
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.1. Introduction
Today, it is often said that ‘big data will transform medicine to precision medicine’. However, data alone are meaningless. To be meaningful, data need to be queried, analyzed, and acted upon. The algorithms that encode causal reasoning and knowledge – not data – will prove transformative. Therefore, our attention needs to transition to new disciplines of data science (or health data science), which will be fundamental for the future of respiratory medicine science. In this article, we discuss the principles and major goals of data science (e.g. causal inference) and outline its current challenges and future directions in the fields of respiratory medicine.
To begin with, it is key to recognize what data science is. While data science is often characterized by its tools (e.g. machine learning), scientific disciplines are primarily defined by their questions and goals. For example, we define medical genetics as the discipline that studies the role of genetic factors in health, not as the discipline that uses sequencers. Accordingly, we classify the major goals of data science into three levels, according to the ladder of causation proposed by Judea Pearl, an influential computer scientist [Citation1]: 1) association and prediction, 2) intervention, and 3) counterfactual causal inference ().
Table 1. Scientific questions, required information, and methods of data science according to the ladder of causation
2. Data science and the ladder of causation
The first goal involves association and prediction. These rely exclusively on probabilistic relationships between the variables in existent data. For example, using data of millions of genetic variants from genome-wide association studies (GWAS), polygenic risk scores predict which patients are more likely to develop complex diseases, such as asthma [Citation2]. Analytics range from logistic regression, to Bayesian networks, to modern machine learning algorithms (e.g. random forests, deep neural network). Of note, machine learning is a subset of artificial intelligence (AI) which uses statistical methods to enable machines to perform statistical tasks, while AI is a technology which enables computers to behave like human intelligence. These machine learning algorithms excel in answering association/prediction queries, as exemplified self-driving cars and the prediction of protein structures. However, there are ongoing obstacles, such as adaptability (to new domains), explainability (or ‘black-box’ algorithms), and particularly the lack of causal reasoning [Citation1].
The second goal of data science is intervention. Intervention examines the probability or value of outcome () given that we intervene and set an exposure to a specific value (
). This can be estimated experimentally using a randomized controlled trials (RCT) and analytically using a causal Bayesian network [Citation1]. RCTs, if their major assumptions hold true (e.g. perfect adherence to randomization, no differential loss to follow-up, and no post-randomization confounding), would yield an unbiased estimate for the causal effect of interest. Therefore, RCTs have been considered the criterion standard for establishing causal inference since proclaimed as such by Ronald Fisher in the 1920s [Citation3]. However, RCTs in medicine may be infeasible or unethical [Citation4] – e.g. examining the health effects of many environmental, prenatal, and lifestyle factors on risk of developing asthma. More importantly, interventional studies cannot answer retrospective causal questions using existent large cohort or consortium data (e.g. ‘what if this group of patients with certain characteristics had been treated with drug
at time
’ – the defining question in precision medicine [Citation5]). To answer these causal queries, we must deploy a new set of tools.
The third goal is counterfactual causal inference – a unified framework of quantitative causal inference [Citation4,Citation6]. Counterfactuals or ‘what if’ reasoning are how humans reason causality. The use of ‘counterfactual’ reasoning enables us to formulate causal questions, codify causal reasoning in machines, and answer questions by leveraging data from not only RCTs but also large observational datasets [Citation1,Citation7]. For the past 20 years, this framework has been quietly transforming epidemiology and data science through the development of an intuitive graphical tool for qualitatively encoding our subject-matter knowledge and a priori assumptions (i.e. causal diagram) and robust analytic methodologies (e.g. inverse-probability weighting for time-varying treatments, targeted learning) [Citation1,Citation4,Citation8]. The key difference from the first goal (i.e. association/prediction) is the role of subject-matter (e.g. clinical ad biological) knowledge. While association/prediction invokes purely probabilistic relationships within existent data, counterfactual causal inference cannot be defined by the probabilities or data alone. Causal inference requires an integration of data and subject-matter knowledge. The latter specifies the causal structure of interest – e.g. causal relationships between the treatment, outcome, confounders, mediators, and colliders [Citation4]. For example, suppose we are interested in the causal effect of obesity on mortality using large cohort data. Data-driven algorithms – without codifying subject-matter knowledge – will learn from the data and fit a regression curve using a statistical model that models factors strongly associated with the exposure and outcome, such as comorbidities. However, this would induce a bias, called collider-stratification bias or ‘obesity paradox’ [Citation9] – i.e. among patients with comorbidities, the mortality is lower in obese individuals – by the data-driven adjustment for (or stratification by) comorbidities. Causal inferences cannot be achieved by systems that operate solely in data-driven association/prediction modes, as do most of today’s machine learning algorithms [Citation1]. In other words, causal questions cannot be answered with data alone, no matter how big our data are and how deep the neural network is.
3. The way forward
The distinction between association/prediction and counterfactual causal inference is becoming less important when subject-matter knowledge is encoded into the algorithms. In simple systems with known deterministic laws or rules (e.g. chess, Go games), such algorithms with reinforcement learning (which learn from numerous trials and errors) could perfectly predict the counterfactual state of system under any hypothetical intervention (or any hypothetical move in chess) [Citation7]. By contrast, respiratory medicine scientists study complex biological systems governed by non-deterministic laws with uncertainty about data. For example, suppose we are interested in the causal effect of severe bronchiolitis in infancy on asthma development. We have incomplete knowledge on the causal structure through which the host genetic factors, immune response, and environments collectively regulate and/or mediate the effect in these heterogeneous disease conditions [Citation10]. Accordingly, most traditional scientists (e.g. epidemiologists) have tended to answer carefully developed but relatively local causal questions (e.g. the average causal effect of specific virus infection during infancy on asthma development) rather than to tackle the global structure of system (e.g. the joint causal effects of viral, microbial, host genetic and immunologic, and environmental factors on asthma development).
Recently, joint efforts between traditional scientists and a new breed of data scientists have begun, accompanied by the integration of sophisticated analytics and causal inference. The first example is the integration of unsupervised machine learning and counterfactual causal inference methods (e.g. causal mediation analysis) to decompose the effects of modifiable disease pathways [Citation11]. Specifically, a recent Finnish study applied the integrated approach to population-based cohort, and identified that effects of early-life antibiotic exposures on subsequent development of asthma are mediated by longitudinal changes in the airway microbiome (modifiable mediator) [Citation11]. As exemplified, causal mediation analyses not only provide better understanding on the disease mechanisms but also offer avenues for the development of new therapeutics targeting modifiable mediators (e.g. modulation of the microbiome).
Second, with the rise of publicly available GWAS datasets from large consortiums and biobanks, Mendelian randomization has become a powerful tool in answering various queries. Mendelian randomization builds on the random assignment of genotypes transferred from parents to offspring at conception and uses the genetic variants as instruments. This method allows scientists to relate the genetic variants for modifiable exposures with health outcomes [Citation12], thereby investigating the causal role of phenotypic risk factors (e.g. obesity) and molecular intermediates (e.g. epigenetic factors, proteins) in respiratory diseases [Citation2]. The advent of Mendelian randomization approaches – in conjunction with the increased availability of expanded data sources (e.g. epigenetic and protein quantitative trait loci studies [Citation13]) – has informed the search for new therapeutic targets.
Third, in a complex system particularly involving multi-omics data, subject-matter knowledge in the underlying causal structure is limited. The causal structure can be, partially, revealed if interventions are properly applied, while these are often difficult or infeasible to conduct. However, the structure can be recovered by leveraging statistical properties of observed data – approaches called causal structure learning [Citation14]. Although previous algorithms had been unable to differentiate a set of candidate causal structures, recently developed ones have the capacity to identify a unique structure (an example shown in ) with mild assumptions [Citation15]. Although the promise of this approach lies in their synergy with, not replacement of, conventional experiments and RCTs, it not only offers well-calibrated hypotheses but also improves counterfactual causal inference.
Figure 1. Causal structural learning to uncover underlying causal structures from data
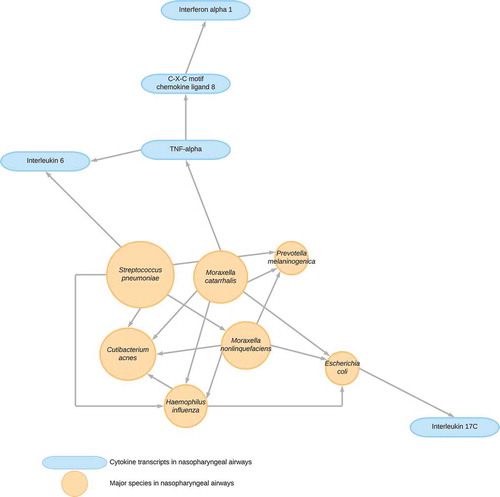
Despite excitement about these innovations, there remain important challenges in the integration of the different disciplines – e.g. how to fulfill standard causal inference assumptions (e.g. consistency when there are non-homogeneous exposures/treatments), how to handle time-varying feedbacks in a complex system, and how to optimize open data approaches with maintaining privacy and security. These are active areas of research.
4. Conclusion
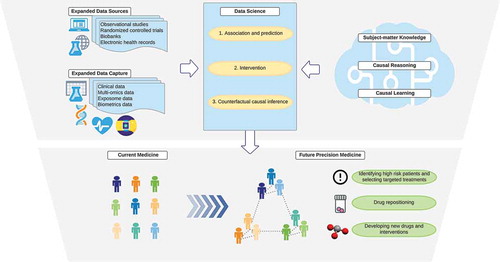
Respiratory medicine research has required scientists to handle a growing amount of data, including clinical, environmental, and multiple levels of omics data. While machine learning algorithms become ubiquitous tools to handle quantitatively ‘big data’, their integration with causal reasoning and knowledge is required to understand how complex systems behave (). This integration in data science qualitatively transforms ‘intelligence’ [Citation7], and shall be an important paradigm of respiratory medicine research in the 21st century. We anticipate that patients – whose lives shape data, knowledge, and algorithms– will benefit the most as this new paradigm advances precision medicine.
Figure 2. Data science that integrates big data and knowledge toward precision medicine
Abbreviations
| GWAS: | = | genome-wide association study |
| RCT: | = | randomized controlled trial |
Declaration of interest
The authors have no relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript. This includes employment, consultancies, honoraria, stock ownership or options, expert testimony, grants or patents received or pending, or royalties.
Reviewer disclosures
Peer reviewers in this manuscript have no relevant financial or other relationships to disclose.
Additional information
Funding
References
- Pearl J. The seven tools of causal inference, with reflections on machine learning. Comm Assoc Comp Mach. 2019;62(3):54–60.
- Zhu Z, Hasegawa K, Camargo CA Jr, et al. Investigating asthma heterogeneity through shared and distinct genetics: insights from genome-wide cross-trait analysis. J Allergy Clin Immunol. 2020;147(3):796–807.
- Fisher RA. Statistical methods for research workers. 1st ed. Edinburgh: Oliver and Boyd; 1925.
- Hernán MA, Robins JM. Causal inference: what if. Boca Raton: Chapman & Hill/CRC; 2020.
- Ashley EA. Towards precision medicine. Nat Rev Genet. 2016;17(9):507.
- Pearl J. Causality. Cambridge: Cambridge University Press; 2009.
- Hernán MA, Hsu J, Healy B. A second chance to get causal inference right: a classification of data science tasks. Chance. 2019;32(1):42–49.
- Schuler MS, Rose S. Targeted maximum likelihood estimation for causal inference in observational studies. Am J Epidemiol. 2017;185(1):65–73.
- Lajous M, Banack HR, Kaufman JS, et al. Should patients with chronic disease be told to gain weight? The obesity paradox and selection bias. Am J Med. 2015;128(4):334–336.
- Hasegawa K, Dumas O, Hartert TV, et al. Advancing our understanding of infant bronchiolitis through phenotyping and endotyping: clinical and molecular approaches. Expert Rev Respir Med. 2016;10:891–899.
- Toivonen L, Schuez-Havupalo L, Karppinen S, et al. Antibiotic treatments during infancy, changes in nasal microbiota, and asthma development: population-based cohort study. Clin Infect Dis. 2020. Epub ahead of print. DOI:10.1093/cid/ciaa262
- Davies NM, Holmes MV, Davey Smith G. Reading Mendelian randomisation studies: a guide, glossary, and checklist for clinicians. BMJ. 2018;362:k601.
- Sun BB, Maranville JC, Peters JE, et al. Genomic atlas of the human plasma proteome. Nature. 2018;558(7708):73–79.
- Glymour C, Zhang K, Spirtes P. Review of causal discovery methods based on graphical models. Front Genet. 2019;10:524.
- Shimizu S. Non-Gaussian methods for causal structure learning. Prev Sci. 2019;20(3):431–441.