Abstract
This paper is devoted to the statistical analysis of a stochastic model introduced in [P. Bertail, S. Clémençon, and J. Tressou, A storage model with random release rate for modelling exposure to food contaminants, Math. Biosci. Eng. 35 (1) (2008), pp. 35–60] for describing the phenomenon of exposure to a certain food contaminant. In this modelling, the temporal evolution of the contamination exposure is entirely determined by the accumulation phenomenon due to successive dietary intakes and the pharmacokinetics governing the elimination process inbetween intakes, in such a way that the exposure dynamic through time is described as a piecewise deterministic Markov process. Paths of the contamination exposure process are scarcely observable in practice, therefore intensive computer simulation methods are crucial for estimating the time-dependent or steady-state features of the process. Here we consider simulation estimators based on consumption and contamination data and investigate how to construct accurate bootstrap confidence intervals (CI) for certain quantities of considerable importance from the epidemiology viewpoint. Special attention is also paid to the problem of computing the probability of certain rare events related to the exposure process path arising in dietary risk analysis using multilevel splitting or importance sampling (IS) techniques. Applications of these statistical methods to a collection of data sets related to dietary methyl mercury contamination are discussed thoroughly.
AMS Subject Classification :
1. Introduction
Food safety is now receiving increasing attention both in the public health community and in scientific literature. For example, it was the second thematic priority of the 7th European Research Framework Program (refer to http://ec.europa.eu/research/fp7/) and advances in this field are starting to be reported in international conferences, as attested by the session statistics in environmental and food sciences in the 25th European Meeting of Statisticians held in Oslo in 2005, or in the 38èmes journées de Statistique held in Clamart, France, in 2006. Additionally, several pluridisciplinary research units dedicated entirely to dietary risk analysis, such as Met@risk (INRA, http://www.paris.inra.fr/metarisk) in France, Biometris (www.biometris.nl) in the Netherlands or the Joint Institute for Food Safety and Applied Nutrition in the United States (www.foodrisk.org) have recently been created. This rapidly developing field involves various disciplines across the medical, biological, social and mathematical sciences. The role of statistics in this field is becoming more and more widely recognized; see the seminal discussion in Citation33, and consists particularly of developing probabilistic methods for quantitative risk assessment, refer to Citation6 Citation15 Citation21 Citation44. Hence, information related to the contamination levels of an increasing number of food products for a wide range of chemicals on the one hand and to the dietary behaviour of large population samples on the other hand is progressively collected in massive databases. The study of dietary exposure to food contaminants has raised many stimulating questions and motivated the use and/or development of appropriate statistical methods for analysing the data, see Citation3 Citation38 for instance. Recent work focuses on static approaches for modelling the quantity X of a specific food contaminant ingested over a short period of time and computing the probability that X exceeds a maximum tolerable dose, eventually causing adverse effects on human health; see Citation37 and the references therein. One may refer to Citation4 Citation33 for a detailed account of dose level thresholds such as the Provisional Tolerable Weekly Intake, meant to represent the maximum contaminant dose one may ingest per week without significant risk. However, as emphasized in Citation5, it is essential for successful modelling to take account of the human kinetics of the chemical of interest when considering contaminants such as methyl mercury (MeHg), our running example in this paper, that is not eliminated quickly, with a biological half-life measured in weeks rather than days, as detailed in Section 2. In Citation5, a dynamic stochastic model for dietary contamination exposure has been proposed, which is driven by two key components: the accumulation phenomenon through successive dietary intakes and the kinetics in man of the contaminant of interest that governs the elimination process. While a detailed study of the structural properties of the exposure process, such as communication and stochastic stability, has been carried out in Citation5, the aim of this paper is to investigate the relation of the model to available data so as to propose suitable statistical methods.
The rest of the article is organized as follows. In Section 2, the dynamic model proposed in Citation5 and its structural properties are briefly reviewed, with the aim of giving an insight into how it is ruled by a few key components. In Section 3, the relation of the dynamic exposure model previously described to available data is thoroughly investigated. In particular, we show how computationally intensive methods permit the analysis of the data in a valid asymptotic theoretical framework. Special emphasis is placed on the problem of bootstrap CI construction from simulation estimates of certain features of the exposure process, which are relevant from the epidemiology viewpoint. Statistical estimation of the probability of certain rare events, such as those related to the time required for the exposure process to exceed some high and potentially critical contamination level, for which naive Monte Carlo methods obviously fail, is also considered. Multilevel splitting genetic algorithms or importance sampling techniques are adapted to tackle this crucially important issue in the field of dietary risk assessment. This is followed by a section devoted to the application of the latter methodologies for analysing a collection of data sets related to dietary MeHg contamination, in which the eventual use of the model for prediction and disease control from a public health guidance perspective is also discussed. Technicalities are deferred to the Appendix.
2. Stochastic modelling of dietary contaminant exposure
In Citation5, an attempt was made to model the temporal evolution of the total body burden of a certain chemical present in a variety of foods involved in the diet, when contamination sources other than dietary, such as environmental contamination for instance, are neglected. As recalled below, the dynamic of the general model proposed is governed by two key components, a marked point process (MPP) and a linear differential equation, in order to appropriately account for the accumulation of the chemical in the human body and its physiological elimination, respectively.
2.1. Dietary behaviour
The accumulation phenomenon of the food contaminant in the body occurs according to the successive dietary intakes, which may be mathematically described by a MPP. Assume that the chemical is present in a collection of P types of food, indexed by p=1,…, P. A meal is then modelled as a random vector Q=(Q (1),…, Q (P)), the pth component Q (p) indicating the quantity of food of type p consumed during the meal, with 1≤p≤P. Suppose that also, for 1≤p≤P, food type p eaten during a meal is contaminated in random ratio C (p) in regards to the chemical of interest. For this meal the total contaminant intake is then
Equipped with this notation, a stochastic process model that carries information about the times of the successive dietary intakes of an individual of the population of interest and the quantities of contaminant ingested, at the same time, may be naturally constructed by considering the MPP , where the T
n
’s denote the successive times when a food of type p∈{1,…, P} is consumed by the individual and the second and third components of the MPP, Q
n
and C
n
, are respectively, the consumption vector and the contamination vector related to the meal eaten at time T
n
. One may naturally suppose that the sequence of quantities consumed
is independent from the sequence
of chemical concentrations.
A given dietary behaviour may now be characterized by stipulating specific dependence relations for the (T
n
, Q
n
)’s. When the chemical of interest is present in several types of food of which consumption is typically alternated or combined for reasons related to taste or nutritional aspects, assuming an autoregressive structure for the (ΔT
n
, Q
n
)’s, with ΔT
n
=T
n
−T
n−1 for all n≥1, seems appropriate. In addition, different portions of the same food may be consumed on more than one occasion, which suggests that, for a given food type p, assuming dependency among their contamination levels ’s may also be pertinent in some cases. However, in many important situations, it is reasonable to consider a very simple model in which the marks
form an i.i.d. sequence independent from the point process
, the latter being a pure renewal process, i.e. durations ΔT
n
in between intakes are i.i.d. random variables. This modelling is particularly pertinent for chemicals largely present in one type of food. Examples include methyl mercury quasi-solely found in seafood products, certain mycotoxins such as patulin exclusively present in apple products, see Section 3.3.2 in Citation18, or chloropropanols, see Section 5.1 in Citation19. Beyond its relevancy for such crucial cases in practice, though simple, this framework raises very challenging probabilistic and statistical questions, as shown in Citation5. So that the theoretical results proved in this latter paper may be used for establishing a valid asymptotic framework, we also set ourselves under this set of assumptions in the present statistical study and leave for further investigation the issue of modelling more complex situations. Hence, throughout the article the accumulation of a chemical in the body through time is described thoroughly by the MPP
with i.i.d. marks U
n
=⟨Q
n
, C
n
⟩ drawn from F
U
(dx)=f
U
(x) dx, the common (absolutely continuous) distribution of the intakes, independent from the renewal process
. Let G(d
t)=g(t) dt denote the common distribution of the inter-intake durations ΔT
n
,
. Then, taking by convention T
0=0 for the first intake time, the total quantity of chemical ingested by the individual up to time t≥0 is
2.2. Pharmacokinetics
Given the metabolic rate of a specific organism, physiological elimination/excretion of the chemical in between intakes is classically described by an ordinary differential equation (ODE), the whole human body being viewed as a single compartment pharmacokinetic model, see Citation20 Citation34 for an account of pharmacokinetic models. Supported by considerable empirical evidence, one may reasonably assume the elimination rate to be proportional to the total body burden of the chemical in numerous situations, including the case of methyl mercury:
Remark 1 (Modelling variability in the metabolic rate)
In order to account for variability in the metabolic rate while preserving monotonicity of the solution x(t), various extensions of the model above may be considered. A natural way consists of incorporating a ‘biological noise’ and randomizing the ODE Equation(3), replacing θ dt by
, where
denotes a time-homogeneous (increasing) Poisson process with intensity θ (and compensator θt):
Let X(t) denote the total body burden of a given chemical at time t≥0. Under the assumptions listed above, the exposure process
X={X(t)}
t≥0 moves deterministically according to the first order differential EquationEquation (3) in between intakes and has the same jumps as (B(t))
t≥0. A typical càd-làgFootnote1 sample path of the exposure process is displayed below in . Let A(t)=t−T
N(t) denote the backward recurrence time at t≥0 (i.e. the time since the last intake at t). The process {(X(t), A(t))}
t≥0 belongs to the class of so-termed piecewise deterministic Markov (PDM) processes. Since the seminal contribution of Citation14, such stochastic processes are widely used in a large variety of applications in operations research, ranging from queuing systems to storage models. Refer to Citation13 for an excellent account of PDM processes and their applications. In most cases, the ΔT
n
’s are assumed to be exponentially distributed, making X itself a Markov process and its study much easier to carry out, see [Citation1, Chapter XIV]. However, this assumption is clearly inappropriate in the dietary context and PDM models with increasing hazard rates are more realistic in many situations.
Figure 1. Sample path of the exposure process X(t).
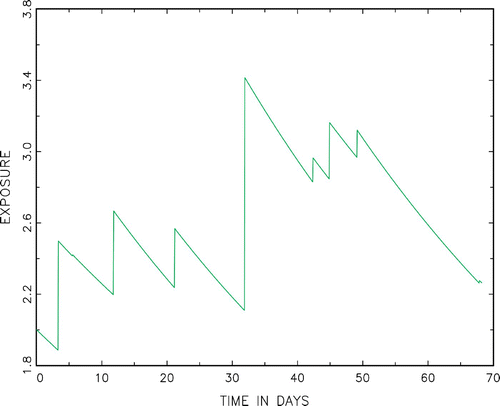
In Citation5, the structural properties of the exposure process X have been thoroughly investigated using an embedded Markov chain analysis, namely by studying the behaviour of the chain describing the exposure process immediately after each intake: X
n
=X(T
n
) for all
. As a matter of fact, the analysis of such a chain is facilitated considerably by its autoregressive structure:
Such autoregressive models with random coefficients have been widely studied in the literature, refer to Citation31 for a recent survey of available results on this topic. The continuous-time process X may be easily related to the embedded chain : solving EquationEquation (3)
gives for all t≥0
2.3. Long-term behaviour
Under the conditions (i)–(iii) listed below, the behaviour of the exposure process X in the long run can be determined. In addition, an (geometric) ergodicity rate can be established when condition (iv) is fulfilled.
-
The inter-intake time distribution G has an infinite tail and either
for some ε>0 or the intake distribution F U has infinite tail.
-
There exists some γ≥1 such that
-
The inter-intake time distribution has first- and second-order finite moments
-
There exists some δ>0 such that
These mild hypotheses can easily be checked in practice as we do in Section 4 for MeHg: assumption (i) stipulates that inter-intake times may be arbitrarily long with positive probability and they may also either be arbitrarily short with positive probability, which may then also satisfy the exponential moment condition (iv), or intakes may otherwise be arbitrarily large with positive probability, but also ‘relatively small’ in the case when (ii) is fulfilled. In the detailed ergodicity study carried out in Citation5, Theorem 2 (respectively, Theorem 3) establishes in particular that under conditions (i)–(iv) (respectively conditions (i)–(ii)), the continuous-time exposure process X(t) (respectively the embedded chain X
n
corresponding to successive exposure levels at intake times) settles to an equilibrium/steady state as (respectively as
), described by a governing, absolutely continuous, probability distribution denoted by μ(d
x)=f(x) dx (respectively,
). The limiting distributions μ and
are related to one another by the following equation, see EquationEquation (15)
in Citation5:
-
the steady-state mean exposure
-
the limiting average time the exposure process spent above some (possibly critical) threshold value u>0,
In Citation5, a simulation study was carried out to evaluate the time to steady state for women of childbearing age in the situation of dietary MeHg exposure, that is the time needed for the exposure process to behave in a stationary fashion, which is also termed burn-in period in the MCMC method context. It was empirically shown that after 5 to 6 half lives, or about 30 weeks, the values taken by the exposure process can be considered as drawn from the stationary distribution, which is a reasonable horizon on the human scale.
3. Statistical inference via computer simulation
We now investigate the relation of the exposure model described in Section 2 to existing data. In the first place, it should be noted that information related to the contamination exposure process is scarcely available at the individual level. It seems pointless to try to collect data for reconstructing individual trajectories: an experimental design measuring the contamination levels of all food ingested by a given individual over a long period of time would not actually be feasible. Inference procedures are instead based on data for the contamination ratio related to any given food and chemical stored in massive data repositories, as well as collected survey data reporting the dietary behaviour of large samples over short periods of time. In the following, we show how computer-based methods may be used practically for statistical inference of the exposure process X(t) from this kind of data. A valid asymptotic framework for these procedures is also established from the stability analysis of the probabilistic model carried out in Citation5.
3.1. Naive simulation estimators
Suppose we are in the situation described above and have at our disposal three sets of i.i.d. data G, C and Q drawn from G, F
C
and F
Q
, respectively, as well as noisy half-life data H such as those described in Citation17. From these data samples, various estimation procedures may be used for producing estimators ,
and
of θ, G and F
U
, also fulfilling conditions (i)–(iii), see Remark A2 in the Appendix. One may refer in particular to Citation3, for an account of the problem of estimating the intake distribution F
U
from contamination and consumption data sets C and Q, see also Section 4. Although the law of the exposure process X(t), given the initial value X(0)=x
0, which is assumed to be fixed throughout this section, is entirely determined by the pharmacokinetic parameter θ and the distributions G and F
U
, quantities related to the behaviour that are of interest from the toxicology viewpoint are generally very complex functionals T(θ, G, F
U
) of these parameters, refuting the possibility of computing plug-in estimates
explicitly. Apart from the mean-value Equation(7)
and the mean-time spent over some threshold value Equation(8)
in steady state, among relevant quantities one may also consider for instance:
-
the mean-time required for exceeding a threshold level u>0, given by
denoting by -
the expected maximum exposure value over a period of time [0, T]
-
the expected overshoot above a level u>0 in steady state
denoting by
Based on the estimate and the probability distributions
,
at our disposal, we are then able to simulate sample paths of the exposure process
governed by these instrumental estimates. Although computing estimates of certain characteristics such as those mentioned above for
may be carried out straightforwardly via Monte Carlo simulation, one should pay careful attention to whether a good approximation of (θ, G, F
U
) also induces a good approximation of the corresponding characteristics of the exposure process, which is far from trivial. Considering the geometry of exposure trajectories shown in , this may be viewed as a stability/continuity problem in the Skorohod space
of càd-làg functions
equipped with an adequate topology (in a way that two exposure paths can possibly be ‘close’, although their respective jumps do not necessarily happen simultaneously) when
(refer to Citation45 for an excellent account of such topological path spaces). This issue has been handled in Theorem 5 of Citation5 using a coupling technique (see also Corollary 6 therein). Theorem A.1 in the Appendix recapitulates these results from a statistical perspective and establishes the strong consistency of simulation estimators, provided that
,
and
are strongly consistent estimates of θ, G and F
U
as the sizes of the data sets H, G, C and Q become large.
In practice, one might also be interested in the behaviour of such estimators as , with the aim of estimating steady-state features such as EquationEquation (7)
or Equation(8)
. The accuracy of simulation estimators not only depends on the closeness between (θ, G, F
U
) and the instrumental parameters
, but also on the runlength
of the simulation. Indeed, a natural way for estimating the probability Equation(8)
that exposure exceeds some prescribed threshold u at equilibrium, for instance, is to compute a Monte Carlo approximation of
for T adequately large. By virtue of Theorem A.1 in the Appendix, for a fixed T, this is a consistent estimate of
, which converges in its turn to
at an exponential rate when
, see Theorem 3 in Citation5. Theorem A.2 in the Appendix shows that the inference method based on this heuristic is strongly consistent for estimating steady-state quantities such as EquationEquation (7)
, Equation(8)
or Equation(11)
, provided that T grows to infinity at a suitable rate. Refer to Section 4.3 for numerical results in the MeHg exposure context.
3.2. Bootstrap and CIs
Now that consistent inference procedures have been described in various important estimation settings, we naturally turn our attention to the problem of assessing statistical accuracy for the estimates thus computed. Given the technical difficulties faced when trying to identify asymptotic distributions of the simulation estimators described in Section 3.1, we take advantage of bootstrap CIs, which are built directly from the data, via the implementation of a simplistic computer algorithm; see Citation23 for an account of the bootstrap theory, and Citation16 for a more practice-oriented overview. Here we discuss the application of the bootstrap-percentile method to our specific setting for automatically producing CIs from simulation estimators.
Let us suppose that the parameter of interest is in the form of , where
and
is a given function defined in the exposure path space. As previously noted, typical choices are
and
for u≥0. We consider the problem of estimating the sampling distribution of a simulation estimator
of F(Φ) computed using instrumental parameter estimates
,
and
fitted from data samples H, G, C and Q:
. Note that here the probability refers to the randomness in the samples H, G, C and Q. The ‘simulated bootstrap’ algorithm is performed in five steps as follows.
Algorithm 1. Simulated bootstrap
-
Make i.i.d. draws with replacement in each of the four data sets H, G, C and Q, yielding the bootstrap samples H*, G*, C* and Q*, with the same sizes as the original samples, respectively.
-
From data samples generated in step 1, compute bootstrap versions
-
From the bootstrap parameters
-
Compute the bootstrap estimate of the sampling distribution of
where -
A bootstrap CI at level
Here the redundant designation ‘simulated bootstrap’ simply emphasizes the fact that a path simulation stage follows the data resampling and parameter recomputing steps. Asymptotic validity of this bootstrap procedure may be established at length by refining the proof of Theorem A.1, based on the Fréchet differentiability notion. Owing to space limitations, technicalities here are omitted.
Remark 1 (Monte-Carlo approximations)
The bootstrap distribution estimate Equation(12) may be practically approximated by iterating B times the resampling step and averaging then over the B resulting bootstrap trajectory replicates:
with b∈{1,…, B}.
3.3. Rare event analysis
The statistical study of the extremal behaviour of the exposure process is also of crucial importance in practice. Indeed, accurately estimating the probability of reaching a certain possibly critical level u within a lifetime is an essential concern from the public health perspective (see the discussion in Section 4). When the toxicological threshold level u of interest is ‘very high’, when compared with the mean behaviour of the exposure process X, crude Monte Carlo (CMC) methods, as those proposed in Section 3.1, completely fail; see for an illustration of this phenomenon. We are then faced with computational difficulties inherent to the issue of estimating the probability of a rare event related to X’s law. In this paper, we leave aside the question of fully describing the extremal behaviour of the exposure process X in an analytical fashion and inferring values for related theoretical parameters such as the extremal index, measuring to what extent extreme values tend to come in ‘small clusters’. Attention is rather focused on practical simulation-based procedures for estimating probabilities of rare events of the form , where T is a reasonable horizon on the human scale, and level u is very large in comparison with the long-term mean exposure m
μ for instance. Here, two methods are proposed for carrying out such a rare event analysis in our setting, each having its own advantages and drawbacks, see Citation22 for a review of available methods for estimating the entrance probability into a rare set. In the first approach, a classical IS procedure is implemented, while our second strategy, based on an adequate factorization of the rare event probability
relying on the Markov structure of the process (X(t), A(t)) (i.e. a Feynman–Kac representation), consists of using a multilevel splitting algorithm, see Citation10. In the latter, simulated exposure trajectories getting close to the target level u are ‘multiplied’, while we let the others die, in the spirit of the popular ReSTART (Repetitive Simulated Trials After Reaching Thresholds) method; refer to Citation43 for an overview. In Section 4, both methodologies are applied in order to evaluate the risk related to dietary MeHg exposure, namely the probability that the total body burden rises above a specific dose of reference.
Figure 2. (Available in colour online). Examples of trajectories in the French adult female population compared with a reference exposure process (Unit: μg/kg bw). The solid red curves are different trajectories with the same initial state x 0=0. The dashed green curve stabilizes at a critical threshold of reference u, see Section 4 for details on its construction.
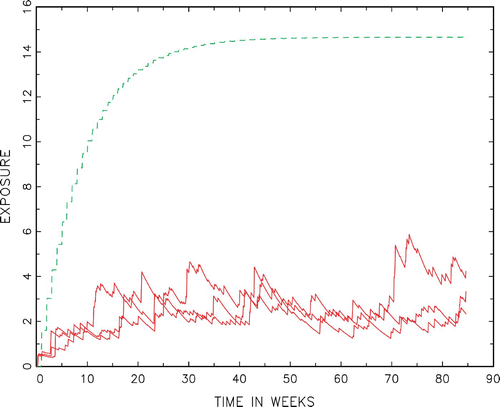
3.3.1. Importance sampling
Importance sampling (IS) is a standard tool in rare event simulation. It relies on simulating exposure paths from a different probability, say, equivalent to the original along a suitable filtration, chosen in a way that the event of interest
is much less rare, or even frequent, under the latter distribution, refer to Citation8 for a recent account of IS techniques and their applications. The rare event probability estimate is then computed by multiplying the empirical quantity output by the simulation algorithm using the new distribution by the corresponding likelihood ratio (importance function).
In our setting, a natural way of speeding up the exceedance of level u by process X is to consider an intake distribution equivalent to F
U
though much larger in the stochastic ordering sense (i.e.
for all x>0), so that large intakes may occur more frequently, and, simultaneously, an inter-intake time distribution
with same support as G(d
t) but stochastically much smaller (namely,
for all t>0), in order that the intake frequency is increased (see Section 4 for specific choices in the MeHg case). In contrast, the elimination process cannot be slowed down, i.e. the biological half-life
cannot be increased, at the risk of no longer preserving equivalence between
and
. To be more specific, let
be the probability measure on the same underlying measurable space as the one on which the original probability
has been defined, making X the process described in Section 2. Under
, the intakes {U
k
}
k≥1, respectively, the inter-intake times {ΔT
k
}
k≥1, are i.i.d. r.v.’s drawn from
, respectively, from
, and X
0=x
0≥0. The distribution
is absolutely continuous with respect to the IS distribution
along the filtration
, t≥0, that is the collection of σ-fields generated by the intakes and inter-intake times until time t. In addition, on
, the likelihood ratio is given by
3.3.2. Multilevel splitting
The approach described above involves specifying an appropriate change of measure (adequate df’s and
), so as to simulate a random variable
with reduced variance under the new distribution
, see Citation8, Chapter 14]. This delicate tuning step is generally based on large-deviation techniques when tractable. Although encouraging results have been obtained for estimating the probability of exceedance of large thresholds (in long time asymptotics) for random walks through IS techniques (for instance refer to [Citation2, Chapter VI], where both the light-tailed and heavy-tailed cases are considered), no method for choosing a nearly optimal change of measure is currently available in our setup, where time T is fixed. For this reason, the so-termed multilevel splitting technique has recently emerged as a serious competitor to the IS methodology, see [Citation22. This approach is indeed termed non-intrusive, insofar as it does not require any modification of the instrumental simulation distributions. Here, it boils down to represent the distribution of the exposure process exceeding the critical threshold u in terms of a Feynman–Kac branching particle model, see Citation30 for an account of Feynman–Kac formulae and their genealogical and interacting particle interpretations. Precisely, the interval [0, u] in which the exposure process X evolves before crossing the level x=u is split into sub-intervals corresponding to intermediary sublevels 0<u
1<⋯<u
m
<u the exposure path must pass before reaching the rare set
and particles, in this case exposure paths, branch out as soon as they pass the next sublevel. Connections between such a physical approach of rare event simulation and approximations of Feynman–Kac distributions based on interacting particle systems are developed at length in Citation10. We now recall the principle of the multilevel splitting algorithm used in Section 4. Suppose that m intermediary sublevels 0<u
1<⋯<u
m
<u
m+1=u, are specified by the user (see Remark 2), as well as instrumental simulation parameters (F
U
, G, θ) and x
0>0. Let N≥1 be fixed and denote the cardinal of any finite set
by
. The algorithm is then performed in m+1 steps as follows.
Algorithm 2. Multi-level Splitting
-
Simulate N exposure paths from x 0<u 1 of runlength T, indexed by k∈{1,…, N} and denoted by
-
For j=1,…, m:
-
Let
-
For each path indexed by k′ in
-
Compute
-
-
Output the estimate of the probability
where P m+1 is defined as the proportion of particles that have reached the final level u among those which have reached the previous sublevel u m , that is
Before illustrating how the procedure works on a toy example, below are two relevant remarks.
Remark 2 (On practical choice of the tuning parameters)
Although a rigorous asymptotic validity framework has been established in Citation10 for Algorithm 2 when the number N of particles gets arbitrarily large, the intermediary sublevels u
1,…, u
m
must be selected by the user in practice. As noted in Citation28, an optimal choice would consist of choosing the sublevels so that the probability to pass from to
should be the same, whatever the sublevel j. Here we mention the fact that, in the numerical experiments carried out in Section 4, the sublevels have been determined by using the adaptive variant of Algorithm 2 proposed in Citation9, where the latter are picked in such a way that all probabilities involved in the factorization Equation(16)
are approximately of the same order of magnitude.
Remark 3 (Validation)
Stating the truth, estimating the probability of rare events such as is a difficult task in practice and, when feasible, the numerical results provided by different possible methods should be compared for assessing the order of magnitude of the rare event probability of interest. It should also be mentioned that, in a very specific case, namely when F
U
and G are both exponential distributions, the distribution of the hitting time τ
u
may be explicitly computed through its Laplace transform using Dynkin’s formula, see Citation27. As an initial attempt, the latter may be thus used for computing a preliminary rough estimate of
.
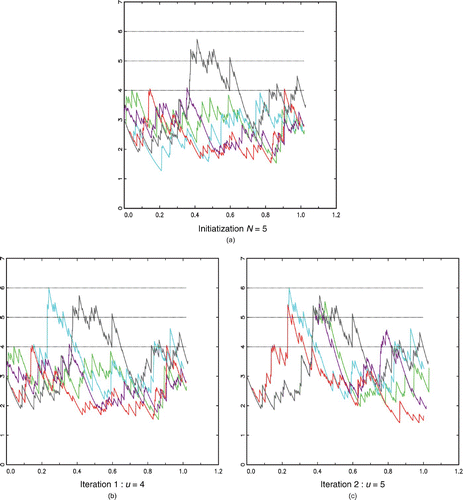
A toy example: illustrates the way Algorithm 2 works in the case of N=5 trajectories starting from x 0=3 with m=2 intermediary levels (u=(4, 5, 6)) and a horizon T equal to one year in the model with exponential intake and inter-intake times distributions. Initially, all curves have reached the first intermediary level (u=4) except the blue curve as shown in (a). It is then restarted from the red curve at the exact point where it first reached u=4 in (b). Now, only the blue and black curves have reached the second intermediary level (u=5). In (c), all the other curves are thus restarted from one of these at the exact point where they first reached u=5. Eventually, only the blue curve reached the level of interest u=6. The probability of reaching 6 in less than one year is estimated by 4/5×2/5×1/5=6.4%.
Figure 3. (Available in colour online). Multilevel splitting: an illustration for N=5 particles starting from x 0=3 with m=2 intermediary levels (u∈{4, 5, 6}) and a horizon T equal to 1 year.
4. Numerical results for MeHg exposure
In this section, we apply the statistical techniques presented in the preceding section for analysing how a population of women of childbearing age (who are female between 15 and 45, for the purpose of this study) are exposed to dietary MeHg, based on the dynamic model described in Section 2. The group suffering the highest risk from this exposure is actually the unborn child as mentioned in the hazard characterization step described in Citation17: the MeHg present in the seafood of the mother’s diet will certainly pass onto the developing foetus and may cause irreversible brain damage.
From the available data sets related to MeHg contamination and fish consumption, essential features of the exposure process are inferred using the simulation-based estimation tools previously described. Special attention is now paid to the probability of exceeding a specific dose derived from a toxicological level of reference in the static setup, namely the Provisional Tolerable Weekly Intake (PTWI), which represents the contaminant dose an individual can ingest weekly over an entire lifetime without appreciable risk, as defined by the international expert committee of FAO/WHO, see Citation17. This means it is crucial to implement the rare event analysis methods reviewed in Section 3.3.
Eventually, the impact of the choice of the statistical methods used for fitting the instrumental distributions is empirically quantified and discussed from the perspective of public health guidelines.
4.1. Description of the data sets
We start off with a brief description of the data sets used in the present quantitative risk assessment. Note that fish and other seafood are the only source of MeHg.
Contamination data C: Here we use the contamination data related to fish and other seafoods available on the French market that have been collected by accredited laboratories from official national surveys performed between 1994 and 2003 by the French Ministry of Agriculture and Fisheries Citation29 and the French Research Institute for Exploitation of the Sea Citation24. This data set comprises 2832 observations.
Consumption data G, Q: The national individual consumption survey INCA Citation11 provides the quantity consumed over a week of an extensive list of foods, among which fish and other seafoods, as well as the time consumption occurred with at least the information about the nature of the meal, whether it be breakfast, lunch, dinner or ‘snacks’. It surveys 1985 adults aged 15 years or over, including 639 adult females between 15 and 45. From these observations, the data set G consists of the actual durations between consecutive intakes, when properly observed, together with right censored inter-intake times, when only the information that the duration between successive intakes is larger than a certain time can be extracted from the observations. Inter-intake times are expressed in hours.
As in Citation5
Citation42, MeHg intakes are computed at each observed meal through a so-termed deterministic procedure currently used in national and international risk assessments. From the INCA food list, 92 different fish or seafood species are determined and a mean level of contamination is computed from the contamination data, as in Citation12
Citation39. Intakes are then obtained through EquationEquation (1) based on these mean contamination levels: this is a simplifying approach that bears the advantage that fish species can be taken into account as extensively explained in Citation39. For comparison sake, all consumptions are divided by the associated individual body weight, also provided in the INCA survey, so that intakes are expressed in micrograms per kilogram of body weight per meal (μg/kg bw/meal).
As previously mentioned, raw data related to the biological half-life of contaminants such as MeHg are scarcely available. Referring to the scientific literature devoted to the pharmacokinetics of MeHg in the human body Citation25
Citation32
Citation35
Citation36, the biological half-life fluctuates at around 44 days. This numerical value, converted in hours, is thus retained for performing simulations, leading to pick for the acceleration parameter estimate
.
4.2. Estimation of the instrumental distributions F U and G
In order to estimate the cumulative distribution functions (cdf) of the intakes and inter-intake times, various statistical techniques have been considered, namely parametric and semi-parametric approaches.
Estimating the intake distribution: By generating intake data as explained in Section 4.1, we dispose of a sample U of n F U =1088 intakes representative of the subpopulation consisting of women of childbearing age, on which the following cdf estimates are based.
Parametric modelling. We first considered two simple parametric models for the intake distribution: the first one stipulates that F
U
takes the form of an exponential distribution with parameter λ
F
U
=1/m
F
U
, while the other assumes it is a heavy-tailed Burr-type distribution (with cdf (1−(1+x
c
)−k
) for c>0 and k>0) in order to avoid underestimating the probability that very large intakes have occurred. For both statistical models, related parameters have been set by the maximum likelihood estimation (MLE). It can be easily established that ML estimates are consistent and asymptotically normal in such regular models and, furthermore, that the cdf corresponding to the MLE parameter is also consistent in the L
1-sense, see Remark A2 in the Appendix. Numerically, based on U we found that by simply inverting the sample mean in the exponential model, whereas in the Burr distribution-based model, MLE yields
and
. Recall that, in the Burr case,
is finite as soon as c
k>γ. One may thus check that the intake distribution estimate fulfills condition (i
i) with γ=4; see Section 2.
Semi-parametric approach: In order to allow for more flexibility and accuracy on the one hand and to obtain a resulting instrumental cdf well-suited for worst case risk analysis on the other hand, a semi-parametric estimator has also been fitted the following way: the piecewise linear left part of the cdf corresponds to a histogram-based density estimator, while the tail is modelled by a Pareto distribution, with a continuity constraint at the change point x K . Precisely, a number K of extreme intakes is used to determine the tail parameter α of the Pareto cdf 1−(τx)−α, τ>0 and α>0, τ being chosen to ensure the continuity constraint. The value of K is fixed through a bias-variance trade-off, following exactly the methodology proposed in Citation39. Numerically, we have α=2.099, τ=5.92, and x K =0.355.
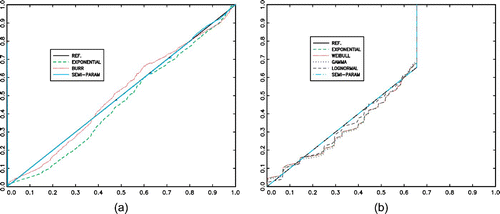
Probability plots are displayed in (a). The semi-parametric estimator clearly provides the best fit to the data. The Burr distribution is nevertheless a good parametric choice. It is preferred to the exponential distribution based on the AIC criteria, whereas the BIC criteria advocates for the exponential distribution.
Figure 4. (Available in colour online). Probability plots (empirical cdf versus fitted cdf), comparison of the different adjustments. (a) F U : Intake distribution. (b) G: Inter-intake time distribution.
Estimating the inter-intake time distribution: We dispose of a sample G of n G =1214 right censored inter-intake times.
Parametric models: In this censored data setup, MLE boils down to maximizing the log likelihood given by
Semi-parametric modelling. Using a semi-parametric approach, a cdf estimate is built from a smoothed Kaplan–Meier estimator F
KM for the left part of the distribution and an exponential distribution for the tail behaviour, with a continuity constraint at the change point. To be exact, the change point corresponds to the largest uncensored observation x
K
and the parameter of the exponential distribution to , in a way that continuity at x
K
is guaranteed. The resulting parameter of the exponential distribution is 0.0073, and x
K
=146 h.
(b) displays the corresponding probability plots. Again, the semi-parametric estimator provides the best fit, except naturally for the tail part because of the right censorship. Based on AIC or BIC criteria, the Exponential distribution is chosen among the proposed parametric distributions. However, the fitted Gamma distribution is marginally more accurate than the Weibull and exponential distributions, since it offers the advantage of having an increasing hazard rate (here, α>1), which is a realistic feature in the dietary context.
4.3. Estimation of the main features of the exposure process
From the perspective of food safety, we now compute several important summary statistics related to the dietary MeHg exposure process of French females of childbearing age using the simulation estimators proposed in Section 3. In chemical risk assessment, once a hazard has been identified, meaning that the potential adverse effects of the compound have been described, it is then characterized, using the notion of threshold of toxicological concern. This pragmatic approach for chemical risk assessment consists of specifying a threshold value, below which there is a very low probability of observing adverse effects on human health. In practice, one experimentally determines the lowest dose that may be ingested by animals or humans, daily or weekly, without appreciable effects. The Tolerable Intake is then established by multiplying this experimental value, known as the Non Observed Adverse Effect Level (NOAEL) by a relevant safety factor, taking into account both inter-species and inter-individual variabilities. This approach dates from the early sixties, see Citation40, and is internationally recognized in food safety, see Citation26. The third and fourth steps of risk assessment consists of assessing the exposure to the chemical of interest for the studied population, and comparing it with the daily or weekly tolerable intake. The first two steps are known as hazard identification and hazard characterization, while the last two are called exposure assessment and risk characterization. In a static setup, when considering chemicals that are not accumulated in the human body and describing exposure by the supposedly i.i.d. sequence of intakes, this boils down to evaluating the probability that weekly intakes exceed the reference dose d, termed the Provisionary Tolerable Weekly Intake (PTWI), see Citation37. Considering compounds with longer biological half-lives, we propose comparing the stochastic exposure process to the limit of a deterministic process of reference . Mimicking the experiment carried out in the hazard characterization step, the latter is built up by considering intakes exactly equal to the PTWI d occurring every week (F
U
is a point mass at d, and G is a point mass at one week, that is 7×24). The reference level is thus given by the affine recurrence relationship
, yielding a reference level
, where the half-life HL is expressed in weeks. For MeHg, the value d=0.7 μg/kg bw/w corresponds to the reference dose established by the US National Research Council currently in use in the United States, see Citation41, whereas the PTWI has been set to d=1.6 μg/kg bw/w by the international expert committee of FAO/WHO, see Citation17. Numerically, this yields X
ref, 0.7=6.42 μg/kg bw and X
ref, 1.6=14.67 μg/kg bw when MeHg’s biological half-life is fixed to HL=6 weeks, as estimated in Citation35. We termed this reference dose as ‘tolerable body burden’ (TBB), which is more relevant than the previous ‘kinetic tolerable intake’ (KTI) determined in Citation42.
In the dynamic setup, several summarizing quantities can be considered for comparison purposes. We first estimated two important features of the process of exposure to MeHg, for all combinations of input distributions: the long-term mean exposure m
μ, the median exposure value in the stationary regime, and the probability of exceeding the threshold X
ref, 0.7 in steady state ; see and . Computation is conducted as follows: M=1000 trajectories are simulated over a run length of 1 year after a burn-in period of 5 years, quantities of interest are then averaged over the M trajectories and this is repeated B=200 times to build the bootstrap CI’s, as described in Section 3.2. The major differences among the 15 models for the stationary mean arise when using the Log Normal distribution for the inter-intake times with a lower estimation for this model presenting a heavy tail (longer inter-intake times are more frequent). All the other models for G lead to similar results in terms of CIs for the mean and median exposures in the long run, whatever the choice for F
U
, refer to . When estimating a tail feature such as the probability of exceeding u=X
ref, 0.7 in steady state, the choice of F
U
becomes of prime importance, since its tail behaviour is the same as that of the stationary distribution μ, see Theorem 3.2 in Citation5. As illustrated by the notion of PTWI, risk management in food safety is generally treated in the framework of worst-case design. In the subsequent analysis, we thus focus on the Burr–Gamma model. Due to its ‘conservative’ characteristics, it is unlikely that it leads to an underestimation of the risk. It indeed stipulates heavy tail behaviour for the intakes and light tail behaviour for the inter-intake times.
Figure 5. Estimation of the steady-state probability of exceeding u=6.42 for the 15 models with 95% confidence intervals (unit: %, M=1000, B=200).
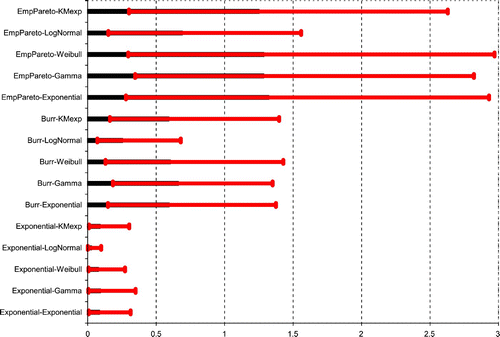
Table 1. Estimation of the steady-state mean and median for the 15 models with 95% confidence intervals (unit: μg/kg bw, M=1000, B=200).
Another interesting statistic is the expected overshoot over a safe level u. In the case of the ‘Burr–Gamma’ model and for u=X ref, 0.7, the estimated expected overshoot is 0.101 μg/kg bw with 95% bootstrap CI [0.033, 0.217], which corresponds to barely less than one average intake. Before turning to the case of level u=X ref, 1.6, illustrates the fact that the exposure process very seldom reaches such high thresholds displaying the estimation of the expected maximum over [0, T] for different values of T.
Figure 6. Estimation of the expected maximum of the exposure process over [0, T] as a function of the horizon T (M=1000, and B=200).
![Figure 6. Estimation of the expected maximum of the exposure process over [0, T] as a function of the horizon T (M=1000, and B=200).](/cms/asset/8be2ffc0-902d-4b75-884e-05c9e2772b49/tjbd_a_422470_o_f0006g.jpg)
Let us now turn to the main risk evaluation, that is, inference of the probability of reaching u=X ref, 1.6=14.67 within a reasonable time horizon. This estimation problem is considered for several time horizons, T=5, 10, 15, and 20 years, in the ‘heavy-tailed’ Burr–Gamma model. Close numerical results, obtained through crude Monte Carlo and multilevel splitting, are shown in .
Figure 7. (Available in colour online). Estimation of the probability of reaching u=X ref, 1.6=14.67 within a reasonable time horizon (Burr–Gamma model, M=1000 is the size of the crude Monte carlo simulation, and 95% simulation intervals are computed over B=100 iterations and shown as error bars in the graphic).
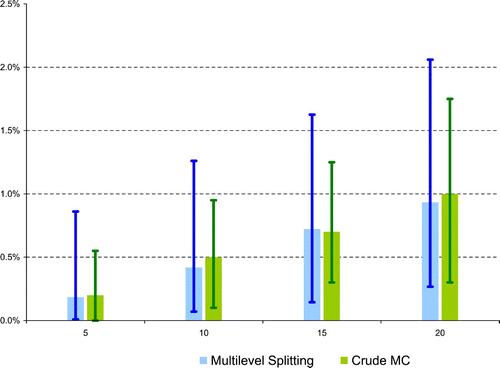
In order to implement the multilevel splitting methodology, a first simulation has been conducted according to the adaptive version proposed by Citation9 using N=1000 particles, so as to determine the intermediary levels u 1,…, u m such that half the particles reach the next sublevel. When T=20 years for instance, the resulting levels are 7.85, 8.65, 9.47, 10.16, 11.07, 11.97, and 13.08 for an estimated probability of 0.52%.
Because they turned out to be inconsistent, empirical results based on the IS methodology are not presented here. This illustrates well the difficulty of choosing the IS distribution properly, as previously discussed.
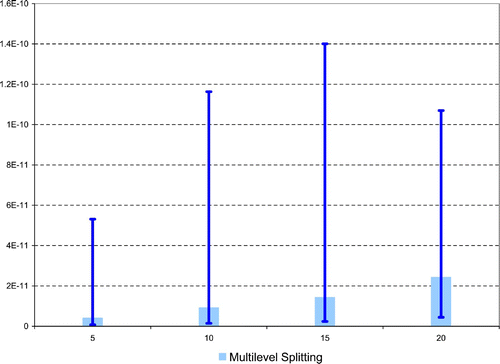
Eventually, we considered the case of the ‘light-tailed’ Exponential–Gamma model, with Exponential intakes and Gamma inter-intake times. In this situation, the crude Monte-carlo procedure is totally inefficient and yields estimates of the probability of reaching the threshold within any of the four time horizons all equal to zero (even if we increase the size of the simulation to M=10, 000 or 100, 000), whereas, in contrast, the multilevel splitting methodology allows to quantify the probability of occurrence of these rare events, as shown in .
Figure 8. Estimation of the probability of reaching u=X ref, 1.6=14.67 within a reasonable time horizon (Exponential–Gamma model, 95% simulation intervals are computed over B=100 iterations and shown as error bars in the graphic).
4.4. Some concluding remarks
Here we have endeavoured to explain how to exploit the data at our disposal, using a simple mathematical model, in order to compute a variety of statistical dietary risk indicators at the population level, as well as their degree of uncertainty. This premier work can be improved in several directions. If more consumption data were available for instance, the inference procedure should take into account the possible heterogeneity of the population of interest in regards to dietary habits: a preliminary task would then consist of adequately stratifying the population in homogeneous classes using clustering or mixture estimation techniques. Considering long term exposure, it could also be pertinent to account for possible temporal heterogeneities and model the evolution of the diet of an individual through time.
Although we showed how to evaluate the fit of various statistical models to the data by means of visual tools or model selection techniques, our present contribution solely aims at providing a general framework and guiding principles for constructing a quantitative dietary risk model. Indeed, certain modelling issues must be left to the risk assessor’s choice, like using extreme value theory for possibly modelling the intake’s tail out beyond the sample (refer to the discussion in Citation39) or incorporating features accounting for the metabolic rate’s variability to the model for instance, according to the availability and quality of the data they require.
Acknowledgements
The first author is also affiliated to CREST-LS, Malakoff, France. The third author is a visiting scholar at the Hong Kong University of Science and Technology, her research is partly supported by Hong Kong RGC Grant #601906.
Notes
Recall that a mapping is said to be càd-làg if for all t>0,
and
Related Research Data
References
- Asmussen , S. 2003 . Applied Probability and Queues , New York : Springer .
- Asmussen , S. and Glynn , P. W. 2000 . Stochastic Simulation , New York : Springer .
- Bertail , P. and Tressou , J. 2006 . Incomplete generalized U-Statistics for food risk assessment . Biometrics , 62 ( 1 ) : 66 – 74 .
- Bertail , P. , Feinberg , M. , Tressou , J. and Verger , P. (Coordinateurs) . 2006 . Analyse des Risques Alimentaires , Paris : TEC&DOC, Lavoisier .
- Bertail , P. , Clémençon , S. and Tressou , J. 2008 . A storage model with random release rate for modelling exposure to food contaminants . Math. Biosci. Eng. , 35 ( 1 ) : 35 – 60 .
- Boon , P. E. , van der Voet , H. and Klaveren , J. D. 2003 . Validation of a probabilistic model of dietary exposure to selected pesticides in Dutch infants . Food Addit. Contam. , 20 ( Suppl. 1 ) : S36 – S39 .
- Brett , M. , Weimann , H. J. , Cawello , W. , Zimmermann , H. , Pabst , G. , Sierakowski , B. , Giesche , R. and Baumann , A. 1999 . Parameters for Compartment-free Pharmacokinetics: Standardisation of Study Design, Data Analysis and Reporting , Aachen, , Germany : Shaker Verlag .
- Bucklew , J. A. 2004 . An Introduction to Rare Event Simulation , Berlin : Springer . Springer Series in Statistics
- Cérou , F. and Guyader , A. 2007 . Adaptative splitting for rare event analysis . Stochast. Anal. Process. , 25 ( 2 ) : 417 – 443 .
- Cérou , F. , Del Moral , P. , LeGland , F. and Lezaud , P. 2006 . Genetic genealogical models in rare event analysis . Alea , 1 : 183 – 196 .
- CREDOC-AFSSA-DGAL . 1999 . “ Enquête INCA (individuelle et nationale sur les consommations alimentaires) ” . Paris : TEC&DOC, Lavoisier . (J.L. Volatier, Coordinateur)
- Crépet , A. , Tressou , J. , Verger , P. and Ch Leblanc , J. 2005 . Management options to reduce exposure to methyl mercury through the consumption of fish and fishery products by the French population . Regul. Toxicol. Pharmacol. , 42 : 179 – 189 .
- Davis , M. H.A. 1984 . Piecewise-deterministic Markov processes: A general class of non-diffusion stochastic models . J. Roy. Statist. Soc. , 46 ( 3 ) : 353 – 388 .
- Davis , M. H.A. 1991 . Applied Stochastic Analysis , London : Taylor & Francis . Stochastics Monographs
- Del Moral , P. 2004 . Feynman–Kac Formulae: Genealogical and Interacting Particle Systems With Applications , New York : Springer . Probability and its Applications
- Edler , L. , Poirier , K. , Dourson , M. , Kleiner , J. , Mileson , B. , Nordmann , H. , Renwick , A. , Slob , W. , Walton , K. and Würtzen , G. 2002 . Mathematical modelling and quantitative methods . Food Chem. Toxicol. , 40 : 283 – 326 .
- Efron , B. and Tibshirani , R. J. 2004 . “ An Introduction to the Bootstrap ” . London : Chapman & Hall . Monographs on Statistics and Applied Probability
- FAO/WHO . 1995 . “ Evaluation of certain food additives and contaminants ” . 859 Forty-fourth report of the Joint FAO/WHO Expert Committee on Food Additives
- FAO/WHO . 2002 . “ Evaluation of certain food additives and contaminants ” . 909 Fifty-seventh report of the Joint FAO/WHO Expert Committee on Food Additives
- FAO/WHO . 2003 . “ Evaluation of certain food additives and contaminants for methylmercury ” . Geneva, , Switzerland : WHO . Sixty first report of the Joint FAO/WHO Expert Committee on Food Additives, Technical Report Series
- Gibaldi , M. and Perrier , D. 1982 . “ Pharmacokinetics ” . In Drugs and the Pharmaceutical Sciences: a Series of Textbooks and Monographs , 2 , New York : Marcel Dekker .
- Gibney , M. J. and van der Voet , H. 2003 . Introduction to the Monte Carlo project and the approach to the validation of probabilistic models of dietary exposure to selected food chemicals . Food Addit. Contam. , 20 ( Suppl. 1 ) : S1 – S7 .
- Glasserman , P. , Heidelberger , P. , Shahabuddin , P. and Zajic , T. 1999 . Multilevel splitting for estimating rare event probabilities . Oper. Res. , 47 ( 4 ) : 585 – 600 .
- Hall , P. 1997 . The Bootstrap and Edgeworth Expansion , Berlin : Springer . Springer Series in Statistics
- IFREMER, Résultat du réseau national d’observation de la qualité du milieu marin pour les mollusques (RNO), 1994–1998
- IPCS, Environmental health criteria 70: Principles for the safety assessment of food. Tech. Rep., WHO, Geneva, 1987, International Programme on Chemical Safety. Available at www.who.int/pcs/
- IPCS, Environmental health criteria 70: Principles for the safety assessment of food additives and contaminants in food. Tech. Rep., Geneva, World Health Organisation, 1987, International Programme on Chemical Safety. Available at www.who.int/pcs/
- Kella , O. and Stadje , W. 2001 . On hitting times for compound Poisson dams with exponential jumps and linear release . J. Appl. Probab. , 38 ( 3 ) : 781 – 786 .
- Lagnoux , A. 2006 . Rare event simulation . Probab. Eng. Inform. Sci. , 20 ( 1 ) : 45 – 66 .
- MAAPAR, Résultats des plans de surveillance pour les produits de la mer, Ministère de l’Agriculture, de l’Alimentation, de la Pêche et des Affaires Rurales, 1998–2002
- NRC (National Research Council) . 2000 . “ Committee on the toxicological effects of methylmercury ” . Washington, DC Tech. Rep.
- Rachev , S. T. and Samorodnitsky , G. 1995 . Limit laws for a stochastic process and random recursion arising in probabilistic modelling . Adv. Appl. Probab. , 27 ( 1 ) : 185 – 202 .
- Rahola , T. , Aaron , R. K. and Miettienen , J. K. 1972 . Half time studies of mercury and cadmium by whole body counting, in Assessment of Radioactive Contamination in Man . Proceedings IAEA-SM-150-13 . 1972 . pp. 553 – 562 .
- Renwick , A. G. , Barlow , S. M. , Hertz-Picciotto , I. , Boobis , A. R. , Dybing , E. , Edler , L. , Eisenbrand , G. , Greig , J. B. , Kleiner , J. , Lambe , J. , Mueller , D. J.G. , Tuijtelaarsand , S. , Vanden Brandt , P. A. , Walker , R. and Kroes , R. 2003 . Risk characterisation of chemicals in food and diet . Food Chem. Toxicol. , 41 ( 9 ) : 1211 – 1271 .
- Rowland , M. and Tozer , T. N. 1995 . “ Clinical Pharmacokinetics: Concepts and Applications ” . Edited by: Lippincott , Williams and Wilkins .
- Smith , J. C. and Farris , F. F. 1996 . Methyl mercury pharmacokinetics in man: A reevaluation . Toxicol. Appl. Pharmacol. , 137 : 245 – 252 .
- Smith , J. C. , Allen , P. V. , Turner , M. D. , Most , B. , Fisher , H. L. and Hall , L. L. 1994 . The kinetics of intravenously administered methyl mercury in man . Toxicol. Appl. Pharmacol. , 128 : 251 – 256 .
- Tressou , J. 2005 . “ Méthodes statistiques pour l’évaluation du risque alimentaire ” . Université Paris X . PhD thesis
- Tressou , J. 2006 . Non parametric modelling of the left censorship of analytical data in food risk exposure assessment . J. Amer. Statist. Assoc. , 101 ( 476 ) : 1377 – 1386 .
- Tressou , J. , Crépet , A. , Bertail , P. , Feinberg , M. H. and Leblanc , J. C. 2004 . Probabilistic exposure assessment to food chemicals based on extreme value theory. Application to heavy metals from fish and sea products . Food Chem. Toxicol. , 42 ( 8 ) : 1349 – 1358 .
- Truhaut , T. 1991 . The concept of acceptable daily intake: an historical review . Food Addit. Contam. , 8 : 151 – 162 .
- Verger , P. , Tressou , J. and Clémençon , S. 2007 . Integration of time as a description parameter in risk characterisation: application to methylmercury . Regul. Toxicol. Pharmacol. , 49 ( 1 ) : 25 – 30 .
- Villén-Altamirano , M. and Villén-Altamirano , J. RESTART: A method for accelerating rare event simulations . 13th Int. Teletraffic Conference, ITC 13 (Queueing, Performance and Control in ATM) . Edited by: Cohen , J. W. and Pack , C. D. pp. 71 – 76 . Amsterdam : North-Holland . Number 15 in North-Holland Studies in Telecommunications. Copenhagen, Denmark
- van der Voet , H. , de Mul , A. and Klaveren , J. D. 2007 . A probabilistic model for simultaneous exposure to multiple compounds from food and its use for risk-benefit assessment . Food Chem. Toxicol. , 45 ( 8 ) : 1496 – 1506 .
- Whitt , W. 2002 . Stochastic-Process Limits. An Introduction to Stochastic-Process Limits and their Application to Queues , Berlin : Springer .
Appendix 1. Technical details
Though formulated in a fairly abstract manner at first glance, the convergence-preservation results stated in Theorem A.1 below are essential from a practical perspective. They automatically ensure, under mild conditions, consistency of simulation-based estimators associated to various functions of statistical interest. Recall that a sequence of estimators of a cumulative distribution function (cdf) F on
is said to be ‘strongly consistent in the L
1-sense’ when
almost surely, as
. Convergence in distribution is denoted by
' in the sequel and we suppose that the Skorohod space
is equipped with the Hausdorff metric d
T
, the euclidean distance between càd-làg curves (completed with line segments at possible discontinuity points), and with the related
topology.
Theorem A.1 (Consistency of simulation estimators, [5])
Let
and for all
, consider a triplet of (random) parameters
that almost surely fulfills conditions (i)–(iv) and defines a stochastic exposure process
. Assume further that
forms an L
1
-strongly consistent sequence of estimators of (G, F
U
) and that
is a strongly consistent estimator of the pharmacokinetics parameter θ.
-
Let
-
Let
Before showing that this result applies to all functionals considered in this paper, a few remarks are in order.
Remark A1 (Monte-Carlo approximation)
When , estimates of the mean F(Φ) may be obtained in practice by replicating trajectories
, m=1,…, M independently from the distribution parameters
and computing the Monte Carlo approximation to the expectation
, that is
Remark A2 (Conditions fulfilled by the distribution estimates)
Practical implementation of the simulation-based estimation procedure proposed above involves computing estimates of the unknown df’s, G and F
U
, according to a L
1-strongly consistent method. These also have to be instrumental probability distributions on , preferably convenient for simulation by cdf inversion. This may be easily carried out in most situations. In the simple case when the continuous cdf on
, F
γ0
, to estimate belongs to some parametric class {F
γ}γ∈Γ with parameter set
such that
and γ↦F
γ(t) for all t≥0 are continuous mappings, a natural choice is to consider the cdf
corresponding to a strongly consistent estimator
of γ0 (computed by MLE for instance). In a nonparametric setup, adequate cdf estimators may be obtained using various regularization-based statistical procedures. For instance, under mild hypotheses, the cdf
associated with a simple histogram density estimator based on an i.i.d. data sample of size n may be shown to classically satisfy, as
,
for all x and
almost surely by straightforward SLLN arguments.
Remark A3 (Rates of convergence)
If the estimator converges to G (resp.
converges to F
U
, resp.
converges to θ) at the rate
(resp.
, resp.
) in probability as
, careful examination of proof of Theorem 2 in Citation5 actually shows that convergence Equation(A2)
takes place in probability at the rate
.
For all , the mapping
is Lipschitz with respect to the Hausdorff distance, strong consistency of simulation estimators of EquationEquation (10)
is thus guaranteed under the assumptions of Theorem A.1.
Besides, is a continuous mapping in the
topology. Thus, we almost surely have
as
in the situation of Theorem A.1. Furthermore, it may be easily shown that
is uniformly integrable under mild additional assumptions, so that convergence in mean also holds almost surely.
Similarly, for fixed T>0, the mapping on that assigns to each trajectory x the temporal mean
(respectively, the ratio
of time spent beyond some threshold u) is continuous. Hence, we almost surely have the convergence in distribution (respectively, in mean by uniform integrability arguments) of the corresponding simulation estimators as
.
The next result guarantees consistency for simulation estimators of steady-state parameters, provided that the runlength T increases to infinity at a suitable rate, compared with the accuracy of the instrumental distributions.
Theorem A.2 (Consistency for steady-state parameters, [5])
Let
be any of the three functions y ↦ y,
or
, with u>0. Set
for any
. Assume that Theorem A.1’s conditions are fulfilled. When
and
so that both
and
almost surely tend to zero, then the following convergences take place almost surely: