
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this paper, we apply a new definition of truncated distribution “Internal Truncated Distribution” on the Wiener process range distribution to delete a few stochastic volatility intervals from its domain. A comprehensive treatment of the statistical properties of this distribution is presented. The usefulness of the proposed distribution is illustrated with the help of a real data set.
1. Introduction
During the first three decades of the twentieth century, Norbert Wiener discovered a new stochastic process called Wiener process . Also, this process is called a standard Brownian motion. The Wiener process has a remarkable importance in the mathematical theory of finance, in particular, the Black–Schools option pricing model. We know that at any time interval
, the Wiener process range is the best random variable which illustrates the difference between the highest and lowest value of the sale price. This range is defined by
, where
and
Early, Feller [Citation1] used the method of images to derive the probability density function of this range. Recently, Withers and Nadarajah [Citation2] gave an expansion for its cumulative distribution function and its quantiles. More recently, Teamah et al. [Citation3] asked an interesting question, that is; what should be done if we need to find the new distribution of the stock price in the time interval
and its value is sandwiched between two certain values
? Already, they answered the above question by using the truncation method on the Wiener process range distribution that was obtained by Feller [Citation1]. Also, Teamah et al. [Citation3] presented some statistical properties of this distribution including reliability properties, moments, stress-strength parameter, order statistics, Bonferroni curve, Lorenz curve and Gini's index.
The idea of the truncation method of any distribution is to delete a certain period from its random variable domain and then find its conditional distribution. The probability of the truncated part is distributed on the other part until the area under the new curve (curve after truncated) becomes equal to one. There are two kinds of truncation: (i) single truncation from one, left or right side of the domain and (ii) double truncation from both sides of the domain. In [Citation4–8], some details about truncated distribution have been discussed.
Here, we have a more interesting question; that is; what happened for the Wiener range distribution if we want to delete some intervals which contain few stochastic volatility of the stock price? In other words, why we consider these intervals (which contain few stochastic volatility) for this distribution? In order to address this problem, we present a new definition called “multi-internal truncated distribution” to delete these intervals from the Wiener process range which has been obtained by Feller [Citation1]. In this definition, we redistribute the probabilities of the truncation parts to the remaining parts. Another feature of this definition allows us to distribute these probabilities with different proportions to the remaining parts.
In this paper, we will present one internal truncated distribution of a Wiener process range (i.e. we want to delete one interval from the range such that
and
) and study comprehensive treatment of the statistical properties. The properties studied include reliability properties, moments, stress-strength parameter, Bonferroni curve, Lorenz curve and Gini's index. The difference between the one internal truncated distribution and distribution of a Wiener process range which has been obtained by Feller [Citation1] are shown as in the given figures through this paper.
This paper is organized as follows. In Section 2, we present the definition of one internal truncated Wiener process range distribution. We discuss some statistical properties for one internal truncated distribution in Section 3. A data set application is presented in Section 4. Section 5 ends this paper with some concluding remarks and future works.
2. One internal truncated distribution of a Wiener process range
Sometimes, we need to delete some values of the domain of the stock price which is assumed to move randomly according to one dimensional Wiener process , where
+ is the set of real numbers, and
is a Wiener process on
with the range
on the time interval
. This range is the difference between
and
. Feller [Citation1] gave the probability density function for the range of
which controls the target's motion as
(1)
(1)
where
and
(see Figure ).
Figure 1. Probability density function of .
In addition, Withers and Nadarajah [Citation2] give its cumulative distribution function by
(2)
(2)
In real life, we know that the value of the stock price in the time interval is sandwiched between two certain values
(see Figure ). In this case, Teamah et al. [Citation3] gave the distribution of this bounded range by make double truncation of (1) as
(3)
(3)
where
and
Figure 2. Distribution function of .
In this work, we aim to delete some values from the domain of the range. These values show that there are no or few stochastic volatility. We are interested in the distribution of multi-internal truncated random variables which is defined by:
Definition 2.1:
Let be a random variable with known probability density function, define
as a corresponding n-internal truncated of the random variable
with pdf
. Then, the probability density function of multi-internal of
is given by
where
.
The idea of the above definition has been drawn from the idea of left, right and double truncation which is studied in [Citation9–11]. In our definition, we distribute the area under the probability curve on the remaining parts with equal proportions.
In our problem, we consider that the range has one interval that contains few stochastic volatility (there are very small changes in option price) and we need to truncate this interval. From Definition 2.1, we can do one internal truncation for (1). Consequently, we get
(4)
(4)
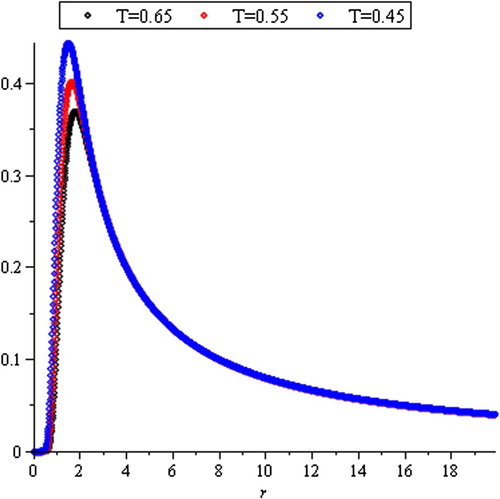
Figure represents the Wiener process range density function after deleting a few stochastic volatility interval with increasing the value of
.
Figure 3. Probability density function of R(T).
It is clear that the probability of the truncated area is equally distributed between the remaining parts and make the probability of some values of R(T) attain its maximum value (approximately 0.73). On the contrary, the maximum probability of some values of R(T) is approximately 0.43 (see Figure ). But the two curves confine two equal areas. From here, we can delete the few stochastic volatility interval from the domain of the Wiener process range by using the probability density function (4).
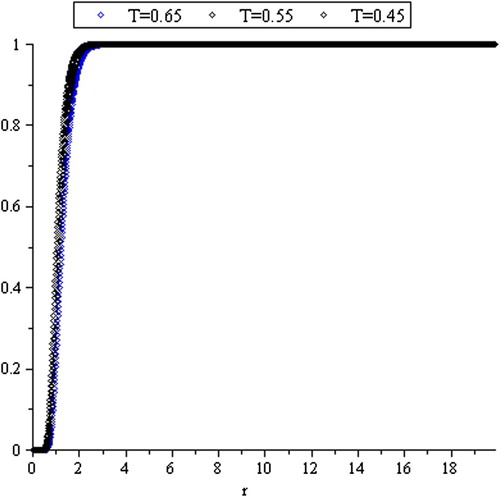
The cumulative distribution function of (4) is given by
Since the time interval which not containing any random fluctuations was deleted, the probability of this interval should be distributed on the other parts. Consequently, we have
(5)
(5)
and it is represented in Figure .
Figure 4. Cumulative distribution function of .
We know that the survival function is given by , but according to Definition 2.1, the internal truncated survival function of
is given by
(6)
(6)
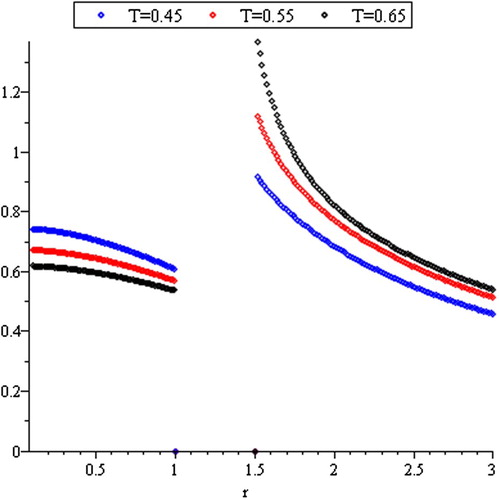
From Figure , we notice that the internal truncated survival function is decreasing by increasing the value of
Figure 5. Survival function of R(T).
3. Some statistical properties
Teamah et al. [Citation3] studied various statistical properties of the stock price distributions that arise when prices follow a Wiener process range distribution (truncated and nontruncated). Rather than presenting the shape of the probability distribution and the hazard rate functions, a comprehensive treatment of the statistical properties of this distribution is presented including, moments, Bonferroni curve, stress-strength parameter, Lorenz curve and Gini's index.
3.1. Reliability properties
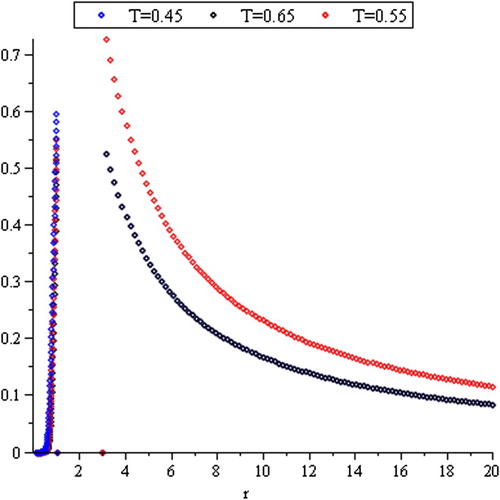
In some cases, the stock price may be changed to a large extent, over a day or a month or a year. This differs continuous movement which known as the price fluctuations, where the price of the stock price is more volatile than other stock price. Thus, the swings between fall and rise of the stock price during the time interval affect the risk rate (hazard rate). The hazard function is a very useful function in lifetime analysis, see Marshall and Olkin [Citation12]. Generally, Teamah et al. [Citation3] studied this effect when the range is bounded. In the case of deleting a few stochastic volatility interval from the range, the hazard rate function is given by
(7)
(7)
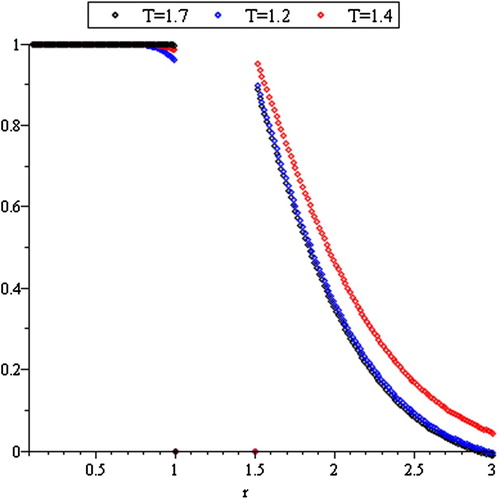
and it is represented in .
Figure 6. Hazard rate function of R(T).
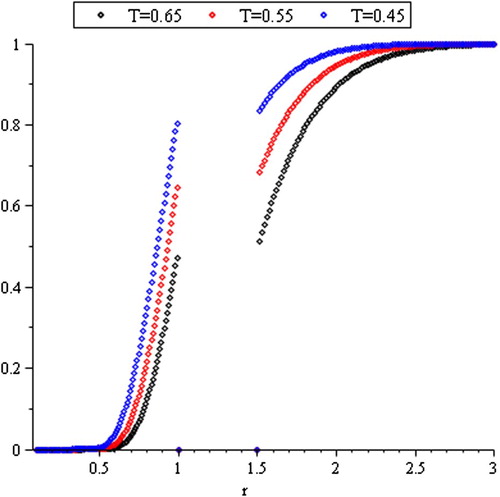
Also, the reversed hazard rate function is
(8)
(8)
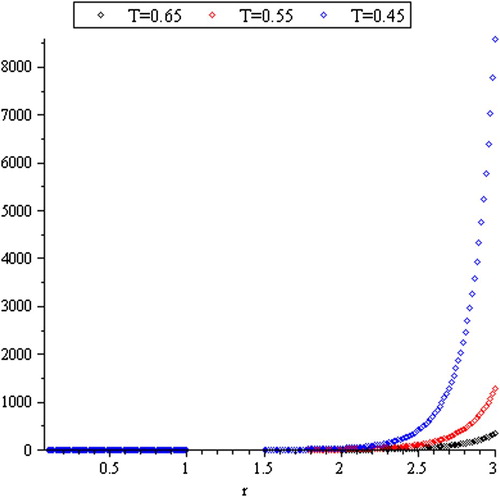
Clearly, when the range increases, the hazard rate approaches zero and increases rapidly as
falls to zero (see ).
Figure 7. Reversed hazard rate function of R(T).
3.2. Moments
Moments are useful for the internal truncated distribution of the Wiener range. The generating, characteristic functions and moments of the range distribution (1) [Citation2] are found. Also, Teamah et al. [Citation3] presented some statistical properties of the double truncated Wiener range distribution including moments. Here, if has one internal truncation and
then the moment generating function (m.g.f.) of
takes the form
(9)
(9)
where and not equal to 0, because when displaying stock for sale (at the moment 0) the difference between the highest and the lowest prices is greater than zero, even by a small percentage
. At this moment, there is only the highest price either the lower price equal to 0.
Assuming that ,
and
Thus, one can get
(10)
(10)
And
It is known that the expansion of the exponential function is valid for
and gives a uniformly convergent series, then we get
Let
, where
(11)
(11) and
(12)
(12) By solving the following equations,
(13)
(13)
(14)
(14)
as diophantine equations, we have the set solution for (13) given by
(15)
(15)
and for (14)
(16)
(16)
Hence, can be written as follows:
(17)
(17)
Also, can be written as follows:
(18)
(18)
In real-life problem and at any time, we do not have the ability to see that the difference between the highest and the lowest prices tends to infinity. Infinity here means that the difference attains its maximum which the statistician and the economists consider them as a known value. Thus, in mathematical calculations we can consider that the greatest and the maximum value of the difference is equal to which tends to infinity (i.e.
).
Now, the integral is equivalent to the integral
which can be calculated as (10). Compensation for
in (17) and (18) we have,
=
(19)
(19)
Consequently, from (17), (18) and (19) we have,
(20)
(20)
According to the solution method by Teamah et al. [Citation3] and using (4), one can obtain the moments of about the origin by
(21a)
(21a)
where is the exponential integral function and
In addition, the characteristic function is given by
(21)
(21)
where
,
and
For a wider view of the main idea of this paper, it could be useful to consider Milev et al. [Citation13,Citation14]. They obtained via moments and entropy valuation for the probability distributions.
3.3. Stress-strength parameter
The probability of mechanical component failure is based on the probability of stress exceeding strength. Thus, let , where
and
are two independent random variables distributed as in (4) and represent the strength and stress of
, respectively. We consider
as the stress-strength parameter which describes the change of stock price. Church and Harris [Citation15] showed that the changing of
at the instant times
that the stress applied to it exceeds the strength. They showed that this function changes satisfactorily whenever
. Thus, for one internal truncated distribution of the range,
can be expressed as
Now, we find by assuming that
Then,
Assuming that
where
and
By the same method, if we let then we have
where
and
Consequently,
(22)
(22)
3.4. Bonferroni curve, Lorenz curve and Gini's index
Lorenz curve and Gini's index are important measures for income inequality. They are useful in business modelling, for example, Lorenz curve is used in consumer finance, to measure the actual percentage of delinquencies attributable to the percentage of people with worst risk scores. Bonferroni curve can also be related to the Lorenz Curve and Gini ratio, see Giorgi and Mondani [Citation16] and Giorgi [Citation17]. These measures have useful applications in reliability and life testing as in Giorgi and Crescenzi [Citation18].
The Lorenz curve can be obtained by using the equation
(23)
(23)
where
The Gini index which is defined as a ratio of the areas on the Lorenez curve is given by
where
is given above;
is given above and
In (21) we showed that the first moment of about zero is finite, exists and non-zero where
is a positive random variable with the smooth cumulative distribution function (5) (i.e. continuous function and the derivatives of all orders exist). Thus, as in Giorgi and Mondani and Giorgi the Bonferroni curve is given by
where
is given by (23) and from (5) we get
.
4. Application
Economists consider a Wiener process is the best representation for the oscillation between the fall and rise of the stock price within a time period . The Wiener process range
is the best random variable which illustrates the difference between the highest and the lowest value of the sale price. In some time intervals, we found that the values of
have approximately the same values under the effect of PDF (1). This phenomenon clearly appear in the long tail distributions. Thus, to get more accurate distribution for
, we need to delete these intervals. For studying the behaviour of
we should study some its statistical properties by using a data set which considered in Withers and Nadarajah [Citation2] and Teamah et al. [Citation3]. Here, we cannot get the real data for
because in stochastic models the data are dependent. When the owners of companies displaying the stock for sale (at the moment 0) the difference between the highest and the lowest prices is greater than zero, even by a small percentage
. Also, after time periods
, the maximum value of the difference is equal to
In this example, we let the small value of
is
(singular point) and the maximum is
. Also, we the values of
and
as in to get the probability density function, cumulative distribution function and the mean value of
. Using (21) we get the mean value of
by
Table 1. The cumulative distribution function and the mean values of  .
.
5. Concluding remarks
In this paper, we introduced a new approach for the truncation method for the statistical distributions. The principal idea of this approach is to delete a certain period from its random variable domain and then find its conditional distribution. The probability of the truncated part is distributed on the other part until the area under the new curve (curve after truncated) becomes equal to one. The idea of the previous approach was to delete the right part or the left part of the random variable definition interval. Our approach (multi-internal truncated distribution) that presented here is more general than this approach as it is possible to delete parts of the left, right and middle of the random variable definition interval.
We considered the distribution of the range for the Wiener process. This distribution is the best for the stock price in a limited range. In this paper, we presented one internal truncated distribution of a Wiener process range (i.e. we deleted one interval from the range such that
and
). We provided a mathematical treatment to find some statistical properties including reliability properties, moments, stress-strength parameter, Bonferroni curve, Lorenz curve and Gini's index. A data set is analysed to clarify the effectiveness of this distribution. We hope that this distribution may attract a wide application in lifetime modelling.
In future research, one can introduce a new type of middle and random truncation for the range of a Wiener process.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Feller W. The asymptotic distribution of the range of sums of independent random variables. Ann Math Stat. 1951;22:427–432. doi: 10.1214/aoms/1177729589
- Withers C, Nadarajah S. The distribution and quantiles of the range of a Wiener process. Appl Math Comput. 2014;232:766–770.
- Teamah A, El-Hadidy M, El-Ghoul M. On bounded range distribution of a Wiener process. Commun Stat - Theory Methods. 2017; forthcoming. doi:10.1080/03610926.2016.1267766.
- Pender J. The truncated normal distribution: applications to queues with impatient customers. Oper Res Lett. 2015;43:40–45. doi: 10.1016/j.orl.2014.10.008
- Chattopadhyay S, Murthy CA, Pal SK. Fitting truncated geometric distributions in large scale real world networks. Theor Comput Sci. 2014;551:22–38. doi: 10.1016/j.tcs.2014.05.003
- Zaninetti L. A right and left truncated gamma distribution with application to the stars. Adv Stud Theor Phys. 2014;23:1139–1147.
- Dodge Y. The Oxford dictionary of statistical terms. 6th ed. Oxford: Oxford University Press; 2003. ISBN 0-19-920613-9.
- Johnson NL, Kotz S, Balakrishnan N. Continuous Univariate distributions, Volume 1. New York: Wiley; 1994. ISBN 0-471-58495-9.
- Ali M, Nadarajah S. A truncated Pareto distribution. Comput. Commun. 2006;30:1–4. doi: 10.1016/j.comcom.2006.07.003
- Nadarajah S. Some truncated distributions. Acta Appl Math 2009;106:105–123. doi: 10.1007/s10440-008-9285-4
- Zaninetti L, Ferraro M. On the truncated Pareto distribution with applications. Cent. Eur. J. Phys. 2008;6(1):1–6.
- Marshall A, Olkin I. Life distributions: structure of nonparametric, semiparametric, and parametric families. Springer New York: Springer Series in Statistics; 2007.
- Milev M, Inverardi P, Tagliani A. Moment information and entropy valuation for probability Densities. Appl Math Comput. 2012;218(9):5782–5795.
- Milev M, Tagliani A. Entropy convergence of finite moment approximations in Hamburger and Stieltjes problems. Stat Probab Lett. 2017;120:114–117. doi: 10.1016/j.spl.2016.09.017
- Church JD, Harris B. The estimation of reliability from stress strength relationships. Technometrics. 1970;12:49–54. doi: 10.1080/00401706.1970.10488633
- Giorgi GM, Mondani R. Sampling distribution of Bonferroni inequality index from exponential population. Sankhya B. 1995;57:10–18.
- Giorgi GM. Concentration index, Bonferroni. In: Encyclopedia of Statistical Sciences. Vol. 2 New York: Wiley; 1998. p. 141–146.
- Giorgi GM, Crescenzi M. A look at the Bonferroni inequality measure in a reliability framework. StatisticaLXL. 2001;4:571–583.