Abstract
Regression analysis is a widely used statistical method for modelling relationships between variables. Multivariate adaptive regression splines (MARS) especially is very useful for high-dimensional problems and fitting nonlinear multivariate functions. A special advantage of MARS lies in its ability to estimate contributions of some basis functions so that both additive and interactive effects of the predictors are allowed to determine the response variable. The MARS method consists of two parts: forward and backward algorithms. Through these algorithms, it seeks to achieve two objectives: a good fit to the data, but a simple model. In this article, we use a penalized residual sum of squares for MARS as a Tikhonov regularization problem, and treat this with continuous optimization technique, in particular, the framework of conic quadratic programming. We call this new approach to MARS as CMARS, and consider it as becoming an important complementary and model-based alternative to the backward stepwise algorithm. The performance of CMARS is also evaluated using different data sets with different features, and the results are discussed.
1. Introduction
Regression modelling is extensively used to establish a relationship between some predictors and a response variable. There are various forms of regression models used for different purposes such as data description, summarization, parameter estimation for learning and control, almost in every field of engineering, and science Citation1. Among them, the linear regression model (LRM) is a well-known global parametric model. However, they only work well in cases where the true underlying relationship is close to the hypothesized function in the model. To overcome the disadvantages of the global parametric approach, nonparametric models are developed locally over specific subregions of the data. Then, the data is analysed for optimum number of subregions, and a simple function is optimally fit to the realization in each subregion Citation2. Multivariate adaptive regression splines (MARS), developed by Friedman Citation3, is such a nonparametric modelling approach of the form
(1)
where y is a response variable, x = (x1, x2, … , xp)T is a vector of predictors and ε is an additive stochastic component which is assumed to have zero mean and finite variance. While the aim of classical parametric regression is to estimate the model parameters, that of the nonparametric regression is to estimate the regression function, f.
The main ability of MARS is to construct flexible models by introducing piecewise linear regressions. Nonlinearity of the models is approximated by different regression slopes in the corresponding intervals of each predictor variable. The slope of each regression line is allowed to change from one interval to another with the condition that there is a ‘knot’ defined in between. Hence, splines are used rather than normal straight lines if there is a need. Predictors to be included in the final model along with their respective knots are found via a fast but intensive search procedure Citation4 in a two-stage process: forward and backward Citation3.
In recent years, MARS has been successfully applied to many areas of science and technology. Some interesting examples can be found in Citation5–12. In this study, we first employ a new approach to regression and classification from the theories of statistical learning, inverse problems and continuous optimization. Indeed, a wealth of real-life motivations give rise to the nonparametric method called classification and regression trees (CART) Citation13 as well as least squares estimation (LSE). We choose one of its most advanced and refined versions and modifications, called MARS, and apply it by Tikhonov regularization and conic quadratic programming (CQP) Citation14. For this study, having introduced linear combinations of the special basis functions (BFs) of MARS, we construct penalized residual sum of squares (PRSS) parameter estimation problem instead of a LSE problem. This estimation problem aims at accuracy and a smallest possible complexity of the model, or equivalently, in stability (robustness, well-conditionedness). Both goals are first combined in the tradeoff that is given in the form of a penalized problem, i.e., of minimizing the residual sum of squares (RSS) and complexity. In fact, we unify some discretized complexity (or energy) terms, and include them into inequality constraints, where we impose a bound on them, and obtain a CQP problem to which we can apply interior point methods Citation15,Citation16 via the program package MOSEK™ Citation17. We call this new approach to MARS as CMARS. In fact, the ‘C’ in CMARS stands for not only ‘Conic’ but also ‘Convex’ and ‘Continuous’.
Afterwards, the implementation of CMARS algorithm developed is illustrated with a numerical example. Furthermore, we apply the two methods on several data sets with different characteristics. Then, their performances are evaluated and compared by using general (method-free) performance measures.
This article is organized as follows. MARS is described in Section 2. In Section 3, CMARS, the proposed alternative to MARS algorithm, is presented. A numerical example is given in Section 4. In Section 5, methods are applied on different data sets, and also, validated and compared. Concluding remarks and further studies are mentioned in the final section.
2. MARS method
MARS algorithm is a flexible approach to high-dimensional nonparametric regression, based on a modified recursive partitioning methodology. It uses expansions in piecewise linear, actually, truncated BFs of the form
(2)
where [q]+ ≔ max {0, q} and τ is a univariate knot. Each function is piecewise linear, with a knot at the value τ, and the corresponding couple of function is called a reflected pair.
The first important advantage of using the piecewise linear BFs is their ability to operate locally. They are zero over some part of their ranges. When they are multiplied together, the result is nonzero only over the small part of the feature space where both component functions are nonzero. As a result regression surface is built up parsimoniously, using nonzero components locally only where they are needed. This is important, since one should use parameters carefully in high dimensions, as they can run out quickly. The use of other BFs, such as polynomials, would produce a nonzero product everywhere, and would not work as well. The second important advantage of using the piecewise linear BFs is related to the computation.
Let us consider the general model on the relation between the predictor and response variables given in (1). The goal is to construct reflected pairs for each predictor xj (j = 1, 2, … , p) with p-dimensional knots τi = (τi,1, τi,2, … , τi,p)T at xi = (xi,1, xi,2, … , xi, p)T or just nearby each data vector (i = 1, 2, … , N) of that predictor.
After these preparations, our set of BFs becomes
(3)
Thus, we can represent f (x) by a linear combination as follows:
(4)
Here ψm (m = 1, 2, … , M) are BFs from ℘ or products of two or more such functions, ψm is taken from a set of M linearly independent basis elements, and θm are the unknown coefficients for the mth BF (m = 1, 2, … , M ) or for the constant 1 (m = 0). A set of eligible knots τi,j is assigned separately for each predictor variable dimension and is chosen to approximately coincide with the predictor levels represented in the data. Interaction BFs are created by multiplying an existing BF with a truncated linear function involving a new variable. In this case, both the existing BF and the newly created interaction BF are used in the MARS approximation. Provided that the observations are represented by the data
(i = 1, 2, … , N ), the form of the mth BF can be written as follows:
(5)
where Km is the number of truncated linear functions multiplied in the mth BF,
is the predictor variable corresponding to the jth truncated linear function in the mth BF,
is the knot value corresponding to the variable
, and
is the selected sign +1 or −1.
The MARS algorithm for estimating the model function f (x) consists of two subalgorithms: the forward stepwise algorithm searches for the BF and at each step, the split that minimizes some lack-of-fit criterion, called generalized cross-validation (GCV), from all the possible splits on each BF is chosen. One can refer to Appendix B for description of GCV. The process stops when a user-specified value Mmax is reached. Then, the backward stepwise algorithm starts to prevent from over-fitting by decreasing the complexity of the model without degrading the fit to the data, and to remove from the model BFs that contribute to the smallest increase in the residual squared error at each stage, producing an optimally estimated model with respect to each number of terms, called α. We note that here α expresses some complexity of estimation, and also note that Mmax is reduced to M.
In this study, we do not employ the backward stepwise algorithm to estimate the function f (x). Instead, as an alternative, we use penalty terms in addition to the LSE to control the lack-of-fit from the viewpoint of the complexity of the estimation Citation14. We will explain the details below.
3. CMARS: an alternative to MARS
3.1. The PRSS problem
The PRSS with Mmax BFs having been accumulated in the forward stepwise algorithm of the MARS approach has the following form:
(6)
where
is the variable set associated with the mth BF, ψm (cf. (5)),
represents the vector of variables which contribute to the mth BF, ψm. Furthermore, we refer to
for α = (α1, α2)T, |α| ≔ α1 + α2, where α1, α2 ∈ {0, 1}.
Indeed, we note that in any case where αi = 2, the derivative vanishes, and by addressing indices r < s, we have employed Schwarz's Theorem. In order not to overload the exposition, we still accept a slight flaw in the notation since in case of |α| = 1 and Km > 1, the integral terms become Km times the number of pairs where r < s. By redefining λm by λm/Km, this little deficiency could be easily corrected. The reader may choose a notation of his or her preference. Furthermore, for convenience, we use the integral symbol ‘∫’ as a dummy in the sense of
, where Qm is some appropriately large Km-dimensional parallelpipe where the integration takes place. We will come back to this below. Finally, since all the regarded derivatives of any function ψm exist except on a set of measure 0 (zero), the integrals and entire optimizsation problems are well defined.
The PRSS problem bases on the tradeoff between both accuracy, that is, a small sum of error squares, and not too high a complexity. This tradeoff is established through the penalty parameters λm. The second goal on a small complexity encompasses two parts: (a) Firstly, the areas where the BFs contribute to an explanation of the observations, should be large. In the case of classification, this means that the classes should be big rather than small. This aim is achieved by a ‘flat’ model which is the linear combination of the BFs, together with our wish to have small residual errors; i.e. the model being ‘lifted’ from the coordinate axes towards the data points (xi, yi) (i = 1, 2, … , N). Here, the basic idea is to dampen the slope of the linear parts of the BFs via the parameters θm, while still guaranteeing a quite satisfactory goodness of data fitting. (b) Secondly, we aim at the stability of the estimation, by taking care that the curvatures of the model function with its compartments according to (4)–(5) are not so high, and hence their oscillations are not so frequent and intense. For detailed information one may refer to Citation18.
Motivated in this way, both first- and second-order partial derivatives of the model function f, better to say, of its additive components, enter our penalty terms in order to keep the complexity of the LSE appropriately low.
In this article, we tackle that tradeoff by penalty methods, such as regularization techniques Citation19, and by CQP Citation16.
If we consider some arrangements in Citation14, the objective function (6) can be expressed in the following form:
(7)
where
denotes any of the predictor vectors and
stands for the corresponding projection vectors of
onto those coordinates which contribute to the mth BF, ψm, they are related with the ith response yi. We recall that those coordinates are collected in the set Vm. Here, CMARS uses up all Mmax basis functions provided by the forward algorithm of MARS, while MARS may eliminate some of them reducing the number of basis functions to M (≤Mmax) using its backward algorithm (Section 2). The second-order derivatives of the piecewise linear functions ψm (m = 1, 2, … , Mmax), and hence, the penalty terms related in Equation (7) vanish. Now, we can rearrange the representation of PRSS as follows:
(8)
where
,
with the point
in the argument. To approximate the multi-dimensional integrals
, again we use discretization forms of it. The discretizations and model approximations as presented in the following are very carefully prepared, and play an important role in order to raise our final model. The final model is linear in unknown parameters, and via the intermediate form of a Tikhonov regularization, we introduce our algorithmic approach which uses that linearity in a conic quadratic regression problem and by the use of interior point methods.
For discretizations, our data point (l = 1, 2, … , N) with
are given. In a natural way, these predictor data
(l = 1, 2, … , N) generate a subdivision of any sufficiently large parallelpipe Q of ℝN which contains each of them as elements. Let Q be a parallelpipe which encompasses all our predictor data; we represent it by
where Qj =: [aj, bj],
(j = 1, 2, … , p) (l = 1, 2, … , N). Without loss of generality, we may assume
. For all j we reorder the coordinates of the predictor data points:
, where
(σ = 1, 2, … , N; j = 1, 2, … , p), and
is the jth component of
, the
predictor vector after reordering. Without loss of generality we may assume
for all σ, φ = 1, 2, … , N with σ ≠ φ; i.e.
(j = 1, 2, … , p).
Indeed, whenever equality is attained for some coordinate, we would obtain subparallelpipes of a lower dimension in the following integration process and its approximation, that is, zero sets. Let us denote
In order to increase the readability of the following formulas, we make a small simplification without loss of generality. In fact, let us think that the canonical projections of the data points into the p input (feature) dimensions are of the same increasing order. So we assume (j = 1, 2, … , p). Otherwise, we could just replace the index (or discrete parameter) lσ by a j-, i.e. feature-depending one, called
. Now, we can write Q as
Based on the aforementioned notation, we discretize our integrals as follows:
We note that in our case subdivision and approximation done for all needs to be done for all with the corresponding variables and lower dimensions of tm also. For this we look at the projection of Q into
related with the special coordinates of tm and we take the subdivision of the corresponding Qm according to the subdivision obtained for Q.
Then, we rearrange PRSS in the following form:
(9)
where
. Let us introduce some more notation related with the sequence
:
(10)
By (10), we can approximate PRSS as:
(11)
For a short representation, we can rewrite the approximate relation (9) as the following:
(12)
where
is an (N × (Mmax + 1))-matrix, ‖·‖2 denotes the Euclidean norm and the numbers Lim are defined by their roots
3.2. Tikhonov regularization applied
Now, we approach our problem PRSS as a Tikhonov regularization problem Citation19 (see Appendix A for detailed explanation). For this purpose we consider formula (12) again, arranging it as follows:
(13)
where
(m = 1, 2, … , Mmax). But, rather than a singleton, there is a finite sequence of the tradeoff or penalty parameters
such that this equation is not yet a Tikhonov regularization problem with a single parameter as such. For this reason, let us make a uniform penalization by taking the same λ for each derivative term. Then, our approximation of PRSS can be rearranged as
(14)
where L is a diagonal (Mmax + 1) × (Mmax + 1)-matrix with the first column
and the other columns being the vectors Lm introduced above. Herewith, we can write L as follows:
Furthermore, θ is an ((Mmax + 1) × 1)-parameter vector to be estimated through the data points. Then, our PRSS problem looks as a Tikhonov regularization problem (26) with ϕ > 0, i.e. λ = ϕ2 for some ϕ ∈ ℝ Citation19. Our Tikhonov regularization problem treats the multiple objective functions and
using a linear combination of them. This combination is a weighted linear sum of the objectives. We set a weight by the penalty parameter λ. However, coming up with meaningful combinations of weights can be challenging. In Section 4, we give more explanations on the choice of the penalty parameter, and of the parameter occurring in the CQP problem which we introduce next.
3.3. CQP problem
The Tikhonov regularization problem (14) can be expressed as a CQP problem. Indeed, based on an appropriate choice of a bound Z ∈ ℝ, we state the following optimization problem:
(15)
Let us underline that this choice of Z should be the outcome of a careful learning process, with the help of model-free or model-based methods Citation20 (refer to Section 4 for more information). In our study, this bound is selected by a trial and error approach as an initial treatment, but in a future work more effective algorithms can be developed for handling the bound. In (15), we have the least squares objective function and the inequality constraint function
which is requested to be nonnegative for feasibility. Now, we equivalently write our optimization problem as follows:
(16)
or equivalently again,
(17)
A CQP problem is generally expressed as the following Citation18,Citation21:
(18)
In fact, we see that our optimization problem is such a CQP program with
In order to write the optimality condition, the dual problem and the primal dual optimal solution for this problem, and we first reformulate the problem (17) as follows:
(19)
where LN+1,
are the (N + 1)-and (Mmax + 2)-dimensional ice-cream (or second-order, or Lorentz) cones, defined by
The dual problem to the latter primal one is given by
(20)
We must note that dual problem constructed in Equation (20) is standard dual problem for convex programming in Equation (17) and so there is no duality gap. Moreover, (t, θ, χ, η, ω1, ω2) is a primal dual optimal solution if and only if
(21)
The penalty parameter λ in the PRSS and the parametrical upper bound Z in a constraint of the CQP are related. λ can be determined via Tikhonov regularization. This regularization method utilizes an efficiency curve that comes from a plotting of the optimal solutions to problem (14) according to a large (finite) number of parameter values, as points in a coordinate scheme with two axes. At one axis, the complexity is denoted, whereas the other axis stands for the length of the residual vector (or goodness-of-fit). In this regularization method, logarithmical scales are employed such that some ‘kink’ (corner) kind of a point on the efficiency boundary, called L-curve according to its more pronounced shape, is obtained. This point is regarded to be the closest to the origin, and it is therefore often chosen, together with the corresponding penalty parameter Citation19. For our approach with CQP, in Citation22, a lot of numerical experience is presented, related with varying upper bounds by using the software package of MOSEK™. The solutions obtained at the upper bounds are expected to be the same non-dominated solutions as obtained above.
In the following section, the implementation of CMARS algorithm is explained with a numerical example. The comparison study of the MARS and CMARS methods will be presented in the next section.
4. A numerical example
The data set used for illustrating the implementation of CMARS algorithm is taken from Citation23, p. 71]. It contains five predictor variables (x1, x2, x3, x4, x5) with 32 observations. Here, we write x as a generic variable in the corresponding space ℝl (l ∈ {1, 2, … , 5}). Later, we substitute x by t1, t2, … , or t5.
While implementing the CMARS algorithm, first, the MARS model is built by using the Salford MARS® v.2 Citation24. In the construction of the model, the maximum number of BFs (Mmax) and the highest degree of interactions are determined by trial and error. In this example, Mmax and the highest degree of interactions are assigned to be five and two, respectively. As a result, the largest model built in the forward MARS algorithm by the software contains the following BFs:
Here, ψ1 and ψ2 are the standard BF and mirror image (reflected) BF for the predictor variable x2, respectively. Let us note that the knot point for ψ1 is −0.159. BF ψ4, on the other hand, uses the function ψ3 to express the interaction between the predictor variables x1 and x4. Similarly, ψ5 represents the interaction between the predictor variables x4 and x5.
From this point on, only two of the BFs are listed above, namely ψ1, which represents the main effect of a variable, and ψ4, which stands for an interaction effect of two predictor variables, are selected to illustrate the implementation details of our CMARS algorithm.
To prevent our optimization problem from nondifferentiability, we do not choose the knot values as data points, but as values very close to them. Actually, we could even choose the knots τi,j farther away from the predictor values , if any such position promises a better data fitting. For example, we select the knot value for ψ1 as τ16,2 = −0.159, which is different from
but very close to it. Similarly, we select the knot values for ψ4 as τ5,1 = − 2.576 (not
), and τ1,4 = −1.517 (not
).
Then, the first and the fourth BFs of the form (5) can be written as follows:
and
As a result, the large model given in (4) becomes
Next, we can write the PRSS objective function in (8) as follows:
Some evaluations for the notations Vm and tm (for m = 1 and 4) in the above equation are given as
Besides, the derivatives for the BFs
(for m = 1 and 4) are stated below. For the BF ψ1(t1), there is no interaction; so r = s = 2. The sum of indicated first- and second-order derivatives for ψ1 is
where
For the BF ψ4(t4), on the other hand, there is an interaction between the predictors x1 and x4, and r = 1 and s = 4 so r < s. Then, the sum of indicated first- and second-order derivatives of ψ4 can be written as
where
If , then the Tikhonov regularization application put the PRSS function in the form of (14) as follows:
The first part of the PRSS objective function and that of the Tikhonov regularization problem are equal to each other. For illustration, the first part is expanded as follows:
When the maximum functions are computed, the RSS becomes
The multi-dimensional integral in the second part of Equation (8) takes the form of (11) by discretizing. The discretized form is denoted by L as given in Equation (14). In order to apply this discretization, first we sort the data set, and then, slightly decrease the first value of each predictor variable and slightly increase the last value of each predictor variable. Thus, adding two new observations to each of the predictor variables, we get a completely new data set totally with 34 observations. In the new data set, for example, the first data value is x1,1 = −2.5759 and the last data value is x32,1 = 2.4197. As a result, the first discretization value of x1 becomes and the last discretization value becomes
.
The Lm (m = 1, 4) values corresponding to BFs ψ1 and ψ4 are calculated as follows:
and
As a result, the L matrix becomes a (6 × 6)-diagonal matrix as follows:
Note that the first column elements of L are all zero and the diagonal elements of this matrix are Lm (m = 1, 2, … , 5) as introduced above.
In Equation (14), is the squared norm of Lθ which is
(22)
From the Equations (12) and (13), we can calculate the objective function PRSS. In order to solve this problem, we reformulate PRSS as a CQP problem by using (17) as follows:
(23)
Our previous CQP problem can be rewritten as follows:
(24)
Here θ38 = 1.9545θ1, θ39 = 0.5999θ2, θ40 = 2.0622θ3, θ41 = 1.6002θ4, θ42 = 13.1962θ5.
As can be seen from Equation (24), our problem involves 32 linear constraints and two quadratic cones. For solving it, we transform (24) into the MOSEK™ format Citation17. For this transformation, we have introduced new unknown variables (θ6, … , θ42), to the linear constraints in these two quadratic cones. By default, MOSEK™ uses an interior-point optimizer to solve CQP problem. It is a well-recognized implementation of the homogeneous and self-dual algorithm, and it computes the interior point solution which is an optimal solution.
We note that our family of optimization problems, indexed by Z, can be regarded as a problem of parametric programming. Such a problem will be analysed by us in future research. Next, we compare the performance of MARS and CMARS algorithms by using the model dependent measures which are GCV (a measure for MARS performance); and ‖Lθ‖2 (measures for CMARS performance). For this purpose, several values of
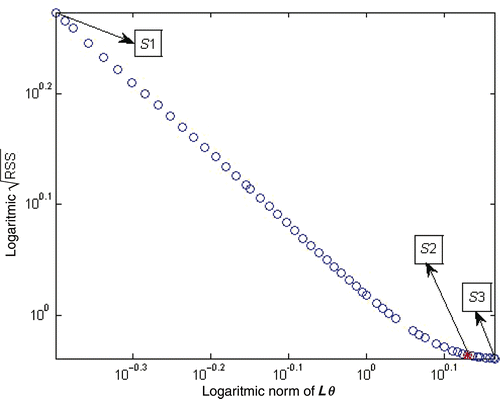
in (24) are used to obtain several corresponding CMARS solutions, each based on five BFs for this particular problem. Among them, three representative solutions of the CMARS algorithm, S1, S2 and S3, are chosen. Here, S1 and S3 are the ones that minimize the objective functions ‖Lθ‖2 and
, respectively. S2, on the other hand, is the CMARS solution that tries to minimize both of them in a balanced manner. To determine S2, a log–log scale curve of
versus ‖Lθ‖2 values of the solutions obtained by solving the CQP problem for various different Z values is plotted (). It is a characteristic L shaped curve, the corner value of which is taken as the S2 solution.
Figure 1. The solutions obtained for different Z values for problem (24).
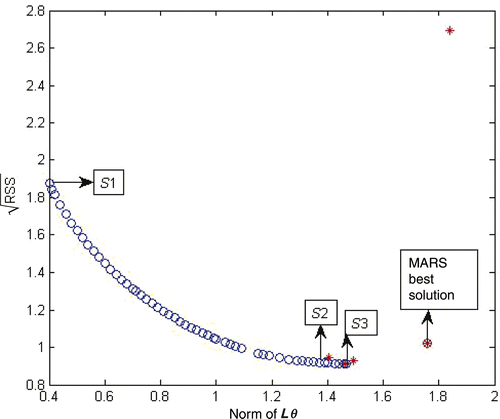
To compare the performances of the methods with respect to the CMARS performance measures, the plot of versus ‖Lθ‖2 is made for both MARS and CMARS solutions (). It reveals, based on our example and data, that CMARS solutions dominate MARS solutions according to these two measures.
Figure 2. Norm of Lθ versus for the solutions of methods (*: MARS solution; o: CMARS solution).
On the other hand, the plot of GCV values for different solutions of CMARS and MARS algorithms indicate that most of the MARS solutions dominate CMARS solutions with respect to GCV measure (). As a result, we can conclude that model-dependent measures may not enable us to distinguish between the performances of the algorithms studied. For that reason, in the next section, we apply MARS and CMARS algorithms to nine data sets having different characteristics, and compare them by using general performance measures.
Figure 3. GCV values for the solutions of methods (*: MARS solution; o: CMARS solution).
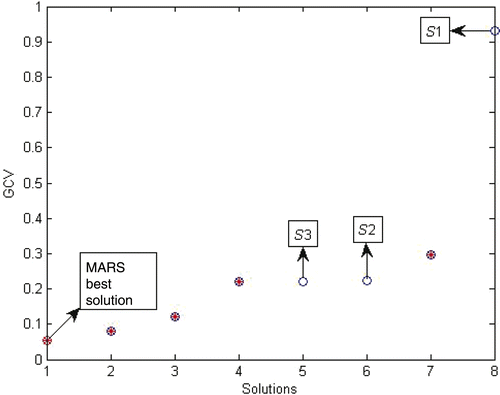
This result is to be expected, since MARS and CMARS optimize for the accuracy and complexity of the models based on their own corresponding measures.
5. Numerical comparison of the methods
In this section, we compare performances of the two methods: MARS and its alternative CMARS with respect to some general measures. For this purpose, first, data sets used in this comparison are described. Then, the cross validation (CV) technique employed for validating and comparing the methods' performances is explained. Next, the measures used in the comparison are described. Afterwards, the findings of our comparison studies are presented. Moreover, performances of the two methods on noisy data are evaluated by Monte Carlo simulation technique.
5.1. Data sets
In order to more realistically compare the performance of the CMARS method with that of the MARS method, nine data sets with different sample size (n) and number of predictors (p) are selected from regression test problems residing in well-known data repositories Citation25,Citation26. Then, these data sets are classified according to two important features of data: size and scale; scale here refers to the complexity in terms of the number of predictors involves in data. For both features three levels are considered: small, medium and large. Information about the data sets used in this study and their classification with respect to size and scale are presented in .
Table 1. Data sets used in the comparison.
Before construction of the models, all data sets are preprocessed to handle missing values, inconsistencies and outliers if there are any. Besides, variables are all normalized to make them comparable. It should be noted here that the ‘Communities and Crime’ data set is reduced in both size and scale to fit it into our classification.
5.2. Validation technique
In our applications, to compare and validate the methods, we have used a 3-times replicated 3-fold CV approach Citation29. In this approach, the original data set is randomly divided into three sub-samples (folds). While one sub-sample is retained for testing the model, the remaining two sub-samples are used for training data (i.e. building models). This process is performed three times; each time taking a different sub-sample for testing. This procedure, in turn, is replicated two more times, with new partitions. Overall, a total of nine test results are obtained. To produce better estimates for each measure, the three results obtained from 3-folds of a replication are averaged, as well as all nine results. Note that, we have applied a stratified CV where necessary (e.g. in metal casting data).
5.3. Criteria and measures used in the comparison
In the comparison, five criteria, namely, accuracy, complexity, stability, robustness, and efficiency are used. The accuracy criterion tries to measure the predictive capability of the model developed. For this purpose, mean absolute error (MAE), multiple coefficient of determination (R2), proportion of residuals within three sigma (PWI) and predicted error sum of squares (PRESS) are selected as the measures. Note here that these are the least correlated accuracy measures among many others extensively used in the literature. Complexity, on the other hand, can be measured by the mean squared error (MSE). Furthermore, in order to measure the change in the performance of the methods on the training and testing data sets, stabilities of above measures are calculated. Formal definitions of all these measures used in the comparison are given in Appendix C. Moreover, robustness of the methods under different data features is also assessed with the help of the spread of performance measures used. For this purpose, standard deviation of the measures is utilized. Finally, the performance of the methods is also evaluated with respect to their efficiency. To measure the efficiency of methods, computational run times of the data sets are recorded, and compared.
5.4. Applications and findings
In the following, the CV approach is applied on all data sets as explained in Subsection 5.2. MARS models are built by using Salford MARS® software program Citation24. CMARS models, on the other hand, are constructed by running the MATLAB® code developed by the authors Citation30.
After the models are built, comparison measures listed in Section 5.3 are defined in Appendix C are calculated for training and testing samples as well as stabilities of the measures for all 3-folds and three replications of each dataset. Then, averages of these nine values are obtained for each measure for MARS and CMARS ().
Table 2. Averages of performance results of the models built for the data sets.
In order to decide whether or not there are statistically significant differences in the performance of the models built, repeated analysis of variance (RANOVA) Citation31 is performed by using the statistical software SPSS™ Citation32, and the following hypotheses are tested for each performance measure separately:
versus
Here, M stands for the expected value of a performance measure (i.e. MAE, MSE, R2, PWI and PRESS) used in the comparisons. When the null hypothesis of RANOVA is rejected at α = 0.05 level of significance, Fisher's Least Significant Difference (LSD) test Citation32 is also performed to identify the statistically different models. Above testing procedure is applied for both training and test data sets in addition to the stabilities of the measures used in the comparisons, and the results are shown in .
Table 3. Overall performances (mean ± standard deviation) of MARS and CMARS methods.
5.5. Results
5.5.1. Overall performance
The mean and standard deviation values of all accuracy and complexity measures for the training and test data sets are presented in as well as those of the stability of the measures. In any data set, greater mean indicates better performance of the associated method while smaller standard deviation indicates more robust method.
Depending on the results presented in , the following conclusions can be drawn:
| • | In all training and test data, and stability comparisons, as far as differences in the means are concerned, there are no cases where MARS is statistically significantly better than CMARS. | ||||
| • | CMARS performs better and is more robust than MARS in training data sets with respect to most of the comparison measures also include the complexity measure, MSE. | ||||
| • | CMARS performs better and is more robust than MARS in testing data sets with respect to all measures. | ||||
| • | CMARS is more stable with respect to most of the measures. | ||||
| • | MARS is more robust than CMARS in stability with respect to most of the measures. | ||||
5.5.2. Performance with respect to sample size
Mean of all accuracy measures for MARS and CMARS for different sample sizes are recorded in .
Table 4. Average of accuracy measures with respect to different sample sizes.
The effect of sample size on the performance of the methods can be summarized as follows:
| • | MARS and CMARS performance decrease as the training/test sample size increases from small to medium; their performance increase as the training/test sample size increases from medium to large (except for PWI and PRESS). MARS and CMARS performance for small and large training samples are mostly similar (except for PRESS); they perform better in small test samples (except for MSE). | ||||
| • | MARS performs better than CMARS mostly on small training samples; CMARS performs better than MARS mostly on medium to large training samples (except for MSE). | ||||
| • | CMARS and MARS perform better mostly on small training/test samples. | ||||
| • | CMARS performs better than MARS on large training and test samples with respect to MSE, a complexity measure. | ||||
| • | CMARS and MARS are more stable on small data sets. | ||||
| • | MARS is more stable than CMARS on medium to large data sets while CMARS is more stable than MARS on small data sets. | ||||
5.5.3. Performance with respect to scale
Mean of all measures for MARS and CMARS for different scales are given in .
Table 5. Average of measures for different problem scales.
The effect of problem scale on the performance of both methods can be evaluated as follows:
| • | MARS and CMARS perform better (or the same) as the scale changes from small to medium and medium to large with respect to the measures (except for PRESS) in training samples. | ||||
| • | MARS and CMARS perform the best on large-scale training data sets (compared to others) with respect to PRESS. | ||||
| • | CMARS performs better than MARS on medium or large-scale training/test data sets. | ||||
| • | CMARS perform better and is more stable than MARS on medium scale with respect to MSE. | ||||
| • | CMARS and MARS are more stable on small-scale data sets. | ||||
| • | MARS is more stable than CMARS on small or large-scale while CMARS is more stable on the medium-scale. | ||||
5.5.4. Interactions among methods, sample size and problem scale
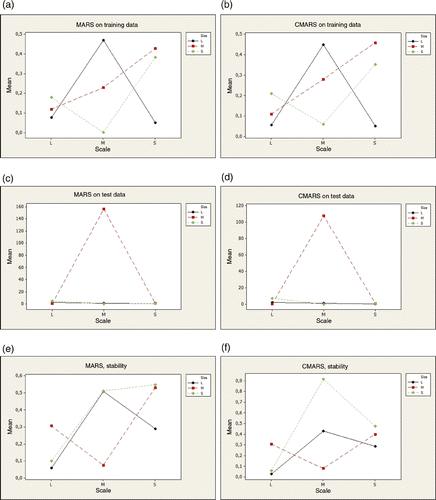
The performance of the methods studied as the sample size changes mainly depends on the problem scale in training samples with respect to MAE (p-value = 0.0), R2 (p-value = 0.0), PWI (p-value = 0.0) and PRESS (p-value = 0.002). This indicates the existence of interaction among the methods, sample size and the scale of data sets. Similar dependency is also detected in test samples with respect to MAE (p-value = 0.001), MSE (p-value = 0.002), PWI (p-value = 0.002) and PRESS (p-value = 0.0). This interaction exists in stability of the measures MAE (p-value = 0.001), MSE (p-value = 0.0), R2 (p-value = 0.049) and PWI (p-value = 0.0) as well. Due to the significant three-way interaction effects, a typical pattern for the best performance of the methods is hard to detect. Nevertheless, interaction plots () can be helpful for determining the best size-scale combination for a method in relation with a measure. To examplify, when the complexity measure, MSE, is considered, similar best performances are obtained on small/large scale and large training/test samples for MARS and CMARS methods. On the other hand, the best stability of MSE is obtained only for large scale and large samples for both methods. In general, but not a rule, we may say that better performances of MARS method are obtained for small size-small scale, and that of CMARS method for small size-medium scale data sets.
Figure 4. Interaction plots of size and scale for the complexity measure, MSE, for MARS and CMARS.
5.5.5. Performance with respect to efficiency
To compare the efficiencies of the methods, in this study, the computational run times (in seconds) for each training data sets are recorded on the computer with Intel (R) Pentium (R) CPU 3.40 GHz processor and 32-bit operating system Windows®. The maximum run time obtained for each training data sets are given in .
Table 6. Classification of run times (in seconds) of the methods with respect to size and scale.
We can summarize as follows:
| • | Run times seem to be related to the sample size but not the problem scale particularly for small size data. | ||||
| • | The least amount of run times for both methods is obtained for small size samples regardless of the scale. | ||||
| • | In small size data sets, run times of CMARS method are almost ten times as much that of MARS method. As sample size increases, they reduce up to three to five times as much to that of MARS. | ||||
5.5.6. Performance on noisy data
Finally, a simulation study is carried out using MATLAB® to see the effect of noise on performance of both methods. For this purpose, a test problem is adopted from Jin et al. Citation33, which is originally taken from Citation34. In this problem, data are artificially created from the following function:
(25)
where the regressors, x1 and x2 are assumed to have uniform (−10, 10) distribution. This data set is referred to as ‘noise-free’ data. To obtain noisy data, normally distributed noise, ε, having zero mean is added to the response, f (x). Here, the variance of the noise is assumed to be 1/100 of the variance of f (x) given in (25). When −5 ≤ x1, x2 ≤ 5, however, the variance of the noise is assumed to be 1254.9/100 = 12.55 (see Citation33, p. 13]). This way we try to locally reduce the error variance. After training data sets each having 100 observations are created as described above with and without noise, MARS and CMARS methods are fitted to them, and both accuracy and complexity measures are obtained. Then, test data are created by rerunning the code with different seeds, and the same measures are calculated. Results are shown in . In addition, to measure the sensitivity of the fits to the noisy data, the performance measures are re-calculated using fitted values obtained for the noisy data, and the noise-free data points (instead of the noisy ones). These latter measures are reported under the category labelled as ‘noisy fit vs noise-free data’ in .
Table 7. Performance results of the methods on noisy data.
As it can be seen in the above table, CMARS method overperforms MARS on noisy data. CMARS fits to noisy data seem to provide not only a closer fit to the noisy data itself but also to noise-free ones compared to MARS. We should note here that the data set used in the comparison is small scale and small data. More analysis with different types of data are needed before generalizing this conclusion.
6. Conclusion and future research
This study provides a new contribution to the well-known MARS method which has been applied in many areas during the last decade. The MARS algorithm is modified by constructing a PRSS as a Tikhonov regularization problem. This problem is then solved by using continuous optimization, particularly, CQP. This provides us an alternative modelling technique for MARS, which is named as CMARS.
For examining the efficiency of the developed method CMARS, it is compared with MARS method by using nine data sets, each with different features. In comparisons, method-free measures, such as R2 and MSE are used.
According to the results, in general, CMARS produces more accurate, robust and stable models than MARS. Besides, it results in less complex and robust models than MARS on test data sets. We should emphasize here that better performance of CMARS on test data with respect to all measures indicates the power of our method. Another important finding is that CMARS performs better than MARS mostly on medium and large training data sets, and large-scale training and test data sets. This finding indicates the success of CMARS as scale increases. In addition, CMARS is more stable on the medium scale data.
Because the performance of the methods are based on the size and the scale and type of data (i.e. training, test, stability), no pattern is detected for the best performance. However, we can say that CMARS method is more successful on medium scale, small data sets. Furthermore, our method performs better than MARS on noisy data. Having the above results of comparison study, we can say that CMARS may be a good alternative to MARS.
At this point, the only drawback of our method is not being as efficient as MARS. And, accuracy gains are small in absolute values compared to the run times; however, they are statistically significantly better only in favour of CMARS. Therefore, to improve CMARS algorithm to reduce computational run time, further research is being carried out. Within this context, an improvement for the forward part of the algorithm is being considered. Because the first part of MARS algorithm determines knot points among the data points for obtaining BFs, increasing the number of data points results in, a one-to-one manner, an increase in the number of knot points. Therefore, it gives rise to complexity. For this reason, a study is underway to determine suitable knot points for the data set by using clustering theory, supported by statistics and optimization theory Citation22.
On the other hand, CMARS has a disadvantage that it uses the model including the maximum number of BFs provided by the MARS algorithm. Hence, it may provide more complex models than MARS. To overcome this deficiency, insignificant model co-efficients can be detected and removed. Hence, the model size can be decreased.
By this article we intented to give a contribution to the theory, methods and applications in the fields of nonparametric regression/classification and data mining, as well as to invite future research challenges.
Acknolwedgements
This study is supported by the Turkish Scientific and Technological Research Institute (TUBITAK) under the project number 105M138. One of the authors, Fatma Yerlikaya-Özkurt, has been supported by the TUBITAK Domestic Doctoral Scholarship Program.
References
- Neter, J, Kutner, M, Wasserman, W, and Nachtsheim, C, 1996. Applied Linear Statistical Models. Boston: WCB/McGrawHill; 1996.
- Zareipour, H, Bhattacharya, K, and Canizares, CA, 2006. Forecasting the hourly Ontario energy price by multivariate adaptive regression splines. Power Engineering Society General Meeting, IEEE; 2006.
- Friedman, JH, 1991. Multivariate adaptive regression splines, Ann. Stat. 19 (1991), pp. 1–141.
- Di, W, 2006. Long Term Fixed Mortgage Rate Prediction Using Multivariate Adaptive Regression Splines. Nanyang: School of Computer Engineering, Nanyang Technological University; 2006.
- Zhou, Y, and Leung, H, 2007. Predicting object-oriented software maintainability using multivariate adaptive regression splines, J. Syst. Software 80 (2007), pp. 1349–1361.
- Deconinck, E, Coomons, D, and Heyden, YV, 2007. Explorations of linear modelling techniques and their combinations with multivariate adaptive regression splines to predict gastro-intestinal absorption of drugs, J. Pharma. Biomed. Anal. 43 (2007), pp. 119–130.
- Tsai, JCC, and Chen, VCP, 2005. Flexible and robust implementations of multivariate adaptive regression splines within a wastewater treatment stochastic dynamic program, Quality Reliability Eng. Int. 21 (2005), pp. 689–699.
- Elith, J, and Leathwick, J, 2007. Predicting species distribution from museum and herbarium records using multiresponse models fitted with multivariate adaptive regression splines, Divers. Distributions 13 (2007), pp. 265–275.
- Haas, H, and Kubin, G, , A multi-band nonlinear oscillator model for speech, Conference Record of the Thirty- Second Asilomar Conference on Signals, Syst. Comput. 1 (1998), pp. 338–342.
- Lee, TS, Chiu, CC, Chou, YC, and Lu, CJ, 2006. Mining the customer credit using classification and regression tree and multivariate adaptive regression splines, Comput. Stat. Data Anal. 50 (2006), pp. 1113–1130.
- Chou, SM, Lee, TS, Shao, YE, and Chen, IF, 2004. Mining the breast cancer pattern using artificial neural networks and multivariate adaptive regression splines, Expert Syst. Appl. 27 (2004), pp. 133–142.
- Ko, M, and Bryson, KMO, 2008. Reexamining the impact of information technology investment an productivity using regression tree and multivariate adaptive regression splines (MARS), Information Technol. Manag. 9 (2008), pp. 285–299.
- Breiman, L, Friedman, JH, Olshen, R, and Stone, C, 1984. Classification and Regression Trees. Belmont, CA: Wadsworth; 1984.
- Taylan, P, Weber, GW, and Yerlikaya, F, , Continuous optimization applied in MARS for modern applications in finance, science and technology, ISI Proceedings of 20th Mini-EURO Conference Continuous Optimization and Knowledge-Based Technologies, Neringa, Lithuania (2008), pp. 317–322.
- Nesterov, YE, and Nemirovski, AS, 1994. Interior Point Polynomial Algorithms in Convex Programming. Philadelphia: SIAM; 1994.
- Nemirovski, A, 2002. A Lecture on Modern Convex Optimization. Israel Institute of Technology; 2002, Available at http://iew3.technion.ac.il/Labs/Opt/opt/LN/Final.pdf.
- MOSEK, A, , very powerful commercial software for CQP. Available at http://www.mosek.com.
- Taylan, P, Weber, GW, and Beck, A, 2007. New approaches to regression by generalized additive models and continuoues optimization for modern applications in finance, science and technology, J. Optim. 56 (2007), pp. 675–698.
- Aster, RC, Borchers, B, and Thurber, C, 2004. Parameter Estimation and Inverse Problems. Burlington, MA: Academic Press; 2004.
- Hastie, T, Tibshirani, R, and Friedman, J, 2001. The Elements of Statistical Learning, Data Mining, Inference and Prediction. New York: Springer; 2001.
- Ben-Tal, A, 2002. Conic and Robust Optimization, Lecture Notes for the Course. Haifa, Israel: Minerva Optimization Center, Technion Israel Institute of Technology; 2002.
- Yerlikaya, F, 2008. A new contribution to nonlinear robust regression and classification with MARS and its application to data mining for quality control in manufacturing. MSc. thesis, Middle East Technical University; 2008.
- Myers, RH, and Montgomery, DC, 2002. Response Surface Methodology: Process and Product Optimization Using Designed Experiments. New York: Wiley; 2002.
- MARS from Salford Systems, , Available at http://www.salfordsystems.com/mars/phb.
- UCI: Machine Learning Repository. Available at http://archive.ics.uci.edu/ml/.
- StatLib: Datasets Archive. Available at http://lib.stat.cmu.edu/datasets/.
- Kartal, E, 2007. Metamodelling complex systems using liner and nonlinear regression methods. MSc. thesis, Middle East Technical University; 2007.
- Bakιr, B, 2006. Defect cause modelling with decision tree and regression analysis: A case study in casting industry. MSc. thesis, Middle East Technical University; 2006.
- Martinez, WL, and Martinez, AR, 2002. Computational Statistics Handbook with MATLAB. London: Chapman and Hall, CRC; 2002.
- MATLAB Version 7.5 (R2007b).
- Davis, CS, 2003. Statistical Methods for the Analysis of Repeated Measures. New York: Springer-Verlag; 2003.
- SPSS 16.0 GPL Reference Guide, Chicago, IL: SPSS Inc, 2007. Available at http://support.spss.com/ProductsExt/SPSS/Documentation/SPSSforWindows/.
- Jin, R, Chen, W, and Simpson, TW, 2001. Comparative studies of metamodelling techniques under multiple modelling criteria, Struct. Multidisc Optim. 23 (2001), pp. 1–13.
- Hock, W, and Schittkowski, K, 1981. Test Examples for Nonlinear Programming Codes. New York: Springer-Verlag; 1981.
- Hansen, PC, 1998. Rank-Deficient and Discrete Ill-Posed Problems: Numerical Aspects of Linear Inversion. Philadelphia: SIAM; 1998.
- Craven, P, and Wahba, G, 1979. Smoothing noisy data with spline functions: Estimating the correct degree of smoothing by the method of generalized cross-validation, Numer. Math. 31 (1979), pp. 377–403.
- Moisen, GG, and Frescino, TS, 2002. Comparing five modelling techniques for predicting forest characteristics, Ecol. Model. 157 (2002), pp. 209–225.
- Osei-Bryson, KM, 2004. Evaluation of decision trees: A multi-criteria approach, Comput. Oper. Res. 31 (2004), pp. 1933–1945.
Appendix
A.1. Tikhonov regularization
This regularization method is used to make ill-posed Citation19,Citation35 problems well-posed (regular or stable). A Tikhonov solution can be expressed quite easily in terms of SVD of the coefficient matrix X of a regarded linear system of equations Xβ = y.
There are different kinds of Tikhonov regularization represented by minimization problems including the penalized length of the solution β, and these problems can be solved using SVD Citation19. Here the norm (length) ‖β‖2 of β represents the complexity of the possible solution Citation19. But, in many situations, it is preferred to obtain a solution which minimizes the norm of first- or second-order derivative of β. These derivatives are given by first- or second-order difference quotients of β, regarded as a function that is evaluated at the ‘points’ i and i + 1. These difference quotients approximate first- and second-order derivatives; all together they are comprised of products Lβ of β with a matrix L that represent the discrete differential operators of first- and second-order, respectively. In the original case, we aim at the norm ‖β‖2 itself, and we have L = I (unit matrix). Herewith, we use the following optimization problem
(26)
Generally, (26) comprises higher-order Tikhonov regularization problems which can be solved using generalized singular value decomposition (GSVD) Citation19. In our article, we apply a Tikhonov regularization problem (Section 3.2) in which we have a different type of L matrix for MARS, and we solve this problem (Section 3.3) by using CQP. In Sections 3.2 and 3.3, we explain and discuss Tikhonov regularization and CQP in detail.
GCV can be used, which shows the lack-of-fit for a MARS model is defined as
(27)
where
Citation36. Here N is the number of sample observations as defined before, u is the number of linearly independent BFs, K is the number of knots selected in the forward process and d is a cost for BF optimization as well as a smoothing parameter for the procedure. Note that if the model is additive then d is taken to be two; if the model contains interaction terms then d is taken to be three Citation3,Citation20.
C.1. General notation
To evaluate the performances of MARS and CMARS, several measures can be used. The performance measures that we use in our applications and their general notation are presented in the following:
| yi | = | ith observed response value, |
| ŷi | = | ith fitted response, |
| = | mean response, | |
| N | = | number of observations, |
| p | = | number of terms in the model, |
| ei = yi − ŷi | = | is the ith ordinary residual, |
| hi | = | is a leverage value for the ith observation, which is the ith diagonal element of the hat matrix, H. The hat matrix is H = X (XT X)−1 XT, where X is an N × p design matrix and rank(X) = p (p ≤ N). |
C.2. Accuracy measures
C.2.1. Multiple coefficient of determination (R2)
This value is a coefficient of determination. It indicates how much variation in response is explained by the model. The higher the R2, the better the model fits the data. The formula is
C.2.2. Mean absolute error (MAE)
MAE measures the average magnitude of error. The smaller the MAE, the better it is. The formula is:
C.2.3. Prediction error sum of squares (PRESS)
PRESS is an assessment of a model's predictive ability. PRESS, similar to the residual sum of squares, is the sum of squares of the prediction error. In general, the smaller the PRESS value, the better the model's predictive ability is. In least squares regression, PRESS is calculated with the following formula:
Many of these measures can be found in any statistic text book such as Citation1.
C.2.4. Proportion of residuals within some user-specified range (PWI)
PWI is the sum of indicator variables over all observations divided by the total number of observations. The indicator variables take the value of one if the absolute value of the difference between actual and predicted response is within some user-specified thresholds Citation37. Here, we have used three ±3σ as a threshold. Hence PWI can be considered as another measure of accurate prediction of the dependent variable.
C.3. Complexity measure
C.3.1. Mean square error (MSE)
MSE is an unbiased estimate of the error variance. It is affected by both residual sum of squares and number of terms in the model. The smaller the MSE, the better it is. The formula is
C.4. Stability
The prediction model obtained from the methods is stable when it performs just as well on both seen (training) and unseen (test) data sets. The stability can be measured by
where CRTR and CRTE are the performance measure values for the test and the training, respectively. Closer values of this measure to one indicate higher stability Citation38.