
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The parameterized generalized inverse eigenvalue problems containing multiplicative and additive inverse eigenvalue problems appear in vibrating systems design, structural design, and inverse Sturm–Liouville problems. In this article, by using the Cholesky factorization and the Jacobi method, we propose two efficient algorithms based on Newton's method and the L-BFGS-B method for solving these problems. To demonstrate the effectiveness of the algorithms, we present three numerical examples.
1. Introduction
In the eigenvalue problems, the information contains the elements of a matrix or a matrix pencil and the unknowns of these problems include all or some of the eigenvalues. Describing and solving these problems by using some effective methods are found in [Citation1,Citation2]. But in the corresponding inverse problems, the data contains the complete information, or part of the eigenvalues or eigenvectors. In fact, the inverse problems include finding a matrix or matrix pencils according to the given information under spectral and structural constraints [Citation3–6]. The current literature on the inverse eigenvalue problems shows that the creation of the inverse eigenvalue problems are inevitable in practical applications. Inverse eigenvalue problems, according to the application may be seen in different forms. In [Citation3], a set of inverse eigenvalue problems was recognized and categorized according to its specifications. A lot of inverse eigenvalue problems are generalized inverse eigenvalue problems. Since many physical problems can be modelled as generalized inverse eigenvalue problems, many different examples of these problems have appeared. For example, the generalized inverse eigenvalue problem over the Hermitian–Hamiltonian matrices with a submatrix constraint was studied in [Citation7]. In [Citation8], Liu et al. considered the generalized inverse eigenvalue problem for centrohermitian matrices. In [Citation9], the generalized inverse eigenvalue problem for generalized snow-like matrices was investigated. A generalized inverse eigenvalue problem in structural dynamic model updating was studied in [Citation10]. In [Citation11], a generalized inverse eigenvalue problem by the Jacobi matrix was considered. In these problems, a set of eigenvalues and a matrix pencil function that contained unknown parameters are given and the goal is finding unknown parameters under some conditions. Due to their many applications, these problems have always been a concern for researchers [Citation12,Citation13].
To simplify the discussion, we introduce the following notation. The symbols and
stand for the sets of all
upper triangular matrices and
lower triangular matrices, respectively. We use A>0 and
, when the matrix A is a positive definite matrix and positive semi-definite matrix, respectively. The symbol
represents the Euclidean norm for vectors and induced norms for matrices. In addition, we denote a matrix pencil pair briefly with the notation
.
The parameterized generalized inverse eigenvalue problem (PGIEP) can be described as follows:
Definition 1.1
Let and
be two given
matrices whose entries are analytic functions of parameters
. Given n real numbers
, find
such that the generalized eigenvalue problem
has the prescribed eigenvalues
.
In many practical applications, such as structural design [Citation14–16], the pencil matrix pair is affine that causes the creation of the special cases of the PGIEP. In this paper, we consider the special case of this problem in the form below:
Problem 1.1
As special type of the PGIEP, in this problem, we set
(1)
(1) where
are
symmetric matrices,
for
and the given eigenvalues
are ordered as
.
The algebraic inverse eigenvalue problem [Citation17] and the additive inverse eigenvalue problems [Citation18] are two special types of Problem 1.1.
Problem 1.1 is considered as one of the most frequent inverse eigenvalue problems that appears in various areas of mathematical and numerical analysis and engineering applications [Citation19–22]. Actually, Problem 1.1 arises in a variety of practical applications of structural engineering, mechanics, and physics. Some of these applications are as follows [Citation14,Citation23,Citation24]:
Studying a vibrating string and [Citation25,Citation26];
Nuclear spectroscopy;
The educational testing problem;
The graph partitioning problem;
Sturm–Liouville problems and preconditioning;
Factor analysis [Citation27] and the design of control systems [Citation18].
We will now describe several examples arising in various areas of applications.
Application 1.1
[Citation28]
Consider inverse Sturm–Liouville problems as follows:
(2)
(2)
(3)
(3) where the purpose is to determine the density function
viewing the eigenvalues
. Using finite differences to solve these problems leads to the inverse eigenvalue problem as follows
in which the goal is to find the matrix
. This is a classical example of the parameterized generalized inverse eigenvalue problems.
Application 1.2
It is showed in [Citation29] that a vibrational mass-spring set can be modelled as a system of ordinary differential equations as fallow:
where the multiplied matrix of this system is a symmetric matrix of physical parameters like
and
. It is possible to write A as the following linear combination of physical parameters
where
when it is assumed that we have the natural frequency of the system as eigenvalues of A, finding the matrix is changed to determining the multipliers
.
Also Problem 1.1 plays an important role in structure design and applied mechanics [Citation19].
Application 1.3
In many practical applications of structures with l elements and n displacement degrees of freedom, such as, truss structure design, by assuming that is a set of design parameters, the global stiffness matrix
and global mass matrix
are defined as:
where
and
are the stiffness and mass matrices of the ith element of the structure. In these problems, the goal is to determine
such that it is the set
of the eigenvalues of the generalized eigenvalue problem
.
On the other hand, various applications of the PGIEP have made it a favourite topic for analysis. Many recent studies have focused on the numerical methods and existence theory for different categories of these problems [Citation3,Citation30,Citation31]. Sufficient and necessary conditions for the solvability of the specific types of the PGIEP were presented in [Citation18,Citation31–36]. In addition, in [Citation37], Dai et al. presented sufficient conditions for guaranteeing the existence of a solution for the parameterized generalized inverse eigenvalue problem. More results in this area can be found in [Citation38,Citation39].
Further more, a review of recent literature on inverse eigenvalue problems shows that there are plenty of results for finding the answer to the PGIEP. In general, different approaches have been used to solve these problems according to their types. These methods can be categorized into three main categories of direct methods, iterative methods and continuous methods [Citation3]. However the similarity of these methods is the confrontation with a nonlinear system of equations or an optimization problem. Since the nonlinear system of equations is simpler in repetitive and continuous methods, these methods have been extensively considered in recent years [Citation3]. Also iterative methods were developed for solving the specific types of the PGIEP [Citation40–42]. Formulations of some of these methods were defined by solving the following nonlinear systems
(4)
(4)
(5)
(5) in which
are the eigenvalues of the generalized eigenvalue problem
, the scalers
are the eigenvalues given in the problem and
is smallest singular value of the matrix
. In the above formulations, the system of nonlinear equations
should be solved. In [Citation42], Newton's method for solving the system of nonlinear equations (Equation4
(4)
(4) ) has been presented, by extending the ideas which were developed by Friedland in [Citation34]. This method requires computing the complete solution of the generalized eigenvalue problem
in each iteration of Newton's method. Also in [Citation43] Shu and Li introduced Homotopy solution for the system of nonlinear equations (Equation4
(4)
(4) ). In [Citation41], an another form of the formulation has been presented by using a QR-like decomposition as follows:
(6)
(6) in which
is obtained by computing QR-like decomposition of
for
as follows:
In addition, Lancaster [Citation44] and Biegler-Konig [Citation45] presented a formulation based on the determinant evaluation for the additive and multiplicative inverse eigenvalue problems, by the following form:
(7)
(7) It should be noted that the formulations (Equation4
(4)
(4) )–(Equation7
(7)
(7) ) are not computationally attractive. To avoid solving an eigenvalue problem in each iteration and to lower computational complexity, we propose a numerical algorithm based on the Cholesky factorization and the Jacobi method. In this paper, we consider the formulation of both methods for solving the Problem 1.1, assuming the existence of a solution.
This paper is organized as follows. We review some basic definitions and theorems for the Cholesky factorization and the Jacobi method in Section 2. In Section 3, first we consider necessary theories for the Cholesky factorization of a matrix dependent on several parameters and then two new algorithms based on the Cholesky factorization and the Jacobi method is proposed. Finally in Section 4 some numerical experiments are presented.
2. Some definitions and theorems
Before starting, we review some basic definitions and theorems for the Cholesky factorization and the Jacobi method quickly.
The Cholesky factorization is a factorization of a positive-definite matrix into the product of a lower triangular matrix and its conjugate transpose, which is helpful for effective numerical solutions [Citation46]. Actually, positive-definite matrices possess numerous significant properties, specifically they can be represented in the form for a non-singular matrix H. The Cholesky factorization is a special type of this factorization, where H is a lower triangular matrix with positive diagonal elements. By a form of Gaussian elimination, we can compute the Cholesky factorization [Citation46]. Balancing
elements in the equation
shows
These equations can be solved to make a column of the matrix H at a time, according to the following form:
There are theorems that show the existence of a Cholesky factorization for symmetric and positive definite matrices. According to one of this theorem if all leading principal minors a matrix
are non-singular, then there exist a diagonal matrix D and two unit upper triangular matrices L and M so that
and if
be a symmetric and non-singular matrix, then, matrices L and M are equal and we can also write
Jacobi method constructs a sequence of similar matrices by using the orthogonal transformations. Jacobi methods for the symmetric eigenvalue problem attract current attention because they are inherently parallel [Citation47]. This method uses Jacobi rotation matrices for diagonalization of symmetric matrices, by the following theorem:
Theorem 2.1
[Citation46]
Let A be an real matrix. For each pair of integers
there exist a
such that
element of matrix
is zero, where
is a rotation matrix.
Actually, the idea of Jacobi method is to reduce the quantity by the above theorem and a sequence of rotation matrices.
3. Main results
In this section, we offer two iterative algorithms based on the Cholesky factorization and the Jacobi method for solving the Problem 1.1.
3.1. Smooth Cholesky factorization
In this subsection, we first review a theorem for the matrix pencil pair [Citation48] and then we extend it for pencil of matrix-valued function
.
Theorem 3.1
Let be the matrix pencil pair and matrices A and B be symmetric and positive definite, respectively, then there exist a real nonsingular matrix X such that matrix
is a real diagonal matrix and
and eigenvalues of the matrix pencil pair
equal to the diagonal elements of the matrix
.
Since matrices and
are matrix-valued functions dependent on several parameters, we present smooth Cholesky factorization for a differentiable matrix-valued function of multiple parameters.
Let be differentiable matrix defined on F, where F is a connected open subset of
. Such that
(8)
(8) in which
(9)
(9) Now, we present an existence for the Cholesky factorization of the matrix
. Then we present a smooth form of Theorem 3.1 for pencil of matrix-valued function
. To this end, we need a preparatory lemma as follows:
Lemma 3.1
If is a differentiable matrix-valued function defined on an open connected domain
then there exists a unit lower-triangular matrix
and an upper-triangular matrix
both unique and differentiable in F, such that
provided that all leading principal minors of
are nonzero for any
. This lemma obtains by using mathematical induction [Citation37].
Also, the Cholesky decomposition has continuity and smoothness properties as explained in the following theorem:
Theorem 3.2
Let be a differentiable matrix-valued function on the a connected open subset
such that at a given point
is a matrix full rank. Assume that there exists one permutation matrix
such that
has a Cholesky factorization
where
is a lower triangular matrix. Then there exists a neighbourhood of
say,
such that for all
the matrix-valued function
has a Cholesky factorization as
where
is a lower triangular matrix.
Proof.
From factorization, there exists a diagonal matrix
and an unit lower triangular matrix
such that
where
is an upper triangular matrix. By defining
as
we have
and
where
Let
where
and
. For as much as the matrix-valued function
is invertible on a neighbourhood of
, as
, and all of its leading principal minors are nonzero for any
, we can define the matrix-valued function,
, as follows:
Straight computations show that
It follows from Lemma 3.1 that there exist an LU decomposition of the matrix
as follow:
where
and
are two unit lower-triangular and unit upper-triangular matrix and both unique.
Assuming
let
Then
,
and
is the LU decomposition of
,
We define the matrix-valued function
as
where
are diagonal entries of
, then
Finally, by defining
we can obtain
and
Let
then
possesses the Cholesky decomposition
Now the proof is complete.
Corollary 3.1
Let be differentiable matrices defined on a connected open subset
such that at a given point, as
the rank
. Assume that matrices
and
are symmetric and positive definite respectively and there exists one lower triangular matrix
such that
has a Cholesky factorization for matrix
then there exists a neighbourhood of
say,
such that for all
there exists a nonsingular matrix-valued function
such that matrix
is real diagonal matrix and
and eigenvalues of the matrix pencil pair
are equal to the diagonal elements of the matrix
.
3.2. Two algorithms based on the smooth Cholesky factorization
In this subsection, we present two algorithms based on the Cholesky factorization for Problem 1.1. At first, we make a system of nonlinear equations which is equivalent to Problem 1.1. For this end, we begin by computing the Cholesky factorization of with complete pivoting as follows:
(10)
(10) where Π is a permutation matrix and H is a lower triangular matrix. We know that
(11)
(11) According to the symmetry of
, we obtain matrix
, such as
(12)
(12) and by assuming
, we get
(13)
(13) where
(14)
(14) The diagonal elements of
are not necessarily in descending order, but this can be achieved by a simple sorting algorithm or use a sorted Jacobi algorithm [Citation49]. So let's assume
. Based on Corollary 3.1, the matrices
and
are similarity matrices and therefor they have equal eigenvalues. As a result, the generalized eigenvalue problem
has the eigenvalues
if and only if
Now, we create a system of nonlinear equations for solving Problem 1.1 as following
(15)
(15) We use Newton's method to solve the system of the nonlinear equations (Equation15
(15)
(15) ). Suppose flow iterate
be sufficiently close to a solution of the nonlinear system (Equation15
(15)
(15) ), then one step of Newton's method for the solution of (Equation15
(15)
(15) ) has the form
(16)
(16) where the Jacobian matrix
has the following form:
(17)
(17) in which, using (Equation13
(13)
(13) ) and the results of Theorem 2.1 of [Citation50], Jacobian matrix
has elements
(18)
(18) Clearly, from the definition of matrices
and
in (Equation1
(1)
(1) ), we obtain
(19)
(19) Thus this method for solving the Problem 1.1 be summarized as follows:
Algorithm 3.1
The algorithm for finding a solution of Problem 1.1
Input: Given matrices and
eigenvalues
and initial guess
Output: Computed solution
For until the iteration sequence
is convergent,
| Step 1. | Compute | ||||
| Step 2. | Compute the Cholesky factorization of | ||||
| Step 3. | Find the rotation matrices | ||||
| Step 4. | Compute | ||||
| Step 5. | If | ||||
| Step 6. | Compute the Jacobian matrix | ||||
| Step 7. | Find | ||||
| Step 8. | Go to Step 1. | ||||
Let Problem 1.1 have a solution . We conclude that if the eigenvalues
have the smooth dependence near
, and the Jacobian at
is non-singularity, the Newton's method given in Algorithm 3.1 converges.
Theorem 3.3
Suppose that the Problem 1.1 has a solution and
are given and that
. Assume that the Jacobian matrix
with elements corresponds to Equation (Equation17
(17)
(17) ) is nonsingular, then there is a neighbourhood
such that, for all
the Algorithm 3.1 generates a well-defined sequence
for which
and convergence is locally quadratic.
Our numerical experiments with the Algorithm 3.1 illustrate that quadratic convergence indeed obtain in practice, but the strong hypotheses of Theorem 3.3 and the absence of the Cholesky factorization of the matrix when c<0, suggest there is still some degree of uncertainty about its performance. So, we provide another formulation. In the first step, the formulation leads to a constrained optimization problem, and then we will solve the constrained optimization problem by using an improved BFGS method. Many algorithms are proposed for solving constrained optimization problems. BFGS is the Newton's approximation method for solving several nonlinear optimization problems that was proposed by (Broyden–Fletcher–Goldfarb–Shanno). In addition, Byrd et al proposed a version of the L-BFGS algorithm for the bound-constrained optimization, namely the L-BFGS-B [Citation51].
In L-BFGS-B algorithm the idea of limited memory matrices to approximate the Hessian of the objective function [Citation52] is used. This algorithm does not require second derivatives or knowledge of the structure of the objective function and can therefore be feasible when the Hessian matrix is not practical to compute [Citation53].
Therefore, we create a constrained optimization problem of the form:
(20)
(20)
where
(21)
(21) Allow the running iterate
be enough close to a solution
of the nonlinear optimization problem (Equation20
(20)
(20) ), then from (Equation21
(21)
(21) ), (Equation12
(12)
(12) ) and Corollary 3.1, we know that the functions
are twice continuously differentiable at
, and their differentiate with respect to
can be expressed as
(22)
(22) Therefore, due to the definition of the function g, its gradient will be as follows
(23)
(23) where
.
Now, we are going to use L-BFGS-B method to solve the the nonlinear optimization problem (Equation20(20)
(20) ) and attain an iteration method for solving Problem 1.1. considering the current iterative
to be at step kth of the L-BFGS-B method, the objective function has to be approximated by a quadratic model at a point
in the following form:
(24)
(24) where
is the limited memory BFGS matrix which approximates the Hessian matrix at point
. Then the algorithm minimizes
according to the bounds given [Citation51]. This is done by finding an active set of bounds using the gradient projection method and minimizing
, treating those bounds as equality constraints.
To do this, first we should find the generalized Cauchy point which is determined as the first local minimizer of
on the piece-wise linear path
where
(25)
(25) Then, by assuming that the variables whose value at
is at lower or upper bound, the active set
is constituted, the following quadratic problem over the subspace of free variables is considered,
(26)
(26) In [Citation51], an algorithm is presented for computation of the generalized Cauchy point. Also, three approaches to minimize
over the space of free variables have been introduced, including a primal iterative method using the conjugate gradient method, a direct primal method based on the Sherman- Morrison-Woodbury formula and a direct dual method using Lagrange multipliers. Global convergence of the L-BFGS Algorithm is presented in [Citation54], and the analyses similar to those methods is possible for the l-BFGS-B Algorithm [Citation52]. More details of L-BFGS-B algorithm was presented in [Citation54].
By using L-BFGS-B algorithm for solving Problem 1.1, an iteration method based on Cholesky decomposition for solving Problem 1.1 is given as follows:
Algorithm 3.2
The algorithm for finding a solution of Problem 1.1
Input: Given matrices and
eigenvalues
and initial guess
Output: Computed solution
For until the iteration sequence
is convergent,
| Step 1. | Compute | ||||
| Step 2. | Compute the Cholesky factorization of | ||||
| Step 3. | Find the rotation matrices | ||||
| Step 4. | Compute | ||||
| Step 5. | Find | ||||
| Step 6. | If | ||||
| Step 7. | Find | ||||
| Step 8. | Go to Step 2. | ||||
In the next section, we will show demeanor of the Algorithms 3.1 and 3.2 by the numerical examples.
4. Numerical experiments
In this section, we apply three numerical experiments to examine convergence of Algorithms 3.1 and 3.2, and show the effectiveness of these algorithms for iteratively computing a solution of Problem 1.1. Also, all codes are run in MATLAB. In our implementations, the iterations were terminated when the current iterate satisfies for the Algorithm 3.1, and in the Algorithm 3.2, the iterations were stopped when the norm
was less than
.
Example 4.1
In this example, we have a parameterized inverse eigenvalue problem in which n = 5,
The eigenvalues are defined to be
Algorithm 3.1 is used to find the unknown vector c. This algorithm supposing the starting vectors
to the same solution
. In addition, we solved this example by using Algorithm 3.2 with assuming these starting vectors and
, we get the similar solution.
Our results show that the linear convergence to the similar solution is also achieved from the starting vector , and the number of iterations with this starting vector is 24. The numerical results for Algorithms 3.1 and 3.2 are displayed in Tables and , respectively. For simplicity, we displayed only every second iterate in Table . In Table , we also compare the numerical accuracy of Algorithms 3.1 and 4.1 in [Citation37].
Table 1. Numerical results for Example 4.1 by using Algorithm 3.1 and 4.1 in [Citation37].
Table 2. Numerical results for Example 4.1 by using the Algorithm 3.2.
Example 4.2
In this example, a parameterized generalized inverse eigenvalue problem is presented which n = 6,
and
matrices
and
for
are determined
where
Algorithms 3.1 and 3.2, on the assumption that the starting vector
, converges to a solution
Table displays the residual for these two algorithms. Also, considering the starting vector
, Algorithm 3.2 converges the same solution. We report the obtained results in Table (for convenience, only every second iterate is displayed).
Table 3. Numerical results for Example 4.2 by using Algorithms 3.1 and 3.2.
Table 4. Numerical results for Example 4.2 by using Algorithm 3.2.
Example 4.3
As the Third example, we consider a 10-bar truss problem and present some computational results to show the usefulness of the Problem 1.1 in structural design. Each bar consists of the following parameters: Young's modulus , eight density
, acceleration of gravity
, non-structural mass at all nodes
and the length
of horizontal and vertical bars. In this problem, the design variables are the areas of cross section of the bars for which the seventh and the eighth bars are fixed with the values
and
. The stiffness and the mass matrices of the structure can be expreseed respectively as,
with
We have to determine the areas of cross sections of the bars such that the given eigenvalues of the structure are
, where
are the specified natural frequencies of the structure.
We apply Algorithm 3.1 with the starting vectors
both Algorithms 3.1 and 4.1 in [Citation37] correspondingly converge to solutions
We demonstrate the results in Table . It is known that there may be as many as
different solutions (see [Citation55]) and, in practice, we may choose the one among them such that it is optimal in a certain sense. Also, we use Algorithm 3.2 with starting vectors parametrized by the first component
and our exams and numerical results show that Algorithm 3.2 always converges to the same solution if
. In Table , the numerical results for Algorithm 3.2 are shown, for two assumptions
and
. However, our implementation showed that the sequence generated by Algorithm 4.1 fails to converge, in these cases and many more.
Table 5. Numerical results for Example 4.3 by using Algorithm 3.1 and 4.1 in [Citation37].
Table 6. Numerical results for Example 4.3 by using Algorithm 3.2.
From the above three examples, we can see that Algorithms 3.1 and 3.2 are feasible for solving Problem 1.1.
But, on the other hand, the potential frailty of the numerical methods to solving optimization problems, such as Problem (Equation20(20)
(20) ), is the sensitivity to the initial guess. To eliminate this frailty, we consider a metaheuristic method as follows.
Particle swarm optimizer (PSO) is a stochastic population-based optimization algorithm that is inspired by the social cooperative and competitive behaviour, such as bird flocking and fish schooling. PSO was proposed by Kennedy and Eberhart [Citation56,Citation57] in 1995. Recently, PSO has emerged as a promising algorithm in solving various optimization problems in the field of engineering and science [Citation58–60]. In PSO, a swarm consists of a number of particles, that each particle represents a potential solution of the optimization task. Each particle moves to a new position according to the new velocity and the previous positions of the particle. PSO shows powerful ability to find optimal solutions and is known for low computational complexity, ease of implementation and few parameters to be adjusted.
In summary, in the PSO each particle moves to a new position according to the new velocity and the previous positions of the particle. This is compared with the best position generated by previous particles in the cost function, and the best one is kept. So each particle accelerates in the direction of not only the local best solution but also the global best position. If a particle discovers a new probable solution, other particles will move closer to it to explore the region more completely in the process [Citation61]. In other words, the algorithm is guided by personal experience (pbest), overall experience (gbest) and the present movement of the particles to decide their next positions in the search space.
Let S denote the swarm size (initial population) in PSO and D denote it's dimension. In general, there are three attributes, current position , current velocity
and past best position
, for particles in the search space to present their features. Each particle in the swarm is iteratively updated according to the aforementioned attributes. Assuming that the function h is the objective function of an optimization problem and the function h need to be minimized, the new velocity of every particle is updated by
(27)
(27) and the new position of a particle is calculated as follows:
(28)
(28) where
is the velocity of jth dimension of the ith particle for
, the
and
denote the acceleration coefficients,
and
are elements from two uniform random sequences in the range
, and r is the number of generations. The past best position of each particle is updated using
and the global best position gbest found from all particles during the previous three steps is defined as:
(29)
(29) Here, by presenting an example we show that the PSO method can be used to determine the answer or an initial guess for problem (Equation20
(20)
(20) ).
Example 4.4
In this example, we have a parameterized inverse eigenvalue problem in which n = 5,
The eigenvalues are given by
In this example, PSO method is implemented by using a random initial population with size 100 within the interval for 20 times. Results for these implementations are illustrated in Table , where k is the number of times the PSO method has been implemented. Also, Figure indicates the results obtained for the objective function.
Figure 1. PSO convergence characteristic for Example 4.4.
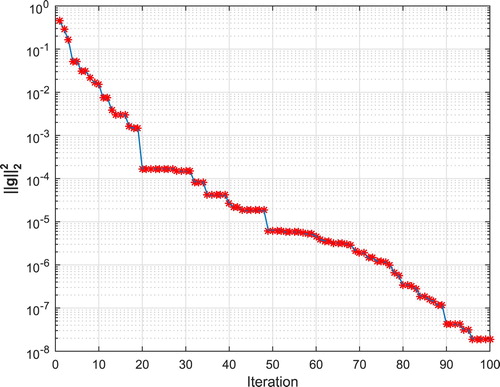
Table 7. Numerical results for Example 4.4 by using PSO method for 20 times.
5. Conclusions
In this work, two iterative methods were presented based on the Cholesky decomposition and the Jacobi method for solving some problems appeared in vibrating systems design and the design of control systems. In these methods, at first we have applied the Cholesky decomposition and rotation matrices to create a system of nonlinear equations or a constrained optimization problem and then we have solved this created system of nonlinear equations and the constrained optimization problem using Newton's method and the L-BFGS-B method, respectively. Numerical results have demonstrated the convergence of these methods and their effect for solving Problem 1.1. In addition, the second algorithm can be easily applied to parameterized generalized inverse eigenvalue problem with constrained unknown parameters. Both algorithms have used the Jacobi method, which is numerically stable and well-suited for implementation on parallel processors.
Acknowledgements
The authors are deeply grateful to the editor and anonymous referees for helpful comments and suggestions which led to a significant improvement of the original manuscript of this paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Saad Y. Numerical[Q3] methods for large eigenvalue problems. Vol. 66 of 2nd revised ed. Philadelphia: SIAM; 2011.
- Güttel S, Tisseur F. The nonlinear eigenvalue problem. Acta Numer. 2017;26:1–94.
- Chu MT, Golub GH. Inverse eigenvalue problems. Oxford: Oxford University Press; 2005. (Algorithms and Applications).
- Hajarian M, Abbas H. Least squares solutions of quadratic inverse eigenvalue problem with partially bisymmetric matrices under prescribed submatrix constraints. Comput Math Appl. 2018;76(6):1458–1475.
- Hajarian M. An efficient algorithm based on Lanczos type of BCR to solve constrained quadratic inverse eigenvalue problems. J Comput Appl Math. 2019;346:418–431.
- Hajarian M. BCR algorithm for solving quadratic inverse eigenvalue problems with partially bisymmetric matrices. Asian J Control. 2020;22(2):687–695.
- Cia J, Chen J. Least-squares solutions of generalized inverse eigenvalue problem over Hermitian-Hamiltonian matrices with a submatrix constraint. Comput Appl Math. 2018;37(1):593–603.
- Liu ZY, Tan YX, Tian ZL. Generalized inverse eigenvalue problem for centrohermitian matrices. J Shanghai Univ Eng Ed. 2004;8(4):448–453.
- Gu W, Li Z. Generalized inverse eigenvalue problem for generalized snow-like matrices. Fourth International Conference on Computational and Information Sciences; 2012; Chongqing, China. IEEE. p. 662–664.
- Yuan YX, Dai H. A generalized inverse eigenvalue problem in structural dynamic model updating. J Comput Appl Math. 2009;226(1):42–49.
- Ghanbari K, Parvizpour F. Generalized inverse eigenvalue problem with mixed eigendata. Linear Algebra Appl. 2012;437(8):2056–2063.
- Gladwell GM. Inverse problems in vibration. Appl Mech Rev. 1986;39(7):1013–1018.
- Gigola S, Lebtahi L, Thome N. Inverse eigenvalue problem for normal J-hamiltonian matrices. Appl Math Lett. 2015;48:36–40.
- Chu MT, Golub GH. Structured inverse eigenvalue problems. Acta Numer. 2002;11:1–71.
- Joseph KT. Inverse eigenvalue problem in structural design. Numer Linear Algebra Appl. 1992;30(12):2890–2896.
- Jiang J, Dai H, Yuang Y. A symmetric generalized inverse eigenvalue problem in structural dynamics model updating. Linear Algebra Appl. 2013;439(5):1350–1363.
- Zhang ZZ, Han XL. Solvability conditions for algebra inverse eigenvalue problem over set of anti-Hermitian generalized anti-Hamiltonian matrices. J Cent South Univ Technol. 2005;12(1):294–297.
- Byrnes CI, Wang X. The additive inverse eigenvalue problem for Lie perturbations. SIAM J Matrix Anal Appl. 1993;14(1):113–117.
- Majkut L. Eigenvalue based inverse model of beam for structural modification and diagnostics: examples of using. Lat Am J Solids Struct. 2010;7(4):437–456.
- Cox SJ, Embree M, Hokanson JM. One can hear the composition of a string: experiments with an inverse eigenvalue problem. SIAM Rev. 2012;54(1):157–178.
- Li K, Liu J, Han J, et al. Identification of oil-film coefficients for a rotor-journal bearing system based on equivalent load reconstruction. Tribol Int. 2016;104:285–293.
- Liu J, Meng X, Zhang D, et al. An efficient method to reduce ill-posedness for structural dynamic load identification. Mech Syst Signal Process. 2017;95:273–285.
- Liu J, Sun X, Han X, et al. Dynamic load identification for stochastic structures based on gegenbauer polynomial approximation and regularization method. Mech Syst Signal Process. 2015;56:3–54.
- Bonnet M, Constantinescu A. Inverse problems in elasticity. Inverse Probl. 2005;21(2):R1.
- Barcilon V. On the multiplicity of solutions of the inverse problem for a vibrating beam. SIAM J Appl Math. 1979;37(3):605–613.
- Hasanov A, Baysal O. Identification of an unknown spatial load distribution in a vibrating cantilevered beam from final overdetermination. J Inverse Ill-posed Probl. 2015;23(1):85–102.
- Mulaik SA. Fundamentals of common factor analysis. In: The Wiley Handbook of psychometric testing: a multidisciplinary reference on survey, scale and test development. New Jersey; 2018. p. 209–251.
- Yang Y, Wei G. Inverse scattering problems for Sturm–Liouville operators with spectral parameter dependent on boundary conditions. Math Notes. 2018;103(1–2):59–66.
- Jensen JS. Phononic band gaps and vibrations in one-and two-dimensional mass–spring structures. J Sound Vib. 2003;266(5):1053–1078.
- Li LL. Sufficient conditions for the solvability of algebraic inverse eigenvalue problems. Linear Algebra Appl. 1995;221:117–129.
- Xu SF. On the sufficient conditions for the solvability of algebraic inverse eigenvalue problems. J Comput Math. 1992;10:17–80.
- Biegler-König FW. Suffcient conditions for the solubility of inverse eigenvalue problems. Linear Algebra Appl. 1981;40:89–100.
- Alexander J. The additive inverse eigenvalue problem and topological degree. Proc Amer Math Soc. 1978;70:5–7.
- Friedland S, Nocedal J, Overto ML. The formulation and analysis of numerical methods for inverse eigenvalue problems. SIAM J Numer Anal. 1987;24(3):634–667.
- Xu S. On the necessary conditions for the solvability of algebraic inverse eigenvalue problems. J Comput Math. 1992;10:93–97.
- Ji X. On matrix inverse eigenvalue problems. Inverse Probl. 1998;14(2):275–285.
- Dai H, Bai ZZ, Wei Y. On the solvability condition and numerical algorithm for the parameterized generalized inverse eigenvalue problem. SIAM J Matrix Anal Appl. 2015;36(2):707–726.
- Rojo O, Soto R. New conditions for the additive inverse eigenvalue problem for matrices. Comput Math Appl. 1992;23:41–46.
- Li L. Some sufficient conditions for the solvability of inverse eigenvalue problems. Linear Algebra Appl. 1991;148:225–236.
- Xu SF. A smallest singular value method for solving inverse eigenvalue problems. J Comput Math. 1996;1:23–31.
- Dai H. An algorithm for symmetric generalized inverse eigenvalue problems. Linear Algebra Appl. 1999;296:79–98.
- Dai H, Lancaster P. Newton's method for a generalized inverse eigenvalue problem. Numer Linear Algebra Appl. 1997;4:1–21.
- Shu L, Wang B, Hu JZ. Homotopy solution of the inverse generalized eigenvalue problems in structural dynamics. Appl Math Mech. 2004;25(5):580–586.
- Lancaster P. Algorithms for lambda-matrices. Numer Math. 1964;6(1):388–394.
- Biegler-König FW. A newton iteration process for inverse eigenvalue problems. Numer Math. 1981;37(3):349–354.
- Golub GH, VanLoan CF. Matrix computations. Vol. 3. Baltimore: JHU Press; 2012.
- Yamamoto Y, Lan Z, Kudo S. Convergence analysis of the parallel classical block Jacobi method for the symmetric eigenvalue problem. JSIAM Lett. 2014;6:57–60.
- Johnson C, Horn R. Matrix analysis. Cambridge: Cambridge university press; 1985.
- Xu D, Liu Z, Xu Y, et al. A sorted jacobi algorithm and its parallel implementation. Trans Beijing Inst Technol. 2010;12:1470–1474.
- Ji-guang S. Sensitivity analysis of multiple eigenvalues (i). Int J Comput Math. 1988;1:28–38.
- Byrd RH, Lu P, Nocedal J, et al. A limited memory algorithm for bound constrained optimization. SIAM J Sci Comput. 1995;16(5):1190–1208.
- Keskar N, Wächter A. A limited-memory quasi-newton algorithm for bound-constrained non-smooth optimization. Optim Methods Softw. 2019;34(1):150–171.
- Haarala N, Miettinen K, Mäkelä MM. Globally convergent limited memory bundle method for large-scale nonsmooth optimization. Math Program. 2007;109(1):181–205.
- Mokhtari A, Ribeiro A. Global convergence of online limited memory BFGS. J Mach Learn Res. 2015;16(1):3151–3181.
- Friedland S. Inverse eigenvalue problems. Linear Algebra Appl. 1977;17(1):15–51.
- Kennedy J, Eberhart R. Particle swarm optimization. Proceedings of the IEEE international conference on neural networks. Vol. 4; 1995. IEEE. p. 1942–1948.
- Shi Y, Eberhart R. A modified particle swarm optimizer. 1998 IEEE international conference on evolutionary computation proceedings. IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360); 1998. p. 69–73.
- AlRashidi MR, El-Hawary ME. A survey of particle swarm optimization applications in electric power systems. IEEE Trans Evol Comput. 2008;13(4):913–918.
- Robinson J, Rahmat-Samii Y. Particle swarm optimization in electromagnetics. IEEE Trans Antennas Propag. 2004;52(2):397–407.
- Abousleiman R, Rawashdeh O. Electric vehicle modelling and energy-efficient routing using particle swarm optimisation. IET Intell Transp Syst. 2016;10(2):65–72.
- Gudise VG, Venayagamoorthy GK. Comparison of particle swarm optimization and backpropagation as training algorithms for neural networks. Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS'03 (Cat. No. 03EX706); 2003; Indianapolis, USA. p. 110–117.