
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This study considers an inverse problem, where the corresponding forward problem is given by a finite-dimensional linear operator T. The inverse problem has the following form: It is assumed that the number of patterns that the unknown quantity can take is finite. Then, even if
the unknown quantity may be uniquely determined from the data. This case is the subject of this study. We propose a method for solving this inverse problem using numerical calculations. A famous inverse problem requires the estimation of the unknown magnetization distribution or magnetic charge distribution in an anisotropic permanent magnet sample from the magnetic force microscopy images. It is known that the solution of this problem is not unique in general. In this work, we consider the case where a magnetic sample comprises cubic cells, and the unknown magnetic moment is oriented either upward or downward in each cell. This discretized problem is an example of the above-mentioned inverse problem:
Numerical calculations were carried out to solve this model problem employing our method and deep learning. The experimental results show that the magnetization can be estimated roughly up to a certain depth.
1. Introduction
Let and
be a linear operator. For a finite set
we consider the natural restriction of
defined on
as
In this study, we consider the inverse problems of the form:
(1)
(1) where
denotes some noise and
may not hold. Since
is a finite set, the map
may be injective even if
Then,
is often nonlinear.
The inverse problem of obtaining the spatial distributions of magnetic properties inside an object from experimental measurements has been investigated by numerous researchers (see [Citation1]). In this study, we consider such a magnetic inverse problem, that is, the magnetization-distribution identification problem represented by an integral equation (see (Equation2(2)
(2) )). This problem requires the estimation of the unknown magnetization distribution or magnetic charge distribution in an anisotropic permanent magnet sample from its magnetic force microscopy (MFM) images. This integral equation is a Fredholm equation of the first kind, and its solution is generally not unique for the given data. In fact, in principle, it is impossible to determine the magnetic charge distribution inside a magnetic material from the MFM images (see [Citation2,Citation3]).
In this work, we assume that an anisotropic magnetic sample is composed of magnetic grains, where each grain has single magnetic domain structure and it is magnetically isolated from the neighbouring magnetic grains by non-magnetic boundary phase. Therefore, no magnetic domain walls exist in the sample. Further, we assume that the magnetic sample comprises cubic cells, and every magnetic grain is composed of one cell or a set of several cells. For example, an ideal hot-rolled magnet sample approximately has such a structure. We consider the following case. First, we apply a strong upward magnetic field to the magnetic sample to make the magnetized state, that is, to make the magnetic moments of all cells of this sample upward. Next, we apply a downward magnetic field to the sample. Then, the orientation of the magnetic moment of each cell either remains upwards or changes downwards. (When a magnetic grain is composed of several cells, the moments of those cells are oriented in the same direction.) To investigate the magnetic performance of the sample, our aim is to know at what positions inside the sample the magnetic moments are reversed from its MFM images as many as possible.
Since the magnet sample is assumed to consist of cubic cells, we discretize the integral equation and consider this discretized inverse problem as a model problem of (Equation1(1)
(1) ). Saito et al. [Citation4] obtained the Green kernel function of the integral equation. Our analysis is based on their formulation. We aim to estimate the magnetization distribution on the surface of the magnet and as deep in the interior as possible. In this study, we propose a method of reconstruction (a sequential estimation-removal method). We conducted computational simulations using this method. The experimental results show that the discretized magnetization can be estimated roughly up to a certain depth. We did not conduct experiments using actual magnets; however, we consider that it is appropriate to employ the high-performance MFM developed by Saito et al. (see [Citation5–7]) when conducting experiments using actual magnets. This MFM only detects the normal component of the magnetic field to a sample surface. In this study, we assume that such an MFM is used.
Various methods have been developed for reconstructing the internal magnetization distribution with some constraints or surface magnetization distribution from the MFM images, e.g. see [Citation8–11], and [Citation12]. However, the authors were unable to identify the research that solved our inverse problem.
The rest of this paper is organized as follows: In Section 2, we describe our magnetization-distribution identification problem and the cell discretization of this problem. This discretized problem is a model problem of the inverse problem (Equation1(1)
(1) ). In Section 3, we propose a method for solving the general inverse problem of the form (Equation1
(1)
(1) ); we call it a sequential estimation-removal method (although it may be known by other names, the authors are unaware of them). This method is based on the idea of earlier estimating a part that can be estimated more accurately (Basic idea 3.2). We divide the target
virtually into several parts, and each part is called a piece (in the case of our discretized magnetization-distribution identification problem, each piece corresponds to a set of several cells). In our proposed method, we estimate and virtually remove the pieces one-by-one from those that can be estimated more accurately. Consequently, the problem is localized, and the computational cost can be reduced. This method requires the linearity of T. In Section 4, we numerically consider the ill-posedness of the discretized magnetization-distribution identification problem and the original infinite-degrees-of-freedom problem, and the relationship between these problems using the results of our numerical experiments. As described in Sections 4.1 and 4.2, these problems are very ill-posed (cf. [Citation2,Citation3]). In Sections 5 and 6, we describe the results of the numerical experiments, in which we attempted to solve the discretized magnetization-distribution identification problem using our sequential estimation-removal method. This method is implemented by employing (artificial) neural networks as described in Section 5, and by utilizing an iterative algorithm as described in Section 6. These can be applied even if
is nonlinear. In particular, the set of neural networks obtained can act as an approximation of
The results of our numerical experiments show that the discretized magnetization μ can be roughly estimated up to a certain depth. Moreover, based on our experiments, the estimation of μ from our method is more accurate than estimating μ at one time. Since we aimed to estimate the magnetic moments as much as possible, the difficulty of estimating this ill-posed inverse problem has been highlighted in Sections 5 and 6.
In Sections 4–6, we consider the following simple and basic case: each magnetic grain comprises only one cell and the orientation of the moments of the cells are independent of each other. Thus we used randomly generated artificial training data and test data, and we did not apply any regularization or any Bayesian prior distribution. To obtain higher accuracy estimates in a real situation, training data that approximates the actual magnetic moment configurations should be used, and some regularization or some Bayesian prior distribution representing the actual magnetic moment configurations should be adopted. We discuss these aspects somewhat in Section 7. Further, in Section 7, we describe an inverse gravimetric problem as a problem for which our method may be applicable.
2. Magnetization-distribution identification problem and its discretization
2.1. Problem
We consider the discretized magnetization-distribution identification problem described in Section 1 as a model problem of the inverse problem (Equation1(1)
(1) ). This problem is a discretization of the problem of solving integral equation (Equation2
(2)
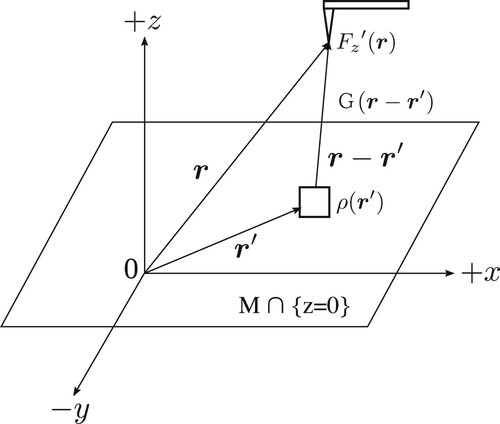
(2) ). This integral-equation formulation is based on [Citation4]. The anisotropic permanent magnet sample is denoted by M. Figure shows the three-dimensional MFM tip Green function
for a dipole type MFM tip, and the rectangle is
Here, we consider the Green function for a point magnetic charge. The magnetization for the dipole type MFM tip is regarded as an infinitesimal magnetic dipole moment, which gives the maximum spatial resolution. In Figure , the z-axis represents the normal direction to the surface of the sample M. Let
denote the magnetic force gradient along the z direction at the position r, that is,
is an
-valued function corresponding to the signal amplitude of an MFM image at r. Then,
is given by the convolution integral of the point magnetic charge distribution
with
as
(2)
(2) where
runs through sample M,
and
Let
denote the magnetization of the MFM tip. In a real situation, both the magnetization components
and
are 0. In the following, we normalize
to 1, where
denotes the vacuum permeability. Then,
is represented by
(3)
(3) Note that
does not become ∞ because the MFM tip is far from the magnetic sample. Our (infinite-degrees-of-freedom) inverse problem requires determining the unknown distribution ρ from the observation data
Figure 1. MFM.
2.2. Simple discretization
Integral Equation (Equation2(2)
(2) ) is a linear Fredholm equation of the first kind. In general, the solution ρ is not unique for given data
(see [Citation2,Citation3]). In this study, as described in Section 1, we consider the following basic and ideal discretized problem of Equation (Equation2
(2)
(2) ) as a model problem of (Equation1
(1)
(1) ).
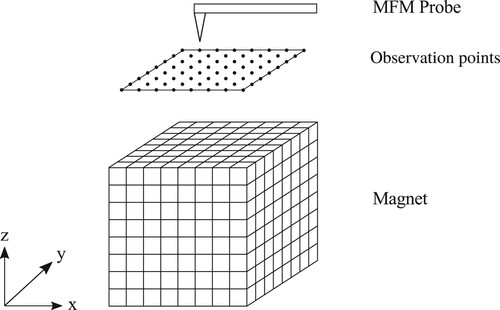
All magnetic samples are cuboids of the same size (see Remark 2.1).
Every magnetic sample is always on the same horizontal plane, and all the observation points are common to all samples.
The MFM probe tip can be considered as a point magnetic dipole.
Every magnetic sample is divided into small cubic cells as in Figure ; we call it cell discretization. Each cell or a set of several cells is a magnetic grain with single magnetic domain structure. (Although it is false if the boundary of a magnetic grain cuts the cell, we consider that it is limited to this case (see Experimental claim 4.3).) Every magnetic grain is magnetically isolated from the neighbouring magnetic grains by the non-magnetic boundary phase.
The length of each side of every cubic cell is normalized to 1.
The normalized value of the magnetic moment is 1 (upward) or
(downward) in each cell. (When a magnetic grain comprises several cells, the moments of those cells are oriented in the same direction.)
Remark 2.1
Further, if we discretize the space around the magnetic sample into cells, we do not need assumption (i). Then, assumption (ii) is ‘the normalized value of the magnetic moment is 1 (upward), (downward), or 0 (space) in each cell’. In this case, the estimation is more difficult than in the case of assumption (i) because the estimation is to select one out of three possibilities. However, it is known which cells are included in the space, that is, which cells have the 0-value moment. The difficulty is mitigated if the information can be used for estimation.
Figure 2. Cell discretization.
We let and
denote the total number of cells, the number of cells in the x-axis direction, in the y-axis direction and in the z-axis direction, respectively. Therefore,
and the cells can be numbered as
. Here, suffix
means that the position of the cell is ath in the horizontal (x –y plane) direction and bth in the vertical direction from the top. (The order in the horizontal direction is determined appropriately.)
Example 2.2
We consider the case of
and
Then, the numbering of cells is as shown in Figure .
Figure 3. Numbering cells.

Let denote the magnetic moment of cell
then,
(upward) or
(downward). We consider the magnetic charge of each cell, which is determined from its moment. If
then the values of charges are 1 and
at the top and bottom faces of cell
respectively. If
then the values of charges are
and 1 at the top and bottom faces of cell
respectively. The values of charges are zero inside each cell and at all vertical faces of each cell. In addition to assumption (vi), we assume
| (vii) | The values of the charge of the top/bottom face are centred at the centre point of the top/bottom face. | ||||
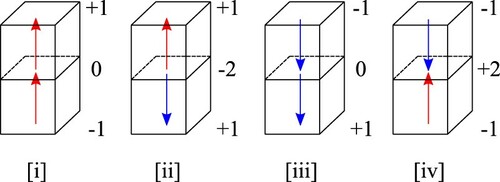
Next, we consider two vertically adjacent cells. The centre points of adjacent faces of these two cells are the same, and the value of the magnetic charge at this point is the sum of the values at the two adjacent centre points. Thus the value is , 0 or 2. Therefore, when the cell-discretized magnetic sample M comprises only two vertically adjacent cells, the possible values of charges are
,
, 0, 1 and 2. Figure illustrates the magnetic moments (up or down arrows) and charges in the four possible cases. Next, we consider the general case. By identifying overlapping points, the total number of the centre points of the top and bottom faces of all cells is given by
These points can be numbered as
…,
Here, suffix
of
means that the position of the charge is ath in the horizontal (x –y plane) direction and bth in the vertical direction from the top. The order in the horizontal direction is the same as that of the cells. Let
denote the magnetic charge at
Then,
or 2.
Figure 4. Magnetic moments and charges.
Let denote the number of the observation points, where we observe the values of
at these points. We number these points appropriately as
and we let
denote the value of
at
Next, we define
(4)
(4) This is a discretization of (Equation3
(3)
(3) ). Put
Thus, we have a discretized equation of (Equation2
(2)
(2) ),
(5)
(5)
The relationship between and
is as follows. Put
where
denotes the moment of
and
are
matrices such that
Then, we have
Thus our discretized (noiseless) inverse problem is now to solve the following system of linear equations:
(6)
(6) This equation is the same as Equation (Equation1
(1)
(1) ) with
and
Since each
is either 1 or
the total number of possible patterns that μ can take is
Let
be the set of the all patterns, that is,
Then, GR is a map from
to
We call
a moment vector. Since
is a finite set, GR may have the inverse map even if
We consider the discretized inverse problem (Equation6(6)
(6) ) under assumption (i)–(vii); however, the original inverse problem is (Equation2
(2)
(2) ). In the rest of this subsection, we consider the relationship between these two problems. Let
denote an observation area, that is, O is an area containing all the observation points. In Figure , O is a two-dimensional square. Let
and
denote appropriate norms of a function defined on O and M, respectively, e.g. they are the
norms. Then, for Equation (Equation2
(2)
(2) ), there exists C > 0 such that
for every ρ because
is bounded on
Only in the rest of this subsection, we denote the length of each side of every cell by Δ and write
as ρ,
as G, and
as f in the discretized Equation (Equation5
(5)
(5) ). We can consider that the vectors
and
are piecewise constant functions defined on O and M, respectively. (Note that the components of these vectors are labelled with
points in O and
points in M, respectively.) Then, we have
and
where
is the operator norm of
Note that
as
because the integral kernel of
is smooth, and there exists
such that
for every
because
Therefore, by using
we have a stability property:
as
and
This stability property ensures the validity of the discretized approximation of the ‘forward’ problem, that is, the problem of determining
from ρ. However, our inverse problem does not have such a stability property. We consider this in Section 4.2.
2.3. Selection of pieces of
In Section 1, we introduced the concept of a piece of Each piece of
is a subset of
and the sum of all pieces is
It is important to select pieces appropriately for problem (Equation1
(1)
(1) ). The properties that pieces are expected to satisfy are described in Sections 3.2 and 3.3. For the inverse problem (Equation6
(6)
(6) ), the following pieces (i.e. subsets) of
can be naturally obtained.
For a moment vector (
denotes the transpose) defined in Section 2.2 and
define
by
Consequently, the ith component of
is equal to the ith component of μ if the component is the magnetic moment of one of the ℓth cells vertically from the top of M, and otherwise, the ith component of
is 0. For example, the non-zero components of
correspond to the cells of the top surface of M. (Furthermore, see Example 2.3.) We define
and we call
the ℓth piece of
In particular,
and
are called the top piece and the bottom piece, respectively. Furthermore,
with a small value of ℓ is called an upper piece while
with a large value of ℓ is called a lower piece. Then, we have
(7)
(7) There exists a natural projection
where the symbol ⊕ denotes the direct sum of vector spaces or their subsets. However,
does not hold because μ does not have zero components and
has zero components.
Example 2.3
We consider the case of Example 2.2. The cells corresponding to the elements
are as shown in Figure . Then, for
we have
and
In this case, the sets of cells corresponding to nonzero components of
and
are
and
respectively.
In the following, we often identify a piece with the set of cells corresponding to it.
3. Inverse problem with a linear forward operator and a sequential estimation-removal method
In this section, we consider the general inverse problems of the form (Equation1(1)
(1) ).
3.1. Inverse problem with a linear forward operator
Let T,
and
be the integers, operators and set as described in Section 1. In the following, we aim to develop an estimation method for the inverse problems of the form (Equation1
(1)
(1) ) with
and
Since
is a finite set,
may be injective even if
Then, the inverse map
exists. However, it is often nonlinear as per the following lemma.
Lemma 3.1
Let L and be the linear subspaces spanned by
and
respectively. Assume that
and
is injective. Then,
cannot be extended to a linear map
Proof.
Since is linear, we have
If
has a linear extension, we have
Therefore,
Then,
is also injective. Hence,
This contradicts the assumption that
Even if T is not injective, there may exist subsets of
such that every
has a unique decomposition of the form:
and
can be uniquely determined by
For simplicity, we denote the map
(8)
(8) by
In general, the map
is also nonlinear. The set of all the vectors of the form of (Equation15
(15)
(15) ) below is an example of
(if
From Section 4 onward, we consider the (discretized) magnetization-distribution identification problem described in Section 2. It is an example of the above-mentioned inverse problem. In this problem, and (practically)
However, in some cases, the inverse map
exists and it is (practically) nonlinear. (The linear space L spanned by
is
Therefore,
and the nonlinearity of
is obtained using Lemma 3.1.) Therefore, it is difficult to solve the inverse problem by employing a linear algebra method. We aim to construct a map N that approximates
for example, by machine learning (deep learning). Further, this map N is expected to be as robust as possible to noise.
3.2. A sequential estimation-removal method
Machine learning is often computationally expensive. In the numerical experiments conducted on our magnetic inverse problem, the deep learning for constructing a neural network, stopped before the value of the loss function becomes small enough. (One of the reasons we think is described in Section 3.4.) Therefore, we divide the problem as follows. Let
and
be subsets of
such that, every
has a unique decomposition of the form:
(9)
(9) where
denotes the sum of vectors in
(see (Equation7
(7)
(7) )). As described in Section 2.3, there exists a natural projection
However,
may not hold, and we call
the ℓth piece of
If T is injective, there exists the inverse map N, i.e. Therefore, we can consider maps
such that
Moreover, for
with
it may be expected that the following holds:
If we have these maps, we can estimate μ as
This method independently estimates
and does not require the linearity of T. In the numerical experiments on our ill-posed magnetic inverse problem, this method was superior to the above-mentioned method that estimates μ at once. However, its performance was considerably inadequate even if
Therefore, we propose a reconstruction method (sequential estimation-removal method) based on the following idea:
Basic idea 3.2: A piece that can be accurately estimated should be estimated earlier.
In this method, we employ the linearity of T to solve the inverse problem (Equation1(1)
(1) ).
Let denote a norm on
To realize Basic idea 3.2, we expect that the pieces
are selected such that the value of
decreases as the value of ℓ increases. First, we expect that the selection satisfies
(10)
(10) for all
and
We call this property piece monotonicity. If this property cannot be obtained, we expect the following property holds:
For every
(Equation10
We call this property weak piece monotonicity. As described in Section 2.3, we call with a small value of ℓ an upper piece while
with a large value of ℓ a lower piece. In particular,
and
are called the top piece and the bottom piece, respectively. To realize Basic idea 3.2, we expect that a piece closer to the top piece can be estimated more accurately. In Section 4.3, it is experimentally shown that the pieces obtained in Section 2.3 for our magnetic inverse problem satisfy piece monotonicity for
with some
(see Table ) and weak piece monotonicity for
(see Table ). In Assumption 3.5, we will describe other properties that pieces are expected to satisfy, and in Section 3.3, we will describe some conditions for Assumption 3.5 to hold.
Example 3.3
We consider the case of the discretized magnetization-distribution identification problem described in Section 2. For example, in the same case of and
as in Examples 2.2 and 2.3, we consider
and
to be equal to each other as
-dimensional vectors.
We consider a reconstruction method based on Basic idea 3.2. First, we consider the case where and
that is, the well-posed case. For
and
given by (Equation9
(9)
(9) ), we define
Then,
Using the linearity of T, we have, for
and then,
and
Therefore, for
there exists
such that it outputs
to the input
i.e.
(11)
(11) Note that
does not give
but
from
Thus we can use
to obtain μ from a given f by the following procedure.
Procedure 3.4
Put
Calculate
Calculate
If
This procedure outputs
In this procedure, the pieces are estimated and removed one-by-one from the top. We call this method a sequential estimation-removal method.
In general, may not be equal to
and there exists some noise
in (Equation1
(1)
(1) ). Therefore, we may not execute Procedure 3.4. In this case, we aim to obtain as much information regarding μ as possible. In the following, we assume that, for every
there exists
such that
for
Set
Then,
and
are the sets of components of the ℓth and lower pieces of all possible observation data values for the case where
and
respectively. We have
and set
Here, considering that
is a finite set, we assume the following.
Assumption 3.5
(For the case where
There exist
(For the case where
There exist
In this assumption, may or may not be
If
Assumption 3.5 (i) always holds for
(see (Equation11
(11)
(11) )).
in (Equation14
(14)
(14) ) is an extension of
in (Equation13
(13)
(13) ) to the case where
Based on Assumption 3.5, Procedure 3.4 can be rewritten as follows.
Procedure 3.6
Suppose that Assumption 3.5 is satisfied.
Steps 1, 2 and 3 are the same steps in Procedure 3.4.
Steps 4 and 5 are steps 4 and 5 in Procedure 3.4, where
This procedure does not output μ. Instead, it outputs
(15)
(15) that is,
cannot be estimated. Even when we define maps that estimate them in some sense, the estimated results may contain errors.
In the experiments in Sections 5 and 6, we use Procedure 3.4 even if to test how deep (large ℓ) a piece our method can estimate. Deep learning in Section 5 and the iterative method in Section 6 can be formally applied even if
3.3. Selection of pieces of
We consider piece monotonicity and weak piece monotonicity to be a naturally expected property of pieces to realize Basic idea 3.2. To execute Procedure 3.6, we must obtain pieces …,
earlier and construct maps
…,
that satisfy Assumption 3.5. This assumption requires that the pieces satisfy some properties, which are somewhat different from (weak) piece monotonicity. This is considered here. Previous to it, we describe the stability/instability of the inverse problem (Equation1
(1)
(1) ). We distinguish the elements of
with a superscript index as
Let
denote a norm on
and
(16)
(16) If
then the inverse problem (Equation1
(1)
(1) ) with
has a unique solution, and
(17)
(17) holds for every
and
As the value of
increases, the stability of the inverse problem (Equation1
(1)
(1) ) increases. In fact, if
holds and
is sufficiently large, then the values of
and
are very different from each other.
For selecting pieces of we consider a sufficient condition for Assumption 3.5 to hold (Lemma 3.8) and make the same consideration as above for each piece. Previously, we consider the following lemma that provides a sufficient condition for Assumption 3.5 (ii) to hold.
Lemma 3.7
Let Assume that
(18)
(18) is satisfied for ℓ and every
Then, Assumption 3.5 (ii) holds for ℓ.
Proof.
Let
From (Equation18
(18)
(18) ), we have that, for every
with
Further,
Thus we have
Therefore, we can define
by
The value of the left-hand side of (Equation18(18)
(18) ) is determined by noise. We separate the noise-independent part from (Equation18
(18)
(18) ), that is, we consider an inequality for T that is similar to (Equation17
(17)
(17) ) for each piece in the following lemma. This is inequality (Equation19
(19)
(19) ). This inequality represents the difficulty of the estimation independent of noise.
Lemma 3.8
Let For ℓ, consider the conditions that there exists
such that
it holds that
it holds that
Put If and only if every
satisfies Lemma 3.8 (i), then Assumption 3.5 (i) holds. If every
satisfies Lemma 3.8 (i) and (ii), then Assumption 3.5 (ii) holds.
Proof.
The first case can be shown via a straightforward calculation. We show the second case. By employing (Equation19(19)
(19) ) and (Equation20
(20)
(20) ), we have
Therefore, (Equation18
(18)
(18) ) holds.
In Lemma 3.8, as the value of decreases, it becomes easier to distinguish between
and
To apply Lemma 3.8 to the inverse problem (Equation1
(1)
(1) ), it is desirable for us to know the value of
Define
(21)
(21) and
(22)
(22) Then, if
holds and inequality (Equation20
(20)
(20) ) can be rewritten as
(23)
(23) As the value of
increases, it becomes easier to distinguish between
and
In general, if the values of
are large, it may hold that the values of
are also large. Therefore, we expect piece monotonicity (otherwise weak piece monotonicity) holds.
Thus, the preparation procedure prior to Procedures 3.4 and 3.6 is given below. In the case where it is particularly useful if the range of values of
is approximately the same for
(Our discretized magnetization-distribution identification problem satisfies this property of this range.)
Procedure 3.9
| 1. | 1. Select | ||||
| 2. | 2. Construct a map | ||||
In step 2 of Procedure 3.9, such a neural network is a piecewise linear function and
is well defined for every
It is expected that
maps every g close to
to
that is, Assumption 3.5 holds approximately.
Since Assumption 3.5 provides the existence of only for
Procedure 3.6 may not accurately estimate
in general. If we attempt to estimate them, errors may occur. Moreover, the errors of the estimates made at the upper piece are transmitted to the lower piece.
3.4. Complexity/number of linear regions
Assume that pieces satisfy piece monotonicity or weak piece monotonicity. Then,
may be more difficult to estimate than
that is, for
the distinction between
and
may be more difficult to identify than the distinction between
and
Now, we sketch one of the reasons.
As an example, we consider the following case:
and
Figure illustrates this case. Set
and
We consider identifying
from (noiseless) observation data
If
is a neural network whose activation function is the rectified linear function, the identification performance of
depends on the number and shape of linear regions in the input space (see [Citation13]). Therefore, we consider using straight lines to identify
or
In the input space of
Next, we can distinguish between
Figure 5. Complexity
Thus, using our sequential estimation-removal method, we can identify (or
by one straight line twice. However, three straight lines are required to distinguish between
and
(e.g.
and
). Therefore, only one straight line is required to distinguish between
and
but three straight lines are required to distinguish between
and
directly from the observation values. These mean that
and
are ‘buried’ in
and
4. Some numerical analysis of our discretized magnetic inverse problem
4.1. ‘Practical’ rank of matrix G
We consider the rank of matrix G. As described below, a ‘practical’ rank of G is significantly low. Since the fractional value of (Equation4(4)
(4) ) for given
is usually not divisible and all components of G will be different from one another, the ‘exact’ rank of G probably will be full. However, in practice, two almost parallel row (or column) vectors should be considered to be exactly parallel. Thus we examine how parallel the row vectors of G are by applying the following procedure. (The modified Gram-Schmidt algorithm was used in implementing this procedure.)
Procedure 4.1
Let
denote the k-th normalized row vector of G. (If
is the kth row vector of G, then
where
denotes the Euclidean norm in
)
| 1. | 1. Let | ||||
| 2. | 2. Using the basis | ||||
| 3. | 3. Calculate
| ||||
| 4. | 4. If If | ||||
| 5. | If If | ||||
Remark 4.2
The distribution of given by Procedure 4.1 depends on the order of
specified by k. Step 2 determines this order except the selection of
In our numerical experiments, we set and recorded the values of
(
is the output). These values represent a ‘practical’ rank of G. In fact, if the value of
is below a certain threshold (for example 0.01), we consider that
belongs to the linear space spanned by
in our numerical calculations. Some results of experiments using this procedure are presented in Tables .
Table 1. ‘Practical’ rank of G (observation points: ).
Table 2. ‘Practical’ rank of G (Observation points: ).
Table 3. ‘Practical’ rank of G (observation points: ).
Table 4. ‘Practical’ rank of G (Observation points: ).
In these tables, ‘charge: ’ means that
magnetic charge points
are arranged as follows: 20 points in the x direction at intervals of 1, 20 points in the y direction at intervals of 1 and h points in the z direction at intervals of 1. Furthermore, ‘observation points:
’ has almost the same meaning. However, when
the interval in the x direction and that in the y direction are 0.5. In Tables , the distances between the top plane of charge points and the bottom plane of observation points are 1, 5 and 10 when the number of charges is
and
respectively. For example, the first row of Table means that the numbers of vectors
with
are 400, 21 and 9 in the cases of
and
respectively.
These experimental results illustrate that a ‘practical’ rank of G is significantly low. In the case of Tables , the numbers of observation points (the numbers of row vectors) are 400 1600, 1600 and 3200, respectively. When the height h of M is 6 or less, that is, when the number of charges of M is
or less, the ‘practical’ rank of G is almost the same irrespective of whether the number of observation points is 400, 1600 or 3200 (cf. [Citation3]). Moreover, based on the results of our experiments described in Section 5.3, even if the number of observation points was
the estimations were almost accurate up to the 5th piece. Therefore, it is hypothesized that having over 400 observation points is not considerably advantageous when using our sequential estimation-removal method. Our inverse problem is analogous to looking into the sea and identifying objects in it. The increase in the number of observation points does not considerably increase the amount of information. It is more difficult to identify objects that are at deeper positions (see Section 4.2).
4.2. Stability/instability
We discuss the stability/instability of our discretized inverse problem (Equation6(6)
(6) ). Some results of our numerical experiments on the distribution of
defined by (Equation16
(16)
(16) ) for T = GR are shown in Figure . In each histogram of Figure , the horizontal and vertical axes represent the ratio
and its frequency, respectively. As the value of
decreases, the difficulty of distinction between
and
increases. If and only if
we can distinguish between
and
Figure 6. Distributions of
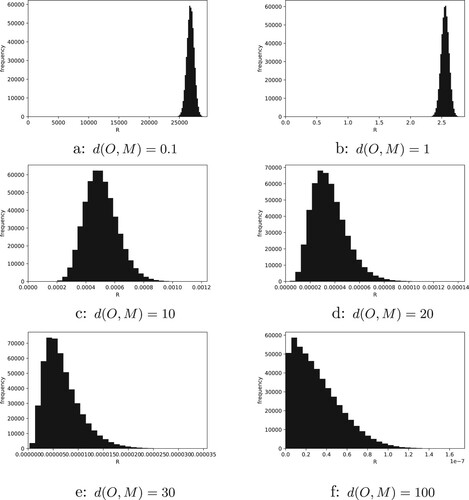
As shown in Figure , all the observation points are placed on the same horizontal plane in these experiments, and the number of observation points is equal to the number of cells in the horizontal direction, that is, The values of the parameters utilized are
and
Let
denote the distance between the horizontal plane O, where the observation points are placed, and the top surface of the magnetic sample M. In Figure , the values of
of Figures (a), (b), …, and (f) are 0.1, 1, 10, 20, 30 and 100, respectively. Note that the length of each side of every cubic cell is normalized to 1. Since the number of elements of
is very large, we did not conduct experiments on all pairs
but on randomly selected pairs. To provide details, we randomly selected 1000 magnetic moment vectors, and we calculated
for all (499,500 possible) pairs of these moment vectors, where the randomness means the following: the probability that the moment of each cell is 1 and the probability that it is
are both 0.5.
Let decompose and
such that
where
is an upper part and
is a lower part. Assume
then
(26)
(26) In such a case, we can also consider that
in Figure is the sum of the depth of the upper pieces and the distance between the horizontal plane O and the top surface of the magnetic sample M. Therefore, for example, we can consider that when we can estimate nine pieces from the top correctly, the histogram of Figure (c) represents the difficulty of estimating the pieces below them.
Thus the experimental results numerically illustrate that the magnetic moment distribution to a certain depth can be estimated from the MFM images, and the estimation becomes difficult as the depth increases. This property is independent of the choice of reconstruction method. One of the reasons for this difficulty is explained below. We consider two cells and
that are horizontally adjacent, and the ratio of distances from
and
(the centre points of the top faces of
and
) to observation point
i.e.
As points
and
become farther away from point
this ratio becomes closer to 1; consequently, the ratio
also becomes closer to 1, where
is the kj-component of G. Thus, using the observed value at point
it becomes difficult to distinguish between the case of
and that of
The above-mentioned experimental results on the distribution of are for a given discretization. Making the cell discretization finer is the same as reducing the size (the length of each side) of each cell. Let the size of cells, the interval between every pair of observation points, and the value of
be smaller at the same ratio; we denote this ratio by s. Then, the shape of the histogram of the distribution of
does not change. Therefore, the shape of the histogram when the size of cells and the interval between the observation points are both multiplied by s without changing
is the same as that of the histogram when only
is multiplied by
For example, we can consider the histogram f of Figure to be the histogram for the case where
the size of cells is
and the interval between the observation points is
This case is the 1/100 subdivision of the case b of Figure (for a magnet sample with
size). Similarly, we can consider cases c, d and e in Figure to be the
1/20 and 1/30 subdivisions of case b, respectively. Thus we have the following experimental claim.
Experimental claim 4.3
The inverse problem (Equation6(6)
(6) ) is unstable for cell subdivision. Therefore, assumption (vi) in Section 2.2 should hold with sufficient accuracy for some cell discretization. In other words, only such magnets can be considered.
This claim is compatible with the property that the solution ρ of integral Equation (Equation2(2)
(2) ) is generally not unique for given data
Procedure 3.4 needs Assumption 3.5, and from Lemma 3.8, Assumption 3.5 is related to defined by (Equation21
(21)
(21) ) and
defined by (Equation22
(22)
(22) ). If
in (Equation26
(26)
(26) ), we have
Some further experimental consideration for
is described in Section 4.3.
4.3. Properties of the pieces of defined in Section 2.3
We consider some properties of the pieces of
defined in Section 2.3 for the case where
(Tables , and ) or
(Tables , and ),
and
We numerically calculated the minimum and average of
(defined by (Equation21
(21)
(21) )), the minimum and maximum of
and the minimum and average of
where
as
-dimensional vectors.
Table 5. Minimum and average of
.
Table 6. Minimum and average of
.
Table 7. Minimum and maximum of
Table 8. Minimum and maximum of
Table 9. Minimum and average of
.
Table 10. Minimum and average of
.
First, for each ℓ we randomly selected 1000 magnetic moment vectors, and we calculated
for all (499,500 possible) pairs of those moment vectors as in the case of Figure . The experimental results of the minimum and average of
are shown in Tables and , where the values are multiplied by 1000 and the fourth digit from the top of each value is rounded off. In the cases of this section, the results of Tables and numerically imply
where
Therefore, from Lemma 3.8 (i) and (Equation22
(22)
(22) ), there exist
of Assumption 3.5 (i) and inequalities (Equation24
(24)
(24) ) satisfy for
However, if the true value of
is smaller than the calculation error, then
may not be obtained by any method.
Next, for each ℓ we randomly selected 10,000 magnetic moment vectors, and we calculated the minimum and maximum of
The experimental results are shown in Tables and , where the values are multiplied by 1000 and the fourth digit from the top of each value is rounded off. Tables and numerically illustrate that piece monotonicity holds for
when
and for
when
When the Green function
of (Equation3
(3)
(3) ) becomes
Therefore, roughly speaking, the values in Tables decrease proportionally to
Next, for each ℓ we randomly selected 10,000 magnetic moment vectors
where
as
-dimensional vectors, and we calculated the minimum and average of
The experimental results are shown in Tables and , where the fourth digit from the top of each value is rounded off. Tables and numerically illustrate that weak piece monotonicity holds for
in the cases considered in this subsection.
Thus, we have the following.
Experimental claim 4.4
As the value of ℓ increases, all the values in Tables – decrease. These tables show numerically that the above-mentioned selection of approximately satisfies the properties in step 1 of Procedure 3.9. Therefore, we consider the selection is appropriate.
This will be correct if we somewhat change the values of
and
4.4. Conclusion of this section
Based on the experimental results of this section, it is possible that and
exist. Then,
is not linear, and it is difficult to solve our inverse problem using a linear algebraic approach. In the following sections, we aim to estimate the magnetic moments as much as possible using our sequential estimation-removal method. In Sections 5 and 6, we utilize assumption (i)–(vii) of Section 2.2. However, the results of this section indicate that the performances of
(Section 5) and the iterative method (Section 6) decrease as ℓ increases. Furthermore, the results of our numerical experiments described in Sections 5 and 6 are compatible with that. One of the reasons is the performance limit of our personal computer (PC); however, it is impossible to estimate magnetic moments at deep positions accurately using any method. In general situations where assumptions (vi) and (vii) are not satisfied, the problem becomes even more difficult.
5. Deep learning and experimental results
To solve the discretized (nonlinear) binary inverse problem (Equation6(6)
(6) ), we consider two numerical methods using Procedure 3.4 with Procedure 3.9. (As described at the end of Section 3.2, we used Procedure 3.4 in the following experiments.) One method is to construct a neural network, such as
while the other method is to employ an iterative algorithm as an approximate
We study the former method in this section and the latter method in the next section. Since f can be easily calculated for any given μ using (Equation6
(6)
(6) ), we can obtain numerous training data. Deep learning of a neural network requires a high computational cost. However, when such a neural network is obtained, it can be applied with a lower computational cost than that of an iterative method. In this and the next sections, we use assumption (i)–(vii) provided in Section 2.2 and the following setting of experiments.
Setting 5.1 As shown in Figure , all the observation points are placed on the same horizontal plane, and the number of observation points is equal to the total number of cells in the horizontal direction, that is,
This setting is based on the results of Section 4.1. In the following experiments, the sizes of
and data are attributed to the performance limit of our PC, especially its memory size (see Table ).
Table 11. Execution environment.
5.1. Structure of neural networks
Based on Setting 5.1, ‘the number of nonzero components of ’
for every ℓ. Therefore, in a neural network
the number of input nodes and that of output nodes are both equal to
We consider our discretized inverse problem to be a type of image classification problem and construct each
using a convolutional autoencoder provided by Keras/Tensorflow (see [Citation14]). (In our numerical experiments, we did not assume any structure for the magnetic moment configurations of the training data; however, if it had some geometrical structure, a convolutional auto encoder would be more effective. Furthermore, if we could construct a neural network suitable for such a geometrical structure, it would be even more effective.)
In our numerical experiments, we set
and
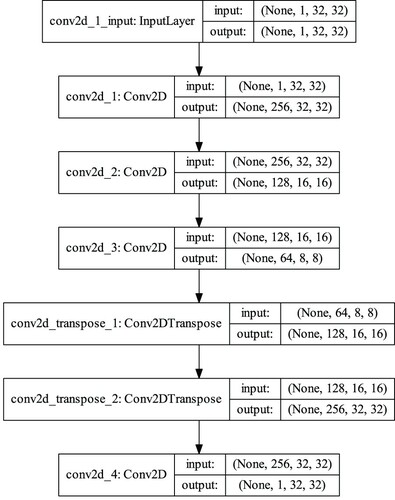
Then, the structure of each
is shown in Figure . This figure was drawn by the plot_model function of the keras.utils module. In our experiments, the values of parameters are as follows:
Size of the kernel:
Strides:
Padding: 0 padding in all layers;
The number of filters, as depicted in Figure , that is, 256.
Figure 7. Convolutional auto encoder.
The activation function is the linear function (the identity function) in the output layer and the rectified linear function in the other layers. Each input node corresponds to the observation value at each observation point. Each output node corresponds to the magnetic moment of each cell. In the training, the loss function is the mean squared error function (Equation25(25)
(25) ) (see [Citation15]). In the tests, it is considered that the value of the magnetic moment is 1 if the output value is greater than 0, and
if it is less than 0.
Remark 5.2
We consider for
where
and
denote the set of all possible
Note that the maximum possible number of the elements of
equals the number of all possible
i.e.
for every
For matrix G defined in Section 2.2, we put
where the size of
is the same as the size of G and
As described in Section 4.1, the ‘practical’ rank of G is smaller than
and the ‘practical’ rank of
decreases rapidly as ℓ increases. Therefore, the ‘practical’ dimension of the space spanned by
decreases as ℓ increases. In general, if
is a d-dimensional hyperplane arrangement that consists of m hyperplanes in general position, the number of regions of
is given by
(see Proposition 2.4 of [Citation16]). Therefore, when using hyperplanes to distinguish
it is almost certain that more hyperplanes will be required as ℓ increases. In other words, the size of neural network
almost certainly have to increase as ℓ increases (cf. [Citation13]). However, we used
depicted in Figure for every ℓ because of the performance limit of our PC.
5.2. Deep learning
In our numerical experiments, unless otherwise noted, we set
the length of each side of every cubic cell of the (discretized) magnetic sample M to 1, and
to 1. The number of elements of
was
and we randomly chose elements
from
to make training data
Such a moment vector μ can be obtained as follows.
Set
Change
Making a neural network is more difficult, as the problem is more complex. Therefore, in our numerical experiment, we set r to be a fixed constant instead of a variable. Then, neural networks with several reversal rates may be used to estimate magnetization, and the estimation result closest to the observed data may be adopted. (In the actual experiments, we can apply a vibrating-sample magnetometer (VSM) to measure the magnitude of the overall magnetic moment of the sample, that is, to measure the reversal rate.) We consider the simple and fundamental case where it is randomly determined which cell moments are reversed. (In the ideal high-performance magnet, the orientation of the moments of the magnetic grains are approximately independent of each other.) Therefore, in our numerical experiment, we made the reversal rate common to all μ. Its value was 0.1, 0.3 or 0.5 (we considered these three cases); we made training data comprising 8000 pairs for each reversal rate. In deep learning, we employed Adam to update weights, where the values of the parameters of Adam were the default values given in [Citation17] (cf. [Citation18]).
In the noiseless cases, we expected based on the experimental analysis in Section 4 (see Remark 5.3). Let
be the obtained neural network by using the training data of reversal rate s, where
and
In our experiments, to examine the performances of these neural networks, we randomly generated a set of test data
consisting of 2000 pairs with fixed reversal rates r = 0.1, 0.2, 0.3, 0.4 and
Let be a set of some reversal rates (in our experiments,
) and assume that we made
When an observation values vector f is given, we calculate
and put
Then, we consider that
is the most appropriate neural network in
for estimating μ such that
for the given f.
The execution environment of our experiments is presented in Table .
5.3. Experimental results of the noiseless cases
The relationship between the theoretical consideration in Section 3, the experimental analysis in Section 4, and the following experimental results is described in Remark 5.3.
For the generated noiseless test data with the reversal rates
and
the rates defined by
are summarized in Table , respectively.
Table 12. Reversal rates.
The estimation performances of
and
are presented in Table . There were
cells in each piece, and the set of test data
consisted of 2000 pairs. Therefore,
magnetic moments should be estimated. In Table , rate r is the reversal rate of the test data and rate s is the reversal rate of
and
means that s is
of Table . The values in Table illustrate what percentage of these 2,048,000 moments were correctly estimated. These values are rounded off to three decimal places. Therefore, 1.000 means a value of 0.9995 or more. Table shows that, up to the 5th piece, the estimations were almost accurate if
Table 13. Estimation performances of each rate.
Further, we conducted experiments in the cases of and
The experimental results when
are illustrated in Table . In the cases of
and
the training of
did not perform well. We consider the reason is as follows. Let
be the observation points and
be the magnet charge points on the top surface of the magnet sample described in Section 2.2. If
and
then
In this case, we have
Therefore, if
is too small, the numerical calculation for estimating the top peace will be unstable. Consequently, in the cases of
and
the performance of
will be considerably poor. The estimation of the top piece fails, then the estimation of the second piece and below also fails. In such a case, it may be appropriate to change the unit of length.
Table 14. Estimation performances of each .
In the case of the estimation performance was the highest, and the estimation performance decreased as the value of
increased. However, even if
the estimation performance of the pieces below the 6th piece was low.
As described in Section 4.2, it is more difficult to estimate magnetic moments at deeper positions. To estimate such difficult-to-identify moments, a sufficiently large neural network and enough training data will be required. Owing to the limitations of our execution environment, we cannot enlarge the neural networks or increase the training data beyond in the above-mentioned experiments. However, in connection with this, we conducted the following experiment: the case of
and the number of filters
were 256 or 512. In the case of
the degree of freedom of the neural network is higher than that of the above-mentioned experiments. Both the reversal rates of the training data (8000 pairs) and the test data (2000 pairs) were 0.5. In this case, since the size of the neural networks is smaller than that in the above-mentioned experiments, we can consider that there are relatively more data. The experimental results are presented in Table . The experimental results of the
case are also listed again for reference, and these three results are similar. As described in Remarks 5.2 and 5.3, a larger neural network may be required as magnetic charges are at deeper positions.
Table 15. Estimation performance for the size of the problem and the number of filters.
In our sequential estimation-removal method, the errors of the estimates that are made at the upper pieces are transmitted to the lower pieces. Thus the neural networks for the lower pieces cannot perform well. This is unavoidable, but if no error occurs in the upper pieces, then the estimation results by using
are better. In the case of
and
the estimation performance of
is shown in Table based on the assumption that no error occurred in the upper pieces. In these experiments, the reversal rates were common to the training data and test data
Table 16. Estimation performance when no error occurs in the upper pieces.
Remark 5.3
According to the experimental results in Tables and in Section 4.3, it is expected that holds for all possible pairs
and
We assume this is true; then, it is theoretically possible to estimate up to the piece of
However, the performance of the neural networks in our experiment are insufficient to estimate the pieces after
It is known that an arbitrary function can be approximated with an arbitrary accuracy using a sufficiently large neural network. Therefore, if sufficiently large neural networks are used, it is expected to be able to estimate the pieces of
However, the authors do not know how large neural networks should be used. Furthermore, even if the minimum value
is positive,
may not be obtained if
is smaller than the calculation error.
5.4. Experimental results on cases with noise
In this section,
and
We used neural networks of
Table presents the experimental results for cases where the data contain noise. The description of the experimental results for 6–10 pieces are omitted. Let
be a noiseless observation values vector,
and set
Let
denote a uniform random number in the interval
Then, in Table , the noised value
was made by
where
and
(The actual MFM measurement error is typically estimated to be within 1 %.) As can be seen from this table, the estimation is extremely difficult when there is noise. We discuss how to avoid this difficulty somewhat in this section and Section 7.
Table 17. Estimation performance for cases with noise.
We roughly estimate the size of which satisfies inequality (Equation23
(23)
(23) ). When
the right-hand side of (Equation23
(23)
(23) ) is minimized if there is only one difference between the components of
and the components of
Then, since the right-hand side of (Equation23
(23)
(23) ) equals
(Equation23
(23)
(23) ) becomes
(27)
(27) From Lemma 3.8 (ii), if (Equation27
(27)
(27) ) holds, then Assumption 3.5 (ii) is satisfied.
In the above numerical experiment, a noise of up to 0.0005 times or 0.005 times the average of the components of f were added to
Therefore,
(28)
(28) Assume
were estimated correctly. Then, for (Equation27
(27)
(27) ) to hold, the value of the right-hand side of (Equation28
(28)
(28) ) must be approximately smaller than the value of
The minimum of
in Table roughly approximates to
From Table ,
Therefore,
In the case where the size of noise is 0.01, (Equation27
(27)
(27) ) holds only for
and in the case where the size of noise is 0.001, (Equation27
(27)
(27) ) holds only for
For ℓ other than these, unique identification is not theoretically guaranteed. However, Lemma 3.8 (ii) gives only a sufficient condition, and from Table , it seems that the moments of a few more pieces can be identified uniquely.
6. Iterative method and experimental results
In this section, we apply an iterative method to approximate of Procedure 3.4. This iterative method is a simple version of Murray–Ng's global smoothing algorithm proposed by [Citation19].
6.1. A simple version of Murray–Ng's global smoothing algorithm
For a given data f, define
Then, our inverse problem is as follows:
Problem 6.1
Minimize subject to
A minimizer of E restricted to is called a binary minimizer. Linear map GR can be naturally extended to a map on
We use this extension in our calculations to obtain a binary minimizer. This approach is called a continuation or continuous approach (see [Citation20,Citation21]). For an algorithm that can perform this, we utilize a simple version of the global smoothing algorithm (GSA) proposed by [Citation19] and [Citation21]. The GSA is an excellent Newton-type iteration algorithm that can be employed for binary optimization problems based on the continuation or continuous approach.
For the extended objective function E on we define
(29)
(29) where η and γ are positive real values. In this iterative algorithm, the starting point
of the iteration must be selected from
and first, we consider large η and small γ. Then, we calculate an approximate minimizer in
of
using an iteration. Next, we make η slightly smaller
and γ slightly larger
and using the obtained approximate minimizer as the new starting point, we calculate an approximate minimizer of
again. The same calculation is repeated while making η smaller and γ larger. In this iteration, the second term of (Equation29
(29)
(29) ) locks μ in
and the third term of (Equation29
(29)
(29) ) brings μ closer to
In the kth step of the iteration of GSA to obtain an approximate minimizer of we must solve the equation
to obtain a vector
as a search direction. To solve this equation, we adopt the minor iteration of [Citation22], p.194, as the conjugate gradient algorithm. It is simpler than Algorithm 5.1 of [Citation21].
6.2. Experimental results
As in Section 5, we utilize assumption (i)–(vii) in Section 2.2 and Setting 5.1. In our numerical experiments, we set and (a)
(b)
and the data were noiseless. We conducted (a) 30 experiments, (b) 10 experiments, for each of the following reversal rates: 0.1, 0.3 and 0.5; the experimental results are shown in Tables and . The values in these tables illustrate what percentage of (a)
magnetic moments, (b)
magnetic moments were correctly estimated.
Table 18. Estimation performance of the iteration method ().
Table 19. Estimation performance of the iteration method ().
In our numerical experiments, the parameters of GSA utilized are as follows:
and
(The symbols other than η are the same as those in [Citation19], and η corresponds to μ in [Citation19].) The starting point was
These values of
and
were the same as those in [Citation19] or 6.2.4 of [Citation21] (cf. Table 5.1 of [Citation21]), and the values of the other parameters were determined based on experiments for several small magnets. We compare the experimental results listed in Table with those listed in Table . According to the results in Tables and , the value of s that minimizes the value of
for the observed value f is probably
Therefore, in comparison, we use
in Table . Then, the results in Table are not better than the results in Table . However, the performance of GSA considerably depends on the values of the parameters.
7. Results and discussion
To solve the discretized magnetization-distribution identification problem, we used the neural networks and an iterative method with our sequential estimation-removal method. The results of numerical experiments showed that the discretized magnetization can be roughly estimated up to a certain depth by applying our method as described in Sections 5 and 6. We aimed to estimate the magnetic moments as much as possible, and therefore, the difficulty of estimating this ill-posed problem was highlighted, as described in Sections 4–6. In our experiments, we used randomly generated artificial training data, and we did not apply any regularization or any Bayesian prior distribution. To obtain higher accuracy estimates from actual (noised) data, training data that approximates the actual magnetic moment configurations should be used; further, some regularization or some Bayesian prior distribution that represents the actual magnetic moment configurations should be applied. To perform these, we must consider the following.
It is important to have a deep knowledge of real magnets.
Based on Basic idea 3.2, we divided the target magnet virtually and consequently localized the problem. On the other hand, regularization/Bayesian prior distribution and realistic magnet data are related to the global structure of the target magnets. We must combine these two perspectives.
These are future issues for us. However, we expect that our methods and ideas described in Sections 2 and 3 can be applied to solve our magnetization-distribution identification problem and some other inverse problems of the form (Equation1(1)
(1) ), e.g. the inverse gravimetric problem (gravity prospecting problem). This problem is to determine the location and shape of subterranean bodies from gravity measurements at the earth's surface, and in general, it is an ill-posed inverse problem (cf. [Citation23,Citation24]).
Here, we describe a two-dimensional model of an inverse gravimetric problem. Let the x-axis be the horizontal axis, the z-axis be the vertical axis, and the line z = 0 be the ground surface. Let and c be real numbers, where a<b and
and put
Let
denote the distribution of mass. Then, the gravitational force
produced by the mass in D is given by
where γ represents the gravitational constant. An inverse gravimetric problem is to estimate
from observation data
in an observation area
where
and
under some appropriate conditions. Assume that D comprises cubic cells like as Figure and
is constant in each cell. Then, it is easily shown that this inverse problem satisfies weak piece monotonicity. We expect that our methods can be applied to solve this problem.
Acknowledgments
The authors are most grateful to Professor Hitoshi Saito (Akita University) for his valuable discussion and advice. The authors also appreciate the helpful comments from the anonymous reviewers.
Data availability
All the data sets used in this study were randomly generated.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Leyva-Cruz JA, Ferreira ES, Miltão MSR, et al. Reconstruction of magnetic source images using the Wiener filter and a multichannel magnetic imaging system. Rev Sci Instrum. 2014;85:074701.
- Mallinson J. On the properties of two-dimensional dipoles and magnetized bodies. IEEE Trans Magn. 1981;17:2453–2460.
- Vellekoop B, Abelmann L, Porthun S, et al. On the determination of the internal magnetic structure by magnetic force microscopy. J Magn Magn Mater. 1998;190:148–151.
- Saito H, Chen J, Ishio S. Description of magnetic force microscopy by three-dimensional tip green's function for sample magnetic charges. J Magn Magn Mater. 1999;191:153–161.
- Cao Y, Kumar P, Zhao Y, et al. Active magnetic force microscopy of Sr-ferrite magnet by stimulating magnetization under an AC magnetic field: direct observation of reversible and irreversible magnetization processes. Appl Phys Lett. 2018;112:223103.
- Cao Y, Zhao Y, Kumar P, et al. Magnetic domain imaging of a very rough fractured surface of Sr ferrite magnet without topographic crosstalk by alternating magnetic force microscopy with a sensitive FeCo–GdOx superparamagnetic tip. J Appl Phys. 2018;123:224503.
- Saito H, Ikeya H, Egawa G, et al. Magnetic force microscopy of alternating magnetic field gradient by frequency modulation of tip oscillation. J Appl Phys. 2009;105:07D524.
- Chang T, Lagerquist M, Zhu JG, et al. Deconvolution of magnetic force images by Fourier analysis. IEEE Trans Magn. 1992;28:3138–3140.
- Hsu CC, Miller CT, Indeck RS, et al. Magnetization estimation from MFM images. IEEE Trans Magn. 2002;38:2444–2446.
- Madabhushi R, Gomez RD, Burke ER, et al. Magnetic biasing and MFM image reconstruction. IEEE Trans Magn. 1996;32:4147–4149.
- Rawlings C, Durkan C. The inverse problem in magnetic force microscopy (MFM) – inferring sample magnetization from MFM images. Nanotechnology. 2013;24:305705.
- Zhao T, Fujiwara H, Mankey J, et al. Reconstruction of in-plane magnetization distributions from magnetic force microscope images. J Appl Phys. 2001;89:7230–7232.
- Montúfar G, Pascanu R, Cho K, et al. On the number of linear regions of deep neural networks. In: Ghahramani, Z, Welling, M, Cortes, C, editors. NIPS'14 Proceedings of the 27th International Conference on Neural Information Processing Systems, Vol 2; MIT Press: Cambridge, USA; 2014. p. 2924–2932.
- Keras Google group. Keras Documentation. https://keras.io/ (accessed on 11 December 2019).
- Keras Google group. Keras losses source. https://github.com/keras-team/keras/blob/master/keras/losses.py (accessed on 9 October 2018).
- Stanley RP. An Introduction to Hyperplane Arrangements. 2006. https://www.cis.upenn.edu/∼cis610/sp06stanley.pdf (accessed on 28 October 2019).
- Keras Google group. Keras optimizer source. https://github.com/keras-team/keras/blob/master/keras/optimizers.py#L392 (accessed on 9 October 2018).
- Kingma DP, Ba JA. A method for stochastic optimizer. Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015); San Diego, USA, 2015; pp. 1–15.
- Murray W, Ng KM. An algorithm for nonlinear optimization problems with binary variables. Comput Optim Appl. 2010;47:257–288.
- Mitchell JE, Pardalos PM, Resende GC. Interior point methods for combinatorial optimization. In: Du DZ, Pardalos PM, editors. Handbook of Combinatorial Optimization, Vol 1; Kluwer Academic Publishers: Dordrecht, Netherlands; 1999. p. 189–298.
- Ng KM. A continuation approach for solving nonlinear optimization problems with discrete variables [PhD thesis]. Stanford: Dept. Management Science and Engineering of Stanford Univ., 2002.
- Dembo RS, Steihaug T. Truncated-Newton algorithms for large-scale unconstrained optimization. Math Program. 1983;26:190–212.
- Groetsch CW. Inverse problems in the mathematical sciences. Braunschweig-Wiesbaden: Friedr. Vieweg & Sohn; 1993.
- Sampietro D and Sansò F. Uniqueness theorems for inverse gravimetric problems. In: Sneeuw N, et al., editors. VII Hotine-Marussi Symposium on Mathematical Geodesy, International Association of Geodesy Symposia 137. Springer-Verlag: Berlin, Heidelberg; 2012. p. 111–115.