
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Spatial technologies offer high flexibility to handle substantial amount of spatial data and wide range of modelling capabilities. Remotely sensed data are the most significant data source used in spatial technologies. However, it is often associated with uncertainties due to atmospheric effects (i.e. absorption and scattering by atmospheric gases and aerosols). Methods based on rigorous treatment of radiative transfer models still have some drawbacks in the inversion of top of atmospheric reflectance values to surface reflectance values on large numbers of satellite images. In this paper, our aim is to represent a more flexible (adaptive) approach for the regional atmospheric correction by employing nonparametric regression splines within the frame of inverse problems and modern techniques of continuous optimization. To achieve this objective, atmospheric correction models obtained through conic multivariate adaptive regression splines, which is an alternative method to multivariate adaptive regression splines by constructing a penalized residual sum of squares as a Tikhonov regularization problem, are applied on a set of satellite images in order to convert the top of atmospheric reflectance values into surface reflectance values. The results are compared with the ones obtained by both multivariate adaptive regression splines and a radiative transfer-based method.
1. Introduction
1.1. Significance of atmospheric correction in remote sensing
Since the day it emerged (namely, in the 1960s), Geographical Information Systems (GIS), together with the parallel developments in Remote Sensing (RS) technologies, have been offering unique capabilities for editing, managing, analysing and automating different kinds of spatial data that provides valuable information required for decision-making.[Citation1]
These technologies have been extensively employed in diverse areas of science and engineering studies such as global warming,[Citation2] sustainable management of natural resources,[Citation3] emergency response systems for natural events,[Citation4] and weather and climate modelling,[Citation5] financial and environmental analysis of investments in energy markets,[Citation6] real estate business,[Citation7] urban development planning,[Citation8] agriculture,[Citation9] farming industry and rural area management,[Citation10,11] and oil and mining industry.[Citation12,13]
Remotely sensed image data have been used as a primary information source in spatial technologies. However, a fundamental problem in RS is the perturbations on surface reflectance data due to absorption and scattering by atmospheric gases and molecules.[Citation14] So, in order to guarantee correct analysis and interpretation of remotely sensed images, the reflectance values of the image pixels must accurately represent the ground surface reflectance values. Failure to correct for the atmospheric effects can inevitably lead to different surface reflectance values, and will definitely have a significant effect on any conclusions drawn from such data. This issue is particularly important in the evaluation of long time series, over which the atmospheric parameters do not remain constant.[Citation15]
1.2. A brief remark on radiative transfer models
Numerous methods and algorithms based on Radiative Transfer (RT) models have been proposed by various authors in order to remove atmospheric effects from images taken by sensors with different technical specs and operational objectives.[Citation16–18]
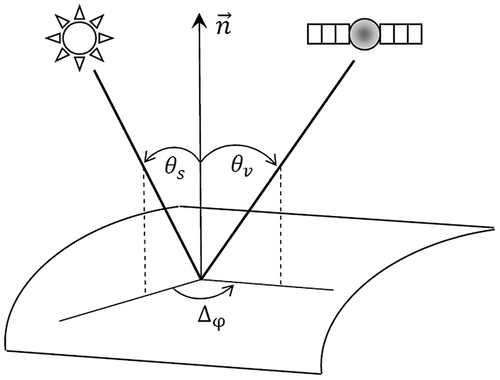
Generally speaking, the goal of RT-based correction schemes is to remove the influence of the atmosphere by modifying Top Of Atmospheric (TOA) reflectance measurement recorded by a sensor. Aerosol and water vapour content (uWV) of the atmosphere have a substantial effect on atmospheric absorption and scattering. Besides, the View Zenith Angle (VZA) and Solar Zenith Angle (SZA) also play a crucial role in determining the effects of the atmosphere (Figure ). When the zenith angle is far from nadir, then the ray path travelled by the photon through the atmosphere gets larger, which increases the probability of an absorption or scattering event in turn.[Citation15,19]
Figure 1. Geometry of the problem (θs: SZA, θv: VZA, Δφ: Relative azimuth).
Even though no atmospheric correction scheme can completely nullify the effects of the atmosphere, the RT in clear atmosphere is now well understood and a significant amount of work has been done in improving the accuracy and quality of correction algorithms.[Citation20]
However, we should emphasize that the high accuracy available with detailed RT models may not actually be reached when working over large areas, due to unknown atmospheric parameters. For large areas and long time periods, these models still need faster methods in order to derive surface reflectances and to retrieve atmospheric parameters.
Additionally, in images, acquired by instruments with high temporal resolution and large field of view, each pixel has a different observational geometry and each atmospheric parameter has to be calculated for each pixel. Hence, it is highly costly and time consuming to employ models based on a rigorous treatment of the RT problem, like Second Simulation of a Satellite Signal in the Solar Spectrum (6S),[Citation21] for the atmospheric correction of bulk numbers of such satellite images in real time.
The Simplified Model for Atmospheric Correction (SMAC) was first introduced nearly two decades ago as an alternative approach to tackle these problems. It is based on the parameterization of detailed RT models.[Citation22] Despite its age and lower level of accuracy as compared to 6S, it is still a preferred atmospheric correction tool for many research groups due to its high speed.[Citation15]
1.3. Nonparametric regression splines with continuous optimization and conic quadratic programming
In our paper, we, for the first time ever, adjust, refine and employ the new regression and classification tool of data mining, Conic Multivariate Adaptive Regression Splines (CMARS),[Citation23] on a subject of RS. Developed as an alternative approach to Multivariate Adaptive Regression Splines (MARS),[Citation24] CMARS converts the second stage of the MARS algorithm (i.e. the backward step) into a Tikhonov Regularization (TR) problem based on Penalized Residual Sum of Squares (PRSS) approach and solves the problem through Conic Quadratic Programming (CQP).
In each dimension of the input variables in CMARS algorithm, a piecewise linear ‘zig-zag’ function is built up, where the linear parts represent and approximate the data over whole intervals. The aim in the regularization of the CMARS approach by addressing first- and second-order derivatives is to obtain ‘easy’ models. This regularization is turned into the language of a CQP model by penalization.
The components of the unknown parameters’ vector are forced to be 0 or, as much as possible, be nearby to vanish, which also implies that the smallest possible number of ‘significant’ coefficients is aimed in CMARS. MARS follows this goal through an ‘index’ called Generalized Cross-Validation (GCV); however, in CMARS, integrated framework of conic and global optimization is employed to reach this goal.
A second class of parameters is the penalty parameters or, equivalently, upper bounds of the complexity. These parameters are already reduced by just single values, per class of variables, and no longer individually per basis functions (BFs), and this means a strong reduction of the entire numbers of parameters, too. Actually, this work on the number of parameters can also be considered as a model selection.[Citation25]
1.3.1. Advantage of using splines
The use of spline functions offer great advantages, in general, and in the context of our modelling in RS, as will be explained now compactly [Citation25]:
Splines, from the perspective of just one dimension (input variable), are ‘piecewise polynomials’. If only polynomials are used, then they would usually converge to plus or minus infinity when the absolute values of the (input) variables grow large. Since real-life processes stay in bounded margins (even if these bounds may be very large) generally, polynomials would need to have a high degree to oscillate sufficiently in order to remain within some reasonable margin. However, with high-degree polynomials it is hard and costly to work, in particular, as the real-life challenges are multivariate, which may need multiplications and, hence, a rapid increase in degree of the occurring multivariate splines. Using splines however permits us, in every dimension, to keep the degree of the polynomial ‘pieces’ very low. Splines are indeed quite ‘flexible’ and sufficiently ‘elastic’ in order to approximate complex and high-dimensional data structures. So, they are often called ‘smoothing splines’, since they ‘smoothly’ approximate discrete data.
The splines of CMARS are more ‘smooth’ even in the sense that their oscillation is kept under control via a penalization of their integrals of squared first- and, especially, second-order derivatives, i.e. their complexity. Then the integrals are discretized, and a programme of TR is obtained and represented in the form of CQP.
The multivariate splines of CMARS are multiplication products of ‘zig-zagging’, piecewise linear functions of degree 1 (or 0), and it can be carefully determined how many dimensions to include into the process of multiplications of those one-dimensional splines in order to prevent the complexity of our model from becoming too high. Let us recall that reducing the complexity can also be expressed as an increase in stability.
Those multiplications are an expression of the fact that there are input variables, which are dependent and, together in groups, contributing to an explanation of response variable by those explanatory input variables.
Finally, differently from the use of ‘stiff’ model formulas, which are motivated by the tradition in science, and in our paper recalled by the formulas (1)–(4), our approach by CMARS is very adaptive and is getting into the data-set with its particular subsets and characteristics of shape.
1.4. Our motive and objective
With this paper, we recommend our adaptive tool for regression and classification, CMARS, to be used in the area of RS, especially, as an alternative to traditional formula-based approaches who have their scientific origins in the natural sciences, especially, in physics. However, we very much respect and appreciate those formulas as they represent important relations between essential, natural dimensions, though on a certain level of abstraction and, sometimes, simplification. Our CMARS approach of learning and modelling is based on both the empirical data and the mathematics of applied probability and, especially, optimization theory, whereby accuracy becomes compromised with complexity. But we herewith do also deliver formulas again, as in the traditional approaches; the formulas now are our CMARS models.
In order to accomplish our goals in this study, CMARS is applied to build a model for the atmospheric correction of a MODerate-resolution Imaging Spectroradiometer (MODIS) image data-set. We also employ MARS for the same purpose, since it has many successful applications in economy, technology and many other branches of science where complex relationships among variables are modelled.[Citation26–28] The atmospheric correction models obtained through CMARS and MARS algorithms are applied on 24 MODIS images, half of which was taken over the Alps region and the other half was taken over Turkey. Atmospherically corrected surface reflectance values for the same areas are also obtained by SMAC algorithm. Then, the results are compared against the surface reflectance values of MODIS Level 2G products,[Citation29] which are already corrected for the atmospheric effects via 6S, and the results are given in terms of both Root-Mean-Square Error (RMSE) and correlation coefficient (r) values.
2. 6S and SMAC methods
Atmospheric correction algorithms have evolved a lot during the last three decades, starting from the empirical line method to the recent RT-based algorithms; however, we do not intend to cover all these methods in a comprehensive manner. Instead, 6S and SMAC methods are briefly introduced based on [Citation22,30,31].
2.1. 6S
The 6S is a computer code that can accurately simulate the surface reflectance values measured by satellite or airborne platforms of land or sea surfaces in the visible and near infrared, which is strongly affected by the presence of the atmosphere along the sun-ground target-sensor path, and its first version was introduced in the late 1990s. As an RT-based correction algorithm, the latest vector version of 6S code (6SV) is the basic code employed for the atmospheric correction of MODIS Level 1B land surface reflectance products,[Citation32] and it has been extensively tested.
The algorithm requires seven input variables: TOA reflectance (i.e. apparent reflectance value of the ground target recorded by the sensor at the top of atmosphere, which is attenuated by the atmospheric effects), SZA, VZA and relative azimuth between the sun and the satellite direction (Δφ) (as shown in Figure ), Atmospheric Optical Depth (AOD), uWV and Ozone (uO3) content. Here, AOD accounts for the degree to which aerosols prevent the transmission of solar radiation by absorption or scattering of light along the sun-ground target-sensor path, whereas uWV and uO3 consider the effect of atmospheric gaseous absorption.
The atmospherically corrected surface reflectance value of a target pixel, , is then given by
(1)
(1)
with(2)
(2)
Here, ,
and
are SZA, VZA and relative azimuth between the sun and the satellite, respectively,
is the spherical albedo of the atmosphere (i.e. the ratio of reflected radiation from the surface to incident radiation upon it over all sun angles), and
denotes the TOA reflectance.
denotes the gaseous transmission,
and
are the total downward and upward atmospheric transmittances, respectively, and finally,
is the atmospheric reflectance. Values of AOD, uWV and uO3 are internally used by the algorithm to calculate the parameters related with the atmospheric scattering and gaseous absorption processes as mentioned above.
2.2. Simplified model for atmospheric correction
Real-time atmospheric correction of large data-sets collected by sensors with high-temporal resolution via detailed RT codes, like 6SV, is operationally impractical. So, SMAC was proposed as an alternative method about two decades ago. Even though 6SV and SMAC operate in a similar manner, the former is based on the rigorous treatment of the RT problem. SMAC employs the simplified forms of the formulas used in 6SV to calculate the process variables. This leads to reduced complexity and quick atmospheric correction on a large data-set. However, since SMAC does not include many components that are modelled within 6SV in a more complex manner, the accuracy of the atmospheric correction is degraded, as compared to 6SV.
Apart from a series of predefined coefficients that depends on the RS instrument, SMAC requires the same input variables as in 6S. Then, the corrected surface reflectance is expressed as(3)
(3)
with(4)
(4)
Despite its age and lower level of accuracy, SMAC approach is still used by many research groups and projects, since it can perform an atmospheric correction in a short time. In addition, when new sensors are introduced, only the band-specific coefficients need to be updated while the routines remain the same. Additionally, SMAC is available as a free and open-source code. This means that it can easily be implemented in an operational data preprocessing computer and can be modified according to user requirements, which is another attractive feature of SMAC algorithm that makes it still popular.
3. Basic overview on MARS and CMARS
In this section, the reader can find the fundamentals of MARS and CMARS based on [Citation23,24,33,34].
3.1. Multivariate adaptive regression splines
Nonparametric regression and classification techniques are mostly the key data mining tools in explaining real-life problems and natural phenomena where many effects often exhibit a nonlinear behaviour. As a form of regression analysis, MARS is a nonparametric regression technique widely used in data mining and estimation theory in order to built flexible regression models for high-dimensional nonlinear data. In MARS model building, piecewise linear BFs are fitted in such a way that additive and interactive effects of the predictors are taken into account to determine the response variable.
MARS uses two stages when building up regression model, namely, the forward and the backward step algorithms. In forward step, BFs are added up until the highest level of complexity is reached. Since the first step creates an over-fit model, preferred and eventual model is obtained by the elimination of BFs in backward step. Selection of BFs is data-based and specific to the problem in MARS, which makes it an adaptive regression procedure suitable for solving high-dimensional problems.
MARS uses expansions of the truncated piecewise linear BFs of the form , where
is the jth component of p-dimensional variable x, and
is the associated knot location of
. The ‘ ± ’ symbol indicates that only the positive or the negative parts are used, respectively, and
,
.
The relation between input and response in general model is expressed as(5)
(5)
where Y is a response variable, is a vector of predictors and
is the error term in the observation with zero mean. MARS builds reflected pairs for each input
with p-dimensional knots
at each input data vectors
of that input
. Then, the collection of BFs is:
(6)
(6)
where N is the total number of observations, p is the dimension of the input space. In order to reach spline fitting in higher dimensions, the tensor products of univariate spline functions are employed, leading to multivariate spline BFs in the following form:(7)
(7)
where Km is the interaction degree of the mth BF and xm denotes the vector of independent variables contributing to the mth BF. Furthermore, is the corresponding input variable of the kth truncated linear function in the mth BF, the corresponding knot value for the variable
is given by
, and finally
.
The forward and the backward step algorithms of MARS are used for the estimation of model function In the forward step, the use of functions from the set C and their products are allowed to represent interaction, which generates a maximal model that overfits the data. The initial model is in the following form:
(8)
(8)
where is either a function or product of two or more functions from the set C. The number of BFs in the current model is indicated by M, and
is the intercept.
In order to compare the possible BFs, a Lack-Of-Fit (LOF) criterion is used. For generating an estimated best model with the optimal value
, where
represents some complexity of the estimation, MARS algorithm first adds BFs and products of the BFs in the forward step. Then, the least significant ones are deleted in the backward step. To find the value for
, MARS uses GCV indicating the LOF and it is given as
. Here, N is the number of sample observations,
with K representing the number of knots which are selected in forward step. The number of linearly independent functions in the model is given by u, and d denotes a cost for each BF optimization. While a larger
value creates a smaller model with less number of BFs, a smaller
value generates a larger model with more BFs. Using the LOF criterion, the best model is chosen according to backward step that minimizes GCV.
3.2. Conic multivariate adaptive regression splines
CMARS has been developed as an alternative method to MARS by utilizing statistical learning, inverse problems and multiobjective optimization theories. Instead of applying backward step of MARS, PRSS with the BFs is built up during forward step. Then, penalty terms are added to the least squares estimation to control the LOF. This introduces a different approach to the complexity and the stability of the problem.
PRSS summed up during the forward step of MARS has the following form:(9)
(9)
Here, denotes the variable set related with the mth BF, and
is the vector of variables contributing to the mth BF. Furthermore,
are penalty parameters, and Qm are suitable integration domains
Finally,
for
,
, where
.
The trade-off between accuracy and complexity in this optimization problem is established through the penalties , and the PRSS can be approximated as a TR problem by rearranging (9) as:
(10)
(10)
where, is the vector of responses,
is an
-matrix,
, and
with
Although a finite sequence of the trade-off or penalty parameters exists, the expression in (10) is still not a TR problem with a single parameter. Therefore, a uniform penalization by taking the same
for each derivative term is applied, and approximation to PRSS may be rewritten as follows:
(11)
(11)
where is a diagonal
-matrix and
denotes an
-parameter vector estimated through the data points. The PRSS problem turns into a classical TR problem with
for some
. A brief introductory to TR can be found in Appendix 1.
The TR problem in (11) can be treated by CQP with a convenient choice of bound :
(12)
(12)
At this point, one has to note that a careful learning process must be followed in order to obtain the values of bound . By applying the modern methods of continuous optimization, the CQP can be written in this basic notation:
(13)
(13)
The parametrical upper bound in the second constraint of the CQP and the penalty parameter
in the PRSS are linked, and the value for
can be obtained via TR. It should also be emphasized that the high importance of the goal of numerical precision (accuracy) as a core target inside of the trade-off stated above. At this point, it is also of value to mention that the issue of non-differentiability is handled by choosing the knots of the splines in each coordinate nearby to but not identical with the data points; by this way, there is no problem in the evaluation of the splines at the data points. Additionally, during the integration of the squared first- and second-order partial derivatives of the BFs of the model in the ‘complexity part’ of the optimization problem, the ‘set of non-differentiability’ is of measure zero.
4. Methodology
4.1. Data-set and retrieval of necessary parameters
The MODIS instrument capture daily data in 36 spectral bands ranging in wavelength from 0.4 to 14.4 μm at varying spatial resolutions (bands 1 and 2: 250 m, bands 3–7: 500 m, bands 8–36: 1000 m) in order to investigate earth’s global dynamics such as radiation budget, cloud cover and atmosphere. MODIS Level 2G surface reflectance product comprises the atmospherically corrected surface reflectance values for the first seven bands, and the vector version of 6S (6SV) is the basic correction algorithm behind this product. The algorithm takes the TOA reflectance values from MODIS Level 1B product, and makes a series of corrections for the absorption and scattering by atmospheric gases and molecules. It also takes into account the coupling between atmospheric and surface bi-directional reflectance function and adjacency effect.
Another product family of MODIS is the Level 3 daily atmospheric product,[Citation35] from which AOD, uWV and uO3 can be retrieved in order to be employed as input in SMAC. All these features make MODIS an attractive and convenient platform for this study.
Twenty-four MODIS images taken by Terra satellite are selected as data-set. Half of the images are over Alps region (Figure ) and the other half is over Turkey (Figure ). Detailed information about the data-set can be found in Table . At this point, we emphasize that all the calculations and operations are performed on the 4th reflective solar band (0.545–0.565 μm).
Figure 2. Alps (A11: 6 November 2002).
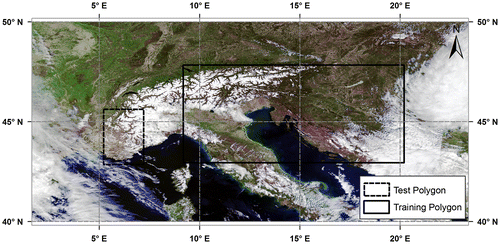
Figure 3. Turkey (T7: 16 July 2012).
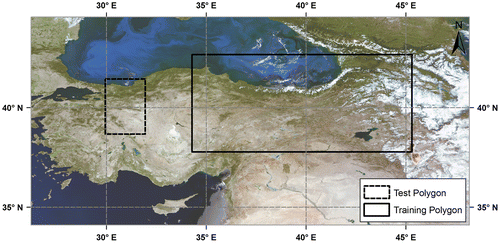
Table 1. TOA reflectance statistics for training and testing sets of Alps (A) and Turkey (T).
TOA reflectance values are retrieved from MODIS Level 1B product, which comprises the 3rd, 4th, 5th, 6th and 7th reflective solar bands at 500 m spatial resolution. Atmospheric parameters required to perform atmospheric correction through SMAC algorithm (i.e. AOD, uWV and uO3) are obtained from MODIS Level 3 daily atmospheric product.
The results obtained by MARS, CMARS and SMAC methods are tested against MODIS Level 2G product. The atmospheric correction algorithm used in this product is based on 6SV method. 6SV has been seriously cross-checked with other complex correction algorithms and has given highly accurate results under various conditions; therefore, it is preferred as a reference in the comparison of the results.
For data processing and modelling, a computer with an Intel Core i5 M430 2.27 GHz processor and 8 GB DDR3 1333 MHz RAM is used.
4.2. MARS & CMARS model training
In the model training phase, for each region (i.e. Alps and Turkey), a training polygon with fixed dimension (i.e. rectangular in shape with an area of 483,000 km2), which includes all basic land-cover types, is drawn on each image. In each training polygon, 5000 points are randomly generated, and for each point, TOA reflectance value and atmospherically corrected surface reflectance value are extracted from MODIS Level 1B and MODIS Level 2G products, respectively, together with the corresponding geographic longitude and latitude. As seen in Table , each month appears once in the data-set. So, month value of the image, from which the corresponding model training parameters are retrieved, is also written in that point data file. In the next step, the training data from each of the training polygons are combined in a single text file, which results in 60,000 data points on aggregate for each region.
In MARS model building, is the vector of predictor variables, where
and
represent the geographic latitude and longitude, respectively,
is the TOA reflectance value, and
is the month indicator (
). The observation equation for MARS is given by
, where
is the atmospherically corrected surface reflectance (i.e. response) obtained from MODIS Level 2G product at
with a measurement error
.
is the function that gives the surface reflectance predicted by MARS, and
is the total number of observations.
Since MARS algorithm allows users to define model-building dimensions such as maximal number of terms, the degree of interaction among predictor variables, different settings are applied, and the model that gives the minimum GCV value and the maximum adjusted R2 [Citation36] value are chosen. All settings in the model training are given in Table . Salford Systems MARS® Version 3 [Citation37] is used for MARS model building.
Table 2. Settings for MARS model training.
In CMARS, BFs, which are considered for the formulation of PRSS in the form of a CQP problem, are created by using MARS®. Next, CMARS model is obtained by running a MATLAB code. Then, the CQP problem is solved by using MOSEKTM software.[Citation38]
5. Results
After constructing MARS and CMARS models for each region through the training phase, the obtained models are tested on each image in the data-set. For testing, both models are applied on a predefined area with a size of 53,700 km2 on each image. In addition to MARS and CMARS models, SMAC algorithm is also employed (Figure ). Then, the surface reflectance values produced by MARS, CMARS and SMAC algorithms for each test area are compared with the ones given by MODIS Level 2G product in terms of RMSE and r (Table ). Details about the processing times can be found in Table .
Figure 4. Test area images for A11 (6 November 2002): (a) CMARS, (b) MARS, (c) SMAC and (d) MODIS Level 2G.
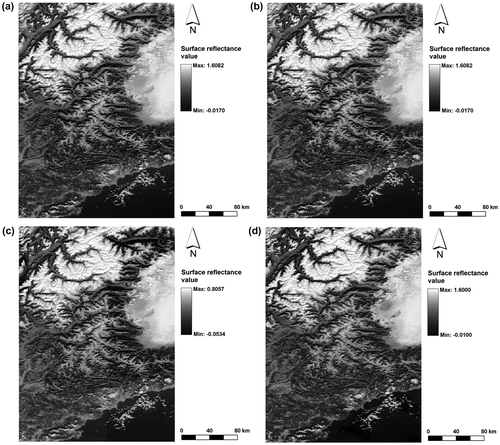
Table 3. Comparison of results for Alps (A) and Turkey (T).
Table 4. Processing times (in seconds) of SMAC, MARS and CMARS for Alps (A) and Turkey (T).
It is evident that CMARS (and MARS) outperforms the traditional RT-based approach SMAC according to the results given in terms of both RMSE and r (Table ). The processing time for the CMARS in the training phase is evidently much longer than the MARS (Table ); however, it must be noted that MARS has already been in the statistical learning and data mining community for more than two decades, and it is available as a standalone and sophisticated software package, whereas different software packages (i.e. MARS®, MATLAB® and MOSEKTM) have to be used for the time being in order to obtain the CMARS model, which naturally increases the processing time.
The average processing time of MARS (34 s) in the testing phase is almost comparable with that of SMAC (25 s). Although the average testing time for CMARS (238 s) is longer than the other two models, it still seems acceptable and competitive for this kind of huge and complex real-life data. As new refinements are made on CMARS, improvement on the processing time will be achieved.
Here, we would also like to emphasize our respect and appreciation to MARS, and we regard CMARS as an additional offer to be considered in different applied contexts, but not as a total replacement of MARS. However, we should further mention that CMARS proposes a ‘model-based’ approach on controlling the complexity, in the form of TR which is very well established in engineering and realized by us in the form of CQP together with its efficient Interior Point Methods, and by this a remarkable support is gained from the more model-based methods of calculus and of modern mathematics in general, in particular, through state-of-the-art continuous optimization theory. Moreover, via the trade-off between precision and complexity, CMARS lets us open our investigations to real-world challenges which include noise in the response (output) variable, namely, to the Theory of Inverse Problems, to Data Mining and to Statistical Learning.
Since we are interested in the multi-criteria antagonism (trade-off) between accuracy and stability (stability may be called as small complexity), this trade-off, keeping the complexity under ‘control’, is realized by us through CMARS in different ways: (i) restraining the discretized integral of first- and second-order derivatives of the BFs within some margin or ‘tolerance’ (under a chosen and prescribed upper bound), and (ii) using modern optimization theory (model-based approach) for a more integrated approach of both the forward and the backward step, which we have in MARS. By this, we are closer also to exploiting the ‘power’ of differential and integral calculus and to future developments in this calculus and in optimization theory. In future, we can also do modifications and elaborations by new and forthcoming principles and techniques of discretization.[Citation25]
Moreover, with CMARS we are now ‘hosted’ in optimization theory and its scientific community; furthermore, we even have a promise of future benefiting from Robust Optimization, which we can apply through the robust counterpart of CMARS, Robust CMARS (RCMARS).[Citation39] It will additionally permit to imply into our modelling the uncertainty in the input variables, which is typical for real-life problems also.
When we insert CMARS or RCMARS into Generalized Partial Linear Models (GPLM), which means linear models from linear regression or logistic regression are combined with a nonlinear model (i.e. (C)MARS), we obtain CGPLM and RCGPLM.[Citation40] All these generalizations of CMARS have been applied to data-sets from various applied fields and led to very good results as compared with MARS, and we intend to apply them at our subject from RS.
Another specific feature of CMARS when viewed within the RS perspective regarding our particular problem, CMARS stays ‘longer’ model-based than MARS since it offers a more direct and intriguing comparison with the traditional ‘formulas’ of RS, which are originated from physics and other natural sciences, where functional relationships between variables are assumed. CMARS permits this by its interactive and adaptive ‘functional model’, which is supported by optimization and applied mathematics and can learn under different forms of uncertainty.
6. Conclusions and outlook
In this paper, we try to shed light onto the areas of data mining and optimization within a real-life perspective by taking the unique advantages of spline functions. Natural phenomena and real-life problems often exhibit a nonparametric and multivariate behaviour, in which the curse of dimensionality may easily prevail. This means, controlled successive multiplications may sometimes be inevitable and useful to represent the multi-dimensional interaction of the model.
High dimensional and complex data-sets can be wisely handled with the inherent smoothing characteristic of splines. As illustrated in our case, splines applied in CMARS are even made smoother through TR and CQP, and enable us to adaptively penetrate into our complex and large data-set.
For this particular problem, it has been shown that our CMARS has absolutely equal effectiveness as MARS as seen from RMSE and r values given in Table ; on the other hand, MARS still performs well and gives satisfactory results on the data-set. This has already been expected because that is what MARS was designed for: to overcome large and complex data. Although MARS seems to perform much better than CMARS in terms of processing time, it should be noted that three software packages have to be used successively for CMARS modelling, but even so, the processing times for CMARS are still in acceptable margin for this kind of RS data.
As our study showed us, CMARS (and MARS) can be employed as an alternative tool for atmospheric correction, and can also be used for other problems associated with earth sciences. By integrating the dynamical progress of scientific advances in modern continuous optimization with the spatial technologies, we can enhance our understanding of the value of spatial data and its inherent structure to reach better modelling capabilities in GIS and RS.
Our further studies in the area of RS will definitely concentrate on the new applications of CMARS, and RCMARS, which will be considered as another new and powerful data mining tool in order to cope with the uncertainties in our huge data-set by applying the principles of robust optimization.
References
- Jankowski P. Integrating geographical information systems and multiple criteria decision-making methods. Int. J. Geog. Inf. Syst. 1995;9:251–273.10.1080/02693799508902036
- Nogué S, Rull V, Vegas-Vilarrúbia T. Modeling biodiversity loss by global warming on Pantepui, northern South America: projected upward migration and potential habitat loss. Clim. Change. 2009;94:77–85.10.1007/s10584-009-9554-x
- Trotter CM. Remotely-sensed data as an information source for geographical information systems in natural resource management a review. Int. J. Geog. Inf. Syst. 1991;5:225–239.10.1080/02693799108927845
- Hsu M, Chen AS, Chen L, Lee C, Lin F, Huang C. A GIS-based decision support system for typhoon emergency response in Taiwan. Geotech. Geol. Eng. 2011;29:7–12.10.1007/s10706-010-9362-0
- Wilhelmi OV, Brunskill JC. Geographic information systems in weather, climate, and impacts. Bull. Am. Meteorol. Soc. 2003;84:1409–1414.10.1175/BAMS-84-10-1409
- Voivontas D, Assimacopoulos D, Mourelatos A, Corominas J. Evaluation of renewable energy potential using a GIS decision support system. Renewable Energy. 1998;13:333–344.10.1016/S0960-1481(98)00006-8
- Zeng TQ, Zhou Q. Optimal spatial decision making using GIS: a prototype of a real estate geographical information system (REGIS). Int. J. Geog. Inf. Sci. 2001;15:307–321.10.1080/136588101300304034
- Masser I. Managing our urban future: the role of remote sensing and geographic information systems. Habitat Int. 2001;25:503–512.10.1016/S0197-3975(01)00021-2
- Beeri O, Peled A. Geographical model for precise agriculture monitoring with real-time remote sensing. ISPRS J. Photogramm. Remote Sens. 2009;64:47–54.10.1016/j.isprsjprs.2008.07.007
- Jeong JS, García-Moruno L, Hernández-Blanco J. A site planning approach for rural buildings into a landscape using a spatial multi-criteria decision analysis methodology. Land Use Policy. 2013;32:108–118.10.1016/j.landusepol.2012.09.018
- Tulloch DL, Myers JR, Hasse JE, Parks PJ, Lathrop RG. Integrating GIS into farmland preservation policy and decision making. Landscape Urban Plan. 2003;63:33–48.10.1016/S0169-2046(02)00181-0
- Coburn, TC, Yarus, JM. Geographic information systems in petroleum exploration and development (AAPG computer applications in geology, no. 4). Tulsa (OK): American Association of Petroleum Geologists; 2000.
- Knox‐Robinson CM, Wyborn LAI. Towards a holistic exploration strategy: using geographic information systems as a tool to enhance exploration. Aust. J. Earth Sci. 1997;44:453–463.10.1080/08120099708728326
- Tso B, Mather PM. Classification methods for remotely sensed data. 2nd ed. Boca Raton (FL): CRC Press; 2009.
- Proud SR, Rasmussen MO, Fensholt R, Sandholt I, Shisanya C, Mutero W, Mbow C, Anyamba A. Improving the SMAC atmospheric correction code by analysis of Meteosat Second Generation NDVI and surface reflectance data. Remote Sens. Environ. 2010;114:1687–1698.10.1016/j.rse.2010.02.020
- Anderson GP, Pukall B, Allred CL, Jeong LS, Hoke M, Chetwynd JH, Adler-Golden SM, Berk A, Bernstein LS, Richtsmeier SC, Acharya PK, Matthew MW. FLAASH and MODTRAN4: state-of-the-art atmospheric correction for hyperspectral data. In: 1999 IEEE Aerospace Conference Proceedings. Vol. 4. Piscataway (NJ); 1999. p. 177–181.
- Bernstein LS, Adler-Golden SM, Sundberg RL, Levine RY, Perkins TC, Ratkowski AJ, Felde G, Hoke ML. A new method for atmospheric correction and aerosol optical property retrieval for VIS-SWIR multi- and hyperspectral imaging sensors: QUAC (QUick atmospheric correction). In: Geoscience and Remote Sensing Symposium, 2005. IGARSS '05. Proceedings. 2005 IEEE International. Vol. 5. Seoul; 2005 July 25–29. p. 3549–3552.
- Tanre D, Deroo C, Duhaut P, Herman M, Morcrette JJ, Perbos J, Deschamps PY. Technical note description of a computer code to simulate the satellite signal in the solar spectrum: the 5S code. Int. J. Remote Sens. 1990;11:659–668.10.1080/01431169008955048
- Richards JA, Jia X. Remote sensing digital image analysis: an introduction. 4th ed. Berlin: Springer; 2006.
- Gao B-C, Montes MJ, Davis CO, Goetz AFH. Atmospheric correction algorithms for hyperspectral remote sensing data of land and ocean. Remote Sens. Environ. 2009;113:S17–S24.10.1016/j.rse.2007.12.015
- Vermote EF, El Saleous NZ, Justice CO. Atmospheric correction of MODIS data in the visible to middle infrared: first results. Remote Sens. Environ. 2002;83:97–111.10.1016/S0034-4257(02)00089-5
- Rahman H, Dedeiu G. SMAC: a simplified method for the atmospheric correction of satellite measurements in the solar spectrum. Int. J. Remote Sens. 1994;15:123–143.10.1080/01431169408954055
- Weber G-W, Batmaz İ, Köksal G, Taylan P, Yerlikaya-Özkurt F. CMARS: a new contribution to nonparametric regression with multivariate adaptive regression splines supported by continuous optimization. Inverse Prob. Sci. Eng. 2011;20:371–400.
- Friedman JH. Multivariate adaptive regression splines. Ann. Stat. 1991;19:1–67.10.1214/aos/1176347963
- Özmen A, Kropat E, Weber G-W. Spline regression models for complex multi-modal regulatory networks. Optim. Method Softw. 2014;29:515–534. doi:10.1080/10556788.2013.821611.
- Deichmann J, Eshghi A, Haughton D, Sayek S, Teebagy N. Application of multiple adaptive regression splines (MARS) in direct response modeling. J. Interact. Marketing. 2002;16:15–27.10.1002/dir.10040
- Krzyscin JW, Eerme K, Janouch M. Long-term variations of the UV-B radiation over Central Europe as derived from the reconstructed UV time series. Ann. Geophys. 2004;22:1473–1485.10.5194/angeo-22-1473-2004
- Leathwick JR, Elith J, Hastie T. Comparative performance of generalized additive models and multivariate adaptive regression splines for statistical modelling of species distributions. Ecol. Modell. 2006;199:188–196.10.1016/j.ecolmodel.2006.05.022
- Vermote EF, Kotchenova SY, Ray JP. MODIS surface reflectance user’s guide (version. 1.3). 2011; [cited 2012 Nov 10]. Available from: http://dratmos.geog.umd.edu/products/MOD09_UserGuide_v1_3.pdf.
- Proud SR, Fensholt R, Rasmussen MO, Sandholt IA. Comparison of the effectiveness of 6S and SMAC in correcting for atmospheric interference in Meteosat Second Generation images. J. Geophys. Res-Atmos, 2010. 115:( D17209)1–14. doi: 10.1029/2009JD013693.
- Vermote E, Tanre D, Deuze J, Herman M, Morcette J-J. Second simulation of the satellite signal in the solar spectrum, 6S: an overview. IEEE Trans. Geosci. Remote Sens. 1997;35:675–686.10.1109/36.581987
- MODIS level 1B product user’s guide. NASA/Goddard Space Flight Center. 2009; [cited 2013 Oct 29]. Available from: http://ccplot.org/pub/resources/Aqua/MODIS%20Level%201B%20Product%20User%20Guide.pdf.
- Hastie T, Tibshirani R, Friedman J. The elements of statistical learning: data mining, inference, and prediction. 2nd ed. New York (NY): Springer; 2009.
- Taylan P, Weber G-W, Yerlikaya Özkurt FY. A new approach to multivariate adaptive regression splines by using Tikhonov regularization and continuous optimization. Top. 2010;18:377–395.10.1007/s11750-010-0155-7
- Hubanks PA, King MD, Platnick S, Pincus R. MODIS atmosphere L3 gridded product algorithm theoretical basis document (Collection 005 Version 1.1). 2008; [cited 2012 Oct 29]. Available from: http://modis-atmos.gsfc.nasa.gov/_docs/L3_ATBD_2008_12_04.pdf.
- Cameron AC, Windmeijer FAG. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997;77:329–342.10.1016/S0304-4076(96)01818-0
- MARS®. Salford Systems. Available from: http://www.salfordsystems.com.
- MOSEKTM. Available from: http://www.mosek.com.
- Özmen A, Weber G-W, Batmaz İ, Kropat E. RCMARS: robustification of CMARS with different scenarios under polyhedral uncertainty set. Commun. Nonlinear Sci. Numer. Simul. 2011;16:4780–4787.
- Özmen A, Weber G-W, Çavuşoğlu Z, Defterli Ö. The new robust conic GPLM method with an application to finance: prediction of credit default. J. Global Optim. 2013;56:233–249.
- Hansen PC. Rank-deficient and discrete Ill-posed problems: numerical aspects of linear inversion. Philadelphia, PA: SIAM; 1998.10.1137/1.9780898719697
Appendix 1. Tikhonov regularization
TR is the most common and well-known form to make ill-posed problems regular and stable.[Citation41] Tikhonov solution can be expressed easily in terms of the Singular Value Decomposition (SVD) of the coefficient matrix A of regarded linear systems of equations where A is an ill-conditioned
-matrix. The standard approach to approximately solve this system of equations is known as Least Square Estimation. It seeks to minimize the residual
. To solve different kinds of TR problem, we use SVD to have a solution that minimizes the objective function including
. However, in many cases, it is preferred to achieve a solution that minimizes some other measure of x, such as the norm of first- or second-order derivatives. They are, in approximate sense, given by first- or second-order difference quotients of x, considered as a function that is evaluated at the points k and k + 1. These difference quotients approximate those derivatives; altogether, they are comprised by products Lx of x with matrices L. These matrices represent the discrete differential operators of first- and second-order, respectively. Hereby, the optimization problem is in the following form:
(14)
(14)
Generally, Equation (14) consists of high-order TR problems, and generalized SVD is used to solve them. In many situations, to obtain a solution which minimizes some other measure x, the norm of the first- or second-derivative is preferred.