
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider two insurance companies with wealth processes given by independent Brownian motions with controllable non-negative drift. The drift rates sum up to 1. The companies aim at finding a strategy for the drift rates to maximize the probability that at least one of them survives forever. We prove that the strategy, where the company with higher wealth obtains the maximal drift rate, is optimal. Our result differs considerably from the numerical result of McKean and Shepp in [H.P. McKean and L.A. Shepp, The advantage of capitalism vs. socialism depends on the criterion, J. Math. Sci. 139(3) (2006), pp. 6589–6594].
Furthermore, we numerically obtain candidates for the optimal strategy if the common aim of the two companies is to maximize a convex combination of the probability that both firms survive and the probability that exactly one firm survives forever. Our numerical results indicate that in general it is optimal to assign the maximal drift rate to one company but whether it is the company with higher or less wealth depends on the size of both wealth processes.
2020 MSCS:
1. Introduction
We consider two insurance companies whose wealth processes are given by independent Brownian motions with controllable non-negative drift, where the drift rates sum up to 1. The controller aims at maximizing the probability that at least one of the firms survives forever, i.e. that the wealth process of at least one company never falls below zero.
We now present two different economic interpretations: in the first, given by McKean and Shepp in [Citation20], a government can influence the drift rates of the wealth processes by a certain tax policy which allows for a total drift of 1. Here the aim of the government is that at least one firm should survive. In the second, two companies collaborate by transfer payments, which are assumed to be absolutely continuous with respect to the Lebesgue measure and to be bounded, and thus, the companies can control the drift rates to maximize the probability that at least one of them survives (see [Citation11, Section 2] for more details). The collaboration of two companies was considered in Actuarial Mathematics recently with different objectives, e.g. to maximize expected discounted dividends until ruin, see, e.g. [Citation10,Citation16], or to maximize the joint survival probability, see, e.g. [Citation1,Citation11].
To maximize the probability that at least one company survives, we show that it is optimal to choose the strategy, where the company with higher wealth obtains the maximal drift rate. This strategy is called push-top strategy. Of course, since one firm should survive and nothing is gained if in addition also the other firm survives, it seems very reasonable that the push-top strategy is optimal, but we are not able to give a simple proof. If one could identify the value function of this control problem as in [Citation20] or [Citation11], then it would be easy to deduce the optimal strategy.
In our proof, we show that the positive quadrant can be separated into two connected sets, where on the one set the drift is fully assigned to one company and on the other set the other company receives the maximal drift rate 1. These two sets are separated by a - curve, which turns out to be the first median because the control problem is symmetric in the initial wealth and the same drift rates are implementable for both firms. Moreover, identifying on which of these sets the first company obtains the maximal drift rate, we conclude that push-top is optimal.
To prove that the positive quadrant can be separated in this way, we follow the ideas and arguments from [Citation13], where the maximal joint survival probability of two companies with wealth processes given by Brownian motions with different volatilities and controlled non-negative drift is analyzed. Maximizing the joint survival probability or equivalently minimizing the ruin probability is a more common objective than maximizing the probability that at least one firm survives. In particular, if the Brownian motions have the same volatility and the drift rates can take values in the same bounded interval, for maximizing the joint survival probability it is optimal to use the so-called push-bottom strategy, where the company with less wealth receives the maximal drift rate, see [Citation20]; and [Citation11] for the case where only transfer payments are admissible for which each company keeps a given minimal positive drift rate. Also if the Brownian motions are correlated the push-bottom strategy is optimal, cf. [Citation14]. If the volatility of one process is small compared to the other one, methods from singular perturbation theory allow to explicitly provide a function which approximates the value function arbitrarily well. An admissible strategy with target functional
exploits the separation of the state space into two connected sets, where on each set exactly one firm has maximal drift rate, and the non-linear separating
- curve can be stated explicitly, cf. [Citation12].
Furthermore, as in [Citation20], we consider a more general problem where we assign different weights to the probabilities that exactly one or both firms survive forever. More precisely, the two firms aim at choosing an optimal allocation of the available drift rate to maximize a convex combination of the probability that both firms survive forever and the probability that exactly one firm survives. Their target functional is given by
(1)
(1) for
. Here we require that
because for
it is better if exactly one firm survives instead of both, which seems unnatural in our economic interpretation. Note that (Equation1
(1)
(1) ) is equal, up to a factor, to a convex combination of the probability that at least one company survives and the probability that both survive. In particular, the problems of maximizing the joint survival probability and the probability that at least one firm survives forever are obtained from (Equation1
(1)
(1) ) for
and
. Moreover, for
we obtain the problem of maximizing the expected number of surviving firms and even more generally, (Equation1
(1)
(1) ) covers the problem of maximizing the γ - moment of the number of surviving firms (up to a factor) with
for
. In [Citation20], McKean and Shepp show that the push-bottom strategy is optimal for
and for
we prove in this paper that push-top is optimal. Using policy iteration and successive over-relaxation, we numerically derive candidates for the optimal strategy for different
. Our results suggest that except for
and
it is optimal to use push-top if both wealth processes are sufficiently small and to implement push-bottom whenever at least one wealth process is large enough. Here the notion of small and large depends on α. Nevertheless, we observe that the region where push-top seems to be optimal is increasing in α.
Even though the ruin probability is one of the most important evaluation criteria for insurance companies, the literature dealing with two or more companies is rather scarce. In [Citation7], simple bounds for the ruin probability in a two-dimensional model are obtained by using results from the one-dimensional case. The Laplace transform in the initial endowments of the probability that at least one company is ruined in finite time in a two-dimensional Cramér–Lundberg model, where claims and premia are divided in some fixed proportions, is derived in [Citation2]. Using techniques of convex analysis, Collamore [Citation8] investigates the probability that a d-dimensional discrete process hits a d-dimensional set A and derives some large deviation results. For specific choices of the set A the hitting probability can be interpreted as a ruin probability. In [Citation3], the asymptotic behaviour of the ruin probability if the initial endowments tend to infinity along a ray under a light-tails assumption on the claim size distribution is analyzed with the help of a change of measure and one-dimensional results.
The paper is organized as follows. In Section 2, we introduce our model. Before proving that the push-top strategy is optimal in Section 3.3, we provide regularity results for the value function (see Section 3.1) and show that the positive quadrant can be divided into two simply connected sets, where on one set the first company receives the maximal drift rate whereas the maximal drift rate is assigned to the second company on the complement (see Section 3.2). In Section 3.4, we discuss some of our model assumptions. Finally, in Section 4, we present candidates for an optimal strategy in a more general problem and explain how we derived them numerically.
2. The model
We consider the following two-dimensional controlled ruin problem. The wealth processes and
of two companies are described by the corresponding two-dimensional stochastic process
with
(2)
(2) where
denote the initial wealth of the companies,
is a two-dimensional Brownian motion and
with
is the control process.
Denote by the positive quadrant and let
and
be the rays forming the boundary of G. We first define the ruin time of the first and second company when the control u is used, respectively; more precisely, let
where we use the convention that
. Furthermore, let
be the first time at which one of the companies respectively both companies are ruined, where
and
for
. To define the process
for all times, we set
Our set of admissible controls
is given by
where
denotes the closure of G in
. In particular, for a strategy
it is sufficient to specify
on G, which is done in the following without further mentioning.
By [Citation24], the stochastic differential equation (Equation2(2)
(2) ) has a unique solution for all admissible strategies
. In addition, we only allow for strategies such that a total drift of 1 is divided between both companies as long as no company has been ruined, i.e. both wealth processes have been positive so far. If one company is ruined, then the maximal drift rate 1 is assigned to the surviving company and if both companies are ruined, the drift is set to 0 afterwards.
Our aim is to maximize the probability that at least one company survives forever, i.e. our target functional is
and the value function is
(3)
(3) The Hamilton–Jacobi–Bellman (HJB) equation and the boundary conditions for the optimal control problem (Equation3
(3)
(3) ) are given by
(4)
(4)
(5)
(5) For the first two boundary conditions in (Equation5
(5)
(5) ), we use that the probability that a Brownian motion with unit drift starting in z never hits zero equals
, see formula 1.2.4(1) in part II, chapter 2 in [Citation6].
Moreover, if V is sufficiently smooth we can deduce that an optimal strategy
for
with
is given by
where for
(6)
(6) In this paper, we show that it is optimal to choose the strategy, where the company with higher wealth obtains the maximal drift rate. This we call the push-top strategy. More precisely,
Theorem 2.1
The optimal strategy for (Equation3
(3)
(3) ) is given by the push-top strategy, i.e.
where
We prove Theorem 2.1 in the following section with the help of several propositions and lemmas.
Remark 2.2
To prove Theorem 2.1, we show
And hence, by (Equation6
(6)
(6) ) we conclude that
.
Remark 2.3
The function from Theorem 2.1 defining the optimal strategy
is unique up to changes on the set
. Indeed, we can change the definition of
on
and obtain indistinguishable processes
,
, because with probability one the set
has Lebesgue measure zero, for details see Appendix C in [Citation4].
Remark 2.4
Observe that if we maximize the probability that both firms survive forever, i.e.
(7)
(7) then McKean and Shepp show in [Citation20] that
and it is optimal to implement the strategy, where the company with less wealth receives the maximal drift rate 1, i.e.
with
is optimal in (Equation7
(7)
(7) ). The strategy
is called push-bottom strategy.
Remark 2.5
McKean and Shepp [Citation20] also consider the problem of finding an optimal strategy maximizing the probability that at least one company survives ( in their setting). Using numerical methods they obtain a region close to the origin where push-top is chosen and push-bottom is used if the wealth of at least one company is sufficiently large, see Figure 2 in [Citation20]. Note that their result contradicts our Theorem 2.1.
3. The optimal strategy for the drift rates
In this section, we prove Theorem 2.1. Our main steps are:
We show that V is the unique bounded solution of (Equation4
(4)
We prove that G is separated into two simply connected sets, where on the one set the maximal drift rate is assigned to one company and on the other set the other company obtains the maximal drift rate 1. These sets are separated by a
Finally, we conclude in Section 3.3 that using the push-top strategy is optimal in (Equation3
Sections 3.1 and 3.2 follow the ideas and arguments from [Citation9] and [Citation13]. We state all the results needed but in the proofs we often only provide the changes to be made in our setting.
3.1. Preliminary results
We derive as in Theorem 3.1, Proposition 3.1 and Proposition 3.2 of [Citation9] that the HJB equation (Equation4(4)
(4) ) with boundary conditions (Equation5
(5)
(5) ) has a bounded solution which coincides with the value function V of problem (Equation3
(3)
(3) ) and V is sufficiently smooth. More precisely, we have
Theorem 3.1
There exists a bounded solution of the HJB equation (Equation4
(4)
(4) ) with boundary conditions (Equation5
(5)
(5) ).
Proposition 3.2
The function W derived in Theorem 3.1 is the value function V of our maximization problem (Equation3(3)
(3) ).
Proposition 3.3
The value function V satisfies .
The proofs are quite similar to the proofs in [Citation9]: For proving Theorem 3.1 we follow the proof of Theorem 3.1 in [Citation9] with the only difference that we use the functions
and for the proof of Proposition 3.2 we apply the arguments of the proof of Proposition 3.1 in [Citation9] but in the second to last part we use
to obtain
instead of
. Proposition 3.3 can be proven exactly as Proposition 3.2 in [Citation9].
3.2. Separating G into two simply connected sets
In this section, we show that G can be divided into two simply connected sets, where company 1 receives the maximal drift rate on one set and company 2 obtains the maximal drift rate on the complement. Here we follow the arguments from [Citation13] and provide all the statements adjusted to our setting.
First we introduce some sets and functions we need later on.
where the closure of N is taken in
. Note that it is not clear so far whether
or
and thus, whether
holds true.
These sets have the following interpretations: On (
) the first (second) company obtains the maximal drift rate. Here we choose R (N) without loss of generality; it is also possible to take P (S), since on
all non-negative drift rates which sum up to 1 can be chosen. On the set
the strategy is changed which means that for any
both types of strategies can be found in the neighbourhood of z.
In the following, all topological notions are understood in the trace topology on with respect to
unless otherwise stated.
Our main result (Theorem 2.1) is based on the next theorem.
Theorem 3.4
It holds that
| (a) | N and P are simply connected sets. | ||||
| (b) |
| ||||
| (c) | C is a | ||||
The proof of Theorem 3.4 follows from several lemmas. Most of them can be proven using the arguments from [Citation13] with some slight modifications. However, the proof of the next lemma requires a different line of arguments.
Lemma 3.5
On the boundary of we have
Remark 3.6
By Lemma 3.5, the interpretation of the sets and
given at the beginning of this section can be extended to R and N.
Proof
Proof of Lemma 3.5
Due to the symmetry of our problem (Equation3(3)
(3) ) and of the value function V, we only show
i.e. the first relation.
Let y>0. Since it holds that
. In the following, we derive a positive function g such that for sufficiently small
and any admissible strategy
(8)
(8) In particular,
(9)
(9) Using (Equation9
(9)
(9) ),
and
implies
Since g is positive and
, the claim follows.
To find g in (Equation8(8)
(8) ) let
and observe that for all admissible strategies
it holds that
(10)
(10)
where
and the last equality follows from the fact that on
the surviving firm obtains a drift of 1 after τ and the probability that it is also ruined, i.e. that
, is given by
which equals
as
by the definition of τ.
Now let , q>2 such that
and
. By the Hölder inequality, we obtain
(11)
(11) Using that for every
the process
is a martingale, which is bounded on
, the optional sampling theorem implies that
(12)
(12) Combining (Equation11
(11)
(11) ) and (Equation12
(12)
(12) ) results in
In particular, for
it holds that
and therefore,
Moreover, let
Then we have
. Observe that
is not an admissible strategy but it helps to construct the auxiliary stopping time
. Since
we have
From equation (25) and the following equation in [Citation9] we conclude that
where
and Φ denotes the cumulative distribution function of a standard normal distribution.
To sum up, it holds that (13)
(13) where
and
for all
by the definition of h.
By (Equation10(10)
(10) ), we have for all
The law of iterated logarithm implies that on
it holds that
Together with (Equation13
(13)
(13) ) this implies
and the claim follows since g>0.
Next we characterize the behaviour of for large values of x or y.
Lemma 3.7
It holds that
where
stands for either
or
.
Proof.
Consider a sequence with
as
. If either
then the claim follows directly from Lemma A.2 in the appendix. To show that as
if
we combine arguments from the proof of Lemmas A.2 and A.3. Due to the symmetry of V, we assume without loss of generality that and
. Moreover, we only show that
as
. Similar arguments can be used to prove
as
.
Let . Let
such that
In addition, let . Since
as
there exists
such that
for all
. Moreover, we have
(14)
(14) Now let
. For the first summand in (Equation14
(14)
(14) ) we use estimate (EquationA2
(A2)
(A2) ) from the proof of Lemma A.2 to obtain
where C>0 is independent of δ,
and
.
For the second summand in (Equation14(14)
(14) ), equation (EquationA4
(A4)
(A4) ) in the proof of Lemma A.3 implies
Hence, for all
we have
We now present additional properties of the function D.
Lemma 3.8
Let be open in
and simply connected. Then the function D is a distributional solution of
Moreover, if
is open in
, simply connected and bounded then we have
,
.
Proof.
Mimicking the proof of [Citation13, Lemma 4.3], where we set and replace
by the Laplace operator
, yields the claim.
In the following, we show that the sets N and P are pathwise connected. First observe that N and P are locally pathwise connected because they are strict sub- and superlevel sets of the continuous function D. Hence, their connected components and connected path components are the same, see, e.g. [Citation21, Theorem 25.5]. Denote by and
the connected component of N containing
and of P containing
, respectively.
Lemma 3.9
It holds that . In particular, it holds that
and
and thus, N and P are pathwise connected.
Proof.
The proof of Lemma 4.4 in [Citation13] applies here if we replace by the Laplace operator Δ and use our Lemma 3.7 to control the behaviour of D for large values of either x or y.
Now we can prove Theorem 3.4.
Proof
Proof of Theorem 3.4
| (a) | To show that N and P are simply connected one can proceed as in the proof of Proposition 4.1 in [Citation13] with the only difference that in the interior of the curve γ the partial differential equation of Lemma 3.8 holds. | ||||
| (b) | Here the proof of Proposition 4.2 in [Citation13] can be used if the anisotropic Laplacian | ||||
| (c) | On can adopt the proof of Proposition 4.3 in [Citation13] with the only difference that the sets N and P have to be interchanged, because in our setting
| ||||
3.3. The push-top strategy is optimal
Lemma 3.10
We have .
Proof.
The symmetry of the value function V implies that for all x>0 and thus, by Theorem 3.4b)
Moreover, since N and P are simply connected by Theorem 3.4a) and using Lemma 3.5 we conclude that
Assume that there exists
with
. Without loss of generality we assume that
. By Theorem 3.4c) in a sufficiently small ball around
the set C is a
– curve in
which does not intersect
. But this contradicts the first part of Theorem 3.4b). Hence,
Finally, we can prove that the push-top strategy is optimal when maximizing the probability that at least one firm survives.
Proof
Proof of Theorem 2.1
The stated HJB equation (Equation4(4)
(4) ) for the control problem (Equation3
(3)
(3) ) is already the simplified version of the equation
which allows us to read off the optimal strategy
with
where
Also recall (Equation6
(6)
(6) ). From Lemma 3.10 we know that
and
and therefore, the push-top strategy is optimal.
3.4. Remarks on the model assumptions
In this section, we discuss some of the model assumptions.
In our model, the companies aim at finding a strategy maximizing the probability that at least one of them never falls below 0. The benchmark level is set to 0 for convenience. Maximizing the probability that at least one of the companies never falls below a given level , i.e. does not become too small, can also be considered since the dynamics (Equation2
(2)
(2) ) and the set of admissible controls allow for shifted processes.
For simplicity, we assume that a total drift of 1 can be divided among the firms. This can be generalized to a total drift and, moreover, we could also require that each firm obtains a minimal drift rate
.
In our model, we consider companies with any initial positive wealth. It may be more realistic to exclude huge insurance companies from our analysis since ruin of these can have a big influence on the whole financial system and may be prevented by the government/ has to be prevented by regulatory guidelines. As in Section 4, where we solve a more general problem numerically, one could assume that a company with a wealth exceeding a threshold M>0 always survives because it is too big to fail. The remaining company then obtains the whole drift rate. In particular, in this case the probability that at least one firm survives forever is 1. But this assumption may lead to technical problems as in a first step we have to analyze the PDE (Equation4(4)
(4) ) with a discontinuous boundary condition. Therefore, we decided to keep the model simpler but solvable.
Ruin of a company may not be desirable because of either the company is ‘too big to fail’ (see above) or regulatory preventions. In this case, different models can be considered. For instance, to measure the risk of an insurance company one could consider the minimal amount of capital injections needed to keep the wealth processes always positive, see, e.g. [Citation19] for a one-dimensional model, where the discounted dividend payments D minus the penalized discounted capital injections Z are maximized, more precisely, Kulenko and Schmidli consider
(15)
(15) where
is a penalization factor,
is a discount factor and
denotes the set of all admissible strategies for the initial capital x, i.e. the set of all strategies such that
where X−D+Z is the surplus process for the strategy
and X is the risk process.
To extend this model to a two-dimensional setting, one could investigate two companies with risk processes X and Y, accumulated dividend processes and
and allow not only for capital injections
and
for X and Y , respectively, but also for transfer payments T between the two companies. Then, similar to (Equation15
(15)
(15) ), one can aim at finding the processes
to maximize the expected discounted dividend payments
minus the penalized discounted capital injections
and minus the cost for the transfer payments T subject to the condition that the surplus processes
and
are always non-negative. We leave this problem for further research.
4. A more general problem
As in [Citation20], we now generalize the control problems (Equation3(3)
(3) ) and (Equation7
(7)
(7) ) in the following way. Denote by
the number of companies which never go bankrupt under strategy u with initial wealth
. We want to maximize the weighted sum of the probabilities that exactly one and both companies survive forever. For this purpose, let
and define
(16)
(16) In particular, for the cases
and
we can already identify the optimal strategy for (Equation16
(16)
(16) ) and in the first case also the value function is known. More precisely,
Note that for the generalized problem (Equation16
(16)
(16) ) corresponds to the problem of maximizing the expected number of surviving firms, see [Citation9] for more details. In addition, we obtain the problem of maximizing the γ - moment
of the number of surviving firms (up to a factor) with
for
in (Equation16
(16)
(16) ).
Remark 4.1
In (Equation16(16)
(16) ) we only allow for
because for
it is better if only one firm survives instead of both which does not really make sense in our economic interpretation.
The HJB equation associated to (Equation16(16)
(16) ) is given by
(17)
(17) Also in this generalized setting an optimal strategy
for
is given by
, where
, cf. equation (Equation6
(6)
(6) ).
Using numerical methods, which are explained in the next section, we obtain a candidate for the optimal strategy for . For
and
this strategy coincides with the theoretical optimal strategy, i.e. push-bottom and push-top, respectively, see Figure . These are the two special cases where only push-bottom respectively push-top is optimal.
Figure 1. The candidates for an optimal strategy for and
with
and N=400. In the white regions push-bottom is optimal and we use black for the regions where push-top is optimal. Here we already know that push-bottom respectively push-top is optimal. Observe that on the diagonal y=x both companies can be pushed. For large values of x and y numerical effects can effect our strategy, see Figure for more details. For details on the numerical methods, see Section 4.1.
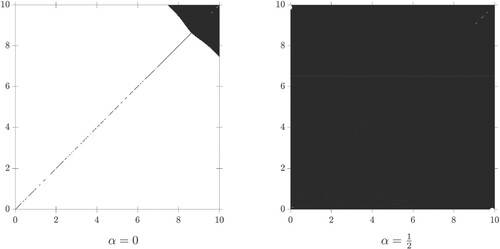
Figure 2. The candidates for an optimal strategy for for different
and N such that
. In the white regions push-bottom is optimal and we use black for the regions where push-top is optimal. In the upper right corner numerical effects appear due to the imposed boundary conditions and the discretization. For increasing
, the region where these numerical effects happen move to the upper right corner. These effects do not influence the strategy in regions which are sufficiently far away.
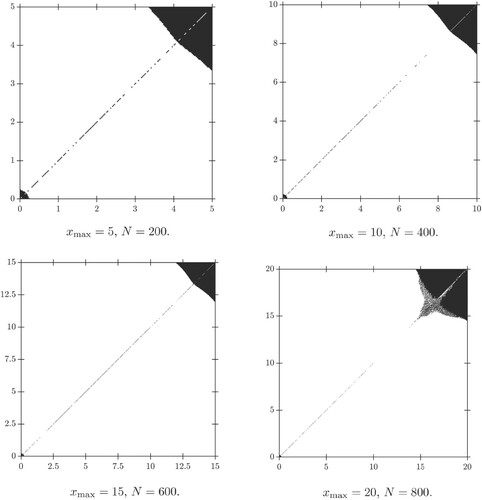
For we find that if the wealth of both companies is small (small depends on α), then the company with higher wealth should obtain the maximal drift rate (i.e. use push-top) whereas if the wealth process of at least one company is sufficiently large then the maximal drift rate 1 is assigned to the company with less wealth (i.e. use push-bottom). Hence, we can split our state space G into two regions, in one push-top is optimal and in the other push-bottom. Observe that the region where it is optimal to use push-top is increasing in α. This is due to the fact that if α increases the probability that exactly one firm survives is given more weight and the probability that none of the firms goes bankrupt has less influence.
Figures and show our candidates for the optimal strategy for different α. In the white regions push-bottom is optimal and we use black for the regions where push-top is optimal.
Figure 3. The candidates for an optimal strategy for with
, N=400 and
. Here we only plot the strategies on
to focus on the black regions where push-top is chosen.
![Figure 3. The candidates for an optimal strategy for α∈{0.2,0.25,0.3,13,0.35,0.4} with xmax=5, N=400 and w=32. Here we only plot the strategies on [0,1]×[0,1] to focus on the black regions where push-top is chosen.](/cms/asset/a65c2d3c-c596-4775-9be5-3e226b78bba3/gssr_a_2284194_f0003_ob.jpg)
Figure 4. The candidates for an optimal strategy for with
, N=800 and
. Here we only plot the strategies on the smaller set
to focus on the black regions where push-top is chosen.
![Figure 4. The candidates for an optimal strategy for α∈{0.45,0.49,0.499,0.4999} with xmax=10, N=800 and w=32. Here we only plot the strategies on the smaller set [0,6]×[0,6] to focus on the black regions where push-top is chosen.](/cms/asset/0940cadb-cb40-4f50-999c-feab9c7177a9/gssr_a_2284194_f0004_ob.jpg)
Remark 4.2
Note that also McKean and Shepp in [Citation20] obtain candidates for optimal strategies for . Since the description on how they obtain their results is a bit short, we provide a detailed explanation of our numerical method in the next section.
4.1. Numerical method: policy iteration and successive over-relaxation
Here we describe the numerical method we use to obtain the candidate for the optimal strategy. We combine two methods:
policy iteration
successive over-relaxation.
The idea of policy iteration used in reinforcement learning (cf. [Citation5,Citation23] for more details) is to start with an initial strategy (Step 0), compute the value of this strategy (Step 1) and improve the strategy appropriately (Step 2). Steps 1 and 2 are then repeated until a fixed point is found (or the value of the new strategy is very close to the value of the old strategy). In particular, a sequence of strategies with increasing values is constructed. For Step 1 observe that the value of a given strategy
satisfies the linear partial differential equation (PDE)
(18)
(18) Note that the PDE for
given in (Equation17
(17)
(17) ) is non-linear. To find J we restrict (Equation18
(18)
(18) ) to a bounded state space and impose additional boundary conditions, discretize the new state space and the derivatives and solve the corresponding linear system of equations using successive over-relaxation, which is a variant of the Gauss–Seidel method and often has an improved convergence rate (see, e.g. [Citation25, chapter 6]). For improving a strategy u in Step 2 we use the optimality criterion from the HJB equation (Equation17
(17)
(17) ) and set
Now we describe our method in more detail: we restrict ourselves to the bounded state space , where
and
are chosen sufficiently large. Due to the symmetry of our problem (Equation16
(16)
(16) ) we set
. We then obtain an approximation
for
on S as follows: for
divide a total drift of 1 among both companies in order to maximize the weighted probabilities in (Equation16
(16)
(16) ). If the wealth process of the first or second company exceeds
, then we consider this firm to survive forever and the other firm obtains a drift rate of 1. In particular, for
we set
where we use that the probability that a Brownian motion with unit drift starting in x hits zero equals
, see formula 1.2.4(1) in part II, chapter 2 in [Citation6]. Moreover, let
Here we do not impose that
to guarantee a boundary condition that is continuous in
. But observe that the boundary condition is not continuous in
and
. Note that
on S.
Step 0: To compute we use policy iteration and thus, start with an initial guess
for the optimal strategy for
.
Step 1: The value for this particular strategy satisfies (Equation18
(18)
(18) ) on
, where u is replaced by
. We discretize our state space S using an equidistant grid with
grid points and mesh size
. For
let
Then we have the following boundary conditions for
:
Using central finite difference quotients for (Equation18
(18)
(18) ) we observe that our approximation
satisfies
for
, where
To solve this system of
linear equations, we use successive over-relaxation (SOR): we start with an initial guess
,
, and define iteratively
for
and
, where
is the so-called relaxation parameter, see, e.g. [Citation25] for a detailed analysis of the SOR method and [Citation15,Citation17,Citation18] for an overview. For w=1 one obtains the Gauss–Seidel method. We continue until
for a given approximation error
and then set
. This is our approximation for the value
of the strategy
on the grid
.
Step 2: To improve the strategy , we use the discretized optimality condition from the HJB equation (Equation17
(17)
(17) ) for
. More precisely, for
define
and for the grid points on the boundary we use forward or backward difference quotients and set
if
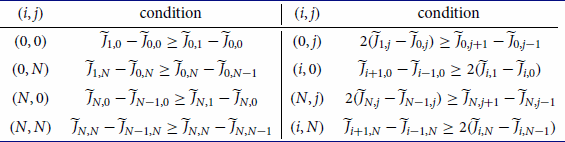
with . Otherwise we set
For
define
We then continue with Steps 1 and 2 for the new strategy
and proceed until we obtain a policy
with
for a given approximation error
. Finally, our approximation for
is given by
and
is a candidate for the optimal strategy for
.
Observe that we only construct a candidate for the optimal strategy on the grid
Remark 4.3
For every strategy
For deriving the value of the initial strategy
In our setting, different relaxation parameters w yield the same candidate for the optimal strategy (except for some differences on the set
Acknowledgments
We thank two anonymous referees for carefully reading the manuscript and highly appreciate their comments, which contributed to improve our paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- S. Ankirchner, R. Hesse, and M. Klein, On the joint survival probability of two collaborating firms, J. Appl. Probab. (2023), pp. 1–16.
- F. Avram, Z. Palmowski, and M. Pistorius, A two-dimensional ruin problem on the positive quadrant, Insurance Math. Econom. 42(1) (2008), pp. 227–234.
- F. Avram, Z. Palmowski, and M. Pistorius, Exit problem of a two-dimensional risk process from the quadrant: exact and asymptotic results, Ann. Appl. Probab. 18(6) (2008), pp. 2421–2449.
- V.E. Beneš, Full “bang” to reduce predicted miss is optimal, SIAM J. Control Optim. 14(1) (1976), pp. 62–84.
- D.P. Bertsekas, Reinforcement Learning and Optimal Control, Athena Scientific Optimization and Computation Series, Athena Scientific, 2019.
- A.N. Borodin and P. Salminen, Handbook of Brownian Motion – Facts and Formulae, 2nd ed., Probability and its Applications, Birkhäuser Verlag, Basel, 2002.
- W.-S. Chan, H. Yang, and L. Zhang, Some results on ruin probabilities in a two-dimensional risk model, Insurance Math. Econom. 32(3) (2003), pp. 345–358.
- J.F. Collamore, Hitting probabilities and large deviations, Ann. Probab. 24(4) (1996), pp. 2065–2078.
- P. Grandits, A ruin problem for a two-dimensional Brownian motion with controllable drift in the positive quadrant, Teor. Veroyatn. Primen. 64(4) (2019), pp. 811–823.
- P. Grandits, A two-dimensional dividend problem for collaborating companies and an optimal stopping problem, Scand. Actuar. J. 2019(1) (2019), pp. 80–96.
- P. Grandits, On the gain of collaboration in a two dimensional ruin problem, Eur. Actuar. J. 9(2) (2019), pp. 635–644.
- P. Grandits, A singular perturbed ruin problem for a two dimensional Brownian motion in the positive quadrant. https://fam.tuwien.ac.at/~pgrand/sing_pert.pdf, preprint, 2020.
- P. Grandits, Some global topological properties of a free boundary problem appearing in a two dimensional controlled ruin problem, Math. Control Signals Syst. 35 (2023), pp. 927–949.
- P. Grandits and M. Klein, Ruin probability in a two-dimensional model with correlated Brownian motions, Scand. Actuar. J. 2021(5) (2021), pp. 362–379.
- A. Greenbaum, Iterative Methods for Solving Linear Systems, Frontiers in Applied Mathematics; Vol. 17, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1997.
- J.-W. Gu, M. Steffensen, and H. Zheng, Optimal dividend strategies of two collaborating businesses in the diffusion approximation model, Math. Oper. Res. 43(2) (2018), pp. 377–398.
- W. Hackbusch, Iterative Solution of Large Sparse Systems of Equations, 2nd ed., Applied Mathematical Sciences; Vol. 95, Springer, 2016.
- A. Iserles, A First Course in the Numerical Analysis of Differential Equations, Cambridge Texts in Applied Mathematics, Cambridge University Press, Cambridge, 1996.
- N. Kulenko and H. Schmidli, Optimal dividend strategies in a Cramér-Lundberg model with capital injections, Insurance Math. Econom. 43(2) (2008), pp. 270–278.
- H.P. McKean and L.A. Shepp, The advantage of capitalism vs. socialism depends on the criterion, J. Math. Sci. 139(3) (2006), pp. 6589–6594.
- J.R. Munkres, Topology, Prentice Hall, Inc., Upper Saddle River, NJ, 2000.
- M. Safonov, On the boundary value problems for fully nonlinear elliptic equations of second order. Math. Res. Report No. MMR 049-94, Austral. Nat. Univ., Canberra, 1994.
- R.S. Sutton and A.G. Barto, Reinforcement Learning: An Introduction, 2nd ed., Adaptive Computation and Machine Learning, MIT Press, Cambridge, MA, 2018.
- A.Y. Veretennikov, On the criteria for existence of a strong solution of a stochastic equation, Theory Probab. Appl. 27(3) (1983), pp. 441–449.
- D.M. Young, Iterative Solution of Large Linear Systems, Academic Press, New York-London, 1971.
Appendix
In this appendix, we prove auxiliary statements for the results in Section 3. The following results describe the behaviour of V and its derivatives for large x or y. Their proofs are based on the proofs of Lemma 4.2, Lemma 6.1 and Lemma 6.2 in [Citation13]. Since in our setting the proofs use similar ideas but are shorter we present them in detail.
Lemma A.1
It holds that
Proof.
Due to the symmetry of the value function V we only show the first claim. Let and y>0. Using the strategy
with
we obtain a lower bound for V . More precisely,
because the first company is ruined almost surely and the survival probability of a Brownian motion with unit drift starting in y>0 equals . Since
, the claim follows.
Lemma A.2
One has
for y>0 and uniformly for
for all
. In addition,
for x>0 and uniformly for
for all
.
Proof.
Let . Then by Lemma A.1 it follows that
. Let
and denote by
the open ball around
with radius
. Let
. For
sufficiently large it holds that
(A1)
(A1) Observe that
satisfies
We now restrict
to B. To apply Theorem 3.1 in [Citation22] note that one can easily check that Conditions (F0), (F1), (F3), (F4), and the first part of (F2) are fulfilled. It remains to show the Lipschitz property of F in
. For this purpose observe that
Now we distinguish several cases:
For we have
If
it holds that
The cases
and
can be treated similarly. Hence,
and therefore, Condition (F2) is fulfilled for K=2.
Theorem 3.1 in [Citation22] now implies that for all for some
it holds that
where ε is an upper bound for
on B, see (EquationA1
(A1)
(A1) ), and
. For the definition of
see Section 2 in [Citation22]. In particular, this implies
(A2)
(A2) With
and
the claim follows.
Note that we cannot conclude that the convergence is uniformly in or
because the right-hand side of (EquationA2
(A2)
(A2) ) explodes e.g. for
and
sufficiently large.
Lemma A.3
If either
then
Proof.
Due to the symmetry of the value function V we only consider the case where
and
. Moreover, we only show
because similar arguments can be used for deriving
.
Let and
such that
and
for all
. Now let
and
. Let
. As in the proof of Lemma 4.2 in [Citation13] let
be a strategy that is optimal in (Equation3
(3)
(3) ) for starting in
; in particular
for some Borel measurable
. If no optimal strategy exists we use an η – optimal strategy for
and proceed similarly. We now define a strategy
for the process started in
in such a way that the paths of the two processes
and
move parallel having distance ε in the first component. For this purpose let
Observe that using
the process started in
is ruined not later than the optimally controlled process started in
and can be ruined earlier with positive probability. Hence, we modify
after the first ruin time
in such a way that it becomes admissible, i.e.
, which means that after the first ruin time the surviving process obtains the maximal drift rate until it hits zero. If both processes are ruined, then
is set to
afterwards.
To sum up, by the definition of strategy it holds that
Figure depicts two different trajectories for our controlled process started in
and the corresponding shifted trajectories for the process started in
until one firm is ruined when started in
.
Figure A1. Two different trajectories for the controlled process started in and the corresponding shifted trajectories for the process started in
until one firm is ruined when started in
, see the proof of Lemma A.3.
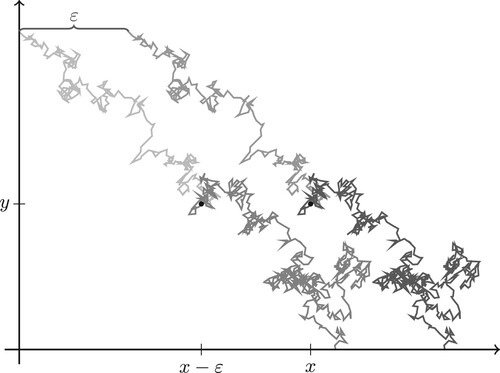
Now let be the first time at which one company is ruined if the initial endowment is given by
and strategy
is used. Then
and the optimality of
for
yield
(A3)
(A3) where
denotes the conditional distribution of
given
and
denotes the conditional distribution of
conditioned on
.
From Lemma 3.5, we know that for all z>0 and hence,
In particular,
for all
sufficiently small. Moreover, it holds that
where
Using formula 1.2.4(1) in part II, chapter 2 in [Citation6] for the second summand on the right-hand side of (EquationA3
(A3)
(A3) ) yields
To sum up, we have
(A4)
(A4) Since
as
uniformly in
we conclude that