The z boundary conditions are a mirrored forcing the vertical velocity to vanish. Additionally, there are sponge boundaries along the left and right sides of the channel. At time t = 0, the flow is perturbed leading to waves that amplify as they travel then break. For this experiment, the model was run with 128 computational nodes in the x direction and 33 nodes (unmirrored) in the z direction. All told the state vector has 8448 elements. The true solution at the end of the assimilation window may be seen in for (a) the vorticity and (b) the temperature. As the waves move across the atmospheric slice, they grow and eventually shear.
Fig. 9. The true solution of (5.1) at time t = 15000, or 200 cycles of 75 seconds, for (a) vorticity and (b) temperature. The vertical axis is the height and the horizontal axis is the distance.
During the assimilation window, the model is advanced, then the filtering is performed with 112 temperature and 112 wind observations. The observations are created by perturbing the truth via
(5.2)
(5.2)
where R is the instrument error covariance and ξ is white noise. For this experiment,
for both the temperature and wind. A 24,000 member ensemble was created by cycling random perturbations through the model. The smaller k = 20 and k = 40 ensembles were drawn from this 24,000 member ensemble and which was also used to create
for the AGR filter. We initialize the
used in the AGR filter with the mean of the k = 20 ensemble for the EnKF. Both the EnKF with k = 20, 40 and the AGR2 filter will use the same observations for a particular t0. Again both types of filters are using localization and inflation tuned to so that the ensemble variance matches the true error variance. We will compute the error averaged over assimilation cycles 100–400 to reduce the influence of the initial conditions.
The error in the mean estimation plots in demonstrate similar results to the one-dimensional KdV example. For the more linear case the AGR2 filter significantly outperforms the EnKF. As t0 is increased, the nonlinearity increases and the AGR2 filter loses its performance advantage over the EnKF until around
As before, the increased nonlinearity has a greater impact on the performance of the AGR2 filter as opposed to the EnKF.
Fig. 10. The averaged L2 error (vertical axis) across the data assimilation window in the mean estimates for particular t0 (horizontal axis) for (a) vorticity and (b) temperature.
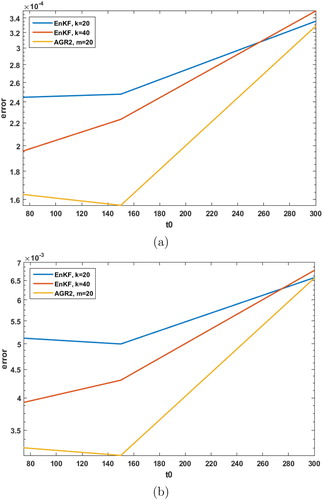
We have presented two example problems comparing the AGR filter and the EnKF. The first example was a one-dimensional KdV model in which the AGR filter outperformed the EnKF but was more influenced by nonlinearity. In the second example, a two-dimensional Boussinesq model was considered. In this case, starting with the AGR filter out performed the EnKF. When
the error in the mean estimation has more than doubled and the performance between the AGR filter and the EnKF are comparable. Again we see that the AGR filter is more affected by the nonlinearity in the model than the EnKF.
6. Final remarks
We have presented a quadrature Kalman filter, the AGR filter, for moderately nonlinear systems. The filter uses numerical quadrature to evaluate the Bayesian formulas for optimal filtering under Gaussian assumptions. The AGR filter has the Gaussian noise assumptions and Gaussian joint distribution assumption from Kalman filtering with the added assumption that the prior distribution is Gaussian. This leads to Gaussian integrals which are evaluated using the second-order polynomial quadrature. Due to the properties of Gaussian distributions, using this polynomial achieves the same precision as a third-order polynomial quadrature. This effective higher order quadrature is key to the success of this filter.
In numerical tests, the AGR filter was found to outperform a comparable square-root EnKF in regions of low-to-moderate nonlinearity for a KdV model and a Boussinesq model. We expect these results to extend to more realistic atmospheric models, given that fourth and higher order terms of the model are sufficiently small. For highly nonlinear dynamical systems, the AGR filter is affected more than the square-root EnKF but may still provide performance benefit if the system is severely under-sampled as demonstrated in the scalar example in Section 3.4. It is also possible to use higher order quadrature to reduce the effect of nonlinearity but this would, of course, increase the computational costs of the filter.
While the Gaussian assumption made in this filter may seem restrictive, this assumption is commonly made, or effectively made, in data assimilation. For example, recent results indicate that it may require an ensemble with on the order of one thousand members to capture non-Gaussianity pdfs present in an EnKF for a simplified general circulation model (Miyoshi et al., 2014). This is already significantly more than the O(100) ensemble members typically used in EnKFs for full complexity atmospheric models. Effectively, a Gaussian assumption is being made due to the sample size. The computational efficiency of the AGR filter means that there is greater opportunity to pursue non-Gaussian pdfs via Gaussian mixture models (GMMs). In GMMs a non-Gaussian distribution is approximated by a series of Gaussian distributions which, in this case, would lead to an optimally weighted ensemble of AGR filters.
A. Formulas
A.1. Expectation formulas
Consider the expectation
(A.1)
(A.1)
(A.2)
(A.2)
(A.3)
(A.3)
where is the expectation. Note that Equation(A.2)
(A.2)
(A.2) follows from Equation(2.1)
(2.1)
(2.1) and Fubini’s theorem and Equation(2.7)
(2.7)
(2.7) follows from Equation(2.3)
(2.3)
(2.3) and wt being Gaussian. Similarly, the predicted covariance is given by
(A.4)
(A.4)
(A.5)
(A.5)
(A.6)
(A.6)
A.2. Covariance
The cross covariance in Equation(2.13)(2.13)
(2.13) is computed via
(A.7)
(A.7)
(A.8)
(A.8)
(A.9)
(A.9)
(A.10)
(A.10)
(A.11)
(A.11)
(A.12)
(A.12)
B. Qquadrature error
B.1. Scalar quadrature error
The quadrature error in evaluating the integrals Equation(2.18) and (2.19)(2.19)
(2.19) comes from the low-order polynomial approximation Equation(3.2)
(3.2)
(3.2) . Consider the estimation error of Equation(3.6)
(3.6)
(3.6) given by
(B.1)
(B.1)
(B.2)
(B.2)
(B.3)
(B.3)
where
are the third and fourth derivatives, respectively, of f. Similarly, the quadrature error for Equation(3.9)
(3.9)
(3.9) is given by
(B.4)
(B.4)
(B.5)
(B.5)
(B.6)
(B.6)
B.2. N-d quadrature error
The estimation error of Equation(3.30) and (3.34)(3.34)
(3.34) is given by
(B.7)
(B.7)
(B.8)
(B.8)
and
(B.9)
(B.9)
(B.10)
(B.10)
(B.11)
(B.11)
where
Note that the error on the mean does not depend on the cross terms in the Jacobian.
Acknowledgments
The authors would like to express their gratitude to Dr Nancy Baker from the U.S. Naval Research Laboratory for her insights and discussions that have greatly improved this manuscript. This research is supported by the Office of Naval Research (ONR) through the NRL Base Program PE 0601153N.
References
- Anderson, J. L. 2001. An ensemble adjustment filter for data assimilation. Mon. Wea. Rev. 129, 2884–2903. doi:10.1175/1520-0493(2001)129<2884:AEAKFF>2.0.CO;2
- Arasaratnam, I. and Haykin, S. 2009. Cubature Kalman filters. IEEE Trans. Automat. Contr. 54, 1254–1269. doi:10.1109/TAC.2009.2019800
- Bishop, C. H., Etherton, B. and Majumdar, S. J. 2001. Adaptive sampling with the ensemble transform Kalman filter, Part I: theoretical aspects. Mon. Wea. Rev. 129, 420–1167. doi:10.1175/1520-0493(2001)129<0420:ASWTET>2.0.CO;2
- Buehner, M., Houtekamer, P. L., Charette, C., Mitchell, H. L. and He, B. 2010. Intercomparison of variational data assimilation and the ensemble Kalman filter for global deterministic NWP. Part II: one-month experiments with real observations. Mon. Wea. Rev. 138, 1567–1586. doi:10.1175/2009MWR3158.1
- Chen, Z. 2003. Bayesian Filtering: From Kalman Filters to Particle Filters, and Beyond. Tech. Rep. Hamilton, Canada: McMaster University.
- Clayton,A. M., Lorenc, A. C. and Barker, D. M. 2013. Operational implementation of a hybrid ensemble/4D-Var global data assimilation system at the Met Office. Qjr. Meteorol. Soc. 139, 1445–1461. doi:10.1002/qj.2054
- Courtier, P., Andersson, E., Heckley, W., Pailleux, J., Vasiljevic̀, D. and co-authors. 1998. The ECMWF implementation of three-dimensional variational assimilation (3D-Var). I: formulation. Q. Q. J. Royal Met. Soc. 124, 1783–1807.
- Daley, R. 1991.Atmospheric Data Analysis. Cambridge University Press, New York.
- Derber, J. and Bouttier, F. 1999. A reformulation of the background error covariance in the ECMWF global data assimilation system. Tellus A 51, 195–221. doi:10.3402/tellusa.v51i2.12316
- Evensen, G. 2003. The ensemble Kalman filter: theoretical formulation and practical implementation. Ocean Dynamics 53, 343–367. doi:10.1007/s10236-003-0036-9
- Haykin, S., Zia, A., Xue, Y. and Arasaratnam, I. 2011. Control theoretic approach to tracking radar: first step towards cognition. Digit. Signal Process. 21, 576–585. doi:10.1016/j.dsp.2011.01.004
- Ho, Y. C. and Lee, R. C. K. 1964. A Bayesian approach to problems in stochastic estimation and control. IEEE Trans. Automat. Control 9, 333–339. doi:10.1109/TAC.1964.1105763
- Hodyss, D., Campbell, W. F. and Whitaker, J. S. 2016. Observation-dependent posterior inflation for the ensemble Kalman Filter. Mon. Wea. Rev. 144, 2667–2684. doi:10.1175/MWR-D-15-0329.1
- Hodyss, D. and Nathan, T. 2002. Solitary Rossby waves in zonally varying jet flows. Physica D96, 239–262.
- Hodyss, D., Viner, K., Reinecke, A. and Hansen, J. 2013. The impact of noisy physics on the stability and accuracy of physics-dynamics coupling. Mon. Wea. Rev. 144, 4470–4486.
- Houtekamer, P. L., Deng, X., Mitchell, H. L., Baek, S. J. and Gagnon, N. 2014. Higher resolution in operational ensemble Kalman Filter. Mon. Wea. Rev. 142, 1143–1162. doi:10.1175/MWR-D-13-00138.1
- Ito, K. and Xiong, K. 2000. Gaussian filters for nonlinear filtering problems. IEEE Trans. Automat. Control 45, 910–927. doi:10.1109/9.855552
- Julier, S., Uhlmann, J. and Durrant-Whyte, H. F. 2000. A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Trans. Automat. Contr. 45, 477–482. doi:10.1109/9.847726
- King, S., Kang, W. and Ito, K. 2016. Reduced order Gaussian smoothing for nonlinear data assimilation. IFAC-Papers OnLine 49, 199–204. doi:10.1016/j.ifacol.2016.10.163
- Kalman, R. E. 1960. A new approach to linear filtering and prediction problems. Trans. ASME, J. Basic Eng. 82, 35–45. doi:10.1115/1.3662552
- Kuhl, D. D., Rosmond, T. E., Bishop, C. H., McLay, J. and Baker, N. L. 2013. Comparison of hybrid ensemble/4DVar and 4DVar within the NAVDAS-AR data assimilation framework. Mon. Wea. Rev. 141, 2740–2758. doi:10.1175/MWR-D-12-00182.1
- Liu, J., Cai, B. and Wang, J. 2017. Cooperative localization of connected vehicles: integrating GNSS with DSRC using a robust cubature Kalman filter. IEEE Trans. Intell. Transport. Syst. 18, 2111–2125. doi:10.1109/TITS.2016.2633999
- Morzfeld, M. and Hodyss, D. 2019. Gaussian approximations in filters and smoothers for data assimilation. Tellus A 71, 1–27.
- Miyoshi, T., Kondo, K. and Imamura, T. 2014. The 10,240-member ensemble Kalman filtering with an intermediate AGCM. Geophys. Res. Lett. 41, 5264–5271. doi:10.1002/2014GL060863
- Poterjoy, J. 2016. A localized particle filter for high-dimensional nonilnear systems. Mon. Wea. Rev. 144, 59–76. doi:10.1175/MWR-D-15-0163.1
- Potter, J. E. 1963. New Statistical Formulas. Space Guidance Analysis Memo 40, Instrumentation Laboratory, MIT, Cambridge, MA.
- Särkkä, S. 2013. Bayesian Filtering and Smoothing. Cambridge University Press, Cambridge.
- Sharma, A., Srivastava, S. C. and Chakrabarti, S. 2017. A cubature Kalman filter based power system dynamic stat estimator. IEEE Trans. Instrum. Meas. 66, 2036–2045. doi:10.1109/TIM.2017.2677698
- Sondergaard, T. and Lermusiaux, P. F. J. 2013. Data assimilation with Gaussian mixture models using the dynamically orthogonal field equations. Part I: theory and scheme. Mon. Wea. Rev. 141, 1737–1760. doi:10.1175/MWR-D-11-00295.1
- Talagrand, O. and Courtier, P. 1987. Variational assimilation of meteorological observations with the adjoint vorticity equation I: theory.Qjr. Meteorol. Soc.116, 1311–1328.
- Tippett, M. K., Anderson, J. L., Bishop, C. H., Hamill, T. M. and Whitaker, J. S. 2003. Ensemble square root filters. Mon. Wea. Rev. 131, 1485–1490. doi:10.1175/1520-0493(2003)131<1485:ESRF>2.0.CO;2
- Whitaker, J. S. and Hamill, T. M. 2002. Ensemble data assimilation without perturbed observations. Mon. Wea. Rev. 130, 1913–1924. doi:10.1175/1520-0493(2002)130<1913:EDAWPO>2.0.CO;2
- Wu, Y., Hu, D., Wu, M. and Hu, X. 2006. A Numerical-integration perspective on Gaussian filters. IEEE Trans. Signal Process. 54, 2910–2921. doi:10.1109/TSP.2006.875389