
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The integration of Large Language Models (LLMs), such as ChatGPT, into the workflows of geotechnical engineering has a high potential to transform how the discipline approaches problem-solving and decision-making. This paper investigates the practical uses of LLMs in addressing geotechnical challenges based on opinions from a diverse group, including students, researchers, and professionals from academia, industry, and government sectors gathered from a workshop dedicated to this study. After introducing the key concepts of LLMs, we present preliminary LLM solutions for four distinct practical geotechnical problems as illustrative examples. In addition to the basic text generation ability, each problem is designed to cover different extended functionalities of LLMs that cannot be achieved by conventional machine learning tools, including multimodal modelling under a unified framework, programming ability, knowledge extraction, and text embedding. We also address the potentials and challenges in implementing LLMs, particularly in achieving high precision and accuracy in specialised tasks, and underscore the need for expert oversight. The findings demonstrate the effectiveness of LLMs in enhancing efficiency, data processing, and decision-making in geotechnical engineering, suggesting a paradigm shift towards more integrated, data-driven approaches in this field.
1. Introduction
Geotechnical engineering, a pivotal field within civil engineering, is concerned with the behaviour of earth materials and the robustness of ground structures. It encompasses the study and practical applications of soil and rock mechanics, geophysics, and other related sciences to infrastructure construction and maintenance. Despite the advances in computational methods and instrumentation, the field faces perennial challenges, such as unpredicted subsurface conditions, environmental constraints, sustainability demands, and the increasing complexity of construction projects. These challenges often result in costly overruns, safety risks, and extended timelines. The inherent variability of geotechnical properties and localised nature of geological data add layers of uncertainty that traditional methods struggle to manage effectively (Phoon, Ching, and Shuku Citation2022; Phoon, Ching, and Wang Citation2019). As a discipline that supports the foundation of infrastructure development, there is an urgent need for innovative solutions that can offer enhanced predictive capabilities, optimise design processes, and streamline decision-making. The integration of robust analytical tools that can handle complex variable data with agility and precision is not just an option but a necessity for future-proofing the discipline. The importance of integrating machine learning and data science into geotechnics has gained much attention in the recent years (Phoon, Ching, and Cao Citation2022; Phoon and Zhang Citation2023), yet the field is still struggling to take fully advantage of the rapid advancement of modern statistical tools (Phoon, Cao, et al. Citation2022).
Large language models (LLMs) represent a significant advancement in the field of artificial intelligence (AI), particularly within the domain of natural language understanding and generation (Zhao et al. Citation2023). These models are designed to comprehend and manipulate language at a near-human level of subtlety and nuance. Trained on extensive datasets encompassing a wide array of knowledge, LLMs represent a new wave of foundation models for generating, translating, summarising, and interpreting texts with human-like proficiency. By integrating them with other analytical tools, LLMs can assist in data analysis, automate repetitive tasks, provide educational support, and facilitate research by synthesising information from a broad corpus of knowledge. In fields where specialised knowledge is paramount, such as geotechnical engineering, LLMs have the potential to act as a powerful auxiliary tool. Kumar (Citation2024) demonstrated some direct uses of LLMs in basic text-related tasks in geotechnical engineering. Kim et al. (Citation2024) demonstrated the MATLAB coding ability of LLMs to perform numerical modelling of geotechnical engineering problems. LLMs process technical documents, extract relevant data, predict outcomes based on historical patterns, and even generate preliminary design concepts. Their ability to rapidly assimilate and apply complex instruction sets makes them ideal candidates for tasks that require both depth of knowledge and breadth of applications. Furthermore, the iterative learning capacity of the LLMs implies that they can continuously refine the outputs based on user feedback, leading to increasingly accurate and relevant applications over time. Recent advancements of LLMs further expanded their applications to fact-oriented tasks (Lewis et al. Citation2020), programming tasks (J. Wang and Chen Citation2023), or even mathematical reasoning tasks (Ahn et al. Citation2024). As industries gravitate towards digitalisation and automation, LLMs stand out as a transformative asset that can augment human expertise and elevate work styles within geotechnical engineering.
This study aims to explore the transformative potential of LLMs, such as ChatGPT (OpenAI Citation2023), in geotechnical engineering. This study sought to establish a forward-thinking approach to workflow acceleration and problem-solving by aligning with the current and future needs of the field. The objectives are twofold: first, to assess the applicability and efficacy of LLMs in handling hands-on geotechnical tasks, and second, to envision a paradigm where such AI-driven tools become integral to the geotechnical profession. This paper examines various case studies and practical examples from a recent workshop organised by the authors, which was dedicated to demonstrating the role of LLMs in simplifying complex problems and enhancing decision-making processes. The study aimed to provide a comprehensive evaluation of its benefits and limitations. The ultimate goal was to pave the way for a new work style in geotechnical engineering that is more efficient, accurate, and adaptable to the rapidly evolving demands of the construction industry and environmental stewardship. This exploration is not only an academic exercise but also a critical step towards realising the potential of AI in one of the most foundational realms of engineering.
2. Background
2.1. Geotechnical engineering: current state-of-the-art
Geotechnical engineering is a field characterised by its diverse challenges, which arise primarily from the unpredictable nature of ground conditions. Typical problems include soil instability, unexpected subsurface materials, groundwater complications, slope failures, liquefaction, and foundation integrity issues. These challenges are critical as they directly impact the safety, sustainability, and financial viability of infrastructure projects (Otake and Honjo Citation2022). Solutions in geotechnical engineering are as varied as the problems and often require a combination of empirical methods, analytical models, and innovative technologies (Cernica Citation1982; Triantafyllidis Citation2020). Soil stabilisation techniques, such as the use of geotextiles and earth reinforcement, are common responses to unstable grounds. Ground improvement methods, such as compaction, grouting, and installation of piles, are employed to enhance soil strength and mitigate settlement issues. In case of water-related challenges, dewatering, waterproofing, and drainage systems are strategically deployed. Advanced geotechnical instrumentation and monitoring are also integral for providing real-time data that inform adaptive management strategies during and after construction.
The development and implementation of these solutions depend heavily on accurate site investigations and analyses. Geotechnical engineers rely on a suite of methods, such as drilling, sampling, in-situ testing, and geophysical surveys, to gather subsurface data (Transportation Research Board, and National Academies of Sciences, Engineering, and Medicine Citation2019). These data were then analysed using various software tools to predict behaviour under different loading conditions and to design appropriate engineering responses. The evolution of computer-aided design (CAD) and the integration of Building Information Modeling (BIM) (Borrmann et al. Citation2018; Dastbaz, Gorse, and Moncaster Citation2017) have significantly enhanced the capacity for precise modelling and simulation in geotechnical engineering. Moreover, sustainability considerations are increasingly driving the adoption of eco-friendly materials and techniques that minimise the environmental impact while still providing structural integrity (Basu, Misra, and Puppala Citation2015).
Geotechnical engineering workflows are complex and multidisciplinary, encompassing a cyclical process from the initial assessment to the post-construction evaluation. The workflow begins with a desk study to collect geological, hydrological, and environmental data, followed by comprehensive field investigations and laboratory testing to determine the ground characteristics and develop an initial conceptual site model (Ching, Wu, and Phoon Citation2021; Phoon, Ching, and Shuku Citation2022; S. Wu, Ching, and Phoon Citation2022). This model is essential for detailed design and analysis and utilises various tools ranging from traditional calculations to advanced software for simulation and modelling. Collaboration is crucial in these projects and involves geologists, engineers, architects, and construction teams working together through project management workflows to share and effectively use information. As a project progresses, the design and testing phases are conducted iteratively to refine solutions, adapt to new findings or changing conditions, and ensure compliance with design specifications and safety standards, underlining the importance of quality assurance and control throughout the project lifecycle (Otake et al. Citation2022).
Recently, digital transformation has begun to reshape these traditional workflows (Phoon, Ching, and Cao Citation2022; Phoon, Ching, and Wang Citation2019; Zhang et al. Citation2021). The adoption of digital tools and platforms has enabled more integrated and dynamic work processes. Data management systems are becoming increasingly sophisticated, allowing for better handling of the increasing amounts of data in geotechnical projects. In addition, emerging technologies such as AI and machine learning are beginning to be integrated, offering the potential for more predictive and adaptive workflows that can enhance decision-making and risk management. As the field continues to evolve, it is expected that these technological advancements will further streamline geotechnical workflows, leading to greater efficiencies and better outcomes for engineering projects (Phoon and Zhang Citation2023). Unlike existing AI technologies, which mainly focus on numerical data or images, LLMs expands the ability of AI to extract information from texts. This form of data is considered one of the richest sources of data and is especially important in geotechnical engineering, where the scarcity of data continues to hinder machine learning applications.
2.2. Large language models
Large Language Models (LLMs) such as GPT-3 (Brown et al. Citation2020) and BERT (Devlin et al. Citation2019) have revolutionised the field of computational linguistics, bringing forth capabilities that extend far beyond basic text generation. These models, characterised by their deep learning architectures based on the attention mechanism (Vaswani et al. Citation2017) and trained on diverse Internet text (Radford et al. Citation2019), have demonstrated proficiency in understanding and generating human-like text. LLMs are particularly adept at tasks requiring complex language understanding, such as answering questions, summarising lengthy documents, translating languages, and generating code. Their significance in interdisciplinary engineering research cannot be overstated. They have the potential to accelerate research by quickly synthesising literature, draughting research papers, and proposing hypotheses.
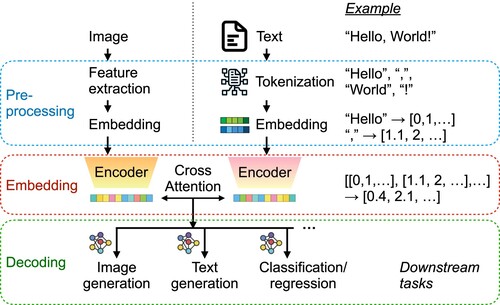
When a text input is processed by a LLM for different downstream tasks such as text generation or image generation, it typically follows three sequential steps: pre-processing, embedding, and decoding (). In the pre-processing step, the text input is first tokenised into smaller units called tokens (typically words or symbols with a single meaning), which are then converted into numerical embeddings that encode the similarity of the tokens in the context of natural language. Previous studies have shown that a successfully trained word-embedding model captures the semantic relationships between words through vector arithmetic (Mikolov et al. Citation2013). This is achieved by representing words as continuous vectors in a high-dimensional space, where the geometric relationships between these vectors encode meaningful linguistic relationships. Subsequently, in the embedding step, a sequence of embedded vectors passes through the LLM, which utilises multiple layers of attention mechanisms to capture the relationships and contexts within the input text. Such learned information is often represented by a single high-dimension vector that can then be used for different output tasks. For text generation, which is the most typical application of LLMs, the model iteratively predicts the next token, generating coherent and contextually relevant text using a text-specialised decoder. For image generation, the text embeddings are often fed into a multimodal model or paired with a pre-trained image generator, which uses the semantic information from the text to create corresponding visual representations. The correspondence between the context in text data and the image data can be established through different mechanisms, such as cross-attention between the embedded vectors of multimodal data (J. Wu et al. Citation2023). The model outputs are then decoded into the final format based on the context-embedded vector from the embedding step, producing an output using the corresponding decoder, depending on the specific task at hand. In many applications, such as materials science (Jablonka et al. Citation2023), embedded vectors are used as inputs for typical machine learning models for classification or regression tasks, demonstrating the ability of LLMs to embed text context into numerical vectors.
Figure 1. Overview of how LLMs work, which can be decomposed into three steps: pro-processing, embedding, and decoding. The right path demonstrates how the input text is used to generate different downstream tasks, including text generation. The left path demonstrates how information from multimodal data is integrated into the LLMs in order to provide extra context to the downstream tasks. Note that the encoder in the embedding step is only an example. Some models, such as GPT-3, use a different type of embedding model.
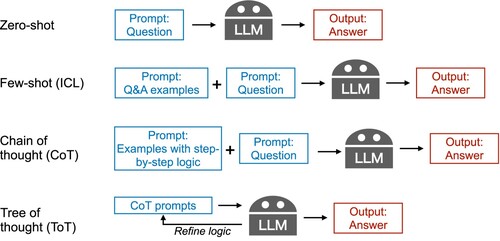
LLMs are capable of learning complex patterns resided in a diverse set of natural language processing (NLP) data through embedding and attention mechanisms. This allows them to serve as foundational models for a wide range of NLP tasks, which has been the main concept driving recent developments in machine learning technologies (Bommasani et al. Citation2022). LLMs generate text based on the context provided by the prompt, which guides the LLMs to attend to the relevant subspace of the learned embedded space. Detailed and context-rich prompts enable the model to produce more accurate and contextually appropriate responses. Prompt engineering is the process of designing and refining the input queries given to LLMs to produce the most relevant and accurate responses for a specific task or application. shows three commonly used prompt engineering techniques. In-context learning (ICL) is the most basic prompt engineering technique that provides direct examples of question and answer (Q%A) pairs before providing the target query to LLMs, which is also known as few-shot learning in the machine learning community (Brown et al. Citation2020). By contrast, making direct queries to LLMs is considered as zero-shot learning. Many scientific problems requires mathematical reasoning, which is often known as the Achilles' heel of standard LLMs. The idea of a chain of thought (CoT) was proposed to address this issue, which suggests including a step-by-step logic that connects a Q&A pair when performing ICL (Wei et al. Citation2022). X. Wang et al. (Citation2023) further improves CoT by self-consistency, which samples the generated answers from CoT and perform a majority voting. To address the fact that a single logic cannot solve all problems, the tree of thought (ToT) technique involves structuring prompts to explore multiple decision paths or sequences, thereby guiding the language model to consider various potential outcomes before generating a response (Yao et al. Citation2023).
Figure 2. Three types of prompt engineering techniques to improve LLM performance from direct query (zero-shot): (1) Few-shot or in-context learning (ICL) refers to providing examples of question and answer (Q&A) pairs before inputting the actual query. (2) Chain of thought (CoT) refers to providing examples of the step-by-step logic used to solve the target query. (3) Tree of thought (ToT) refers to optimising the CoT prompts through a feedback loop from the LLMs' answers.
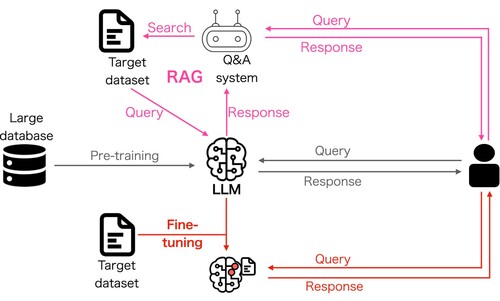
In addition, LLMs have advanced capabilities that extend beyond basic text generation, offering a range of sophisticated functionalities, such as fine-tuning (Dinh et al. Citation2022), and Retriever-Augmented Generation (RAG) (Lewis et al. Citation2020), each enhancing their application in specialised domains (). Fine-tuning Large Language Models (LLMs) involves taking a pre-trained LLM and further training it on a smaller, task-specific dataset to adapt the model to perform well in a particular application. This process leverages the extensive knowledge that the model data have already gained during pre-training with big data while customising it for specialised tasks such as sentiment analysis, text classification, or question answering. Ouyang et al. (Citation2022) introduced one of the most successful implementations of this idea, which is to improve the alignment of LLMs with human intentions using reinforcement learning from human feedback. Another well-known limitation of LLMs is their high risk of causing hallucinations because of the tendency of LLMs to fill in gaps or make up information based on patterns learned during training. Retrieval-Augmented Generation (RAG) is an approach designed to enhance the capabilities of language models in knowledge-intensive tasks by integrating retrieval mechanisms with generative models (Lewis et al. Citation2020). This makes LLMs more informed and accurate, particularly in fields requiring up-to-date knowledge. By leveraging these functionalities, LLMs can provide nuanced, accurate, and contextually relevant outputs, thereby significantly enhancing their utility in various sectors.
Figure 3. Overview of two important extensions to basic LLM use (gray path): (1) Fine-tuning (red path) refers to further training the LLM using a small set of data from a target task. (2) RAG (purple path) refers to a technique to link the LLM with external databases to help the LLM provide more accurate answers.
The significant impact of LLMs in science has been seen across different disciplines, such as materials science (Jablonka et al. Citation2023; Zheng et al. Citation2023) and geoscience (Deng et al. Citation2023; Ma et al. Citation2023), but not yet in geotechnics. In the realm of geotechnics, the capabilities of LLMs to assist in multimodal modelling and decision-making are invaluable. They serve as a bridge between various disciplines, enabling engineers to integrate insights from environmental science, material science, and structural dynamics into cohesive solutions. LLMs can rapidly search through vast databases of scientific literature and return concise summaries by processing natural language queries. They can also interpret and convert complex text data into more understandable formats, such as knowledge graphs (Peng et al. Citation2023), which support engineers in making informed decisions. This becomes particularly relevant when dealing with the intricate data analyses often required in geotechnical engineering, where understanding the interplay between the various physical and mechanical properties of soils and rocks is essential. Geotechnical engineering is a field that is rich in text data but scarce in numerical data, making the implementation of big data technologies difficult. The rise of LLM technology serves as a perfect opportunity to reevaluate the potential of AI use in geotechnical engineering. This study demonstrates this potential through four case studies, each of which uses of a different set of LLM features introduced in this section (see Section 3.2 for more details).
3. Methodology
We gathered geotechnics experts through a two-day workshop that is dedicated to the purpose of this study to ensure that the results of this study are relevant. A workshop was organised to explores the potential applications of LLMs within geotechnical engineering, with a diverse group of participants from academia, industry, and government sectors in Japan. The workshop facilitated a hands-on assessment of the capabilities of the LLMs, focussing on accelerating interdisciplinary research and simplifying complex analytical tasks through multimodal modelling centred around LLM's framework. Because of the short timeframe of this workshop, we focussed on a set of relatively straightforward techniques and tools related to LLMs. For example, ICL was investigated, but fine-tuning was not included; the commercial implementation of RAG provided in ChatGPT (OpenAI Citation2023) by OpenAI was tested rather than using a customised RAG algorithm. Text embedding was tested using models and Application Programming Interface (API) systems provided by OpenAI without fine-tuning to a geotechnical engineering context. However, our preliminary results represent a useful starting point and serve as insightful guidelines for a more advanced implementation of LLMs in geotechnical problems. In this section, we briefly explain the details of the workshop organisation and four case studies.
3.1. Workshop organisation and participants
The workshop was held at The Institute of Statistical Mathematics in Tokyo, Japan, on November 3–4, 2023. The event brought together 20 diverse participants, including students, researchers, professors, engineers, and senior managers from academia, industry, and government sectors. The ambitious goal was to solve geotechnical problems using LLMs in a two-day workshop, culminating in the creation of this academic paper with LLM's assistance within a month post-event. The composition of the participants was diverse: 14 from academia (including six professors and eight students), three from industry, and three from the government sector. The group included two data scientists and 18 geotechnical engineers, with varying levels of experience in LLMs and coding. The demographic spread was quite broad, with a notable skew towards male participants.
The workshop was meticulously organised by two data scientists and two geotechnical engineers starting in early October 2023. Initially, 30 potential participants with various levels of experience in machine learning and geotechnical engineering were shortlisted, resulting in 20 participants attending a physical workshop because of 10 volunteered dropouts. Two pre-event tutorial sessions were held, focussing on LLM basics and practical applications in geotechnical engineering, to prepare participants, particularly those with limited LLM experience. These sessions aimed to familiarise the participants with LLMs, gather feedback, and identify specific geotechnical problems for exploration. Subsequently, the participants were grouped into five working teams based on their shared interests in specific geotechnical issues, combining senior experts and junior members with coding skills.
To maximise the effectiveness of the workshop, the organisers focussed on using ChatGPT as the primary tool because it is a user-friendly all-in-one service as opposed to other LLM options. This decision was made considering the limited time and varying expertise levels of the participants. Although ChatGPT was the core tool, most of the workshop's work could be replicated using other LLMs, including open-source or free alternatives, highlighting the adaptability and broad potential of LLMs for addressing geotechnical challenges.
During the workshop, each small group initiated their project by defining the problem setup and gathering relevant data. They then developed a preliminary workflow incorporating the various functionalities of ChatGPT, which was shared with all participants for discussion and refinement. After workflow finalisation, the groups concentrated on solution implementation, supported by three all-around assistants. The workshop concluded with each group presenting their results and planning an academic paper to report their findings. Following the workshop, a significant update to ChatGPT enabled the construction of customised GPT models (abbreviated as GPTs hereafter) for specific tasks. Leveraging this new function, a smaller team of four participants was formed to develop GPT applications tailored to the different geotechnical challenges encountered during the workshop and to assist in composing this paper. More details of the workshop organisation can be found in the “event_report.pdf” of Supplementary Information (SI).
3.2. Case study selection
Four case studies were selected for the workshop, which were strategically aligned with both the challenges and opportunities in geotechnical engineering, particularly focussing on the application of LLMs such as ChatGPT. These challenges include the scarcity of large and comprehensive databases in geotechnics, where data is often sparse, uncertain, and incomplete. Geotechnical data typically exist in various formats, including text and less organised numerical data, and are frequently multimodal, encompassing photographs, textual descriptions, time series, and numerical figures. Building a set of relevant descriptors is a major bottleneck to applying machine learning in geotechnical problems. Case studies were selected to demonstrate how LLMs and their extended functionalities could innovatively address these issues by taking advantage of different aspects of LLM's framework (). The success of these case studies underscores the potential of LLMs in transforming geotechnical engineering, offering a new pathway to more efficient, accurate, and universally accessible solutions in this field. In the following section, we briefly explain the motivation and problem setup of the four case studies. presents an overview of how GPTs are used in each study. We also provide links to GPTs used in the case studies in the “GPT_links.pdf” of SI that are publicly available for testing and our chat history for the studies. More details of the case studies can be found in Section 4 and in the “event_report.pdf” (see the Geotechnical Problem section) of SI.
Figure 4. Overview of GPT uses in (a) the slope stability assessment study, (b) the microzoning by seismic risk study, (c) the simulation parameter recommendation study, and (d) the site similarity prediction study.
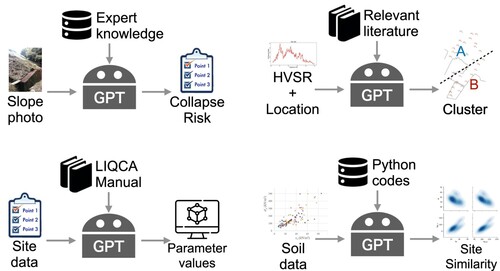
Table 1. Summary of the different aspects of the LLM framework considered in each case study.
3.2.1. Slope stability assessment
This study was motivated by the high cost and subjective nature of regular slope inspections in Japan, which are crucial to social safety. These inspections, which are typically conducted through site visits and visual assessments by experts, often lead to vague and subjective criteria, making it challenging to develop accurate quantitative models for risk assessment. This case study aims to leverage the strong image recognition ability of deep learning and multimodal capabilities of the LLM framework to create a virtual inspector model, potentially revolutionising the assessment of slope stability.
Model input: photos of the slope.
Model output: descriptions of the features in the photo that are related to the risk of slope collapse, text assessment of the collapse risk, and a percentage value of the collapse risk.
Data: ten slope photos with expert labelled descriptions and collapse risk assessment (four used for few-shot learning and six used for performance test).
Performance evaluation: compare the difference between the probability of collapse predicted by LLM and labelled by an expert.
3.2.2. Microzoning by seismic risk
The focus was on the assessment of seismic risk for city planning and building code development, particularly in areas with high seismic activity. This case study aims to test the ability of LLMs to integrate multimodal datasets, such as horizontal-vertical spectral ratio (HVSR) data (Yamada et al. Citation2015) and sensor locations, using natural language for decision-making. The challenge was in the subjective nature of seismic risk assessment, which often relies on the engineer's judgment when combining spatial and spectral data.
Model input: figures of HVSR curves and location coordinates at multiple sites of interest.
Model output: grouping of “similar” sites.
Data: HVSR curves and location coordinates at ten expert-selected sites used in a previous project conducted by the experts, and a document that includes descriptions of features to look for in the HVSR curves when determining site similarity.
Performance evaluation: compare grouping of the sites predicted by LLM and labelled by experts using visual inspection and knowledge from their project.
3.2.3. Simulation parameter recommendation
This study was motivated by the complexities involved in using LIQCA (Oka et al. Citation1994, Citation1999), which is a simulation software used for effective stress dynamic analysis in geotechnical engineering (Liquefaction analysis method LIQCA Development group Citation2007). Setting the 13 necessary parameters, including both mechanical and fitting parameters, to simulate the complex liquefaction behaviour requires specialised knowledge (Otake et al. Citation2022). This case study explores the capacity of GPT models to provide recommendations for setting these parameters, potentially simplifying a complex and expert-driven process.
Model input: query of how to set the 13 LIQCA parameters for a given soil name.
Model output: the values of 13 LIQCA parameters.
Data: the LIQCA manual that provides guidance on parameter settings, one standard parameter set of Toyoura sand for LLM as a reference, and parameter sets of 27 reference soils for visual performance evaluation (not provided to LLM).
Performance evaluation: expert opinions on the distance between the predicted parameters by LLM and the known parameters of the closet reference soil in the two-dimensional space projected by principal component analysis (PCA).
3.2.4. Site similarity prediction
This case was inspired by a challenge competition during the Joint Workshop on the Future of Machine Learning in Geotechnics and Use of Urban Geoinformation for Geotechnical Practice in 2023 (Phoon and Shuku Citation2024). The challenge involved the quantitative identification and extraction of geotechnically similar sites from a pre-documented database (Sharma, Ching, and Phoon Citation2022, Citation2023), a process known as the “site recognition challenge”. This approach is particularly appealing to geotechnical engineers because it allows for an experiential and judgment-based acceptance or rejection of identified similar sites, thereby making the process more explainable and relatable.
Model input: five clay properties of an unknown target site.
Model output: rankings of similarity between the target site and 16 sites in a given database.
Data: 5 clay properties collected from 16 sites and a separate dataset that contains the same 5 clay properties of an unknown target site.
Performance evaluation: because the ground truth was not provided by the competition organiser, we take the solution using hierarchical Bayesian model (Sharma, Ching, and Phoon Citation2022, Citation2023) as a reference to compare with.
4. Results
4.1. Overview
The results of the workshop's case studies collectively showcased the proficiency of LLMs, particularly ChatGPT, in geotechnical engineering tasks, revealing common strengths and limitations across diverse applications. In tasks such as slope stability assessment and microzoning for seismic risk, GPTs demonstrated a strong ability for multimodal data interpretation, effectively combining textual descriptions with image analysis to assess landslide risks and seismic data. This capability was further highlighted in site similarity prediction, where GPTs efficiently handled fuzzy classification problems and streamlined data analysis even for those without deep expertise in data science.
A recurring theme in these studies was the model's reliance on context and pre-provided examples for accurate predictions. For instance, in the simulation parameter recommendation, GPTs required a standard parameter set to make logical descriptions and parameter predictions, reflecting the need for contextual grounding. Across all cases, although GPTs showed the potential to integrate complex data and provide insightful analyses, their output often required refinement to meet expert-level expectations. GPTs with few-shot learning often show a better performance, as expected. This is probably because we used a general purpose LLM, which requires examples in the prompts to help the model pays attention to the subspace of the embedded space that is relevant to the query. In addition, GPTs are generative (probabilistic) models whose outputs are non-deterministic in nature. The expert knowledge behind the examples in the prompts served as a strong prior to reducing the uncertainty of the posterior of the output text. In some cases, we can use the text samples generated by the probabilistic LLM to improve the robustness of the final answer to a user query (X. Wang et al. Citation2023). In the following section, we summarise the results of each case study.
4.2. Slope stability assessment
In this study, an expert prepared ten diverse slope photographs from various regions in Japan, each labelled with a landslide risk percentage ranging from 0% (very safe) to 100% (already collapsed). The risk assessment criteria, recorded as text data, involved three key aspects: determining a baseline risk level based on soil moisture, adjusting this baseline with factors that influence slope stability (e.g. the presence of retaining walls reducing risk), and setting the risk to 100% if any slope cracks were observed. These criteria were designed to encapsulate the multifaceted nature of slope stability risk assessment, considering both visual and environmental factors.
Two GPT models were developed to address this issue. Users were required to upload a slope photo, after which the models provided descriptions of the slope environment, assessed the landslide risk, and assigned a risk percentage. The “Slope Stability Inspector: Zero-shot” model offered minimal preloaded knowledge for standard response generation, while the “Slope Stability Inspector: Few-shot” model included expert judgment and scoring scheme knowledge for landslide risk, supplemented with training examples for few-shot learning. The ten photos were divided into four for training and six for testing, with evaluations conducted three times (each time in a different order of inputting the test photos) for each model to account for the models' memory of the input history.
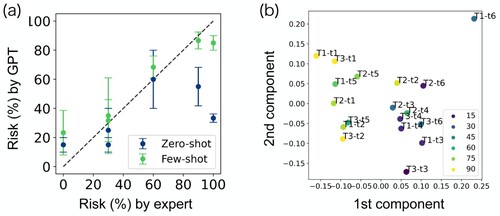
According to the experts' opinion, our results revealed the zero-shot GPT's capability in accurately describing photos relevant to landslide risk assessment, demonstrating strong multimodal modelling skills (see “chat_history.pdf” in SI). However, its risk percentage predictions varied significantly. Conversely, the few-shot model yielded more stable and expert-aligned risk predictions, highlighting the ability of the GPT in in-context learning and adjustment with minimal examples ((a)). To verify that the descriptions generated by GPT are actually used for predicting the risk, we investigated the predictive power of text embedding of the descriptions. Our analysis of text embeddings from GPT's descriptions showed a clear correlation between the predicted collapse probabilities and the principal components of the embedding vectors ((b)). These outcomes underscore the unique strengths of the GPT in handling vague concepts and reasoning, distinguishing it from conventional machine learning models. This study not only affirms the potential of GPT in geotechnical engineering but also opens new avenues for embedding complex concepts into numerical spaces for machine learning applications.
Figure 5. Results of collapse probability prediction from GPT models. (a) Prediction performance of the zero-shot and few-shot GPT models based on the expert-assigned risk values for the six test photos. The error bars denote the standard deviation of the GPT predictions over three independent trials. (b) The first two principal components of the embedding vector for the photo descriptions generated by the few-shot GPT model. A total of 18 descriptions (3 trials of the 6 test photos) are plotted and the colours correspond to the predicted collapse probability.
4.3. Microzoning by seismic risk
In this study, data were collected and processed in the form of HVSR from various sites in Japan. These data were converted into PNG images to capture the HVSR shapes and were accompanied by the geographical locations of the corresponding sensors. The dataset also included expert recommendations on grouping these sensors to form distinct sub-regions. This setup aimed to utilise the capabilities of LLMs to analyse and interpret complex seismic data, which is crucial for effective city planning and building code development in seismic risk areas.
To address this challenge, two GPT models were developed, each requiring users to upload figures of HVSR data. The first model was designed with minimal instructions, whereas the second model had access to prior knowledge concealed within a PDF document. The task was to assess the ability of the models to describe the HVSR data and group the sites accordingly. The study explored the differences in the models' performance with and without the document and further incorporated location data to assess the impact of spatial information on the grouping task. The models were tasked with mimicking the expert's criterion that clusters HVSR curves with similar shapes together. However, the sites close to each other should be clustered into the same group. Limited by the maximum number of files to be uploaded to ChatGPT simultaneously, we selected 10 sites with a mixture of HVSR shapes obtained from the four sensor clusters ().
Figure 6. Results of microzoning predicted by the GPT model without domain knowledge based on HVSR curves at 10 selected sites from 4 location clusters. Four locations with a single outstanding peak below 2 Hz are grouped together (red) and the other six locations are grouped together (blue), which is a reasonable result without considering the spatial distance between the sites.
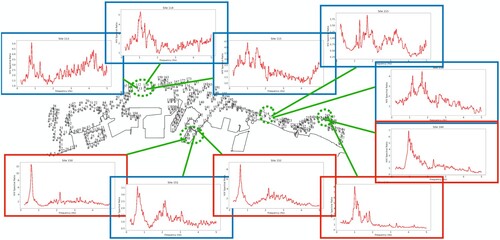
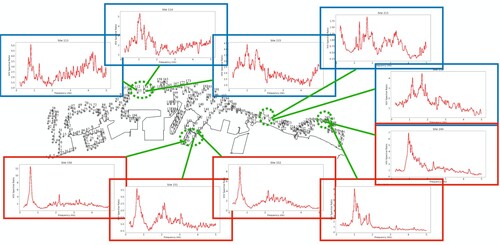
The results indicated that the baseline GPT model could identify key features in the HVSR data, such as the rough location and width of peaks, particularly those significant in the 0.2 Hz–2 Hz range (see “chat_history.pdf” in SI). Such key features were mentioned in the PDF document, for which GPT was able to pick up successfully (see “GPT_links.pdf” in SI). When location data were provided, the model automatically generated Python codes to decipher the spatial relationships between sites, leading to grouping results that aligned precisely with expert recommendations (). However, its performance in peak recognition and HVSR shape analysis was limited, which was attributed to the specialised nature of GPT's image model for more complex photos. Despite these limitations, this study demonstrated the potential of LLMs in leveraging multimodal data for decision-making in geotechnical engineering, suggesting avenues for improvement such as few-shot learning and the incorporation of LLM's ability to generate analysis codes for HVSR data as prior knowledge.
Figure 7. Results of microzoning predicted by the GPT model with domain knowledge based on HVSR curves at 10 selected sites from 4 location clusters. The result is almost the same as , except one of the blue site is now assigned to be red because the neighbouring sites are all grouped as red. This clustering result coincides perfectly with the experts' opinion.
4.4. Simulation parameter recommendation
In this study, 27 high-quality soils with well-documented parameter values from the literature were used (Liquefaction analysis method LIQCA Development group Citation2007; Otake et al. Citation2022; Otsushi et al. Citation2010). PCA was performed on this dataset with the first two principal components used to visualise the high-dimensional parameter space (). This approach was independent of the GPTs' construction, for which information about these soils was not provided to the models. Instead, the reduced dimension space served as a basis for evaluating the GPTs' performance. The complexity of dealing with 13 parameters was mitigated by mapping these values onto a simpler two-dimensional space, facilitating a more effective assessment of the model's predictive performance.
Figure 8. First two principal component space of the 13 dimensional parameter space of LIQCA. A generally understandable feature space was found, indicating stiffness, strength, and dilatancy level in three different directions. The different colours represent four soil categories grouped by geotechnical knowledge: (1) Cluster1 – experimental sand (loosely packed, Dr = 50%–70%) usually has a relatively high stiffness and dilatancy but strength is low. (2) Cluster2 – fill soil (reclaimed soil, such as in Port Island, Rokko Island, etc.) typically has a high stiffness but low dilatancy. (3) Cluster3 – natural deposit soil (relatively high fine particle content rate) has very diverse properties, scattering around the whole space. (4) Cluster4 – experimental sand (densely packed, Dr = 75%) usually has a distinctively high stiffness and strength.
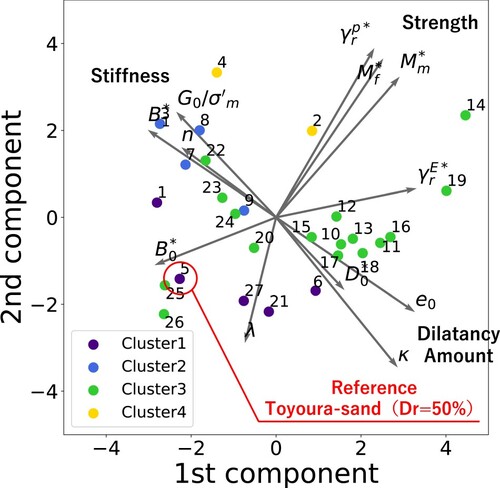
The problem setup was divided into two parts. First, from the 27 soil samples collected, we provided the GPT model with an example of LIQCA parameters for Toyoura sand (relative density Dr = 50%), a world-renowned experimental sand, as a reference point. The GPT model was then instructed to estimate the LIQCA parameters for Toyoura sand, which was characterised as densely packed with a high relative density (Dr = 75%). Additionally, we assessed GPT's knowledge of the general soil types, including sand and reclaimed soil, in Niigata City, an area well-known for liquefaction. The intention was to determine whether GPT can contribute to the estimation of LIQCA parameters using its extensive prior knowledge of sand.
The results showed that the GPT model can provide logical descriptions of the sand samples and select relevant contexts from the provided manual. However, it struggled to provide numerical values for the parameters without using a standard parameter set as a reference. The model understood terms like “compaction” and “high dilatancy”, predicting numerical values for LIQCA parameters, but its adjustments didn't entirely align with expert expectations. Despite this, the model provided a reasonable understanding of different sands, such as Niigata sand, and could distinguish between different geotechnical properties. The model tended to prioritise general geotechnical knowledge over specific manual information, indicating a bias towards the more broadly available literature.
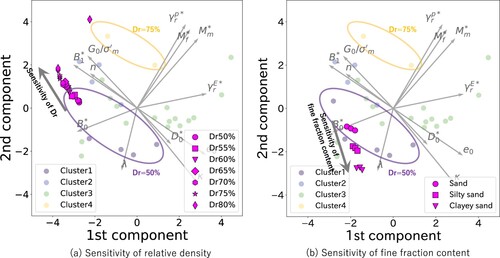
shows an analysis of the sensitivity of GPT predictions to relative density and linguistic expressions for fine fraction content, such as “silty sand” and “clayey sand”. As
increases, GPT consistently adjusted the parameter set in the direction of the increasing stiffness. The parameter adjustment in is not coincidental but is a result of the consistent performance of GPT. Although quantitative justification has not been verified, parameter adjustments are generally consistent with the basic understanding of geotechnical engineers based on experts' opinions. Thus, the results confirm the potential of using LLMs to assist in implementing sophisticated numerical analyses. This trial highlighted the GPTs' potential to be further fine-tuned and integrated into tools, such as LIQCA.
Figure 9. Recommeded parameter values by the GPT models projected to the same space as in . (a) Estimation of Toyoura-sand with varying relative densities, (b) Estimation of general soil types, including sand from Niigata and fill soil. It is evident that the GPT model primarily expresses the “difference in relative density” by adjusting parameters related to stiffness. The parameters for the sand from Niigata City, known for its homogeneous grain size, are estimated to be similar to those of Toyoura sand with a relative density (Dr) of 50%. The fill soil is differentiated from both Niigata sand and Toyoura sand mainly by altering the parameters associated with strength. See “chat_history.pdf” in SI for more details.
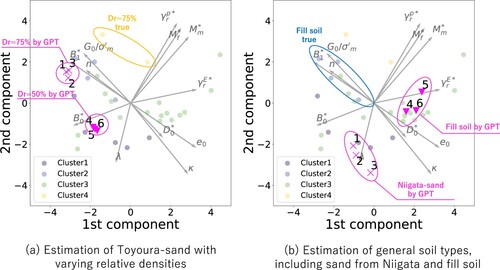
Figure 10. Results of the sensitivity analysis on linguistic information regarding relative density () and soil classification (fine fraction content). Figure (a) illustrates the shift in the parameter set as the relative density (
) gradually increases, starting from the parameters on the edges of the set at
50% (No. 1 parameter set in ). Figure (b) displays the shift in the parameter sets for “silty sand” and “clayey sand” from the approximate centre of the parameter set in Cluster 1 (experimental sand such as Toyoura sand with
50%).
4.5. Site similarity prediction
In the site recognition problem tackled during the student contest of the 1st FOMLIG workshop (Phoon and Shuku Citation2024), the data used comprised clay properties collected from 16 different sites globally, along with a separate dataset containing similar properties from an unknown target site. Each site was defined as a collection of records from tests conducted within a project boundary, with data including undrained shear strength, preconsolidation stress, corrected cone tip resistance, plastic index, and vertical effective stress. This comprehensive dataset provides a robust foundation for assessing site similarities based on these key geotechnical properties.
Our approach involved creating scatter plots for 10 selected property pairs from the 5 clay properties for each of the 16 sites, using a standardised x-range and y-range for contour consistency. The Python functions for generating these plots were provided to the GPT as prior knowledge to ensure consistency in plot creation. The same set of scatter plots was then created for unknown target sites. The scatter plots of each site were summarised in a single image with a two-by-five layout, which was then used by GPT to compare the image similarities between the target site and the other 16 sites. The comparison was based solely on the shape contours of the 10 plots in these images, providing a visual similarity measure.
The results are promising, with GPT ranking of the 16 reference sites according to similarity in a manner generally consistent with those obtained through a hierarchical Bayesian site similarity measure (Ching, Wu, and Phoon Citation2021; Sharma, Ching, and Phoon Citation2022) (, ). GPT successfully discriminated image features and quantified site-specific similarities without relying on explicit mathematical formulas. This study highlights the capability of the GPT as a convenient tool for accelerating basic data analysis tasks, particularly beneficial for individuals without expertise in data science. In addition, it serves as a proof-of-concept for the potential of GPTs in handling fuzzy classification problems through a combination of image and natural language analyses, which is a common type of problem in geotechnical engineering. Unfortunately, we were unable to further compare our results with the ground truth because they were not openly available according to the rules of the contest.
Figure 11. Result of similarity measure between the unknown target site and the 16 sites from the global database. The unknown site is supposed to be similar to site 13, which has the highest similarity value given by the GPT model.
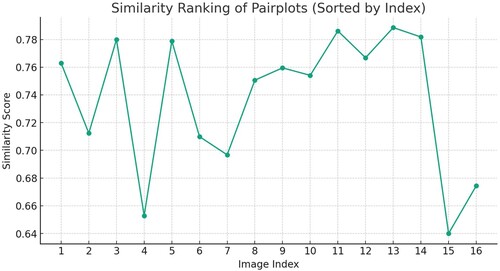
Table 2. Comparison of top 7 similarity ranking results.
5. Discussion
5.1. Potential of LLMs in geotechnics
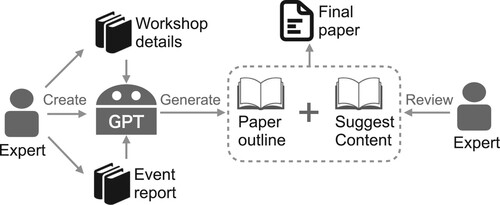
The potential of LLMs in geotechnical engineering is highlighted by their proficiency in handling a wide range of routine tasks that are common across various fields. LLMs excel in summarising documents, translating text, conducting basic data analyses, and managing simple image-based design tasks. Such abilities are particularly beneficial in geotechnical engineering, where the processing and interpretation of diverse data forms are frequently necessary. For instance, LLM played an important role in the creation of this paper. We built a GPT, which is also publicly available for testing (see “GPT_links.pdf” in SI), to solely support the writing of this paper. The details of our workshop organisation and schedule as well as a detailed report on all the results of the event were provided to the GPT model as prior knowledge. The model was then used to provide recommendations for the title of the paper, paper structure, and contents of each section (). On top of the human language generation, LLMs can also be used for automation of computation simulation or data analyses thanks to their ability to generate programming codes (Kim et al. Citation2024). However, the potential of LLMs extends beyond these general features.
Figure 12. Workflow of the production of this paper. The authors are responsible for the production of the documents recording the workshop details and results of the studies conducted during the event, building the customised GPT model, and the final review and composition of the paper. The GPT model serves as a generator of writing idea, including the overall structure of the paper, paper title, and recommending corresponding content in each section of the paper.
In this study, we demonstrated that by building on this foundational utility, the capacity of LLMs for natural language processing allows them to serve as a pivotal tool for multimodal data analysis, a common requirement in geotechnical engineering when combined with other foundational models. This is crucial considering the often sparse nature of geotechnical data, which typically include a mix of text, images, time series, and numerical figures. For example, LLMs can interpret soil report narratives alongside numerical test results, thereby offering a comprehensive understanding of geotechnical conditions. Furthermore, their ability to navigate and utilise the inherent ambiguities and subtleties of human language makes them adept at leveraging vague information, which is frequently encountered in geotechnical data owing to a lack of quantitative details. Through text embedding (), such vague information can be converted into numerical vectors that provide an extra source of input data for training machine learning models.
The generative nature of LLMs also positions them effectively for data imputation or data augmentation, enhancing their applicability in geotechnical engineering where such issues are prevalent. Such features have been used to demonstrate the possibility of further improving model performance through self-learning (Ferdinan, Kocoń, and Kazienko Citation2024) or iterative ensemble methods (Chen, Saha, and Bansal Citation2023). Moreover, the capability of LLMs to provide reasoned predictions is a crucial advantage over conventional machine learning methods, especially for geotechnical engineers, who often face complex decision-making scenarios. This reasoning ability, combined with the versatility and multimodal data processing capacity of LLMs, suggests that they can be more effective than traditional machine learning methods in addressing the unique challenges of geotechnical engineering. The integration of LLMs into geotechnical workflows, as demonstrated in various applications, signifies a shift towards more efficient, insightful, and data-driven approaches in the field.
Finally, the interdisciplinary nature of geotechnical engineering, which often involves a combination of soil mechanics, environmental considerations, and structural dynamics, renders LLMs particularly valuable. Our workshop showcased how participants (mainly beginners in LLMs and data science), within just two days, could leverage LLMs to bridge the gap between geotechnics and data science. This rapid integration into interdisciplinary research is indicative of the ability of LLMs to streamline complex cross-disciplinary studies.
5.2. Challenges of LLMs in geotechnics
Although LLMs offer significant potential in geotechnical engineering, there are inherent challenges to their application in complex engineering tasks. A fundamental limitation arises from the very nature of LLMs: they generate responses based on a probabilistic model that predicts the next word in a sequence. The “logic” presented in their answers is not true logical reasoning but rather an illusion created by the model's ability to capture probabilistic relationships between words. This means that while LLMs can provide seemingly logical responses, they should not be solely relied upon for final solutions in complex engineering tasks. For example, when tasked with predicting the stability of a slope, an LLM may generate a coherent and logical-sounding response; however, this answer is based on word probabilities rather than a deep understanding of geotechnical principles. In other words, we recommend that human experts are still more suitable for taking the final responsibilities of decision-making for geotechnical problems.
Another challenge lies in the LLMs' ability to embed text-based data into numerical vectors while retaining context. Although this feature enhances the efficiency of descriptor extraction from textual data, it is difficult to control the context focus within these embeddings precisely. For example, in the slope stability assessment problem, the current GPT model is not sensitive enough to consistently separate the cases that have insignificant differences in collapse probability (). In geotechnical engineering where specific details can be crucial, such as in soil analysis reports, the inability to direct focus on a few keywords relevant to specific soil properties can lead to incomplete or misleading interpretations. To tackle this issue, we recommend investing in building a domain-specific LLM for geotechnical engineering as a community effort.
The generative nature of LLMs also presents challenges, particularly when knowledge-intensive answers or answers derived from precise instructions are required. LLMs are inherently designed to generate content, which can be problematic in scenarios requiring precise and unambiguous responses. For example, it was difficult for us to ask the current GPT models to fine-tune the clustering result in the microzoning problem based on specific instructions from the experts. Consequently, additional tools and methods are often necessary to complement LLMs for such tasks. For instance, when generating specific design parameters for a geotechnical structure, an LLM may need to be paired with specialised software that can provide the required numerical precision. Fortunately, there has been open software to handle this functionality (LangChain Contributors Citation2023).
Fine-tuning LLMs to produce highly accurate answers is another challenge. While fine-tuning is expected to be an important technique for creating LLM specialised for a unique task, the complexity of their training and sensitive control of the vastness of their data sources means that achieving precision in their outputs, especially in specialised fields such as geotechnical engineering, can be a nontrivial task. In order to fully harvest the power of LLMs to solve geotechnical problems that cannot be solved using conventional machine learning tools, it is important for the experts in geotechnical engineering to join forces with the data scientists. Active communication between the two communities is necessary to build a benchmark dataset for fine-tuning LLMs that address different types of geotechnical problems.
6. Conclusions
In conclusion, the workshop and subsequent explorations into LLMs like ChatGPT have demonstrated significant potential for transforming geotechnical engineering workflows. The diverse applications and case studies discussed in this paper reveal LLMs are powerful tools capable of handling a wide range of tasks, from basic data analysis to complex, multimodal problem-solving. The ability of the LLM framework to process and interpret mixed forms of data, including text and images, and its capacity for natural language understanding, makes it particularly valuable in the geotechnical field, where data are often sparse and multifaceted. These capabilities, combined with their generative nature, position LLMs as effective solutions for uncertainty quantification and handling of incomplete data, which are common challenges in geotechnical projects.
However, the application of LLMs in this domain is challenging. The nature of LLMs as probabilistic models that generate responses based on word relationships means that they cannot be solely relied upon for final solutions in complex engineering tasks. The need for expert oversight and tailored inputs to achieve optimal results is evident. In addition, fine-tuning LLMs for highly accurate and specialised responses in geotechnical engineering remains a complex task, highlighting the importance of effective interface design to ensure seamless integration with other systems and tools.
The integration of LLMs into geotechnical engineering signifies a shift towards more efficient, data-driven, and insightful approaches. The interdisciplinary nature of geotechnical engineering, which encompasses soil mechanics, environmental considerations, and structural dynamics, makes LLMs particularly valuable. This workshop exemplified how even beginners in LLMs and data science can rapidly integrate these tools into their work, underscoring the potential of LLMs to streamline complex cross-disciplinary studies. Future work would be focussed on more quantitative evaluations of the impact of LLMs on geotechnical engineering project timelines, costs, and safety. As the field evolves, LLMs are expected to play a pivotal role in shaping the future of geotechnical engineering, driving innovation, and enhancing the efficacy of workflows in this fundamental engineering realm.
Supplemental Material
Download PDF (32.9 KB)Supplemental Material
Download PDF (116.5 KB)Supplemental Material
Download PDF (382.9 KB)Supplemental Material
Download PDF (86.1 KB)Supplemental Material
Download Zip (32.5 MB)Supplemental Material
Download Zip (131.1 KB)Supplemental Material
Download (1.4 KB)Acknowledgments
During the preparation of this work the authors used OpenAI's ChatGPT-4 to make an outline of the paper and provide recommendations for the content based on a customised GPT model created by the authors. This service is used because this is part of the purpose of the paper, which is to demonstrate the potential large language models in geotechnics. After using this tool/service, the authors reviewed and edited the content as required and took full responsibility for the content of the publication. Wu, Otake, Mizutani, and Liu were the four workshop organisers of the workshop and contributed equally. Asano and Sato provided additional assistance for customised GPT development post-event. All other authors have been listed in the alphabetical order of their last names.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Ahn, Janice, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. 2024. “Large Language Models for Mathematical Reasoning: Progresses and Challenges.” arXiv 2402.00157.
- Basu, Dipanjan, Aditi Misra, and Anand J. Puppala. 2015. “Sustainability and Geotechnical Engineering: Perspectives and Review.” Canadian Geotechnical Journal 52 (1): 96–113. https://doi.org/10.1139/cgj-2013-0120.
- Bommasani, Rishi, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, et al. 2022. “On the Opportunities and Risks of Foundation Models.” arXiv 2108.07258.
- Borrmann, André, Markus König, Christian Koch, and Jakob Beetz, eds. 2018. Building Information Modeling: Technology Foundations and Industry Practice. Cham, Switzerland: Springer Cham.
- Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models are Few-Shot Learners.” In Advances in Neural Information Processing Systems, edited by H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, Vol. 33, 1877–1901. Red Hook, NY: Curran Associates, Inc.
- Cernica, John N. 1982. Geotechnical Engineering -- Soil Mechanics -- Solutions Manual. Hoboken, NJ: John Wiley & Sons Ltd.
- Chen, Justin Chih-Yao, Swarnadeep Saha, and Mohit Bansal. 2023. “ReConcile: Round-Table Conference Improves Reasoning via Consensus Among Diverse LLMs.” arXiv 2309.13007.
- Ching, Jianye, Stephen Wu, and Kok-Kwang Phoon. 2021. “Constructing Quasi-Site-Specific Multivariate Probability Distribution Using Hierarchical Bayesian Model.” Journal of Engineering Mechanics 147 (10): 04021069. https://doi.org/10.1061/(ASCE)EM.1943-7889.0001964.
- Dastbaz, Mohammad, Chris Gorse, and Alice Moncaster, eds. 2017. Building Information Modelling, Building Performance, Design and Smart Construction. Cham, Switzerland: Springer Cham.
- Deng, Cheng, Tianhang Zhang, Zhongmou He, Yi Xu, Qiyuan Chen, Yuanyuan Shi, Luoyi Fu, et al. 2023. “K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization.” arXiv 2306.05064.
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), edited by Jill Burstein, Christy Doran, and Thamar Solorio, Minneapolis, Minnesota, June, 4171–4186. Minneapolis, MN: Association for Computational Linguistics.
- Dinh, Tuan, Yuchen Zeng, Ruisu Zhang, Ziqian Lin, Michael Gira, Shashank Rajput, Jy yong Sohn, Dimitris Papailiopoulos, and Kangwook Lee. 2022. “LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks.” In Advances in Neural Information Processing Systems, edited by Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho. Red Hook, NY: Curran Associates, Inc.
- Ferdinan, Teddy, Jan Kocoń, and Przemysław Kazienko. 2024. “Into the Unknown: Self-Learning Large Language Models.” arXiv 2402.09147.
- Jablonka, Kevin Maik, Qianxiang Ai, Alexander Al-Feghali, Shruti Badhwar, Joshua D. Bocarsly, Andres M. Bran, Stefan Bringuier. 2023. “14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon.” Digital Discovery 2 (5): 1233–1250. https://doi.org/10.1039/D3DD00113J
- Kim, Daehyun, Taegu Kim, Yejin Kim, Yong-Hoon Byun, and Tae Sup Yun. 2024. “A ChatGPT-MATLAB Framework for Numerical Modeling in Geotechnical Engineering Applications.” Computers and Geotechnics 169:106237. https://doi.org/10.1016/j.compgeo.2024.106237.
- Kumar, Krishna. 2024. “Geotechnical Parrot Tales (GPT): Harnessing Large Language Models in Geotechnical Engineering.” Journal of Geotechnical and Geoenvironmental Engineering 150 (1): 02523001. https://doi.org/10.1061/JGGEFK.GTENG-11828.
- LangChain Contributors. 2023. “LangChain: A Framework for Developing Applications Powered by Large Language Models.” Accessed May 2024. https://github.com/langchain-ai/langchain.
- Lewis, Patrick, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, et al. 2020. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” In Advances in Neural Information Processing Systems, edited by H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, Vol. 33, 9459–9474. Red Hook, NY: Curran Associates, Inc.
- Liquefaction analysis method LIQCA Development group. 2007. Accessed October 2023. https://liqca.org/.
- Ma, Kai, Shuai Zheng, Miao Tian, Qinjun Qiu, Yongjian Tan, Xinxin Hu, HaiYan Li, and Zhong Xie. 2023. “CnGeoPLM: Contextual Knowledge Selection and Embedding with Pretrained Language Representation Model for the Geoscience Domain.” Earth Science Informatics 16: 3629–3646. https://doi.org/10.1007/s12145-023-01112-6
- Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean. 2013. “Distributed Representations of Words and Phrases and their Compositionality.” In Advances in Neural Information Processing Systems, edited by C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger, Vol. 26. Red Hook, NY: Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
- Oka, F., A. Yashima, T. Shibata, M. Kato, and R. Uzuoka. 1994. “FEM-FDM Coupled Liquefaction Analysis of Porous Soil Using An Elasto-Plastic Model.” Applied Scientific Research 52 (3): 209–245. https://doi.org/10.1007/BF00853951.
- Oka, F., A. Yashima, A. Tateishi, Y. Taguchi, and A. Yamashita. 1999. “A Cyclic Elasto-Plastic Constitutive Model for Sand Considering a Plastic-Strain Dependence of the Shear Modulus.” Géotechnique 49 (5): 661–680. https://doi.org/10.1680/geot.1999.49.5.661.
- OpenAI. 2023. ChatGPT Accessed October 2023. https://chat.openai.com/chat.
- Otake, Yu, and Yusuke Honjo. 2022. “Challenges in Geotechnical Design Revealed by Reliability Assessment: Review and Future Perspectives.” Soils and Foundations 62 (3): 101129. https://doi.org/10.1016/j.sandf.2022.101129.
- Otake, Yu, Kyohei Shigeno, Yosuke Higo, and Shogo Muramatsu. 2022. “Practical Dynamic Reliability Analysis with Spatiotemporal Features in Geotechnical Engineering.” Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards 16 (4): 662–677.
- Otsushi, Kazutaka, Tomoo Kato, Takashi Hara, Atsushi Yashima, Yu Otake, Kazuhiko Sakanashi, and Ayumi Honda. 2010. “Study on a Liquefaction Countermeasure for Flume Structure by Sheet-Pile with Drain.” In Geotechnical Society of Singapore -- International Symposium on Ground Improvement Technologies and Case Histories, ISGI'09, 437–443. Singapore: Research Publishing Services. https://doi.org/10.3850/GI123.
- Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, et al. 2022. “Training Language Models to Follow Instructions with Human Feedback.” In Advances in Neural Information Processing Systems, edited by S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Vol. 35, 27730–27744. Red Hook, NY: Curran Associates, Inc.
- Peng, Ciyuan, Feng Xia, Mehdi Naseriparsa, and Francesco Osborne. 2023. “Knowledge Graphs: Opportunities and Challenges.” Artificial Intelligence Review 56 (11): 13071–13102. https://doi.org/10.1007/s10462-023-10465-9.
- Phoon, Kok-Kwang, Zi-Jun Cao, Jian Ji, Yat Fai Leung, Shadi Najjar, Takayuki Shuku, Chong Tang, et al. 2022. “Geotechnical Uncertainty, Modeling, and Decision Making.” Soils and Foundations 62 (5): 101189. https://doi.org/10.1016/j.sandf.2022.101189.
- Phoon, Kok-Kwang, Jianye Ching, and Zijun Cao. 2022. “Unpacking Data-Centric Geotechnics.” Underground Space 7 (6): 967–989. https://doi.org/10.1016/j.undsp.2022.04.001.
- Phoon, Kok-Kwang, Jianye Ching, and Takayuki Shuku. 2022. “Challenges in Data-Driven Site Characterization.” Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards 16 (1): 114–126. https://doi.org/10.1080/17499518.2021.1896005.
- Phoon, Kok-Kwang, Jianye Ching, and Yu Wang. 2019. “Managing Risk in Geotechnical Engineering – From Data to Digitalization.” In Proc. of 7th Int. Symp. on Geotechnical Safety and Risk, 13–34. London, UK: International Society for Soil Mechanics and Geotechnical Engineering.
- Phoon, Kok-Kwang, and Takayuki Shuku. 2024. “Future of Machine Learning in Geotechnics (FOMLIG), 5–6 Dec 2023, Okayama, Japan.” Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards 18 (1): 288–303. https://doi.org/10.1080/17499518.2024.2316882.
- Phoon, Kok-Kwang, and Wengang Zhang. 2023. “Future of Machine Learning in Geotechnics.” Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards 17 (1): 7–22. https://doi.org/10.1080/17499518.2022.2087884.
- Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models are Unsupervised Multitask Learners.” OpenAI Report.
- Sharma, Atma, Jianye Ching, and Kok-Kwang Phoon. 2022. “A Hierarchical Bayesian Similarity Measure for Geotechnical Site Retrieval.” Journal of Engineering Mechanics 148 (10): 04022062. https://doi.org/10.1061/(ASCE)EM.1943-7889.0002145.
- Sharma, Atma, Jianye Ching, and Kok-Kwang Phoon. 2023. “A Spectral Algorithm for Quasi-Regional Geotechnical Site Clustering.” Computers and Geotechnics 161:105624. https://doi.org/10.1016/j.compgeo.2023.105624.
- Transportation Research Board, and National Academies of Sciences, Engineering, and Medicine. 2019. Manual on Subsurface Investigations. Washington, DC: The National Academies Press.
- Triantafyllidis, Theodoros, ed. 2020. Recent Developments of Soil Mechanics and Geotechnics in Theory and Practice. Cham, Switzerland: Springer Cham.
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention is All you Need.” In Advances in Neural Information Processing Systems, edited by I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Vol. 30. Red Hook, NY: Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Wang, Jianxun, and Yixiang Chen. 2023. “A Review on Code Generation with LLMs: Application and Evaluation.” In 2023 IEEE International Conference on Medical Artificial Intelligence (MedAI), 284–289. Red Hook, NY: Curran Associates.
- Wang, Xuezhi, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” In The Eleventh International Conference on Learning Representations. OpenReview.
- Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. “Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models.” In Advances in Neural Information Processing Systems, edited by S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Vol. 35, 24824–24837. Red Hook, NY: Curran Associates, Inc.
- Wu, Stephen, Jianye Ching, and Kok-Kwang Phoon. 2022. “Quasi-Site-specific Soil Property Prediction Using a Cluster-Based Hierarchical Bayesian Model.” Structural Safety 99:102253. https://doi.org/10.1016/j.strusafe.2022.102253.
- Wu, Jiayang, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S. Yu. 2023. “Multimodal Large Language Models: A Survey.” arXiv 2311.13165.
- Yamada, M., S. Yagi, T. Nagao, and A. Nozu. 2015. “An Efficient Detection Method of the Peak Frequency of Microtremor H/V Spectral Ratio by Using a Low-Pass Filter.” Butsuri-Tansa (Geophysical Exploration) 68 (2): 119–129.
- Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R. Narasimhan. 2023. Advances in Neural Information Processing Systems. Red Hook, NY: Curran Associates.
- Zhang, Wengang, Jianye Ching, Anthony T. C. Goh, and Andy Y. F. Leung. 2021. “Big Data and Machine Learning in Geoscience and Geoengineering: Introduction.” Geoscience Frontiers 12 (1): 327–329. https://doi.org/10.1016/j.gsf.2020.05.006.
- Zhao, Wayne Xin, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, et al. 2023. “A Survey of Large Language Models.” arXiv 2303.18223.
- Zheng, Zhiling, Oufan Zhang, Christian Borgs, Jennifer T. Chayes, and Omar M. Yaghi. 2023. “ChatGPT Chemistry Assistant for Text Mining and the Prediction of MOF Synthesis.” Journal of the American Chemical Society 145 (32): 18048–18062. https://doi.org/10.1021/jacs.3c05819.