
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Data assimilation combines observations with numerical model data, to provide a best estimate of a real system. Errors due to unresolved scales arise when there is a spatio-temporal scale mismatch between the processes resolved by the observations and model. We present theory on error, uncertainty and bias due to unresolved scales for situations where observations contain information on smaller scales than can be represented by the numerical model. The Schmidt-Kalman filter, which accounts for the uncertainties in the unrepresented processes, is investigated and compared with an optimal Kalman filter that treats all scales, and a suboptimal Kalman filter that accounts for the large-scales only. The equation governing true analysis uncertainty is reformulated to include representation uncertainty for each filter. We apply the filters to a random walk model with one variable for large-scale processes and one variable for small-scale processes. Our new results show that the Schmidt-Kalman filter has the largest benefit over a suboptimal filter in regimes of high representation uncertainty and low instrument uncertainty but performs worse than the optimal filter. Furthermore, we review existing theory showing that errors due to unresolved scales often result in representation error bias. We derive a novel bias-correcting form of the Schmidt-Kalman filter and apply it to the random walk model with biased observations. We show that the bias-correcting Schmidt-Kalman filter successfully compensates for representation error biases. Indeed, it is more important to treat an observation bias than an unbiased error due to unresolved scales.
1. Introduction
In atmospheric data assimilation, observations are combined with numerical model data, weighted by their respective error statistics, to provide a best estimate of the current atmospheric state, known as the analysis. This is achieved through comparison of observations with the numerical model equivalent of those observations. The errors associated with the observation-model comparison are the instrument error and representation error (Janjić et al., Citation2018). The representation error consists of the pre-processing error, the observation operator error and the error due to unresolved scales that occurs when there is a mismatch between the numerical model resolution and the scales resolved by the observation. The error due to unresolved scales depends on the observation footprint, which could be smaller or larger than the model grid, depending on the observation type and choice of model. For models which contain information on scales smaller than those observed, the standard approach to account for scale-mismatch would be to average the model state over the observation area (Janjić et al., Citation2018). However, for the purposes of this paper, we focus only on situations where the observation information content includes smaller scales than can be resolved by the model. In order to obtain the best analysis from these observations the representation error must be treated correctly by the data assimilation system.
Methods of accounting for uncertainty due to unresolved scales include, for example, prediction through ensemble statistics (Karspeck, Citation2016; Satterfield et al., Citation2017) and the use of a stochastic superparameterization (Grooms et al., Citation2014). In this manuscript we will consider two approaches: the standard approach where the uncertainty due to unresolved scales is included in the observation error covariance matrix (e.g. Hodyss and Satterfield, Citation2016; Fielding and Stiller, Citation2019) and an alternative approach where unresolved processes are considered in state space and hence accounted for through the state error covariance (Janjić and Cohn, Citation2006).
Compensating for representation error through the standard approach involves using an observation error covariance matrix that takes into account both the instrument and representation uncertainty. This can then be used within a standard variational or sequential data assimilation scheme. Estimates of the observation uncertainty may be obtained using a statistical method, to estimate the entire observation error covariance matrix (e.g. Desroziers et al., Citation2005; Stewart et al., Citation2014; Waller et al., Citation2016a, Citation2016b; Cordoba et al., Citation2017). Alternatively each component of the representation error statistics can be estimated separately and then combined with the instrument error covariance. For example the error due to unresolved scales may be approximated using high resolution observations (Oke and Sakov, Citation2008) or high resolution model data (Daley, Citation1993; Liu and Rabier, Citation2002; Waller et al., Citation2014; Schutgens et al., Citation2016).
The Schmidt-Kalman filter (SKF) (Schmidt, Citation1966) is an example of a filter which uses the statistics of the unresolved processes in state space, without ever evaluating the unresolved state itself, to compensate for the error due to unresolved scales. This approach allows for consideration of flow-dependent correlations between the resolved errors and the unresolved processes at the cost of additional assumptions, approximations and increased computational expense. Janjić and Cohn (Citation2006) have shown that the SKF can produce positive results despite the approximations and assumptions required for implementation in a geophysical context. In this paper we provide new results that determine in which observation and model uncertainty regimes the SKF performs best. In addition we compare the SKF to two other Kalman filtering approaches.
The SKF is deemed a suboptimal filter as it does not minimise the mean-square-error of its estimated states (Janjić and Cohn, Citation2006). In contrast, the Kalman filter that treats all scales is deemed optimal (for linear models and Gaussian statistics) (Nichols, Citation2010). In practice, suboptimal filters that do not treat all scales are often used. The analysis error covariances propagated by suboptimal filters are not representative of the true error statistics due to omitted or incorrectly specified filter components. As such, the true analysis error equations have been derived to evaluate the performance of suboptimal filters (e.g. Brown and Sage, Citation1971; Asher and Reeves, Citation1975; Asher et al., Citation1976). In this article we reformulate previous theory on true analysis error equations to include representation error (section 4) and evaluate the performance of the SKF.
A further issue noted by Janjić and Cohn (Citation2006) is the potential for the representation error to be biased. This is because the error due to unresolved scales is sequentially correlated in time and correlated with the state resolved by the model. Other authors have circumvented this bias by careful construction of their numerical model (Janjić and Cohn, Citation2006). However, in operational data assimilation, most observations are biased and the innovations need to be corrected or the bias accounted for within the assimilation (Dee, Citation2005). Bias correction can be incorporated into the data assimilation algorithm by augmenting the state vector with a bias term (Friedland, Citation1969; Jazwinski, Citation1970; Ignagni, Citation1981) which can be estimated along with the state variables. This method of bias correction is commonly used with variational data assimilation systems (e.g. Derber and Wu, Citation1998; Dee, Citation2004; Zhu et al., Citation2014; Eyre, Citation2016) but has also been applied with ensemble data assimilation systems (e.g. Fertig et al., Citation2009; Miyoshi et al., Citation2010; Aravéquia et al., Citation2011). To the best of our knowledge a bias correction scheme has yet to be implemented in conjunction with the SKF; in section 7 we introduce a bias-correcting SKF as a new method to compensate for biases due to unresolved scales.
In summary, the objective of this paper is to investigate under which model and observation error regimes the SKF is most effective. The theoretical aspects of representation error will be reviewed in section 2 with particular emphasis on the error due to unresolved scales. Section 3 details how the SKF can be used to account for error due to unresolved scales and introduces the optimal Kalman filter (OKF) and a reduced-state Kalman filter (RKF). In section 4 we state the standard true analysis error equation and reformulate it to include representation error for each filter.
To evaluate the performance of the SKF in a numerical example we use a Gaussian random walk model. The numerical experiment methodology and model formulation are described in section 5 and results are presented in section 6. Our results show that the SKF provides the largest improvement in performance compared with the RKF when there is large error variance due to unresolved scales and small instrument error variance. In section 7 we discuss observation bias correction schemes in sequential data assimilation and introduce a novel SKF with bias correction scheme. The methodology and model formulation for the numerical experiments with biased observations is discussed in section 8 and results are presented in section 9. Our results show the SKF with bias correction can simultaneously treat observation biases and compensate for the error due to unresolved scales. We summarise and draw conclusions from our results in section 10.
2. Theoretical framework
In this section we introduce a theoretical framework and the notation used in this paper. We begin by describing a numerical model (section 2.1) and observations (section 2.2). In data assimilation, the error statistics used in filters may not reflect the true uncertainties they are intended to model. To help distinguish between these two sets of statistics throughout this manuscript we will define any true error statistics with a tilde (∼). Error statistics used in or obtained from filter calculations will be referred to as perceived error statistics and have no tilde.
The mathematical framework used to examine the error due to unresolved scales in this manuscript is to estimate the projection of some state from a high, but finite dimensional real vector space, onto a lower dimensional subspace using observations and knowledge of the system dynamics, following a similar philosophy to Liu and Rabier (Citation2002) and Waller et al. (Citation2014). Our approach differs from that of Janjić and Cohn (Citation2006) which begins from the standpoint of infinite dimensional function spaces.
2.1. Model configuration
In this section we introduce the perfect and forecast models. We assume that the phase-space for the large-scale dynamics is a subspace of the phase-space for the full high dimensional system. The complement of the subspace for the large-scales will correspond to the phase-space for the small-scale dynamics. The notation for the models will be in a partitioned form that separates the large and small scales. In particular, we denote the true, complete state at time tk as such that
and
Here, and throughout this paper, any component with a t-superscript indicates that it is a true variable. The l- and s-superscripts correspond to the large- and small-scale processes within the complete system dynamics. (We have deviated from the resolved/unresolved nomenclature of Janjic and Cohn 2006 for clarity, since the different filters used in our experiments resolve different scales).
An ideal linear model for the true state of a finite dimensional process can be expressed through the dynamical system
(2.1)
(2.1)
such that the matrix blocks
and
From a numerical modelling perspective, this partitioned description of the dynamics would be suited to a pseudospectral discretization (e.g. Fourier modes).
In numerical weather prediction (NWP), the true models that govern the evolution of the atmosphere are unknown and have to be approximated. For our approximation of the true dynamical system Equation(2.1)(2.1)
(2.1) , we assume that any subgrid-scale parameterizations used to approximate the contribution from the small-scale processes to the large-scale state are contained within the large-scale model (Janjić and Cohn, Citation2006; Janjić et al., Citation2018). Hence, the model block
and our approximate dynamical model describing the complete system satisfies
(2.2)
(2.2)
In Equation(2.2)(2.2)
(2.2) each model block has the same dimensions as its true model counterpart. The large- and small-scale model errors are given by
and
respectively. Model errors are assumed to be random and unbiased with covariance given by
(2.3)
(2.3)
Here, using to indicate the mathematical expectation over the corresponding error distribution, the matrices
and
(with
) are the true model error covariances of the large-scale, the small-scale and cross-covariances between the large- and small-scale, respectively. We note that for the purposes of this work, the model error distribution is assumed to be stationary, so that
is not a function of time.
Analogously, the complete forecast state satisfies
(2.4)
(2.4)
The forecast errors can then be defined as
(2.5)
(2.5)
where
and
are the large- and small-scale forecast errors respectively. The true forecast error covariance is denoted
(2.6)
(2.6)
Here, and
(with
) are the true forecast error covariances of the large-scale, the small-scale and cross-covariances between the large- and small-scale, respectively.
This formulation of the complete finite-dimensional dynamics allows us to consider several filters with different approaches to the treatment of large- and small-scales. Moreover, we can consider the interactions between scales and the effect they have on the modelling of observations.
2.2. Observations and their uncertainties
In this section we express the equations relating the observations, to the model state in a partitioned form and describe their uncertainties. For the rest of this section, we assume that the model state and observations are valid at the same time, and drop the time subscript, k. At time tk, the observations are related to the true model state as
(2.7)
(2.7)
where
is the instrument error, assumed to be random and unbiased with covariance
and
and
are the true linear observation operators which map the large- and small-scale states into observation space respectively. The observation operator
is the (linear) finite-dimensional counterpart to the continuum observation operator of Janjić and Cohn (Citation2006). We will not consider nonlinear observation operators in the remainder of this paper.
Throughout this paper, we assume that there is no pre-processing error. Hence, we will be concerned with the two cases described in sections 2.2.1 (all scales analysed) and 2.2.2 (large scales analysed) below. Case 1 shows the form of the representation error for filters that resolve all scales and is pertinent to the theoretical optimal Kalman filter discussed in section 3.2. Case 2 shows the form of the representation error for filters typically used in operational practice and is pertinent to the reduced-state Kalman filter and the Schmidt-Kalman filter discussed in sections 3.3 and 3.4 respectively.
2.2.1. Case 1: All scales analysed
In this case we assume that both the large- and small-scale states are estimated. The total observation error (observation departure from the true state), can be expressed as
(2.8)
(2.8)
where
and
are the blocks of the observation operator used by the filter, acting on the large- and small-scale state components, respectively. Using Equation(2.7)
(2.7)
(2.7) , we rewrite
as
(2.9)
(2.9)
where
is the large-scale observation operator error and
is the small-scale observation operator error. Thus, the representation error for this case consists solely of observation operator error,
The observation operator errors,
and
will each be assumed to be unbiased, so that in this case, the representation error is also unbiased. The representation error covariance for this case will be denoted by
The total observation error covariance is given by
where we have assumed that the representation error and instrument error are mutually uncorrelated.
2.2.2. Case 2: Large scales analysed
In this case, we assume that only the large-scale state is estimated such that
(2.10)
(2.10)
where the observation operator used consists only of the block acting on the large-scales. The decomposition of
can be obtained by setting
in Equation(2.9)
(2.9)
(2.9) :
(2.11)
(2.11)
The filter observation operator does not act on the small scales, so the term is replaced by
the error due to unresolved scales. The representation error for Case 2 is thus
with covariance
EquationEquations (2.10)
(2.10)
(2.10) and Equation(2.11)
(2.11)
(2.11) are analogous to equation (1) in Janjić et al. (Citation2018) with the pre-processing error omitted. The complete observation error covariance for Case 2 is given by
where we have assumed that the representation error and instrument error are mutually uncorrelated. As in Case 1,
is assumed to be unbiased. However, we will see in section 2.3 that the expected value of
is likely to be non-zero.
2.3. Bias due to unresolved scales
Analysing only the large-scales will result in an error due to unresolved scales (section 2.2.2) that is sequentially correlated in time and correlated with the resolved state, leading to a potential bias (Janjić and Cohn, Citation2006). Assuming that the large-scale observation operator is unbiased, taking the expectation of the error due to unresolved scales, Equation(2.11)(2.11)
(2.11) , (and reintroducing the time subscript k) results in
(2.12)
(2.12)
where
denotes the mathematical expectation over the distribution of representation errors at time k. Using dynamical system Equation(2.1)
(2.1)
(2.1) , repeated substitution for the equation governing
into the expected error due to unresolved scales yields
(2.13)
(2.13)
Here the underlined terms represent the contribution from the large scales. For many non-trivial models, these terms will not be identically zero, and potentially introduce a bias even if the initial value for the small-scale state is zero, For example, Janjić and Cohn (Citation2006) solved a model of non-divergent linear advection on a sphere using a truncated expansion in spherical harmonics. Introducing a shear flow results in a dynamical system where the unresolved small-scales do not directly influence the resolved large-scales, but the large-scales influence the small-scales. This yields an error and bias due to unresolved scales. Janjić and Cohn (Citation2006) were able to mitigate the bias using specific initial conditions. However, this experimental freedom would not be available in less-idealized situations. Therefore, when accounting for the unresolved scales in data assimilation we must also determine and treat any bias arising. In the new results in sections 5-6 below, we carefully construct our model to avoid bias due to unresolved scales. However, we revisit this problem in sections 7-9 where we use filters with bias-correction schemes.
3. Sequential linear filters and representation uncertainty
In this section we describe the general linear filtering framework that we use for data assimilation in our theoretical investigations and numerical experiments. We consider three filters in more detail: an optimal Kalman filter (OKF) that takes account of all scales; a reduced-state Kalman filter (RKF) that disregards the small-scales; and the Schmidt-Kalman filter (SKF) that provides analyses of the large-scale state through consideration of both the large- and small-scale uncertainties.
3.1. A linear filter
A linear filter algorithm can be divided into analysis update and model prediction steps. The general form of the analysis update at time tk, is given by
(3.1)
(3.1)
where
is the analysis (state estimate),
is the forecast state,
is the gain matrix and
is the innovation, defined as the observation-minus-forecast departure. In this general setting we have not defined the dimensions of the vectors and matrices in Equation(3.1)
(3.1)
(3.1) , as this will depend on the specific choice of filter. For example, the state x in Equationequation (3.1)
(3.1)
(3.1) could be either the complete state
or just the large-scale state
There are various approaches to determine the gain matrix which will be discussed in sections 3.2, 3.3 and 3.4.
The perceived analysis error covariance update calcluated by the filter at time tk is given by
(3.2)
(3.2)
where I is the identity matrix,
is the observation operator and
is the perceived forecast error covariance. EquationEquation (3.2)
(3.2)
(3.2) is known as the short form of the analysis error covariance update. This equation only provides the correct estimate of the analysis error covariance if the background and observation error statistics used in the filter reflect the true error statistics. The use of a suboptimal gain and the short form update Equationequation (3.2)
(3.2)
(3.2) will result in the filter producing incorrect error statistics. The true error statistics will be derived in section 4.
For the model prediction step, the forecast state at time is evolved from the analysis at the previous time-step and is given by
(3.3)
(3.3)
where M is a linear model. A model error term is not included in the forecast state update as linear filters estimate the mean state and we have assumed that the model error is unbiased. However, the error in the model M is accounted for in the forecast error covariance update given by
(3.4)
(3.4)
which will be discussed further in section 4. We note that Equation(3.4)
(3.4)
(3.4) will only produce correct error statistics when
and Q are equal to their true statistics counterparts.
EquationEquations (3.1)(3.1)
(3.1) –Equation(3.4)
(3.4)
(3.4) form the core components of the linear filter algorithm. In the following sections we discuss three linear filters, each based on the Kalman filter (Kalman, Citation1960), that we will use in this paper. summarizes the key vectors and matrices used in these three Kalman filters.
Table 1. The filter matrices and vectors for the Optimal Kalman filter (OKF), reduced-state Kalman filter (RKF) and Schmidt Kalman filter (SKF). The equations for the three filters are obtained through substituting these terms into (3.1) - (3.4). As discussed in section 3.4, we note that while the SKF uses in the innovation only, the complete observation operator is used in the calculation of
and
3.2. The optimal kalman filter (OKF)
For the optimal Kalman filter (OKF), we assume that we are able to model the processes for all scales and know the correct error statistics for the initial state, observations and model. Therefore, the perceived error statistics for the OKF will be equivalent to the true error statistics. The OKF simultaneously updates the large- and small-scale states, and
so that the analysis update takes the form
(3.5)
(3.5)
cf. Equation(3.1)
(3.1)
(3.1) . The gain matrix for the OKF is partitioned into large- and small-scale components
and
respectively, and is given in . This is the optimal Kalman gain which minimises the trace of the analysis error covariance (e.g. Nichols, Citation2010). The analysis error covariance update is calculated using Equation(3.2)
(3.2)
(3.2) with state error covariances with the same block structure as the forecast error covariance Equation(2.6)
(2.6)
(2.6) .
As the OKF filters all scales, the total observation error is described by Case 1 (all scales analysed, section 2.2.1). Hence, the observation error covariance for the OKF is
For the OKF forecast step we use the matrix
(3.6)
(3.6)
as our forecast model in Equation(3.3)
(3.3)
(3.3) and the partitioned model error covariance given in in the forecast error covariance prediction Equation(3.4)
(3.4)
(3.4) .
In summary, the analysis and forecast updates for the OKF state and covariance are a partitioned form of Equation(3.1)(3.1)
(3.1) - Equation(3.4)
(3.4)
(3.4) . By treating all scales in the assimilation the OKF has no error due to unresolved scales in the associated observation equation. However, due to computational constraints and inadequate knowledge of small-scale processes it is not possible to apply this technique in practice. Hence, methods that approximate the influence of small-scale processes must be employed instead.
3.3. The reduced-state kalman filter (RKF)
The suboptimal Kalman filter which estimates only the large-scale state and completely neglects the modelling of small-scale processes will be referred to as the reduced-state Kalman filter (RKF).
The analysis and forecast update equations for the RKF are simply the linear filter Equationequations (3.1)-(3.4) where, as described in , we use the large-scale state, error covariances and observation operator. Thus, the forecast innovation is
(3.7)
(3.7)
where the second inequality can be established by adding and subtracting the term
Assuming each error has zero-mean, taking the expectation of the outer product of Equation(3.7)
(3.7)
(3.7) yields the true innovation covariance (i.e. all contributing error covariances are true error statistics). However, the innovation covariance used by the RKF is given by
(3.8)
(3.8)
where the large-scale forecast error covariance, instrument error covariance and representation error covariance are perceived error statistics. The influence of any small-scale processes is now accounted for through the representation error covariance
which needs to be approximated.
Reduced-state methods form an attractive approach in situations where computational expense is an important consideration. However, it is necessary to approximate the representation error covariance, Hence, the Kalman gain for the RKF will not minimise the analysis error covariance and the filter will be suboptimal.
3.4. The Schmidt-Kalman filter (SKF)
The Schmidt-Kalman Filter (SKF) estimates only the large-scale state, but the statistics of any unmodelled processes are used to determine the Kalman gain for the filtered state (Schmidt, Citation1966; Janjić and Cohn, Citation2006). A summary of the relevant equations is included in .
As only the large-scale state is estimated the forecast innovation is computed using the large-scale state, and observation operator,
To determine the innovation covariance we start with the innovation Equation(3.7)
(3.7)
(3.7) and add and subtract the term
This allows us to write the innovation in the form
(3.9)
(3.9)
The innovation is now written in terms of the observation errors corresponding to case 1 (where all scales are analysed, see section 2.2.1), the large-scale forecast error mapped into observation space, and the term
the true small-scale state mapped into observation space. Assuming each error and
has zero mean, taking the expectation of the outer product of Equation(3.9)
(3.9)
(3.9) gives the true innovation covariance. The innovation covariance used by the SKF is given by
(3.10)
(3.10)
Here, we have abused our notation, to write as the perceived approximation of
such that
Using this notation for the cross-covariances of the SKF is common amongst other literature on the filter (e.g. Janjić and Cohn, Citation2006; Janjić et al., Citation2018). Following Janjić and Cohn (Citation2006), we employ a prescribed error covariance
as a time-independent approximation of
We note that as the small-scale error covariance is prescribed, the innovation covariance is an inexact approximation. The innovation covariance for the SKF is theoretically the same as the innovation covariance for the RKF Equation(3.8)
(3.8)
(3.8) but expressed in a different form that includes contributions from the small scale processes.
The analysis state update for the SKF is given by
(3.11)
(3.11)
where
is the Schmidt-Kalman large-scale gain. To obtain an analysis error covariance update equation we augment
with
and substitute into Equationequation (3.2)
(3.2)
(3.2) . This is justified as the unfiltered state is assumed to have a small magnitude. Large uncertainty in the small-scale state or a small magnitude observation operator for this state would also justify this assumption (Simon, Citation2006). As the short-form analysis error covariance update for the SKF is not symmetric, we calculate
and
through the short-form update only and set
Thus, the SKF analysis error covariance update equations are
(3.12)
(3.12)
(3.13)
(3.13)
(3.14)
(3.14)
We note that the term will usually be non-zero for the SKF. This term couples the large-scale uncertainty to the small-scale variability. If this term were zero, the large-scale state and uncertainty estimates produced by the RKF and SKF may still differ because of the differing innovation covariances between the filters.
The SKF treatment of the forecast step has a similar philosophy to the analysis step. The state prediction Equation(3.3)(3.3)
(3.3) is obtained through evolving the large-scale state
with the large-scale forecast model
(3.15)
(3.15)
The large-scale and cross-covariance blocks of the forecast error covariance are calculated using the complete forecast model and model error covariance in Equation(3.4)(3.4)
(3.4) . The SKF forecast error covariance update equations are
(3.16)
(3.16)
(3.17)
(3.17)
(3.18)
(3.18)
The prescribed small-scale error covariance is assumed constant in time and is not updated.
The appeal of the SKF is in its ability to compensate for small-scales without estimation of the small-scale state. Practical implementation of the SKF would require the filter to be adapted to nonlinear models. However, even for linear systems, the models evolving the small-scale processes would be unknown and their influence on the error covariances would need to be quantified. Additionally, the propagation of the state cross-covariances poses a considerable computational cost.
3.5. Discussion
The OKF, SKF and RKF represent three different approaches for dealing with observation uncertainty due to unresolved scales (see ). The OKF analyses all scales, thus avoiding the error due to unresolved scales altogether, while the RKF completely disregards the small-scale processes and accounts for the error due to unresolved scales through the representation error covariance matrix. The SKF, however, takes a compromise approach where only the large-scale state is estimated, but the uncertainty in all-scales is accounted for in the estimation. Additionally, the SKF accounts for the flow-dependence of the correlations between the large-scale errors and small-scale processes (albeit approximately) through the cross-covariances in the analysis and forecast error covariances given in Equationequations (3.13)(3.13)
(3.13) , Equation(3.14)
(3.14)
(3.14) , Equation(3.17)
(3.17)
(3.17) and Equation(3.18)
(3.18)
(3.18) . Applications where it is a poor approximation to neglect these cross-covariances will benefit the most from using the SKF (as opposed to the RKF where these cross-covariances are neglected).
4. True analysis error equations
A standard metric for assessing the quality of a data assimilation scheme is through examination of the magnitude of its analysis errors (e.g. Liu and Rabier, Citation2002). Under an unrealistic and restrictive set of conditions the Kalman filter is known to be optimal in a minimum mean-square-error sense and to produce the true error statistics describing its analysis and forecast (e.g. Todling and Cohn, Citation1994; Nichols, Citation2010). In contrast, both the SKF and RKF described in section 3 will incorrectly estimate the true analysis and forecast error covariances due to their treatment of the small-scales in the filter calculations. In this section we extend the existing literature on the true analysis error equations to include representation error so that we may evaluate the analysis obtained through the SKF and RKF.
To obtain the true analysis error equation for a linear filter we assume that we have exact knowledge of the truth and that both the true and filter models and observation operators are linear. Under this regime, the true analysis error at time tk has been derived by Moodey (Citation2013) and is given by
(4.1)
(4.1)
where
is the analysis error, ηk is the model error (see section 2.1),
is the total observation error which will be specified for different cases in subsections 4.1 − 4.2 and
and
are the Kalman gains and observation operators for the analysis state updates respectively. Therefore, the Kalman gain is calculated from the error statistics perceived by a filter. We assume that
and
each have zero-mean and are mutually uncorrelated. (We note that this assumption excludes a consideration of bias due to unresolved scales. However, this is considered further in section 7). Under these assumptions the true analysis error covariance is obtained through taking the expectation of the outer product of Equationequation (4.1)
(4.1)
(4.1) with itself to give
(4.2)
(4.2)
where
(4.3)
(4.3)
Here we remind the reader that we have used tildes to indicate true error covariances, to help distinguish these from the covariances perceived by the filters, which may be suboptimal. EquationEquation (4.2)(4.2)
(4.2) is known as the Joseph-formula (Gelb, Citation1974). The true analysis error covariance Equation(4.2)
(4.2)
(4.2) is valid for any gain matrix. The Joseph-formula is equivalent to the short form analysis error covariance Equation(3.2)
(3.2)
(3.2) for the optimal case (OKF) in exact arithmetic.
The true analysis error covariance can be calculated separately from the assimilation. In subsections 4.1 − 4.2 we use Equation(4.1)(4.1)
(4.1) and Equation(4.2)
(4.2)
(4.2) to determine the true analysis error equations and error covariances for Cases 1 and 2 described in sections 2.2.1 and 2.2.2. Case 1 corresponds to analysing all scales and includes the OKF. Case 2 corresponds to analysing the large-scale state only and includes the RKF and SKF. summarizes the matrices and vectors used in the true error calculations.
Table 2. Matrices and vectors used in the true error calculations for Case 1 and 2 described in sections 4.1 and 4.2. The tildes indicate true error covariances. Case 1 corresponds to analysing all scales and includes the OKF. Case 2 corresponds to analysing the large scales only and includes the RKF and SKF. The true analysis error equation, analysis error covariance and forecast error covariance for each case are obtained by substituting the corresponding components into Equationequations (4.1)(4.1)
(4.1) , (Equation4.2)
(4.3)
(4.3) and Equation(4.3)
(4.3)
(4.3) respectively.
4.1. Case 1: true analysis error covariance when all scales are filtered
To obtain the true analysis error equation we assume that we have complete knowledge of all scales as with the OKF. As in section 2.2.1 the observation error will consist of instrument error, and the observation operator error for large- and small-scales,
Under these assumptions the true analysis error equation will be a partitioned form of Equationequation (4.1)
(4.1)
(4.1) and the true analysis error covariance will be a partitioned form of Equation(4.2)
(4.2)
(4.2) with the components given in column 1 of .
4.2. Case 2: true analysis error covariance when only large-scales are filtered
The true analysis error equation for case 2 applies to filters that estimate the large-scale state only like the RKF and SKF. Using Equationequation (4.1)(4.1)
(4.1) and the state gain matrices and observation operators, the large-scale analysis error for the RKF and SKF is given by
(4.4)
(4.4)
We note that the observation errors correspond to case 2 described in 2.2.2 as both the RKF and SKF filter the large-scale state only. Hence, the effect of the small-scale processes on in Equationequation (4.4)
(4.4)
(4.4) is determined through the error due to unresolved scales
We observe that the true large-scale error covariance may thus be written in terms of the representation error covariance as
(4.5)
(4.5)
However, the true error statistics contributing to the true analysis error covariance are unknown in practice making the use of Equation(4.5)(4.5)
(4.5) to evaluate filter performance unfeasible. For theoretical experiments where most error statistics can be prescribed, determining
requires a Monte Carlo approach due to its dependence on
Alternatively, a different form of the analysis error equation may be more practical.
Assuming we know the true behaviour for the small-scales we can express the true analysis error equation for the RKF and SKF as
(4.6)
(4.6)
where
and
We note that as the small-scale state isn’t estimated the small-scale gain is a zero matrix of dimension
We also note that, while the large- and small-scale errors ostensibly appear uncoupled in Equationequation (4.6)
(4.6)
(4.6) , they are in fact coupled as
and
each depend on
Adding and subtracting the term
from the large-scale component of the analysis error, Equation(4.6)
(4.6)
(4.6) may be written as
(4.7)
(4.7)
Using the definitions of the small-scale observation operator error Equation(2.9)(2.9)
(2.9) , the error due to unresolved scales Equation(2.11)
(2.11)
(2.11) and the small-scale forecast error Equation(3.9)
(3.9)
(3.9) we find that
(4.8)
(4.8)
Thus the right-hand-side of Equation(4.7)(4.7)
(4.7) can be evaluated without knowledge of the error due to unresolved scales specifically. Instead, this can be written in terms of the observation operator error and a small-scale forecast:
(4.9)
(4.9)
The partitioned case 2 error Equationequation (4.9)(4.9)
(4.9) can be used to obtain the true analysis error covariance for the SKF and RKF without knowing the full representation error covariance
However, when using this form of the analysis error equation to obtain the true error statistics the correlations between
and
may be non-negligible. We note that, while
and
will also be unknown in practice, they could be approximated offline with high-resolution models.
5. Experiment methodology
5.1. Gaussian random walk model
We now consider the methodology for numerical experiments where we apply the three filters to the simple model system
(5.1)
(5.1)
such that
and
(Brown and Hwang, Citation2012). This system uses one variable for the large-scale state, xl, and one variable for the small-scale state, xs. The large-scale state xl and small-scale state xs are random walk variables driven by the errors ηl and ηs whose structures are determined by the variances
and
respectively. There are no cross-covariances in the model error statistics. The model component
is the contribution from the large-scale processes to the small-scale state. The observations will be taken to be the sum of the large- and small-scale states plus instrument error.
The random walk model Equation(5.1)(5.1)
(5.1) will first be used for a “nature run” from which observations can be created. The filters described in section 3 will then be used to assimilate these observations and the true large-scale analysis error variance calculated at the end of the assimilation window. As the RKF and SKF are suboptimal, they propagate inexact error variances. Therefore, the true error variances for the RKF and SKF are calculated using Equation(4.9)
(4.9)
(4.9) to provide a comparison between their performances.
Through our experimental design we are able to easily control the magnitude of the observation error due to unresolved scales by adjusting The relationship between
and the error due to unresolved scales is described in section 5.3. This framework also allows for the determination of the optimal
as well as the sensitivity of the SKF to this modelled variance.
5.2. Initial conditions and filter parameters
For our experiments, we choose the initial conditions for the true state (nature run) to be and
so that the true resolved state is an order of magnitude larger than the unresolved state. Setting the small-scale true state to zero also ensures that the representation errors are initially unbiased.
We set the initial conditions for the forecast state and forecast error covariance to be
(5.2)
(5.2)
where
and
are perturbations from the true states. We have assumed that the initial large- and small-scale forecast errors are uncorrelated.
For our first set of experiments we set the model component so that the representation errors remain unbiased throughout the assimilation. The large-scale model error variance,
is used throughout our experiments while
will vary for different experiments.
Observations are assimilated every time-step. The true observation operator is which is used by all three filters; this ensures that there is no observation operator error. Unless otherwise specified, the instrument error variance is set to
and
so that each filter correctly accounts for the instrument error. For the RKF, we set
so that the filter completely ignores the small-scale processes. The prescribed small-scale error variance
is varied throughout our experiments.
To calculate the true analysis error variance with Equation(4.9)(4.9)
(4.9) , we neglect the variance of
and the correlations between
and
as the solution for
is exponentially decaying with time. This method of calculating the true analysis error covariance has been validated against a Monte Carlo approach.
5.3. Determining the small-scale variability over the assimilation window
For the SKF and RKF, which do not update the small-scale state, the true small-scale analysis and forecast error statistics are equal at the same time-step. Setting the true small-scale error covariance, denoted
is evolved through the difference equation
(5.3)
(5.3)
For the Gaussian random walk model, we may use a scalar version of this equation, given by
(5.4)
(5.4)
where
and
Noting that the summation term in Equation(5.4)
(5.4)
(5.4) is a geometric series we can express
as
(5.5)
(5.5)
For large k, the first term in Equationequation (5.5)(5.5)
(5.5) decays to zero while the second term tends to the limit
Hence, after a burn-in period the error due to unresolved scales for the SKF and RKF is primarily determined by the size of
and increases each time-step.
6. Numerical experiments
In this section we apply the OKF, RKF and SKF to the random walk model defined in section 5.1 with filter parameters and error statistics assumptions detailed in section 5.2.
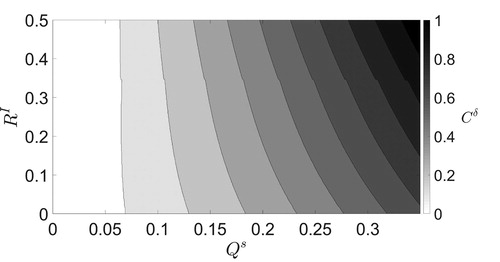
6.1. Determining the optimal Cs
Before using the SKF, we first need to approximate the matrix (see ). To find the optimal value of
over the whole assimilation window we carry out numerical experiments for a range of values of
and
Both of these parameters will affect the magnitude of the true large-scale analysis error variance. For each
parameter pair, we test a number of values of
to determine the value of
which gives the smallest true large-scale analysis error variance at the final assimilated observation. As we are calculating the variances only, the calculation is deterministic and the choice of noise realisation is irrelevant. For this experiment, we assimilate 15 observations. We start with
and increase
in steps of
until
The optimal values of that produce the minimum large-scale analysis error variance for the SKF at the final time-step are shown in . The optimal value of
increases as both
and
increase. In particular, the optimal value of
is most sensitive to any increase in
as the error due to unresolved scales is primarily determined by this error variance in our model. While not as sensitive, we find that large
also affects the optimal value of
This is because the optimal value of
is a function of
and
after the initial time. We also find that for small
and
the optimal value of
over the whole assimilation window is similar to
given by Equationequation (5.5)
(5.5)
(5.5) for the final time-step. For large
and
the optimal value of
is approximately 1.4 times larger than
evaluated at the final time-step.
Fig. 1. Contour plot of the values of that give the minimum true large-scale analysis error variance at the final assimilated observation for the SKF for different ratios of
and
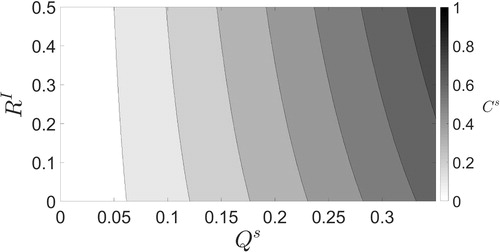
In operational settings we would not be able to optimise in this way. However, it may be possible to approximate part of the representation error covariance using high resolution observations (Oke and Sakov, Citation2008) or model data (Waller et al., Citation2014) and use these approximate representation error values to guide the choice of
To mimic this situation in our experiments, we create an ensemble of 50,000 realizations of xs for the length of the assimilation windows using the random walk model Equation(5.1)
(5.1)
(5.1) and calculate the variance, averaged over the whole ensemble and time. The variance of this ensemble will be denoted
. The variance,
, represents an approximation to the total small-scale variability over the assimilation window. We now compare the values of
computed in with the values of S.
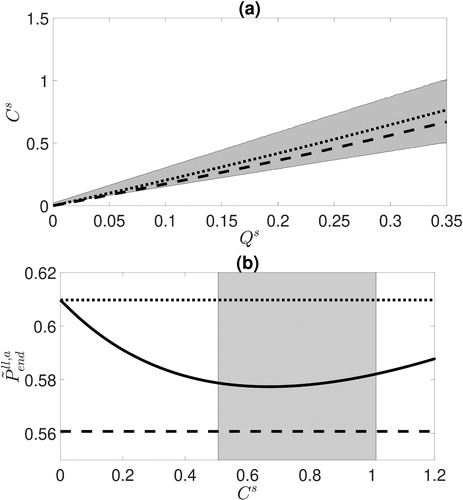
shows the optimal values when
(dashed line) and
(dotted line) for different values of
The grey region shows all points between
and 2S. As
is increased the variance
also increases. Both optimal
lines lie within the shaded region for nearly all
We note that when there is little small-scale variability (i.e.
) the optimal
values are less than
but both are close to zero. shows the effect of changing
on the SKF true large-scale analysis error variance (solid line) when
and
in comparison to the true large scale analysis error variances for the RKF and OKF. Thus, for these experiments, a reasonable rule of thumb to avoid areas where the SKF under- or overcompensates for the error due to unresolved scales, is to choose
Fig. 2. (a): The optimal values when
(dashed line) and
(dotted line) as functions of
The grey region shows all points between S (lower edge) and 2S (upper edge) for different values of
(b): The effect of changing
on the final true large-scale analysis error covariance for the SKF (solid line) when
and
Also shown are the OKF and RKF true large-scale analysis error variance (lower dashed line and upper dotted line respectively). The grey region shows all points between
(left edge) and
(right edge). The optimal value of
(i.e. the minimum of the solid line) lies in this region.
6.2. Comparison of the SKF with the RKF and OKF
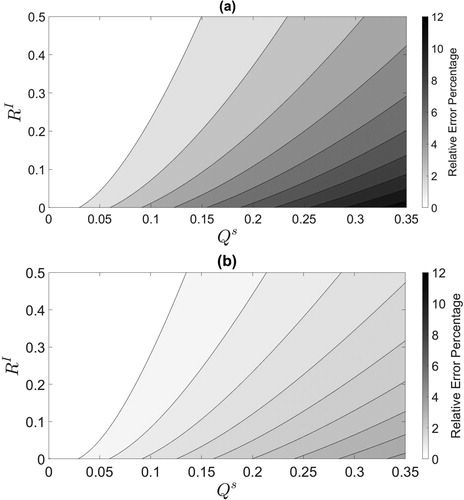
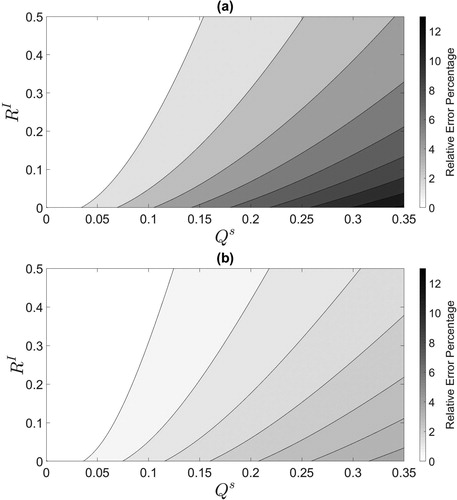
Using the optimal values of calculated in , we now carry out experiments comparing the SKF and RKF for a range of values of
and
relative to the OKF. The results are illustrated in terms of relative error percentage for the RKF in and the SKF in . The relative error percentage is defined as
(6.1)
(6.1)
where
indicates the absolute value and each term is evaluated at the end of the assimilation window. In these experiments, the SKF always has a true analysis error variance smaller than or equal to the RKF. When there is no error due to unresolved scales (i.e.
) we have that
is the optimal value for
and the SKF would reduce to the RKF. The largest relative error percentages for both the RKF and SKF occur when there is large uncertainty due to unresolved scales (large
) and small
and the smallest differences are when
is small. We also find that larger values of
limit the difference in performance between the RKF and SKF with the OKF. Therefore, the benefits of using the SKF are most apparent when there is considerable error due to unresolved scales and small instrument error. Comparing to we see that, for any fixed value of
as the uncertainty due to unresolved scales is increased the improvement of the SKF over the RKF will also increase.
Fig. 3. (a): Comparison of the RKF to the OKF in terms of relative error percentage given by Equationequation (6.1)(6.1)
(6.1) . (b): Comparison of the SKF with optimal
to the OKF at the final time-step in terms of relative error percentage.
To examine the performance perceived by the filter we compare it to the true performance of the filter at the final time-step. Before discussing the results, we note that the SKF perceived analysis error variance will not be a smooth field for the parameter pairs considered. This is because in section 6.1 the optimal value of
was calculated to a limited precision of 0.001.
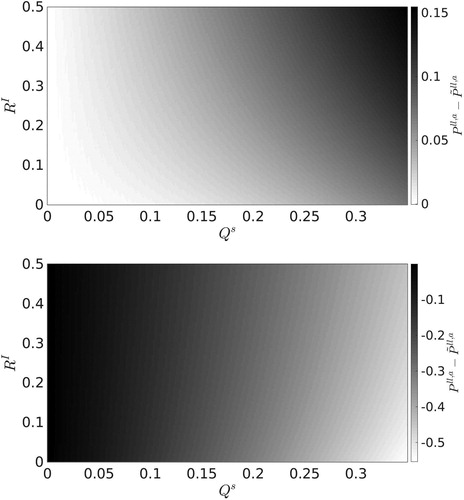
In we plot the difference between the perceived and true analysis error variance at the final time-step. We note that the magnitude of the difference between the perceived and true error variances is smallest for large and
Here, the SKF (RKF) perceived error variance is approximately 1.25 (0.5) times the size of the true error variance. The SKF perceived-minus-truth difference shown in panel (a) is always positive for non-negligible representation uncertainty. This shows the SKF is a conservative filtering strategy when compensating for observations exhibiting error due to unresolved scales. As both
and
are increased the SKF perceived-minus-truth difference increases. This is due to two reasons. The first reason is because the perceived analysis error variance,
increases with larger
as it is calculated using the short form update Equation(3.2)
(3.2)
(3.2) and the optimal
will be larger for higher values of
and
The second reason is because, for non-negligible representation uncertainty, the true analysis error variance,
will decrease as
approaches its optimal value. An illustrative case is provided by for high representation uncertainty and low instrument uncertainty. shows the RKF perceived-minus-truth difference. This is always negative for non-negligible representation uncertainty. This shows the RKF is an overconfident filtering strategy for observations exhibiting error due to unresolved scales. The RKF is most overconfident in regimes of low instrument uncertainty and high representation uncertainty.
Fig. 4. (a): Difference between the perceived and true analysis error variances at the final time-step for the SKF with optimal (b): Difference between the perceived and true analysis error variances at the final time-step for the RKF.
7. Representation error bias correction through state augmentation
Up to this point we have not considered observation bias in our numerical experiments. However, in operational data assimilation, most observations or their respective observation operators exhibit systematic errors which are referred to as biases. A common approach for correcting observation biases online in a Kalman filter algorithm is to augment the state vector with a bias term (Dee, Citation2005; Fertig et al., Citation2009). The bias state will then be estimated and evolved along with the state variables through the data assimilation algorithm (Friedland, Citation1969).
In section 2.3 we showed that observation errors may exhibit a representation error bias when there is a contribution from the large-scale processes to the small-scale state (i.e., when ). Throughout the remainder of this manuscript we only consider bias due to unresolved scales which is linked to the state-space representation of the small-scale processes. Since we know the exact form and origin of the observation bias in this study we may treat it as a model bias. Therefore, we consider the augmented state vector x with form
(7.1)
(7.1)
where
is the bias state. Thus,
is intended to represent
(cf. Equation(2.13)
(2.13)
(2.13) ). For bias correction through state augmentation we require a prior estimate of the bias and a model to forecast it. Using Equation(2.2)
(2.2)
(2.2) , the forecast model for the bias state is given by
(7.2)
(7.2)
where we have assumed the model for the bias to be perfect. Random noise can be added to Equation(7.2)
(7.2)
(7.2) to indicate that the bias evolution model is not perfect (Ménard, Citation2010) but is not explored here. In operational centres the model for individual sources contributing to the bias will be unknown and models describing the total bias will be used instead. These models for the bias will be obtained from assumptions imposed on the bias such as assuming it evolves slowly or is constant in time (e.g., Lea et al., Citation2008). In cases such as these, the bias estimate will likely be poor as the variation of the bias with the evolution of the large-scale processes will be completely unaccounted for.
We now examine how a bias correction scheme can be implemented in conjunction with the SKF (section 7.1) and the RKF (section 7.2) to correct a bias due to unresolved scales. summarizes the components for these two filters which are then substituted into the filter equations detailed in section 3.1.
Table 3. The filter matrices and vectors for the SKFbc and RKFbc. The equations for the the two filters are obtained through substituting these terms into Equation(3.1)(3.1)
(3.1) –Equation(3.4)
(3.4)
(3.4) .
7.1. The Schmidt-Kalman filter with observational bias correction
Bias correction through state augmentation is a common method used in operational centres but use of a bias correction scheme with the SKF, which will be denoted SKFbc, is novel.
We assume that we have knowledge of the processes for all scales. We further assume that we have a model and prior estimate for the bias. The filtered state vector for the SKFbc is given by Equationequation (7.1)(7.1)
(7.1) and only includes the large-scale state and the bias term. The small-scale state is split into a biased and unbiased component, i.e.
(7.3)
(7.3)
such that
The unbiased small-scale processes,
will be accounted for through their statistics. The full observation operator for the SKFbc is given by
(7.4)
(7.4)
where
and
are the linear observation operators which map the bias and unbiased small-scale states into observation space respectively. However, as with the SKF, the analysis update Equationequation (3.1)
(3.1)
(3.1) uses a forecast innovation that takes no account of the unbiased small-scales,
(7.5)
(7.5)
This innovation is unbiased and hence the large-scale analysis errors are also unbiased. The Kalman gain for the SKFbc consists of a large-scale gain and a bias estimate gain
given by
(7.6)
(7.6)
where
is the perceived cross-covariance between the large-scale errors and bias estimate errors,
is the perceived cross-covariance between the large-scale errors and unbiased small-scale errors,
is the perceived covariance of the bias estimate errors and
is the perceived cross-covariance between the bias estimate errors and unbiased small-scale errors. The perceived augmented innovation covariance D is given in . This increases the uncertainty the filter attributes to the forecast innovation compared with the standard SKF. The additional uncertainty is a result of the errors accrued in the estimation of the bias. The term
in the SKFbc innovation error covariance corresponds to the variability of the unbiased small-scale processes.
The SKFbc equations are obtained from augmenting the large-scale terms with bias terms and defining the cross-covariance terms appropriately. The analysis state update for the SKFbc is then
(7.7)
(7.7)
To obtain the analysis error covariance update we augment the gain Equation(7.6)(7.6)
(7.6) with
and substitute into the short-form analysis error covariance update Equation(3.2)
(3.2)
(3.2) . To mirror the SKF analysis error covariance update Equationequations (3.12)-(3.14), we express the SKFbc analysis error covariance update equations as
(7.8)
(7.8)
(7.9)
(7.9)
(7.10)
(7.10)
Since in the context of the SKFbc the complete model evolving all scales is assumed to be known, it is appropriate to update the bias term using this model Equation(7.2)(7.2)
(7.2) . Thus, the forecast state update is given by
(7.11)
(7.11)
For the forecast error covariance we need the model for the unbiased small-scale processes. To determine this model we use the definition Equation(7.3)(7.3)
(7.3) together with the bias evolution Equationequation (7.2)
(7.2)
(7.2) , to give
(7.12)
(7.12)
Note that the small-scale model error is assumed to be unbiased. To mirror the SKF forecast error covariance update Equationequations (3.16)-(3.18), we express the SKFbc forecast error covariance updates as
(7.13)
(7.13)
(7.14)
(7.14)
(7.15)
(7.15)
The prescribed unbiased small-scale error covariance is assumed constant in time and is not updated.
The SKFbc allows us to correct biases due to unresolved scales and consider the effects of the unbiased small-scale processes on the large-scale state. A key advantage in this method is that the cross-correlations between the large-scale errors and small-scale errors are retained. However, the SKF is a computationally expensive procedure. This issue is exacerbated by the use of state augmentation for bias correction.
7.2. The reduced-state Kalman filter with observation bias correction
To save on the computational expense incurred by the SKFbc we can disregard the unbiased small-scale processes to obtain the reduced-state Kalman filter with bias correction (RKFbc). As before, we augment the large scale state vector with a bias term, so that the estimated state is given by Equation(7.1)(7.1)
(7.1) . The observation operator is also augmented and takes the form,
(7.16)
(7.16)
As with the SKFbc, the forecast innovation Equation(7.5)(7.5)
(7.5) used in the analysis update Equation(3.1)
(3.1)
(3.1) takes no account of unbiased small scale error. Therefore, a properly specified observation error covariance for the RKFbc contains both instrument error and representation error (i.e.
).
Similarly to the SKFbc, the Kalman gain for the RKFbc consists of a large-scale gain and a bias estimate gain
given by
(7.17)
(7.17)
where the perceived innovation covariance
is given in . Thus, the analysis state update for the RKFbc is obtained through substitution of the gain matrix Equation(7.17)
(7.17)
(7.17) and forecast innovation Equation(7.5)
(7.5)
(7.5) into the linear filter analysis state update Equationequation (3.1)
(3.1)
(3.1) . Likewise, the analysis error covariance update equation is obtained through substitution of the gain matrix Equation(7.17)
(7.17)
(7.17) into the short form analysis error covariance update Equation(3.2)
(3.2)
(3.2) along with the observation operator Equation(7.16)
(7.16)
(7.16) .
For the RKF we assumed knowledge of the large-scale processes only. Hence, the model for the bias due to unresolved scales would be unknown and further assumptions required for the observation bias correction scheme. Nevertheless, to provide a direct comparison we will use the same model as the SKFbc Equation(7.11)(7.11)
(7.11) for the forecast state update. This model and a consistent model error covariance matrix (see ) are used for the augmented analysis error covariance update Equation(3.2)
(3.2)
(3.2) .
Comparison of the OKF column in and the RKFbc column in shows the two filters have similar components as a result of the bias correction through state augmentation approach. The key difference between the two filters is the model error covariance expressions. The OKF accounts for the uncertainty in all scales and so uses the full model error covariance. The RKFbc accounts for the uncertainty in the large-scales and the estimate of the bias. Since the model for the bias Equation(7.2)(7.2)
(7.2) has been assumed perfect the RKFbc will only account for large-scale model error. We note that, as no knowledge of the small-scale processes is assumed for the RKFbc, the forecast model will differ in practice from that of the OKF as the RKFbc bias forecast model would come from additional assumptions placed on the bias.
The RKFbc is a computationally cheaper alternative to the SKFbc for online bias correction that takes no account of unbiased small-scale errors, except through the choice of observation error covariance.
7.3. True analysis error equations for bias correcting filters
The true analysis error equation for the SKFbc and RKFbc will differ from the case 2 true analysis error Equationequation (4.4)(4.4)
(4.4) due to the innovation Equation(7.5)
(7.5)
(7.5) . The change will only be in the large-scale part of the true analysis error equations as the small-scale state is not analysed by either filter. The large-scale true analysis error equation for the bias correction filters is obtained from subtracting
from the case 2 true analysis error Equationequation (4.4)
(4.4)
(4.4) which produces
(7.18)
(7.18)
The true large-scale analysis error covariance for the bias correcting filters is then given by
(7.19)
(7.19)
The difference between the true analysis error covariance for the non-bias correcting filters and Equation(7.19)(7.19)
(7.19) is that
has been replaced with
which corresponds to the uncertainty due to unresolved scales and the uncertainty in the estimate of the bias. Similarly to Equation(4.5)
(4.5)
(4.5) , Equationequation (7.19)
(7.19)
(7.19) is still dependent on
and so a different form may be more suitable.
Using the definitions of the small-scale observation operator error Equation(2.9)(2.9)
(2.9) , the error due to unresolved scales Equation(2.11)
(2.11)
(2.11) , the small-scale forecast error Equation(3.9)
(3.9)
(3.9) and the identity Equation(4.8)
(4.8)
(4.8) we can rewrite Equation(7.18)
(7.18)
(7.18) as
(7.20)
(7.20)
which is analogous to Equation(4.9)
(4.9)
(4.9) . In order to use Equation(7.20)
(7.20)
(7.20) to obtain the true error statistics the correlations between
and
must be considered.
8. Experimental methodology for bias correcting filters
8.1. Gaussian random walk model
To investigate the performance of the SKFbc and the RKFbc we will apply them to the random walk model detailed in section 5.1. To introduce a bias into the observations we will set the contribution from the large-scale processes to the small-scale state to be nonzero in Equation(5.1)
(5.1)
(5.1) . As in Equation(5.1)
(5.1)
(5.1) , the true observation operator for the large- and small-scale states is
and consequently the observation operator for the bias state
and the unbiased small-scale state
To calculate the true large-scale analysis error variance of the RKFbc and SKFbc we proceed as discussed in section 7.3. Noting that and
are forecast by the same equation and tend to the same bias for large times we may neglect the variance of
and the correlations between
and
as they will be small at the end of the assimilation window.
8.2. Initial conditions and filter parameters
The random walk model with is used to create a reference or truth trajectory for the large- and small-scale states. For our experiments we set
and
This choice for the small-scale truth is the limit of
for the deterministic version of the random walk model (i.e. Equation(5.1)
(5.1)
(5.1) with no model noise). Using these initial conditions, the model equivalent of the observations will be biased at each time-step. The initial prior large- and small-scale estimates are set as
(8.1)
(8.1)
where
and
where we take
and
Similarly, we set the initial prior bias estimate as
where
We take the initial cross-covariances between the forecast errors for the large-scale and bias state errors to be zero. The modelled unbiased small-scale error variance
for the SKFbc will be varied for our experiments. We also take the unbiased small-scale errors to be initially uncorrelated with large-scale and bias estimate forecast errors. We set the large-scale model error variance as
throughout our experiments while
will be varied. Unless otherwise specified, the instrument error variance will be set to
For the RKFbc, we set
so that the filter completely ignores the unbiased small-scale processes.
9. Numerical experiments with bias correcting filters
9.1. Comparison between bias correcting filters and non-bias correcting filters
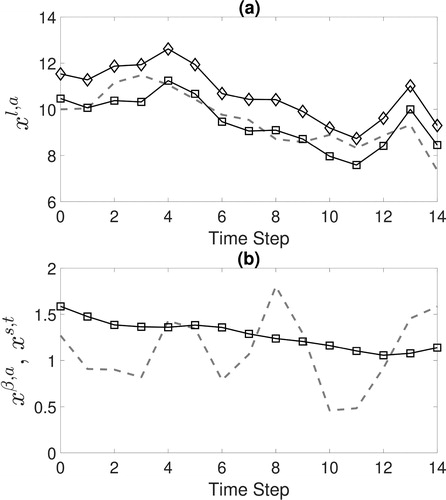
We now consider the case of assimilating biased observations with standard and bias correcting filters. shows the analyses created by the SKF and SKFbc when assimilating biased observations for a single realization of the background, observation and model errors where As optimal modelled small-scale error variances have not been calculated for the random walk model with
we set
These are suboptimal choices for both filters which results in a small difference in the true analysis error variances between the SKFbc (SKF) and RKFbc (RKF). Panel (a) shows an almost constant offset between the solutions of the bias-correcting and non-bias correcting schemes. Furthermore, calculating the time average of the squared analysis errors we find the SKF error is over four times larger than the SKFbc error.
Fig. 5. (a): The large-scale analysis for the SKFbc (square markers) and SKF (diamond markers) obtained through assimilation of biased observations to recreate the true large-scale state (grey dashed line). For this realization the large-scale analysis mean-square-error for the SKFbc is 0.29 and for the SKF is 1.53. (b): The SKFbc bias analysis estimate (square markers) and the true small-scale state (grey dashed line) for the same realization as panel (a).
For this realization, the time average of the squared analysis errors for the RKFbc and the SKFbc are the same to two decimal places. However, the SKFbc does have a smaller true large-scale analysis error variance than the RKFbc and the difference increases more as is more optimally chosen. The same is true for the RKF and SKF with modelled variance
In we see the bias value estimated by the SKFbc and the small-scale true model solution for a particular realization, which is dominated by noise. The bias state is intended to estimate the expected value of the small-scale state evolved with the filter forecast model such that it is unaffected by small-scale noise (see Equation(7.3)
(7.3)
(7.3) ). Using Equation(2.2)
(2.2)
(2.2) we see that
where the angular brackets indicate the mathematical expectation over the distribution of the small-scale model errors. Here, we have plotted
which is dependent on the large-scale noise and small-scale noise (cf. Equation(2.2)
(2.2)
(2.2) ). From this panel we see that the bias estimate is consistent with the small-scale true model solution.
Additional experiments using persistence as the forecast model for the bias state with the SKFbc have been carried out. We find that the time average of the SKFbc squared analysis errors is approximately three times smaller than the time average of the SKF squared analysis errors without bias correction. Nevertheless, the mean-square analysis errors for the SKFbc with the persistence bias model are more than 50% larger than when using Equation(7.2)(7.2)
(7.2) . Additionally, when using persistence as the forecast model for the bias state in the RKFbc we find the time average of the squared analysis errors is also approximately three times less than the SKF error. Hence, for this system it is more important to treat the bias due to unresolved scales than compensate for the unbiased error due to unresolved scales.
9.2. Determining the optimal  over the assimilation window
over the assimilation window
In this section we determine the optimal over the whole assimilation window.
For the SKF, we found that the choice of was key to the performance of the filter. We follow a similar procedure to section 6.1 to find the optimal values of the unbiased small-scale error covariance
Our experiments have an assimilation window of 15 time-steps with an observation assimilated at each time-step. To find the optimal
for given parameter values for
and
we calculate the true large-scale analysis error variance of the SKFbc for
ranging from 0 to 1 in steps of
and save the value that produces the smallest variance at the final time-step.
shows the optimal for different values of
and
The behaviour is qualitatively similar to
with the SKF shown in but numerical comparison is not meaningful as a different model is used. In particular, the size of
is primarily determined by the magnitude of
However, we find that an increase in
can also result in a larger
being optimal. If
is increased, the optimal
decreases as the uncertainty caused by the contribution from the large-scale processes to the small-scale state becomes more important.
Fig. 6. The values of which give the minimum true large-scale analysis error variance at the end of the assimilation window for the SKFbc.
9.3. Comparison of the bias correction filters
In this section we evaluate the performance of the SKFbc and RKFbc relative to the OKF and examine their perceived error variances.
We now compare the SKFbc and RKFbc with the OKF in terms of relative error percentage Equation(6.1)(6.1)
(6.1) , plotted in . The SKFbc provides most improvement over the RKFbc for large
and small
This behaviour is qualitatively similar to the comparison between the RKF and SKF with the OKF shown in . We have also examined the perceived and true analysis error variances for the RKFbc and SKFbc (not plotted). The results are qualitatively similar to those given in section 6.2 for the RKF and SKF. Indeed, for non-negligible representation uncertainty the SKFbc (RKFbc) is a conservative (overconfident) filtering strategy as the perceived-minus-truth difference is positive (negative).
Fig. 7. (a): Comparison of the RKFbc to the OKF in terms of relative error percentage given by Equationequation (6.1)(6.1)
(6.1) . (b): Comparison of the SKFbc with optimal
to the OKF at the final time-step in terms of relative error percentage.
10. Summary and conclusion
Observations of the atmospheric state may contain information on spatio-temporal scales unable to be represented by a numerical model. The resulting error caused by this scale mismatch between the observations and numerical model is known as the error due to unresolved scales. To obtain accurate analyses from assimilation of these observations requires that the data assimilation algorithm correctly account for this error.
In this work we have considered the ability of linear filters to compensate for the error due to unresolved scales. We considered a finite dimensional true state which could be partitioned into a large-scale state resolved by a numerical model and a small-scale state unresolved by a numerical model. The representation error was defined in this framework and a bias due to unresolved scales was shown to occur when there is a contribution from the large-scale processes to the small-scale state.
For our experiments we considered three filters: the Schmidt-Kalman filter (Janjić and Cohn, Citation2006) that analyses the large-scales but models the uncertainty on all scales; the optimal Kalman filter, which analyses all scales, and a reduced-state Kalman filter, which completely disregards the small-scale processes.
The three filters were tested numerically on a random walk model with one variable for the large-scale processes and one variable for the small-scale processes. The observations were taken to be the sum of the large- and small-scale states with added noise to simulate instrument error. To obtain the best performance from the Schmidt-Kalman filter we had to tune the modelled small-scale error covariance to compensate for the variability of the small-scale processes which grew over the first half of the assimilation window. The Schmidt-Kalman filter works best in regimes of high error due to unresolved scales and low instrument error provided a suitable approximate small-scale error covariance is used. Examination of the perceived error variances revealed the analysis uncertainty calculated by the Schmidt-Kalman filter is greater than the true analysis uncertainty when accounting for error due to unresolved scales.
The novel use of the Schmidt-Kalman filter with an observation bias correction scheme was introduced as a means to correct the bias due to unresolved scales. The Schmidt-Kalman filter with a bias correction scheme proved to be a suitable method to treat observation biases and compensate for due to unresolved scales. In our experiments we found it was more important to treat an observation bias than to compensate for an unbiased error due to unresolved scales.
An important note to make regarding these experiments was that we had complete knowledge of the small-scale processes. This allowed for minimal approximations to be made to implement the Schmidt-Kalman filter and to tune the modelled error variances. In an operational setting, where all the small-scale processes are likely to be unknown, further approximations would be required. Additionally, the Schmidt-Kalman filter is a computationally expensive method due to the augmentation and propagation of the state error covariances. This must also be addressed before the filter could be considered for large problems.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Aravéquia, J. A., Szunyogh, I., Fertig, E. J., Kalnay, E., Kuhl, D. and co-authors. 2011. Evaluation of a strategy for the assimilation of satellite radiance observations with the local ensemble transform Kalman filter. Mon. Weather Rev. 139, 1932–1951. doi:10.1175/2010MWR3515.1
- Asher, R. B., Herring, K. D. and Ryles, J. C. 1976. Bias, variance, and estimation error in reduced order filters. Automatica 12, 589–600. doi:10.1016/0005-1098(76)90040-6
- Asher, R. B. and Reeves, R. M. 1975. Performance evaluation of suboptimal filters. IEEE Trans. Aerosp. Electron. Syst. AES-11, 400–405. doi:10.1109/TAES.1975.308092
- Brown, R. G. and Hwang, P. Y. 2012. Introduction to Random Signals and Applied Kalman Filtering. John Wiley & Sons, Hoboken, NJ, p. 192, Chapter 5.
- Brown, R. and Sage, A. 1971. Analysis of modeling and bias errors in discrete-time state estimation. IEEE Trans. Aerosp. Electron. Syst. AES-7, 340–354. doi:10.1109/TAES.1971.310375
- Cordoba, M., Dance, S. L., Kelly, G. A., Nichols, N. K. and Waller, J. A. 2017. Diagnosing atmospheric motion vector observation errors for an operational high-resolution data assimilation system. Q. Meteorol. Soc. 143, 333–341. doi:10.1002/qj.2925
- Daley, R. 1993. Estimating observation error statistics for atmospheric data assimilation. Ann. Geophysicae 11, 634–647.
- Dee, D. P. 2005. Bias and data assimilation. Q. J. R. Meteorol. Soc. 131, 3323–3343. doi:10.1256/qj.05.137
- Dee, D. 2004. Variational bias correction of radiance data in the ECMWF system. In: Proceedings of the ECMWF Workshop on Assimilation of High Spectral Resolution Sounders in NWP, Reading, UK, ECMWF.
- Derber, J. C. and Wu, W.-S. 1998. The use of TOVS cloud-cleared radiances in the NCEP SSI analysis system. Mon. Wea. Rev. 126, 2287–2299. doi:10.1175/1520-0493(1998)126<2287:TUOTCC>2.0.CO;2
- Desroziers, G., Berre, L., Chapnik, B. and Poli, P. 2005. Diagnosis of observation, background and analysis-error statistics in observation space. Q. J. R. Meteorol. Soc. 131, 3385–3396. doi:10.1256/qj.05.108
- Eyre, J. 2016. Observation bias correction schemes in data assimilation systems: a theoretical study of some of their properties. Q. J. R. Meteorol. Soc. 142, 2284–2291. doi:10.1002/qj.2819
- Fertig, E., Baek, S.-J., Hunt, B., Ott, E., Szunyogh, I. and co-authors. 2009. Observation bias correction with an ensemble Kalman filter. Tellus A: Dyn. Meteorol. Oceanogr. 61, 210–226. doi:10.1111/j.1600-0870.2008.00378.x
- Fielding, M. and Stiller, O. 2019. Characterizing the representativity error of cloud profiling observations for data assimilation. J. Geophys. Res. Atmos. 124, 4086–4103. doi:10.1029/2018JD029949
- Friedland, B. 1969. Treatment of bias in recursive filtering. IEEE Trans. Automat. Contr. 14, 359–367. doi:10.1109/TAC.1969.1099223
- Gelb, A. 1974. Applied Optimal Estimation. MIT Press, Cambridge, MA, and London, UK, Chapter 8, pp. 305–306.
- Grooms, I., Lee, Y. and Majda, A. J. 2014. Ensemble Kalman filters for dynamical systems with unresolved turbulence. Comput. Phys. 273, 435–452. doi:10.1016/j.jcp.2014.05.037
- Hodyss, D. and Satterfield, E. 2016. Mathematical concepts of data assimilation. In: Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (eds. S. K. Park and L. Xu) Vol. 3. Springer, Berlin, pp. 177–194.
- Ignagni, M. 1981. An alternate derivation and extension of Friendland’s two-stage Kalman estimator. IEEE Trans. Automat. Contr. 26, 746–750. doi:10.1109/TAC.1981.1102697
- Janjić, T., Bormann, N., Bocquet, M., Carton, J., Cohn, S. and co-authors. 2018. On the representation error in data assimilation. Q. J. R. Meteorol. Soc. 144, 1257–1278. doi:10.1002/qj.3130
- Janjić, T. and Cohn, S. E. 2006. Treatment of observation error due to unresolved scales in atmospheric data assimilation. Mon. Weather Rev. 134, 2900–2915. doi:10.1175/MWR3229.1
- Jazwinski, A. H. 1970. Stochastic Processes and Filtering Theory. Academic Press, New York, NY, Chapter 7, p. 212.
- Kalman, R. E. 1960. A new approach to linear filtering and prediction problems. Journal of Basic Engineering 82, 35–45. doi:10.1115/1.3662552
- Karspeck, A. R. 2016. An ensemble approach for the estimation of observational error illustrated for a nominal 1° global ocean model. Mon. Wea. Rev. 144, 1713–1728. doi:10.1175/MWR-D-14-00336.1
- Lea, D., Drecourt, J.-P., Haines, K. and Martin, M. 2008. Ocean altimeter assimilation with observational-and model-bias correction. Q. J. R. Meteorol. Soc. 134, 1761–1774. doi:10.1002/qj.320
- Liu, Z.-Q. and Rabier, F. 2002. The interaction between model resolution, observation resolution and observation density in data assimilation: A one-dimensional study. Q J. R Meteorol. Soc. 128, 1367–1386. doi:10.1256/003590002320373337
- Ménard, R. 2010. Bias estimation. In: Data Assimilation: making Sense of Observations (eds. W. Lahoz, B. Khattatov and R. Menard). Springer, Berlin, pp. 113–135.
- Miyoshi, T., Sato, Y. and Kadowaki, T. 2010. Ensemble Kalman filter and 4D-Var intercomparison with the Japanese operational global analysis and prediction system. Mon. Weather Rev. 138, 2846–2866. doi:10.1175/2010MWR3209.1
- Moodey, A. J. 2013. Instability and regularization for data assimilation. PhD thesis, University of Reading.
- Nichols, N. 2010. Mathematical concepts of data assimilation. In: Data Assimilation: making Sense of Observations (eds. W. Lahoz, B. Khattatov and R. Menard). Springer, Berlin, pp. 13–39.
- Oke, P. R. and Sakov, P. 2008. Representation error of oceanic observations for data assimilation. J. Atmos. Oceanic Technol. 25, 1004–1017. doi:10.1175/2007JTECHO558.1
- Satterfield, E., Hodyss, D., Kuhl, D. D. and Bishop, C. H. 2017. Investigating the use of ensemble variance to predict observation error of representation. Mon. Weather Rev. 145, 653–667. doi:10.1175/MWR-D-16-0299.1
- Schmidt, S. F. 1966. Application of state-space methods to navigation problems. In: Advances in Control Systems (ed. C. T. Leondes) Vol. 3. Elsevier, Amsterdam, pp. 293–340.
- Schutgens, N. A., Gryspeerdt, E., Weigum, N., Tsyro, S., Goto, D. and co-authors. 2016. Will a perfect model agree with perfect observations? The impact of spatial sampling. Atmos. Chem. Phys. 16, 6335–6353. doi:10.5194/acp-16-6335-2016
- Simon, D. 2006. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches. Wiley-Blackwell, Hoboken, NJ, pp. 309–312, Chapter 10.
- Stewart, L. M., Dance, S. L., Nichols, N. K., Eyre, J. R. and Cameron, J. 2014. Estimating interchannel observation-error correlations for IASI radiance data in the Met Office system. Q. J. R. Meteorol. Soc. 140, 1236–1244. doi:10.1002/qj.2211
- Todling, R. and Cohn, S. E. 1994. Suboptimal schemes for atmospheric data assimilation based on the Kalman filter. Mon. Wea. Rev. 122, 2530–2557. doi:10.1175/1520-0493(1994)122<2530:SSFADA>2.0.CO;2
- Waller, J. A., Ballard, S. P., Dance, S. L., Kelly, G., Nichols, N. K. and co-authors. 2016a. Diagnosing horizontal and inter-channel observation error correlations for SEVIRI observations using observation-minus-background and observation-minus-analysis statistics. Remote Sens. 8, 581. doi:10.3390/rs8070581
- Waller, J. A., Dance, S. L., Lawless, A. S., Nichols, N. K. and Eyre, J. 2014. Representativity error for temperature and humidity using the Met Office high-resolution model. Q. J. R. Meteorol. Soc. 140, 1189–1197. doi:10.1002/qj.2207
- Waller, J. A., Simonin, D., Dance, S. L., Nichols, N. K. and Ballard, S. P. 2016b. Diagnosing observation error correlations for Doppler radar radial winds in the Met Office UKV model using observation-minus-background and observation-minus-analysis statistics. Mon. Wea. Rev. 144, 3533–3551. doi:10.1175/MWR-D-15-0340.1
- Zhu, Y., Derber, J., Collard, A., Dee, D., Treadon, R. and co-authors. 2014. Enhanced radiance bias correction in the National Centers for Environmental Prediction’s gridpoint statistical interpolation data assimilation system. Q. J. R. Meteorol. Soc. 140, 1479–1492. doi:10.1002/qj.2233