
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper focuses on prior information for improved sparsity reconstruction in electrical impedance tomography with partial data, i.e. Cauchy data measured on subsets of the boundary. Sparsity is enforced using an norm of the basis coefficients as the penalty term in a Tikhonov functional, and prior information is incorporated by applying a spatially distributed regularization parameter. The resulting optimization problem allows great flexibility with respect to the choice of measurement subsets of the boundary and incorporation of prior knowledge. In fact, the measurement subsets can be chosen completely arbitrary. The problem is solved using a generalized conditional gradient method applying soft thresholding. Numerical examples with noisy simulated data show that the addition of prior information in the proposed algorithm gives vastly improved reconstructions, even for the partial data problem. Moreover, numerical examples show that a reliable reconstruction for the partial data problem can only be found close to the measurement subsets. The method is in addition compared to a total variation approach.
1. Introduction
The inverse problem in electrical impedance tomography (EIT) consists of reconstructing an electrical conductivity distribution in the interior of an object from electrostatic boundary measurements on the surface of the object. EIT is an emerging technology with applications in medical imaging,[Citation1] geophysics [Citation2] and industrial tomography.[Citation3] The underlying mathematical problem is known as the Calderón problem in recognition of Calderón’s seminal paper.[Citation4]
Consider a bounded domain with smooth boundary
. In order to consider partial boundary measurements, we introduce the subsets
for the Neumann and Dirichlet data, respectively. Let
with
a.e. denote the real-valued conductivity distribution in
. Applying a boundary current flux
(Neumann condition) through
gives rise to the interior electric potential
characterized as the solution to
(1.1)
(1.1)
where is an outward unit normal to
. The latter condition in (Equation1.1
(1.1)
(1.1) ) is a grounding of the total electric potential along the subset
. To be precise, we define the spaces
consisting of boundary functions with mean zero, and the spaces
consisting of functions with mean zero on designed to encompass the partial boundary data. Since
is real valued, it is sufficient to consider the above spaces as real vector spaces, for the use of real-valued Cauchy data in the measurements. Using standard elliptic theory, it follows that (Equation1.1
(1.1)
(1.1) ) has a unique solution
for any
. This defines the Neumann-to-Dirichlet map (ND-map)
as an operator from
into
by
, and the partial ND-map as
.
The data for the classical Calderón problem is the full operator with
. The problem is well studied and there are numerous publications addressing different aspects of its solution; we mention only a few: the uniqueness and reconstruction problem was solved in [Citation5–Citation10] using the so-called complex geometrical optics (CGO) solutions; for a recent survey see [Citation11]. Stability estimates of log type were obtained in [Citation12, Citation13] and shown to be optimal in [Citation14]. Thus any computational algorithm must rely on regularization. Such computational regularization algorithms following the CGO approach were designed, implemented and analysed in [Citation15–Citation19].
Recently, the partial data Calderón problem have been studied intensively. In 3D uniqueness has been proved under certain conditions on and
,[Citation20–Citation24] and in 2D the general problem with localized data i.e.
for some, possibly small, subset
has been shown to possess uniqueness.[Citation25] Also stability estimates of log–log type have been obtained for the partial data problem [Citation26]; this suggests that the partial data problem is even more ill-posed and hence requires more regularization than the full data problem. Recently, a computational algorithm for the partial data problem in 2D was suggested and investigated in [Citation27].
The boundary condition in (Equation1.1(1.1)
(1.1) ) is the continuum model which is related to the above-mentioned uniqueness results, and actual electrode measurements can be seen as an approximation to this model, see for instance [Citation28]. Another more realistic model is the Complete Electrode Model (CEM) introduced in [Citation29]. The approach to the reconstruction problem in EIT considered here can be formulated with CEM as well, see [Citation30, Citation31].
A general approach to linear inverse problems with sparsity regularization was given in [Citation32], and in [Citation33, Citation34] the method was adapted to non-linear problems using a so-called generalized conditional gradient method. In [Citation30, Citation35, Citation36], the method was applied to the reconstruction problem in EIT with full boundary data. A study was made in [Citation31] with 3D sparse reconstruction with current injection and voltage measurements on disjoint sets of electrodes on a planar EIT device, where it was possible to reconstruct a 2D position of an inclusion close to the measured boundary. In this paper, we seek a general approach with regards to the measurement boundaries and
, and the use of prior information to improve the reconstruction further away from the measured boundary. In the numerical examples in Section 4 we consider the case of local data, with Cauchy data on the same part of the boundary. For other approaches to EIT using optimization methods, we refer to [Citation37].
In this paper, we will focus on the partial data problem for which we develop a reconstruction algorithm based on a least squares formulation with sparsity regularization. The results are twofold: first we extend the full data algorithm of [Citation36] to the case of partial data, second we show how prior information about the spatial location of the perturbation in the conductivity can be used in the design of a spatially varying regularization parameter. We will restrict the treatment to 2D, however everything extends to 3D with some minor assumptions on the regularity of the Neumann data.[Citation38]
The data considered here consist of a finite number of Cauchy data, corresponding to the number of applied current patterns, taken on the subsets and
, i.e.
(1.2)
(1.2)
We assume that the true conductivity is given as , where
is a known background conductivity. Define the closed and convex subset
(1.3)
(1.3)
for some , and
where
. Similarly define
The inverse problem is then to approximate given the data (Equation1.2
(1.2)
(1.2) ).
Let denote a chosen orthonormal basis for
. For sparsity regularization, we approximate
by
using the following Tikhonov functional [Citation36]
(1.4)
(1.4)
with
for . The regularization parameter
for the sparsity-promoting
penalty term
is distributed such that each basis coefficient can be regularized differently; we will return to this in Section 3. It should be noted how easy and natural the use of partial data is introduced in this way, simply by only minimizing the discrepancy on
on which the Dirichlet data are known and ignoring the rest of the boundary.
This paper is organized as follows: in Section 2 we derive the Fréchet derivative of and reformulate the optimization problem using the generalized conditional gradient method as a sequence of linearized optimization problems. In Section 3, we explain the idea of the spatially dependent regularization parameter designed for the use of prior information. Then, in Section 4 we show the feasibility of the algorithm by several numerical examples, and finally we conclude in Section 5.
2. Sparse reconstruction
In this section, the sparse reconstruction of based on the optimization problem (Equation1.4
(1.4)
(1.4) ) is investigated for a bounded domain
with smooth boundary
. The penalty term emphasizes that
should only be expanded by few basis functions in a given orthonormal basis, and the level of sparsity is controlled by the regularization parameter. Using a distributed regularization parameter, it is possible to further apply prior information about which basis functions that should be included in the expansion of
. The partial data problem comes into play in the discrepancy term, in which we only fit the data on part of the boundary. Ultimately, this leads to the algorithm given in Algorithm 1 at the end of this section.
Denote by the unique solution to (Equation1.1
(1.1)
(1.1) ) and let
be its trace (note that
). Let
,
for
, then following the proofs of Theorem 2.2 and Corollary 2.1 in [Citation35] whilst applying the partial boundary
we have
(2.1)
(2.1)
Here is the linear map that maps
to
, where
is the unique solution to
(2.2)
(2.2)
It is noted that resembles a Fréchet derivative of
evaluated at
due to (Equation2.1
(2.1)
(2.1) ), however
is not a linear vector space, thus the requirement
.
The first step in minimizing using a gradient descent-type iterative algorithm is to determine a derivative to the discrepancy terms
.
Lemma 2.1
Let for
, and
be a characteristic function on
. Then
(2.3)
(2.3)
for some , and the Fréchet derivative
of
on
evaluated at
is given by
(2.4)
(2.4)
Proof
For the proof, the index is suppressed. First it is proved that
for some
, which is shown by estimates on
and
where
. Note that
and
, i.e.
. Now using [Citation35, Theorem 3.1], there exists
such that
(2.5)
(2.5)
where . Since
then
. It has already been established in (Equation2.5
(2.5)
(2.5) ) that
for
, so
. By Hölder’s generalized inequality
and as then
. Let
be the conjugate exponent to
, then
, i.e. the Sobolev imbedding theorem [Citation39] implies that
as
. Thus
.
Now it will be shown that can be identified with
.
is by the chain rule (utilizing that
) given as
(2.6)
(2.6)
where is enforcing that the integral is over
. The weak formulations of (Equation1.1
(1.1)
(1.1) ), with Neumann data
, and (Equation2.2
(2.2)
(2.2) ) are
(2.7)
(2.7)
(2.8)
(2.8)
Now by letting in (Equation2.7
(2.7)
(2.7) ) and
in (Equation2.8
(2.8)
(2.8) ), we obtain using the definition
that
Remark 2.2
It should be noted that is related to the Fréchet derivative
of
evaluated at
, by
.
Define
For a gradient-type descent method, we seek to find a direction for which the discrepancy decreases. As
it is known from Riesz’ representation theorem that there exists a unique function in
, denoted by
, such that
(2.9)
(2.9)
Now points in the direction of steepest descend among the viable directions. Furthermore, since
the boundary condition
will automatically be fulfilled for the approximation. In [Citation40],
is called a Sobolev gradient, and it is the unique solution to
for which (Equation2.9(2.9)
(2.9) ) is the weak formulation.
In each iteration step, we need to determine a step size for an algorithm resembling a steepest descent
. Here a Barzilai–Borwein step size rule [Citation36, Citation41, Citation42] will be applied, for which we determine
such that
in the least squares sense
(2.10)
(2.10)
Assuming that yields
(2.11)
(2.11)
A maximum step size is enforced to avoid the situations where
.
With inspiration from [Citation42], will be initialized by (Equation2.11
(2.11)
(2.11) ), after which it is thresholded to lie in
, for positive constants
and
. It is noted in [Citation42] that Barzilai–Borwein step rules lead to faster convergence if we do not restrict
to decrease in every iteration. Allowing an occasional increase in
can be used to avoid places where the method has to take many small steps to ensure the decrease of
. Therefore, one makes sure that the following so called weak monotonicity is satisfied, which compares
with the most recent
steps. Let
and
, then
is said to satisfy the weak monotonicity with respect to
and
if the following is satisfied [Citation42]
(2.12)
(2.12)
If (Equation2.12(2.12)
(2.12) ) is not satisfied, the step size
is reduced until this is the case. To solve the non-linear minimization problem for (Equation1.4
(1.4)
(1.4) ), we iteratively solve the following linearized problem
(2.13)
(2.13)
Here is an orthonormal basis for
in the
-metric, and
is the projection of
onto
to ensure that (Equation1.1
(1.1)
(1.1) ) is solvable (note that
does not imbed into
, i.e.
may be unbounded). By use of the map
defined below, known as the soft shrinkage/thresholding map with threshold
,
(2.14)
(2.14)
the solution to (Equation2.13(2.13)
(2.13) ) is easy to find directly (see also [Citation32, Section 1.5]):
(2.15)
(2.15)
where are the basis coefficients for
.
Remark 2.3
The soft threshold in (Equation2.15(2.15)
(2.15) ) assumes that the coefficients
are real valued, as in this case with real-valued conductivity
and Cauchy-data. For complex-valued admittivity
, appropriate use of complex conjugation is required for the derivative in Lemma 2.1, and a minimizer for (Equation2.13
(2.13)
(2.13) ) can be found in [Citation42].
The projection is defined as
(2.16)
(2.16)
where is the following truncation that depends on the constant
in (Equation1.3
(1.3)
(1.3) )
Since and
, it follows directly from [Citation43, Lemma 1.2] that
and
are well defined, and it is easy to see that
is a projection.
Remark 2.4
In the numerical examples in Section 4, the value of is chosen small enough that the truncation in
does not occur during the iterations. If tight bounds on
are known a priori, the truncation may lead to improved rate of convergence and gives reconstructions in the correct dynamic range.
It should also be noted that since
, thus we may choose
as the initial guess in the algorithm. The algorithm is summarized in Algorithm 1. In this paper, the stopping criterion is when the step size
gets below a threshold
.
Remark 2.5
Note that corresponds to only having the discrepancy term in (Equation2.13
(2.13)
(2.13) ), while the penalty term
leads to the soft thresholding in (Equation2.15
(2.15)
(2.15) ).
Remark 2.6
The functional in (Equation1.4
(1.4)
(1.4) ) is non-convex. Thus, the best we can hope is to find a local minimum. The quality of the reconstruction depends on the initial guess, and as we expect the reconstruction to be sparse, then
is a reasonable initial guess.
Remark 2.7
The main computational cost lies in computing , which involves solving
well-posed PDE’s (note that
can be reused from the evaluation of
), where
is the number of current patterns used in the measurements. It should be noted that each of the
problems consists of solving the same problem, but with different boundary conditions, which leads to only having to assemble and factorize the finite element method (FEM) matrix once per iteration.
3. Prior information
Prior information is typically introduced in the penalty term for Tikhonov-like functionals, and here the regularization parameter determines how much this prior information is enforced. In the case of sparsity regularization, this implies knowledge of how sparse we expect the solution is in general. Instead of applying the same prior information for each basis function, a distributed parameter is applied. Let
where is the usual regularization parameter, corresponding to the case where no prior information is considered about specific basis functions. The
will be used to weight the penalty depending on whether a specific basis function should be included in the expansion of
. The
are chosen as
i.e. if we know that a coefficient in the expansion of should be non-zero, we can choose to penalize that coefficient less. Using a basis with localized support, the sparsity assumption translates to an assumption on the support of the inclusion.
3.1. Applying the FEM basis
In order to improve the sparsity solution for finding small inclusions, it seems appropriate to include prior information about the support of the inclusions. There are different methods available for obtaining such information assuming piecewise constant conductivity [Citation44, Citation45] or real-analytic conductivity.[Citation46] An example of the reconstruction of is shown in Figure , where it is observed that numerically it is possible to reconstruct a reasonable convex approximation to the support. Thus, it is possible to acquire estimates of
for free, in the sense that it is gained directly from the data without further assumptions on the location.
Figure 1. (a) Phantom with kite-shaped piecewise constant inclusion . (b) Reconstruction of
using monotonicity relations from the approach in [Citation45] by use of simulated noiseless data.
![Figure 1. (a) Phantom with kite-shaped piecewise constant inclusion δσ. (b) Reconstruction of ∗suppδσ using monotonicity relations from the approach in [Citation45] by use of simulated noiseless data.](/cms/asset/e2994832-b434-4b0b-a935-b34a2ec79b19/gipe_a_1047365_f0001_oc.gif)
Another approach is to consider other reconstruction methods such as total variation (TV) regularization that tends to give good approximations to the support, but has issues with reconstructing the contrast if the amplitude of is large as seen in Section 4.3. The idea is to be able to apply such information in the sparsity algorithm in order to get good contrast in the reconstruction while maintaining the correct support, even for the partial data problem.
Suppose that as a basis we consider a FEM basis for the subspace
of piecewise affine elements. This basis comprises basis functions that are piecewise affine with degrees of freedom at the mesh nodes, i.e.
at mesh node
in the applied mesh. Let
, then
, i.e. for each node there is a basis function for which the coefficient contains local information about the expanded function; this is convenient when applying prior information about the support of an inclusion. Note that the FEM basis functions are not mutually orthogonal, since basis functions corresponding to neighbouring nodes are non-negative and have overlapping support. However, for any non-neighbouring pair of nodes the corresponding basis functions are orthogonal.
When applying the FEM basis for mesh nodes , the corresponding functional is
It is evident that the penalty corresponds to determining inclusions with small support, and prior information on the sparsity corresponds to prior information on the support of . We cannot directly utilize (Equation2.15
(2.15)
(2.15) ) due to the FEM basis not being an orthonormal basis for
, and instead we suggest the following iteration step:
(3.1)
(3.1)
Note that the regularization parameter will depend quite heavily on the discretization of the mesh, i.e. for the same domain a good regularization parameter will be much larger on a coarse mesh than on a fine mesh. This is quite inconvenient, and instead we can weight the regularization parameter according to the mesh cells, by having
. This leads to a discretization of a weighted
-norm penalty term:
where is continuous and
. For a triangulated mesh, the weights
consists of the node area computed in 2D as 1/3 of the area of
. This corresponds to splitting each cell’s area evenly amongst the nodes, and it will not lead to instability on a regular mesh. This will make the choice of
almost independent of the mesh, and is used in the numerical examples in the following section.
Remark 3.1
The corresponding algorithm with the FEM basis is the same as Algorithm 1, except that the update is applied via (Equation3.1(3.1)
(3.1) ) instead of (Equation2.13
(2.13)
(2.13) ).
4. Numerical examples
In this section we illustrate, through several examples, the numerical algorithm implemented using the finite element library FEniCS.[Citation47] We consider the full data case first without prior information and then with prior information, and afterwards we do the same for the partial data case. Finally, a brief comparison is made with another sparsity promoting method based on TV.
For the following examples is the unit disk in
(however, the algorithm can be applied to any bounded domain with smooth boundary). The regularization parameter
is chosen manually by trial and error. The other parameters are
,
,
,
,
, and the stopping criteria are when the step size is below
. We take
with the applied Neumann data of the form
and
for
and
being the angular variable. Such trigonometric current patterns are realistic approximations to electrode measurements, see for instance [Citation28]. For the partial data, an interval
is considered, and
and
are scaled and translated such that they have
periods in the interval.
When applying prior information, the coefficients are chosen as
where the support of
is assumed, and
elsewhere. It should be noted that in order to get fast transitions for sharp edges when prior information is applied, a local mesh refinement is used during the iterations to refine the mesh where
is large.
For the simulated Dirichlet data, the forward problem is computed on a very fine mesh, and afterwards interpolated onto a different much coarser mesh (with roughly 2800 triangle elements) in order to avoid inverse crimes. White Gaussian noise has been added to the Dirichlet data on the discrete nodes on the boundary of the mesh. The standard deviation of the noise is chosen as
as in [Citation36], where the noise level is fixed as
(corresponding to 1% noise) unless otherwise stated.
Figure 2. Numerical phantoms. (a) Circular piecewise constant inclusion. (b) Kite-shaped piecewise constant inclusion. (c) Multiple inclusions.
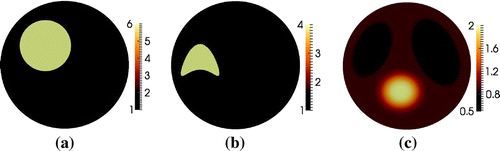
Figure shows the numerical phantoms: where one is a simple circular inclusion, another is the non-convex kite-shaped phantom. Finally, we also shortly investigate the case of multiple smoother inclusions.
4.1. Full boundary data
For , it is possible to get quite good reconstructions of both shape and contrast for the convex inclusions as seen in Figure , and for the case with multiple inclusions there is a reasonable separation of the inclusions.
Figure 3. Full data sparse reconstruction of the phantoms in Figure without prior information on the support of inclusions.
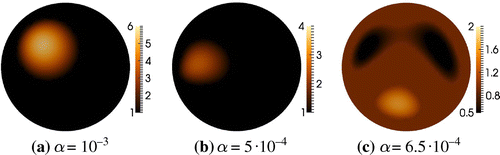
For the kite-shaped phantom, we only get what seems like a convex approximation of the shape. It is seen in [Citation36] that the algorithm is able to reconstruct some types of non-convex inclusions such as the hole in a ring-shaped phantom, however those inclusions are much larger which makes it easier to distinguish from similar convex inclusions.
We note that the method is very noise robust. Figure demonstrates that even unreasonably large amounts of noise lead to only small deformations in the shape of the reconstructed inclusion.
Figure 4. Left: Dirichlet data corresponding to for the phantom in Figure (a), with 10% and 50% noise level. Middle: full data reconstruction for 10% noise level. Right: full data reconstruction for 50% noise level.
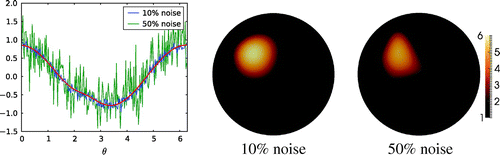
Figure 5. Full data sparse reconstruction of the phantom in Figure (a) varying the assumed support given by a dilation . The colour bar is truncated at
. For
, the contrast in the reconstruction is higher than in the phantom.
![Figure 5. Full data sparse reconstruction of the phantom in Figure 2(a) varying the assumed support given by a dilation δr. The colour bar is truncated at [1,6]. For δr<0, the contrast in the reconstruction is higher than in the phantom.](/cms/asset/b3e0573d-31ce-413a-9f0b-f034c8e18ca1/gipe_a_1047365_f0005_oc.gif)
In order to investigate the use of prior information, we consider the phantom in Figure (a), and let denote a ball centred at the correct inclusion and with radius
. Now we can investigate reconstructions with prior information assuming that the support of the inclusion is
for
being the correct radius of the inclusion. Figure shows that underestimating the support of the inclusion
is heavily enforced, and the contrast is vastly overestimated in the reconstruction as shown in Figure (note that this cannot be seen in Figure as the color scale for the phantom is applied).
Figure 6. Behaviour of full data sparsity reconstruction based on the phantom in Figure (a) by varying characterizing the assumed support. The correct support of the inclusion is a ball
while the assumed support is
.
is the average of reconstruction
over
and
is the average on the complement of
.
is the maximum of
on the mesh nodes.
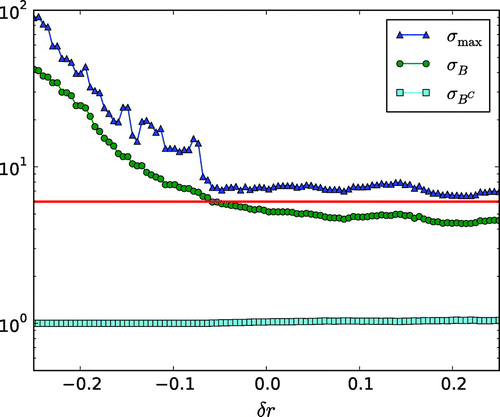
Interestingly, when overestimating the support, the contrast and support of the reconstructed inclusion does not suffer particularly. Intuitively, this corresponds to increasing such that the assumed support of
contains the entire domain
, which corresponds to the case with no prior information. Denote by
the average of the reconstruction
on
, the correct support of the inclusion, and by
the average of
on the complement to
. Denote by
the maximum of
on the mesh nodes. Then Figure gives a good indication of the aforementioned intuition, where around
both
and
level off around the correct contrast of the inclusion (the red line) and stays there for
. It should be noted that even a 25% overestimation of the support leads to a better contrast in the reconstruction than if no prior information was applied, as seen in Figure .
Having an overestimation of the support for also seems to be a reasonable assumption. Definitely there is the case of no prior information which means that
is assumed to be
. If the estimation comes from another method such as TV regularization, then the support is typically slightly overestimated while the contrast suffers.[Citation48] Thus, we can use the overestimated support to get a good localization and contrast reconstruction simultaneously.
Figure shows how the reconstruction of the kite-shaped phantom can be vastly improved. Note that not only is better approximated, but the contrast is also highly improved. It is not surprising that we can achieve an almost perfect reconstruction if
is exactly known, however it is a good benchmark to compare the cases for the overestimated support as it shows how well the method can possibly do.
4.2. Partial boundary data
For the partial data problem we choose for
.
In Figure we observe that with data on the top half of the unit circle, it is actually possible to get very good contrast and also reasonable localization of the two large inclusions. There is still a clear separation of the inclusions, while the small inclusion is not reconstructed at all. With data on the bottom half, the small inclusion is reconstructed almost as well as with full boundary data, but the larger inclusions are only vaguely visible. This is the kind of behaviour that is expected from partial data EIT, and in practice it implies that we can only expect reasonable reconstruction close to where the measurements are taken.
In the rightmost reconstruction in Figure , there is a small artefact to the left in a region where a reliable reconstruction is expected. This may be due to the partial data problem being very noise sensitive and the low number of current patterns ().
Figure 7. Full data sparse reconstruction of the phantom in Figure (b). The applied prior information for the overestimated support is a 10% dilation of the correct shape.

Figure 8. Sparse reconstruction of the phantom in Figure (c). Left: . Middle:
. Right:
.

Figure 9. Sparse reconstruction of the phantom with a ball inclusion in Figure (a). (a) 50% boundary data, no prior. (b): 50% boundary data with 5% overestimated support. (c): 25% boundary data, no prior. (d): 25% boundary data with 5% overestimated support.

Figure 10. Sparse reconstruction of the phantom with a kite-shaped inclusion in Figure (b). (a) 50% boundary data, no prior. (b) 50% boundary data with 10% overestimated support. (c) 25% boundary data, no prior. (d) 25% boundary data with 10% overestimated support.
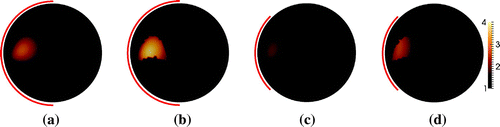
In Figures and panels (a) and (c) it is observed that as the length of becomes smaller, the reconstructed shape of the inclusion is rapidly deformed. By including prior information about the support of
, it is possible to rectify the deformation of the shape, and get reconstructions with almost the correct shape but with a slightly worse reconstructed contrast compared to full boundary data reconstructions. This is observed for the ball- and kite-shaped inclusions in Figures and , respectively.
4.3. Comparison with TV regularization
Another sparsity promoting method is TV regularization, which promotes a sparse gradient in the solution. This can be achieved by minimizing the functional(4.1)
(4.1)
where the discrepancy terms remain the same as in (Equation1.4
(1.4)
(1.4) ), but the penalty term is now given by
(4.2)
(4.2)
Here is a constant that implies that
is differentiable, but chosen small such that
approximates
. The computational cost for determining the derivative of
is the same as for the sparsity regularization in (Equation1.4
(1.4)
(1.4) ), as it is dominated by the same
PDE’s (see Remark 2.7). Minimizing the functional (Equation4.1
(4.1)
(4.1) ) is implemented numerically using a plain steepest descend method.
For the numerical examples, the piecewise constant phantoms in Figure panels (a) and (b) are used, with the same noise level as in the previous sections. The value is used for the penalty term in all the examples.
It should be noted that the colour scale in the following examples is not the same scale as for the phantoms, unlike the previous reconstructions. This is because the TV reconstructions have a significantly lower contrast, in particular for the partial data reconstructions, and would be visually difficult to distinguish from the background conductivity in the correct colour scale.
Figure 11. TV reconstruction of the phantom with a ball inclusion in Figure (a). (a) Full boundary data. (b) 50% boundary data. (c) 25% boundary data.
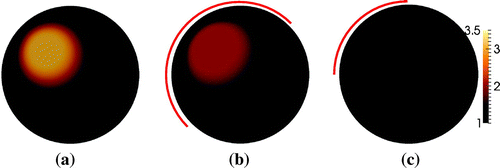
Figure 12. TV reconstruction of the phantom with a kite-shaped inclusion in Figure (b). (a) Full boundary data. (b) 50% boundary data. (c) 25% boundary data.
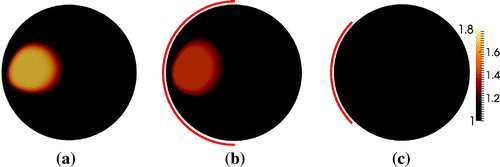
As seen from Figures and , the support of the inclusion is slightly overestimated in the case of full boundary data, and for the partial data cases the support is slightly larger than the counterparts in Figures and . It is also noticed that the TV reconstructions have a much lower contrast than the sparsity reconstructions, and the contrast for the TV reconstructions is severely reduced when partial data are used. It is also observed that the same type of shape deformation occurs for both methods in case of partial data.
A typical feature of the TV regularization is piecewise constant reconstructions; however, the reconstructions seen here have constant contrast levels with a smooth transition between them. This is partly due to the slight smoothing of the penalty term with the parameter to make it differentiable, but mostly because the discrepancy terms are not convex which may lead to local minima. The same kind of smooth transitions is also observed in TV-based methods for EIT in [Citation48].
5. Conclusions
We have extended the algorithm developed in [Citation36], for sparse reconstruction in electrical impedance tomography, to the case of partial data. Furthermore, we have shown how a distributed regularization parameter can be applied to utilize spatial prior information. This lead to numerical results showing improved reconstructions for the support of the inclusions and the contrast simultaneously. The use of the distributed regularization parameter enables sharper edges in the reconstruction and vastly reduces the deformation of the inclusions in the partial data problem, even when the prior is overestimated.
The optimization problem is non-convex and the suggested algorithm is therefore only expected to find a local minimum. Initializing with the background conductivity in the numerical examples yields acceptable reconstructions for both full boundary data and partial boundary data.
The algorithm can be generalized for 3D reconstruction, under further assumptions on the boundary conditions and the amplitude of the perturbation
. This will be considered in a forthcoming paper [Citation38].
Additional information
Funding
Notes
No potential conflict of interest was reported by the authors.
References
- Holder DS. Electrical impedance tomography: methods, history and applications. Bristol: IOP Publishing Ltd; 2005.
- Abubakar A, Habashy TM, Li M, Liu J. Inversion algorithms for large-scale geophysical electromagnetic measurements. Inverse Prob. 2009;25:30 p. Article ID 123012.
- York TA. Status of electrical tomography in industrial applications. Proc. SPIE Int. Soc. Opt. Eng. 2001;4188:175–190.
- Calderón AP. On an inverse boundary value problem. In: Seminar on numerical analysis and its applications to continuum physics (Rio de Janeiro, 1980). Rio de Janeiro: Sociedade Brasiliera de Matemática; 1980. p. 65–73.
- Sylvester J, Uhlmann G. A global uniqueness theorem for an inverse boundary value problem. Ann. Math. (2). 1987;125:153–169.
- Nachman AI. Reconstructions from boundary measurements. Ann. Math. (2). 1988;128:531–576.
- Novikov RG. A multidimensional inverse spectral problem for the equation -Δψ+(u(x)-Eu(x))ψ=0. Funktsional. Anal. i Prilozhen. 1988;22:11–22, 96.
- Nachman AI. Global uniqueness for a two-dimensional inverse boundary value problem. Ann. Math. (2). 1996;143:71–96.
- Astala K, Päivärinta L. Calderón’s inverse conductivity problem in the plane. Ann. Math. (2). 2006;163:265–299.
- Haberman B, Tataru D. Uniqueness in Calderón’s problem with Lipschitz conductivities. Duke Math. J. 2013;162:496–516.
- Uhlmann G. Electrical impedance tomography and Calderón’s problem. Inverse Prob. 2009;25:39 p. Article ID 123011.
- Alessandrini G. Stable determination of conductivity by boundary measurements. Appl. Anal. 1988;27:153–172.
- Alessandrini G. Singular solutions of elliptic equations and the determination of conductivity by boundary measurements. J. Differ. Equ. 1990;84:252–272.
- Mandache N. Exponential instability in an inverse problem for the Schrödinger equation. Inverse Prob. 2001;17:1435–1444.
- Siltanen S, Mueller J, Isaacson D. An implementation of the reconstruction algorithm of A. Nachman for the 2D inverse conductivity problem. Inverse Prob. 2000;16:681–699.
- Knudsen K, Lassas M, Mueller JL, Siltanen S. Regularized D-bar method for the inverse conductivity problem. Inverse Prob. Imaging. 2009;3:599–624.
- Bikowski J, Knudsen K, Mueller JL. Direct numerical reconstruction of conductivities in three dimensions using scattering transforms. Inverse Prob. 2011;27:015002, 19.
- Delbary F, Hansen PC, Knudsen K. Electrical impedance tomography: 3D reconstructions using scattering transforms. Appl. Anal. 2012;91:737–755.
- Delbary F, Knudsen K. Numerical nonlinear complex geometrical optics algorithm for the 3D Calderón problem. Inverse Prob. Imaging. 2014;8:991–1012.
- Bukhgeim AL, Uhlmann G. Recovering a potential from partial Cauchy data. Comm. Partial Differ. Equ. 2002;27:653–668.
- Kenig CE, Sjöstrand J, Uhlmann G. The Calderón problem with partial data. Ann. Math (2). 2007;165:567–591.
- Knudsen K. The Calderón problem with partial data for less smooth conductivities. Comm. Partial Differ. Equ. 2006;31:57–71.
- Zhang G. Uniqueness in the Calderón problem with partial data for less smooth conductivities. Inverse Prob. 2012;28:105008, 18.
- Isakov V. On uniqueness in the inverse conductivity problem with local data. Inverse Prob. Imaging. 2007;1:95–105.
- Imanuvilov OY, Uhlmann G, Yamamoto M. The Calderón problem with partial data in two dimensions. J. Am. Math. Soc. 2010;23:655–691.
- Heck H, Wang JN. Stability estimates for the inverse boundary value problem by partial Cauchy data. Inverse Prob. 2006;22:1787–1796.
- Hamilton SJ, Siltanen S. Nonlinear inversion from partial EIT data: computational experiments. In: Stefanov P, Zworski M, editors. Inverse problems and applications. Vol. 615, Contemporary mathematics. Providence (RI): American Mathematical Society; 2014. p. 105–129.
- Mueller JL, Siltanen S. Linear and nonlinear inverse problems with practical applications. Vol. 10, Computational science & engineering. Philadelphia (PA): Society for Industrial and Applied Mathematics (SIAM); 2012.
- Somersalo E, Cheney M, Isaacson D. Existence and uniqueness for electrode models for electric current computed tomography. SIAM J. Appl. Math. 1992;52:1023–1040.
- Gehre M, Kluth T, Lipponen A, Jin B, Seppänen A, Kaipio JP, Maass P. Sparsity reconstruction in electrical impedance tomography: an experimental evaluation. J. Comput. Appl. Math. 2012;236:2126–2136.
- Gehre M, Kluth T, Sebu C, Maass P. Sparse 3D reconstructions in electrical impedance tomography using real data. Inverse Prob. Sci. Eng. 2014;22:31–44.
- Daubechies I, Defrise M, De Mol C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Comm. Pure Appl. Math. 2004;57:1413–1457.
- Bredies K, Lorenz DA, Maass P. A generalized conditional gradient method and its connection to an iterative shrinkage method. Comput. Optim. Appl. 2009;42:173–193.
- Bonesky T, Bredies K, Lorenz DA, Maass P. A generalized conditional gradient method for nonlinear operator equations with sparsity constraints. Inverse Prob. 2007;23:2041–2058.
- Jin B, Maass P. An analysis of electrical impedance tomography with applications to Tikhonov regularization. ESAIM: Control Optim. Calcul. Varia. 2012;18:1027–1048.
- Jin B, Khan T, Maass P. A reconstruction algorithm for electrical impedance tomography based on sparsity regularization. Int. J. Numer. Methods Eng. 2012;89:337–353.
- Borcea L. Electrical impedance tomography. Inverse Prob. 2002;18:R99–R136.
- Garde H, Knudsen K. 3D reconstruction for partial data electrical impedance tomography using a sparsity prior. Submitted, 2014. Available from: http://arxiv.org/abs/1412.6288
- Adams RA, Fournier JJF. Sobolev spaces. 2nd ed. Vol. 140, Pure and applied mathematics (Amsterdam). Amsterdam: Elsevier/Academic Press; 2003.
- Neuberger JW. Sobolev gradients and differential equations. 2nd ed. Vol. 1670, Lecture notes in mathematics. Berlin: Springer-Verlag; 2010.
- Barzilai J, Borwein JM. Two-point step size gradient methods. IMA J. Numer. Anal. 1988;8:141–148.
- Wright SJ, Nowak RD, Figueiredo MAT. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009;57:2479–2493.
- Stampacchia G. Le problème de dirichlet pour les équations elliptiques du second ordre à coefficients discontinus. Ann. lnst. Fourier. 1965;15:189–257.
- Kirsch A, Grinberg N. The factorization method for inverse problems. Vol. 36, Oxford lecture series in mathematics and its applications. Oxford: Oxford University Press; 2008.
- von Harrach B, Ullrich M. Monotonicity-based shape reconstruction in electrical impedance tomography. SIAM J. Math. Anal. 2013;45:3382–3403.
- von Harrach B, Seo JK. Exact shape-reconstruction by one-step linearization in electrical impedance tomography. SIAM J. Math. Anal. 2010;42:1505–1518.
- Logg A, Mardal KA, Wells GN. Automated solution of differential equations by the finite element method. Vol. 84, Lecture notes in computational science and engineering. Heidelberg: Springer; 2012; the FEniCS book.
- Borsic A, Graham BM, Adler A, Lionheart W. In vivo impedance imaging with total variation regularization. IEEE Trans. Med. Imaging. 2010;29:44–54.