
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The largest outbreak of Ebola to date is the 2014 West Africa Ebola outbreak, with more than 10,000 cases and over 4000 deaths reported in Liberia alone. To control the spread of the outbreak, multiple interventions were implemented: identification and isolation of cases, contact tracing, quarantining of suspected contacts, proper personal protection, safely conducted burials, improved education, social awareness and individual protective measures. Devising rigorous methodologies for the evaluation of the effectiveness of the control measures implemented to stop an outbreak is of paramount importance. In this paper, we evaluate the effectiveness of the 2014 Ebola outbreak interventions. We rely on model selection to determine the best model that explains the 2014 Ebola outbreak data in Liberia which is the simplest model with a social distancing term. We couple structural and practical identifiability analysis with the computation of confidence intervals to pinpoint the uncertainty in the parameter estimations. Finally, we evaluate the efficacy of control measures using the Ebola model with social distancing. Among all the control measures, we find that social distancing had the most impact on the control of the 2014 Ebola epidemic in Libreria followed by isolation and quarantining.
1. Introduction
Emerging infectious diseases present challenge to public health every day. Mathematical models can facilitate combating these diseases by projecting potential cases, estimating key parameters of the outbreak, evaluating and optimizing control strategies. The use of mathematical modelling in the control of deadly diseases, such as the Ebola Viral Diseases (Ebola) outbreak of 2014–2015 in West Africa [Citation5], has become wide spread, and numerous models have been created targeting different objectives.
Early in the West Africa Ebola epidemic, a number of mechanistic models were developed, fitted to data and used to predict cases or estimate the reproduction number . Chretien et al. [Citation9] reviewed the models in 66 articles and found that almost all of them estimated
and many of them made projections. The study concluded that articles that estimated
‘using the same data sources at about the same time reported varied results ', a conclusion that is hardly surprising, given the variety of modelling approaches, methods to compute
, uncertainty in the data and a wide-spread un-identifiability of the models. Ignoring the cumulative incidence [Citation13], which in essence codes additional information about the data, further decreases our ability to make estimates that give a coherent picture, potentially useful for public health officials.
The Ebola epidemic in West Africa is over and now is the time to understand the key implications of modelling emerging outbreaks. One of the lessons learned is that not all diseases develop the same in their early (and perhaps more advanced) stages. Chowell et al. [Citation7] suggest that the incidence growth for Ebola in West Africa, particularly on local level, was not exponential, as it might be in an outbreak of influenza, but more reminiscent of the subexponential growth of HIV in the US. This is probably due to public awareness and social distancing. We also find that models with mass action or standard incidence, which comprise a large percentage of the models used, are not adequate to explain the full data sets not only for the Ebola outbreak but also for the worldwide prevalence and death of HIV [Citation22]. For this reason, we use here a modified incidence with an exponential term, incorporated to depict social distancing as the outbreak unfolds. The role of human behaviour in the development and control of infectious disease outbreak cannot be underestimated [Citation15], yet this key component has been included little in models of Ebola outbreak in West Africa.
Most of the models developed for the 2014–2015 Ebola outbreak are based on earlier models of outbreaks from 1995 to 2000 in Congo, Uganda and the Philippines [Citation8,Citation18]. Early and newer models were used for parameter estimation and computation of without investigation of their identifiability. The computation of the confidence intervals quantifies the uncertainty involved in our estimates but these intervals will be different if the model is identifiable in the first place. Only recently, the identifiability of epidemic models is beginning to be investigated [Citation10,Citation24] and these results have not been connected to the confidence intervals.
Several papers address efficacies of interventions, some focusing on specific measures, such as contact tracing [Citation1] or combinations such as isolation, contact tracing and supportive treatment [Citation23]. Other modelling efforts take a more comprehensive view and investigate the impact of multiple control scenarios [Citation20,Citation21]. In general, there are two main ways to incorporate interventions. In the first one, interventions are envisioned as a change in the parameters of a basic model [Citation20], while in the second one interventions are incorporated as the part of the model [Citation21]. The first approach creates difficulties in evaluating which parameter is affected by which control measure and how [Citation20], while the second leads to a much more complex model, holding a greater potential of not being identifiable [Citation21]. Evaluating the efficacies of multiple control measures during the Ebola outbreak, we introduce a mixed approach that collapses a model incorporating multiple interventions to our simple baseline model without interventions but in the process we can evaluate which parameters are affected and how.
In this study, the Ebola outbreak data are collected from the World Health Organization (WHO) reports published at its website [Citation28]. Using the WHO data, we perform model selection on eight Ebola outbreak models, clustered into two groups – depending on whether they incorporate or not a social distancing term. The group without the social distancing term consists of a basic model, a model with exposed class, a model with a quarantined class and a model with both exposed and quarantined class. The second group consists of the same four models but each incorporating a social distancing term. We then use the Akaike Information Criterion (AIC) to choose the model that explains the WHO data best, thus contrasting models with various components: properties of the disease, interventions and/or human behaviour. Once we select the best model, we address the question of the well-posedness of the parameter estimation problem, termed as structural identifiability of the mathematical model. Structural identifiability studies whether the parameters of the model can be recovered from the observed state (output) under ideal conditions such as noise-free data and error-free computation. We analyse the structural identifiability of the selected model without the social distancing term and the practical identifiability of the selected Ebola model considered in this study. We then evaluate the impact of the control measures implemented for the Ebola outbreak by applying the sensitivity methods to rank the public health interventions (education, quarantining, isolation, safe burial and social distancing).
The paper is organized as follows: the Ebola outbreak models are introduced in Section 2 and the AIC criterium is used to compare these models against the data. The structural and practical identifiability of the best fitted models with and without social distancing are performed in Section 3. Confidence intervals for the estimated parameters are also computed. Based on the results of Section 3, in Section 4, the impact of the control measures is evaluated. We then summarize and discuss the results in Section 5.
2. Model selection for Ebola
In this section, we introduce the selection of ordinary differential equation models for Ebola. Ebola is transmitted through bodily fluids, so the main path of transmission is direct [Citation4]. There are two possible outcomes of Ebola infection: death and recovery. References suggest that recovered individuals may continue to be infectious for about 7 weeks after recovery [Citation29]. After 7 weeks, recovered individuals are assumed to be no longer infectious. To encompass the specificity of Ebola, we split the recovered class into two subclasses: recovered but infectious and recovered but no longer infectious. Furthermore, recently deceased individuals who suffered from Ebola continue to be infectious for as long as the body secretes fluids [Citation4]. We incorporate this into the models by allowing deceased individuals to transmit the disease. To introduce the first model, let S be the number of susceptible individuals, I be the number of infectious individuals, R be the number of recovered but still infectious individuals, be the number of removed individuals including the recovered and deceased individuals who are no longer infectious, and D be the number of individuals who died from Ebola. The dependent variables are summarized in Table .
Table 1. List of state variables used in Ebola models.
Ebola is typically modelled as an outbreak disease, and these models do not contain natural human birth and death due to the short duration of the outbreak. The first mathematical model we consider for Ebola takes the following form,
(1)
(1) where β is the transmission rate for Ebola, α is the disease-induced death rate, γ is the recovery rate, η is the rate of progression from infectious to non-infectious recovery,
is the coefficient of reduction or enhancement of transmission of recovered individuals and
is the coefficient of reduction or enhancement of transmission of dead individuals. The relative contribution to the infection of recovered individuals in class R and the deceased individuals in class D is not known.
We introduce total of eight models for Ebola. The parameters for these eight models are summarized in Table . Next, we introduce the nested submodels of the global model ().
Table 2. List of parameters in Ebola models.
In moving to more complicated models, we consider the stages of infection and control measures implemented for Ebola outbreak. Many models of Ebola currently used to describe the unprecedented outbreak in West Africa have an exposed and isolated classes [Citation3,Citation14,Citation25]. Besides the first model , we introduce three more models: one that includes an exposed class,
, (
), one that includes an isolated class,
, (
), and one that includes both an exposed and an isolated class (
). The second model,
, which includes the exposed class is given by the following equations:
(2)
(2) Here the newly infected individuals move into an exposed class, and then they progress to the infectious class. All other classes are as in
(Equation1
(1)
(1) ). Next we introduce a model with isolated class but without an exposed class. The model
which includes the isolated class is given as follows.
(3)
(3) Since the supportive care reflects positively on the disease survivability, the isolated individuals recover and die from the disease at different rates than infectious individuals. The next model
includes both exposed and isolated classes and is given by the following equations:
(4)
(4) In the first four models (
), the new incidences are modelled by ‘mass-action’ term which states that the number of contacts and the probability that the contact will result in transmission of the infection is assumed in a homogenous population. Thus the behavioural influences of individuals towards an emerging Ebola outbreak are not considered. We continue by including behavioural influences in modelling new incidences. Behaviour epidemiology of infectious diseases is an emerging subdiscipline that studies the complex interaction between the human behaviour in response to an infectious disease and the impact of that behaviour on the disease characteristics and dynamics. Behaviour modifications are typically incorporated into mathematical models through including additional classes that signify alternative behaviour [Citation15]. In this article, we use a different, more parsimonious approach by incorporating social distancing as an exponential term modifying transmission. Influence of social distancing in the new cases is modelled by multiplying the mass action incidence term with the exponential term
where κ denotes the rate of social distancing. As the number of infections and disease-induced deaths increase in the population, number of contacts per individual will decrease due to social distancing. We incorporate social distancing into these four models (
) and obtain total of eight outbreak Ebola models. The models
through
incorporate social distancing to the first four models. The model
is constructed by adding social distancing to the model (
). Hence, the model
takes the following form:
(5)
(5) Similarly, the model (
) is constructed by adding the social distancing term to the model (
). The eight-model modelling framework is summarized in Table . The model (
) is referred as the global model, since all the remaining models are nested in this model. All models are special cases of the following global model:
(6)
(6) The parameters of the models
–
are estimated by fitting in the least squares sense to cumulative number of Ebola cases (
) and the cumulative number of Ebola deaths (
) in Liberia. Thus we use an optimization routine in MATLAB to minimize the following Sum of Squares Errors (SSE) for both data sets
where
are the cumulative number of cases and
are the cumulative number of deaths given by WHO at time
. The cumulative cases and deaths given by WHO are plotted in Figure (a,b). To minimize the SSE, we use the Nelder–Mead iterative solver built in MATLAB.
Figure 1. WHO reported data: (a) cumulative number of incidences as reported by WHO for 2014 Liberia Ebola outbreak and (b) cumulative number of deaths as reported by WHO for 2014 Liberia Ebola outbreak.
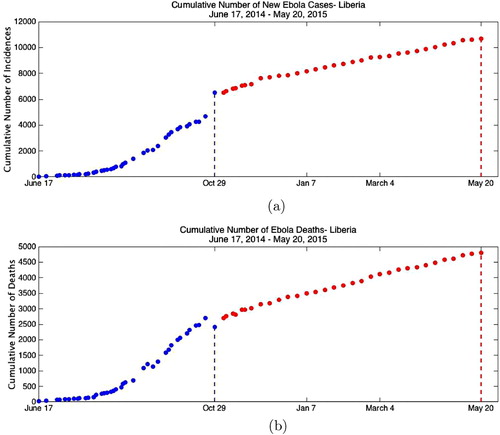
Figure 2. Fitting results. (a) Piecewise fit of cumulative incidences. The WHO reported cumulative incidences are plotted together with the model output. The model
is evaluated with the fitted parameters given in Table . (b) Piecewise fit of cumulative deaths. The WHO reported cumulative deaths are plotted together with the model
output. The model
is evaluated with the fitted parameters given in Table .
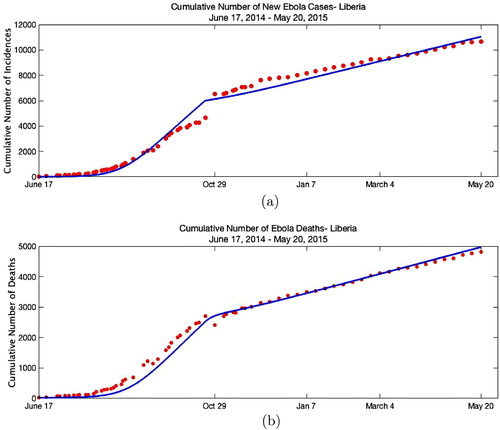
Table 3. List of nested models.
As for every iterative optimization procedure, it is crucial to define initial values for each parameter that would find a global minimum. In an attempt to choose the best initial parameter values for the iterative solver, we performed the following procedure. Because of the structural identifiability issues of the models considered in this research, the rate that the recovered individuals loose their infectiousness is fixed, that is η is set to 1/25 (details are given in Section 3). The incubation period of the Ebola is 2 to 21 days, hence the initial guess for the parameter σ is set to 1/12. A random number generator is used to generate initial values for α, , γ and
on the interval [0.05, 2], initial values for
and
on the interval [0,1], initial value of ν on the interval [0.1, 2]. The proportion of isolated in all infected classes is targeted for
. Thus, with the assumption that
, the value for ξ was then calculated as
. The basic reproduction number
of the models
,
,
and
is given by
The basic reproduction number
of the models
and
is given by
The basic reproduction number
of the models
and
is given by
A random value for
on the interval (http://www.livescience.com/48962-ebola-transmission-rate-down.html) [1, 3] is selected, then using the value of
the initial guess for the parameter β is obtained.
The results of the fitting with SSE values of each model are presented in Table . Since, for each model different number of parameters are fitted comparing SSE values in determining the best model is not appropriate. Hence, the corrected Akaike Information Criterion (AIC) is used to decide which model(s) best describes the data [Citation2].
Table 4. List of SSE and AIC for different models.
Data for several of the recently affected countries by Ebola, such as Sierra Leone, Liberia and Guinea can be obtained from [Citation28]. The cumulative number of incidences and deaths in Liberia were reported by WHO starting on 17 June 2014 continuing till 20May 2015. The outbreak in Liberia was declared over on 9 May 2015, 42 days after the death of the last confirmed case. We collected the data from these reports published by WHO at its website [Citation28]. The cumulative cases are the total number of confirmed, probable and suspected cases. The data are not evenly distributed till 26 November 2015. After that the reports are given every week, and hence the data after 26th November are evenly distributed. Observing the data, one can see that there is an unusual increase of cumulative cases on 29th October and a decrease on cumulative deaths. The WHO report on 29th October states that ‘increase in the cumulative total number of cases compared with the situation report of 22nd October results from a more comprehensive assessment of patient databases. The additional cases have occurred throughout the epidemic period, not only since 22nd October [Citation27] '. (All the WHO reports are available from the authors if requested.)
As seen from Figure (a), there is a jump in the cumulative number of incidences reported by WHO on 29 October 2014. To incorporate the steep revision made on 29th October through the epidemic period, time-dependent social distancing rate is imposed, hence model becomes
(7)
(7) Here
denotes the Heaviside function and
is the time data point corresponding to 29 October 2014. The fitted values of the parameters of the model
are given in Table . As given in Table , the estimated period of infectiousness
agrees with the results given in [Citation12]. The confidence intervals presented in Table are computed using the Statistical Toolbox (nlparci) in MATLAB. For the death data, we use data reported by WHO. However, for a fraction of hospitalized cases the definitive outcome (death or recovery) was not recorded in individual records. Therefore, the cumulative number of deaths reported to the WHO during the Ebola outbreak in West Africa was an underestimate of the actual number. In particular, work of the WHO-led team [Citation26] suggests that early in the epidemic the case-fatality proportion might have been up to 70% while the published WHO data for Liberia for the early stage of the epidemic suggest that it was approximately 50%. To examine the impact of this discrepancy on the estimated parameters of the selected model, we increase the death cases by 20% and fit to the increased data. The new estimates of the parameters are presented in Table together with the confidence intervals. Results suggest that the change in the parameters is relatively small.
Table 5. Parameter estimates of the Ebola model  .
.
Table 6. Parameter estimates of the Ebola model when cumulative deaths have been increased by 20.
3. Identifiability and parameter estimation
The purpose of this study is to evaluate the efficacy of control measures implemented to limit the spread of the Ebola outbreak. Hence, these results highly depend on accurately estimating the parameters of the outbreak model from the reported data by the health organizations. So, it is crucial to study the well-posedness of the parameter estimation problem for the given observations such as cumulative incidences and deaths. A model is said to be identifiable if for given large enough set of data points, free of errors, it is theoretically possible to uniquely determine the parameter values from the observations that generated these data points. If two or more parameter sets can lead to the same observational output, the model is called non-identifiable. If the model is not identifiable, then it is not possible to estimate the ‘true values’ of the parameters. There are multiple ways to test for the identifiability of a model: Taylor's or Generating series approaches, identifiability tableaus, differential algebra approach and others [Citation6]. In this study, we use the differential algebra approach which is designed specifically to test for the identifiability of (nonlinear) differential equation models. We briefly explain the differential algebra approach here, but for more detailed review we refer the reader to [Citation17]. To set up the problem, without loss of generality the outbreak models can be expressed in the following compact form:
(8)
(8) where
denotes the parameters of the system,
denotes the states of the system and
is the initial values. The observations, which in this study are cumulative number of cases and deaths, are given by the output function
. The definition of the structural identifiability is given in the literature as [Citation17].
Definition 3.1
A parameter set is called structurally globally (or uniquely) identifiable if for every
in the parameter space
That is any unequal parameter set yields different observations and hence the corresponding noise-free data are as well distinct.
The first step in differential algebra approach is to find the input–output equations of the dynamical model (Equation8(8)
(8) ). This is done by reducing the model to its characteristic set via Ritt's algorithm. The characteristic set is then used to derive the input–output equations which contains all the identifiability information of the model. Input–output equations simply put are a subset of the characteristic set. The characteristic set of a dynamical ODE model is not unique, hence it depends on the chosen ranking of the state variables. However, the coefficients of the input–output equation can be fixed uniquely by normalizing the equations to make them monic.
To illustrate the approach on a simple example, consider the following simplification of the model ,
(9)
(9) Suppose now that we observe the cumulative incidences. Hence,
If we know the initial number of susceptibles,
, cumulative incidences are equivalent to observing S. To obtain an input–output equation, we eliminate the unobserved states, I and R from the system, and obtain equation in S and its derivatives. We express I from the first equation, we differentiate I with respect to t and we eliminate I and
from the second equation. We obtain the following input–output equation:
(10)
(10) Within the differential algebra approach, the ODE model is said to be structurally identifiable if the map from the parameter space to the coefficients of the input–output equations is injective [Citation10]. Thus the definition of the structural identifiability becomes
Definition 3.2
The dynamical model is globally identifiable if and only if
where
are the coefficients of the normalized input–output equation.
Suppose to the contrary that there exist another set of parameters which produced the same observation, then
yield to the following set of equations:
Therefore, if we only observe cumulative incidence, we can only identify β and the sum of
but not α and γ individually. So, we claim that the model (Equation9
(9)
(9) ) is not identifiable from the cumulative incidence observations.
Suppose now that in addition to the cumulative incidence, we observe cumulative deaths, which for most diseases, including Ebola, are done. In this case, we add another variable CD which gives the cumulative deaths. We have CD
and the output function is
In this case, in addition to the input–output equation (Equation10
(10)
(10) ), we obtain a second input–output equation which may contain CD and its derivatives. To obtain the second input–output equation, in the equation CD
we replace I with its expression in terms of S and
obtained from the first equation. We get
So, if there is another input–output equation with parameters
and
, then
and
. Thus we can identify β, α and
. But since we can identify α and
, this means that we can identify γ. Therefore, model (Equation9
(9)
(9) ) is identifiable only when both cumulative incidences and deaths are observed.
The situation is similar with the model (Equation1
(1)
(1) ). We need to fit both cumulative incidences and cumulative deaths to expect identifiability. With the model
computing the input–output equation is not possible by hand. We use MAPLE to derive the input–output equation in each case. After that, we use MATHEMATICA to solve the systems
for the coefficients. In the case of the model
(Equation1
(1)
(1) ), we obtain the following solutions:
(11)
(11) Hence, there are two sets of solutions and therefore, the model
(Equation1
(1)
(1) ) is not identifiable. We select and fix η from additional biological information. Because η is the duration of infectiousness of the recovered class and it is estimated to last up to 7 weeks [Citation29], we set
. That is having
in (Equation11
(11)
(11) ), the parameters of the model
(Equation1
(1)
(1) ) become identifiable. Since, the model
(Equation1
(1)
(1) ) is the simplest model among the nested models of
through
, we fix η to 1/25 while estimating the parameters of models
through
.
Structural identifiability analysis of the model (Equation7
(7)
(7) ) is not possible by means of differential algebra approach, since the approach requires
to be rational functions of the state variables
. Because of the social distancing term, we cannot further analyse the structural identifiability of the model
, but we study the practical identifiability of the model
(Equation7
(7)
(7) ) by Monte Carlo simulations.
Let denote the parameters, and
denote the states of the system (Equation7
(7)
(7) ). We assume that initial values of the system can be determined by other means, and we are only interested in the parameters that would determine the reproduction number. Since for identifiability issues, we fix
, through least squares, we would like to recover the true parameter set,
The observations of the system,
made at the data time points
, are obtained by adding the observational errors to the model output, hence
where
represents the vector output of the system involving both cumulative incidences and deaths and
is the vector of observations made at discrete time
. The random variables
represent the measurement errors which cause the observations
to drift away from the smooth exact path
. In a more general setting, the errors satisfy the following form, which allows fairly wide range of error models,
(12)
(12) where
.
are assumed to be independent, identically distributed random variables with mean zero and finite variance
. The mean and the variance of the random variables
satisfy,
, Var
respectively. For the model (Equation7
(7)
(7) ), the cumulative number of incidences can be determined from the susceptible population by the following representation:
and the cumulative deaths, CD
will be evaluated by augmenting the following differential equation to the model (Equation7
(7)
(7) ),
Hence,
and
With this setting, the least squares problem is to find the parameter set
which minimizes the following cost functional:
(13)
(13)
The Monte Carlo simulations we performed are outlined in the following steps. We take the estimated parameters given in Table as the true parameter set.
Solve the epidemiological model numerically with the true parameters
Generate M=1000 residual vectors
Fit the model
Calculate the average relative estimation error for each parameter in the set
Repeat steps 1 through 4 with increasing level of noise, that is take
We present the results of Monte Carlo simulations in Tables and with AREs computed with increasing error levels . The computed AREs give an insight about the identifiability of the parameters of the model
. If a model is structurally identifiable, then when there is no noise in the data (when
), the AREs would be 0 or very close to 0. As the standard deviation (
) increases, the AREs of the parameters increase as well. The parameters which are not practically identifiable would be very sensitive to the error levels in the data and AREs of those parameters would be larger than the measurement error (for example, see
and
in Table ). Since
and
are practically unidentifiable, we fix those parameters to the estimated values, and observe that the AREs of the rest of the parameters have increased with the exception of unidentifiable parameters κ and
(see Table ).
Table 7. Monte Carlo simulations.
Table 8. Monte Carlo simulations when and are fixed to estimated values.
4. Control strategies
Main control strategies for Ebola include early identification and isolation of cases, contact tracing and quarantining of suspected contacts, proper personal protection, safely conducted burials, improved education and social awareness about risk factors of Ebola infection and individual protective measures. Quarantine and isolation have been previously modelled in connection with SARS [Citation19]. The impact of social awareness has been included in several articles on Ebola [Citation11,Citation21]. The contact tracing is implicitly incorporated in the quarantine and isolation but Ebola model with explicit contact tracing was considered in [Citation1]. We include quarantine, isolation, education (awareness), safe burial and social distancing. The WHO publishes ‘How to conduct safe and dignified burial of a patient who has died from suspected or confirmed Ebola virus disease’ on October 2014 (http://www.who.int/csr/resources/publications/ebola/safe-burial-protocol/en/).
To elucidate the impact of control measures on the parameters of our baseline model (), we consider an expanded model with the education included explicitly. We denote the non-educated susceptibles by
and the educated susceptibles by
, quarantined susceptibles by
, individuals in their incubation period by E, quarantined latent by
and isolated individuals by Q, recovered educated by
and recovered non-educated by
. Quarantining occurs at a rate
for educated individuals and rate ρ for others.
Quarantined susceptibles move to educated susceptible class at rate θ, infected individuals move to the isolation class at rate ξ and the quarantined latent individuals move to the isolation class at rate . Isolated individuals recover at rate
and move to the educated recovered class. The state variables for the model with control measures are summarized in Table and the parameters of the model are summarized in Table . The model with control measures takes the form:
(14)
(14) where
. To understand the impact of the control measures on the parameters, we collapse the model with control measures (Equation14
(14)
(14) ) to the model
as given in (Equation7
(7)
(7) ). The susceptibles S in model
are the sum of classes
,
and
in model (Equation14
(14)
(14) ). Adding the first three equations in (Equation14
(14)
(14) ), we obtain
(15)
(15) where
is the proportion of individuals of class
in all susceptible individuals (
), for i=N,E. In model (Equation14
(14)
(14) ), this proportion is a dynamic variable. In model
, this proportion is a constant. We assume it is a constant. Furthermore,
is the proportion of quarantined latent individuals (
) among all infected (
),
is the proportion of isolated individuals among all infected and
is the proportion of latent individuals among all infected. In addition,
and
are the fractions of educated and non-educated individuals among all recovered. The population proportions and their formulations are presented in Table .
Table 9. List of state variables used in model (Equation14(14) (14) ).
Table 10. List of new parameters introduced in model (Equation14(14) (14) ).
Table 11. List of population fractions used in evaluating the control measures.
We have assumed that individuals who have been isolated before recovery are educated after recovery, while individuals who have not been isolated, are not educated. This assumption can be easily relaxed. The sum corresponds to the class of all infected individuals in model
and
corresponds to the class of all recovered individuals. Comparing (Equation15
(15)
(15) ) with the first equation in
we see that β is replaced by
. While
may be obtained from the literature, that is not the case for
and
. Let the hat denote the average of a function, that is
where T is the time at the end of the epidemic (data). Taking the average of the equation for
, we have
since
. Consequently,
. Here we have assumed that the constant values of the proportion education, non-educated and quarantines can be estimated from the corresponding fractions of the function averages over the interval
. Combining this equation with the equation that
, we obtain
(16)
(16) Substituting
into
, we have the following controlled value of β:
Furthermore, we notice that the coefficient in front of the number of infected individuals in the force of infection has changed from one to
The proportions of isolated and quarantined individuals will have to be estimated from the literature. We will discuss the value of later. Next we notice that the controlled version of
takes the form
In estimating
and
, we notice that
Hence,
From here we obtain
(17)
(17)
Total susceptible individual in (Equation14
(14)
(14) ) equals to the susceptible class S in model
, total infected class
in (Equation14
(14)
(14) ) equals to the total infected class I in model
and total recovered
in (Equation14
(14)
(14) ) equals to the recovered class R in
, comparing (Equation15
(15)
(15) ) with
we obtain
(18)
(18) Fitting the model
to the WHO data, we obtain the controlled values
which are related to the model with control measures (Equation14
(14)
(14) ) through following equations:
(19)
(19) In Tables and , we list the effect of each control measure on the parameters of model
. For instance, to evaluate the effect of quarantining on model
parameters, we set the proportion of the population undergoing all other control measures to zero in (Equation19
(19)
(19) ). Hence, setting
and
, we obtain
and
by (Equation17
(17)
(17) ). Then (Equation19
(19)
(19) ) becomes
(20)
(20) Thus quarantining effects the parameters
and γ of model
as shown in (Equation20
(20)
(20) ). The results of the similar analysis for all the other control measures are presented in Tables and . As seen in these tables, counter-intuitively education effects only parameters β and
. With this methodology, we determine which control measures effect which parameters of the model
, and then with this information we evaluate the efficacy of the control measures.
Table 12. Control strategies and their impact on parameters where is the estimated value of κ under the control measures.
Table 13. Control strategies and their impact on parameters where is the estimated value of κ under the control measures.
To evaluate the efficacy of the control measures, we adapt the methodology introduced by Martcheva [Citation16]. The methodology is based on the sensitivity analysis and elasticities of the parameters on the cumulative number of incidences and deaths. Sensitivity analysis of the model predictions to small changes in parameters can help determine which parameters should be the best targets for disease control and slowing the epidemic. For instance, let λ be a quantity depending on two parameters of different scales; . Then the sensitivity of λ with respect to parameters p and q is
The sensitivity
gives the amount of change occurred in λ in response to small changes in p. However, since p and q are parameters with different scales, the effect of changes in p and q on λ cannot be easily compared. We use the normalized sensitivity, called elasticity, of the quantity λ with respect to parameter p given by
The elasticity
gives how much and in what way the quantity λ will be affected by small changes in p. A negative elasticity means that
increase in the parameter p will result in
decrease in λ. Similarly, a positive elasticity means
increase in the parameter p will result in
increase in λ. Suppose λ is either cumulative incidences or deaths, then the efficacy of the control measure on λ is defined as the combined elasticity of parameters influenced by the control measure. For instance, the quarantining will effect the parameters
and γ, hence the efficacy of the quarantining on cumulative incidences (CI) is calculated by
We calculate the sensitivities by calculating the sensitivity functions. Namely, if the model is given in the compact form as in (Equation8
(8)
(8) ), then the sensitivity functions are
(21)
(21) We obtain the sensitivities by numerically solving model
together with its sensitivity functions at the final time of the WHO data, that is on May 20. The efficacy of control measures together with the parameters influenced are given in Tables and .
Table 14. Efficacies of control strategies on cumulative incidences.
Table 15. Efficacies of control strategies on cumulative deaths.
5. Discussion
In this study, we first perform model selection analysis for the 2014 Ebola outbreak in Liberia. We develop eight nested models of the Ebola outbreak where each model incorporates the two main characteristics of the Ebola infection: (i) the recovered individuals continue to be infectious for up to 7 weeks after recovery and (ii) deceased individuals who are not yet buried continue to transmit the disease if safe burial practices are not implemented during funerals. Then with increasing complexity, the nested models incorporate latent period of Ebola infection, isolation of infected individuals and social distancing. By fitting all these eight models to the WHO reported cumulative incidences and deaths, and using the AIC we found that the best model that explains the 2014 Liberia Ebola outbreak is
, the model with social distancing but without the exposed and isolated classes.
The evaluation of effectiveness of the interventions implemented to control an outbreak depends on accurately estimating model parameters. Since there are no direct ways of estimating epidemiological parameters such as transmission, recovery and disease-induced mortality rates, the indirect methods are used to estimate the parameters of mathematical model from the incidence reports provided by health agencies as the outbreak progresses. However, the inverse problems are ill-posed and the estimates of the parameters in fitting might not be reliable. Thus we continue with studying the identifiability of the parameters of the Ebola outbreak models introduced in this study. We first perform structural identifiability of the model . The structural identifiability methods analyse whether the parameters are uniquely identifiable given that the correct model is used and the process is observed in continuous time without error. This is a priori analysis and can be applied without considering the actual data. We used differential algebra approach to study the structural identifiability of model
parameters and concluded that if the duration of infectiousness of recovered individuals is fixed, then all the parameters are structurally identifiable. Since model
is the simplest of all eight models considered in this study, we fix the infectiousness period of recovered individuals to 25 days in all the fittings performed in this study. However, despite being structurally identifiable a model may not be practically identifiable, since noisy data may produce parameters with infinite confidence intervals. We further analysed the best fitted model
for practical identifiability. Monte Carlo simulations stated that the parameters
and
are practically unidentifiable and the ARE of the parameters have decreased when
and
fixed to estimated values.
In evaluating the effectiveness of the control measures, it is crucial to distinguish which parameters are affected by the control measures. When several interventions implemented at the same time, it is not clear to determine the impact on the parameters by the control measures. We introduce a new methodology to specify the influence of the control measures on the parameters of the model. The methodology we introduce in this study allows incorporation of control measures which are not modelled in the base line model. We then evaluate the efficacy of isolation, quarantining, education, safe burial and social distancing using the methodology in [Citation16]. We found that among all the interventions social distancing was the most effective control measures in 2014 Ebola infections in Liberia.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Necibe Tuncer http://orcid.org/0000-0002-6388-2499
Additional information
Funding
References
- C. Browne, H. Gulbudak and G. Webb, Modeling contact tracing win outbreaks with application to Ebola, JTB 384 (2015), pp. 33–49. doi: 10.1016/j.jtbi.2015.08.004
- K.P. Burnham, D.R. Anderson, Model selection and multimodel inference: A practical information-theoretic approach. 2nd ed. Springer, New York, 2002.
- A. Camachoa, A.J. Kucharskia, S. Funka, J. Bremanb, P. Piotc and W.J. Edmundsa, Potential for large outbreaks of Ebola virus disease, Epidemics 9 (2014), pp. 70–78. doi: 10.1016/j.epidem.2014.09.003
- Centers for Disease Control and Prevention, Ebola (Ebola Virus Disease). Available at http://www.cdc.gov/vhf/ebola/transmission/index.html?s_cid=cs_3923
- Centers for Disease Control and Prevention, About Ebola Virus Disease. Available at http://www.cdc.gov/vhf/ebola/about.html
- O.-T. Chis, J.R. Banga and E. Balsa-Canto, Structural identifiability of systems biology models: A critical comparison of methods, PLoS One 6(11) (2011), pp. e27755. doi: 10.1371/journal.pone.0027755
- G. Chowell, C. Viboud, L. Simonsen, Perspectives on model forcasts of the 2014–2015 Ebola epidemic in West Africa: lessons and the way forward. BMC Med. 15(42) (2017), pp. 1–8
- G. Chowella, N.W. Hengartnerb, C. Castillo-Chaveza, P.W. Fenimorea and J.M. Hyman, The basic reproductive number of Ebola and the effects of public health measures: The cases of Congo and Uganda, J. Theor. Biol. 229(1) (2004), pp. 119–126. doi: 10.1016/j.jtbi.2004.03.006
- J.P. Chretien, S. Raley and D.B. George, Mathematical modeling of the West Africa Ebola epidemic, eLife 4 (2015) e09186. doi: 10.7554/eLife.09186
- M. Eisenberg, S. Robertson and J. Tien, Identifiability and estimation of multiple transmission pathways in cholera and waterborne disease, JTB 324 (2013), pp. 84–102. doi: 10.1016/j.jtbi.2012.12.021
- S.M. Fast, S. Mekaru, J.S. Brownstein, T.A. Postlethwaite and N. Markuzon, The role of social mobilization in controlling Ebola virus in Lofa County, Liberia, PLOS Curr. Outbreaks 7 (2015). doi:10.1371/currents.outbreaks.c3576278c66b22ab54a25e122fcdbec1.
- H. Feldmann and T.W. Geisbert, Ebola haemorrhagic fever, Lancet 377(9768) (2011), pp. 849–862. doi: 10.1016/S0140-6736(10)60667-8
- A.A. King, M. Domenech de Cells, F.M.G. Magpantay and P. Rohani, Avoidable errors in the modelling of outbreaks of emerging pathogens, with special reference to Ebola, Proc. R. Soc. Lond. Ser. B282(1806) (2015), pp. 20150347. doi: 10.1098/rspb.2015.0347
- J. Legrand, R.F. Grais, P.Y. Boelle, A.J. Vallerron and A. Flahault, Understanding the dynamics of Ebola epidemics, Epidemiol. Infect. 135 (2007), pp. 610–621. doi: 10.1017/S0950268806007217
- P. Manfredi, A. d'Onofrio, Modeling the interplay between human behavior and the spread of infectious diseases, Springer, New York, 2013.
- M. Martcheva, Avian Flu: Modeling and implications for control, J. Biol. Syst. 22(151) (2014).
- H. Miao, X. Xia, A.S. Perelson and H. Wu, On identifiability of nonlinear ODE models and applications in in viral dynamics, SIAM Rev. 53(1) (2011), pp. 3–39. doi: 10.1137/090757009
- M.E. Miranda, T.G. Ksiazek, T.J. Retuya, A.S. Khan, A Sanchez, C.F. Fulhorst, P.E. Rollin, A.B.Calaor, D.L. Manalo, M.C. Roces, M.M. Dayrit and C.J. Peters, Epidemiology of Ebola (Subtype reston) virus in the Philippines, J. Infect. Dis. 179 (1996), pp. 115–119. doi: 10.1086/514314
- A. Mubayi, C. Kribs-Zaleta, M. Martcheva and C. Castillo-Chavez, A cost-based comparison of quarantine strategies for new emerging diseases, Math. Biosci. Eng. 7(3) (2010), pp. 689–719. doi: 10.3934/mbe.2010.7.687
- C.M. Rivers, E.T. Lofgren, M. Marathe, S. Eubank and B.L. Lewis, Modeling the impact of interventions on an epidemic of Ebola in Sierra Leone and Liberia, PLOS Curr. Outbreaks (2014). doi:10.1371/currents.outbreaks.fd38dd85078565450b0be3fcd78f5ccf.
- A. Shen, Y. Xiao and L. Rong, Modeling the effect of comprehensive interventions on Ebola virus transmission, Sci Rep 5 (2015), pp. 15818. doi: 10.1038/srep15818
- S. Swanson, A simple model for human immunodeficiency virus based on Erlang's method of stages, SIURO 10 (2017), pp. 65–80. doi: 10.1137/17S015732
- The New England Journal of Medicine, Ebola 2014 New Challenges, New Global Response and Responsibility. Available at http://www.nejm.org/doi/full/10.1056/nejmp1409903
- N. Tuncer, H. Gulbudak, V. Cannataro and M. Martcheva, Structural and practical identifiability issues of immuno-epidemiological vector-host models with application to Rift Valley Fever, Bull. Math. Biol. 78(9) (2016), pp. 1796–1827. doi: 10.1007/s11538-016-0200-2
- G. Webb, C. Browne, X. Huoet al., A model of the 2014 Ebola epidemic in West Africa with contact tracing. PLOS Current Outbreaks, (2015). doi:10.1371/currents.outbreaks.846b2a31ef37018b7d1126a9c8adf22a
- WHO Ebola Response Team, Ebola virus disease in West Africa – the first 9 months of the epidemic and forward projections, N. Engl. J. Med. 371 (2014), pp. 1481–1495. doi: 10.1056/NEJMoa1411100
- WHO Ebola Situation Reports. Available at http://apps.who.int/iris/bitstream/10665/137376/1/roadmapsitrep_29Oct2014_eng.pdf?ua=1
- World Health Organization, Ebola Virus Disease Outbreak News. Available at http://www.who.int/csr/don/archive/disease/ebola/en/
- World Health Organization, Frequently Asked Questions on Ebola Virus Disease. Available at http://www.who.int/csr/disease/ebola/faq-ebola/en/