
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the present work, we investigate the inverse problem of identifying simultaneously the denoised image and the weighting parameter that controls the balance between two diffusion operators for an evolutionary partial differential equation (PDE). The problem is formulated as a non-smooth PDE-constrained optimization model. This PDE is constructed by second- and fourth-order diffusive tensors that combines the benefits from the diffusion model of Perona–Malik in the homogeneous regions, the Weickert model near sharp edges and the fourth-order term in reducing staircasing. The existence and uniqueness of solutions for the proposed PDE-constrained optimization system are provided in a suitable Sobolev space. Also, an optimization problem for the determination of the weighting parameter is introduced based on the Primal–Dual algorithm. Finally, simulation results show that the obtained parameter usually coincides with the better choice related to the best restoration quality of the image.
1. Introduction
Inverse problems are extensively studied in many areas and applications [Citation1]. Among them, the image processing and especially denoising task. The inverse problem discussed in this paper can be viewed as a variational denoising of images with total variation regularization [Citation2–4]. It is well known that the difficult choices of the weighting parameters generalize several combined first- and second-order TV-type regularization methods [Citation5,Citation6]. A major difficulty encountered in this kind of problem is how to choose the appropriate weighting parameter. In fact, there exists a vast amount of mathematical approaches on how to identify this parameter, see for example [Citation7,Citation8] and the references therein. Many of the above papers deal with the iterative and statistical approaches, which are always based on statistical estimation of the noise distribution [Citation9,Citation10]. Some successful methods are used with the total variation denoising problem, where the authors incorporated the statistical choice of a spatially variable into the standard model [Citation11,Citation12]. Other choice of the weighting parameter is based on the geometry of the image and also a specified threshold. In [Citation13], the authors propose a new algorithm which determine the weighting parameter λ based on the maximum of the Signal to Noise Ratio (SNR) of the denoised image. Similar work is also proposed in [Citation14] with satisfactory result. For a more detailed overview of methods for selecting the weighting parameter λ in general inverse problems, see [Citation15] and references therein. In a recent work, a new choice of the weighting parameter is proposed based on the learning of the noise model through a nonsmooth PDE-constrained optimization model [Citation16]. This approach is adopted for several noise distributions and has shown promising results for determining an optimal weighting parameter in the fidelity term and may be used for other variational image regularization. This weighting parameter is computed based on a training set of original and noisy images, while no information is required concerning the type or strength of the noise. In the last decade, the combined first- and high order regularizations have given an interesting success in several image processing tasks, see [Citation6,Citation17–19]. These regularizations have been introduced to reduce the staircasing effect. However, the selection of the weighting parameter λ that controls the balance between the first- and high order terms is always delicate. Indeed, an automatic selection of this parameter is desired. Recently, the bilevel techniques have had great success in this direction. The bilevel optimization is well known and understood in machine learning. This technique is considered as a semi-supervised learning method because of the ability of adapting itself to a given training set and valuable solutions. For instance, in [Citation20], the bilevel optimization was proposed for finite dimensional Markov field models. Optimal inversion and exploratory acquisition setup are studied in terms of optimal model design [Citation21]. Lately, the image processing has known the introduction of parameter learning for functional variational regularization models by several works [Citation16,Citation22–26]. One of the very interesting contributions is [Citation27] where a spatially varying regularization parameter in total variation image denoising is computed. Before that, a weighted total variation model is also investigated with bilevel optimization strategy [Citation28,Citation29]. More recently and using the same principle, a bilevel minimization framework for an automated selection of the regularization parameter in the total generalized variation (TGV) case is introduced with efficient results. However, for our knowledge, the bilevel techniques are not yet studied before for the PDE denoising models.
To avoid the problem of the blurring effect in the homogeneous regions and also to keep safe the coherence-enhancing property of the image, we propose a new PDE with two diffusion operators. This PDE takes in consideration the advantage of Perona–Malik diffusion behaviour in flat regions [Citation30], the efficiency of Weickert filter effect [Citation31–33] near sharp edges and also the ability of the fourth-order operator in avoiding the staircasing effect. Thus, taking into account these proprieties, the proposed PDE enhances the local information in images much better. However, the construction of this PDE using a convex combination between two operators requires the introduction of a weighting parameter . This parameter affects the contrast of the restored image as well as the smoothness degree. In general, the choice of this parameter is not easy and it is always based on the image properties, the noise type and its nature. In this paper, we propose a PDE-constrained optimization model that compute the weighting parameter λ as well as the denoised image X without any knowledge of the image features and the noise type. In fact, we propose the study of the following optimal problem (where the attached to data term is considered to be the
norm since it is robust against impulse noise, see [Citation2] for more details)
(1)
(1) where
and X is a solution of the following problem:
(2)
(2) where Y is the filtered image of the noisy one
using a bilateral filter [Citation34], ν is the exterior normal and
is the restored image at the time T. With
and β is the regularization parameter. D is an anisotropic diffusion tensor and
is the Structure tensor defined by
(3)
(3) where
is constructed using a convolution of X with a Gaussian kernel. While
and
represent two Gaussian convolution kernels such as
. The function D is calculated using the tensor
eigenvalues and the eigenvectors as follows:
(4)
(4) where
and
are respectively the eigenvalues and the eigenvectors of the tensor structure
, the eigenvalues
are calculated as
(5)
(5) The functions
and
represent the isotropic or anisotropic diffusion on image regions. Recently, an efficient choice of these functions is introduced in [Citation35], where the authors consider the behaviour of the Weickert model according to the two directions
and
. The proposed coefficients take into account the diffusion in the vicinity of the contours and corners where the eigenvalues
and
are very high. This choice is proposed as follows:
(6)
(6) where
and
are two thresholds defining the diffusion with respect to the directions
and
, respectively.
We recall that λ is the weighting parameter to be estimated in (Equation1(1)
(1) ) and
is the set of admissible functions defined by
with
and
are positive constants.
Before resolving the control problem (Equation1(1)
(1) ), we have to check the existence and uniqueness of a solution of the state problem (Equation2
(2)
(2) ). In order to establish the existence of the solution X to the problem (Equation2
(2)
(2) ), we introduce the following set of hypotheses:
| H1 | – The tensor | ||||
| H2 | – The initial condition verifies | ||||
The use of the proposed PDE-constrained with the right weighting parameter identification can cope with the famous total generalized variation denoising method [Citation36,Citation37] in the image reconstruction quality. Such a problem is considered in the framework of optimization which is challenging and generally difficult to solve, since:
The weighting parameter λ depends on the nature of the data, the noise level and type.
The nonlinear dependence of the observed noised image with respect to the noise.
The large computational cost due to the determination of the denoised image and the weighting parameter in the same time in the presence of numerous operators of first and high orders.
Our contribution is then to take into consideration these difficulties and provide a constraint denoising model that increases the quality of the restored image and estimates the weighting parameter λ. Moreover, inspired by the success of the Primal–Dual algorithm in accelerating the resolution of convex optimization problems [Citation38–41], we propose a new Primal–Dual algorithm adopted for PDE-constrained problems.
The rest of this paper is organized as follows: in Section 2, the variational formulation and estimations are given. Then, the existence and uniqueness results of the state problem and the optimal one are given in Sections 3 and 4 respectively. After, Section 5 presents the suggested Primal–Dual algorithm. Finally, in Section 6, we illustrated the benefits of the proposed approach by using comparative experiments with some state-of-art denoising methods.
2. Variational formulation and a priori estimates
In this section, we give the variational formulation of the problem (Equation2(2)
(2) ) and a priori estimates of the solution X. Indeed, the variational formulation of the problem (Equation2
(2)
(2) ) is stated as follows:
(7)
(7) For more details about the space
, see Appendix 2.
In order to show the existence of a solution to the problem (Equation7(7)
(7) ), we use Schauder fixed point Theorem [Citation42]. For this reason, we need to show a priori estimates of the solution to the problem (Equation7
(7)
(7) ) in
.
Lemma 2.1
Assume that assumptions are satisfied, then there exists three constants
for i = 1, 2, 3, such that the weak solution of the problem (Equation7
(7)
(7) ) satisfies the following a priori estimations:
(8)
(8)
(9)
(9)
(10)
(10)
Proof.
Consider , then for
we take
in the variational formulation (Equation7
(7)
(7) ), we get:
we integrate with respect to t over
(11)
(11) Since
we find
On the other hand, we have
is coercive, where the coercivity constant is α, then
which implies that
where the constant
. Consequently, we have
(12)
(12) We have also
(13)
(13) Since we have
then
with
Let's prove now the estimation of
. From the variational formulation (Equation7
(7)
(7) ), we have
(14)
(14) Using the Hölder inequality and the fact that
is bounded in
, we find
(15)
(15) or
and
, we obtain
(16)
(16) Using norm equivalence and Poincaré inequality we have
(see Appendix 2),
and by integrating on
, we obtain
(17)
(17) This achieves the proof.
3. Existence and uniqueness of the state problem
In this section, based on the above estimates, we will show the existence and uniqueness of the solution for the problem (Equation7(7)
(7) ) for a fixed
The main difficulties encountered in this study come from the strong nonlinearity of the conductivity part of Equation (Equation2
(2)
(2) ). To overcome these difficulties, we use the Schauder fixed point [Citation42]. The idea of the proof is inspired from the paper [Citation43]. In order to prove the existence of a solution to the problem (Equation7
(7)
(7) ) we will prove some lemmas that will be useful for the theorem of the existence. Let's now define the following operator G by
(18)
(18) where X is the unique solution of
(19)
(19) and
(20)
(20) The operator G is well defined, thanks to two things: first, the existence of the solution for the problem (Equation19
(19)
(19) ) by the equivalent of Lax–Milgram theorem for parabolic equation which called Lions theorem. This theorem is stated in the comments part of the Chapter 10 of [Citation44] (also it is stated in pages 509−510 of the book [Citation45]) and it is mentioned in the part of parabolic equation from the book [Citation46]. Second, using the same techniques as in the proof of Lemma 2.1, it's easy to prove that for all
, we have
.
To prove that G admits a unique fixed point X, which is the solution of (Equation7(7)
(7) ). We have to show that G is continuous and compact. The following lemma show the continuity of the operator G.
Lemma 3.1
The operator G is continuous in V.
Proof.
In order to prove the continuity of the map G, let us consider the sequence in
, such that
(21)
(21) we have to prove that
(22)
(22) Let
(respectively X) be the unique solution of
(respectively
) for the formulation Equation19
(19)
(19) , which means
(23)
(23)
(24)
(24) Using Equations (Equation23
(23)
(23) ) and (Equation24
(24)
(24) ), and by taking
, we find
Integrating now on
and using the fact that the operator
is smooth enough, we have
(25)
(25) Using the fact that D is coercive, and using the Hölder inequality, we obtain
(26)
(26)
(27)
(27) Using the Young inequality for the right terms, we find
(28)
(28) and using the Poincaré inequality:
we obtain
(29)
(29)
(30)
(30) For
chosen and since we have
(31)
(31) we find that
(32)
(32) By the equivalence between the norms
and
(see Appendix 2), we find that the operator G is continuous.
Let's show now that G is compact.
Lemma 3.2
The operator G is compact in V.
Proof.
Now, let us show that G is compact. For this, let be a bounded sequence in
, and let
be the unique solution of (Equation19
(19)
(19) ) to
Indeed, by taking
and integrating over t and using the same proof as in Lemma 2.1, we have
(33)
(33) We have also
(34)
(34) Now, thanks to the compact embedding of
in
and the continuous embedding of
in
. From Aubin–Lions Lemma [Citation45–47], we have
is compactly embedded in
which means we can extract a subsequence denoted again
that converges in
. This implies that the operator G is compact.
The following theorem shows the existence of weak solution for the problem (Equation7(7)
(7) )
Theorem 3.1
The problem (Equation7(7)
(7) ) admits a unique solution in
.
Proof.
Existence We have that the operator G is well defined. From Lemmas 3.1 and 3.2, G is continuous and compact in V, which implies the existence of the fixed point by using the Schauder fixed point [Citation42].
Uniqueness To prove the uniqueness of the solution, we assume that and
are two distinct solutions of the problem (Equation7
(7)
(7) ). By subtracting the weak formulations of the solutions
and
, we obtain
(35)
(35) taking
, we get
(36)
(36) Then, we have
By using the fact that D is bounded and by the Hölder inequality, we find
Since the operator
is smooth enough, we have
(37)
(37) Then
(38)
(38) Using the Young inequality, we find
(39)
(39) By taking
and by using the Grönwall inequality, we conclude that
(40)
(40) Finally, we get the uniqueness of the solution.
4. Existence of solution for the optimization problem
We prove now the existence of the solution to the optimal control problem (Equation1(1)
(1) ) we need the following compactness lemmas.
Lemma 4.1
is compact for the topology defined by the strong convergence in
.
Proof.
Let's be a sequence in
. Then we have
(41)
(41) and
(42)
(42) Our aim is to show that we can extract a subsequence denoted again
such that
and
From the estimations (Equation41
(41)
(41) ) and (Equation42
(42)
(42) ) we have
(43)
(43) Using the compact embedding of
in
, we can extract a subsequence denoted again
such that
From estimation (Equation42
(42)
(42) ) we find
is the space of bounded measures, using the Banach–Alaoglu–Bourbaki theorem in [Citation44], we find
Which conclude the compactness of
.
Now we will prove the continuity of the map . Which means that if
converges to
in
, then
the solution of (Equation7
(7)
(7) ) converges to
solution of (Equation7
(7)
(7) ).
Proposition 4.1
Let be a sequence from
that converges in
to
and
solution of (Equation7
(7)
(7) ) related to
, we have
| (1) | The sequence | ||||
| (2) | The cost functional J verifies
| ||||
Proof.
Let's
be a sequence of
We have
Let's show that the cost functional J verifies
The following theorem shows the existence of optimal solution to the problem (Equation1(1)
(1) ).
Theorem 4.1
The problem (Equation1(1)
(1) ) admits at least a solution in
Proof.
Let's be a minimizing sequence of J in
such that
Using Lemma 4.1, which means that
is compact, then we can extract a subsequence denoted again
that converge to
in
. In other hand, from Proposition 4.1, we have J is lower semicontinuous, then:
we have also
Then
This concludes that the problem (Equation1
(1)
(1) ) admits a solution in
5. The proposed algorithm and numerical approximation
In this section, we give the proposed algorithm based on the Primal–Dual algorithm and the numerical approximation of the state and adjoint problems.
5.1. The proposed algorithm
Recently, an extension of the A. Chambolle and T. Pock Primal–Dual algorithm (proposed in [Citation38]) to nonsmooth optimization problems, which involves complex nonlinear operators coming from PDE-constrained optimization problems [Citation49]. Inspired by this work, we propose an efficient Primal–Dual algorithm, well adapted to the evolutionary PDE-constrained problem, where two operators are involved (which to our knowledge has not already been treated). Indeed, we transform the studied PDE into an optimization problem of the following form:
(64)
(64) where
and
are proper, convex and lower semicontinuous functional and K is a nonlinear operator involving the solution of the PDE in (Equation2
(2)
(2) ). First, we construct the operator
that maps λ to the solution X of the PDE in (Equation23
(23)
(23) ) at final time T, which is defined by
where X is the weak solution of
(65)
(65) Let's transform the problem (Equation1
(1)
(1) ) to the form (Equation64
(64)
(64) ). The problem (Equation1
(1)
(1) ) is given as follows:
(66)
(66) where the functions
and
are given as follows:
and
We define also the operators
,
such as
and
. The operator K is then defined by
(67)
(67) where
is nonlinear operator and
is linear, with these notations, we have
(68)
(68) Now, we can apply the iterations of the Primal–Dual Algorithm [Citation38] to our problem (Equation66
(66)
(66) ), we obtain the following iterative algorithm:
(69)
(69) where the
denotes the Legendre-Fenchel conjugate of the functional
is given by
(70)
(70) where
.
In order to give the Primal–Dual algorithm, we have to expression the proximal operator function and
(for more details see [Citation49]). For this, we have
(71)
(71) where
and
(72)
(72) We need also to define the operator
, which is the adjoint derivative of the operators K defined by
(73)
(73) where
denotes the adjoint of the Gâteaux derivative of the operator
it is given by the following expression:
(74)
(74) where
in Algorithm 1 and P is the solution of the following adjoint problem:
(75)
(75) where
is the derivative of
with respect to state solution X.
For the proof of the Gâteaux derivative of the operator and the calculation of
, see Appendix 1.

After introducing all the operators needed, the proposed algorithm is given as follows:
For more details about the convergence of Algorithm 1, see [Citation49].
5.2. Numerical approximation
This part provides all the ingredients needed to implement the Primal–Dual algorithm adopted to the problem (Equation64(64)
(64) ). We discretize first the time interval
into a series of M subdomains, namely
Using a semi-discretization with respect to time for the problem (Equation2
(2)
(2) ) and the problem (Equation75
(75)
(75) ), we have
(76)
(76) and
(77)
(77) The discretization of the gradient operator
knowing that
is the discrete image, and
the set of discrete images.
(78)
(78) we also need to define the discretization of the adjoint operator of the gradient ” div ” :
”, satisfying the following relation:
(79)
(79) With:
and
(80)
(80) We define also the second-order differential operator
, where
,
, and
are given in discrete form such as
(81)
(81) and
(82)
(82) On the other hand, we have
(83)
(83) For the approximation of
we use the following approximation:
or
for
6. Numerical results
In this section, we present numerous experiment results to see the contribution of the proposed model. In fact, the results are divided into two categories: the first one is devoted to the results of the case where λ is a scalar and the second deals with the case of λ is spatially varying. For a fair comparison, our method and the compared ones are implemented using Matlab 2013a on the platform: 3 GHz dual-core central processing unit (CPU) and 8 Gbytes RAM. The stopping criterion is the relative residual error becoming less than :
(84)
(84) In the following numerical experiments, we fix the values of
and
(the lower and upper bounds of the parameter λ in
) for the proposed algorithm such as
and
.
6.1. The case of scalar λ
In this part, we are interested in the case where the parameter λ is constant. We focus on image denoising task with the aim to reduce the staircasing effect and intensity loss for different noise type. We compare our model to the classical Rudin, Osher and Fatemi (ROF) model [Citation3] solved by the Bregman iteration [Citation50], the nonlocal means (NLM) model [Citation51,Citation52], the combined TV and TV regularization (TV+TV
) [Citation19,Citation53] solved by Bregman iteration and the TGV model [Citation36,Citation37] solved by the Primal–Dual algorithm. Note that all parameters for the compared models were optimized in order to meet the higher Peak signal-to-noise ratio (PSNR) values.
We start with the first test, where the image of Pirate is considered. The image size is pixels. We construct a corrupted version of the original image by adding a with Gaussian noise of zero mean and standard deviation
. For this example, the chosen parameters (
) for the TV+TV
and TGV methods optimized the PSNR value as we can see in Figure . Concerning the NLM model we chose the size of the neighbourhood
and the threshold that determines isotropic/anisotropic neighbourhood selection
, while we take
for the ROF model. These parameters are chosen using the same procedure for all the remaining tests.
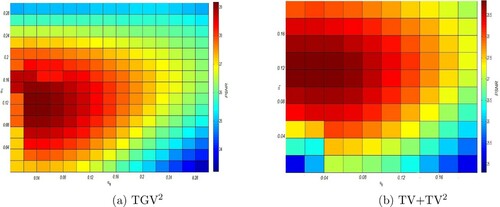
Figure 1. Plot of the PSNR values of the restored image using the TGV and TV+TV approach with respect to the parameters
and
. We can see that the highest achieved PSNR for the TGV
approach is related to the values
and
. For the TV+TV
model, the best PSNR corresponds to the values
and
. Note that the original image is the Pirate one corrupted by Gaussian noise of variance 0.3.
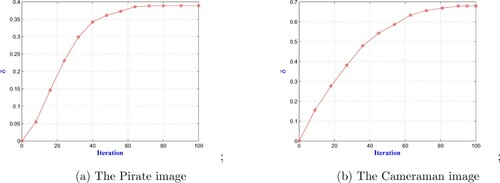
In Figure , we show the respective denoised results by different methods. Visually, our method can achieve a reconstruction which is close to one obtained by the TGV method while the other models are outperformed. In the second denoising test, we take the Cameraman image which is a challenging textural image. We consider also the Gaussian noise but with a higher standard deviation . In order to see the robustness of the proposed method, we present in Figure the restored image with different approaches including the proposed one. Once again, we can observe that visually the proposed method can achieve a better reconstructed result compared to other methods. To see the evolution of the obtained weighting parameter λ, we plot in Figure the values of λ with respect to the iterations for the two above examples. It is then observed that the obtained parameter for the Pirate image is
, while for the Cameraman image the parameter is
.
Figure 2. The obtained denoised image compared to other classical approaches for the (Pirate image), where the noise is considered to be Gaussian of : (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) TV+TV
[Citation19] (e) TGV model [Citation36] and (f) Our model.
![Figure 2. The obtained denoised image compared to other classical approaches for the (Pirate image), where the noise is considered to be Gaussian of σ=0.3: (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) TV+TV2 [Citation19] (e) TGV model [Citation36] and (f) Our model.](/cms/asset/0fbed0dd-f9f8-488a-bf96-1125ea42ea3e/gipe_a_1867547_f0002_oc.jpg)
Figure 3. The obtained denoised image compared to other classical approaches for the (Cameraman image), where the noise is considered to be Gaussian of : (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) TV+TV
[Citation19], (e) TGV model [Citation36] and (f) our model.
![Figure 3. The obtained denoised image compared to other classical approaches for the (Cameraman image), where the noise is considered to be Gaussian of σ=0.5: (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) TV+TV2 [Citation19], (e) TGV model [Citation36] and (f) our model.](/cms/asset/723fe932-8946-4e77-8eaf-d2f402adec63/gipe_a_1867547_f0003_oc.jpg)
Figure 4. The computation of the parameter λ with respect to the iteration for the two images Pirate and Cameraman: (a) The Pirate image and (b) The Cameraman image.
For the third and fourth experiments, we change the nature of noise which is considered as an impulse one. For that, we change the fidelity term for the compared methods which is now considered as the L norm since it success in handling the impulse noise (see [Citation2,Citation54,Citation55]). First, we consider the Cameraman image corrupted by an impulse noise with parameter 0.3. Figure shows the obtained denoised image using different approaches with L
norm, we can see once again that the proposed method can efficiently reduce the impulse noise without destroying image features, even though the TGV method reduces the noise better than our approach. For the fourth test, we increase the impulse noise level which is taken with parameter 0.5. Figure illustrates the restored image using different regularization methods, we can observe that the proposed approach is visually very sharp compared to the TGV result. Also, we plot in Figure the evolution of the parameter λ with respect to the iterations for the third and fourth examples. It is then observed that the obtained parameter for the Cameraman image is
, while for the Penguin image the parameter is
. Furthermore, to better perform the proposed denoising method over the other methods, a quantitative evaluation is used. In fact, we provide two metrics: PSNR [Citation56] and the mean structure similarity (SSIM) [Citation57]. The PSNR measures signal strength relative to noise in the image while the SSIM metric gives an indication on the quality of the image related to the known characteristics of human visual system. Tables and illustrate the PSNR and SSIM values related to the above simulated tests. We can notice that the proposed model outperforms the compared methods. Moreover, to better compare the quality of reconstructions, we present two tables that indicate the normalized
and
-distances between true image and the restored ones. Tables and illustrate the normalized
and
-distances values for the four above simulated tests, respectively. Once again, the proposed approach is always with the lower values, which confirm its robustness.
Figure 5. The obtained denoised image compared to other classical approaches for the Cameraman image, where the noise is considered to be impulse one of parameter 0.3: (a) Noisy image, (b) ROF [Citation3], (c) NLM [Citation51], (d) L-TV+TV
[Citation19], (e) L
-TGV [Citation36] and (f) Our model.
![Figure 5. The obtained denoised image compared to other classical approaches for the Cameraman image, where the noise is considered to be impulse one of parameter 0.3: (a) Noisy image, (b) ROF [Citation3], (c) NLM [Citation51], (d) L1-TV+TV2 [Citation19], (e) L1-TGV [Citation36] and (f) Our model.](/cms/asset/c90d365a-eedf-4a5d-9cc6-dbaaa0706d16/gipe_a_1867547_f0005_oc.jpg)
Figure 6. The obtained denoised image compared to other classical approaches for the (Penguin image), where the noise is considered to be impulse one of parameter 0.5: (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) L-TV+TV
[Citation19], (e) L
-TGV model [Citation36] and (f) Our model.
![Figure 6. The obtained denoised image compared to other classical approaches for the (Penguin image), where the noise is considered to be impulse one of parameter 0.5: (a) Noisy image, (b) ROF model [Citation3], (c) NLM model [Citation51], (d) L1-TV+TV2 [Citation19], (e) L1-TGV model [Citation36] and (f) Our model.](/cms/asset/43fd1e32-80cb-49e3-a903-a3f4e88281c3/gipe_a_1867547_f0006_oc.jpg)
Figure 7. The computation of the parameter λ with respect to the iteration for the two images Camerman and Penquin: (a) The Pirate image and (b) The Penguin image.
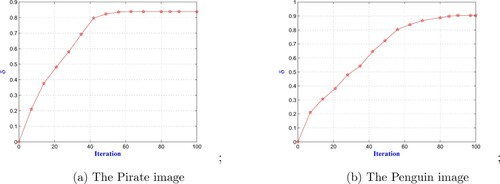
Table 1. The PSNR table.
Table 2. The SSIM table.
Table 3. The normalized distance table.
Table 4. The normalized distance table.
6.2. The space variant case
We now present extensive results to perform the weighted proposed PDE, where the parameter λ is space variant. In fact we are particularly interested to present the results in the space
which is the most used space in the literature (especially
space), see [Citation27–29,Citation58–60], and also the proposed set of admissible filtering weights
defined by
We start by a first experiment where we consider the Lena image which is contaminated by a Gaussian noise with variance
. Then, we use the proposed Algorithm 1 to compute the clean image X and the approximate weighted parameter λ using two different choices of the space of admissible weights λ. The restored image and the spatially variant λ (projected in the image grid:
) using the two sets are displayed in Figure .We can observe that the restored image using
is little sharp compared to the one restored in
, especially near edges. In particular, the approximate λ for the two cases is higher in homogeneous regions and texture, and weaker near edges where the variation is stronger. The next set of experiments is considered to see the behaviour of the proposed weighted PDE with respect to different noise levels using the two admissible spaces. For that, we consider four images which essentially contain combination of large piecewise constant parts and smooth areas. The restored images using the two sets
and
are depicted in Figures and , respectively. The noisy images are obtained by adding Gaussian noise with variances
and 0.5, respectively in the same order from the top to the bottom of Figures and .From the surface representation of λ, we can detect that λ is smooth enough for
and piecewise constant for the case of
. For the both cases the shapes of λ are related to the one of the obtained image X, even if for
the shape of λ is almost the same as the picture. In addition, the same remark as for the previous test remains valid since the values of λ are higher near homogeneous areas.
Figure 8. The restored image and the parameter λ using the two admissible sets of the Lena image: (a) Noisy, (b) X using , (c) λ using
, (d) X using
and (e) λ using
.
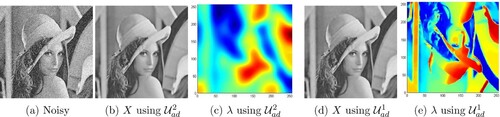
Figure 9. The restored image X and the corresponding weighted parameter λ using the admissible set . The Baboon image is contaminated by Gaussian noise with
, Penguin image is contaminated by
, Zebra image is contaminated by
, Tiger image is contaminated by
. The used parameters for these tests are:
,
and
: (a) Noisy, (b) Obtained X, (c) λ and (d) Image of λ.
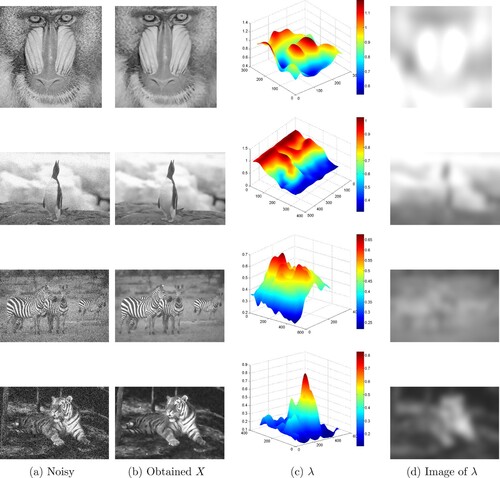
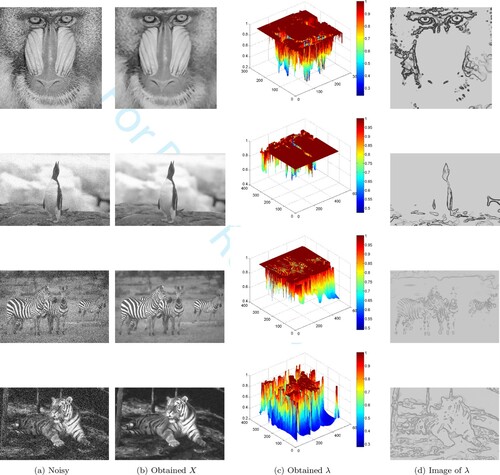
Figure 10. The restored image X and the corresponding weighted parameter λ using the admissible set . the Baboon image is contaminated by Gaussian noise with
, Penguin image is contaminated by
, Zebra image is contaminated by
, Tiger image is contaminated by
. The used parameters for these tests are:
,
and
: (a) Noisy, (b) Obtained X, (c) Obtained λ and (d) Image of λ.
The following four tests concern the comparison between the proposed weighted PDE and the spatially dependent regularization parameters for TV image denoising (SDRTV) [Citation27]. For a fair comparison, we consider the same conditions for our approach as for SDRTV one (where ). For that, we set
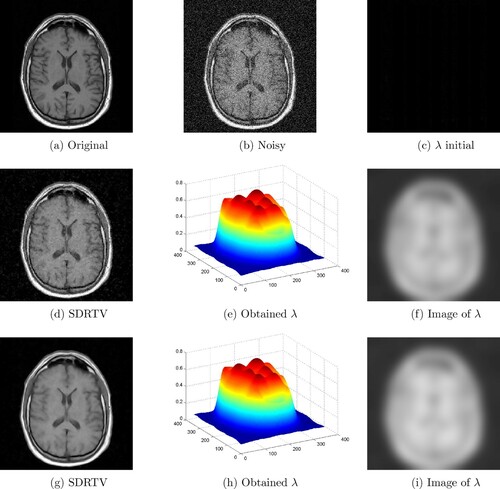
for our method and we consider two comparative results. In the two experiments, we treat the denoising problem with brain scan images. The first set consists of image of
pixels and Gaussian noise with zero mean and variance
. The second one consists of image of
pixels and Gaussian noise with zero mean and variance
. The used parameters for SDRTV method are
,
and
. The computed semismooth Newton method, on the whole domain, converges when kmax = 40 iterations. Note that the compared results are done without domain decomposition. For our method, the used parameters are
,
and
. The corresponding results are shown in Figures and , respectively. By a visual comparison, we can see that the proposed PDE yields significant improvement compared to the SDRTV method. In addition, from the surface representation of λ for the two methods, we can see that λ is continuous and its shape is related to the one of the original image (especially in homogeneous areas).
Figure 11. Comparison between the obtained clean image X and the SDRTV method with the respective computation of the spatially dependent parameter λ of the Head image: (a) Original, (b) Noisy, (c) λ initial, (d) SDRTV, (e) Obtained λ, (f) Image of λ, (g) Proposed PDE, (h) Obtained λ and (i) Image of λ.
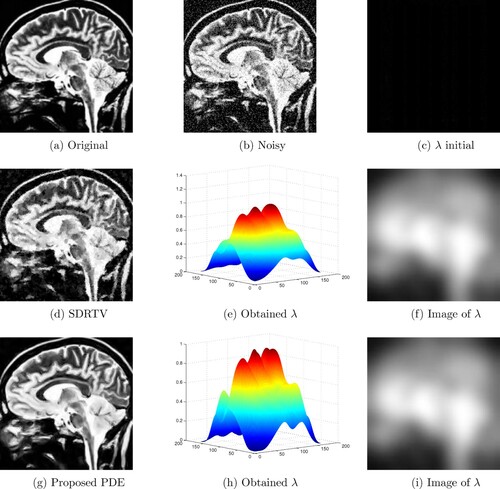
Figure 12. Comparison between the obtained clean image and the SDRTV method and the respective computation of the spatially dependent parameter λ of the Brain image: (a) Original, (b) Noisy, (c) λ initial, (d) SDRTV, (e) Obtained λ, (f) Image of λ, (g) SDRTV, (h) Obtained λ and (i) Image of λ.
We now consider the proposed admissible set such as for our method and we propose two experiment results where we compare our PDE with the SDRTV approach (
). We keep the same parameters as for the previous tests. The noise is considered to be Gaussian one with variances
and
, respectively. The recovered images are depicted in Figures and , respectively. Once again, our method outperforms the SDRTV by a visual comparison. In addition the approximate λ tends to capture more information from the image, which can be interpreted by the less regularity of the proposed set of admissible λ.
Figure 13. Comparison between the obtained clean image X and the SDRTV method with the respective computation of the spatially dependent parameter λ of the Dolphins image: (a) Original, (b) Noisy, (c) λ initial, (d) SDRTV, (e) Obtained λ, (f) Image of λ, (g) Obtained X, (h) Obtained λ and (i) Image of λ.
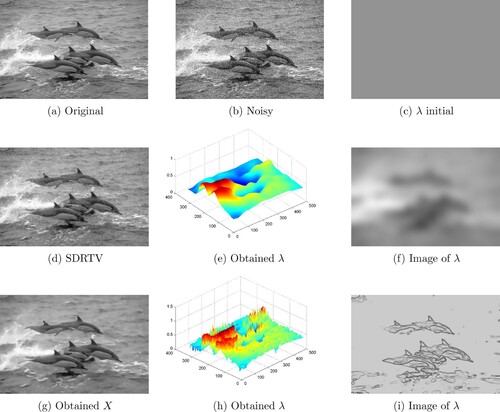
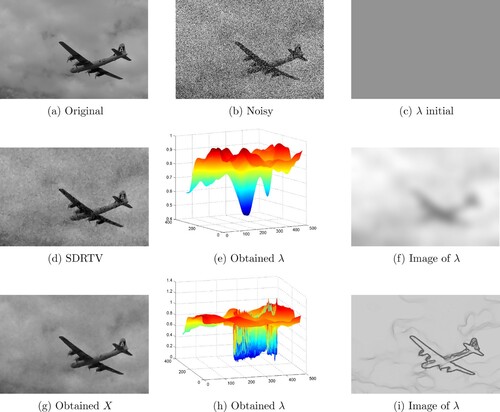
Figure 14. Comparison between the obtained clean image X and the SDRTV method with the respective computation of the spatially-dependent parameter λ of the Plane image: (a) Original, (b) Noisy, (c) λ initial, (d) SDRTV, (e) Obtained λ, (f) Image of λ, (g) Obtained X, (h) Obtained λ and (i) Image of λ.
6.3. Robustness of the proposed PDE
In this part, we use four simulated images to perform the choice of the proposed PDE-constrained with the space variant choice of λ. To show the efficiency of the proposed PDE in recovering essential image features, we use some comparisons to other competitive denoising PDEs. In fact, the obtained results are compared to the Fourth-order partial differential equations for image enhancement (FOPDE) [Citation61], Adaptive fourth-order partial differential equation filter for image denoising (AEFD) [Citation62] and the adaptive fourth-order partial differential equation for image denoising (AFOD) [Citation63]. The four tests are done using different levels of Gaussian noise, with and 60, respectively. In Figure , we present the restored image of the four noisy images using the compared enhancement PDEs and our. We can see obviously the robustness of the proposed PDE in avoiding different artefacts compared with the other ones. The used parameters are tuned with respect to the best obtained PSNR. For example the used parameters for the Tiger image are:
,
,
,
and 50 iterations for the AEFD approach.
,
,
,
,
and 100 iterations for the AFOD approach.
,
,
,
,
,
and 120 iterations for the FOPDE method. Note that the used parameters of our approach are:
,
,
,
and 50 iterations number.
Figure 15. Comparison between the obtained clean image X and the respective computation of the spatially dependent parameter λ for the scalar case and for it two set of admissible values and
for the Fishes image: (a) Original, (b) Noisy, (c) scalar λ, (d) weighted
and (e) weighted
.
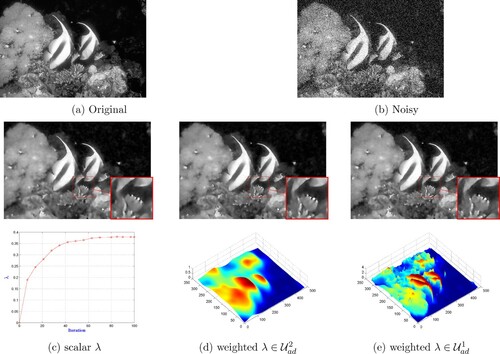
Figure 16. The obtained denoised image compared to other PDE approaches with respect to both quality measures PSNR and SSIM. First row: noisy images. Second row: FOPDE. Third row: AEFD. Fourth row: AFOD. Fifth row: Our approach. (a) PSNR = 19.17, SSIM = 0.327. (b) PSNR = 15.40, SSIM = 0.377. (c) PSNR = 15.12, SSIM = 0.310. (d) PSNR = 14.08, SSIM = 0.286. (e) PSNR = 23.79, SSIM = 0.539. (f) PSNR = 22.61, SSIM = 0.588. (g) PSNR = 20.66, SSIM = 0.548. (h) PSNR = 20.41, SSIM = 0.422, (i) PSNR = 26.19, SSIM = 0.719, (j) PSNR = 23.95, SSIM = 0.650, (k) PSNR = 23.62, SSIM = 0.647. (l) PSNR = 28.48, SSIM = 0.747. (m) PSNR = 26.94, SSIM = 0.746, (n) PSNR = 25.62, SSIM = 0.741, (o) PSNR = 22.81, SSIM = 0.627, (p) PSNR = 24.96, SSIM = 0.597, (q) PSNR = 28.14, SSIM = 0.826, (r) PSNR = 27.65, SSIM = 0.821, (s) PSNR = 26.03, SSIM = 0.765 and (t) PSNR = 31.91, SSIM = 0.872.

7. Conclusion
In this paper, we have introduced a fourth-order PDE-constrained optimization model to treat the denoising task. This PDE is elaborated using a convex combination between two operators controlled by a weighting parameter, which is the solution of the optimal problem. This PDE takes the advantage of the Perona–Malik equation with much regularity and the efficiency of a nonlinear filter to restore tiny and sharp edges. The existence and uniqueness of the proposed PDE-constrained is proved using the Schauder fixed point theorem and the well-posedness of the optimization model is established using the control theory in a suitable space. The results part demonstrates, visually and quantitatively the performance and the contribution of this new PDE over the other denoising approaches. In summary, the proposed approach gives promising analytic strategy for determining an optimal solution for the denoised image and also the parameter λ. As further developments of this method, it may be generalized for other operators and different regularization functional. Another very important generalization of the proposed model is to move from a simple denoising model to more general inverse problems involving linear and nonlinear operators.
Acknowledgments
We are very grateful to the anonymous referees for the remarkable corrections and useful suggestions that have much improved this paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Kirsch A. An introduction to the mathematical theory of inverse problems. Vol. 120. Germany: Springer Science & Business Media; 2011.
- Chan TF, Esedoglu S. Aspects of total variation regularized l 1 function approximation. SIAM J Appl Math. 2005;65(5):1817–1837.
- Rudin LI, Osher S, Fatemi E. Nonlinear total variation based noise removal algorithms. Phys D Nonlinear Phenom. 1992;60(1-4):259–268.
- Hintermüller M, Holler M, Papafitsoros K. A function space framework for structural total variation regularization with applications in inverse problems. Inverse Probl. 2018;34(6):064002.
- Liu J, Ni G, Yan S. Alternating method based on framelet l 0-norm and tv regularization for image restoration. Inverse Probl Sci Eng. 2019;27(6):790–807.
- Laghrib A, Ezzaki M, El Rhabi M, et al. Simultaneous deconvolution and denoising using a second order variational approach applied to image super resolution. Comput Vis Image Underst. 2018;168:50–63.
- Chantas G, Galatsanos NP, Molina R, et al. Variational bayesian image restoration with a product of spatially weighted total variation image priors. IEEE Trans Image Process. 2010;19(2):351–362.
- Rodríguez P, Wohlberg B. Efficient minimization method for a generalized total variation functional. IEEE Trans Image Process. 2009;18(2):322–332.
- Frick K, Marnitz P, Munk A. Statistical multiresolution estimation for variational imaging: with an application in poisson-biophotonics. J Math Imaging Vis. 2013;46(3):370–387.
- Dong Y, Hintermüller M, Rincon-Camacho MM. Automated regularization parameter selection in multi-scale total variation models for image restoration. J Math Imaging Vis. 2011;40(1):82–104.
- Bertalmío M, Caselles V, Rougé B, et al. Tv based image restoration with local constraints. J Sci Comput. 2003;19(1–3):95–122.
- Almansa A, Ballester C, Caselles V, et al. A tv based restoration model with local constraints. J Sci Comput. 2008;34(3):209–236.
- Strong DM, Aujol J-F, Chan TF. Scale recognition, regularization parameter selection, and Meyer's g norm in total variation regularization. Multiscale Model Simulat. 2006;5(1):273–303.
- Gilboa G, Sochen NA, Zeevi YY. Estimation of optimal pde-based denoising in the snr sense. IEEE Trans Image Proces. 2006;15(8):2269–2280.
- Vogel CR. Computational methods for inverse problems. Vol. 23. US: SIAM; 2002.
- De los Reyes JC, Schönlieb C-B. Image denoising: learning the noise model via nonsmooth pde-constrained optimization. Inverse Problems Imaging. 2013;7(4):1183–1214.
- Chan T, Marquina A, Mulet P. High-order total variation-based image restoration. SIAM J Sci Comput. 2000;22(2):503–516.
- Osher S, Solé A, Vese L. Image decomposition and restoration using total variation minimization and the h. Multiscale Model Simul. 2003;1(3):349–370.
- Papafitsoros K, Schönlieb C-B. A combined first and second order variational approach for image reconstruction. J Math Imaging Vis. 2014;48(2):308–338.
- Chen Y, Ranftl R, Pock T. Insights into analysis operator learning: from patch-based sparse models to higher order mrfs. IEEE Trans Image Process. 2014;23(3):1060–1072.
- Haber E, Tenorio L. Learning regularization functionals–a supervised training approach. Inverse Probl. 2003;19(3):611.
- De los Reyes JC, Schönlieb C-B, Valkonen T. The structure of optimal parameters for image restoration problems. J Math Anal Appl. 2016;434(1):464–500.
- De los Reyes JC, Schönlieb C-B, Valkonen T. Bilevel parameter learning for higher-order total variation regularisation models. J Math Imaging Vis. 2017;57(1):1–25.
- Chung C, De los Reyes JC, Schönlieb C-B. Learning optimal spatially-dependent regularization parameters in total variation image restoration. arXiv preprint arXiv:1603.09155.
- Kunisch K, Pock T. A bilevel optimization approach for parameter learning in variational models. SIAM J Imaging Sci. 2013;6(2):938–983.
- Calatroni L, Cao C, De Los Reyes JC, et al. Bilevel approaches for learning of variational imaging models. Variat Methods Imaging Geom Control. 2017;18(252):2.
- Van Chung C, De los Reyes J, Schönlieb C. Learning optimal spatially-dependent regularization parameters in total variation image denoising. Inverse Probl. 2017;33(7):074005.
- Hintermüller M, Rautenberg CN. Optimal selection of the regularization function in a weighted total variation model. part i: modelling and theory. J Math Imaging Vis. 2017;59(3):498–514.
- Hintermüller M, Rautenberg CN, Wu T, et al. Optimal selection of the regularization function in a weighted total variation model. part ii: algorithm, its analysis and numerical tests. J Math Imaging Vision. 2017;59(3):515–533.
- Perona P, Shiota T, Malik J. Anisotropic diffusion. In: Geometry-driven diffusion in computer vision. Springer; 1994. p. 73–92.
- Weickert J. Coherence-enhancing diffusion filtering. Journal of Computer Vision¡/DIFdel¿Int J Comput Vis. 1999;31(2-3):111–127.
- Weickert J, Scharr H. A scheme for coherence-enhancing diffusion filtering with optimized rotation invariance. J Vis Commun Image Represent. 2002;13(1-2):103–118.
- Burgeth B, Didas S, Weickert J. A general structure tensor concept and coherence-enhancing diffusion filtering for matrix fields. In: Visualization and processing of tensor fields. Springer; 2009. p. 305–323.
- Elad M. On the origin of the bilateral filter and ways to improve it. Image Processing¡/DIFdel¿IEEE Trans Image Process. 2002;11(10):1141–1151.
- El Mourabit I, El Rhabi M, Hakim A, et al. A new denoising model for multi-frame super-resolution image reconstruction. Signal Processing. 2017;132:51–65.
- Bredies K, Kunisch K, Pock T. Total generalized variation. SIAM J Imaging Sci. 2010;3(3):492–526.
- Valkonen T, Bredies K, Knoll F. Total generalized variation in diffusion tensor imaging. SIAM J Imaging Sci. 2013;6(1):487–525.
- Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. J Math Imaging Vis. 2011;40(1):120–145.
- Zhang X, Burger M, Osher S. A unified primal-dual algorithm framework based on bregman iteration. J Sci Comput. 2011;46(1):20–46.
- Laghrib A, Hakim A, Raghay S. An iterative image super-resolution approach based on bregman distance. Signal Proces Image Commun. 2017;58:24–34.
- Afraites L, Hadri A, Laghrib A. A denoising model adapted for impulse and gaussian noises using a constrained-pde. Inverse Probl. 2020;36(2):025006.
- Gilbarg D, Trudinger NS. Elliptic partial differential equations of second order. Springer; 2015.
- Catté F, Lions P-L, Morel J-M, et al. Image selective smoothing and edge detection by nonlinear diffusion. SIAM J Numer Anal. 1992;29(1):182–193.
- Brezis H. Analyse fonctionnelle. Masson: Paris; 1983.
- Dautray R, Lions J. Mathematical analysis and numerical methods for science and technology: evolution problems I. US: Springer; 1992.
- Zeidler E. Nonlinear functional analysis and its applications: III: variational methods and optimization. US: Springer Science & Business Media; 2013.
- Aubin JP. Un théorème de compacité. Acad Sci Paris. 1963;256:5042–5044.
- Simon J. Compact sets in the space lp(0,t;b). Ann. Mat. Pura Appl. 1987;146:65–96.
- Clason C, Valkonen T. Primal-dual extragradient methods for nonlinear nonsmooth pde-constrained optimization. SIAM J Optim. 2017;27(3):1314–1339.
- Wu C, Tai X-C. Augmented lagrangian method, dual methods, and split Bregman iteration for rof, vectorial tv, and high order models. SIAM J Imaging Sci. 2010;3(3):300–339.
- Buades A, Coll B, Morel J-M. Non-local means denoising. Image Process On Line. 2011;1:208–212.
- Maleki A, Narayan M, Baraniuk RG. Anisotropic nonlocal means denoising. Appl Comput Harmon Anal. 2013;35(3):452–482.
- Papafitsoros K, Schoenlieb CB, Sengul B. Combined first and second order total variation inpainting using split Bregman. Image Process On Line. 2013;3:112–136.
- Duval V, Aujol J-F, Gousseau Y. The tvl1 model: a geometric point of view. Multiscale Model Simul. 2009;8(1):154–189.
- Nikolova M. A variational approach to remove outliers and impulse noise. J Math Imaging Vis. 2004;20(1-2):99–120.
- De Boer JF, Cense B, Park BH, et al. Improved signal-to-noise ratio in spectral-domain compared with time-domain optical coherence tomography. Opt Lett. 2003;28(21):2067–2069.
- Wang Z, Simoncelli EP, Bovik AC. Multiscale structural similarity for image quality assessment. In: The thirty-seventh asilomar conference on signals, systems & computers. Vol. 2. IEEE; 2003, p. 1398–1402.
- Bredies K, Dong Y, Hintermüller M. Spatially dependent regularization parameter selection in total generalized variation models for image restoration. Int J Comput Math. 2013;90(1):109–123.
- Hintermüller M, Papafitsoros K. Generating structured nonsmooth priors and associated primal-dual methods. In: Handbook of numerical analysis. Vol. 20. Elsevier; 2019. p. 437–502.
- Hintermüller M, Papafitsoros K, Rautenberg CN, et al. Dualization and automatic distributed parameter selection of total generalized variation via bilevel optimization. arXiv preprint arXiv:2002.05614.
- Yi D, Lee S. Fourth-order partial differential equations for image enhancement. Appl Math Comput. 2006;175(1):430–440.
- Liu X, Huang L, Guo Z. Adaptive fourth-order partial differential equation filter for image denoising. Appl Math Lett. 2011;24(8):1282–1288.
- Zhang X, Ye W. An adaptive fourth-order partial differential equation for image denoising. Comput Math Appl. 2017;74(10):2529–2545.
- Casas E, Fernandez L. Distributed control of systems governed by a general class of quasilinear elliptic equations. J Diff Equ.
- Ciarlet PG. The finite element method for elliptic problems. Vol. 40. US: Siam; 2002.
- Eymard R, Herbin R, Linke A, et al. Convergence of a finite volume scheme for the biharmonic problem.
Appendices
Appendix 1
The next propositions show the differentiability of the solution operator . This result leads us to get an expression of the operator
using the proper adjoint state.
Proposition A.1
Let be the solution of Equation (Equation2
(2)
(2) ) at t = T associated to each parameter λ. The operator
is Gâteaux differentiable and its derivative at λ, in direction h, is given by the unique solution
of the following linearized equation:
(A1)
(A1) where
is the derivative of
with respect to state X.
Proof.
We decompose the proof in tree steps:
Step 1 Let and X be the unique solutions to (Equation2
(2)
(2) ) corresponding to
and λ, respectively for
and small ϵ. Let's show the priori estimations of the difference of the two solutions
and X. Taking the difference between the equations of
and X, we have:
(A2)
(A2) we can rewrite (EquationA2
(A2)
(A2) ) as follows:
(A3)
(A3)
(A4)
(A4)
(A5)
(A5)
(A6)
(A6) and
(A7)
(A7) Step 2 In the second step, we consider the sequence
, with
and we prove the weak convergence of
to
solution of Equation (EquationA1
(A1)
(A1) ).
We have the corresponding Equation (EquationA3(A3)
(A3) ) at
is given as follows:
(A8)
(A8) Using the mean value theorem in integral form we get that:
(A9)
(A9) where
with
.
Using the estimations (EquationA4(A4)
(A4) ) and (EquationA7
(A7)
(A7) ) Aubin–Lions and Aubin–Simon lemmas [Citation45–48], we can extract a subsequence denoted again
such that
strongly in
and
strongly in
as
Using the same techniques of convergence we can extract a subsequence denoted again
such that
strongly in
and
strongly in
, and thanks to the smoothness of D, and form the definition we have
is continuous. We can pass to the limit in (EquationA9
(A9)
(A9) ) to obtain the following formula:
(A10)
(A10) Consequently,
corresponds to the solution of the linearised equation (EquationA1
(A1)
(A1) ) with
(A11)
(A11)
(A12)
(A12)
(A13)
(A13) and
(A14)
(A14) Step 3 Now, we will prove that the sequence
converges strongly in
to
. As a consequence of the previous step, it suffices to prove that:
Let consider two Matrix:
and M are symmetric and positive definite. Using Cholesky decomposition we obtain lower triangular matrices
and L such that
Applying the same convergence as in step 2 in the weak formulation (EquationA9
(A9)
(A9) ) with the function test is
and integrating by parts we obtain
(A15)
(A15) Using the above equation and (EquationA10
(A10)
(A10) ), we prove by the same argumentation as in ([Citation64], Theorem 3.1, Step 3) that which implies that
We can find by using the same techniques that This complete the proof.
Based on the differentiability properties of the solution operator, we give in next proposition the expression of adjoint derivative operator .
Proposition A.2
We have:
(A16)
(A16) where P is the solution of the following adjoint problem:
(A17)
(A17)
Proof.
To prove the result (Equation74(74)
(74) ), we take
as function test in the variational form of system (EquationA1
(A1)
(A1) ) and (Equation75
(75)
(75) ), which give:
(A18)
(A18) and
(A19)
(A19) Taking
in Equation (EquationA18
(A18)
(A18) ) and
in Equation (EquationA19
(A19)
(A19) ) and use the formula
it immediately shows that
To finish this the proof, we use the proposed notation
and
then, we have
which completes the proof.
Appendix 2
We introduce the functional space which is defined as the closure of
in
Thanks to the Lipschitz regularity of the boundary, which leads to the definition
The space
equipped by the norm
which is equivalent to the
for every
(see [Citation65,Citation66]). Indeed, the Poincaré inequality
and
leads to
Besides, the following equality which is an immediate consequence of two integrations by parts
Now we give the definition of some useful operators. We have
and