
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A common approach to solve an inverse problem, i.e. to single out the model parameters that explain the observed phenomena, is to iteratively minimize a residual function, which expresses the difference between the observations (measured data) and the forward response of the estimated model (recalculated data). The convergence properties of the solver can be difficult to control and to analyse, especially when dealing with global optimizers applied to non-linear inverse problems. In this paper, we plot the residual vs. a single scalar, the Euclidian distance in the variable space. We show how this can be used to avoid misleading solutions given by the local minima. The performance of this approach is investigated in three examples with increasing complexity (in terms of dimensions). Moreover, we propose to exploit the distance indicator in a new hybrid inversion strategy that combines a simulated annealing algorithm and a local approach and that reduces the computational cost of the optimization.
1. Introduction
A common approach to solve an inverse problem, i.e. to single out the model parameters (variable space) that explain an observed phenomena, is to iteratively minimize a residual function, which expresses the sum of the squared difference (L2 norm) between the observations (measured data) and the forward response of the estimated model (recalculated data).Citation[1]
As in a wide variety of physical problems, the law linking the model to the data is non-linear and multimodal, the solution requires techniques based on systematic search. This explores the variable space, it computes the residual for each explored point and it finds the model corresponding to the minimal data residual.
For this class of inverse problems, the retrieval may results in unsatisfactory solutions, as local search for the least squares solution is likely to get trapped in secondary minima. A global search can avoid sub optimal solutions, but it is time and computation consuming Citation[2] due to convergence issues.[Citation3–Citation8] In problems with a small number of dimensions (⩽three), either an exhaustive search or the visualization of the problem solution overcomes these difficulties.
These considerations suggested to the authors the idea of combining the advantages of a global optimizer with the efficient convergence of a local search engine. To do so, the authors resort to a criterion that ensures that the switch from the global approach to the local one takes place unambiguously, i.e. in the region where the solution is unique.
With high dimensional optimization problems, it is not practical to plot the residuals. But collapsing the variable space to one dimension makes the displaying of the residuals easy. Among other choices, this can be performed using the Euclidian distance between a reference point and each point in the variable space. Collapsing an nD quantity to a 1D one introduces ambiguities and distortions. In this perspective, Euclidian distance benefits of the L2-norm propriety of emphasizing the weight of both little and great errors better than any L1-norm criterion.
The inversion works as follows: the global optimizer stops its function calls as soon as it reaches the 1D interval containing a unique minimum. Then, a local search refines the solution. In this framework, one can choose whichever global and local optimizer either according to the specific problem or to its availability.
The global optimizer applied in this work is based on the simulated annealing technique as it intrinsically takes into account the available information about the physical system, such as the bounds of some model parameters or a rough estimate of their values.Citation[9]
Analysing the global optimization behaviour of the simulated annealing algorithm, it can be observed that a significant part of the computational effort is spent in the final steps of the optimizing procedure, when the region containing the best local optimum has already been identified.[Citation10,Citation11] This reveals that it is attractive to stop the algorithm before of its standard procedure of termination, activating a local search technique to find the best local optimum. In this work, the employed local search engine is a standard iterative gradient method. The original implementation of the simulated annealing Citation[9] was re-formulated to include the stop criterion that triggers the switch between the global and the local approach.
The performance of this approach is investigated in three examples with increasing complexity. These were chosen in order to focus on some of the aspects that could affect the quality of the retrieved solution.
The first example is related to the alignment of time series, which has its interest in a range of application involving stochastic processes and data mining. This example highlights the misleading effect of local minima and it is useful to discuss possible countermeasures. The second example pertains to the Atmospheric Sciences and it consists of the retrieval of the two-dimensional structure of the atmospheric specific absorption coefficient from the observations of a ground-based scanning radiometer. The third example considers a homogenous 1D seismic inversion aiming to retrieve the acoustic impedances IP. Here, we discuss the re-parameterization of the variable space. The original concept of Drufuca and Rovetta was formalized and implemented by Rovetta in his master thesis Citation[12] and later included in his PhD thesis.Citation[13]
The paper is organized as follows. Section 2 describes the distance indicator together with its properties. Section 3–5 reports the benefits of the proposed approach to the solution of the inverse problem for the three chosen examples. Conclusions are drawn in Section 6. Details about the hybrid simulated annealing implementation are given in Appendix 1.
2 The distance indicator
Let us assume that the forward problem is described by the vectorial non-linear function and that the dimension of the vector y (data space), and the dimension of the vector m, (variable space), are equal to N and M, respectively.
The inversion scheme aims to identify the vector m for which an objective function is minimized. It is evaluated as the square of the amplitude of the residual:
(1)
(1)
where the apex T stands for the transpose. A mono-dimensional representation of this function can be achieved by using the concept of Euclidian distance, whose square is equal to:(2)
(2)
with mref a reference value for m. The choice of the reference depends on the specific problem. It could be an estimate from a previous forward solution or a first guess from known physical properties of the application under study. At each function call in the simulated annealing, the objective function and the distance d are computed.
The distance d has the purpose of collapsing the dimensions of the variable space to one only. This facilitates the monitoring of the evolution of the objective through the iterations. In the initial stages, more than one attractive basin will be observable while, near convergence, there will be only one. Near convergence one can avoid the lengthy process of simulated annealing, as one can resort to a more efficient local search engine, for instance, a gradient approach. Essentially, the stopping criterion is based on a heuristically set parameter that the authors named sensitivity on the convergence criterion. This parameter governs the switch between the two approaches according to the minimum acceptable value of the distance error standard deviation. Details about the stopping criterion are given in Appendix 1, where the advantages of the hybrid strategies are reported.
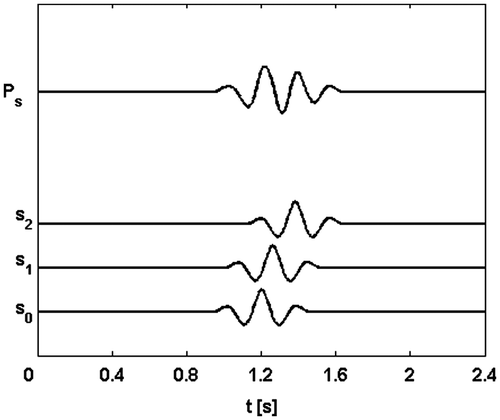
To underline the potentiality of this approach, let us consider a simple two-dimensional problem of aligning in the time domain two signals (M = 2), s1 and s2, with respect to a reference one, s0 (Figure ).
Figure 1 2D example without noise; starting point: low energy stack of the two not aligned signals s1 and s2 with respect to the reference one s0.
The data residual can be defined as:(3)
(3)
where m = τ is the vector of the model parameters and it collects the time delay of the signals s1 and s2, with respect to s0, while y = 2s0 is the vector of the data space. is the ith component of
. The distance is computed in the time delay domain by choosing as reference the delay τ0 = 0 of the signal s0.
It can be proved Citation[14] that the minimization of the cost function corresponds to the maximization of the stack power
(sum of the signals), with τ0 = 0. PS is shown in Figure , as a function of both τ1 and τ2, after normalization.
Figure 2 Normalized stack power PS of the signals si; i = 0, … , 2, as a function of the delay times and
. The pick corresponding to the global maximum is marked with a white circle.
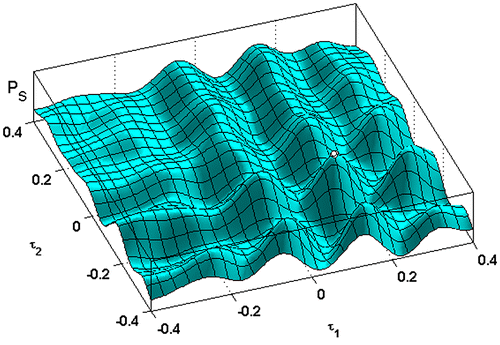
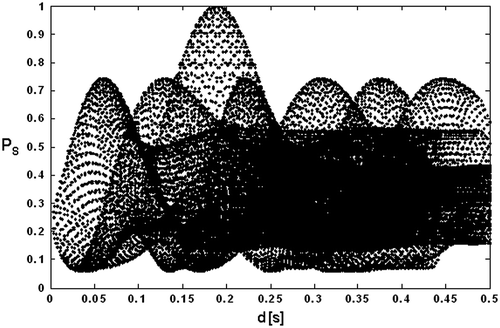
Figure shows the stack power PS computed for all the investigated points vs. the distance d = . The domain of local stationariness and the global maximum of the stack power function are well detected. It is useful to underline that the sampling is uniform in the domain of the time delays, but not in the domain of the distance.
Figure 3 Normalized stack power PS of the signals si; i = 0, … , 2, as a function of the distance. The domain of local stationariness and the global maximum are well detected.
Because of the high multimodality of the objective function, the maximization of the stack power can be achieved by a global optimization algorithm based on a controlled exploration of the domain of the time delays.
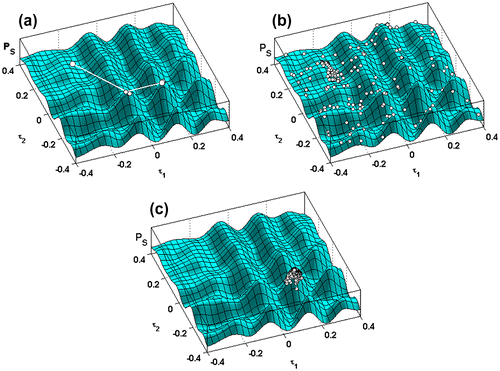
A simulated annealing algorithm, referred to as SAA in the following, helps us in tracking the evolution of the maximization process, according to the changing values of the control parameter TA, known as the annealing temperature.Citation[9] The behaviour of the algorithm from the starting point to the convergence is shown in Figure . Some evaluations of the stack power at different annealing temperatures are represented in Figure . At high temperatures, the algorithm works as a common uniform sampler, while at low temperatures, the sampling interval is located in the model domain corresponding to the highest posterior probability density of the global maximum.
Figure 4 Normalized stack power PS: path of the SAA from the starting solution to the final one; evaluations of the objective function at different annealing temperatures: starting temperature, T0 = 300 (a), intermediate temperature, TA = 23 (b) and final one Tf = 14 (c).
The visual representation of the data residual is possible in this example because of the dimension of the model space. When the model dimensions are greater than three, a way to give a visual representation of the data residual is through the distance of the model space that singles out the properties of local stationariness, as it is shown in the following sections.
3 Optimal signal alignment
In this section, the performance of the distance indicator is validated against a generalization of the previous example by increasing the number of signals to align. Let us consider M signals si (i = 1, … , M), with a delay time τi with respect to a reference signal s0.
If the number of samples for each signal is equal to N, then the stack power can be valued as:(4)
(4)
with τ0 = 0.
The optimal alignment, obtained maximizing PS, is the result of a multidimensional non-linear optimization problem and again its solution was achieved by means of SAA.
The data-set discussed in this example is a noisy one (SNR = 4 dB with uniform noise in the signal bandwidth) with N = 600 and M = 20. Following the standard SAA approach, the starting and the final temperatures of the algorithm are and
, respectively. According to (A1), the total number of evaluations of the objective function is equal to
, being NS = 20 and NT = 100.
Figures show the raw and the aligned data, respectively, whereas Figure illustrate the normalized stack power PS vs. the distance at different annealing temperatures.
Figure 5 Example with noise and model space of 20 dimensions; starting point: not aligned signals si; i = 1, … , 20 and stack with low energy.
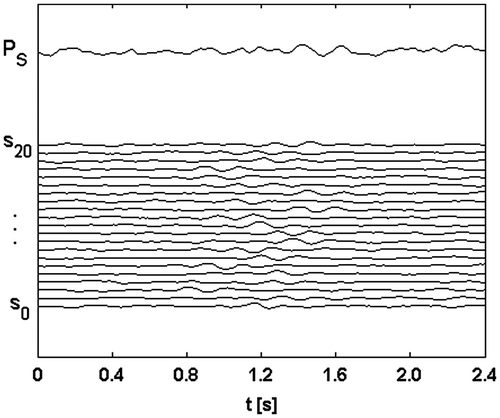
Figure 6 Example with noise and model space of 20 dimensions; final solution: optimal signal alignment and stack with maximum energy.
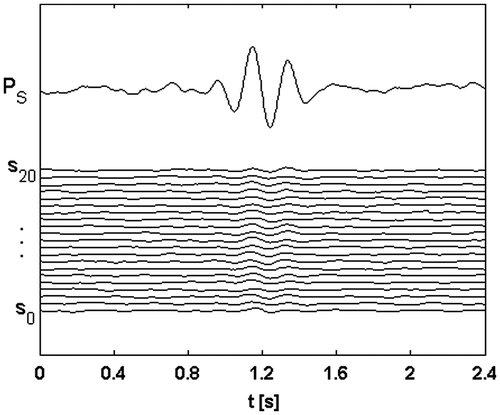
Figure 7 Example with noise and variable space of 20 dimensions. Distances at different annealing temperatures: starting temperature T0 = 300 (a); TA = 156, corresponding to the sixteenth change of temperature; two local maxima can be detected (b); final temperature, Tf = 117; the global maximum has been found (c).
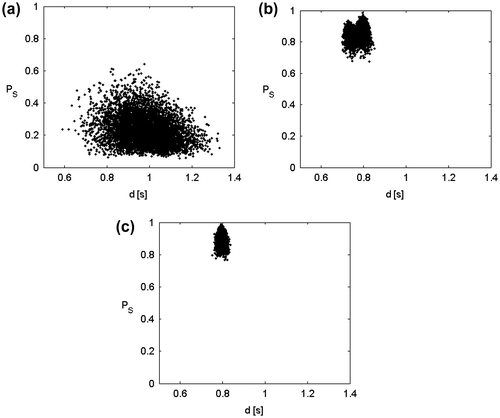
When the annealing temperature TA of the algorithm is high it is not possible to detect the domains of stationariness of the objective function (Figure ). These latter become observable only when TA reduces significantly (Figure ), and at convergence, after 24 changes of the annealing temperature, the algorithm identifies the best one among all of the local maxima (Figure ).
By using the distance indicator, the region containing the global maximum is detected at the 16th iteration. The number of function evaluation reduces of 1/3. At this point the solution is refined with a gradient method.
4 The retrieval of two-dimensional absorption coefficient structure from a scanning radiometer
This second example shows the retrieval of the 2D structure of the atmospheric specific absorption coefficient through a tomographic acquisition of the brightness temperature values. These are collected at the frequency of 23.8 GHz by using a ground-based radiometer located at Spino d’Adda, 30 km SE of Milan (Italy). Here, we recall the basic considerations and we show a result obtained through global optimization, while the reader is referred to Citation[15] for the details of the experiment and the modelling. The central idea is to infer the status of the atmosphere, i.e. the integrated water vapour content, by means of the values of the measured brightness temperature.Citation[16] The problem is intrinsically ill-posed because of many factors among which there are the predominant vertical trend with respect to the horizontal one Citation[17] and the limited number of tomographic projections.Citation[18]
The algorithm performs the inversion of the non-linear function that describes the forward problem, linking the absorption coefficients to the brightness temperatures radiative transfer equation.Citation[16]
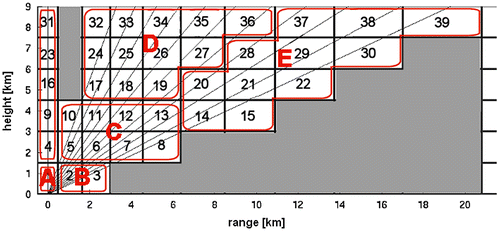
The scanned vertical plan is divided into M bins as shown in Figure . Each bin gives a contribution to the measured brightness temperature TBi in the direction θi through the following scheme:(5)
(5)
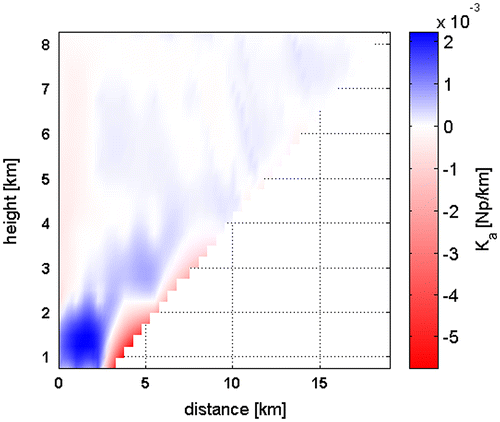
Figure 8 The scanned vertical plan is divided in resolution bins – black boxes – with constant atmospheric specific absorption coefficient. Maximum altitude is fixed at 9 km and range at 23 km, according to the elevation of the lowest scan. Solid lines represent the propagation path seen by the radiometer antenna. Since the problem is ill-conditioned, a re-parameterization led to collapse the 39 bins into 5 macrocells – depicted in red – according to a clustering strategy.
where . Tj and kj are the physical temperature and the specific absorption coefficient in the jth bin, Δrij is the length of the ray corresponding to the ith angle and the jth bin (
= 0 if the ray does not cross the bin).
is the optical thickness linking the jth bin to the receiver through the ith elevation angle. In Equation (5), the contribution from TC has been neglected Citation[15] and the integrated water content is accounted for through its specific absorption coefficient.
The data-set is composed of 12 brightness temperature values observed along paths with different elevation angle with respect to the local horizon, as depicted in Figure .
Figure 9 Observed brightness temperatures (circles) vs. the co-elevation angle.
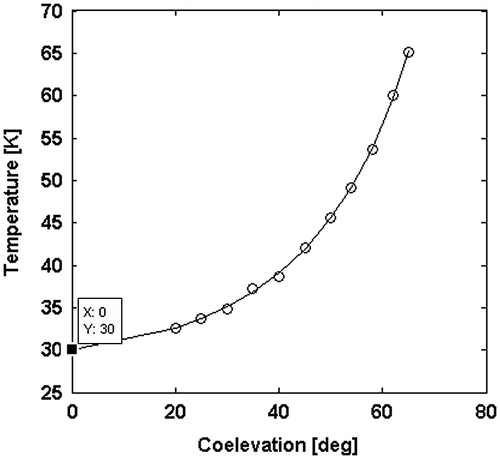
After re-parameterization, through a clustering strategy, the cardinality of the model space is reduced to M = 5 (see Figure ).
We find an approximate solution through:(6)
(6)
in which f(K) is the matricial formulation of the forward problem as it appears in Equation (5). TB and K are the vector in the data and in the variable space, respectively.
The observations and the recalculated data from the estimated model are computed as variation with respect to a common reference – chosen as the vertical trend of the standard atmosphere Citation[19] – and then compared in Figure . The recalculated data are close to the observed data (Rd = 0.5). Figure shows the solution of the inverse problem, which is the 2D structure of the atmospheric specific absorption coefficient after vertical detrending and interpolated with a kriging technique.
Figure 10 Observations (circles) and recalculated data (asterisks) as variation with respect to the vertical trend of the standard atmosphere.
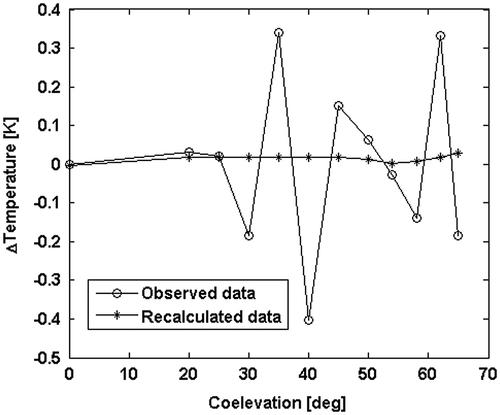
Figure 11 Estimate of the two dimensional specific absorption coefficient k of the atmosphere after vertical detrending: the solution is interpolated with a kriging technique.
The starting and the final temperatures of the standard SAA are equal to T0 = 100, Tf = 0.9 and the number of the total evaluations of the objective function is , being NS = 20 and NT = 195 (A1). The hybrid SAA requires 37 annealing temperature reductions, instead of 121, thus resulting in a computational cost reduction of about 69%.
During its execution, it can happen that SAA evaluates the objective function in points of the variable space that lay outside of the observation domain, whose bounds are given. In such a situation, the algorithm rejects the point and it chooses a different one inside the observation domain with a random selection.
At high temperatures, the explored domain is quite large because of both the long exploration steps of the algorithm and the occurrence of the bound events. There is not any attraction domain and the data residuals are quite high (Figure ).
Figure 12 Data residual as a function of the distance at different annealing temperatures: T0 = 100 (a); TA = 72 (b); Tf = 0.9 (c).
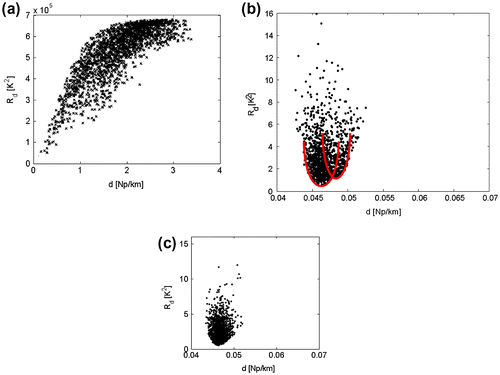
When the model parameters approach the convergence, the local minima with the lowest data residual can be easily identified (Figure ). At the convergence, when all the estimated parameters are close to the minimum, chosen as the solution of the inverse problem, the shape of the domain corresponding to the global optimum is shown and the data residuals are all low (Figure ). In this case, plots of the data residual vs. the distance permit to verify the presence of the global minimum.
5 1D homogeneous seismic inversion
The last application concerns the seismic experiment where elastic waves produced by explosions or vibrating controlled sources are propagated through the Earth and recorded at or near the surface in order to map the underground geology. Specifically, we focus on the seismic inversion problem whose objective is to infer from the seismograms (observed data), acquired by an array of receivers lying on the ground, the underlying earth structure (model parameters).[Citation20,Citation21]
To simplify the problem, a layered model of the Earth is used: the rock densities ρ and the elastic wave velocities v vary with the depth z only. Moreover, the seismic experiment is conducted with one source and one receiver, located at the same position on the surface (zero-offset measurement). Data collected with this set-up only contain information on the travel time between the layer’s interfaces and on the contrast in acoustic impedances at these interfaces. Therefore, without imposing additional constraints, the unknown quantities that can be estimated are the acoustic impedances IP (the product of the rock densities with the velocities vP of the P-waves).[Citation22,Citation23]
Nonetheless, to discuss the parameterization of the model space by using the distance indicator, the problem is first inverted for a model vector m, made up of the rock densities ρ and from the P-wave velocities vP of the 20 micro-layers (the dimensions of the variable space are M = 40).
The observations are generated from a synthetic model, by using an algorithm based on the well-known reflectivity method .Citation[24] They are shown in Figure .
Figure 13 Observed data. nS denote the number of samples of the seismogram.
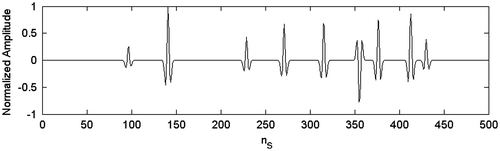
The solution of the forward problem used by SAA in the inversion process is a coarse approximation: the interface scatter coefficients are calculated by means of the transmission line theory [Citation25,Citation26] and the seismograms by the convolution theory. The differences in the algorithms used to compute the observed synthetic data (reflectivity method) and the data recalculated by the estimated model (transmission line theory and convolution theory), imply a modelling noise corresponding to an SNR on the seismograms of about 23 dB.
The number of the layers of the posterior model is unknown and for this reason it is necessary to use an over-parameterized a priori model. To simplify the problem, a synthetic model with 10 layers is used to compute the data, while the a priori model with 20 micro-layers is employed in the inversion.
The mapping of the data residual Rd on the domain of the distance d is discussed varying the annealing temperature TA from T0 = 10−3 to Tf = 7 × 10−12. At the highest temperatures, the analysed domain is quite large due to the long exploration steps of the algorithm. Also, there are not evident attraction domains and all the residual data are high (Figure ).
Figure 14 Inversion for vP and ρ. Data residual as a function of the distance at different annealing temperatures: T0 = 10−3 (a); TA = 2 × 10−9 (b); Tf = 7 × 10−12 (c). The white mark corresponds to the optimal solution at each annealing temperature.
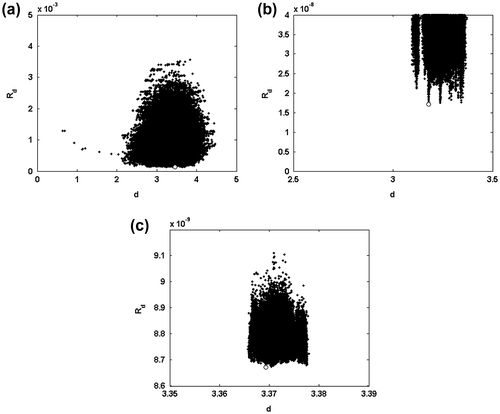
At lower temperatures, the domains of attraction can be observed and some local minima with lower data residual can be detected (Figure ). Finally, at the convergence, all the model parameters are close to the minimum chosen like the model domain of the solution (Figure ).
The optimizing algorithm evaluates the objective function 14 million of times. This corresponds to 1/5th of the number of evaluations required by the standard SAA algorithm.
A correct inversion of such a model vector (rock densities and P-wave velocities) is not possible because of the high condition number of the inverse problem: this is shown by the presence of a number of minima with the same data residual. Therefore, the solution (i.e. one of these minima) is not reliable and a re-parameterization of the model space is mandatory. Then, the problem is inverted for a model vector m, composed of the acoustic impedances IP of the 20 micro-layers (the variable space dimensions reduce to M = 20).
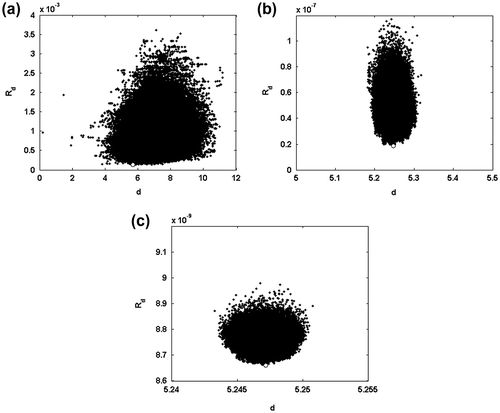
Let us consider again the data residual Rd(d): at high temperatures (Figure ), the behaviour is similar to the one shown in the previous inversion, but at lower temperatures, there are not many local minima with the same data residual, the objective function is convex and the solution is reliable (Figures ).
Figure 15 Inversion for IP. Data residual as a function of the distance at different annealing temperatures: T0 = 10−3 (a); TA = 2 × 10−9 (b); Tf = 7 × 10−12 (c). The white mark corresponds to the optimal solution at each annealing temperature.
The estimated and the effective models are compared in Figure . The matching is optimal but in the last layer, which cannot be solved because it is low unbounded.
Figure 16 Acoustic impedances IP vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
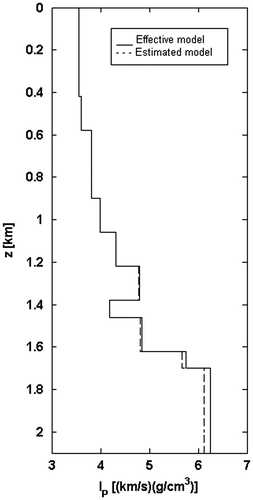
It is interesting to underline that in the previous example the global minimum (white circle marker in Figure ) can be detected at the 66th iteration on the total number of 84: again, the SAA is stopped before it normally completes its execution and the solution is retrieved with a local technique (gradient algorithm), in order to reduce the computational cost (see Appendix 1).
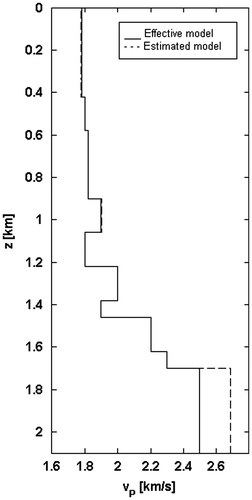
Once the acoustic impedances IP are estimated, it is also possible to recover the rock densities ρ and the P-wave velocities vP by introducing a modelling constraint, i.e. that every impedance contrast corresponds to an interface between layers. The values of ρ and vP, obtained under this assumption, are compared with the actual model and shown in Figures.
Figure 17 Rock densities ρ vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
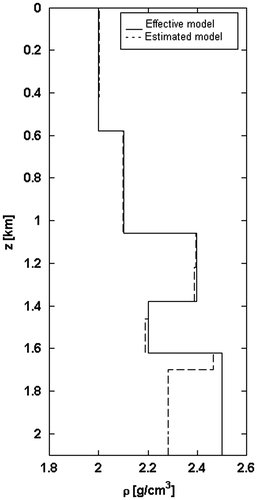
Figure 18 P-wave velocities vP vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
We generalized the problem to the case of a seismic inversion with many receivers at different offsets from the source location. This acquisition scheme permits to retrieve both elastic impedances IP and IS. In the post-processing phase, by introducing the same modelling constraint of the zero-offset problem, it is possible to estimate the rock densities, the P-wave and S-wave velocities.
The forward model employed in the inversion algorithm requires a ray tracer. The differences between data computed with this algorithm and those obtained with the reflectivity method (employed to generate the observed synthetic data) lead to a modelling noise corresponding to an SNR on the seismograms of about 26 dB. The inversion procedure is practically the same of the zero-offset case.
In the following, we show an example based on the measurements from five geophones and one a priori model of 20 micro-layers (the cardinality of the model is equal to M = 40).
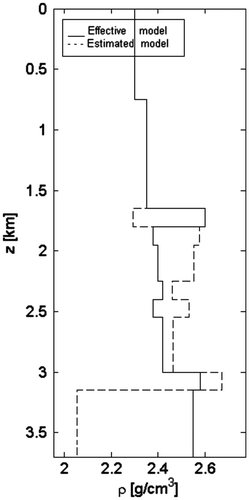
The observed data are shown in Figure , while the results of the inversion are depicted in Figures . The estimated elastic impedances and velocities fit their actual values with a good accuracy, except for the last layer, as pointed in the previous example. The additional constraint is not strong enough to allow the retrieval of the rock densities (Figure ).
Figure 19 Observed data. nS denote the number of samples of the seismograms.
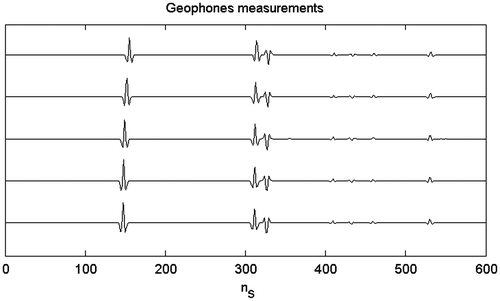
Figure 20 P-wave impedances IP vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
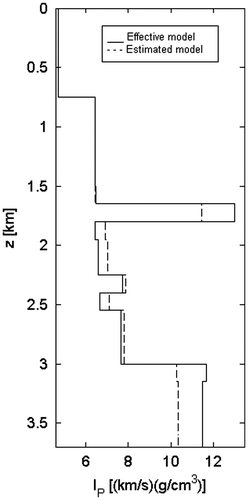
Figure 21 S-wave impedances IS vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
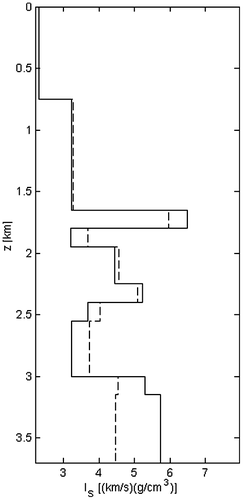
Figure 22 P-wave velocities vP vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
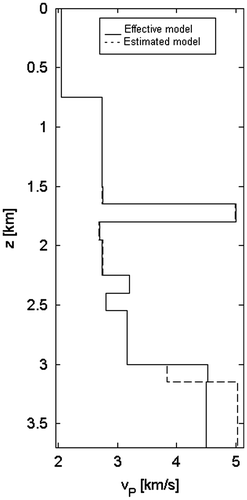
Figure 23 S-wave velocities vS vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
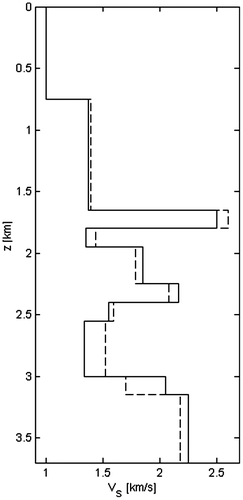
Figure 24 Rock densities ρ vs. the depth z; comparison between the effective model (solid line) and the estimated model (dashed line).
The results obtained in these seismic inversion examples show how the distance indicator can be helpfully used in order to discuss the re-parameterization of the model space. This method is attractive, especially, if applied to the inverse problems where the null-space is not perfectly known and where a conditioning analysis is difficult to obtain.
6 Conclusions
The solution of non-linear inverse problems could result in unsatisfactory retrieved models when a local search approach is adopted and an exhaustive exploration is not viable because of the problem dimensions. Indeed, a parsimonious exploration of the model space is necessary when using global optimizer in applications where the cost function is highly multimodal and therefore the convergence of the solution and its properties, such as the detection of the local minima and the influence of constraints or a priori knowledge, are particularly demanding.
The main result of this paper is that the use of a distance indicator, defined as the Euclidian distance in the model space, helps in following the evolution of a global optimizer, even in those cases in which a visual representation of the function to optimize is not viable, i.e. the dimensions of variable space are greater than three. The key of this approach is that the distance indicator clearly identifies the region near the optimum. At this stage, one could stop the iterative calculations of the global optimizer and solve the problem through local optimization.
To illustrate the performance of such an approach, three problems with different degree of complexity were chosen ranging from optimal signal alignment to geophysical parameters inversion, through global optimization based upon the SAA. In all the examples, the Euclidean distance proved to be a useful tool in describing the evolution of the object function.
Acknowledgements
The authors would like to thank one of the reviewers for his suggestion to deepen the discussion about the motivation in choosing the Euclidian distance from a reference point as a metric. He suggested investigating different norms and approximations of the reference point. These issues will stimulate our future work.
Notes
This article was originally published with errors. This version has been amended. Please see Corrigendum (http://dx.doi.org/10.1080/17415977.2014.918742)
References
- Tarantola A. Inverse problem theory. Philadelphia, PA: SIAM; 2004.
- Mosegaard K, Tarantola A. Monte carlo sampling of solutions to inverse problems. J. Geophys. Res. 1995;100:431–447.
- Locatelli M. Convergence properties of simulated annealing for continuous global optimization. J. Appl. Probab. 1996;33:1127–1140. Available from: http://www.jstor.org/stable/3214991.
- Gilbert JCh, Nocedal J. Global convergence properties of conjugate gradient methods for optimization. Siam J. Optim. 1992;2:21–42.
- Storn R, Price K. Differential evolution – a simple and efficient adaptive scheme for global optimization over continuous spaces. Technical Report TR-95-012, ICSI, Mar 1995, ftp.icsi.berkeley.edu.
- Rocca P, Benedetti M, Donelli M, Franceschini D, Massa A. Evolutionary optimization as applied to inverse scattering problems. Inverse Prob. 2009;25:1–41. doi:10.1088/0266-5611/25/12/123003.
- Mingjun Ji, Klinowski J. Convergence of taboo search in continuous global optimization. Proc. R. Soc. A. 2006;462:2077–2084. doi:10.1098/rspa.2006.1678.
- Xinchao Z. A greedy genetic algorithm for unconstrained global optimization. J. Syst. Sci. Complexity. 2005;18:102–110.
- Corana A, Marchesi M, Martini C, Ridella S. Minimizing multimodal functions of continuous variables with the simulated annealing algorithm. ACM Trans. Math. Softw. 1987;13:262–280.
- Goffe WL. SIMANN: a global optimization algorithm using simulated annealing, studies in nonlinear dynamics and econometrics. Quart. J. 1996;1:169–173.
- Purushothama GK, Jenkins L. Simulated annealing with local search – a hybrid algorithm for unit commitment. IEEE Trans. Power Syst. 2003;18:273–278.
- Rovetta D. Applicazioni a problemi di inversione non lineare : simulated annealing [Master thesis]. Milan: Politecnico di Milano; 2002.
- Rovetta D. Inverse problem analysis [PhD dissertation]. Milan: Politecnico Di Milano; 2006.
- Rothmann DH. Large near-surface anomalies, seismic reflection data and simulated annealing [PhD dissertation]. SEP, Stanford (CA); October 1985.
- Bosisio AV, Drufuca G. Retrieval of two-dimensional absorption coefficient structure from a scanning radiometer at 23.8 GHz. Radio Sci. 2003;38:3.1–3.9. doi:10.1029/2002RS002628.
- Ulaby FT, Moore RK, Fung AK. Microwave remote sensing volume I: microwave remote sensing fundamentals and radiometry. Reading, MA: Addison Wesley; 1981.
- Bean BR, Dutton EJ. Radio meteorology. New York: Dover; 1968.
- Kak AC. Principles of computerized tomographic imaging. New York: IEEE Press; 1988.
- Salonen E, Karhu S, Jokela P, Zhang W, Uppsala S, Alamo H, Sarkkula S. Study of propagation phenomena for low availabilities, Appendix A – Standard Atmospheres, ESTEC 8025/88/NL/PR Final report, Norwijck (NL); 1990.
- Ma XQ. A constrained global inversion method using an over-parameterized scheme: application to poststack seismic data. Geophysics. 2001;66:613–626.
- Ma XQ. Simultaneous inversion of prestack seismic data for rock properties using simulated annealing. Geophysics. 2002;67:1877–1885.
- Becquey M, Lavergne M, Willm C. Acoustic impedance logs computed from seismic traces. Geophysics. 1979;44:1485–1501.
- Oldenburg D, Scheuer T, Levy S. Recovery of acoustic impedance from reflection seismograms. Geophysics. 1983;48:1318–1337.
- Fuchs K, Müller G. Computation of synthetic seismograms with the reflectivity method and comparison with observations. Geophys. J. R. Astr. Soc. 1971;23:417–433.
- Pilant WL. Elastic waves in the earth. Amsterdam: Elsevier; 1979.
- Ramo S, Whinnery JR, Van Duzer T. Fields and waves in communication electronics. New York, NY: Wiley; 1965.
Appendix 1.
Optimization with a global algorithm based on the concept of distance
The global optimization performed by the SAA is computationally cumbersome, especially in the final step of the optimizing procedure, where the domain of the variable space containing the best local optimum has already been identified. Therefore, it is welcome to quit the algorithm at this stage and to adopt a hybrid strategy, thus decreasing considerably the total computational cost.
The chosen approach combines SAA with the gradient method and it executes two main steps:
exploration of the domain of the objective function and localization of the model domain where the probability to find the global optimum is high; this leads to the identification of a model domain with only one optimum (stopped simulated annealing).
inverse problem solution through local optimization having set as guess the optimum solution singled out at the step 1.
The hybrid and the original implementations of the SAA have the same nested cycle’s structure and they both evaluate NF times the error function f to be optimized:(A1)
(A1)
This is an index of the computational cost and it depends on M, the dimensions of the variable space, on NS and NT, constants chosen with the strategy of Corana Citation[9] and on NR, the number of temperature reductions.
The hybrid algorithm stops at the end of the step 1, whence NR and NF are smaller of the corresponding values given by the standard approach. In particular, NF is a computational index of the complete inversion process because it is far higher than the cost of the linear optimization employed at the step 2 to refine the solution.
If i is the index denoting the model parameters (i = 1, … , M), j denotes the successive points for each temperature reduction () and k covers successive temperature reductions (
), then the point j of the variable space, evaluated at the temperature reduction k, is denoted by mjk and the corresponding model parameter i is mijk.
The solution of the forward problem, described by the non-linear function g, for an estimated model vector mjk, is the vector:(A2)
(A2)
For each particular iteration j and temperature reduction k, the error function is sampled and its square value is equal to:(A3)
(A3)
with , the component n of the
vector,
the component n of gobs, the observed data vector and N the dimensions of the data space (
).
a and b are the vectors of the lower and upper bounds of the model domain:(A4)
(A4)
r = b – a is called range vector because it represents the maximum range of the model parameters, which is also the distance between the upper and the lower bounds.
The stopping criterion is based on the geometric concept of distance. At the jth iteration of the kth temperature reduction, the square of the distance is:(A5)
(A5)
with the component i of a reference point
.
The vector of the weights p, used to normalize the inhomogeneous model parameters, is calculated as:(A6)
(A6)
being rmax the maximum value among the components of the range vector. When a model parameter is larger than the other ones, this ratio tends to 1; on the other side, when a model parameter is smaller than the others, pi ≫ 1: all the model parameters thus contribute to the distance calculation as they were homogeneous quantities.
The optimal distance, dopt,k, corresponding to the distance in the variable space between the optimum point mopt,k and the reference point mref, the smallest distance dmin,k, the largest distance dmax,k and , a measure of the distance dispersion around dopt,k, are then computed:
(A7)
(A7)
The best optimum for the hybrid algorithm is found when , called sensitivity on the convergence criterion, is a parameter set by the user. We recommend choosing
in the range from 10−3 to 10−1.
Then, the solution is refined by a local optimization, starting from the model point of the best previously found solution.