?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Stochastic epidemic models with two groups are formulated and applied to emerging and re-emerging infectious diseases. In recent emerging diseases, disease spread has been attributed to superspreaders, highly infectious individuals that infect a large number of susceptible individuals. In some re-emerging infectious diseases, disease spread is attributed to waning immunity in susceptible hosts. We apply a continuous-time Markov chain (CTMC) model to study disease emergence or re-emergence from different groups, where the transmission rates depend on either the infectious host or the susceptible host. Multitype branching processes approximate the dynamics of the CTMC model near the disease-free equilibrium and are used to estimate the probability of a minor or a major epidemic. It is shown that the probability of a major epidemic is greater if initiated by an individual from the superspreader group or by an individual from the highly susceptible group. The models are applied to Severe Acute Respiratory Syndrome and measles.
1. Introduction
In the twenty-first century, one of the biggest threats to public health is the spread of infectious diseases [Citation35]. According to the World Health Organization, population mobility and the interconnectedness of the world's population have contributed to the global spread of infectious diseases [Citation31,Citation35]. Infectious diseases are one of the leading causes of death globally and the third leading cause of death in the United States [Citation30]. Emerging and re-emerging infectious diseases include Severe Acute Respiratory Syndrome (SARS), Middle East Respiratory Syndrome (MERS), Ebola, Zika, influenza A, yellow fever, cholera, measles, pertussis, tuberculosis, and AIDS [Citation35].
Recent emerging diseases have been attributed to highly infectious individuals, called superspreaders, who spread the disease to a large number of people [Citation25]. Historically, superspreading events came to the forefront at the beginning of twentieth century. In the early 1900s, an individual referred to as Typhoid Mary was identified as a superspreader; she infected 51 people before being recognized as the source of infection [Citation23]. Superspreading events have been identified in disease outbreaks of SARS, MERS, and Ebola [Citation40]. Superspreading events are due to many reasons including physiological, immunological, and behavioural differences in individuals or due to emergence of a new pathogen or exposure to a new environment [Citation34]. During the SARS outbreak in China in 2003, a total of 774 people died and 8096 were infected [Citation40]. The index case, a superspreader, was responsible for infecting 125 people. During the MERS outbreak in 2015 in South Korea, 186 people were infected, and 36 people died [Citation40]. Two superspreaders were responsible for infecting 106 people [Citation40].
The waning of vaccine effectiveness or loss of protection from prior infection also cause some re-emerging diseases. Individuals may be highly susceptible to infection due to waning immunity. For example, in pertussis the immunity from vaccination remains effective for 4–12 years, whereas immunity from prior infection is much longer, 4–20 years [Citation32,Citation38]. For measles, the immunity from vaccination can protect against re-infection for up to 20 years for two doses but is less effective for only one dose [Citation22]. In a measles outbreak in 2011, 110 high school students were infected; the attack rate was much less for students with two vaccine doses [Citation11].
Modelling superspreaders has been the subject of many recent papers (e.g. [Citation9,Citation13,Citation20,Citation24–27]). Chowell et al. [Citation9] modelled superspreaders in an MERS epidemic by considering a complex SEIR model with hospitalization, where specific superspreaders were modelled. In [Citation24], Lee et al. extended the model for an MERS epidemic in South Korea with an SEIJR model, where J represented infectious individuals that were isolated. In a mathematical model for SARS with superspreaders, Mkhatshwa and Mummert [Citation27] included four different classes in their model, susceptible, infected, superspreader, and recovered classes. In a two-group model applied to spread of SARS [Citation26], transmission between patients in a hospital and outside visitors were analysed in terms of the final epidemic size. These preceding models were ordinary differential equations (ODEs). In the papers by James et al. [Citation20] and Lloyd-Smith et al. [Citation25], discrete-time branching processes were employed to relate transmission heterogeneity to superspreading events and to fit models to particular outbreaks. Lloyd-Smith et al. [Citation25] showed for a heterogeneous population that average quantities such as the basic reproduction number do not adequately describe the effect of individual variation. Edholm et al. [Citation13] developed a continuous-time Markov chain (CTMC) two-group model for superspreaders and non-superspreaders. They applied their stochastic model to MERS and Ebola, performed extensive numerical simulations, and used branching process approximations to compare disease epidemics initiated by superspreaders to non-superspreaders.
Similar to the model of Edholm et al. [Citation13], we apply stochastic two-group models, CTMC models, and branching process approximations. We extend the two-group setting to consider the case where the transmission rate is dependent on either infectious or susceptible hosts, applicable to emerging and re-emerging infectious diseases. In addition, we prove there is a difference in probability of a minor or major epidemic, that is dependent on the particular group. It is verified that the probability of a major epidemic is greater if initiated by an infected individual from the highly infectious group (superspreader) or if initiated by an infected individual from the highly susceptible group. We discuss applications to SARS and measles.
In the next section, a two-group SIR model for epidemic spread is described, a system of ODEs. This model serves as a framework for formulation of two stochastic generalizations, CTMC models that include groups with either high and low infectivity or high and low susceptibility. In Section 4, continuous-time multitype branching processes are used to approximate the probability of a minor or a major epidemic. In Section 5, we show that the results extend to SEIR models when the group sizes are constant. We apply these models to potential SARS [Citation26] and measles epidemics [Citation11]. The sensitivity of and the probability estimates to group size and transmission and recovery rates are also investigated.
2. Two-group SIR model
Consider a SIR model for a heterogeneous population with two groups. The model has two susceptible, two infectious and two recovered groups with different transmission and recovery rates for each group. The model has the following form:
(1)
(1) for k=1, 2. The transmission rate from an infected individual in group j to a susceptible individual in group k is
and the recovery rate of an infected individual in group k is
. The total population size
is constant and each group size
is constant. The initial conditions are non-negative,
,
,
and
for k=1, 2. For simplicity, we let
denote all recovered individuals.
Two specific models are considered that distinguish between transmission dependent on the infectivity or the susceptibility of the host population. They are referred to as Model 1 and Model 2, respectively. In Model 1, the spread of disease is a result of high infectivity of the host, as in emerging diseases, such as MERS or SARS, where the presence of superspreaders may result in a large outbreak [Citation8,Citation33]. In Model 2, disease spread is a result of the lack of immunity in the host population from an infectious disease that may have either previously circulated in the population, as in re-emerging diseases, such as measles or pertussis [Citation11,Citation38].
For the two models, we assume that the transmission rate is separable [Citation36]. Either transmission depends primarily on the infectivity of the host,
or the susceptibility of the host
The basic reproduction number
, the average number of secondary infections generated by one infected individual, is computed using the next generation approach [Citation12,Citation19,Citation36]. The basic reproduction number is
(2)
(2) for m=I, S.
2.1. Model 1
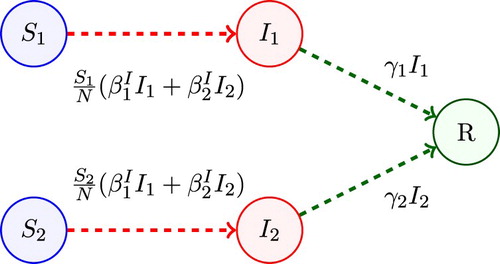
In Model 1, the population is divided into two groups, where each group is defined by the ability to transmit the infection. The two groups are referred to as non-superspreaders and superspreaders. Superspreaders have been identified in diseases such as SARS, MERS, and Ebola [Citation40]. Group 1 represents non-superspreaders, where and
denote susceptible and infected non-superspreaders and in group 2,
and
denote susceptible and infected superspreaders. Individuals remain superspreaders or non-superspreaders during the course of the epidemic. Susceptible individuals
infected by an individual from group
or
become infected non-superspreaders (
) and susceptible individuals
infected by
or
become infected superspreaders (
). Therefore, the transmission rates depend on the infective group,
or
. A compartmental diagram for Model 1 is given in Figure . The basic reproduction number for Model 1 follows from Equation (Equation2
(2)
(2) ). That is,
(3)
(3) In the special case that all individuals are either non-superspreaders or superspreaders (
or
), the basic reproduction number simplifies to either
or
, respectively.
Figure 1. Compartmental diagram for Model 1.
2.2. Model 2
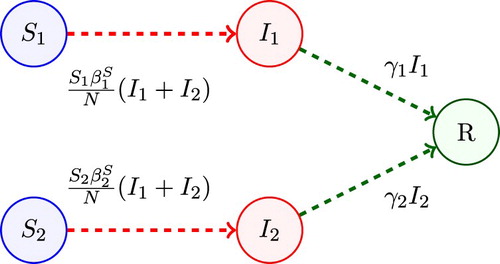
Model 2 is applicable to re-emerging diseases, such as measles or pertussis. The population is divided into two groups, dependent on the susceptibility to infection. One group of individuals has immunity to the disease due to vaccination or to a prior infection of the disease referred to as the low-susceptible group (group 1) and a second group of individuals has little or no immunity as they have either not been vaccinated or the vaccine has waned over time. Group 2 is referred to as the high-susceptible group.
Variabies and
represent the number of susceptible and infected individuals from the low-susceptible group 1 and
and
are the number of susceptible and infected individuals from the high-susceptible group 2. Individuals from
after being infected by either
or
become
and individuals from
after being infected by either
or
become
. The transmission parameters depend on host susceptibility for each group,
or
. A compartmental diagram of Model 2 is given in Figure . The basic reproduction number is
(4)
(4) If there is a single group, either low-susceptible or high-susceptible, (
or
), then the basic reproduction numbers simplify to
or
, respectively.
Figure 2. Compartmental diagram for Model 2.
3. CTMC models
We formulate a stochastic CTMC model with discrete random variables for the number of individuals. Stochastic variability may lead to a minor epidemic with a few individuals infected instead of a full scale epidemic with many individuals infected. For simplicity, the same notation for the variables is used for the CTMC model as for the ODE model. That is,
with
and
. Let
, and
for k=1, 2. The values of these random variables are denoted by lower case variables,
and r.
3.1. Model 1
The infinitesimal transition probabilities define the CTMC Model 1, e.g. [Citation1,Citation21]. For example, the transition from a susceptible to an infectious individual for the non-superspreader group is defined as follows:
A list of the four events corresponding to either infection or recovery is given in Table .
Table 1. Infinitesimal transition probabilities for Model 1.
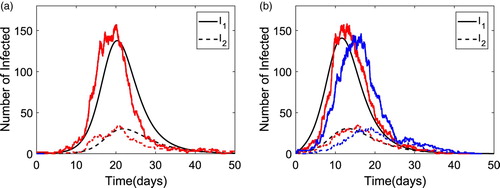
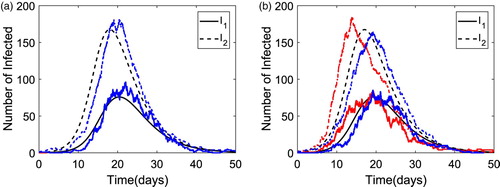
The solution dynamics for Model 1 are illustrated for the two infectious classes in Figure for the ODE and CTMC Model 1 when with population size N=1000 and the highly infectious group size
. The group reproduction numbers are
and
. In Figure (a), an epidemic is initiated by a non-superspreader,
and
, whereas in Figure (b), the epidemic is initiated with a superspreader,
and
. The ODE solution and two sample paths of the CTMC model are plotted in each figure. For the two sample paths in Figure (a), only one sample path yields a major epidemic, while the other path yields a minor epidemic with a few infectious cases. However, in Figure (b), both sample paths yield a major epidemic. It is notable that an epidemic occurs earlier when initiated with a superspreader than with a non-superspreader [Citation13].
Figure 3. Numerical solution of the ODE model and two sample paths of the CTMC for Model 1 with parameter values
,
,
,
and
(
). The number of non-superspreaders is plotted with a solid curve whereas superspreaders are plotted with a dashed curve. In (a),
and
, only one sample path illustrates a major epidemic and in (b),
and
, both sample paths illustrate a major epidemic. (a)
(0)=0. (b)
(0)=1.
3.2. Model 2
The CTMC for Model 2 can be defined in a similar way as in Model 1 with the exception that the transmission rates depend on host susceptibility. The infinitesimal transition probabilities are given in Table .
Table 2. Infinitesimal transition probabilities for Model 2.
An example of the solution dynamics of the infectious classes are plotted for Model 2 in Figure when . The same parameter values are applied as in Figure , except the population size is N=5000 with high-susceptible group size
. Two sample paths of the CTMC Model 2 are graphed with the ODE solution. To obtain an outbreak size similar to that in Model 1 (Figure ), a larger population size is assumed.
Figure 4. Numerical solution of the ODE model and two sample paths of the CTMC for Model 2 with parameter values ,
and
(
). The number of infectious individuals from the low-susceptible group is plotted with a solid curve whereas the number of infectious individuals from the high-susceptible group is plotted with a dashed curve. In (a),
and
, only one sample path illustrates a major epidemic and in (b),
and
, both sample paths illustrate a major epidemic. (a)
(0)=0. (b)
(0)=1.
4. Multitype branching process approximation
The CTMC model is approximated by a Galton–Watson multitype branching process (BP) near the disease-free equilibrium (DFE) [Citation5,Citation18]. In the BP approximation, it is assumed that the population is at the DFE and a small number of infectious individuals is introduced into the population. The goal is to use the BP approximation to estimate the probability of a minor or a major epidemic. The probabilities for an infection or a recovery are defined for an infectious individual in each group, through a generating function. The transmission dynamics for infectious individuals within each group and
act like a multitype birth and death process, where a birth is a new infection and death is a recovery. The probability of a minor epidemic in the CTMC model corresponds to the probability of ultimate extinction (as
) in the birth and death process. It is verified in Appendix 1 from the backward Kolmogorov equations and from the assumption about independence of
and
that for a small number of infectious individuals, the probability of ultimate extinction is the minimal fixed point of the offspring probability generating functions (pgfs). An offspring pgf for
has the general form
where
is the probability there are ℓ infectious individuals of type
and m of type
generated from one infectious individual of type 1 given
and
. A similar definition applies to
, given
and
. A fixed point
of the pgfs,
, j=1, 2 lies in
. The independent assumption in the BP approximation and the differential equations derived from the Kolmogorov equations yield estimates for the probability of ultimate extinction. Applying this estimate to the CTMC model, it can be interpreted as the probability of a minor epidemic, given
and
,
where (
is the minimal fixed point in
, e.g. [Citation3–5,Citation18,Citation39]. In addition, the probability of a major epidemic in the CTMC model is approximately
4.1. Model 1
The BP approximation of the CTMC model near the DFE is a linear approximation of the rates, and
These rates are defined in Table .
Table 3. Branching process approximation for Model 1.
For Model 1, the offspring pgf for non-superspreaders, given and
, is
(5)
(5)
k=1,2. The term
is the probability of recovery of a non-superspreader,
is the probability of infecting another non-superspreader and
is probability of infecting a superspreader. The offspring pgf for superspreaders, given
and
, is
(6)
(6)
, k=1,2. The term
is the probability of recovery of a superspreader,
is the probability of infecting another superspreader, and
is the probability of infecting a non-superspreader [Citation3].
Application of multitype BP theory, Equations (Equation5(5)
(5) ) and (Equation6
(6)
(6) ) and the backward Kolmogorov differential equations lead to an ODE for probability of disease extinction at time t [Citation3,Citation5,Citation18]. The steady-state solutions of this equation are the fixed points of pgfs (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) (probability of ultimate extinction). When
, there are at least two steady-states, one with
and at another one with
. The minimal fixed point is stable and this point yields the probability of ultimate extinction (or the probability of a minor epidemic in the CTMC model). When
, there is only one fixed point,
, so that the probability of ultimate disease extinction is equal to one. Details of this derivation are given in Appendix 1.
In Figure , the dashed curves are probability of a minor epidemic when initiated by a non-superspreader or a superspreader
. The points marked by ‘x’ are estimates for the probability of a minor epidemic calculated from 10,000 sample paths of the CTMC model. A threshold of 20 is assumed to indicate an outbreak. The peak level of infection for both infected groups in the deterministic model reaches values greater than 20 for
, therefore, this a reasonable assumption for numerical computations. In particular for each sample path, if
, then it is considered a major epidemic, but if the total number infected hits zero before reaching 20, then it is classified as a minor epidemic. Figure shows that the CTMC estimate of a minor epidemic (proportion hitting zero from 10,000 sample paths) agrees with the BP estimate.
Figure 5. Graphs of the probability of minor epidemic as a function of the number of superspreaders. The probability of a minor epidemic if it is initiated by a non-superspreader (
or a superspreader (
and the value of
are graphed for Model 1. Parameter values are
and
where the size of the superspreader population ranges from
to 110. The BP analytical estimates of probability of a minor epidemic (dashed and dashed-dot curves) are compared to estimates computed from 10,000 sample paths of the CTMC model (marked by a ‘x’).
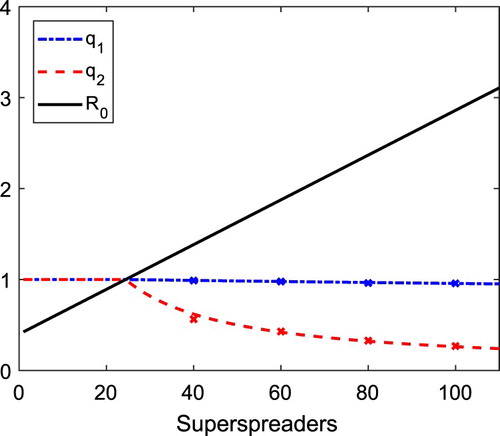
Figure illustrates that the probability of a minor epidemic when initiated by a non-superspreader is greater than when initiated by a superspreader. We verify this result always holds true when and
. The proof is relegated to Appendix 3.
Theorem 4.1
Assume that and
in the BP approximation for Model 1. Then the probability of a minor epidemic when initiated by a non-superspreader is greater than the probability of a minor epidemic when initiated by a superspreader,
. In addition, if
then
. In the special case
.
In the special case of a single group, the result of Theorem 4.1 simplifies to the classic result of Whittle [Citation39]. Whittle verified for the classic SIR CTMC model, , where
.
4.2. Model 2
The transition rates for the BP approximation of the CTMC Model 2 near the DFE are given in Table .
Table 4. Branching process approximation for Model 2.
The offspring pgf for an individual from the low-susceptible group () is given by
(7)
(7) where
is the probability of recovery,
is the probability of infecting an
individual and
is the probability of infecting an
individual. The offspring pgf for an individual from the high-susceptible group (
) is given by
(8)
(8) where
is the probability of recovery,
is the probability of infecting an
individual, and
is the probability of infecting an
individual (see, e.g. [Citation3]).
In Figure , the values of the probability of a minor epidemic and
as estimated from the BP approximation are compared with a numerical estimate computed from 10,000 sample paths of the CTMC. Of these 10,000 sample paths, the proportion of sample paths such that
hits zero before reaching a value of 20 is assumed to be an estimate of
or
. (We choose 20 as a threshold, as the peak level of infection for both infected groups in the deterministic model is greater than 20).
Figure 6. Graphs of the probability of minor epidemic are graphed as a function of , the high-susceptible group. The probability of a minor epidemic if initiated by an individual from the low-susceptible group (
or high susceptible group (
and the value of
are graphed for Model 2. Parameter values are
and N=5000, where the size of the high-susceptible group ranges from
to 600. The BP analytical estimates of probability of a minor epidemic (dashed and dashed-dot curves) are compared to estimates from 10,000 sample paths of the CTMC model (marked by a ‘x’).
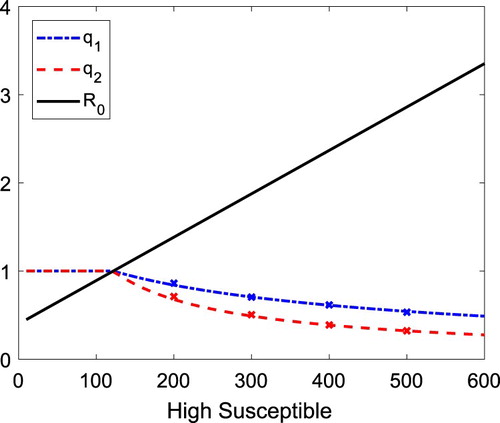
In the stochastic Model 2, it is the magnitude of the recovery rates rather than transmission rates that differentiates the probability estimates for a minor epidemic between the two groups. The proof of the following theorem is given in Appendix 4.
Theorem 4.2
Assume and
in the BP approximation of Model 2. Then the probability of a minor epidemic when initiated by an infected individual from the low-susceptible group is greater than when initiated by an infected individual from the high-susceptible group,
. In addition, if
, then
. In the special case
,
5. SEIR two-group model with multiple latent stages
We show that the previous results for multitype BP extend to models with m latent or exposed stages, , k=1, 2 for the case that the group sizes are constant. During a latent or exposed stage, individuals are infected but not yet infectious, meaning they do not spread the infection to others. Multiple exposed stages account for the delay prior to the infectious period. In particular, the ODE model for stages
and
is the same as in (Equation1
(1)
(1) ) but the other stages have the form:
where the new parameter
is the transition rate between the k and k+1 latent stage,
, with initial conditions
,
,
and
. New infections are due to the infectious stages
. We make the same assumptions regarding the transmission rates as in model (Equation1
(1)
(1) ),
for Model 1 and
for Model 2. Another important assumption is that there are no deaths. Each group size is constant. Applying the next generation matrix approach [Citation36], it follows that
has the same expression as in Equation (Equation2
(2)
(2) ).
For the corresponding CTMC SEIR model, the infinitesimal transition rates for the latent stages are
In the BP approximation of the CTMC SEIR model with two groups and m latent stages, there are 2m+2 pgfs. However, as there are no deaths in any of the 2 m latent stages, given
, it follows that the jth latent stage progresses to the next latent stage
or to
with probability one. It follows that the probability of disease extinction beginning from any latent stage
is the same as the probability of disease extinction beginning from
(Appendix 3). Therefore, Theorems 4.1 and 4.2 are applicable to the SEIR models with two groups.
In the next two sections, we apply Model 1 and 2 with one latent stage to hypothetical models of SARS and measles. The BP approximation is used to estimate the probability of a major epidemic and the estimate is compared to CTMC simulations.
6. Application to SARS
SARS, a recent emerging disease, was first identified in the early part of the twenty-first century. In 2003, an outbreak of SARS occurred in Singapore with a total 206 cases, as reported in [Citation16]. Three superspreaders were identified who infected a total 76 individuals. The index case was a superspreader who was admitted to a hospital on March 1 and was isolated on March 6. By this time, the index case had infected 24 individuals. Two other superspreaders infected 25 and 27 individuals, respectively. Magal et al. [Citation26] formulated an ODE two-group model with no latent stage, where the two groups are individuals inside and outside of a hospital setting. We use their model as motivation to formulate a hypothetical model for SARS, but applying the assumptions in Model 1 with a latent stage, a homogeneous mixing population, and two transmission rates for the infectious individuals, We use some parameter values comparable to Magal et al. [Citation26] for population sizes N=2500 and
(Magal: N=2300 and
),
(Magal:
outside of the hospital), and the recovery rate for group 1,
(Magal:
outside of the hospital). We consider a range of values for
and
(Table ), where
and
. Generally, SARS patients are contagious when they exhibit symptoms [Citation29]. The latent period reported by the Centers for Disease Control is 2–7 days [Citation29]. Therefore, we assume the transition rate from
to
is
per day for groups k=1,2. Estimates for the basic reproduction number for SARS in Singapore include a range of 2.3 to 4 prior to a issuance of a global alert [Citation37]. With control efforts in place for SARS, estimates for the basic reproduction number range from 0.49 to 2.47 [Citation10]. We explore a wider range of
values in Table . A summary of the parameter values for our example of the two-group SEIR Model 1 for SARS is given in Table .
Table 5. Parameter values for SARS.
Table 6. The BP approximation of a major epidemic (either  or ) is compared to the CTMC simulations based on 10,000 sample paths.
or ) is compared to the CTMC simulations based on 10,000 sample paths.
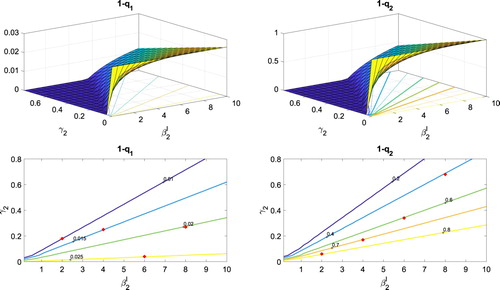
The probabilities and
of a major epidemic when the epidemic is initiated by one non-superspreader or by one superspreader, respectively, are graphed in Figure as a function of the transmission rate
and the recovery rate
. In addition, the contours of this surface are graphed for fixed values of the probabilities. The surfaces and contours are computed from the BP approximation. It can be easily seen that
. On each of the contours, a value is selected and compared with the value obtained from 10,000 sample paths of the CTMC model. The results are recorded in Table . The ‘x’ marks on the contours in Figure are the estimates from the CTMC simulations. If a sample path reaches
, the epidemic is assumed to be major. If the value of
hits zero before reaching 15, it is assumed to be a minor epidemic. The proportion of sample paths out of 10,000, where the infected population reaches 15 or greater is the estimate for a major epidemic. There is good agreement between the BP approximation and the CTMC simulations, as shown in Table . Evident in the top two graphs in Figure , are the differences in the vertical scales. The probability of a major epidemic, initiated with an infected superspreader is significantly greater than if initiated with an infected non-superspreader. (The value of 15 is chosen as a threshold since the peak value of infected for both groups is greater than 15 in the deterministic models for the range of
values in Table .)
Figure 7. Probability of a major epidemic and
are plotted as a function of the transmission
and recovery
rates given one non-superspreader or one superspreader. Other parameter values for SARS are taken from Table . In addition, contours for each surface are graphed at the bottom of the figures, for several fixed probabilities.
As the values of depend on
(Theorem 4.1), we performed a sensitivity analysis of the basic reproduction number
, given in Equation (Equation3
(3)
(3) ), with respect to parameters
, i=1, 2. Applying the method in [Citation7], the normalized forward sensitivity index for
with respect to the parameter p equals
The sensitivity indices only need to be determined for
, i=1,2, since the sensitivity with respect to the other parameters
and
have the same magnitude as
(either ±). The sensitivity indices, reported in Table , show that
is much more sensitive to the group 2 parameters
,
, and
than to group 1 parameters. For the parameter values in Table , the proportional contribution of the basic reproduction number by group 1 ( non-superspreaders) is relatively small
as compared to group 2 (superspreaders).
7. Application to measles
Measles is a highly contagious disease. The basic reproduction number for measles during an outbreak has often been estimated to be in the range of 12–18 but some upper estimates for in the pre-vaccine era, are very large, 27 (Canada), 57 (UK), 203 (Africa), and 770 (Western Europe) (various regions employed different estimation methods and types of models) [Citation17]. In the post-vaccine era, estimates for
during an outbreak range from 4.6 to 32.1 [Citation17]. Measles infection can be prevented with high vaccination coverage and in this case the reproduction number is much lower. In 2011, De Serres et al. [Citation11] reported a measles outbreak in a high school setting. The index case was a teacher with a single dose of the measles vaccine. The index case was removed immediately after onset of a rash. The students in this high school had either no vaccination or 1-dose or 2-doses with the 2-doses administered at different ages 12 months, 15 months or later. Out of a total of 1306 high school students 110 students were infected during the outbreak. The attack rate was highest for students with no vaccine, 82%, with less than 5% for those with 1-dose or 2-doses. We apply Model 2 for a measles outbreak in a population with a highly susceptible subgroup with no vaccine coverage and another group with partial immunity due to vaccination or prior infection. We assume there is a latent period and homogeneous mixing of individuals in the population.
The outbreak size is smaller for Model 2 than for Model 1 for the same population size. Therefore, in Model 2, to distinguish between minor and major epidemics, we assume the total population size is N=5000 with 500 high-susceptible individuals, . The transmission rate for low-susceptible individuals is assumed to be
with recovery rate
(2 days for the infectious period). Thus, the proportional group 1 reproduction number is
. To ensure the basic reproduction number is greater than one, the proportional basic reproduction number for the high-susceptible group 2 must satisfy
. We assume
and
. The incubation period for measles is an average range of 10-12 days, according to the Centers for Disease Control [Citation28]. Also, the virus can survive outside the host for up to two hours and an individual is infectious for about 4 days prior to exhibiting symptoms (a rash) [Citation28]. Therefore, we take the smallest value, and let
per day. Table is a summary of the parameter values applied in Model 2 for measles.
Table 7. Parameter values for measles.
The probabilities and
of a major epidemic when initiated by one individual from the low-susceptible or high-susceptible group, respectively, are graphed in Figure as a function of transmission rate
and recovery rate
. Below these surfaces, are the contours for fixed probabilities. The surfaces and contours are computed from the BP approximation. To compare the values from the BP approximation to the CTMC models, a value is selected on each contour where
. Ten thousand sample paths of the CTMC model are used to estimate the probability of a major epidemic. If the number of infected individuals
reaches a total of 15 or greater, it is considered a major epidemic and if not it is considered a minor epidemic. The proportion (out of 10,000), where infected individuals reach 15 or greater is recorded as a dot on a contour and is listed in Table . The differences in the top two graphs in Figure are only evident as a function of increasing recovery rate
(Theorem 4.2). The steep rise of
or
and sensitivity to the transmission rate
can be clearly seen in these graphs. The transmission rate
for group 2 increases the probability of a major epidemic when initiated with either an infected individual from a low-susceptible or a high-susceptible group (compare with the top left Figure .) We performed a sensitivity analysis of the basic reproduction number
(Equation (Equation4
(4)
(4) )) with respect to parameters
, i=1,2 (similar to the analysis in Table ). The basic reproduction number
is much more sensitive to the parameters from group 2 (high-susceptible) than from group 1 (low-susceptible).
Figure 8. Probability of a major epidemic, and
, initiated by one low-susceptible individual or one high-susceptible individual, respectively, are graphed as a function of transmission rate (
) and recovery rate (
) of the high-susceptible individuals. Other parameter values for measles are taken from Table . In addition, contours for each surface are graphed at the bottom of the figures, for several fixed probabilities.
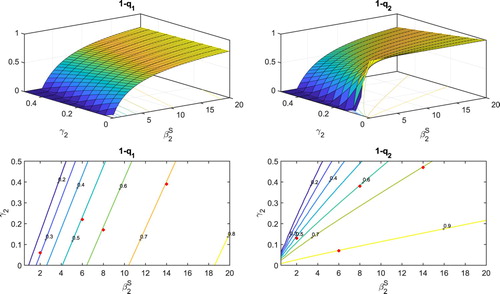
Table 8. The BP approximation of a major epidemic (either or ) is compared to the CTMC simulations based on 10,000 sample paths.
The values of in Table are relatively small given the large values reported for measles in [Citation17]. But the reproduction numbers for the high-susceptible group 2 are relatively large, i.e.
ranges from 15.4 to 85.7.
8. Discussion
Two CTMC SIR epidemic models with two groups are studied, where transmission depends either on the infectious individuals (Model 1) or susceptible individuals (Model 2). Model 1 is applicable to emerging diseases, new diseases which have not previously circulated in the population, such as SARS or MERS. It is assumed that all individuals are susceptible to infection. However, in Model 1, one group of individuals, known as superspreaders, transmit the disease to a large number of other individuals, whereas the remaining individuals have a much lower transmission rate and are referred to as non-superspreaders. Model 2 is applicable to re-emerging diseases, such as measles or pertussis. In Model 2, one group of individuals has immunity due to vaccination or to a prior infection of the disease and the second group has little or no immunity as individuals either have not been vaccinated or the vaccine has waned over time. The two groups are distinguished as either low- or high- susceptible groups, respectively.
A multitype BP approximation of the CTMC models is applied to the infected groups of individuals. It is shown analytically for Model 1, that the basic reproduction numbers within each group, , distinguish between the probability of a major or a minor epidemic for the two groups. If the outbreak is triggered by an infected superspreader, then there is a greater probability of a major epidemic than if initiated by a non-superspreader (Theorem 4.1). However, for Model 2, it is the recovery rates of the two susceptible groups that distinguishes which group has a greater probability of a major epidemic (Theorem 4.2). These analytical results are extended to an SEIR model with multiple latent stages and the results are confirmed in numerical simulations of the nonlinear CTMC models and exhibited in two applications, SARS (Model 1) and measles (Model 2), as illustrated in Figures –. A major conclusion in this analysis is that
alone is insufficient to determine the probability of a major epidemic. Our analytical and numerical results demonstrate the importance of the heterogeneity in transmission and recovery rates in a large group of individuals and the transmission and recovery rates of the first individuals to become infected.
The two-group model can be extended to a multigroup model with groups. For example, the extension of the basic reproduction number in (Equation2
(2)
(2) ) to a multigroup model is simply
for m=I,S and Theorems 4.1 and 4.2 can be extended to n groups.
There are several limitations to the BP approximation of the CTMC epidemic models and to the model applications. To apply the BP approximation, the population size must be sufficiently large and second, the value of must be greater than one and not too close to one. These restrictions ensure that it is possible to distinguish between a minor and major epidemic in the CTMC models. For many infectious diseases, transmission rates cannot be separated according to individual infectivity or susceptibility as in our two-group models. Populations are often highly heterogeneous and transmission rates may depend on both the infectiousness and the susceptibility of individuals within the population which in turn depend on behavioural, physiological, and environmental factors (e.g. [Citation6,Citation14,Citation15,Citation25,Citation34]).
Acknowledgments
This research was partially supported by the National Science Foundation [grant number DMS-1517719]. We thank the reviewers and the editor for helpful suggestions on the original manuscript.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- L.J.S. Allen, An Introduction to Stochastic Processes with Applications to Biology, 2nd ed., CRC Press, Boca Raton, Fl., 2010.
- L.J.S. Allen, Stochastic Population and Epidemic Models Persistence and Extinction, Springer International Publishing, Switzerland, 2015.
- L.J.S. Allen, A primer on stochastic epidemic models: Formulation, numerical simulation, and analysis, Infect. Dis. Model. 2 (2017), pp. 128–142.
- L.J.S. Allen and P. van den Driessche, Relations between deterministic and stochastic thresholds for disease extinction in continuous- and discrete-time infectious disease models, Math. Biosci. 243 (2013), pp. 99–108. doi: 10.1016/j.mbs.2013.02.006
- K.B. Athreya and A.P. Ney, Branching Processes, Springer-Verlag, New York, 1972.
- L. Bolzoni, L. Real, and G. De Leo, Transmission heterogeneity and control strategies for infectious disease emergence, PLoS. One 2 (2007), pp. 747. Available at https://doi.org/10.1371/journal.pone.0000747.
- N. Chitnis, J.M. Hyman, and J.M. Cushing, Determining important parameters in the spread of malaria through the sensitivity analysis of a mathematical model, Bull. Math. Biol. 70 (2008), pp. 1272–1296. doi: 10.1007/s11538-008-9299-0
- S.Y. Cho, J. Kang, Y.E. Ha, G.E. Park, J.Y. Lee, J.H. Ko, J.Y. Lee, J.M. Kim, C. Kang, I.J. Jo, J.G. Ryu, J.R. Choi, S. Kim, H.J. Huh, C.S. Ki, E.S. Kang, K.R. Peck, H.J. Dhong, J.H. Song, D.R.Chung, and Y.J. Kim, MERS-CoV outbreak following a single patient exposure in an emergency room in South Korea: An epidemiological outbreak study, Lancet 388 (2016), pp. 994–1001. doi: 10.1016/S0140-6736(16)30623-7
- G. Chowell, S. Blumberg, L. Simonsen, M. Miller, and C. Viboud, Synthesizing data and models for the spread of MERS-CoV, 2013: Key role of index cases and hospital transmission, Epidemics 9 (2014), pp. 40–51. doi: 10.1016/j.epidem.2014.09.011
- G. Chowell, C. Castillo-Chavez, P.W. Fenimore, C.M. Kribs-Zaleta, L. Arriola, and J.M. Hyman, Model parameters and outbreak control for SARS, Emerg. Infect. Dis. 10 (2004), pp. 1258–1263. doi: 10.3201/eid1007.030647
- G. De Serres, N. Boulianne, N. Brousseau, M. Benoit, S. Lacoursiere, F. Guillemette, J. Soto, M.Ouakki, B. Ward, and D. Skowronski, Higher risk of measles when the first dose of a 2-dose schedule of measles vaccine is given at 12–14 months versus 15 months of age, Clin. Infect. Dis. 55 (2012), pp. 394–402. doi: 10.1093/cid/cis439
- O. Diekmann, J. Heesterbeek, and J. Metz, On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogeneous populations, J. Math. Biol. 28 (1990), pp. 365–382. doi: 10.1007/BF00178324
- C.J. Edholm, B.O. Emerenini, A.L. Murillo2018 Searching for superspreaders: Identifying epidemic patterns associated with superspreading events in stochastic models, in Understanding Complex Biological Systems with Mathematics, Chapter 1, pp. 1–29, Springer Nature, Switzerland
- Z. Feng, A.N. Hill, A.T. Curns, and J.W. Glasser, Evaluating targeted interventions via meta-population models with multi-level mixing, Math. Biosci. 287 (2017), pp. 93–104. doi: 10.1016/j.mbs.2016.09.013
- A.P. Galvani and R.M. May, Dimensions of superspreading, Nature 438 (2005), pp. 293–295. doi: 10.1038/438293a
- G. Gopalakrishna, P. Choo, Y. Leo, B.K. Tay, Y.T. Lim, A.S. Khan, and C.C. Tan, SARS transmission and hospital containment, Emerg. Infect. Dis. 10 (2004), pp. 395–400. doi: 10.3201/eid1003.030650
- F.M. Guerra, S. Bolotin, G. Lim, J. Heffernan, S.L. Deeks, Y. Li, and N.S. Crowcroft, The basic reproduction number (R0) of measles: A systematic review, Lancet Infect. Dis. 17 (2017), pp. e420–e428. doi: 10.1016/S1473-3099(17)30307-9
- T.E. Harris, The Theory of Branching Processes, Springer-Verlag, Berlin, Heidelberg, 1963.
- H. Hethcote, The mathematics of infectious disease, SIAM Rev. 42 (2000), pp. 599–653. doi: 10.1137/S0036144500371907
- A. James, J.W. Pitchford, and M.J. Plank, An event-based model of superspreading in epidemics, Proc. R. Soc. Lond. [Biol] 274 (2007), pp. 741–747. doi: 10.1098/rspb.2006.0219
- S. Karlin and H. Taylor, A Second Course in Stochastic Processes, Academic Press, New York, 1981.
- M. Kontio, S. Jokinen, M. Paunio, H. Peltola, and I. Davidkin, Waning antibody levels and avidity: Implications for MMR vaccine-induced protection, J. Infect. Dis. 206 (2012), pp. 1542–1548. doi: 10.1093/infdis/jis568
- J.W. Leavitt, Typhoid Mary: Captive to the Public's Health, Beacon Press, Boston, 1996.
- J. Lee, G. Chowell, and E. Jung, A dynamic compartmental model for the Middle East respiratory syndrome outbreak in the Republic of Korea: A retrospective analysis on control interventions and superspreading events., J. Theoret. Biol. 408 (2016), pp. 118–126. doi: 10.1016/j.jtbi.2016.08.009
- J.O. Lloyd-Smith, S.J. Schreiber, P.E. Kopp, and W.M. Getz, Superspreading and the effect of individual variation on disease emergence, Nature 438 (2005), pp. 355–359. doi: 10.1038/nature04153
- P. Magal, O. Seydi, and G. Webb, Final size of an epidemic for a two group SIR model, SIAM J. Appl. Math. 76 (2016), pp. 2042–2059. doi: 10.1137/16M1065392
- T. Mkhatshwa and A. Mummert, Modeling super-spreading events for infectious disease: Case study SARS, Int. J. Acad. Med. 41 (2011), pp. 82–88. doi: 10.1111/j.1445-5994.2010.02339.x
- National Center for Immunization and Respiratory Diseases, Epidemiology and prevention of vaccine-preventable diseases. Available at https://www.cdc.gov/vaccines/pubs/pinkbook/meas.html (last access date 2/1/2018).
- National Center for Immunization and Respiratory Diseases, Division of Viral Diseases, Severe Acute Respiratory Syndrome (SARS). Available at https://www.cdc.gov/sars/about/faq.html (last access date 2/1/2018).
- National Institutes of Health (US), Biological Sciences Curriculum Study, Bethesda (MD). Available at https://www.ncbi.nlm.nih.gov/books/nbk20370/ (last access date 2/1/2018).
- N.I. Nii-Trebi, Emerging and neglected infectious diseases: Insights, advances, and challenges, Biomed. Res. Int. 2017 (2017), pp. ID 5245021, 15 pages. doi: 10.1155/2017/5245021
- E. Rothstein and K. Edwards, Health burden of pertussis in adolescents and adults, Pediatr. Infect. Dis. J. 24 (2005), pp. S44–S47. doi: 10.1097/01.inf.0000160912.58660.87
- Z. Shen, F. Ning, W. Zhou, X. He, C. Lin, D.P. Chin, Z. Zhu, and A. Schuchat, Superspreading SARS events, Beijing 2003, Emerg. Infect. Dis. 10 (2004), pp. 256–260. doi: 10.3201/eid1002.030732
- R.A. Stein, Super-spreaders in infectious diseases, Int. J. Infect. Dis. 15 (2011), pp. e510–e513. Available at https://www.ncbi.nlm.nih.gov/pubmed/21737332. doi: 10.1016/j.ijid.2010.06.020
- A.J. Tatem, D.J. Rodgers, and S.I. Hay, Global transport networks and infectious disease spread, Adv. Parasit. 62 (2006), pp. 293–343. doi: 10.1016/S0065-308X(05)62009-X
- P. van den Driessche and J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci. 180 (2002), pp. 29–48. doi: 10.1016/S0025-5564(02)00108-6
- J. Wallinga and P. Teunis, Different epidemic curves for severe acute respiratory syndrome reveal similar impacts of control measures, Amer. J. Epidemiol. 160 (2004), pp. 509–516. doi: 10.1093/aje/kwh255
- A.M. Wendelboe, A. van Rie, S. Salmaso, and J.A. Englund, Duration of immunity against pertussis after natural infection or vaccination, Pediatr. Infect. Dis. J. 24 (2005), pp. S58–S61. doi: 10.1097/01.inf.0000160914.59160.41
- P. Whittle, The outcome of a stochastic epidemic: A note on Bailey's paper, Biometrika 42 (1955), pp. 116–122.
- G. Wong, W. Liu, Y. Liu, B. Zhou, Y. Bi, and G.F. Gao, MERS, SARS, and Ebola: The role of super-spreaders in infectious disease, Cell Host Microbe 18 (2015), pp. 398–401. doi: 10.1016/j.chom.2015.09.013
Appendix 1. Probability generating functions for model 1
The pgf G for the branching process approximation is a function that defines the number of new infections given that the initial number infected is and
. The definition for G is
where
,
denotes the expectation of X, and the transition probabilities
The extinction probabilities are computed from G when
with initial conditions
and
or with
and
.
In the branching process approximation, it is assumed that the events are independent and thus,
(A1)
(A1) The preceding identity and the backward Kolmogorov differential equation are used to derive differential equations for the extinction probabilities.
Applying Table , the backward Kolmogorov differential equations for the transition probabilities of the branching process approximation for Model 1 have the following form (see, e.g. [Citation3]):
(A2)
(A2) Differentiating Equation (EquationA1
(A1)
(A1) ) with respect to t for
and for
, and applying the definition and the identity (EquationA1
(A1)
(A1) ) results in the following partial differential equations:
(A3)
(A3)
(A4)
(A4) Substituting the backward Kolmogorov differential equations (EquationA2
(A2)
(A2) ) into (EquationA3
(A3)
(A3) ) and applying the identity in (EquationA1
(A1)
(A1) ) several times to simplify the expressions, we obtain the following differential equation for
:
(A5)
(A5) where
is defined in (Equation5
(5)
(5) ). A similar derivation applies to the infected class
, after substituting (EquationA2
(A2)
(A2) ) into (EquationA4
(A4)
(A4) ):
(A6)
(A6) where
is defined in (Equation6
(6)
(6) ). The extinction probabilities
and
are the solutions of the differential equations in (EquationA5
(A5)
(A5) ) and (EquationA6
(A6)
(A6) ) when
. Therefore, the probability of ultimate extinction, as
, given the initial data
or
, is the steady-state solution of these equations, that is, the fixed points of the pgfs
and
.
Appendix 2. Probability generating function for model 2
Applying Table , the backward Kolmogorov differential equations for the branching process approximation of Model 2 have the following form, e.g. [Citation3]:
(A7)
(A7) Applying the identities in (EquationA3
(A3)
(A3) ) and substituting the backward Kolmogorov differential equations (EquationA7
(A7)
(A7) ), yields the following differential equation for
:
Similarly using (EquationA7
(A7)
(A7) ) in (EquationA4
(A4)
(A4) ) with
yields
Appendix 3. Probability generating functions for SEIR model
The pgfs for the general case of the SEIR model with m exposed stages and k groups is dependent on the variables , where the u variables are for the exposed stages and the v variables are for the infected stages. In particular, the pgfs for each of the
given
and the remaining exposed and infected states are initially zero are
The pgf for
when
and the remaining variables are initially zero in Model 1 is
A similar expression applies to Model 2,
As demonstrated in the previous two subsections, the backward Kolmogorov equations and assumptions regarding independence of the variables near the DFE leads to differential equations for the generating functions. For the special case of one exposed stage and two groups, let
,
and
. Then the generating function satisfies
In particular,
(A8)
(A8) Evaluating the generating function G when the u and v variables are zero gives the probability of extinction starting from either
(
) or
(
). The probability of ultimate extinction is the fixed point of these pgfs. Therefore, it follows from the expressions in (EquationA8
(A8)
(A8) ) that the probability of ultimate extinction beginning from
is the same as for
for k=1, 2.
Appendix 4. Proof of Theorem 4.1
In multitype continuous-time branching processes, the probability of ultimate extinction is the minimal fixed point of the system of pgfs in the unit square, (e.g. [Citation2,Citation4,Citation5,Citation18]). Suppose the fixed points of the pgfs for the BP approximation in (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) are
which are the solutions of the equations
and
:
(A9)
(A9)
(A10)
(A10) Rearranging the preceding equations gives two curves:
(A11)
(A11)
(A12)
(A12) The curve
intersects the line
at two points:
and
and the curve
intersects the line
at
and
, where both points may or may not lie in the set
. In addition, function
in (EquationA11
(A11)
(A11) ) is concave down with respect to
and function
in (EquationA12
(A12)
(A12) ) is concave down with respect to
.
To verify Theorem 4.1, three cases are considered (i) 1 with
and
; (ii)
with
and
; (iii)
1 with
1 and
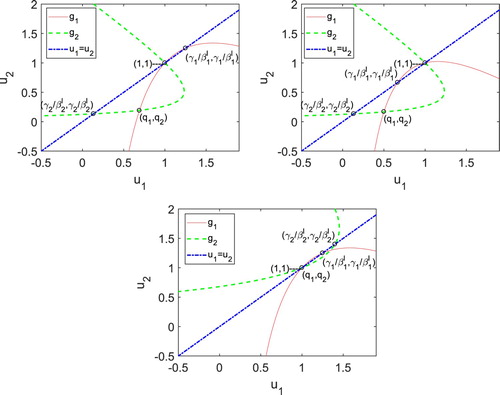
. See Figure for the three cases.
Assume
Assume
Assume
In the special case, , then
. The curve
intersects
at (1,1) and (
). Therefore,
.
Appendix 5. Proof of Theorem 4.2
Suppose the fixed points of the pgfs are . Consider the functions
and
given in Equations (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ), respectively,
(A13)
(A13)
(A14)
(A14) Rewriting Equation (EquationA13
(A14)
(A14) ) and (EquationA14
(A13)
(A13) ):
(A15)
(A15)
(A16)
(A16) The functions
and
have the same properties as the functions
and
, similar to the proof of Theorem 4.1 in Appendix 4. Functions
and
are both concave down with respect to the axes
and
, respectively, the curve
intersects the line
at
, and
(A17)
(A17) The curve
intersects the line
at
and
(A18)
(A18) Notice that the difference between the two points in (EquationA17
(A17)
(A17) ) and (EquationA18
(A18)
(A18) ) is the recovery rates,
and
. We assume
. The proof follows in a manner similar to Theorem 4.1 by noting the order of the points of intersections of the curves
and
with the line
Similar to Theorem 4.1 in Appendix 4, when
we consider two different cases: (i)
and (ii)
.
Since ,
. In the first case (i) when
,
and
is less than one. So
. In the second case (ii) when
,
and
. So
. Hence,
and
intersect
only at (1, 1), so
.
In the special case that , the two curves,
and
, have two points of intersection, namely
and
where this latter fixed point is the expression given in (EquationA17
(A17)
(A17) ) or in (EquationA18
(A18)
(A18) ). If
, then
and if
, then
Figure A1. Curves ,
and the line
in cases (i), (ii) and (iii). (a) Case (i). (b) Case (ii). (c) Case (iii).