Abstract
In this article we test the ability of the stochastic differential model proposed by Fatone et al. [Maximum likelihood estimation of the parameters of a system of stochastic differential equations that models the returns of the index of some classes of hedge funds, J. Inv. Ill-Posed Probl. 15 (2007), pp. 329–362] of forecasting the returns of a long-short equity hedge fund index and of a market index, that is, of the Hedge Fund Research performance Index (HFRI)-Equity index and of the S&P 500 (Standard & Poor 500 New York Stock Exchange) index, respectively. The model is based on the assumptions that the value of the variation of the log-return of the hedge fund index (HFRI-Equity) is proportional up to an additive stochastic error to the value of the variation of the log-return of a market index (S&P 500) and that the log-return of the market index can be satisfactorily modelled using the Heston stochastic volatility model. The model consists of a system of three stochastic differential equations, two of them are the Heston stochastic volatility model and the third one is the equation that models the behaviour of the hedge fund index and its relation with the market index. The model is calibrated on observed data using a method based on filtering and maximum likelihood proposed by Mariani et al. [Maximum likelihood estimation of the Heston stochastic volatility model using asset and option prices: An application of nonlinear filtering theory, Opt. Lett., 2 (2008), pp. 177–222] and further developed in Fatone et al. [Maximum likelihood estimation of the parameters of a system of stochastic differential equations that models the returns of the index of some classes of hedge funds, J. Inv. Ill-Posed Probl. 15 (2007), pp. 329–362; The calibration of the Heston stochastic volatility model using filtering and maximum likelihood methodsin Proceedings of Dynamic Systems and Applications, Vol. 5, G.S. Ladde, N.G. Medhin, C. Peng, and M. Sambandham, eds., Dynamic Publishers, Atlanta, USA, 2008, pp. 170–181]. That is, an inverse problem for the stochastic dynamical system representing the model is solved using the calibration procedure. The data analysed is from January 1990 to June 2007, and are monthly data. For each observation time, they consist of the value at the observation time of the log-returns of the HFRI-Equity and of the S&P 500 indices. The calibration procedure uses appropriate subsets of data, that is the data observed in a 6 months time period. The 6 months data time period used in the calibration is rolled through the time series generating a sequence of calibration problems. The values of the HFRI-Equity and S&P 500 indices forecasted using the calibrated models are compared to the values of the indices observed. The result of the comparison is very satisfactory. The website http://www.econ.univpm.it/recchioni/finance/w8 contains some auxiliary material including some animations that helps the understanding of this article. A more general reference to the work of some of the authors and of their coauthors in mathematical finance is the website: http://www.econ.univpm.it/recchioni/finance.
1. Introduction
In this article we test on real data the model proposed in Citation1 that describes the dynamics of a market index and of the index of some classes of hedge funds. Let us recall the model. We denote with t the time variable, and with (xt, zt, vt), t > 0, a stochastic process. We interpret xt, t > 0, as the log-return of a market index, zt, t > 0, as the log-return of the index of a class of hedge funds and vt, t > 0, as the stochastic variance of the market index. For t > 0 xt, zt and vt are real random variables. In this article we consider the S&P 500 index as market index and the HFRI-Equity hedge fund index as index of a class of hedge funds. The model proposed in Citation1 can be used with several other choices of the meaning for the indices. In Citation1 the dynamics of the stochastic process (xt, zt, vt), t > 0, is modelled with the following system of stochastic differential equations with initial conditions:
(1)
(2)
(3)
where
,
,
, t ≥ 0, are standard Wiener processes such that
and
,
, t > 0, are their stochastic differentials. The quantities
χ, ϵ, θ, β and γ are real constants known as model parameters. We choose χ, ϵ, θ to be positive constants such that
. This last assumption guarantees that when
is positive with probability one, vt, solution of (3) remains positive with probability one for t > 0. Note that
,
,
are random variables that we assume to be concentrated on a point with probability one. For simplicity, we identify these random variables with the points where they are concentrated. In real markets, the random variables
and
are observable and the random variable
cannot be observed. We note that, as shown later, without loss of generality we can choose
,
. We choose
to be a positive constant that must be determined in the calibration of the model. Moreover we assume that
(4)
where ⟨·⟩ denotes the expected value of ·, and the quantities ρ1,2, ρ1,3, ρ2,3 ∈ [−1, 1] are constants known as correlation coefficients. We remind that the autocorrelation coefficients of
, i = 1, 2, 3, are equal to one.
Equations (1) and (3) are the well-known Heston stochastic volatility model Citation2. This model was introduced with the aim of overcoming some limitations of the Black–Scholes model Citation3 that are pointed out by market data such as, for example, the assumption of constant volatility. Letting St, t > 0, be the price at time t of an asset, the Heston model (1) and (3) describes the dynamics of the log-return xt = log(St/S0), t > 0, of the asset and of its stochastic variance vt, t > 0. Note that with the previous choice, when t = 0 we have and in a similar way we have
. A systematic data analysis has shown that the Heston stochastic volatility model is well-suited to model the behaviour of several market indices such as, for example, the S&P 500 index, the Down-Jones Industrials index and the Nasdaq Composite index (see Citation4,Citation5). We note that Equation (3) is known as the equation that defines the mean-reverting process with speed χ and parameters θ and ϵ.
The model introduced in Citation1 and considered here is obtained adding to the Heston stochastic volatility model (1) and (3) a third equation, that is Equation (2), that describes the behaviour of the log-return of the index of some classes of hedge funds. In fact statistical studies, such as Citation6–9, of the time series of the data relative to the log-returns of the indices of several classes of hedge funds have shown that the log-returns of the indices of some classes of hedge funds are related to the log-returns of the S&P 500 index. In particular in Citation9 some discrete time models are proposed to study nine different classes of hedge funds. The model proposed in Citation9 to describe the dynamics of the index of the ‘long-short equity’ class of hedge funds is based on the assumption that up to a stochastic additive error there exists a kind of direct proportionality between the behaviour of the variation of the log-return of the index of the ‘long-short equity’ class of hedge funds and the variation of the log-return of the S&P 500 index. In Citation9, this assumption is supported by convincing empirical evidence. We can conclude that interpreting zt, t > 0, as the log-return at time t of an index of the ‘long-short equity’ class of hedge funds, that is the HFRI-Equity index, xt, t > 0, as the log-return at time t of the S&P 500 index and vt, t > 0, as the stochastic variance of xt, t > 0, the system of stochastic differential Equations (1–3) can be seen as a reasonable translation in continuous time of the model proposed in Citation9. In fact Equation (2) states that dzt is given by the sum of β dxt and a random disturbance given by .
The calibration problem of model (1–3) can be stated as follows: given a discrete set of time values t = ti, i = 0, 1, …, n, such that t0 = 0, ti < ti+1, i = 0, 1, …, n − 1, and the observation , of the log-returns of the market and of the hedge fund indices, that is the observation of (xt, zt), at time t = ti, i = 0, 1, …, n, determine the values of the parameters appearing in (1), (2) and (3), of the correlation coefficients ρ1,2, ρ1,3, ρ2,3 and of the initial stochastic variance
. For later convenience we define tn+1 = +∞. The choice t0 = 0 corresponds to choosing the origin of the time axis in the first observation time where we choose
. The choice of the origin of the time axis can be changed without changing substantially the problem considered. Note that the calibration problem is an inverse problem for the model (1), (2) and (3). In fact the calibration problem consists of the reconstruction of the parameters of the model, of the correlation coefficients of the Wiener processes and of the initial stochastic variance from the observation at discrete times of the variables xt, zt, t > 0.
In order to study time series of real data, the calibration problem of model (1–3) stated previously has been solved using the approach suggested in Citation1 based on the methods of filtering and maximum likelihood. This approach was introduced in the context of mathematical finance in Citation10 and further developed in Citation1,Citation11.
We consider the time series of monthly data of the S&P 500 and of the HFRI-Equity indices covering a period of 210 months from 31 January, 1990 to 30 June, 2007. The observation times will be denoted by , i = 1, 2, …, 210, and, for later convenience, we introduce
corresponding to 31 December, 1989 and the observations of the values of the indices at time
. From these data we derive the time series of the log-returns. We have applied the calibration procedure mentioned above using as data the data contained in a window of six consecutive observation times (that is a window covering the data relative to a period of 6 months). This choice is motivated in Section 3. The numerical results obtained considering the 206 (6 months) data windows obtained from the data time series are presented in Section 3 and show that the solutions of the calibration problems considered are really associated with the data time series, that is they are ‘stable’ when the time window of the data used in the calibration is shifted. In fact, as shown in Figures , the vector as Θ* solution of the calibration problem, as a function of the time window of the data used in the calibration, can be grouped into three sets associated with the data of three non-overlapping time periods and in these three sets the vectors Θ* found are approximately constants (see Section 3 for further details). After having calibrated the model using the data belonging to a 6 month window we use the resulting estimate of Θ to make the forecasts of the market and of the hedge fund indices 1, 3 and 6 months in the future counting as future the time after the last observation time contained in the data window used in the calibration. The forecasted values of the market and of the hedge fund indices are obtained using some formulae derived in Citation1 that adapt to the model (1–3) standard formulae of filtering theory. For the convenience of the reader these formulae are recalled in Section 2.
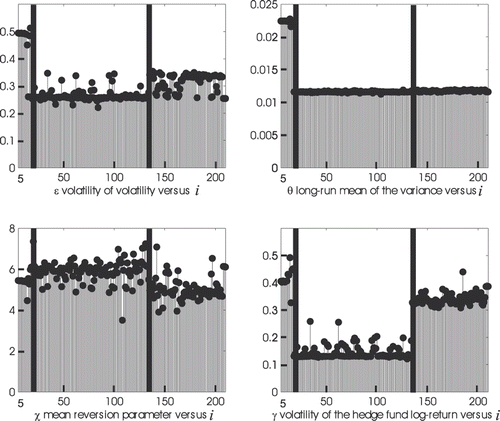
Figure 1. Reconstruction of the parameters ε, θ, χ, γ (in ordinate) of the model (1–3), as a function of the index i (in abscissa) of the last observation time contained in the data window used in the calibration.
The quality of these forecasts is established a priori (i.e.‘model implied’) using filtering theory and a posteriori (i.e. ‘empirically’) comparing the forecasted values with the historical data. The results obtained suggest that the model proposed describes satisfactorily the data, and that high quality forecasts (several months in the future) of the value of the hedge fund index returns can be obtained using the model. Forecasts of approximately the same quality are obtained for the returns of the market index. We remark that the forecasts that are expected to be good a priori (‘model implied’) on the basis of filtering theory are a posteriori (‘empirically’) better than the average forecast, that is, compared to historical data, these forecasts are better than the average forecast. This last fact can be really relevant in practical situations.
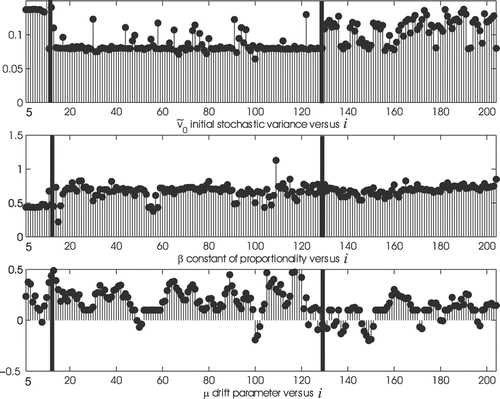
Figure 2. Reconstruction of the initial stochastic variance and of the parameters β,
(in ordinate) of the model (1–3), as a function of the index i (in abscissa) of the last observation time contained in the data window used in the calibration.
From a macro point of view the three different time periods selected by the data analysis do not correspond exactly to different business cycles but they represent relevant economic periods that could be interesting to describe briefly.
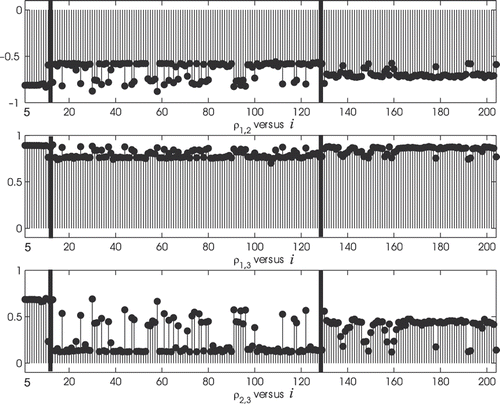
Figure 3. Reconstruction of the correlation coefficients ρ1,2, ρ1,3, ρ2,3 (in ordinate) of the model (1–3), as a function of the index i (in abscissa) of the last observation time contained in the data window used in the calibration.
Period 1 started with the end of the US expansion, which began after the 1987 collapse and it finished in the bulk of the 1990–1991 US recession started in July 1990. So Period 1 includes the end of an economic expansion and the starting point of a recession.
Period 2 is the longest US economy expansion ever seen in the US history. So, a long positive performing cycle that had its peak in March 2001 (Period 3) and that caused one of the major bubbles in US history (Period 3).
Period 3 includes two different environments: the burst of the so called ‘US IT bubble’ (with the end of the 1990s economic growth) and the recovery period still in place in 2008 (and started technically in March 2003).
The traditional approach followed by practitioners to forecast zt, t > 0, is the use of discrete time models and linear regression analysis, with which (referred to our notation) one determines only zt as a function of xt and one does not consider vt; a more sophisticated method is to use multi-regressions (linear or quadratic), but always in order to describe (HFRI returns) in respect to different explicative variables (generally market indices). One supposes that volatility does not follow a stochastic process and that the past history of a fund, or of an index, can be repeated in the future, with a confidence level. Volatility at time t depends on N previous data, that is
(5)
where
is the estimated value of the volatility at time t, Δt is the discrete time step, xt−iΔt, i = 1, 2, …, N, are observed log-returns and
is the average of the observed log-returns. This strongly restrictive assumption leads to calculate values of β in the linear regression that depends too much from the data period considered: in our case, the total β calculated in the entire observation period (from 31 January, 1990 to 30 June, 2007) will be completely different with respect to the three values of β (different among themselves) calculated in the three periods (that is: Period 1: from 31 January, 1990 to 31 October, 1990; Period 2: from 30 November, 1990 to 31 October, 2000; Period 3: from 30 November, 2000 to 30 June, 2007).
Several approaches have been used to overcome this difficulty such as, for example, those proposed by Bollerslev Citation12 and Pearson Citation13. As shown in Citation6, this last approach is quite useful in the case of hedge indices when used to study data since the year 2000, however, it is less satisfactory when applied to single funds.
This article is organised as follows: in Section 2 we present the calibration procedure and the formulae used to make the forecasts of the log-returns of the indices and of the stochastic variance. Numerical results are presented in Section 3. In particular, the analysis of the forecasted log-returns is carried out and their quality is established. In Section 4 we draw some conclusions. Finally, in the Appendix we give some formulae useful for the implementation in a computer code of the numerical methods summarized in Section 2.
2. The calibration procedure and the formulae used to forecast the log-returns
Let us summarize the procedure used to solve the calibration problem formulated in the Introduction and let us recall some formulae used to forecast the log-returns xt, zt, t > 0, the stochastic variance vt, t > 0, and to evaluate the quality of the forecasts. A more detailed explanation of these formulae is contained in Citation1.
Let
∈ ℝ10 be the vector of the model parameters, of the correlation coefficients and of the initial stochastic variance and let ℳ = Θ =
|χ > 0, ϵ > 0, θ > 0, β ≥ 0, γ ≥ 0,
be the set of feasible vectors. It is easy to see that the conditions that define ℳ express some elementary properties of the Heston stochastic volatility model and of the correlation coefficients. In detail, we denote with
t > 0, the set of observations of the variables xt and zt available at time t > 0 and, given Θ, we denote with
(x, z, v) ∈ ℝ × ℝ × ℝ+, t > 0, the joint probability density function of having xt = x, zt = z and vt = v at time t > 0 conditioned to the observations contained in ℱt, t > 0, and to the initial condition
. We remark that the initial conditions
and
are already contained in ℱt, t > 0. Note that we assume that the observations are known exactly, that is, they are known without the uncertainty that usually is represented in the observation process as an additive random variable. The (inverse) calibration problem considered here is translated into the following optimization problem:
(6)
where the log-likelihood function F(Θ) is given by
(7)
that is, the function F(Θ) is the sum of logarithms of integrals in dv′ of the probability density functions
, i = 0, 1, …, n − 1, of making the observations actually made, that is, for i = 0, 1, …, n − 1, the probability of observing
at time t = ti+1 given the fact that the observations ℱti have already been made at time t = ti. Note that for i = 0, 1, …, n, when ti < t < ti+1 we have ℱt = ℱti. In (7),
denotes the left limit of
as t → ti.
The optimization problem (6) is a maximum likelihood problem and its solution Θ* is the solution of the calibration problem, that is, the components of Θ* are the estimates of the model parameters, of the correlation coefficients and of the initial stochastic variance obtained from the data.
We note that the choice (7) of the log-likelihood function as objective function of problem (6) is only one possible choice between many other possibilities.
Let us consider the joint probability density function (x, z, v) ∈ ℝ × ℝ × ℝ+, t > 0, of having xt = x, zt = z, vt = v given ℱt, t > 0, and Θ. Recall that
. The joint probability density function
is the solution of a filtering problem, and in Citation1 it has been shown that is given by
(8)
where pf (x, z, v, t, x′, z′, v′, t′|Θ), (x, z, v), (x′, z′, v′) ∈ ℝ × ℝ × ℝ+, t, t′ > 0, t − t′ > 0, is the fundamental solution of the Fokker–Planck equation associated with the system of stochastic differential Equations (1–3) and
(9)
where δ is Dirac's delta. Similar filtering problems for the Heston model have been studied in Citation10,Citation11.
In order to determine the vector Θ we solve the calibration problem, that is, we solve the optimization problem (6). We use a computationally efficient procedure presented in Citation1 and summarized in the Appendix to evaluate the functions , v ∈ ℝ+, i = 1, 2, …, n, on a grid in the v variable. We maximize the (log-)likelihood function (7) using as optimization method a variable metric steepest ascent method introduced in Citation1 obtained adapting to the present circumstances the method developed in Citation14 to solve the linear programming problem. This method is a kind of steepest ascent method based on an iterative procedure that searches the maximum likelihood estimate Θ*, solution of (6), beginning from an initial guess Θ0 ∈ ℳ and that for k = 1, 2, … generates at step k a vector Θk ∈ ℳ satisfying the inequality F(Θk) ≥ F(Θk−1). That is, the objective function is monotonically non-decreasing along the sequence {Θk}, k = 0, 1, …. In the numerical experiment, presented in Section 3, in this optimization procedure we use the following condition as stopping rule:
(10)
where δ1 and kmax are positive constants that will be chosen later.
Given the joint probability density function (x, z, v) ∈ ℝ × ℝ × ℝ+, t ≥ 0, (in particular, given Θ obtained solving the optimization problem (6)) we can forecast the values of the market index log-return, of the hedge fund index log-return xt, zt, t > 0, t ≠ ti, i = 0, 1, …, n, and of the stochastic variance vt, t > 0, using, respectively, the mean values
t > 0, conditioned to the observations contained in ℱt, t > 0, of the random variables xt, zt, vt, t > 0, that is,
(11)
(12)
(13)
The notation 𝔼(· | +) means expected value of · conditioned to +. As shown in Citation1 from formulae (8), (11–13) and (36) of the Appendix, we can deduce that
(14)
(15)
(16)
Recall that we use the notation tn+1 = +∞. Note that from (14) and (15) it follows that
and
i = 0, 1, …, n.
The main advantage of formulae (14–16) when compared to formulae (11–13) consists of the fact that (14–16) contain only a one-dimensional integral that can be evaluated numerically very efficiently once the integrand function is known on a suitable one-dimensional grid, whilst (11–13) contain a three-dimensional integral whose numerical evaluation requires the knowledge of the integrand function on a three-dimensional grid.
The ‘model implied’ quality of the estimates (11–13) (or equivalently of the estimates (14–16)) depends on the variance of the random variables xt, zt, vt, t > 0, conditioned to the observations contained in ℱt, t > 0, that is, we can estimate the (‘model implied’) quality of the estimates (11–13) computing, respectively, the quantities
(17)
(18)
(19)
As shown in Citation1, denoting with ξt, t > 0, the state variable xt, t > 0, or the state variable zt, t > 0, and with
and
the observation
or the observation of
, i = 0, 1, …, n, and the mean value conditioned to the observation contained in ℱt, t > 0, of ξt, t > 0, respectively, an elementary computation gives the following formula for the conditioned variance of the state variables xt and zt, t > 0:
(20)
where the constants l1, l2, l3 and l4 are defined as follows:
(21)
(22)
(23)
(24)
and finally, for the conditioned variance vt, t > 0, we have
(25)
Note that Σ2(·|ℱt, Θ) = 𝔼((· −𝔼(·|ℱt, Θ))2|ℱt, Θ), t > 0, and that the estimates (11–13) are supposed to be of high quality when the variances (17–19) are small. In the data analysis described in Section 3 we use formulae (11–13) to forecast the values of xt, zt, t > 0, t ≠ ti, i = 0, 1, …, n, and of the stochastic variance vt, t > 0, coherently with the observations contained in ℱt, t ≥ 0. The quality of the forecasts of the values of xt, zt, t > 0 is evaluated ‘model implied’ using formula (20) and established ‘empirically’ comparing the forecasts with the historical data. We recall that the stochastic variance vt, t > 0, cannot be observed.
3. Analysis of the S&P 500 and HRFI-Equity data
Let us present the results obtained applying the procedure described in Section 2 to the historical time series of 210 monthly data relative to the variation ΔIx,i of the S&P 500 index Ix,i, and the variation ΔIz,i of the HFRI-Equity index Iz,i, i = 1, 2, …, 210. The variations ΔIx,i, ΔIz,i of Ix,i−1, Iz,i−1, respectively, are measured in per cent i = 1, 2, …, 210. The data cover the period of 210 months from 31 January, 1990 to 30 June, 2007. The observation dates , i = 1, 2, …, 210, are the last day of the month (i.e. 31 January, 28 February, 31 March, 30 April, 31 May, 30 June, 31 July, 31 August, 30 September, 31 October, 30 November, 31 December). First of all, we have processed the data ΔIx,i, ΔIz,i, in order to get the time series of the observed log-return
, of the S&P 500 index and of the observed log-return
, i = 1, 2, …, 210, of the HFRI-Equity index. We have added to these data the observation at date
corresponding to 31 December, 1989. We choose Ix,0 = Iz,0 = 1 and
. We have used the following recursive formulae to construct the log-returns:
(26)
(27)
Recall that
,
correspond to the log-returns at time
(31 December, 1989). The indices Ix,0, Iz,0 are chosen equal to one and Ix,i, Iz,i, are related to the monthly log-returns
,
, i = 1, 2, …, 210, given in (26) and (27) by the following formulae:
(28)
(29)
that is, we have
(30)
(31)
In the following, we refer to Ix,i, Iz,i, i = 0, 1, …, 210, and to xt, zt, t > 0, as the S&P 500 index, the HFRI-Equity index and their log-returns, respectively, as a function of time. The quantities Ix,i, Iz,i, i = 0, 1, …, 210, are not the actual values of the indices since they are obtained starting the data time series from the values Ix,0 = 1, Iz,0 = 1. We can conclude that the values of the indices have been rescaled dividing them by suitable normalization constants.
We consider a window of six observation times (that is a window covering a time period of 6 months) corresponding to 12 data and we move from a window to the next one removing the data relative to the first observation time of the window and adding the data corresponding to the observation time that follows the last observation time of the window. That is the j-th window contains the data , i = 1, 2, …, 6, j = 1, 2, …, 206. For each data window we solve the calibration problem (6). That is, we solve 206 calibration problems. Recall that in the solution of each calibration problem, coherently with the statement of the problem given in the Introduction, we translate the zero of the time axis to the first observation time of the data window considered and we adapt the data to this translation of the time origin. The choice of data windows made of the observations relative to six consecutive observation times, that is the choice of 6 months data windows, is motivated by the fact that several numerical experiments have shown that the estimates of the parameter vector Θ obtained from the calibration remain substantially unchanged when we use in the calibration data corresponding to data windows made of the observations relative to 12, or 24 consecutive observation times. The solution of a calibration problem using the data corresponding to a window of six consecutive observation times requires about 1 min of CPU time on a Centrino Duo Intel Personal Computer using a Fortran 90 code. However, the 206 calibration problems considered here are independent from the others and can be solved in parallel when adequate computing resources are available (for example, they can be solved in parallel on the ENEA grid). That is, the CPU time required to solve the 206 calibration problems that use a 6 months data window as data is approximately 206 min on 1 processor, or 1 min on 206 processors.
The data analysis presented in this section investigates two problems. The first one consists of understanding if the calibration procedure described in Section 2 to determine the value of the vector Θ, that is, the procedure used to solve the maximum likelihood problem (6), gives values of Θ that are really associated with the data time series, that is, values of Θ that are not an artefact of the computational procedure used to determine them. The second one, to be faced only if the first one is solved positively, is the problem of evaluating the ability of these estimated values of Θ of forecasting the values of xt, zt in the future, that is the ability of forecasting using the model (1–3) and formulae (14) and (15) the values xt and zt relative to observation times posterior to the observation times contained in the data window used to estimate the vector Θ. This ability is evaluated a priori (‘model implied’) using formula (20) and established a posteriori (‘empirically’) comparing the forecasted values to the observations actually made.
As said previously, we have solved 206 calibration problems relative to the 206 data windows described above determining 206 values of the vector Θ. In the solution of the 206 maximization problems (6) we have chosen the initial guess of the maximization procedure to be always the same and in the stopping criterion (10), we have chosen δ1 = 5 × 10−4 and kmax = 10,000. The choice of the initial guess is made exploiting the following information:
| a. | the standard deviation of the time series of log-returns of xt and zt to choose the initial guesses of the stochastic variance | ||||
| b. | the time series of the ratio | ||||
| c. | the empirical correlation between the time series ΔIx,i, ΔIz,i, i = 1, 2, …, 210, to choose the initial guess of the correlation coefficient ρ1,3. The magnitude of the initial guesses of the correlation coefficients ρ1,2, ρ2,3 is chosen to be of the order 10−2. | ||||
Figures show (in ordinate) the components of the vector Θ obtained solving the maximum likelihood problem (6), as a function of i, the value of the index of the last observation time contained in the data window used in the calibration (in abscissa). That is, the vector Θ obtained using a given data window is associated with the index of the last observation time of the data contained in the window. Let Θ*,i be the vector Θ obtained solving problem (6) using the 6 months data window ending at time
, i = 5, 6, …, 210. Figures show that, as a function of i, the parameters ε, γ, the initial stochastic variance
and the correlation coefficients ρ1,2 and ρ2,3 appear to be approximately given by piecewise constant functions. In particular, two observation times (the black bars in Figures ) where the piecewise constant functions jump are evidenced, the first one after approximately the first year of observation (that is around 31 October, 1990) and the second one after approximately 11 years of observation (that is around 31 October, 2000). That is, the data analysis carried out and illustrated in Figures shows that roughly speaking the data can be divided into three periods:
| • | Period 1: this period (from the beginning of the time series up to the first black bar) is very small and goes from 31 December, 1989 to 31 October, 1990; | ||||
| • | Period 2: this period (between the first and the second black bar) is quite long and goes from 30 November, 1990 to 31 October, 2000; | ||||
| • | Period 3: this period (after the second black bar until the end of the time series) goes from 30 November, 2000 to 30 June, 2007. | ||||
Note that the values of the initial stochastic variance obtained from the solution of the calibration problems are approximately constant over Period 1. This is probably due to the fact that monthly data are considered so that the micro structure of the variance is lost. Indeed, it is possible that the estimates of obtained are of low quality. This is due to the fact that
is a parameter whose calibration is difficult. In Citation10,Citation11 we have already faced the difficulty of estimating the initial stochastic variance when we have studied the calibration problem for the Heston model. We remark that in Citation15 the initial stochastic variance is not estimated together with the other parameters of the model as we do here. In fact in Citation15 the Black–Scholes implied volatility and the adjusted integrated volatility are used to estimate the initial stochastic variance.
We remark that shows that the correlation coefficient ρ1,3 that measures the correlation between the stochastic differentials present in the equation of the log-return of the S&P 500 index and one of the stochastic differentials present in the equation of the log-return of the HFRI-Equity hedge fund index is almost constant and approximately equal to one over the entire observation period. This fact seems to confirm the validity of model (1–3) which assumes that the behaviour of the HFRI-Equity hedge fund index is strongly related to the behaviour of the S&P 500 index. Furthermore, the fact that the parameter β is substantially constant (exception made when we go from Period 1 to Period 2 when β goes approximately from 0.5 to 0.7) confirms the assumption of the existence of a kind of ‘proportionality’ between the variations of the log-returns of the HFRI-Equity hedge fund index and of the S&P 500 index.
Let us study the bias of the estimates , j = 1, 2, …, 206, solutions of the maximum likelihood problem (6) on some time windows chosen as representatives of the data time series. We use the bootstrap method proposed in Citation16 to generate new sample ‘data’. To fix the ideas we consider 5–6 months data windows: the first one falls in the first period (months 1–6 of the data time series), the second one falls between the first and the second period (months 10–15 of the data time series), the third one falls in the second period (months 70–75 of the data time series), the fourth one falls between the second and the third period (months 138–144 of the data time series), and the last one falls in the third period (months 190–195 of the data time series). The results obtained in these data windows represent the results obtainable with a more systematic analysis of the data time series. We use as reference estimate of the vectors Θ,
, in the window j, j = 1, 2, …, 5, the solution of the maximum likelihood problem (6) (see Citation1). Note that we have:
,
,
,
,
. Let NR be a positive integer, to measure the bias of the corresponding estimators we generate NR replicas of the observed data in each window and we estimate the vectors Θ relative to these sets of replicated data. That is, for j = 1, 2, …, 5, in the window j, a sample Θj,k
, k = 1, 2, …, NR is generated by solving the maximum likelihood problem (6) with the replicas of the observed data and the relative bias:
(32)
We consider NR = 100 and NR = 1000. Tables show the values of the relative bias
, j = 1, 2, …, 5, of the estimated parameters. Moreover let
, k = 1, 2, …, NR, j = 1, 2, …, 5, i = 1, 2, …, 10, be the relative errors of the components of the estimated vectors. For i = 1, 2, …, 10, j = 1, 2, …, 5, we compute the standard deviation of these samples. For j = 1, 2, …, 5, shows the mean (over i, i = 1, 2, …, 10) of these standard deviations and the biggest of these standard deviations with the corresponding parameter name. The relative bias shown in Tables for most of the parameters is satisfactorily small. In fact, the phenomenological character of the model that we are considering suggests that it is dubious to pretend very accurate results.
Table 1. Relative bias of the parameter estimators in the five windows (NR = 100).
Table 2. Relative bias of the correlation coefficients and of the initial stochastic variance in the five windows (NR = 100).
Table 3. Relative bias of the parameter estimators in the five windows (NR = 1000).
Table 4. Relative bias of the correlation coefficients and of the initial stochastic variance in the five windows (NR = 1000).
Table 5. Mean of the standard deviations of the relative errors of the components of the estimated vectors and worst standard deviation and parameter where it occurs (NR = 1000).
We propose a second way of studying the bias of the estimated values of the vector Θ. We divide the 206 estimates of Θ obtained solving the 206 calibration problems in three sets. The first set, named Set 1 (relative to Period 1), corresponds to the estimates of Θ obtained using the first 13 data windows, the second one, named Set 2 (relative to Period 2), corresponds to the estimates of Θ obtained using the data windows that go from the 14th to the 130th data windows and the last one, named Set 3 (relative to Period 3), collects the estimates of Θ obtained using the data windows that go from the 131th to the 206th data windows. From these sets we proceed as follows. Let us consider, for example, Set 2. We further divide the elements of Set 2 into groups of estimates coming from disjoint data windows. Note that this procedure is applied only to Sets 2 and 3; in fact, Set 1 has too few elements to work with to make sense out of this procedure. We take as reference estimate of the vector Θ the mean value of Θ over a subset of disjoint 6 months data windows extracted from Sets 2 and 3. and show quantities similar to those shown in Tables obtained using these means as reference estimates of Θ and the solutions of the calibration problems as samples to evaluate the bias.
Table 6. Relative bias of the parameter estimators in Set 2 (Period 2) and Set 3 (Period 3).
Table 7. Relative bias of the correlation coefficients and of the initial stochastic variance in Set 2 (Period 2) and Set 3 (Period 3).
We note that the two procedures to study the bias are different. First of all, the first procedure uses replicated data, that is, a kind of synthetic data, while the second procedure uses only observations. That is, the ‘replicas’ are obtained starting from observations made in different time periods. Moreover, the first procedure measures the bias of the estimate in each window taking as reference estimate the value of the vector Θ obtained solving the calibration problem using as data the (real) observations made in that window. The second procedure measures the bias choosing as reference estimate the mean value of the optimal vectors Θ* computed using as data a subset of disjoint data windows contained in Period 2 and Period 3. Indeed, this second choice of the reference estimate has a negative effect on the magnitude of the bias obtained for the parameters whose value is not really constant during the time period considered. In fact this choice gives good results for the parameter χ in Period 2, and for the parameters ε, θ and γ in Period 3 (). The same choice is not well-suited for the parameters ,
, ρ2,3 ( and ) and we can expect these parameters to be biased. We observe that when we use in the second procedure to estimate the bias the mean over the components i = 1, 2, …, 10 of the standard deviations of the relative errors considered in is 0.0620 in Period 2 and 0.0611 in Period 3. In both periods, the parameter having the largest standard deviation is μ (about 25%) followed by the parameters ρ2,3 (about 20%) and γ (about 5%) in Period 2 and in Period 3 by ρ2,3 (about 8%) and
(about 5%).
The first procedure to estimate the bias, based on replicated data, does not suffer from the previous effect since the time window of 6 months is a reasonable time interval where all the parameters are constant. Note that Tables show that the estimates of the initial stochastic variance and of the parameter γ are biased since in the last three windows, the relative bias does not decrease when NR increases.
We can conclude that the data analysis carried out by solving the 206 maximum likelihood problems associated with the observation windows considered previously shows a convincing evidence of the fact that the values of the vector Θ determined by the maximum likelihood procedure are really associated with the data time series and supports some of the assumptions made to build model (1–3). That is, the results of the data analysis presented solve in the affirmative the first problem posed.
The second problem posed to our data analysis is the investigation of the quality of the forecasted values of the log-returns of the indices obtained using the model (1–3) and the values of Θ determined solving the calibration problem shown in Figures . That is, we use the values of the vectors Θ determined solving the maximum likelihood problem and formulae (14) and (15) to forecast the values of the log-returns and
and of the increments of the HFRI-Equity index
, i = 5, 6, …, 210 − m, m = 1, 2, …, 6, that is, 1 month, 2 months, … up to 6 months in the future. Recall that here ‘future’ means the time after the last observation time contained in the data window used to estimate the vector Θ.
Let Ntot be a positive integer that denotes the number of forecasted values m months in the future of returns of the S&P 500 index and of the HFRI-Equity index used in this study. Note that below we will choose Ntot independent of m, m = 1, 2, …, 6. The forecasted values are compared with the historical data and the following quantities have been defined to measure the accuracy of the forecasted values:
(33)
where quantities
,
, are given by
(34)
(35)
The quantities
,
,
are the observed values (real data) and the quantities
,
,
are the corresponding m months in the future forecasted values and
, j = 1, 2, …, m, are the variations of the index Iz,4+i+j−1 computed using the forecasted values
, i = 1, 2, …, Ntot, m = 1, 2, …, 6. Finally, we have computed the mean value of the quantities
, i = 1, 2, …, Ntot, that is
, m = 1, 2, …, 6.
In we show the values of the quantities εx,m, εz,m, εvar,m and sm, as a function of the forecasting period, m = 1, 2, …, 6 (1, 2, …, 6 months in the future), when we consider Ntot = 200 observation times.
Table 8. Quality of the forecasted values of the log-returns xt and zt and of the forecasted increment of the hedge fund index established comparing with historical data.
We note that the quantities εx,m, εz,m are the mean values of the relative errors committed on the forecasted values m months in the future of the returns xt and zt of the S&P 500 index and of the HFRI-Equity index, respectively, and that εvar,m is the mean value of the absolute errors committed on the forecasted values m months in the future of the HFRI-Equity index Iz,t = ezt, m = 1, 2, …, 6.
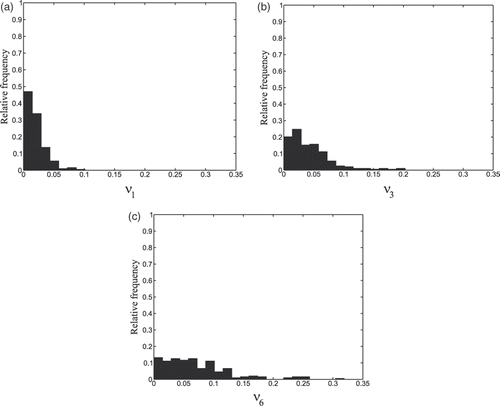
Finally, we show the histograms of the absolute errors committed on the quantities at,m, that is, the histograms of the values taken by the function νm(t) = |at,m − ât,m|, , i = 1, 2, …, Ntot, m = 1, 3, 6 ().
Figure 4. Histogram of the values taken by (a) ν1, (b) ν3 and (c) ν6.
We conclude this section by showing the values forecasted using formulae (11) and (12) of the log-return xt of the S&P 500 index, and of the log-return zt of the HFRI-Equity index 1 month, 3 months and 6 months in the future (stars) and the corresponding historical data (squares) on a period covering 204, 202 and 198 months, respectively (Figures ).
Figure 5. Forecasted values of the S&P 500 xt (a) and of the HFRI-Equity zt (b) 1 month in the future (*) and historical data of the log-return of the indices (□).
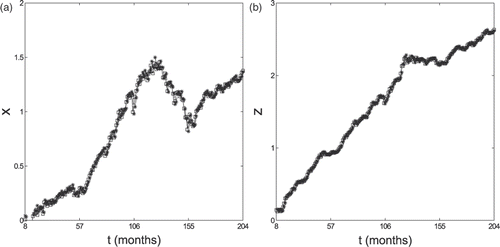
Figure 6. Forecasted values of the S&P 500 xt (a) and of the HFRI-Equity zt (b) 3 months in the future (*) and historical data of the log-return of the indices (□).
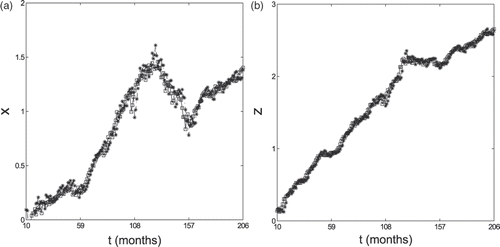
Figure 7. Forecasted values of the S&P 500 xt (a) and of the HFRI-Equity zt (b) 6 months in the future (*) and historical data of the log-return of the indices (□).
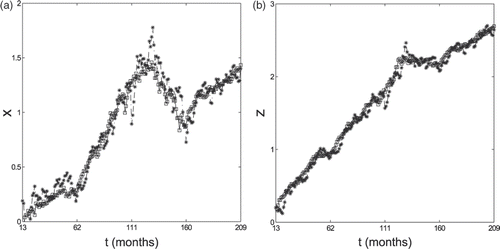
We note that, as expected, the quality of the forecasts of the returns of xt and zt degrades when we look further into the future, that is, for example, the forecasted values 1 month in the future are of higher quality than the forecasted values 6 months in the future. However, the forecasted values of zt 6 months in the future are somehow satisfactory. In particular, we can say that our forecasts seem more reliable when compared to the forecasts obtained by traditional (multi)regression methods (these last ones do not have very high R2 (determination coefficient) for hedge indices, in fact for the linear regression between HFRI-Equity and S&P 500, with our monthly data, R2 is only 0.44). Moreover, when we consider 3 and 6 months in the future the forecasted values of HFRI-Equity index are of higher quality than S&P 500 ones. Recall that independently from equity movements, the relationship between HFRI-Equity and S&P 500 is stable (in the time period considered), with a constant β around 0.5–0.7. This is the case even if in the 3–6 months time periods of the forecasts is more likely that the market conditions have changed and that, therefore, the model parameters resulting from the calibration must be changed.
Obviously, it is not scientifically proved that the stability of this relationship remains true in totally different time contexts; however, its observed stability in this huge time period (1990–2007) leads us to consider it for strategic allocation choices. Each qualitative forecast about S&P 500, elaborated by the investment department of an asset management firm, according to macroeconomic convictions, can be translated in allocation decisions for long/short equity strategy, particularly to 6 months periods. Just because it is very difficult to determine macro scenario on this time horizon, the possibility of using a (demonstrated) stable relationship can be considered as an useful guide in the investments. This is even more important if we consider that in the hedge funds universe, statistically, only investments for medium/long period are satisfying in terms of performance, while a more tactical point of view is usually less gratifying.
Let us now try to establish the quality of the forecasts a priori (‘model implied’), that is, before comparing with the historical data.
shows the observations and the forecasted values corresponding to the first 46 observation times. A complete table relative to the entire data time series is contained at the website: http://www.econ.univpm.it/recchioni/finance/w8.
Table 9. The first 46 monthly data and the forecasted values of the log-returns of the HFRI-Equity index 1 month  and 6 months in the future compared with the historical data of the 1 month log-return and of the 6 months log-return .
and 6 months in the future compared with the historical data of the 1 month log-return and of the 6 months log-return .
Note that in some values are highlighted in bold font. These values are some of the most satisfactory forecasted values of the returns at,m, 1 month and 6 months in the future when compared with historical data. We have computed the conditioned variance of the state variable zt (formula (20)) that is, the conditioned variance of the forecasted values of the returns the HFRI-Equity index. We have found that the conditioned variances relative to the forecasted values of the returns 1 month and 6 months in the future marked in bold font in are significantly smaller than the remaining conditioned variances. For example, while the mean value of the conditioned variances of the forecasted values of the returns of the HFRI-Equity index 1 month in the future is 1.27 × 10−2 the values of the conditioned variances of the forecasted values marked in bold (in time order) are 7.4 × 10−3, 4.4 × 10−3, 6.1 × 10−3, that is, the conditioned variance of the bold forecasts is reduced by approximately a factor 0.5 with respect to the mean value. Note that we have variances smaller than 4.4 × 10−3 only 1 time in the historical series of the variances and that this smallest value is 4.8 × 10−4. The same happens in the case of the forecasted values 6 months in the future where the mean value of the conditioned variances is 2.5 × 10−2 and the conditioned variances of the forecasted values marked in bold font (in time order) are 9.94 × 10−3, 9.96 × 10−3, 1.18 × 10−2 and 1.23 × 10−2. That is, also in this last case the conditioned variances of the forecasted values marked in bold is reduced by approximately a factor 0.5 of the mean value. Finally, we note that the smallest variance in the historical series of the conditioned variances of the 6 months in the future forecasted values is 87.81 × 10−4 and all the remaining values in the time series are greater than 9.94 × 10−3. We can conclude that the value of the conditioned variance allows us to assign ‘a priori’ (‘model implied’) a degree of reliability to the forecasted values, that is, a small conditioned variance corresponds to a great degree of reliability of the forecasted values and this is confirmed by the comparison with the historical data. This fact may be of great relevance in practical situations since by using the conditioned variances we can evaluate a priori the quality of the forecasts of returns of the HFRI-Equity index. A similar analysis can be carried out for the forecasts of returns of the S&P 500 index obtaining similar results.
4. Conclusions
The results contained in this article show that models made of stochastic differential equations can be used to solve well-known statistical and econometric problems. Moreover, the proposed stochastic differential model appears to work well also on relatively small data time windows possibly because the model has captured some relevant features of the data. The forecasts obtained from the model seem to be of high quality. In fact, as remarked in Section 3, these forecasts seem to be more accurate than those obtained by traditional (multi)regression methods.
Finally, the data analysis presented suggests several possible directions of future research. We mention only one of them. We remark that the previous analysis shows that the forecasts of the returns of the HFRI-Equity index are more accurate than those of the S&P 500 index. This fact suggests the idea of introducing a new stochastic model (not necessarily the Heston model) to describe the dynamics of the log-return of the HFRI-Equity index and then of trying to use the dynamics of the HFRI-Equity index to describe the dynamics of the S&P 500 index. Indeed, since the variation of the HFRI-Equity index is smoother than the variation of the S&P 500 index, it should be easier to find ‘ad hoc’ stochastic models of the HFRI-Equity index instead of modelling directly the behaviour of the S&P 500 index. This new model corresponds to the inversion of the cause–effect relation that has been used in the work of Pillonel and Solanet Citation9 and in the model proposed in Citation1, and was used here to describe the relation between the market and the hedge fund indices.
In the website http://www.econ.univpm.it/recchioni/finance/w8, we show the forecasted values of the indices Ix,t and Iz,t compared with the historical data and we provide some animations relative to the forecasting experiment during the complete observation period.
Acknowledgements
The numerical experiment reported in this article has been performed using the computing grid of ENEA (Roma, Italy). The support and sponsorship of ENEA are gratefully acknowledged.
References
- Fatone, L, Mariani, F, Recchioni, MC, and Zirilli, F, 2007. Maximum likelihood estimation of the parameters of a system of stochastic differential equations that models the returns of the index of some classes of hedge funds, J. Inv. Ill-Posed Probl. 15 (2007), pp. 329–362.
- Heston, SL, 1993. A closed-form solution for options with stochastic volatility with applications to bond and currency options, Rev. Financial Stud. 6 (1993), pp. 327–343.
- Black, F, and Scholes, M, 1973. The pricing of options and corporate liabilities, J. Political Economy 81 (1973), pp. 637–659.
- Harvey, A, and Whaley, R, 1992. Market volatility prediction and the efficiency of the S&P 500 Index Option Market, J. Financial Econ. 31 (1992), pp. 43–74.
- Dragulescu, AA, and Yakovenko, VM, 2002. Probability distribution of returns in the Heston model with stochastic volatility, Quanti. Finance 2 (2002), pp. 443–453.
- Agarwal, V, and Naik, N, 2004. Risk and portfolio decisions involving hedge funds, Rev. Financial Stud. 17 (2004), pp. 63–98.
- Harri, A, and Brorsen, BW, 2004. Performance persistence and the source of returns for hedge funds, Appl. Financial Econ. 4 (2004), pp. 131–141.
- Lubochinsky, C, Fitzgerald, MD, and McGinty, L, 2002. The role of hedge funds in international financial markets, Economic Notes 31 (2002), pp. 33–57.
- Pillonel, P, and Solanet, L, 2006. "Predictability in hedge fund index returns and its application in fund of hedge funds style allocation". In: Master's thesis in Banking and Finance. Hautes Etudes Commerciales (HEC): Université de Lausanne; 2006, Available at http://www.hec.unil.ch/cms_mbf/master_thesis/0403.pdf.
- Mariani, F, Pacelli, G, and Zirilli, F, 2008. Maximum likelihood estimation of the Heston stochastic volatility model using asset and option prices: An application of nonlinear filtering theory, Opt. Lett. 2 (2008), pp. 177–222.
- Fatone, L, Mariani, F, Recchioni, MC, and Zirilli, F, 2008. "The calibration of the Heston stochastic volatility model using filtering and maximum likelihood methods". In: Ladde, GS, Medhin, NG, Peng, C, and Sambandham, M, eds. Proceedings of Dynamic Systems and Applications. Vol. 5. Atlanta, USA: Dynamic Publishers; 2008. pp. 170–181.
- Bollerslev, T, 1986. Generalized autoregressive conditional heteroskedasticity, J. Economet. 31 (1986), pp. 307–327.
- Pearson, K, 1901. On lines and planes of closet fit to systems of points in space, Phil. Mag. 2 (1901), pp. 559–572.
- Herzel, S, Recchioni, MC, and Zirilli, F, 1991. A quadratically convergent method for linear programming, Linear Algebra Appl. 152 (1991), pp. 255–289.
- Ait-Sahalia, Y, and Kimmel, R, 2007. Maximum likelihood estimation of stochastic volatility models, J. Financial Econ. 83 (2007), pp. 413–452.
- Vinod, HD, and Lopez-de-Lacalle, J, 2009. Maximum entropy bootstrap for time series: The meboot R Package, J. Stat. Software 29 (2009), pp. 1–19.
- Lipton, A, 2001. Mathematical Methods for Foreign Exchange. Singapore: World Scientific; 2001.
Appendix
As shown in Citation1 (arguing as done in [Citation17, p. 605] for the Heston stochastic volatility model) an explicit formula of the fundamental solution pf (x, z, v, t, x′, z′, v′, t′|Θ), (x, z, v), (x′, z′, v′) ∈ ℝ × ℝ × ℝ+, t, t′ > 0, t − t′ > 0, of the Fokker–Planck equation associated with the system of stochastic differential Equations (1–3) can be derived, that is
(36)
where ι denotes the imaginary unit, Iν(z), z ∈ ℂ, is the modified Bessel function of positive real order
and
(37)
(38)
(39)
(40)
(41)
(42)
(43)
Let us give the formulae derived in Citation1 that is needed to implement the computational method used to evaluate (8). Letting V, L, K, E be positive real numbers, we use the following formulae:
(44)
where
(45)
and
(46)
We recall that τi+1 = ti+1 − ti, i = 0, 1, …, n − 1, and that
. For i = 1, 2, …, n, the procedure to approximate the integrals (45) and (46) is based on an expansion in powers of τi, as τi goes to zero, (see Citation1, Section 3 for further details). The first-order approximation in τi gives the following formula:
(47)
where
is given by
(48)
where m* is a positive integer (see Citation1), p1,1 = 1, p2,1 = −0.44721359549996, p3,1 = −1.3416407864998, the quantity μ(k, ξ) is given by formula (37), and the quantities dj,m,ζ, j = 1, 2, 3, m = 0, 1, …, m*, ζ = 0, 1, …, 4m − 1, are given by
(49)
(50)
where α(k, ξ, τ) is given by
(51)
Note that the quantities defined in (49) and (50) are the coefficients of a truncated wavelet expansion of the function e−α(k,ξ,τ)v′, and that when (k, ξ) = (0, 0) these expressions are not well-defined. However, it is easy to see that when (k, ξ) = (0, 0) the values of (49) and (50) can be determined with some elementary manipulations of the formulae written above. The index m* is a parameter that tells where the wavelet expansion has been truncated.
We note that using the fast Fourier transform algorithm the computational cost of evaluating formula (47) on a suitable grid of Nλ points in the λ variable using R points to discretize the integrals in the k and ξ variables is O(2R2 + 2Nλ log Nλ), as R and Nλ go to infinity, where O(·) is the Landau symbol. This reduces dramatically the cost associated with a naive approach (an approach that does not take advantage of the fast Fourier transform algorithm) that we indicate as being , as R and Nλ go to infinity.