
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper aims to propose estimation methods for one-inflated positive Poisson (OIPP) distribution and compare their properties in terms of unbiasedness, consistency, efficiency and deficiency. All estimators considered in the study are asymptotically unbiased and consistent. The maximum likelihood estimator (MLE) for the OIPP distribution is asymptotically normal. When compared to the MLE, the ordinary least square estimator (OLSE) is the most efficient, followed by the method of moments estimator (MME) and the ratio of probability estimator (RPE). A novel one-inflation index was also proposed to assess the presence of excess ones in the dataset for the positive Poisson distribution to determine whether a one-inflated distribution is required for model fitting. A real dataset with a large number of ones, as identified by the proposed one-inflation index, was used for model fitting. It is found that the OLSE and MLE are the best estimators for an OIPP distribution.
1. Introduction
In discrete count data distribution, one method of modelling positive data is to truncate the distribution at zero, resulting in a zero-truncated distribution. Positive count data modelling can be traced back to the mid-twentieth century, when the first zero-truncated distribution, known as the zero-truncated Poisson distribution [Citation1], was proposed. The probability mass function of the zero-truncated Poisson distribution is given as.
where
and the maximum likelihood estimator (MLE) of
can be obtained numerically by solving
(1)
(1) Subsequently, other estimators for a zero-truncated Poisson distribution were developed and analysed [Citation2–5]. An asymptotically unbiased estimator of
was proposed [Citation2] as follows:
(2)
(2) where
is the frequency of
-valued data and
is the maximum number taken by
. Similarly, an efficient estimator of
was proposed [Citation3] as follows:
(3)
(3)
Both (1) and (3) were used to estimate the mortality rate of the number of gall-cells per flower-head [Citation4], and it was discovered that both estimators provide similar estimates for mortality rate estimation. In addition to the estimators in (1–3), a minimum variance unbiased estimator of was proposed [Citation5] as follows:
(4)
(4) where
,
and
is the Stirling number of the second kind. The function used for this estimator is dependent on the subdomain as shown in (4).
The negative binomial distribution was modified to the zero-truncated negative binomial distribution as an alternative to the zero-truncated Poisson distribution. As a result, the moment estimator for the zero-truncated negative binomial distribution was proposed [Citation6] and further modified, resulting in a simpler but more efficient estimator [Citation7]. A zero-truncated distribution based on the Poisson–Lindley distribution likelihood was also proposed, leading to the development of estimation methods based on the method of moments and maximum likelihood [Citation8].
Inflated models based on the zero-truncated distribution have been studied to incorporate a large number of ones in the dataset. The proposed distributions include the one-inflated positive Poisson [Citation9], one-inflated zero-truncated negative binomial [Citation10], one-inflated positive Poisson mixture [Citation11] and one-inflated positive Poisson–Lindley [Citation12] models, which are all commonly used to estimate the population size of individuals in capture–recapture experiments. The inflation parameter in the one-inflated model is critical for reflecting the desire and ability of a captured subject to avoid recapture [Citation9]. In line with [Citation9], the goal of our study is to propose multiple estimation methods for an OIPP distribution and to identify the best estimators by considering various estimator properties. An inflation index that can assess the presence of excess ones in the dataset was also developed and analysed.
This paper is structured as follows: Section 2 provides a brief overview of the OIPP distribution and its statistical properties. Section 3 proposes estimation methods for an OIPP distribution. Section 4 discusses two simulation studies that were conducted to investigate the performance of the proposed estimation methods in terms of unbiasedness, consistency, efficiency and deficiency. Section 5 proposes a novel one-inflation index to assess the presence of excess ones in a dataset for the positive Poisson distribution to determine whether a one-inflated distribution is required for model fitting. The performance of the proposed index is also addressed in the same section. In Section 6, a dataset is fitted to the OIPP distribution using the proposed estimation methods and model fittings. Section 7 concludes the study.
2. One-inflated positive Poisson (OIPP) distribution and its statistical properties
Let , then the probability mass function of Y is given in (5), where
refers to the rate parameter and
refers to the one-modification parameter for the oIPP distribution.
(5)
(5) If
, then the distribution is known as an OIPP distribution [Citation9]. If
, the OIPP distribution is reduced to a zero-truncated Poisson distribution [Citation1]. It is possible for
to be negative, such as
, in which case the distribution is known as a one-deflated positive Poisson distribution. In this study, we restrict
to ensure the one-inflation property. The formulae for the first two moments about the origin, the dispersion index and the moment generating function are given respectively as
(6)
(6)
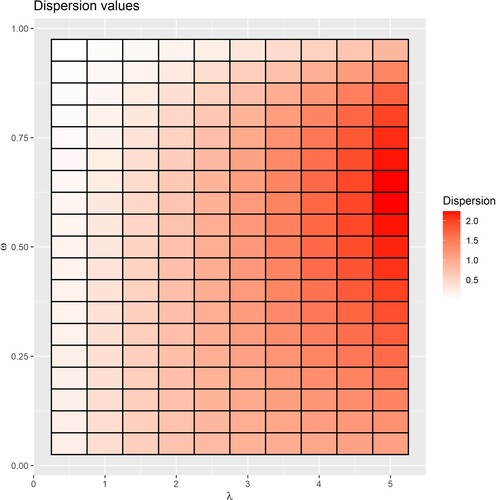
Figure illustrates the dispersion index of various pairs of parameters and
. The heatmap in Figure shows that the OIPP distribution can be either underdispersed or overdispersed.
Figure 1. Heatmap of dispersion index for various pairs of parameters and
.
For , the OIPP distribution is unimodal, which can be deduced based on the decreasing function from the following ratio:
3. Estimation of parameters for OIPP distribution
Several estimation methods for an OIPP distribution were developed based on the method of moments, maximum likelihood, one-proportion, ratio of probability and ordinary least squares. Fitting a model to a dataset based on its method of moments, maximum likelihood and/or ordinary least squares estimators is a common practice in statistical modelling. On the other hand, the one-proportion and ratio of probability estimators are rarely used.
3.1. Method of moments estimator (MME)
The method of moments estimator (MME) is obtained by equating sample moments with theoretical moments. By equating the first two sample moments with the first two equations in (6), the MMEs of and
are obtained by solving.
and
where
for
data, and
and
are the respective MMEs of
and
.
3.2. Maximum likelihood estimation (MLE)
The log-likelihood function for a random variable Y that follows the OIPP distribution is given as.
where
refers to the number of
-valued observations and
. By differentiating
with respect to
and
and setting it to zero, the respective MLEs of
and
can be obtained by solving
and
where
and
and
are the respective MLEs of
and
.
A one-proportion estimator (OPE) is the extension to the estimator for the generalized negative binomial distribution. The OPE for the generalized negative binomial distribution can be obtained by comparing the first two sample moments and the sample proportion of zeros to the population proportion [Citation13]. Similarly, the zero-inflated Poisson distribution parameter estimator is obtained by equating the empirical probability with the theoretical probability of zero-valued observations [Citation14]. For the OIPP distribution, the OPE of is obtained by equating the theoretical proportion of ones to the sample proportion of one, while the OPE of
is obtained by equating the population mean to the sample mean. Surprisingly, the OPEs of
and
are identical to their respective MLEs.
Theorem 1:
The MLE of
is consistent and asymptotically normal, such that.
where
is the Fisher information of
with
and
.
Proof:
The regularity conditions under which the MLE is consistent and asymptotically normal is satisfied by the OIPP distribution (see [Citation15, Chapter 6]), therefore
where
, and
and
are respectively given as
and
Solving the summation in
yields
From Theorem 1, the asymptotic
confidence interval of
is given as.
Theorem 2:
The MLE of
is consistent and asymptotically normal, such that
where
is the Fisher information of
with
and
.
Proof:
The regularity conditions under which the MLE is consistent and asymptotically normal is satisfied by the OIPP distribution (see [, Chapter 6]), therefore
where
and
.
Substituting in the derivation above yields
Theorem 2 implies that the asymptotic
confidence interval of
is given as
3.3. Ratio of probability estimator (RPE)
The ratio of probability estimator (RPE) is the extension to the estimator for the generalized negative binomial distribution that can be obtained either by equating the ratio of one-valued observations to two-valued observations or by equating the first two theoretical moments with the sample moments [Citation13]. The same method has been employed to obtain the parameter estimators for the zero-inflated Poisson–Lindley distribution [Citation16]. Our study is premised on [Citation13,Citation16], in which the respective estimators of and
were obtained by considering the ratio of probability for 3-valued observations to 2-valued observations and by equating the population mean with the sample mean. Parameter
can be eliminated by considering the ratio of probability for 3-valued observations to 2-valued observations, allowing parameter
to be easily obtained as follows:
By further equating
to the empirical ratio of
, the resulting RPE of
is given as
where
is the RPE of
and
can only be obtained when both
and
are greater than zero. Note that the formula of
is very simple, hence can be solved manually.
The calculation of RPE of is similar to the calculation of MME of
. Notice that the RPE of
is a special case of the general form of the Zelterman estimator studied by Böhning [Citation17] given as
, where
. Since the OIPP distribution is an extended zero-truncated Poisson distribution, it is only appropriate to use the first approach given by Böhning [Citation17]. This entails truncating the Poisson model at all counts except 2 and 3, resulting in the following log-likelihood function.
with maximum likelihood estimate
(refer to [Citation17] for a detailed explanation). Based on the findings in [Citation17], the variance of RPE of
, which is a special case of Zelterman estimator, can be written as
The variance can be further estimated by substituting with
, resulting in
Identical results can be obtained using the second approach given by Böhning [Citation17], which considers the nonparametric multinomial approach. Based on the variance and the estimated variance formulae, it can be concluded that the RPE of
is consistent since as
increases, so does
. Also, the one-inflation and unimodality properties indicate that
, resulting in zero
and
.
3.4. Ordinary least squares estimator (OLSE)
The ordinary least squares estimator (OLSE) is an estimator that minimizes the function of the squared difference between theoretical and empirical cumulative functions. Suppose is the order statistics of the data that follows the OIPP distribution. It is known that
for
. However, for count data, the expected value of the order statistics is best expressed with respect to the data frequency, such that
. The OLSE of
and
can be obtained by minimizing the following function:
where
is an indicator function and
is the frequency of
-valued data. The estimators
and
that give the smallest
are the OLSEs of
and
, respectively. The resulting estimators have invariance property since OLSE is a special case of the minimum-distance estimation [Citation18].
4. Simulation study
Two simulation studies were conducted to evaluate the performance of the proposed estimators in terms of unbiasedness, consistency and efficiency. Both simulation studies used to ensure that
and
, so that the RPEs of
and
can be obtained.
4.1. Unbiasedness and consistency properties of the estimators
The first simulation study was conducted to evaluate the unbiasedness and consistency of the proposed estimators. The setting for the first simulation study is as follows:
Simulation setting:
Step 1. Generate random data samples that follow a positive Poisson distribution with parameters
and
, where
and
.
Step 2. Change the value of data to 1 at random to ensure the one-inflation property.
Step 3. Estimate the parameters using MME, MLE, RPE and OLSE.
Step 4. Repeat Steps 1–3 for a total of 2000 times, and calculate bias and mean squared error
for parameter
using the following respective formulae
and
where
is the estimated
and
. The absolute value of the deviation about the true parameter was considered when computing the bias to provide a smooth trend of bias as
increases and avoid bias value fluctuations.
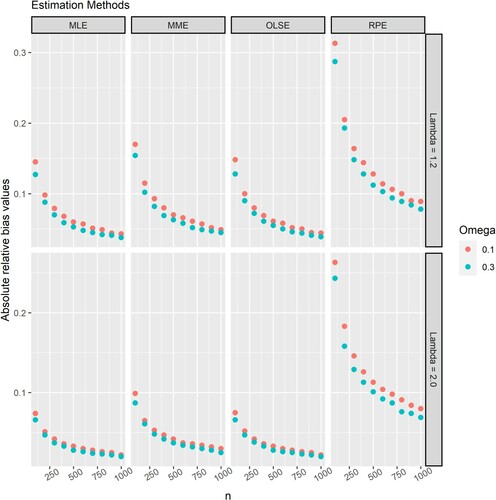
Figures and respectively illustrate the bias of the proposed estimators of and
. Based on Figures and , the following conclusions can be drawn:
The estimators are asymptotically unbiased. As
increases, the bias of the estimators of both
The biases of MMEs, MLEs and OLSEs are similar and significantly smaller than those of RPEs for the same sample size and parameters.
The estimators with the lowest to highest bias for any given sample size are MLE, OLSE, MME and RPE.
Figure 2. The absolute relative bias of the estimator of when estimated using the MLE, MME, OLSE and RPE for
and
.
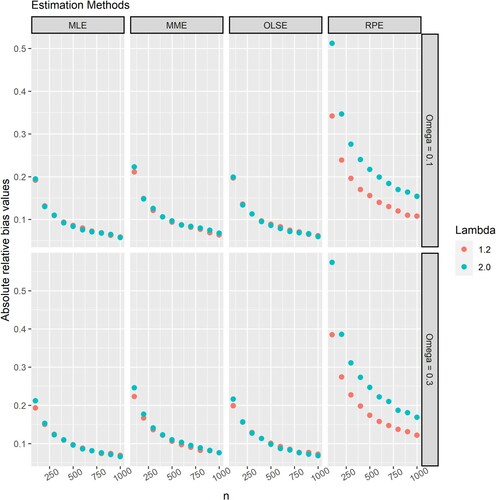
Figure 3. The absolute relative bias of the estimator of when estimated using the MLE, MME, OLSE and RPE for
and
.
Figures and respectively illustrate the mean squared error of the estimators of and
using the proposed estimation methods. Based on Figures and , the following conclusions can be drawn:
The estimators are consistent for all parameters. As
The mean squared error of MMEs, MLEs and OLSEs are similar and significantly smaller than those of RPEs for the same sample size and parameters.
The estimators with the lowest to highest mean squared error for any given sample size are MLE, OLSE, MME and RPE.
Figure 4. The mean squared error of the estimator of when estimated using the MLE, MME, OLSE and RPE for
and
.
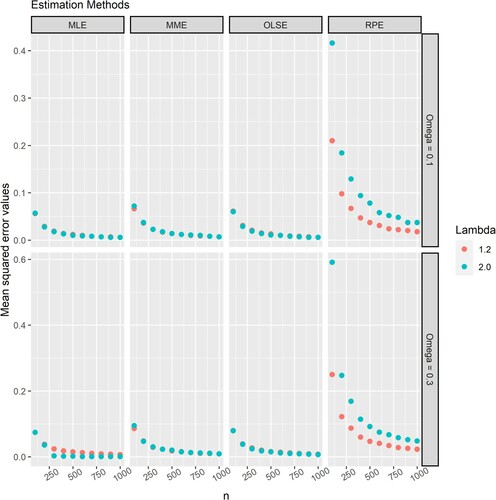
Figure 5. The mean squared error values of estimator when estimated using the MLE, MME, OLSE and RPE for
and
.
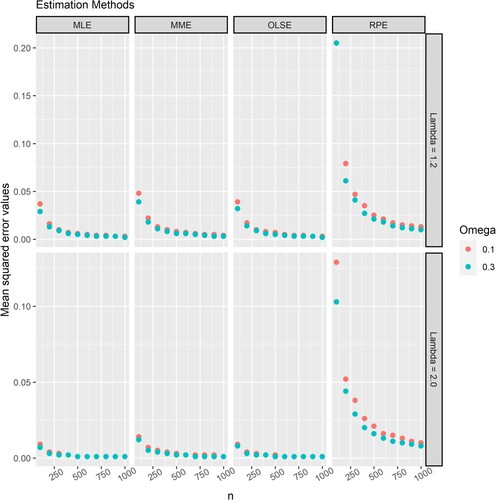
In short, the proposed estimators are asymptotically unbiased and consistent for all values of parameters. RPE has a significantly larger bias and mean squared error than other estimators, but it still may provide a good model fitting for very large samples . The best to worst estimators in terms of unbiasedness and consistency are MLE, OLSE, MME and RPE.
4.2. Efficiency property of the estimators
The second simulation study was conducted to evaluate the efficiency of the proposed estimators compared to the efficiency of the MLE. The setting for the second simulation study is as follows:
Simulation setting:
Step 1. Generate random data samples that follow the positive Poisson distribution with parameters
and
.
Step 2. Change the value of data to 1 at random to ensure the one-inflation property.
Step 3. Estimate the parameters using MME, MLE, RPE and OLSE.
Step 4. Repeat Steps 1–3 for a total of 2000 times, and calculate the efficiency of all estimators compared to the efficiency of the MLE using
where
is the MME, RPE and OLSE of
, and
is the MLE of
. Since the asymptotically unbiased property has been established and variance can be represented as the sum of mean squared error and squared bias, the efficiency of the estimators can be calculated using the following formula:
Figure and Figure respectively illustrates the efficiency of the proposed estimators of and
in percentage compared to the efficiency of the MLE. Based on Figure and Figure , the following conclusions can be drawn:
The MME of
The MME of
The RPE of
The RPE of
The OLSEs of
Figure 6. The efficiency of the estimators of when estimated using the MME, RPE and OLSE with respect to the MLE.
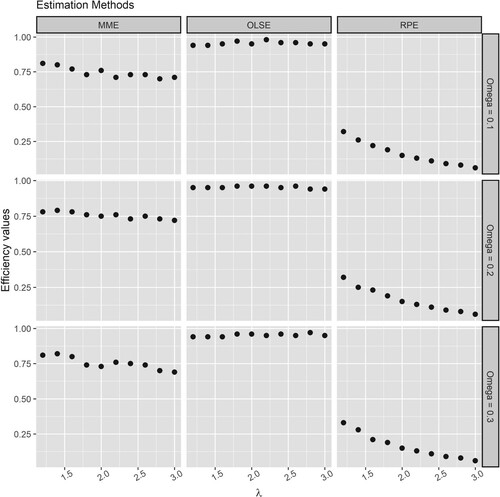
Figure 7. The efficiency of the estimators of when estimated using the MME, RPE and OLSE with respect to the MLE.
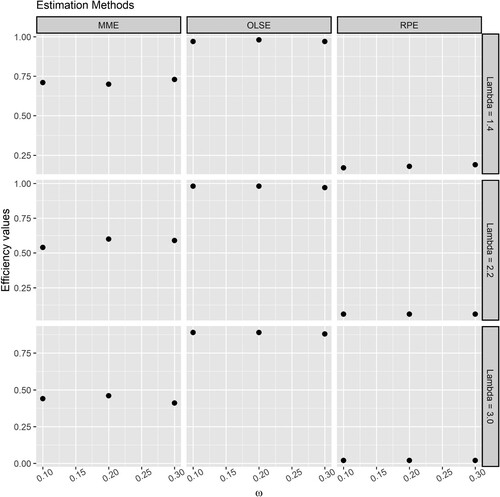
It can be concluded that the OLSE is almost as efficient as the MLE but more efficient than the MME and RPE. Also, the MME is significantly more efficient than the RPE.
Another way to evaluate estimator performance is by calculating the joint efficiencies of the estimators for the two parameters using the deficiency criterion [Citation19], which is defined as.
where
and
are the estimators of
and
, respectively. Figure shows that the joint efficiency decreases as the sample size grows for given
and
. The MLE, MME and OLSE have similar joint efficiencies, whereas RPE has a substantially larger joint efficiency, even when the sample size is as large as 1000. According to the deficiency criterion, the MLE is the most efficient estimator. The estimators with the best to worst efficiency are MLE, OLSE, MME and RPE. These findings corroborate the findings in Figure and Figure .
Figure 8. The joint efficiency of the estimators of and
when estimated using the MLE, MME, OLSE and RPE for
and
.
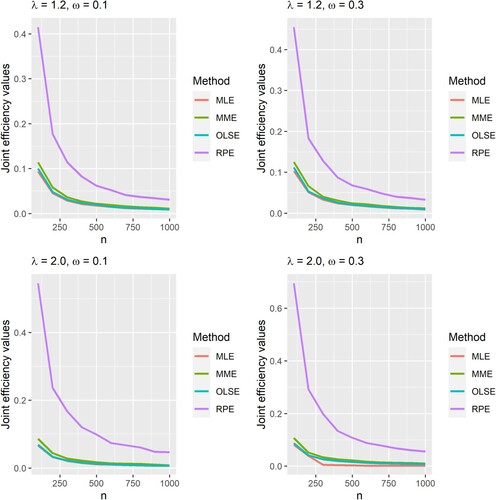
5. One-inflation index under positive Poisson distribution
A novel index called the one-inflation index was developed to determine whether a one-inflated distribution is required to model a dataset. By definition, a -inflation index is an index that assesses the presence of
-valued data with respect to a certain distribution. For instance, the zero-inflation index, denoted as
, assesses the presence of excess zeros in a dataset for a Poisson distribution [Citation20,Citation21]. Another zero-inflation index, denoted as
, was introduced to assess the presence of excess zeros in the dataset for a negative binomial distribution [Citation22]. The formulae of
and
are respectively given as.
and
where
is the proportion of zeros,
is the mean and
is the variance. When the sample zero-inflation index is greater than zero, this indicates that there are excess zeros in the dataset. Following the works in [Citation20–22], a new one-inflation index is proposed to assess the presence of excess ones in the dataset for a positive Poisson distribution. The one-inflation index is denoted as
where
is the proportion of ones and
is the dispersion index. If a random variable follows the positive Poisson distribution, then
, while
indicates that the dataset contains a large number of ones for the positive Poisson distribution. The presence of excess ones in the sample data can be determined by computing the sample one-inflation index. As an example, a dataset of size 5000 that follows the OIPP distribution was simulated, and the one-inflation index
for a positive Poisson distribution are shown in Table .
Table 1. The sample proportion of one-valued data, sample mean, sample variance, sample dispersion index and sample one-inflation index for the one-inflated positive Poisson distribution for various pairs of parameters and
, based on a dataset of size 5000.
According to Table , the index correctly assesses the presence of excess ones in the sample data. When , this implies that the index is very close to zero, which indicates that there is no excess of ones in the data for the OIPP distribution since this distribution reduces to a positive Poisson distribution. Trivially, a smaller
yields a higher proportion of ones in the positive Poisson distribution and a lower proportion of ones contributed by
in the OIPP distribution. Therefore, the resulting index will be comparatively low (refer to Table for
and all values of
). However, when
is large, the proportion of ones in the positive Poisson distribution will be small, while the proportion of ones contributed by
in the OIPP distribution will be large. This results in a high index value (refer to Table for
and positive
). It can be concluded that the one-inflation index is useful to assess the presence of excess ones in a dataset for a positive Poisson distribution.
This one-inflation index can be a viable alternative to the score test proposed by Godwin and Böhning [Citation9], in which the null hypothesis of the test states that there is no inflation in the data. The score test [Citation9] is given as.
where
and
. The information about whether a dataset contains excess ones or not needs to be considered in statistical modelling. If the dataset contains excess ones, then one-inflated positive count data distributions should be considered.
6. Applications
A dataset on the frequency of a person being arrested for drunk driving [Citation23] was used to demonstrate and analyse the performance of the proposed estimators in fitting real data. The sample one-inflation index of 0.1545 implies that the dataset contains a substantial number of ones in the data that cannot be explained by a positive Poisson distribution. The model fitting to the data using a positive Poisson distribution yields . The estimated value of
generates a score
, hence rejecting the null hypothesis of no inflation. Therefore, the OIPP distribution is appropriate for model fitting for this dataset.
The chi-square goodness-of-fit test and the root mean squared error (RMSE) of the fitted data were used to evaluate the proposed estimators, in which where
is the number of data groups and
is the estimated frequency for the respective
. In general, the best estimator provides adequate goodness of fit and has the lowest RMSE.vn
The results of the model fitting for the frequency of a person being arrested for drunk driving based on the proposed estimators are shown in Table . Based on the goodness-of-fit test and p-values, all estimators are found to be adequate except for RPE. The RMSE of the OLSE is found to be significantly smaller compared to other estimators. Therefore, the OLSE provide the best fit for describing the frequency of a person being arrested for drunk driving.
Table 2. The results of model fitting of the frequency of a person being arrested for drunk driving based on the MME, MLE, RPE and OLSE for the OIPP distribution.
7. Conclusions
Several estimators for the OIPP distribution were proposed in this study, namely MME, MLE, RPE, OPE and OLSE, in which the MLE and OPE both yield identical results. Two comprehensive simulation studies were conducted to evaluate the unbiasedness, consistency and efficiency of the proposed estimators. According to the results, the proposed estimators are asymptotically unbiased and consistent. The best to worst estimators based on the bias, mean squared error, efficiency and deficiency values are MLE, OLSE, MME and RPE. A one-inflation index to assess the presence of excess ones in a dataset for a positive Poisson distribution was also proposed. Based on the chi-square goodness-of-fit test and RMSE, the OLSE provides the best fit to the dataset adopted in this study. Therefore, both MLE and OLSE are the best estimators for the OIPP distribution.
Acknowledgements
The authors gratefully acknowledge the financial support received in the form of research grants from the Ministry of Education, Malaysia [FRGS/1/2019/STG06/UKM/01/5]; and Universiti Kebangsaan Malaysia [GUP-2019-031].
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- David FN, Johnson NL. The truncated Poisson. Biometrics. 1952;8:275–285.
- Moore PG. The estimation of the Poisson parameter from a truncated distribution. Biometrika. 1952;39:247–251.
- Plackett RL. The truncated Poisson distribution. Biometrics. 1953;9:485–488.
- Finney DJ, Varley GC. The truncated Poisson distribution. Biometrics. 1955;11:387–394.
- Tate RF, Goen RL. Minimum variance unbiased estimation for the truncated Poisson distribution. Ann Math Stat. 1958;29:755–765.
- Sampford MR. The truncated negative binomial distribution. Biometrika. 1955;42:58–69.
- Brass W. Simplified methods of fitting the truncated negative binomial distribution. Biometrika. 1958;45:59–68.
- Ghitany ME, Al-Mutairi DK, Nadarajah S. Zero-truncated Poisson-Lindley distribution and its application. Math Comput Simul. 2008;79:279–287.
- Godwin RT, Böhning D. Estimation of the population size by using the one-inflated positive Poisson model. J R Stat Soc: Ser C. 2017;66:425–448.
- Godwin RT. One-inflation and unobserved heterogeneity in population size estimation. Biometrical J. 2017;59:79–93.
- Godwin R. The one-inflated positive Poisson mixture model for use in population size estimation. Biometrical J. 2019;61:1541–1556.
- Tajuddin, R. R. M., Ismail, N., Kamarulzaman, I., 2021. Estimating population size of criminals: a new Horvitz-Thompson estimator under one-inflated positive Poisson-Lindley model. Crime & Delinquency. doi:10.1177%2F00111287211014158
- Famoye F. Parameter estimation for generalized negative binomial distribution. Commun Stat – Simu Comput. 1997;26:269–279.
- Wagh YS, Kamalja KK. Zero-inflated models and estimation in zero-inflated Poisson distribution. Commun Stat – Simu Comput. 2018;47:2248–2265.
- Hogg, R.V., McKean, J.W., Craig, A.T. Maximum likelihood estimation, in Introduction to mathematical statistics, 6th ed. Pearson Prentice Hall, New Jersey, pp. 313, 2005.
- Borah M, Nath AD. A study of the inflated Poisson Lindley distribution. J Indian Soc Agr Stat. 2001;54:317–323.
- Böhning D. A simple variance formula for population size estimators by conditioning. Stat Methodol. 2008;5:410–423.
- Drossos CA, Philippou AN. A note on minimum distance estimates. Ann I Stat Math. 1980;32:121–123.
- Akgül FG, Şenoğlu B, Arslan T. An alternative distribution to Weibull for modeling the wind speed data: Inverse Weibull distribution. Energ Convers Manage. 2016;114:234–240.
- Puig P. Characterizing additively closed discrete models by a property of their maximum likelihood estimators, with an application to generalized Hermite distributions. J Am Stat Assoc. 2003;98:687–692.
- Puig P, Valero J. Count data distributions. J Am Stat Assoc. 2006;101:332–340.
- Blasco-Moreno A, Pérez-Casany M, Puig P, et al. What does a zero mean? Understanding false, random and structural zeros in ecology. Methods Ecol Evol. 2019;10:949–959.
- Van der Heijden PGM, Cruyff M, Van Houwelingen HC. Estimating the size of a criminal population from police records using the truncated Poisson regression model. Statistica Neerlandica. 2003;57:289–304.