
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this article, we study the balancing principle for Tikhonov regularization in Hilbert scales for deterministic and statistical nonlinear inverse problems. While the rates of convergence in deterministic setting is order optimal, they prove to be order optimal up to a logarithmic term in the stochastic framework. The two-step approach allows us to consider a data-driven algorithm in a general error model for which an exponential behaviour of the tail of the estimator chosen in the first step is valid. Finally, we compute the overall rate of convergence for a Hammerstein operator equation and for a parameter identification problem. Moreover, we illustrate these rates for the last application after we study some large sample properties of the local polynomial estimator in a general stochastic framework.
AMS SUBJECT CLASSIFICATIONS:
1. Introduction
Solving inverse problems in a deterministic setting involves reconstructing a mathematical object in an ill-posed operator equation (see e.g. [Citation1]). The original article [Citation2] considers the stochastic extension of inverse problems to (Gaussian) random fields and formalize it as a statistical estimation question by discretization with the help of sample functions. Loosely speaking, statistical inverse problems are inverse problems with random noise. Moreover, classical statistical problems like convolution or error-in-variables models could be rewritten as linear statistical inverse problems [Citation3].
In this paper, we consider the problem of estimating an unknown, not directly observable quantity from the noisy values of an element
related to
by the operator equation
(1)
(1)
where is a nonlinear, injective operator between two Hilbert spaces
and
. We assume that the equation is ill-posed, in the sense that
is not continuous. First, we have at our disposal the data Y perturbed by deterministic noise such that
(2)
(2)
where ,
is the normalized deterministic error and
is the deterministic noise level. The results obtained in the framework (Equation2
(2)
(2) ) are further utilized in the stochastic process setting that is generalized here to the abstract noise model
(3)
(3)
where is a normalized Hilbert space process,
is the corresponding stochastic noise levels, and the relation (Equation3
(3)
(3) ) is understood in the weak sense. Our general noise model is inspired by [Citation4] and its relation to several common used statistical models was investigated in [Citation3]. A classical example is the inverse nonparametric regression problem, where the data are indirectly related to the functional mean by an operator equation in contrast to the direct regression where we observe noisy values of this function.
A first method for solving nonlinear inverse problems in the statistical setting, inspired by Tikhonov regularization and named Method of Regularization, was studied by O’Sullivan, Lukas and Wahba (see [Citation5–Citation7]). The straightforward generalization of this method to the infinite-dimensional noise model is
where is an initial guess for
. However, in the important case when
is white noise
is infinite with probability 1 for all
, so
is not well-defined.
Since our aim is to focus on data-driven methods, we will like to include statistical models that go beyond the additive setting and for whom the direct statistical problem (like the direct nonparametric regression problem) is already studied and better understood. Hence, we choose a two-step estimator as suggested and studied in [Citation8] that gives us the flexibility to embed progress made in the direct stochastic setting into statistical nonlinear inverse problems. In the deterministic case, a pre-smoothing step allows to overcome the oversmoothing effect of the Tikhonov and Landweber regularization method (see [Citation9]). Data estimation in this framework could be achieved by Tikhonov regularization, regularization of the embedding operator or by wavelet shrinkage (see [Citation10]). In the first step, a possibly biased estimator of
is determined from the data Y such that the error estimate
(4)
(4)
holds true and the rate of convergence that depends on the stochastic noise
is known. This is a nonparametric regression problem which has been studied intensively in the statistical literature if
is a Gaussian white noise process and the smoothness conditions are ellipsoids in the Sobolev spaces
on the domain (0, 1) (see [Citation11] and references therein). In this case, the optimal rates of convergence (Equation4
(4)
(4) ) for adaptive and non-adaptive estimators are
. Moreover, this rate will also hold for non-Gaussian white noise if the error probability distribution is regular in classical sense since in this case the distribution-free nonparametric regression problem is asymptotically equivalent to a homoskedastic Gaussian shift white noise model (see [Citation12,Citation13]).
will play the role of thenoise level in the next step. In the second step, the estimator
is constructed as the solution of the Tikhonov minimization problem
(5)
(5)
Therefore, this method allows the discretization of the problem (Equation3(3)
(3) ) for a large variety of designs and the unknown noise level is de facto estimated in the first step. On the other hand, this step can make the computation cumbersome and it is superfluous for designs for which methods and convergence analysis are already available (like for Poisson noise in [Citation14]). Moreover, the rates of convergence depend on the nature of the noise through the tail behaviour of the stochastic method chosen in the first step, making necessary to specify conditions on the error probability distribution to concretize this result for different settings. It follows from [Citation8] that the method is consistent in the sense that for any choice of minimizing elements
we have
(6)
(6)
if and
. Moreover, in [Citation15] rates of convergence for a large set of smoothness classes expressed with the help of Hilbert scales were computed and optimality of this method was proved for linear operators. Regularization in Hilbert scales was studied for the first time by Natterer [Citation16] for linear and by Neubauer [Citation17] for nonlinear deterministic inverse problems. Linear statistical inverse problems have been studied in a Hilbert scale framework in [Citation4,Citation18–Citation22]. In [Citation15] rates of convergence were obtained for nonlinear statistical inverse problems in Hilbert scale for a-priori choice of the regularization parameter
. A-priori choice of the regularization parameter yields order-optimal rates of convergence but requires the knowledge of the noise levels
and
, and of the smoothness of the solution q. We focus in this paper on an adaptive tuning parameter rule, the balancing principle, which was proposed by Lepskii for the choice of the regularization parameter for a regression problem in [Citation23]. His principle of bounding the best possible accuracy by a function which is non-increasing with respect to
-values was used by Mathé and Pereverzev to obtain order-optimal estimators in variable Hilbert scales (see [Citation24]). Afterwards this principle was applied by different authors for deterministic linear and nonlinear inverse problems [Citation24–Citation26].
Our aim is to study rates of convergence of the two-step method with balancing principle choice of the regularization parameter in a general noise model for a large class of smoothnesses expressed with the help of Hilbert scales. This extends the method in [Citation15] to a fully data-driven algorithm in both steps for a general class of additive noise models, including some non-Gaussian white noise processes, as specified before. To this aim, we introduce in the following section Hilbert scales and their corresponding norms
, and prove rates of convergence of the error for the Lepskii estimator in nonlinear deterministic inverse problems. In addition to the common assumptions on the operator F as in [Citation15], a smallness condition on the noise level
is necessary as it is usual the case for Lepskii tuning methods. The deterministic rates of convergence allow us to get rates of convergence of
with respect to
that are order optimal up to a log-factor for nonlinear statistical inverse problems under a supplementary condition on the tail behaviour of the estimator
in Section 2.2. The overall rate of convergence for the two-step method depends on the nature of the noise through the asymptotic behaviour of the tail and the mean square error of the estimator chosen in the first step. We will illustrate the overall capacity of the two-step approach to reach order optimal (up to a logarithmic term) rates of convergence in the Section 3 of our article, containing the numerical simulation for the reconstruction of a reaction coefficient from Gaussian noisy data in the setting of an inverse nonparametric regression. The asymptotic equivalence between this discrete model and that of the Gaussian white noise (Equation3
(3)
(3) ) is discussed for example in [Citation11] as well as the relation between the variance in the continuous setting and the sample size n:
. We also present new results regarding this behaviour for the local polynomial estimator in the case of errors with Gaussian or log-concave probability distribution, that are useful to illustrate the numerical performance of our algorithm in the last section. Due to the great flexibility of the two-step method, methodological progress in the study of the local polynomial estimator in a large class of statistical models like binary response model, inhomogeneous exponential and Poisson models by adaptive weights smoothing could provide the necessary tools to deal with non-Gaussian settings (see [Citation27]). The study of the overall optimal rates of convergence for these cases is subject of further research.
Two different applications are considered in this paper: one statistical inverse problem defined by the Hammerstein operator, for which we also define the corresponding Hilbert scale and the problem of the reconstruction of a reaction coefficient already studied in [Citation15]. We compute the overall rate of convergence for these two examples that turns out to be optimal up to a log-factor, and graphically compare the numerical and theoretical rates of convergence for the second application in the last section.
2. Balancing principle for nonlinear inverse problems in Hilbert scales
The overall rate of convergence of the two-step method for the balancing choice of the regularization parameter depends on the stochastic model and can be computed by considering first the deterministic setting and afterwards extending it to the statistical framework. In the following, we focus on the rates of convergence for the Lepskii choice of the regularization parameter for nonlinear inverse problems in Hilbert scales separately in a deterministic and in a stochastic framework. The order optimal rates of convergence proved in the deterministic setting and the properties of the nonparametric estimator in the pre-smoothing step lead to optimal up to a logarithm term rates of convergence in the Gaussian stochastic case.
2.1. Rates of convergence for balancing principle in deterministic setting
We consider in this section a deterministic framework, meaning that we assume the noise model (Equation2(2)
(2) ). To characterize the smoothness of the solution
, a Hilbert scale is defined in the following with the help of a densely defined, unbounded, self-adjoint, strictly-positive operator L in the Hilbert space
. We consider the set
of the elements x for which all powers of L are defined
is dense in
and, by spectral theorem,
is well-defined for all
. For
and
, let
Then the Hilbert space is defined as the completion of
with respect to the norm
and
is called the Hilbert scale induced by L. A comprehensive introduction in Hilbert scales can be found in [Citation1,Citation28]. In our proofs we are going to use repeatedly the interpolation inequality
(7)
(7)
which holds for any . We define our estimator
as
(8)
(8)
where and
is an initial guess. We obtain rates of convergence for the deterministic error
if the following assumptions on the operator F hold:
Assumptions 2.1:
| (A) | (assumptions on F) If | ||||
| (B) | (smoothing properties of | ||||
| (C) | (Lipschitz continuity of | ||||
We define the estimator corresponding to the exact data
by
(11)
(11)
We treat the noise free error and the data noise error
separately as it is common for this adaptive methods (see e.g. [Citation29]).
Theorem 2.2:
If the Assumptions 2.1 hold true and if fulfills
(12)
(12)
then the estimation
holds true, where and K is a constant dependending on
.
For a better readability of this paper, the proof can be found in the Appendix 1. The interval for the smoothness degree is due to the technical condition (Equation7
(7)
(7) ) and can be interpreted as a saturation limit (see e.g. [Citation17]). The exponent of
in the bound on the noise free error is similar to those computed for linear inverse problems, but the constant depends on the
norm of
. It was not the aim of this research, to overcome this restriction, but it might be an interesting topic to study.
Theorem 2.3:
Under the assumptions of Theorem 2.2 we have that(13)
(13)
where and
are constants dependending on
, respectively
.
The proof of this Theorem can also be found in Appendix 1. This is based, together with the proof of the previous theorem, on the computation of bounds for the noise-free and data noise term in and
norms, and the interpolation inequality (Equation7
(7)
(7) ). The classical results for the linear inverse problems yield a decreasing function in
as upper-bound for the data noise error term. Due to the non-linearity, the product
appears in the upper bound and because of the adaptivity, we can control it only through expressions containing the term
. The constants can be explicitely computed i.e.
(14)
(14)
but for the sake of simplicity we renounced to formally calculate them in the proof. Finally, we get a sum between an increasing and a decreasing function in the tuning parameter, and we define an adaptive choice of the regularization parameter based on this. To ensure consistency of the method, a smallness conditions on and c needs to be fulfilled, as we will see below. First, we present a direct consequence of the previous results.
Corollary 2.4:
Under the assumptions and notations of Theorems 2.2 and 2.3, it holds(15)
(15)
where and
are the constants from Theorem 2.3.
The choice of the regularization parameter gives the order optimal rate of convergence
with which depends on
, p, s, q,
,
and c.
Proof The first inequality follows immediately from Theorems 2.2 and 2.3 and allows us to estimate the tuning parameter , by balancing between the upper bounds of the approximation and noise-free errors. For
we get
Figure 1. Upper bounds for the nonlinear data noise error (dotted line), Lepskii rule (dashed line), linear data noise error (full line) for error level
(left, diamond) and 0.01 (right, diamond), and the corresponding minimum points for
(circle).
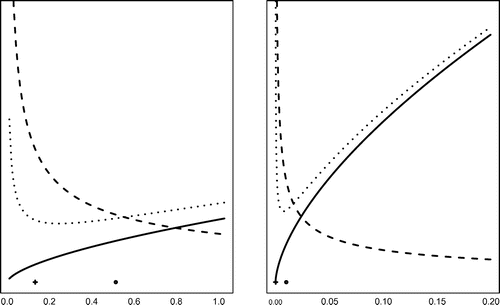
We discuss now an adaptive choice of the regularization parameter based on the balancing principle and on the previous bounds computed in Theorems 2.2 and 2.3. We follow here the approach from [Citation24,Citation25,Citation30]. Hence, we estimate the value of the regularization parameter that approximates the minimizer of the total error
by the minimizer of the bounding sum resulting from the aforesaid theorems. This optimum is computed from a finite set of possible parameters
where ,
is usually equal to
, and we denote
. We define the non-increasing function
,
and the function ,
with the constants and
as in Theorem 2.3. It can be easily checked that
is non-decreasing on the set M if
since the minimum point of the real-valued expression
is smaller than
in our setting.
If the inequality(16)
(16)
holds, then we can formulate a rule to choose the tuning parameter and define an order-optimal estimator independent from smoothness q. Condition (Equation16
(16)
(16) ) assures the existence of at least one intersection point between the curves defined by
and
and is similar to the one usual used in the framework of the linear inverse problems, as the Figure also illustrates. It implies as well that our results will be valid only for
distances c and noise levels small enough such that the right hand side term of (Equation16
(16)
(16) ) bounds an algebraic expression involving these two values. An explicit example of this relationship is given in Section 4.2.
Therefore, we determine the regularization parameter in the set M for which the following inequality holds
and . The computation of
and
is unfeasible, since q is unknown, therefore we approximate them by
where ,
and
(see [Citation29] for details). Moreover, a simplified version of Lepskii criterion was also presented in the aforementioned article, which had the origins in the quasi-optimality choice of the regularization parameter proposed by Tikhonov and Glasko. In this case, we choose the estimator
corresponding to the regularization parameter
with the index
If condition (Equation16(16)
(16) ) holds, all three sets defined above are different from the empty set and, for
, not equal to M.
Theorem 2.5:
If the assumptions of Theorem 2.2 and the inequality (Equation16(16)
(16) ) hold true, we have that
and we get order optimal rates of convergence both for and
i.e.
for constants and
which depends on
and c.
Proof The inequalities in Theorem 2.5 follow from the order relation between the sets involved in the definition of the three tuning rules. fulfills
for any since
, and it is obvious that
for (see [Citation29]). Since the proof of the second part of the theorem is similar for both rates of convergence, we just show the second result in the following paragraph. From the previous inequality
it holds that
and we can write
Moreover, the definition of allows us to obtain order optimal rates of convergence (see e.g. [Citation15,Citation16] and references therein for a discussion about optimal rates for Tikhonov regularization in Hilbert scales.)
Remark 1:
The last condition (Equation16(16)
(16) ) implies that our results will be valid only for a set of noise levels depending on the
norm c. Generally, the feasibility of the estimator depends on the initial guess, and this problem can be solved for example by considering different a-priori values and applying the algorithm for each of them.
2.2. Rates of convergence for balancing principle in stochastic setting
In this section we consider the stochastic noise model (Equation3(3)
(3) ) and apply the two-step method for this statistical inverse problems. Hence, we choose first an estimator
as data and its known rate of convergence (Equation4
(4)
(4) ) as noise level. We define the estimators
as
(17)
(17)
where and
is an initial guess. In the following, the balancing principle is going to be applied in a similar way as in the previous section and rates of convergence are going to be proven. These results are obtained under the supplementary condition for the tail of the probability distribution of the estimator
(18)
(18)
for any greater than 1 such that
, where
,
and
are positive universal constants and
. We choose the set of regularization parameters as
with and the estimator
with
The rates of convergence for this estimator can be computed using similar techniques as in [Citation31,Citation32].
Theorem 2.6:
If the assumptions of Theorem 2.2 and the conditions (Equation16(16)
(16) ) and (Equation18
(18)
(18) ) are fulfilled then, for all
, we have the following error bound for
where is a constant which depends on
,
,
and
.
Proof For fulfilling the conditions of the Theorem 2.6 we denote
(19)
(19)
as the set of extreme values of the error of the estimator
. Due to the bias-variance decomposition
we can rewrite the inequality (Equation19(19)
(19) ) as
From Cauchy-Schwarz inequality, the set inclusion holds
leading to
From (Equation18(18)
(18) ) we get
(20)
(20)
for all such that
. With the help of conditional expectation we can write
where is the complementary set of
in
. We apply the deterministic convergence result for Lepskii choice of the regularization parameter (see Theorem 2.5) on the set
for
and use the exponential inequality (Equation20
(20)
(20) ) to bound
for noise levels
. This yields
Remark 2:
Like in the deterministic setting, we can choose a simplified version for the choice of the regularization parameter that reduces the computational cost. We select the estimator with
In the same way as in the Theorem 2.6 we can prove that the rate of convergence is equal to(21)
(21)
3. Applications
3.1. Hammerstein operator
In the last section, we compute the overall rate of convergence of the two-step method for an inverse problem originating in a non-linear integral equation and inspired by [Citation33]. We consider here the Hammerstein operator(22)
(22)
where is a function in the space of Hölder continuous functions
with bounded second derivative
(23)
(23)
for all , and
denotes the Sobolev space of index 1 of functions on the interval [0, 1]. Our inverse problem is to determine a from the knowledge of F(a). Similar conditions as in Assumptions 2.1 were used in [Citation34] to study the Landweber iterative method in Hilbert scales. The following properties of the operator F and its Fréchet derivative are going to be useful for choosing an appropriate Hilbert scale. The detailed proofs of the following theoretical results can be found in [Citation35].
Lemma 3.1:
F is a continuous, compact, weakly closed and Fréchet differentiable operator with the Fréchet derivative(24)
(24)
The adjoint of the Fréchet derivative is given by(25)
(25)
Here is defined by
.
We assume from now on that(26)
(26)
In this case, the operator F is injective and we determine the set in order to choose a Hilbert scale which fulfills Assumptions 2.1. Let the linear integral operator
be defined as
.
is the composition of three operators:
, the multiplication operator
and
. The operator
has the range
and
as is in
. Note that due to (Equation26
(26)
(26) ) there exists
such that
for all since
. Since the restriction
is an isomorphism by elliptic regularity results and since is equivalent to
we finally get
As the operators and
are injective, we have that
is bijective between
and
and
for all
.
We would like to have a Hilbert scale with the following properties: it holds
(27a)
(27a) (or higher regularity of
) to be able to show Assumptions 2.1, and we need
to be a member of the Hilbert scale, e.g.(27b)
(27b) Unfortunately, the restriction
is not self-adjoint and we need to consider the operator defined underneath as the generator of the Hilbert scale below.
Proposition 3.2:
The operator
is self-adjoint in , and
(27c)
(27c)
It follows thereof that the Hilbert scale generated by the operator
has the desired properties (Equation27a
(27a)
(27a) ), (Equation27b
(27b)
(27b) ) and (Equation27c
(27c)
(27c) ).
Theorem 3.3:
For the Hilbert scale defined before and under the supplementary conditions (Equation23
(23)
(23) ) and (Equation26
(26)
(26) ), Assumption 2.1(B) is fulfilled with
. Moreover, Assumptions 2.1(C) is also satisfied under the same conditions if the diameter of
in
-norm is smaller than a
.
Proof Assumptions 2.1(C) is equivalent to(28)
(28)
for all for some
such that
. It follows, by (Equation25
(25)
(25) ) that
The last inequality holds because
Hence, the diameter should be smaller than
.
Proposition 3.4:
If and
, where
is the biggest integer smaller than q, then
.
Proof Since the composition between and
belongs to
(see [Citation36]), it follows immediately that
, for
.
Now, the overall rate of convergence can be computed.
Corollary 3.5:
In the case of the stochastic noise model (Equation3(3)
(3) ), assuming
white noise with Gaussian or regular non-Gaussian probability distribution, if the conditions of Theorem 3.3 hold true and if
,
,
, and
, then
can be estimated such that the rate of convergence (Equation4
(4)
(4) ) holds true with
. If the white noise has Gaussian distribution and the condition (Equation16
(16)
(16) ) holds, then we get the rates of convergence
while for regular concave log-probability distributions we obtain
Proof The first statement follows from Proposition 3.4, from asymptotic equivalence in Le Cam’s sense between nonparametric regression with regular error distribution i.e. presenting a locally asymptotic stochastic expansion (for exact definition of the regularity conditions see [Citation12]) and the white noise with drift, and from the theory of nonparametric regression (see [Citation11]). The smoothness of is Sobolev of order
, and rates of convergence on Sobolev balls were computed for nonparametric regression problems in the last reference and they correspond to the statement from the Corollary 3.5. The second statement is a consequence of the rates of convergence computed in [Citation37], Theorem 2.6 and Lemma 4.3.
3.2. Reconstruction of a reaction coefficient
To illustrate the convergence behaviour of our method, we consider in this section a parameter identification problem as a nonlinear operator equation and compute over-all rates of convergence for the Lepskii estimator based on theoretical properties already proved in [Citation15]. Furthermore, we compare its numerical and theoretical rates of convergence for different smoothness conditions with the help of Monte-Carlo simulations.
3.2.1. Theoretical rates of convergence
The direct problem is modeled by the differential equation
where f and g are infinitely smooth, and the domain is chosen to be (0, 1) for simplicity. For a given bound
we introduce the set
(29)
(29)
and we formulate the inverse problem of identifying the parameter knowing
as an operator equation with the help of parameter-to-solution operator
(30)
(30)
The Hilbert scale will be generated by the square root
of the positive, self-adjoint operator B defined by
We notice that the elements of this Hilbert scale with integer index are subsets of Sobolev spaces with Dirichlet boundary conditions on the even derivatives
In [Citation15] it was proven that the operator F together with this choice of Hilbert scale fulfills the Assumptions 2.1 for and
when the condition
(31)
(31)
and the smallness condition on the D(F) hold, and that the regularity of the parameter with
determines the smoothness of the exact data
. Hence, we can get an over-all convergence rate results in this case, also.
Corollary 3.6:
In the case of the stochastic noise model (Equation3(3)
(3) ), assuming
white noise with Gaussian or regular non-Gaussian probability distribution, for the Hilbert scale defined above
and under the supplementary condition (Equation32
(32)
(32) ) and if
,
,
, and
, then
can be estimated such that the rate of convergence (Equation4
(4)
(4) ) holds true with
. If the white noise has Gaussian distribution and the conditions (Equation16
(16)
(16) ) holds, then we get the rates of convergence
while for regular concave log-probability distributions we obtain
4. Numerical simulations
In this final section we present the employment of the balancing principle and the influence of the smoothness of the parameter on the rate of convergence of
in the two-step method for the reconstruction of a reaction coefficient by numerical simulations. First, we choose the local polynomial estimator as the pre-smoothing method and review some of its properties in the framework of a discretized version of the problem (Equation3
(3)
(3) ). A new result about the tail behaviour (Equation18
(18)
(18) ) of the local polynomial estimator in a general, non-Gaussian noise model (see [Citation38] for a review of the literature on this subject) is also proved. Moreover, the values of
and
for parameter-to-solution operator (Equation31
(31)
(31) ), and the empirical overall rate of convergence for the two-step method are computed, and the rates are illustrated in our graphics for different smoothnesses of
.
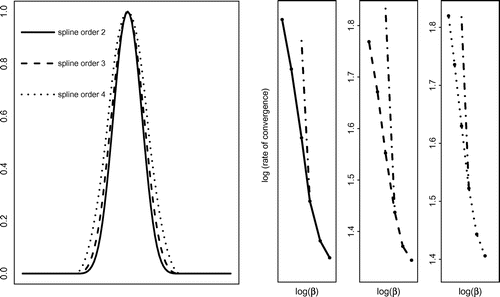
Figure 2. Exact parameter (full line -
, dashed line -
, dotted line -
), and its corresponding empirical and theoretical (dashed - dotted) rate of convergence on a log-log scale
4.1. Tail behaviour of local polynomial estimator
In the first step, we consider the nonparametric regression problem of estimating from the data
such that
(32)
(32)
where are independent, centred random variables with
and
is a deterministic design. In the case of Gaussian nonparametric regression, when
are independent, identically normal distributed N(0, 1), this is the discretized version of the Gaussian white noise model in (Equation3
(3)
(3) ) with
the standard Wiener process on [0,1] and the stochastic noise level
(see e.g. [Citation11]).
As usual in this setting, we assume that belongs to the Hölder class
on
i.e. it is a
times differentiable function whose derivative
satisfies
where is the integer part of
. For the case that the co-domain
of the operator F is the Sobolev space
, the compact embedding of the Hilbert space
into the Hölder space
follows from the Morrey’s inequality (as in [Citation39]).
The regression function can be locally approximated by
for small enough. The vector
can be estimated by means of the local polynomial estimator of order
.
Definition 4.1:
The local polynomial estimator of order d of is defined by
(33)
(33)
where ,
is a kernel i.e. an integrable function satisfying
,
is the bandwidth and
is an integer. The local polynomial estimator of order d of
is the first element of the vector
and is denoted by
.
The existence and uniqueness of the optimization problem (Equation34(34)
(34) ) was proven in [Citation11] under the following hypothesis which will assume to hold from now on.
Assumptions 4.2:
| (A) | There exists an | ||||
| (B) | The frequency of the points | ||||
| (C) | K is bounded by a constant | ||||
Consequently, the local polynomial estimator of order d of as well as of
exist and are given by
(34)
(34)
We focus in the following on the tail behaviour of the local polynomial estimator for a fixed bandwidth h under different noise conditions.
Lemma 4.3:
Let us assume that the vector of errors has a log-concave, continuous distribution on
i.e. the logarithm of this probability density is concave on the set where its logarithm is defined. If the Assumptions 4.2 hold, we have
where is an universal constant,
and
.
Moreover, if the errors are independent, centred Gaussian random variables, then it holds
where is an universal constant.
Proof From (Equation35(35)
(35) ) we can write
This is a positive polynomial of order two with symmetric coefficients in the random variables . In this case, results regarding the higher moments are already available (see Theorem 7 in [Citation40]). For the sake of completeness we reproduce this result in Appendix 1 (see Lemma 1) and use it to bound the moments of the polynomial
as
where ,
and
is an universal constant. From the Markov inequality we get
(35)
(35)
Let us choose now the integer such that
. For values of t such that
we can apply the previous inequality and obtain
The second inequality in Lemma 4.3, leading to Chernoff bound like estimates, is a direct consequence of hypercontractivity inequalities for Gaussian Hilbert spaces (see Theorem 6.7 in [Citation41]).
Remark 3:
The log-concave probability distributions include normal, exponential, logistic, chi-square, chi and Laplace. A survey of these can be found in [Citation42]. The stochastic error is assumed to be a zero mean stochastic process with bounded covariance operator. Therefore, considering a general class of distributions larger than the Gaussian fit into the general setting of our problem. Due to Lemma 4.3, the overall rate of convergence of the two-step method will depend of the class of probability distributions to which the discretized noise term belongs to.
Remark 4:
Results about asymptotically optimality of local polynomial estimator with the regularization parameter chosen by cross-validation were proved in [Citation43,Citation44]. Details about practical implementation of this method could be found in [Citation45].
Remark 5:
An adaptive local polynomial estimator based on a particular implementation of Lepskii scheme and its convergence properties for local and global risks for a wide range of characterizations of smoothness and accuracy measures are presented in [Citation37]. The rates of convergence depend on the smoothness in the scale of Sobolev spaces of the exact data , the degree of the polynomial and the index of the Lebesgue norm of the global risk, and are optimal or optimal up to a logarithmic term, as expected from [Citation46,Citation47].
Remark 6:
A data-driven approach leading to adaptive estimation of both polynomial order and the bandwidth with the help of cross-validation can be found in [Citation48]. This method is uniformly consistent for a large class of functions and reaches the optimal rate for the case of correctly specified parametric model i.e. when
is a polynomial whose order does not depend on sample size. Nevertheless, an order optimal approach aiming to adaptively tailor the degree and the tuning parameter of the local polynomial estimator is still an open problem.
4.2. Rate of convergence of the Tikhonov estimator for the balancing principle
In the following we compute and illustrate the empirical rate of convergence of the Tikhonov estimator for the balancing principle in the stochastic setting with the local polynomial estimator as pre-smoothing method. Since theoretical and numerical results imply that the Lepskii constant depend on the chosen application, we present a result concerning the computation of this constant for the inverse problem defined in (Equation31
(31)
(31) ). To this aim, the values of
and
are given in the following lemma under general conditions for the direct operator.
Lemma 4.4:
If the assumptions from Corollary 3.6 are fulfilled and the supplementary conditions(36)
(36)
hold, then we have
where D is the length of the interval .
Proof The Fréchet derivative of the operator defined in (Equation31(31)
(31) ) is
where (see [Citation1]).The following bounds follow from the Gelfand triple structure of the Hilbert scale and the Banach algebra property of the Hilbert space
(see [Citation15] and references within):
where k and C are Sobolev constants corresponding to embedding of , respectively
into
. From [Citation49,Citation50] it follows that these constants take the values
and
.
Under the supplementary conditions (3.6), classical methods in partial differential equations lead to following bounds on the solution of the direct problem
where for an
(see e.g. Exercise 4 in [Citation51]). Since
and
we get and
from Lemma 3.6.
Remark 7:
The computation of the Lepskii constant is also feasible for smooth domains in
,
. For example, results about the value of the Poincaré constant for convex domains in
,
are available in [Citation52].
In our numerical simulations, the unknown parameter is chosen as a B-spline of order 2, 3 or 4 which corresponds to smoothness up to
,
respectively
, and its upper bound
is equal to 1. The use of different larger values of
does not change the asymptotic rates of convergence, hence the method is robust with respect to
. The exact data
has smoothness up to
,
respectively
corresponding to the chosen B-splines. From Sobolev embedding theorem, this implies a Hölder condition of order up to 4, 5 and 6.
The Gaussian white noise was discretized such that we obtain an inverse regression problem with equidistant deterministic design and normally distributed errors with variance
. Since the discrete regression design is asymptotically equivalent to the Guassian white noise model (Equation3
(3)
(3) ) (see e.g. [Citation11]), we consider the increasing sample sizes n 1000 , 2512 , 6310 , 15849 , 39811 , 100000 instead of letting the noise level going to 0 in the theoretical noise model, and 100 simulations for each sample size.
Remark 8:
Theorem 2.6 holds for noise levels that fulfill the inequality (Equation16(16)
(16) ). In our numerical example, we can explicitly formulate the relation between the noise level
and the
norm of the difference between the initial guess and exact solution c. From Lemma 4.4, we get the values
and
since
,
,
and
for a choice of the exact data
. The values of the constants
and
can be accordingly derived as
and, for a choice of the initial value for the regularization parameter , (Equation16
(16)
(16) ) becomes
For we have
and the sufficient conditions for this inequality to hold are and
. Hence, for a noise level of 0.01, our initial guess should be as close in the
norm to the exact solution as 0.16 to ensure that condition (Equation16
(16)
(16) ) holds. Moreover, the quality of the reconstruction is very sensitive to the choice of the a-priori guess.
To illustrate the rates of convergence for the two-step method with Lepskii choice of the regularization parameter, we used in the first step of the algorithm a local polynomial estimator with Gaussian kernel for the direct regression problem as stated in (Equation33(33)
(33) ) and an a-priori chosen bandwidth. We chose quadratic local polynomial estimator, since the linear estimator shows larger bias in regions with higher curvatures , and we varied the values of the bandwidth by using a constant
chosen from the grid between 0.1 and 1 with step size 0.1 as factor to the a-priori value
. The empirical values of the rates of convergence
were computed by leave-1-out cross-validation and used in the second step of the method. An exhaustive introduction to the application of the local polynomial estimator and its challenges can be found in [Citation45]. The tail behaviour for this estimator fulfills the condition in Theorem 2.6 as a consequence of Lemma 4.3. For a polynomial of degree 2, it follows from Theorem 5.10 and Remark 5.13 in [Citation41] that
and
.
In the second step, we applied the balancing principle to choose the regularization parameter as studied in Theorem 2.6. The Lepskii factor was chosen from a grid of values between 0.1 and 0.05, by minimizing the empirical mean square error, and the Lepskii constant is computed as
. An overview of the constants used for simulations and computation is given in the Table .
We present in Figure the convergence rates for the chosen smoothness of the exact solution, considering the sample sizes 1000 , 2512 , 6310 , 15849 , 39811 , 100000. The logarithm of the empirical estimation of the expected squared error of
is plotted over the logarithm of the empirical values of the rates of convergence of the local polynomial estimator for the three choices of
shown in Figure . The empirical rates of convergence are plotted in full, dashed and dotted lines according to the three different smoothness conditions, while the theoretical ones corresponding to a line with slope
are illustrated in the dashed-dotted lines. Starting with a sample size
, the linear trend dominates, approaching asymptotically the theoretical linear slopes.
Table 1. Overview of the constants.
Acknowledgements
The author would like to thank the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme ‘Variational methods and effective algorithms for imaging and vision’ when work on this paper was also undertaken.
Additional information
Funding
Notes
No potential conflict of interest was reported by the author.
References
- Engl HW , Hanke M , Neubauer A . Regularization of inverse problems. Vol. 375, Mathematics and its applications. Dordrecht: Kluwer Academic Publishers Group; 1996.
- Sudakov VN , Halfin LA . A statistical approach to the correctness of the problems of mathematical physics. Dokl Akad Nauk SSSR. 1964;157:1058–1060.
- Bissantz N , Hohage T , Munk A , et al . Convergence rates of general regularization methods for statistical inverse problems and applications. SIAM J Numer Anal. 2007;45(6):2610–2636.
- Mathé P , Pereverzev S . Optimal discretization of inverse problems in Hilbert scales. Regularization and self-regularization of projection methods. SIAM J Numer Anal. 2001;38:1999–2021.
- O’Sullivan F . Convergence characteristics of methods of regularization estimators for nonlinear operator equations. SIAM J Numer Anal. 1990;27(6):1635–1649.
- Lukas MA . Robust generalized cross-validation for choosing the regularization parameter. Inverse Probl. 2006;22(5):1883–1902.
- Wahba G . Spline models for observational data. Vol. 59, CBMS-NSF regional conference series in applied mathematics. Philadelphia (PA): Society for Industrial and Applied Mathematics (SIAM); 1990.
- Bissantz N , Hohage T , Munk A . Consistency and rates of convergence of nonlinear Tikhonov regularization with random noise. Inverse Probl. 2004;20(6):1773–1789.
- Klann E , Ramlau R . Regularization by fractional filter methods and data smoothing. Inverse Probl. 2008;24(2):025018, 26.
- Klann E , Maaß P , Ramlau R . Two-step regularization methods for linear inverse problems. J Inverse Ill-Posed Probl. 2006;14(6):583–607.
- Tsybakov AB . Introduction to nonparametric estimation. Springer series in statistics. New York (NY): Springer; 2009. Revised and extended from the 2004 French original, Translated by Vladimir Zaiats.
- Grama I , Nussbaum M . Asymptotic equivalence for nonparametric regression. Math Methods Statist. 2002;11(1):1–36.
- Meister A , Reiß M . Asymptotic equivalence for nonparametric regression with non-regular errors. Probab Theory Rel Fields. 2013;155(1–2):201–229.
- Werner F , Hohage T . Convergence rates in expectation for Tikhonov-type regularization of inverse problems with Poisson data. Inverse Probl. 2012;28(10):104004, 15.
- Hohage T , Pricop M . Nonlinear Tikhonov regularization in Hilbert scales for inverse boundary value problems with random noise. Inverse Probl Imag. 2008;2(2):271–290.
- Natterer F . Error bounds for Tikhonov regularization in Hilbert scales. Appl Anal. 1984;18(1–2):29–37.
- Neubauer A . Tikhonov regularization of nonlinear ill-posed problems in Hilbert scales. Appl Anal. 1992;46(1–2):59–72.
- Mair BA , Ruymgaart FH . Statistical inverse estimation in Hilbert scales. SIAM J Appl Math. 1996;56(5):1424–1444.
- Nussbaum M , Pereverzev S . The degree of ill-posedness in stochastic and deterministic noise models. Berlin: WIAS; 1999. Technical Report.
- Goldenshluger A , Pereverzev S . On adaptive inverse estimation of linear functionals in Hilbert scales. Bernoulli. 2003;9:783–807.
- Tautenhahn U . Error estimates for regularized solutions of nonlinear ill-posed problems. Inverse Probl. 1994;10(2):485–500.
- Polzehl J , Spokoiny V . Error estimates for regularization methods in Hilbert scales. SIAM J Numer Anal. 1996;33(6):2120–2130.
- Lepskiĭ OV . A problem of adaptive estimation in Gaussian white noise. Teor Veroyatnost i Primenen. 1990;35(3):459–470.
- Mathé P , Pereverzev S . Geometry of linear ill-posed problems in variable Hilbert scales. Inverse Probl. 2003;19(3):789–803.
- Lu S , Pereverzev S , Ramlau R . An analysis of Tikhonov regularization for nonlinear ill-posed problems under general smoothness assumptions. Inverse Probl. 2007;23(1):217–230.
- Bauer F , Hohage T . A Lepskij-type stopping rule for regularized Newton methods. Inverse Probl. 2005;21(6):1975–1991.
- Polzehl J , Spokoiny VG . Adaptive weights smoothing with applications to image restoration. J R Stat Soc Ser B Stat Methodol. 2000;62(2):335–354.
- Kreĭn SG , Petunin JI . Scales of Banach spaces. Uspehi Mat Nauk. 1966;21(2 (128)):89–168.
- Pereverzev S , Schock E . On the adaptive selection of the parameter in regularization of ill-posed problems. SIAM J Numer Anal. 2005;43(5):2060–2076. electronic.
- Mathé P . The Lepskiĭ principle revisited. Inverse Probl. 2006;22(3):L11–L15.
- Bauer F , Pereverzev S . Regularization without preliminary knowledge of smoothness and error behaviour. Eur J Appl Math. 2005;16(3):303–317.
- Bauer F . An alternative approach to the oblique derivative problem in potential theory [PhD thesis]. Aachen: Universität Kaiserslautern; 2004.
- Neubauer A . On Landweber iteration for nonlinear ill-posed problems in Hilbert scales. Numer Math. 2000;85(2):309–328.
- Egger H , Neubauer A . Preconditioning Landweber iteration in Hilbert scales. Numer Math. 2005;101(4):643–662.
- Pricop M . Tikhonov regularization in Hilbert scales for nonlinear statistical inverse problems. Uelvesbüll: Der Andere Verlag; 2007.
- Renardy M , Rogers RC . An introduction to partial differential equations. 2nd ed. Vol. 13, Texts in applied mathematics. New York (NY): Springer-Verlag; 2004.
- Goldenshluger A , Nemirovski A . On spatially adaptive estimation of nonparametric regression. Math Methods Statist. 1997;6(2):135–170.
- Avery M . Literature review for local polynomial regression, unpublished manuscript; 2013. Available from: http://www4.ncsu.edu/mravery/AveryReview2.pdf
- Adams RA , Fournier J . Sobolev spaces. 2nd ed. Vol. 140, Pure and applied mathematics. Oxford: Elsevier Science; 2003.
- Carbery A , Wright J . Distributional and lq norm inequalities for polynomials over convex bodies in R n . Math Res Lett. 2001;8(3):233–248.
- Janson S . Gaussian Hilbert spaces. Vol. 129, Cambridge tracts in mathematics. Cambridge: Cambridge University Press; 1997.
- Bagnoli M , Bergstrom T . Log-concave probability and its applications. Econom Theory. 2005;26(2):445–469.
- Xia Y , Li WK . Asymptotic behavior of bandwidth selected by the cross-validation method for local polynomial fitting. J Multivariate Anal. 2002;83(2):265–287.
- Li Q , Racine J . Cross-validated local linear nonparametric regression. Statist Sinica. 2004;14(2):485–512.
- Fan J , Gijbels I . Local polynomial modelling and its applications. Vol. 66, Monographs on statistics and applied probability. London: Chapman & Hall; 1996.
- Lepskiĭ OV . Asymptotically minimax adaptive estimation. I. Upper bounds. Optimally adaptive estimates. Teor Veroyatnost i Primenen. 1991;36(4):645–659.
- Lepskiĭ OV . Asymptotically minimax adaptive estimation. II. Schemes without optimal adaptation. Adaptive estimates. Teor Veroyatnost i Primenen. 1992;37(3):468–481.
- Hall PG , Racine JS . Infinite order cross-validated local polynomial regression. Department of Economics Working Papers McMaster University;2013.
- Chua SK , Wheeden RL . A note on sharp 1-dimensional Poincaré inequalities. Proc Amer Math Soc. 2006;134(8):2309–2316. electronic.
- Talenti G . Best constant in Sobolev inequality. Ann Mat Pura Appl (4). 1976;110:353–372.
- Taylor ME . Partial differential equations. I. Vol. 115, Applied mathematical sciences. New York (NY): Springer-Verlag; 1996.
- Payne LE , Weinberger HF . An optimal Poincaré inequality for convex domains. Arch Rat Mech Anal. 1960;1960(5):286–292.
Appendix 1
Proof of the Theorem 2.2:
As is a solution of the minimization problem for the Tikhonov functional, the following inequality holds
It follows that
From Assumption 2.1 C it follows that
Replacing the difference in the previous inequality we obtain
(37)
(37)
Using now Assumption 2.1 B we get that
Since we assumed that we have that
where . We apply the interpolation inequality (Equation7
(7)
(7) ) for
and obtain
(A1)
(A1)
Then it holds
and we can write
From (EquationA2(A2)
(A2) ) we have that
and it follows
and(A2)
(A2)
Using the interpolation inequality (Equation7(7)
(7) ) the desired rate of convergence is obtained
with K a constant that depends on .
Proof of the Theorem 2.3:
Let be a solution of the optimization problem (Equation8
(8)
(8) ) and let us consider the Lagrange-Euler equation for the optimization problem (Equation8
(8)
(8) ). From classical results for calculus of variations we know that the first variation of the Tikhonov functional
defined as the right hand side in (Equation8
(8)
(8) ), is null for every direction
and, since we have Fréchet differentiability in
it follows that
for all
. This means
Due to the same arguments, since is the solution of the minimization problem (Equation11
(11)
(11) ) and from the Lagrange-Euler equation it follows
As we have that
and we can choose the direction
in both equalities. It follows that
Taking the difference between these two relations we obtain(A3)
(A3)
From Assumption 2.1 we can write the Taylor polynomial as
and we get
We denote the three integrals as respectively
and, from Assumption 2.1, we can bound their norms by
We write now the relation (EquationA4
(A4)
(A4) ) as
Using the Taylor formula we get
It follows
From Cauchy-Schwarz inequality, Assumptions 2.1 and the norm estimates for ,
and
we have
We can rewrite this inequality as(A4)
(A4)
As we have
and it holds
To simplify the notation, we introduce a positive constant that will vary from line to line in the following paragraphs. We have that
and this implies(A5)
(A5)
since we computed the rates of convergence for the norm of the approximation error
in (EquationA3
(A3)
(A3) ). Using (EquationA3
(A3)
(A3) ) and (EquationA6
(A6)
(A6) ) in (EquationA5
(A5)
(A5) ) we notice that
From (EquationA6(A6)
(A6) ) it holds
We apply now the interpolation inequality (Equation7(7)
(7) ) to obtain
Since for all x, y positive and
, we get the following inequality
meaning that
where we used the inequalities and
to bound the numerical constants. We now apply four times the Young inequality
which holds for all ,
and
with
. For the second term we take
,
and
, for the fourth
,
and
, for the fifth
,
and
, for the sixth term
,
and
. This yields
(A6)
(A6)
where and can be easily computed from the second term and from an upper bound for
, and
is a constant that depends on
such that
.
For the sake of completeness, we state now the following result from [Citation40] that was applied in our article in the proof of Lemma 4.3.
Lemma A.1:
Let be a polynomial of degree at most d. Suppose
and
is a log-concave probability measure on
. Then there is an absolute constant C such that