
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Enhancing traffic signal optimisation has the potential to improve urban traffic flow without the need for expensive infrastructure modifications. While reinforcement learning (RL) techniques have demonstrated their effectiveness in simulations, their real-world implementation is still a challenge. Real-world systems need to be developed that guarantee a deployable action definition for real traffic systems while prioritising safety constraints and robust policies. This paper introduces a method to overcome this challenge by introducing a novel action definition that optimises parameter-level control programmes designed by traffic engineers. The complete proposed framework consists of a traffic situation estimation, a feature extractor, and a system that enables training on estimates of real-world traffic situations. Further multimodal optimisation, scalability, and continuous training after deployment could be achieved. The first simulative tests using this action definition show an average improvement of more than 20% in traffic flow compared to the baseline – the corresponding pre-optimised real-world control.
1. Introduction
In the context of the predicted and observed increase in the urban population (United Nations & Social Affairs, Citation2018), the existing infrastructure and traffic control are increasingly reaching their limits. To avoid a cost-intensive and often spatially unfeasible expansion of the infrastructure in urban regions, an optimisation of the traffic flow is preferable. This work aims to enhance the efficiency of current infrastructure by controlling traffic lights with AI-based approaches. This can help reduce traffic pollution and energy usage, improve traffic flow and positively impact economic and social factors. In the past, various methods have been developed to achieve this objective (Qadri et al., Citation2020; Shaikh et al., Citation2022; Zhao et al., Citation2012). Thanks to advances in algorithms, computation, and simulation, a promising method that emerged in recent years is Reinforcement Learning (RL) and its extension, Deep Reinforcement Learning (DRL). Previous research has demonstrated that intersections controlled using DRL can outperform fixed and vehicle-adaptive traffic signal control methods (Liang et al., Citation2019; Lin et al., Citation2018; Mannion et al., Citation2016). Nevertheless, there remains the problem of transferring these fundamental concepts to reality. Prior research has mainly focused on simulated traffic systems and has often failed to consider real-world traffic networks while using basic fixed-time control systems as a benchmark. The most significant research gap relates to the action space used. Real traffic signal systems have limited control capabilities, making most control approaches, including the most widely used approach – unrestricted selection of the next phase – impractical for real-world implementations (C. Chen et al., Citation2020; Chu et al., Citation2020).
Therefore, this work addresses the challenge of implementing DRL for real-world traffic light control, including an aligned action space for real-world implementation. It builds upon our previous work on this topic, in which an initial concept for a real-world implementation (Meess et al., Citation2022b) and an approach to effectively transfer agents that are trained in simulations to the real-world (Meess et al., Citation2022a) were presented. It reemphasizes the concept of a real-world implementation of DRL agents into real-world traffic light systems and shows the first proof of the core concept. Specifically, it demonstrates how the action space within the concept optimises the existing traffic light controllers on a parameter level. Meanwhile, the controller remains adaptive to the current local traffic and can improve the traffic flow within the simulation for a single intersection. These changes made by the agent to the control devices are called parameter levels since they incorporate the adjustment opportunities of a traffic signal system already planned by traffic engineers and applicable today.
2. Reinforcement learning
At the core of our work is developing an RL-system specifically designed to optimise traffic light signal systems. In the realm of RL, the fundamental objective is for an agent to learn to maximise a numerically defined reward by dynamically interacting with its environment. The agent hereby receives a representation of the current, often not fully observable, state of the environment at every point in time. Based on this representation, the agent chooses an action
which influences the environment. The agent then acquires feedback from the environment, the reward
. The agent aims to maximise the cumulative reward, the return
. Thus, the agent aims to adapt its actions so that, given a state
, the action is chosen to maximise the return. The mapping of how the agent acts given a particular state is called policy
. During training, the agent tries finding the optimal policy
. The RL framework thereby relies on the Markovian property, which declares that the future state of a process depends only on the current state and not on how that state was reached. RL has two main branches of algorithms: Q-learning and policy-gradient methods. In policy-gradient algorithms, the policy is represented directly as
. The agent tries to reach the optimal policy by adapting the parameters
, typically through gradient ascent. Q-learning algorithms, on the other side, try to find the optimal action-value function
by updating the action-value function
using the Bellman equation Sutton and Barto (Citation2018). Given
, the best action at the current state can be found with:
Q-learning algorithms generally have low variance and high bias, while policy-gradient algorithms have low bias but high variance (Z. Wang et al., Citation2016). Therefore, it is suggested that Q-learning and policy-gradient algorithms be combined to generate a method with low bias and variance. Such algorithms are called actor-critic. Here, the actor, which learns policy gradient like, chooses the action to take while the critic informs the actor how good the action was and how it should adjust using the action-value function. All RL algorithms rely on a good function approximation for the action value and if applicable, the policy function. Modern RL uses neural networks trained by back-propagation as a function approximator. This combination is considered as DRL. Building on this general framework, the state-of-the-art Soft Actor-Critic (SAC) was introduced in (Haarnoja et al., Citation2018). It utilises a stochastic policy by formulating its actions as a probability distribution. Additionally, it takes advantage of clipped double-Q Learning to reduce the optimisation bias and uses a maximum entropy approach to simultaneously maximise its expected return and the entropy of the explored states to efficiently solve the trade-off between exploration and exploitation. The SAC and other state-of-the-art algorithms have already found application in various domains, such as robotics Andrychowicz et al. (Citation2020) and manufacturing optimisation L. Wang et al. (Citation2021). The success of RL and DRL algorithms in the various domains motivated their use for the task of traffic light optimisation. Here, the agent controls the signals of the traffic light system, the state representation is assembled from the current traffic at the intersection, and the reward is composed of traffic flow parameters. Hence, the agent iteratively learns to improve the traffic flow by setting the traffic light signals according to the current traffic. A systematic analysis of past research in this field is presented in Noaeen et al. (Citation2022). Recent works’ RL-based traffic light optimisation design decisions are discussed in the reviews provided by Haydari and Yilmaz (Citation2020) and Gregurić et al. (Citation2020).
3. Issues in the application
The research on RL for optimising traffic lights was conducted primarily within simulated traffic environments. As stated in Mankowitz et al. (Citation2019) and Dulac-Arnold et al. (Citation2021) RL- and DRL-systems inherently pose several challenges when applying them in real-world systems. Additional challenges arise for the specific traffic signal control application, some presented in R. Chen et al. (Citation2022). In total, the following issues emerge and need to be solved to enable the use of DRL agents in traffic signal optimisation:
Real-world training: Training in real systems is difficult since agents cannot perform unrestricted arbitrary actions, and thus the opportunity for exploration is limited. Moreover, since the agent learns to optimise the policy
through many interactions with the environment, training an algorithm online in the original environment is very time-consuming. Hence, initial training must be done in simulated environments, which can be parallelised and run faster than in real-time. Further, it needs to be enhanced that the policy trained in simulation can then almost seamlessly be deployed to reality (Kaspar et al., Citation2020).
Uncertainty in traffic state: While simulations can provide reliable and accurate extraction of almost all state information, achieving such precision in detecting vehicles in the real world is significantly more challenging. This is due to the possibility of distortions or inaccuracies in the state values, which can arise from missing or faulty detectors (Bachechi et al., Citation2022; R. Chen et al., Citation2022). Hence, the observability of the Markov process is hidden, and hidden Markov models must be considered.
Robust Policy: Traffic states in real networks are complex and highly dynamic. Thus, even using neural networks as function approximators, the learned policies cannot always be guaranteed to be sufficiently robust at unseen states, especially given the uncertainty in the state information (R. Chen et al., Citation2022).
Safety constraints: DRL controllers must consistently adhere to the prevailing safety and operational constraints presented in technical regulations like FGSV (Citation2015/2021) or DOT (Citation2012) are always enforced. To ensure safety, separate mechanisms such as designing possible actions are necessary. (R. Chen et al., Citation2022; Dulac-Arnold et al., Citation2021).
Real-world traffic: Most implementations of traffic control strategies have only been done in small, symmetrical networks and often use traffic demand based on distribution functions as reviewed in Noaeen et al. (Citation2022), which do not adequately reflect real-world traffic conditions.
Multimodality: Simulations often overlook modes of transportation beyond cars, such as public transit, bikes, and pedestrians. As a result, implementing traffic control strategies without considering multimodal traffic may not properly account for the traffic modalities not represented in the simulation (M. Li et al., Citation2010; L. Wang et al., Citation2022). Moreover, advances in public transport are not utilised (Bhouri et al., Citation2015).
Baselines: Many DRL implementations for traffic signal optimisation have been evaluated against inadequate control methods, such as fixed-time controls and uncoordinated traffic-actuated controls. However, comparisons with state-of-the-art traffic-actuated controls, carefully designed and calibrated by traffic engineers and widely utilised in practice, are rarely carried out.
Action space: Simulations allow for the flexible choice of action definitions, including the ability to change traffic light phases at any time, as shown in . In contrast, real-world traffic control units do not allow this level of flexibility.
Table 1. Excerpt of previous works for DRL in traffic signal optimisation and their system design decisions with regard to the issues mentioned above.
Scalability: The DRL method for traffic signal optimisation needs to be scalable to MARL approach to enable network-wide optimisation.
To the best of our knowledge, no past research has addressed all issues to the extent that a scalable deployment into real systems is enabled. shows the key contributions of the past years with an indication of the main design decisions in the respective work to indicate which issues were covered.
However, the deployment possibilities of those methods are limited, which will further be discussed in Subsection 4.1. The safety constraints and robustness of the policies are also related to the chosen action definition. Regarding safety constraints, all studies mentioned in created systems that are save-by-design, i.e., do not allow conflicting traffic signal groups within their action definitions. For the setup presented in Müller et al. (Citation2021) the safe-by-design approach was extended by an additional safety layer in Müller and Sabatelli (Citation2022). Here, also a robust policy is achieved by introducing traffic engineering domain knowledge through action masking. Other works either did not include robustness guarantees (Bouktif et al., Citation2021; C. Chen et al., Citation2020; Chu et al., Citation2020; Wei et al., Citation2018), included predefined minimum or maximum green times within their action space (Aslani et al., Citation2017; Z. Li et al., Citation2021; Wu et al., Citation2020) or restricted the differences of the actions between two subsequent cycles (Liang et al., Citation2019). Relatively little focus has been placed in past research concerning uncertainty in the traffic state. Busch et al. (Citation2020) compared DRL Agents with and without state information highlighting the importance of including traffic information. The use of recurrent neural network (RNN) structures to reduce the uncertainty was introduced in Zeng et al. (Citation2018)] while Rodrigues and Azevedo (Citation2019) used dropout within the neural network structures following the same intention. Tan et al. (Citation2020) included adversarial training schemes to overcome noisy approximations of the state representation.
In general, research has not yet succeeded in solving all the issues mentioned above within one framework. This work, therefore, presents a concept that combines state-of-the-art DRL methods with existing traffic engineering methods to do so, which consequently enables a system that can be deployed into real systems.
4. Concept for real-world implementation
In the following section, the approach for the implementation of RL in real-world environments will be described in detail. For this purpose, the conventional traffic adaptive control scheme for traffic signal systems and the associated definition of the action space for the agents are discussed first. Subsequently, the scheme for the simulative training on real data and the later transfer into reality is presented. It represents the foundation for minimising the sim-to-real gap and thereby makes RL applicable for practical traffic optimisation. For this purpose, after the description of the different building blocks, it will be discussed how the components and the ensembled framework address the open issues presented in the previous section.
4.1. Traffic lights control scheme
Many cities already use traffic-actuated controls for traffic lights. The most widespread method for traffic actuated control in Germany is the time-gap-control (Oertel et al., Citation2011). A simplified schematic representation of a phase transition from phase to phase
for one intersection following this scheme can be found in . For this method, already pre-optimised frame signal plans are defined by traffic engineers within which the individual traffic signal systems can switch independently, depending on their current traffic situation. The frame signal plans consist of phase duration boundaries for the respective phases, which are called T-Times. The minimum T-time
is the minimum time for the phase extension/the earliest possible transition time, and the maximum T-time
is the maximum time for the phase extension/the latest possible transition time. The traffic controller will switch to the next phase if either no vehicles are detected by the available sensors associated with the respective phase for a defined time after
has elapsed, or if
is reached. Thereby, the choice of
and
has to be in line with the frame signal plans which define a valid interval by the minimal and maximal admissible T-Times
and
to guarantee a consistent sequence of phases for all possible choices of
and
. With the adaptation of the
and
times within this interval, the frame signal plan can be adapted to different traffic situations. Within the T-time interval, the individual traffic lights retain a high degree of autonomy and can react flexibly to their respective individual traffic volumes in time. Since traffic demand changes in certain patterns throughout the day, several programmes are used that respond to these basic patterns. These in turn differ in the
and
times as well as in the phase definition and sequence.
Figure 1. Simplified scheme of the time gap control.
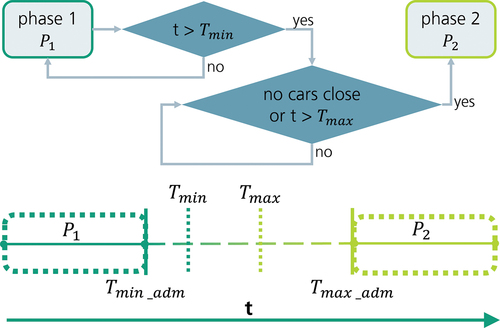
The presented approach intends to have a DRL agent determine these T-times. This counteracts the problem of the lack of transparency and robustness of the policies since the DRL agent influences the traffic light control only on a parameter level. The final decision on when to switch the traffic lights is left to the local controller. This also ensures that all safety constraints, as requested by FGSV (Citation2015/2021), are met as they are already embedded in the local controller. Since the T-times are the established method of controlling traffic lights dynamically in Germany and since they can be technically controlled via a central traffic control server, T-times are a practically applicable way of implementing DRL-based traffic light controls in many real road networks.
4.2. Actions definition
In order to create a coordinated DRL network that is transferable to real-world applications, it is necessary to select the action space analogous to the specifications of actual traffic light controllers. Section 3 introduced the different action definitions present in the literature. However, these methods cannot be implemented directly by the controllers of the traffic lights as these usually do not allow for direct manipulation of the traffic light phases nor the specific change in the phase durations within the traffic cycle but expect minimum and maximum T-time per phase transition as described in the previous Subsection. Further, these times are in turn coupled with the round-trip time of the system. In addition due to the high flexibility of the action definitions known from related research, they often also incorporate no or rather weak proof of robustness and minimal performance guarantees. Therefore, the practical alignment of this work requires a new approach for the definition of the action space, which does not directly manipulate the phases of the traffic lights, but optimises the parameters of the established control scheme presented in Subsection 4.1. Specifically, the minimum and maximum T-time are optimised based on the current traffic volume after each cycle of the traffic signal system within the predefined limits. For each phase transition from crossing
there is a maximum and minimum admissible T-time
. For the actually applied T-times indicated by
, the following must holdFootnote1:
For this work, it is assumed that the admissible times and
have a fixed value per phase transition
and crossing
depending on the respective active programme. With this assumption, the set of actions
for a single agent can be redefined as:
With the following side conditions:
Where is the total number of phase transitions per crossing
and
indicates the lower,
the upper value for the decision interval per phase. Thus, a continuous action space with two values per phase is obtained. Due to the fact that real-life systems only work in discrete intervals of one second, it holds for every subset
of
:
All phase-changing decisions follow the already pre-planned phases and transition schemes of the existing system-wide traffic control planning. Thereby it is ensured that the predefined safeties hold and the traffic control can be influenced without changing the phase sequence. One additional advantage is, that this approach can directly be implemented in the traffic controller without changing the control scheme whereas the DRL agents directly communicate with the traffic management computer and thereby control the adjustable parameters. With this strategy, a new action set can be defined per intersection in each round trip. This is also the upper limit for the updating frequency of the system, as currently broadly used traffic light control units can only update their behaviour once per cycle. For such an action space definition, the following challenges need to be considered when designing the DRL agent:
The action space consists of (dis-) continuous actions; the majority of the related work only deals with discrete action spaces
The action space is rather big (
The action space is constrained by the
The actions within the action space depend on other actions that are defined at the same time
T-times can have a different meaning depending on the active programme.
Furthermore, the complexity of the optimisation task is raised by still using the local traffic controller to manipulate the traffic signals, which is influenced by local dependencies. Also, traffic state information to the agent is in general sparseFootnote2, which is inherent to the weak observability of real-world traffic networks and the uncertainty of the behaviour of traffic participants as well as the rather long cycle times and decision intervals in which this information is provided. This is in turn as well the additional look-ahead distance for each action the agent takes until it receives its reward.
To meet these challenges and to ensure that the stated constraints hold, the actions are defined as follows:
Where is the respective output layer of the actor NN for the distinctive element of the action set of one agent. This approach and the definition range of the output layer between 0 and 1 ensure that the actions stay in the admissible range and the dependencies are met. Through this configuration, the robust policy, safety constraints, and action definition issues introduced in Section 3 are resolved. Moreover, the coordination of intersections, e.g., for enabling green waves, is simplified since already pre-coordinated traffic signal plans are used as a basis.
4.3. Training and transfer to the real-world
This section outlines the setup for training and transferring trained agents to real-world applications. The purpose of this setup is to address the issues mentioned in Section 3 by tackling the unresolved problems that arise when transferring DRL traffic optimisation to real-world applications. The setup is divided into three main components. The Core RL-System, the Simulation Based Training Environment, and the Real Life Productive Environment. The components, their interactions, and the subcomponents are described below. A schematic representation can be found in . This concept is yet to be fully implemented, the current implementation status of the work is described in Section 5.
Figure 2. Full concept for the RL training based on real-world data and transfer to the real-world application based on DRIVERS.
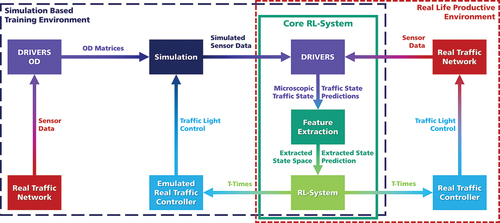
4.3.1. Core RL-System
The Core RL-System provides the main component of the system. It consists of DRIVERS (Dynamic, Reactive and Intelligent Vehicle movEments – Real-Time Simulation), which is used to generate the microscopic traffic information from raw sensor data. The Feature Extractor processes this information into a state representation. The RL-System, which contains the RL agents and generates the actions (T-times) based on the provided state and optimised for the defined reward. The Core RL-System represents an encapsulated unit that only requires the sensor data as input and outputs the actions as T-times. Therefore it can be used seamlessly in the Simulation Based Training Environment as well as in the Real Life Productive Environment. The components of the core RL-system are:
DRIVERS: In most traffic networks, a large number of sensors (e.g., induction loops) are installed which represent the current state of the network. However, the original data is often too sparse, inconsistent, and contains errors such as high/low counter values and failures. This low observability results in uncertainty in the traffic state estimation. The installation of additional and precise sensors in a large traffic network is very costly and time-consuming. To counter this problem a traffic estimation model named DRIVERS is used. DRIVERS creates a microscopic state representation out of real-world detector data (Kemper, Citation2006, 2015). For this purpose, it generates Origin-Destination (OD) matrices which represent the current traffic flow in the system. These OD-Matrices are generated using the information minimisation model and highly correspond to the real traffic on a macroscopic level (Kemper, Citation2015; Pohlmann, Citation2010). This approach generates traffic demands which usually achieve a correlation coefficient
Feature Extractor: The Feature Extractor is the entity in the system that extracts the traffic information out of the DRIVERS simulation. Specifically, it generates a state representation and reward signal after every traffic signal cycle for each optimised intersection. In the representation of the states and rewards, multimodal transport will also be covered. To reduce the uncertainty of the state representation of a single-time snippet compared to the real traffic state and support the agent in understanding the system dynamics Bakker (Citation2001), a series of recent states are accumulated. Those accumulated states are then stacked together with previous cycles based on the number of recent cycles to be taken into account and thus assemble the complete state representation per step. In addition to information about the current traffic, information about the current signal programme is transferred to the state as a one-hot encoded vector. The information is significant for the agent as it determines boundary conditions of
RL-System: The RL-System provides the T-Times corresponding to the action definition described in 4.2. The selection is based on the features provided by the Feature Extractor. In general, the DRL agents are trained in the Simulation Based Training Environment. But also an additional offline training of the agents during the deployment in the real-world system could be supported by this structure. At the current status, three of the most common DRL algorithms for continuous action spaces are implemented (compare Section 2). As step-size, one cycle time of the traffic light is used, while in turn, the simulation is running much more precisely. This is due to the fact that when simulating the whole road network, different traffic lights might have different cycle times and therefore generate their state, action, next state, and reward sequence within a different frequency. In addition, the next state and corresponding reward are highly delayed as they are only accessible when the next cycle is completed. Since the goal is not to only optimise single intersections but to extend the concept to several intersections and entire traffic networks, a MARL setup is created. For this purpose, a DRL agent is assigned to each intersection that should be optimised within the traffic network. The respective agent has its own decision-making, following the action definition proposed in Section 4.2, and is able to take actions that affect the environment. In this multi-agent setup, each agent automatically retrieves the state and reward for its relevant area in the traffic network and follows its own RL-Loop. Within the network, the traffic light signal systems at the intersections can be planned with different cycle times. Since the agents output an action after each cycle, the multi-agent system must be able to output the agents’ actions at different times. Therefore, an asynchronous structure is necessary. All in all, a MARL-system is achieved that is scalable to complete traffic networks even with varying cycle times. Moreover, the methods of cooperative multi-agent reinforcement learning Oroojlooy and Hajinezhad (Citation2022) and especially the concept presented in Meess et al. (Citation2022a) can support the learning process of the agents and enable cooperation between the agents to further improve the performance of the overall system.
4.3.2. Simulation based training environment
The Simulation Based training environment serves as a training and evaluation environment for the Core RL-System. Here the system can be trained and evaluated based on current and historical traffic scenarios. The training environment only accesses the sensor data and interacts with a simulation imitating the real-world traffic network so it does not affect the Real Traffic Network itself. Once the Core RL-System has been sufficiently trained and evaluated, it will be used seamlessly in the Real Traffic Network. The components of the training environment are presented below:
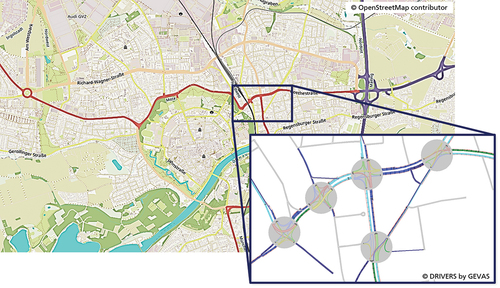
Real Traffic Network: The Real Traffic Network is a fundamental component of the system in both, the Simulation Based Training Environment as well as for the Real World Productive Environment. In the Simulation Based Training Environment, the Real Traffic Network is used to generate a realistic traffic demand minimising the simulation-to-reality gap. Therefore, the induction loop data of the relevant traffic network is gathered and fed into the DRIVERS OD instance. In the Real Life Productive Environment, the Real Traffic Network again makes the induction loop sensor data available to DRIVERS. Additionally, it receives the traffic light control actions for the Real Traffic Controller, which will then influence the real-world traffic lights. For the current setup, a cut-out of the traffic network of Ingolstadt as shown in is used to as the traffic network.
DRIVERS OD: DRIVERS OD is an instance of the DRIVERS programme. It is used to acquire realistic traffic demands and patterns out of real-world traffic networks. It is mainly used to generate OD Matrices from the sensor data of the Real Traffic Network. The generated OD Matrices represent traffic patterns that are used to train the agents in the simulation. They are saved to provide the agent with a broad set of training traffic scenarios.
Simulation: The traffic simulation is used to perform the training of the DRL agents on a broad scale. For this purpose, the Simulation of Urban MObility (SUMO) is used. SUMO is an open-source microscopic traffic simulation developed by the German Aerospace Centre Behrisch et al. (Citation2011). The SUMO Simulation serves as a surrogate for the real network during training. Here, actions can be carried out and their effects evaluated without affecting real traffic networks. The SUMO simulation uses the traffic network developed in Harth et al. (Citation2021), which represents a digital twin of the traffic network of Ingolstadt. In addition, we employ an emulation of the real traffic light controller within the simulation. Therefore, traffic lights in the simulation are controlled by signal plans developed by traffic engineers for the Real Traffic Network. These plans are optimisable in the same way as the Real Traffic Network by T-times. To generate realistic traffic states in the simulation, the OD matrices generated by DRIVERS OD are converted into different concrete traffic flows via the SUMO demand definition using random seeds. Therefore the stored historical OD matrices or the current live OD matrices can be used. This makes it possible to simulate a large number of different real traffic states in a short time. During traversal within the network, each vehicle’s velocity is simulated upon the application of a car-following model. SUMO employs a variant of the car-following model originally developed by Krauß (Citation1998). The lane-changing behaviour is employed according to Krajzewicz (Citation2010). This makes it possible to retrieve a large number of microscopic traffic data through an interface with the simulation. However, this data cannot be processed directly from SUMO by the RL-System, as this would not be available in reality. To achieve a standardised database for the RL, the output of the simulation is processed by DRIVERS. For this purpose, the simulated detector values are inserted into the DRIVERS of the Core RL-System. DRIVERS, which can be operated with the real detector values as well as with the detector values simulated by SUMO, then represent the standardised data basis for the Feature Extractor. This improves the seamless transferability of the system from simulation to reality.
Emulated Real Traffic Controller – Real Traffic Controller: To provide a realistic representation of the actual traffic-actuated control, the control of the traffic lights in the simulation environment is based on the original TRENDS kernel. The TRENDS (TRaffic ENgineering Development System) kernel is a control programme, which is used in real traffic networks and is operated in the local control unit of the traffic light (GEVAS software GmbH, Citation2015, Citation2020). It operates on top of the traffic light controller and allows the execution of TRELAN (TRaffic Engineering LANguage) (GEVAS software GmbH, Citation2020) sequence logics in the traffic light. TRELAN is a description language for traffic light sequence logic and is based on the German guidelines for traffic light signals (FGSV, Citation2015/2021). TRELAN enables the implementation of traffic-actuated controls, including the widely spread time-gap-control – based on T-times. The implemented logic is usually individually created by traffic engineers for the respective traffic lights. Usually, the TRENDS kernel processes input values (sensors) in order to control the output values (signal images) according to the defined TRELAN logic. These outputs are then passed on to the physical traffic light controller and executed. In the simulation, the TRENDS kernel is implemented by a middleware. This middleware is part of the simulation environment and handles the inputs and outputs of the TRENDS kernel. It also receives the T-times generated by the DRL agents and passes them on to the TRENDS kernel. In the simulation, the same TRELAN logic is used as in the Real Traffic Network. This ensures, that that the control procedure in the simulation follows the controls of the real network one-to-one.
Figure 3. Traffic network of Ingolstadt together with the corresponding microscopic traffic simulation and estimation representation by DRIVERS.
4.3.3. Real life environment
After the RL Agents have been sufficiently trained and evaluated in the simulation, the Core RL-System can be connected to the city’s traffic computer using the same interfaces as for the simulation framework. Here, the data of the induction loops can be retrieved online via the city’s communication interface and will then be transferred to DRIVERS to enable the microscopic traffic simulation, running in parallel with the real-world traffic. At the same time, the T-times determined by the agents can be communicated jointly over a traffic server to all systems to be optimised. The state space for the agents can be retrieved through the same pipeline as during the training in the simulation environment as through DRIVERS the same kind of data is available in both configurations. The agents provide the T-times to the TRENDS kernels of the traffic signal controllers identically to their emulated counterparts in the simulation environment.
4.3.4. Concept summary
The resulting concept results in a Simulation Based Training Environment which can be seen as a digital twin of the Real Traffic Network, traffic demand, and traffic control. The reduced simulation-to-reality gap enables the training of the DRL agents in simulation that can then be transferred to the Real Life Productive Environment. By doing so, we also address the challenges presented in Section 3. provides a summary of which components address each specific issue.
Table 2. Mapping of concept components to the issues discussed in Section 3.
5. First steps towards real-world implementation
In the first phase of developing DRL for real-world traffic optimisation, the primary focus is on showing a proof-of-concept for the newly designed action space, which is suitable for real traffic controllers. Therefore, in addition to the components of the mandatory RL parts (RL agents and Feature Extractor), only the connection to the real traffic demand and the coupling with the emulated TRENDS kernel were initially implemented besides the core simulation within the simulation framework. Here, the real simulated road network and traffic light system are already in use. Only the integration of DRIVERS for the generation of the microscopic state space has not yet been fully implemented in this first step such that the state space and reward signal are generated directly from the simulation. The current framework in its implementation state is outlined in .
Figure 4. First training scheme for training based on real-world data and real-world compliant control concept.
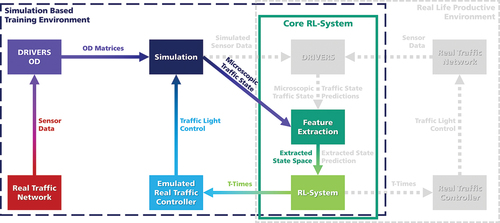
5.1. Current training-setup
For the initial proof-of-concept, only one traffic light was optimised using DRL agents in the framework outlined above. Here, the state space described in Subsection 4.3 including the presented Feature Extractor was used as well as the new action definition. At the same time, the agent communicates with the emulated TRENDS kernel which translates the actions in T-times for the context of the simulation, such that the traffic is controlled realistically. Within the Feature Extractor component, a state representation is chosen that extracts the number of vehicles of all approaching lanes because of the performance presented in Zheng et al. (Citation2019). For the reward, the idea of the performance index presented in Brilon (Citation2015) is followed, which enables a comparison of different methods of coordinating traffic managementFootnote3:
where represents the average waiting time of approaching vehicles,
the average number of stops, and
the traffic volume at the approaching edges. The parameters
and
weigh the waiting time and stops respectively and are set to
, as suggested in Brilon (Citation2015). The reward is afterwards scaled to values between
since normalised rewards have positive effects on the training (Henderson et al., Citation2018). For the agent itself, we implemented the SAC algorithm introduced in 2 which showed superior performance compared to other state-of-the-art algorithms, like DDPG (Lillicrap et al., Citation2019) and PPO (Schulman et al., Citation2015) applied on the current single agent optimisation setting. In the current training setup, a reduced traffic network consisting of the five intersections that are shown in is implemented, whereas the intersection in the middle is optimised. The traffic demand generated using the DRIVERS-OD instance presented in Subsection 4.3 accords to the real-world traffic demand for different days and times during the week in Ingolstadt. As different traffic light programmes are active during the day, T-times can have different meanings throughout the day. Therefore, the agent has to understand the correspondence between the programme number, which is one-hot-encoded in the state space, the T-time, and the current traffic situation to perform well compared to the unmodified original traffic actuated control, used as a benchmark.
Comprehensive first optimisation results for a single intersection show that a significant improvement can be achieved by the agent compared to the local adaptive traffic light control. shows the progression of the reward, which is again computed based on the normalised performance index over time for one exemplary traffic scenario. The benchmark, which is running real-world/benchmark parameters for the used traffic adaptive control by TRENDS, is compared to the optimised parameters obtained per round trip by the agent, whereas the RL agent’s actions are translated for the same traffic adaptive control by TRENDS.
Figure 5. Optimized agent performance at a single crossing. Blue and red lines indicate agent and benchmark rewards, respectively, with corresponding standard deviations shown in shaded areas.
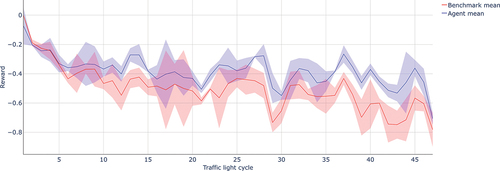
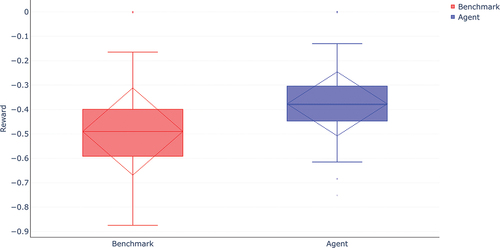
With regard to the cumulative performance of the two control methods in comparison, it can be seen that the control optimised via DRL enables a noticeably better performance index. On average, an improvement of 23.1% can be achieved on the simulated real traffic volumes. At the same time, the optimisation enables better consistency in the permeability of the intersection, which is evidenced by the lower standard deviation as can be seen in .
Figure 6. Comparison of mean, median, upper and lower quantiles, standard deviation, and outliers between the benchmark and the agent across all data points. The dotted lines represent the mean, +1 standard deviation, and −1 standard deviation.
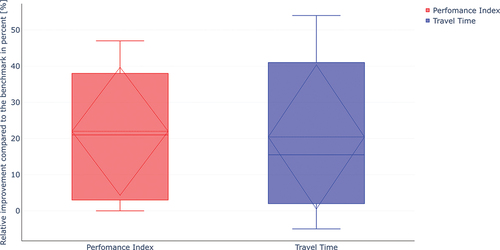
A second study on a wider range of traffic patterns and day-times shows that this improvement is to be expected as an average value over the course of the week. shows the average improvement of the agent in terms of Performance Index and travel time through the crossing for different traffic scenarios compared to the benchmark. It can be noted, that on average an improvement of around 20% can be achieved for both, the Performance index and travel time over the crossing. In particular the median improvement in the Performance Index (solid line) of the agent compared to the benchmark is 21%, while the mean improvement (dotted line) is 22%. Accordingly, the median improvement in travel time (solid line) is 15.5%, while the mean improvement in travel time (dotted line) is 20.4%. The analysis excludes night times with minimal traffic volume to improve the representativeness for relevant traffic volumes. These improvements indicate the adaptability of the agent to learn and optimise under different traffic conditions and programmes. It can also be noted, that the optimisation is not always leading to major improvements, as there are some traffic situations where the agent can not outperform the real-world control scheme. On the other hand, in some traffic scenarios improvements of more than 40% are possible.
Figure 7. Comparison of agent-based traffic actuated control improvements in percentage relative to real-world traffic actuated control with default T-times. Median improvements are indicated with a solid line, while mean improvements are indicated with a horizontal dotted line. The dotted triangular lines represent +1 standard deviation and −1 standard deviation.
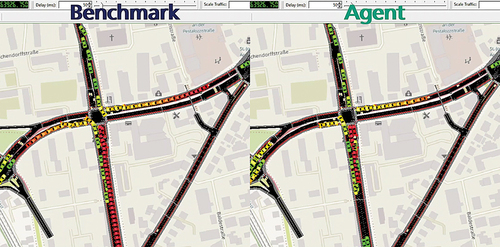
shows an exemplary comparison between the emerging traffic state on the crossing around 5:40 p.m. The crossing in the centre is to be optimised. The qualitative performance of the benchmark traffic actuated control (left) can be compared to the DRL agent-based traffic actuated control (right). The colouration of the cars indicates their current speed: red cars are standing, yellow cars are driving slow, and green cars are driving fast. It can be seen, that the benchmark control leads to a huge traffic jam in the south-to-north direction. This indicates that the local traffic actuation itself is not sufficient to handle the traffic volumes within this real-world traffic scenario. The agent on the other hand adjusts its T-times in a way that the unbalanced traffic volume can be handled without further issues while making additional use of the microscopic flexibility based on the controllers’ local traffic actuation.
Figure 8. Visual comparison between the benchmark behavior and the agent’s behavior on a simulative example traffic volume.
Overall, the results show a significant improvement in the performance index and thereby according to Brilon (Citation2015) an improvement in traffic control is achievable through the newly defined action space which also positively affects the travel time through the crossing. This can be achieved even without giving the agent the possibility to directly manipulate the phases within the intersection, as it is usually done in DRL-based traffic light control optimisation. This shows, that this DRL approach is able to provide substantial improvement contributions to traffic optimisation for traffic systems already by optimising the traffic controllers on a parameter level. Via this method, all the mandatory certainties and guarantees for traffic systems can be maintained, which would usually be lost when applying DRL in the conventional fashion.
6. Conclusion and next steps
This work outlined the key issues in the application of DRL agents for traffic signal optimisation and proposed a concept to overcome those issues without cost-intensive infrastructure changes or the need to fully restructure the traffic control systems. Also, the first proof of our concept is shown, by implementing and testing a key component of the concept. Here an agent was designed, which optimises the existing traffic controllers on a parameter level for a single intersection. By this training setup, it can be shown, that agents using the chosen action definition are able to improve the performance index and travel time compared to the baseline by more than 20% on average.
As the training process is heavily slowed by the complex co-simulation of the different parts within the framework, further work aims at a distributed simulation approach that uses the capabilities of cloud computing and the advancements in distributed DRL. This will make it possible to test a broader range of configurations. Hereby, further investigations into the reward definitions, state representation, and the agent´s hyperparameters will be enabled which is necessary to achieve a configuration with maximal performance. Furthermore, advanced methods to achieve cooperative MARL will be implemented. With regard to the state representation, in addition to other feature-based information, the deterministic traffic state encoding method known in the literature and described in Haydari and Yilmaz (Citation2020) will be used to generate an image-like representation of the traffic state. In the future, multimodal transport will also be considered when generating the presentation. Besides the representation itself, it will also be investigated how to best aggregate the traffic information within the cycle such that the agent understands the system dynamics in the best possible way and how to incorporate traffic predictions described in Subsection 4.3. In parallel with the steps to get the best out of the current training setup, the current implementation needs to be extended with the DRIVERS system within the Core RL-System and the Feature Extractor instance needs to be connected to DRIVERS to fully implement the whole concept. Only then training can be carried out with the traffic information that will later be available in the real-world production environment system. After the initial simulative proof for this approach, the system will be applied in the real road network of Ingolstadt by switching from the simulation branch to the Real Life Productive Environment.
Table 3. Definition of mathematical symbols used in this work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1. See for a detailed explanation of the mathematical symbols referenced in this study.
2. This issue is addressed by the traffic situation estimator, see Subsection 4.3.
3. EquationEquation 10(10)
(10) represents a slimmed-down variant of the PI presented in Brilon (Citation2015), since no multimodal traffic is currently being optimised, and the lanes are not weighted.
References
- Andrychowicz, O. M., Baker, B., Chociej, M., Jozefowicz, R., McGrew, B., & Pachocki, J. (2020). Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1), 3–20. https://doi.org/10.1177/0278364919887447
- Aslani, M., Mesgari, M. S., & Wiering, M. (2017). Adaptive traffic signal control with actor- critic methods in a real-world traffic network with different traffic disruption events. Transportation Research Part C: Emerging Technologies, 85, 732–752. https://www.sciencedirect.com/science/article/pii/S0968090X17302681
- Bachechi, C., Rollo, F., & Po, L. (2022). Detection and classification of sensor anomalies for simulating urban traffic scenarios. Cluster Computing, 25(4), 2793–2817. https://doi.org/10.1007/s10586-021-03445-7
- Bakker, B. (2001). Reinforcement learning with long short-term memory. Advances in Neural Information Processing Systems, 14. https://proceedings.neurips.cc/paper/2001/hash/a38b16173474ba8b1a95bcbc30d3b8a5-Abstract.html
- Behrisch, M., Bieker, L., Erdmann, J., & Krajzewicz, D. (2011). Sumo–simulation of urban mobility: An overview. In Proceedings of Simul 2011, the third International Conference on Advances in System Simulation, Barcelona, Spain.
- Bhouri, N., Mayorano, F. J., Lotito, P. A., Salem, H. H., & Lebacque, J. P. (2015). Public transport priority for multimodal urban traffic control. Cybernetics and Information Technologies, 15(5), 766. https://doi.org/10.1515/cait-2015-0014
- Bouktif, S., Cheniki, A., & Ouni, A. (2021). Traffic signal control using hybrid action space deep reinforcement learning. Sensors, 21(7), 2302. https://doi.org/10.3390/s21072302
- Brilon, W. (2015). Handbuch für die bemessung von straßenverkehrsanlagen. FGSV.
- Busch, J. V., Latzko, V., Reisslein, M., & Fitzek, F. H. (2020). Optimised traffic light management through reinforcement learning: Traffic state agnostic agent vs. holistic agent with current v2i traffic state knowledge. IEEE Open Journal of Intelligent Transportation Systems, 1, 201–216. https://doi.org/10.1109/OJITS.2020.3027518
- Chen, R., Fang, F., & Sadeh, N. (2022). The Real Deal: A Review of Challenges and Opportunities in Moving Reinforcement Learning-Based Traffic Signal Control Systems Towards Reality. ATT ’22: Workshop on Agents in Traffic and Transportation, Vienna, Austria.
- Chen, C., Wei, H., Xu, N., Zheng, G., Yang, M., Xiong, Y., Xu, K., and Li, Z. (2020). Toward a thousand lights: Decentralized deep reinforcement learning for large-scale traffic signal control. In Proceedings of the Aaai Conference on Artificial Intelligence, New York, USA (Vol. 34., pp. 3414–3421).
- Chu, T., Wang, J., Codecà, L., & Li, Z. (2020). Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 21(3), 1086–1095. https://doi.org/10.1109/TITS.2019.2901791
- Cools, S.-B., Gershenson, C., & D’Hooghe, B. (2013). Self-Organizing Traffic Lights: A Realistic Simulation. Advances in Applied Self-Organizing Systems (pp. 45–55). London: Springer. https://doi.org/10.1007/978-1-4471-5113-5_3
- DOT. (2012). Manual on uniform traffic signal control devices. US Department of Transportation.
- Dulac-Arnold, G., Levine, N., Mankowitz, D. J., Li, J., Paduraru, C., Gowal, S., & Hester, T. (2021). Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis. Machine Learning, 110(9), 2419–2468. https://doi.org/10.1007/s10994-021-05961-4
- FGSV. (2015/2021). Guidelines for traffic signals (rilsa). German Road and Transport Research Association.
- GEVAS software GmbH. (2015). Vtcontrol. Author.
- GEVAS software GmbH. (2020). Open trelan user manual. Author.
- Gregurić, M., Vujić, M., Alexopoulos, C., & Miletić, M. (2020). Application of deep reinforcement learning in traffic signal control: An overview and impact of open traffic data. Applied Sciences, 10(11), 4011. https://doi.org/10.3390/app10114011
- Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor.
- Harth, M., Langer, M., & Bogenberger, K. (2021). Automated calibration of traffic demand and traffic lights in sumo using real-world observations. In Sumo Conference Proceedings (Vol. 2. pp. 133–148).
- Haydari, A., & Yilmaz, Y. (2020). Deep reinforcement learning for intelligent transportation systems: A survey. IEEE Transactions on Intelligent Transportation Systems, 23(1), 11–32. https://doi.org/10.1109/TITS.2020.3008612
- Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., & Meger, D. (2018). Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, USA (Vol. 32).
- Kaspar, M., Osorio, J. D. M., & Bock, J. (2020). Sim2real transfer for reinforcement learning without dynamics randomization. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, USA (pp. 4383–4388).
- Kemper, C. (2006). Dynamische simulation des verkehrsablaufs unter verwendung statischer verflechtungsmatrizen [ Unpublished doctoral dissertation]. Universität Hannover.
- Kemper, C. (2015). Drivers. Mobil.tum 2015 – international scientific conference on mobility and transport technologies, solutions and perspectives for intelligent transport systems. 14.
- Krajzewicz, D. (2010). Traffic Simulation with SUMO – Simulation of Urban Mobility. Fundamentals of Traffic Simulation. International Series in Operations Research & Management Science (Vol. 145., pp. 269–293). New York, USA: Springer. https://doi.org/10.1007/978-1-4419-6142-6_7
- Krauß, S. (1998). Microscopic modeling of traffic flow: Investigation of collision free vehicle dynamics (Report No. DLR-FB-98-08). U.S. Department of Energy Office of Scientific and Technical Information.
- Li, M., Alhajyaseen, W., & Nakamura, H. (2010). A traffic signal optimization strategy considering both vehicular and pedestrian flows. In Compendium of Papers Cd-rom, the 89th Annual Meeting of the Transportation Research Board, Washington , USA (pp. 10–14).
- Liang, X., Du, X., Wang, G., & Han, Z. (2019). A deep reinforcement learning network for traffic light cycle control. IEEE Transactions on Vehicular Technology, 68(2), 1243–1253. https://doi.org/10.1109/TVT.2018.2890726
- Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y. Silver, D. Wierstra, D. (2019). Continuous control with deep reinforcement learning.
- Lin, Y., Dai, X., Li, L., & Wang, F.-Y. (2018). An efficient deep reinforcement learning model for urban traffic control.
- Li, Z., Yu, H., Zhang, G., Dong, S., & Xu, C.-Z. (2021). Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning. ArXiv , abs/Transportation Research Part C: Emerging Technologies, 2104(9936), 103059. https://doi.org/10.1016/j.trc.2021.103059
- Mankowitz, D. J., Dulac-Arnold, G., & Hester, T. (2019). Challenges of real-world reinforcement learning.
- Mannion, P., Duggan, J., & Howley, E. (2016). An Experimental Review of Reinforcement Learning Algorithms for Adaptive Traffic Signal Control. Autonomic Road Transport Support Systems. Autonomic Systems. (pp. 47–66). Springer. https://doi.org/10.1007/978-3-319-25808-9_4
- Meess, H., Gerner, J., Hein, D., Schmidtner, S., & Elger, G. (2022a). Real world traffic optimization by reinforcement learning: A concept. In International Workshop on Agent- based Modelling of Urban Systems (abmus) Proceedings: 2022, Auckland, New Zealand (pp. 49–54).
- Meess, H., Gerner, J., Hein, D., Schmidtner, S., & Elger, G. (2022b). Reinforcement learning for traffic signal control optimization: A concept for real-world implementation. Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand (pp. 1699–1701).
- Müller, A., Rangras, V., Ferfers, T., Hufen, F., Schreckenberg, L., Jasperneite, J., Schnittker, G., Waldmann, M., Friesen, M., and Wiering, M. (2021). Towards real-world deployment of reinforcement learning for traffic signal control. 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, USA (pp. 507–514).
- Müller, A., & Sabatelli, M. (2022). Safe and psychologically pleasant traffic signal control with reinforcement learning using action masking. 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China (pp. 951–958).
- Noaeen, M., Naik, A., Goodman, L., Crebo, J., Abrar, T., Abad, Z. S. H. Bazzan, A.L. Far, B. (2022). Reinforcement learning in urban network traffic signal control: A systematic literature review. Expert Systems with Applications, 199, 116830. https://doi.org/10.1016/j.eswa.2022.116830
- Oertel, R., Wagner, P., Krimmling, J., & Körner, M. (2011). Verlustzeitenbasierte lsasteuerung eines einzelknotens. Straßenverkehrstechnik (pp. 561–568).
- Oroojlooy, A., & Hajinezhad, D. (2022). A review of cooperative multi-agent deep reinforcement learning. Applied Intelligence, 53(11), 13677–13722. https://doi.org/10.1007/s10489-022-04105-y
- Pandit, K., Ghosal, D., Zhang, H. M., & Chuah, C.-N. (2013). Adaptive traffic signal control with vehicular ad hoc networks. IEEE Transactions on Vehicular Technology, 62(4), 1459–1471. https://doi.org/10.1109/TVT.2013.2241460
- Pohlmann, T. (2010). New approaches for online control of urban traffic signal systems [ Unpublished doctoral dissertation]. Technische Universität Braunschweig.
- Qadri, S. S. S. M., Gökçe, M. A., & Öner, E. (2020). State-of-art review of traffic signal control methods: Challenges and opportunities. European Transport Research Review, 12(1), 1–23. https://doi.org/10.1186/s12544-020-00439-1
- Rodrigues, F., & Azevedo, C. L. (2019). Towards robust deep reinforcement learning for traffic signal control: Demand surges, incidents and sensor failures. In2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand (pp. 3559–3566).
- Schulman, J., Levine, S., Abbeel, P., Jordan, M., & Moritz, P. (2015). Trust region policy optimization. In International Conference on Machine Learning, Lille, France (pp. 1889–1897).
- Shaikh, P. W., El-Abd, M., Khanafer, M., & Gao, K. (2022). A review on swarm intelligence and evolutionary algorithms for solving the traffic signal control problem. IEEE Transactions on Intelligent Transportation Systems, 23(1), 48–63. https://doi.org/10.1109/TITS.2020.3014296
- Sutton, R. S., & Barto, A. G. (2018). In Reinforcement Learning: An Introduction. MIT press.
- Tan, K. L., Sharma, A., & Sarkar, S. (2020). Robust deep reinforcement learning for traffic signal control. Journal of Big Data Analytics in Transportation, 2(3), 263–274. https://doi.org/10.1007/s42421-020-00029-6
- Treiber, M., Hennecke, A., & Helbing, D. (2000, August). Congested traffic states in empirical observations and microscopic simulations. Physical Review E, 62(2), 1805–1824. https://doi.org/10.1103/PhysRevE.62.1805
- United Nations, D. O. E., & Social Affairs, P. D. (2018). World urbanization prospects: the 2018 revision. Custom data acquired via website. https://population.un.org/wup/DataQuery/
- Varaiya, P. (2013). Max pressure control of a network of signalized intersections. Transportation Research Part C: Emerging Technologies, 36, 177–195. https://doi.org/10.1016/j.trc.2013.08.014
- Wang, Z., Bapst, V., Heess, N., Mnih, V., Munos, R., Kavukcuoglu, K., & de Freitas, N. (2016). Sample efficient actor-critic with experience replay. International Conference on Learning Representations (ICLR), Toulon, France.
- Wang, L., Ma, Z., Dong, C., & Wang, H. (2022). Human-centric multimodal deep (HMD) traffic signal control. IET Intelligent Transport Systems, 17(4), 744–753. https://doi.org/10.1049/itr2.12300
- Wang, L., Pan, Z., & Wang, J. (2021). A review of reinforcement learning based intelligent optimization for manufacturing scheduling. Complex System Modeling and Simulation, 1(4), 257–270. https://doi.org/10.23919/CSMS.2021.0027
- Wei, H., Zheng, G., Yao, H., & Li, Z. (2018). Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM Sigkdd International Conference on Knowledge Discovery & Data mining, London, UK (pp. 2496–2505).
- Wu, T., Zhou, P., Liu, K., Yuan, Y., Wang, X., Huang, H., & Wu, D. O. (2020). Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks. IEEE Transactions on Vehicular Technology, 69(8), 8243–8256. https://doi.org/10.1109/TVT.2020.2997896
- Zeng, J., Hu, J., & Zhang, Y. (2018). Adaptive traffic signal control with deep recurrent q-learning. In 2018 IEEE Intelligent Vehicles Symposium (iv), Changshu, China (pp. 1215–1220).
- Zhao, D., Dai, Y., & Zhang, Z. (2012). Computational intelligence in urban traffic signal control: A survey. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(4), 485–494. https://doi.org/10.1109/TSMCC.2011.2161577
- Zheng, G., Zang, X., Xu, N., Wei, H., Yu, Z., Gayah, V. Xu, K. Li, Z. (2019). Diagnosing reinforcement learning for traffic signal control. arXiv preprint arXiv:1905.04716.
