
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article is devoted to a Lagrange principle application to an inverse problem of a two-dimensional integral equation of the first kind with a positive kernel. To tackle the ill-posedness of this problem, a new numerical method is developed. The optimal and regularization properties of this method are proved. Moreover, a pseudo-optimal error of the proposed method is considered. The efficiency and applicability of this method are demonstrated in a numerical example of an image deblurring problem with noisy data.
1. Introduction
A lot of inverse problems of mathematical physics are posed as linear integral equations.[Citation1] There are many known methods of solving equations of this type. Their description can be found in several monographs, for instance, in [Citation1–Citation3]. In this paper, the image deblurring problem of solving a two-dimensional integral equation of the first kind with a positive kernel is studied. This problem arises in atmospheric optics, an application described in detail in [Citation4]. Obviously, this problem belongs to the class of ill-posed problems. Mathematical techniques known as regularization methods have been developed to deal with this ill-posedness. These methods, such as variational regularization methods and iterative regularization methods,[Citation5–Citation10] can be used to solve the inverse problem of two-dimensional integral equation of the first kind. But in many cases, it is possible to find a set of a priori constraints to turn the problem into the well-posed one. For instance, the well-known problem of inversion of a continuous injective operator with a compact set of a priori constraints has this property.[Citation6] Several concrete compact sets of solution function with special form, such as sets of bounded monotone function, bounded convex function, etc., were studied in papers [Citation11–Citation15]. In this paper, instead of the compact we use the balanced property of the solution set, which helps us to estimate an error of the proposed method.
By the definition of regularization methods [Citation16], we see that if one found a specific regularization method, there must exist various regularization methods. Each has its specific error of an obtained approximate solution. It is desirable that the method has as small error as possible. For this purpose, the problem of reconstructing the solution of two-dimensional integral equation of the first kind is reformulated in a form of an optimal recovery problem.[Citation17–Citation24] In this paper, using optimal recovery theory and Lagrange principle, we propose a new numerical method for solving two-dimensional integral equation of the first kind with a positive kernel on a fixed grid. The regularization and optimization properties of this method are proved. A corresponding pseudo-optimal error of this method is also calculated. In the end of this paper, a numerical example of the image deblurring problem with noisy data will be solved.
2. Statement of a problem
Denote the segments from :
,
,
and
. Let
be the space of real continuous functions and
be the space of square-integrable functions. Let
:
be a linear integral operator with a positive and continuous (by all arguments) kernel
. Our problem is to find a so-called (pseudo-)optimal regularized solution
from the following integral equation
(1)
(1)
where
is a set of a priori information of the exact solution. Here, a bound of the solution and a Lipschitz constant of the solution function
are two given positive numbers, and
:
.
In optics, function is called a light source. The kernel
is known as a point spread function. The right-hand side
is called a (blurred) continuous image. Integral equation of the first kind (Equation1
(1)
(1) ) can not only be used to model the diffraction of light from the sources as it propagates through the atmosphere, but also model the distortion due to imperfections in optical devices like telescopes and microscopes.[Citation4,Citation25,Citation26]
Denote the integral operator with a positive and continuous kernel as
. Suppose that instead of the exact kernel
and right-hand side
(where
and
is the unknown exact solution of problem (Equation1
(1)
(1) )) we are given approximate admissible data
and
such that:
(2)
(2)
where – error levels,
is an
matrix, which will be called data of measurements,
– the induced Euclidean norm; i.e.
, and
is any linear bounded projection operator. Using the above information the following inequalities hold:
(3)
(3)
The number will be called a predictive error of problem (Equation1
(1)
(1) ). Denote the pair of errors
. Obviously,
as
.
In practice, finding an analytical solution of Equation (Equation1(1)
(1) ) is impossible. Instead of an analytical solution, we consider a discrete one by some numerical methods. That is to say, for problem (Equation1
(1)
(1) ) instead of a solution function
we consider the value of solution
at some fixed points; i.e. we need to find an approximation
of the matrix
(where
and
are some corresponding grids on
and
; i.e.
and
). Then, from the obtained approximate matrix
we construct a continuous function
using an approximation rule and prove that
as
and
.
First of all, let us consider a method of recovery of the value of the function at a point
. Define set
as a set of all a priori information of the problem (Equation1
(1)
(1) )
(4)
(4)
where the predictive error is defined by (Equation3
(3)
(3) ).
Definition 2.1
A method of recovery of the value of the function at a point
is called any functional
:
. The error of the recovery method
is given by
(5)
(5)
Definition 2.2
The optimal error of recovery of the value of the function at the point
is given by
(6)
(6)
where the infimum is taken over all functionals (maybe nonlinear) :
. Any functional
for which the infimum in (Equation6
(6)
(6) ) is attained we call an optimal recovery method of the function
at the point
.
Now, let us discuss how to find a functional (a method of recovery of the value of the function
at the point
). Note that set
is a bounded convex and balanced set in space
, then by theorem Smolyak [Citation19,Citation27] we see that among all optimal recovery methods there exists a linear one. Moreover, by the Riesz-Fréchet representation theorem, problems (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) can be rewritten as the following problem
(7)
(7)
where denotes the Euclidean inner product.
3. Reduction to a finite-dimensional problem and its solving method
In order to solve a problem of optimal recovery in finite-dimensional space instead of the problem (Equation7(7)
(7) ), which is posed in the infinite-dimensional space
, we introduce a projection operator
:
and a bilinear interpolation operator
:
such that
(8)
(8)
where (
) is the standard basis in
(
) and coefficient
is the value of the function
at the point
; i.e.
.
(9)
(9)
for and
. Here
is an
matrix. For simplicity, we use the uniform grid (
and
for any index
) and the Tchebycheff norm for matrix
(
).
Define a set of discrete a priori information , which is a finite-dimensional analogue of the set
, as
(10)
(10)
For problem (Equation7(7)
(7) ), we consider an auxiliary problem of optimal recovery of a real number
in the finite-dimensional space
:
(11)
(11)
Define an approximation error of the problem (Equation11
(11)
(11) ) as
(12)
(12)
In a similar way as the method described in the paper [Citation28], it is not difficult to prove that for any fixed indices and
sequence
as
. Hence, instead of the infinite-dimensional problem (Equation7
(7)
(7) ) we can only consider its finite-dimensional analogue – the problem (Equation11
(11)
(11) ). The extreme value of the problem (Equation11
(11)
(11) ) is as close as the extreme value of the initial problem (Equation7
(7)
(7) ) if numbers
,
are sufficiently large.[Citation23]
Now, let us solve the finite-dimensional problem (Equation11(11)
(11) ). Above all, define operators
and
, which help us introduce problem (Equation11
(11)
(11) ) into a matrix form.
Definition 3.1
Given a matrix , one can obtain a vector
by stacking the columns of
. This defines a linear operator
,
This corresponds to lexicographical column ordering of the components in the matrix . The symbol
denotes the inverse of the
operator. That means the following equalities hold
whenever and
.
Remark 1
Similarly, we can define operator such that
Denote as the inverse of the
operator. Let
, and
.
Note that , hence, using operators
and
we can introduce set
to the following matrix form
(13)
(13)
where the matrix
can be obtained by any numerical integration methods.[Citation29,Citation30] In this article, we use trapezoidal rule.
Now, instead of problem (Equation11(11)
(11) ) we consider the following problem
(14)
(14)
Connect this problem to another extremal problem, which is called associated problem to (Equation14(14)
(14) )
(15)
(15)
where(16)
(16)
The optimization problem (Equation15(15)
(15) ) always exists an unique solution for a fixed error level
since
is a bounded convex set in
.
Now, consider the sensitivity result of optimization problem (Equation15(15)
(15) ). The theory of point-to-set maps [Citation31] has been used for the analysis of this type of the optimization problem. Hogen [Citation32,Citation33] has provided an excellent development of those properties of point-to-set maps that are especially useful in deriving such results. The following theorem is a result of the case in which the parameter of the problem appears in the constraints.
Theorem 3.2
[Citation33,Citation34] Suppose that is a compact convex set,
(not necessarily convex) is continuous on
, and the components of
are both lower semicontinuous and strictly convex on
. Then the perturbation function associated with the convex programme
is defined on as
is continuous on its effective domain in .
Remark 2
| (1) | By above theorem it is easy to show that the objective function | ||||
| (2) | Obviously, | ||||
At the end of this section, let us formulate a theorem,[Citation19,Citation28] which is the basic for the algorithm proposed in this article.
Theorem 3.3
(Lagrange Principle) Denote by ,
the Lagrange function of problem (Equation14(14)
(14) ). Vector
will be called a Lagrange multiplier of the problem (Equation14
(14)
(14) ). If an element
is an admissible point in the problem (Equation15
(15)
(15) ); i.e.
, then
| (1) | two following conditions are equivalent:
| ||||||||||||||||
| (2) | in the case when these two equivalent conditions hold, | ||||||||||||||||
Remark 3
| (1) | Lagrange Principle makes possible to reduce a problem of optimal recovery (Equation14 | ||||
| (2) | In order to find an optimal approximation of matrix | ||||
4. Lagrange multiplier selection method
Define , which will be called a Lagrange multiplier matrix of the problem (Equation14
(14)
(14) ). Obviously, the equality
holds, where
,
is the standard basis in
. In this section, we indicate that Lagrange multiplier matrix
plays the role of the regularization parameter for the ill-posed problem (Equation1
(1)
(1) ), and we are going to find a so-called pseudo-optimal regularization Lagrange multiplier matrix. Above all, consider some definitions of spaces, to which the integral operator with a positive kernel
belongs. For simplicity, here, we only consider the finite-dimensional case.
Definition 4.1
A matrix is called a positive matrix (on a cone) if
and
the inequality
holds, where
means that all components of the vector
are nonnegative. Moreover, a matrix
is called a generalized positive matrix if for any fixed matrix
the matrix
for sufficiently small parameter
is a positive one, where
is a diagonal matrix with nonnegative real numbers on the diagonal.
Remark 4
| (1) | Obviously, the finite-dimensional approximation of the integral operator with a positive kernel | ||||
| (2) | For the infinite dimensional case, one can use the corresponding concepts in vector lattices.[Citation35] | ||||
Now, let us discuss how to find a pseudo-optimal regularization Lagrange multiplier matrix . Lagrange Principle shows that for every fixed index
there exists a Lagrange multiplier
such that
(17)
(17)
where – a supremum of the associated problem (Equation15
(15)
(15) ) for a fixed index
. After a simpler transformation we can obtain
(18)
(18)
Let and denote
as the solution
with parameter
. By Remark 2 in Section 3 we have
. The vector representation of system of inequations (Equation18
(18)
(18) ) is
(19)
(19)
Denote as a set of solutions of inequalities (Equation19
(19)
(19) ). Theorem 3.3 asserts that
. For a general algebraic equation, in [Citation28], using the simplex algorithm and the set of active constraints index the author proposed an algorithm of finding all solutions of inequalities (Equation19
(19)
(19) ). In many cases, the solution set is infinite. In [Citation23], using singular value decomposition the author found a so-called optimal regularization Lagrange multiplier matrix under some assumptions. In this paper, using the property of generalized positive matrix
we can also find a pseudo-optimal regularization Lagrange multiplier matrix.
In a similar way as the method described in [Citation23], among all solutions in set we choose a Lagrange multiplier, which has the following form
(20)
(20)
where ,
– regularization parameter, which will be defined later and
is a
symmetric matrix, obtained from the discretization of some penalty functionals. For instance, for the squared
-norm penalty functional we have
and for the Sobolev
penalty functional we have
, where
is a
symmetric tridiagonal matrix.[Citation36]
Above all, let us show the well-postness of the definition (Equation20(20)
(20) ). For simplicity, we only consider the case
. Indeed, by the singular value decomposition of the matrix
we have
, where
and
are unitary matrices with size
and
respectively,
is a rectangular diagonal matrix with nonnegative real numbers on the diagonal such that
. Here
denotes the rank of
. Hence,
, where
, which implies
is invertible for
,
and
,
.
Now, consider the condition of the regularization parameter .
Lemma 4.2
If for all
, then for sufficiently small error
and grid scales
,
the following two conditions are equivalent:
| (1) | The columns of the matrix | ||||
| (2) | The regularization parameter | ||||
Proof
First, by the definition of generalized positive matrix the composite matrix
is a positive one for sufficiently small parameter
. Then, put formula (Equation20
(20)
(20) ) into inequality (Equation19
(19)
(19) ) and use the property of positive operator
we see:
, inequality
holds. Rewrite this vector inequality by components
After a simpler transformation we can obtain ,
:
(23)
(23)
From above inequalities, we can see what a regularization parameter should be. First, we indicate that for sufficiently small error
the right-hand side of inequality (Equation23
(23)
(23) ) is always negative. Indeed, by the positivity on a cone of the matrix
and the positivity of
, we know that
for all
. If one denotes
(24)
(24)
then for any we have
(25)
(25)
which implies the negativity of the right-hand side of inequality (Equation23(23)
(23) ) in the condition of sufficiently small error
.
If , then for any
inequality (Equation23
(23)
(23) ) holds for a sufficiently small error
(i.e.
). Thus, inequality (Equation23
(23)
(23) ) is equivalent to the following two inequalities:
| (a) | If | ||||
| (b) | If | ||||
Obviously, we should indicate the rationality of the condition of Lemma 4.2; i.e. we should prove that for every fixed index ,
In addition, regularization parameter must be nonnegative; i.e. we should indicate the following inequality
All these problems can be answered by the following lemma:
Lemma 4.3
If for sufficiently small error
and grid scales
,
, then the following inequalities hold for
:
(26)
(26)
where function is defined by (Equation22
(22)
(22) ).
Proof
First, let us prove inequality . From the proof of Lemma 4.2, we know that for a sufficiently small error
,
the inequality
holds. Then by the condition
we can obtain the positivity of function
. Finally, by the property of functional
we proved the first assertion.
Now, we are going to indicate that for any fixed index the value of
is finite. Indeed, for any admissible point the value of function
is finite. Finally, by the assumption of the lemma and the inequality
, we obtain the rightmost inequality of (Equation26
(26)
(26) ).
Similarly, it is not difficult to obtain the two left inequalities of (Equation26(26)
(26) ). This completes the proof of this lemma.
The following lemma indicates that if one chooses the penalty matrix as the unity matrix then set
is nonempty.
Lemma 4.4
For all ,
.
Proof
Obviously, means that
for all
, which implies that
. Now let us prove the lemma by contradiction. Assume that
for an index
(note that, generally speaking,
). Then by the a priori information of the solution
(the boundedness and the Lipschitz continuity of the solution) we have
. Note that for the integral equation with a positive kernel we have that
. This implies that
By condition we obtain
, which is equivalent to
Obviously, above equality will not hold for sufficiently small error and grid scales
,
. It follows that the assumption that
must be false and hence
, which is equivalent to
, proving the claim.
4.1. Regularization parameter selection methods
From Lemma 4.2, we can see what constraints of regularization parameter should be satisfied. In this subsection, we will introduce some methods of constructing a regularization parameter
, which help us to get a pseudo-optimal regularization algorithm. First, introduce the definition of the regularization matrix
.
Definition 4.5
The diagonal matrix , which is defined by
(27)
(27)
will be called a regularization matrix of problem (Equation14(14)
(14) ).
By Lemma 4.3 we see that :
. The following example shows that
in practice.
Example 1: Consider a matrix equation with the positive coefficient matrix . Assume that
,
,
and
. Then
and we have
The associate problem (Equation14(14)
(14) ) gives that
. Finally, we obtain
The following lemma provides a sufficiency condition of .
Lemma 4.6
If for all
, then for sufficiently small error
and grid scales
,
:
for all
.
Proof
Define by (Equation24
(24)
(24) ). By inequalities (Equation25
(25)
(25) ) and the boundedness of solution
we have
which yields the required result by the definition of . Here,
is an
vector, whose components are all unities. The last inequality, which holds for sufficiently small error level and grid scales, can be proved by the method, described in the proof of Lemma 4.2.
Using the regularization matrix , we can introduce various regularization parameter selection methods. Here, we only introduce two simplest regularization parameter selection methods – an a priori method and an a posteriori method. Above all, we assume that
.
4.1.1. A priori regularization parameter selection 
The a priori regularization parameter can be defined as
(28)
(28)
where(29)
(29)
Here is
-dimensional unity matrix.
It is very easy to obtain following properties of the selected regularization parameter , proposed by formula (Equation28
(28)
(28) ).[Citation5]
Lemma 4.7
(a) :
; (b)
; (c)
, where
is the
-th element on the diagonal of the matrix
.
4.1.2. A posteriori regularization parameter selection
An a priori parameter choice is not suitable in practice since a good regularization parameter requires knowledge of the unknown solution
. This knowledge is not necessary for a posteriori parameter choice. Here, the a posteriori regularization parameter
can be defined by
(30)
(30)
where the nonnegative number is the regularization parameter, which is chosen by the generalized discrepancy principle [Citation11,Citation13]; i.e. it is a positive root of the following functional
(31)
(31)
where .
By the theory of generalized discrepancy principle in ill-posed problems [Citation5,Citation6] the following assertions hold
Lemma 4.8
(a) ; (b)
.
5. The optimal and regularization properties of the algorithm
Denote as the class of all continuous operators acting from the space
into the space
.
Definition 5.1
The family :
is called a family of pointwise regularization methods of the problem (Equation1
(1)
(1) ) on a given grid
if for any fixed point
in the grid
satisfy
(32)
(32)
where the set of a priori information of problem (Equation1
(1)
(1) ) is defined by (Equation4
(4)
(4) ). Denote
as a pointwise regularization method of the problem (Equation1
(1)
(1) ) on a given grid
.
The least upper bound in problem (Equation32
The value
Remark 5
As compared with the classical regularization operator, the pointwise regularization method has stronger regularization property. Indeed, using the bilinear interpolation operator we can obtain the classical regularization operator for the problem (Equation1
(1)
(1) ) by the compound operator
; i.e.
Definition 5.2
A regularization method of problem (Equation1
(1)
(1) ) is called pseudo-optimal, if for any fixed number
and for any regularization method
:
of problem (Equation1
(1)
(1) ) there exists a pair of numbers
such that on this fixed grid
the following inequality holds
(33)
(33)
where the number will be called an error of the finite-dimensional approximation of the problem (Equation14
(14)
(14) ).
Define a regularization method of the problem (Equation1
(1)
(1) ) by
(34)
(34)
where ,
is a Lagrange multiplier matrix of
problems (Equation14
(14)
(14) ), which was defined by (Equation20
(20)
(20) ), and the regularization parameter
is chosen neither by an a prior method (Equation28
(28)
(28) ), or by an a posteriori method (Equation30
(30)
(30) ).
Remark 6
Mapping , defined by (Equation34
(34)
(34) ), does not linearly depend on
, since the value of matrix
depends on
.
Before formulating the fundamental theorem in this work, consider the definition of complete bounded finite dimensional approximation, which stands a crucial point when proving the regularizing property of our proposed method.
Definition 5.3
A family of operators is called complete bounded finite dimensional approximation of the space
if it satisfies the following two conditions simultaneously.
| (1) | There exists a constant | ||||
| (2) |
| ||||
At the end of this section, let us formulate a fundamental theorem, which is the basic result in this article.
Theorem 5.4
If and
is complete bounded finite dimensional approximation of the space
. Then, the regularization method
, which was defined by (Equation34
(34)
(34) ), is a pseudo-optimal pointwise regularization method of problem (Equation1
(1)
(1) ). Consequently, the operator
is a pseudo-optimal regularization operator of problem (Equation1
(1)
(1) ).
Proof
The (pointwise) regularization property of the proposed method (
) can be proved by the method of combination of the proof of the regularization property in [Citation37] (the author used the complete bounded finite dimensional approximation operators
to obtain the regularizing property of the proposed method) and the proof of the classical Tikhonov regularization algorithm of ill-posed problems.[Citation7]
Now, let us prove the optimal property of the proposed method . First, note that for any fixed error of the finite-dimensional approximation
there exists a pair of numbers
such that following two inequalities hold [Citation28]
where – an element of matrix
in the
-th row and
-th column.
Fix a grid . Consider any regularization method (maybe nonlinear)
:
of the problem (Equation1
(1)
(1) ) on this given grid. Define a helping mapping
such that
. Define
. For every fixed index
, by Lagrange Principle and the definition of regularization method
(Equation34
(34)
(34) ) we have
where holds by Lagrange Principle and
holds by theorem Smolyak [Citation19,Citation27] about existence of linear optimal recovery methods.
From above inequalities we can obtain
which implies the desired result.
Figure 1. Left: the truecolor image of the galaxy cluster, whose digital representation is an array. Right: the inexact the point spread function
.

Figure 2. Reconstructions with noiseless projections . (1) the exact blurred image
, (2) the blurred image with noisy
, (3) reconstruction, obtained by our method using a priori regularization parameter selection
, (4) reconstruction, obtained by our method using a posteriori regularization parameter selection
.
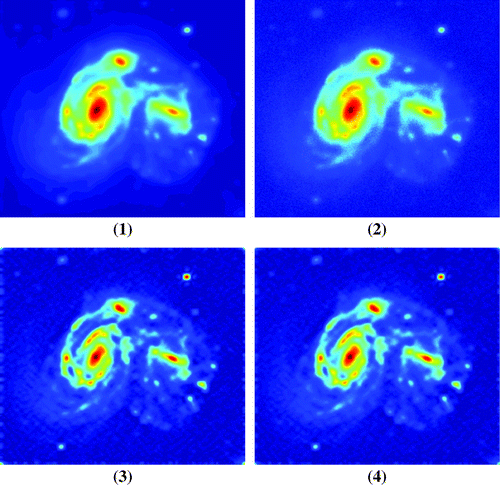
Figure 3. Reconstructions with noiseless projections . (1) the exact blurred image
, (2) the blurred image with noisy
, (3) reconstruction, obtained by our method using a priori regularization parameter selection
, (4) reconstruction, obtained by our method using a posteriori regularization parameter selection
.
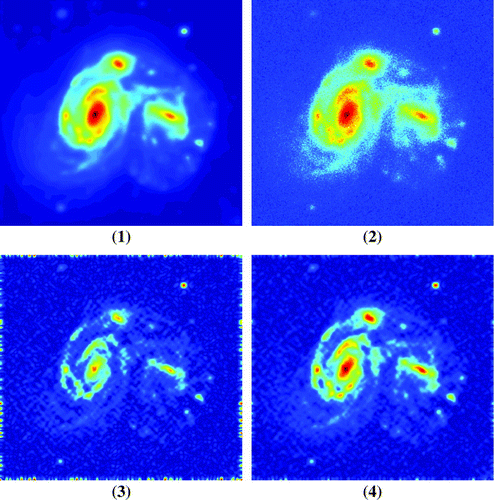
Table 1. The total pseudo-optimal errors of the proposed pseudo-optimal pointwise regularization method for problem (35) and relative errors of reconstructions presented in Figures and .
6. A solution algorithm of the inverse problem for two-dimensional integral equation of the first kind with a positive kernel
In this section, let us describe steps of a pseudo-optimal regularized solution algorithm of an optimal recovery problem (Equation7(7)
(7) ) for two-dimensional integral equation of the first kind with a positive kernel (Equation1
(1)
(1) ). This algorithm is based on the theory mentioned above.
| (1) | Using an a priori information | ||||
| (2) | For every fixed index | ||||
| (3) | Calculate the vector of suprema of the associated problems with parameter | ||||
| (4) | If | ||||
| (5) | Calculate the regularization matrix | ||||
| (6) | Computer the Lagrange multiplier matrix | ||||
| (7) | The result is that: the matrix | ||||
7. Numerical experiments
In this section, we present a numerical experiment illustrating the ability of our method to reconstruct the solution of the following two-dimensional image deblurring problem:(35)
(35)
where
In our simulations, the inexact point spread function is given by (see the right figure in Figure )
The blurred discrete image with noisy data is given by
(
,
), where
describe measurement errors. We generated the exact image
using a forward solver and added independent and identically distributed Gaussian random variables. Denote
as the exact discrete image, and
as the blurred continuous image, where the bilinear interpolation operator
is defined in the similar way as (Equation9
(9)
(9) ). Define error level
as
. Set
,
and
. The model solution is a galaxy cluster – Arp 272, which is a remarkable collision between two spiral galaxies, NGC 6050 and IC 1179, and is part of the Hercules Galaxy Cluster, located in the constellation of Hercules (see the left figure in Figure ).
We discretize the integral operator (Equation35(35)
(35) ) using the trapezoidal rule based on the composite trapezoidal quadrature rule. The Fast Fourier Transform, carried out with Matlab’s built-in functions fft2 and ifft2, is used for convolution. Figures and show reconstructions from data with different noiseless projections
and
, generated using our proposed pseudo-optimal pointwise regularization method.
For any different noiseless projections and
, the total pseudo-optimal errors of our method
are always the same, and equal
. Due to the model problem, we can calculate the relative errors of obtained approximate solutions. The total pseudo-optimal error
of our method and relative error of reconstruction are displayed in Table .
8. Conclusion
The results of numerical experiments showed that the proposed method is an efficient and feasible algorithm for solving two-dimensional integral equation of the first kind with a positive kernel. Comparing with the standard regularization methods, the pseudo-optimal pointwise regularization method guarantees the pseudo-optimal error of the method. This proposed regularization method can not only solve -dimensional (
) integral equation of the first kind with a positive kernel, but also solve any generalized positive operator on some Banach lattice [Citation35]. The application of this work is of great help in image processing, optics and gravity measurement.
Acknowledgements
We thank referees for their extremely helpful comments. We are especially grateful to the associate editor for his helpful comments on versions of the manuscript and for his patience and persistence.
Additional information
Funding
Notes
No potential conflict of interest was reported by the authors.
References
- Arfken GB, Weber HJ. Mathematical methods for physicists. San Diego (CA): Harcourt; 2001.
- Polyanin AD, Manzhirov AV. Handbook of integral equations. Boca Raton (FL): CRC Press; 1998.
- Krasnov M, Kiselev A, Makarenko G. Problems and exercises in integral equations. Moscow: Mir Publishers; 1971.
- Roggemann MC, Welsh B. Imaging through turbulence. Boca Raton (FL): CRC Press; 1996.
- Tikhonov AN, Leonov AS, Yagola AG. Nonlinear Ill-posed problems. London: Chapman and Hall; 1998.
- Tikhonov AN, Goncharsky AV, Stepanov VV, Yagola AG. Numerical methods for the solution of Ill-posed problems. Dordrecht: Kluwer Academic Publishers; 1995.
- Wang YF, Yagola AG, Yang CC. Optimization and regularization for computational inverse problems and applications. 1st ed. Berlin: Springer-Verlag; 2011.
- Ivanov VK, Vasin VV, Tanana VP. Theory of linear Ill-posed problems and its applications. Utrecht: VSP; 2002.
- Beilina L, Klibanov MV. Appoximate global convergence and adaptivity for coefficient inverse problems. New York (NY): Springer-Verlag; 2012.
- Bakushinsky AB, Goncharsky AV. Ill-Posed problems: theory and applications. Dordrecht: Kluwer Academic Publishers; 1994.
- Yagola AG, Leonov AS, Titarenko VN. Data errors and an error estimation for ill-posed problems. Inverse Prob. Sci. Eng. 2002;10:117–129.
- Dorofeev KYu, Nikolaeva NN, Titarenko VN, Yagola AG. New approaches to error estimation to ill-posed problems with applications to inverse problems of heat conductivity. J. Inverse Ill-Posed Prob. 2002;10:155–169.
- Titarenko VN, Yagola AG. Error estimation for ill-posed problems on piecewise convex functions and sourcewise represented sets. J. Inverse Ill-Posed Prob. 2008;14:1–14.
- Wang YF, Zhang Y, Lukyanenko DV, Yagola AG. A method of restoring the restoring aerosol particle size distribution function on the set of piecewise-convex functions. Numer. Methods Prog. 2011;13:67–73. Russian.
- Wang YF, Zhang Y, Lukyanenko DV, Yagola AG. Recovering aerosol particle size distribution function on the set of bounded piecewise-convex functions. Inverse Prob. Sci. Eng. 2013;21:339–354.
- Tikhonov AN, Arsenin VY. Solutions of Ill-posed problems. New York (NY): Wiley; 1977.
- Micchelli CA, Rivlin TJ. Lectures on optimal recovery. Lecturenotes in mathematics. Heidelberg: Springer Verlag; 1985.
- Micchelli CA, Rivlin TJ. A survey of optimal recovery. In: Optimal estimation in approximation theory. New York (NY): Plenum Press; 1977.
- Magaril-Ilyaev GG, Osipenko KY, Tikhomirov VM. Optimal recovery and extremum theory. Comput. Methods Funct. Theory. 2002;2:87–112.
- Bayev AV, Yagola AG. Optimal recovery in problems of solving linear integral equations with a priori information. J. Inverse Ill-Posed Problems. 2007;15:569–586.
- Arestov VV. Best recovery of operators and related problems. Proc. Steklov Inst. Math. 1989;189:320.
- Traub JF, Wozniakowski H. Best recovery of operators and related problems. New York (NY): Academic Press; 1980.
- Zhang Y, Lukyanenko DV, Yagola AG. Using Lagrange principle for solving linear ill-posed problems with a priori information. Numer. Methods Prog. 2013;14:468–482. Russian.
- Zhang Y, Lukyanenko DV, Yagola AG. An optimal regularization method for convolution equations on the sourcewise represented set. J. Inverse Ill-Posed Prob. 2015;23. doi:10.1515/jiip-2014-0047
- Jain AK. Fundamentals of digital image processing. New York (NY): Prentice-Hall; 1989.
- Bertero M, Boccacci P. Introduction to inverse problems in imaging. Bristol: IOP Publishing; 1998.
- Smolyak SA. On optimal restoration of functions and functionals of them dissertation [dissertation]. Moscow: Moscow State University; 1965. Russian.
- Bayev AV. The Lagrange principle and finite-dimensional approximations in the optimal inverse problem for linear operators. Numer. Methods Prog. 2006;7:323–336. Russian.
- Davis PJ, Rabinowitz P. Methods of numerical integration. New York (NY): Academic Press; 1975.
- Stoer Josef, Bulirsch Roland. Introduction to numerical analysis. New York (NY): Springer-Verlag; 1980.
- Berge C. Topological spaces. Patterson EM, translator; New York (NY): Macmillan; 1963.
- Hogen WW. Point-to-set maps in mathematical programming. SIAM Res. 1973;15:591–603.
- Hogen WW. The continuity of the perturbation function of a convex program. Oper. Res. 1973;21:351–352.
- Fiacco A. Introduction to sensitivity and stability analysis in nonlinear programming. New York (NY): Academic press; 1983.
- Schaefer HH. Banach lattices and positive operators. New York (NY): Springer-Verlag; 1974.
- Vogel CR. Computational methods for inverse problems. Philadelphia: SIAM; 2002.
- Bayev AV. An optimal regularizing algorithm for the recovery of functionals in linear inverse problems with sourcewise represented solution. Zh. Vychisl. Mat. Mat. Fiz. 2008;48:1933–1941. Russian.