
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we introduce a new distribution generated by an integral transform of the probability density function of the weighted exponential distribution. This distribution is called the weighted exponential-Gompertz (WE-G). Its hazard rate function can be increasing and bathtub-shaped. Several statistical properties of the new model are obtained, such as moment generating function, moments, conditional moments, mean inactivity time, mean residual lifetime and Rényi entropy. The maximum likelihood estimation of unknown parameters is introduced. A real data application demonstrates the performance of the new model.
1. Introduction
Numerous extended distributions have been extensively used over the last decades for modelling data in several areas. Recently, there has been an increased interest in defining new families of distributions by adding one or more parameters to the baseline distribution which provide great flexibility in modelling data in practice. For example, Eugene et al. [Citation1] proposed the beta generated method that uses the beta distribution with parameters and
as the generator. The cumulative distribution function (cdf) of a beta generated random variable
is defined as
(1)
(1) where G(x) is the cdf of any random variable X.
Zografos and Balakrishnan [Citation2] have presented a new family of distributions generated by a gamma random variable. This family has the following cdf
(2)
(2) where
is a survival function which is used to generate a new distribution.
Also, Ristic’ and Balakrishnan [Citation3] introduced a new family of distributions with survival function defined as
(3)
(3)
On the same line, we provide a new family of distributions generated by the weighted exponential distribution.
A random variable has a weighted exponential (WE) distribution if its pdf is given by
(4)
(4) where
is the shape parameter and
is the scale parameter.
The corresponding cdf is
(5)
(5)
More details on the WE distribution can be founded in Gupta and Kundu [Citation4].
In this paper, we introduce a new family of distributions generated by an integral transform of the pdf of a random variable which follows WE distribution. The survival function of this family is defined by
(6)
(6) and the pdf
(7)
(7)
where and
are the baseline cdf and pdf which depends on a
parameter vector
and
are two additional parameters. Henceforth, we refer this family as WE-G family.
Now we give some motivations for the WE-G family of distributions:
Motivation 1:
In fact, the particular case of Equation (7) for and
with parameter
is the exponential with parameter
Motivation 2:
Further, if in addition to
for
the Equation (7) gives the pdf of Kumaraswamy's distribution with parameters
Motivation 3:
It is observed that when the family (7) reduced to transmuted-G family with parameter
proposed by Shaw and Buckley [Citation5] with pdf
Motivation 4:
Substituting in Equation (7), we obtained the pdf of the generalized transmuted-G family with parameters
proposed by Nofal et al. [Citation6] as
Motivation 5:
If we take the family defined by Equation (7) gives the Kumaraswamy-G family with parameters
proposed by Cordeiro and de Castro [Citation7].
In the following sections, we study the properties of a special case of this family, when is the cdf of the Gompertz distribution. In this case, the random variable
is said to have the weighted exponential-Gompertz distribution.
The reminder of this paper is organized as follows. In Section 2, the weighted exponential-Gompertz distribution is studied in detail. In Section 3, we provide expansions for weighted exponential-Gompertz cumulative and density functions. In Section 4, we present various properties of the new model such as moment generating function, moments and conditional moments. Also, some reliability properties including mean inactivity time function, mean and variance of (reversed) residual lifetime of the our model are discussed in Section 5. In Section 6, Rényi entropy is justified for our proposed model. Order statistics are obtained in Section 7. In Section 8, the maximum likelihood estimator of the parameters of our model is obtained. Section 9 gives an application to a real data set.
2. Weighted exponential-Gompertz distribution
The Gompertz (G) distribution has the pdf
(8)
(8) and its cdf is
(9)
(9)
The Gompertz distribution plays an important role in modelling reliability, human mortality and actuarial data that have hazard rate with an exponential increase. An extension version of Gompertz is the weighted Gompertz distribution discussed by Bakouch and Abd El-Bar [Citation8].
From Equations (6–9), we introduce the weighted exponential-Gompertz (WE-G) distribution.
Definition:
A random variable is said to follow a
distribution, if its pdf has the form
(10)
(10)
The survival and the hazard rate functions corresponding to (10) are, respectively, defined by
(12)
(12) and
(13)
(13)
Figure illustrates the shapes of the pdf of the WE-G distribution for some various values of the shape parameters and
in the case of
and
for graphs (a), (b), (c) and in the case of
and
for graph (d). It can be summarized some of the shape properties of our model as:
The pdf is monotonically decreasing when
and
The pdf is reversed-J when
The pdf is left-skewed when
The pdf is right-skewed when
Figure 1. Plots of the density function of WE-G distribution for some values of and
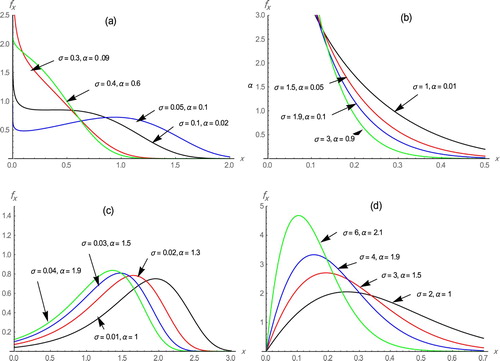
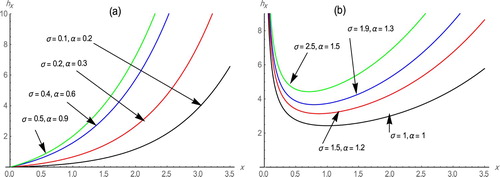
Figure gives some of the possible shapes of the hazard rate function of the WE-G distribution for some various values of the shape parameters and
in the case of
and
for graph (a) and in the case of
and
for graph (b). It can be summarized some of the shape properties of the hazard rate function of WE-G as:
The hazard rate function is an increasing function for
hazard rate function is bathtub shaped for
Figure 2. Plots of the hazard rate function of WE-G distribution for some values of and
3. Expansions for the cdf and pdf
In this section, we discuss some useful expansions for the cdf and pdf of the distribution.
3.1. Expansion for the cdf
In this subsection, we introduce the expansion forms for the cdf for
We can express the WE-G cdf as an infinite linear combination of exponentiated Gompertz distribution
(14)
(14) where
and
denotes the exponentiated Gompertz distribution with parameters
and
We also obtain another expansion of the cdf of WE-G as:
From Equation (11) and expanding the term the cdf of WE-G can be rewritten as
Using power series expansion for and binomial expansion for
the cdf admits the following expansion
(15)
(15) where
3.2. Expansion for the pdf
Here, we provide simple expansions for the WE-G pdf.
Firstly, expanding the term in Equation (10) yields
Using again binomial expansion for we can express the pdf of WE-G
(16)
(16) whose weighted coefficients are
(17)
(17)
We also obtain the expression for the pdf of WE-G as a linear combination of Gompertz density function as:
(18)
(18) where
and
denotes the density function of Gompertz distribution with parameters
and
Therefore, the density function of WE-G can be expressed as an infinite linear combination of Gompertz densities.
4. Statistical properties of WE-G
In this section, we derive the main statistical properties of model for instance, the moment generating function, moments, central moments and conditional moments.
4.1. Moment generating function
Theorem 4.1:
If has the
distribution, then the moment generating function (mgf) of
is given as follows
(19)
(19)
Proof:
The mgf of a continuous random variable is defined as
Solving the above integral, we have
which completes the proof.
4.2. Moments, central moments and conditional moments
Theorem 4.2:
The WE-G random variable has the rth moment function about the origin is
(20)
(20)
Proof:
The rth moment about origin is defined by
By using the expansion form of pdf that given in Equation (16) yields
Since,
then the above integral yields the rth moment given by Equation (20).
In particular, the first four moments of are
(21)
(21)
and
Hence, the skewness and kurtosis
can be obtained using the following relations,
where
Proposition 4.1:
Let be a random variable following the WE-G distribution, then the central moments is
(22)
(22)
Proof:
By the definition of central moments, we have
(23)
(23) Substituting by the Equation (20) into Equation (23) after some simple calculations, we obtain
Remark 4.1:
The variance of model is obtained from Equation (22) for
Note: In the next sections, we will make use of the following lemma.
Lemma 4.1:
Let
Proposition 4.2:
The conditional moments of the WE-G distribution is
Proof:
The proof follows from the following definition
5. Reliability measures of WE-G
Here, we derive the expression for the mean and strong mean inactivity time functions, mean and variance of residual lifetime and reversed residual lifetime of the WE-G model.
5.1. Mean inactivity time function
The mean inactivity time (MIT) and strong mean inactivity time (SMIT) functions are an important characteristic in many applications to describe the time, which had elapsed since the failure. Many properties and applications of MIT and SMIT functions can be found in Kayid and Ahmad [Citation9], Izadkhah and Kayid [Citation10] and Kayid and Izadkhah [Citation11]. Let be a lifetime random variable with cdf
Then the MIT and SMIT respectively, are defined by
(24)
(24) and
(25)
(25)
Proposition 5.1:
The MIT function of with WE-G distribution is
(26)
(26)
Proposition 5.2:
The SMIT function of with WE-G distribution is
(27)
(27)
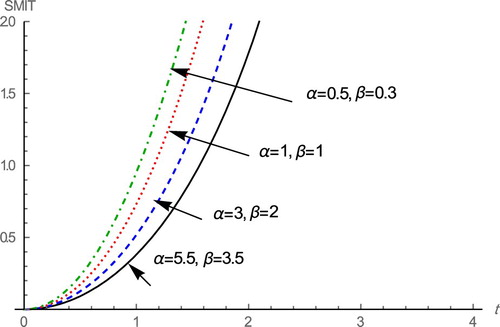
From Tables and it is observed that the MIT and SMIT are increasing for decreasing values of and
respectively.
Table 1. MIT and SMIT of WE-G distribution.
Table 2. MIT and SMIT of WE-G distribution.
From Figures and , it is note that MIT and SMIT functions of the WE-G distribution are increasing for decreasing values of and
in the case of
and
Figure 3. Plot of MIT function for different values of the parameters and
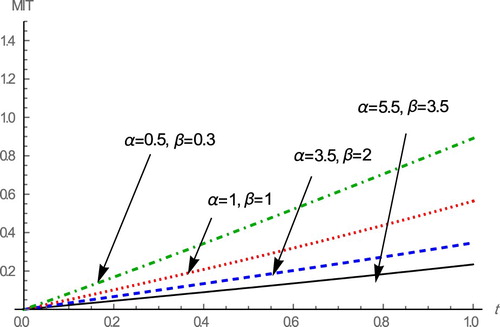
Figure 4. Plot of SMIT function for different values of the parameters and
5.2. Residual lifetime function
The residual life is the period from time until the time of failure and defined by the conditional random variable
Proposition 5.3:
The mean and variance of for the WE-G distribution are
and
respectively, where
and
can be obtained using (20),
defined by (12) and
is defined by Lemma 1 for
Proof:
The proof follows directly from the definitions:
and
5.3. Reversed residual life function
The reversed residual life is the time elapsed from the failure of a component given that its life and defined as the conditional random variable
Proposition 5.4:
The mean and variance of for the WE-G distribution are given by
and
respectively, where
defined by Equation (11).
Proof:
The proof follows using the following definitions
6. Rényi entropy
The entropy of a random variable X is a measure of variation of the uncertainty. The Rényi entropy (Rényi [Citation12]) defined as
(28)
(28)
In our case
We expand the following term as
Now, applying the power series in the last term of the above equation, we obtain the form of as
where
One can evaluate the integral of as
Then, the Rényi entropy is given by
7. Order statistics
Let be a random sample from the
distribution, and let
denote the
order statistic. The pdf of
order statistic for (
), is
(29)
(29) where
and
are the pdf and cdf of the WE-G, respectively. Using the definition of binomial expansion for the term:
, then
can be expressed as
(30)
(30)
We can write from Equation (11)
(31)
(31)
Inserting Equations (10) and (31) in Equation (30), then the pdf of reduces to
(32)
(32) where
Finally, the pdf of can be expressed as
(33)
(33) where
and
is the exp-G pdf with power parameter
Hence, the pdf of
of a WE-G is a mixture of exp-Gompertz density. So, the moments and mgf of WE-G order statistics follow directly from linear combinations of those quantities for exp-Gompertz distributions, where El-Gohary et al. [Citation13] studied the generalized Gompertz distribution.
8. Estimation and inference
Let be the random sample from the WE-G with parameters
and
. Then The log-likelihood function is
(34)
(34)
Setting the first derivatives of Equation (34) with respect to and
, respectively, to zero, we have
(35)
(35)
(36)
(36)
(37)
(37)
(38)
(38)
The maximum likelihood estimates and
can be obtained by solving the non-linear Equations (35–38) numerically for
and
by using the statistical software Mathematica package.
For interval estimation of , we require the information matrix.
(39)
(39) where the elements of the matrix
are given in the Appendix.
The variance-covariance matrix would be where
is the inverse of the observed information matrix.
9. Data application
In this section, we provide a practical example to illustrate the perform of the new model. To illustrate the good performance of our model, we use package Mathematica software. For comparison purpose, we consider the following distributions: Gompertz distribution:
Shifted Gompertz
Weighted exponential-log logistic
Weighted exponential-Weibull
The data set represents the failure time of 50 devices (Aarset [Citation15]) and listed in Table . For Aarset data, we obtain the maximum likelihood estimates (MLE's) and the respective standard errors of each distribution. Further, we use the goodness-of – fit statistics in order to provide the Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC) and Hannan-Quinn Information Criterion (HQIC), Kolmogorov-Smirnov (K-S) test, the p-value of K-S, Cramer-von Misses () and Anderson Darling (
). Table provides the MLE's and the respective standard errors for comparison distributions. Tables and provides the values of AIC, BIC, HQIC, K-S, p- value, W* and A* of the comparison distributions. Hence, we conclude that our model provides the better fit. Figure shows the estimated densities and estimated survival functions for the considered distributions of data set. We note that the proposed model is more appropriated to fit the data, again. We also, plot the profiles of the log-likelihood function in Figures to show that the likelihood equations have a unique solution in the parameters of WE-G distributions. Some descriptive statistics of the Aarset data can be found in Table , that indicates negative skewness and kurtosis.
Figure 5. (a) Estimated density function and (b) Estimated survival function of Aarset data.
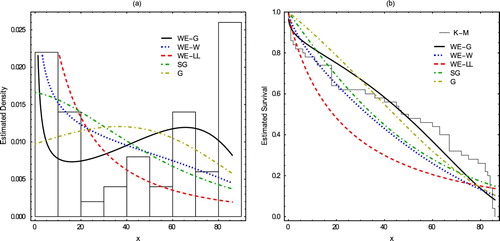
Figure 6. The profiles of the log-likelihood function of .
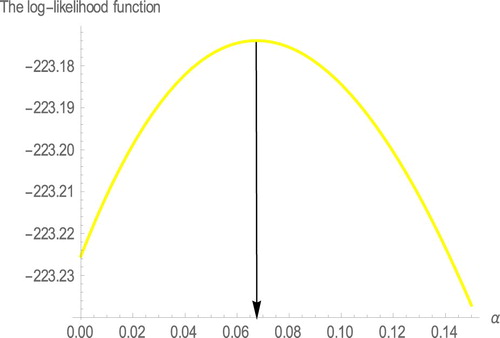
Figure 7. The profiles of the log-likelihood function of .
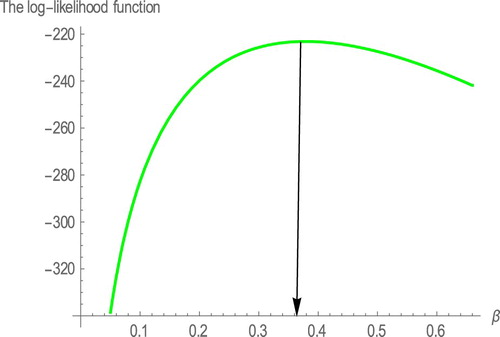
Figure 8. The profiles of the log-likelihood function of
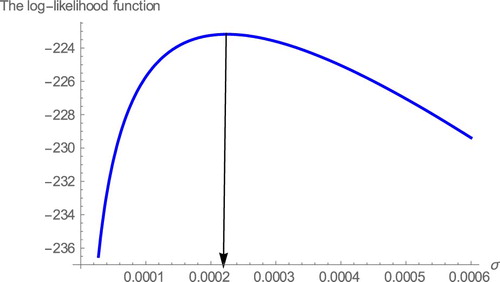
Figure 9. The profiles of the log-likelihood function of .
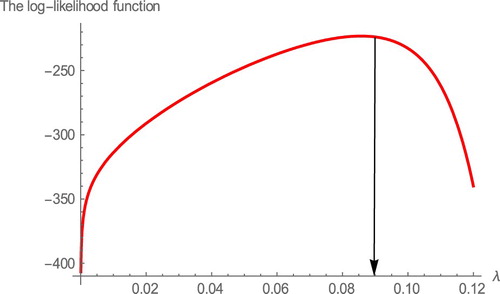
Table 3. Aarset data set.
Table 4. MLEs of the parameters (standard errors in parentheses).
Table 5. AIC, BIC and HQIC statistics.
Table 6. W*, A* statistics, K-S statistic and it’s corresponding p-value.
Table 7. Descriptive statistics – Aarest data.
The observed information of the Aarset data and the variance-covariance matrices are respectively
and
The 90% confidence intervals (CIs) for the parameters and
are (0, 5.75831 ], (0, 1.3415], (0, 0.0012579) and [0.0384075, 0.132916 ], respectively.
10. Concluding remarks
In this paper, a new extension version of the Gompertz distribution generated by integral transform of the pdf of the weighted exponential distribution is introduced with its important properties. Estimation using the method of maximum likelihood is straightforward. Moreover, the new model with other distributions is fitted to real data set and it is shown that this model has a better performance among the compared distributions. Some issues for future research may be considering different estimation methods of the unknown parameters. In addition, the new model properties can be compared with process based on two-piece distributions (Maleki and Mahmoudi [Citation16] and Hoseinzadeh et al. [Citation17]).
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Eugene N, Lee C, Famoye F. Beta-normal distribution and its applications. Communi Stat Theory Methods. 2002;31:497–512. doi: 10.1081/STA-120003130
- Zografos K, Balakrishnan N. On families of beta-and generalized gamma-generated distributions and associated inference. Stat Methodol. 2009;6:344–362. doi: 10.1016/j.stamet.2008.12.003
- Ristic MM, Balakrishnan N. The gamma-exponentiated exponential distribution. J Stat Comput Simul. 2012;82:1191–1206. doi: 10.1080/00949655.2011.574633
- Gupta RD, Kundu D. A new class of weighted exponential distribution. Statistics. 2009;43:621–634. doi: 10.1080/02331880802605346
- Shaw WT, Buckley IR. The alchemy of probability distribution: beyond Gram-Charlier expansions, and a skew-kurtotic-normal distribution from a rank transmutation map. Tech Rep. 2009. Available from http://arxiv.org/abs/0901.0434.
- Nofal ZM, Afify AZ, Yousof HM, et al. The generalized transmuted-G family of distributions. Communi Stat Theory Methods. 2016. doi:10.1080/03610926.2015.1078478.
- Cordeiro GM, De Castro M. A new family of generalized distributions. J Stat Comput Simul. 2011;81:883–893. doi: 10.1080/00949650903530745
- Bakouch HS, Abd El-Bar AMT. A new weighted Gompertz distribution with applications to reliability data. Appl Math. 2017;62:269–296. doi: 10.21136/AM.2017.0277-16
- Kayid M, Ahmad IA. On the mean inactivity time ordering with reliability applications. Prob Eng Inform Sci. 2004;18:395–409. doi: 10.1017/S0269964804183071
- Izadkhan S, Kayid M. Reliability analysis of the harmonic mean inactivity time order. IEEE Trans Reliab. 2013;62:329–337. doi: 10.1109/TR.2013.2255793
- Kayid M, Izadkhah S. Mean inactivity time function, associated orderings and classes of life distribution. IEEE Trans Reliab. 2014;63:593–602. doi: 10.1109/TR.2014.2315954
- Rényi A. On measures of entropy and information. In Proceedings of the 4th Berkeley symposium on Mathematical Statistics and Probability I. 1961. Berkeley: Univ. California Press. MR0132570; p. 547–561.
- El-Gohary A, Alshamrani A, Al-Otaibi AN. The generalized Gompertz distribution. Appl Math Modeling. 2013;37:13–24. doi: 10.1016/j.apm.2011.05.017
- Bemmaor AC. Modeling the diffusion of new durable goods: word-of-mouth effect versus consumer heterogeneity. In: B Pras, editor. Research traditions in marketing. Boston, MA: Kluwer; 1994. p. 201–223.
- Aarset MV. How to identify bathtub hazard rate. IEEE Trans Reliab. 1987;36:106–108. doi: 10.1109/TR.1987.5222310
- Maleki M, Mahmoudi MR. Two-piece location-scale distributions based on scale mixtures of normal family. Communi Stat Theory Methods. 2017;46:12356–12369. doi: 10.1080/03610926.2017.1295160
- Hoseinzadeh A, Maleki M, Khodadadi Z, et al. The skew-reflected- Gompertz distribution for analyzing symmetric and asymmetric data. J Comput Appl Math. 2019;349:132–141. doi: 10.1016/j.cam.2018.09.011
Appendix
The elements of the observed information matrix
are:
and
where