
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A model-free adaptive control for non-affine discrete time systems is developed by utilising the output feedback and action-critic networks. Fuzzy rules emulated network (FREN) is employed as the action network and multi-input version (MiFREN) is implemented as the critic network. Both networks are constructed using human knowledge based on IF–THEN rules according to the controlled plant and the learning laws are established by reinforcement learning without any off-line learning phase. The theoretical derivation of the convergence of the tracking error and internal signal is demonstrated. The numerical simulation and the experimental system are given to validate the proposed scheme.
1. Introduction
Due to the complexity of controlled plants nowadays, it is commonly difficult or impossible to establish its mathematical model especially for the discrete time system [Citation1]. By utilising only input–output data of the controlled plant, the model-free approaches have been developed [Citation2, Citation3]. On the other hand, the performance of the controllers is related to data's quality and quantity [Citation4]. For some engineering applications, it is very difficult to access all state variables, thus the output feedback is still a preferable scheme [Citation5, Citation6]. Furthermore, the close-loop analysis and stability approaches have been proposed [Citation7, Citation8, Citation9] to guarantee the performance of controllers. From the engineering point of view, the stability analysis beside of closed-loop's performance is only a basic minimum requirement even for the artificial intelligence controller [Citation10]. Therefore, the optimal controllers are more desirable for modern applications [Citation11] or by nature view [Citation12].
To ensure the closed-loop performance with the optimisation of the predefined cost function, the schemes based on adaptive dynamic programming have been utilised but the mathematic models have been required for its iterative learning [Citation13, Citation14]. With the model-free aspects, reinforcement learning (RL) algorithms have been developed to solve optimal control [Citation15, Citation16] with the estimated solution of the Hamilton–Jacobi–Bellman equation [Citation17, Citation18]. To mimic the RL process, the approaches based on action-critic networks have been derived by artificial neural networks ( ANNs) under considering the controlled plant as a black box [Citation19, Citation20]. Nevertheless, even the mathematic model is unknown but the engineer still has basic human knowledge of the controlled plant such that ‘IF higher output is required THEN more control effort should be supplied’. Thus, the controlled plant can be considered as a grey box.
To integrate the human knowledge as IF–THEN format into the controller, fuzzy logic systems ( FLSs) have been utilised in control applications [Citation21] also including the optimal problems [Citation22]. By including the learning ability to FLS, the integrations between FLS and ANN have been developed such as fuzzy neural network (FNN) [Citation23] and fuzzy rules emulated network (FREN) [Citation24, Citation25]. Thereafter, the approaches of using FNN and FREN for solving the optimal problem with RL have been proposed [Citation26, Citation27] when the controlled plants have been considered as a class of affine systems. On the other hand, the problem of non-affine systems has been studied in Ref. [Citation28] by the approach of critic-action networks when the state feedback has been utilised for gaining enough information to tune ANNs.
In this work, the output feedback model-free controller is proposed when the control effort is non-affine with respect to system dynamics. The controller is designed by the action network called FRENa with the set of IF–THEN rules according to the controlled plant. Thereafter, the long-term cost function is estimated by the multi-input version of FREN called MiFRENc when IF–THEN rules are established under the general aspect for minimising both tracking error and control energy. The learning laws are derived with the RL approach to tune all adjustable parameters of FRENa and MiFRENc aiming to minimise the tracking error and the estimated cost function. Furthermore, the closed-loop analysis is provided by the Lyapunov method to demonstrate the convergence of the tracking error and internal signals.
This paper is organised as follows. Section 2 introduces a class of systems under our investigation and problem formulation. The proposed scheme is introduced in Section 3 including the network architectures with IF–THEN rules of FRENa and MiFRENc and their formulations. The learning laws and closed-loop analysis are derived in Section 4. Section 5 provides the results of the simulation and experimental system.
2. Controlled Plant as a Class of Nonlinear Discrete-Time Systems
In this work, the controlled plant for a class of non-affine discrete time systems is considered as
(1)
(1)
where
is the plant's output with respect to the control effort
,
is an unknown nonlinear function,
and
are unknown system orders and
denotes a bounded disturbance such that
. For further analysis, the following assumptions are expressed according to the unknown nonlinear function
with respect to the control effort
.
Assumption 2.1
The derivative of with respect to
is existed and bounded such that
(2)
(2)
where
and
are positive constants.
Remark 2.2
The condition mentioned in (Equation2(2)
(2) ) indicates that the controlled plant in (Equation1
(1)
(1) ) is a positive control direction. That will assist the setting of IF–THEN rules according to the change of control effort
altogether with the change of output
.
Referring to condition (Equation2(2)
(2) ), it is clear that the change of output
with respect to the change of control effort
can be rewritten as
(3)
(3)
where
and
and
are constants according to
and
, respectively. This will lead to the setting of IF–THEN rules such that
IF is positive-large, THEN
should be positive-large
or
IF is negative small, THEN
should be negative small.
By utilising those IF–THEN rules, the adaptive controller based on FRENs will be established in the next section.
3. RL Controller
The proposed controller is illustrated by the block diagram in Figure . In this work, the plant is selected as a DC motor current control. Only the armature current is measured as the output (mA) when the control effort
(V) is the voltage fed to the driver unit. Thus, the IF–THEN rules mentioned in Section 2 can be rewritten according to the physical nature such that
Figure 1. Closed-loop system architecture.
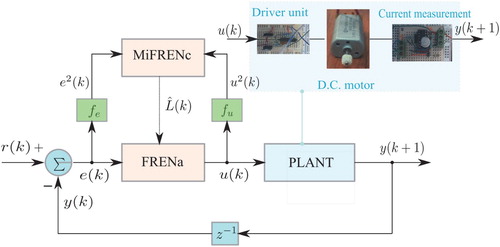
IF we apply positive-large change of control voltage [], THEN we should have positive-large change of armature current [
].
According to this knowledge, the action network (FRENa) is first established to generate the control effort when the input is the tracking error
defined as
(4)
(4)
where
is the desired trajectory. Second, the critic network is designed using MiFRENc to produce the estimated long-term cost function
for the controller FRENa. The details of two networks and its IF–THEN rules are given as follows.
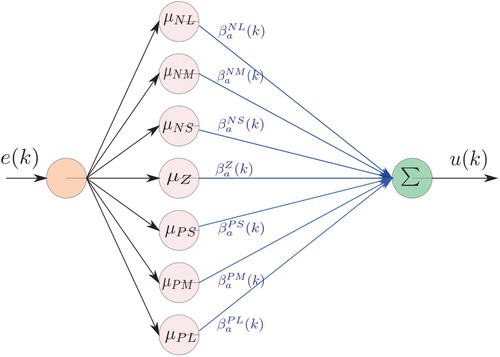
3.1. Controller or Action Network
To utilise the action network, the IF–THEN rules with the relation between the tracking error and the control effort
are first established. By considering the basic knowledge such that, positive-large
means lack of
in positive-large. In order to compensate, it clearly requires that the control effort
should be positive-large. For conclusion, we have IF
is positive-large, THEN
should be positive-large. With seven linguistic levels, it leads to the design of IF–THEN rules as
Table
where notations of linguistic variables N, P, L, M, S and Z denote negative, positive, large, medium, small and zero, respectively.
Employing this set of IF–THEN rules, the network architecture of FRENa is illustrated by Figure . According to the network architecture in Figure and the function formulation of FREN in Ref. [Citation24], the control effort is determined by
(5)
(5)
where
(6)
(6)
and
(7)
(7)
Figure 2. Action network or controller based on FREN.
Let us consider FRENa as the function estimator of the unknown control effort, thus it exists the ideal control effort with the ideal parameter
such that
(8)
(8)
where
is a bounded residual error
.
By using the dynamics (Equation1(1)
(1) ) with the control laws (Equation5
(5)
(5) ) and (Equation8
(8)
(8) ), the tracking error
is rearranged as
(9)
(9)
Recalling Assumption 1 and using mean value theorem, the error dynamic (Equation9
(9)
(9) ) can be rewritten as
(10)
(10)
where
(11)
(11)
and
. Employing the control laws (Equation8
(8)
(8) ) and (Equation5
(5)
(5) ), it yields
(12)
(12)
Let us define
,
and
(13)
(13)
and we obtain
(14)
(14)
It is worth to note that the tracking error obtained by (Equation14
(14)
(14) ) is functional by
and the unknown but bounded
such that
. This relation will be used for the performance analysis afterward.
3.2. Estimated Cost–Function or Critic Network
In this work, the long-term cost function is employed by an infinite-horizon of the tracking error
and the control effort
with the discount factor
as
(15)
(15)
where
(16)
(16)
where p and q are positive constants and
.
in (Equation15
(15)
(15) ) is functional by two input arguments with the quadratic functions (
) of
and
. Thus, an adaptive network MiFRENc is utilised to estimate
as the block diagram in Figure . In order to design MiFRENc, IF–THEN rules are first established by Table . Thereafter, the network architecture of MiFRENc is illustrated by Figure . By utilising the network in Figure and results in Ref. [Citation24], the estimated cost function
is determined by
(17)
(17)
where
(18)
(18)
and
(19)
(19)
Figure 3. Estimated cost function or critic network.
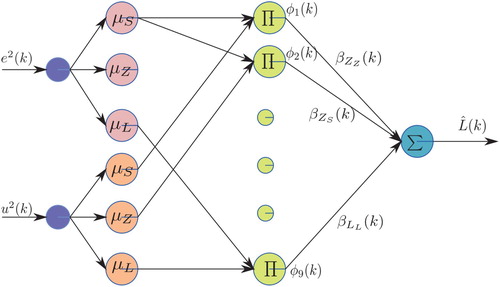
Table 1. MiFRENc: IF–THEN rules.
Using the universal approximation property of MiFREN [Citation24], there exists an ideal parameter such that
(20)
(20)
where
is a bounded residual error such that
. Adding and subtracting
on the left-hand side of (Equation17
(17)
(17) ) yields
(21)
(21)
where
and
.
In order to improve the performance of FRENa and MiFRENc, the learning laws will be developed and explained in the next section.
4. Learning Algorithms and Performance Analysis
4.1. Action Network Learning Law
Considering the tracking error within as (Equation14
(14)
(14) ) and the estimated cost function
, in this work, the error function of action network is given as
(22)
(22)
Thereafter, the cost function to be minimised is utilised as
(23)
(23)
Applying the gradient descent, the tuning law for
is derived as
(24)
(24)
where
is the learning rate. By using the chain rule and (Equation13
(13)
(13) ), it yields
(25)
(25)
Recalling (Equation24
(24)
(24) ) with (Equation25
(25)
(25) ) and using
in (Equation22
(22)
(22) ), it leads to
(26)
(26)
By eliminating
in (Equation14
(14)
(14) ), the learning law (Equation26
(26)
(26) ) is rewritten as
(27)
(27)
The final learning law of FRENa given by (Equation27
(27)
(27) ) is a practical one because all parameters required on the left-hand side are certainly obtained at the time index k + 1.
4.2. Critic Network Learning Law
In general, the error function of critic networks is employed by the estimated cost function . Therefore, in this work, the error function
is given as
(28)
(28)
where δ is a positive constant. In order to tune
, the cost function
is defined as
(29)
(29)
Applying the gradient descent at (Equation29
(29)
(29) ) with respect to
, we have
(30)
(30)
where
is the learning rate. Using the chain rule along
in (Equation29
(29)
(29) ),
in (Equation28
(28)
(28) ) and
in (Equation17
(17)
(17) ), it yields
(31)
(31)
Rewriting (Equation30
(30)
(30) ) with (Equation31
(31)
(31) ), it leads to
(32)
(32)
Finally, we have a practical tuning law for MiFRENc.
4.3. Closed-Loop Analysis
In the following theorem, the closed-loop performance of the output feedback controller is demonstrated while the tracking error and internal signals are bounded.
Theorem 4.1
For the non-affine discrete time system mentioned in Section 2, the performance of the closed-loop system configured by the structure of FRENa and MiFRENc in Section 3 is guaranteed in terms of the bonded tracking error and internal signals when the designed parameters are selected as follows:
(33)
(33)
(34)
(34)
and
(35)
(35)
where
and
are upper limits of
and
, respectively.
Proof : The proof is given in Appendix.
The validation of the proposed control scheme will be presented in the next section for the computer simulation system with a non-affine discrete time system and the hardware implementation system for DC motor current control plant.
5. Simulation and Experimental Systems
5.1. Simulation System and Results
The controller developed in this work is first implemented on the nonlinear discrete time given as
(36)
(36)
It is worth to mention that the mathematic model in (Equation36
(36)
(36) ) is used only to establish the simulation. In this test, the desired trajectory is given as
(37)
(37)
where
as the maximum time index,
and
. To follow (Equation33
(33)
(33) ), δ is selected as
and
. By using this setting and (Equation35
(35)
(35) ), the learning rate of MiFRENc is determined as
(38)
(38)
In this case, the learning rate for MiFRENc is selected as
. To select the learning rate of FRENa, let us chose
and
as 1 and 6, respectively. By using (Equation34
(34)
(34) ), the learning rate of FRENa is determined as
(39)
(39)
Thus, the learning rate for FRENa is selected as
.
Figures and illustrate the setting of membership functions for FRENa and MiFRENc, respectively. The initial setting of adjustable parameters for FRENa and MiFRENc is given as Table .
Figure 4. FRENa membership functions: simulation case.
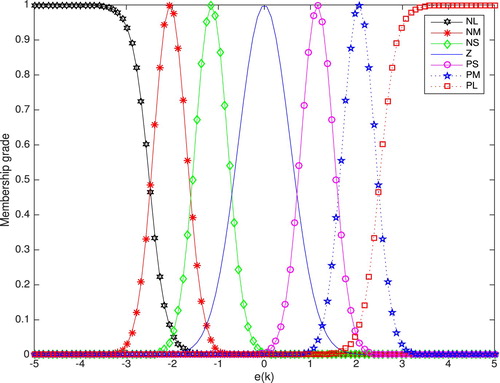
Figure 5. MiFRENc membership functions: simulation case.
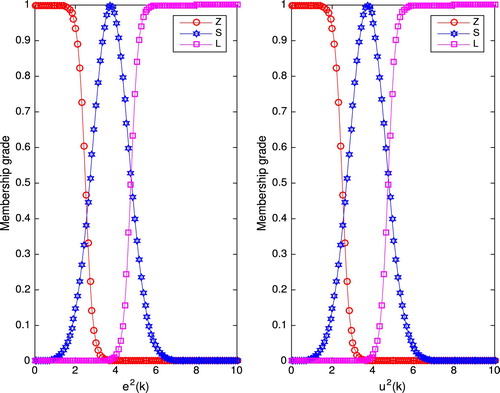
Table 2. Initial setting : simulation system.
Figure displays the tracking performance with both plots of and
and Figure represents the control effort
. The estimated cost function
is illustrated in Figure . The phase plane trajectory of
and
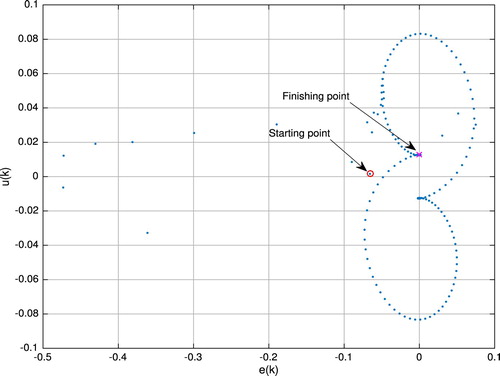
is depicted in Figure to demonstrate the closed-loop system's behaviour.
Figure 6. Tracking performance and
: simulation system.
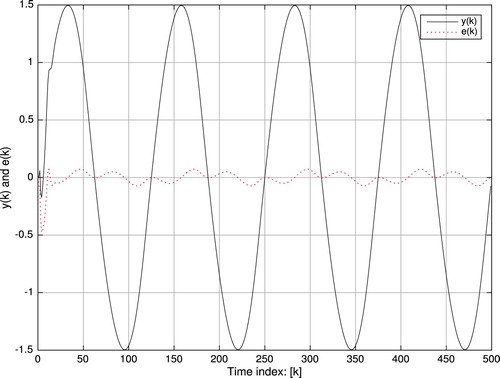
Figure 7. Control effort : simulation system.
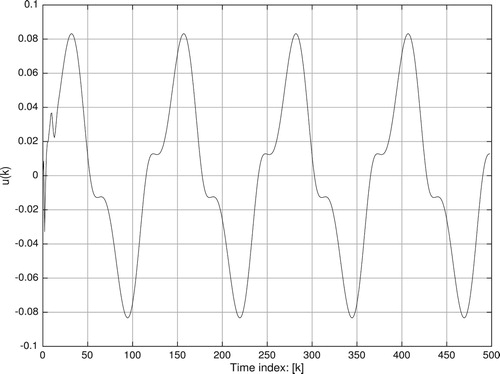
Figure 8. Estimated cost function : simulation system.
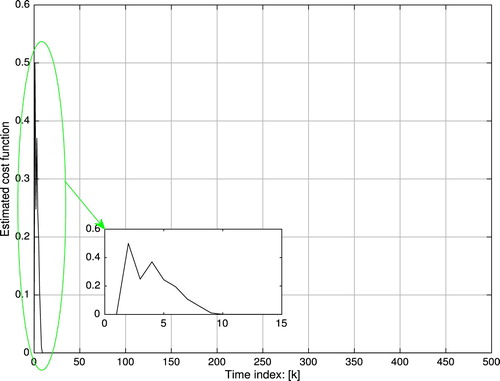
Figure 9. and
: simulation system.
5.2. Experimental System and Results
The experimental system is constructed by a DC motor current control. The output is the armature current (mA) and the input
is the control voltage applied to the driver circuit depicted in Figure . Same as the simulation systems, let us select
,
,
and
. Thus, the learning rate of FRENa is designed as
(40)
(40)
In this case, we select
. For MiFRENc, we use the same learning rate as the simulation system such that
because of the same network architecture. The desired trajectory is given as
(41)
(41)
where
(42)
(42)
(43)
(43)
and
2000.
Figures and represent the setting of membership functions of FRENa and MiFRENc, respectively. All adjustable parameters for FRENa and MiFRENc are initialised as the setting in Table .
Figure 10. FRENa membership functions: experimental system.
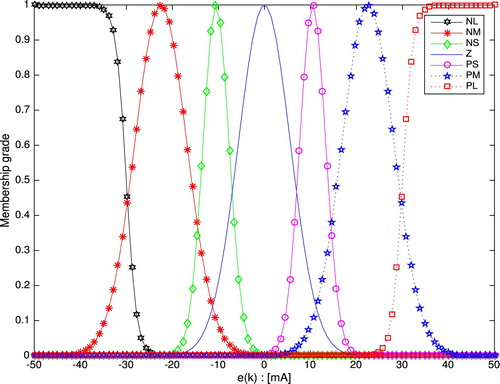
Figure 11. MiFRENc membership functions: experimental system.
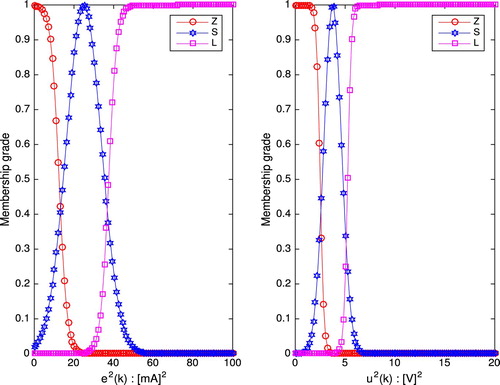
Table 3. Initial setting : experimental system.
Figure displays the motor current and the tracking error
to demonstrate the performance of the closed-loop system. The maximum absolute value of tracking error is
(mA) and the average absolute value of tracking error at steady state is 0.4924 (mA) when
1500–2000. Figure shows the control effort
. The estimated cost function
is illustrated in Figure . The phase plane trajectory of
and
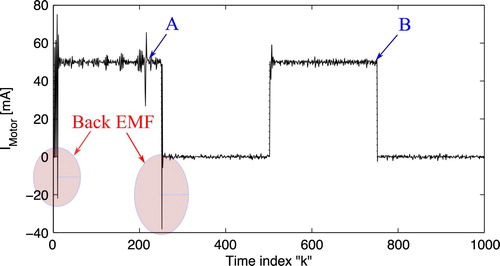
is plotted in Figure . Thus, the large variation is detected because of the back-EMF. In order to evaluate the proposed scheme working under the situation of back-EMF, the pulse-train trajectory is implemented with the response displayed in Figure . It is clear that the effect of back-EMF is eliminated within the second pulse (B).
Figure 12. Tracking performance and
: experimental system.
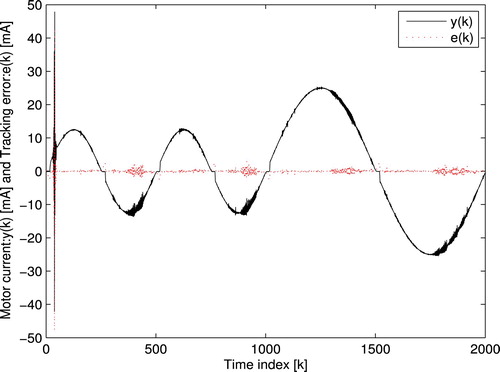
Figure 13. Control effort : experimental system.
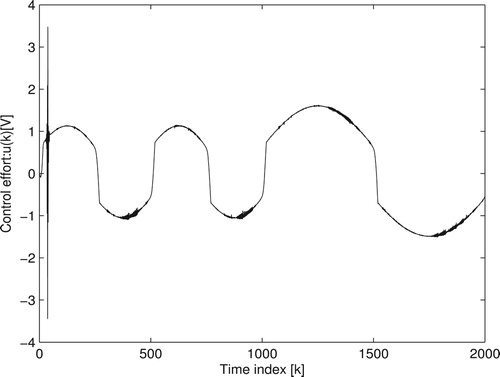
Figure 14. Estimated cost function : experimental system.
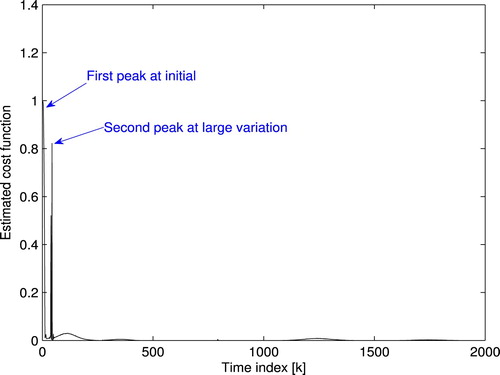
Figure 15. and
: experimental system.
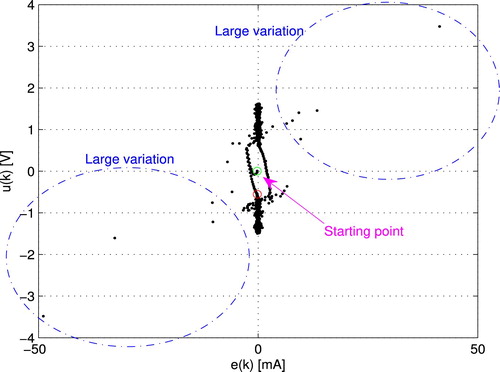
Figure 16. Pulse response: experimental system.
6. Conclusions
A model-free adaptive control for a class of non-affine discrete time systems has been developed by RL. The closed-loop system has been established by the output feedback with two adaptive networks FRENa and MiFRENc. The initial settings of FRENa and MiFRENc have been conducted according to the human knowledge of the controlled plant within the format of IF–THEN rules. The performance has been enchanted by the learning laws for both FRENa and MiFRENc while the tracking error and internal signals have been guaranteed the convergence over the reasonable compact sets. The numerical system and experimental results have represented to verify theoretical conjecture.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
C. Treesatayapun
C. Treesatayapun received the Ph.D. in elec- trical engineering from Chiang-Mai University, Thailand, in 2004. He was a production engineer at SAGA Elec- tronics (JRC-NJR) from 1998-2000 and was a head of electrical engineering program at North Chiang-Mai University, Thailand from 2001- 2007. He is currently a senior researcher at Department of robotic and advanced manufac- turing, Mexican Research Center and Advanced Technology, CINVESTAV-IPN, Saltillo campus, Mexico. His current research interests include automation and robotic system control and optimization, adaptive and learning algorithms and electric machine drives.
References
- Hou ZS, Wang Z. From model-based control to data-driven control: survey, classification and perspective. Inf Sci. 2013;235:3–35.
- Zhu Y, Hou ZS. Data-driven MFAC for a class of discrete-time nonlinear systems with RBFNN. IEEE Trans Neural Netw Learn Syst. 2014;25(5):1013–1020.
- Wang X, Li X, Wang J, et al. Data-driven model-free adaptive sliding mode control for the multi degree-of-freedom robotic exoskeleton. Inf Sci. 2016;327:246–257.
- Lin N, Chi R, Huang B. Data-driven recursive least squares methods for non-affined nonlinear discrete-time systems. Appl Math Modell. 2020;81:787–798.
- Kaldmae A, Kotta U. Input–output linearization of discrete-time systems by dynamic output feedback. Eur J Control. 2014;20:73–78.
- Treesatayapun C. Data input–output adaptive controller based on IF–THEN rules for a class of non-affine discrete-time systems: the robotic plant. J Intell Fuzzy Syst. 2015;28:661–668.
- Liu YJ, Tong S. Adaptive NN tracking control of uncertain nonlinear discrete-time systems with nonaffine dead-zone input. IEEE Trans Cybern. 2015;45(3):497–505.
- Zhang CL, Li JM. Adaptive iterative learning control of non-uniform trajectory tracking for strict feedback nonlinear time-varying systems with unknown control direction. Appl Math Model. 2015;39:2942–2950.
- Precup RE, Radac MB, Roman RC, et al. Model-free sliding mode control of nonlinear systems: algorithms and experiments. Inf Sci. 2017;381:176–192.
- Raj R, Mohan BM. Stability analysis of general Takagi–Sugeno fuzzy two-term controllers. Fuzzy Inf Eng. 2018;10(2):196–212.
- Zhang X, Zhang HG, Sun QY, et al. Adaptive dynamic programming-based optimal control of unknown nonaffine nonlinear discrete-time systems with proof of convergence. Neurocomputing. 2012;35:48–55.
- Eftekhari M, Zeinalkhani M. Extracting interpretable fuzzy models for nonlinear systems using gradient-based continuous ant colony optimization. Fuzzy Inf Eng. 2013;5(3):255–277.
- Liu D, Wang D, Yang X. An iterative adaptive dynamic programming algorithm for optimal control of unknown discrete-time nonlinear systems with constrained inputs. Inf Sci. 2013;220(20):331–342.
- Jiang H, Zhang H. Iterative ADP learning algorithms for discrete-time multi-player games. Artif Intell Rev. 2018;50(1):75–91.
- Liu D, Wang D, Zhao D, et al. Neural-network-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming. IEEE Trans Autom Sci Eng. 2012;9(3):628–634.
- Kiumarsi B, Lewis FL, Modares H, et al. Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics. Automatica. 2014;50(4):1167–1175.
- Yang Q, Jagannathan S. Reinforcement learning controller design for affine nonlinear discrete-time systems using online approximators. IEEE Trans Syst Man Cybern B Cybern. 2012;42(2):377–390.
- Ha M, Wang D, Liu D. Event-triggered constrained control with DHP implementation for nonaffine discrete-time systems. Inf Sci. 2020;519:110–123.
- Xu B, Yang C, Shi Z. Reinforcement learning output feedback NN control using deterministic learning technique. IEEE Trans Neural Netw Learn Syst. 2014;25(3):635–641.
- Liu YJ, Li S, Tong S, et al. Adaptive reinforcement learning control based on neural approximation for nonlinear discrete-time systems with unknown nonaffine dead-zone input. IEEE Trans Neural Netw Learn Syst. 2019;30(1):295–305.
- Allam E, Elbab HF, Hady MA, et al. Vibration control of active vehicle suspension system using fuzzy logic algorithm. Fuzzy Inf Eng. 2010;2(4):361–387.
- Niftiyev AA, Zeynalov CI, Poormanuchehri M. Fuzzy optimal control problem with non–linear functional. Fuzzy Inf Eng. 2011;3(3):311–320.
- Fei J, Wang T. Adaptive fuzzy-neural-network based on RBFNN control for active power filter. Int J Mach Learn Cybern. 2019;10:1139–1150.
- Treesatayapun C, Uatrongjit S. Adaptive controller with fuzzy rules emulated structure and its applications. Eng Appl Artif Intell. 2005;18:603–615.
- Treesatayapun C. Adaptive control based on IF–THEN rules for grasping force regulation with unknown contact mechanism. Robot Comput Integr Manuf. 2014;30:11–18.
- Abouheaf M, Gueaieb W. Neurofuzzy reinforcement learning control schemes for optimized dynamical performance. 2019 IEEE International Symposium on Robotic and Sensors Environments (ROSE). Ontario, Canada; 2019 June. p. 17–18.
- Treesatayapun C. Fuzzy-rule emulated networks based on reinforcement learning for nonlinear discrete-time controllers. ISA Trans. 2008;47:362–373.
- Wei Q, Lewis FL, Sun Q, et al. Discrete-time deterministic q-learning: a novel convergence analysis. IEEE Trans Cybern. 2017;47(5):1224–1237.
Appendix 1.
Proof of Theorem 4.1
Let us refer to the standard Lyapunov function as
(A1)
(A1)
where
,
,
and
are positive constants satisfying the following conditions:
(A2)
(A2)
(A3)
(A3)
(A4)
(A4)
and
(A5)
(A5)
Utilising (Equation14
(14)
(14) ),
is obtained as
(A6)
(A6)
Recalling the tuning law in (Equation26
(26)
(26) ),
is expressed as
(A7)
(A7)
Applying the lower bound and upper bound of
, it leads to
(A8)
(A8)
By using the learning law of MiFRENc in (Equation32
(32)
(32) ),
is derived as
(A9)
(A9)
Recalling
in (Equation28
(28)
(28) ) with
and
and using (EquationA10
(A10)
(A10) ), it yields
(A10)
(A10)
or
(A11)
(A11)
By using (EquationA11
(A11)
(A11) ) and (Equation16
(16)
(16) ), (EquationA9
(A9)
(A9) ) can be derived as
(A12)
(A12)
Finally,
is formulated as
(A13)
(A13)
Recalling (EquationA6
(A6)
(A6) ), (EquationA8
(A8)
(A8) ), (EquationA12
(A12)
(A12) ) and (EquationA13
(A13)
(A13) ),
is rewritten as
(A14)
(A14)
where
(A15)
(A15)
(A16)
(A16)
(A17)
(A17)
(A18)
(A18)
(A19)
(A19)
and
(A20)
(A20)
According to the conditions in (EquationA2
(A2)
(A2) ) – (EquationA5
(A5)
(A5) ),
,
,
and
are always positive. Furthermore, by setting the membership functions of FRENa and MiFRENc, the upper limits exist such that
(A21)
(A21)
and
(A22)
(A22)
Combining with (Equation34
(34)
(34) ) and (Equation35
(35)
(35) ), it leads to
(A23)
(A23)
and
(A24)
(A24)
By this mean, we have
(A25)
(A25)
(A26)
(A26)
and
(A27)
(A27)
The proof is completed here.