
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this study, we aimed to describe a modern, efficient, and reproducible methodology to optimize respiration rate parameters coupled with transport properties in mass balances describing Modified atmosphere packaging (MAP) systems. We considered mass balances for three different respiration rate j film (exponential, competitive and uncompetitive Michaelis–Menten kinetics) coupled with transport properties for two different packaging films. Experiments were conducted to validate the methodology using grapes placed in a polypropylene container opened on the top and sealed with packaging films. The methodology relies on a numerical optimization procedure called the Trust-Region-Reflective algorithm. We determined the predictive capability of models using goodness-of-fit criteria and assessed parameter uncertainty through standard errors. We also calculated the first-order optimality measure and the relative change in the sum of squares to verify the convergence of the implemented algorithm. Results showed that the respiration rate parameters obtained with this methodology for the exponential model provided a better fit than for the other two models. The fitting for the kinetic models is not very suitable since we found that the normalized standard errors were rather high. In conclusion, the methodology is robust, and we expect that it serves as a tool for assessing MAP technology design.
Nomenclature
| = |
| |
| = |
| |
| ℓ | = | Film thickness, m |
| = | External | |
| = | External | |
| V | = | Packaging headspace volume, m |
| R | = | Universal gas constant, kPa m |
| T | = | Storage temperature, K |
| m | = | Product mass, kg |
| = | Respiration rate of | |
| = | Respiration rate of | |
| = | Maximum | |
| = |
| |
| K | = | Ratio between the respiration rates in the exponential model, dimensionless |
| = | Kinetic constant for | |
| = | Michaelis constant for half-reaction rate in the MMC and MMU models, mol | |
| = | Competitive inhibition constant ( | |
| = | Uncompetitive inhibition constant ( | |
| = |
| |
| = | Parameters vector, unit of the corresponding parameter | |
| = | Upper bound for parameters vector, unit of the corresponding parameter | |
| = | Lower bound for parameters vector, unit of the corresponding parameter | |
| = | Sum of squares or objective function, mol | |
| = | Norm of the step at iteration k + 1, unit of the corresponding parameter | |
| = | Relative change in the sum of squares at iteration k + 1, dimensionless | |
| = | Gradient operator with respect to | |
| = | Variance of the residuals for j dataset, mol | |
| = | Root mean square error for j dataset, mol | |
| = | Coefficient of determination for j dataset, dimensionless | |
| = | Covariance matrix for j dataset, [unit of the corresponding parameter] | |
| = |
| |
| = | Number of mol | |
| = | Number of mol | |
| S | = | Surface area of the film, m |
| j | = | Superscript for each packaging film, j = 1 for PSF503 and j = 2 for PPCX |
| i | = | Subscript for experimental data, |
| k | = | Number of iterations of the optimization algorithm |
| I | = | Number of experimental data, I = 240 |
| t | = | Time, h |
| = | Nonlinear least-squares estimator (nonlinear LSE) for j dataset, unit of the corresponding parameter | |
| = | Standard errors for j dataset, unit of the corresponding parameter | |
| = | Normalized standard errors for j dataset, dimensionless | |
| = | Initial guess for optimizing modelling parameters for j dataset, unit of the corresponding parameter | |
| = | Experimental concentration at time i for j film | |
| = | Theoretical concentration at time i for j film | |
| = | i-component of the residuals vector for j film, mol | |
| = | Gaussian noise, unit of the corresponding data or parameter | |
| = | Standard deviation of the Gaussian noise, unit of the corresponding data or parameter | |
| = | Perturbed nonlinear LSE, unit of the corresponding parameter | |
| = | Perturbed initial parameters vector, unit of the corresponding parameter | |
| = | Relative error in the nonlinear LSE computed from perturbed data or perturbed initial parameters, dimensionless | |
| = | Relative error for the perturbed initial parameters, dimensionless | |
| = | Relative error in the | |
| = | Relative error in the | |
| = | Relative change in the sum of squares evaluated at perturbed nonlinear LSE, dimensionless |
1. Introduction
The respiration rate plays a significant role in the postharvest quality of fresh fruit and vegetables [Citation1]. The deterioration rate in these products is proportional to the respiration rate [Citation2]. For this reason, modifying the air composition in packaging headspace is necessary to reduce the respiration rate [Citation3]. Modified atmosphere packaging (MAP) is the suitable technology to reach this target [Citation4].
We must emphasize that a MAP system is a complex dynamical process in which the respiration rate and packaging transport properties of the packaging film have to be coupled in a mass balance for and
concentrations to accurately simulate underlying phenomena [Citation5]. Due to the high biological variability of fresh products, respiration rate parameters are characterized by great uncertainty, and this has led researchers to obtain them by empirical formulae not based on first principles, which were proposed first by [Citation6] who used the mass balance principle in MAP technology. Several empirical models have been developed to get the respiration rate; for example, polynomial models, exponential models, and Michaelis–Menten kinetic models; the authors in Refs [Citation7,Citation8] do a complete review of the models used for the respiration rate. In previous models, the respiration rate is considered to be independent of the packaging transport properties, and it is fitted to the empirical data through standard regression techniques. Then, this respiration rate is used in the mass balance to obtain the gas concentrations for fitting models to experimental data. There are few studies that address optimization of respiration rate parameters coupled with transport properties of the packaging film based on the mass balance principle; we highlight the reference [Citation9]. These authors carried out parameter estimation of the respiration rate combined with gas balance; however, there is no clear explanation of methodology implementation. This is only referenced in an article dated in the late 1970s. Dealing with parameter uncertainty is an essential issue for a robust design of MAP technology which has only been addressed by [Citation10]. These authors use the so-called interval analysis technique to study the impact of parameter uncertainty in a MAP model describing the evolution of gas composition inside packaging. However, the implementation of the technique is rather difficult to understand and reproduce; moreover, there is no mention of the optimization algorithm used, which makes it very difficult to use by the MAP technology-related community.
Parameter estimation involves solving the inverse problem: given a model and measurements of some state or output variables, the parameters that characterize the system, i.e. those producing a good fit of the model with the data, need to be identified [Citation11]. This problem is difficult since no unique analytical or numerical solution is usually available [Citation11]. Even if a unique solution was available, suitable initial guesses are required by optimization solvers to compute parameter estimates for fitting a model to experimental data [Citation11]. From the previous discussion, the main goal of the present study was to describe a hybrid approach [Citation12], i.e. a methodology that holistically mixes mathematical modelling and experimental design, which is required as it has been shown in literature for better understanding the studied system by fitting parameters of a given model with a specific scenario and for obtaining models with predictive capability. In particular, we aim to develop a modern, efficient, and reproducible methodology for optimization respiration rate parameters, whose implementation illustrated by collecting data from white table grapes stored in MAP using two packaging film types and three models for the respiration rate coupled to the transport properties of the films materials: exponential model, and Michaelis–Menten kinetic models with competitive and uncompetitive inhibition of . The methodology relies on a numeric procedure called the Trust-Region-Reflective optimization algorithm. At the same time, we compared the predictive power of each model using goodness-of-fit criteria and assessed parameter uncertainty through standard errors.
This article organizes as follows. In Section 2.1, we describe the experimental procedure to collect data associated with white table grapes stored in MAP, and in Section 2.2 mass balance principles for and
concentrations that we use in this work. In Section 2.3, the methodology that relies on a practical identifiability approach is fully described. To make that, we introduce practical identifiability techniques to carry out parameter estimation (Section2.3.2), to assess goodness-of-fit to data (Section2.3.3), as well as quantifying parameter uncertainty of the proposed mass balance models (Section 2.3.4). We illustrate in detail the methodology implementation by showing (in Section 3) and discussing (in Section 4) the results of the practical identifiability analysis to the proposed models for the collected data, and finally, in Section 5, we summarize and conclude.
2. Material and methods
2.1. Experimental procedure
We purchased the table grapes in the organoleptic ripening state at the local market in Salerno, Italy. These bunches of grapes were immediately de-stemmed manually by cutting the stalk pedicel. Berries from bunches of grapes were then selected to obtain homogeneous samples in terms of colour, size, firmness, and defect- or disease-free. The samples of approximately 0.125 kg each (around 24 randomly selected berries per sample) were placed in six 1000 polypropylene plastic containers and one millimetre thick. With this thickness, from the experimental point of view, a negligible mass transfer can be considered in the container. Packaging headspace volume was calculated in three replicates as the difference between the total container volume and sample volume (5e−4 m
). The six containers were separated into lots of three (duplicated) and each batch was sealed at the top with a specific film. A packaging machine (Food Pack-Speedyn, ILPRA SpA, Mortara (PV), Italy) was used to thermally seal the three containers of each batch in the upper part with the specified films and an available surface of 4e−2 m
was left for gas exchange. The films used for each lot were PSF530 (100% polyester film, with a thickness of 25 µ m), characterized by a high
barrier (Sealed Air Global Italy Rho (MI), Italy) and PPCX (Polypropylene copolymer film, with a thickness of 35 µ m), characterized by a medium
barrier (Carton Pack
, Rutigliano (BA), Italy). Figure depicts the two-dimensional cross-section of one of the containers. The selected packaging criterion was passive MAP (pMAP) [Citation13], and the sealed containers were stored at 283 K.
Figure 1. Two-dimensional cross-section of the polypropylene container. The container is open at the top for allowing the mass transfer of and
through the film, whereas the other three sides are considered impervious, i.e. no mass transfer through them.
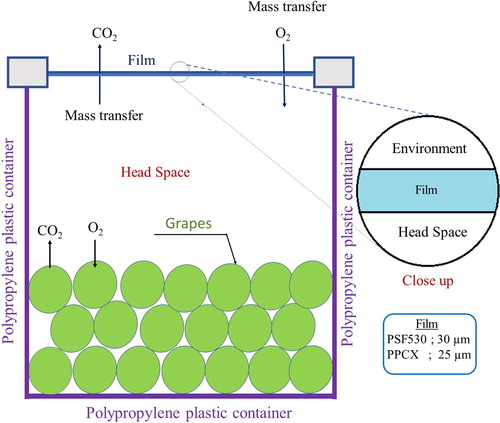
The headspace gas composition was periodically analysed to measure and
concentrations with a gas analyser (Servomex Mod. 1450 Food Package Analyzer, Crowborough, Sussex, UK) during 10 d of storage. The sample volume from the packaging headspace for gas analysis was approximately 10 cm
, which is substantial. For this reason, measurements were taken only every 24 h to avoid overly drastic deviations in headspace gas concentrations. Considering that there were 10 d of storage, the number of experimental points was only 10. To achieve better parameter estimation results, these 10 experimental points were extended by standard least-squares nonlinear regression to provide data in 240 points. The extended data was designated as
where the superscript j stands for each film type j
, where
, whereas the subscript i denotes each datum at time i (
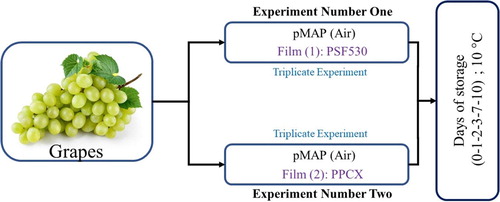
where I = 240 is the number of extended data for each j film). We must emphasize that the extension of the experimental data to obtain a larger dataset has nothing to do with the parameter estimation methodology, which is described and implemented in the present study. The extended data considered in the rest of the article corresponds to the mean of the extended data obtained in the three triplicated lots. The experimental schematic for each batch is shown in Figure .
Figure 2. Experimental schematic for pMAP of each lot stored in triplicate for the two films: PSF530 (25 µm thickness) and PPCX (35 µm thickness).
2.2. Mathematical modelling
In the present study, we considered different mass balance principles for and
concentrations, which described the time variation of these variables inside MAP during storage. Simpler models, which neglect spatial diffusion, are mathematical systems based on ordinary differential equation (ODE). These models can generally be stated as
(1)
(1)
(2)
(2)
The variables and parameters of the previous general mass balance principle are
(resp.
), which is the number of mol
(resp.
) at time t, S is the surface area of the film,
is the
permeability through each film,
is the
permeability through each film, ℓ is film thickness,
is the external
partial pressure,
is the external
partial pressure, V is the packaging headspace volume, R is the universal gas constant, T is the storage temperature, m is the product mass, and
and
are the respiration rate of
and
, respectively. The values for the physical parameters and constants, which are independent of the film material and used in the mass balance (Equation1
(1)
(1) )–(Equation2
(2)
(2) ), are displayed in Table .
Table 1. Physical parameters for general mass balance principle determined experimentally, except for the values of  , , and R that were obtained from the reference [Citation14].
, , and R that were obtained from the reference [Citation14].
The transport properties and film thickness are found in Table . These parameters were obtained from the technical specification sheet of each film.
Table 2. Parameters specific to each film type.
The right-hand side of the mass balance (Equation1(1)
(1) )–(Equation2
(2)
(2) ) represents the respiration rate of fresh products combined with the gas flow through the film; it is expressed as the net rate at which
and
concentrations change (mol h
). The mass balance described by (Equation1
(1)
(1) )–(Equation2
(2)
(2) ) has to be complemented with initial conditions for both variables, i.e. it mathematically corresponds to an initial value problem:
(3)
(3)
(4)
(4)
In the present study, we considered three model types for the respiration rates
and
at the right-hand side of the mass balance given by (Equation1
(1)
(1) )–(Equation2
(2)
(2) ). The first model is a modification of the one used by [Citation9], referred to as the exponential model, and states that the respiration rate terms are described by the following equations:
(5)
(5)
(6)
(6)
The parameters to be estimated in the model (Equation1
(1)
(1) )–(Equation2
(2)
(2) ) for the respiration rates
and
(mol kg
h
) defined by (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ), respectively, are grouped in the vector
. The parameters in the vector
are
that stands for the maximum
consumption rate (kg
h
),
that denotes the
inhibition factor (mol
), and K that represents the ratio between the respiration rates (dimensionless). The exponential model is a modification of the Michaelis–Menten model that considers competitive inhibition of
at high
concentrations.
The second and third models of the present study consist in assuming that the role of in respiration is mediated by competitive and uncompetitive inhibition mechanisms of the Michaelis–Menten type [Citation7]. In the first case, the maximum respiration rate of
is influenced at high
concentrations, whereas in the second case,
is not influenced by
; these models are referred to as competitive Michaelis–Menten (MMC) and uncompetitive Michaelis–Menten (MMU). These mathematical models for the respiration rates
and
are defined by the following equations:
(7)
(7)
(8)
(8)
(9)
(9)
The MMC model corresponds to the respiration rates
and
defined by (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ), respectively, where the kinetic parameters are grouped in the vector
. On the other hand, the MMU model corresponds to the respiration rates
and
defined by (Equation7
(7)
(7) ) and (Equation9
(9)
(9) ), respectively, where the kinetic parameters are grouped in the vector
. For MMC and MMU models, the parameters in the vector
are
that stands for the maximum
consumption (mol kg
h
),
that denotes the oxygen concentration at which the reaction rate is half of
(
mol),
and
stand for the competitive and uncompetitive inhibition constants (
mol), respectively.
The respiration rate for the exponential model defined in (Equation5
(5)
(5) ) is obtained by linearizing
defined in Equation (Equation7
(7)
(7) ), which results in
where
takes into account competitive inhibition of the
respiration rate when the
concentration is high, because
decreases when the
concentration increases at high values according to Equation (Equation5
(5)
(5) ). For all the models, the respiration rates of
and
,
and
, respectively, depend on parameters that were grouped in a vector
. We designated this dependence by
and
.
2.3. Identifiability analysis of modelling parameters
Mathematical models described in the previous section can be written under the general (vector) form as
(10)
(10)
(11)
(11)
where
is the vector of the MAP system state variables given by
for all
,
is the initial time,
a sufficiently long time so as to let the system evolve,
is the initial state, and
is defined by
(12)
(12)
and corresponds to the right-hand side of the ODE system given by Equations (Equation1
(1)
(1) )–(Equation2
(2)
(2) ). With this notation, we obtain each of the studied models by replacing the corresponding respiration rates
and
in
along with the parameters vector
. For example, the exponential model is obtained by replacing
and
as defined in Equation (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) with
.
2.3.1. Direct and inverse problem
Given a parameters vector , the direct problem consists of finding the (unique) solution
of the mathematical model given by Equations (Equation10
(10)
(10) )–(Equation11
(11)
(11) ). The solution to the direct problem is required to solve the inverse problem. The present study aimed to develop a clear, reproducible, and modern methodology to solve the parameter identification problem and compare the fit performance of different mathematical models to experimental data in such a way as to be able to decide which model best fits a given dataset. This procedure is referred to as the inverse problem, i.e. given experimental data that measures the vector
of concentrations at some time points to identify the parameters vector
such that the mathematical model given by Equations (Equation10
(10)
(10) )–(Equation11
(11)
(11) ) fits the data in the sense of the least-squares. More precisely, to solve the inverse problem of parameter estimation, it is necessary to find the vector
so that the sum of squares
(13)
(13)
is minimized, where
(14)
(14) at times
, and for each dataset j = 1, 2. The objective function defined in (Equation13
(13)
(13) ) corresponds to the sum of squares of the residuals
, i.e. of the differences between the experimental concentrations
and the theoretical concentrations
given in (Equation14
(14)
(14) ), where
corresponds to the
and
concentrations obtained from each model evaluated at
at times
and for a given value of the parameters vector
.
The minimum of sum of squares is designated as
for each dataset j = 1, 2. The vector
is called nonlinear least-squares estimator, hereafter denoted as nonlinear LSE. To minimize
we used the Trust-Region-Reflective algorithm implemented in Matlab
under the subroutine lsqnonlin.
To assess the quality of the optimal solution , we also computed some metrics that allowed us to evaluate convergence associated with the algorithm, as well as a stopping criterion necessary to exit from it. The details to implement the lsqnonlin solver are discussed in Section 2.3.2. Once the nonlinear LSE (
) was found for each dataset j = 1, 2 and for each proposed model (exponential, MMU and MMC), we compared the three models for their data fit performance. This was achieved by computing a number of goodness-of-fit criteria, which are explained in Section 2.3.3. Finally, we computed the standard errors associated with the nonlinear LSE to assess parameter uncertainty as explained in Section 2.3.4.
2.3.2. Parameter estimation
The numerical algorithm used to optimize the objective function defined in Equation (Equation13(13)
(13) ) is described in the present subsection and summarized, as well as schematized in Section 2.3.5.
We used the Trust-Region Interior Reflective (TIR) method, which was developed in [Citation15], to minimize in Equation (Equation13
(13)
(13) ). Convergence is theoretically achieved under general conditions. However, the initial parameter estimate usually has to be close to the optimal solution to obtain convergence. Our models are simple to handle because their right-hand sides are autonomous (independent on time), formed by a negative exponential or a rational function (quotients of polynomials) at the variables, and depend on the parameters in a very regular way. The solution
systematically depends on the parameters vector
; in particular, it can be proven that it is infinitely differentiable with respect to
. We were able to efficiently minimize the objective function in Equation (Equation13
(13)
(13) ) with these good properties. We used the lsqnonlin solver implemented in Matlab
[Citation16] with the TIR method, which is especially adapted for solving nonlinear least-squares minimization problems.
To make so, we have to evaluate the objective function , which requires to solve the direct problem, i.e. to compute the numerical solution of the initial value problem given by Equations (Equation10
(10)
(10) )–(Equation11
(11)
(11) ) or the ODE system given by Equations (Equation1
(1)
(1) )–(Equation2
(2)
(2) ), which is the same, with initial conditions defined by Equations (Equation3
(3)
(3) )–(Equation4
(4)
(4) ) at times
for different parameters vectors
depending on each dataset j = 1, 2. The initial conditions were established as the first measurement taken for each experiment to reproduce the real behaviour of
and
concentrations, i.e. for each j = 1, 2 we defined
at time
h in which the first extended datum was computed from the experimental data (Section 2.1). We computed the numerical solution of the direct problem using the ode45 Matlab
solver, which is based on an explicit Runge–Kutta type formula [Citation17].
For every dataset j = 1, 2, the input arguments that we used for the lsqnonlin subroutine are provided in Table .
Table 3. Input arguments for lsqnonlin solver.
Moreover, we used the following options in the lsqnonlin solver from Matlab. Firstly, we chose the TIR method as the optimization algorithm, which is the default. Secondly, the maximum number of iterations was set at 10,000, while the maximum number of function evaluations was set at 20,000. Finally, the function tolerance and the norm of the step tolerance were both set at 1
17. The norm of the step
measures the change between two successive iterates
and
, which is defined as
(15)
(15) On the other hand,
(16)
(16) is the relative change in the sum of squares. The stopping criterion for our algorithm is defined as
(17)
(17) When the previous condition is met, the algorithm stops at iteration k + 1 and returns an approximation of the nonlinear LSE
, as well as an approximation of the Jacobian matrix
evaluated at
for each dataset j = 1, 2; see Section 2.3.4 for details. To check the convergence of the algorithm, we also provided the first-order optimality measure, which measures how close the approximation is to the actual minimum of the sum of squares. The first-order optimality measure is defined as the infinity norm of the gradient of the objective function evaluated at the nonlinear LSE
, i.e. the optimal solution that approximately minimizes
, which in turn is given by the maximum absolute value of the partial derivatives of the objective function with respect to the
variables:
(18)
(18) Other metrics that quantify convergence are the relative change in the sum of squares
(Equation (Equation16
(16)
(16) )), the norm of the step
(Equation (Equation15
(15)
(15) )), and the number of iterations k + 1. The metrics
and k + 1 are displayed for the lsqnonlin solver at the end of its execution.
2.3.3. Goodness-of-fit criteria
We used statistical methods (from the context of nonlinear least-squares regression) to quantify the fit performance of each model with respect to data. More precisely, once the nonlinear LSE was found for each dataset j = 1, 2 and for each proposed model, a number of goodness-of-fit criteria can be computed, which evaluate to what extent these models are fitted to each dataset. We computed
, i.e. the variance of the residuals, the root mean square error (RMSE), and the coefficient of determination, respectively, and which are given by [Citation18,Citation19]:
(19)
(19)
(20)
(20)
(21)
(21)
where
designates the mean value of the data
for each gas concentration
or
and each dataset j = 1, 2. The variance
and the RMSE
measure model fit with respect to each dataset j = 1, 2 (in absolute terms), whereas
measures model fit to each dataset with respect to the data mean, i.e.
close to 1 means that the model explains the variability of data better than its mean.
2.3.4. Parameter uncertainty
If the residuals were normally distributed or if the data number
were sufficiently large, then the estimated covariance matrix of the nonlinear LSE
would be expressed as
(22)
(22)
(23)
(23)
For each dataset j = 1, 2, the matrix
is the so-called sensitivity function, and it quantifies the variation of the state variable
with respect to changes in the parameter
. Sensitivity analysis can provide information about the relevance of data measurements to identify parameters; it then yields the basis for new tools to design inverse problem studies; see [Citation20] for more details. By using the covariance matrix in Equation (Equation22
(22)
(22) ), we could compute the standard error (
) and the normalized standard errors (
) associated to the nonlinear LSE
from which we could quantify the accuracy of the parameter estimate. Both quantities are defined by
(24)
(24) The quantities given by Equations (Equation22
(22)
(22) )–(Equation24
(24)
(24) ) are asymptotic, i.e. they are valid only if the data number I is sufficiently large, because the nonlinear least-squares estimators are in fact asymptotically normally distributed [Citation18,Citation19]. In the present study, we have I = 240 data for each film, which made it feasible to accurately compute the normalized standard errors (
).
2.3.5. Summary of the numerical methodology
The steps followed for our numerical methodology are hereby summarized. For each dataset j = 1, 2 and for each of the proposed models (exponential, MMC, and MMU) we:
Arbitrarily assigned an initial parameters vector and designated it as
Executed the lsqnonlin solver as explained in Section 2.3.2 starting from the point
Checked convergence. By default, the lsqnonlin solver displays the first-order optimality measure (Equation (Equation18
Computed the goodness-of-fit criteria described in Section 2.3.3 and the normalized standard errors described in Section 2.3.4. The aim was to compare the predictive capabilities of the proposed models to achieve the best model and evaluate parameter uncertainty. The outputs of this step are the variance of the residuals
For step (1), there is no general method to obtain the initial guess ) because it depends on each dataset and each model. We used a trial and error method to achieve good initialization to successfully perform the optimization process. For step (2), the optimization solver internally evaluates the objective function
. To do this, the numerical solution of the direct problem, ODE system given by Equations (Equation1
(1)
(1) )–(Equation2
(2)
(2) ) with initial conditions in Equations (Equation3
(3)
(3) )–(Equation4
(4)
(4) ), or in vector form, the initial value problem defined in Equations (Equation10
(10)
(10) )–(Equation11
(11)
(11) ), was computed by the ode45 Matlab
solver based on a Runge–Kutta type method, as mentioned in Section 2.3.2. The initial conditions (Equation (Equation3
(3)
(3) ) and (Equation4
(4)
(4) )) correspond to the first datum
for each dataset j = 1, 2. Figure depicts the numerical methodology implemented in this study.
Figure 3. Schematic diagram of the numerical methodology.
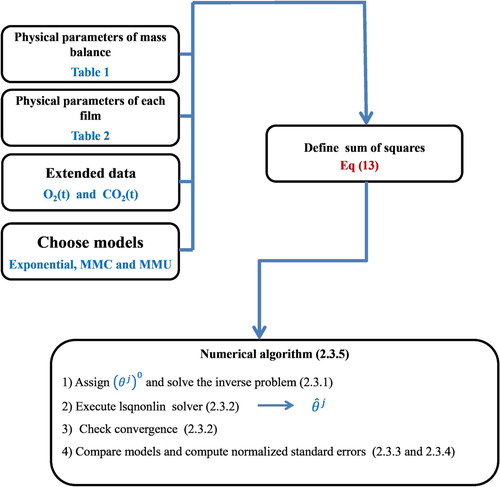
The numerical methodology, summarized in Figure , requires the physical parameters for the mass balance (given in Table ), those specific for each film (given in Table ), the extended data for and
concentrations, and choosing one of the three models, exponential, MMU and MMC. All these inputs are required to define the sum of squares given in Equation (Equation13
(13)
(13) ), which is the main input for the numerical optimization algorithm described in Section 2.3.2 that also requires the assignation of an initial parameters vector to compute an approximation of the nonlinear LSE.
3. Results
In this section, we present our numerical results concerning the and
concentration curves fitted to each dataset using the proposed models (exponential, MMU, and MMC). For each dataset (film j = 1, 2), the numerical results are shown in the following way:
Initial guesses, nonlinear LSE, and normalized standard errors are shown in Tables , , and for the exponential, MMU, and MMC models, respectively.
Convergence metrics, initial and optimal values of the sum of squares, as well as fit performance are shown in Tables , , and for the exponential, MMU, and MMC models, respectively.
Fitted curves are depicted in Figure , , and for the exponential, MMU, and MMC models, respectively.
Effect of the uncertainty of data measurement and initial guess on parameter estimate are shown in Section 3.4.
Figure 4. Fitted curves for the exponential model. (a) Film PSF530 (b) Film PPCX.
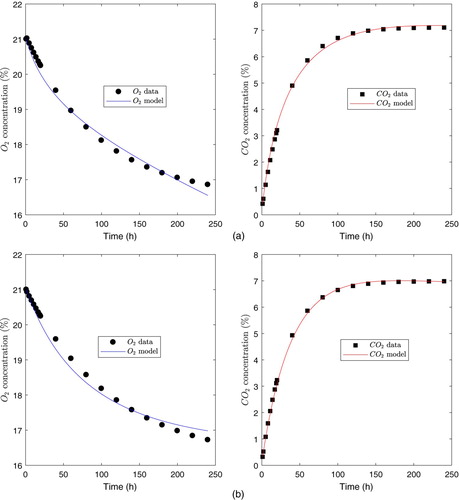
Figure 5. Fitted curves for the MMU model. (a) Film PSF530. (b) Film PPCX.
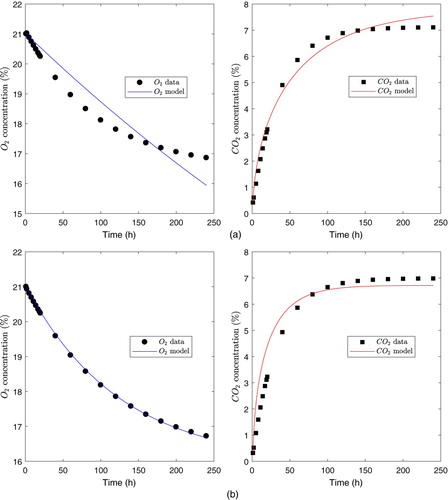
Figure 6. Fitted curves for the MMC model. (a) Film PSF530. (b) Film PPCX.
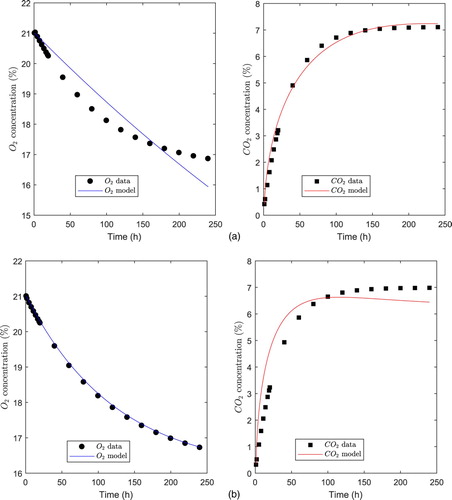
Table 4. Values for initial and optimal nonlinear LSE, and normalized standard errors for exponential model.
Table 5. Convergence metrics, initial and optimal values and fit performance for the exponential model.
Table 6. Values for initial and optimal nonlinear LSE, and normalized standard errors for the MMU model.
Table 7. Convergence metrics, initial and optimal values and fit performance for the MMU model.
Table 8. Values for initial and optimal nonlinear LSE, and normalized standard errors for the MMC model.
Table 9. Convergence metrics, initial and optimal values and fit performance for the MMC model.
We recall that the initial guesses and nonlinear LSE were designated by and
, respectively, while the normalized standard errors were denoted by
and defined in Equation (Equation24
(24)
(24) ). The initial guess
was computed as summarized in Step (1), while the nonlinear LSE
was computed as summarized in Step (2) of the previous section. The convergence metrics
,
, and
defined in Equations (Equation15
(15)
(15) ), (Equation16
(16)
(16) ), and (Equation18
(18)
(18) ), respectively, are the outputs arguments of the lsqnonlin Matlab
solver. We note that the number of iterations that are necessary to converge corresponds to k + 1 in the nomenclature of Matlab
(k starts at 0). The sum of squares
was defined by Equation (Equation13
(13)
(13) ), while fit performance was quantified by the goodness-of-fit criteria
,
and
defined in Equations (Equation19
(19)
(19) )–(Equation21
(21)
(21) ).
3.1. Results for the exponential model
Table shows the initial parameter estimate , the nonlinear LSE
, and the normalized standard errors
computed for each dataset j = 1, 2.
In addition, Table shows the convergence metrics, initial and optimal values of the sum of squares, as well as fit performance for each dataset j = 1, 2.
Finally, Figure depicts the fit of the exponential model to the datasets j = 1, 2. Few data points are shown to differentiate them from the theoretical curves.
3.2. Results for the MMU model
In the present study, besides the options chosen for the lsqnonlin solver, we set as the upper bound for the parameter the maximum experimental value for the
concentration because
represents the half of the latter.
Table shows the initial parameter estimate , the nonlinear LSE
, and the normalized standard errors
computed for each dataset j = 1, 2.
In addition, Table shows the convergence metrics, initial and optimal values of the sum of squares, as well as fit performance.
Finally, Figure depicts the fit of the MMU model to the datasets j = 1, 2. Few data points are shown to differentiate them from the theoretical curves.
3.3. Results for the MMC model
As for the MMU model, we also set as the upper bound for the parameter the maximum experimental value for the
concentration.
Table shows the initial parameter estimate , the nonlinear LSE
, and the normalized standard errors
computed for each dataset j = 1, 2.
In addition, Table shows the convergence metrics, initial and optimal values, as well as fit performance for the MMC model.
Finally, Figure depicts the fit of the MMC model to the datasets j = 1, 2. Few data points are shown to differentiate them from the theoretical curves.
3.4. Effect of the uncertainty of data measurement and initial guess on parameter estimate
In this subsection, we quantify the effect of the uncertainty of data measurement and initial guess on parameter estimate. To make that, we considered two simulated datasets constructed using the exponential model and the nonlinear LSE computed for the two film types. More precisely, we have taken for j = 1, 2 from Table and computed the concentrations curves for
and
using the exponential model evaluated at these two nonlinear LSE, and we used them to generate exact data. Then, we perturbed these datasets by adding Gaussian noise to each of them to simulate the measurement errors on data. From these perturbed data, we computed parameter estimates using as initial guesses the nonlinear LSE that generated the exact datasets for the optimization algorithm, thereby quantifying the effect of uncertainty of data measurement on parameter estimate.
Exact data were perturbed by adding Gaussian noise to the exact data, where we choose
to verify the condition
for both films types, thereby to not obtain negative perturbed data.
Figure depicts the perturbed and exact data for both film types, where few data points are shown to differentiate them.
Figure 7. Simulated data obtained from the exponential model. (a) Film PSF530. (b) Film PPCX.
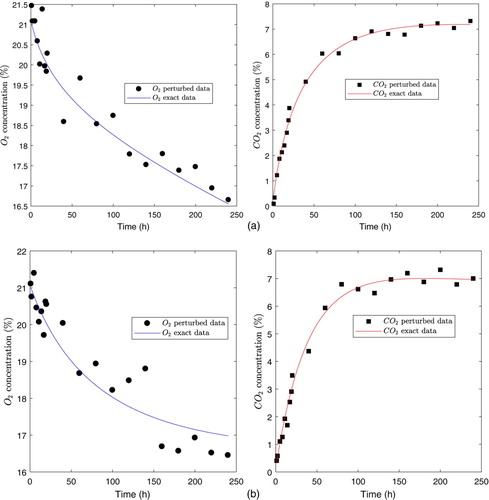
Table shows the relative errors for parameter estimate and variables of the exponential model, as well as the convergence metrics computed by the optimization solver.
Table 10. Relative errors and convergence metrics for perturbed data with Gaussian noise.
Convergence metrics ,
,
correspond to the first-order optimality measure defined in (Equation18
(18)
(18) ), the relative change in the sum of squares defined in (Equation16
(16)
(16) ), the optimal value of the objective function, respectively, where the three previous metrics are evaluated at the perturbed nonlinear LSE
. Also, k + 1 and
correspond to the number of iterations and the initial value of the objective function, respectively.
Finally, to quantify the effect of the uncertainty of initial guess on parameter estimate, we have taken the initial guesses considered for the exponential model in Table , and we perturbed them by adding Gaussian noise
, choosing
(all the components of
equal to the maximum initial parameters vector value), taking care that all the perturbed initial parameters vector components,
, be positive for the two films j = 1, 2.
Table shows the relative errors for initial and optimal parameter estimates for the exponential model, as well as the convergence metrics computed by the optimization solver. All these quantities were similarly computed as we made for Table .
Table 11. Relative errors and convergence metrics for perturbed initial parameters with Gaussian noise.
4. Discussion
When we analyse the convergence metrics of the numerical method in Table (first three columns), we observe that they are very successful for the exponential model. We conclude that our method approximately converges, i.e. the nonlinear LSE is very close to the actual minimum for each dataset j = 1, 2. On the other hand, fit performance is very good, which is reflected by the fact that the variance and RMSE explained by the exponential model are rather low, while the coefficient of determination is very close to 1. In addition, from the data in Table , we can observe that the normalized standard errors
are rather low (less than 4%), which provides a very accurate parameter estimation. This is in accordance with the fitted curves, shown in Figure , that are very close to the data for the exponential model. Figure also shows that the
concentration reaches equilibrium before the
concentration, which is determined by the distribution of data. The time to reach equilibrium also depends on the permeability ratio. In fact,
permeability for Film PSF530 is an order of magnitude less than
permeability, and
decays faster than in Film PPCX, for which permeability for both,
and
, have the same order of magnitude.
In the case of MMU model, from the data in Table we can observe that convergence metrics are relatively successful. We conclude that our method approximately converges, i.e. the nonlinear LSE is relatively close to the actual minimum for each dataset j = 1, 2. However, according to data shown in Table , normalized standard errors
are rather high (greater than 34%), which provides an inaccurate parameter estimation for the MMU model compared to the exponential model. This is in accordance with the fitted curves, shown in Figure , which confirms that the fit is relatively inaccurate for the MMU model. On the other hand, Figure (a) shows that the fit to data for Film PSF530 is more inaccurate, which is numerically confirmed by the fact that the variance and RMSE are higher, while the coefficient of determination is lower than for Film PPCX (Table ). This is also confirmed by higher normalized standard errors for components 1 and 3 of the nonlinear LSE for film PSF530 compared to Film PPCX (
and
in Table ), which indicates that parameters
and
are more inaccurately estimated for Film PSF530.
A similar discussion as for MMU model also applies for the MMC model. In fact, similar convergence metrics for the MMC model are shown in Table . We can, therefore, conclude that our method approximately converges, i.e. the nonlinear LSE is relatively close to the actual minimum for each dataset j = 1, 2. On the other hand, similar fit performance is observed for both models, because values for the goodness-of-fit criteria are very similar. On the other hand, Table indicates that normalized standard errors
are rather high (greater than 50 %), which implies an inaccurate parameter estimation for the MMC model. If we analyse Figure , a better fit is observed for Film PSF530 than for Film PPCX. On the other hand, we can observe that its fit to data is better for the PPCX film in the case of the
. In contrast, the fit to data is better for film PSF530 film in the case of the
.
When quantifying the effect of data measurement errors for the exponential model, we found from Table that the relative error for parameter estimate is of the same order of magnitude that for and
concentrations (for both films types), and convergence metrics for perturbed data are successful, which implies the robustness of the proposed methodology.
Finally, when quantifying the uncertainty of initial guess on parameter estimate, we found from Table that the computed parameter estimates were almost the same, which implies that our method is stable. It is worth noting that the issue of the suitable choice of the initial guess is crucial when no a priori information is available on the actual values of the model parameters, or when having the observation of only a partial combination of the model variables [Citation11].
5. Summary and conclusions
In this work, we have described in a clear way and successfully implemented a modern and efficient parameter estimation methodology which we believe is useful to apply for all the MAP technology-related community. We have illustrated our methodology to carry out parameter estimation for two datasets corresponding to two film types. The numerical results obtained for the three models proposed show that the exponential one is that best fits for both datasets, which means that the respiration rate exponentially decays when the concentration increases. It is worth noting that the Michaelis–Menten models are not as appropriate as the exponential model since the last has the best convergence metrics, as well as the best normalized standard errors. On the other hand, the type of film is a fundamental variable in MAP systems. In this sense, results for the exponential model are similar for both film types, whereas results for the Michaelis–Menten models are different. On the other hand, the methodology proposed is robust since we can compute suitable parameter estimate when data have uncertainties in their measurement, as well as when appropriate initial guesses are not known a priori, i.e. no a priori information is available on the actual values of the model parameters.
We expect that our methodology serves as a tool for assessing MAP technology design since it is relatively easy to apply, and the only requirement is a conventional PC endowed with Matlab software. However, it is worth noting that this is made to avoid implementing the optimization algorithm, and in this sense, any software having a suitable predefined optimization toolbox may serve to our purpose.
Disclosure statement
The authors declare no conflict of interest.
Additional information
Funding
References
- Mangaraj S, Goswami TK. Modeling of respiration rate of litchi fruit under aerobic conditions. Food Bioproc Tech. 2008 Oct;4(2):272–281. doi: 10.1007/s11947-008-0145-z
- Makino Y. Oxygen consumption by fruits and vegetables. Food Sci Technol Res. 2013 Sept;19:523–529. doi: 10.3136/fstr.19.523
- Heydari A, Shayesteh K, Eghbalifam N, et al. Studies on the respiration rate of banana fruit based on enzyme kinetics. Int J Agric Biol. 2010;12(1):145–149.
- Yahia EM. Introduction. In: Yahia EM, editor. Modified and controlled atmospheres for the storage, transportation, and packaging of horticultural commodities. Chapter 1. Boca Raton: CRC press; 2009. p. 1–16.
- Del Nobile M, Sinigaglia M, Conte A, et al. Influence of postharvest treatments and film permeability on quality decay kinetics of minimally processed grapes. Postharvest Biol Technol. 2008;47(3):389–396. Available from: http://www.sciencedirect.com/science/article/pii/S0925521407002335 doi: 10.1016/j.postharvbio.2007.07.004
- Henig YS, Gilbert SG. Computer analysis of the variables affecting respiration and quality of produce packaged in polymeric films. J Food Sci. 1975;40(5):1033–1035. Available from: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1365-2621.1975.tb02261.x
- Fonseca SC, Oliveira FA, Brecht JK. Modelling respiration rate of fresh fruits and vegetables for modified atmosphere packages: a review. J Food Eng. 2002;52(2):99–119. Available from: http://www.sciencedirect.com/science/article/pii/S0260877401001066 doi: 10.1016/S0260-8774(01)00106-6
- Belay ZA, Caleb OJ, Opara UL. Modelling approaches for designing and evaluating the performance of modified atmosphere packaging (map) systems for fresh produce: a review. Food Packag Shelf Life. 2016;10:1–15. Available from: http://www.sciencedirect.com/science/article/pii/S2214289416300813 doi: 10.1016/j.fpsl.2016.08.001
- Del Nobile M, Baiano A, Benedetto A, et al. Respiration rate of minimally processed lettuce as affected by packaging. J Food Eng. 2006;74(1):60–69. Available from: http://www.sciencedirect.com/science/article/pii/S0260877405001068 doi: 10.1016/j.jfoodeng.2005.02.013
- Guillard V, Guillaume C, Destercke S. Parameter uncertainties and error propagation in modified atmosphere packaging modelling. Postharvest Biol Technol. 2012;67:154–166. Available from: http://www.sciencedirect.com/science/article/pii/S0925521411003140 doi: 10.1016/j.postharvbio.2011.12.014
- Cumsille P, Godoy M, Gerdtzen ZP. Parameter estimation and mathematical modeling for the quantitative description of therapy failure due to drug resistance in gastrointestinal stromal tumor metastasis to the liver. PLoS One. 2019 May;14(5):1–27. doi: 10.1371/journal.pone.0217332
- Cumsille P, Coronel A, Conca C, et al. Proposal of a hybrid approach for tumor progression and tumor-induced angiogenesis. Theor Biol Med Model. 2015;12(1):13. doi: 10.1186/s12976-015-0009-y
- Charles F, Guillaume C, Gontard N. Effect of passive and active modified atmosphere packaging on quality changes of fresh endives. Postharvest Biol Technol. 2008;48(1):22–29. Available from: http://www.sciencedirect.com/science/article/pii/S0925521407003407 doi: 10.1016/j.postharvbio.2007.09.026
- Yunus CA, Afshin GJ. Heat and mass transfer: fundamentals and applications. Chapter 14. New York: McGraw-Hill Education; 2015. p. 835–906.
- Coleman TF, Li Y. An interior trust region approach for nonlinear minimization subject to bounds. SIAM J Optim. 1996;6(2):418–445. doi: 10.1137/0806023
- MathWorks. Nonlinear least squares (curve fitting) [internet]; 2017. Available from: https://www.mathworks.com/help/optim/nonlinear-least-squares-curve-fitting.html
- Shampine LF, Reichelt MW. The matlab ode suite. SIAM J Sci Comput. 1997;18(1):1–22. doi: 10.1137/S1064827594276424
- Banks HT, Davidian M, Samuels JR. An inverse problem statistical methodology summary. In: Chowell G, Hyman JM, Bettencourt LMA, et al., editors. Mathematical and statistical estimation approaches in epidemiology. Dordrecht: Springer; 2009. p. 249–302.
- Greene WH. Econometric analysis. New Jersey (NY): Pearson; 2012.
- Banks H, Dediu S, Ernstberger S. Sensitivity functions and their uses in inverse problems. J Inverse Ill-Pose P. 2008;15(7):683–708.