
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The linear inverse problem is discretized to be an n-dimensional ill-posed linear equations system . In the present paper, an invariant manifold defined in terms of the square norm of a residual vector
is used to derive an iterative algorithm with a fast descent direction
, which is close to, but not exactly equal to, the best descent direction
. The matrix
is obtained by using a vector regularization method together with a matrix conjugate gradient method to find the right inversion of
:
. The vector regularization iterative algorithm is proven to be Lyapunov stable, and the direct inversion method with solution expressed by
converges fast. The accuracy and efficiency of them are verified through the numerical tests of linear inverse problems under a large random noise.
Introduction
It is known that an iterative method for solving the system of algebraic equations can be derived from the discretization of a certain ordinary differential equations (ODEs) system.[Citation1, Citation2] In particular, the descent methods can be interpreted as the discretizations of gradient flows.[Citation3] Indeed, it has a long time history that continuous algorithms have been investigated in many literature, for example, Gavurin [Citation4], Alber [Citation5] and Hirsch and Smale [Citation6]. Chu [Citation7] has developed a systematic approach to the continuous realization of several iterative algorithms in numerical linear algebra. The Lyapunov methods used in the analysis of iterative methods have been made by Ortega and Rheinboldt [Citation8], and Bhaya and Kaszkurewicz [Citation1, Citation9, Citation10].
The author and his co-workers have developed several methods to solve ill-posed system of linear equations: the fictitious time integration method as a filter,[Citation11] a modified polynomial expansion method, [Citation12] the Laplacian preconditioners and postconditioners,[Citation13] a vector regularization method,[Citation14] a relaxed steepest descent method,[Citation15, Citation16] an optimal iterative algorithm with an optimal descent vector,[Citation17] an adaptive Tikhonov regularization method,[Citation18] the best vector iterative method,[Citation19] the globally optimal vector iterative method,[Citation20] the optimally scaled vector regularization method,[Citation21] an optimally generalized Tikhonov regularization method,[Citation22] as well as an optimal tri-vector iterative algorithm.[Citation23] As a continuation of these works, in this paper, we propose a more simple and robust method to solve(1)
(1) where
is an unknown vector determined from a given coefficient matrix
, which might be unsymmetric, and the input
which might be polluted by random noise. Many linear-type inverse problems can be discretized into the above form.
A measure of the ill-posedness of Equation (Equation1(1)
(1) ) is the condition number of
:
(2)
(2) where
is the Frobenius norm of
.
For every matrix norm , we have
, where
is a radius of the spectrum of
. The Householder theorem states that for every
and every matrix
, there exists a matrix norm
depending on
and
such that
. So far, the spectral condition number
can be used as an estimation of the condition number of
by
(3)
(3) where
is the collection of all the eigenvalues of
. If the Frobenius norm in Equation (Equation2
(2)
(2) ) is replaced by the operator norm, then Equations (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ) lead to the same condition number. Turning back to the Frobenius norm, we have
(4)
(4) In particular, for the symmetric case
. Roughly speaking, the numerical solution of Equation (Equation1
(1)
(1) ) may lose the accuracy of k decimal points when
.
Instead of Equation (Equation1(1)
(1) ), we can solve a normal linear system:
(5)
(5) where
(6)
(6) We consider an iterative method for solving Equation (Equation5
(5)
(5) ) and define for any vector
the steepest descent vector
(7)
(7) Ascher et al. [Citation24], and also Liu and Chang [Citation25] have viewed the gradient descent method:
(8)
(8) as a forward Euler scheme of the following system of ODEs:
(9)
(9) The absolute stability bound
(10)
(10) must be obeyed if a uniform stepsize is employed.
Specifically, Equation (Equation8(8)
(8) ) presents a steepest descent method (SDM), if
(11)
(11) When
is small, the calculated
may deviate from the real steepest descent direction to a great extent due to a round-off error of computing machine, which usually leads to the numerical instability of SDM. An improvement of SDM is the conjugate gradient method (CGM), which enhances the search direction of the minimum of a quadratic functional by imposing an orthogonality to the residual vector at each iterative step. The algorithm of CGM for solving Equation (Equation5
(5)
(5) ) is summarized as follows.
Give an initial
, compute
For
Even if the CGM works very well for most linear systems, the CGM does lose some of its luster for some linear inverse problems. The gradient descent methods enjoy a fictitious time integration method with different stepsizes. This is particularly useful for image deblurring. The concept of optimal descent vector was first developed by Liu and Atluri [Citation26] for solving non-linear algebraic equations. In this paper, we explore the concept of best descent vector [Citation19] and use it as a guidance to develop a new method to solve linear algebraic equations.
The remaining parts of this paper are arranged as follows. The vector regularization method for inverting non-singular matrix is introduced in Section 2. In Section 3, we start from an invariant manifold to derive a non-linear ODEs system for the numerical solution of Equation (Equation1(1)
(1) ) with the descent direction to be
, where
is solved from the vector regularization method as a right inversion of the coefficient matrix
given in Equation (Equation1
(1)
(1) ). Then, a Lyapunov stable dynamics on the invariant manifold is constructed in Section 4, resulting in a vector regularization iterative algorithm (VRIA). The linear inverse problems are solved in Section 5 to display some advantages of the VRIA and the direct inversion method (DIM). Finally, the conclusions are drawn in Section 6.
A vector regularization method
The vector regularization method for inverting non-singular matrices was first developed by Liu et al. [Citation14]. Recently, Liu [Citation21] has developed a systematic method to determine the vector regularization parameter.
Let us begin with the following matrix equation:(13)
(13) if
is the inversion of a given non-singular
matrix
, where
is the
identity matrix. Numerically, we can say that the above
is a left inversion of
due to
. Then, multiplying the above equation by
from the left side we have
(14)
(14) from which we can solve for
by the following matrix conjugate gradient method (MCGM):
Assume an initial
Calculate
For
The above algorithm is suitable for finding the left inversion of , i.e.
; however, we need to solve
(22)
(22) when we want
to be a right inversion of
. Mathematically, the left inversion is equal to the right inversion. But, numerically, they are hardly being equal, especially for ill-conditioned matrices.
For the right inversion, we can supplement, as in Equation (Equation21(21)
(21) ), another equation:
(23)
(23) Then, the combination of Equations (Equation26
(26)
(26) ) and (Equation27
(27)
(27) ) leads to the following over-determined system:
(24)
(24) Multiplying the transpose of the leading matrix on both sides, we can obtain an
matrix equation:
(25)
(25) which is then solved by the following MCGMR:
Let
Assume an initial value
Calculate
For
Invariant manifold method
The most simple way for solving the linear equations system (Equation1(1)
(1) ) is
(28)
(28) where we can apply the MCGML to find
from the given matrix
. This inversion method is usually quite dangerous and unstable when there exists a noise on
. The error of noise will be amplified by
to cause a large error of
, when the singular values of
are clustered near to zero value. In Section 5.1, we will give a numerical example to reveal this type phenomenon.
Instead of Equation (32), we search an iterative method based on the idea of MCGMR. For the linear equations system (Equation1(1)
(1) ), which is expressed to be
in terms of the residual vector:
(29)
(29) we can introduce a scalar homotopy function:
(30)
(30) We expect
to be an invariant manifold in the space-time domain
for a dynamical system
to be specified further. When
, the manifold defined by Equation (Equation34
(34)
(34) ) is continuous and differentiable, and thus the following differential operation makes sense:
(31)
(31) which is obtained by taking the time differential of Equation (Equation34
(34)
(34) ) with respect to t, considering
and using Equation (Equation33
(33)
(33) ).
We suppose that the evolution of is governed by a vector
:
(32)
(32) where
(33)
(33) We hope
is near to
for a fast convergence (see Section 4.2), i.e.
(34)
(34) Then, we can apply the MCGMR to find the right inversion
of
by
(35)
(35) Inserting Equation (Equation36
(36)
(36) ) into Equation (Equation35
(35)
(35) ) we can derive
(36)
(36) where
(37)
(37) Hence, in our algorithm if Q(t) can be guaranteed to be a monotonically increasing function of t, we have an absolutely convergent property in solving the linear equations system (Equation1
(1)
(1) ) by decreasing
according to
(38)
(38) where
(39)
(39) is determined by the initial value
.
Dynamics on the invariant manifold
In order to keep on the manifold (Equation43
(43)
(43) ), we can consider the evolution of
along the path
by
(40)
(40) Because of
we can introduce a new independent variable
, such that the above equation can be written as
(41)
(41) where we have inserted Equation (Equation41
(41)
(41) ) for
. It is an autonomous non-linear dynamical system for
.
First, we note that is an equilibrium point of Equation (Equation46
(46)
(46) ). It is known that the Lyapunov’s second, or direct, method provides a stronger stability condition of the equilibrium point of a nonlinear dynamical system.[Citation27] To describe the Lyapunov theorem we need to define the positive-definite function. A real scalar function
is defined to be positive-definite in some closed bounded region D of state space if for all
in D,
By using the Lyapunov function and from Equation (Equation45
(45)
(45) ), it is easy to prove that
(42)
(42) In Section 4.2, we will prove
. Then, by using the Lyapunov stability theory, the ODEs in Equation (Equation40
(40)
(40) ) are asymptotically stable to
, and the iterative algorithm derived from it with a suitable selection of
is stable.
Discretizing, yet keeping on the manifold
Now we discretize the foregoing continuous time dynamics (Equation40(40)
(40) ) into a discrete time dynamics by applying the forward Euler scheme:
(43)
(43) where
(44)
(44) is a steplength.
Similarly, we use the forward Euler scheme to integrate Equation (Equation45(45)
(45) ):
(45)
(45) and taking the square norms of both the sides and using Equation (Equation43
(43)
(43) ), we can obtain
(46)
(46) Thus, the following scalar equation is derived:
(47)
(47) where
(48)
(48) by using the Cauchy–Schwarz inequality:
As a result,
remains to be an invariant manifold in the space time of
for the discrete time dynamical system
,
, which will be explored further in the next section.
An iterative dynamics
Let(49)
(49) which is an important quantity to assess the convergent property of our numerical algorithm for solving linear equations system (Equation1
(1)
(1) ).
From Equations (Equation53(53)
(53) ) and (Equation55
(55)
(55) ), it follows that
(50)
(50) of which we can take a preferred solution of
to be
(51)
(51) Let
(52)
(52) and the condition
in Equation (Equation57
(57)
(57) ) is automatically satisfied; hence, from Equations (Equation57
(57)
(57) ) and (Equation54
(54)
(54) ), it follows that
(53)
(53) where
(54)
(54) is a parameter. Finally, from Equations (Equation49
(49)
(49) ), (Equation54
(54)
(54) ) and (Equation60
(60)
(60) ), we can obtain the following algorithm:
(55)
(55) Under conditions (Equation54
(54)
(54) ) and (Equation61
(61)
(61) ), from Equations (Equation55
(55)
(55) ) and (Equation59
(59)
(59) ), we can prove that the new algorithm satisfies
(56)
(56) which means that the residual error is absolutely decreased. In other words, the convergence rate of present iterative algorithm is greater than one:
(57)
(57) The property in Equation (Equation64
(64)
(64) ) is very important, since it guarantees that the new algorithm is absolutely convergent to the true solution.
From Equations (Equation48(48)
(48) ), (Equation50
(50)
(50) ) and (Equation60
(60)
(60) ), we can derive
(58)
(58) By using the Lyapunov stability, the best choice of
is the one that makes
as negative as possible and which can be achieved by rendering
as small as possible. In principle, if we can use
as a search direction, by Equations (Equation41
(41)
(41) ) and (Equation54
(54)
(54) ) we have
and with
being the minimum of
. This is, however, impossible because the exact inverse
is hard to be found, and so instead, we use
as a search direction and solve
to near
by using the MCGMR in Section 2. In doing so, we have a fast convergence iterative algorithm to solve the ill-posed linear problem (Equation1
(1)
(1) ) on one hand, and on the other hand, because
is not exactly equal to
, we can avoid the ill-posedness to magnify the noisy error by
. Indeed, the present iterative algorithm is a trade-off between accuracy and regularization. We need to point out that for an ill-posed linear system (Equation1
(1)
(1) ), the solution given by
is unstable. Our algorithms are finding
, not finding
, which is less ill-conditioned than the finding of
. The descent direction detected by
is not exactly equal to the best descent direction
, which is an approximation. Because we have taken the direction
into account, the iterative algorithm based on
can converge quite fast.
vector regularization iterative algorithm
Since the fictitious time variable is now discrete, , we let
denote the numerical value of
at the
-th step. Thus, we arrive at a purely iterative algorithm from Equation (Equation62
(62)
(62) ):
(59)
(59) Then, the following VRIA is available:
For a given
Select
For
Linear inverse problems
In this section, we will apply the method of fundamental solutions (MFS) to discretize some inverse problems into a set of linear algebraic equations. In recent years, a few different meshless boundary collocation methods, like the singular boundary method, have been proposed and developed which are different but highly related to the MFS examined in this paper.[Citation28, Citation29] The regularization method proposed in this paper can also be an efficient alternative for these methods for solving the ill-posed linear inverse problems.[Citation30, Citation31]
Example 1
When the backward heat conduction problem (BHCP) is considered in a spatial interval of by subjecting to the boundary conditions at two ends of a slab:
(61)
(61) we solve
under a final time condition:
(62)
(62) The fundamental solution of Equation (Equation68
(68)
(68) ) is given as follows:
(63)
(63) where H(t) is the Heaviside function.
The method of fundamental solutions (MFSs) has a broad application in engineering computations. However, the MFS has a serious drawback in that the resulting system of linear equations is always highly ill-conditioned. In the MFS, the solution of u at the field point can be expressed as a linear combination of the fundamental solutions
:
(64)
(64) where N is the number of source points,
are unknown coefficients and
are source points located in the complement
of
. For the heat conduction equation, we have the basis functions
(65)
(65) It is known that the location of source points in the MFS has a great influence on the accuracy and stability. In a practical application of MFS to solve the BHCP, the source points are uniformly located on two straight lines parallel to the t-axis and not over
, which was adopted by Hon and Li [Citation32] and Liu [Citation33], showing a large improvement than the line location of source points below the initial time. After imposing the boundary conditions and the final time condition on Equation (Equation72
(72)
(72) ), we can obtain a linear equations system:
(66)
(66) where
(67)
(67) The number
of collocation points does not necessarily equal to the number N of source points.
Since the BHCP is highly ill-posed,[Citation34] the ill-conditioning of the coefficient matrix in Equation (Equation74
(74)
(74) ) is serious. To overcome the ill-posedness of Equation (Equation74
(74)
(74) ), we can employ both the DIM and VRIA to solve this problem. Here, we compare the numerical solution with an exact solution:
For
the value of final data is in the order of
, which is small in comparison with the value of the initial temperature
to be retrieved, which is
.
In order to test the stability of the proposed algorithm, we add a random noise on the final time data by(68)
(68) where
denotes the level of noise and R(i) are random numbers between
.
Fig. 1 For example 1 of a BHCP under an adding noise 0.001, comparing the exact solution with the numerical solutions obtained by the inversions from MCGML and MCGMR.
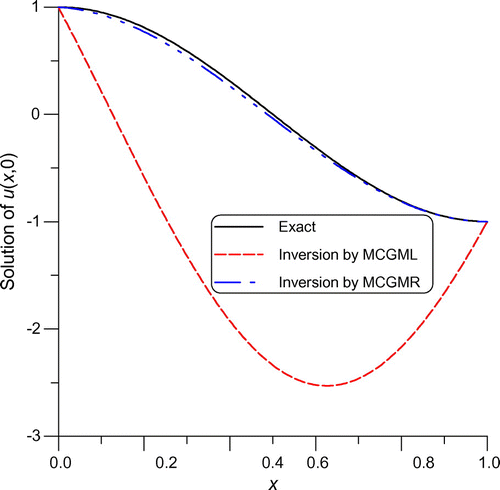
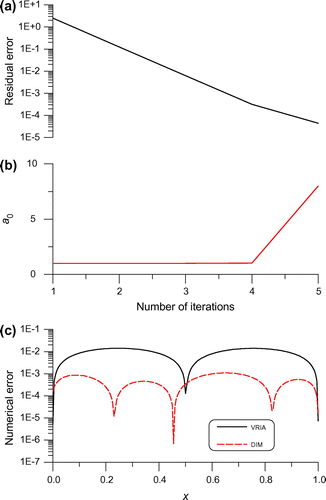
Fig. 2 For example 1 of a BHCP under a large relative noise 0.1, (a) the residual error, (b) the value of , and (c) comparing the numerical errors.
We take ,
, and hence
, and the noise with an intensity
is adding on the right-hand side. We first apply the MCGML to find the left inversion of
under a convergence criterion
, which is convergent with 714 iterations to find the inverse matrix
, such that the solution of
can be written as
(69)
(69) Unfortunately, the noisy error is largely amplified in the above solution, which causes an incorrect solution as shown in Figure by the red dashed line with the maximum error being 2.34. Conversely, when we apply the MCGMR to find the right inversion
of
, which is convergent with 914 iterations, and give the solution by
(70)
(70) which is named a DIM in this paper, the numerical solution is close to the exact solution as shown in Figure by the blue dashed-dotted line, with the maximum error being 0.0478.
The MCGML is a feasible algorithm to find the left inversion of an ill-conditioned matrix. When the MCGML can provide a very accurate solution of in Equation (Equation77
(77)
(77) ), the noise is also being magnified, which pollutes the numerical solution of
. Hence, we do not suggest to directly use Equation (Equation77
(77)
(77) ) to find the solution of
, when the data
are noisy and
is ill-conditioned. The reason is that the noise in
would be enlarged when the elements in
are quite large.
We take ,
, and hence
, and a relative random noise with intensity
is added in the final time data:
(71)
(71) We first apply the MCGMR to find the right inversion of
by imposing a convergence criterion
, which is convergent with 74 iterations to find the right inverse matrix
. Then, we use the DIM as shown in Equation (Equation78
(78)
(78) ) to solve this BHCP, of which the maximum error of initial condition is 0.088. Moreover, when the value of
is reduced to
, the MCGMR is convergent with 128 iterations to find the inverse matrix
, and the DIM used
in Equation (Equation78
(78)
(78) ) leads to the maximum error being
, which is shown in Figure . To the best knowledge of the author, this accuracy is never seen before for this highly ill-posed BHCP under a large noise with
.
With , we also apply the VRIA in Section 4.3 to solve this problem, where we take
and
and with
as an initial guess. In Figure , we show the residual error obtained by the VRIA, which is convergent only through 5 iterations. By adding 127 for the number of finding
, the total number of iterations for the VRIA is 132, which is larger than 128 iterations for the DIM. The values of
as shown in Figure is very small, which causes a fast convergence of the VRIA. It can be seen that the algorithm of VRIA is convergent very fast only through five iterations that its residual error reduces from 2.5 to
. We found that more smaller convergence criterion of
would not lead to more accurate solution. The numerical error is compared with that obtained by the DIM in Figure with the maximum error being 0.014, which is greater than that obtained by the DIM. This result is much better than that obtained by Liu [Citation21, Citation22], and also than that obtained by Liu et al. [Citation35].
Example 2
Let us consider the following inverse problem to recover the external force for an ODE:
(72)
(72) In a time interval of
, the discretized data
are supposed to be measurable, which are subjected to the random noise with an intensity
. Usually, it is very difficult to recover the external force
from Equation (Equation80
(80)
(80) ) by the direct differentials of the noisy data of the displacements, because the differential is an ill-posed linear operator.
To approach this inverse problem by the polynomial interpolation, we begin with(73)
(73) Now, the coefficient
is split into two coefficients
and
to absorb more interpolation points; in the meanwhile,
and
are introduced to reduce the condition number of the coefficient matrix.[Citation36] We suppose that
(74)
(74) and
(75)
(75) The problem domain is
, and the interpolating points are:
(76)
(76) Substituting Equation (Equation82
(82)
(82) ) into Equation (Equation81
(81)
(81) ), we can obtain
(77)
(77) where we let
. Here,
and
are unknown coefficients. In order to obtain them, we impose the following
interpolated conditions:
(78)
(78) Thus, we obtain a linear equations system to determine
and
:
(79)
(79) We note that the norm of the first column of the above coefficient matrix is
. According to the concept of equilibrated matrix,[Citation37] we can derive the optimal scales for the current interpolation with a half-order technique as
(80)
(80) where
is a scaling factor.[Citation38] The improved method uses m order polynomial to interpolate
data nodes, while regular method with a full order can only interpolate
data points.
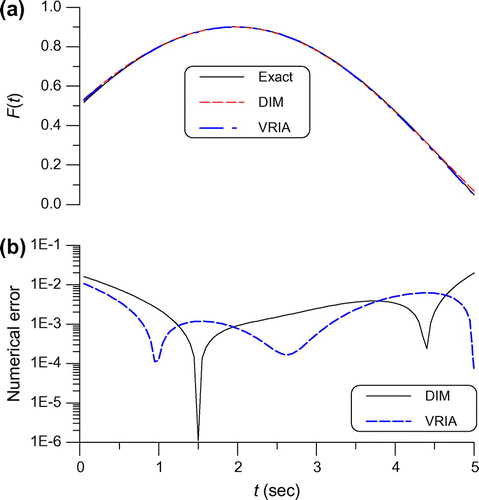
Fig. 3 For example 2 under a large noise 0.01, (a) comparing the numerical and exact solutions, and (b) the numerical errors.
Now, we fix and
and consider the exact solution to be
, which is obtained by inserting the exact value of
into Equation (Equation80
(80)
(80) ). The parameters used are
, and
. When we use the MCGMR, it is convergent with nine iterations under
. We compare the numerical solution obtained by the DIM with the data given by
in Figure , of which the maximum error is found to be
as shown in Figure by solid line. Then, we apply the VRIA to solve this problem under
and
, where we first use the MCGMR to find
, which is convergent with five iterations under
. Then, using the initial guess
, we let VRIA run 20 for iterations. We compare the numerical solution obtained by the VRIA with the exact data in Figure by dashed-dotted line, of which the maximum error is 0.0106 as shown in Figure by dashed line.
Example 3
We solve the Cauchy problem of the Laplace equation under the incomplete boundary conditions:(81)
(81) where
and
are given functions, and
is a given contour to describe the boundary shape. The contour in the polar coordinates is specified by
, which is the boundary of the problem domain
, and
denotes the outward normal direction. We need to find the boundary data on the lower half contour for the completeness of boundary data.
In the MFS, the trial solution of u at the field point can be expressed as a linear combination of the fundamental solutions
:
(82)
(82) where n is the number of source points,
are the unknown coefficients,
are the source points and
is the complementary set of
. For the Laplace Equation (Equation90
(90)
(90) ), we have the fundamental solutions:
(83)
(83) In the practical application of MFS, usually the source points are distributed uniformly on a circle with a radius R, such that after imposing the boundary conditions (Equation91
(91)
(91) ) and (Equation92
(92)
(92) ) on Equation (Equation93
(93)
(93) ), we can obtain a linear equations system:
(84)
(84) where
(85)
(85) in which
, and
(86)
(86) This example poses a great challenge to test the efficiency of linear equations solver, because the Cauchy problem is highly ill-posed. A noise with intensity
is imposed on the given data. We fix
and take a circle with radius
to distribute the source points. Under
, we can find
through six iterations. Then, we start from the initial guess
, and apply the VRIA to solve Equation (Equation95
(95)
(95) ) through 5 iterations as shown in Figure . In Figure , we compare the numerical solution with the exact data given by
, where
, of which the maximum error is
. The DIM converges with 25 iterations under the convergence criterion
. As shown in Figure the maximum error of DIM is 0.0957.
Fig. 4 For example 3 of a Cauchy problem under a large noise 0.1, (a) showing residual error, and (b) comparing the numerical and exact solutions.
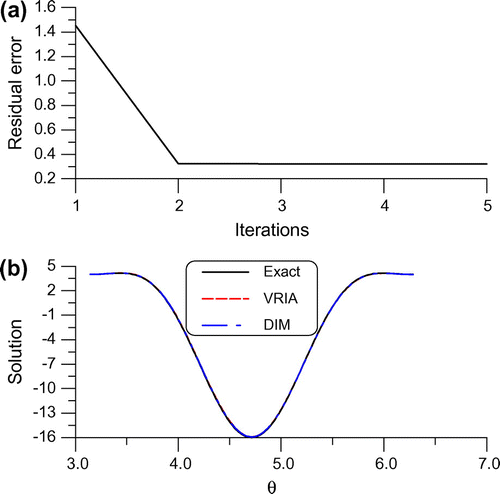
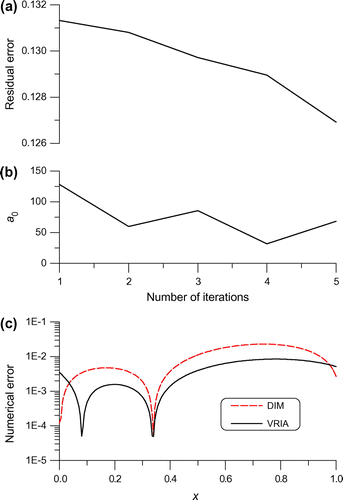
Fig. 5 For example 4 of an inverse heat source problem under a large noise 0.1, (a) the residual error, (b) the value of and (c) comparing the numerical errors.
Example 4
In this section, we apply the VRIA and DIM to identify an unknown space-dependent heat source function H(x) for a one-dimensional heat conduction equation:(87)
(87) In order to identify H(x), we can impose an extra condition:
(88)
(88) We propose a numerical differential method by letting
. Taking the differentials of Equations (98), (99), (101) with respect to t, and letting
, we can derive
(89)
(89) This is an inverse heat conduction problem (IHCP) for v(x, t) without using the initial condition.
Therefore, as being a numerical method, we can first solve the above IHCP for v(x, t) by using the MFS in Section 5.1 to obtain a linear equations system, and then the method introduced in Section 4 is used to solve the resultant linear equations system; hence, we can construct u(x, t) by(90)
(90) which automatically satisfies the initial condition in Equation (100).
From Equation (106), it follows that(91)
(91) which together with
being inserted into Equation (98), leads to
(92)
(92) Inserting Equation (102) for
into the above equation and integrating it, we can derive the following equation to recover H(x):
(93)
(93) For the purpose of comparison we consider the following exact solutions:
(94)
(94) In Equation (109), we disregard the ill-posedness of
, and suppose that the data
are given exactly. We solve this problem by the DIM and VRIA with
and the convergence criterion is
. A random noise with an intensity
is added on the data
. In the solution of
, the DIM is convergent through 57 iterations and its numerical error as shown in Figure by dashed line is small with the maximum error being 0.023. We compute
under
, which is convergent with 28 iterations. Then, by starting from the initial guess of
by
, we let the VRIA run five iterations, whose residual error and
are respectively shown in Figure . The numerical error obtained by the VRIA is shown in Figure by solid line with the maximum error being 0.0086. It is amazing that the accuracy of the VRIA is very good when one knows that the maximum value of H(x) is about 38. This example shows again that the proposed DIM and VRIA can solve linear inverse problems with good efficiency and accuracy, and as well is robustness against the large noise with intensity
being imposed on the data in the right-hand side.
Conclusions
For solving an ill-posed linear equations system under a large noisy disturbance and with
as being a residual vector, we have derived a very simple iterative algorithm including a parameter
:
(95)
(95) where
(96)
(96) The Lyapunov stability theorem guarantees that the present algorithm is stable and fast convergent because the search direction
is close to the best descent direction
with
being a right inversion of
. The new algorithm is a VRIA, which has a superior computational efficiency and accuracy in solving ill-posed linear problems. This assertion is further identified by four linear inverse problems, revealing that the proposed DIM and VRIA can solve very well the linear inverse problem with a high robustness against a large noise
being imposed on the data in the right-hand side.
Acknowledgments
First, the author is grateful to the anonymous referees for their comments which substantially improved the quality of this paper. Taiwan’s National Science Council project NSC-99-2221-E-002-074-MY3 granted to the author is highly appreciated. On the other hand, the author would acknowledge the promotion to be a Lifetime Distinguished Professor of National Taiwan University, since 2013.
References
- Bhaya A, Kaszkurewicz E. Control perspectives on numerical algorithms and matrix problems. Philadelphia, PA: Society for Industrial and Applied Mathematics; 2006.
- Liu C-S, Atluri SN. A novel time integration method for solving a large system of on-linear algebraic equations. Comput. Model. Eng. Sci. 2008;31:71–83.
- Helmke U, Moore JB. Optimization and dynamical systems. Berlin: Springer; 1994.
- Gavurin MK. Nonlinear functional equations and continuous analogs of iterative methods. Izv. Vyssh. Uchebn. Zaved. 1958;5:18–31.
- Alber YI. Continuous processes of the Newton type. Differ. Equ. 1971;7:1461–1471.
- Hirsch MW, Smale S. On algorithms for solving f(x) = 0. Commun. Pure Appl. Math. 1979;32:281–312.
- Chu MT. On the continuous realization of iterative processes. SIAM Rev. 1988;30:375–387.
- Ortega IM, Rheinboldt WC. Iterative solutions of nonlinear equations in several variables. New York: Academic Press; 1970.
- Bhaya A, Kaszkurewicz E. Steepest descent with momentum for quadratic functions is a version of the conjugate gradient method. Neural Networks. 2004;17:65–71.
- Bhaya A, Kaszkurewicz E. A control-theoretic approach to the design of zero finding numerical methods. IEEE Trans. Autom. Control. 2007;52:1014–1026.
- Liu C-S, Atluri SN. A Fictitious time integration method for the numerical solution of the Fredholm integral equation and for numerical differentiation of noisy data, and its relation to the filter theory. Comput. Model. Eng. Sci. 2009;41:243–261.
- Liu C-S, Atluri SN. A highly accurate technique for interpolations using very high-order polynomials, and its applications to some ill-posed linear problems. Comput. Model. Eng. Sci. 2009;43:253–276.
- Liu C-S, Yeih W, Atluri SN. On solving the ill-conditioned system Ax = b: general-purpose conditioners obtained from the boundary-collocation solution of the Laplace equation, using Trefftz expansions with multiple length scales. Comput. Model. Eng. Sci. 2009;44:281–311.
- Liu C-S, Hong HK, Atluri SN. Novel algorithms based on the conjugate gradient method for inverting ill-conditioned matrices, and a new regularization method to solve ill-posed linear systems. Comput. Model. Eng. Sci. 2010;60:279–308.
- Liu C-S. A revision of relaxed steepest descent method from the dynamics on an invariant manifold. Comput. Model. Eng. Sci. 2011;80:57–86.
- Liu C-S. Modifications of steepest descent method and conjugate gradient method against noise for ill-posed linear systems. Commun. Numer. Anal. 2012;Article ID cna-00115:24.
- Liu C-S, Atluri SN. An iterative method using an optimal descent vector, for solving an ill-conditioned system Bx = b, better and faster than the conjugate gradient method. Comput. Model. Eng. Sci. 2012;80:275–298.
- Liu C-S. A dynamical Tikhonov regularization for solving ill-posed linear algebraic systems. Acta Appl. Math. 2013;123:285–307.
- Liu C-S. The concept of best vector used to solve ill-posed linear inverse problems. Comput. Model. Eng. Sci. 2012;83:499–525.
- Liu C-S. A globally optimal iterative algorithm to solve an ill-posed linear system. Comput. Model. Eng. Sci. 2012;84:383–403.
- Liu C-S. Optimally scaled vector regularization method to solve ill-posed linear problems. Appl. Math. Comp. 2012;218:10602–10616.
- Liu C-S. Optimally generalized regularization methods for solving linear inverse problems. Compu. Mater. Contin. 2012;29:103–127.
- Liu C-S. An optimal tri-vector iterative algorithm for solving ill-posed linear inverse problems. Inv. Prob. Sci. Eng. 2013;21:650–681.
- Ascher U, van den Doel K, Hunag H, Svaiter B. Gradient descent and fast artificial time integration. M2AN. 2009;43:689–708.
- Liu C-S, Chang CW. Novel methods for solving severely ill-posed linear equations system. J. Marine Sci. Tech. 2009;17:216–227.
- Liu C-S, Atluri SN. An iterative algorithm for solving a system of nonlinear algebraic equations, F(x) = b, using the system of ODEs with an optimum α in ẋ = λ[αF + (1 − α)BFF]; Bij = ∂Fi/∂xj. Comput. Model. Eng. Sci. 2011;73:395–431.
- Mohler RR. Nonlinear systems, Volume 1: dynamics and control. Englewood Cliffs (NJ): Prentice-Hall; 1991.
- Chen W, Gu Y. An improved formulation of singular boundary method. Adv. Appl. Math. Mech. 2012;4:543–558.
- Gu Y, Chen W, He X-Q. Singular boundary method for steady-state heat conduction in three dimensional general anisotropic media. Int. J. Heat Mass Transfer. 2012;55:4837–4848.
- Lin J, Chen W, Wang F. A new investigation into regularization techniques for the method of fundamental solutions. Math. Comput. Simul. 2011;81:1144–1152.
- Fu Z, Chen W, Zhang C. Boundary particle method for Cauchy inhomogeneous potential problems. Inv. Prob. Sci. Eng. 2012;20:189–207.
- Hon YC, Li M. A discrepancy principle for the source points location in using the MFS for solving the BHCP. Int. J. Comput. Meth. 2009;6:181–197.
- Liu C-S. The method of fundamental solutions for solving the backward heat conduction problem with conditioning by a new post-conditioner. Num. Heat Transfer B: Fundam. 2011;60:57–72.
- Liu C-S. Group preserving scheme for backward heat conduction problems. Int. J. Heat Mass Transfer. 2004;47:2567–2576.
- Liu C-S, Zhang SY, Atluri SN. The Jordan structure of residual dynamics used to solve linear inverse problems. Comput. Model. Eng. Sci. 2012;88:29–47.
- Liu C-S. A highly accurate multi-scale full/half-order polynomial interpolation. Comput. Mater. Contin. 2011;25:239–263.
- Liu C-S. An equilibrated method of fundamental solutions to choose the best source points for the Laplace equation. Eng. Anal. Bound. Elem. 2012;36:1235–1245.
- Liu C-S. A two-side equilibration method to reduce the condition number of an ill-posed linear system. Comput. Model. Eng. Sci. 2013;91:17–42.