
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Introduction: Big data are reshaping the future of medicine. The growing availability and increasing complexity of data have favored the adoption of modern analytical and computational methodologies in every area of medicine. Over the past decades, asthma research has been characterized by a shift in the way studies are conducted and data are analyzed. Motivated by the assumptions that ‘data will speak for themselves’, hypothesis-driven approaches have been replaced by data-driven hypotheses-generating methods to explore hidden patterns and underlying mechanisms. However, even with all the advancement in technologies and the new important insight that we gained to understand and characterize asthma heterogeneity, very few research findings have been translated into clinically actionable solutions.
Areas covered: To investigate some of the fundamental analytical approaches adopted in the current literature and appraise their impact and usefulness in medicine, we conducted a bibliometric analysis of big data analytics in asthma research in the past 50 years.
Expert opinion: No single data source or methodology can uncover the complexity of human health and disease. To fully capitalize on the potential of ‘big data’, we will have to embrace the collaborative science and encourage the creation of integrated cross-disciplinary teams brought together around technological advances.
1. Introduction
Asthma is a common chronic disorder which has long been recognized as a heterogeneous disease [Citation1]. It is characterized by the variable symptom expression, airway inflammation, and therapeutic responses, making the clinical diagnosis challenging and long-term prognosis uncertain [Citation2,Citation3]. In the era of big data, technological advances and an ever-increasing quantity of available data in healthcare offer a unique opportunity to improve our understanding of this complex disease [Citation4]. Studies of asthma increasingly involve the collection of large and diverse datasets that include various sources of data (e.g. clinical, environmental, omics, imaging, electronic health records, etc.), and modern big data analytics offer a powerful tool to mine knowledge from them [Citation5]. In this context, classical hypothesis-driven approaches have in recent years been replaced by complex data-driven analytical techniques that interrogate the data in an unbiased fashion to discover hidden patterns and associations in a quest to mine knowledge from big data [Citation6]. Such hypothesis-generating techniques have been extensively applied to the discovery of asthma subtypes and their pathophysiological mechanism [Citation7–18], its relation with allergic sensitization [Citation19–23] and environmental exposures [Citation24–29], the discovery of biomarkers [Citation30–40] and asthma prediction [Citation41–46]. However, many challenges remain unmet, and very few research findings have been translated into clinical practice. For example, there is a lack of universally accepted diagnostic tools, especially in childhood asthma [Citation47]. Moreover, the definition of asthma subtypes remains controversial [Citation48]: while the existence of asthma endotypes is universally acknowledged, there is no consensus on how best to define them [Citation3,Citation49].
In this review, we aim to analytically investigate the methodological shift toward data-driven analyses in asthma research and critically appraise the impact of modern analytical techniques. In particular, we wish to highlight the advantages and pitfalls of their application in the current literature and provide our interpretation on the difficulty in deriving clinically meaningful insights about the disease development and its pathophysiological mechanism. To this end, we conducted a bibliometric analysis highlighting the relevant characteristics such as publication trends and topics that influence the research in asthma. On the premise that their principal goals differ significantly, we distinguish between studies that adopted classical Multivariate Statistics (MS) and Bayesian Statistics (BS) versus more recent Machine Learning (ML) and Artificial Intelligence (AI) methodologies. In Sections 2 and 3, we briefly introduce the reader to different methodologies. In Section 4 we describe the analytical approach adopted to perform the bibliometric analysis. The main results are discussed in Section 5, and our commentary and view on the current status of the field are presented in Section 6.
2. Harnessing the power of statistics and machine learning
According to the HACE theorem [Citation50], ‘big data starts with large-volume, heterogeneous, autonomous sources with distributed and decentralized control, and seeks to explore complex and evolving relationships among data’. These characteristics make large complex medical ‘big data’ a challenging framework for discovering useful knowledge [Citation6]. Therefore, it is not surprising that, despite the extraordinary availability and accessibility, only a portion of the data is integrated, understood, and analyzed [Citation51]. Modern statistics, ML and AI methodologies offer unique tools to harness high volumes of data, integrate them from various sources, and mine them to extract meaningful information.
AI and ML have become trendy terms in medicine and healthcare, and often they are used interchangeably. However, although they are closely related, there are important differences. AI is a computer science field that aims to produce computer systems and machines that can mimic human intelligence, thereby performing intellectual tasks such as decision-making and problem-solving. ML is a subfield of AI, where machines are trained to learn how to process and mine the data to identify features and relations to make predictions and identify patterns. Using mathematical, statistical and computational tools, ML enables machines to automatically learn and improve from past data and experiences without being explicitly programmed. It is of note that whilst ML as a discipline is fairly new, the statistical and mathematical foundations have been in existence for more than a century; the recent exponential growth in computational power enabled implementation of this statistical/mathematical groundwork [Citation6]. Most of the statistical concepts used in ML are drawn from the Multivariate statistics (MS) framework, a collection of statistical models that deal with the analysis of multivariate data, for which observations are measured on more than one variable and where there is an inherent interdependence between the variables [Citation52]. Our perspective on the relationship between different methodologies/fields is depicted in ().
Figure 1. The relationship between statistical and computer science disciplines
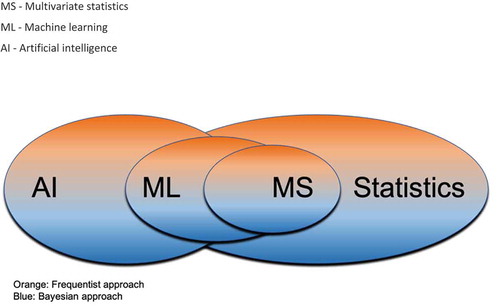
One of the main differences between machine learning and traditional multivariate statistics techniques lies in their purpose. Machine learning focuses on prediction models and on making the prediction as accurate as possible. It uses algorithms to learn rules from available data and create models able to generalize to new unseen instances. For example, in medicine, extant data can be used to train models that can then be used to predict future disease states or development of symptoms in later life. Statistics and multivariate analysis, instead, primarily seek to infer the relationship between variables. They use present observations to build models that can enhance the understanding of the phenomena at hand. In medical research, their focus is on the investigation of causality and associations to explain the disease and understand uncertainty in the modeling assumptions [Citation6].
In medicine, traditional regression-based models often involve a small number of variables to predict the value of an outcome or the probability of an event, and are often used to infer association rather than to establish a prediction rule [Citation53]. Their popularity is motivated by their high degree of interpretability: results are easy to understand, interpret and contextualize in a clinical setting, and underlying biological mechanisms can be discovered. In contrast, the interpretation of results from ML can be challenging. The lack of interpretability is apparent in artificial neural networks (ANNs), which are highly parameterized, non-linear models with sets of processing units called neurons [Citation54] that can approximate and learn the relationship between predictors and outcomes in a complex system. Despite their remarkable predictive power, the fitted models do not provide insights into the relative importance of the predictors or covariates, their underlying relationships and structures, in relation to the modeled outcomes [Citation54]. On the other hand, ML has many appealing properties. While the application of classical statistical models relies on the definition of several modeling assumptions, such as additivity, linearity and distributional assumptions, which are seldom met in clinical practice, ML models are free from prior distributional assumptions. These computational techniques can easily incorporate and model complex interactions between a high number of variables, which are difficult to assert in a statistical model. Moreover, while most multivariate statistics techniques incur computational issues in the presence of high-dimensional data – e.g., the number of predictors is often larger than the number of observations – ML can easily handle this large-scale data. Another critical advantage of ML lies in its ability to accommodate and combine different types of data: structured and unstructured data can be integrated into investigations of the prediction of disease diagnosis, prognosis and response to treatment.
Recently, the adoption of ML and AI models has been accelerated by the increasing availability and accessibility of Electronic Health Records (EHRs). Given that a great proportion of data are stored in textual format, the field of Natural Language Processing (NLP) is of particular relevance, and the correct use of NLP can help in many practical clinical purposes, from diagnosis to management [Citation55]. NLP refers to a specific area of ML in which the input is represented by a written or spoken information. While in a classical framework, the researcher can work with ‘structured’ data characterized by a precise organization of the information, in the NLP context, the information is ‘unstructured’, i.e. there is no common structure in which the information is stored and presented (e.g. different length of the audio or text, different use of language, etc.). In this context, pre-processing of data is essential: the documents, words, phrases or letters need to be translated into numbers\vectors. Technically speaking, it means to project each document, word, phrase, or letter into a vector-space. With a numerical (vector) representation of text, researchers can rely on structured data sets that can be used as any other sources of information. Consequently, supervised or unsupervised ML or MS models can be applied. For an in-depth analysis of clinical applications of text mining, we refer the reader to a comprehensive review on the application of NLP in asthma [Citation55] and an open access book on clinical text mining [Citation56].
3. A philosophical debate: Bayesian versus frequentist approach
Without the intention of being exhaustive, the purpose of this section is to introduce two opposing philosophies of statistical analysis, namely the Bayesian and the frequentist. Both are valid, although they differ methodologically and perhaps philosophically [Citation57].
In the frequentist approach, the scientist uses models that hold under specific assumptions and extract all the information from the data, without introducing any external information. The intention is to ‘let the data speak for themselves’, under the belief that the experimental design completely respects the assumptions needed to use a specific model. In this setting, the unknown population value, for example disease prevalence, is considered as a fixed, unvarying quantity, without a probability distribution [Citation58]. The aim is to obtain point or confidence intervals estimates for such quantity from the available data or test hypotheses around these parameters.
In contrast, the Bayesian approach uses a probabilistic framework for obtaining such estimates. This approach is based on the Bayes’ theorem, which underpins the subjectivist approach to statistics and logic of evidential support, and allows for the use of some knowledge or belief that we already have (commonly referred to as the prior) to help us calculate the probability of a related event. Bayesian methods are formulated on the premise that unknown parameters have probability distributions that can be constructed using our prior knowledge, before adding the information which comes from the data. In this framework, prior knowledge can be incorporated explicitly in the analytic model and combined with the data at hand to formulate a posterior distribution over the parameters of interests. This is one of the most characterizing aspects of Bayesian statistics and the feature that clearly distinguishes it from the frequentist perspective, where the prior knowledge cannot be explicitly included, but only drawn from the available data and translated into the assumptions we make about the statistical models for the data. However, the key question is not which of the two approaches is ‘better’, but rather, which method is best suited for the scientific question being addressed [Citation6].
4. Literature review
4.1. Search strategy
We systematically searched the literature up to 2020 using Scopus database to capture papers relevant to the application of MS, BS and ML and AI in asthma research. Scopus is an online bibliometric database developed by Elsevier that boasts a broad coverage of scientific resources and high accuracy [Citation59]. We built three separate queries to investigate the impact of each discipline in asthma research. The term ‘asthma’ was included in all searches combined with different search terms for the three individual categories:
Multivariate statistics (MS): ‘principal component’ OR ‘discriminant analysis’ OR ‘correspondence analysis’ OR ‘canonical correlation’ OR ‘Markov models’ OR ‘factor analysis’ OR ‘structural equation’ OR ‘latent variable’ OR ‘multidimensional scaling’ OR ‘clustering’ OR ‘latent class’ OR ‘cluster analysis’ OR ‘latent profile’ OR ‘profile regression’ OR ‘mixture models’.
Machine learning and artificial intelligence (ML&AI): ‘artificial neural networks’ OR ‘deep learning’ OR ‘supervised learning’ OR ‘unsupervised learning’ OR ‘support vector machine’ OR ‘SVM’ OR ‘decision trees’ OR ‘classification trees’ OR ‘regression trees’ OR ‘random forest’ OR ‘machine learning’ OR ‘artificial Intelligence’.
Bayesian statistics (BS): ‘Bayesian’ OR ‘Bayes’.
We wish to point out that although we appreciate that several of the listed methodologies are nowadays included in both MS and ML&AI, we assigned them according to the field in which they were initially developed. However, to capture this overlap to some extent, we included in the ML query, broad terms such as ‘unsupervised’ and ‘supervised learning’. The description of the individual methodologies is beyond the scope of this review, and we refer the readers to well-known texts on MS [Citation52,Citation60], ML&AI [Citation60–63] and BS [Citation64]. We omitted the term ‘big data’ in the search as we wished to highlight both a ‘big-data’ context and a ‘small sample size’ scenario. Specifically, while some of the methodologies of interest for this review require a big data set, other models are also appropriate in a small sample context.
4.2. Bibliometric analysis
To understand the state of the literature and to investigate the possible differences among the considered methodologies – MS, BS and ML&AI – we performed a bibliometric analysis on the set of articles returned from the search queries using the bibliometrix [Citation65] package in R, which is a language and environment for statistical computing and graphics and provides readily available codes to implement a wide variety of statistical models. Bibliometrics is an analytical discipline that utilizes statistical, and ML approaches to analyze scientific production in a given research field. From bibliographic data (e.g. authors, words, journals, countries, keywords), descriptive statistics can be used to evaluate author and country production, journal sources, and co-word analysis to identify significant themes in asthma research. On the premise that article keywords provide a suitable description of documents’ content, the analysis of keywords co-occurrences can reveal possible links between the topics covered in the articles. This analysis can provide insights into the knowledge structure of a scientific field. Keyword co-occurrence network and strategic thematic map [Citation66,Citation67] were used to investigate patterns and themes in the research field of asthma. Networks provide a representation of the relationships occurring in a system. A graph is generated assuming keywords as a set of nodes and a set of links established using their co-occurrences. This approach provides a schematic representation of the research themes and their relations. More details can, then, be extrapolated in the thematic map, where themes are embedded in a two-dimensional representation defined by the centrality and density indices. The centrality index captures the degree of interaction among networks; in other words, it is ‘a measure of the importance of a theme in the development of the entire research field analysed’ [Citation66]. Instead, the density measures the internal strength of the network, and it captures the level of development of a specific theme. The interpretability of the results relies on the definition of four quadrants in the two-dimensional embedding space, and the themes’ relevance can be interpreted based on their position with respect to the quadrants.
4.3. Probabilistic topic modeling
To further explore the knowledge structure of the asthma research field, we applied Latent Dirichlet Allocation (LDA) on title, keywords, and abstract [Citation68,Citation69]. LDA is an unsupervised ML approach that allows uncovering potentially hidden topic information in document sets by revealing recurring clusters of co-occurring words. LDA is a probabilistic topic model that represents each document as a random mixture over latent topics, and each topic is characterized by a distribution over words [Citation68]. The topic distributions in all documents share a common Dirichlet prior, and the word distributions of topics share a common Dirichlet prior as well. LDA aims at inferring the latent structure that is likely to have generated the observed corpus [Citation70].
Given a collection of documents, , where each document is considered as a sequence of
words
and each word is an item from a vocabulary indexed by
, we assume that there are
latent topics,
, defined as a distribution over the vocabulary. Then, the conditional distribution, known as the posterior, can be defined as [Citation69]:
where are the per-corpus topic proportions,
the per-corpus topic assignments and
the set of observed words. Both the topic proportions and the topic distributions over the vocabulary follow a Dirichlet distribution. As the posterior distribution is intractable for exact inference, inference algorithms need to be used to approximate it. Hence, topic models rely on sampling-based algorithms or variational algorithms [Citation68]. The analysis was performed with ad-hoc routines [Citation70] and the Text Analytics Toolbox of MATLAB [Citation71].
5. Asthma research and themes
Three separated searches, using the search strategy described above, were launched on Scopus and the bibliographic data were extracted by applying the queries to the contents of title, abstract and keywords. The search was limited to the subject area of Medicine, and erratum or undefined documents were excluded from the analysis. Articles were then manually downloaded in the BibTeX file format. All available information was retrieved. The searches resulted in 1922, 501 and 255 for MS, ML&AI and BS, respectively. After combining these three lists and removing the articles without abstract, we found 2395 unique articles.
5.1. The publication trends
The retrieved studies were conducted between 1965 and 2020 and involved 12,607 authors, with 0.19 article per author and 5.26 authors per article, and a collaboration index of 5.46 (). Only 95 authors produced single-authored articles, while the remaining 12,512 authors were involved in multi-author publications, and the average number of citations per article was 30.38. () shows the evolution of the asthma research field and the impact of modern analytical approaches. To evaluate the changes in scientific production over time, and we adopted the three research stages defined in Aparicio et al. [Citation72]. Accordingly, we identified i) the initial stage, from 1965 to 1988, with 56 articles published, with a rate of three articles per year; ii) the development stage, which spanned 1989–1999, with 179 articles and an average of 16 articles per year, and iii) the expansive stage, from 2000 to 2020, with 2160 articles published (with publication rate of almost 103 articles per year). In this bibliographic collection, MS techniques made their first appearance in 1965 and had remarkable growth throughout the whole period. Among the three disciplines, MS has the highest contribution to the scientific production of this field. The first paper utilizing BS methodologies dates back to 1982, while more modern ML techniques have seen their first application in asthma research in 1989 and have since gained increasing popularity. 1744 articles (72.8%) adopted MS techniques only, 355 articles (14.8%) utilized only ML&AI techniques, while BS models were applied to 191 (8.0%), exclusively. In 95 articles, the three analytical methodologies were used in pairs, while 10 papers mentioned all three of them (). () shows the 10 most influential authors in the field. Research output for the top 10 most productive countries is shown in (). Considering productivity in terms of the number of articles published, the USA ranked first (599, 34.9%), followed by the UK (163, 9.5%) and the Netherlands (82, 4.8%). The frequency of publication varied among the top countries, from 3.1% to 34.9%. With productivity defined as the number of citations, only the USA and the UK remained in the same positions. Other countries that made up the top 10 were Switzerland (2785) and Georgia (1537).
Figure 2. Annual publication production
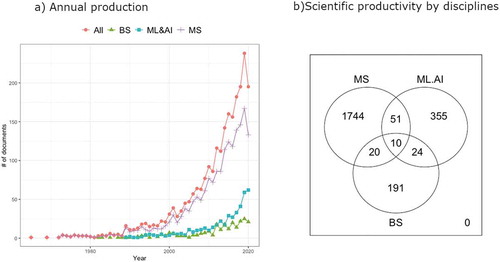
Table 1. Summary information on retrieved asthma studies, 1965–2020
Table 2. The 10 most productive authors in the application of Multivariate statistics (MS), Machine learning and artificial intelligence (ML&AI) and Bayesian statistics (BS) to asthma research
Table 3. The 10 most productive countries in the application of Multivariate statistics (MS), Machine learning and artificial intelligence (ML&AI) and Bayesian statistics (BS) to asthma research SCP: single country publications; MCP: multiple country publications
5.2. Conceptual framework
In the co-occurrence network (), the top 50 keywords are shown, and the Louvain community detection algorithm [Citation73] identified 4 key research themes, that we qualitatively labeled as:
Figure 3. Themes in asthma research fields
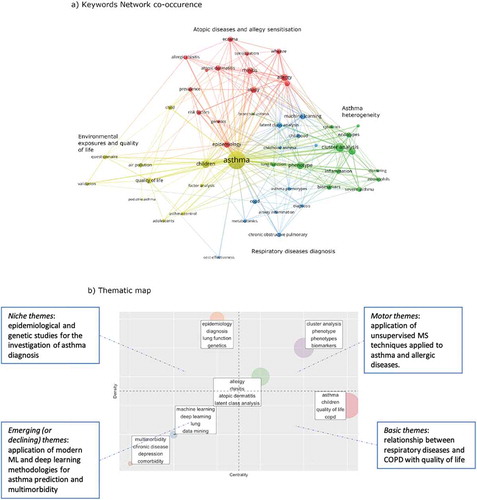
1) Asthma heterogeneity (green); this theme comprised studies related to disentangling asthma heterogeneity using unsupervised data-driven approaches on clinical and biological data to uncover different ‘phenotypes’ of asthma and their underlying pathophysiological mechanisms.
2) Atopic diseases (red), which referred to the investigation of the relationship between asthma and atopic diseases and allergic sensitization.
3) Respiratory diseases diagnosis (blue). This theme is characterized by the use of unsupervised and supervised machine learning techniques to classify and predict respiratory diseases, evaluate novel diagnostic tools and identify risk factors.
4) Environmental exposures and quality of life (yellow), where we found references to the investigation of the effect of environmental exposure on asthma and the relationship between social and psychological factors and asthma.
These themes were further characterized on the thematic map (), which captures a more detailed definition of the knowledge structure, highlighting the importance of the themes in the research field. Themes appearing on the upper right panel have high centrality and high density and are known as motor themes; these are well-developed themes and play a central role in the conceptual structure of the scientific field. In this quadrant, we found themes related to unsupervised MS techniques applied to asthma and allergic diseases. This is not surprising, given that in the past decades, a large number of studies have adopted these data-driven approaches in an attempt to characterize the heterogeneity of asthma and allergic diseases. The upper left quadrant is characterized by high density and lower centrality; themes in this quadrant are well developed but present a high degree of specialization and are marginal in the overall field. The theme in this area concerns epidemiological studies that aim at investigating asthma diagnosis with a focus on the genetic component. Themes that appear on the lower left part are emerging or declining themes characterized by low density and centrality. The emerging themes here concerned the application of modern ML and deep learning methodologies to asthma research, with a focus on the prediction of the disease, and the study of multimorbidity. Finally, themes in the lower right quadrant have low density and high centrality, meaning that they are essential for the field’s scientific structure, but are not well-developed. Here, we found the theme related to the assessment of the relationship between respiratory diseases and COPD with quality of life.
5.3. Research topics in asthma literature
In LDA, the topics are assumed to be latent variables, which need to be meaningfully interpreted. To this end, we examined, for each topic, the top 50 keywords, depicted in () where word relevance is measured normalizing the posterior word probabilities per topic by the geometric mean of the posterior probabilities for the word across all topics [Citation70]. The eight identified topics reveal important areas of asthma research. Topics 1, 2, 3, 4, 5 and 7 confirmed the themes discovered in the previous analyses and provided additional insights into their structure. In particular, Topic 1, including terms such as ‘phenotypes’, ‘cluster’, ‘asthma’ ‘lung’, ‘COPD’, and Topic 4, with words ‘sensitization’, ‘allergic’, ‘wheeze’, ‘phenotypes’, ‘eczema’, ‘rhinitis’, dealt with the application of unsupervised statistical and ML methodologies to understand and characterize asthma heterogeneity and its relation to allergic sensitization, and to investigate the hypothesis related to the atopic march.
Figure 4. Word-clouds for the eight topics in asthma research
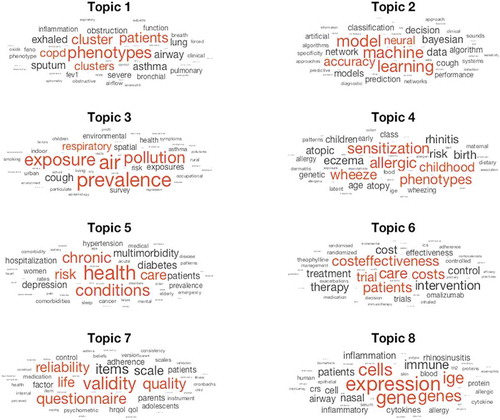
Asthma diagnosis and prediction are considered in Topic 2, characterized by words like ‘machine’, ‘learning’, ‘accuracy’, ‘model’, ‘Bayesian’. Topic 3, with top words ‘prevalence’, ‘pollution’, ‘air’, ‘exposure’ and Topic 7, with terms ‘validity’, ‘questionnaire’, ‘quality’, ‘life’ further characterize the research aimed at understanding the relationship between environmental exposures and social and psychological factors with asthma. The latter emphasized the studies that looked at the definition and validation of suitable questionnaires to capture patients’ symptoms and perceived quality of life. Moreover, the LDA model highlighted the body of literature devoted to the investigation of multimorbidity of chronic diseases and its risk factors (Topic 5 with top words ‘health’, ‘chronic’, ‘condition’, ‘multimorbidity’), the studies aimed at the evaluation of asthma treatment through clinical trials (Topic 6) and the examination of possible pathophysiological mechanisms and discovery of genetics and biological markers for disease diagnosis and treatment (Topic 8 – ‘gene’, ‘expression’, ‘IgE’, ‘cell’, ‘immune’, ‘cytokine’).
To further analyze the impact of the big data analytics in asthma research, we focused on the distribution of application of MS, ML&AI and BS methodologies for the retrieved topics (). Interestingly, 50% of the studies involving ML&AI are linked to Topic 2 (asthma diagnosis), compared to only 0.5% to studies aimed at questionnaires construction and validation. 42.4% of articles adopting Bayesian approaches were concerned with asthma diagnosis, 20.0% investigated environmental exposures, and 10.6% evaluated the efficacy of asthma treatments. Multivariate statistical techniques are evenly spread across the different topics, with higher prevalence in Topics 1, 4, 7 and 8. Clustering approaches and dimensionality reduction techniques, such as principal component analysis (PCA) and factor analysis (FA), were among the most commonly applied methods, followed by supervised machine learning algorithms and different Bayesian modeling approaches ().
Figure 5. Distribution of the big data analytics approaches in the eight topics
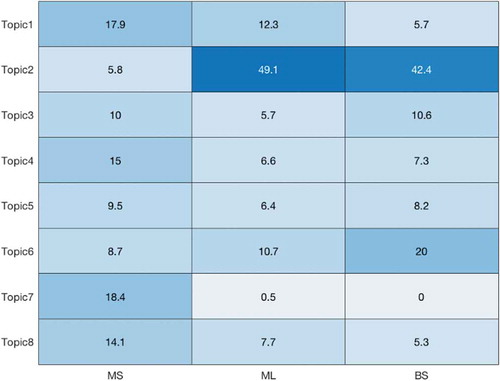
Table 4. Distribution of the major methodologies across the selected articles
6. Expert opinion
The exciting potential of modern analytical approaches has been welcomed across many different areas of medicine. They promise new opportunities to extract useful information from previously untapped and rapidly growing data sources that can be translated into a more refined disease diagnosis and prognosis, understanding of disease endotypes and etiology, and the development of personalized treatment plans.
Our analysis of 2935 academic publications offers potentially essential insights. The temporal evolution of academic production followed three significant stages. The initial and development stages were followed by the expansive stage, which started in 2000. In these past two decades, the number of articles using complex analytical techniques in asthma increased exponentially. The predominant themes concerned the investigation of disease subtyping and etiology, improving diagnostic accuracy, and targeting treatments.
From the year 2000, multivariate statistical models have appeared more and more frequently in asthma research and have covered all the main topics. By contrast, ML and AI techniques have become popular only in the last decade, and they have focused around a few key topics, such as disease diagnosis and treatment evaluation.
These findings offer evidence of a preference toward the inferential goal in asthma research. The popularity of MS methods draws attention to the long-lasting interest in precision medicine and disease subtyping. The extensive use of these techniques echoes the medical scientific community’s need to obtain, more than accurate predictions, interpretable solutions that can be used to derive useful insights for the definition of asthma endotypes and their underlying pathophysiological mechanisms. In this context, cluster analysis and unsupervised MS models that, by integrating different types of data, can explore different domains of the disease, represent a flexible and powerful analytical tool to identify homogeneous subpopulations of similar patients that can guide treatment decisions for a given individual.
By contrast, in recent years, the advent of modern large-scale experimentations (such as microarrays and advanced Omics technologies) and the accessibility of new data sources (such as electronic patients’ records) have provoked a surge of studies involving cutting-edge ML and AI prediction models in an attempt to obtain automated systems that can accurately diagnose asthma by modeling increasingly large datasets. The volume, velocity and variety of big data often demand complex analytical approaches to enable their analysis. This is particularly evident when dealing with unstructured data, such as images and textual data.
However, despite their potential, real-world implementations of machine learning and AI algorithms in clinical practice are rare. Furthermore, in recent years, there has been a growing concern around accuracy, reliability, security and privacy related to big data analytics in healthcare in general, and asthma specifically [Citation6,Citation74–79]. In a similar fashion, we posit that, among others, there are two main aspects that can explain the growing distrust in big data analytical approaches. One factor is inherent to the methodological characteristics of ML algorithms, while the other can be considered as an extrinsic factor, related to how these models are adopted and contextualized in healthcare. The former aspect can be scrutinized in the context of the long-standing debate on the difference between machine learning and statistics and their effectiveness and applicability. In his seminal paper, Breiman identified two different cultures: the ‘data modeling’ (statistics), and the ‘algorithmic modeling’ (ML and AI) cultures, roughly analogous to the explanatory/predictive dichotomy [Citation80]. In contrast to Breiman’s claim that algorithmic models are more flexible and accurate, especially when dealing with complex big data scenarios, many statisticians have contended that, even though these models accurately predict the outcome of interest, the lack of an explicit data-generating model can nullify their usefulness in scientific investigation [Citation80,Citation81]. In a recent article, Efron argues that ‘Abandoning mathematical models comes close to abandoning the historic scientific goal of understanding nature’ [Citation82]. The lack of interpretability is, therefore, at the core of the debate. Although ML is the avant-garde of predictive big data analytics, it is prone to the identification of spurious and irrelevant patterns, especially if data are of poor quality [Citation78]. The difficulties in understanding how the model processed the data can prevent the detection of such issues. Two streams of research ensued from these considerations. On the one hand, scientific efforts are being made to make black-box models more interpretable and suitable for explanatory purposes [Citation54,Citation83,Citation84]. On the other hand, evidence has been gathered in favor of the adoption of more interpretable models [Citation85–88] (e.g. logistic regression, linear discriminant analysis, decision trees), showing how simple methods typically yield performance almost as good as more sophisticated methods [Citation86]. For example, a recent study which reviewed current literature to compare the performance of logistic regression with ML for clinical prediction modeling found no evidence of the superior performance of ML over classical regression models [Citation89].
We believe that the argument on the incompatibility of these two approaches to investigation is not helpful and could be detrimental to scientific progress. We would argue that different emphases pursued by the two ‘cultures’ can be an asset in the attempt to characterize multifaceted heterogeneous long-term conditions. There is no single best model that can address different research questions. Combination of predictive and explanatory models can offer insights on different domains and aspects of the disease that could not be gathered by a single approach, and can be more effective for identifying distinct disease subtypes and explain their etiology. Probabilistic approaches and Bayesian inference should not be regarded with suspicion but should be explored and considered a beneficial modeling framework in which valuable prior knowledge about likely causal mechanisms can be explicitly incorporated.
The ‘extrinsic’ aspect that affects the failure of modern ML and AI approaches in clinical practise, has been extensively discussed [Citation3,Citation6,Citation79,Citation90] and relates to the practical use and implementation of these techniques. Modern computational and analytical methods can help identifying unexpected structure in data to generate hypotheses; however, these should not be accepted without a critical appraisal of the results and corroboration of the derived hypotheses [Citation6]. One of the dangers of ready accessibility of healthcare data, and analytical models for their analysis, is that the process of data mining can become uncoupled from the scientific process of interpretation, understanding the provenance of the data, and external validation [Citation6,Citation90 ].
We wish to highlight the potential danger of ill-considered use of readily available computational software for data analysis. These have favored the application of complex methodologies without expressly demanding the knowledge of the methodological properties underpinning the models. Most statistical analyses have assumptions, which often involve properties of the sample, variables, and models. Analytical methodologies have been criticized for the lack of reproducibility and practical usefulness. However, too often, this is the consequence of the incorrect use of these methods: the modeling choices made by inexperienced researchers can be flawed and draw inconsistent conclusions.
To fully harness the potential of ML, AI and modern statistical approaches in shaping the future clinical decision-making system, technological and methodological advances will need to be coupled with clinical and data analytical expertise. There is a mounting necessity to define a unified framework to describe how to undertake effective and ethical research in ML and AI in healthcare [Citation73]. Data scientists and medical professionals should engage in continuous collaboration and conversation to guarantee that the application of data analytics respects both the theoretical and methodological foundations, and the inherent characteristics of the data, the context and the research question under investigation. Not only findings but also methodological choices need to be carefully evaluated to assure relevant scientific discoveries. Bigger healthcare data need to be analyzed in ways that produce meaningful clinical interpretation to ensure that the findings can be translated into better diagnoses and properly personalized prevention and treatment plans [Citation6].
To achieve this, we need to accept that no single source of data or methodology can uncover the underlying complexity of human health and disease. To fully capitalize on the potential of ‘big data’, we will have to enhance the effectiveness of collaborative science and encourage the creation of integrated cross-disciplinary teams brought together around technological advances. Such teams are by necessity cross-institutional (and increasingly cross the geographical boundaries), and we need to develop and implement incentives for academic researchers engaged in team science, including clear pathways for a progression in their academic careers, including tenure and promotion, which currently favor ‘solo’ scientists.
Article highlights
Studies of asthma increasingly involve collection of large and diverse datasets that include various sources of data (clinical, environmental, omics, imaging, electronic health records, etc.), and modern statistics, machine learning and artificial intelligence methodologies offer a powerful tool to mine knowledge from them
However, this is a challenging framework for discovering useful knowledge, and despite their undoubted potential, real-world deployments of machine learning algorithms and artificial intelligence in clinical practice are rare
Modern computational methods can be valuable for identifying unexpected structure in data to generate hypotheses; however, these should not be accepted without a critical appraisal of the results and corroboration of the derived hypotheses
There has been a growing concern around accuracy, reliability, security and privacy related to the use of big data analytics, and a mounting necessity to define a framework to describe how to undertake effective and ethical research in ML and AI in healthcare
One of the dangers of ready accessibility of healthcare data, and models for their analysis, is that the process of data mining can become uncoupled from understanding the provenance of the data, external validation the scientific process of interpretation
We wish to highlight the potential danger of ill-considered use of readily available computational software for data analysis: the modeling choices made by inexperienced researchers can be flawed and draw inconsistent conclusions
To fully harness the potential of ML, AI and modern statistical approaches in shaping the future clinical decision-making system, technological and methodological advances will need to be coupled with clinical and data analytical expertise.
To fully capitalize on the potential of ‘big data’, we will have to encourage the creation of cross-disciplinary teams which are increasingly and by necessity cross-institutional and cross the geographical boundaries.
To facilitate this process, we need to develop and implement incentives for “team scientists), including clear pathways for a progression in their academic careers, as current pathways favor ‘solo’ scientists.
Declaration of interest
A Custovic reports personal fees from Novartis, personal fees from Thermo Fisher Scientific, personal fees from Philips, personal fees from Sanofi, personal fees from Stallergenes Greer, outside the submitted work. The authors have no other relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript apart from those disclosed.
Reviewer disclosures
Peer reviewers on this manuscript have no relevant financial or other relationships to disclose.
Additional information
Funding
References
- Rackemann FM. A working classification of asthma. Am J Med. 1947;3:601–606.
- Pavord ID, Beasley R, Agusti A, et al. After asthma: redefining airways diseases. Lancet. 2018;391:350–400.
- Oksel C, Haider S, Fontanella S, et al. Classification of pediatric asthma: from phenotype discovery to clinical practice. Front Pediatr. 2018;6. DOI:https://doi.org/10.3389/fped.2018.00258
- Haider S, Custovic A. Breaking down silos in asthma research: the case for an integrated approach. EMJ Innov. 2019;3:82–92.
- Custovic A, Custovic D, Kljaic Bukvic B, et al. Atopic phenotypes and their implication in the atopic march. Expert Rev Clin Immunol. 2020;16:9, 873–881.
- Belgrave D, Henderson J, Simpson A, et al. Custovic A: Disaggregating asthma: big investigation versus big data. J Allergy Clini Immunol. 2017;139:400–407.
- Belgrave DC, Custovic A, Simpson A. Characterizing wheeze phenotypes to identify endotypes of childhood asthma, and the implications for future management. Expert Rev Clin Immunol. 2013;9:921–936.
- Prosperi MC, Sahiner UM, Belgrave D, et al. Challenges in identifying asthma subgroups using unsupervised statistical learning techniques. Am J Respir Crit Care Med. 2013;188:1303–1312.
- Henderson J, Granell R, Heron J, et al. Associations of wheezing phenotypes in the first 6 years of life with atopy, lung function and airway responsiveness in mid-childhood. Thorax. 2008;63:974.
- Oksel C, Granell R, Haider S, et al. Distinguishing wheezing phenotypes from infancy to adolescence. A pooled analysis of five birth cohorts. Ann Am Thoracic Soci. 2019;16:868–876.
- Martinez FD, Wright AL, Taussig LM, et al. Asthma and wheezing in the first six years of life. The group health medical associates. N Engl J Med. 1995;332(3):133–138.
- Belgrave DCM, Simpson A, Semic-Jusufagic A, et al. Joint modeling of parentally reported and physician-confirmed wheeze identifies children with persistent troublesome wheezing. J Allergy Clini Immunol. 2013;132(575–583):e512.
- Belgrave DCM, Granell R, Simpson A, et al. Developmental profiles of Eczema, Wheeze, and Rhinitis: two population-based birth cohort studies. PLoS Med. 2014;11. DOI:https://doi.org/10.1371/journal.pmed.1001748.
- Belgrave DCM, Buchan I, Bishop C, et al. Trajectories of lung function during childhood. Am J Respir Crit Care Med. 2014;189:1101–1109.
- Duijts L, Granell R, Sterne JAC, et al. Childhood wheezing phenotypes influence asthma, lung function and exhaled nitric oxide fraction in adolescence. Euro Respir J. 2016;47(2):510–519.
- Fitzpatrick AM, Bacharier LB, Guilbert TW, et al. Phenotypes of recurrent wheezing in preschool children: identification by latent class analysis and utility in prediction of future exacerbation. J Allergy Clini Immunol: In Pract. 2019;7(915–924):e917.
- Krautenbacher N, Flach N, Böck A, et al. A strategy for high-dimensional multivariable analysis classifies childhood asthma phenotypes from genetic, immunological, and environmental factors. Allergy: Eur J Allergy Clini Immunol. 2019;74:1364–1373.
- Weinmayr G, Keller F, Kleiner A, et al. Asthma phenotypes identified by latent class analysis in the ISAAC phase II Spain study. Clini Exp Allergy. 2013;43:223–232.
- Fontanella S, Frainay C, Murray CS, et al. Machine learning to identify pairwise interactions between specific IgE antibodies and their association with asthma: a cross-sectional analysis within a population-based birth cohort. PLoS Med. 2018;15(11):e1002691.
- Howard R, Belgrave D, Papastamoulis P, et al. Evolution of IgE responses to multiple allergen components throughout childhood. J Allergy Clin Immunol. 2018;142:1322–1330.
- Lazic N, Roberts G, Custovic A, et al. Multiple atopy phenotypes and their associations with asthma: similar findings from two birth cohorts. Allergy: Eur J Allergy Clin Immunol. 2013;68:764–770.
- Roberts G, Fontanella S, Selby A, et al. Connectivity patterns between multiple allergen specific IgE antibodies and their association with severe asthma. J Allergy Clini Immunol. 2020;146:821–830.
- Simpson A, Tan VYF, Winn J, et al. Beyond atopy: multiple patterns of sensitization in relation to asthma in a birth cohort study. Am J Respir Critic Care Med. 2010;181:1200–1206.
- Bacharier LB, Beigelman A, Calatroni A, et al. Longitudinal phenotypes of respiratory health in a high-risk urban birth cohort. Am J Respirat Critic Care Med. 2019;199:71–82.
- Boudier A, Chanoine S, Accordini S, et al. Data-driven adult asthma phenotypes based on clinical characteristics are associated with asthma outcomes twenty years later. Allergy: Eur J Allergy Clini Immunol. 2019;74:953–963.
- Carreiro-Martins P, Viegas J, Papoila AL, et al. CO2 concentration in day care centres is related to wheezing in attending children. Eur J Pediatrics. 2014;173:1041–1049.
- Carreras G, Chellini E, Blangiardo M. A Bayesian model for studying urban air pollution and respiratory symptoms in children. Inter J Environ Health. 2012;6(2):125–140.
- O’ Lenick CR, Chang HH, Kramer MR, et al. Ozone and childhood respiratory disease in three US cities: evaluation of effect measure modification by neighborhood socioeconomic status using a Bayesian hierarchical approach. Environ Health: A Global Access Sci Source. 2017;16(36).
- Virot E, Godet J, Khayath N, et al. Cluster analysis of indoor environmental factors associated with symptoms of mite allergy. Ann Allergy, Asthma Immunol. 2019;123:280–283.
- Broadbent L, Manzoor S, Zarcone MC, et al. Comparative primary paediatric nasal epithelial cell culture differentiation and RSV-induced cytopathogenesis following culture in two commercial media. PLoS One. 2020;15(3):1–12.
- Abdel-Aziz MI, Brinkman P, Vijverberg SJH, et al. Sputum microbiome profiles identify severe asthma phenotypes of relative stability at 12 to 18 months. J Allergy Clini Immunol. 2020;147(1):123–134.
- Clark H, Granell R, Curtin JA, et al. Paternoster L: Differential associations of allergic disease genetic variants with developmental profiles of eczema, wheeze and rhinitis. Clini Exper Allergy. 2019;49(11):1475–1486.
- Custovic A, Belgrave D, Lin L, et al. Cytokine responses to rhinovirus and development of asthma, allergic sensitization, and respiratory infections during childhood. Am J Respir Crit Care Med. 2018;197:1265–1274.
- Wu J, Prosperi MCF, Simpson A, et al. Relationship between cytokine expression patterns and clinical outcomes: two population-based birth cohorts. Clini Exper Allergy. 2015;45:1801–1811.
- Dong Z, Ma Y, Zhou H, et al. Integrated genomics analysis highlights important SNPs and genes implicated in moderate-to-severe asthma based on GWAS and eQTL datasets. BMC Pulm Med. 2020;270.
- Moss LC, Gauderman WJ, Lewinger JP, et al. Using Bayes model averaging to leverage both gene main effects and G × E interactions to identify genomic regions in genome-wide association studies. Genet Epidemiol. 2019;43:150–165.
- Ober C, McKennan CG, Magnaye KM, et al. Expression quantitative trait locus fine mapping of the 17q12-21 asthma locus in African American children: a genetic association and gene expression study. Lancet Respir Med. 2020;8:482–492.
- Modena BD, Bleecker ER, Busse WW, et al. Gene expression correlated with severe asthma characteristics reveals heterogeneous mechanisms of severe disease. Am J Respir Crit Care Med. 2017;195:1449–1463.
- Su MW, Lin WC, Tsai CH, et al. Childhood asthma clusters reveal neutrophil-predominant phenotype with distinct gene expression. Allergy: Eur J Allergy Clin Immunol. 2018;73:2024–2032.
- Yeh YL, Su MW, Chiang BL, et al. Genetic profiles of transcriptomic clusters of childhood asthma determine specific severe subtype. Clin Exp Immunol. 2018;48:1164–1172.
- Goto T, Camargo CA, Faridi MK, et al. Machine learning approaches for predicting disposition of asthma and COPD exacerbations in the ED. Am J Emerg Med. 2018;36:1650–1654.
- Himes BE, Dai Y, Kohane IS, et al. Prediction of Chronic Obstructive Pulmonary Disease (COPD) in asthma patients using electronic medical records. J Am Med Inf Assoc. 2009;16:371–379.
- Kothalawala DM, Kadalayil L, Weiss VBN, et al. Prediction models for childhood asthma: a systematic review. Pediatr Allergy Immunol. 2020;31:616–627.
- Ullah R, Khan S, Ali H, et al. A comparative study of machine learning classifiers for risk prediction of asthma disease. Photodiagnosis Photodyn Ther. 2019;28:292–296.
- Spyroglou II, Spöck G, Chatzimichail EA, et al. A Bayesian logistic regression approach in asthma persistence prediction. Epidemiol Biostatistics Public Health. 2018;15:e12777-12771-e12777–12714.
- Tibble H, Tsanas A, Horne E, et al. Predicting asthma attacks in primary care: protocol for developing a machine learning-based prediction model. BMJ Open. 2019;9(7).
- Latzin P, Fuchs O. Asthma diagnosis in children: more evidence needed. Lancet Child Adolesc Health. 2017;1:83–85.
- Oksel C, Granell R, Mahmoud O, et al. Causes of variability in latent phenotypes of childhood wheeze. J Allergy Clin Immunol. 2019;143(1783–1790):e1711.
- Custovic A. “Asthma” or “Asthma Spectrum Disorder”? J Allergy Clin Immunol Pract. 2020;8:2628–2629.
- Tamhane D, Sayyad S. Big data using HACE theorem. Int J Advanc Res Comput Eng Technol. 2015;4:18–23.
- Rajula HSR, Verlato G, Manchia M, et al. Comparison of conventional statistical methods with machine learning in medicine: diagnosis, drug development, and treatment. Medicina (B Aires). 2020;56:455.
- Mardia KV, Kent JT, Kent JT, et al. Multivariate Analysis. London ; New York : Academic Press; 1979.
- Azzolina D., Baldi I, Barbati G, et al. Machine learning in clinical and epidemiological research: Isn’t it time for biostatisticians to work on it?. Epidemiology Biostatistics and Public Health. 2019;16:4.
- Zhang Z, Beck MW, Winkler DA, et al. opening the black box of neural networks: methods for interpreting neural network models in clinical applications. Ann Transl Med. 2018;6(11):216
- Juhn Y, Liu H. Artificial intelligence approaches using natural language processing to advance EHR-based clinical research. J Allergy Clin Immunol. 2020;145:463–469.
- Dalianis H. clinical text mining: secondary use of electronic patient recordsnull. Springer Nature, Switzerland: Springer; 2018.
- Gill CJ, Sabin L, Schmid CH. Why clinicians are natural Bayesians. BMJ. 2005;330:1080–1083.
- Bland JM, Altman DG. Bayesians and frequentists. BMJ. 1998;317:1151–1160.
- Falagas ME, Pitsouni EI, Malietzis GA, et al. Comparison of PubMed, Scopus, Web of Science, and Google Scholar: strengths and weaknesses. Faseb J. 2008;22:338–342.
- Hastie T, Tibshirani R, Friedman JH. The elements of statistical learning: data mining, inference, and prediction. New York: Springer; 2009.
- Mitchell TM. Machine Learning. New York, NY United States: McGraw-Hill; 1997.
- Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, MA, USA: MIT Press; 2016.
- Murphy KP. Machine Learning: a probabilistic perspective. Cambridge, MA, USA: MIT Press; 2012.
- Gelman A, Carlin JB, Stern HS, et al. Bayesian data analysis. Boca Raton: CRC Press; 2013.
- Aria M, Cuccurullo C. bibliometrix: an R-tool for comprehensive science mapping analysis. J Informetrics. 2017;11:959–975.
- Cobo MJ, López-Herrera AG, Herrera-Viedma E, et al. An approach for detecting, quantifying, and visualizing the evolution of a research field: a practical application to the Fuzzy Sets Theory field. J Informetrics. 2011;5:146–166.
- Cobo MJ, Martínez MA, Gutiérrez-Salcedo M, et al. Herrera-Viedma E: 25 years at Knowledge-Based Systems: a bibliometric analysis. Knowledge-Based Syst. 2015;80:3–13.
- Blei DM, Ng AY. Jordan MI: Latent dirichlet allocation. J Mach Learn Res. 2003;3:993–1022.
- Blei DM. Probabilistic topic models. Commun ACM. 2012;55:77–84.
- Tontodimamma A, Nissi E, Sarra A, et al. Thirty years of research into hate speech: topics of interest and their evolution. Scientometrics, 2021; 126:157–179.
- MATLAB: version 9.9.0.1467703 (R2020b). Edited by: The MathWorks Inc.; 2020.
- Aparicio G, Iturralde T. Maseda A: Conceptual structure and perspectives on entrepreneurship education research: a bibliometric review. Eur Res Manage Business Econ. 2019;25:105–113.
- Blondel VD, Guillaume J-L, Lambiotte R. Lefebvre E: Fast unfolding of communities in large networks. J Stat Mech Theor Exper. 2008;2008: P10008.
- Vollmer S, Mateen BA, Bohner G, et al. Machine learning and artificial intelligence research for patient benefit: 20 critical questions on transparency, replicability, ethics, and effectiveness. BMJ. 2020;368:l6927.
- Kelly CJ, Karthikesalingam A, Suleyman M, et al. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019;17:195.
- Jones LD, Golan D, Hanna SA, et al. Artificial intelligence, machine learning and the evolution of healthcare. Bone Joint Res. 2018;7:223–225.
- Wachter RM. The digital doctor: hope, hype, and harm at the dawn of medicine’s computer age. New York: McGraw-Hill Education, 2015.
- Dhindsa K, Bhandari M. Sonnadara RR: What’s holding up the big data revolution in healthcare? BMJ. 2018;363:k5357.
- Belgrave D. Custovic A: The importance of being earnest in epidemiology. Acta Paediatrica. 2016;105:1384–1386.
- Breiman L. Statistical modeling: the two cultures (with comments and a rejoinder by the author). Statist Sci. 2001;16:199–231.
- Mukhopadhyay S, Wang K. Breiman’s “Two Cultures” Revisited and Reconciled. ArXiv. 2005.13596.
- Efron B. Prediction, Estimation, and Attribution. J Am Stat Assoc. 2020;115:636–655.
- Guidotti R, Monreale A, Ruggieri S, et al. A survey of methods for explaining black box models. ACM Comput Surv. 2018;51(Article):93.
- Murdoch WJ, Singh C, Kumbier K, et al. Definitions, methods, and applications in interpretable machine learning. Proc Nat Acad Sci. 2019;116:22071–22080.
- Rudin C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Mach Intell. 2019;1:206–215.
- Hand DJ. Classifier technology and the illusion of progress. Statist Sci. 2006;21:1–14.
- Duin RPW. A note on comparing classifiers. Pattern Recognit Lett. 1996;17:529–536.
- Holte RC. Very simple classification rules perform well on most commonly used datasets. Mach Learn. 1993;11:63–90.
- Christodoulou E, Ma J, Collins GS, et al. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J Clin Epidemiol. 2019;110:12–22.
- Williams SM, Moore JH. Big data analysis on autopilot? BioData Min. 2013;6:22.