

ABSTRACT
In the field of natural language processing, there is no specialized dataset for the Analects, which makes it difficult to assess whether language models can find the semantic relevance between the Analects and modern Mandarin. To address this issue, this paper proposes a dataset named AMPD (Analects-Mandarin Parallel Dataset), which includes the Analects and its corresponding modern Mandarin, keywords and their annotations in the Analects, as well as sentiment. Additionally, we propose four baseline tasks and benchmark them by implementing currently popular algorithms respectively.
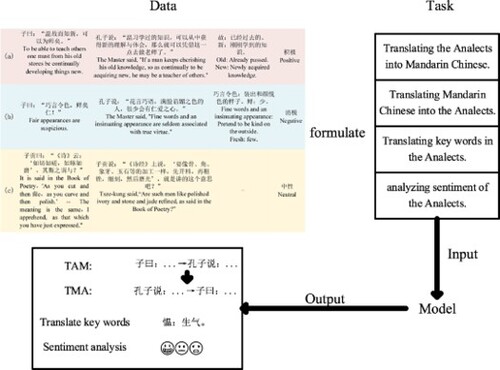
GRAPHICAL ABSTRACT
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
6 Due to the limitation of the graphics memory, we are unable to conduct experiments with longer sequences.