Abstract
For the complex systems modeller, uncertainty is ever-present. While uncertainty cannot be eliminated, we suggest that formally incorporating an assessment of uncertainty into our models can provide great benefits. Sources of uncertainty arise from the model itself, theoretical flaws, design flaws, and logical errors. Management of uncertainty and error in complex systems models calls for a structure for uncertainty identification and a clarification of terminology. In this paper, we define complex systems and place complex systems models into a common typology leading to the introduction of complex systems specific issues of error and uncertainty. We provide examples of complex system models of land use change with foci on errors and uncertainty and finally discuss the role of data in building complex systems models.
Keywords:
1. Introduction
A fundamental goal of complex systems analyses is to gain insight into the diverse interactions operating in a system that produce particular dependent outcomes. However, the very nature of complex systems suggests that the greater the complexity in the system, the more difficult it is to identify the salient interactions or hinge points in a system. The development of models of complex systems is confounded by the difficulty in reducing a complex system to these key salient interactions. In many cases, data are inadequate to specify all elements of a system or inappropriate for interaction definition, and therefore the model developer must build in assumptions into each representation of a system. This is particularly true for models of complex human–environment systems where data span a broad array of social and biophysical domains. Obviously, this presents a problem that has, in fact, reduced the efficacy and acceptance of complex systems models and threatens to relegate them as a curiosity and class of model generalized far beyond what is reasonable. There are many examples of papers presenting a tightly constrained predictive model of nominal land cover classes proclaiming particular goodness of fit or model fidelity. While this issue is common, it is also increasingly common to find valid criticisms of complex systems models (cf. The Economist Citation2003). One major criticism of complexity science is that error and uncertainty are rarely measured or defined. When combined with models of land use and cover change, uncontrolled or unknown uncertainty and error conditions create conditions where the output of the model becomes simply one manifestation of reality that has no particular significance over randomness.
A primary objective of spatial analysis, whether conducted for scientific discovery or for management and decision-making, is the generation of geographic information and knowledge. The building blocks for this knowledge-generation consist of two factors: geospatial data, and sets of spatial operations (Shortridge, Messina, Hession, and Makido Citation2006). It is possible to design accuracy specifications for a data set with a single purpose. However, the variety of applications for a particular data set can extend far beyond the producer's original intent. This presents a problem for the accuracy or reliability specifications approach to data quality, since the data producer does not know in advance whether the data are of suitable quality for any particular application.
Knowledge production arises through the thoughtful application of spatial operations to data. However, analytical results are subject to the uncertainty in the underlying data used to produce those results. Mismatches arise between these results and the actual situation on the ground because of two general factors: lack of fidelity between the spatial data employed and reality, and inadequate specification of the spatial or complex systems operations employed on the data. Characterizing these mismatches has been the focus of a great deal of research in the GIScience community, and substantial progress has been made. In this paper, we discuss the basis for a complex systems approach for the analysis of land change science. An important issue in the study of complex systems is the ability to disentangle the relationships that exist in social–ecological systems. Critically, issues of data error and data uncertainty obfuscate the identification of relationships in these systems. We focus on the role of error and uncertainty derived from both data and from the spatial operations that are inherent in complex systems models. We highlight key issues of error and uncertainty in the complex systems community by tying together operations, data, and management issues. To frame the discussion, we begin with an overview of complex systems and the relevant sub-contexts of agent-based models and cellular automata, followed by sections linking error and uncertainty to these distinct modelling frameworks and conclude with a discussion and possible solutions.
2. Complex systems
A complex system is one in which seemingly complex patterns or processes have at their heart simpler origins. There are many different definitions of complex systems, although from a broader disciplinary perspective, complexity science is concerned with three key kinds of complexity (cf. Byrne Citation1998, Cilliers Citation1998, Lissack Citation2001; Manson Citation2001; Reitsma Citation2002). The first, algorithmic complexity, measures the structural complexity of a system in algorithmic or computational terms. The second, deterministic complexity, explores seemingly complex systems via rubrics of nonlinearity, chaos, and catastrophe. The third and most common form of complexity research is aggregate complexity, which examines how complex systems such as economies or ecosystems emerge from the local interactions of individual elements.
Complexity science contends that many systems are best understood as being driven by prototypical processes such as emergence (when synergistic interactions among system elements create unforeseen outcomes) or sensitivity to initial conditions (where small changes in one part of a system lead to disproportionately large ones elsewhere later in time). Algorithmic, deterministic, and aggregate complexity in turn examine these characteristic processes to a varying extent. Similarly, complex systems, by virtue of possessing hallmark complex processes, exhibit characteristic patterns such as fractals and power-law distributions that are seen as a result of these processes and are therefore signatures of complexity (Malanson Citation1999; Manson Citation2001).
Complex systems can require complex models. Longstanding approaches, such as statistics and system dynamics modelling, fruitfully illuminate many features of complex systems but researchers increasingly complement these methods with others that explicitly incorporate complexity concepts such as emergence and sensitivity to initial conditions (Young et al. Citation2006). Algorithmic and deterministic approaches characterize systems via information measures, nonlinear mathematics, and stylized system models. Methods embedded in aggregate complexity include biologically inspired methods (e.g. genetic programming or artificial life modelling, artificial neural nets) and those based on discrete automata (e.g. cellular automata or agent-based models; Parker, Manson, Janssen, Hoffmann, and Deadman Citation2003).
More broadly, complex approaches are necessary because some features of complex phenomena are difficult or impossible to model with approaches that make assumptions of superposition, equilibrium, and linearity (Arthur Citation1999). While complexity research can take a classical view of science in which theory generates testable hypotheses that are evaluated against reality, it increasingly relies on the epistemological supposition that the reality and theory of a complex system can only be linked effectively by computer models. In essence, the model becomes the hypothesis, because it is the only means of effectively representing enough salient features of a complex system simultaneously. The primacy of modelling as a means of understanding key features of complex systems makes it the key epistemology of complexity (Henrickson and McKelvey Citation2002; O'Sullivan Citation2004).
Land Use and Land Cover (LULC) theory in population–environmental systems poses challenges that are met by complex models. Land Change Science (LCS) emphasizes that land change lies at the interface of coupled human–environment systems, as it is the result of interactions among social systems, ecological dynamics, and actors such as households or firms whose behaviour is the proximate cause of land change (Gutman et al. Citation2004). Land Change Science therefore relies on studies of actors and societal structures that drive land-change dynamics; on field-based studies of environmental feedbacks; and on satellite observation of patterns and rates of land change (Messina and Walsh Citation2001). There is a corresponding need to understand interactions among actors, society, and the environment at multiple scales in space (e.g. individuals, households, communities, nations) and time (e.g. years, decades, and longer) (Verburg and Veldkamp Citation2005). In the face of these myriad theoretical and methodological approaches, the land change research community has broadly adopted integrated computer models that combine empirical data with theories of actor behaviour in social and ecological systems.
Complex LULC models meet the methodological needs of LCS while also addressing the corollaries of complex systems more generally. Approaches such as agent-based models or cellular automata are very flexible in their specification and operation, making them ‘virtual laboratories’ to test theories and models of LULC dynamics (Doran and Gilbert Citation1994). Complex models can also explicitly capture interdependencies, heterogeneity, and nested hierarchies among individual actors and between actors and their environment (Parker et al. Citation2003). Approaches such as agent-based modelling, genetic programming, or neural networks offer direct models of human adaptation, learning, and cognition. Finally, land change is a complex spatiotemporal phenomena that exhibits characteristics such as nonlinearity, self-organization, deterministic chaos, and path dependence (Brown, Page, Riolo, Zellner, and Rand Citation2005). These features are best examined with methods that embrace, or at least accommodate, the hallmark processes and patterns of complexity.
3. Error and uncertainty in models of LULC
The need to develop models of LULC as a complex phenomenon raises a number of challenges concerning uncertainty and error. Given the rapidity of growth in complexity-based LULC modelling and the paucity of pre-existing work or standards, many modellers either scrimp on model evaluation or use standard statistical methods that do not account for complexity (Verburg and Veldkamp Citation2005). More broadly, while there is a good deal of research on mathematical and statistical evaluation of error and uncertainty (Costanza Citation1989; Heuvelink Citation1996; Walker Citation2003; Pontius, Huffaker, and Denman Citation2004), complex models of human–environment issues raise broader methodological, conceptual, and policy challenges that remain largely unmet (Manson Citation2006). Methodologically, particularly important issues are raised by the role of sensitivity in complex systems and the problems of modelling multiscalar systems. There are also significant conceptual challenges concerning the persistent and troubling conflation of pattern and process, which is related to the challenge of reconciling models that must balance simplicity and complexity.
4. Complex system models
Most complex system models are mathematical models, and as such may be characterized by their respective purpose, mode, stochasticity, and generality. As simulations based on the global consequences of local interactions, complex systems models typically consist of an environment or framework in which the interactions occur with individuals defined in terms of procedural rules. Most complex systems models are dynamic spatial simulation models, and should simulate continuously dynamic change. Unfortunately, current computing systems are not precisely capable of handling continuous dynamics, and thus, most operational complex systems models can be characterized as dynamic, discrete-change, and stochastic (Crawford, Messina, Manson, and O'Sullivan Citation2005).
Since the relevant terminology is not fixed and a large number of closely related words are employed, some particularly important ones are defined here. It is difficult to compose definitions for truly generic spatial phenomena; and thus the following language relates more closely to field-modelled phenomena, rather than entity-modelled phenomena:
accuracy: a general term for the degree to which a spatial data set conforms to the idealized phenomenon, as specified by the conceptual model. The means by which this may be quantified depends on various factors, including the conceptual model itself, the application domain, associated data quality specifications, and the type of available reference information, if any.
Error: the difference between the actual condition of the measured spatial phenomenon and its representation in the data set. ‘Actual condition’ implies an independently collected reference measure to compare against a portion of the data set. The comparison may be complicated by mismatches between the ontological bases for the spatial data set and the reference data set (Bishr Citation1998; Fonseca, Davis, and Camara Citation2003), inaccuracies in the reference, and the relatively restricted set of sampled locations over which reference information are typically available.
Quality: synonymous with accuracy, but more applied in data production and distribution. Generally describes a variety of specified factors with possibly quite different quality measures. Much government produced or funded spatial data must meet particular quality specifications in order to be approved for distribution (FGDC Citation1998). For US federal government data, documented data quality components are positional and attribute accuracy, logical consistency (such as topological characteristics), completeness, and the source materials, or lineage (Veregin Citation1999). Increasingly data quality is couched in fitness for use terminology; however, it remains unclear how this mandate is to be met.
Uncertainty: for spatial data, this is the degree to which the fidelity of the data to the phenomenon at a location is open to question. In the words of Unwin (Citation1995), it is a measure of doubt. Employing a stochastic conceptual model of the phenomenon of interest, uncertainty is the degree of variability we attach to data values. Spatial data may also be subject to uncertainty due to vagueness in category definitions such as land cover classes (Fisher Citation1999).
4.1. Agency
Agency is one of the most poorly defined areas of complex systems modelling despite being among the most fundamental (O'Sullivan, Manson, Messina, and Crawford Citation2006). Here, we define agency as, quite simply, an algorithm. An agent is easily conceived of as an entity, and the traditional entity–relationship diagram could be employed (Chen Citation1976). In the hierarchy of complex system models, the broadest definition is the agent-based model. Individual (agent)-based models are a subset of multi-agent systems. Individual-based models are distinguished by the fact that each ‘agent’ corresponds to an autonomous individual in the simulated environment. Frequently individual-based models with multiple individuals are referred to, incorrectly, as multi-agent systems. Multi-agency requires multiple algorithms, not, merely, multiple copies of the same individual. If an agent is not discretely definable by an algorithm of some decision-making or reacting activity, then it is not an agent. Some authors confuse the environment with the agents acting upon those environments (e.g. when a pixel or plot of land is used as a decision-making entity). This confusion obviously introduces a significant source of error or uncertainty. One might consider the nature of the model, the entity structure, the implicit or explicit parameterization of process through rules or any of a number of potential error sources.
4.2. Cellular Automata
Cellular Automata (CA) models are spatially explicit, grid-based, immobile individual-based models. In CA, pattern trajectories, from almost all initial states, tend to merge with time into concentrated ‘attractor’ states. These attractor states, by definition, include only a very small fraction of the total list of all possible states. Searching for repeating patterns in multiple spatial and temporal scales, or hierarchical patterns, theoretically permits the description of the physical nature of a system. However, uncertainty emerges from the inability of the researcher to accurately define the internal processes of the complex system modelling implementation used. This is even more problematic under scenarios using tightly constrained models. In essence, multiple interactions impossible to characterize using traditional mathematical forms give the appearance of complexity while actually being more precisely defined as complicated (Messina Citation2004).
CA models have been used extensively within the land use change literature (Wu Citation1996; Clarke and Gaydos Citation1998). Within the hierarchy of cellular models and complex characteristics, there are four classes of models and associated output (Wolfram Citation1983, Citation1984):
-
Class 1: Evolution into a homogenous arrangement;
-
Class 2: Evolution into endlessly cycling periodic structures;
-
Class 3: Evolution producing aperiodic, seemingly random patterns;
-
Class4: Complex patterns with localized structures moving through space and time are generated.
In Class 4 CA models, the class typically associated with ‘complexity’, a particular final pattern may evolve from many different initial conditions. These types of systems require computational or algorithmic complexity equal to the explicit simulation in place (Manson Citation2001). These systems are, in effect, unpredictable in a purely deterministic sense and must be resolved by explicit simulation. However, the sources of uncertainty are accumulative and not directly measurable (Messina and Walsh Citation2005).
In managing computability in complex systems models, program design and error management are crucial. The entity–relationship model and its ontological and computing derivatives form the logical foundation. Following Duckham (Citation2000), the error-sensitive development process can be thought of as three distinct stages: (1) deciding upon the core data quality concepts, (2) developing and implementing an error-sensitive data model based on these concepts, and (3) developing interfaces for the error-sensitive model to deliver the error-sensitive services and functionality to users. In land use applications of complex systems models, uncertainty is almost entirely a function of the error-sensitivity of the data model. The basic formulation of complex systems implementations almost always follows well-defined deterministic model structures. As such, two sources of user error emerge: (1) model suitability, and (2) model parameterization. As an example of the potential for confusion, cellular automata models are frequently used in LULC modelling. Typically, traditional CA models are homogeneous where all cells are identical and fully occupy space. Conversely, a grid-based individual-based model might occupy only a few cells and more than one distinct manifestation of that individual type might live on the same grid. In these two cases the models are defined by the nature of the implementation and the initial ontological properties of the system under study, but, importantly, are distinct logical models, often typologically used as equivalent, and are not testable for accuracy or error using the same methods.
4.3. Agent-based models
Agent-based models (ABMs) pose additional uncertainty challenges beyond those faced in Cellular Automata approaches. ABMs for human–environment interactions (or LULC) may be considered a sub-class of automata in that they are often explicitly addressing the geographic environment based on a grid with defined rule sets for the interactions between humans and the environment (Parker et al. Citation2003). However, ABMs add an additional layer of complexity in the (potentially) heterogeneous representation of agents acting in a system and in the definition of agent-interactions. The types of agents incorporated into ABMs of land cover change vary, but households (Deadman, Robinson, Moran, and Brondizio Citation2004; Evans and Kelley Citation2004; Brown et al. Citation2005) and communities (Jepsen et al. Citation2006; Wada, Rajan, and Shibasaki Citation2007) are most commonly used. In an ABM, cell states are the product of cell-based rules and agent behaviours and the validation of those within-model behaviours is a particular challenge for ABM. There is considerable debate surrounding the general topic of decision-making theory and the manner in which these theories are applied in models of real world settings. A particular target of debate has been characterizations of actors as perfectly informed, rational decision-makers (Rabin Citation1998; Gintis Citation2000; Henrich et al. Citation2001). Field- and laboratory-based approaches from experimental economics have been utilized to try to provide insight into fundamental decision-making strategies across societies (Henrich et al. Citation2001; Evans and Kelley Citation2006), and these tools can provide a foundation for model development but thus far have not been used to validate specific ABMs directly. Thus, the uncertainty regarding the factors contributing to diverse decision-making strategies leads to models that incompletely characterize the breadth of processes that lead to various landscape outcomes.
Modellers have various choices in characterizing the decision-making processes of actors. Household decisions are often made without clearly identifying the role of individuals within the household. Indeed this is one means by which modellers simplify the decision-making process driving a land change system. Yet ethnographic research has identified great richness among the diversity of household structures and the role of specific individuals in a household as a function of age or gender. Identifying households as a decision-making entity is to simplify the within-household dynamics that lead to household decisions. To date, many models lack the empirical data to clearly demarcate these within household dynamics and there is an opportunity for research integrating ethnographic methods with ABMs to address this data-driven element of uncertainty in ABMs of land change systems.
Another critical challenge in agent-based modelling is the difficulty in characterizing and validating the role of agent interactions in a model. Social network data certainly provide an opportunity to address this issue, but are rarely available longitudinally, and even when available it is not always possible to identify agent interactions as the specific reason a particular behaviour diffuses among households in a landscape. In addition, the interactions inherent in ABMs imply that actors are not independent decision-makers. Yet this property of independence is necessary for the application of standard parametric statistical techniques to analyse the relationship between actor characteristics, land-use decisions and landscape outcomes.
5. Error and data production
The quality of the spatial data employed in complex models is a vital and under-researched source of uncertainty in the results of those models. Data are critical for the modelling process in many ways: they may be analysed to determine key parameters (i.e. model calibration), they may serve as spatial layers characterizing initial conditions, and they may be employed to assess results (i.e. model validation). Fidelity of these data to the real-world phenomena they represent is therefore important to establish, as the potential impact of error is widespread in the modelling process.
Error assessment is a common component of the spatial data production process. In numerous countries the means by which this is conducted is regulated by standards (FGDC Citation1998). In the US, spatial data quality standards include five critical, though non-orthogonal, components: lineage, positional accuracy, attribute accuracy, logical consistency, and completeness (Guptill and Morrison Citation1995). Of the five, positional and attribute accuracy are the most amenable to the quantitative assessment of error. The specific means by which an assessment is conducted depends upon the properties of both the spatial phenomenon being measured and the data type employed to capture it, but standard summary measures are employed to report accuracy; these include the root mean square error (RMSE) for interval and ratio data types and percent correctly classified for categorical data types. In both cases, existing reference data at a set of locations are employed to calculate the metric.
How does the error assessment of spatial data relate to the challenge of estimating uncertainty in the output from complex models? We suggest that the application of data-oriented error assessment methods to these models takes two distinct forms: the first considers the spatial output of a model as a spatial data set itself, while the second considers the impact of error in the spatial data inputs on the quality of model results.
The first case is really a validation challenge: if the model is characterizing a spatial process that exists and can be measured (e.g. forest species composition in 2006 for a study region of interest), then standard data quality metrics may be employed to characterize the ability of the model to reproduce reality. If the model is projecting into the future, or characterizes patterns that are not directly measurable, then the lack of reference data makes the calculation of these metrics impossible.
The second case offers a more complex challenge than simply calculating suitable accuracy metrics; as a practical matter the modeller is not interested in the precise RMSE of some input Digital Elevation Model (DEM), or the overall classification accuracy of a related land cover data set. Instead, the modeller is interested in the propagation of uncertainty from these input data sets through the model to the results. Error propagation may be identified analytically for relatively simple problems, but for complex models stochastic (Monte Carlo) simulation is employed (Heuvelink Citation1998; Zhang and Goodchild Citation2002). In the stochastic simulation approach, an error model capable of generating statistically valid realizations of the input spatial processes (captured imperfectly by the available spatial data) is used to generate a series of simulated spatial data sets. These realizations are used as inputs to the operational model of interest; if n realizations are generated, n spatial outputs are produced. By studying the differences between these outputs, the modeller can determine the impact of spatial data uncertainty on model results.
Many examples of spatial error propagation for landscape models exist in the literature. Canters, De Genst, and Dufourmont (Citation2002) use this approach to evaluate input uncertainty on landscape classification using land cover and terrain data. Aerts, Goodchild, and Heuvelink (Citation2003) demonstrate the utility of stochastic simulation for quantifying uncertainty in spatial decision support. An analytical approach to error propagation is adopted by Bachmann and Allgöwer (Citation2002) to investigate data-based uncertainties in fire modelling. Ehlschlaeger, Shortridge, and Goodchild (Citation1997) evaluate the spatial and cost variability of cross-country routing due to elevation uncertainty, while Fisher (Citation1991) considers viewshed uncertainty. Little research, however, has been published on the propagation of error for complex models, perhaps due to the difficulty of developing appropriate error models and integrating them within the landscape change model (Heuvelink Citation2002; Shortridge et al. Citation2006). A notable exception is work by Yeh and Li (Citation2006), which investigates the uncertainty in an urban growth CA model due to uncertainty in land cover classification. They employ a simple model to randomly perturb the initial land cover data set, creating many realizations, and study the impact on the CA model, which proved to be sensitive. While outcomes are highly dependent on the particular characteristics of the landscape model and the input data error, we speculate that many other models may be greatly affected by this error.
6. Managing error and uncertainty
Error and uncertainty pose particular challenges to LULC modellers because their models necessarily span social and physical domains. Broad system representations that incorporate complex social dynamics and complex physical dynamics complicate the careful observation of the interactions between these domains. Therefore, a fundamental role of the modeller is to disentangle this complexity and reduce a system to the salient components and processes that affect system behaviour. With respect to land cover change models, the outcome of system behaviour is a land cover state. Most models are calibrated to fit the location and proportion of land cover or simply to the proportion of land cover alone. Remotely sensed images are often used as the data source for these observed land cover targets. In many land change systems, the rate of land cover change is overwhelmed by the degree of error commonly encountered in land cover classifications derived from remotely sensed images. For example, classification errors of 10–20% are commonly noted in the literature, yet rates of land cover change between time intervals rarely exceed this amount (Pontius et al. Citation2004).
This contrast presents various challenges for land cover change modellers. presents a hypothetical diagram of observed and modelled forest cover. The observed data points are bounded by tails depicting a hypothetical range of classification error. The real-world land cover proportion lies somewhere within the bounding tails. Between 1975 and 1985, the model comes close to predicting the actual land cover proportion in both time points and the model successfully represents land cover trajectory (increasing forest cover). The rate of forest increase is misrepresented, but the model gets the direction of forest cover change correct. From 1985 to 1995, the observed data indicate that forest cover slightly decreased, but the model shows forest cover increasing. Thus, the trajectory of forest cover in the model does not match the best measure of observed forest cover. But given the uncertainty of the land cover data in 1985 and 1995, it is possible that the real-world trajectory of land cover change is actually one of increase. In other words, it is plausible that the observed forest cover proportion in 1985 is actually at the low end of the classification error tail, and the observed forest cover proportion in 1995 is actually at the high end of the classification tail. So, from 1985 to 1995, it is impossible to confidently determine that the model is incorrect even though the trajectory of change contradicts the best data measurement. From 1995 to 2005, notice that the model correctly predicted an increase of forest cover. However, the rate of forest cover change is under-estimated and here our model is outside the bounds of our classification error. In this scenario, one would want to focus attention on calibrating the model only in the 1995–2005 time interval. Efforts to further calibrate our model for the other time intervals would be less useful given the uncertainty in the observed data.
Figure 1. Observed versus modelled land cover change figures often incorporate trend lines and error bars depicting the hypothetical range of error. However, hidden within these trend lines are variable confidences leading to a convoluted decision-making process regarding error management.
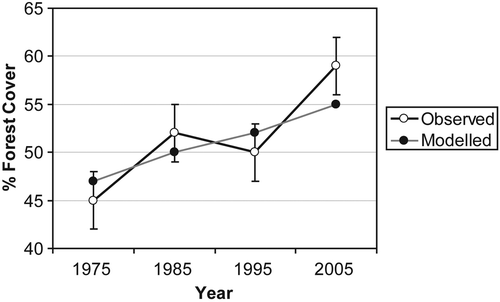
Efforts to fit models are complicated by the complex interactions that result in land cover change. For example, the increase in forest cover from 1995 to 2005 may be the product of changes in zoning (policy), changes in smallholder attitudes about environmental protection, or demographic change. In cases where multiple independent variables have coincident change it is not possible to quantitatively identify which factor may be the determining factor. Thus the research must rely on qualitative interpretation and theoretical justification to support the basis for findings from models.
Qualitative data sources present a potentially under-utilized resource for informing models of land cover change and in understanding the bounds to which quantitative data can inform model design, calibration and interpretation. Agents are often incorporated into models of land cover change with a specific decision-making framework. For example, Deadmen et al. (2004) used a heuristic decision-making approach, while Evans and Kelley (Citation2004) used a utility maximization approach. Quantitative data from household interviews can be used to calibrate a model for parameters such as household size, wealth, and area in cultivation. But the descriptive data commonly included in structured surveys do not necessarily identify the decision-making strategies employed by a particular actor. Qualities such as risk aversion, past experience, future expectations and the ability to evaluate information from disparate sources all play a role in how a particular actor makes land management decisions. Because these more intangible elements are difficult to capture in structured surveys they may be considered sources of uncertainty in models of land cover change. Here it is then important to distinguish between models designed for prediction versus models designed more specifically to provide insight into the dynamics of a system. A model that excludes elements of risk or experience may be deemed appropriate if it is designed for prediction and the predictive power of the model meets some minimum desired level of accuracy. Models designed for a specific type of insight into a system are more likely to benefit from the inclusion of intangible elements.
While quantitative data whether collected by survey, remotely, or by other means remain the core informing data of land change science, qualitative data may serve many other purposes as well. Unstructured interviews are particularly well suited to the development of hypotheses (Huigen, Overmars, and De Groot Citation2006) that may later be tested statistically with structured interviews. Qualitative data have also been used to characterize the decision-making process of actors (Gladwin Citation1989; Huigen et al. Citation2006) in ways that lead to richer insights into decision-making dynamics than analysis of survey instruments focused on descriptive characteristics. Likewise, role-playing games (Castella, Trung, and Boissau Citation2005) combine stakeholder participation and models or abstract or real-world situations to both gain insight into stakeholder behaviour, but also to use models to allow stakeholders to gain insight into the processes operating in complex social–ecological systems. Given the focus of agent-based models on household or individual behaviours, qualitative techniques are somewhat perhaps under-represented in the current land cover change research, with a few notable exceptions (e.g. Huigen et al. Citation2006).
7. Model validation
When it comes to understanding and managing error through the validation of models, researchers within land change science face a number of challenges. The very nature of complex systems models frequently precludes the use of quantitative validation techniques that are associated with many traditional computer science models. Historically argued as a limitation the result of a focus more on understanding the processes driving a complex system rather than on predicting specific outcomes, it more likely reflects the lack of tools or methods necessary to perform such quantitative analyses (Santner, Williams, and Notz Citation2003). In constructing a complex systems model, the modeller must make a series of explicit and implicit assumptions about the system, many of which cannot be tested due to a lack of suitable data from the real system. For example, in CA models, a wide variety of assumptions are made regarding the representation of space, its resolution when represented as a grid and the possible state of each cell in the grid, and the way in which human decision-making is represented in the transition rules that determine how cell states change over time. In ABMs, a considerable number of assumptions are made regarding the representation of human decision making, from the resolution of the agents (community, household, or individual) to the algorithms used by the agents. The complex nature of the problem or question being addressed makes it difficult to place boundaries around the system being modelled. These boundaries must define the spatial and temporal scale and extent of the system, as well as the entities, interactions, and processes to be included. Further, the use of random variables in these models and the emergent properties and path dependencies of complex systems models means that they are better suited to exploring the potential solution space, or the dynamics, of a complex system rather than predicting specific historic or future land use states. Certainly, quantitative procedures exist to test the replicative or predictive validity of a simulation. Statistical procedures for comparing the output of a simulation with that of a real system have been described in Law and Kelton (Citation1991) and spatial statistical procedures exist for comparing maps (see e.g. Pontius et al. Citation2004; Visser and de Nijs Citation2006). However, we may be focusing too much on replicative validity, comparing land use state at time t produced by the model with that observed in the real world. Reproducing, or failing to reproduce, land use quantity and distribution at a specific time tells us little of the larger solution space of the model or the important processes driving change over time. It is no argument that we may not need to validate if we only want to explore the potential solution space, here we also need to know if the determined solution space or emergence correspond with reality. We could however say that in many cases ABMs are only for exploring the result of possible interactions for abstract or hypothetical conditions, which are hard to validate based on real-world data. The correct spatial pattern of land use change may be simulated by a model based on processes that do not exist in reality or multiple patterns of land use change may be simulated by the same process using slight variations in input variables. Pijanowski, Pithadia, Shellito, and Alexandridis (Citation2005) have shown that highly calibrated models are often less capable of predicting future changes in urban land use as compared to models that are less accurately (tightly) calibrated. Moreover, models with high performance using standard validation techniques on historic data may be less capable of exploring possible future solution spaces because they are constrained to the historic processes of change.
The emergent properties of a good complex systems model and the unpredictable nature of the output produced by that model make the use of many quantitative validation techniques troublesome. Preferably the processes and interactions leading to the model outcome should be validated but quantitative techniques are often lacking. What are needed are sets of techniques for qualitatively evaluating the output of these models. Indeed, many modellers have relied more on qualitative descriptions, or the use of aggregate descriptions of model output to characterize the solution space of a particular model. Others have developed techniques for exploring the important behavioural aspects of model behaviour including path dependency and agent heterogeneity. Castella et al. (Citation2006) use participatory sessions and individual interviews within the simulated villages to ground-truth algorithms and collectively discuss the discrepancies between the outcome of the model and the villagers' own representations of their situation. These successive interactions and repeated adjustments of the local ABM resulted in a common agreement on the way the model represented their reality. A semi-quantitative method of model validation and comparison has been presented by Castella and Verburg (Citation2007), who compared and validated a spatial dynamic model and an ABM based on both standard map comparison techniques but also on the way that processes that were directly observed during fieldwork were represented in the simulation results. Interestingly, the spatial dynamic model performed better based on the standard map comparison techniques, while the multi-agent model turned out to be better able to represent the structure of land use related to the location of villages which is most important in land use decision making in the area. In spite of these first attempts, a great deal more work needs to be done in the development of techniques for the qualitative and quantitative assessment of these models.
In the face of the many challenges confronting the development of complex systems models, it would be useful to identify some best practices to guide both the efforts of the individual modeller and the broader evolution of the discipline. At the disciplinary level, we face a variety of challenges that include the lack of a core set of theoretical models, the lack of comparability between models, and the lack of a standard set of techniques for constructing and analysing these models (Windrum, Fagiolo, and Moneta Citation2007). The way forward for complex systems models of land use change may lie in the use of models for the development of ‘what if’ scenarios of change, much like general circulation models are used to explore climate change scenarios and their associated impacts. A research agenda for the development of complex land change models could identify the common questions that underlie the field, while identifying the important methodological issues related to understanding the behaviour of these models.
For the individual modelling effort, modellers must be careful when defining the experimental frame that is used to characterize the real systems being studied. The definition of the experimental frame for any modelling exercise is rooted in the theoretical foundations of the field of the researchers developing the model. Much like the story of the blind men and the elephant, researchers from different fields approach the study of a land use change problem from different perspectives, making different assumptions and relying on different theoretical foundations. It is important, through the use of an experimental frame, to explicitly outline the boundaries of the models, the specific entities and relations being captured in the model, and the theoretical foundation guiding the assumptions that are made regarding the processes that drive the behaviour of the model. Clarifying these things will also aid in the development of specific goals and objectives for the model (are we exploring a process or predicting a future state). These goals and objectives allow the modeller to identify model outputs that are of interest to the discipline, as well as the appropriate quantitative or qualitative techniques for characterizing that output.
8. Conclusions
For the purpose of developing an uncertainty typology, it may be useful to consider the modelling of complex environmental systems as a data processing and analysis effort. In this manner, one can determine elements of uncertainty in model output that are largely due to the data or to the model. Data are a critical element in each stage of the modelling exercise. Data are employed in model design and calibration to determine important parameters and to estimate good values for those parameters. Data serve as key inputs for the model; in a dynamic land cover model, for example, initial cover conditions may be derived from a spatial data set. Finally, data can be employed to validate model results. Lack of fidelity between data and the phenomena they represent can therefore have demonstrable impacts on complex system model design, execution, and validation.
Sources of uncertainty also arise from the model itself. Theoretical flaws arise when a model leaves out critical drivers or includes irrelevant ones. Design flaws occur because the model contains logical errors – implementations that do not function as their developers wished. Models may be highly sensitive to initial conditions and parameter settings. Lack of robustness may be a particular concern for agent-based models, which can behave in highly nonlinear ways. Finally, the nature of the system being modelled may introduce uncertainty; a synthetic experiment, or one projecting into the future, or one exploring alternative scenarios, may not be externally verifiable. Internal validation may be a special problem for complex models, since their emergent properties may be very difficult to predict. Finally, model outcomes are stochastic, and so may not be expected to correspond directly with validation data.
Models of complex systems are useful tools to enable policy-makers and practitioners to understand the processes operating in socio-ecological systems, and plausible future scenarios with potential unintended consequences from specific policy prescriptions. For the complex systems modeller, uncertainty is a constant companion, and it is critical to convey the implications of model error and uncertainty to those who might use the models or the products of those models. Thus, the application of these models must be taken with great care, and an important research direction remains to formalize practices for identifying and managing uncertainty in complex environmental models. Of the many potential policy issues that surround complex systems, perhaps the most important are the science–policy gap, or differences among scientific, policy, and public communities (Bradshaw and Borchers Citation2000). While it is clear that uncertainty cannot be eliminated, and likely that complex systems modellers alone will have little impact on the science–policy gap, we maintain that formally incorporating an assessment of the uncertainties in our models can provide great benefits both within the modelling community and to the broader applications community as well.
Related Research Data
References
- Aerts , J. , Goodchild , M. and Heuvelink , G. 2003 . Accounting for Spatial Uncertainty in Optimization with Spatial Decision Support Systems . Transactions in GIS , 7 ( 2 ) : 211 – 230 .
- Arthur , W. B. 1999 . Complexity and the Economy . Science , 284 ( 5411 ) : 107 – 109 .
- Bachmann , A. and Allgöwer , B. 2002 . Uncertainty Propagation in Wildland Fire Behaviour Modelling . International Journal of Geographical Information Science , 16 ( 2 ) : 115 – 127 .
- Bishr , Y. 1998 . Overcoming the Semantic and Other Barriers to GIS Interoperability . International Journal of Geographical Information Science , 12 ( 4 ) : 299 – 314 .
- Bradshaw , G. and Borchers , J. 2000 . Uncertainty as Information: Narrowing the Science-Policy Gap . Conservation Ecology , 4 ( 1 ) Article, 7.
- Brown , D. G. , Page , S. E. , Riolo , R. , Zellner , M. and Rand , W. 2005 . Path Dependence and the Validation of Agent-Based Spatial Models of Land Use . International Journal of Geographical Information Science , 19 ( 2 ) : 153 – 174 .
- Byrne , D. 1998 . “ Complexity Theory and the Social Sciences ” . London : Routledge .
- Canters , F. , De Genst , W. and Dufourmont , H. 2002 . Assessing Effects of Input Uncertainty in Structural Landscape Classification . International Journal of Geographical Information Science , 16 ( 2 ) : 129 – 149 .
- Castella , J. C. , Trung , T. N. and Boissau , S. 2005 . Participatory Simulation of Land-Use Changes in the Northern Mountains of Vietnam: The Combined Use of an Agent-Based Model, a Role-Playing Game, and a Geographic Information System . Ecology and Society , 10 ( 1 ) : 27
- Castella , J. C. , Slaats , J. , Quang , D. , Geay , F. , Van Linh , N. and Hanh Tho , P. 2006 . Connecting Marginal Rice Farmers to Agricultural Knowledge and Information Systems in Vietnam Uplands . The Journal of Agricultural Education and Extension , 12 ( 2 ) : 109 – 125 .
- Castella , J. C. and Verburg , P. H. 2007 . Combination of Process-Oriented and Pattern-Oriented Models of Land-Use Change in a Mountain Area of Vietnam . Ecological Modelling , 202 ( 3–4 ) : 410 – 420 .
- Chen , P. 1976 . The Entity-Relationship Model: Toward a Unified View of Data . ACM Transactions on Database Systems , 1 ( 1 ) : 9 – 36 .
- Cilliers , P. 1998 . “ Complexity and Postmodernism: Understanding Complex Systems ” . New York : Routledge .
- Clarke , K. C. and Gaydos , L. 1998 . Loose Coupling a Cellular Automaton Model and GIS: Long-Term Growth Prediction for San Francisco and Washington/Baltimore . International Journal of Geographical Information Science , 12 ( 7 ) : 699 – 714 .
- Costanza , R. 1989 . Model Goodness of Fit: A Multiple Resolution Procedure . Ecological Modelling , 47 : 199 – 215 .
- Crawford , T. , Messina , J. , Manson , S. and O'sullivan , D. 2005 . Complexity Science, Complexity Systems, and Land Use Research . Environment and Planning B , 32 : 792 – 798 .
- Deadman , P. , Robinson , D. , Moran , E. and Brondizio , E. 2004 . Colonist Household Decision-Making and Land-Use Change in the Amazon Rainforest: An Agent-Based Simulation . Environment and Planning B: Planning and Design , 31 ( 5 ) : 693 – 709 .
- Doran , J. and Gilbert , N. 1994 . “ Simulating Societies: An Introduction ” . In Simulating Societies: The Computer Simulation of Social Phenomena , Edited by: Gilbert , N. and Doran , J. 1 – 18 . London : UCL Press .
- Duckham , M. . Error-Sensitive GIS Development: Technology and Research Themes, . in Proceedings of the 4th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, . July 12–14 , Amsterdam. pp. 183 – 190 . The Netherlands
- Ehlschlaeger , C. , Shortridge , A. and Goodchild , M. 1997 . Visualizing Spatial Data Uncertainty Using Animation . Computers and Geosciences , 23 ( 4 ) : 387 – 395 .
- Evans , T. and Kelley , H. 2004 . Multi-Scale Analysis of a Household Level Agent-Based Model of Landcover Change . Journal of Environmental Management , 72 ( 1–2 ) : 57 – 72 .
- Evans , T. and Kelley , H. 2006 . Spatially Explicit Experiments for the Exploration of Land-Use Decision-Making Dynamics . International Journal of Geographical Information, Science , 20 ( 9 ) : 1013 – 1037 .
- Federal Geographic Data Committee (FGDC) . 1998 . Content Standard for Digital Geospatial Metadata (version 2.0), FGDC-STD-001–1998).
- Fisher , P. 1991 . First Experiments in Viewshed Uncertainty: The Accuracy of the Viewshed Area . Photogrammetric Engineering and Remote Sensing , 57 ( 10 ) : 1321 – 1327 .
- Fisher , P. 1999 . “ Models of Uncertainty in Spatial Data ” . In Geographical Information Systems , 2nd , Edited by: Longley , P. A. , Goodchild , M. F. , Maguire , D. J. and Rhind , D. W. 191 – 205 . New York : Wiley .
- Fonseca , F. , Davis , C. and Camara , G. 2003 . Bridging Ontologies and Conceptual Schemas in Geographic Information Integration . GeoInformatica , 7 ( 4 ) : 355 – 378 .
- Gintis , H. 2000 . Game Theory Evolving: A Problem-Centered Introduction to Modeling Strategic Interaction , Princeton : Princeton University Press .
- Gladwin , C. 1989 . Ethnographic Decision Tree Modeling , Thousand Oaks, CA : Sage Publications .
- Guptill , S. and Morrison , J. 1995 . Elements of Spatial Data Quality , London : Pergamon Press .
- Gutman , G. , Janetos , A. , Justice , C. , Moran , E. , Mustard , J. , Rindfuss , R. , Skole , D. and Turner , B. L. 2004 . Land Change Science: Observing, Monitoring, and Understanding Trajectories of Change on the Earth's Surface , Dordrecht : Kluwer Academic Publishers .
- Henrich , J. , Boyd , R. , Bowles , S. , Camerer , C. , Fehr , E. , Gintis , H. and Mcelreath , R. 2001 . In Search of Homo Economicus; Behavioral Experiments in 15 Small-Scale Societies . The American Economic Review , 91 : 73 – 78 .
- Henrickson , L. and Mckelvey , B. . Foundations of ‘New’ Social Science: Institutional Legitimacy from Philosophy, Complexity Science, Postmodernism, and Agent-Based Modeling . Proceedings of the National Academy of Sciences . Vol. 99 , pp. 7288 – 7295 . (90003)
- Heuvelink , G. 1998 . Error Propagation in Environmental Modelling , Bristol : Taylor & Francis .
- Heuvelink , G. B.M. 1996 . Identification of Field Attribute Error Under Different Models of Spatial Variation . International Journal of Geographical Information Systems , 10 ( 8 ) : 921 – 935 .
- Heuvelink , G. B.M. 2002 . “ Analysing Uncertainty Propagation in GIS: Why is It Not That Simple? ” . In Uncertainty in Remote Sensing and GIS , 155 – 165 . Hoboken, NJ : John Wiley & Sons .
- Huigen , M. , Overmars , K. and de Groot , W. 2006 . “ Multiactor Modeling of Settling Decisions and Behavior in the San Mariano Watershed, the Philippines: a First Application With the Mameluke Framework ” . In Ecology and Society Vol. 11 , Article 33.
- Jepsen , M. , Leisz , S. , Rasmussen , K. , Jakobsen , J. , Moller-Jensen , L. and Christiansen , L. 2006 . Agent-Based Modelling of Shifting Cultivation Patterns, Vietnam . International Journal of Geographical Information Science , 20 ( 9 ) : 1067 – 1085 .
- Law , A. and Kelton , W. 1991 . Simulation Modeling and Analysis , New York : McGraw-Hill .
- Lissack , M. 2001 . Special Issue: What is Complexity Science? . Emergence , 3 ( 1 )
- Malanson , G. 1999 . Considering Complexity . Annals of the Association of American Geographers , 89 ( 4 ) : 746 – 753 .
- Manson , S. M. 2001 . Simplifying Complexity: A Review of Complexity Theory . Geoforum , 32 ( 3 ) : 405 – 414 .
- Manson , S. M. 2006 . Bounded Rationality in Agent-Based Models: Experiments With Evolutionary Programs . International Journal of Geographic Information Science , 20 ( 9 ) : 991 – 1012 .
- Messina , J. P. 2004 . A Complex Systems Approach to the Spatial and Temporal Simulation of Florida Bay Algal Communities . GIScience & Remote Sensing , 41 ( 3 ) : 228 – 243 .
- Messina , J. P. and Walsh , S. J. 2001 . 2.5D Morphogenesis: Modeling Land Use and Land Cover Dynamics in the Ecuadorian Amazon . Plant Ecology , 156 ( 1 ) : 75 – 88 .
- Messina , J. P. and Walsh , S. J. 2005 . Dynamic Spatial Simulation Modeling of the Population-Environment Matrix in the Ecuadorian Amazon . Environment and Planning B , 32 : 835 – 856 .
- O'sullivan , D. 2004 . Complexity Science and Human Geography . Transactions of the Institute of British Geographers , 29 ( 3 ) : 282 – 295 .
- O'sullivan , D. , Manson , S. M. , Messina , J. P. and Crawford , T. W. 2006 . Space, Place, and Complexity Science . Environment and Planning A , 38 ( 4 ) : 611 – 617 .
- Parker , D. C. , Manson , S. M. , Janssen , M. , Hoffmann , M. J. and Deadman , P. J. 2003 . Multi-Agent Systems for the Simulation of Land Use and Land Cover Change: A Review . Annals of the Association of American Geographers , 93 ( 2 ) : 316 – 340 .
- Pijanowski , B. C. , Pithadia , S. , Shellito , B. A. and Alexandridis , K. 2005 . Calibrating a Neural Network-Based Urban Change Model for Two Metropolitan Areas of the Upper Midwest of the United States . International Journal of Geographical Information Science , 19 ( 2 ) : 197 – 216 .
- Pontius , R. G. , Huffaker , D. and Denman , K. 2004 . Useful Techniques of Validation for Spatially Explicit Land-Change Models . Ecological Modelling , 179 ( 4 ) : 445 – 461 .
- Rabin , M. 1998 . Psychology and Economics . Journal of Economic Literature , 36 ( 1 ) : 11 – 46 .
- Reitsma , F. 2002 . A Response to ‘Simplifying Complexity . Geoforum , 34 ( 1 ) : 13 – 16 .
- Santner , T. J. , Williams , B. J. and Notz , W. I. 2003 . The Design and Analysis of Computer Experiments , New York : Springer-Verlag .
- Shortridge , A. , Messina , J. , Hession , S. and Makido , Y. . Towards an Ontologically-Driven GIS to Characterize Spatial Data Uncertainty . Progress in Spatial Data Handling . Edited by: Riedl , A. , Kainz , W. and Elms , G. pp. 465 – 476 . Berlin : Springer-Verlag .
- Sklar , F. H. and Hunsaker , C. T. 2001 . “ The Use and Uncertainties of Spatial Data for Landscape Models: An Overview With Examples From the Florida Everglades ” . In Spatial Uncertainty in Ecology: Implications for Remote Sensing and GIS Applications , Edited by: Hunsaker , C. T. , Goodchild , M. F. , Friedl , M. A. and Case , T. J. 15 – 46 . New York : Springer .
- The Economist . 4 December 2003 . The Father of Fractals (B. Mandelbrot). 4 December ,
- Unwin , D. J. 1995 . Geographical Information Systems and the Problem of ‘Error and Uncertainty . Progress in Human Geography , 19 ( 4 ) : 549 – 558 .
- Verburg , P. and Veldkamp , A. 2005 . Introduction to the Special Issue on Spatial Modeling to Explore Land Use Dynamics . International Journal of Geographical Information Science , 19 ( 2 ) : 99 – 102 .
- Veregin , H. 1999 . “ Data Quality Parameters ” . In Geographical Information Systems , 2nd , Edited by: Longley , P. A. , Goodchild , M. F. , Maguire , D. J. and Rhind , D. W. 177 – 189 . New York : Wiley .
- Visser , H. and De Nijs , T. 2006 . “ The Map Comparison Kit ” . In Environmental Modelling & Software Vol. 21 , 346 – 358 .
- Wada , Y. , Rajan , K. and Shibasaki , R. 2007 . “ Modelling the Spatial Distribution of Shifting Cultivation in Luangprabang, Lao PDR ” . In Environment and Planning B – Planning and Design Vol. 34 , 261 – 278 .
- Walker , R. 2003 . Evaluating the Performance of Spatially Explicit Models . Photogrammetric Engineering and Remote Sensing , 69 ( 11 ) : 1271 – 1278 .
- Windrum , P. , Fagiolo , G. and Moneta , A. 2007 . Empirical Validation of Agent-Based Models: Alternatives and Prospects . Journal of Artificial Societies and Social Simulation , 10 ( 2 ) Article 8.
- Wolfram , S. 1983 . Statistical Mechanics of Cellular Automata . Reviews of Modern Physics , 55 : 601 – 644 .
- Wolfram , S. 1984 . Cellular Automata as Models of Complexity . Nature , 311 : 419 – 424 .
- Wu , F. 1996 . A Linguistic Cellular Automata Simulation Approach for Sustainable Land Development in a Fast Growing Region . Computers, Environment and Urban Systems , 20 : 367 – 387 .
- Yeh , A. G. and Li , X. 2006 . Errors and Uncertainties in Urban Cellular Automata Computers . Computers, Environment and Urban Systems , 30 ( 1 ) : 10 – 28 .
- Young , O. , Lambin , E. , Alcock , F. , Haberl , H. , Karlsson , S. , Mcconnell , W. , Myint , T. , Pahl-Wostl , C. , Polsky , C. , Ramakrishnan , P. S. , Scouvart , M. , Schroeder , H. and Verburg , P. 2006 . A Portfolio Approach to Analyzing Complex Human-Environment Interactions . Institutions and Land Change. Ecology and Society , 11 ( 2 ) : 31
- Zhang , J. and Goodchild , M. 2002 . “ Uncertainty in Geographical Information ” . London : CRC Press .