
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
It is well known that the problem of numerical differentiation is an ill-posed problem and one requires regularization methods to approximate the solution. The commonly practiced regularization methods are (external) parameter-based like Tikhonov regularization, which has certain inherent difficulties associated with them. In such scenarios, iterative regularization methods serve as an attractive alternative. In this paper, we propose a novel iterative regularization method where the minimizing functional does not contain the noisy data directly, but rather a smoothed or integrated version of it. The advantage, in addition to circumventing the use of noisy data directly, is that the sequence of functions constructed during the descent process tends to avoid overfitting, and hence, does not corrupt the recovery significantly. To demonstrate the effectiveness of our method we compare the numerical results obtained from our method with the numerical results obtained from certain standard regularization methods such as Tikhonov regularization, Total-variation, etc.
1991 Mathematics Subject Classifications:
1. Introduction
In many applications, we want to calculate the derivative of a function measured experimentally, that is, to differentiate a function obtained from discrete noisy data. The problem consists of calculating stably the derivative of a smooth function g given its noisy data such that
, where the norm
can be either the
-norm. This turns out to be an ill-posed problem, since for a small δ such that
we can have
arbitrarily large or even throw
out of the set of differentiable functions. Many methods and techniques have been introduced in the literature regarding this topic (see [Citation1–13] and references therein). They mostly fall into one of three categories: difference methods, interpolation methods and regularization methods. One can use the first two methods to get satisfactory results provided that the function is given precisely, but they fail miserably when they encounter even small amounts of noise, if the step size is not chosen appropriately or in a regularized way. Hence in such scenarios, regularization methods need to be employed to handle the instability arising from noisy data, with Tikhonov's regularization method being very popular in this respect. In a regularization method, the instability is bypassed by reducing the numerical differentiation problem to a family of well-posed problems, depending on a regularization (smoothing) parameter. Once an optimal value for this parameter is found, the corresponding well-posed problem is then solved to obtain an estimate for the derivative. Unfortunately, the computation of the optimal value for this parameter is a nontrivial task, and usually it demands some prior knowledge of the errors involved. Though there are many techniques developed to find an appropriate parameter value, such as the Morzov's discrepancy principle, the L-curve method and others, still sometimes the solution recovered is either over-fitted or over-smoothed; especially when g has sharp edges, discontinuities or the data has extreme noise in it. An attractive alternative is the iterative regularization methods, like the Landweber iterations. In an iterative regularization method (without any explicit dependence on external parameters), one can start the minimization process first and then use the iteration index as an regularization parameter, i.e. one terminates the minimization process at an appropriate time to achieve regularization. More recently iterative methods have been investigated in the frame work of regularization of nonlinear problems, see [Citation14–18].
In this paper, we propose a new smoothing or regularization technique that doesn't involve any external parameters, thus avoiding all the difficulties associated with them. Furthermore, since this method does not involve the noisy data directly, it is very robust to large noise level in the data as well as to errors with non-zero mean. Thus it makes the method computationally feasible when dealing with real-life data, where we do not expect to have any knowledge of the errors involved or when there is extreme noise involved in the data.
Let us briefly outline our method. First, we lay out a brief summary of a typical (external) parameter-dependent regularization method, and then we present our new (external) parameter-independent smoothing technique. For a given differentiable function g the problem of numerical differentiation, finding , can be expressed via a Volterra integral equation:Footnote1
(1)
(1) where
and
(2)
(2) for all
. Here one can attempt to solve Equation (Equation1
(1)
(1) ) by approximating ϕ with the minimizer of the functional
However, as stated earlier, the recovery becomes unstable for a noisy g. So, to counter the ill-posed nature of this problem regularization techniques are introduced: one instead minimizes the functionalFootnote2
(3)
(3) where β is a regularization parameter and D is a differentiation operator of some order (see [Citation1,Citation14]). This converts the ill-posed problem to a family of conditionally well-posed problems depending on β. The first term (fitting term) of the functional
ensures that the inverse solution fits well with the given data, when applied by the forward operator
, and the second term (smoothing term) in (Equation3
(3)
(3) ) controls the smoothness of the inverse solution. Since the minimizer of the second term is not the solution of the inverse problem, unless it is a trivial solution, one needs to balance between the smoothing and fitting of the inverse recovery by finding an optimal value
. Then the exact solution ϕ is approximated by minimizing the corresponding functional
.
Given that an important key in any regularization technique is the conversion of an ill-posed problem to a (conditionally) well-posed problem, we make this our main goal. We start with integrating the data twice, which helps in smoothing out the noise. Thus (Equation1(1)
(1) ) can be reformulated as: find a ϕ that satisfies
(4)
(4) where
and
. Equivalently,
or
(5)
(5) Now we find the solution of (Equation4
(4)
(4) ) by approximating it with the minimizer of the following functional:
(6)
(6) where
is the solution, for a given ψ, of the following boundary value problem:
(7)
(7)
(8)
(8) Note that unlike the functionals
and
which are defined on the data g directly, the functional G is defined rather on the transformed data
. Thus one can see that when the data g has noise in it then working with the smoothed (integrated) data
is more effective than working with the noisy data g directly. It will be proved in later sections that this simple change in the working space from g to
drastically improves the stability and smoothness of the inverse recovery of ϕ, without adding any further smoothing terms.
Remark 1.1
Typically, real-life data have zero-mean additive noise in it, i.e.
(9)
(9) for
, such that
and
(or equivalently,
), where μ is the probability density function of the random variable ε. Therefore, integrating the data smooths out the noise present in the original data (
) and hence, the new data (
, as defined by (Equation5
(5)
(5) ) for
) for the transformed equation (Equation4
(4)
(4) ) has a significantly reduced noise level in it, see the comparison in Figure .
We prove, in Section 3, that the functional G is strictly convex and hence has a unique global minimum which satisfies (Equation1(1)
(1) ), that is,
satisfies
. The global minimum is achieved via an iterative method using an upgraded steepest gradient or conjugate-gradient method, presented in Section 4, where the use of an (Sobolev)
-gradient for G instead of the commonly used
-gradient is discussed and is a crucial step in the optimization process. In Section 5, we shed some light on the stability, convergence and well-posedness of this technique. In Section 6, the Volterra operator
is improved for better computation and numerical efficiency but keeping it consistent with the theory developed. In Section 7, we provide some numerical results and compare our method of numerical differentiation with some popular regularization methods, namely Tikhonov regularization, total variation, smoothing spline, mollification method and least square polynomial approximation (the comparison is done with results provided in [Citation1,Citation2,Citation19]). Finally, in Section 8 we present an efficient (heuristic) stopping criterion for the descent process when we don't have any prior knowledge of the error norm.
2. Notations and preliminaries
We adopt the following notations that will be used throughout the paper. All functions are real-valued defined on a bounded closed domain . For
,
:=
denotes the usual Banach space of p-integrable functions on
and the space
contains the essentially bounded measurable functions. Likewise the Sobolev space
contains all the functions for which f,
, with weak differentiation understood, and the space
. The spaces
and
are Hilbert spaces with inner-products denoted by
and
, respectively.
Remark 2.1
Note that although the Volterra operator is well defined on the space of integrable functions (
), we will restrict it to the space of
functions, that is, we shall consider
to be the searching space for the solution of (Equation1
(1)
(1) ), since it is a Hilbert space and has a nice inner product
. Hence the domain of the functional G is
. It is not hard to see that the Volterra operator
is linear and bounded on
.
Remark 2.2
From Remark 2.1, since we have
. Thus our problem space to be considered is
, that is,
. Note that since we will not be working with g directly but rather with
, integrating twice makes
. This is particularly significant in the sense that we are able to upgrade the smoothness of the working data or information space from
to
and hence improve the stability and efficiency of numerical computations. This effect can be seen in some of the numerical examples presented in Section 7 where the noise involved in the data is extreme.
Before we proceed to prove the convexity of G and the well-posedness of the method, we will manipulate further to push it to an even nicer space. From Equation (Equation5
(5)
(5) ), we have
Now redefining the working data as
, we have
(10)
(10) and this gives
,
and
. Thus
and the negative Laplace operator
is a positive operator in
on the domain
, since for any
(11)
(11) and equality holds when
, which implies
. Here, and until otherwise specified, the notations Δ and ∇, will mean
,
, respectively, throughout the paper. The functional
in (Equation6
(6)
(6) ) is now redefined, with the new u, as
(12)
(12) The positivity of the operator
in
on the domain
also helps us to obtain an upper and lower bound for
, for any
. First we get the trivial upper bound
(13)
(13) To get a lower bound we note from (Equation8
(8)
(8) ) that
, thus
(14)
(14) where
is the smallest eigenvalue of the positive operator
on
. Hence, we get the bounds of
in terms of the
norm of
as
(15)
(15) Equation (Equation15
(15)
(15) ) indicates the stability of the method and the convergence of
to u in
if
, as is explained in detail in Section 5.
3. Convexity of the functional G
In this section, we prove the convexity of the functional G, together with some important properties.
Theorem 3.1
An equivalent form of G, for any
is
For any
The first G
The second Gâteaux derivative,Footnote5 at any
For the proof of Theorem 3.1, we also need the following ancillary result.
Lemma 3.2
For fixed we have, in
(22)
(22)
Proof.
Subtracting the following equations:
we have
(23)
(23) and using
we get, via integration by parts,
Now from (Equation14
(14)
(14) ) we have
, and using the Cauchy–Schwarz inequality, we have
where
. Hence
in
, since the operator
is bounded and
are fixed, which implies the right hand side is of
.
3.1. Proof of Theorem 3.1
The proof of first two properties (i) and (ii) are straight forward via integration by parts and using the fact that .
In order to prove (iii) and (iv), we use Lemma 3.2.
| (iii) | The Gâteaux derivative of the functional G at ψ in the direction of | ||||
| (iv) | Finally, the second Gâteaux derivative for the functional G at ψ is given by
| ||||
In this section, we proved that the functional G is strictly convex and hence has a unique minimizer, which is attained by the solution ϕ of the inverse problem (Equation1(1)
(1) ). We next discuss a descent algorithm that uses the
-gradient to derive other gradients that provide descent directions, with better and faster descent rates.
4. The descent algorithm
Here we discuss the problem of minimizing the functional G via a descent method. Theorem 3.1 suggests that the minimization of the functional G should be computationally effective in that ϕ is not only the unique global minimum for G but also the unique zero for the gradient, that is, for
. Now for a given
, let
denote an update direction for ψ. Then Taylor's expansion gives
or, for sufficiently small
, we have
(26)
(26) So if we choose the direction h in such a way that
, then we can minimize G along this direction. Thus we can set up a recovery algorithm for ϕ, forming a sequence of values
We list a number of different gradient directions that can make
.
The
First, notice from Theorem 3.1 that at a given
The
One can circumvent this problem by opting for the Sobolev gradient
Dirichlet Neuberger gradient :
Neumann Neuberger gradient :
Robin or mixed Neuberger gradient :
This excellent smoothing technique was originally introduced and used by Neuberger. In addition to the flexibility at the end points, it enables the new gradient to be a preconditioned (smoothed) version of
The
If one wishes to further boost the descent speed (by, roughly, a factor of 2) and make the best use of both the gradients, then the standard Polak–Ribi
Remark 4.1
Though the –
conjugate gradient boost the descent rate, it (sometimes) compromises the accuracy of the recovery, especially when the noise present in the data is extreme, see Table when
. Now one can also construct a
–
conjugate gradient based only on the Sobolev gradient. This is smoother than the
–
conjugate gradient (as Sobolev gradients are smoother, see Equation (Equation28
(28)
(28) )) and hence improves the accuracy of the recovered solution (specially for smooth recovery), but it is tad slower than the
–
conjugate gradient. Finally, the simple Sobolev gradient (
) provides the most accurate recovery, but at the cost of the descent rate (it the slowest amongst the three), see Tables and .
4.1. The line search method
We minimize the single variable function , where
, via a line search minimization by first bracketing the minimum and then using some well-known optimization techniques like Brent minimization to further approximate it. Note that the function
is strictly decreasing in some neighbourhood of
as
.
In order to achieve numerical efficiency, we need to carefully choose the initial step size . For that, we use the quadratic approximation of the function
as follows:
(32)
(32) which gives the minimizing value for α as
(33)
(33) Now since
is derived from the quadratic approximation of the functional G, it is usually very close to the optimal value, thereby reducing the computational time of the descent algorithm significantly. Now if, for
,
then we have a bracket,
, for the minimum and one can use single variable minimization solvers to approximate it.
In this section, we saw a descent algorithm, with various gradients, where starting from an initial guess , we obtain a sequence of
-functions
for which the sequence
is strictly decreasing. In the next section, we discuss the convergence of the
's to ϕ and the stability of the recovery.
5. Convergence, stability and conditional well-posedness
Exact data: We first prove that the sequence of functions constructed during the descent process converges to the exact source function in the absence of any error term and then proves the stability of the process in the presence of noise in the data.
5.1. Convergence
First we see that for the sequence produced by the steepest descent algorithm, described in Section 4, we have
, since the functional G is non-negative and strictly convex (with the global minimizer ϕ,
) and
. In this section, we prove that if for any sequence of functions
such that
, then
in
, where
denotes weak convergence in
.
Theorem 5.1
Suppose that is any sequence of
-functions such that the sequence
tends to zero. Then
converges weakly to ϕ in
and
converges strongly to u in
. Also, the sequence
converges weakly to
in
where
and
.
Proof.
The proof of in
is trivial from the bounds of
in Equation (Equation15
(15)
(15) ), which gives
(34)
(34) To see the weak convergence of
to ϕ in
, we first prove that the sequence
converges weakly to
in
. Since
converges strongly to u in
, this implies
and
converge weakly to
and u in
, respectively. Now we will use the fact that
is dense in
(in
-norm), i.e. for any
and
there exists a
such that
. So for any
we have, using
,
(35)
(35) which tends to zero as
. Hence by the density of
in
, it can be proved that the sequence
converges weakly to
in
.
To prove convergence of to
weakly in
, we can use
and (Equation35
(35)
(35) ). Therefore, our proof will be complete if we can show that the range of
is dense in
in
-norm. Again we start with any
, and using
, we have
i.e.
. Hence we have
dense in
in
-norm. For convergence of
to
, note that
and
. And since
converges weakly to
in
implies
converges weakly to
in
.
Remark 5.2
It can be further proved that the sequence converges strongly to ϕ in
. To prove this, first, one needs to analyse the operator associated with the minimizing functional G as defined in (Equation12
(12)
(12) ), i.e. from the definition of
in (Equation7
(7)
(7) ) together with the criterion
we have (from (Equation10
(10)
(10) ), with
and
, by the definition of
)
(36)
(36) From the expression (Equation36
(36)
(36) ), the operator
is both linear and bounded, and hence minimizing the functional G in (Equation12
(12)
(12) ) is equivalent to Landweber iterations corresponding to the operator L. Then from the convergence theories developed for Landweber iterations the sequence
converges to ϕ strongly in
, for details on iterative regularization see [Citation14,Citation16].
Theorem 5.1 proves that for the given function we are able to construct a sequence of smooth functions,
, that converges (weakly) to
in
. This is critical since, when the data has noise in it one needs to terminate the descent process at an appropriate instance to attain regularization, see Section 5.3, and the (weak) convergence helps us to construct such a stopping criterion in the absence of noise information (δ), see Section 8.
Noisy data: In this section, we consider the data has noise in it and shows that the sequence of functions constructed during the descent process using the noisy data still approximates the exact solution, under some conditions.
5.2. Stability
Here we prove the stability of the process. We will prove this by considering the problem of numerical differentiation as equivalent to finding a unique minimizer of the positive functional G, this makes the problem well-posed. That is, for a given , and hence a given
and the functional G, the problem of finding (derivative)
such that
is equivalent to finding the minimizer of the functional G, i.e. a
such that
, for any small
, is a conditionally well-posed problem. It is not hard to prove that if two functions g,
are such that
, where
is small, then the corresponding u,
also satisfyFootnote6
, for some constant C.
Theorem 5.3
Suppose the function in the perturbed version of the function u such that
where
and let ϕ,
denote their respective recovered functions, such that
and
. Let the functional G, without loss of generality, be defined based on
that is,
then we have
(37)
(37) where C is some constant.
Proof.
Since and
, the proof follows from the definitions of the corresponding functionals, as
In the next theorem, we prove that if a sequence of functions converges to
in
, then it also approximates ϕ in
, that is, if
is small, then
is also small where
and
are the functionals formed based on u and
, respectively.
Theorem 5.4
Suppose for a sequence of functions the corresponding sequence
converges to zero, where the functional
is formed based on
then for the original u such that
for small
there exists a
such that for all
for some constant c and
is the functional based on u.
Proof.
For u, and any
, we have
and
, then
and hence from Theorem 5.1, the result follows.
5.3. Conditional well-posedness (iterative-regularization)
As explained earlier, in an external-parameter based regularization method (like Tikhonov-type regularizations) first, one converts the ill-posed problem to a family of well-posed problem (depending on the parameter value β) and then, only after finding an appropriate regularization parameter value (say ), one proceeds to the recovery process, i.e. completely minimize the corresponding functional
(as defined in (Equation3
(3)
(3) )). Whereas in a classical iterative regularization method (not involving any external-parameters like β), one cannot recover a regularized solution by simply minimizing a related functional completely, instead stopping the recovery process at an appropriate instance provides the regularizing effect to the solution. That is, one starts to minimize some related functional (to recover the solution) but then terminates the minimization process at an appropriate iteration before it has reached the minimum (to restrict the influence of the noise), i.e. here the iteration stopping index serves as a regularization parameter, for details see [Citation14,Citation16].
In this section, we further explain the above phenomenon by showing that if one attempts to recover the true (or original) solution ϕ by using a noisy data then it will distort the recovery. First we see that for an exact g (or equivalently, an exact u) and the functional constructed based on it (i.e. ) we have the true solution (ϕ) satisfying
. However, for a given noisy
, with
, and the functional based on it (i.e.
) we will have
, see Theorem 5.5. So if we construct a sequence of functions
, using the descent algorithm and based on the noisy data
, such that
then (from Theorem 5.1) we will have
, where
is the recovered noisy solution satisfying
. This implies initially
and then upon further iterations
diverges away from ϕ and approaches
. Hence, the errors in the recoveries
follow a semi-convergence nature, i.e. decreases first and then increases. This is a typical behaviour of any ill-posed problem and is managed, as stated above, by stopping the descent process at an appropriate iteration
such that
but close to zero (due to the stability Theorems 5.3 and 5.4). Following similar arguments as in (Equation15
(15)
(15) ), we can have a lower bound for
.
Theorem 5.5
Given two functions u, their respective recovery ϕ,
such that
and
and let the functional
be defined based on
that is,
then we have
(38a)
(38a) as an
-lower bound and for a
-lower bound, we have
(38b)
(38b) where
is the smallest eigenvalue of
on
.
Therefore, combining Theorems 5.3 and 5.5 we have the following two-sided inequality for , for some constants
and
,
Thus, when
we have
which implies
in
. Now though we would like to use the bounds in Theorem 5.5 to terminate the descent process, but we do not known the exact g (or equivalently, the exact u), and hence cannot use that as the stopping condition. However, if the error norm
is known then one can use Morozov's discrepancy principle, [Citation22], as a stopping criterion for the iteration process, that is, terminate the iteration when
(39)
(39) for an appropriate
,Footnote7 and for unknown δ one usually goes for heuristic approaches to stop the iterations, an example of which is presented in Section 8.
6. Numerical implementation
In this section, we provide an algorithm to compute the derivative numerically. Notice that though one can use the integral operator equation (Equation1(1)
(1) ) to recover ϕ inversely, for computational efficiency we can further improve the operator and the operator equation, but keeping the theory intact. First we see that the adjoint operator
can also provide an integral operator equation of interest,
(40)
(40) where
and
for all
. Now we can combine both the operator equations (Equation1
(1)
(1) ) and (Equation40
(40)
(40) ) to get the following integral operator equation:
(41)
(41) where
and for all
,
(42)
(42) The advantage of the operator equation (Equation41
(41)
(41) ) over (Equation1
(1)
(1) ) or (Equation40
(40)
(40) ) is that it recovers ϕ symmetrically at the end points. For example if we consider the operator equation (Equation40
(40)
(40) ) for the recovery of ϕ, then during the descent process the
-gradient at ψ will be
(similar to (Equation19
(19)
(19) )) which implies
for all
. Hence the boundary data at a for all the evolving
's are going to be invariant during the descent.Footnote8 As for (Equation1
(1)
(1) ), since
, the boundary data at b for all the evolving
's are going to be invariant during the descent. Even though one can opt for the Sobolev gradient of G at ψ,
, to counter that problem but, due to the intrinsic decay of the base function
for all
's at a or b, the recovery of ϕ near that respective boundary will not be as good (or symmetric) as at the other end. On the other hand if we use the operator equation (Equation41
(41)
(41) ) for the descent recovery of ϕ then the
-gradient at ψ is going to be
(43)
(43) where
(44)
(44) Thus
and
, and hence the recovery of ϕ at both the end points will be performed symmetrically. Now one can derive other gradients, like the Neuberger or conjugate gradient based on this
-gradient, for the recovery of ϕ depending on the scenarios, that is, based on the prior knowledge of the boundary information (as explained in Section 4).
Corresponding to the operator equation (Equation41(41)
(41) ), the smooth or integrated data
will be
(45)
(45) Thus our problem set up now is as follows: for a given
(and hence a given
) we want to find a
such that
(46)
(46) Our inverse approach to achieve ϕ will be to minimize the functional G which is defined, for any
, by
(47)
(47) where u is as defined in (Equation45
(45)
(45) ) and
is the solution of the boundary value problem
(48)
(48) Since our new problem set up is almost identical to the old one, the previous theorems and results developed for
can be similarly extended to T. Next we provide a pseudo-code, Algorithm 1, for the descent algorithm described earlier.
Remark 6.1
If prior knowledge of and
is known then
can be defined as a straight line joining them and we use Dirichlet Neuberger gradient for the descent. If no prior information is known about
and
, then we simply choose
and use the Sobolev gradient or conjugate gradient for the descent. It has been numerically seen that having any information of
or
and using it, together with appropriate gradient, significantly improves the convergence rate of the descent process and the efficiency of the recovery. In the examples presented here we have not assumed any prior knowledge of
or
to keep the problem settings as pragmatic as possible.
Remark 6.2
To solve the boundary value problem (Equation29(29)
(29) ) while calculating the Neuberger gradients we used the invariant embedding technique for better numerical results (see [Citation23]). This is very important as this technique enables us to convert the boundary value problem to a system of initial and final value problems and hence one can use the more robust initial value solvers, compared to boundary value solvers, which normally use shooting methods.
Remark 6.3
For all the numerical testings presented in Section 7, we assumed to have prior knowledge on the error norm (δ) and used it as a stopping criteria, as explained in Section 5.3, for the descent process. We also compare the results obtained without any noise information (i.e. using heuristic stopping strategy, see Section 8) with the results obtained using the noise information, see Tables and in Section 8.

7. Results
A MATLAB program was written to test the numerical viability of the method. We take an evenly spaced grid with in all the examples, unless otherwise specified. In all the examples, we used the discrepancy principle (see (Equation39
(39)
(39) )) to terminate the iterations when the discrepancy error goes below δ (which is assumed to be known). In Section 8, we discuss the stopping criterion when δ is unknown.
Example 7.1
Comparison with standard regularization methods
In this example, we compare the inverse recovery using our technique with some of the standard regularization methods. We again perturbed the smooth function , here we consider the regularity of the data as
(i.e.
for k = 0), on
by random noises to get
, where ε is a normal random variable with mean 0 and standard deviation σ. Like in [Citation1], we generated two data sets, one with
(the dense set) and other with
(the sparse set). We tested with
on both the data sets and
only on the dense set. We compare the relative errors,
, obtained in our method (using Neumann
-gradient) with the relative errors provided in [Citation1], which are listed in Table . Here we can see that our method of numerical differentiation outperforms most of the other methods, in both the dense and sparse situation. Though Tikhonov method performs better for k = 2, that is when g is assumed to be in
, but for the same smoothness consideration,
or k = 0, it fails miserably. In fact, one can prove that the ill-posed problem of numerical differentiation turns out to be well-posed when
for k = 1, 2, see [Citation14], which explains the small relative errors in Tikhonov regularization for k = 1, 2. As stated above, the results in Table are obtained using the Sobolev gradient, whereas Tables and show a comparison in the recovery errors using different gradients and different stopping criteria, as well as the descent rates associated with them. To compare with the total variation method, which is very effective in recovering discontinuities in the solution, we perform a test on a sharp-edged function similar to the one presented in [Citation1] and the results are shown in Example 7.4. Hence we can consider this method as an universal approach in every scenarios.
Table 1. Relative errors in derivative approximation.
Table 2. Relative errors and the descent rates using different gradients.
Table 3. Relative errors and the descent rates using different gradients.
In the next example, we show that one does not have to assume the normality conditions for the error term, i.e. the assumption that the noise involved should be iid normal random variables is not needed, which is critical for certain other methods, rather it can be a mixture of any random variables.
Example 7.2
Noise as a mixture of random variables
In the previous example, we saw that our method holds out in the presence of large error norm. Here we show that this technique is very effective even in the presence of extreme noise. We perturb the function on
to
,Footnote9 where ε is the error function obtained from a mixture of uniform(
, δ) and normal(0, δ) random variables, where
. Figure shows the noisy
and the exact g, and Figure (a) shows the computed derivative
vs.
. The relative error for the recovery of
is 0.0071.
Figure 1. Noisy .
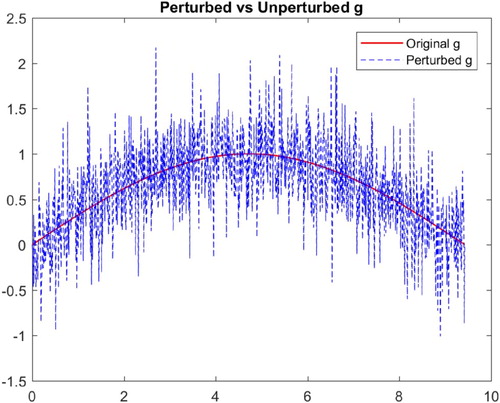
Figure 2. Inverse recovery of the derivative and
: (a) derivative
vs. ϕ and (b) recovery of
.
In the next example, we further pushed the limits by not having a zero-mean error term, which is again crucial for many other methods.
Example 7.3
Error with non-zero mean
In this example, we will show that this method is impressive even when the noise involved has nonzero mean. We consider the settings of the previous example: on
is perturbed to
but here the error function ε is a mixture of uniform(-0.8δ, 1.2δ) and normal(0.1, δ), for
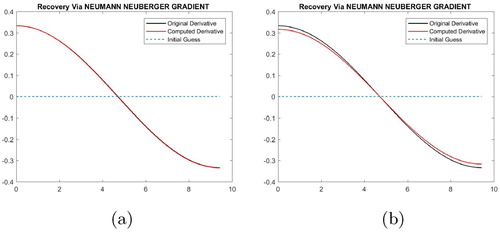
. Figure (b) shows the recovery of the derivative ϕ versus the true derivative. The relative error of the recovery for ϕ is around 0.0719.
In the following two examples, we provide the results of numerical differentiation done on a piece-wise differentiable functions and compare it with the results obtained in [Citation1,Citation2].
Example 7.4
Discontinuous source function
Here we selected a function randomly from the many functions tested in [Citation2]. The selected function has the following definition:
The function
is piecewise differentiable except at the point t = 0.5, where it has a sharp edge. The function is then perturbed by a uniform(
, δ) random variable to get the noisy data
, shown in Figure a, where we even increased the error norm in our testing from
in [Citation2] to
0.01 in our case. Figure shows the recoveries using the method described here and comparing it with the result obtained in [Citation2], one can see that our recovery outperforms, especially at the boundary points, the recovery in [Citation2]. We also compare it with a similar result obtained in [Citation1]Footnote10 using a total variation regularization method, shown in Figure (b).
Figure 3. Recoveries using out method: (a) numerical derivative and (b) smooth approximation
.
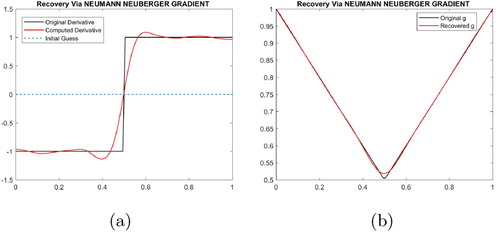
Figure 4. (a) Noisy data for Example 7.4 and (b) total variation regularization from [Citation1].
![Figure 4. (a) Noisy data for Example 7.4 and (b) total variation regularization from [Citation1].](/cms/asset/7c1cc03b-a261-421f-a9cf-9de70b630ec5/gipe_a_1763983_f0004_oc.jpg)
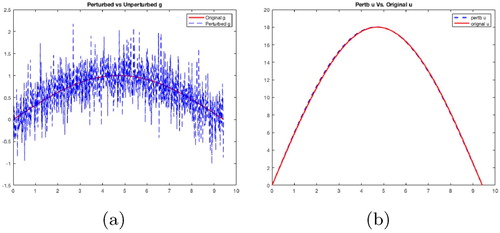
Figure 5. Integration smooths out the noise present in the data: (a) noisy vs exact g and (b) noisy
vs exact u.
8. Stopping criterion II
As explained in Section 5.3, in the presence noise, one has to terminate the descent process at an appropriate iteration to achieve regularization. The discrepancy principle [Citation24–26] provides a stopping condition provided the error norm (δ) is known. However, in many of the practical situations it is very hard to determine an estimate of the error norm. In such cases, heuristic approaches are taken to determine stopping criteria, such as the L-curve method [Citation27,Citation28]. In this section, we present a new heuristic approach to terminate the iterations when the error norm (δ) is unknown. First we notice that the minimizing functional G used here, as defined in (Equation12(12)
(12) ), does not contain the noisy
directly, rather an integrated (smoothed) version of it (
), as compared to a minimizing functional (such as
, defined in (Equation3
(3)
(3) )) used in any standard regularization method. Hence, in addition to avoiding the noisy data from affecting the recovery, the integration process also helps in constructing a stopping strategy, which is explained below. Figure shows the difference in g and
vs. u and
, from Example 7.2. We can see, from Figure (b), that the integration smooths out the noise present in
to get
, whereas the noise level in
is
. Consequently, the sequence
, constructed during the descent process, converges (weakly) in
to
, rather than strongly to
, that is, for any
the sequence
converges to zero. In other words, the integration mitigates the effects of the high oscillations originating from the random variable and also of any outliers (as its support is close to zero measure). Also, since the forward operator T (as defined in (Equation42
(42)
(42) )) is smooth, the sequence
first approximate the exact g (as it is also smooth,
), with the corresponding sequence
approximating
, and then the sequence
attempts to fit the noisy
, which leads to a phenomenon known as overfitting. However, when
tries to overfit the data (i.e. fit
) the sequence values
increases, since the ovefitting occurs in a smooth fashion (as T is a smooth operator) and, as a result, increases the integral values. This effect can be seen in Figure (a),
descent for Example 7.1 (when
), and in Figure (b),
descent for Example 7.2. One can capture the recoveries at these fluctuatingFootnote11 points (of either
,
or
) and choose the recovery corresponding to the earliest iteration for which
fits through
. Choosing the early fluctuating iteration is especially important when dealing with data with large error level, such as in Example 7.1 (
) and Example 7.2. For example, from Figure (b) if one captures the recovery at iteration 4 then the relative error in the recovery is only 8% (see Figure a). However, even if an appropriate early iteration is not selected, still the recovery errors saturate after certain iterations, rather than blowing up. This is significant when dealing with data having small to moderate error level, such as in Example 7.1 (
), where one can notice (in Figure b) that the relative errors of the recoveries attain saturation after recovering the optimal solution, since
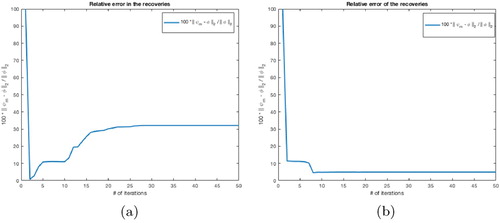
for small δ. Tables and show the relative errors of the recoveries obtained using this heuristic stopping criterion.
Figure 6. Fluctuations during the descent process. (a) , Example 7.1 (
) and (b)
, Example 7.2.
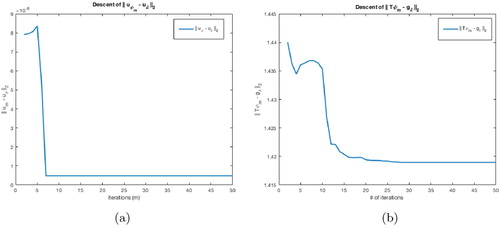
Figure 7. Relative errors in the recoveries during the descent process: (a) Example 7.2 and (b) Example 7.1 ().
Remark 8.1
Note that this phenomena does not occur in Landweber iterations, since one minimizes the functional containing the noisy data directly, i.e.
. Figure (a) shows the descent of
, when Landweber iterations are implemented for Example 7.1 (
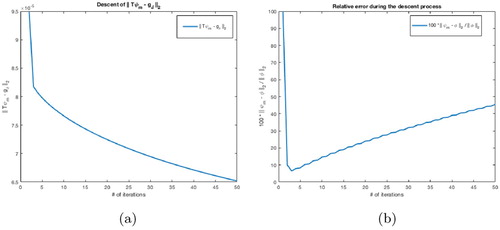
) and Figure (b) shows the corresponding descent of the relative errors of the recovered solutions, where can see no fluctuations in Figure (a) but the semi-convergence in Figure (b). Therefore, without any prior knowledge of δ it is hard to stop the descent process and avoids the ill-posedness. Whereas, notice the saturation of the relative errors of the recovery (Figure (b)) when we implement our method to the same problem.
Figure 8. Landweber iterations on Example 7.1 (): (a)
-descent and (b) relative errors descent.
9. Conclusion and future research
This algorithm for numerical differentiation is very effective, even in the presence of extreme noise, as can be seen from the examples presented in Section 7. Furthermore, it serves as a universal method to deal with all scenarios such as when the data set is dense or sparse and when the function g is smooth or not smooth. The key feature in this technique is that we are able to upgrade the working space of the problem from to
, which is a much smoother space. Additionally, this method also enjoys many advantages of not encountering the involvement of an external regularization parameter, for example one does not have to determine the optimum parameter choice to balance between the fitting and smoothing of the inverse recovery. Even the heuristic approach for the stopping criteria also provides us with a much better recovery, and hence it's very applicable in the absence of the error norm.
In a follow-up paper, we improve this method to calculate derivatives of functions in higher dimensions and for higher order derivatives. Moreover, we can extend this method to encompass any linear inverse problems and thereby generalize the theory , which will be presented in the coming paper where we will apply this method to recover solution of Fredholm Integral Equations, like deconvolution or general Volterra equation.
Acknowledgments
I am very grateful to Prof. Ian Knowles for his support, encouragement and stimulating discussions throughout the preparation of this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 The technicality as to how far g can be weakened so that the solution of equation (Equation1(1)
(1) ) is uniquely and stably recovered (finding the ϕ inversely) will be discussed later.
2 Again the domain space for the functionals ,
and G are discussed in details later.
3 It can be further proved that it's also the first Frchet derivative of G at ψ.
4 Hence is also a linear and bounded operator in
.
5 Again, it can be proved that it's the second Frchet derivative of G at ψ.
6 Just for simplicity, we assume .
7 In our experiments, we considered and the termination condition as
.
8 As explained in the -gradient version of the descent algorithm for G, in Section 4.
9 To be consistent with , we kept
and
, but can be avoided.
10 Where the test function is on
and the data set is 100 uniformly distributed points with
.
11 the fluctuating occurs since the values of tends to decrease first (when approximating the exact g) and then increases (when making a transition from g to
) and eventually decreases (when trying to fit the noisy
, i.e. overfitting)
References
- Knowles I, Renka RJ. 2014. Methods for numerical differentiation of noisy data. Proceedings of the variational and topological methods: theory, applications, numerical simulations, and open problems, Vol. 21. San Marcos (TX): Texas State University; 2014. p. 235–246.
- Lu S, Pereverzev SV. Numerical differentiation from a viewpoint of regularization theory. Math Comp. 2006;75(256):1853–1870.
- Wei T, Hon YC. Numerical derivatives from one-dimensional scattered noisy data. J Phys: Conf Ser. 2005;12:171–179.
- Ramm AG, Smirnova AB. On stable numerical differentiation. Math Comp. 2001;70(235):1131–1153.
- Háo DN, Chuong LH, Lesnic D. Heuristic regularization methods for numerical differentiation. Comput Math Appl. 2012;63(4):816–826.
- Jauberteau F, Jauberteau JL. Numerical differentiation with noisy signal. Appl Math Comput. 2009;215(6):2283–2297.
- Stickel JJ. Data smoothing and numerical differentiation by a regularization method. Comput Chem Eng. 2010;34:467–475.
- Zhao Z, Meng Z, He G. A new approach to numerical differentiation. J Comput Appl Math. 2009;232(2):227–239.
- Wang Z, Wang H, Qiu S. A new method for numerical differentiation based on direct and inverse problems of partial differential equations. Appl Math Lett. 2015;43:61–67.
- Murio DA. The mollification method and the numerical solution of ill-posed problems. New York: A Wiley-Interscience Publication, John Wiley & Sons, Inc.; 1993.
- Hào DN. A mollification method for ill-posed problems. Numer Math. 1994;68(4):469–506.
- Hào ÐN, Reinhardt H-J, Seiffarth F. Stable numerical fractional differentiation by mollification. Numer Funct Anal Optim. 1994;15(5–6):635–659.
- Hào DN, Reinhardt H-J, Schneider A. Stable approximation of fractional derivatives of rough functions. BIT Numer Math. 1995;35(4):488–503.
- Engl HW, Hanke M, Neubauer A. Regularization of inverse problems. Vol. 375. Dordrecht: Kluwer Academic Publishers Group; 1996; Mathematics and its applications.
- Kaltenbacher B. Some Newton type methods for the regularization of nonlinear ill-posed problems. Inverse Probl. 1997;13:729–753.
- Kaltenbacher B., Neubauer A., Scherzer O. Iterative regularization methods for nonlinear ill-posed problems. Vol. 6. Berlin: Walter de Gruyter GmbH & Co. KG; 2008; Radon series on computational and applied mathematics.
- Bakushinskii AB. The problems of the convergence of the iteratively regularized Gauss–Newton method. Comput Math Math Phys. 1992;32:1353–1359.
- Hanke M. A regularizing Levenberg-Marquardt scheme, with applications to inverse groundwater filtration problems. Inverse Probl. 1997;13:79–95.
- Knowles I, Wallace R. A variational method for numerical differentiation. Numer Math. 1995;70(1):91–110. 65D25 (49M10) [96h:65031].
- Neuberger JW. Sobolev gradients in differential equations. New York: Springer-Verlag; 1997. (Lecture notes in mathematics; vol. 1670).
- Knowles I. Variational methods for ill-posed problems. In: Neuberger JM, editor. Variational methods: open problems, recent progress, and numerical algorithms (Flagstaff, Arizona, 2002). Providence (RI): American Mathematical Society; 2004. p. 187–199. (Contemporary mathematics; vol. 357).
- Morozov VA. Methods for solving incorrectly posed problems. New York: Springer-Verlag; 1984.
- Fox L, Mayers DF. Numerical solution of ordinary differential equations. London: Chapman & Hall; 1987.
- Gfrerer H. An a posteriori parameter choice for ordinary and iterated Tikhonov regularization of ill-posed problems leading to optimal convergence rates. Math Comput. 1987;49:507–22.
- Morozov VA. On the solution of functional equations by the method of regularization. Sov Math Dokl. 1966;7:414–417.
- Vainikko GM. The principle of the residual for a class of regularization methods. USSR Comput Math Math Phys. 1982;22:1–19.
- Hansen PC. Analysis of discrete ill-posed problems by means of the L-curve. SIAM Rev. 1992;34(4):561–580.
- Lawson CL, Hanson RJ. Solving least squares problems. Englewood Cliffs (NJ): Prentice-Hall; 1974.