
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The rapid adoption of Cloud, Fog, and Edge computing paradigms, along with Digital Twin (DT) technology, is being observed across numerous domains. Smart Agriculture is one such domain, where diverse requirements exist for applications that range from Augmented Reality, Satellite, and auto harvesters to a multitude of agricultural devices and sensors. While the integration of Cloud, Fog, and Edge computing can address various challenges, it can also pose some difficulties, including resource allocation, resource scheduling, and task scheduling. To address these challenges and enhance the productivity and sustainability of Smart Agriculture, this paper presents a novel architecture based on Cloud, Fog, Edge computing, and Multi-Agent Systems (MAS), incorporating the concept of Digital Twin. This proposed architecture is implemented in Smart Agricultural farms and fields, opening up new contemporary applications in the Agriculture domain.
1. Introduction
The practice of agriculture is a complex and demanding process that encompasses a wide variety of activities, starting from the preparation of the soil through tillage, all the way to the final stage of harvesting crops. At each stage of the agricultural process, multiple systems interact to support farming activities and facilitate communication among stakeholders, including farmers, and agronomists. These processes have become increasingly digital. Smart agriculture is linked to collecting data from different data sources including autonomous tractors, harvesters, robots and drones, sensors, and actuators. For example, in crop farming, the agricultural data harvested (such as humidity, temperature, pH and soil conditions) is typically analysed to maximise crop yield whilst minimising costs (e.g. nutrients, pesticides). Agriculture 4.0 [Citation1], also known as Smart Agriculture or Agriculture IoT, refers to the use of advanced technologies such as the Internet of Things (IoT), artificial intelligence (AI), and robotics to improve the efficiency and productivity of agriculture. It involves the integration of these technologies into all stages of agricultural production, from planting to harvesting, in order to optimise crop yields, reduce waste, and improve sustainability [Citation2].
Cloud computing, Fog computing, and Edge computing are all computing models that offer different levels of decentralisation and proximity to end-users. Cloud computing refers to the delivery of computing resources over the internet from a centralised location [Citation3]. Fog computing extends this model by bringing the cloud closer to the edge of the network, typically at the local network level, to provide faster response times and better quality of service [Citation4]. Fog computing can also help reduce the amount of data that needs to be sent to the cloud, by processing and analysing data locally before sending it to the cloud. Edge computing takes this concept further by bringing the computing resources even closer to the end-users, typically at the device or sensor level [Citation5]. This enables real-time processing and analysis of data, reducing the need for data to be sent to the cloud or fog nodes. Edge computing is particularly useful in applications such as autonomous vehicles, smart homes, and industrial automation, where low latency and high reliability are critical.
The combination of Cloud-Fog-Edge computing addresses several issues in Cloud-based computing applications by bringing Cloud services and resources to Edge devices. Edge computing primarily focuses on the IoT level, while Fog computing is more focussed on the infrastructure level. Edge computing does not support handling multiple IoT applications, whereas Fog computing supports this capability. Data collection, processing, and storage mainly occur at the network edge and Edge devices in Edge computing, whereas they occur near the edge and core networking in the Fog layer [Citation5]. The authors of [Citation6] explore how these new models address the limitations of the Cloud by providing techniques for moving computation, data analysis, and storage closer to the network's edge. Although the integration of Cloud-Fog-Edge computing is attractive, it is not a straightforward process, and several challenges arise, such as resource management (including sharing and allocation), task management, and scheduling (such as workflow and task scheduling). Multi-agent systems are a potential solution to the challenges mentioned above in the integration of Cloud, Fog, and Edge computing paradigms. Multi-agent systems incorporate social aspects and human reasoning to solve problems [Citation7].
In recent years, Digital Twin (DT) technology has been a rising part of new digital technologies that support digital transformation by enabling new business models and decision support systems. Various domains, including Smart Cities [Citation8], Manufacturing [Citation9], Healthcare [Citation10], construction [Citation11], and Industry [Citation12], have already incorporated or are in the process of incorporating data, information, and analytics capabilities in their services. A DT is a digital representation of a physical model that predicts the future based on real and historical data. Four levels of digital representation exist: Pre-Digital Twin, Digital Twin, Adaptive Digital Twin, and Intelligent Digital Twin [Citation13]. Agriculture has received less attention in DT research, but its application has potential benefits such as cost reductions, detailed information, catastrophe prevention, positive economic impacts, decision-making aid, and more efficient management.
1.1. Main motivation
Farming is a challenging industry that requires striking a balance between producing high-quality crops and achieving a sufficient quantity of them. One of the ways that technology has sought to address these challenges is through the creation of digital twins, which are virtual models of physical objects or systems. While creating a digital twin for plants is difficult due to the unique growth patterns of each plant, it is comparatively easy to make a digital twin for a greenhouse or enclosed environment due to the controlled environment it provides. To ensure high accuracy, the digital twin must monitor and control environmental conditions such as temperature, humidity, and CO2 levels. However, creating a model of a real farm can be complex due to various factors, including the availability and quality of data, as well as the necessity to integrate information from multiple sources. These sources may include IoT devices, satellites, drones, weather stations, and observations. The objective is to enhance decision-making capabilities while also providing data that can be utilised by other systems or stakeholders. Despite the challenges, digital twin technology has the potential to revolutionise the farming industry by providing valuable insights and allowing farmers to experiment with different scenarios to optimise their production.
In this paper, we present a novel architecture for implementing a digital twin for a farm that encompasses a variety of fields. Our approach incorporates the use of multi-agents, microservices, linked-data, and ontologies. Additionally, we discuss the deployment of the digital twin in a Cloud-Fog-Edge infrastructure.
1.2. Main contribution
Our approach aims to be holistic by using not only semantically interoperable JSON-LD based data models [Citation14] that break the traditional approach of restrictive proprietary data silos and vertical architectures limiting interoperability [Citation15], but also by allowing service composition within the Smart Farming scenario [Citation16]. We have devised a series of Digital Twins of farms, as well as a high-level composite of fields DT. As stated by Falcão et al. [Citation17], field data is essential for Farm Management Information Systems (FMIS), service providers, and stakeholders to reliably plan or conduct an operation. By having Field Digital Twins, we can gather essential and critical information (agronomic, environmental, geographic) from the fields and incorporate it into our system.
The use of linked data concepts fosters service discovery while allowing data to be available and reducing redundancy [Citation18]. Since most FMISs vendors develop their data vaults as closed/locked data sources, external services have to rely on connectors or pay for specific scenarios. Likewise, the integration of data relies on the availability of such elements and hinders the generation of information and knowledge that might be critical for stakeholders. By moving past syntactic interoperability [Citation19] and adopting linked data principles, we ensure that the used data models are easily discovered and that their internals are understood by any system or stakeholder. We make certain that the reference vocabulary is readily available to all those who interact with the Digital Twins. Moreover, we ensure that any data exchanges between the Digital Twins and other systems adhere to the principles of linked data interoperability.
The proposed solution presented in this article builds on and extends the high-level architecture proposed in [Citation20]. Specifically, we extend our work to provide an overview of the Digital Twin framework that complements the Cloud-Fog-Edge computing infrastructure.
2. Related work
Over the last decade, digital twin technology has gained more attention from both industry and academia. Numerous domains have started to apply DT in real-world applications and have achieved benefits such as improved efficiency, increased productivity, cost reduction, and better decision-making. Digital twin technology can be used for predictive maintenance, product design and development, asset management, supply chain optimisation, and remote operations.
Smart agriculture is a rapidly growing field that utilises digital technologies to optimise agricultural practices and increase efficiency. Digital twin technology is a promising tool that can be used in smart agriculture to create a virtual replica of a physical farming system, enabling farmers to simulate, monitor, and optimise their operations. This technology can be combined with other emerging technologies such as Multi-Agent Systems (MAS) and Cloud-Fog-Edge computing to further enhance its capabilities and benefits.
This section discusses related works in the areas of Cloud-Fog-Edge computing, Smart Agriculture, Multi-Agent systems, and Digital Twin technology.
2.1. Cloud-Fog-Edge and smart agriculture
Several studies have introduced the concepts of Cloud-Fog-Edge computing in the smart agriculture domain. Some studies focus on one of these paradigms, while others apply combinations of them, such as Cloud-Fog-Edge, Cloud-Fog, Cloud-Edge, Fog-Edge, or Cloud-sensors. In our recent systematic literature review [Citation5], we reviewed the role of Cloud, Fog, and Edge computing in Smart Agriculture. We identified six agricultural application domains where these computing paradigms can be applied, and discussed the benefits and objectives of smart agricultural applications such as low latency, low cost, saving bandwidth, and reducing data traffic. While most research in smart agriculture has focussed on Cloud-based and sensor applications, we suggest that combining Cloud, Fog, and Edge computing could bring more advantages and new opportunities in the smart agricultural domain. The review also identifies challenges such as security and privacy, data processing, and poor internet connectivity that need to be addressed.
There are few research papers that propose architectures in the combination of Cloud-Fog-Edge and Smart Agriculture. An example of this is seen in [Citation5], where a three-layered architecture for Smart Agriculture utilising Cloud, Fog, and Edge is proposed. The Cloud layer is primarily used for storing and analysing large-scale data, loading algorithms and data analytical tools to Fog nodes, and backing up data for future analysis. The Fog layer is installed in local farms and responsible for real-time data analytics such as predicting pests and diseases, yield prediction, weather prediction, and agricultural monitoring automation. It makes decisions on real-time data and performs reasoning analysis. The Edge layer comprises end devices, tractors, sensors, and actuators and collects data and transfers it to the Fog layer for analysis. The processed and analysed data can be uploaded to the Cloud layer for backup or further analysis. The authors of [Citation21] proposed an IoT-based Edge-Fog-Cloud architecture for smart agriculture system. The aim of this architecture is to solve existing real-time processing issues in terms of reducing energy consumption, CO2 emission, and network traffic, compared to the traditional cloud-based architecture. Other available architectures include the Latency-Adjustable Cloud/Fog Computing Architecture [Citation22], as well as a conceptual Things-Fog-Cloud based architecture that incorporates mechanisms for detecting and treating outliers [Citation23].
2.2. Digital twin with other technologies: Cloud-Fog-Edge, multi-agent systems, and semantic web
Digital twin technology is becoming increasingly popular and has applications in a variety of domains, including manufacturing, healthcare, transportation, construction, and energy. Additionally, due to the relatively new and emerging nature of digital twin technology, there may still be many industries that have not yet fully explored or implemented this technology. However, the combination of DT technology with the Cloud-Fog-Edge paradigm is a relatively new area of research that has emerged as a result of the increasing use of edge computing and the need to process data in real-time closer to the source.
The use of Cloud-Fog-Edge and DT together has the potential to enhance the capabilities of digital twin technology and to provide more efficient and effective solutions in various domains. As such, this is an area of active research and development, and there is ongoing work to explore the full potential of this combination. For example, [Citation24] examines how suitable the use of a cloud-fog architecture is to handle the real-time requirements of Digital Twins. Few other research articles have explored different domains in recent years, such as smart manufacturing [Citation25], smart agriculture [Citation20], and robotics [Citation26, Citation27].
Moreover, the use of agents with DT has received considerable attention across various domains. Multi-agent systems can optimise the performance of DT by coordinating the actions of multiple agents. Agents can work collaboratively to identify the root cause of a problem and suggest the best course of action. They can also reconfigure the system, change parameters, or switch to a different operating mode. Depending on the system's requirements, agents can be designed to act as AI solutions or software paradigms.
In 2021, authors of [Citation28] presented a generic Digital Twin model for use in a manufacturing multi-agent system. In this work, the agents are implemented as microservices using the concept of ‘Agents-as-a-Service.’ The concept of agent-based digital twins was proposed in [Citation29]. This approach integrates the digital twin paradigm with agents in a modelling and design framework based on mirror worlds, particularly in the healthcare domain. Additionally, the role of multi-agent systems in digital twins for Industry 4.0 is described in [Citation30], and an experimental setup for integrating a simulation model of Hamburg's traffic system with real-time sensor data is presented by Clemen et al. [Citation31]. In the agriculture domain, authors of [Citation32] propose the creation of digital twins using knowledge bases, multi-agent technology, and machine learning methods. Finally, authors of [Citation33] analyse the potential synergies between MAS and digital twins to support reasoning at both individual and collective levels.
In addition to the above, the current trend in Digital Twins is Semantic Digital Twins, which is an approach rooted in semantic technologies such as ontologies, constraints, and knowledge graphs. This topic is quite popular in the manufacturing domain [Citation34–36]. In agriculture, the use of semantic technologies such as ontologies and knowledge graphs is gaining popularity [Citation15, Citation20], although the adoption is still relatively slow compared to other domains.
3. Proposed architecture
In this section, we introduce an approach to implementing a Digital Twin for Smart Agriculture through the use of agents in a Cloud-Fog-Edge infrastructure. First, we introduce the Cloud-Fog-Edge architecture, followed by a clear description of the DT architecture.
3.1. Cloud-Fog-Edge architecture
The proposed architecture [Citation20], as shown in Figure , comprises three layers: Cloud, Fog, and Edge. The Cloud layer serves as the primary domain for big data and data analytics, providing data storage and anonymisation services for farm data, as well as machine learning and data analysis support. It hosts various services for yield prediction, disease identification, pest identification, and growth stage estimation, along with analytical tools to support forecasting outcomes such as expected yield, crop waste, and revenues.
Figure 1. Proposed high level architecture for MAS-Cloud-Fog-Edge.
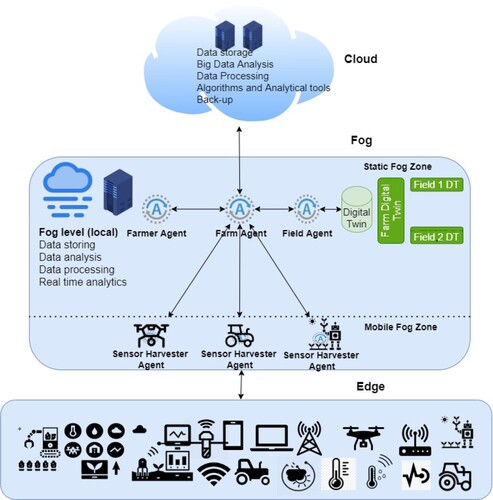
The second layer of the architecture is the Fog layer, which represents the Farm Management System. The layer deploys a Multi-Agent System responsible for overseeing various activities specific to the farm. The Fog layer is divided into two sub-strata: static Fog nodes hosted within the farm and mobile Fog nodes associated with farm equipment, such as tractors, combine harvesters, drones, or agricultural robots. The static Fog nodes provide local data storage and computing services for in-situ farm data analysis, while the mobile Fog nodes enable the extension of the Fog to areas of the farm with sporadic or no Internet connectivity.
Finally, the Edge layer includes any agricultural devices hosting sensors (such as in-situ soil moisture sensors and tractor-mounted Normalised Difference Vegetation Index (NDVI) sensors) or actuators deployed on the farm, whether in the fields or as part of farm equipment such as tractors or combine harvesters. Edge devices are directly connected to static Fog services wherever internet connectivity is available. In areas without connectivity, data from these devices is harvested on-demand or opportunistically through data collection services hosted on mobile Fog nodes.
3.2. Digital twin architecture
A central component of our approach is the Digital Twin of fields. It provides the primary context for activities of the Field agents and underpins the recommendations that agents make. For example, determining the right time to irrigate, identifying appropriate nutrients to apply, recognising any missing nutrients, estimating the possible harvest day, and selecting the appropriate time for pesticide application, etc. Raw sensor data is harvested from Edge devices deployed across the farm by a specific type of task agent known as a Sensor Harvester. Third-party data sources supplement it (e.g. weather, satellite, or even financial data) and are used in conjunction with Cloud-based Data Analytics services to provide insights that the agents can apply. Some insights help improve the accuracy of the Digital Twin; others facilitate decision-making activities, helping to identify when a Field Management Plan may need to be altered or how it should be altered. These Cloud-based services are also used in the formation of these plans. Using the Digital Twin model in this architecture helps farmers get information on the fields and overall farm behaviour. It also forecasts yield prediction, growth stage, nutrient information, and weather-report.
The referenced DT architecture [Citation37], as illustrated in Figure , consists of four layers: an external layer, a microservices layer, a knowledge/hypermedia layer, and a decision layer. The external layer, which is the lowest layer, provides the resources that the DT uses, including data services, advisory services, and prediction services. Examples of data services include Farm Management Information Systems (FMIS), historical weather services, and cloud-based sensor data repositories for accessing deployed IoT sensor data. These services can be hosted either as part of the farm's digital platform or externally by third parties. The microservices layer is responsible for abstracting external layer services into a standard format based on the agreed set of ontologies and providing additional internal data services that are specific to the DT. For instance, the internal data services include a Farm Management Plan service that captures critical decision points for the upcoming season and services that host real or simulated behaviour of the crop over the growing season.
Figure 2. Digital Twin architecture.
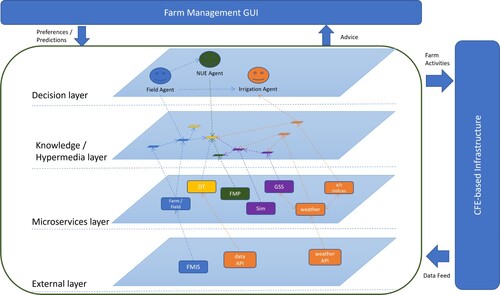
Knowledge/Hypermedia layer encompasses a set of resources created by the microservices available in the previous layer. These resources are all linked-data documents whose structure is underpinned by a suite of agreed-upon ontologies. The Field agent, located in the upper Decision layer, is responsible for deciding which microservices to use to create the resources. Linked data is critical to this layer and the Decision agents, as it represents data in a form that can be easily transformed into knowledge. As a result, this layer functions as a knowledge graph that spans the DT and provides an index to all the data contained within it. Decision layer is the final layer and is responsible for all decision-making related to the Digital Twin. It includes the initialisation of the twin and recommendations. A library of agent designs is provided to support various decision-making and monitoring activities of the Digital Twin. A Field Agent is created to oversee each Digital Twin. It uses the farm management plan, the farmer's preferences, and the details of the agricultural system being managed to monitor and make decisions throughout the season. The Field Agent is responsible for engaging other agents specified in this layer to take action as needed.
To ensure that our architecture is future-proofed, we have designed it to be agnostic to implementing the Digital Twin. To cater for this, our architecture is also designed to allow the incorporation of new tasks. To achieve this, task descriptions are encoded using a flexible format, and new task types can be supported by creating new task-specific agents. Our vision aligns with the recently proposed idea of the Computing Continuum [Citation38] which is concerned with developing digital infrastructure that is used by complex workflows typically combining real-time data generation and processing and computation [Citation39]. Additionally, this architecture can increase sensors (soil moisture probes, NDVI sensors, weather stations), and facilitate upgrading equipment such as guidance in tractors and variable spray booms/map-based variable treatment.
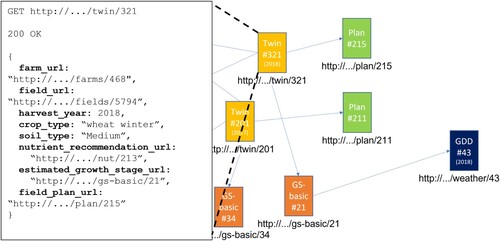
The use of Linked Data with Digital Twins has proven to both promote Knowledge Sharing and facilitating interoperability across domains as previously discussed by Abanda et al. [Citation40]. In our approach, we aim at integrating heterogeneous data sources (including geospatial data) which often contains decision-making information [Citation41]. By adopting the Linked Data Paradigm, our Farm Digital Twin models form a collection of Linked Data Sets (with their own URIs, JSON-DL data structures) that are then published on the Web to be accessed by other DTs and/or systems as depicted by Figures and .
Figure 3. Current implementation diagram.
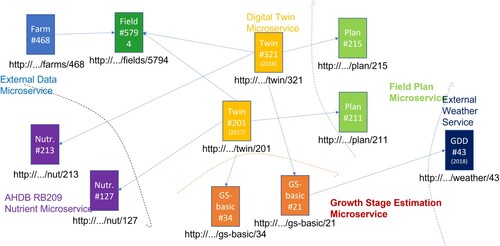
Figure 4. Sample twin model.
3.3. Opportunistic sensing
Opportunistic sensing is a data collection technique in which sensors and other data-gathering devices take advantage of unplanned or spontaneous opportunities to collect data. This approach relies on the fact that sensors can be placed in various locations or attached to different objects to capture data in an opportunistic manner, without needing to follow a specific pre-defined plan or schedule. This technique has become more prevalent with the rise of the Internet of Things (IoT), which allows for the deployment of a large number of connected sensors and devices that can take advantage of such opportunities to collect data. The data collected through opportunistic sensing can be used for various applications such as environmental monitoring, traffic analysis, healthcare, and agriculture.
In our approach, a number of sensors are installed on the farm. When edge devices such as drones, robots, tractors, or harvesters interact with these sensors to collect data, they must be able to do so even in areas where internet connectivity is unavailable. Therefore, they must still collect the data and transfer it to the data collection point or devices. Collecting data in areas without internet connectivity is possible only through opportunistic sensing.
3.4. Semantic web and linked data
Semantic Web Technologies have proven useful when integrating data [Citation42–44] from heterogeneous sources. In our approach, we aim at generating new data as a ‘collection of interrelated datasets’Footnote1 following the Linked data principles [Citation45] by using HTTP URIs to identify resources combined with a JSON-LD data model to represent the resource descriptions.
Likewise, Linked Data has given us the opportunity of integrating data from different sources (weather stations, humidity sensors, NDVI sensors, Field DTs) while assigning each resource a Unique Resource Identifier that provides traceability and the possibility of connecting data sets of data that affect the behaviour and performance of a field under a specific plan (or with specific crop, soil, characteristics) that will, in turn, provide insight on the decisions carried out by the agents and the associated available data at the time.
3.5. Cloud or Fog: deciding the optimal infrastructure for implementing digital twins
This section provides a brief discussion of the optimal approach for implementing a digital twin in either the Cloud or Fog computing environment.
Digital twins can be implemented using either Cloud-based or Fog-based computing. Cloud computing provides access to remote servers that offer vast amounts of data processing and storage, making it a good option for applications that require advanced analytics and simulations. It also enables collaboration and shared decision-making among multiple users in different locations. However, Cloud-based digital twins may suffer from high latency due to the distance between the sensors generating data and the remote servers hosting the digital twin. Additionally, continuous connectivity is required for Cloud-based digital twins to function properly.
Fog computing, on the other hand, offers a distributed computing infrastructure that brings computation and data storage closer to the devices and sensors generating the data. This reduces latency and improves real-time performance, making it an ideal option for applications that require real-time processing and decision-making. For digital twins, this means that the data generated by sensors and devices can be processed locally, and only relevant data is sent to the cloud for further analysis. Fog-based digital twins are also a better option in areas with limited connectivity, as they can operate in offline mode and synchronise data when connectivity is restored.
The choice between Cloud-based and Fog-based digital twins depends on the specific use case and the required processing capabilities. While Cloud-based digital twins provide a wide range of resources and easy access, Fog computing enables faster processing and real-time decision-making in a distributed environment. Both computing paradigms have advantages and limitations, and the choice of implementation should be made based on the needs of the application and the available resources.
The choice between Cloud-based and Fog-based digital twins is dependent on the specific use case and requirements. Cloud-based digital twins are best suited for applications that require high computational power and data storage, allowing for advanced analytics and simulations. However, in cases where connectivity is limited or intermittent, Fog-based digital twins can operate offline and synchronise data when connectivity is restored. For example, in the agricultural domain, farms with a poor internet connection may benefit from a Fog-based digital twin, where data collected from sensors is processed locally and only relevant information is sent to the cloud for further analysis. Ultimately, the choice of implementation should be based on the unique needs of the application and the available resources.
It's important to note that data management is crucial in implementing digital twins in either the Cloud or Fog computing environment. Best practices for data collection, storage, and analysis should be followed, and data privacy and security should be considered. Finally, the role of emerging technologies such as 5G and edge computing should be taken into account, as they may influence the implementation of digital twins in the future.
4. Design and current implementation
The proposed architecture is designed to focus on a sub-field level, and grid level, unlike existing systems that mainly focus at the whole farm level or for controlled environment farming. This level of granularity allows for more accurate issue identification and timely decision-making for farmers. Additionally, the system employs the Cloud-Fog-Edge architecture style, which enables it to function effectively in both connected and disconnected environments due to the nature of Cloud and Fog. This section provides a brief overview of the system's design and implementation.
In our scenario, we are considering the sample farm as illustrated in Figure . Typically, farms in countries such as the UK and Ireland resemble the pictures shown. A farm is considered to be a collection of fields. Our implementation of a Cognitive Digital Twin is primarily focussed on arable farming, with a particular emphasis on winter wheat. As shown in Figure , our implementation is primarily developed as a decentralised linked-data structure consisting of a suite of semantic microservices. The output generated by these microservices is then consumed by a Hypermedia Multi-Agent System that follows the MAMS [Citation46] architectural style. This approach allows for a more scalable and modular design that can handle the complexity of a digital twin system.
Figure 5. Sample farm: collection of fields.

The implementation of a digital twin for arable farming involves several steps. The first step is to identify historical data sources and their associated APIs. These APIs are used to create the first version of the external layer of the digital twin. As illustrated in Figure , the digital twin for arable farming consists of two core services: the digital twin for farms and the digital twin for fields. Since a farm can contain multiple fields, these two core services are created as linked structures that represent the state of both the farm and the fields.
We have implemented a set of microservices that extract the required data from external APIs. For example, one of such microservices accesses historical data for farms and fields. We then transform this data into an internal linked-data representation using JSON-LD. The internal microservices are responsible for filtering and semantically enriching the raw data. They also manage the links between the different resources. For instance, a farm resource includes hyperlinks to the associated field resources, and each field resource links back to the farm resource. One of the external data sources critical to the DT is the weather service, which provides both historical and current weather data for the field being twinned. We have implemented this service during the initial development cycle of the DT.
External APIs
AHDB RB209 API: To obtain information on Nutrient Management recommendation. RB209Footnote2 is a publicly available guidance document designed to help farmers and land managers assess the fertilisers needed for the various crops they plan to grow.
Weather API: This API provides access to both historical and real-time weather data.
API for accessing historical farm and field data: This API allows access to historical data related to farms and fields.
Internal Microservices
AHDB Nutrient Recommendation Service: This microservice generates nutrient recommendations based on a field's location, crop type, expected annual rainfall, underlying soil type, and other factors.
Weather Service: This service offers historical as well as current weather data for the field that is being twinned.
Growth Stage Service: The Growth Stage microservice predicts the growth stage for the upcoming season by utilising the Zadoks Growth Stage model [Citation47]. This model defines a decimal scale that maps to the various growth stages of cereal crops. The transitions between growth stages are determined based on a series of thresholds for thermal time, which is an agro-climatic index. The thermal time is derived from the sum of the average daily temperature (within given bounds) from the crop's drilling date in the ground.
Field Plan Service: This microservice is responsible for managing field plans, and it collaborates with other microservices to create comprehensive plans for the fields.
Farm Plan Service: This service captures crucial decision points for the upcoming season and services hosting real/simulated behaviour of the throughout the growing season.
As illustrated in Figure , the digital twin is decomposed into internal and external data sources and a number of microservices.
As explained in Section 3.2 the overall Digital Twin implemented using a four-layer architecture. The implementation of Digital Twin incrementally done with each increment involving a number of steps. The first step is to identify the historical data sources and their associated APIs, which form the initial version of the External layer of the twin. A set of microservices is then implemented to extract the required data from these external APIs and transform it into an internal linked-data representation. The internal microservices handle tasks such as filtering and semantically enriching the raw data. They also manage the links between different resources. For instance, a farm resource should contain hyperlinks to the associated field resources, and each field resource should have a link to the farm resource. Among the crucial external data sources for the Digital Twin is the weather service. This service should provide both historical and current weather data for the twinned field and needs to be implemented during the initial development cycle of the Digital Twin.
After integrating the initial set of external data sources, the subsequent phase involves generating predictions for the upcoming season. This task requires access to a growth stage model, with the most commonly used one being the Zadoks Growth Stage model [Citation47]. This model utilises a decimal scale that corresponds to different growth stages of cereal crops. The transition between these growth stages is determined by specific thresholds for thermal time, which is an agro-climatic index calculated from the cumulative average daily temperature within defined boundaries from the crop's date of planting (drilling date). For a more comprehensive understanding of this model, refer to the RB209 handbook.Footnote3
Regarding agents, we have developed an initialisation agent responsible for navigating the farms and fields recorded in the farm database. This agent generates an initial DT for each field using the available yearly data. Currently, the data is informally represented in JSON format instead of JSON-LD. We have intentionally adopted a ‘schema last’ approach to first explore the structure and content of the DT resources before formalising those choices through the adoption of suitable ontologies.
5. Discussion
In this paper, we introduce a Digital Twin architecture for the agriculture domain in a Cloud-Fog-Edge infrastructure. In agriculture, there are two main types of growing environments: open and closed. In an open environment, crops are grown in a natural environment without any artificial enclosure, while in a closed environment, crops are grown inside an enclosed structure, such as a greenhouse, polytunnel, or indoor farm. Closed environments offer growers greater control over environmental conditions, including temperature, humidity, light, and CO2 levels. This allows farmers to create ideal growing conditions, regardless of external climate conditions, and results in more predictable and consistent crop yields. In contrast, open environments are subject to the natural climate, which can be unpredictable and challenging to manage. When designing a Digital Twin for agriculture, the environment plays a critical role. Controlled environments provide more accurate and consistent data compared to open environments. However, applying Digital Twin technology in both open and closed environments can provide numerous benefits to farmers, including real-time monitoring, optimisation, and remote management.
In open environment farms, there can be significant variability in the data collected from sensors within the same farm. To address this issue, our work aims to create a Digital Twin not only for the farm and field levels but also at a more granular level, down to the 10mx10m grid, as depicted in Figure . This approach enables the management zones to adapt to changes over time while ensuring the stability of the patches or grid, thereby offering enhanced opportunities to monitor, trace, and identify the behaviour of fields and their specific needs.
Figure 6. Farm-field-zone.
By creating a more granular Digital Twin, we can make fine predictions for each zone and optimise outputs accordingly. This approach can provide several benefits for open environment agriculture. First, it allows for more accurate and precise monitoring of environmental conditions within each zone. Second, it enables farmers to optimise crop management strategies based on specific conditions in each zone, leading to increased productivity and reduced waste. Finally, it can help farmers identify areas where they can make improvements in their farming practices, leading to more sustainable and efficient agricultural practices overall.
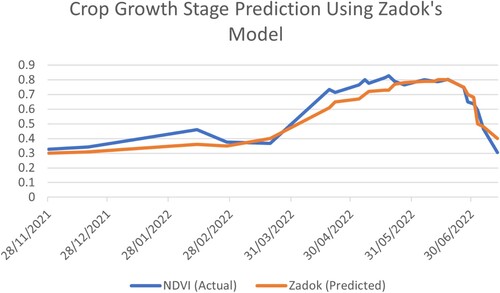
Currently, we use Zadok's model to predict the crop growth stage which is depicted in Figure . While this model is widely used and relatively simple, it may not be the most accurate model for all crops and growing environments. Therefore, we plan to explore alternative models that may be better suited for our specific use case. By evaluating and optimising different models for crop growth stage prediction, we can improve the accuracy and precision of our Digital Twin. This, in turn, can lead to more informed decision-making and better crop management strategies.
Figure 7. Crop growth stage prediction using Zadok’s model.
The volumes of data and computation required for digital twin applications in agriculture can vary greatly depending on the specific use case and the level of granularity of the digital twin. For instance, a digital twin created for a large-scale farm with a single crop may require a lower volume of data, while a digital twin for a smaller farm with multiple crops and granular level monitoring may require a higher volume of data. In addition to the size of the farm and the level of granularity, the frequency of data collection can also impact the volume of data and computation required. For example, if data is collected at a high frequency, such as per hour or per day/week, it can result in a higher volume of data that needs to be processed and analysed. Also, the types of sensors and data sources used can also affect the volume of data and computation required for digital twin applications in agriculture. For instance, if satellite imagery is used to monitor crops, it can result in a higher volume of data that needs to be processed and analysed compared to using traditional sensors. In general, digital twin applications in agriculture require the collection and analysis of data from various sources such as sensors, weather stations, satellite imagery, and other data streams. This data is then processed and analysed to create a virtual representation of the physical environment and enable real-time monitoring, prediction, and optimisation of crop growth and yield.
To provide some context, this particular work utilised data from approximately 17,393 fields, incorporating information from 1182 farms. The data sources encompass soil test data, nutrient data, and weather data. These datasets are valuable for making informed decisions regarding yield prediction, crop growth projection, nutrient recommendations, disease and pest outbreaks, and irrigation recommendations.
6. Conclusion and future work
This paper proposes a novel approach for integrating multi-agent systems (MAS) and Cloud-Fog-Edge architecture with Digital Twin technology in the context of Smart Agriculture. The paper also discusses the use of agents and semantic linked-data concepts. In addition, the paper provides a clear description of the implementation of Digital Twins not only for farms but also for individual fields. One of the main benefits of our approach is the ability to adapt and evolve the DT's decision-making services over time by extending the model to new data streams or incorporating new modelling techniques. The MAMS architectural style has been crucial to the success of this approach, as it enables seamless integration of agents and microservices. Additionally, this approach takes a comprehensive approach by using semantically interoperable JSON-LD based data models that enable better interoperability and service composition within the Smart Farming scenario. Unlike traditional approaches that rely on proprietary data silos and vertical architectures, our approach is designed to break down these barriers and promote better data exchange and collaboration.
Future research will investigate the use of semantic web technologies to enable greater interoperability. A library of internal microservices is currently being developed and the most suitable ontologies are being identified. The DT will be further developed, and decision agents will be introduced to enhance decision-making capabilities.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Zhai Z, Martínez JF, Beltran V, et al. Decision support systems for agriculture 4.0: survey and challenges. Comput Electron Agric. 2020;170:105256. doi: 10.1016/j.compag.2020.105256
- Raj M, Gupta S, Chamola V, et al. A survey on the role of internet of things for adopting and promoting agriculture 4.0. J Netw Comput Appl. 2021;187:103107. doi: 10.1016/j.jnca.2021.103107
- Costa B, Bachiega J Jr., de Carvalho LR, et al. Orchestration in fog computing: a comprehensive survey. ACM Comput Surv (CSUR). 2022;55(2):1–34. doi: 10.1145/3486221
- Rani A, Prakash V, Darbari M. Fog computing paradigm with internet of things to solve challenges of cloud with IoT. In: Advancements in Interdisciplinary Research: First International Conference, AIR 2022; Prayagraj, India; 2022 May 6–7; Revised Selected Papers; 2023. p. 72–84.
- Kalyani Y, Collier R. A systematic survey on the role of Cloud, Fog, and Edge computing combination in smart agriculture. Sensors. 2021;21(17):5922. doi: 10.3390/s21175922
- Escamilla-Ambrosio P, Rodríguez-Mota A, Aguirre-Anaya E, et al. Distributing computing in the internet of things: Cloud, Fog and Edge computing overview. In: NEO 2016. Springer; 2018. p. 87–115.
- Villarrubia G, De Paz JF, Iglesia DH, et al. Combining multi-agent systems and wireless sensor networks for monitoring crop irrigation. Sensors. 2017;17(8):1775. doi: 10.3390/s17081775
- Farsi M, Daneshkhah A, Hosseinian-Far A, et al. Digital twin technologies and smart cities. Berlin/Heidelberg, Germany: Springer; 2020.
- Cimino C, Negri E, Fumagalli L. Review of digital twin applications in manufacturing. Comput Ind. 2019;113:103130. doi: 10.1016/j.compind.2019.103130
- Erol T, Mendi AF, Doğan D. The digital twin revolution in healthcare. In: 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey; 2020. p. 1–7.
- Opoku DJ, Perera S, Osei-Kyei R, et al. Digital twin application in the construction industry: a literature review. J Build Eng. 2021;40:102726. doi: 10.1016/j.jobe.2021.102726
- Liu M, Fang S, Dong H, et al. Review of digital twin about concepts, technologies, and industrial applications. J Manuf Syst. 2021;58:346–361. doi: 10.1016/j.jmsy.2020.06.017
- Madni AM, Madni CC, Lucero SD. Leveraging digital twin technology in model-based systems engineering. Systems. 2019;7(1):7. doi: 10.3390/systems7010007
- Svetashova Y, Schmid S, Sure-Vetter Y. New facets of semantic interoperability: adding JSON-JSON-LD transformation functionality to the BIG IoT API. In: ISWC (Posters, Demos & Industry Tracks), Vienna, Austria; 2017.
- Ramanathan G, Vachtsevanou D, Garcia K, et al. Semantic knowledge for autonomous smart farming. IFAC-PapersOnLine. 2022;55(32):217–222. doi: 10.1016/j.ifacol.2022.11.142
- Mayer S, Verborgh R, Kovatsch M, et al. Smart configuration of smart environments. IEEE Trans Autom Sci Eng. 2016;13(3):1247–1255. doi: 10.1109/TASE.8856
- Falcão R, Matar R, Rauch B. Using i4. 0 digital twins in agriculture. Preprint; 2023. arXiv:2301.09682.
- Lakka E, Petroulakis NE, Hatzivasilis G, et al. End-to-end semantic interoperability mechanisms for IoT. In: 2019 IEEE 24th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD). IEEE; 2019. p. 1–6.
- Valle PHD, Garcés L, Nakagawa EY. A typology of architectural strategies for interoperability. In: Proceedings of the XIII Brazilian Symposium on Software Components, Architectures, and Reuse, Salvador, Brazil; 2019. p. 3–12.
- Kalyani Y, Collier R. Towards a new architecture: multi-agent based Cloud-Fog-Edge computing and digital twin for smart agriculture. International Symposium on Intelligent and Distributed Computing. Cham: Springer International Publishing; 2022.
- Alharbi HA, Aldossary M. Energy-efficient Edge-Fog-Cloud architecture for IoT-based smart agriculture environment. IEEE Access. 2021;9:110480–110492. doi: 10.1109/ACCESS.2021.3101397
- Tsipis A, Papamichail A, Koufoudakis G, et al. Latency-adjustable cloud/fog computing architecture for time-sensitive environmental monitoring in olive groves. AgriEngineering. 2020;2(1):175–205. doi: 10.3390/agriengineering2010011
- Montoya-Munoz AI, Rendon OMC. An approach based on fog computing for providing reliability in iot data collection: a case study in a colombian coffee smart farm. Appl Sci. 2020;10(24):8904. doi: 10.3390/app10248904
- Knebel FP, Wickboldt JA, de Freitas EP. A Cloud-Fog computing architecture for real-time digital twins. Preprint; 2020. arXiv:2012.06118.
- Qi Q, Zhao D, Liao TW, et al. Modeling of cyber-physical systems and digital twin based on Edge computing, Fog computing and Cloud computing towards smart manufacturing. In: International Manufacturing Science and Engineering Conference. vol. 51357. American Society of Mechanical Engineers; 2018. p. V001T05A018.
- Girletti L, Groshev M, Guimarães C, et al. An intelligent edge-based digital twin for robotics. In: 2020 IEEE Globecom Workshops (GC Wkshps). IEEE; 2020. p. 1–6.
- Xu W, Cui J, Li L, et al. Digital twin-based industrial cloud robotics: framework, control approach and implementation. J Manuf Syst. 2021;58:196–209. doi: 10.1016/j.jmsy.2020.07.013
- Braun S, Mostafa Y, Ulmer J, et al. Agents-as-a-service-a novel approach to on-premise digital twins. In: 2021 IEEE 17th International Conference on Intelligent Computer Communication and Processing (ICCP). IEEE; 2021. p. 125–130.
- Croatti A, Gabellini M, Montagna S, et al. On the integration of agents and digital twins in healthcare. J Med Syst. 2020;44:1–8. doi: 10.1007/s10916-020-01623-5
- Gorodetsky V, Kozhevnikov S, Novichkov D, et al. The framework for designing autonomous cyber-physical multi-agent systems for adaptive resource management. In: International Conference on Industrial Applications of Holonic and Multi-Agent Systems. Springer; 2019. p. 52–64.
- Clemen T, Ahmady-Moghaddam N, Lenfers UA, et al. Multi-agent systems and digital twins for smarter cities. In: Proceedings of the 2021 ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, Virginia, USA; 2021. p. 45–55.
- Laryukhin V, Skobelev P, Lakhin O, et al. Towards developing a cyber-physical multi-agent system for managing precise farms with digital twins of plants. Cybern Phys. 2019;8(4):257–261. doi: 10.35470/2226-4116
- Mariani S, Picone M, Ricci A. About digital twins, agents, and multiagent systems: a cross-fertilisation journey. Preprint; 2022. arXiv:2206.03253.
- Schraudner D, Harth A. A restful interaction model for semantic digital twins. In: SeDiT@ESWC, Hersonissos, Greece; 2022.
- Eleftheriou OT, imara AD, Kotis KI, et al. Saving energy with comfort: a semantic digital twin approach for smart buildings. In: SeDiT@ESWC, Hersonissos, Greece; 2022.
- Katsigarakis K, Lilis GN, Rovas D, et al. A digital twin platform generating knowledge graphs for construction projects. In: SeDiT@ESWC, Hersonissos, Greece; 2022.
- Kalyani Y, Rahman S, Collier RW. Integration of hypermedia-agents, microservices and digital twin for smart agriculture. In: Proceedings of the PoEM 2022 Workshops and Models at Work co-located with Practice of Enterprise Modelling 2022; London, United Kingdom; 2022 Nov 23–25; volume 3298 of CEUR Workshop Proceedings. CEUR-WS.org; 2022.
- Antoniu G, Valduriez P, Hoppe H-C, et al. Towards integrated hardware/software ecosystems for the Edge-Cloud-HPC continuum; 2021. doi: 10.5281/zenodo.5534464.hal-03358930
- Rosendo D, Silva P, Simonin M, et al. E2clab: exploring the computing continuum through repeatable, replicable and reproducible edge-to-cloud experiments. In: 2020 IEEE International Conference on Cluster Computing (CLUSTER). IEEE; 2020. p. 176–186.
- Abanda FH, Tah JHM, Keivani R. Trends in built environment semantic web applications: where are we today? Expert Syst Appl. 2013;40(14):5563–5577. doi: 10.1016/j.eswa.2013.04.027
- Prudhomme C, Homburg T, Ponciano J-J, et al. Interpretation and automatic integration of geospatial data into the semantic web: towards a process of automatic geospatial data interpretation, classification and integration using semantic technologies. Computing. 2020;102:365–391. doi: 10.1007/s00607-019-00701-y
- Kalaycı EG, González IG, Lösch F, et al. Semantic integration of Bosch manufacturing data using virtual knowledge graphs. In: The Semantic Web–ISWC 2020: 19th International Semantic Web Conference; Athens, Greece; 2020 Nov 2–6; Proceedings, Part II 19. Springer; 2020. p. 464–481.
- Ibáñez L-D, Millard I, Glaser H, et al. An assessment of adoption and quality of linked data in European open government data. In: The Semantic Web–ISWC 2019: 18th International Semantic Web Conference; Auckland, New Zealand; 2019 Oct 26–30, Proceedings, Part II 18. Springer; 2019. p. 436–453.
- Hitzler P. A review of the semantic web field. Commun ACM. 2021;64(2):76–83. doi: 10.1145/3397512
- Bizer C, Heath T, Berners-Lee T. Linked data: the story so far. In: Semantic Services, Interoperability and Web Applications: Emerging Concepts. IGI Global; 2011. p. 205–227.
- Collier RW, O'Neill E, Lillis D, et al. Mams: multi-agent microservices. In: Companion Proceedings of The 2019 World Wide Web Conference, San Francisco, USA; 2019. p. 655–662.
- Zadoks JC, Chang TT, Konzak CF. A decimal code for the growth stages of cereals. Weed Res. 1974;14(6):415–421. doi: 10.1111/wre.1974.14.issue-6