Abstract
The diameter distribution of nanometric particles is estimated from multiangle dynamic light scattering (MDLS) measurements by solving an ill-conditioned nonlinear inverse problem through Tikhonov and Bayesian methods. For both methods, the data inputs are the angle-dependent average diameters of the particle size distribution (PSD), which are in turn calculated from the measured autocorrelation functions of the light intensity scattered by a dilute sample of particles. The performances of both methods were tested on the basis of: (i) two simulated polymer latexes that involved PSDs of different shapes, widths and diameter ranges; and (ii) two real polystyrene latexes obtained by mixing two well-characterized standards of narrow PSDs (of known nominal diameters and standard deviations). For PSDs exhibiting highly asymmetric modes, or modes of quite different relative concentrations, the Bayesian method produced PSD estimates better than those obtained through Tikhonov regularization.
Nomenclature
| = |
Table |
| = |
|
1. Introduction
The particle size distribution (PSD) is an important physical characteristic of several particulate systems, such as aerosols, emulsions, suspensions, dispersions and powders. The PSD can strongly influence the rheological behaviour and the stability of heterogeneous fluids, the coagulation or film formation processes of latexes, the magnetic and optical properties of dispersions, the taste and texture of foods, the coverage properties of paints, the burning rate of fuels and explosives, the quality properties of inks and toners, etc. Citation1.
Dynamic light scattering (DLS) Citation2, elastic light scattering Citation3 and turbidity Citation4 are fast and reliable optical techniques frequently used for determining average diameters of dilute systems that contain particles in the sub-micrometric range. When the PSD is estimated from light scattering and/or turbidity measurements, then the estimation procedure consists in inverting the mathematical model that describes the light extinction (scattering + absorption) suffered by light rays traversing a highly dilute sample of the particulate system. Typically, the Mie theory Citation5 is used for describing the light extinction under single scattering regime (i.e. in the absence of multiple scattering). The estimation procedure normally involves the solution of a linear ill-conditioned inverse problem (ICIP). Unfortunately, optical measurements contain a relatively small amount of information on the PSD; and for this reason only low-resolution PSDs can be estimated. The combination of two or more independent sets of measurements allows increasing the information content and can improve the quality of the PSD estimate. Previous works have combined turbidity and elastic light scattering measurements Citation6, DLS measurements taken at several angles (or multi-angle DLS measurements) Citation7,Citation8 and turbidity and multi-angle DLS measurements Citation8. In some cases, the combination of independent measurements can lead to the necessity of solving a non-linear ICIP.
Classical approaches for solving linear and non-linear ICIPs are based on Tikhonov regularization techniques Citation9,Citation10, which have been applied to estimate PSDs Citation1,Citation2,Citation6,Citation7. On the other hand, statistical methods based on Bayesian inference Citation11,Citation12 have scarcely been applied to sizing nanoparticles. For example, a Bayesian method was applied to solve the linear ICIP of estimating the PSD of ferrofluids from magnetization measurements, for particle diameters lower than 20 nm Citation13,Citation14. Bayesian methods have also been used for solving other linear and non-linear ICIPs Citation12,Citation15, but as far as the authors are aware, no application of Bayesian inference to the estimation of PSDs from optical techniques has yet been published.
In what follows, we will restrict our analysis to the case of DLS. In a DLS experiment, a dilute sample is irradiated with a monochromatic laser light, and the light scattered at different angles fluctuates due to the Brownian particle motion. In single-angle DLS, a digital correlator calculates the (discrete) second-order autocorrelation function of the fluctuating scattered light collected at a given angle,
, where τj (j = 1, 2, … , M) represents the time delay. In multi-angle DLS (MDLS), a set of R measurements is obtained by collecting
at the R different
. From such measurements, R angle-dependent average particle diameters,
, can be estimated through the cumulants method Citation16. Therefore,
can be considered as a set of R indirect measurements of the average diameters.
Typically, the discrete number-PSD is denoted by f (Di), where the ordinates of f (Di) represent the number-fractions of particles contained in the diameter intervals [Di, Di+1], with i = 1, … , N. All the Di values are spaced at regular intervals ΔD along the diameter range [Dmin, Dmax]; thus, Di = Dmin + (i – 1) ΔD, with ΔD = (Dmax – Dmin)/(N – 1). It can be proven that f (Di) is theoretically related to the (noise-free) average diameters through the following non-linear expression Citation1,Citation7:
(1)
where
is the light scattered at the angle
by a particle of diameter Di, and can be calculated by the Mie scattering theory Citation5. Then, the estimation of the PSD f (Di) from the indirect measurements
consists in inverting the non-linear Equation (1) for known values of the
coefficients.
The ill-conditioning characteristic of the inverse problem can be evidenced in . Two quite different PSDs (fa: bimodal, and fb: unimodal) were defined (). To simulate the MDLS measurements, the following procedure is used. Each (noise-free) is related to its corresponding (first-order and normalized) autocorrelation function of the electric field,
, through Citation7:
(2)
where
is the measured baseline, β (<1) is an instrumental parameter and M is the number of points of each autocorrelation function. At each
,
is related to f (Di) as follows Citation7:
(3)
with
(4)
where
are normalization factors that insure
= 1 Citation7 and adopt different values at different
, λ is the in vacuo wavelength of the incident laser light, nm is the refractive index of the non-absorbing medium (pure water), kB is the Boltzmann constant, T is the absolute temperature and η is the medium viscosity at T.
Figure 1. The ill-conditioned problem. (a) Two arbitrary PSDs. (b) Mie coefficients corresponding to nanometric particles (at 5 angles). (c) Normalized autocorrelation measurements. (d) Derived DLS average diameters.
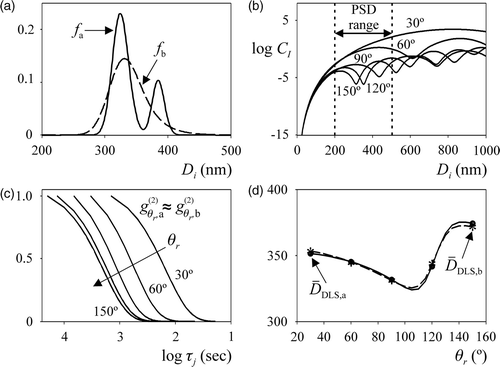
The coefficients CI in Equations (1) and (3) also depend on the particle refractive index (np), λ, and the laser light polarization, and can be calculated on the basis of the Mie scattering theory Citation5. For λ = 632.8 nm, np = 1.5729, and a vertically polarized laser, the CI coefficients are represented at five different angles (30°, 60°, 90°, 120° and 150°) in . For Di < 100 nm, all CI coefficients are practically independent of (i.e. the light is scattered according to the Rayleigh regime Citation5), and therefore no additional information on the PSD could be extracted by measuring at several angles. The noise-free autocorrelation measurements were calculated from Equations (2) to (4), and then normalized according to
(see ). At any selected angle, the measurements corresponding to both PSDs are practically overlapped. The application of the cumulants method Citation16 on the
produces the average diameters
and
indicated in , where the symbols correspond to the five selected angles, and the curves represent the theoretical continuous measurements at all angles. Note that both PSDs practically produce the same derived average diameters. As a consequence, the involved inverse problem is ill-conditioned. Although normalized autocorrelations
and
() are almost identical, their original
exhibit small differences that cause the differences between
and
().
In this work, a Tikhonov regularization technique and a Bayesian method are used for estimating PSDs of particulate systems on the basis of the average DLS diameters derived from MDLS measurements of highly diluted samples that ensure a single scattering regime. The performances of both inversion strategies are compared on the basis of simulated and experimental examples that involve PSDs of different shapes, widths and diameter ranges. summarizes the utilized calculation paths. In simulated examples, the PSD is assumed to be known, Equations (2) to (4) are used to calculate the noise-free measurements , and a random noise ε is then added to obtain the noisy measurements
. In experimental examples, the DLS equipment directly produces
. In all examples, the cumulants method Citation16 is applied to estimate the indirect measurements,
. Finally, both inversion methods are used to estimate the PSDs by solving the nonlinear ICIP of Equation (1). Sections 2 and 3 explain the inversion methods. Sections 4 and 5 show some simulated and experimental examples that were used to assess and compare the two inversion strategies. Finally, some conclusions are given in section 6.
Figure 2. PSD estimation from MDLS measurements: schematic data treatment paths.
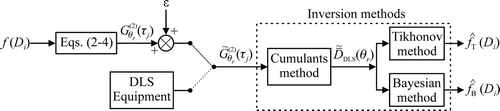
2. Estimation of the PSD through a Tikhonov Regularization Method
Let us call and
the vectors containing the ordinates of the (unknown) PSD and the measured average diameters, respectively. For solving the non-linear ICIP, a Tikhonov regularization method (stated as an optimization problem) is proposed as follows Citation10:
(5)
where
(R × 1) contains the average diameters corresponding to the estimated PSD,
, which are directly calculated by injecting
into Equation (1), W (R × R) is the covariance matrix of the measurement errors, α is a regularization parameter, H (N × N) is a regularization matrix and
represents the 2-norm of a vector. We will assume that the measurement errors are uncorrelated and normally distributed with mean zero and standard deviation σr (r = 1, … , R), then W = diag(σ12, … , σR2). Concerning the penalty term in Equation (5), the parameter α will be calculated through the L-curve method Citation17; and the matrix H will be implemented as a discrete second derivative operator to ensure high smoothness in the estimated PSD, as normally expected in practical applications.
As a first attempt to solve Equation (5), a sequential quadratic programming algorithm was applied on several simulated examples; but the PSD estimates resulted highly dependent of the chosen initial guess, thus revealing the existence of local minima. Therefore, a more effective optimization algorithm able to find the global minimum was required. Particle swarm optimization (PSO) algorithms proved to be powerful tools for solving linear and nonlinear optimization problems, in continuous as well as in discrete domains Citation18. Here, a PSO algorithm in the form of a linearly decreasing inertia weight PSO (LDW-PSO) is used Citation19.
In a PSO algorithm, the search is performed by using a large population of ‘particles’. (To avoid confusions, the term ‘particle’ corresponding to the PSO algorithm is here indicated between apostrophes.) Then, in the context of a PSO algorithm, a ‘particle’ corresponds to an individual; i.e. each ‘particle’ is a candidate PSD to represent the sought solution to the optimization problem.
During the execution of a PSO algorithm, each ‘particle’ continuously moves through the search space until some relatively stable state is reached Citation18. A PSO algorithm combines an ‘exclusively social model’ (which suggests that individuals ignore their own experience and adjust their knowledge according to the success of other individuals in the neighborhood), with an ‘exclusively cognitive model’ (which treats individuals as isolated beings). A ‘particle’ changes its position according to these two models.
The i-th ‘particle’ Xi is a point in a N-dimensional space, i.e. Xi = (xi,1, … , xi,N). The best position reached by Xi corresponds to the minimum value of the cost function [Equation (5)], and is represented by Pi = (pi,1, … , pi,N). The best position reached by the entire ‘particle’ population is represented by G = (g1, … , gN). The position change rate (or velocity) of Xi is represented by Vi = (vi,1, … , vi,N). The ‘particles’ are manipulated according to the following model:
(6)
(7)
where k stands for the iteration number, c1 and c2 are two positive constants, R1 and R2 are two random numbers in the range (0, 1) Citation19 and w is the inertial weight Citation19. Equation (6a) is used to calculate the updated ‘particle’ velocity, vi,j(k + 1), according to (i) its previous velocity, vi,j(k), (ii) its current location distance to its best historical position, [pi,j – xi,j (k)], and (iii) its current location distance to the best position found within the group, [gj – xi,j (k)]. Then, the ‘particle’ moves from its old position, xi,j (k), to its new position, xi,j (k + 1), according to Equation (6b). This process is iteratively repeated until reaching the algorithm convergence, which is assumed to occur when G does not exhibit significant changes.
3. Estimation of the PSD Through a Bayesian Inference Method
Let us consider f and as random vectors. Then, the Bayes theorem can be stated as Citation11
(8)
where
is the posterior probability density, i.e. the conditional probability of f given the measurements
,
;
is the prior probability density, i.e. a statistical model for the information about the unknown parameters prior to the measurements;
is the likelihood function, which gives the relative probability density of different measurements outcomes
corresponding to a fixed f and
is the marginal probability density of the measurements, which plays the role of a normalizing constant.
Since the random measurement noise is assumed independent, additive and Gaussian, then the likelihood function can be stated as Citation11,Citation13,Citation15:
(9)
where K1 is a known constant that depends on the covariance matrix of the measurement errors, W.
The prior probability density function should include all a priori information available on the PSD. In practice, the PSD is generally accepted to be a smooth non-negative function; and among several possible smoothness conditions, we here particularly adopt that the PSD exhibit bounded second derivatives. Then, the maximum entropy principle Citation13 enables us to write:
(10)
where K2 is a constant (strictly unnecessary for implementing the estimation procedure), and γ is a smoothing parameter that can also be obtained by the L-curve method Citation17. By substituting Equations (8) and (9) into Equation (7), we obtain:
(11)
In a statistical sense, the most likely solution of the estimation problem is the so-called maximum a posteriori (MAP), i.e. that f which maximizes Equation (10). Maximization of
can be obtained by minimizing the exponent of Equation (10), i.e.
(12)
The minimization of the quadratic problem in Equation (11) is similar to the Tikhonov regularization of Equation (5). As a consequence, the MAP solution will coincide with the Tikhonov estimate. In this context, the Tikhonov inversion method may be considered as a particular case of a (more general) Bayesian inference method.
An alternative PSD estimate can be obtained by evaluating the mean of instead of its maximum, i.e.
(13)
It is important to note that if
were a Gaussian distribution, then the maximum of Equation (10) would coincide with its mean, and therefore the PSD estimates obtained through Equations (11) and (12) would become identical. However, since
is not a Gaussian distribution [see Equation (10)], then the solutions obtained through Equations (11) and (12) will be different.
Unfortunately, the PSD estimation through Equation (12) would require solving high-dimension integrations for evaluating in Equation (10), and the numerical procedure would be extremely time-consuming. To overcome such problem, a Markov Chain Monte Carlo (MCMC) method is usually proposed for sampling Equation (10), and inference on
can be obtained from inference on the samples. Here a MCMC method implemented in the form of the Metropolis–Hasting algorithm Citation11,Citation15 was used for sampling
. The reason for using the Metropolis–Hasting algorithm is due to its simplicity for drawing samples from
.
3.1. Metropolis–Hasting algorithm
The Metropolis–Hasting algorithm is used to draw a sequence of samples from . The algorithm can be summarized in the following steps Citation11,Citation15:
| 1. | Start with any initial distribution f1 that satisfies | ||||
| 2. | Use the current f k to obtain a new candidate f*, from some jumping distribution q(f k, f*), which is the probability of returning f* given f k. | ||||
| 3. | Given the candidates f k and f*, calculate the acceptance factor:
| ||||
| 4. | Choose a random value U from a uniform distribution on (0,1). If U ≤ ξ, set f k+1 = f*; otherwise, f k+1 = f k. | ||||
| 5. | Set k = k + 1 and return to step 2 to generate the sequence {f1, … , f k}. | ||||
After a total number of K iterations, the iterative procedure generates a Markov chain {f1, … , fK}, provided that the transition probabilities from f k to f k+1 depend only on f k and not on {f1, … , f k-1}. After a sufficiently large burn-in period (of B iterations), the chain approaches an stationary state, and samples from the set {fB+1, … , fK} are samples from . More details concerning MCMC and the Metropolis–Hasting algorithm can be consulted in Citation11,Citation15.
Once the Markov chain is obtained, the estimated PSD, , can be calculated from Equation (12), i.e.
(15)
In what follows, we will refer to ‘Tikhonov inversion’ (TI) as the classical inversion method carried out to solve Equation (5), which also produces the MAP solution of Equation (10). Also, we will refer to ‘mean-based Bayesian inference’ (m-BI) as the method for solving the estimation problem through Equation (14).
4. Simulated Examples
The proposed inversion methods were first tested through simulated examples, because in these cases the solutions are a priori known, and therefore the performance of the algorithms can be adequately evaluated and compared. Two PSDs corresponding to hypothetical polystyrene (PS) latexes with spherical particles of diameters in the range 200–550 nm were considered. In all cases, the discrete diameters were spaced at regular intervals of ΔD = 1 nm. Both PSDs exhibited different shapes, widths and diameter ranges; and were selected to evaluate the ability of the proposed methods to deal with different kind of PSDs. All testing cases were defined on the basis of discrete number-PSDs, f (Di).
The first PSD, f1(Di), was an asymmetric exponentially modified Gaussian (EMG), obtained by convoluting a Gaussian (of mean diameter = 340 nm, and standard deviation σG = 10 nm), with a decreasing exponential function (of decay constant τ = 20 nm), i.e.
(16)
where ‘*’ represents the convolution product.
The second PSD, f2(Di), was the weighted sum of two normal-logarithmic distributions, as follows:
(17)
were each mode
is obtained through
(18)
with the following parameters: {
= 350 nm, σL,1 = 0.05}, for f2,1(Di), and {
= 450 nm, σL,2 = 0.05}, for f2,2(Di). Therefore, f2(Di) is a bimodal PSD with asymmetric modes.
The light source was a vertically polarized He–Ne laser of wavelength λ = 632.8 nm. At such wavelength, the refractive indexes are np = 1.5729, for the PS particles, and nm = 1.3319, for the dispersion medium (pure water). Measurement angles were selected to vary from 30° to 140°, at regular intervals of 10°. The above-detailed optical parameters were used to evaluate CI(θr,Di) Citation5, and are required to simulate the noise-free measurements through Equations (2) to (4). In addition, each
was contaminated with additive and uncorrelated noises (similar to those observed in typical experiments), to obtain the noisy measurements
, i.e.
(19)
where ε is a Gaussian random sequence of mean zero and variance one. From
, the noisy first-order autocorrelation function of the electric field,
, was calculated through Equation (2), and the noisy derived measurements
were obtained through the cumulants method Citation16.
From the (r = 1, … , R), the TI and m-BI methods were applied for estimating f1 and f2. In all estimation procedures, a diameter axis in the range 100–1100 nm, with N = 101 points regularly spaced each 10 nm, was selected. In order to estimate W, hundreds of simulations were implemented on many PSDs, for different noise realizations in Equation (18). For each PSD, the standard deviation of the resulting
, σr, were calculated at each angle θr. Independently of the PSD, it was observed that σr are adequately approximated through: σr = 0.0025 mean{
}. This expression is particularly appropriate in experimental cases where only a few measurements can be carried out at each angle, which would avoid a reasonable estimation of σr. Then, the covariance matrix was built as W = diag(σ12, … , σR2).
For solving the ICIP through the TI method, a LDW-PSO algorithm with 25 ‘particles’ was implemented. The usual parameters c1 = c2 = 2 were directly adopted from literature Citation19. The PSO algorithm was initialized by assigning to each ‘particle’ a random PSD of components sampled from a uniform distribution. Both simulated PSDs were used as testing examples, for adjusting the inertia function as well as the criterion for stopping the algorithm. The inertia function was selected as a linear function that decreased from w = 0.5 (for the first iteration) to w = 0.1 (for the iteration 10,000). After several runs, 10,000 iterations were adopted as a reliable criterion for stopping the optimization procedure.
For solving the ICIP through the m-BI method, the Metropolis–Hasting algorithm was initialized with positive random values (f1) selected from a uniform distribution. A Gaussian jumping distribution [q(f k, f*)] with zero mean and standard deviation of 0.001 was utilized. From q(f k, f*) a new sample f* is derived from f k by modifying the i-th component of f k, where i is randomly selected from a uniform distribution. Again, both simulated PSDs were used as testing examples. The Markov chain length was adopted after many trial-and-error simulations. First, it was observed that short chain lengths produced noisy and non-repetitive estimates. Then, the chain length was gradually increased and more repetitive PSD estimates were obtained. Very long chain lengths (e.g. >1,000,000) importantly increased the computing time but did not produce meaningful changes in the PSD estimates. Therefore, a Markov chain length of 500,000 was finally selected as a trade-off between a reasonable PSD estimate and an excessive computing time. Moreover, with a Markov chain length of 500,000, a reasonable repeatability for different MCMC realizations was verified in each example. For the simulated PSDs, the evolution of revealed that the Markov chain reaches equilibrium in a burn-in period B = 15,000 states.
The regularization parameter, α, was selected according to the L-curve method Citation17, as follows: (1) Equation (5) was solved for a large set of α values, (2) for each α, the corresponding PSD estimate was used to evaluate the two terms of Equation (5): T1 =
and T2 =
, (3) a cubic spline was used to fit T1 vs. T2, which produced an L-shaped curve when plotted in a log–log scale, (4) the final α was chosen as that value corresponding to the maximum curvature point of the L-curve. In spite of the non-linearity of Equation (5), the characteristics of the L-curve method Citation17 were reproduced. A similar procedure should be implemented for selecting the smoothness parameter, γ, from Equation (11). However, Equations (5) and (11) are equivalents, and therefore γ = α was directly selected in each example.
To evaluate the quality of the estimations, the following performance indexes were defined:
(20)
(21)
where
were obtained by injecting each estimated PSD,
, into Equation (1). The index
evaluates the ability of each inversion method to estimate the ‘true’ PSD,
, and the index
quantifies the errors in the recuperation of the noisy measurements,
, from the estimated PSD. Note that in a real measurement, it would be impossible to calculate
because
is unknown; however, this criterion was adopted for the simulated examples to investigate the limitations of the proposed methodology.
Each example was simulated 25 times to investigate the effect of the artificial random noise ε added to the measurements [Equation (18)] on the final results. For each example, shows the final average performance indexes [,
] and their corresponding standard deviations [
,
]. The maximum and minimum values of
and
[
,
,
,
] are also indicated. In the case of the bimodal PSD, f2, the results corresponding to
and
are indicated for each mode. In all cases, the m-BI method produced better PSD estimates as suggested by the lower values of
,
and
. In addition, the lower values of
produced by the m-BI method indicate a more reduced sensitivity of the PSD estimates to the measurement noise, when compared to the results obtained from the TI method. In contrast, the TI method produced better recuperations of the measurements, as indicated by the smaller values of
,
and
. These results can be justified by the fact that the m-BI method does not aim at minimizing the measurement errors, and therefore larger values of
are obtained.
Table 1. Simulated examples.
and present the results corresponding to a particular realization of the examples and , respectively. From the simulated measurements indicated in and the proposed inversion methods produced the PSD estimates of and . In all figures, the ordinates are Fj(Di) = fj(Di) Di3 [instead of fj(Di)] to highlight the estimation errors at large diameters. Note that Fj(Di) represents a weight-PSD; i.e. the ordinates of Fj(Di) represent the weight-fractions corresponding to the discrete diameters. The estimated mean diameters,
, are shown in and . In all figures, subscripts T and B added to the estimated variables stand for TI and m-BI, respectively.
Figure 3. Simulated example for the PSD f1. (a) Average diameters i) calculated from the ‘noisy’ MDLS measurements (dots), and ii) simulated with the estimated PSDs. (b, c) The simulated PSD and its estimates from the TI method (b) and m-BI method (c). (d) Estimated PSD obtained from the m-BI method and the standard deviations calculated from the samples obtained through the Metropolis–Hasting algorithm.
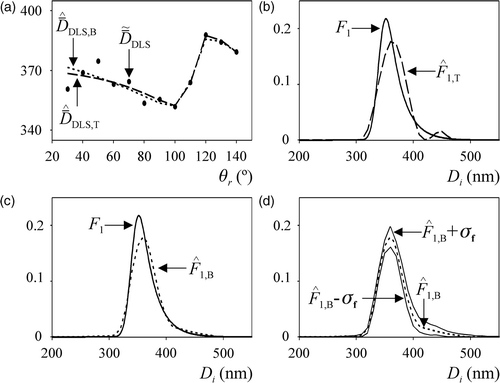
Figure 4. Simulated example for the PSD f2. (Legends as in ).
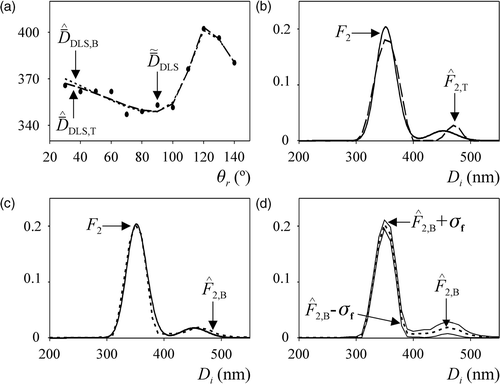
show that the Tikhonov regularization produced an erroneous mode around 450 nm, when estimating f1. Such a spurious mode is due to the presence of measurement noises. Complete compensation of the erroneous mode was impossible even after applying a stronger regularization. On the other hand, m-BI technique seems to be less influenced by measurement noises, and produced an acceptable unimodal estimate (). In addition, while the TI method was unable to acceptably estimate the asymmetry in f1, the m-BI method produced an accurate estimate. In the case of the bimodal PSD, f2, both methods predicted the two modes, but the m-BI technique produced an estimate closer to the true PSD. In , the mode corresponding to larger diameters was estimated through the TI method as a narrower mode of higher mean diameter (). In contrast, the m-BI approach produced a wider estimate that almost coincides with the true PSD ().
A statistical analysis of the set {fB+1, … , fK} was conducted to get information on the precision of the PSD estimate obtained on the basis of the m-BI method. and show the estimates of f1 and f2, and the confidence bands defined by their corresponding standard deviations, σf, calculated from the Markov chains. Uncertainties resulted larger at the asymmetric zone of the unimodal PSD f1, and for the mode of higher diameters of the bimodal PSD f2.
Even though not shown, for unimodal PSDs with small asymmetries, for relatively broad PSDs, for bimodal PSDs with modes of similar concentrations, and/or for PSDs of higher diameters, both inversion methods produce accurate and similar estimates. In contrast, for PSDs with particles of small sizes (<150 nm), both inversion methods predict unreal spike distributions. These deteriorated predictions are quite reasonable because the shape of PSDs with particles of small diameters slightly contributes to modify the average diameters measured at the different angles, and therefore the measurements have low information content on the true PSD. All predicted spikes can be eliminated by increasing the regularization parameters, but excessively broad PSDs will be produced.
5. Experimental Examples
TI and m-BI inversion methods were also applied to evaluate experimental examples. Two latexes (L1 and L2) of bimodal PSDs were obtained by mixing two narrow and unimodal standards of PS (from Polysciences), of nominal diameters 300 and 1000 nm. The number fraction of the secondary mode (with particles of 1000 nm) was gravimetrically determined, yielding: xL1,2 ≈ 1.05% for latex L1, and xL2,2 ≈ 2.10% for latex L2.
MDLS measurements were carried out at 30°C and nine detection angles: [30° 40° 50° 60° 70° 80° 90° 110° 130°], with a general-purpose laser light-scattering photometer (Brookhaven Instruments, Inc.) fitted with a vertically polarized He–Ne laser (λ = 632.8 nm), and a digital correlator (model BI-2000 AT). The total measurement times ranged from 200 to 500 s. All latexes were well diluted in distilled, filtered and deionized water, yielding mean intensities lower than 200,000 counts/s at each detection angle, as recommended for avoiding multiple scattering Citation7.
The average diameters, , were calculated by applying the quadratic cumulants method Citation16 onto the measured
; and are indicated by dots in and These values were fed into the proposed inversion methods for estimating the PSDs indicated in and . In both experimental examples, the same discrete diameter axis adopted for the simulated examples was utilized. The components of the W, σr, were estimated from the expression described in the previous section, but simplified to the present case where only a single DLS measurement was available at each angle: σr = 0.0025
. The regularization parameter α was selected through the L-curve method. As in the case of the simulated examples, γ = α was adopted. Since the experimental data involved diameter and measurement vectors of dimensions close to those of the simulated examples, then the Markov chain length and the burn-in period were kept unchanged (i.e. 500,000 and 15,000, respectively). These last values were also checked to be appropriate after several PSD estimations with higher and lower values.
Figure 5. Experimental example for latex L1. (a) Average diameters i) calculated through the cumulants method Citation16 (dots), and ii) simulated with the estimated PSDs. (b, c) Comparison of the ‘true’ PSD with its estimates from the TI method (b) and m-BI method (c). (d) Estimated PSD obtained from the m-BI method and the standard deviations calculated from the samples obtained through the Metropolis–Hasting algorithm.
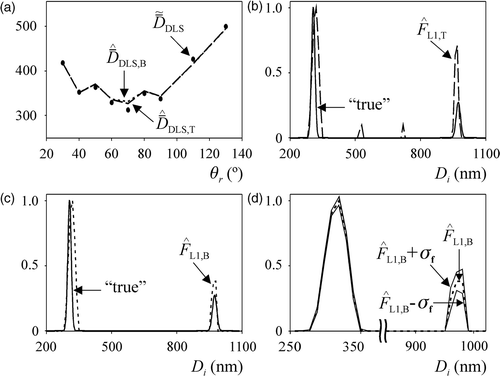
Figure 6. Experimental example for latex L2. (Legends as in ).
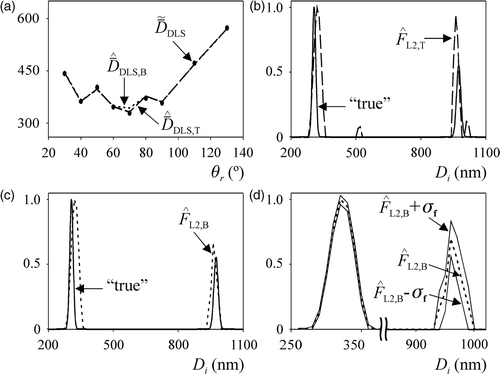
For evaluating the performance of the numeric inversion methods, ‘true’ PSDs must be adopted for latexes L1 and L2. These PSDs were defined on the basis of the nominal diameter and the standard deviation of each standard, which were reported by the manufacturer after characterization through disk centrifuge (DC) Citation1. The reported mean diameters and standard deviations were = 306 nm and σPS1 = 8 nm, for the first standard; and
= 974 nm and σPS2 = 10 nm, for the second standard. Then, the ‘true’ PSDs were represented by bimodal distributions, with Gaussian modes centred at the diameters
and
, with standard deviations σPS1 and σPS2, and with number fractions xL1,1 = 98.95% and xL1,2 = 1.05%, respectively, for the first and second mode of latex L1; and xL2,1 = 97.90% and xL2,2 = 2.10%, respectively, for the first and second mode of latex L2.
shows the nominal diameters, number fractions and performance indexes calculated for the ‘true’ and the estimated PSDs. Note that Jf is discriminated for each main mode of L1 and L2.
Table 2. Experimental examples.
From and and , the m-BI method produced better PSD estimates, except for the smallest mode of L2, where the TI method showed a slightly better performance. Although the TI method produced acceptable estimation of the main modes of L1 and L2, it also estimated erroneous intermediate modes. On the other hand, the m-BI method produced bimodal PSDs that practically coincided with the ‘true’ PSDs, and it was able to adequately estimate the average diameter and number fraction of each mode of L1 and L2.
and show the confidence bands for the PSD estimates obtained through the m-BI method. In both figures, the abscissa axes were conveniently expanded for a better visualization of the high diameter modes, where larger uncertainties were again observed.
6. Conclusions
A Tikhonov regularization technique and a mean-based Bayesian inference method were analysed as feasible numerical tools for solving the non-linear and ill-conditioned inverse problem that arises when the PSD of nanometric particles is estimated from MDLS measurements. The algorithms were implemented and fairly compared on the basis of simulated and experimental examples corresponding to PSDs of polystyrene latexes.
In general, the m-BI method produced improved PSDs with respect to the TI technique. The m-BI approach seems to be more efficient to deal with noisy measurements, without predicting the spurious intermediate modes observed with the TI methods. This can be justified by analysing the JD index. In fact, the TI method tends to overweight the measurement noises and therefore yields lower JD indexes than the m-BI method. Major differences between m-BI and TI predictions were observed for (i) highly asymmetric unimodal PSDs; and (ii) bimodal PSDs including modes of highly different concentrations. In case (i), the TI method normally predicts a spurious mode; and in case (ii), the m-BI method produces a better estimation of the low concentration mode.
All data processing was made in a standard PC with a Pentium(R) Dual-Core (2 GHz) processor and a RAM memory of 3 GB. Once the regularization parameter was chosen, the m-BI method required around 90 s to complete the 500,000 Markov chains plus the 15,000 burn-in periods; while the TI method required around 30 s to reach the optimum of Equation (5). Although the TI method reached the solution three times faster than the m-BI method, this advantage becomes almost negligible when it is compared to the global time required to obtain a PSD estimate. In fact, such a typical global time may reach 2–3 h, involving the sample preparation, the room conditioning, the equipment stabilization, the measurements at several angles (normally 200–500 s per angle), and the data processing. Thus, the advantages of m-BI method rely on its improved ability for estimating an accurate PSD in a global computing time similar to that of the TI method.
Acknowledgements
The authors are grateful for the financial support received from CONICET, MinCyT, Universidad Nacional del Litoral, Universidad Tecnológica Nacional (Argentina) and CNPq - Project 490.556/207-8 of the Program PROSUL (Brazil).
References
- Gugliotta, LM, Clementi, LA, and Vega, JR, 2010. "Particle size distribution. Main definitions and measurement techniques". In: Gugliotta, LM, and Vega, JR, eds. Measurement of Particle Size Distribution of Polymer Latexes. Kerala, India: Research Signpost – Transworld Research Network; 2010. pp. 1–58.
- Gugliotta, LM, Vega, JR, and Meira, GR, 2000. Latex particle size distribution by dynamic light scattering: Computer evaluation of two alternative calculation paths, J. Col. Int. Sci. 228 (2000), pp. 14–17.
- Finsy, R, Deriemaeker, L, Geladé, E, and Joosten, J, 1992. Inversion of static light scattering measurements for particle size distributions, J. Col. Int. Sci. 153 (1992), pp. 337–354.
- Llosent, MA, Gugliotta, LM, and Meira, GR, 1996. Particle size distribution of SBR and NBR latexes by UV-Vis turbidimetry near the Rayleigh region, Rubb. Chem. Technol. 69 (1996), pp. 696–712.
- Bohren, C, and Huffman, D, 1983. Absorption and Scattering of Light by Small Particles. New York: John Wiley; 1983.
- Vega, JR, Frontini, GL, Gugliotta, LM, and Eliçabe, GE, 2003. Particle size distribution by combined elastic light scattering and turbidity measurements. A novel method to estimate the required normalization factor, Part. Part. Syst. Charact. 20 (2003), pp. 661–669.
- Vega, JR, Gugliotta, LM, Gonzalez, VDG, and Meira, GR, 2003. Latex particle size distribution by dynamic light scattering. A novel data processing for multi-angle measurements, J. Colloid Int. Sci. 261 (2003), pp. 74–81.
- Gonzalez, VDG, Gugliotta, LM, Vega, JR, and Meira, GR, 2005. Contamination by larger particles of two almost-uniform latexes: Analysis by combined dynamic light scattering and turbidimetry, J. Colloid Int. Sci. 285 (2) (2005), pp. 581–589.
- Tikhonov, AN, and Arsenin, V, 1977. Solution of Ill-posed Problems. New York: Wiley; 1977.
- Engl, HW, Hanke, M, and Neubauer, A, 1996. Regularization for Inverse Problems. The Netherlands: Kluwer Academic Publishers, Dordrecht; 1996.
- Armstrong, N, and Hibbert, DB, 2009. An introduction to Bayesian methods for analyzing chemistry data. Part I: An introduction to Bayesian theory and methods, Chemom. Intell. Lab. Syst. 97 (2009), pp. 194–210.
- Hibbert, DB, and Armstrong, N, 2009. An introduction to Bayesian methods for analyzing chemistry data. Part II: A review of applications of Bayesian methods in chemistry, Chemom. Intell. Lab. Syst. 97 (2009), pp. 211–220.
- Xue, DS, and Si, MS, 2006. Bayesian inference approach to particle size distribution estimation in ferrofluids, IEEE Trans. Magn. 42 (2006), pp. 3657–3660.
- Lei, G, Shao, KR, Li, YB, Yang, GY, Guo, Y, Zhu, J, and Lavers, JD, 2009. Bayesian inversion method and its information determination for the estimation of particle size distribution in ferrofluids, IEEE Trans. Magn. 45 (10) (2009), pp. 3981–3984.
- Mota, CAA, Orlande, HRB, Carvalho, MOM, Kolehmainen, V, and Kaipio, JP, 2010. Bayesian estimation of temperature-dependent thermophysical properties and transient boundary heat flux, Heat Transf. Engrg. 31 (2010), pp. 570–580.
- Koppel, DE, 1972. Analysis of macromolecular polydispersity in intensity correlation spectroscopy: the method of cumulants, J. Chem. Phys. 57 (1972), pp. 4814–4820.
- Hansen, PC, and O’Leary, DP, 1993. The use of the L-curve in the regularization of discrete Ill-posed problems, SIAM J. Sci. Comput. 14 (1993), pp. 1487–1503.
- Rocca, P, Benedetti, M, Donelli, M, Franceschini, D, and Massa, A, 2009. Evolutionary optimization as applied to inverse scattering problems, Inverse Probl. 25 (2009), pp. 1–41.
- Shi, Y, and Eberhart, R, 1998. A modified particle swarm optimizer,. Singapore: Proceedings of the IEEE Conference on Evolutionary Computation, ICEC; 1998, pp. 69–73.