
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This work is to investigate the image reconstruction of electrical impedance tomography from the electrical measurements made on an object's surface. An -norm (0<p<1) sparsity-promoting regularization is considered to deal with the fully non-linear electrical impedance tomography problem, and a novel type of smoothing gradient-type iteration scheme is introduced. To avoid the difficulty in calculating its gradient in the optimization process, a smoothing Huber potential function is utilized to approximate the
-norm penalty. We then propose the smoothing algorithm in the general frame and establish that any accumulation point of the generated iteration sequence is a first-order stationary point of the original problem. Furthermore, one iteration scheme based on the homotopy perturbation technology is derived to find the minimizers of the Huberized approximated objective function. Numerical experiments show that non-convex
-norm sparsity-promoting regularization improves the spatial resolution and is more robust with respect to noise, in comparison with
-norm regularization.
1. Introduction
Electrical impedance tomography (EIT) principle is that by applying a constant current across the interested object, the voltage distribution resulting on the surface electrodes will reflect the internal conductivity distribution. In recent years, based on the fast development in imaging technology, EIT with the advantages of low-cost instrumentation, easy portability and non-ionizing radiation is an emerging technology and has attracted considerable interest in medical imaging, geophysical exploration, environmental cleaning and non-destructive testing of materials, etc.
Due to the limited measurement data, image reconstruction in EIT is a highly non-linear ill-posed problem. The ill-posedness makes the conductivity reconstruction extremely sensitive to small perturbation from modelling errors and measurement noise, which causes reconstructed images to still suffer from inherent low spatial resolution and instability. Therefore, various imaging algorithms based on the penalty term regularization have been developed to achieve desired and stable reconstructions, and have delivered very encouraging reconstructions, for example, standard Tikhonov regularization [Citation1], total variation (TV) regularization [Citation2,Citation3], -norm regularization [Citation4–8], and hybrid regularization of several different methods [Citation9–11], etc. The most widespread method is Tikhonov regularization, in which the objective function consists of a quadratic fitting fidelity term and an
-norm penalty term, with the aim of matching measurement data and suppressing noises, respectively. However, it often tends to smooth out edges for the reconstructed images in EIT. Another much attention-grabbing method is the
-norm regularization, regarded as the convex relaxation of NP-hard
-norm regularization. It is often used to enforce sparsity and can preserve the details and reduce the noise effect in the reconstruction results effectively.
-norm regularization with split-Bregman method is adopted to conduct the EIT imaging problem in [Citation5,Citation11]. It shows that
-norm regularization generates more precise reconstructed images compared with classical Tikhonov regularization and TV regularization.
There is already quite a lot of evidence that non-smooth and non-convex regularization terms can provide better reconstruction results than smooth convex or non-smooth convex regularization functions. Recently, many researchers have shown that using the non-smooth and non-convex lower-order -norm (0<p<1) to relax the
-norm is a better choice than using
-norm, and has attracted much attention and has been evidenced in extensive computational studies, see [Citation12–16] and reference therein. However, it is difficult in general to design efficient algorithms for solving
regularized problem. It was presented in [Citation17] that finding the global minimizer is strongly NP-hard; while calculating a local minimum could be done in polynomial time. Some effective and efficient algorithms have been presented to find a local minimizer. In [Citation18,Citation19], based on different ϵ-approximations of
-norm, iteratively reweighted algorithms are developed to tackle this approximation problem. In [Citation20,Citation21], the smoothing approaches by adopting smoothing functions are also used to solve non-convex
regularized minimization problem. The critical technique for this type of algorithms is to transform the non-convex and non-smooth sparsity terms into smooth approximate functions by adding relaxation parameters.
The -norm (0<p<1) regularized minimization can produce desirable sparse approximations. This paper is inspired to use
-norm (0<p<1) as the penalty term for the EIT image reconstruction, aiming at enforcing better sparsity. In order to make the proposed optimal problem numerically tractable, we first consider the smoothing approximation of the original minimization problem using a smoothing Huber function of the absolute value function. We then present a general frame of the smoothing algorithm and show its convergence. Furthermore, we derive a method based on the homotopy perturbation technology for minimizing this Huberized approximation objective function. The numerical results indicate that
-norm (
) regularization promotes the localization of targets and is more robust with respect to noise compared with
-norm regularization. In a word, this paper applies non-convex
-norm (
) sparsity-promoting regularization combined with a novel gradient-type iteration scheme to investigate the effects of sparsity regularization on the non-linear EIT image reconstruction.
The rest of this paper is built up as follows. Section 2 provides a brief review on the basic mathematical formulation for the EIT problem. In Section 3, we first introduce the smoothing problem to approximate the original regularized problem by using Huber potential function, and then propose the smoothing algorithm in the general frame and show that any accumulation point of the generated iteration sequence is a stationary point of the original problem. Moreover, one modified Landweber iteration method is formulated for handling the optimization of the smoothing approximation problem. Section 4 reports some numerical simulations to test the performance of our proposed method on experimental data collected on a 2D phantom. Finally, a short conclusion is drawn in Section 5.
2. Forward and inverse models
We shall in this section make a brief review on the basic mathematical formulation for the EIT problem. The image reconstruction in EIT is actually composed of the forward and inverse problems. We first introduce the following notation. Let us consider an open-bounded and simply connected domain with a smooth boundary Γ, and
be L electrodes which are assumed to be perfect conductors. We assume furthermore that the electrodes
are connected and separated from each other, i.e.
for
. The union of the electrode patches is denoted by
. Let
denote the conductivity distribution. The class of admissible conductivities is given by
for some fixed constant
, and the condition
reflects the fact that inclusions are located inside the object.
2.1. Forward problem and finite element approximation
We consider a typical acquisition experiment for EIT. Assume that L electrodes have been fixed around the surface of the object. Current is injected through some subset of these electrodes to excite the object under investigation, and the induced voltages are measured at all L electrodes. This procedure is repeated many times with different electrodes until a sufficient amount of data has been obtained. Mathematical models for the measurement are described in [Citation22]. The complete electrode model (CEM), as nowadays the standard model for medical applications, includes the effect of the contract impedance, and is accordingly the most accurate physically realizable model for reproducing EIT experimental data, which is defined by Laplace's equation
(1)
(1) and the following boundary conditions
(2)
(2) In these equations, u is the electrical potential inside the object domain Ω,
are the known contact impedance, and n is the unit outward normal to Γ and
, and
and
are the constant potential on electrode ℓth and the current sent to the ℓth electrode, respectively.
Additionally, in order to ensure the solvability and the uniqueness, CEM consists of the elliptic boundary value problem (Equation1(1)
(1) )–(Equation2
(2)
(2) ) together with the following two other conditions for conservation of charge and an arbitrary choice of a ground:
(3)
(3) We denote the electrical voltage vector
and the current vector
.
The EIT forward problem is to calculate potentials u in Ω and U on the electrodes from known conductivity σ, injected currents I, and contact impedances . In practice, the system (Equation1
(1)
(1) )–(Equation3
(3)
(3) ) can not be solved analytically for any arbitrary distribution, and therefore numerical approximations must be used to find an approximate solution. The finite element method (FEM) was employed to discretization in simulation, and we refer to [Citation23] for more details on the forward solution and FEM approximation of the CEM.
denotes the
-based Sobolev space with smoothness index 1. The weak formulation of the forward problem can be stated as follows: given a current vector
, a conductivity distribution σ and positive contact impedance
, to find the solution
such that
(4)
(4) where the strictly elliptic bilinear form b is defined by
Indeed, the existence and uniqueness of a solution
has been shown using the Lax–Milgram Lemma in [Citation22].
Then we consider the piecewise linear function as the finite element basis function, and the solution domain Ω will be divided into small triangles elements. We approximate the potential distribution u within Ω as
(5)
(5) and potentials U on the electrodes as
(6)
(6) where N is the number of nodes in finite element mesh,
, etc, and
and
are the coefficients to be determined. For notational reasons we identify
and
with their coordinates and write
,
. By substituting these two approximations into variational Equation (Equation4
(4)
(4) ) and by choosing
and
, we obtain a discrete linear system
(7)
(7) where the data vector
,
with
and
, and the determined coefficient vector
, and the stiffness matrix
with
After solving the determined coefficients
, we can use (Equation6
(6)
(6) ) to find the approximate potentials
on the electrodes.
With the aid of the above FEM discretization, a mathematical description between the applied electrode current data I and the computed electrode voltage data is provided by the following non-linear forward operator equation
(8)
(8) where F is the solution operator (also called the forward operator), which depends linearly on I but non-linearly on σ. For a fixed current vector I, we can view
as a function of σ only, i.e.
.
Notice that it is important to distinguish between the PDE operator and the forward operator
. Though both are associated with the model problem, their meaning is not the same. Indeed,
describes the forward problem, while
actually represents its solution.
2.2. Inverse problem
Assuming measurement data corrupted with additive Gaussian noise e, the mathematical observation model response can be formulated as the fully non-linear operator equation:
In practice, the conductivity distribution σ is not known. What we know is merely all pairs of injected current data and resulting voltage data on the electrodes. Then the EIT inverse problem is to reconstruct the unknown conductivity σ from unavoidably noisy boundary measurement data
, also called image reconstruction. EIT image reconstruction can be formulated as minimizing the discrepancy functional between the measurement data and the model predictions in the form:
(9)
(9) known as data fidelity.
However, in practice we are limited to a finite number of electrodes and a finite number of current patterns. Due to the limited but noisy measurement data, EIT image reconstruction (Equation9(9)
(9) ) is ill-posed in the sense that small errors in the data can lead to very large deviations in the reconstructions. Hence, some appropriate sort of regularization strategy is beneficial, and it is incorporated into the imaging process, either implicitly or explicitly, in order to obtain physically meaningful images.
3. Inversion approach with  regularization
regularization
To combat the ill-posedness, the solution is often constrained by a priori assumption about the conductivity field, e.g. smoothness or sparsity. Application of non-smooth reconstruction techniques is important for EIT imaging process, as it involves discontinuous or small profiles. It has been shown that employing a sparse solver may result in images that show fewer artefacts. This work considers the non-smooth and non-convex sparsity regularization, which minimizes the following functional
(10)
(10) where
with
is the
quasi-norm, and then takes the minimizer as an approximation to the true conductivity
. The scalar
is known as a regularization parameter, and controls the tradeoff between the data fidelity term and regularity term.
The choice p = 2 raising the classical smoothness penalty yields the prominent Tikhonov regularization (i.e. regularization), which provides stability but force solutions to be smooth in some sense thus eliminating the possibility of non-smooth solutions, while the choice
also enforces the sparsity and p = 1 results in
sparsity regularization.
Nevertheless, since the quasi-norm is non-convex and non-smooth, the
regularized minimization problem (Equation10
(10)
(10) ) is hard to solve; in fact, it is strongly NP-hard [Citation24]. Finding a global minimizer of problem (Equation10
(10)
(10) ) is much more computational challenges. Non-smoothness for problem (Equation10
(10)
(10) ) refers to nondifferentiability. Hence it has a difficulty in calculating the gradient in the optimization by use of the gradient-based method. In order to make it numerically tractable, we here consider a smoothing approximation version of this problem. We first establish the smooth approximation of
based on a smooth approximate function of the absolute value function.
3.1. Smoothing approximation
Throughout this paper, denotes the set of all non-negative (or positive) numbers, and
denotes the
-norm. For any
,
denotes an n-dimensional vector whose ith component is
, that is,
.
Let for any
, and
and then we have
which implies
and hence,
Function
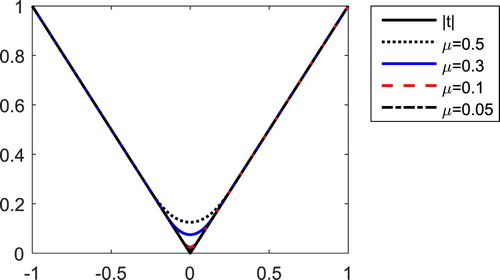
is also known as Huber potential function [Citation25,Citation26], which is very often used in robust statistics. Figure shows the graphics of the functions
and
. It is obviously that the approximation effect is better if smaller the parameter μ. The following simple properties show that the function
is a nice smoothing approximation of the absolute value function
.
Figure 1. The graphics of and
.
Proposition 3.1
For any we have that
However, is not twice differentiable at
. For
, the second derivative of
satisfies
, hence
is strictly convex in
. For any
, let
the cost function
can be rewritten as
(12)
(12) Moreover, let
, and then we have
(13)
(13)
Proposition 3.2
Given . For any
we have
Proof.
Using the fact that for
, we have that for any
,
which implies
i.e.
(14)
(14) Thus, by the definition of
and
, it follows that
which completes the proof.
From Proposition 3.2, it is easy to see that
It is known that the forward operator
generated by CEM is uniformly bounded and continuous and is also Fr
chlet differentiable with respect to conductivity σ. We briefly recall the following property for the forward operator
(see [Citation27,Citation28]).
Lemma 3.3
Let be a fixed current vector. For any
the forward operator
is uniformly bounded and continuous and is also Fr
chlet differentiable with respect to σ. Moreover, the Fr
chlet derivative
is bounded and Lipschitz continuous, and the following estimations are satisfied:
Therefore, for any , since the function
is continuously differentiable, it follows from (Equation13
(13)
(13) ) that the function
is continuously differentiable. These demonstrate that the function
is a nice smoothing approximation of the function
.
As a consequence, it is very natural that the original variational problem (Equation10(10)
(10) ) can be approximated by the following smoothing unconstrained regularized problem
(15)
(15) Thus we can design algorithm to solve the minimization problem (Equation15
(15)
(15) ) iteratively, and gradually make
so that a solution of original problem (Equation10
(10)
(10) ) can be found.
3.2. Convergence of algorithm
We first review the first-order stationary point of (Equation10(10)
(10) ) (see, for example, [Citation15,Citation19]).
Definition 3.4
For any , let
denote an
diagonal matrix whose diagonal is formed by the vector σ.
is a first-order stationary point of (Equation10
(10)
(10) ) if
(16)
(16) where
.
Denote the gradient of the regularized penalty term in (Equation15
(15)
(15) ) as
where for any
,
with
being calculated by (Equation11
(11)
(11) ). Then the first-order necessary condition of problem (Equation15
(15)
(15) ) is given by
(17)
(17) This means that
is a stationary point of problem (Equation15
(15)
(15) ) if it satisfies (Equation17
(17)
(17) ).
Based on the cost function and its gradient
, we in a general framework can present the following smoothing method:

Theorem 3.5
Suppose that the sequence is generated by the above smoothing method. Then
Every accumulation point of
Let
Proof.
We first show that the level set for an arbitrary given initial point
is bounded. If
is unbounded, then there exists a sequence
such that
. We have from (Equation14
(14)
(14) ) that
(18)
(18) and then
implies
, which contradicts with the result that
for all k. Therefore, we can obtain that the sequence
is bounded.
Thus, there exists at least a convergent subsequence of . Let
be an accumulation point of
, and denote
without loss of generality. Let
and
.
(i) From the first-order necessary condition (Equation17(17)
(17) ) for problem (Equation15
(15)
(15) ), we have
Furthermore,
(19)
(19) By the definition of
and the above argument, we have
and then we obtain
Since
as
, it from Proposition 3.1 (i) and (iii) follows that
Therefore, by (Equation19
(19)
(19) ) we have
i.e.
satisfies (Equation16
(16)
(16) ), which implies that
is a stationary point of problem (Equation10
(10)
(10) ).
(ii) Let be a global minimizer of (Equation10
(10)
(10) ). Then from the following three inequalities
take
, we obtain that
. Thus we deduce that
is a global minimizer of (Equation10
(10)
(10) ).
In [Citation15], Chen et al. established lower bounds for the absolute value of non-zero entries in any local optimal solution of -
minimization model. This establishes a theoretical justification by eliminating those small enough entries in an approximate solution and gives an explanation why the
-
minimization model generates more sparse solutions when the norm parameter 0<p<1. Below is the lower bound theory for non-zero entries of the stationary point of the smoothing problem (Equation15
(15)
(15) ) under the assumption that the smoothing parameter
is sufficiently small. The lower bound clearly shows the relationship between the sparsity of the solution and the choice of the regularization parameter.
Theorem 3.6
For any sufficiently small let
be a stationary point of problem (Equation15
(15)
(15) ) contained in the level set
for an arbitrary given initial
. Denote
then we have
Proof.
Since is a stationary point of problem (Equation15
(15)
(15) ), the corresponding first-order necessary condition gives
which implies
Using
and the boundedness of the adjoint operator
, we have
(20)
(20) with a positive constant B, here we can choose
.
Suppose but
, then we have that
(21)
(21) From (Equation20
(20)
(20) ) and (Equation21
(21)
(21) ), we can get
This is a contradiction to
. Thus, the desired result holds.
3.3. Homotopy perturbation iteration method
The basic idea of image reconstruction for EIT is to repeatedly solve the forward problem while updating σ according to some criteria. The regularized minimization problem (Equation10(10)
(10) ) is complicated by high-degree non-linearity of the forward operator F and non-smoothness of the
-norm penalty. Now we focus on the smooth minimization problem (Equation15
(15)
(15) ). Problem (Equation15
(15)
(15) ) is a continuously differentiable, unconstrained optimization problem.
Homotopy perturbation technology as an effective method has been applied to solve various of non-linear equations in different branches of science and engineering [Citation29–31]. The essential idea is to introduce a homotopy parameter and combine the traditional perturbation method with the homotopy technique. Its most notable feature is that usually only a few perturbation terms can be sufficient to acquire a reasonably accurate solution. It has also been extended to homotopy perturbation iteration (HPI) for solving non-linear ill-posed inverse problems [Citation32–34]. The numerical results show that HPI method can save calculation time and promote calculation efficiency greatly with almost the same accuracy, in contrast to the classical Landweber iteration. In this section, we develop one novel type of iteration scheme combining with the homotopy perturbation technique for problem (Equation15(15)
(15) ).
We first consider the standard local linearized iterative approach for the non-linear inversion model, i.e. using a linearized step at each iteration. Using an iterative framework, and let be the first two terms in a Taylors series expansion at
, i.e.
where
is the Jacobian of the forward operator with respect to σ evaluated at
, our proposed smoothing approximation problem (Equation15
(15)
(15) ) becomes that
(22)
(22) Moreover, using the notation
, the minimizer of (Equation22
(22)
(22) ) satisfies the Euler equation:
(23)
(23) here
represents the transpose of a matrix. Setting a fixed point homotopy function
which satisfies
(24)
(24) where
is an embedding homotopy parameter. The corresponding solution σ of (Equation24
(24)
(24) ) depends on the variable λ, thus it can be regarded as a function of parameter λ, i.e.
. Obviously, from (Equation24
(24)
(24) ), we will have
(25)
(25) As the parameter λ changed continuously from 0 to 1, the trivial problem
is continuously deformed to the original problem
, i.e. the function
changed continuously from
to the approximate solution σ.
We then further expand as a Taylor series at
and ignore the higher-order term, i.e.
(26)
(26) where
denotes the Hessian of
. Since
as
, the Hessian
can be approximated as
with
Then we obtain
(27)
(27) According to the homotopy perturbation technique, we assume that the solution
of (Equation27
(27)
(27) ) can be expressed as the following power series of λ (i.e. the series solution),
(28)
(28) Substituting (Equation28
(28)
(28) ) into (Equation27
(27)
(27) ) and taking
, we can obtain
(29)
(29) Equating the coefficients of like powers of λ, we can get
(30)
(30) As
for the power series solution (Equation28
(28)
(28) ), we get the approximate solution σ of (Equation23
(23)
(23) ), i.e.
(31)
(31) Following the formula (Equation31
(31)
(31) ), one iteration scheme can be obtained by the first-order approximation truncation (i.e. N = 1):
(32)
(32) which is the Landweber iteration (LI) method. When using the second-order approximation truncation (i.e. N = 2), it can yield another novel iteration scheme:
(33)
(33) which is called a homotopy perturbation iteration (HPI) method. Here
is an appropriately chosen step size. In fact, a constant step size leads usually to a slow convergence of gradient methods. A proper choice of parameter
in each iteration step is crucial for a satisfying convergence speed of the iteration process. Therefore, we here suggest the following choice of the step size [Citation35]:
for some positive constant
and
.
In order to use the HPI method to produce a useful approximate solution the iteration must be terminated properly. We will employ the discrepancy principle as a stopping rule, which determines the stopping index by
for some sufficiently large
, i.e.
is the calculated approximate solution.
3.4. Algorithm realization
It needs to be emphasized that non-convex regularization has demonstrated its great potential in recovering sparse parameters (i.e. the number of non-zero elements of parameters is very limited). Next we give some discussion on two types for the sparsity representation as follows:
Case I: the spatial sparsity. The unknown physical conductivity often consists of the background conductivity
plus a number of interesting features. Let
be known and
be the inhomogeneity conductivity (i.e. inclusions/anomalies). The conductivity fields with simple and small anomalies away from the background will have the spatial sparsity (i.e. most zero elements for the inhomogeneity conductivity
). Making use of this a sparsity priori information, instead of attempting to find the approximation σ to
, we seek an approximation
to
. Therefore,
regularized minimization problem becomes
(34)
(34) Then we apply the derived HPI scheme to recovery the inhomogeneity
, respectively, and can obtain the following form:
(35)
(35) and set
and repeat the iteration until the stopping rule is achieved.
Case II: the transform domain sparsity. When with a smooth conductivity parameter, we need to resort to the sparsity representation in the transform domain. We can combine the regularized problem with a wavelet method because a wavelet transformation can convert a smooth parameter into a sparse parameter in the transform domain. Then we arrive at the sparsity-promoting
regularized minimization problem:
(36)
(36) where
stands for the sparse representation of σ under a transformation matrix W. Using the derived HPI scheme, we can obtain the following form:
(37)
(37)
Finally, the complete minimization procedure is summarized as the following Algorithm 4.
4. Numerical results
In this section, we consider some 2D numerical simulations to demonstrate the performance of our proposed smoothing optimization algorithm. Numerical simulations are conducted to investigate the effect of the -norm regularization with p = 2, 1, 0.5, 0.25 on the EIT image reconstruction. The numerical results are compared with standard Tikhonov regularization and
-norm regularization, which is identical to the
-norm sparsity regularization with p = 2 and p = 1, respectively. All calculations are done by using MATLAB R2015a on a Lenovo-BTCG00LL with an Intel(R) Core(TM) i7-8550U [email protected] GHz and 8.00 GB memory.

The forward model with CEM was based on the EIDORS toolkit for a linear finite element solver written in Matlab developed by Vauhkonen [Citation36]. A 16 equally spaced electrode system is modelled surrounding two-dimensional circle meshes for simulations. We use constant injection current between adjacent electrodes and adjacent voltage measurement between all other electrodes. Two different finite elements meshes are used for the forward and inverse solvers to avoid inverse crimes. The forward solutions are generated with 1049 nodes and 1968 elements, and the inverse computations are implemented with coarse meshes of 279 nodes and 492 elements to reduce the computational burden. Since we do not perform experimentations, we should obtain the boundary voltage data relying on computer simulation. The noisy measurement data are generated in the form of where
denotes the exact synthetic measurements, δ is a relative noise level, and n is the random variable following uniform distribution in [0,1].
Selection of parameters is essential to the quality of reconstructed images, because an inappropriate parameter can lead to a meaningless result. The choice of the regularization parameter α depends on the inversion model and the noise level. Generally speaking, the order of magnitude of α should be in accordance with that of the elements of . In all numerical results, the regularization parameter α is selected by experience for relative optimal value. We choose
,
, set
for the discrepancy criterion, and take the initial guess
as the background conductivity. We choose the step length
with
and
. Reconstructed image quality is quantitatively evaluated by relative error (RE) with respect to the true phantom, where RE=
. A smaller image error indicates a better image quality.
In our simulations, a circular domain which contains different inclusions is investigated. Figure shows four numerical phantom models used for testing our proposed method. The phantoms from left to right have various inclusions. The resistivity values are 4 for the background, 1 Ωm for the blue colour parts and 8 Ωm for the red colour parts. Unless stated, all reconstructed images next will be displayed by the unified colorbars from 1 to 8.
Figure 2. Three simulation phantoms. (a) Phantom A. (b) Phantom B. (c) Phantom C. (d) Phantom D.
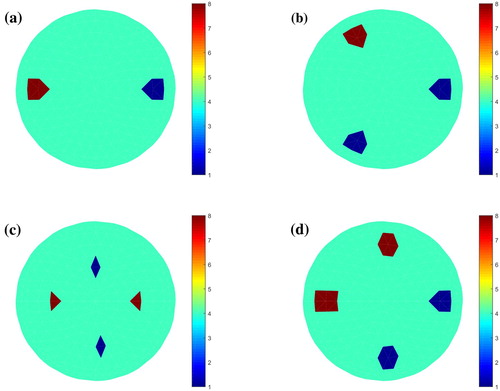
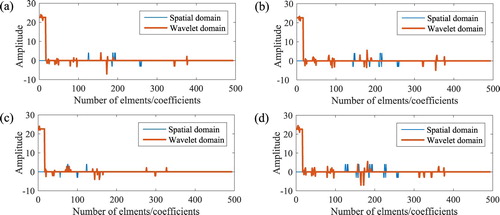
Figure 3. Comparison for sparsity graph of the elements of inhomogeneities and sparsity graph of the haar wavelet coefficients. (a) Phantom A. (b) Phantom B. (c) Phantom C. (d) Phantom D.
In this simulation, let the background conductivity be known, and we consider the spacial sparsity for the inhomogeneity conductivity
. The reconstructions for case I by LI method and HPI method with p = 0.5 are performed and discussed. We report the performance of reconstructions under noise levels
and
in terms of the number of iteration (Iters), CPU running time (minutes) and relative error (RE). For each noise level, Table shows the reconstructed results. Numerical results show that HPI method reduces the number of iterations and saves the amount of computational time especially for smaller noise level, and produces more accurate results in terms of image error than LI method. This also demonstrates that HPI method has a remarkable acceleration effect. Meanwhile, as can be expected, a little deterioration in the spatial resolution shows with the increase of noise level. In order to visualize the reconstruction accuracy of LI method and HPI method, we next plot the reconstructed images in the third column of Figure , which appears the acceptable results.
Figure 4. Reconstructions for various parameter p. (a) Using noisy data with noise level . (b) Using noisy data with noise level
. (All displayed by the unified colorbars from 1 to 8.)
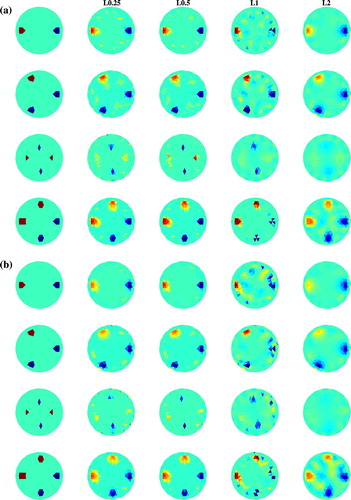
Table 1. Numerical results for case I by LI and HPI method with p = 0.5 under two different noise levels δ.
In Figure , we display the comparison for sparsity graph of the elements of inhomogeneities and sparsity graph of the haar wavelet coefficients. It can be seen that most elements/coefficients are around zero, that is, there exist many small elements/coefficients. Hence both the inhomogeneity of space domain and the Haar wavelet transformation can effectively provide one sparsity representation. The less bumps show that the sparsity degree is better. Figure obviously shows that there is better sparsity for the spatial domain. Indeed, the effective sparsity representation is key and the sparsity degree impacts the imaging results. Table lists the comparison of reconstructed image errors by HPI method at the noise level with Case I and Case II, respectively. As we are expected, HPI method with Case I obtains better results because of better sparsity, especially for Phantom A and Phantom D.
Table 2. Comparison of RE for Case I and Case II by HPI under .
Finally, we compare the reconstructed images by regularization for various parameter p. The studies in [Citation17] have demonstrated that
regularizer can be represented by the
regularizer because when
, the
regularizer always yields the best sparse solution and when
, the
regularizer has a sparse property similar to that of the
regularizer. Hence, in Figure , depicted with the same colour scale for all images, we show the reconstructions using
sparsity regularization with HPI method for p = 1, 0.5, 0.25 under two various noise levels, and the results are compared with Tikhonov regularization which is identical to the
regularization with p = 2. It is visible that severe artefacts strongly appear with the larger noise in the input data when p = 1. But the non-convex
-norm sparsity regularization removes the artefacts, and especially yields better reconstructions with sharper edges and less artefacts when p = 0.5. The noconvex
-norm sparsity regularization is effective to enhance the localization and reduce the artefacts. It is clear that a little deterioration in the spatial resolution shows with smaller inclusions for Phantom C since maybe more measurement information is required. Thus it can be seen from Figure that the
-norm sparsity regularization reduces the influences of noise and is effective to improve the quality of the reconstructed images.
5. Conclusion
This work investigates the effect of -norm (0<p<1) sparsity-promoting regularization on imaging quality of the fully non-linear EIT inverse problem. Due to the involved non-smoothness, the proposed gradient-based non-linear iteration scheme combines a smoothing function to approximate the
-norm penalty. Numerical simulations with synthetic data are carried out to evaluate the feasibility and effectiveness. Results show that non-convex
-norm sparsity regularization can improve the spatial resolution and the robustness to noise, and appears to yield reconstructions superior to the ones obtained by
-norm regularization. In order to obtain more effective sparse representation in the transformation domain, we next will focus on the study of adaptive sparse representation with a merit of representing flexibly when maintaining features of inclusions. Using HR rule to choose the regularization parameter will also be our next work.
Acknowledgements
The author thanks the four anonymous referees for useful comments and suggestions which improve the presentation of the paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Vauhkonen M, Vadsz D, Karjalainen PA, et al. Tikhonov regularization and prior information in electrical impedance tomography. IEEE Trans Med Imaging. 1998;17(2):285–293.
- Borsic A, Graham BM, Adler A, et al. Total variation regularization in electrical impedance tomography. Inv Probl. 2007;99:A12.
- Hinze M, Kaltenbacher B, Quyen TNT. Identifying conductivity in electrical impedance tomography with total variation regularization. Numerische Mathematik. 2018;138(3):723–765.
- Jin B, Khan T, Maass P. A reconstruction algorithm for electrical impedance tomography based on sparsity regularization. Int J Numer Methods Eng. 2012;89(3):337–353.
- Wang J, Ma J, Han B, et al. Split Bregman iterative algorithm for sparse reconstruction of electrical impedance tomography. Signal Process. 2012;92(12):2952–2961.
- Gehre M, Kluth T, Sebu C, et al. Sparse 3D reconstructions in electrical impedance tomography using real data. Inv Prob Sci Eng. 2014;22(1):31–44.
- Pham Muoi Q. Reconstructing conductivity coefficients based on sparsity regularization and measured data in electrical impedance tomography. Inv Prob Sci Eng. 2015;23(8):1366–1387.
- Garde H, Knudsen K. Sparsity prior for electrical impedance tomography with partial data. Inv Prob Sci Eng. 2016;24(3):524–541.
- Chung ET, Chan TF, Tai XC. Electrical impedance tomography using level set representation and total variational regularization. J Comput Phys. 2005;205(1):357–372.
- Liu J, Ling L, Li G. A novel combined regularization algorithm of total variation and Tikhonov regularization for open electrical impedance tomography. Phys Meas. 2013;34(7):823.
- Wang J, Han B, Wang W. Elastic-net regularization for nonlinear electrical impedance tomography with a splitting approach. Appl Anal. 2019;98(12):2201–2217.
- Chartrand R. Exact reconstruction of sparse signals via nonconvex minimization. IEEE Signal Process Lett. 2007;14(10):707–710.
- Nikolova M, Ng M, Zhang S, et al. Efficient reconstruction of piecewise constant images using nonsmooth nonconvex minimization. SIAM J Imaging Sci. 2008;1(1):2–25.
- Xu ZB, Zhang H, Wang Y, et al. L1/2 regularization. Sci China Series F (Inf Sci),. 2010;53(6):1159–1169.
- Chen X, Xu F, Ye Y. Lower bound theory of nonzero entries in solutions of l2−lp minimization. SIAM J Sci Comput. 2010;32(5):2832–2852.
- Lai MJ, Wang J. An unconstrained lq minimization with 0<q≤1 for sparse solution of underdetermined linear systems. SIAM J Optim. 2011;21(1):82–101.
- Ge D, Jiang X, Ye Y. A note on the complexity of ℓp minimization. Math Program. 2011;129(2):285–299.
- Chen X, Zhou W. Convergence of the reweighted ℓ1 minimization algorithm for ℓ2−ℓp minimization. Comput Optim Appl. 2014;59(1–2):47–61.
- Lu Z. Iterative reweighted minimization methods for lp regularized unconstrained nonlinear programming. Math Program. 2014;147(1–2):277–307.
- Chen X, Zhou W. Smoothing nonlinear conjugate gradient method for image restoration using nonsmooth nonconvex minimization. SIAM J Imaging Sci. 2010;3(4):765–790.
- Chen X. Smoothing methods for nonsmooth. nonconvex minimization. Math Program. 2012;134(1):71–99.
- Somersalo E, Cheney M, Isaacson D. Existence and uniqueness for electrode models for electric current computed tomography. SIAM J Appl Math. 1992;52(4):1023–1040.
- Woo EJ, Hua P, Webster JG, et al. Finite-element method in electrical impedance tomography. Med Biol Eng Comput. 1994;32(5):530–536.
- Chen X, Ge D, Wang Z, et al. Complexity of unconstrained ℓ2- ℓp minimization. Math Program. 2014;143(1–2):371–383.
- Huber PJ. Robust statistics. New York (NY): John Wiley and Sons; 1981.
- Black MJ, Rangarajan A. On the unification of line processes, outlier rejection, and robust statistics with applications in early vision. Int J Comp Vis. 1996;19(1):57–91.
- Lechleiter A, Rieder A. Newton regularizations for impedance tomography: convergence by local injectivity. Inv Prob. 2008;24(6):065009.
- Jin B, Maass P. An analysis of electrical impedance tomography with, applications to Tikhonov regularization. ESAIM Control Optim Calcul Var. 2012;18(4):1027–1048.
- He JH. Homotopy perturbation technique. Comp Methods Appl Mech Eng. 1999;178(3–4):257–262.
- He JH. Homotopy perturbation method for bifurcation of nonlinear problems. Int J Nonlin Sci Numer Simul. 2005;6(2):207–208.
- Jafari H, Momani S. Solving fractional diffusion and wave equations by modified homotopy perturbation method. Phys Lett A. 2007;370(5–6):388–396.
- Cao L, Han B, Wang W. Homotopy perturbation method for nonlinear ill-posed operator equations. Int J Nonlin Sci Numer Simul. 2009;10(10):1319–1322.
- Wang J, Wang W, Han B. An iteration regularization method with general convex penalty for nonlinear inverse problems in Banach spaces. J Comput Appl Math. 2019;361:472–486.
- Long H, Han B, Tong S. A new Kaczmarz type method and its acceleration for nonlinear ill-posed problems. Inv Probl. 2019;35:055004.
- Jin Q, Wang W. Landweber iteration of Kaczmarz type with general non-smooth convex penalty functionals. Inv Probl. 2013;29(8):085011.
- Vauhkonen M, Lionheart WRB, Heikkinen LM, et al. A matlab package for the EIDORS project to reconstruct two-dimensional EIT images. Physiol Meas. 2001;22(1):107–111.