
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Mazucheli et al. introduced a new transformed model referred as the unit-Weibull (UW) distribution with uni- and anti-unimodal, decreasing and increasing shaped density along with bathtub shaped, constant and non-decreasing hazard rates. Here we consider inference upon stress and strength reliability using different statistical procedures. Under the framework that stress–strength components follow UW distributions with a known shape, we first estimate multicomponent system reliability by using four different frequentist methods. Besides, asymptotic confidence intervals (CIs) and two bootstrap CIs are obtained. Inference results for the reliability are further derived from Bayesian context when shape parameter is known or unknown. Unbiased estimation has also been considered when common shape is known. Numerical comparisons are presented using Monte Carlo simulations and in consequence, an illustrative discussion is provided. Two numerical examples are also presented in support of this study.
Significant conclusion: We have investigated inference upon a stress–strength parameter for UW distribution. The four frequentist methods of estimation along with Bayesian procedures have been used to estimate the system reliability with common parameter being known or unknown.
1. Introduction
Many physical phenomena from different disciplines are often modelled using some known probability models which include, among others, Burr family of distributions, lognormal, gamma, exponential, Weibull distributions. These probability distributions can model a variety of data exhibiting significant variability. One particular probability model of specific significance is the well-known Weibull distribution. Over the last five decades or so, several new modifications of this particular model have been proposed and studied by many researchers, such as exponentiated Weibull [Citation1–3], extended Weibull [Citation4,Citation5], modified Weibull [Citation6–8], odd Weibull [Citation9], Weibull-X class [Citation10], Weibull-G model [Citation11], extended Weibull-G family [Citation12] and so on. These distributions are generally derived by adding some additional parameters to the original probability distribution under consideration. Besides, most of these generalizations share one interesting characteristic that they are based on the support over positive part of the real line. Such inferential trend often leads to insufficient number of distributions with finite support. But at the same time, probability distributions with support on finite range are also of importance in many studies. Physical characteristics of many life test experiments quite often lead to data which may lie in some finite range. Data on fractions, percentages, per capita income growth, fuel efficiency of vehicles, height and weight of individuals, survival times from a deadly disease etc. are likely to lie in some bounded positive intervals. Kumaraswamy [Citation13] studied a two-parameter distribution with support on finite interval and investigated many useful applications of this distribution in meteorological inference. Mazucheli et al. [Citation14,Citation15] derived some useful classical estimates for unknown parameters of a unit-gamma distribution and also introduced unit Birnbaum–Saunders distribution, besides, different estimation methods are used to estimate the model parameters. Further, Mazucheli et al. [Citation16] developed and studied properties of a unit Gompertz distribution and derived inferences for its unknown parameters. Mazucheli et al. [Citation17] initially studied various characteristics of a unit Weibull distribution. Through several applications they showed that this particular model can be treated as an useful alternative to the Kumaraswamy and beta distributions in life test studies. We, here, consider multicomponent reliability estimation under unit Weibull probability distribution. This distribution can assume different shapes – monotonic, unimodal, anti-unimodal based on model parameters and such flexibility makes it quite suitable for fitting various data arising in reliability analysis and industrial experiments.
Traditionally, a system consisting more than one component is referred to as multicomponent system, see [Citation18,Citation19]. Under this framework, a system with k independent strength components properly functions if at least s−out−of−k (
strength variables exceed the stress Y. Such a system is often called as (“s−out−of−k:G”) system. Physical aspects of many investigations may lead to multi-component systems and many such examples abound in practice. Such structures are extensively utilized in industrial experiments, military radio networks, bridge construction, building communication networks, etc. In recent past, many scholars have studied multicomponent stress–strength models largely owing to the growing interest on this topic, see for instance, works of [Citation20–23], Dey and Moala [Citation24] and many others. Seadawy et al. [Citation25], Seadawy et al. [Citation26], Ahmad et al. [Citation27], Riaz et al. [Citation28], Abbasi et al. [Citation29] have also studied some complex structures.
The probability distribution of a unit Weibull distribution, with range in the interval , is given by
(1)
(1) and
(2)
(2) where
govern shape of UW distribution. We write this distribution as
.
Various frequentist procedures are discussed to estimate the unknown multicomponent reliability function. We further estimate this unknown parametric function using Bayes procedure against proper and improper prior distributions under a well-known loss function. Next, we have constructed asymptotic, two bootstrap and HPD intervals. Further, UMVUE of the multicomponent reliability is discussed as well under the case that common shape is known. To the our knowledge, this estimation problem based on unit Weibull distribution is not discussed before using the aforementioned methods of estimation.
Contribution of this work is many fold as UW distribution has not been discussed much in the literature. We derive inference for under various classical methods like maximum likelihood estimator (MLE), least square estimator (LSE) and weighted LSE (WLSE) and maximum product of spacing (MPS) estimators. These estimators are evaluated against estimated risks and average bias values computed using various sample sizes. We further estimate
by Bayesian method based on proper and improper priors. Interval estimation is taken care as well. We have constructed asymptotic interval, bootstrap intervals and highest posterior density (HPD) interval. We compare these estimates using their length and coverage probabilities. The uniformly minimum variance unbiased estimator (UMVUE) of
, with known common scale, is derived as well. Our aim is to provide a guideline for selecting the better inference procedure among different classical and Bayesian methods. This would be of deep interest to reliability engineers.
The reliability of system is briefly illustrated in Section 2. In the same section, we describe four classical estimation methods, namely, MLE, LSE, WLSE and MPS to estimate multicomponent reliability and construct asymptotic and two bootstrap (boot−t and boot−p) CIs of multicomponent reliability when all parameters of the system are unknown. Further Bayes estimator is discussed when the prior distributions of β, and
are gamma variables and also independent. In sequel, the HPD interval of multicomponent reliability is also constructed. Subsequently in Section 3, frequentist and Bayesian inference of multicomponent reliability are derived under the assumption that β is known. Simulations results are evaluated in Section 4 to examine numerical performance of proposed procedures. Two real-life examples are studied in Section 5. Finally, paper is concluded in Section 6.
2. Inference for  with unknown β
with unknown β
Suppose denote strength components with cdf as given in (Equation2
(2)
(2) ). Likewise variable Y denotes associated stress acting on the system with distribution function
. Then we have (see Rao et al. [Citation19])
(3)
(3) We next derive some useful inference of this parametric function using different procedures when common shape is unknown or known.
2.1. MLE of
Suppose that are taken from
distribution and Y follows a
distribution where parameters
and β are assumed as unknown. Under this framework, we get that
After some simplification, we have
(4)
(4) We proceed by assuming that n structures are subjected to a test. The likelihood, based on observed data
and
, of
is
The log-likelihood turns out to be
(5)
(5) Partially differentiating the loglikelihood, respectively, w.r.t
,
and β and equating to zero yield following results.
The MLE of
is
(6)
(6) Similarly, from
we get the MLE
of
as
(7)
(7) Finally,
is solved for β to obtain its MLE
satisfying
(8)
(8) The above likelihood equation is nonlinear and can be solved numerically using some iterative technique. Plugging MLE of β in Equations (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ), we can obtain
and
, respectively. Now MLE
of
turns out to be
2.2. Asymptotic interval
Here a confidence interval of the multicomponent reliability is given using MLE. The Fisher information of is
The elements of
are
After some simplification, we get
Similarly, we have
and
From the large sample theory, the MLE of reliability is normal with average given by
. The associated variance is computed as
where we have
and similarly
is evaluated. Thus
CI of the parametric function is given by
, where
is associated percentile of normal
variable and
is computed at respective MLEs.
2.3. Bootstrapping
We develop boot-p and boot-t intervals for (see Efron [Citation30] and Hall [Citation31] for further details).
2.3.1. Boot-p
Obtain samples
Iterate above stage, say nboot times.
Now if
2.3.2. Boot-t
Simulate bootstrap samples
Evaluate
Iterate above two stages sufficient number of times.
Suppose
2.4. Least square and weighted least square estimates
The LSE method is initially discussed by Swain et al. [Citation32]. Here we obtain this estimator for the multicomponent reliability . Note that LSE
of
can be computed by minimizing
, that is,
. So LSE
is the solution of the following equation:
where
follow
distribution. The LSE
of
is computed similarly by solving the following equation:
where
follow
distribution. Thus LSE of
turns out to be
Next, weighted least square estimates (WLSE)
of
is computed by minimizing the following function:
and thus the required estimate is determined from the following equation:
The WLSE estimate
of
is similarly computed from the equation presented below:
So WLSE of
is given by
2.5. Maximum product of spacing (MPS) estimates
Here we obtain another estimator called MPS estimates of the multicomponent reliability as discussed in [Citation33]. Here spacing of a random sample of size nk is defined as also
and
. The desired estimate
of
is computed by maximizing the geometric mean
of spacing. Alternatively we maximize
and compute the desired estimate of
from the following equation:
Next using a sample of size n from the Y variable, define
also
and
. The MPS estimate
of
is determined from equation presented as
Thus the MPS estimate of
can be obtained as
2.6. Bayesian inference
We discuss Bayesian inference of the parametric reliability function. Parameters are a priori assumed to be independently distributed as gamma variables with hyperparameters
, where
and
, respectively, are shape and reverse of scale, index i takes values as 1, 2 and 3. The corresponding pdf is
After some simplification, the joint posterior distribution is derived to be
(9)
(9) The normalizing constant can easily be computed. The required estimator is
(10)
(10) The above integral is relatively difficult to be solved analytically. However, the corresponding posterior expectation can be approximated numerically. We now use [Citation34] procedure and MH algorithm [Citation35,Citation36] to compute
.
2.6.1. Lindley's method
Here Bayes estimator of the multicomponent reliability is obtained by Lindley's approximation method. This method is based on asymptotic expansion useful for evaluating Bayes procedures. The expectation of with respect to the given posterior distribution is
(11)
(11) where
and
denote the log-likelihood function and logarithm of the associated prior, respectively. From this method, the approximate Bayes estimator is given by
(12)
(12) where
Furthermore,
Further
is component
. Next we take the quantity
as
and respective MLEs are utilized for evaluation purposes. Expressions of Equation (Equation12
(12)
(12) ) are computed below:
In a likewise manner, we also evaluate
,
,
,
and also notice that
.
2.6.2. MH algorithm
This iterative procedure is widely used for evaluating Bayes estimates of different parametric functions such as , among others. The posterior of
given observations is derived in previous section. Thus the marginal posteriors of
and
are seen to be gamma distributed, respectively. While marginal posterior of other parameter β is not evaluated in known form. We simulate samples for β using normal proposal distribution. Accordingly, Bayes estimate
of
can be obtained from the following procedure.
Step:
1: Select an adequate guess of
.
2: In ith iteration obtain sample utilizing a normal distribution with mean
and variance
.
3: Obtain a sample from the gamma
variable where
and
.
4: Obtain a sample from the gamma
variable where
and
.
5: Set where
6: Simulate a number u from a random variable U which follows a uniform model on .
7: We take the sample as ,
,
provided the inequality
holds.
8: Based on the above sample, we compute at
.
9: Now iterate stages 2 to 7 to obtain posterior estimates .
Now the required Bayes estimate is given by
where
is burn-in samples. The HPD interval of
is constructed from the posterior samples (see Chen and Shao [Citation37]).
3. Inference for with known β
We now proceed to derive some more frequentist and Bayesian inference of unknown parametric function under assumption that where
is a known constant. We mention that the expression of the reliability is identically same as considered in previous sections since it does not depend on
.
3.1. MLE
Suppose that denotes an observed value generated from the model as listed in Equation (Equation2
(2)
(2) ) where
being unknown shape and
being known shape. Similarly sample y is drawn when
is unknown. The likelihood is then given by
The log-likelihood function can be obtained as
(13)
(13) We partially differentiate the above function with respect to unknown parameters
and
, respectively. Then solving these likelihood equations, respective MLEs of
and
are obtained as
(14)
(14) and
(15)
(15) Thus the estimate
of
is evaluated using the invariance property. From large sample theory, we know that this MLE is normally distributed. The associated mean is given by
. Similarly variance is
The
confidence interval of the reliability
is
where
is the corresponding percentile of the normal
distribution. It is also noted that
is the estimated value of
.
3.2. UMVUE of
Here UMVUE of the reliability
is derived. It is enough to find the UMVUE of
as UMVUEs satisfy linearity property. We see that
is a complete sufficient statistic for
. Further with
has a
pdf and
also has a
pdf where
. Now let
and
where
. We verify that this is unbiased for estimating
Now UMVUE of
is derived using the Lehmann–Scheffe theorem as follows:
(16)
(16) where
. The conditional distributions involved in the previous equation is derived using [Citation38]. We evaluate following cases: (i)
, (ii)
and (iii)
.
Case (i):
Case (ii)
Case (iii)
The desired UMVUE is now obtained as
(17)
(17)
3.3. Bayesian inference
Bayesian inference for the reliability is discussed here when β is known. It is assumed that and
are independently distributed as gamma
and
, respectively. The corresponding joint posterior distribution is given by
(18)
(18) The Bayes estimator has the following form:
(19)
(19) Next we try to evaluate the above expression. We take
. Also assume that
. We observe that
,
. The inverse transformations are
and
with
. The above double integral is given by
where
and
. Using hypergeometric series representation the above integral is expressed as
when
,
and
, also
is the convergence region. We now have
In this particular case, Bayes estimate appears in closed-form expression. Such estimates may also be computed from Lindley and MH methods as well. So for comparison purposes, Bayesian inference of the multicomponent reliability is derived from the latter two methods as well.
3.3.1. Bayes from Lindley technique
Bayesian inference of from this particular technique turns out as
where
. We also have
for positive integer indices i and j taking values as 1, 2, 3, with their sum i + j being three. Also with i and j taking values as 1 and 2, we have
. Also
,
. It should be noted that
denotes ith row and jth column entry of inverse of matrix
where
. The corresponding mode
of the posterior distribution is used to compute the desired estimates and also
is assigned as
for our problem. Let
be equal to
,
be equal to
We also have
. Thus we have
(20)
(20)
3.3.2. M–H algorithm
Note that marginal posteriors of and
are gamma
and
, respectively. We generate samples using the following algorithm and then apply it to compute the Bayes procedure.
Step:
1: Select the adequate choice of
.
2: Obtain a sample using
variable where
and
.
3: Obtain a sample using
variable where
and
.
4: Evaluate where
5: Simulate a number u from a random variable U which follows a uniform model on .
6: We take the sample as ,
provided the inequality
holds.
7: Compute at
8: Now iterate stages 2 to 7 to obtain posterior estimates
Considering as discarded samples, the estimated value of the parameter
turns out to be
.
The credible intervals are evaluated similarly as computed for unknown β case.
4. Numerical experiments
Here simulation experiments are performed to compare the performance of various methods proposed for estimating the reliability function. This study is performed against various sample sizes by assuming different values of
Evaluation of estimators is done under mean square error (MSE) and average biases (ABs).
The performance of asymptotic, boot-t, boot-p and HPD intervals is evaluated using interval length and coverage probabilities criteria.
All estimates are computed when n is assigned as
Both the cases, β known or unknown, are taken into consideration for estimating the reliability.
First consider unknown β case. In this situation, strength–stress components are observed assuming
In Tables , , and , for a given n, three values are listed columnwise for each estimate. Among these, the first value denotes the estimated value of
In Tables –, estimation results for
We mention that in Tables , , and , for a given n, two values are listed columnwise for each estimate. Among these, the first value denotes average length (AL) of interval of
In Tables and , we have tabulated AL and coverage probabilities of various intervals. From these tables, it is observed that the average lengths of the intervals decrease with the increase in sample size, as expected. The average interval length of HPD interval is smaller than their counter parts.
Next β known case is presented. Tables and contain estimation results of reliability under frequentist and Bayes techniques when
The strength and stress characteristics are observed for
Moreover, in Tables and , we provide widths and associated probabilities of 95% intervals. From Tables and , we observe that the MSE and ABs for the estimates of
Note that maximum likelihood and unbiased estimators show good performance in comparison with Bayes counterparts, however, Bayes estimates have an advantage over these two estimates in terms of bias and MSE values. Tabulated values also indicate that MLEs show good behaviour than UMVU estimates.
We further notice that Lindley and M–H inferences slightly vary when compared with corresponding exact Bayes inference and for large sample sizes their MSE and ABs tend to become close to each other. The Bayes estimates of
Table 1. Estimation results for with unknown β.
Table 2. Estimation results for with unknown β.
Table 3. Interval estimation results for with unknown β.
Table 4. Interval estimation results for with unknown β.
Table 5. Estimation results for with known .
Table 6. Estimation results for with known .
Table 7. Interval estimation results for with known .
Table 8. Interval estimation results for with known .
5. Data analysis
Data Set I: We present a real-life numerical example in support of estimation procedures considered for evaluating the system reliability based on UW distribution. The data represent breaking strength of Jute fibre [Citation39]. We have considered 15mm gauge length data for analysis. The diameters of jute fibres are measured with an XSP-8CA digital biological microscope. Consider s = 1 and , then we observe that
becomes identical with the sixth observation of considered data. Thus we see that observations
are from first to fifth observations. Similarly
is the 12th observation and also
are from 7 to 11th data points. Here k is a positive integer ranging from 1 to 5. Data processing for total 30 observations gives n as 5. Observation
is given below:
We also update observations X and Y by
,
, respectively and then checked using goodness test whether the considered data sets can be fitted to the UW model. The MLEs of respective unknown parameters of all the competing distributions are evaluated numerically. The KS ( Kolmogorov–Smirnov) test statistic is taken into consideration for model evaluation. Table contains associated probability values for all the competing models. It is seen that UW distribution can be considered a good representative model given data. We have also plotted P–P and Q–Q plot (Figure ) of the given data sets and observe that data fitted satisfactorily. In Figure , we plotted curve of the profile likelihood function. This is concave in nature, i.e. unimodal function and maximum at
for strength data as well as
for stress data set. In Table , estimation results for the unknown reliability are evaluated for the complete data case. In fact all intervals are also computed. Bayesian inference is performed against improper prior distributions.
Figure 1. PP–QQ plots of the unit Weibull distribution for Data I.
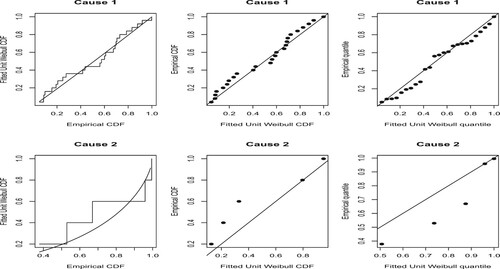
Figure 2. Plotting of profile likelihood of Unit Weibull distribution for Data I.
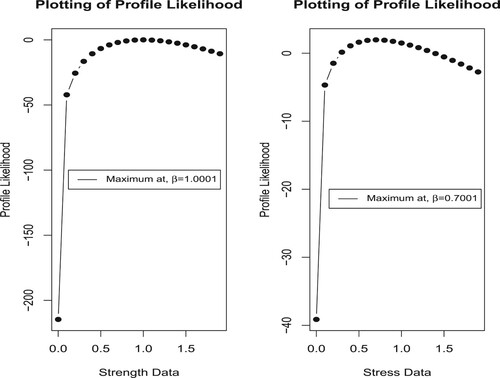
Table 9. Test of goodness results for Data I.
Table 10. Estimation results for Data I.
Further equivalence testing between UW stress and strength parameters
The estimates of corresponding log likelihoods under data I with
We see that null hypothesis
Data Set II:
The second data set defines 12 core samples from petroleum reservoirs that were sampled by 4 cross-sections. There are a total of 48 observations in this study. Core samples are measured for permeability and each cross-section defined using following components: total area of pores, total perimeter of pores and shape. The data set is available in R language [Citation40], especially on data.frame named rock. Table contains associated estimates for all competing models. We see that UW distribution is a good representative model for the given data. We have also plotted P–P and Q–Q plots (Figure ) of the data. We observe that data fitted satisfactorily by the UW model. In Figure , we plotted curve of the profile likelihood function. This is concave in nature, i.e. unimodal function with maximum at for strength data and
for stress data. Following [Citation41], we further explore histogram plot of bootstrap samples for the logit of
based on 3000 replications, see Figure . The histogram resembles of a normal distribution with approximate mean 1.727348 and standard deviation 0.5171634. Further associated K–S estimate (0.029392) and P-value (0.06314) also indicate normality of bootstrap samples for the logit of
. In Table , estimates for the unknown reliability are evaluated for the complete data case. Associated intervals are also computed. We mention that Bayesian computations are performed against improper prior distribution.
Figure 3. PP–QQ plots of the unit Weibull distribution for Data II.
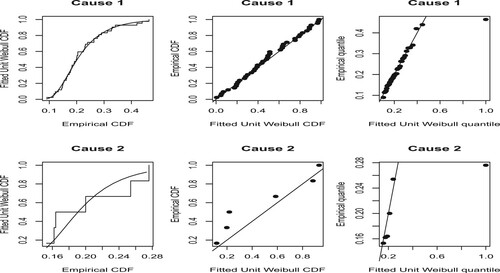
Figure 4. Plotting of profile likelihood of Unit Weibull distribution for Data II.
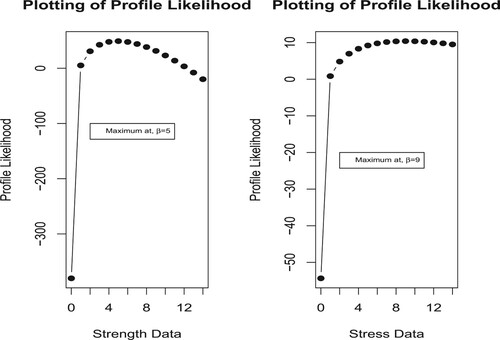
Figure 5. Plotting of logit of Unit Weibull distribution for Data II.
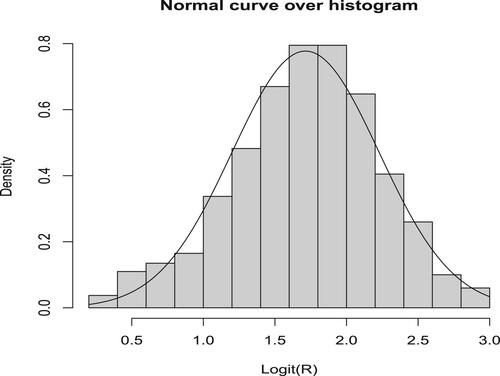
Table 11. Goodness of fit for Data II.
Table 12. Estimation results for Data II.
We consider s = 1 and which is like 1-out-of-7: G system. Let
denote the 8th breaking stress and
,
, be the failure times of observations numbered 1 to 7. Further let
denote the 16th observation and
be the failure times from 9 to 15. We carry on this data processing up to 48th failure, then we get n = 6 data for Y. The obtained data
are as follows:
Further equivalence testing between UW stress and strength parameters
The estimates of corresponding log likelihoods under data II with
We see that null hypothesis
6. Conclusion
We have investigated inference upon a stress–strength parameter for UW distribution. The four frequentist methods of estimation have been used to obtain the system reliability with known and unknown β. Besides, asymptotic and two bootstrap CIs are obtained. Further Bayes inferences of are studied against different approximation techniques. The Bayes credible interval is discussed utilizing posterior samples generated from an MCMC method. Besides, unbiased estimation of reliability is also evaluated for known β case. Our numerical results suggest that Bayes procedure yields better inference compared to MLE and UMVUE. It is also seen that asymptotic, bootstrap and Bayesian intervals exhibit relatively good CP behaviour. However, width of Bayes intervals remains narrower than the corresponding asymptotic and bootstrap CIs. We present two numerical examples to demonstrate and observe the reliability for one system configuration. We found that WLSE provides marginally better results than the corresponding LSE estimates. Further inference obtained from the MPS method shows good behaviour than the WLSE method. We further note that MLE also improves LSE and WLSE. However, MLE and MPS methods are incomparable as in some case MLE performs better than MPS and in other case opposite behaviour is observed. We observe that if proper prior is available then Bayesian procedures have an advantage over the other methods. Overall, better inference of this particular parametric function can be derived under known β case. Although inference is studied when stress–strength components have the UW distributions, however, such studies can be conducted under assumption stress–strength components have different distributions. Moreover, estimation for the multicomponent stress–strength reliability for system with dependent components seems also of interest and importance in practice, which will be studied in the future. In near future, we also try to study such problems under some censoring schemes.
Acknowledgements
Authors thank the reviewer and Editor for their useful comments to improve our manuscript. This work was funded by Deanship of Scientific Research at Princess Nourah bint Abdulrahman University, through the Program of Research Project(Grant No. 41-PRFA-P-14).
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Mudholkar GS, Srivastava DK. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans Reliab. 1993;42:299–302.
- Mudholkar GS, Srivastava DK, Freimer M. The exponentiated Weibull family: a reanalysis of the bus-motor-failure data. Technometrics. 1995;37:436–445.
- Singh U, Gupta PK, Upadhyay SK. Estimation of parameters for exponentiated-Weibull family under type-II censoring scheme. Comput Statist Data Anal. 2005;48:509–523.
- Marshall AW, Olkin I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika. 1997;84:641–652.
- Zhang T, Xie M. Failure data analysis with extended Weibull distribution. Comm Statist Simul Comput. 2007;36:579–592.
- Jiang H, Xie M, Tang LC. Markov chain Monte Carlo methods for parameter estimation of the modified Weibull distribution. J Appl Stat. 2008;35:647–658.
- Lai CD, Xie M, Murthy DNP. A modified Weibull distribution. IEEE Trans Reliab. 2003;52:33–37.
- Ng HKT. Parameter estimation for a modified Weibull distribution, for progressively type-II censored samples. IEEE Trans Reliab. 2005;54:374–380.
- Cooray K. Generalization of the Weibull distribution: the odd Weibull family. Stat Model. 2006;6:265–277.
- Alzaatreh A, Famoye F, Lee C. A new method for generating families of continuous distributions. METRON. 2013;71(1):63–79.
- Bourguignon M, Silva RB, Cordeiro GM. The Weibull-G family of probability distributions. J Data Sci. 2014;11:1–27.
- Korkmaz MC. A new family of the continuous distributions: the extended Weibull-G family. Commun Fac Sci Univ Ank Ser A1 Math Stat. 2019;68(1):248–270.
- Kumaraswamy P. A generalized probability density function for double-bounded random processes. J Hydrol (Amst). 1980;46(1–2):79–88.
- Mazucheli J, Menezes AFB, Dey S. Improved maximum-likelihood estimators for the parameters of the unit-gamma distribution. Commun Statist Theory Methods. 2018a;47(15):3767–3778.
- Mazucheli J, Menezes AFB, Dey S. The unit-Birnbaum–Saunders distribution with applications. Chil J Stat. 2018b;9(1):47–57.
- Mazucheli J, Menezes AFB, Dey S. Unit-Gompertz distribution with applications. Statistica. 2019;79(1):25–43.
- Mazucheli J, Menezes AFB, Ghitany ME. The unit-Weibull distribution and associated inference. J Appl Probab Stat. 2018;13(2):1–22.
- Bhattacharyya G, Johnson RA. Estimation of reliability in a multicomponent stress–strength model. J Am Stat Assoc. 1974;69(348):966–970.
- Rao GS, Aslam M, Kundu D. Burr-XII distribution parametric estimation and estimation of reliability of multicomponent stress–strength. Commun Statist Theory Methods. 2015;44:4953–4961.
- Dey S, Mazucheli J, Anis M. Estimation of reliability of multicomponent stress–strength for a Kumaraswamy distribution. Commun Statist Theory Methods. 2017;46:1560–1572.
- Kayal T, Tripathi YM, Dey S, et al. On estimating the reliability in a multicomponent stress–strength model based on Chen distribution. Commun Statist Theory Methods. 2020;49(10):2429–2447.
- Kizilaslan F, Nadar M. Classical and Bayesian estimation of reliability in multicomponent stress–strength model based on Weibull distribution. Rev Colomb Estadstica. 2015;38(2):67–484.
- Pak A, Gupta AK, Khoolenjani NB. On reliability in a multicomponent stress–strength model with power Lindley distribution. Rev Colomb Estadstica. 2018;41(2):251–267.
- Dey S, Moala FA. Estimation of reliability of multicomponent stress–strength of a bathtub shape or increasing failure rate function. Int J Qual Reliab Manag. 2019;36(2):122–136.
- Seadawy AR, Luc D, Yue C. Travelling wave solutions of the generalized nonlinear fifth-order KdV water wave equations and its stability. J Taibah Univ Sci. 2017;11:623–633.
- Seadawy AR, Iqbal M, Luc D. Nonlinear wave solutions of the Kudryashov–Sinelshchikov dynamical equation in mixtures liquid–gas bubbles under the consideration of heat transfer and viscosity. J Taibah Univ Sci. 2019;13:1060–1072.
- Ahmad H, Seadawy AR, Khan TA, et al. Analytic approximate solutions for some nonlinear parabolic dynamical wave equations. J Taibah Univ Sci. 2020;14:346–358.
- Khaliq Q, Riaz M, Ahmad S. On designing a new Tukey-EWMA control chart for process monitoring. Int J Adv Manufacturing Technol. 2016;82(1–4):1–23.
- Abbasi SA, Khaliq QUA, Omar MH, et al. On designing a sequential based EWMA structure for efficient process monitoring. J Taibah Univ Sci. 2020;14(1):177–191.
- Efron B. The jackknife, the bootstrap, and other resampling plans. Philadelphia (PA): SIAM; 1982.
- Hall P. On some simple estimates of an exponent of regular variation. J R Statist Soc Ser B (Method). 1982;44(1):37–42.
- Swain JJ, Venkatraman S, Wilson JR. Least-squares estimation of distribution functions in Johnson's translation system. J Stat Comput Simul. 1988;29(4):271–297.
- Cheng R, Amin N. Estimating parameters in continuous univariate distributions with a shifted origin. J R Statist Soc Ser B (Method). 1983;45(3):394–403.
- Lindley DV. Approximate bayesian methods. Trabajos Estadst Invest Oper. 1980;31(1):223–245.
- Hastings WK. Monte Carlo sampling methods using Markov chains and their applications. Biometrika. 1970;57(1):97–109.
- Metropolis N, Rosenbluth AW, Rosenbluth MN, et al. Equation of state calculations by fast computing machines. J Chem Phys. 1953;21(6):1087–1092.
- Chen M-H, Shao Q-M. Monte Carlo estimation of Bayesian credible and HPD intervals. J Comput Graph Stat. 1999;8(1):69–92.
- Basirat M, Baratpour S, Ahmadi J. Statistical inferences for stress–strength in the proportional hazard models based on progressive type-II censored samples. J Stat Comput Simul. 2015;85(3):431–449.
- Xia Z, Yu J, Cheng L, et al. Study on the breaking strength of jute fibres using modified Weibull distribution. Comp Part A Appl Sci Manufac. 2009;40(1):54–59.
- Team RC. R: a language and environment for statistical computing. 2013.
- Al-Mutairi DK, Ghitany ME, Kundu D. Inferences on stress–strength reliability from Lindley distributions. Commun Statist Theory Methods. 2013;42(8):1443–1463.