
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Stress-strength models are of special importance in reliability literature and engineering applications. This paper deals with the estimation problem of a stress-strength model incorporating multi-component system. The system is regarded as alive only if at least out of
strength components exceed the stress. The reliability of such system is obtained when strength and stress variables have Weibull distributions. Maximum likelihood estimator of
and asymptotic confidence intervals are obtained based on upper record values. Bayesian estimator under squared error and linear exponential loss functions using gamma prior distributions and the corresponding credible intervals are obtained. Due to the lack of explicit forms for the Bayes estimates, the Markov Chain Monte Carlo (MCMC) method is employed. A simulation study is implemented to assess the performance of estimates. A real-life example is presented to show how the proposed model may be utilized in breaking strength of jute fibre data.
1. Introduction
Record values can be viewed as order statistic from a sample whose size is determined by the values and the order of occurrence of the observations. Record values and associated statistics have an important role in many real-life applications involving data related to meteorology, hydrology, sports and life tests. In industry and reliability, many products may fail under stress. For example, a wooden beam breaks when sufficient perpendicular force is applied to it, a battery dies under the stress of time, an electronic component ceases to function in an environment of too high temperature. In such experiments for getting the precise failure point, measurements may be made sequentially and only values larger (or smaller) than all previous ones are recorded. Data of this type are called record data. The development of the general theory of statistical analysis of record values began with the work, as pioneered in Chandler [Citation1]. For an excellent review of records and their properties, one may refer to Nagaraja [Citation2], Ahsanullah [Citation3], Ahsanullah [Citation4].
Let be an infinite sequence of identically independent distributed (IID) random variables with probability density function
and cumulative distribution function
Then, an observation
is said to be an upper record value if it exceeds all its previous observations, i.e.
for every
An analogous definition can be given for a lower record value.
The stress-strength reliability of a system defines the probability that the system will function properly until the strength exceeds the stress. Due to the manufacturing variability and uncertain factors, the strength of the system varies also when the system is put to use, it is subjected to the stress which is again random in nature. These manufacturing variables and uncertain factors can be used material, production style, humidity, temperature of the environment, etc. The genesis of this problem can be seen in Birnbaum [Citation5]. Many authors have been interested in estimating a single component stress-strength version based on record values due to its important role in many fields. The survival probability of stress-strength based on record values is considered in Baklizi [Citation6] for generalized exponential distribution. Subsequent papers extended this work assuming various lifetime distributions for stress-strength random variables, for instance, in Baklizi [Citation7,Citation8,Citation9], for one and two parameter exponential distribution, Essam [Citation10] for type I generalized logistic distribution, Baklizi [Citation11] for two-parameter Weibull distribution, Tarvirdizade and Kazemzadeh Garehchobogh [Citation12] for inverse Rayleigh distribution, Al-Gashgari and Shawky [Citation13] for exponentiated Weibull distribution, Hassan et al. [Citation14] for exponentiated inverted Weibull distribution and Hassan et al. [Citation15] for generalized inverted exponential distribution.
Bhattacharyya and Johnson [Citation16] observed that, in several practical scenarios, the performance of a system depends on more than one component and these components have their own strengths. Multicomponent stress-strength (MSS) models have great applications range from communication and industrial systems to logistic and military systems. For examples, an aircraft generally contains more than one engines (k) and assume that for takeoff at least (1 ≤
≤ k) engines are needed. So, the aircraft will take off smoothly, if
out of k engines work; in engineering, a power system powering a manufacturing unit has k fuse cut-outs arranged in a parallel way. The power system will keep powering the manufacturing unit as long as at least
(1 ≤
≤ k) fuse cut-outs are working. Also, consider an automobile with a V-8 engine that works if four cylinders are rung. So, it can be represented as 4-out-of-8: G system. In suspension bridges, the deck is supported by a series of vertical cables hung from the towers. Suppose a suspension bridge consists of k number of vertical cable pairs. The bridge will only survive if a minimum
number of vertical cables through the deck are not damaged when subjected to stresses due to 153 American Journal of Applied Mathematics and Statistics wind loading, heavy traffic, corrosion etc. For extensive
out of k and related systems one may refer to Kuo and Zuo [Citation17].
A multicomponent system of components having strengths following
IID random variables
and each component experiences a random stress Y. The system is regarded as alive only if at least
out of
strengths exceeds the stress. Let
be independent,
be the CDF of
and
be the common CDF of
. Then the reliability in the MSS model which is developed in Bhattacharyya and Johnson [Citation16] is defined in the following form:
(1)
(1) where
are IID with common distribution function
and subjected to the common random stress Y.
The applicability of the reliability in the MSS model based on the samples of upper record values appears strongly in industrial tests, where most of the systems fail when they are exposed to high levels of stress. For example, if a sample of electrical power stations consists of eight generating units, the light amount of electricity is generated if at least six generating units are operating. In some experimental energy tests, these power stations are exposed to a high level of stress in order to test its ability to carry out its functions (supply the region demand of electricity) at high levels of stress. It is expected that most of the systems of most of a lot of these power stations will collapse immediately under a high level of stress. If a few power stations can function for a short period of time under these high levels of stress, it will be recorded as a first observation to obtain the sample of the upper record values. If the longer period of time occurs, it will be recorded as a second observation and so on to obtain a sample of the upper record values.
Recently, several researchers have paid attention to develop inferential procedures for the reliability of MSS models. The reliability in the MSS model based on a simple random sample has been developed in Kuo and Zuo [Citation17] and Pandey and Uddin [Citation18]. A considerable amount of the literature on the estimation of reliability in the multicomponent system for some lifetime distributions has been studied by several authors; see for examples; Rao [Citation19], Rao et al. [Citation20], Rao [Citation21], Kizilaslan and Nadar [Citation22]. Recently, Pak et al. [Citation23] investigated Bayesian estimation of the reliability of an MSS system for the bathtub-shaped distribution when the available data are reported in terms of record values. Jamal et al. [Citation24] considered maximum likelihood and Bayesian estimation methods for MSS reliability for Pareto distribution based on the upper record values.
This article deals with the estimation of the MSS reliability defined in (1), the underline distribution of the strength and stress follows non-identical Weibull distribution when the considered data are of a record type. The expression for the reliability of the multicomponent system is obtained in Section 2. Maximum likelihood (ML) estimators are employed to obtain the asymptotic distribution and confidence intervals of
. Steps of numerical study and the corresponding results are given in Subsections 2.1 and 2.2, respectively. In Section 3, Bayesian estimators of
are computed for a commonly known shape parameter
, and unknown parameters
and
as well as the highest posterior density credible intervals are also constructed. The MCMC method is employed under squared error (SE) and linear exponential (LINEX) loss functions for independent gamma priors in Subsection 3.1. Numerical results are outlined in Subsection 3.2. Real data are employed to assess the theoretical results in Section 4. Finally, concluding remarks appear in Section 5.
2. Maximum likelihood estimator of 
The Weibull distribution is a very popular distribution that has been extensively used over the past decades for modelling data in reliability, engineering and biological studies. It has numerous varieties of shapes and demonstrates considerable flexibility that enables it to have increasing, constant and decreasing failure rates. Therefore, it is used for many applications for example in hydrology, industrial engineering, weather forecasting and insurance. Weibull distribution is of special interest, because the Weibull distribution arises naturally from the extreme value theorem (Murthy et al. [Citation25]) and thus it has a meaningful physical interpretation in many real applications (Ye et al. [Citation26]). The probability density function (PDF) and cumulative distribution function (CDF) of the Weibull distribution are given as follows:
(2)
(2) and,
(3)
(3)
Here, the ML estimator of the reliability in the MSS model based on upper record values is derived. Assuming that the strengths and stress random variables are independent, they are distributed as two-parameter Weibull distribution.
Let be the strengths of a system which is subjected to the stress
. Assuming that
be a random sample from Weibull distribution with parameters
and
be a random variable from Weibull distribution with parameters
are independent from unknown parameters
and common shape parameter
, respectively. Therefore, the reliability of
-out-of-
system for Weibull distribution can be computed by using (1)–(3) as follows:
(4)
(4)
After the simplification, then will be
(5)
(5)
In order to derive the ML estimator of and
let
be a set of the first observed
upper record values from Weibull distribution with parameters
and
be an independent set of the observed first
upper record values from Weibull distribution with parameters
where
is assumed known. The likelihood function of the observed record values
and
is obtained, as follows:
(6)
(6) and,
(7)
(7)
Therefore, the joint log-likelihood function of the observed and
denoted by
takes the following form:
(8)
(8) The ML estimator of
and
, say
and
when
assumed to known to be obtained by differentiating (8) and equating by zero. Then
and
take the following forms
(9)
(9) Hence, the ML estimator of
, denoted by
, is obtained by using (5) and (9) as follows:
(10)
(10)
Now to obtain the asymptotic confidence interval (ACI) for firstly, the asymptotic variance (AV) of the ML estimator is obtained as follows:
(11)
(11) and,
(12)
(12)
The AV of an estimate of which is a function of two independent statistics
and
is given in Hassan and Basheikh [Citation27].
(13)
(13)
In this work, to avoid the difficulty in deriving we obtain AV for
and (2,4) separately as follows:
(14)
(14)
(15)
(15) As n
, therefore, an asymptotic
confidence interval of
for both
is given by
(16)
(16) where
is the upper
quantile of the standard normal distribution,
is the value of
at the ML estimator,
is the lower limit of the confidence interval and
is the upper limit of the confidence interval.
2.1. Numerical study
In this subsection, an extensive numerical investigation is carried out to evaluate the performance of ML estimate (MLE) of at different values of
and
for different samples size of record values for the strengths and stress random variables. The performance of the point estimator depends mainly on the absolute biases (ABs) and mean square errors (MSEs). The length of intervals is the main principle of the performance of the ACI. The numerical study is designed through the following steps:
Generate samples of the upper record values using some specified values of parameters.
The values of
The true values of reliability in the MSS model with the given combinations of
The samples of the upper record values of strength and stress random variables
The MLEs of
Compute the average ABs and average MSEs for reliability estimates over 5000 replications (see Tables –).
Obtain the asymptotic variance of
Compute the lower and upper limits of the ACI of
Table 1. The numerical results of MLE of at .
Table 2. The numerical results of the MLE of at .
Table 3. The numerical results of the MLE of at .
Table 4. The numerical results of the MLE of at .
Table 5. The numerical results of the MLE of at .
Table 6. The numerical results of the MLE of at .
Table 7. The numerical results of the MLE of at .
2.2. Numerical results
Numerical results are reported in Tables – and represented through Figures –. The following results can be observed on the properties of the reliability estimates as follows:
The AB of
The MSEs of
For
For
For
For
The ALs of ACI of
As seen in Tables –, the ALs of ACI of
For
At
At
For
For
Figure 1. MSEs of for different values of
at
in the case of
.
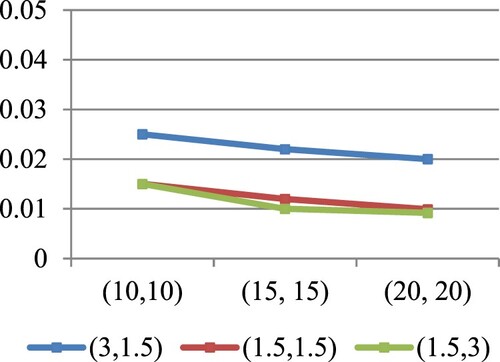
Figure 2. MSEs of for different values of
at
in the case of
.
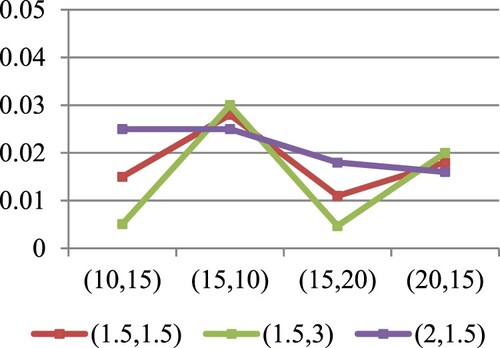
Figure 3. MSEs of for different values of
at
in the case of
.
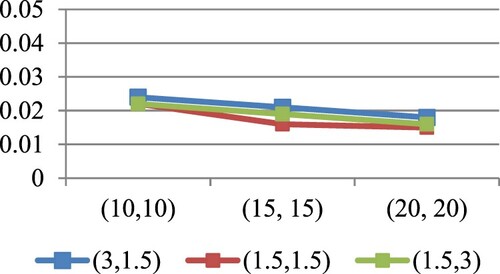
Figure 4. The ALs of for different values of
at
in the case of
.
3. Bayesian estimators of
In this section, we assume that the parameters and
are unknown and have independent gamma prior distributions with parameters
i = 1, 2, respectively. Hence, assuming independence of parameters, the joint prior distribution of parameters, denoted by
is as follows:
(16)
(16)
Based on the observed sample, the joint density function of and the data are
(17)
(17)
Thus, we can write the posterior density function of as
(18)
(18)
It is well known that assuming SE loss function, the Bayesian estimator of denoted by
is its posterior mean which is obtained by
(19)
(19)
Additionally, the Bayesian estimator of under LINEX loss function, denoted by
is given as follows:
(20)
(20)
Since the posterior density function has a complex form, it is difficult to derive a closed form for the Bayesian estimator of
. Therefore, the MCMC technique is used to approximate these integrations. Metropolis-Hastings (M-H) algorithm will be implemented to compute the Bayes estimates and credible intervals width under SE and LINEX loss functions.
3.1. MCMC method
In order to investigate the behaviour of the multicomponent reliability , Monte Carlo simulation is carried out. The Bayes estimates are obtained using gamma priors under SE and LINEX loss functions. The Bayesian estimate performances of
are measured based on ABs, estimated Risks (ERs) and ALs via R 3.4.3. Three sets of parameter values are considered as
and different choices of sample sizes as
. The true value for
is 0.54, 0.75 and 0.82 and for
is 0.39, 0.6 and 0.69. Three different sets of hyper-parameters values are considered as; Prior I:
; Prior II:
and Prior III:
Also, we take
All the results are based on the number of replications = 5000.
The M–H algorithm is one of the most famous subclasses of the MCMC method in the Bayesian literature to simulate the deviates from the posterior density and produce good approximate results. The major difficulty in the implementation of the Bayesian procedure is that of obtaining the posterior distribution. The MCMC is used to simulate samples from the posterior density and then obtain the Bayesian estimate under SE loss function and
under LINEX loss function.
The approximate Bayes estimate of is obtained by applying the M-H algorithm technique. The M–H algorithm uses an acceptance/rejection rule to converge to the target distribution. According to Lynch [Citation28], the M–H algorithm proceeds as follows:
Step 1: Initialize a starting parameter value
Step 2: For
Step 3: Generate
Step 4: Draw a candidate parameter
Step 5: If
Step 6: Set
3.2. Simulated results
Here, the simulated outcomes are listed in Tables – and represented through Figures –, so from these tables we detect the following observations about the performance of the reliability estimates as follows:
The ER of
The ER of
The ER of
The AL of
Figure 5. ER of estimates for
at
under SE and LINEX loss functions for prior I.
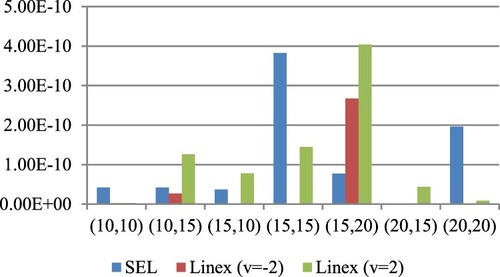
Figure 6. ER of estimates for
at
under SE and LINEX loss functions for prior I.
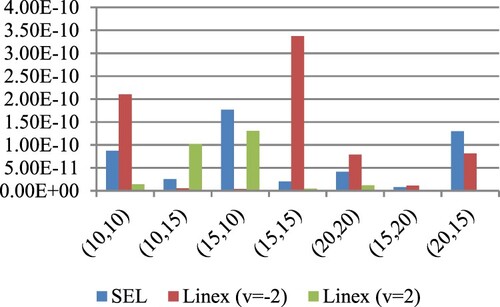
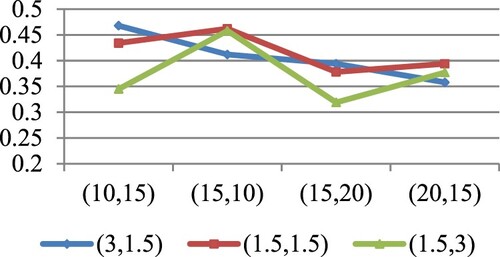
Figure 7. ER of estimates for
at
under SE and LINEX loss functions for prior III.
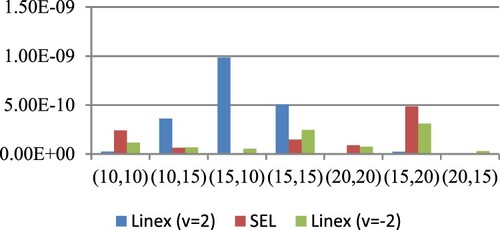
Figure 8. AL of estimates for
at
under SE and LINEX loss functions for prior III.
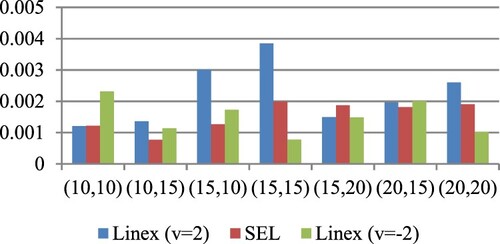
Table 8. AB, ER and AL of Bayes estimate of for prior I at.
Table 9. AB, ER and AL of Bayes estimate of for prior II at .
Table 10. AB, ER and AL of Bayes estimate of for prior III at .
4. Real data application
In this section, the analysis of a pair of real data sets is presented for illustrative purposes. These two data sets were used by Xia et al. [Citation29]. The data stand for the strength data measured in MPa, tensile properties of jute fibres were evaluated in accordance with ASTM C 1557–03 at seven different gauge lengths (2, 3, 5, 10, 15, 20, and 25 mm). Thirty samples were mounted for testing at each of these gauge lengths. We consider the data sets consisting of the breaking strength of jute fibre at 10 mm in gauge lengths, which represents the strength measurement (Data Set 1) and 20 mm in gauge lengths, which represents the stress measurement (Data Set 2), with sample sizes 30 each (see Tables –).
Table 11. Data Set 1 (gauge lengths of 10 mm).
Table 12. Data Set 2 (gauge lengths of 20 mm).
The two data sets are fitted separately with the Weibull distribution using the Kolmogorov–Smirnov (K-S) goodness-of-fit test and the results are reported in Table .
Table 13. K-S goodness of fit and corresponding P-values for data sets 1 and 2.
The K–S goodness of fit statistic and the corresponding P-value indicate that the Weibull distribution fits the data sets. From Tables and , the upper record values are obtained as follows:
Here, assuming two different choices for the MSS system, we compute the estimates of reliability parameter
by using the ML and Bayesian procedures developed in the present paper. Using the above record values, the MLEs of the reliability,
for
= (1,3), (2,4), are 0.9 and 0.8, respectively.
To analyse the data from the Bayesian procedure, three different sets of values for the hyper-parameters are considered as Prior I: ; Prior II:
and Prior III:
Table provides the Bayes estimates of
under SE and LINEX loss functions. It is observed that the Bayes estimates obtained based on prior I, II and III are close to the MLEs at (
) = (1,3) while employing
= (2,4) leads to Bayes estimates are greater than the MLEs. Considering prior I and prior III, we conclude that the Bayes estimate of
under LINEX at v = 2 is preferable to the other estimates. Regarding prior II, we conclude that the Bayes estimate of
under SE is preferable to the other estimates. Generally, as the values of
increase, the value of
estimate decreases (see Table ).
Table 14. The Bayes estimate of for the real data.
5. Conclusion
This article concerns the estimation of multicomponent stress-strength reliability based on record data. The reliability of such a system is obtained when the strength and stress variables are independently Weibull distribution with different scale parameters. The reliability in MSS is estimated by using the maximum likelihood and Bayesian methods of estimation when the samples are drawn from strength and stress distributions and their measurements are in terms of the upper record values. The ML estimator is employed to obtain the asymptotic distribution and confidence intervals for Considering SE and LINEX loss functions, all the Bayes estimates are computed by assuming gamma priors on the parameters. Since the Bayes estimates of the interested reliability parameter could not be obtained analytically, we employ the MCMC to obtain the Bayes estimates. To assess the accuracy of the different estimators, Monte Carlo simulations are conducted.
From the simulation study, we conclude that, the average bias and average MSE decrease as the sample size increases for both values of . It verifies the consistency property of the MLE of
Also, the lengths of asymptotic confidence intervals of
decrease as the sample size increases. Overall, the performance of the confidence interval is quite good for all combinations of parameters. Regarding the sizes of record value samples for the strengths and stress variables
it is observed that the MSEs and the lengths of asymptotic confidence intervals tend to decrease as
increases.
Regarding the MCMC method, we conclude that the estimated risk of prior I under SE loss function takes the smallest value at , while the estimated risk under LINEX
takes the smallest value at
among other priors in most of the situations. The AB of prior I has the smallest value under SE and LINEX
at
while the AB gets the smallest value for LINEX
at
among other priors in most of the cases. Generally, prior I is preferable to prior II and III in approximately most of the situations due to their absolute biases and estimated risks values. Finally, the application to real data shows that the reliability estimates approach one for this model which indicates its importance in practice.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Chandler KN. The distribution and frequency of record values. J Royal Stat Soc Series B. 1952;14(2):220–228. DOI:10.1111/j.2517-6161.1952.tb00115.x.
- Nagaraja HN. Record values and related statistics. Commun Stat Theory Methods. 1988;17(7):2223–2238. DOI: 10.1080/03610928808829743.
- Ahsanullah M. Record statistics. Commack: Nova Science Publishers; 1995.
- Ahsanullah M. Record values-theory and applications. Lanham: University Press of America; 2004.
- Birnbaum Z. On a use of the Mann-Whitney statistic. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; 1956. The Regents of the University of California. DOI:10.1007/978-3-642-04898-2_615.
- Baklizi A. Likelihood and Bayesian estimation of Pr(X < Y) using lower record values from the generalized exponential distribution. Comput Stat Data Anal. 2008;52(7):3468–3473. DOI:10.1016/j.csda.2007.11.002.
- Baklizi A. Estimation of Pr(X < Y) using record values in the one and two parameter exponential distributions. Commun Stat Theory Methods. 2008;37(5):692–698. DOI:10.1080/03610920701501921.
- Baklizi A. Bayesian inference for Pr(Y < X) in the exponential distribution based on records. Appl Math Model 2014;38(5–6):1698–1709. DOI:10.1016/j.apm.2013.09.003.
- Baklizi A. Interval estimation of the stress–strength reliability in the two-parameter exponential distribution based on records. J Stat Comput Simul. 2014;84(12):2670–2679. DOI: 10.1080/00949655.2013.816307.
- Essam AA. Bayesian and non-Bayesian estimation of from type I generalized logistic distribution based on lower record values. Aust J Basic Appl Sci 2012;6(3):616–621. DOI: 10.12988/ijcms.2013.39111.
- Baklizi A. Inference on P[Y < X] in the two-parameter Weibull model based on records: international scholarly research network. Probab Stat. 2012;2012. DOI: 10.5402/2012/263612. http://www.hindawi.com/journals/isrn/2012/263612/.
- Tarvirdizade B, Kazemzadeh Garehchobogh H. Interval estimation of stress-strength reliability based on lower record values from inverse Rayleigh distribution. J Qual Reliab Eng 2014;2014. DOI:10.1155/2014/192072.
- Al-Gashgari F, Shawky A. Estimation of P(Y < X) using lower record data from the exponentiated Weibull distributions: classical and MCMC approaches. Life Sci J 2014;11(7):768–777.
- Hassan AS, Muhammed HZ, Saad MS. Estimation of stress-strength reliability for exponentiated inverted Weibull distribution based on lower record values. J Adv Math Comput Sci 2015;11(2):1–14. DOI:10.9734/BJMCS/2015/19829.
- Hassan AS, Marwa A, Nagy HF. Estimation of P(Y < X) using record values from the generalized inverted exponential distribution. Pak J Sta Oper Res 2018;14(3):645–660. DOI:10.18187/pjsor.v14i3.2201.
- Bhattacharyya G, Johnson RA. Estimation of reliability in a multicomponent stress-strength model. J Am Stat Assoc 1974;69(348):966–970. DOI:10.1080/01621459.1974.10480238.
- Kuo W, Zuo MJ. Optimal reliability modeling: principles and applications. Hoboken (NJ): John Wiley & Sons; 2003.
- Pandey M, Uddin MB. Estimation of reliability in multi-component stress-strength model following a Burr distribution. Microelectron Reliab 1991;31(1):21–25. DOI:10.1016/0026-2714(91)90340-D.
- Rao GS. Estimation of reliability in multicomponent stress-strength based on generalized exponential distribution. Rev Colomb Estad 2012;35(1):67–76.
- Rao GS, Kantam R, Rosaiah K, et al. Estimation of reliability in multicomponent stress-strength based on inverse Rayleigh distribution. J Ind Prod Eng 2013;30(4):256–263. DOI:10.1080/21681015.2013.828787.
- Rao GS. Estimation of reliability in multicomponent stress-strength based on generalized Rayleigh distribution. J Mod Appl Stat Methods. 2014;13(1):24. DOI:10.22237/jmasm/1398918180.
- Kizilaslan F, Nadar M. Classical and Bayesian estimation of reliability in multicomponent stress-strength model based on Weibull distribution. Rev Colomb Estad 2015;38(2):467–484. DOI:10.15446/rce.v38n2.51674.
- Pak A, Khoolenjani NB, Rastogi MK. Bayesian inference on reliability in a multicomponent stress-strength bathtub-shaped model based on record values. Pakistan J Stat Oper Res 2019;15(2):431–444. doi: 10.18187/pjsor.v15i2.2398
- Jamal QA, Arshad M, Khandelwal N. Multicomponent stress strength reliability estimation for Pareto distribution based on upper record values. arXiv Preprint ArXiv. 2019;1909:13286.
- Murthy DP, Xie M, Jiang R. Weibull models. New York: John Wiley & Sons; 2004.
- Ye Z-S, Hong Y, Xie Y. How do heterogeneities in operating environments affect field failure predictions and test planning? Ann Appl Stat 2013;7(4):2249–2271. DOI: 10.1214/13-AOAS666.
- Hassan AS, Basheikh H. Estimation of reliability in multicomponent stress-strength model following exponentiated Pareto distribution. Egypt Stat J Inst Stat Stud Res Cairo Univ 2012;56(2):82–95. https://scholar.cu.edu.eg/?q=dr_amal/publications/estimation-reliability-multi-component-stress-strength-model-following-exponent.
- Lynch SM. Introduction to applied Bayesian statistics and estimation for social scientists. New York: Springer; 2007.
- Xia Z, Yu J, Cheng L, et al. Study on the breaking strength of jute fibres using modified Weibull distribution. Compos Part A Appl Sci Manuf. 2009;40(1):54–59. DOI: 10.1016/j.compositesa.2008.10.001.