
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Agriculture plays a vital role in Indian economy. On considering the overall geographical space verses population in India, 7% of population is chronicled in Tamilnadu, with 3% of water and 4% of land resources. Thus an automated prediction system becomes essential for predicting the crop based on the nutritional security of the country. In this paper, effort has been made to process the uncertainties by hybridizing rough set on intuitionistic fuzzy approximation space (RSIFAS) [Acharjya DP, Tripathy BK. Rough sets on intuitionistic fuzzy approximation spaces and knowledge representation. Int J Artif Int Comput Res. 2009;1 (1):29–36.] and neural network [Hecht NR. Theory of the backpropagation neural network. Proceedings of the international Joint Conference on neural networks, 1 (1989), 593–605.]. RSIFAS identifies the almost indiscernibility among the natural resources, and helps in reducing the computational procedure on employing data reduction techniques whereas neural network helps in prediction process. It helps to find the crops that may be cultivated based on the available natural resources. The proposed model is analyzed on data accumulated from Vellore district of Tamilnadu, India and achieved 93.7% of average classification accuracy. The model is compared with earlier models and found 6.9% better accuracy while prediction.
1. Introduction
In India, for over 58.4% of its population, agriculture is the principal means of livelihood. In addition, the agricultural merchandises are considered as the main commodity for the international trading. To sustain the growth of the Indian economy, there is a need for a drastic growth in agriculture productivity. For agriculture, the land and water are the main resources, which are inadequate in nature. Consequently, it is necessary to devise a lucrative cropping system with the accessible resources and to increase the productivity. Ever since, the market competition is high, a premeditated planning is mandatory to improve the performance to accomplish a profitable yield in the cropping system. The perfect planning in the development and production of the cropping system may step back due to uncertainty in forecasting the harvesting and demand for the crop. Therefore, to investigate the information for future planning can be achieved by a prediction model. A prediction model developed with the prior knowledge gives more accuracy towards the real-life situations. Thus, the proposed prediction model is based on soil and water resources available in some region to forecast the production of agricultural crops, with reduced risk of loss. Due to the lack of natural and human resources, many farmers agree themselves to alter the agriculture land into marketable land. This attitude has to be changed so as to retain the farmers and especially young generation to take up agriculture as their main occupation, and the income from the farm holding should be amplified significantly.
The area of study of this paper restricted to Vellore district in Tamil Nadu where agriculture is the main vocation. The small and marginal farmers in this region play a key role in the overall improvement in agriculture towards the development of the Indian economy. Thus, the adoption of appropriate cropping system by these farmers needs to be focused. Indian government has taken some productivity measure to improve the crop production by: training the farmers, relaxing the seed cost and loan amount etc. To tackle the increasing competency, it becomes more essential to develop a crop suitability information system to improve the productivity, and profit for the farmers. To develop such an effective system, data collected from various sources such as soil, water, seedling methodologies and meteorological conditions must be analysed properly instead of saving as archives.
Analysing data and discovering knowledge is a challenging and increasingly important task as it contains uncertainties. Additionally, it is not always useful to users as it may not certainly satisfy user’s choice due to the presence of redundancy, inconsistency and vagueness. Many traditional tools used for discovering knowledge are deterministic, crisp and precise. Thus, it is essential to use some intelligent techniques so as to process the uncertainties present in the data. The emergence of intelligent computing techniques like fuzzy set [Citation1], rough set [Citation2,Citation3], rough set on fuzzy approximation space (RSFAS) [Citation4,Citation5], rough set on intuitionistic fuzzy approximation space (RSIFAS) [Citation6], soft set [Citation7], near set [Citation8], fuzzy rough set [Citation9], rough set on two universal sets [Citation10], neutrosophic set [Citation11] etc. plays a vital role in knowledge discovery. Further, RSFAS is hybridised with Bayesian classification, soft set and neural network [Citation12,Citation13,Citation14,Citation15,Citation16] in the development of prediction system.
In this paper, effort has been taken to predict decisions from the uncertain and imprecise data by means of RSIFAS and neural network. The concept of RSIFAS is based on almost indiscernibility present in the data set. The objects in the information system are approximated by a pair of sets, called as lower and upper approximations based on the intuitionistic fuzzy proximity relation. The motivation behind the utilisation of RSIFAS is to obtain -equivalence classes, where the attribute values are not qualitative. Further, the classified information system is trained and tested with back propagation neural network that comforts to explore decisions for unknown associations of the attribute values. This helps us to predict a specific crop that is to be cultivated in a specific area on deliberating various conditions such as soil, water characteristics and rainfall.
The remaining part of the paper is planned accordingly: Section 2 presents basics of RSIFAS, whereas Section 3 discusses the basics of feed-forward back propagation neural network. The proposed research design is presented in Section 4. Section 5 deals with analyses of the performance of the trained data with the testing data according to known feature values. An experimental comparative study of the proposed model with various existing techniques is given in Section 6. The paper is concluded by a conclusion in Section 7.
2. An Information System
Procuring knowledge for classification is one of the most essential intentions of data mining and inductive learning. But, in real-life problems, it is not enough to deal with simple classification as it contains uncertainties. To deal with such problems, the classification using RSIFAS was introduced. Before, we discuss the classification power of RSIFAS, one should know about an information system. An information system is a table that offers a suitable way to describe in detail about the finite set of objects of the universe by finite set of attributes thereby representing all available information and knowledge. From the view of rough set theory, it is common in defining the information system as a data set represented as a table in which every column head represents an attribute that can be measured for each object.
More formally, an information system is a quadruple , where
is a non-empty finite set of objects called the universe and
is a non-empty finite set of attributes,
, where
is the set of values that attribute
may take. The mapping
provides the information about each object. Further, if
, where C is the set of conditional attributes and D is the decision attribute, we call the information system as decision system. For example, consider the information system as shown in where each attribute values are quantitative rather qualitative. It is clear that the attribute values are almost identical rather that matching each other. To deal with such almost similarity, the concept of RSIFAS is introduced.
Table 1. Information system.
2.1. Foundations of Rough Set on Intuitionistic Fuzzy Approximation Space
Pawlak’s rough set [Citation2] is used to identify the indiscernibility between the attribute values with the help of an equivalence relation. But, in several real-life applications, it is observed that the values of the attributes are not exactly the same but almost the same. To decide the amount of identity between two attribute values, the equivalence relation is replaced with fuzzy tolerance relation on each domain of attributes [Citation4]. Again, it fails to include hesitation that may arise during the knowledge extraction phase. Therefore, fuzzy tolerance relation is further replaced with intuitionistic fuzzy tolerance relation and the concept of RSIFAS was introduced [Citation6]. For example, on a particular period of time if the maximum temperatures at two different places are 36.6°C and 36.9°C, then the temperatures at these places are approximately identical rather than completely identical. At this instant, RSIFAS reduces to RSFAS if there is no hesitation. Similarly, RSIFAS reduces to rough set if there is no hesitation and the attribute values are exactly the same. Therefore, RSIFAS generalises Pawlak’s approach of indiscernibility. To disclose the article, foundations such as notions and concepts of RSIFAS are briefly presented in this section.
Let be a non-empty finite set of discourse called universe and
is a particular element of
. An intuitionistic fuzzy set
of
is defined as
, where
and
defines the degree of membership and degree of non-membership, respectively, for every element
such that
. The value
is called the hesitation part, which may cater either membership value or non-membership value or both. For simply, we will use
to denote the intuitionistic fuzzy set X [Citation17].
An intuitionistic fuzzy relation on
is an intuitionistic fuzzy set defined on (
) characterised by the membership
and the non-membership
where
An intuitionistic fuzzy relation IR on U is said to be an intuitionistic fuzzy (IF) proximity relation if it satisfies the following conditions, where
represents the degree of membership and
represents the degree of non-membership between two objects
and
.
and
Let and
. Then for any
, the
is given as
and
. We say that the two objects
and
are
similar with respect to
if
and we write
. Two objects
and
are said to be
identical with respect to IR, if there exists a sequence of elements
in U such that
. In the above case, we say that
is transitively
similar to
with respect to IR. It is clearly seen that for any
,
is an equivalence relation on U. Let us denote
be the set of equivalence classes generated by the equivalence relation
. The
- equivalence class of an element x in U is denoted as
. The pair
is called an intuitionistic fuzzy approximation space [Citation6].
Let . Then the
-lower and
-upper approximation of X in the generalised approximation space
is denoted as
, where
(1)
(1)
(2)
(2)
A given set
is said to be
rough if and only if
. Likewise, a given set X is said to be
crisp if
. Equivalently, a set X is said to be
rough if the boundary
such that
3. Feed-forward Back Propagation Neural Network
Artificial neural networks (ANN) are a model inspired by the organisation of the human brain. It is generally presented as a system of interconnected simple processing elements called neurons. It has gone far away from the biological stimulations in exchanging the messages between neurons. The exchanging of messages is carried out by every neuron in the network after receiving the input signal from the environment. The input signal is processed through hidden neurons and finally sent as output signal. Each neuron is connected with at least one neuron, and each connection have numeric weights [Citation18,Citation19]. These weights are generally tuned in the training phase. This makes the network adaptive to input and capable of learning. The learning process is evaluated by a value called weight coefficient. The set of input neurons is activated by activation function and is passed to the other neurons in the next layer. This process is repeated until the desired output neuron is approximated.
The construction of the feed-forward neural network is essential in categorising, establishing and summarising data. The architecture consists of three layers such as input layer, hidden layer and output layer. The input layer is the first layer where the input is fed in to the network, whereas the output layer is the last layer where the desired output is produced. The layer(s) present in between the input and output layer are called hidden layers. The network is constructed as such of the human brain as each neuron in one layer is connected with all the neurons in the next layer. The interconnection initiated by the input layer and the mapping of input layer and the net layer is characterised by the weight coefficient. More formally, the input from the ith node of the input layer to the jth node in the next hidden layer is denoted as . The connection from the ith node to the jth node is characterised by the weight coefficient
and the threshold coefficient
of the ith neuron. Based on all the inputs, each node determines a net input value
by using Equation (3). The output value
of the ith neuron is determined by Equation (4), where
is the sigmoid function which acts as the activation function in the back propagation neural network
(3)
(3)
(4)
(4)
4. Research Design Development
Research design development and problem definition is most significant in applied research. It includes collection of data, preparation of data, removal of noise, classification, identification of techniques, validation of the model and moreover comparison of the model with the existing models. The proposed model consists of two stages. In the initial stage, RSIFAS is used for data classification whereas in the final stage, back propagation algorithm of feed-forward neural network is used for the prediction of unseen associations of attribute values. An abstract view of the proposed research design is depicted in .
Figure 1. The proposed research design.
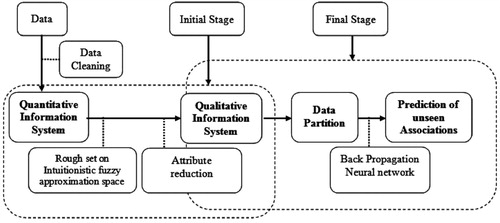
Before we process data at the initial stage, a sequence of cleaning task such as abstracting noise, consistency check and data plenary are carried out to ascertain that the data are as precise as possible. The target data are processed using intuitionistic fuzzy tolerance relation to obtain almost indiscernibility of data values for each attributes. The classification generated produces the -equivalence classes, where
is the degree of belongingness and
the degree of non-belongingness, respectively. It is obvious that the degree of belongingness must be high and degree of non-belongingness must be low to get good appropriate classification. On making the belongingness as 1 (100%) and non-belongingness as 0, the model fails to analyse the information system as each classification will contain exactly one object. It is because of the attribute values present in the system are non-qualitative. The membership and non-membership relation have been premeditated such that the sum of their values lies between [0, 1] and additionally, these functions must be symmetric.
The empirical study that we consider is related to crop suitability prediction of Vellore district of Tamil Nadu. The information system contains attributes such as soil pH, moisture, organic matter etc. It provides information about various agriculture contingency factors of different places along with the crops that are cultivated in these places. A place may not be rich in all agriculture contingency factors for the production of any type of crops. However, out of these, some agriculture contingency factors may have greater importance for the production of a particular crop than the others. On varying the values of and
, the factors may deviate from each other. Indeed, if we decrement the value of
and increment the value of
, progressively the number of factors shall become indispensable. The membership and non-membership relation have been premeditated such that the sum of their values lies between [0, 1] and additionally, these relations must be symmetric. The first requirement necessitates a major of 2 in the denominators of the non-membership functions [Citation6,Citation20].
The degree of belongingness and the degree of non-belongingness
between two objects
and
is defined in Equations (5) and (6), respectively, where
is the value of the object
for the attribute
(5)
(5)
(6)
(6)
The reduced qualitative information system is divided into training data set of 55% and testing data set of 45%. The training data set is alimented into neural network to predict the decision for the new unseen objects. The testing data are used to validate the training phase and to ensure higher accuracy. The article uses back propagation neural network in the final stage to obtain the decisions. The process consists of three layer such as input layer, hidden layer and output layer, as shown in . The attribute values,
of the training data set are fed in the input layer. In the subsequent hidden layer, the actual mapping between the input and output layer is carried out. The number of hidden nodes is generally computed based on trial and error bases based on mean square error and mean percentile error. Let us assume total number of hidden nodes as h. Let us denote hidden node as
. The output nodes are denoted as
, where
is the total number of objects in the training data set.
Figure 2. Design of back propagation neural network.
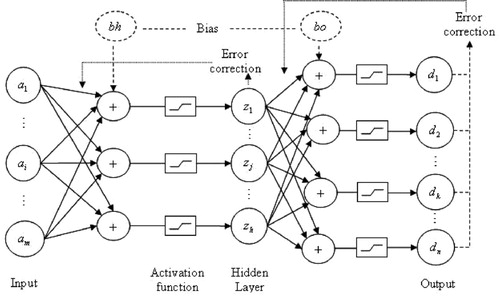
The feed-forward back propagation algorithm [Citation21] is basically gradient descent model where the local minima are identified to converge the input, to the output functions. To facilitate this mean square error between the desired, and actual output is calculated to be minimum. This learning consists of two computational phases such as forward pass and backward pass. Forward pass is a feed-forward propagation of the inputs through the network. The following notions are used in the back propagation algorithm.
bok: bias on output unit
epoch: one training loop on considering all the input vector
Algorithm 1(Back Propagation Algorithm)
Input: Training Vector ‘
Output: The trained data set.
Initialise weight vector of the input layer
Initialise weight vector of the hidden layer
Initialise mean square error, MSE = 0; epoch = 0 and learning rate LR.
Each input unit receives the input value
Each hidden unit
Apply activation function to all the interconnection weight
Each output unit
Apply activation function to all the interconnection weight
For each output unit
Increase epoch by 1, i.e. epoch = epoch + 1
If (AMSE ≤ 0.5) or (epoch =
Each output unit
Each hidden unit
The error information term can be calculated as
Each output unit
The bias correction term
Each hidden unit
The bias correction term
5. An Empirical Study on Crop Suitability Prediction
The major objective of the research model taken in to consideration is to analyse and to predict the suitable place for cultivating the agriculture crop to yield maximum benefit with the existing resources on a various period of time. Usually, a layman depends on some agriculture research centre or some advice from the agriculture officers to lay the crops on their land. But in practical, it is time-consuming process. The proposed model act as a tool for a layman to identify the crop to be cultivated in a place based on the richness of various components of the specific crop. To make apparent research model, we considered a real-life problem pertaining to crop cultivation in Vellore district of Tamil Nadu. Historical data from 2011 to 2014 of Krishi Vigyan Kendra of Vellore district are collected. The major resource such as soil and land classification is considered based on the survey of agriculture department of Vellore district, Tamil Nadu. Additionally, Tamil Nadu state agriculture departments has divided Tamil Nadu into seven agro-climate zones such as cauvery delta zone, north-eastern zone, western zone, north western zone, high altitude zone, southern zone and high rainfall zone based on various components such as rainfall, soil, irrigation, another physical and ecological features. Among this, Vellore district is categorised under north-eastern zone which entertains an average rainfall of 1099.1 mm per year. The index map as per Krishi Vigyan Kendra of the study area is depicted in .
Figure 3 Index map of the study area.
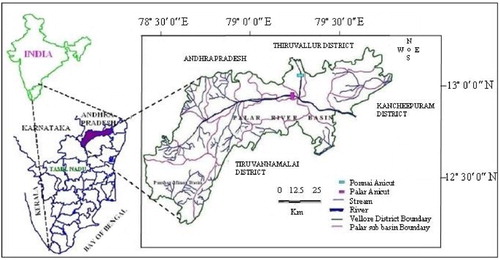
Furthermore, Vellore district has been distributed into nine agricultural divisions in 2011 and is further separated into 20 blocks. A total of 4799 villages of 20 blocks were documented according to Krishi Vigyan Kendra whose main occupation is agriculture. Most of the villages produce major agricultural crops such as paddy, cholam, cumbu, ragi, samai, red gram, black gram etc. Apart from this, some villages produce horticulture crops such as banana, mango, guava, sapota etc. as fruit crops and also vegetable crops such as brinjal, tomato, onion, sweet potato etc. Some also yield flower crops and spices such as jasmine, chrysanthemum, marigold and chillies, turmeric, respectively. In this paper, effort has been taken to collect data from some villages whose main occupation is agriculture. The administrative block boundary map of Vellore district in 2009 on which the study is carried out is shown in . For better understanding, the agriculture divisions along with the blocks are presented in .
Figure 4. Administrative blocks of the study area.
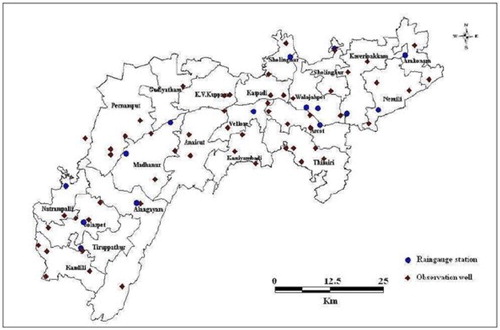
Table 2. Agricultural divisions in Vellore district
The most common attributes for crop production of Vellore district includes, soil component, water components, rainfall during north-east monsoon, rainfall during south-west monsoon, organic manure, moisture etc. Soil and water components are different at various places and depend on several factors. So, it is essential to identify the availability of NPK (Nitrogen, Phosphorus, Potassium) ratio on soil at congruous stage afore cultivation. It minimises the use of inorganic chemical fertilisers. These parameters form the attribute set of analysis. The data collected from Krishi Vigyan Kendra and agriculture department are consolidated and presented in Tables 3 and . represents the notations of various attributes, possible values and max range value of each attribute whereas depicts the consolidated sample data considered to our study.
Table 3. Notation representation table
Table 4. Sample agriculture information system
The information system presented in provides the information about 20 crops that are cultivated at various blocks of agriculture divisions of Vellore district. The information system contains essential attributes such as soil pH, moisture, organic matter etc. whereas objects are considered as crops. The decision attribute is considered as agricultural division where the particular crop is essentially cultivated to get maximum yield. The main objective of this study is to help farmers in identifying the crops suitable for their land. But the maximum yield rate depends on the various components like soil, water, rainfall etc. But, land and water are the crucial resource in nature. Additionally, a cultivation land may not rich in all the parameters to engender highest productivity. But, these factors are almost indiscernible and hence can be classified by using intuitionistic fuzzy proximity relation.
5.1. Initial Stage of an Empirical Study
This section demonstrates the proposed model by considering data collected from Krishi Vigyan Kendra for extracting information. The collected data contains 26 attributes, out of which to maintain consistency, the core and the reduct is applied for attribute reduction. Thus, the reduced data set is processed with intuitionistic fuzzy proximity relation. To provide a clear understanding, we considered the sample data set presented in and employed intuitionistic fuzzy proximity relation. Simultaneously, rough set helps to eliminate the parameters that are superfluous in an information system. The computations are carried out by using Eqnuations (5) and (6) [Citation22]. The results are presented in for attribute (Soil pH) and for the attribute
(Moisture), on considering the random selection of 55% of the total objects (11 objects) shown in . The process is repeated for all the 15 attributes present in the considered information system. Let
be the intuitionistic fuzzy proximity relation corresponding to the attributes
. On taking into account the length of the paper, the computation of intuitionistic fuzzy proximity relation for the other attributes is omitted.
Table 5. Intuitionistic fuzzy tolerance relation for the attribute a1
Table 6. Intuitionistic fuzzy proximity relation for the attribute a2
On considering the degree of membership and non-membership values as ,
, it can be seen from that
,
;
,
;
,
;
,
;
,
;
,
;
,
;
,
;
and
.
Therefore, the objects are
indiscernible. Also, the object
is not
indiscernible with any other objects. Thus, the almost equivalence class generated is given as
In the same way, the computation is conceded for 20 crops (objects) and the almost equivalence class obtained for the attributes
are given below. It is seen that the attribute values of soil pH
are classified into four categories, namely very high, high, moderate and low. Alike, the attribute values of other attributes are also classified.
Unlike the attribute
, the attribute
is categorised into five categories, namely very high, high, moderate, low and very low. Similarly, the attributes
are categorised into 6, 5, 4, 5, 5, 6, 7, 6, 3, 4, 6, 7 and 3 categories, respectively. The maximum number of categories is observed to be 7. Let the categories are very high (Vh), high (H), moderate (M), low (L), very low (Vl), poor (P) and negligible (Ne). This condenses the quantitative information system into qualitative information system, as shown in .
5.2. Final Stage of Empirical Study
The steps involved in the final process of the empirical study are discussed in this section. Predicting the places for cultivating agricultural crops on real data sets is considered as the main objective of this article. We used back propagation feed-forward neural network (BPNN) method for the investigation taken into consideration. The method is based on minimising the mean square error (MSE) and mean percentile error (MPE). The back propagation algorithm as discussed in Section 5.4 is used to train the data set. Based on the input attribute values, and
are computed as discussed in Equations (3) and (4), respectively.
Table 7. Qualitative information system of sample dataset
Back propagation neural network is a supervised learning technique and so the training process can be terminated by declaring certain conditions. The process terminates if the network has procured the average mean square error (MSE) ≤0.5 or the number of pre-defined epochs. Generally, the number of neurons in the hidden layer is identified through trial and error basis based on MSE and MPE to get better performance. The weight coefficient is recorded, so as to identify the effect of the number of hidden neurons acquired to map the input space and the output space. The result of recording shows that the best result is obtained at 17th hidden neurons in a single hidden layer architecture. While preserving the number of neurons as 17 and the learning rate as 0.5, the MSE obtained as 0.188 with the number of epochs as 300. It is also observed that on increasing the number of hidden neurons as much as more than 200 and the number of hidden layers ≥2, the combinations could not achieve the MSE ≤0.188. So, the analysis is restricted to 17 hidden neurons with a single hidden layer. The results of MSE and MPE against the number of neurons are depicted in Figures and , respectively.
Figure 5. Number of hidden nodes using MSE.
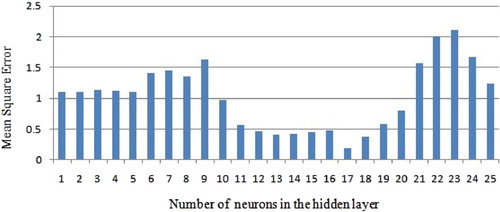
Figure 6. Number of hidden nodes using MPE.
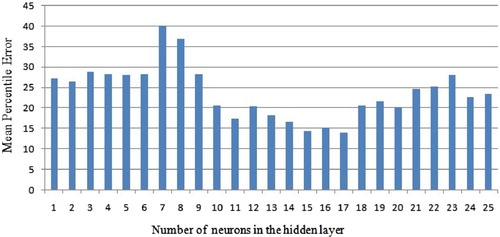
The training model is then tested with rest nine objects of qualitative information system presented in . The validation process is presented in . From , it is clear that all objects are correctly classified. Thus, the accuracy of the training process is computed as below
But, in the experimental study, it is observed that the average classification accuracy of 93.7% is achieved on increasing the number of objects to 2193. The validation process along with an experimental comparative study was carried out in Section 6 to check its viability.
Table 8. Validating the training data
6. Comparative Analysis and Results
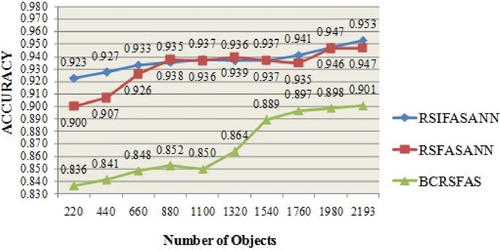
Experimental analysis has been carried out to get the efficiency of the proposed model, RSIFASANN. The experiments were conducted with a computer having Intel Pentium Processor, 8GB RAM, Windows 10 operating system and MATLAB R2008a. For analysis purpose, data are collected from Krishi Vigyan Kendra (KVK), Vellore, India. The data for 4799 villages were collected. But after careful observation, it is identified that 2193 villages are having agriculture crop production as their main occupation. The intuitionistic fuzzy proximity relation is employed on whole data for getting almost equivalence classes. This phase changes the quantitative information system to qualitative information system. Further, the qualitative data set of 2193 objects are validated with the training model. Additionally, we have chosen a model which integrates Bayesian classification and RSFAS (BCRSFAS) [Citation12]. Also, the proposed model is compared with the previous work of hybridising RSFAS with Neural network as (RSFASANN). We have randomly selected 220 objects and predicted the decision using BCRSFAS and the proposed model RSIFASANN. Further, the number of objects is randomly increased by 220. The classification accuracy against both the models was checked. The process is repeated till the whole data set of 2193 objects. The results obtained are presented in . The average accuracy obtained by the proposed model RSIFASANN is 93.7. The accuracy of model RSIFASANN is higher than the accuracy of RSFASANN and the accuracy of RSFASANN is higher than BCRSFAS.
Table 9. Comparative analysis and results.
The comparative graph is depicted in for better visualisation. From the above analysis, it is clear that the classification accuracy of RSIFASANN is higher than the other two models and hence can be considered as a better model.
Figure 7. Experimental comparative graph.
6.1. N-fold Cross-validation
Generally, a classifier is induced from the training data using a learning algorithm. It is a known fact that every classifier is associated with some prediction error. But, the prediction error is unknown, and it is difficult to calculate. At the same time, it is essential to estimate the error from the data while analysing the data in training phase. This error which is estimated based on the data considered is called the estimated predicted error. This estimated predictor error is to be validated by means of its variance and bias.
In the proposed technique, the data set is divided into training (55%) and testing data (45%). Back propagation algorithm is used as the classifier and the estimated predicted error is calculated based on the means square error and mean percentile error, by training the model with varied number of learning rate. The obtained MSE is observed as 0.188 on training the model with one hidden layer. Even though, the model is tested with more than one hidden layer, but the results are convincing enough to have a single hidden layer. Thus, out of 2193 data, the training data of 1203 data set were trained using back propagation algorithm and the testing data of 990 are tested with the least means square error. Further, the validation is performed using N-fold cross-validation and the results are presented as follows.
In N-fold cross-validation, the data set is divided into N-folds, a classifier is learned using (N – 1) folds, and an error value is calculated by testing the classifier in the remaining fold. Finally, the N-CV estimation of the error is the average value of the errors committed in each fold. Thus, the N-CV error estimator depends on two factors: the training set and the partition into folds.
The experimental analysis is performed using R language. The data set contains 15 conditional at tributes and one predictive attribute. The data set is divided with various number of folds such as N = 10, 15, 20 and 25. The MSE are recorded with respect to various fold values. A sample of the results computed using R language for N = 10 is given in , and the overall MSE is recorded in . The mean square error obtained for fold 1 is 2.6, whereas the overall mean square error obtained is 2.44. We have analysed the mean square error and overall mean square error on varying N and is presented in .
Figure 8. Mean square error of Fold 1 for N = 10.
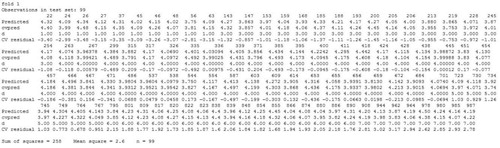
Figure 9. Overall mean square error over all folds for N = 10.

Table 10. Overall mean square error across various folds
It is seen from the that the average MSE obtained is greater than the average MSE obtained using neural network. Thus, we can say the validation carried out by hybridising rough computing with neural network provides better accuracy in prediction.
7. Conclusion
In this paper, we hybridised RSIFAS with neural network for the prediction of unseen associations of attribute values. The initial process of the proposed model reduces quantitative information system to qualitative information system using RSIFAS. The final process predicts the decision of unseen associations using back propagation neural network. The model is analysed over 20 blocks of Vellore district, Tamil Nadu. The experimental analysis depicts that the proposed model attained the average classification accuracy of 93.7%, whereas that of BCRSFAS is 86.8%. It indicates that the proposed model has 6.9% more classification accuracy than BCRSFAS. Additionally, it facilitates the farmers to take decision on the crops to be cultivated on their land.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
A. Anitha
Dr. A. Anitha is an Associate Professor in the School of Information Technology at VIT, Vellore, India. She received the MCA degree from Adhi Parasakthi College of Science, Kalavai, Tamil Nadu, India. She has published many international journal and conference papers to her credit. Her research interest includes data mining, fuzzy logic, neural network and rough sets. She is associated with the professional bodies CSI.
D. P. Acharjya
Dr. D. P. Acharjya is a Professor in the School of Computing Sciences and Engineering at VIT, Vellore, India. He received his MSc from NIT, Rourkela, India; M. Tech. in Computer Science from Utkal University, India; and PhD in Computer Science from Berhampur University, India. He has been awarded the Gold Medal in M. Sc.; Eminent Academician Award; Outstanding Educator and Scholar Award; The Best Citizens of India Award; and Bharat Vikas Award from various organizations of India. He has authored 84 international and national journal and conference papers. Besides, he has published 4 books and 17 book chapters with international publishers. In addition, he has edited 7 books with international publishers like CRC Press; Springer; and IGI Global, USA. His research interest includes rough sets, knowledge representation, machine learning, bio-inspired computing, and business intelligence. He is associated with many professional bodies, such as ACM, IACSIT, IAENG, CSTA, IRSS, CSI, ISTE, OITS, ISIAM, IMS, and AMTI.
References
- Zadeh LA. Fuzzy sets. Inf Control. 1965;8:338–353.
- Pawlak Z. Rough sets. Int J Comp Inform Sci. 1982;11:341–356.
- Pawlak Z. Rough sets – theoretical aspects of reasoning about data. Dordrecht: Kluwer Academic Publishers; 1991.
- De SK. Some aspects of fuzzy sets, rough sets and intuitionistic fuzzy sets [PhD Thesis]. Kharagpur: IIT, India; 1999.
- Acharjya DP, Tripathy BK. Rough sets on fuzzy approximation spaces and applications to distributed knowledge systems. Int J Artif Intell Soft Comput Inderscience. 2008;1(1):1–14.
- Acharjya DP, Tripathy BK. Rough sets on intuitionistic fuzzy approximation spaces and knowledge representation. Int J Artif Int Comput Res. 2009;1 (1):29–36.
- Molodstov D. Soft set theory-first results. Comp Math Appl. 1999;37(4/5):19–31.
- Peters J. Near sets-general theory about nearness of objects. Appl Math Sci. 2007;1:2609–2629.
- Dubois D, Prade H. Rough fuzzy sets and fuzzy rough set. Int J Gen Syst. 1990;17(2/3):191–209.
- Liu G. Rough set theory based on two universal sets and its applications. Knowl Base Syst. 2010;23:110–115.
- Smarandache F. Neutrosophic set – a generalization of the intuitionistic fuzzy set. Int J Pure Appl Math. 2005;24:287–297.
- Acharjya DP, Roy D, Rahaman AM. Prediction of missing associations using rough computing and Bayesian classification. Int J Intell Syst Appls. 2012;4 (11):1–13.
- Das TK, Acharjya DP. A decision making model using soft set and rough set on fuzzy approximation spaces. Int J Intel Syst Technol Applic . 2014;13(3):170–186.
- Anitha A, Acharjya DP. Neural network and rough set hybrid scheme prediction of missing associations. Int J Bioinform Res Appl. 2015;11(6):503–524.
- Ahn BS, Cho SS, Kim CY. The integrated methodology of rough set theory and artificial neural network for business failure prediction. Expert Syst Appl. 2000;18(2):65–74.
- Rao DVJ, Mitra P. A rough association rule based approach for class prediction with missing attribute values). Proceedings of the 2nd Indian international Conference on Artificial Intelligence; 2005. 20–22.
- Atanasov KT. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986;20:87–96.
- Rumelhart DE, McClelland JL. Parallel distributed processing: exploration in microstructure of cognition. Cambridge: Foundations MIT Press; 1986.
- Lippmann RP. An introduction to computing with neural nets. IEEE ASSP Mag. 1987;4(1): 4–22.
- Acharjya DP. Knowledge extraction from information system using rough computing. In: M Usman, editor. Improving knowledge discovery through the integration of data mining techniques. IGI Global, Pennsylvania, USA, 2015, p. 161–182.
- Hecht Nielsen R. Theory of the backpropagation neural network). Proceedings of the international Joint Conference on neural networks, 1 (1989), 593–605.
- Tripathy BK, Acharjya DP. Knowledge mining using ordering rules and rough sets on fuzzy approximation Spaces. Int J Adv Sci Techn. 2010;1(3):41–50.