?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Heavy-tailed distributions play an important role in modelling data in actuarial and financial sciences. In this article, nine new methods are suggested to define new distributions suitable for modelling data with an heavy right tail. For illustrative purposes, a special sub-model is considered in detail. Maximum likelihood estimators of the model parameters are obtained and a Monte Carlo simulation study is carried out to assess the behaviour of the estimators. Furthermore, some actuarial measures are calculated. A simulation study based on these actuarial measures is done. The usefulness of the proposed model is proved empirically by means of two real data sets. Finally, Bayesian analysis and performance of Gibbs sampling for the data sets are also carried out.
1. Introduction
In many applied areas, particularly in finance and actuarial sciences, data are usually positive, and their distribution is unimodal hump shaped and extreme values yield tails which are heavier than those of the standard well-known distributions. Classical distributions are not flexible enough to cater such heavy-tailed data sets. For example, (i) the Pareto distribution, which is widely used in modelling financial data sets, does not provide a reasonable fit for many applications and (ii) the Weibull model covers better the behaviour of small losses, but fails to cover the behaviour of large losses; see Bhati and Ravi [Citation1]. In such situation, heavy-tailed distributions are reliable and accurate candidate models to employ. For positive data, heavy-tailed distributions are those whose right tail probabilities are greater than the exponential one (see Beirlant et al. [Citation2]), that is
where
is the cumulative distribution function (cdf). For further detail, see McNeil [Citation3] and Resnick [Citation4]. Due to the importance of the heavy-tailed distributions in actuarial practice, the actuaries are motivated to introduce new flexible distributions. In this regard, serious attempts have been made and still growing rapidly. The new developments have been made through many different approaches such as (i) transformation of variables, (ii) composition of two or more distributions, (iii) compounding of distributions and (iv) finite mixture of distributions.
Recent studies of Eling [Citation5] and Adcock et al. [Citation6] identify that skew-normal and skew student t distributions are the best competitors as the skewed distributions adjust right-skewness and high kurtosis; for further detail see, Shushi [Citation7] and Punzo [Citation8]. However, insurance losses and financial risks take values on the positive real line and hence these skew class of distributions may not be appropriate as they are defined on . In such situations, the transformation of variables, particularly the exponential transformation, has proven to be substantial; see, for example, Azzalini et al. [Citation9]. Bagnato and Punzo [Citation10] showed that the transformation approach is simple to use but most often the inference as well as computation of the other distributional characteristics become complicated.
Another promising approach for obtaining new flexible heavy-tailed families of distributions, which gives reasonably good fit for heavy-tailed losses, is the method of composition; see Paula et al. [Citation11], Klugman et al. [Citation12], Nadarajah and Abu Bakar [Citation13], and Bakar et al. [Citation14]. However, it should be noted that the new distributions obtained by the composition approach involve more than three parameters causing difficulties in the estimation process and computational efforts are required.
Another prominent approach is compounding of distributions to cater data modelling with unimodality, right-skewness and heavy tails [Citation8,Citation15,Citation16]. However, the density obtained via this method may not have a closed form expression which makes the estimation more cumbersome as shown in Punzo et al. [Citation15]. For a brief review about compounding of distributions, we refer to Tahir and Cordeiro [Citation17].
Finite mixture models represent a further approach to define very flexible distributions which are also able to capture, for instance, multimodality of the underlying distribution [Citation18–20]. The price to pay for this greater flexibility is a more complicated and computationally challenging inference.
Furthermore, Dutta and Perry [Citation21] performed an empirical analysis of loss distributions and risk was estimated by different approaches such as Exploratory Data Analysis and other empirical approaches. These authors rejected the idea of using the exponential, gamma and Weibull models in modelling insurance losses due to the poor results. They concluded that “one would need to use a model that is flexible enough in its structure”, and this encourages researchers to search for more flexible probability distributions providing greater accuracy in fitting heavy-tailed insurance losses.
Carrying out this branch of distribution theory, Alzaatreh et al. [Citation22] defined the T-X family method to introduce new families of distributions. Let be the probability density function (pdf) of a random variable, say T, where
and let
be a function of
of a random variable, say X, satisfying the conditions given below:
,
The cdf of the T-X family of distributions is defined by
(1)
(1) where
satisfies the conditions stated above. The pdf corresponding to (Equation1
(1)
(1) ) is
For the contributed work based on the idea of T-X approach, we refer to Ahmad et al. [Citation23]. Using the approach of T-X method, one can introduce new members of survival family [Citation24] via the cdf
(2)
(2) where
is the survival function of the baseline distribution.
Recently, Mahdavi and Kundu [Citation25] proposed a new prominent approach for introducing statistical distributions via the cdf given by
(3)
(3) with additional parameter α.
Under these premises, we are motivated to propose new families of distributions. Taking inspiration from (Equation1(1)
(1) )–(Equation3
(3)
(3) ), in this article, nine new families of distributions are proposed.
The paper is outlined as follows: new development to the heavy-tailed distributions is presented in Section 2. In Section 3, we define a special sub-model of the proposed family and provide plots of the density function. We derive some statistical properties in Section 4. Some characterizations results are provided in Section 5. Maximum likelihood estimation of the model parameters is addressed in Section 6. In the same section, the Monte Carlo simulation study is provided. Actuarial measures of the proposed method along with a simulation study are provided in Section 7. In Section 8, we provide two applications to real data to illustrate the importance of the new family. Bayesian analysis as well as a Gibbs sampling procedure for the considered data sets are discussed in Section 9. Finally, some concluding remarks are presented in Section 10.
2. New contribution to heavy-tailed distributions
As we mentioned in Section 1, the researchers are often in search of new heavy-tailed distributions suitable for modelling insurance losses. In this section, we propose some new useful methods to obtain heavy-tailed extended versions of the existing distributions.
2.1. New extended exponentiated-X family
Taking inspiration from (Equation1(1)
(1) ), we introduce a new flexible class of distributions. The proposed class is called a new extended exponentiated-X (NEEx-X) family. Let T ∼ exp(1), then its cdf is given by
(4)
(4) The density function corresponding to (Equation4
(4)
(4) ) is
(5)
(5) If
follows (Equation5
(5)
(5) ) and setting
in (Equation1
(1)
(1) ), we define the cdf of the NEEx-X family given by
(6)
(6) where
is the cdf of the baseline distribution depending on the parameter
. The pdf of the NEEx-X family is
where
. For a = 1, the NEEx-X family gives the new extended-X(NE-X) family.
2.2. New type-I cosine exponentiated-X family
Again taking inspiration from (Equation1(1)
(1) ), we introduce another new family of distributions, called new type-I cosine exponentiated-X(NTICEx-X) family. If
follows (Equation5
(5)
(5) ) and setting
in (Equation1
(1)
(1) ), we define the cdf of the NTICEx-X family via
(7)
(7) with pdf
For
the NTICEx-X family gives the new type-I cosine-X(NTIC-X) family.
2.3. Type-I cosine exponentiated-X family
Taking inspiration from (Equation2(2)
(2) ), we introduce a new method of proposing distributions. The proposed method is called type-I cosine exponentiated-X(TICEx-X) family of distributions. If
follows (Equation5
(5)
(5) ) and setting
in (Equation2
(2)
(2) ), we define the cdf of the TICEx-X family given by
(8)
(8) The density function corresponding to (Equation8
(8)
(8) ) is
For a = 1, the TICEx-X family gives the new Type-I cosine-X (TIC-X) family.
2.4. The exponent power exponentiated-X family
Take inspiration from (Equation3(3)
(3) ), we introduce a new method of proposing probability distributions, called the exponent power exponentiated-X (EPEx-X) family of distributions. The cdf of the EPEx-X family is defined by the following expression
(9)
(9) The pdf corresponding to (Equation9
(9)
(9) ) is
For
in (Equation9
(9)
(9) ), we introduce a sub-case of the EPEx-X family, called the exponent power-X (EP-X) family by cdf
(10)
(10) The pdf corresponding to (Equation10
(10)
(10) ) is
(11)
(11) For
the EP-X family gives the new reduced exponent power-X (REP-X) family.
3. The exponent power-Weibull distribution: a new heavy-tailed distribution
In this section, we define a special sub-model of the exponent power-X family, called exponent power-Weibull (EP-W) distribution. Let be the cdf of the Weibull distribution given by
, where
. Then, the cdf of the EP-W distribution has the following expression
(12)
(12) The pdf corresponding to (Equation12
(12)
(12) ) is given by
(13)
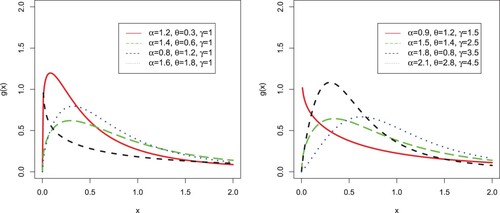
(13) Some possible shapes for the pdf of the EP-W distribution, for selected values of the model parameters, are sketched in Figure .
Figure 1. Different plots for the pdf of the EP-W distribution.
4. Statistical properties
In this section, we study some statistical properties of the EP-W distribution such as quantile function, moments and moment generating function (mgf). Some key advantages of the EP-W distribution are:
The mean and variance of the distribution are in explicit forms and simple to calculate.
The quantile function of the distribution has a closed form which makes it easier to generate random numbers.
4.1. Quantile function
Let X be the random variable follow the EP-W distribution with cdf (Equation12(12)
(12) ). Then, the quantile function (qf) of X, say
, can be obtained by inverting (Equation12
(12)
(12) ) as follows
(14)
(14) where u ∈ (0,1). The qf of the EP-W distribution has a closed form expression. In particular, the first quartile, second quartile (median) and third quartile are obtained by substituting
0.25, 0.5 and 0.75 in (Equation14
(14)
(14) ), respectively.
4.2. Moments
Some of the most important features and characteristics of a model can be obtain through its moments. The rth moment of a random variable X, say , with pdf (Equation13
(13)
(13) ) is derived as
(15)
(15) On solving, we have
where
. Using the definition of Beta type-II distribution, we have
(16)
(16) For r = 1, in (Equation16
(16)
(16) ), we get the first raw moment (mean) of the EP-W distribution given by
(17)
(17) Similarly, the second raw moment of the EP-W distribution is given by
(18)
(18) Now, the variance of the proposed distribution is obtained by using the following relation
(19)
(19) Using (Equation17
(17)
(17) ) and (Equation18
(18)
(18) ) in (Equation19
(19)
(19) ), we obtain the variance of the EP-W distribution. Furthermore, the mgf of the EP-W distribution,
, is given by
The graphs of skewness and kurtosis of the EP-W distribution along with the corresponding contour plots are presented in Figures and , respectively.
Figure 2. Skewness and the corresponding contour plot of the EP-W distribution.
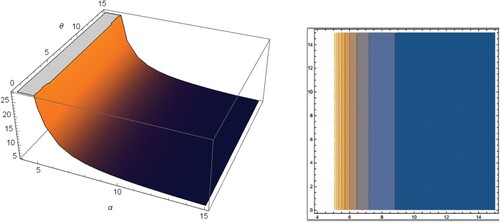
Figure 3. Kurtosis and the corresponding contour plot of the EP-W distribution.
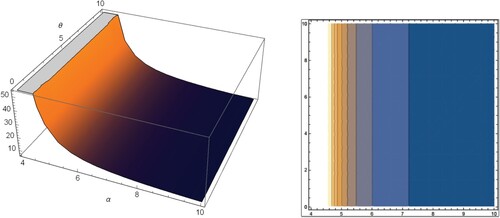
From Figures and , it is clear that for fixed values of θ, the skewness is decreased when α is increased. (ii) For fixed values of α, the skewness is increased when θ is increased. (iii) For fixed values of θ, the kurtosis is decreased when α is increased.
5. Characterization results
In designing a stochastic model for a particular data set, an investigator will be vitally interested to know if their selected model fits the necessary requirements. To this end, the investigator will rely on the characterizations of the selected distribution. Thus, the problem of characterizing a distribution is important in various fields and has recently attracted the attention of many researchers. Consequently, various characterization results have been reported in the literature. These characterizations have been established in different directions. This section is devoted to certain characterizations of the EP-X distribution based on a simple relationship between two truncated moments. Due to the nature of the cdf of this distribution, our characterizations may be the only possible ones. The first characterization result employs Theorem 1 of Glänzel [Citation26], given in Appendix. As shown in Glänzel [Citation27], this characterization is stable in the sense of weak convergence and can also be employed when the cdf does not have a closed form. We would like to mention that the goal of Theorem A.1 is to make as simple as possible.
Proposition 5.1
Suppose X is a continuous random variable. Let and
for
. Then X has density function (Equation11
(11)
(11) ) if and only if the function η, defined in Theorem A.1, is given by
Proof.
Suppose X is a random variable with density function (Equation11(11)
(11) ), then we have
and
Conversely, if η is of the above form, then
and consequently
Now, according to Theorem A.1, X has pdf (Equation11
(11)
(11) ).
Corollary 5.1
Suppose is a continuous random variable and
is as in Proposition 5.1. Then X has density function (Equation11
(11)
(11) ) if and only if there exist functions
and η defined in Theorem A.1 satisfying the following first-order differential equation
Corollary 5.2
The differential equation in Corollary 5.1 has the following general solution
(20)
(20) in which D is a constant. We like to mention that a set of functions satisfying the above first-order differential equation is given in Proposition 5.1 with
Clearly, there are other triplets
satisfying the conditions of Theorem A.1.
6. Maximum likelihood estimation and Monte Carlo simulation study
In this section, we use the maximum likelihood method to estimate model parameters and also provide a Monte Carlo simulations to assess the behaviour of these estimators.
6.1. Maximum likelihood estimation
In this sub-section, we obtain the maximum likelihood estimators (MLEs) of the model parameters of the EP-W distribution from complete samples only. Let be an observed sample of size n obtained from (Equation13
(13)
(13) ). The corresponding log-likelihood function can be expressed as
(21)
(21) The partial derivatives of (Equation21
(21)
(21) ) with respect to the parameters
are given, respectively, by
(22)
(22)
(23)
(23) and
(24)
(24) Solving
simultaneously yields the MLEs
of
6.2. Monte Carlo simulation study
In this sub-section, we perform a Monte Carlo (MC) simulation study with the objective to assess the behaviour of the MLEs of EP-W model via the optim()R-function with the argument method = "L-BFGS-B"; see Appendix. It is used for maximizing the log-likelihood function of a probabilistic model. We consider 750 MC-replicates under different sample sizes . For each sample size, we compute the average MLEs, mean square errors (MSE), Biases and Absolute biases. The results obtained after performing the MC simulation are provided in Table and displayed graphically in Figures –.
Figure 4. Plots of MLEs and MSEs of the EP-W model for ,
and
.
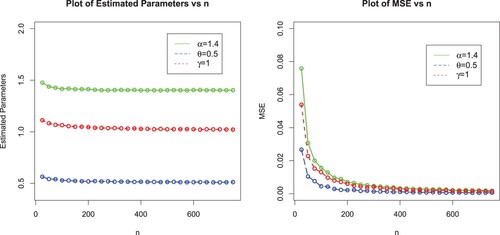
Figure 5. Plots of Biases and absolute biases of the EP-W model for ,
and
.
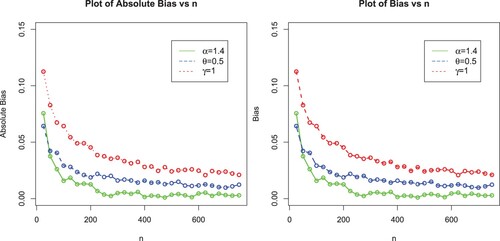
Figure 6. Plots of MLEs and MSEs of the EP-W model for ,
and
.
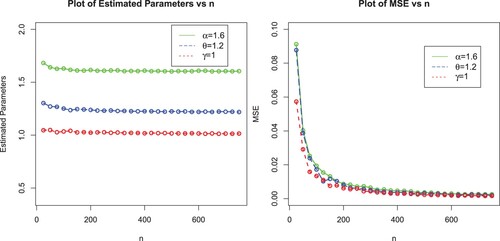
Figure 7. Plots of biases and absolute biases of the EP-W model for ,
and
.
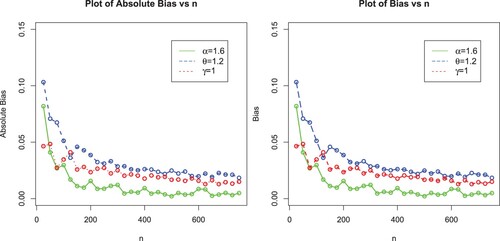
Table 1. Simulation results for the EP-W distribution.
7. Actuarial measures
One of the most important tasks of financial and actuarial sciences institutions is to evaluate the exposure to market risk in a portfolio of instruments, which arise from changes in underlying variables such as prices of equity, interest rates or exchange rates. In this section, we calculate some important risk measures including value at risk (VaR), tail value at risk (TVaR), tail variance (TV) and tail variance premium (TVP) for the proposed distribution, which play a crucial role in portfolio optimization under uncertainty.
7.1. Value at risk
In the context of actuarial sciences, the VaR is widely used by practitioners as a standard financial market risk measure. It is also known as the quantile risk measure or quantile premium principle. The VaR is always specified with a given degree of confidence say q (typically 90%, 95% or 99%), and represent the percentage loss in portfolio value that will be equaled or exceeded only X per cent of the time. VaR of a random variable X is the qth quantile of its cdf, see Artzner [Citation28]. If X follows the EP-W distribution, then its VaR is
(25)
(25)
7.2. Tail value at risk
Another important measure is TVaR, also known as conditional tail expectation (CTE) or tail conditional expectation (TCE), used to quantifies the expected value of the loss given that an event outside a given probability level has occurred. If X follows the EP-W distribution, then its TVaR is derived as
(26)
(26) Using (Equation13
(13)
(13) ) in (Equation26
(26)
(26) ), we get
Using the series
we have
(27)
(27) Let
, then from (Equation27
(27)
(27) ), we have
Finally, we get
(28)
(28)
7.3. Tail variance
The TV is one of the most important actuarial measures which considers the tail variance beyond the VaR. The TV of a EP-W distributed random variable is
(29)
(29) Consider
On solving, we get
Finally, we have
(30)
(30) Using (Equation28
(28)
(28) ) and (Equation30
(30)
(30) ) in (Equation29
(29)
(29) ), we get the expression for the TV of the EP-W distribution.
7.4. Tail variance premium
The TVP is another important measure playing an essential role in insurance sciences. The TVP of the EP-W distributed random variable is
(31)
(31) where
. Using the expression (Equation28
(28)
(28) ) and (Equation29
(29)
(29) ) in (Equation31
(31)
(31) ), we get the tail variance premium of the proposed distribution.
7.5. Numerical study of the risk measures
In this sub-section, we provide numerical study of the VaR, TVaR, TV and TVP for the Weibull and EP-W distributions for different sets of parameters. The process is described below:
Random sample of size n = 100 are generated from the Weibull and EP-W distributions and parameters have been estimated via the maximum likelihood method.
1000 repetitions are made to calculate the VaR, TVaR, TV and TVP for these distributions.
The numerical results of the risk measures are provided in Tables and and displayed graphically in Figures – corresponding to each table.
Figure 8. Graphical sketching of the results of VaR and TVaR provided in Table .
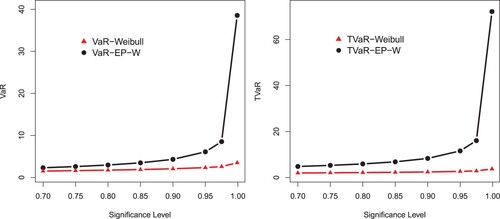
Figure 9. Graphical sketching of the results of TV and TVP provided in Table .
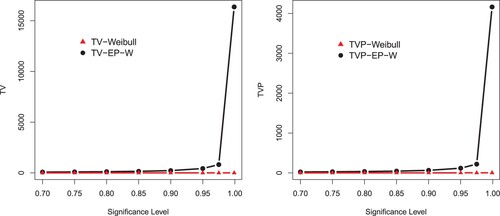
Figure 10. Graphical display of the results of VaR and TVaR provided in Table .
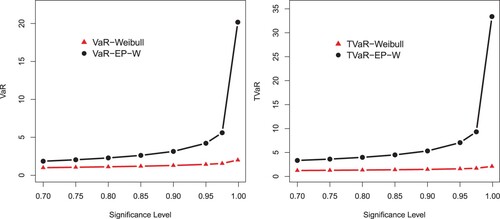
Figure 11. Graphical display of the results of TV and TVP provided in Table .
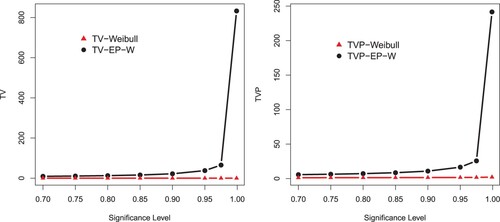
Table 2. Simulation results of the actuarial measures for the selected values of the parameters.
Table 3. Simulation results of the actuarial measures for the selected values of the parameters.
Table 4. Estimated values with standard error (in parentheses) of the competing models.
The simulation is performed for the Weibull and EP-W for the selected values of parameters. A model with higher values of the Risk measures is said to have a heavier tail. The simulated results provided in Tables and show that the proposed EP-W model has higher values of the risk measures than the traditional Weibull distribution. The simulation results are graphically displayed in Figures –, which show that the proposed model has heavier tail than the Weibull distribution.
8. An application to a medical care insurance data set
In this section, we use two insurance data sets to illustrate the importance and flexibility of the proposed distribution. The comparison of the proposed distribution is made with a nested model, the Weibull distribution, and with some other non-nested models such as the generalize exponential (GE), Lomax, Burr, exponentiated Weibull (EW), generalized odd Burr III-Weibull (GOBXIII-W) and generalized log-Moyal (GLM) distributions. It is important to emphasize that the EW distribution is a popular model for analysing data in the applied areas; see Mudholkar and Srivastava [Citation29]. The GE is another non-nested model and offers the characteristics of the Weibull and gamma distributions; see Gupta and Kundu [Citation30]. The Lomax and Burr-XII (B-XII) distributions are prominent competitors for modelling large losses and offer a wide range of applications in financial sciences. The proposed EP-W model is also compared with the GLM distribution of Bhati and Ravi [Citation1]. We also considered the five-parameter non-nested GOBXIII-W distribution of Haq et al. [Citation31]. The cdfs of the competing distributions are:
The EW distribution
The GE distribution
The Lomax distribution
The B-XII distribution
The GOBXIII-W distribution
The GLM distribution
Next, we consider certain analytical measures in order to verify which distribution fits better the considered data. These analytical measures include (i) discrimination measures such as Akaike information criterion (AIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC), Consistent Akaike information criterion (CAIC), and (ii) two other goodness of fit measures including Anderson–Darling (AD) test statistic and Cramer-von Mises test statistic. The discrimination measures are given by
The AIC is
The BIC is
The HQIC
The CAIC is
The AD test statistic is given by
The CM test statistic is given by
For the optimization and calculation of the analytical measures, we use the optim()R-function with the argument method="BFGS"; see Appendix.
8.1. Data 1: medical care insurances
Here, we illustrate the EP-W distribution by analysing a heavy-tailed data set representing medical care insurances. The data set is available at https://data.world/datasets/insurance. The maximum likelihood estimates with the standard error (in parentheses) of the fitted models for the analysed data are presented in Table . The analytical measures of the EP-W and other considered models are provided in Table . Based on the above-mentioned measures, the proposed model fits the heavy-tailed medical care insurance data set better than the other models. In support of the results provided in Table , the estimated pdf and cdf of the proposed distribution are plotted in Figure . The PP and Kaplan–Meier survival plots are sketched in Figure . The proposed model may be an interesting alternative to the other existing models in the literature for modelling positively skewed heavy tail data. The practical application to the medical care insurance data shows that the proposed distribution should be taken into account among other possible distributions for insurance data in which the properties of a heavy-tailed distribution are present.
Figure 12. Estimated pdf and cdf of the EP-W model corresponding to medical care insurance data.
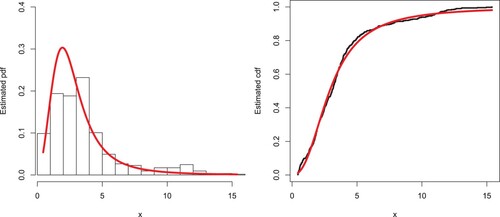
Figure 13. PP plot and Kaplan Meier survival plots of the EP-W model for the medical care insurance data.
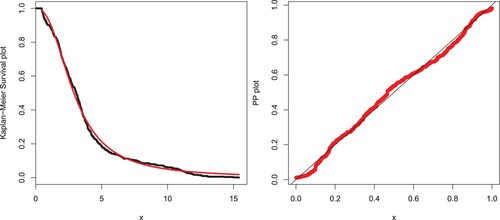
Table 5. Discrimination and goodness of fit measures of the competing models.
8.2. Data 2: vehicle insurance losses
The second data set, available at https://data.world/datasets/insurance, refers to vehicle insurance losses. The competing models are also applied to these data. The estimates with the standard error (in parentheses) of the model parameters are provided in Table . The analytical measures of the EP-W and other considered models are provided in Table . We can see that the EP-W model again outperforms all the fitted competitive models under these statistics. For the second data set, the fitted density and distribution functions of the EP-W model are plotted in Figure . We note that the EP-W distribution best captures the fitted pdf and cdf. The PP and Kaplan–Meier survival plots of the EP-W model are shown in Figure . From Figure , we can see that the proposed model is closely followed by the PP and Kaplan–Meier survival plots.
Figure 14. Estimated pdf and cdf plots of the EP-W distribution for the vehicle insurance loss data.
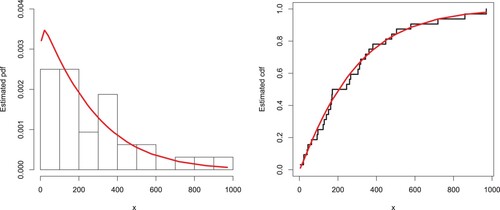
Figure 15. PP and Kaplan–Meier survival plots of the EP-W distribution for the vehicle insurance loss data.
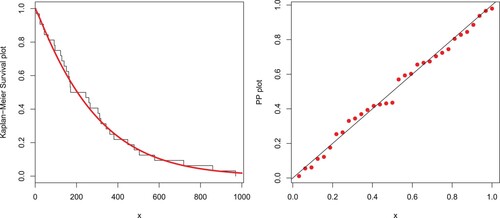
Table 6. Estimated values with standard error (in parentheses) of the competing models for data 2.
Table 7. Discrimination and goodness of fit measures of the competing models for data 2.
9. Bayesian estimation
Bayesian inference procedure has been taken into consideration by many statistical researchers, especially those in the field of the survival analysis and reliability engineering. In this section, a complete sample data is analysed through Bayesian point of view. We assume that the parameters α, γ and θ of EP-W distribution have independent prior distributions as
where a,b,c,d,e and f are positive. Hence, the joint prior density function is formulated as follow:
(32)
(32) In the Bayesian estimation the actual value of the parameter, may be adversely affected by the loss when choosing an estimator. This loss can be measured by a function of the parameter and the corresponding estimator. Five well-known loss functions and associated Bayesian estimators and corresponding posterior risk are presented in Table .
Table 8. Bayes estimator and posterior risk under different loss functions.
For more details see Calabria and Pulcini [Citation32]. Next, we provide the posterior probability distribution for a complete data set. We define the function ϕ as
The joint posterior distribution in terms of a given likelihood function
and joint prior distribution
is defined as
(33)
(33) Hence, we obtain the joint posterior density of the parameters α, γ and θ for the complete sample data by combining the likelihood function and the joint prior density (Equation33
(33)
(33) ). Therefore, the joint posterior density function is given by
(34)
(34) where K is given by
It is clear from Equation (34) that there is no closed form for the Bayesian estimators under the Five loss functions described in Table Equation8
(8)
(8) , so we suggest using a MCMC procedure based on 10,000 replicates to compute Bayesian estimators. The corresponding Bayesian estimates and posterior risk are provided in Table . Table provides
credible and HPD intervals for each parameter of the EP-W distribution. The posterior samples extracted by using Gibbs sampling technique. Moreover, we provide the posterior summary plots in Figures –. These plots confirm that the sampling process is of the prime quality and the convergence does occur.
Figure 16. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Trace plots of each parameter of EP-W distribution.
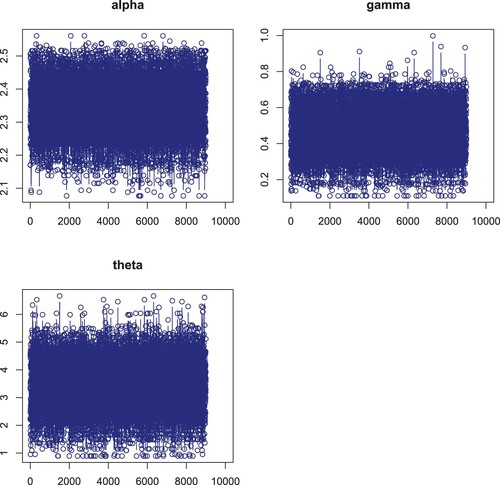
Figure 17. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Autocorrelation plots of each parameter of EP-W distribution.
Figure 18. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Histogram plots of each parameter of EP-W distribution.
Table 9. Bayesian estimates and their posterior risks of the parameters under different loss functions based on the medical care insurance data.
Table 10. Credible and HPD intervals of the parameters α, γ and θ for the medical care insurance data.
For the vehicle insurance losses, the Bayesian estimates along with corresponding the posterior risk are provided in Table . Table provides credible and HPD intervals for each parameter of the EP-W distribution. The posterior samples extracted by using Gibbs sampling technique. Corresponding to the vehicle insurance data set, the posterior summary plots are provided in Figures –. These plots confirm that the sampling process is of the prime quality and the convergence does occur.
Figure 19. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Trace plots of each parameter of EP-W distribution for the vehicle insurance losses data.
Figure 20. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Autocorrelation plots of each parameter of EP-W distribution.
Figure 21. Plots of Bayesian analysis and performance of Gibbs sampling for Insurance data set. Histogram plots of each parameter of EP-W distribution.
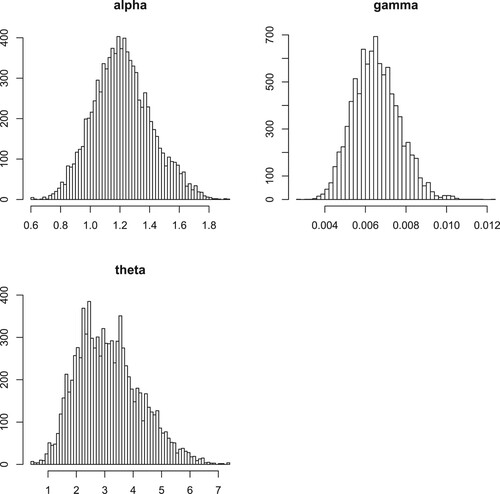
Table 11. Bayesian estimates and their posterior risks of the parameters under different loss functions based on the vehicle insurance losses data.
Table 12. Credible and HPD intervals of the parameters α, γ and θ for the vehicle insurance losses data.
10. Concluding remarks
To cater data in financial and actuarial sciences, a number of methods to define heavy-tailed distributions have been proposed. In this regard, we further carried this branch of distribution theory and proposed nine new families of distributions. A three-parameter special model, called EP-W distribution, is studied in detail. Some mathematical properties along with certain characterizations are derived. Actuarial measures of the proposed model are also calculated and a simulation study has been conducted to show the usefulness of the proposed method in actuarial sciences. To prove the potential of the EP-W distribution, we considered two insurance data sets and compared its goodness of fit with other well-known distributions. The proposed distribution outclassed the competitive models by considering certain analytical measures. We hope that the new development will attract wider applications in the financial and insurance sciences and would be quite helpful for the new comers in the field of distribution theory.
Acknowledgments
The authors are grateful to the Editor-in-Chief, the Associate Editor and the anonymous referees for many of their valuable comments and suggestions which lead to this improved version of the paper. The first two authors also acknowledge the support of the Yazd University, Iran.
Disclosure statement
This article is drafted from the Ph.D work of Mr. Zubair Ahmad.
Data availability statement
This work is mainly a methodological development and has been applied on secondary data related to financial and insurance sciences, but if required, data will be provided.
References
- Bhati D, Ravi S. On generalized log-Moyal distribution: a new heavy tailed size distribution. Insur Math Econ. 2018;79:247–259. doi: 10.1016/j.insmatheco.2018.02.002
- Beirlant J, Matthys G, Dierckx G. Heavy-tailed distributions and rating. ASTIN Bull. 2001;31(1):37–58. doi: 10.2143/AST.31.1.993
- McNeil AJ. Estimating the tails of loss severity distributions using extreme value theory. ASTIN Bull. 1997;27(1):117–137. doi: 10.2143/AST.27.1.563210
- Resnick SI. Discussion of the Danish data on large fire insurance losses. ASTIN Bull. 1997;27(1):139–151. doi: 10.2143/AST.27.1.563211
- Eling M. Fitting insurance claims to skewed distributions: are the skew-normal and skew-student good models. Insur Math Econ. 2012;51(2):239–248. doi: 10.1016/j.insmatheco.2012.04.001
- Adcock C, Eling M, Loperfido N. Skewed distributions in finance and actuarial science: a review. Eur J Financ. 2015;21(13-14):1253–1281. doi: 10.1080/1351847X.2012.720269
- Shushi T. Skew-elliptical distributions with applications in risk theory. Eur Actuar J. 2017;7:277–296. doi: 10.1007/s13385-016-0144-9
- Punzo A. A new look at the inverse Gaussian distribution with applications to insurance and economic data. J Appl Stat. 2019;46(7):1260–1287. doi: 10.1080/02664763.2018.1542668
- Azzalini A, Del Cappello T, Kotz S. Log-skew-normal and log-skew-t distributions as models for family income data. J Inco Dist. 2002;11:12–20.
- Bagnato L, Punzo A. Finite mixtures of unimodal beta and gamma densities and the k-bumps algorithm. Comput Stat. 2013;28(4):1571–1597. doi: 10.1007/s00180-012-0367-4
- Paula GA, Leiva V, Barros M, et al. Robust statistical modeling using the Birnbaum Saunders t distribution applied to insurance. Appl Stoch Models Bus Ind. 2012;28(1):16–34. doi: 10.1002/asmb.887
- Klugman SA, Panjer HH, Willmot GE. Loss models: from data to decisions. 4th ed. John Wiley and Sons, Inc; 2012. (Wiley series in probability and statistics).
- Nadarajah S, Abu Bakar SA. New composite models for the Danish fire insurance data. Scand Actuar J. 2014;2014(2):180–187. doi: 10.1080/03461238.2012.695748
- Bakar SA, Hamzah N, Maghsoudi M, et al. Modeling loss data using composite models. Insur Math Econ. 2015;61:146–154. doi: 10.1016/j.insmatheco.2014.08.008
- Punzo A, Bagnato L, Maruotti A. Compound unimodal distributions for insurance losses. Insur Math Econ. 2018;81:95–107. doi: 10.1016/j.insmatheco.2017.10.007
- Mazza A, Punzo A. Modeling household income with contaminated unimodal distributions. In: Petrucci A, Racioppi F, Verde R, editors. New statistical developments in data science; 2019. p. 373–391. (Springer proceedings in mathematics & statistics; vol. 288).
- Tahir MH, Cordeiro GM. Compounding of distributions: a survey and new generalized classes. J Stat Distrib Appl. 2016;3(1):1–35. doi: 10.1186/s40488-016-0052-1
- Bernardi M, Maruotti A, Petrella L. Skew mixture models for loss distributions: a Bayesian approach. Insur Math Econ. 2012;51(3):617–623. doi: 10.1016/j.insmatheco.2012.08.002
- Miljkovic T, Grr̈n B. Modeling loss data using mixtures of distributions. Insur Math Econ. 2016;70:387–396. doi: 10.1016/j.insmatheco.2016.06.019
- Punzo A, Mazza A, Maruotti A. Fitting insurance and economic data with outliers: a flexible approach based on finite mixtures of contaminated gamma distributions. J Appl Stat. 2018;45(14):2563–2584. doi: 10.1080/02664763.2018.1428288
- Dutta K, Perry J. A tale of tails: an empirical analysis of loss distribution models for estimating operational risk capital. New Engl Econ Rev. 2006;6(13):1–85.
- Alzaatreh A, Lee C, Famoye F. A new method for generating families of continuous distributions. Metron. 2013;71(1):63–79. doi: 10.1007/s40300-013-0007-y
- Ahmad Z, Hamedani GG, Butt NS. Recent developments in distribution theory: a brief survey and some new generalized classes of distributions. Pak J Stat Oper Res. 2019;15(1):87–110. doi: 10.18187/pjsor.v15i1.2803
- Jamal F, Nasir M. Some new members of the T-X family of distributions. Proceedings of the 17th International Conference on Statistical Sciences; 2019 Jan; Lahore, Pakistan. <hal-01965176v2>.
- Mahdavi A, Kundu D. A new method for generating distributions with an application to exponential distribution. Commun Stat-Theory M. 2017;46(13):6543–6557. doi: 10.1080/03610926.2015.1130839
- Glänzel W. A characterization theorem based on truncated moments and its application to some distribution families. Mathematical Statistics and Probability Theory. Dordrecht: Springer; 1987. p. 75-84.
- Glänzel W. Some consequences of a characterization theorem based on truncated moments. Statistics. 1990;21(4):613–618. doi: 10.1080/02331889008802273
- Artzner P. Application of coherent risk measures to capital requirements in insurance. N Am Actuar J. 1999;3(2):11–25. doi: 10.1080/10920277.1999.10595795
- Mudholkar GS, Srivastava DK. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans Reliab. 1993;42(2):299–302. doi: 10.1109/24.229504
- Gupta RD, Kundu D. Exponentiated exponential family: an alternative to gamma and Weibull distributions. Biom J. 2001;43(1):117–130. doi: 10.1002/1521-4036(200102)43:1<117::AID-BIMJ117>3.0.CO;2-R
- Haq MAU, Elgarhy M, Hashmi S. The generalized odd Burr III family of distributions: properties, applications and characterizations. J Taibah Univ Sci. 2019;13(1):961–971. doi: 10.1080/16583655.2019.1666785
- Calabria R, Pulcini G. Point estimation under asymmetric loss functions for left-truncated exponential samples. Comm Statist Theory Methods. 1996;25(3):585–600. doi: 10.1080/03610929608831715
Appendix
Theorem A.1
Let be a given probability space and let
be an interval for some d<e (
might as well be allowed). Let
be a continuous random variable with the distribution function F and let
and
be two real functions defined on H such that
is defined with some real function η. Assume that
and F is twice continuously differentiable and strictly monotone function on the set H. Finally, assume that the equation
has no real solution in the interior of H. Then F is uniquely determined by the functions
and η, particularly
where the function s is a solution of the differential equation
and C is the normalization constant, such that
.
We like to mention that this kind of characterization based on the ratio of truncated moments is stable in the sense of weak convergence (see, Glänzel [Citation27]), in particular, let us assume that there is a sequence of random variables with distribution functions
such that the functions
,
and
satisfy the conditions of Theorem A.1 and let
,
for some continuously differentiable real functions
and
. Let, finally, X be a random variable with distribution F. Under the condition that
and
are uniformly integrable and the family
is relatively compact, the sequence
converges to X in distribution if and only if
converges to η, where
This stability theorem makes sure that the convergence of distribution functions is reflected by corresponding convergence of the functions
and η, respectively. It guarantees, for instance, the “convergence” of characterization of the Wald distribution to that of the Lévy–Smirnov distribution if
. A further consequence of the stability property of Theorem A.1 is the application of this theorem to special tasks in statistical practice such as the estimation of the parameters of discrete distributions. For such purpose, the functions
and, specially, η should be as simple as possible. Since the function triplet is not uniquely determined it is often possible to choose η as a linear function. Therefore, it is worth analysing some special cases which helps to find new characterizations reflecting the relationship between individual continuous univariate distributions and appropriate in other areas of statistics. In some cases, one can take
which reduces the condition of Theorem A.1 to
. We, however, believe that employing three functions
and η will enhance the domain of applicability of Theorem A.1.
R Code for analysis
Note: In the following R-code, a is used for α, t is used for θ, g is used for γ and pm is used for proposed model.