Abstract
A disaggregated approach to land cover survey is developed utilising data primitives. A field methodology is developed to characterise five attributes: species composition, cover, height, structure and density. The utility of these data primitives, as land cover ‘building blocks’ is demonstrated via classification of the field data to multiple land cover schema. Per-pixel classification algorithms, trained on the basis of the classified field data, are utilised to classify a SPOT 5 satellite image. The resultant land cover maps have overall accuracies approaching 80%. However, significantly lower validation accuracies are demonstrated to be a function of sample fraction. The aggregation of attributes to classes under-utilises the potential of remote sensing data to describe variability in vegetation composition across the landscape. Consequently, land cover attribute parameterisation techniques are discussed. In conclusion, it is demonstrated that data primitives provide a flexible field data source proven to support multiple land cover classification schemes and scales.
1. Introduction
Land cover is an integral part of landscape modelling, monitoring and management with accurate, relevant and contemporary land cover information increasingly being required to support multiple applications and user communities (Defries and Belward Citation2000). An overarching definition of land cover encompasses the (bio)physical cover of the earth's surface (Di Gregorio and Jansen Citation2000). Despite this succinct definition, historically, the mapping of land cover has encompassed both land cover and use descriptors. The reasons for this confusion are reviewed by Fisher, Comber, and Wadsworth (Citation2005). Several practitioners have identified a need to separate land cover and use concluding that such a separation is necessary to ensure consistency in data collection and enable effective application of the data (Di Gregorio and Jansen Citation2000; Comber Citation2008). Despite these conclusions, the separation of land cover and use is rarely achieved (Di Gregorio and Jansen Citation2000).
Land cover mapping is a generalisation process from which a single representation of reality is extracted. The thematic and cartographic properties of this representation are application specific and uniquely tied to the institutional, political and technological factors influencing its creation (Comber, Fisher, and Wadsworth Citation2003). These factors determine not only the characteristics of the mapping product but also its flexibility, interoperability and relevance to other applications (Herold, Latham, Di Gregorio, and Schmullius Citation2006). It is not uncommon for users to have to compromise by moving to a higher level of the land cover classification scheme, or to manipulate land cover data to enable its inclusion in their own application. Over time, with technological advances and changing political objectives, the factors influencing the creation of land cover products inevitably change (Wadsworth, Comber, and Fisher Citation2006). This leads to the creation of an alternative representation of land cover and consequently, issues of data compatibility and comparison (Comber et al. Citation2003).
Any land cover map, because of categorisation and classification, results from the extensive manipulation of the input data. This has prompted authors to describe land cover products as ‘geographic information’ as opposed to ‘geographic data’ (Comber, Fisher, and Wadsworth Citation2005; Wadsworth et al. Citation2006). Comber et al. (Citation2005) argue that the increased availability of land cover maps, within the user community, and lack of appropriate metadata has led to the mistreatment of this geographic information. Disassociation of the user and abstraction process may lead to users who do not fully understand the inherent meanings and semantics contained within the land cover representation (Comber et al. Citation2005). Equally, users often lack an appreciation of the accuracy with which these land cover classes can be identified and mapped. These factors can result in inappropriate data manipulation and analysis.
To efficiently tackle the issues outlined, several authors have advocated a mapping approach, which (a) separates the concepts of land use and cover (Comber Citation2008; Comber, Fisher, and Wadsworth Citation2008a); (b) develops a ‘common language’ so as to improve interoperability and the communication of land cover information between multiple users (Herold et al. Citation2006; Herold Citation2009); (c) supports context-sensitive mapping via the creation of multiple land cover representations from a single data product (Comber, Fisher, and Brown Citation2007); (d) standardises land cover products while still allowing flexibility in both the resultant land cover classes and user applications (Di Gregorio and Jansen Citation2000; Herold Citation2009); and, (e) standardises diagnostic criteria so enabling a uniform basis for data comparisons (Jansen and Di Gregorio Citation2002).
A recurrent element within these objectives is the standardisation of land cover concepts. This can be achieved via (a) standardisation of class nomenclature and data collection methodologies; examples include CORINE Land Cover (Bossard, Feranec, and Otahel Citation2000) and Global Land Cover 2000 (GLC2000) (Bartholome and Belward Citation2005); or, (b) standardisation of the constituent language, or vocabulary, of land cover definitions. Ahlqvist (Citation2008) describes these alternatives as single and hybrid ontological approaches, respectively. Single ontological approaches, in which all class nomenclature is explicitly defined, are often prohibitive as they: (a) require the description of an extensive number of classes (Di Gregorio and Jansen Citation2000); (b) restrict class descriptions potentially reducing the relevance and flexibility of the product (Herold et al. Citation2006); and, (c) are prone to different user interpretation and hence the designation of the same feature to different classes, a characteristic counterintuitive to the standardisation process (Di Gregorio and Jansen Citation2000).
A practical alternative, receiving increasing predominance in the literature, are hybrid ontological approaches. Hybrid ontological approaches, as defined by Ahlqvist (Citation2008), are based on the definition of a standardised vocabulary which constitutes the basic ‘building blocks’ of the land cover classification system. These ‘building blocks’ or data primitives describe a concept at its most fundamental level (Comber Citation2008). A land cover class (concept) is represented by several data primitives (or domains) within a specified region of the conceptual space. Similarity between land cover classes is assessed as a function of the overlap between their constituent descriptive terms (Ahlqvist Citation2004).
Data primitives, as the basis of land cover mapping, have been advocated by several authors. Previous studies have demonstrated the utility of these concepts in: (a) reducing semantic issues surrounding descriptive class names (Di Gregorio and Jansen Citation2000); (b) distinguishing class boundaries on the basis of diagnostic criteria (Di Gregorio and Jansen Citation2000); (c) separating the concepts of land cover and land use (Comber Citation2008); (d) standardising diagnostic criteria as the basis of change detection (Jansen and Di Gregorio Citation2002); and, (e) facilitating the integration of existing classifications with differing nomenclature (Ahlqvist Citation2004, Citation2005; Wadsworth et al. Citation2008; Herold, Hubald, and Di Gregorio Citation2009 amongst others).
The data primitive approach to land cover mapping is exemplified by the FAO Land Cover Classification Scheme (LCCS) (Di Gregorio and Jansen Citation2000). LCCS is an a priori classification system, designed to support mapping projects worldwide independent of mapping scale. This is achieved via a standardised set of diagnostic criteria (classifiers) that enable the description of land cover in a hybrid ontological approach (Ahlqvist Citation2008). To encompass land cover variability, and the fact that all classifiers cannot be associated with all land cover types, LCCS classifiers are designed within a hierarchical structure. An initial dichotomous phase allocates land cover to one of eight major land cover types. The subsequent modular-hierarchical phase refines the description of land cover via a subset of relevant environmental and technical classifiers (Di Gregorio and Jansen Citation2000). One criticism of LCCS is its fixed, Boolean logic, approach to categorical and classifier definitions. This compartmentalised view has been criticised as restricting the descriptive ability of the LCCS classifiers (Ahlqvist Citation2008). Consequently, Ahlqvist (Citation2008) has proposed modifications to LCCS which support the full range of attribute values on a standardised measurement scale.
In this article, a methodological approach which further investigates the utility of data primitives (termed ‘land cover attributes’) in land cover map production is developed. Quantitative, continuous, data primitives form the basis of field survey and subsequent land cover map production. The definition of data primitives, and their parameterisation in the field, is described as are two contrasting techniques by which these detailed field data can be extrapolated to the entire study area, that is, land cover map construction and attribute parameterisation.
2. Methodology
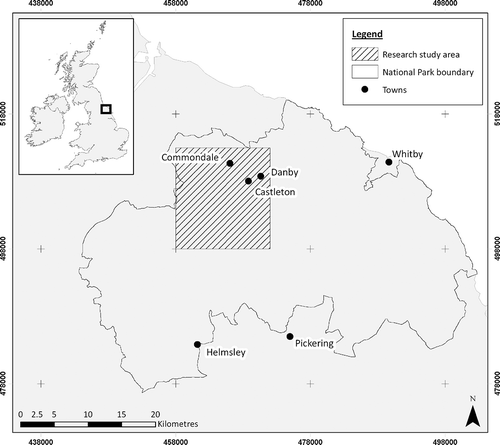
For logistical reasons, this research was conducted within a 200 km2 study area located in the northwest of the North York Moors National Park (NYMNP), United Kingdom (). Land cover in the study area can be subdivided into two distinct, elevation-controlled strata. Upland plateaus are characterised by moorland habitats including heath (dry and wet), peat bog and grass moor. At lower elevations, bracken and acid grassland dominate the uplands although steep slopes can also be characterised by coniferous plantations. Pasture and cultivated land are typical in the lowlands.
Figure 1. Location of the research study area and North York Moors National Park.
2.1. Land cover attribute definition
The research aim dictated that land cover attributes, compatible with current NYMNP mapping, form the basis of the field survey. Land cover attributes were defined as those parameters, or data primitives, used to delineate the boundary between discrete vegetation assemblies. Definition of these attributes was achieved by interrogation of current land cover class descriptions utilised within the NYMNP.
Five vegetation mapping schemes, Phase 1 habitat maps (P1) (JNCC Citation1993), Land Cover Map 2000 (LCM2000) (Fuller et al. Citation2002), Monitoring Landscape Change in the National Parks (MLCNP) (Taylor, Bird, Brewer, Keech, and Stuttard Citation1991a), the National Land Use Database (NLUD) (Harrison Citation2006) and CORINE (Bossard et al. Citation2000) were considered in addition to the Natural England Favourable Habitats Management Plan (Backshall, Manley, and Rebance Citation2001). Factors identified as frequently delineating land cover boundaries within these classification schemes are summarised in .
Table 1. Attributes, common to each land cover classification scheme, used in the delineation of land cover class boundaries
To minimise field survey burden, a subset of attributes, as indicated in , was measured at each sample point during the field survey. In addition, ancillary data sources, where available and of sufficient accuracy, were used to characterise certain land cover and landscape attributes. This is exemplified by the NEXTMap Digital Terrain Model which was used to parameterise the topographic variables of elevation, slope and aspect.
From , it is evident that the land cover attributes measured during the field survey were primarily biological in nature, that is, they recorded data about the vegetation and its environment. This concurs with research by Comber et al. (Citation2008a) who, via a semantic analysis of forest definitions, concluded that biological data primitives tended to be associated with land cover. Conversely, land use descriptors were associated with data primitives describing the socio-economic functions of the land (Comber et al. Citation2008a).
2.2. Field survey
Traditionally, land cover surveys have required the delineation and classification of vegetation assemblies, in the field, to represent homogenous land cover classes. This approach places considerable emphasis upon decision-making by the field surveyor. As a consequence, where class definitions are imprecise, ambiguous or based on subjective criteria inconsistencies between surveyors can occur (Di Gregorio and Jansen Citation2000). The magnitude and potential significance of these inconsistencies have been demonstrated by Cherrill and McClean (Citation1999) and Bird, Taylor, and Brewer (Citation2000), amongst others. The aim of this research was to improve field survey consistency via the inclusion of measurements that parameterised easily identifiable land cover attributes within objective measurement techniques.
The current field survey was restricted to moorland and agro-pastoral land covers, sites characterised by small shrub and grass species, to enable the definition of a single field survey protocol. This protocol was based on a frame quadrat of 1 m2, subdivided into 100 cells, as recommended by Gilbertson, Kent, and Pyatt (Citation1985). Within each quadrat, measurements were made of: (a) percentage cover, the total cover proportion of a given species as measured by its presence/absence in each quadrat cell; (b) species composition, that is the presence/absence of target species within the quadrat. Species were defined as ‘target species’ if they were characteristic of a habitat, environmental condition or management regime; (c) species height, a measure of vegetation height within the quadrat so as to give an indication of vegetation structure; and, (d) heather species structure, that is the height, density and life cycle stage (Webb Citation1986) of each individual heather plant, of all species types, within the quadrat.
The aforementioned land cover attributes were selected, as the basis of field survey measurements, as they were (a) frequently used to delineate land cover class boundaries within the target classification schemes (); (b) not quantifiable via ancillary data; and (c) established vegetation structure/composition measures easily parameterised within established field measurement techniques.
The quadrat-based measurements were tested and subsequently modified, within a pilot study, to ensure the inclusion of techniques that were robust, repeatable, objective and practically achievable with the resources available to the survey. This process was exemplified by the exclusion of visual estimates of percentage cover, found to be prone to observer bias, in favour of a presence/absence technique. This technique, which measured the presence/absence of each species in each quadrat cell, although still rapid to implement was found to substantially improve the standardisation of percentage cover measurements.
Quadrat measurements were located on a systematic aligned 950 m grid of sample points. The optimum grid interval was defined to maximise the number of samples surveyed within a two-month field campaign. To ensure field measurements were representative of the sample site, four quadrat measurements were taken, one at each of the compass point cardinals, at a distance of 1 m from the central sample point.
The field survey was conducted during July and August 2004. The timing of this survey was purely logistical and did not consider seasonal variability in the multi-spectral characteristics of vegetation species. Because of survey delays, 225 of the intended 240 samples were surveyed. Of these 225 samples, land cover attribute measurements, as prescribed in the field survey protocol, were achieved at 69% of sample sites. The remaining samples occurred in wooded (8%) and developed (1%) land covers or were inaccessible (19%).
This high proportion of inaccessible sites (19%) was attributed to the prerequisite that the surveyor reach the actual sample location to undertake quadrat-based measurements. This is, typically, not a requirement of traditional land cover surveys as cover can be inferred from a distance or vantage point. Within the current research, inaccessible sample points tended to fall within the agro-pastoral and bracken land covers because of land ownership and physical access issues, respectively. Inaccessible samples resulted in the under-representation of the agro-pastoral and bracken land covers in the field survey data. This sample bias was not evident in the original sample design and was purely a consequence of sample site access.
2.3. Land cover map construction
The research aimed to develop a methodology whereby multiple land cover maps could be derived from the integration of: (a) detailed land cover attribute measurements, as collected during the field survey, and (b) a temporally and spatially coincident SPOT 5 satellite image. To ensure high spatial accuracy, when comparing these data sources, field survey data were located using network-corrected GPS surveys and the SPOT 5 satellite image ortho-corrected to within a single pixel (10 m). Fundamental to this methodology was the training and subsequent classification of the SPOT 5 satellite image on the basis of the field-derived land cover attributes. The validity of this proposed approach was tested by the construction of land cover maps, within the study area, according to the MLCNP, NLUD and P1 classification schemes. This subset of land cover classification schema was selected to ensure a representative range of classification scales and techniques.
The land cover map construction methodology was separated into two distinct stages: land cover attribute classification and image classification (). These methodological elements are discussed further in subsequent sections.
Figure 2. Overview of the land cover map construction methodology.
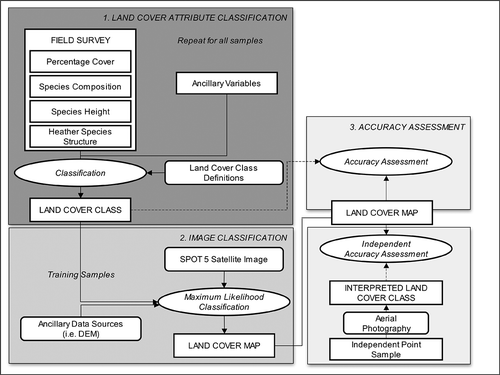
2.3.1. Land cover attribute classification
The ability of land cover attributes to act as ‘building blocks’ for the derivation of land cover classes was assessed by the classification of the field survey samples according to the MLCNP, NLUD and P1 classification schemes. This classification process was based on a comparison of the land cover attributes, as recorded at each sample point, to the pre-defined class thresholds and classification rule-sets of each classification scheme. This enabled the categorisation of each sample point to the most appropriate MLCNP, NLUD and P1 classes.
The construction of MLCNP, NLUD and P1 land cover classes, from the field survey data, was possible as the land cover attributes were defined to represent the criteria used to delineate or define land cover classes within each of the classification schemes (Section 2.1). Consequently, there was a pre-defined association between the land cover attributes and target classification schemes.
Following conventional land cover mapping approaches, each field data sample was required to represent a single, unique land cover class as defined in the MLCNP, NLUD or P1 classification schemes. Samples encompassing multiple land covers were classified as a mosaic, where such a definition existed within the classification scheme, or as a single class based on the dominant land cover.
2.3.2. Image classification
The classification of land cover attributes, as recorded at each field survey location, resulted in the derivation of a series of points at which the MLCNP, NLUD and P1 land cover class was known. This reference, or training, data informed the supervised classification of the SPOT 5 satellite image. Classification was implemented in a per-pixel, maximum-likelihood classification algorithm and utilised all of the available SPOT 5 multi-spectral bands. The maximum-likelihood classifier was selected because of its ease of operation and applicability across a range of landscape types. The applicability of object-orientated classifiers to land cover map construction were also investigated. However, results are not included in this article.
3. Results
3.1. Land cover attribute classification
In an automated classification approach, the land cover attributes, as recorded at each sample, must be compared to pre-defined class definitions, or rule-sets, to determine the most similar and hence appropriate land cover class. The definition of these rule-sets was dependent upon land cover class descriptors defining the expected vegetation species and their expected spatial extent. The MLCNP, NLUD and P1 classification schemes were not consistent in their definition of such species and cover thresholds. This was exemplified by the P1 classification in which, dry dwarf shrub (D1.1) is defined as ‘vegetation with greater than 25% cover of Ericoids/small gorse species in relatively dry situations’ (JNCC Citation1993). This threshold of 25% cover, in addition to the typical species list, formed the basis of field data classification. Conversely, for the bracken land cover class (C1) the class definition, ‘areas dominated by Pteridium aquilinum or scattered patches of the species’ (JNCC Citation1993), includes no direct reference to the fractional cover at which the species is considered dominant. However, it might be inferred that dominance occurs when the fractional cover exceeds 50%.
Land cover definitions typically include ancillary and contextual information, in addition to species composition, to delineate land cover boundaries. For example, improved grassland (CO21) within the NLUD classification encompasses ‘areas of intensively managed grassland that show evidence of enclosure for stock control purposes and/or for fodder/hay’ (Harrison Citation2006). The land cover attributes, included within the current field data, contained no direct measurement of the enclosure or management characteristics of the land cover parcel containing the sample point. However, site context data, recorded at the scale of the sample point, did contain text descriptors of the containing land cover parcel where the sample point fell in an agro-pastoral land cover. Context issues in part result from a disparity between the point sample of the field survey and land cover polygons characteristic of the MLCNP, P1 and NLUD classification schemes. When delineating homogenous areas in the field, contextual information is automatically included by the surveyor. At the scale of a point sample, contextual information can only be inferred from site descriptors (where available) or appropriate surrogates, for example the vegetation species present may be indicative of management regime.
In a hybrid, semi-automated approach, field data classifications were first implemented on the basis of pre-defined thresholds or, where these data were not available, iterative testing of user-defined thresholds, for example dominance was assumed to occur at 50% cover; and second, on sample site text descriptors. This procedure resulted in 153, 172 and 177 classified samples for the MLCNP, NLUD and P1 classifications, respectively. Residual samples, when compared to the total 225 surveyed, remained unclassified; a consequence of missing or inaccurate field data. The accuracy achieved in classifying the land cover attributes (field data) could not be determined, in the current research, because of the lack of a suitable reference dataset.
3.2. Land cover map construction: per-pixel classification
Classification of the 2004 SPOT 5 multi-spectral image in a per-pixel maximum-likelihood classifier, trained on the classified field data samples, resulted in overall accuracies of 81%, 80% and 76%, at the field data (training) samples, for the MLCNP, NLUD and P1 classification schemes, respectively (). Despite these high overall classification accuracies, a visual interpretation of the classification outputs concluded that while broad trends in land cover had been captured, the map contained obvious areas of misclassification. Validation of the classification output, at an independent set of sample points (), confirmed the visual interpretation as overall classification accuracies decreased to 52%, 59% and 45%, respectively (). These accuracies, via a Kappa statistics analysis, were determined to be significantly lower, at the 95% confidence level, than those reported at the field data (training) samples ().
Table 2. Kappa statistics comparison of the overall accuracy achieved at the field data versus independent validation samples for each land cover classification
The overall accuracies, stated above, concealed the distribution of class-specific user and producer accuracies within the MLCNP, NLUD and P1 classification outputs. Inspection of the confusion matrices indicated that land cover classes similar in their vegetative components, for example improved and semi-improved pasture, were consistently misclassified in each of the classification schemes. However, spectral confusion, and subsequent misclassification, was not isolated to land covers in the same broad categories, for example improved pasture and upland heath were frequently confused. As a consequence of this spectral confusion, no land cover classes could be identified as being consistently well or poorly classified.
Independent accuracy assessments, of the classification outputs, were based upon land cover class information, derived via aerial photograph interpretation (API), at a series of independent sample points (). To determine the influence of API errors on the reported validation accuracy statements, the MLCNP, NLUD and P1 land cover class was independently derived, via API, at each of the field survey samples. A comparison of the API and field data–derived (reference) land cover classes concluded that correspondence between the datasets, for the MLCNP, NLUD and P1 schema, was approximately 84%, 88% and 73%, respectively. Disparities between the field- and API-derived land cover classes reflected: (a) the potential misclassification of field survey samples, and (b) API errors attributed to misclassification, temporal change and the inclusion of land cover classification parameters, in particular within the P1 classification scheme, irresolvable via API.
Training of the per-pixel, maximum-likelihood classifier on the API, as opposed to field survey–derived samples, resulted in overall accuracies of 68% and 71% in the MLCNP and NLUD classifications, respectively. The Kappa statistics indicated that this represented a significant decrease in accuracy, at the 95% confidence level, when compared to the field data–trained classification accuracies of 81% and 80%, respectively (). The P1 classification was excluded from this analysis because of the low API accuracy, and therefore inherent errors, associated with the dataset. On the basis of the MLCNP and NLUD results, it was concluded that API inaccuracies had the potential to influence the reported independent accuracy statements. Field data classifications were repeated iteratively to investigate the utility of including ancillary data within the per-pixel classification. Ancillary datasets incorporated included: (a) the normalised difference vegetation index (NDVI), derived from the SPOT 5 image; and (b) topographic (elevation/aspect) parameters derived from the 5 m resolution NEXTMap Digital Terrain Model. Relationships between these parameters and land cover type were demonstrated for each classification scheme. However, classification improvements were highly variable. For example, the inclusion of NDVI within the P1 classification resolved errors of omission but not commission between the woodland and upland heath land cover types. Such inconsistencies in the classification outputs were attributed to the small training sample fraction.
3.2.1. The influence of sample fraction
As stated previously, classification results were highly variable. Equally, in each of the multi-spectral and ancillary data classifications, a significant difference was observed between overall accuracies calculated at the field and validation samples. As both the field (training) and validation data were independent and based on a random sample design, such a significant difference would not be expected.
An assumption of the maximum-likelihood algorithm is that the training data are representative of land cover variability across the study area. When trained on a low sample fraction such an assumption is expected to be invalid (Van Niel, McVicar, and Datt Citation2005). Within the current research, classification of the land cover attributes (field data) resulted in 153, 172 and 177 training samples for the MLCNP, NLUD and P1 classifications, respectively. This represented a sample fraction, for each classification, of less than 1% of the total study area. Equally, the number of training samples for each land cover class did not fall between 40 and 120, that is, between 10 and 30 times the number of wavebands contained in the remote sensing image, as recommended by several authors (Jensen Citation1986; Mather Citation1999; Pal and Mather Citation2003). Consequently, the current sample fraction was deemed too low to support the assumptions of the maximum-likelihood classification algorithm. Significantly lower classification accuracies at the independent sample locations were therefore, in part, a consequence of the inability of the maximum-likelihood classifier to accurately characterise land cover class variability across the study area.
4. Discussion
4.1. Land cover construction
The measurement of land cover attributes, and a disaggregated approach to field survey, is advocated as the utilisation of objective techniques minimises known issues of surveyor variability (Cherrill and McClean Citation1999; Bird et al. Citation2000). Further, the classification of land cover attributes against pre-defined thresholds ensures a classification procedure which is objective, repeatable and transparent. However, although advocated for reasons of objectivity and repeatability within field survey, the measurement of land cover attributes is resource intensive. This is particularly evident when the approach is compared to traditional land cover surveys.
This research has reaffirmed that classification methodologies are reliant upon training samples which are representative of land cover variability across the study area. The derivation of reliable classification accuracies within the land cover construction approach is therefore, in part, reliant on an improved sample fraction. This increased sampling requirement has serious implications, given the resource-intensive nature of land cover attribute measurement, in terms of the necessary field survey effort. Consequently, it is proposed that the operational implementation of this methodology is likely to be reliant upon the successful integration of the land cover attribute approach within current vegetation-monitoring activities, for example the upland heath habitat surveys or the UK countryside survey (Haines-Young et al. Citation2000).
Taylor, Bird, Keech, and Stuttard (Citation1991b) expressed concerns regarding the accuracy achievable via the automated classification of SPOT (20 m resolution) imagery to represent MLCNP land cover classes. Within the current research, classification accuracies of between 76% and 80% were achieved at the field data (training) samples. However, the same classifications were significantly less accurate at an independent set of validation samples. These significant accuracy differences have been attributed to a small training sample fraction. Mehner, Cutler, Fairbairn, and Thompson (Citation2004), implementing a similar classification methodology with IKONOS imagery and an improved sample fraction, reported independent land cover classification accuracies approaching 80%. Hence, when trained on an improved sample fraction, accuracies approaching those of the training samples might be expected within the current land cover map construction method. This level of accuracy will however be dependent upon the pre-defined land cover classes, spatial/spectral/temporal resolution of the remote sensing data and applicability of ancillary data sources.
The MLCNP, NLUD and P1 classification schemes represent a broad spectrum of classification scales and methodologies. It is therefore expected that land cover attributes could be utilised to reconstruct multiple ‘user’-defined classification schemes. This construction is limited by two constraints. First, the class nomenclature must incorporate those land cover attributes recorded in the field. Second, consideration must be given to the spectral properties of the resultant land cover classes prior to their inclusion within remote sensing techniques. The MLCNP and P1 classifications were designed for implementation within API and field survey mapping techniques, respectively. Land cover classes are therefore defined on the basis of their visual characteristics, in the case of MLCNP, and dominant species, in the case of P1. The resultant land cover classes, within these schemas, were demonstrated to be insufficiently distinct, in their multi-spectral properties, to enable their accurate identification within automated, multi-spectral classification algorithms. This is a known issue when utilising remote sensing techniques to support habitat mapping (e.g. Lucas, Rowlands, Brown, Keyworth, and Bunting Citation2007). Such constraints may require a compromise between an ‘ideal’ mapping solution and one which is technically feasible within current remote sensing technologies.
Subject to the considerations outlined, the land cover attributes approach to field data collection and subsequent land cover classification is considered advantageous, in comparison to standard land cover mapping techniques, as it:
| 1. | Enables the derivation of land cover classes on the basis of discrete attributes. Consequently, subjectivity in land cover class delineation and issues relating to semantics are eliminated or at least reduced. This ensures a classification procedure which is both transparent and open to retrospective analysis. | ||||
| 2. | Provides flexibility in land cover class definition subsequent to field survey. Land cover attributes are not tied to any particular land cover scheme; consequently, land cover definitions can be modified from existing schema or designed to meet user-specific applications. This enables cross-comparisons to be made both between schema and over time. | ||||
| 3. | Is efficient in terms of field survey effort as multiple, independently classified, land cover maps can be derived from a single set of field data and coincidental satellite image. | ||||
4.2. Land cover parameterisation
The land cover construction methodology follows traditional land cover surveys in that the vegetation assemblies are delineated and classified into discrete, homogenous land cover classes. It has long been established that such an approach is, in some landscapes, too simplistic with vegetation types best represented by a continuum (Burrough and Frank Citation1996). In addition to potentially misrepresenting vegetation communities, the aggregation of land cover attributes to a single, internally homogenous, land cover class under-utilises the potential of the detailed vegetation composition and structural information held in the field survey database. It is in this context that methodologies which retain the disaggregated nature of the field survey data, that is methodologies which parameterise the land cover attributes themselves across the entire study area, should be investigated.
The utility of sub-pixel and geostatistical classification techniques in mapping ‘land cover attributes’ has previously been demonstrated (Foody and Trodd Citation1993; Dungan Citation1998, amongst others). Analysis, conducted within the current research, has been limited because of the previously described sample fraction issues. However, initial comparisons have begun to demonstrate that the accurate identification of all vegetation to the species level (as recorded in the field survey) is unlikely to be achieved with medium spatial/spectral resolution sensors. It is in this context that spectrally separable species groupings or habitats which represent ‘data primitives’ must be defined. This definition is complex as multiple species can belong to multiple habitats and habitats containing similar species may not be spectrally distinct. Comber et al. (Citation2008b) utilise Possibility Theory as a means of managing uncertainties surrounding the aggregation of similar species to habitats. The utility of these techniques and alternative approaches are proposed as areas of future research.
Land cover attribute parameterisation represents the ‘ideal’ approach to land cover mapping in terms of providing a flexible mapping solution as the disaggregated field survey data are retained. This is advantageous as it preserves small-scale detail regarding vegetation composition and enables the subsequent derivation of land cover classes, if required. This derivation is based on the combination and delineation of continuous parameters into land cover classes within an objective and transparent rule-set. Such an approach ensures no observer bias or subjectivity and offers users flexibility in land cover class definition. In essence, the methodology provides the user with geographic data which they can interpret to meet their own requirements.
As a consequence of these advantages future research will focus on the utility of land cover attributes, and a disaggregated approach to field survey, to support land cover parameterisation. This research agenda will be driven by a need to identify first, an appropriate sample design and sample fraction able to: (a) encompass a disaggregated approach to field survey, and (b) support sub-pixel/geostatistical classification techniques. Second, identify the appropriate measurement scale of land cover attributes (species or species associations) so to ensure the derived parameters are spectrally distinct at a scale comparable to the mapping objectives and spatial/spectral resolution of the remotely sensed image.
Ultimately, the subdivision of land cover map construction and parameterisation may prove too simplistic an approach to land cover mapping within a highly diverse landscape. Given that land cover attributes support classification at multiple scales (sub-pixel, pixel and object) a more integrated multi-scaled approach to land cover mapping will form the basis of future research.
5. Conclusions
Land cover attributes, although resource intensive to collect, ensure an objective, consistent approach to field survey which results in a flexible reference database. This database, via its integration with remote sensing technologies, has been demonstrated to support accuracy assessment and classifier training at multiple classification schemes and scales. Land cover attributes, when integrated with remote sensing data sources, have the potential to ensure a mapping approach, which (a) standardises land cover terminology via the incorporation of data primitives concepts; (b) enables context-sensitive mapping; (c) supports multiple users hence increasing data interoperability; (d) segregates fully the concepts of land cover and use; and (e) ‘future-proofs’ mapping by ensuring changes in the institutional, political and technological factors which influence land cover class definition can be accommodated retrospectively. It is in this context that land cover attributes, or data primitives, are proposed as fundamentally important to the development of standardised, flexible approaches to the mapping of discrete vegetation habitats.
Acknowledgements
This research was submitted in partial fulfilment of a Ph.D. degree at the Cranfield University (UK). The authors wish to thank staff at the North York Moors National Park Authority for help in field surveys and data access. The extensive fieldwork undertaken as part of this research was in part funded by the North Moors National Park Authority and the Dudley Stamp Memorial Trust. SPOT 5 satellite imagery was made available to the project via the EU-funded OASIS programme. The assistance of this project is gratefully acknowledged. The authors would also like to thank Professor Simon Jones (RMIT University) and two anonymous reviewers for insightful comments on earlier drafts of this paper.
References
- Ahlqvist , O. 2004 . A parameterized Representation of Uncertain Conceptual Spaces . Transactions in GIS , 8 ( 4 ) : 493 – 514 .
- Ahlqvist , O. 2005 . Using Uncertain Conceptual Spaces to Translate Between Land Cover Categories . International Journal of Geographical Information Science , 19 ( 7 ) : 831 – 857 .
- Ahlqvist , O. 2008 . In Search of Classification that Supports the Dynamic Science: The FAO Land Cover Classification Scheme and Proposed Modifications . Environment and Planning B: Planning and Design , 35 : 169 – 186 .
- Bartholome , E. and Belward , A.S. 2005 . GLC: 2000 A New Approach to Global Land Cover Mapping from Earth Observation Data . International Journal of Remote Sensing , 26 : 1959 – 1977 .
- Bird , A.C. , Taylor , J.C. and Brewer , T.R. 2000 . Mapping National Park Landscapes from Ground, Air and Space . International Journal of Remote Sensing , 21 ( 13 and 14 ) : 2719 – 2736 .
- Backshall , J. , Manley , J. and Rebance , M. 2001 . The Upland Management Handbook , English Nature Science Series 6. Peterborough: English Nature .
- Bossard , M. , Feranec , J. and Otahel , J. “CORINE Land Cover Technical Guide: Addendum 2000,” . Technical Report 40 . 2000 . European Environment Agency
- Burrough , P.A. and Frank , A.U. , eds. 1996 . Geographic Objects with Indeterminate Boundaries , London : Taylor Francis .
- Cherrill , A. and McClean , C. 1999 . The Reliability of ‘Phase 1’ Habitat Mapping in the UK: The Extent and Types of Observer Bias . Landscape and Urban Planning , 45 : 131 – 143 .
- Comber , A. 2008 . The Separation of Land Cover from Land Use with Data Primitives . Journal of Land Use Science , 3 ( 4 ) : 215 – 229 .
- Comber , A. , Fisher , P. and Brown , A. “Uncertainty, Vagueness and Indiscernibility: The Impact of Spatial Scale in Relation to the Landscape Elements,” . Proceeding of the 5th International Symposium on Spatial Data Quality . 13–15th June , Enschede . Edited by: Stein , A. , Shi , W. and Bijker , W. Enschede,ITC
- Comber , A. , Fisher , P. and Wadsworth , R. 2003 . Actor-Network Theory: A Suitable Framework to Understand How Land Cover Mapping Projects Develop? . Land Use Policy , 20 : 299 – 309 .
- Comber , A. , Fisher , P. and Wadsworth , R. 2005 . What is Land Cover?” . Environment and Planning B: Planning and Design , 32 : 199 – 209 .
- Comber , A.J. , Fisher , P.F. and Wadsworth , R.A. 2008a . Using Semantics to Clarify the Conceptual Confusion Between Land Cover and Land Use: The Example of ‘Forest’ . Journal of Land Use Science , 3 ( 2–3 ) : 185 – 198 .
- Comber , A. , Brown , A. , Medcalf , K. , Lucas , R. , Clewley , D. , Breyer , J. , Bunting , P. and Keyworth , S. 2008b . “ Moving From Pixels to Parcels: The Use of Possibility Theory to Explore the Uncertainty Associated Object Oriented Remote Sensing ” . In Headway to Spatial Data Handling, Lecture notes in Geoinformation and Cartography , Edited by: Ruas , A. and Gold , C. Berlin: Springer .
- Defries , R.S. and Belward , A.S. 2000 . Global and Regional Land Cover Characterisation From Satellite Data: An Introduction to the Special Issue . International Journal of Remote Sensing , 21 : 1083 – 1092 .
- Di Gregorio , A. and Jansen , L.J.M. 2000 . “ Land Cover Classification System (LCCS): Classification Concepts and User Manual ” . In Environment and Natural Resources Service (SDRN) , Rome : Food and Agriculture Organisation .
- Dungan , J. 1998 . Spatial Prediction of Vegetation Quantities Using Ground and Image Data . International Journal of Remote Sensing , 19 ( 2 ) : 267 – 285 .
- Fisher , P.F. , Comber , A.J. and Wadsworth , R.A. 2005 . “ Land Use and Land Cover: Contradiction or Complement ” . In Re-Presenting GIS , Edited by: Fisher , P. and Unwin , D. Chichester : Wiley .
- Foody , G. and Trodd , N.M. 1993 . Non-Classificatory Analysis and Representation of Heathland Vegetation From Remotely Sensed Imagery . Geo Journal , 29 ( 4 ) : 343 – 350 .
- Fuller , R.M. , Smith , G.M. , Sanderson , J.M. , Hill , R.A. , Thomson , A.G. , Cox , R. , Brown , N.J. , Clarke , R.T. , Rothery , P. and Gerard , F.F. 2002 . “ Land Cover Map 2000 ” . In Draft Final Report , Centre for Ecology and Hydrology .
- Gilbertson , D.D. , Kent , M. and Pyatt , F.B. 1985 . Practical Ecology for Geology and Biological Survey Mapping and Data Analysis , London : Unwin Hyman .
- Haines-Young , R.H. , Barr , C.J. , Black , H.I.J. , Briggs , D.J. , Bunce , R.G.H. , Clarke , R.T. , Cooper , A. , Dawson , F.H. , Firbank , L.G. , Fuller , R.M. , Furse , M.T. , Gillespie , M.K. , Hill , R. , Hornung , M. , Howard , D.C. , McCann , T. , Morecroft , M.D. , Petit , S. , Sier , A.R.J. , Smart , S.M. , Smith , G.M. , Stott , A.P. , Stuart , R.C. and Watkins , J.W. 2000 . Accounting for Nature: Assessing Habitats in the UK Countryside , London : DETR .
- Harrison , A.R. 2006 . National Land Use Database: Land Use and Land Cover Classification , London : Office of the Deputy Prime Minister . version 4.4
- Herold , M. 2009 . “ Assessment of the Status of the Development of the Standards for Terrestrial Essential Climate Variables: Land Cover (T9) ” . In Global Terrestrial Observing System , Rome : FAO .
- Herold , M. , Hubald , R. and Di Gregorio , A. Translating and Evaluating Land Cover Legends Using the UN Land Cover Classification System (LCCS) . GOFC-GOLD Report No.43 . 2009 . Jena: GTOS
- Herold , M. , Latham , J.S. , Di Gregorio , A. and Schmullius , C.C. 2006 . Evolving Standards in Land Cover Characterisation . Journal of Land Use Science , 1 ( 2–4 ) : 157 – 168 .
- Jensen , J.R. 1986 . Introductory Digital Image Processing: A Remote Sensing Perspective , Upper Saddle River, NJ: Prentice-Hall .
- Jansen , L.J.M. and Di Gregorio , A. 2002 . Parametric Land Cover and Land-Use Classifications as Tools for Environmental Change Detection . Agriculture, Ecosystems and Environment , 91 : 89 – 100 .
- JNCC . 1993 . Handbook for Phase 1 Habitat Survey: A Technique for Environmental Audit , Peterborough : Joint Nature Conservation Committee .
- Lucas , R. , Rowlands , A. , Brown , A. , Keyworth , S. and Bunting , P. 2007 . Rule-Based Classification of Multi-Temporal Satellite Imagery for Habitat and Agricultural Land Cover Mapping . ISPRS Journal of Photogrammetry and Remote Sensing , 62 : 165 – 185 .
- Mather , P.M. 1999 . Computer Processing of Remotely-Sensed Images: An Introduction , 2nd , Chichester : Wiley .
- Mehner , H. , Cutler , M. , Fairbairn , D. and Thompson , G. 2004 . Remote Sensing of Upland Vegetation: the Potential of High Spatial Resolution Satellite Sensors . Global Ecology and Biogeography , 13 : 359 – 369 .
- Pal , M. and Mather , P.M. 2003 . An Assessment of the Effectiveness of Decision Tree Methods for Land Cover Classification . Remote Sensing of Environment , 86 : 554 – 565 .
- Taylor , J.C. , Bird , A.C. , Brewer , T.R. , Keech , M.A. and Stuttard , M.J. 1991a . Landscape Change in the National Parks of England and Wales: Methodology (Final Report Volume – II) , Silsoe : Silsoe College .
- Taylor , J.C. , Bird , A.C. , Keech , M.A. and Stuttard , M.J. 1991b . Landscape Change in the National Parks of England and Wales: Application of Satellite Remote Sensing (Final Report Volume – XIV) , Silsoe : Silsoe College .
- Van Niel , T.G. , McVicar , T.R. and Datt , B. 2005 . On the Relationship Between Training Sample Size and Data Dimensionality: Monte Carlo Analysis of Broadband Multi-Temporal Classification . Remote Sensing of Environment , 98 : 468 – 480 .
- Wadsworth , R. , Balzter , H. , Gerard , F. , George , C. , Comber , A. and Fisher , P. 2008 . An Environmental Assessment of Land Cover and Land Use Change in Central Siberia Using Quantified Conceptual Overlaps to Reconcile Inconsistent Data Sets . Journal of Land Use Science , 3 ( 4 ) : 251 – 264 .
- Wadsworth , R.A. , Comber , A.J. and Fisher , P.F. 2006 . “ Expert Knowledge and Embedded Knowledge: Or Why Long Rambling Class Descriptions are Useful ” . In Progress in Spatial Data Handling 12th International Symposium on Spatial Data Handling , Edited by: Riedl , A. , Wolfgang , K. and Elmes , G.A. Berlin : Springer .
- Webb , N. 1986 . Heathlands , London : Collins .