
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This article is devoted to the study of nonstationary Iterated Tikhonov (nIT) type methods (Hanke M, Groetsch CW. Nonstationary iterated Tikhonov regularization. J Optim Theory Appl. 1998;98(1):37–53; Engl HW, Hanke M, Neubauer A. Regularization of inverse problems. Vol. 375, Mathematics and its Applications. Dordrecht: Kluwer Academic Publishers Group; 1996. MR 1408680) for obtaining stable approximations to linear ill-posed problems modelled by operators mapping between Banach spaces. Here we propose and analyse an a posteriori strategy for choosing the sequence of regularization parameters for the nIT method, aiming to obtain a pre-defined decay rate of the residual. Convergence analysis of the proposed nIT type method is provided (convergence, stability and semi-convergence results). Moreover, in order to test the method's efficiency, numerical experiments for three distinct applications are conducted: (i) a 1D convolution problem (smooth Tikhonov functional and Banach parameter-space); (ii) a 2D deblurring problem (nonsmooth Tikhonov functional and Hilbert parameter-space); (iii) a 2D elliptic inverse potential problem.
1. Introduction
In this article we investigate nonstationary Iterated Tikhonov (nIT) type methods [Citation1,Citation2] for obtaining stable approximations of linear ill-posed problems modelled by operators mapping between Banach spaces. The novelty of our approach consists in the introduction of an a posteriori strategy for choosing the sequence of regularization parameters (or, equivalently, the Lagrange multipliers) for the nIT iteration, which play a key role in the convergence speed of the nIT iteration.
This new a posteriori strategy aims to enforce a pre-defined decay of the residual in each iteration; it differs from the classical choice for the Lagrange multipliers (see, e.g. [Citation2,Citation3]), which is based on an a priori strategy (typically geometrical) and leads to an unknown decay rate of the residual.
The inverse problem we are interested in consists of determining an unknown quantity from given data
, where X, Y are Banach spaces. We assume that data are obtained by indirect measurements of the parameter, this process being described by the ill-posed operator equation
(1)
(1) where
is a bounded linear operator, whose inverse
either does not exist, or is not continuous. In practical situations, one does not know the data y exactly; instead, only approximate measured data
are available with
(2)
(2) where
is the (known) noise level. A comprehensive study of linear ill-posed problems in Banach spaces can be found in the text book [Citation4] (see, e.g. [Citation1] for a corresponding theory in Hilbert spaces).
Iterated Tikhonov type methods are typically used for linear inverse problems. In the Hilbert space setting we refer the reader to [Citation2] for linear operator equations, and also to [Citation5] for the nonlinear case. In the Banach space setting the research is still ongoing. Some preliminary results can be found in [Citation3] for linear operator equations; see [Citation6] for the nonlinear case; see also [Citation7]. In all references above, a priori strategies are used for choosing the Lagrange multipliers.
1.1. Main results: presentation and interpretation
The approach discussed in this manuscript is devoted to the Banach space setting, and consists in adopting an a posteriori strategy for the choice of the Lagrange multipliers. The strategy used here is inspired by the recent work [Citation8], where the authors propose an endogenous strategy for the choice of the Lagrange multipliers in the nonstationary iterated Tikhonov method for solving (Equation1(1)
(1) ), (Equation2
(2)
(2) ) when X and Y are Hilbert spaces. The penalty terms used in our Tikhonov functionals are the same as in [Citation6] and consist of Bregman distances induced by (uniformly) convex functionals, e.g. the sum of the
-norm with the TV -seminorm. In our previous work [Citation9], we implemented the method proposed in this paper and investigated its numerical performance (two different ill-posed problems were solved). Here, we extend our previous results by presenting a whole convergence analysis. Additionally, the corresponding algorithm is implemented for solving three benchmark problems and more details concerning the computation of the minimizers of the Tikhonov functional are provided; our numerical results are compared with the ones obtained using the nIT method using the classical geometrical choice of Lagrange multipliers [Citation6].
In what follows, we briefly interpret the main results: The proposed method defines each Lagrange multiplier such that the residual of the corresponding next iterate lies in an interval which depends on both the noise level and the residual of the current iterate (see (Equation23(23)
(23) )). This fact has the following consequences: (1) it forces a geometrical decay of the residual (Proposition 4.1); (2) it guarantees the possibility of computing multipliers in agreement with the theoretical convergence results (Theorems 4.6, 4.8 and 4.9); (3) the computation of the multipliers demands less numerical effort than the classical strategy of computing the multipliers by solving an equation in each iteration; (4) the next iterate is not uniquely determined by the current one; instead, it is chosen within a set of successors of the current iterate (Definition 4.7). We also address the actual computation of the Lagrange multipliers. Since each multiplier is implicitly defined by an inequality, we discuss a numerically efficient strategy for computing them, which is based on the decrease rate of the past residuals (Section 5.1).
1.2. Outline of the article
This manuscript is outlined as follows: In Section 2 a revision of relevant background material is presented. In Section 3 the new nIT method is introduced. Section 4 is devoted to the convergence analysis of the nIT method. In Section 5 possible implementations of our method are discussed; the evaluation of the Lagrange multipliers is addressed, as well as the issue of minimizing the Tikhonov functionals. Section 6 is devoted to numerical experiments, while Section 7 is dedicated to final remarks and conclusions.
2. Background material
For details on the material discussed in this section, we refer the reader to the textbooks [Citation4,Citation10].
Unless the contrary is explicitly stated, we always consider X a real Banach space. The effective domain of the convex functional is defined as
The set
is always convex and we call f proper provided it is non-empty. We call f uniformly convex if there exists a continuous and strictly increasing function
with the property
implies
such that
(3)
(3) for all
and
Of course f uniformly convex implies f strictly convex, which in turn implies f convex. The functional f is lower semi-continuous (in short l.s.c.) if for any sequence
satisfying
, it holds
It is called weakly lower semi-continuous (w.l.s.c.) if above property holds true with
replaced by
Obviously, every w.l.s.c functional is l.s.c. Further, any Banach space norm is w.l.s.c.
The sub-differential of a functional is the point-to-set mapping
defined by
Any element in the set
is called a sub-gradient of f at x. The effective domain of
is the set
It is clear that the inclusion
holds whenever f is proper.
Sub-differentiable functionals and l.s.c. convex functionals are very close related concepts. In fact, a sub-differentiable functional f is convex and l.s.c. in any open convex set of On the other hand, a proper, convex and l.s.c. functional is always sub-differentiable on its effective domain.
The definition of sub-differential readily yields
If
are convex functionals and there is a point
where f is continuous, then
(4)
(4) Moreover, if Y is a real Banach space,
is a convex functional,
is a bounded linear operator and h is continuous at some point of the range of A, then
for all
and
where
is the Banach-adjoint of A. Consequently,
(5)
(5) If a convex functional
is Gâteaux-differentiable at
then f has a unique sub-gradient at x, namely, the Gâteaux-derivative itself:
The sub-differential of the convex functional
(6)
(6) is called the duality mapping and is denoted by
It can be shown that for all
Thus, the duality mapping has the inner-product-like properties:
for all
By using the Riesz Representation Theorem, one can prove that
for all
whenever X is a Hilbert space.
Banach spaces are classified according with their geometrical characteristics. Many concepts concerning these characteristics are usually defined using the so called modulus of convexity and modulus of smoothness, but most of these definitions can be equivalently stated observing the properties of the functional f defined in (Equation6(6)
(6) ).Footnote1 This functional is convex and sub-differentiable in any Banach space X. If (Equation6
(6)
(6) ) is Gâteaux-differentiable in the whole space X, this Banach space is called smooth. In this case,
and therefore, the duality mapping
is single-valued. If the functional f in (Equation6
(6)
(6) ) is Fré chet-differentiable in X, this space is called locally uniformly smooth and it is called uniformly smooth provided f is uniformly Fréchet-differentiable in bounded sets. As a result, the duality mapping is continuous (resp. uniformly continuous in bounded sets) in locally uniformly smooth (resp. uniformly smooth) spaces. It is immediate that uniform smoothness of a Banach space implies local uniform smoothness, which in turn implies smoothness of this space. Moreover, none reciprocal is true. Similarly, a Banach space X is called strictly convex whenever (Equation6
(6)
(6) ) is a strictly convex functional. Moreover, X is called uniformly convex if the functional f in (Equation6
(6)
(6) ) is uniformly convex. It is clear that uniform convexity implies strict convexity. It is well-known that both uniformly smooth and uniformly convex Banach spaces are reflexive.
Assume f is proper. Then, choosing elements with
we define the Bregman distance between x and y in the direction of
as
Obviously,
and, since
it additionally holds that
Moreover, it is straightforward proving the Three Points Identity:
for all
and
Further, the functional
is strictly convex whenever f is strictly convex, and in this case,
iff
When f is the functional defined in (Equation6(6)
(6) ) and X is a smooth Banach space, the Bregman distance has the special notation
i.e.
Since
is the identity operator in Hilbert spaces, a simple application of the polarization identity shows that
in these spaces.
It is not difficult to prove (see e.g. [Citation9]) that if is uniformly convex, then
(7)
(7) for all
and
where ϕ is the function in (Equation3
(3)
(3) ). In particular, in a smooth and uniformly convex Banach space X, the above inequality reads
We say that a functional has the Kadec property if for any sequence
the weak convergence
, together with
, implies
It is not difficult to prove (see e.g. [Citation6]) that any proper, w.l.s.c. and uniformly convex functional has the Kadec property. In particular, the norm in a uniformly convex Banach space has this property.
Concrete examples of Banach spaces of interest are the Lebesgue space the Sobolev space
and the space of
summable sequences
All these Banach spaces are both uniformly convex and uniformly smooth provided that
.
3. The nIT method
In this section, we present the nonstationary iterated Tikhonov (nIT) type method considered in this article, which aims to find stable approximate solutions to the inverse problem (Equation1(1)
(1) ), (Equation2
(2)
(2) ). The method proposed here is in the spirit of the method in [Citation6]. The distinguishing feature is the use of an a posteriori strategy for the choice of the Lagrange multipliers, as detailed below.
For a fixed r>1 and a uniformly convex penalty term f, the nIT method defines sequences in X and
in
iteratively by
where the Lagrange multiplier
is to be determined using only information about A, δ,
and
.
Our strategy for choosing the Lagrange multipliers is inspired by the work [Citation8], where the authors propose an endogenous strategy for the choice of the Lagrange multipliers in the nonsationary iterated Tikhonov method for solving (Equation1(1)
(1) ), (Equation2
(2)
(2) ) when X and Y are Hilbert spaces. This method is based on successive orthogonal projection methods onto a family of shrinking, separating convex sets. Specifically, the iterative method in [Citation8] obtains the new iterate projecting the current one onto a levelset of the residual function, whose level belongs to a range defined by the current residual and by the noise level. Moreover, the admissible Lagrange multipliers (in each iteration) shall be chosen in a non-degenerate interval.
Aiming to extend this framework to the Banach space setting, we are forced to introduce Bregman distance and Bregman projections. This is due to the well-known fact that in Banach spaces the metric projection onto a convex and closed set C, defined as , loses the decreasing distance property of the orthogonal projection in Hilbert spaces. In order to recover this property, one should minimize in Banach spaces the Bregman distance, instead of the norm-induced distance.
For the remaining of this article we adopt the following main assumptions:
There exists an element
such that
f is a w.l.s.c. function.
f is a uniformly convex function.
X and Y are reflexive Banach spaces and Y is smooth.
Moreover, we denote by the μ-levelset of the residual functional
, i.e.
Note that, since A is a continuous linear operator, it follows that
is closed and convex. Now, given
and
, we define the Bregman projection of
onto
, as a solution of the minimization problem
(8)
(8) It is worth noticing that a solution of the problem (Equation8
(8)
(8) ) depends on the sub-gradient ξ. Furthermore, since
is strictly convex (which follows from the uniformly convexity of f), problem (Equation8
(8)
(8) ) has at most one solution. The fact that the Bregman projection is well defined when
(in this case we set
) is a consequence of the following lemma.
Lemma 3.1
If then problem (Equation8
(8)
(8) ) has a solution.
Proof.
Assumption (A.1), together with equation (Equation2(2)
(2) ) and the assumption that
, implies that the feasible set of problem (Equation8
(8)
(8) ), i.e. the set
is nonempty.
From Assumptions (A.2) and (A.3) it follows that
is proper, convex and l.s.c. Furthermore, relation (Equation7
(7)
(7) ) implies that
is a coercive function. Hence, the lemma follows using the reflexivity of X together with [Citation11, Corollary 3.23].Footnote2
Note that if , then
and
for all
. Furthermore, with the available information of the solution set of (Equation1
(1)
(1) ),
is the set of best possible approximate solution for this inverse problem. However, since problem (Equation8
(8)
(8) ) may be ill-posed when
, our best choice is to generate
from
as a solution of problem (Equation8
(8)
(8) ), with
and
such that we guarantee a reduction of the residual norm while preventing ill-posedness of (Equation8
(8)
(8) ).
For this purpose, we analyse in the sequel the minimization problem (Equation8(8)
(8) ) by means of Lagrange multipliers. The Lagrangian function associated to problem (Equation8
(8)
(8) ) is
Note that, for each
, the function
is l.s.c. and convex. For any
define the functions
(9)
(9) The next lemma provides a classical Lagrange multiplier result for problem (Equation8
(8)
(8) ), which will be useful for formulating the nIT method.
Lemma 3.2
If then the following assertions are equivalent
x is a solution of (Equation8
there exists
Proof.
It follows from (Equation2(2)
(2) ), Assumption (A.1) and the hypothesis
that
satisfies
This inequality implies the Slater condition for problem (Equation8
(8)
(8) ). Thus, since A is continuous and
is l.s.c., we conclude that x is a solution of (Equation8
(8)
(8) ) if and only if there exists
such that the point
satisfies the Karush–Kuhn–Tucker (KKT) conditions for this minimization problem [Citation12], namely
If we assume
in the relations above, then the definition of the Lagrangian function, together with the strictly convexity of
, implies that
is the unique minimizer of
. Moreover, since
, we conclude that the pair
does not satisfy the KKT conditions. Consequently, we have
and
. The lemma follows using the definition of
.
We are ready to present the nIT method for solving (Equation1(1)
(1) ).

Properties (Equation4(4)
(4) ) and (Equation5
(5)
(5) ), together with the definition of the duality mapping
, imply that the point
minimizes the optimization problem in [3.2] if and only if
(10)
(10) Hence, since Y is a smooth Banach space, the duality mapping
is single valued and
Consequently,
in step 3.2 of Algorithm 1 is well defined and it is a sub-gradient of f at
.
Notice that the stopping criteria in Algorithm 1 corresponds to the discrepancy principle, i.e. the iteration stops at step defined by
(11)
(11)
Remark 3.3
Novel properties of the proposed method
The strategy used here is inspired by the recent work [Citation8], where the authors propose an endogenous strategy for the choice of the Lagrange multipliers in the nonstationary iterated Tikhonov method for solving (Equation1
The penalty terms used in our Tikhonov functionals are the same as in [Citation6] and consist of Bregman distances induced by (uniformly) convex functionals, e.g, the sum of the
We present a whole convergence analysis for the proposed method, characterizing it as a regularization metod.
4. Convergence analysis
In this section, we analyse the convergence properties of Algorithm 1. We begin by presenting the following result that establishes an estimate for the decay of the residual . It can be proved in much the same manner as [Citation8, Proposition 4.1], and for the sake of brevity we omit the proof here.
Proposition 4.1
Let be the (finite) sequence defined by the nIT method (Algorithm 1), with
and
as in (Equation2
(2)
(2) ). Then,
where
is defined by (Equation11
(11)
(11) ).
As a direct consequence of Proposition 4.1 we have that in the noisy data case, the discrepancy principle terminates the iteration after finitely many steps, i.e. . Furthermore, the corollary below gives an estimate for the stopping index
.
Corollary 4.2
Let be the (finite) sequence defined by the nIT method (Algorithm 1), with
and
as in (Equation2
(2)
(2) ). Then, the stopping index
defined in (Equation11
(11)
(11) ), satisfies
In the next proposition we prove monotonicity of the sequence and we also estimate the gain
, where
satisfies Assumption (A.1).
Proposition 4.3
Let be the (finite) sequence defined by the nIT method (Algorithm 1), with
and
as in (Equation2
(2)
(2) ). Then, for every
satisfying Assumption (A.1) it holds
(12)
(12) for
Proof.
Using the three points identity we have
(13)
(13) where the second equality above follows from the definition of
. Simple manipulations of the second term on the right hand side above yield
(14)
(14) Combining these two relations we obtain
where the last inequality follows from (Equation2
(2)
(2) ). Since
, we have
. Thus,
We deduce (Equation12
(12)
(12) ) from the above inequality.
Corollary 4.4
Let be the sequence defined by the nIT method (Algorithm 1) with
and
be the sequence of corresponding Lagrange multipliers. Then, for all
and any
satisfying (A.1), we have
(15)
(15) Consequently, using a telescopic sum, we obtain
(16)
(16)
Proof.
In the exact data case, i.e. and
, equality (Equation14
(14)
(14) ) becomes
Combining the formula above with (Equation13
(13)
(13) ), when
, we deduce (Equation15
(15)
(15) ). The result in (Equation16
(16)
(16) ) follows directly from (Equation15
(15)
(15) ).
We now fix a and
, and study the existence and uniqueness of a vector
with the property
(17)
(17) Such an element
is called a
minimal-distance solution and it is the equivalent of the
minimal-norm solution of (Equation1
(1)
(1) ) in the Hilbert space setting [Citation1].
Lemma 4.5
There exists a unique element satisfying (Equation17
(17)
(17) ).
Proof.
Let be a sequence satisfying
and
then the sequence
is bounded, and because f is uniformly convex we have that
is bounded as well. Since X is reflexive, there exist a vector
and a subsequence
such that
It follows that
and because f is w.l.s.c. we have
which implies that
is a
minimal-distance solution.
Suppose now that are two
minimal-distance solutions. Since f is strictly convex, so is
, and for any
we obtain
which contradicts the minimality of x.
In the next theorem we prove strong convergence of the sequence generated by the nIT algorithm in the noise-free case to the solution .
Theorem 4.6
Let be the sequence defined by the nIT method (Algorithm 1) with
and
the sequence of the corresponding Lagrange multipliers. Then,
converges strongly to
Proof.
We first prove that is a Cauchy sequence in X. Let
and
a solution of (Equation1
(1)
(1) ), using the three points identity we have
(18)
(18)
We observe that
(19)
(19) where the second equality above follows form the definition of
and the inequality is a consequence of the properties of the duality mapping
. Proposition 4.1, with
, implies that
for all
. Therefore, we have
Combining the inequality above with (Equation18
(18)
(18) ) we deduce that
From (Equation15
(15)
(15) ) it follows that the sequence
is monotonically decreasing. Thus, by inequality above and (Equation16
(16)
(16) ) we have
as
, and from the uniform convexity of f we obtain that
is a Cauchy sequence in X. Therefore, there is
such that
as
, and since Proposition 4.1 implies that
as
and A is a continuous map, we conclude that
.
Now, we prove that We first observe that
, which yields
Thus,
(20)
(20) Next, we prove that
(21)
(21) which in view of (Equation20
(20)
(20) ) will ensure that
proving that
Indeed, using equation (Equation19
(19)
(19) ) with
, for m>l, we have
as
Then, given
there exists
such that
Now,
Since
as
we conclude that there exists a number
such that
Therefore,
implies
which proves (Equation21
(21)
(21) ) as we wanted.
Our intention in the remainder of this section is to study the convergence properties of the family as the noise level δ approaches zero. To achieve this goal we first establish a stability result connecting
to
. Observe that in general,
is not uniquely defined from
which motivates the following definition.
Definition 4.7
Let be pre-fixed constants.
is called a successor of
if
There exists
The residual
In other words, there must exist a nonnegative Lagrange multiplier , s.t. the minimizer
of the corresponding Tikhonov functional in (Equation22
(22)
(22) ) attains a residual
in the interval (Equation23
(23)
(23) ) (which is defined by convex combinations of the noise level δ with the residual at the current iterate
).
In the noisy-data case, as long as the discrepancy principle is not satisfied, the interval in (Equation23(23)
(23) ) is a subset of
(24)
(24) because
Therefore, if we consider a sequence generated by Algorithm 1 with the inequalities in [3.2] replaced by a more restrictive condition, as in item 3 of Definition 4.7, all the previous results still hold. Further, since
and
it is clear that interval (Equation23
(23)
(23) ) is non-empty.
We note that interval (Equation23(23)
(23) ) becomes close to the interval (Equation24
(24)
(24) ) as
and therefore, the former interval is only a bit larger than the last one for
In the noise-free case, (Equation23
(23)
(23) ) reduces to the non-empty interval
(25)
(25) and according to Theorem 4.6, the sequence
converges to
whenever
is a successor of
for all
. In this situation, we call
a noiseless sequence.
Now, we study the behaviour of for fixed k, as the noise level δ approaches zero. For the sake of the notation, we define
for
(compare it with (Equation22
(22)
(22) )).
Theorem 4.8
Stability
Let be a positive-zero sequence and fix
Assume that the sequences
are fixed, where
is a successor of
for
Further, assume that Y is a locally uniformly smooth Banach space. If
is not a solution of (Equation1
(1)
(1) ), then there exists a noiseless sequence
such that, for every fixed number
there exists a subsequence
(depending on k) satisfying
Proof.
Assume that is not a solution of
We use an induction argument: since
and
for every
the result is clear for
The argument consists in successively choosing a subsequence of the current subsequence, and to avoid a notational overload, we denote a subsequence of
still by
Suppose the result holds true for some
Then, there exists a subsequence
satisfying
(26)
(26) where
is a successor of
for
Because
is a successor of
it is true that
for all j. Due to the same reason, there exists a non-negative number
such that
with the resulting residual
lying in the interval (Equation23
(23)
(23) ). Our task now is proving that there exists a successor
of
and a subsequence
of the current subsequence such that
and
as
. Since the proof is relatively large, we divide it in 4 main steps: 1. we find a vector
such that
(27)
(27) for a specific subsequence
2. using the third item in Definition 4.7 we show that the sequence
is bounded. Then, we choose a convergent subsequence and define
(28)
(28) as well as
(29)
(29) 3. we prove that
which guarantees that
4. Finally, we prove that
(30)
(30) which in view of (Equation27
(27)
(27) ) will guarantee that
as
since f has the Kadec property, see last paragraph in Section 2. The last result in turn, will prove that
Finally, we validate that
is a successor of
completing the induction argument.
Step 1: From (Equation12(12)
(12) ) and the uniform convexity of f follows that the sequence
is bounded. Thus, there exists a subsequence
of the current subsequence, and a vector
such that (Equation27
(27)
(27) ) holds true.
Step 2: We claim that, for each fixed, there exists a constant
such that
(31)
(31) Indeed, assume the contrary. Then, there is a subsequence satisfying
as
But in this case,
This, together with the lower bound of interval (Equation23
(23)
(23) ) implies that
is a solution of Ax=y because
(32)
(32) and we have a contradiction. Thus (Equation31
(31)
(31) ) is true. We fix a convergent subsequence and define
as in (Equation28
(28)
(28) ) and
as in (Equation29
(29)
(29) ).
Step 3: Observe that
Thus, from (Equation27
(27)
(27) ) and the induction hypothesis it follows that
Now, the weak lower semi-continuity of f, together with (Equation27
(27)
(27) ) and the induction hypothesis, implies that
(33)
(33)
From (Equation27
(27)
(27) ) we have
(34)
(34) which together with (Equation28
(28)
(28) ) and the lower semi-continuity of Banach space norms yields
This proves that
because
is the unique minimizer of
Thus,
as
The above inequalities also ensure that
Taking a subsequence if necessary, we can assume that the following sequences converge:
(35)
(35) and
(36)
(36) We can also assume for this subsequence that
(37)
(37) Step 4: Define
and obseve that from (Equation33
(33)
(33) ), the inequality
holds. Thus, it suffices to prove that
to ensure that
which will prove (Equation30
(30)
(30) ). We assume that a>c and derive a contradiction. From (Equation28
(28)
(28) ), (Equation35
(35)
(35) ), (Equation36
(36)
(36) ), (Equation37
(37)
(37) ), together with the definition of limit, it follows the existence of a number
such that
implies
Therefore, for any
it holds
which leads to an obvious contradiction, proving that
as we wanted. Hence (Equation30
(30)
(30) ) holds, and since f has the Kadec property, it follows, in view of (Equation27
(27)
(27) ), that
This last result, together with the continuity of the duality mapping in locally uniformly smooth Banach spaces, implies that
It only remains to prove that belongs to interval (Equation25
(25)
(25) ), which will guarantee that
is a successor of
But this result follows from applying the limit
to the sequence
which belongs to interval (Equation23
(23)
(23) ).
Theorem 4.9
Regularization
Let be a positive-zero sequence and fix
Assume that the sequences
are fixed, where
is a successor of
for
Further, assume that Y is a locally uniformly smooth Banach space. Then,
(38)
(38)
Proof.
The result is clear if is a solution of
Assume this is not the case. We first validate that the sequence
has no convergent subsequences. Indeed, if for a subsequence
it is true that
as
, then since
for all
we must have
for m large enough. From Theorem 4.8, the subsequence
has itself a subsequence (which we still denote by
) which converges to
this is,
But
is a solution of Ax=y since
As in the proof of Theorem 4.8 (see (Equation32
(32)
(32) )) we conclude that
is a solution of
contradicting our assumption. Therefore
as
We now prove that each subsequence of has itself a subsequence which converges to
This will prove (Equation38
(38)
(38) ). We observe that since any subsequence of
is itself a positive-zero sequence, it suffices to prove that
has a subsequence which converges to
.
Our first step is proving that, for every fixed, there exists a subsequence (which we still denote by
) depending on ε, and a number
such that
(39)
(39) In fact, fix
and let
be the noiseless sequence constructed in Theorem 4.8. Since
is a successor of
for all
the sequence
converges to
(see Theorem 4.6). Then, there exists a natural number
such that
From Theorem 4.8 there exists a subsequence (still denoted by
) depending on N, and a number
depending on ε, such that
Since
there is a number
such that
for all
It follows from (Equation12
(12)
(12) ) and the three points identity that for
which proves (Equation39
(39)
(39) ).
Choosing we can find a subsequence
and select a number
such that
Since the current subsequence
is also a positive-zero sequence, the above reasoning can be applied again in order to extract a subsequence of the current one satisfying (Equation39
(39)
(39) ) with
. We choose a number
such that the inequality
holds true. Using induction, it is therefore possible to construct a subsequence
with the property
which implies that
and since f is uniformly convex,
5. Algorithms and numerical implementation
5.1. Determining the Lagrange multipliers
As before, we consider the function , where
represents the minimizer of the Tikhonov functional
In order to choose the Lagrange multiplier in the k-th iteration, our strategy consists in finding a
such that
, where
Here
are pre-defined constants.
We have employed three different methods to compute : the well-known secant and Newton methods and a third strategy, here called adaptive method, which we now explain: fix
,
,
and some initial value
. In the k-th iteration,
, we define
, where
The idea behind the adaptive method is observing the behaviour of the residual in last iterations and trying to determine how much the Lagrange multiplier should be increased in the next iteration. For example, the residual
lying on the left of the target interval
, means that
was too large. We thus multiply
by a number
in order to reduce the rate of growth of the Lagrange multiplier
, trying to hit the target in the next iteration.
Although the Newton method is efficient, in the sense that it normally finds a good approximation for the Lagrange multiplier in very few steps, it has the drawback of demanding the differentiability of the Tikhonov functional, and therefore it cannot be applied in all situations.
Because it does not require the evaluation of derivatives, the secant method can be used even for a nonsmooth Tikhonov functional. A disadvantage of this method is the high computational effort required to perform it.
Among these three possibilities, the adaptive strategy is the cheapest one, since it only demands one minimization of the Tikhonov functional per iteration. Further, this simple strategy does not require the derivative of this functional, which makes it fit in a large range of applications.
Note that this third strategy may generate a such that
in some iterative steps. This is the reason for correcting the factors
in each iteration. In our numerical experiments, the condition
was satisfied in almost all steps.
5.2. Minimization of the Tikhonov functional
In our numerical experiments, we are interested in solving the inverse problem (Equation1(1)
(1) ), where
, with
, is linear and bounded, noisy data
are available, and the noise level
is known.
In order to implement the nIT method (Algorithm 1), a minimizer of the Tikhonov functional (Equation22(22)
(22) ) needs to be calculated in each iteration step. Minimizing this functional can be itself a very challenging task. We have used two algorithms for achieving this goal in our numerical experiments: 1. The Newton method was used for minimizing this functional in the case
and with a smooth function f, which induces the Bregman distance in the penalization term. 2. The so called ADMM method was employed in order to minimize the Tikhonov functional for the case p=2 (Hilbert space) and a nonsmooth functional f. In the following, we explain the details.
First we consider the Newton method. Define the Bregman distance induced by the norm-functional
which leads to the smooth penalization term
see Section 2. The resulting Tikhonov functional reads
where
is the current iterate.Footnote3 In this case, the optimality condition (Equation10
(10)
(10) ) reads:
(40)
(40) where
is the minimizer of
and
.
In order to apply the Newton method to the nonlinear equation (Equation40(40)
(40) ), one needs to evaluate the derivative of F, which (whenever exists) is given by
. Next we present an explicit expression for the Gâteaux-derivative
(the derivation of this expression is postponed to Appendix A, where the Gâteaux-differentiability of
in
, for
, is investigated). Given
, with
, it holds
(41)
(41) where the linear operator
is to be understood in pointwise sense. In the discretized setting,
is a diagonal matrix whose
th element on its diagonal is
with
being the
th point of the chosen mesh.
In our numerical simulations, we consider the situation where the sought solution is sparse and, therefore, the case is of our interest. We stress the fact that (EquationA2
(A2)
(A2) ) (see Appendix A) holds true even for 1<p<2 whenever
. Using this fact, one can prove that (Equation41
(41)
(41) ) holds for these values of p, e.g. if g does not change signal in Ω (i.e, either g>0 in Ω, or g<0 in Ω) and the direction h is a bounded function in this set. However, these strong hypotheses are very difficult to check, and even if they are satisfied, we still expect having stability problems for inverting the matrix
if the function g attains a small value in some point of the mesh, because the function in (EquationA2
(A2)
(A2) ) satisfies
as
. In order to avoid this kind of problem in our numerical experiments, we have replaced the
th element on the diagonal of the matrix
by
.
The second method that we used in our experiments was the well-known Alternating Direction Method of Multipliers (ADMM), which has been implemented to minimize the Tikhonov functional associated with the inverse problem , where
,
, and
is a nonsmooth function.
ADMM is an optimization scheme for solving linearly constrained programming problems with decomposable structure [Citation13], which goes back to the works of Glowinski and Marrocco [Citation14], and of Gabay and Mercier [Citation15]. Specifically, this algorithm solves problems in the form:
(42)
(42) where
and
are convex proper l.s.c. functions,
and
are linear operators, and
.
ADMM solves the coupled problem (Equation42(42)
(42) ) performing a sequences of steps that decouple functions ϕ and φ, making it possible to exploit the individual structure of these functions. It can be interpreted in terms of alternating minimization, with respect to x and z, of the augmented Lagrangian function associated with problem (Equation42
(42)
(42) ). Indeed, ADMM consists of the iterations
where
and
is the augmented Lagrangian function
The convergence results for ADMM guarantee, under suitable assumptions, that the sequences
,
and
generated by the method are such that
,
and
, where
is the optimal value of problem (Equation42
(42)
(42) ) and
is a solution of the dual problem associated with (Equation42
(42)
(42) ).
For minimizing the Tikhonov functional using ADMM we introduce an additional decision variable z such that problem of minimizing for
is rewritten into the form of (Equation42
(42)
(42) ).
The specific choice of the functions ϕ, φ and the operators M and B is problem dependent (for a concrete example see, e.g. Section 6.2). This allows us to exploit the special form of the functional , and also to pose the minimization problem in a more suitable form, in order to be solved numerically.
In all numerical simulations presented in Section 6, the ADMM method is stopped when becomes smaller than a predefined threshold.
6. Numerical experiments
6.1. Deconvolution
In what follows we consider the application of the nIT method to the deconvolution problem modelled by the linear integral operator
where the kernel K is the continuous function defined by
This benchmark problem is considered in [Citation3]. There, it is observed that
is continuous and bounded for
. Thus,
is compact for
.
In our experiment, A is replaced by the discrete operator , where the above integral is computed using a quadrature formula (trapezoidal rule) over an uniform partition of the interval
with 400 nodes.
The exact solution of the discrete problem is the vector with
,
,
,
,
and
, elsewhere.Footnote4
We compute , the exact data, and add random Gaussian noise to
to get the noisy data
satisfying
.
We follow [Citation3] in the experimental setting and choose ,
(discrepancy principle), and
. For the parameter space, two distinct choices are considered, namely
and
.
Numerical results for the deconvolution problem are presented in Figure
(for simplicity, all legends in this figure refere to the space ; however, p=1.001 is used in the computations). The following methods are depicted:
(BLUE)
(GREEN)
(RED)
(PINK)
(BLACK)
Figure 1. Deconvolution problem: Numerical experiments.
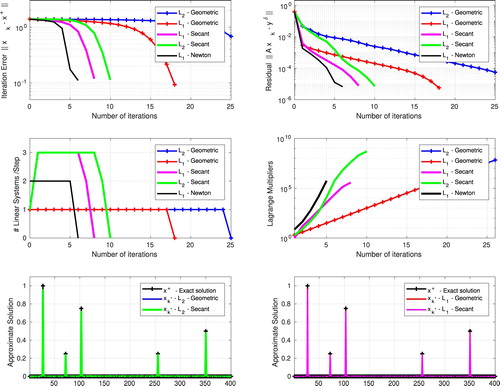
The six pictures in Figure represent:
[TOP] Iteration error in
[CENTER] Number of linear systems/step (left); Lagrange multipliers (right);
[BOTTOM] exact solution and reconstructions with
6.2. Image deblurring
In the sequel an application of the nIT method to an image deblurring problem is considered. This is a finite dimensional problem with spaces and
. The vector
represents the pixel values of the original image to be restored, and
contains the pixel values of the observed blurred image. In practice, only noisy blurred data
satisfying (Equation2
(2)
(2) ) is available. The linear transformation A represents some blurring operator.
In the numerical simulations we consider the situation where the blur of the image is modelled by a space invariant point spread function (PSF). The exact solution is the Barbara image (see Figure ), and
is obtained adding artificial noise to the exact data y=Ax (here A is the covolution operator corresponding to the PSF).
Figure 2. Image deblurring problem: (LEFT) Point Spread Function; (CENTER) Exact image; (RIGHT) Blurred image.

For this problem the nIT method is implemented with two distinct penalization terms, namely (
penalization) and
(
penalization). Here
is a regularization parameter and
is the total variation norm of x, where
is the discrete gradient operator. We minimize the Tikhonov functional associated with the
penalization term using the ADMM described in Section 5.
In our experiments the values ,
and
are used. Moreover,
and
are chosen as initial guesses.
In Figure , the exact solution, the convolution kernel, and the noisy data are shown. The reconstructed images are shown in Figure , while the numerical results are presented in Figure . The following methods were implemented:
(BLUE)
(RED)
(PINK)
(GREEN)
Figure 3. Image deblurring problem: Reconstructions (TOP LEFT) –Geometric; (TOP RIGHT)
–Geometric; (BOTTOM LEFT)
–Secant; (BOTTOM RIGHT)
–Adaptive.

Figure 4. Image deblurring problem: Numerical experiments.
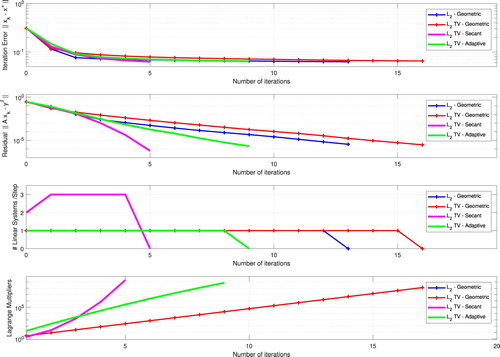
The four pictures in Figure represent:
[TOP] Iteration error
[CENTER TOP] Residual
[CENTER BOTTOM] Number of linear systems solved in each step;
[BOTTOM] Lagrange multiplier
Remark 6.1
The Tikhonov functional associated with the penalization term is minimized using the ADMM in Section 5. Note that, if
then one needs to solve
in each iteration. In order to use ADMM, we sate this problem into the form of (Equation42
(42)
(42) ) by defining
,
,
,
, B=I and d=0.
6.3. Inverse potential problem
The third application considered in this section, the Inverse Potentinal Problem (IPP), consists of recovering a coefficient function , from measurements of the Cauchy data of its corresponding potential on the boundary of the domain
.
The direct problem is modelled by the linear operator , where
solves the elliptic boundary value problem
(43)
(43) Since
, the Dirichlet boundary value problem in (Equation43
(43)
(43) ) admits a unique solution (known as potential)
[Citation16].
The inverse problem we are concerned with, consists in determining the piecewise constant source function x from measurements of the Neumann trace of w at . Using the above notation, the IPP can be written in the abbreviated form (Equation1
(1)
(1) ), with data
.
In our implementations we follow [Citation8] in the experimental setup: we set and assume that
is a function with sharp gradients (see Figure ).
The boundary value problem (Equation43(43)
(43) ) is solved for w using
, and the exact data
for the inverse problem is computed. The noisy data
for the inverse problem is obtained by adding to y a normally distributed noise with zero mean, in order to achieve a prescribed relative noise level.
In our numerical implementations we set (discrepancy principle constant),
(relative noise level), and the initial guess
(a constant function in Ω). For the parameter space we choose
with p=1.5, while the data space is
.
Numerical results for the Inverse potential problem are presented in Figure . The following methods are depicted:
(RED)
(BLACK)
(BLUE)
Figure 5. Inverse Potential problem: Numerical experiments.
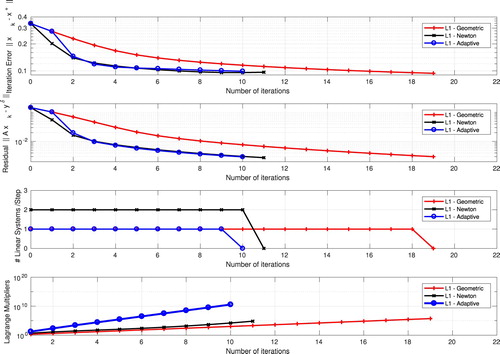
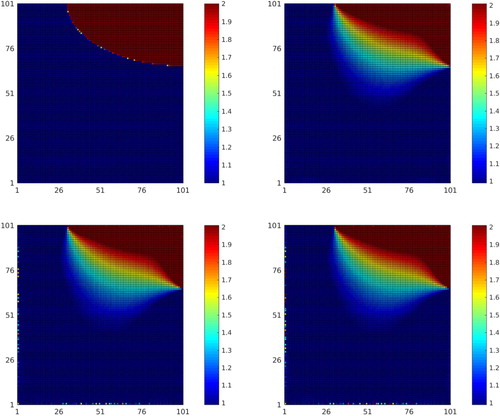
Figure 6. Inverse Potential problem: (TOP LEFT) Exact solution . Reconstructions (TOP RIGHT)
–Geometric; (BOTTOM LEFT)
–Newton; (BOTTOM RIGHT)
–Adaptive.
The four pictures in Figure represent: [TOP] Iteration error in -norm; [
] Residual in
-norm; [
] Number of linear systems/step; [BOTTOM] Lagrange multipliers.
The corresponding reconstruction results are shown in Figure : [] Exact Solution; [
] geometric method; [
] Newton method; [
] Adaptive method.
7. Conclusions
In this manuscript we investigate a novel strategy for choosing the regularization parameters in the nonstationary iterated Tikhonov (nIT) method for solving ill-posed operator equations modelled by linear operators acting between Banach spaces. The novelty of our approach consists in defining strategies for choosing a sequence of regularization parameters (i.e. Lagrange multipliers) for the nIT method.
A preliminary (numerical) investigation of this method was conducted in [Citation9]. In the present manuscript we derive a complete convergence analysis, proving convergence, stability and semi-convergence results (see Section 4). In Sections 6.1 and 6.2 we revisit two numerical applications discussed in [Citation9]. Moreover, in Section 6.3 we investigate a classical benchmark problem in the inverse problems literature, namely the 2D elliptic Inverse Potential Problem.
The Lagrange multipliers are chosen (a posteriori) in order to enforce a fast decay of the residual functional (see Algorithm 1 and Section 4). The computation of these multipliers is performed by means of three distinct methods: (1) a secant type method; (2) a Newton type method; (3) an adaptive method using a geometric sequence with non-constant growth rate, where the rate is updated after each step.
The computation of the iterative step of the nIT method requires the minimization of a Tikhonov Functional (see Section 4). This task is solved here using two distinct methods: (1) in the case of smooth penalization and Banach parameter-spaces the optimality condition (related to the Tikhonov functional) leads to a nonlinear equation, which is solved using a Newton type method; (2) in the case of nonsmooth penalization and Hilbert parameter-space, the ADMM method is used for minimizing the Tikhonov functional.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 The differentiability and convexity properties of this functional are independent of the particular choice of
2 This Lemma guarantees that, given a reflexive Banach space E, and a nonempty closed convex set , then any convex l.s.c proper function
achieves its minimum on A.
3 Here (Equation1(1)
(1) ) is replaced by
.
4 Notice that we are dealing with a discrete inverse problem, and discretization errors associated to the continuous model are not being considered.
5 For the purpose of comparison, the iteration error is ploted in the in -norm for both choices of the parameter space
and
.
References
- Engl HW, Hanke M, Neubauer A. Regularization of inverse problems. Dordrecht: Kluwer Academic Publishers Group; 1996. (Mathematics and its applications; 375). MR 1408680.
- Hanke M, Groetsch CW. Nonstationary iterated Tikhonov regularization. J Optim Theory Appl. 1998;98(1):37–53. doi: 10.1023/A:1022680629327
- Jin Q, Stals L. Nonstationary iterated Tikhonov regularization for ill-posed problems in Banach spaces. Inverse Probl. 2012;28(3):104011.
- Schuster T, Kaltenbacher B, Hofmann B, et al. Regularization methods in Banach spaces. Berlin: de Gruyter; 2012.
- De Cezaro A, Baumeister J, Leitão A. Modified iterated Tikhonov methods for solving systems of nonlinear ill-posed equations. Inverse Probl Imaging. 2011;5(1):1–17. doi: 10.3934/ipi.2011.5.1
- Jin Q, Zhong M. Nonstationary iterated Tikhonov regularization in Banach spaces with uniformly convex penalty terms. Numer Math. 2014;127(3):485–513. MR 3216817 doi: 10.1007/s00211-013-0594-9
- Lorenz D, Schoepfer F, Wenger S. The linearized bregman method via split feasibility problems: analysis and generalizations. SIAM J Imaging Sci. 2014;7(2):1237–1262. doi: 10.1137/130936269
- Boiger R, Leitão A, Svaiter BF. Range-relaxed criteria for choosing the Lagrange multipliers in nonstationary iterated Tikhonov method. IMA J Numer Anal. 2019;39(1). DOI:10.1093/imanum/dry066
- Machado MP, Margotti F, Leitão A. On nonstationary iterated Tikhonov methods for ill-posed equations in Banach spaces. In: Hofmann B, Leitão A, Zubelli JP, editors. New trends in parameter identification for mathematical models. Cham: Springer International Publishing; 2018. p. 175–193.
- Cioranescu I. Geometry of Banach spaces, duality mappings and nonlinear problems. Dordrecht: Kluwer Academic Publishers Group; 1990. (Mathematics and its applications; 62). MR 1079061.
- Brezis H. Functional analysis, Sobolev spaces and partial differential equations. New York: Springer; 2011. (Universitext). MR 2759829.
- Rockafellar RT Conjugate duality and optimization, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1974, Lectures given at the Johns Hopkins University, Baltimore, Md., June, 1973, Conference Board of the Mathematical Sciences Regional Conference Series in Applied Mathematics, No. 16. MR 0373611.
- Eckstein J, Bertsekas DP. On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math Program. 1992;55(3):293–318. MR 1168183. doi: 10.1007/BF01581204
- Glowinski R, Marrocco A. Sur l'approximation, par éléments finis d'ordre un, et la résolution, par pénalisation-dualité, d'une classe de problèmes de Dirichlet non linéaires. Rev. Française Automat. Informat. Recherche Opérationnelle Sér. Rouge Anal. Numér.. 1975;9(R-2):41–76. MR 0388811.
- Gabay D, Mercier B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput Math Appl. 1976;2(1):17–40. doi: 10.1016/0898-1221(76)90003-1
- Evans LC. Partial differential equations. Providence, RI: American Mathematical Society; 1998. (Graduate studies in mathematics; 19).
Appendix
In this appendix we discuss how to compute the Gâteaux derivative of . Given
, the key idea for deriving a formula for
is to observe the differentiability of the function
. This function is differentiable in
whenever p>1 and, in this case it holds
(A1)
(A1) Furthermore, γ is twice differentiable in
if
, with derivative given by
(A2)
(A2) This formula still holds true for
but only in
. In this case,
does not exist and
grows to infinity as x approaches to zero.
Since can be identified with
(A3)
(A3) (see [Citation10]), which looks very similar to
in (EquationA1
(A1)
(A1) ), the bounded linear operator
should be in some sense similar to
in (EquationA2
(A2)
(A2) ). We then fix
with
and try to prove (Equation41
(41)
(41) ), i.e.
where the linear operator
is to be understood in pointwise sense. This ensures that
is Gâteaux-differentiable in
and its derivative
can be identified with
.
Note that, given , equality (Equation41
(41)
(41) ) holds iff
, where
is defined by
. This is equivalent to prove that
In view of (EquationA3
(A3)
(A3) ) and (EquationA2
(A2)
(A2) ), it follows that for each
fixed we have
Thus, making use of Lebesgue's Dominated Convergence Theorem, we conclude that
which proves (Equation41
(41)
(41) ).