
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In epidemic modelling, the emergence of a disease is characterized by the low numbers of infectious individuals. Environmental randomness impacts outcomes such as the outbreak or extinction of the disease in this case. This randomness can be accounted for by modelling the system as a continuous time Markov chain, . The probability of extinction given some initial state is the probability of hitting a subset of the state space associated with extinction for the initial state. This hitting probability can be studied by passing to the discrete time Markov chain (DTMC),
. An approach is presented to approximate a DTMC on a countably infinite state space by a DTMC on a finite state space for the purpose of solving general hitting problems. This approach is applied to approximate the probability of disease extinction in an epidemic model. It is also applied to evaluate a heterogeneous disease control strategy in a metapopulation.
1. Introduction
Early mathematical models of disease considered infection in a single population compartmentalized into susceptible and infectious classes [Citation34,Citation44]. Such models continue to be of interest to researchers to this day [Citation2,Citation10,Citation13,Citation24,Citation32,Citation36,Citation37]. In recent years, increases in mobility, or the processes by which individuals change their location, has motivated researchers to adapt models to consider the spatio-temporal spread of disease [Citation7]. One technique to capture spatial heterogeneity is called metapopulation modelling [Citation6,Citation8,Citation31]. In these models, the population is broken down into subpopulations called patches. Individuals experience patch-specific local interactions as well as migration between patches. Patches are often considered to be separate spatial locations [Citation8]. Deterministic metapopulation models of the spread of infectious disease are often concerned with the asymptotic behaviour of solutions in a neighbourhood of the disease-free equilibrium and those in a neighbourhood of an endemic equilibrium [Citation4,Citation5,Citation8,Citation9,Citation27]. Another important topic for analysis is the question of persistence or extinction of the disease. In deterministic models, the basic reproduction number [Citation19,Citation45] is often used to formulate a sharp threshold for the persistence of the disease [Citation18,Citation23,Citation28,Citation39,Citation47].
When considering the case of the emergence or reemergence of the disease, it becomes necessary to account for the effects of random fluctuations on the dynamics of the system. One technique to account for this stochasticity is to formulate a continuous time Markov chain (CTMC) model. In this setting, random fluctuations will always ultimately lead to the extinction of the disease. Keeling describes a stochastic population as persistent if extinction events are rare [Citation31]. This can be measured by calculating the mean extinction time and comparing it to ecological time scales [Citation30–32] or by calculating the probability of extinction. The probability of extinction is often impossible to calculate directly from the Markov chain, but it can sometimes be approximated by the extinction of a branching process [Citation3,Citation12,Citation37,Citation38]. In the case of a single infectious type, a branching process model takes the form of the classical Galton-Watson branching process (GWbp) [Citation3,Citation48,Citation51]. In the case of multiple infectious types, the branching process takes the form of a multitype branching process [Citation3,Citation26,Citation37,Citation38]. Whether there is a single infectious type or multiple, we will generally refer to approximation via branching process techniques as the branching process approximation. However, the branching process approximation is not appropriate in all cases [Citation38]. In any case, the probability of extinction is the probability of hitting the subset of the state space associated with the extinction of the disease.
CTMC models of biological processes typically assume that the time until the next transition is exponentially distributed. In this case, the hitting problem can be studied by first passing to the embedded discrete time Markov chain (DTMC). In this article, we present an approach to approximate the general hitting problem in a discrete time Markov chain called local approximation in time and space (LATS). We prove that the hitting probability calculated using LATS converges asymptotically to the true hitting probability in Section 3.3. We illustrate this approach via applications in Sections 4 and 5. There are ulterior motives for the choices of applications in Sections 4 and 5. In addition to providing an example of two ways in which the LATS technique provides an approximation of the probability of extinction, the application in Section 4 illustrates that LATS approximation is accurate at small population sizes (when branching process approximations fail) and that LATS provides insight into the most likely path to extinction or outbreak. In Section 5, the LATS technique is used to calculate an atypical hitting problem, illustrating its robustness as a method for approximating general, rather than specific hitting problems.
Stochastic Susceptible-Infected-Susceptible (SIS) models have been a topic of study dating back to the work of Bailey [Citation11]. While some authors have modelled stochasticity using stochastic differential equations [Citation24], we will focus on SIS models in the form of Markov processes. West and Thompson [Citation50] analysed continuous and discrete time SI models and Allen and Burgin [Citation2] compared deterministic and stochastic SIS models. Epidemiological models in the form of stochastic SIS models in metapopulations have been studied in various ways [Citation5,Citation10]. In particular, several authors have considered optimal control [Citation13,Citation35,Citation36]. To illustrate the utility and robustness of the LATS technique, we will formulate the optimal control problem as a hitting problem and analyse it using LATS.
In contrast with branching process approximation, the LATS approach can be used to answer any question about a stochastic metapopulation that can be posed as a hitting problem. For example, the probability of extinction in a single patch may provide important information about a metapopulation. Since patches in a metapopulation are typically coupled together by the migration of their residents, extinction in one patch is a transient event. However, the probability of extinction in a single patch can be used as a patch-specific indicator of disease risk. To illustrate this, we consider a two-patch SIS model in which disease control that reduces the rate of infection by 20% can only be deployed in a single patch. The probability of extinction in a single patch is used to determine the optimal strategy for deployment. We also calculate the optimal strategy using various standard techniques, for comparison.
The article is organized as follows: we begin by recalling the necessary mathematical preliminaries in Section 2. The LATS approach is presented in Section 3. Section 4 illustrates an application of LATS to calculate the probability of the extinction of the disease in a single population where branching process techniques are not suitable. In Section 5, we formulate an optimal control problem in a metapopulation SIS model as a hitting problem to show that analysis via the LATS technique is perhaps more sensitive to the preferences of decision-makers than standard techniques such as the probability of total extinction and .
2. Mathematical background and preliminaries
The LATS technique, which is presented in Section 3, combines basic results from the theory of Markov chains, including collapsed Markov chains, and graph theory to formulate an approximation of a given CTMC. For applications to epidemic models, we will typically be concerned with CTMCs which have exponentially distributed waiting times. However, LATS can be applied more generally. In this section, we first recall existing definitions and results pertinent to the development of LATS. A more thorough introduction to the theory of Markov chains can be found in [Citation1,Citation20,Citation22,Citation29,Citation33,Citation40,Citation41].
2.1. Embedded Markov chain
Let be a homogeneous CTMC on a countable state space S. We ignore the special case of an explosive process [Citation1,Citation40]. Let
be the collection of random jump times such that
jumps to a new state at each time
and remains in the state
for
. The random variables
represent the random amount of time
spends in state
for each i and are called interevent times. The CTMC
can be characterized by its transition probabilities
for transition from state i to state j in S. The collection of all transition probabilities can be written as a (possibly infinite) matrix
. If
, then
, otherwise
. For
, define
Let
and define the generator matrix
. Let
be the off diagonal ith row sum of Q. The CTMC
admits a DTMC
, known as the embedded Markov chain.
has the property that
Define
(1)
(1) and for
(2)
(2) Then the matrix
is the probability transition matrix of the embedded DTMC
. It is equivalent to say that
is formed by conditioning
on the fact that a transition has taken place and replacing the index of time with the index of the number of transitions. Since we restrict our discussion to homogeneous CTMCs on a countable state space, any CTMC we consider admits an embedded DTMC. The notation
and T to denote the embedded CTMC and its probability transition matrix can be found in [Citation1] and is used to differentiate between the CTMC and its embedded chain, but is not the standard notation for a DTMC. For the discussions that follow we adopt the following more standard notation for DTMCs.
Let be a homogeneous discrete time Markov chain on a countable state space S. Let P be the probability transition matrix associated with
. For
the one-step transition probability from i to j is given by
The m-step transition probability from i to j is given by
Since
is a homogeneous DTMC,
and
are independent of n. Then
and
. If there is an m>0 such that
, then we say that j is reachable from i. If j is reachable from i and i is reachable from j, we say that i and j communicate. Communication is an equivalence relation which partitions S into equivalence classes called communication classes. We say a communication class C is closed if whenever
and j is reachable from i, then
. A state which is in a communication class which is not closed is called a transient state. The probability of first reaching state j from state i in with respect to
is called a hitting probability. The following definitions of the m-step hitting probability and hitting probability come from Pinsky and Karlin [Citation41], while the notation is more similar to that of Norris [Citation40], but modified to suit our purposes. The probability of first hitting state j from state i in exactly m transitions with respect to
is an m-step hitting probability and given by
(3)
(3) The probability of first hitting j from i with respect to
is
(4)
(4)
2.2. Graph theory
We now recall a few notions from graph theory [Citation14,Citation15,Citation49]. A graph is a set of vertices
together with a set of edges
. The graph
is called a directed graph or a di-graph if
is a set of ordered pairs such that
whenever there is a directed edge from vertices u to v. We say that u is the tail and v is the head of edge
. The out-degree of a vertex v is the number of edges with tail v. The out-degree of the graph
is the supremum of the out-degrees taken over all the vertices. For our purposes, we will consider the case that
is a countable set. In this case,
can be enumerated as a sequence
for
. Define the (possibly infinite) matrix
with entry
if
and
otherwise. The matrix A is called the adjacency matrix of the graph
. Clearly, A encodes the edge set
. If the vertex set
is understood, then A defines the graph
. A u,v-path of length k is a sequence
where
,
and
for
. The graph distance between vertices u and v, denoted
, is defined as the length of the shortest u,v-path. We take the convention that
if u=v and
if there is no path from u to v. Since
is a directed graph, the graph distance is typically a quasi-metric (i.e. it meets all the conditions of a metric except symmetry). The ball of radius r in the graph
centred at the vertex v, denoted
, is the subset of vertices u such that
.
Let us return our attention to the DTMC on the countable state space S with probability transition matrix
. Let A be the adjacency matrix induced by P such that
(5)
(5) In this way,
induces a di-graph,
, with states in the state space S as vertices. By the definition of A given in (Equation5
(5)
(5) ), if there is a positive probability of transitioning from i to j in
, then there is an edge
in
. Therefore, if
, then there is a, i,j-path in
of length m. It follows that the distance in the induced graph is given by
. In addition, the ball of radius r in the induced graph centred at i is
.
2.3. Finite absorbing Markov chains
Now let be a homogeneous DTMC on a finite state space S with the properties that there is at least one closed communication class, there is at least one communication class which is not closed and that all closed communication classes are singletons. This makes
an absorbing Markov chain. The closed communication classes of an absorbing Markov chain are called absorbing states. A more complete discussion of finite absorbing Markov chains can be found in Chapter 3 of [Citation33]. Let P be the probability transition matrix of
. Suppose that
and S contains j<m absorbing states. By simultaneously exchanging rows and columns of P, we can put it in its canonical form
(6)
(6) where I is the
-identity matrix and D is the substochastic
matrix. The matrix
is called the fundamental matrix of
.
Theorem 2.1
[Citation33]
Let be a homogeneous DTMC on the state space S with
. Let the probability transition matrix of
be given by (Equation6
(6)
(6) ). Then
where
. Furthermore, for
and
, the entry,
, associated with i and k is the probability of hitting the absorbing state
from the transient state
,
.
2.4. Collapsed chains
We now return to our discussion of the homogeneous DTMC on the countable state space S with probability transition matrix P. Following Hachigian [Citation25], consider the collapsed process
where f is a many-to-one function on S onto the state space of
. Suppose that the states of
are denoted by the countable sequence
. For each α in the index set I, we say that the subset of states i of S given by
are collapsed into the single state
of the process
. It is not generally the case that the process
possesses the Markov property. It is natural to ask under what conditions the process resulting from collapsing a Markov process is again Markov. Several researchers have made contributions to this field [Citation16,Citation17,Citation25,Citation42,Citation43]. The following result gives a sufficient condition in the case
is a finite state space Markov chain. The result is given for non-homogeneous chains.
Theorem 2.2
[Citation17]
Let ,
, be a non-homogeneous Markov chain with any given initial distribution vector p and the state space
. Let
, and
be r pairwise disjoint subsets of
. Let
,
, be the collapsed chain defined by
if and only if
. Then a sufficient condition for
to be Markov is that
is independent of k in
for
.
3. Local approximation in time and space
In this section, we present a technique called LATS for studying certain features of homogeneous DTMCs or homogeneous CTMCs by first passing to the embedded DTMC. As such, the details will be presented in terms of a DTMC on a countable state space S with probability transition matrix P. In broad strokes, LATS consists of first restricting to a subset of the state space S, modifying this subset to form a state space
so that
induces a DTMC
on
. We will show that
faithfully approximates
locally in time and space. We then collapse
on
to an absorbing DTMC
on the collapsed state space
. Analysis of the collapsed chain
is more straightforward and less computationally expensive.
3.1. Neighbourhood of a set of states
The first step in the LATS technique is to form a subset of a set the state space S. Let . For any
define
.
Definition 3.1
Let be a homogeneous DTMC on a countable state space S. Let
and
. The N-neighbourhood of the set T with respect to
is defined as
(7)
(7) where
is the ball of radius N centred at s in the graph
induced by
as described in Section 2.2.
Note that , since
by convention. Let
be the submatrix of the probability transition matrix P associated with the states in
. If T is a proper subset of S, then R is typically a substochastic matrix. In order to extend
to a stochastic matrix, we must extend the N-neighbourhood by adding an additional absorbing state. Let
be the Dirac delta function with
when i=j and zero otherwise.
Definition 3.2
By the state space associated with we mean
, where g is a new state associated with escape from
. Define the transition matrix
on
by
(8)
(8)
is a stochastic matrix which can be written
(9)
(9)
Since is stochastic, it induces a DTMC,
, on the state space
. If the out-degree of the graph and the set of initial states T are both finite, then the state space
is finite. The next result shows that for any initial distribution supported on states in T,
approximates
locally in time.
Theorem 3.1
Let be the probability transition matrix of the DTMC
on the countable state space S, let
and
. Suppose that
and
are as defined in (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ) above. For
,
for all
.
Proof.
Let . By definition, for
,
. By the Chapman–Kolmogorov equation, for
Suppose that
are states in S such that
. Then
is a path of length m from x to i in the induced graph
. By definition,
. It follows that
. Therefore,
Let π be any initial distribution on S. Let be the support of π. If
, then there is a distribution on
, say
, which is supported on
and equal to π there. Theorem 3.1 shows that the evolution of the distribution π in the chain
is completely captured by the evolution of the distribution
in the chain
for the first N transitions.
3.2. Collapsing 
The definition of is related to the graph
induced by the underlying Markov chain
by (Equation7
(7)
(7) ). If the set of initial states T and the out-degree of
are both finite, then
is finite for each N. Nevertheless,
may be quite large, making a direct analysis of
difficult. In order to reduce the complexity of the mathematical analysis of
, as well as the computational expense for calculations, the next step is to collapse
to an absorbing DTMC
. As noted in Section 2.4,
is a collapsed chain for any many-to-one function f from the state space of
to the state space of
. However, not all collapsed chains are themselves Markov. We recalled the definition of a closed communication class above. Now we make a more general definition of a closed subset of the state space.
Definition 3.3
Let be a homogeneous DTMC on the finite state space S and let
. We say that C is closed with respect to communication if, whenever
and
, then
.
As noted above, we seek a function f so that is an absorbing Markov chain. Absorbing states in a collapsed chain are either the result of the identity map on an absorbing state in the original chain or they are the result of collapsing a subset of the state space which is closed with respect to communication. Theorem 3.2 shows that collapsing a closed set results in a Markov chain.
Theorem 3.2
Let be a homogeneous DTMC on a countable state space S. Let
be a proper subset of the state space which is closed with respect to communication. Let f be a many-to-one function given by
Then
is a Markov chain.
Proof.
Let and
. Since C is closed with respect to communication, for all
and
Therefore, the closed set C is mapped to an absorbing state c. Let
. Then
is inherited from
. Furthermore,
Now let
. Consider
(10)
(10) Since
, there exists
such that
. Then
To form the state space of the chain
, we eliminated the complement of the N-neighbourhood
in the state space S and replaced it with an absorbing state g. In light of Theorem 3.2, we see that the escape state g can be formed, for example, by making all states in the complement of
absorbing and collapsing the resulting closed (possibly infinite) set.
Corollary 3.3
Let be a homogeneous DTMC on a countable state space S. Suppose that
is a decomposition of S into the union of disjoint sets
, where
is closed with respect to communication for all
. Let f be a many-to-one map such that
for all
and
is the identity. Then
has the Markov property. If
and
, then
where
and
are hitting probabilities as in (Equation4
(4)
(4) ).
To approximate the behaviour of a homogeneous DTMC near a set of initial states , we first form the DTMC
on a local state space
either by adjoining an absorbing state to the N-neighbourhood,
described by (Equation7
(7)
(7) ) or by making the contrivance that
is closed with respect to communication and collapsing it. Theorem 3.1 shows that
approximates the behaviour of
for N transitions on the condition that
. If we are not concerned with the behaviour of
once it enters a closed communication class, we may further simplify the approximation by forming the collapsed chain
, where f identifies closed communication classes with absorbing states and f is the identity map on transient states. In the next section, we show how LATS can be used to answer the question: what is the probability of first hitting a particular subset of the state space from a particular state in the chain
?
3.3. LATS approximation of hitting probabilities
Let be a homogeneous DTMC on a countable state space S. In this section, we describe how LATS can be used to approximate the general hitting problem with respect to
. By the general hitting problem, we mean to determine the probability
where
and
. If
, then
is trivial. However, it is not so trivial if
. For example, if S is finite but very large or S is countably infinite, then the general hitting problem can be difficult or even impossible to determine from direct analysis of
.
For , the probability of first hitting y from x, given by
, can be reformulated in terms of x,y-paths in the induced graph
. By a path of length m which first hits y from x in the graph
we mean an x,y-path of length m, as in Section 2.2, with
,
and
for
. Let
be the family of such paths with index set
. For
, let
be the probability of path
. Then
(11)
(11) Equation (Equation4
(4)
(4) ) implies that
is a good approximation of
for N sufficiently large. Since
depends on N, so does
and
. For
and
, the path
is entirely contained in
. In particular,
and
. It follows that
increases to
as N increases to infinity.
In order to describe how to use LATS to approximate the general hitting problem, we make the following assumption.
Assumption 3.1
A1
Suppose that induces a graph
with finite out-degree. Suppose that T and V are disjoint, proper subsets of S and the goal is to find the probability
for all
. For fixed
, form
,
and
. This induces the DTMC
as described in Section 3.1. Since both N and the out-degree of
are finite, if T is finite, so is
. Now make all states in the set
absorbing. Then
is closed with respect to communication. Collapse
to a single absorbing state, which we denote y. In addition, collapse all remaining closed communication classes of
. Denote the collapsed chain
, its state space
and its probability transition matrix
.
Given (A1), by Corollary 3.3, is Markov and
for all
. Since
depends on N, so does
.
Proposition 3.4
Assume (A1) and suppose that such that
. Then x is a transient state in
.
Proof.
Since , for some
there is a x,v-path in
. Either
or
. If
, then there is an x,y-path in the graph induced by
. Since there is a path from x to y, y is reachable from x. Since y is an absorbing state, the singleton
is a closed communication class. Therefore, x is not reachable from y. Hence, x is transient in
. If
, then
can be formed by making all states in
absorbing and collapsing
to the single absorbing state g. Since
, there is a path from x to g in the graph induced by
. The rest of the proof follows the arguments of the previous case.
Theorem 3.5
Assume (A1). For , if
, then
. If
, then
and
is non-increasing as a function of N. If
increases to S with N, then
.
Proof.
Let be the collection of all paths of length m which first hit V from x in the graph induced by
and let
be the probability of
. If all of the vertices that comprise the path
are elements of
, we write
. If the vertices of
are not all contained in
, we write
. By the Law of Total Probability,
. By construction,
. In the case
, there is a vertex of
which is an element of
. Then
corresponds to an x,g-path in the collapsed chain
. Therefore,
. It follows that
. Since
is non-decreasing in N,
is non-decreasing. The final claim follows from the fact that if
.
Theorem 3.5 proves that approximates
and
is an upper bound on the error of the approximation. To show that error goes to zero requires the additional assumption that
increase to S as N increases to infinity. This seems like a very strong assumption. However, biological phenomena are typically modelled by generalized birth–death processes, which satisfy this assumption. In these and other cases for which the assumption holds, the proof only shows that the error goes to zero asymptotically. However, we will see that in applications the approximation can be very accurate for N<30.
Corollary 3.6
Assume (A1). For and
(12)
(12)
Proof.
Let be the collection of all paths of length k which first hit V from x in the graph induced by
. Let
be the probability of path
. If
, then
(13)
(13)
Theorem 3.7
Assume (A1). For fixed , if
, then
is a finite absorbing Markov chain with probability transition matrix
with canonical form (Equation6
(6)
(6) ). Furthermore, for
and
,
where
is the entry in the row associated with x and column associated with y in the mth power of the probability transition matrix
. Furthermore,
is the entry in the row associated with x and column associated with y of
as in Theorem 2.1.
Proof.
By (A1), the out-degree of the graph , induced by
, is finite. Let
be the out-degree of
. It follows that
. Since
,
is a finite Markov chain. The result of collapsing a set which is closed with respect to communication is an absorbing state. By construction,
consists entirely of absorbing states and transient states and is therefore an absorbing Markov chain. That
is the entry in the row associated with x and column associated with y of
is a direct application of Theorem 2.1 to the finite absorbing Markov chain
. From Corollary 3.6
, for
. Since y is an absorbing state,
This is a powerful result for practical applications. Since I−D is a nonsingular M -matrix, to find a hitting probability using the LATS method we can use either of for sufficiently large n or
. We will exhibit the practicality of this technique and the nature of the convergence for a particular DTMC by way of example in the next section.
4. LATS vs. branching process techniques
Infectious Salmon Anemia virus (ISAv) causes Infectious Salmon Anemia (ISA) in a variety of finfish including Atlantic salmon (Salmo salar). ISA causes high mortality [Citation21] and affects all major salmon producing countries [Citation46]. It is an important disease to the salmon culture industry which has caused significant economic losses according to the Global Aquaculture Alliance. Deterministic models of an ISAv outbreak in one and two patches are proposed and analysed in [Citation39]. The one-patch model is given by
(14)
(14) where S denotes susceptible fish, I denotes infected fish and V denotes free-virus in the environment. Susceptible fish experience logistic population growth with birth and death rates β and μ, respectively. The rates of infection due to contact with infected individuals and contact with free-virus are given by η and ρ, respectively. The rate of mortality of infected fish is given by α and the rate infected fish shed virus particles into the environment is δ. Free-virus denatures and is cleared from the environment at rate ω. By scaling the system, we may eliminate η and ρ. This yields the reduced system
(15)
(15) The state variable V in the reduced system represents the number of infectious doses of free-virus in the environment.
The basic reproduction number is shown to be a critical parameter with the sharp threshold separating persistence of the disease (
) and its extinction (
). The emergence of the disease is characterized by low prevalence of the disease in the environment and few infected individuals. This setting demands the use of stochastic modelling techniques to account for inherent random fluctuations. Continuous time Markov chain companion models are developed and analysed in [Citation38]. The CTMC model of a single patch is given by
and associated infinitesimal transition probabilities
with transition rates
given in Table .
Table 1. State transitions and rates for the single patch CTMC,
For deterministic epidemic models, it is common for to be the invasion criterion that implies persistence. In that case, the disease persists with certainty for all time. In the case
, the disease goes extinct with certainty. For stochastic epidemic models, there is always a chance that the disease will go extinct. We say that the disease persists if the event that the disease goes extinct is rare. That is, the probability of extinction is close to zero. The probability of extinction is the probability of hitting the subset of the state space associated with extinction starting from an initial state in its complement. If the initial state is near the disease-free quasistationary distribution and certain other assumptions hold, then the probability of extinction can be approximated by a branching process [Citation3,Citation26,Citation37]. In this case,
is shown once again to be a critical parameter, where
implies almost sure extinction and
implies that the probability of extinction is less than 1 [Citation5]. The additional assumptions are that all transitions are independent and that the initial susceptible population is sufficiently large.
Biologically speaking, assuming that all transitions are independent is a strong assumption, but one that is commonly made in the formulation of mathematical models. Since I and V are distinct types of infectious individuals, is approximated using a multitype branching process. The offspring probability generating function (pgf) for the multitype branching process is
(16)
(16) where
is the population size at the disease-free distribution of
. It is easy to verify that
. If
, then there exists a unique
in
such that
. In this case, the probability of the extinction of all infectious types, given that there are initially i individuals of type I and j individuals of type V, is given by
[Citation3,Citation26].
The branching process approximation of is a linearization and therefore doesn't capture nonlinear behaviour of
. This is the reason that the branching process approximation diverges from the Monte Carlo approximation in Figure . For the purpose of this illustration, we assume that
are fixed and allow β to vary. We assume that there is initially one individual of type I and no individuals of type V. Therefore, the branching process probability of extinction is given by
, which is a continuous function of the parameters. Monte Carlo simulations are performed at 10 unit increments of β from
to
. At data point
, the branching process approximation of the probability of extinction is
while Monte Carlo simulation gives 0.3893.
Figure 1. The size of the susceptible population at the disease-free quasistationary distribution is given by . β is the independent variable, while
are fixed. The probability of extinction is approximated using branching process approximation (blue), numerical simulation via Gillespie algorithm (red) and LATS (black).
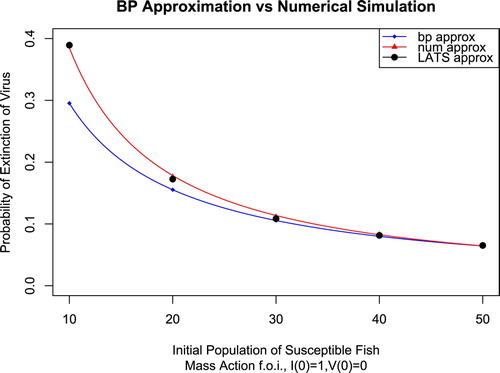
Using LATS to approximate the probability of extinction faithfully captures the behaviour of near the disease-free distribution, including any nonlinear behaviour. As a result, the LATS approximation in Figure remains accurate as β is varied. The fact that LATS detects nonlinear behaviour is one of the benefits of this technique.
Since is a non-explosive process, for both branching process approximation and LATS, we first pass to the embedded DTMC, which we denote
. We say an outbreak has occurred in
when
, where
are the numbers of infected individuals and infectious doses of free-virus at the outbreak quasistationary distribution (equivalent to the endemic equilibrium of the deterministic model (Equation15
(15)
(15) )). We say extinction has occurred when
. In Assumption (A1), above, we consider the set of initial states T and seek to approximate the probability of hitting a single set V. In this case, we let T be the singleton
and define the sets
and
to be the sets associated with outbreak and extinction, respectively. The sets E and O are disjoint. It is therefore possible to treat them both as V is treated in (A1). Suppose
and
. The result is the collapsed state space
, which consists of the 3 absorbing states e (associated with extinction), o (associated with outbreak), and g (associated with escape from the neighbourhood) and all remaining states are transient. By Theorem 3.7,
(17)
(17) Since
and
, by (Equation4
(4)
(4) ), it follows that the entries
and
increase
and
, respectively. By construction, there is no
-path of length N in the graph induced by
. Therefore,
. Table illustrates the convergence of
and
to
and
, respectively.
Table 2. This table illustrates the convergence of entries in the row associated with of to the hitting probabilities and .
Theorem 3.5 shows that the LATS collapsed chain approximates the probabilities of extinction and outbreak another way, as well. That is,
(18)
(18) Since the LATS collapsed chain
is a finite absorbing chain, by Theorem 2.1,
has canonical form given by (Equation6
(6)
(6) ) and
for j=e,o or g and where
. In applications, approximating hitting probabilities with respect to
using the LATS collapsed chain
via entries of the matrix H may converge faster and with less computational expense than approximating via the
power of the matrix
. This is illustrated in Table .
Table 3. This table illustrates the convergence of entries in the row associated with of to the hitting probabilities and .
The results in Table illustrate that for N=25, the probability that realizations with the initial state in the LATS collapsed chain
leave the N-neighbourhood before hitting the absorbing states associated with outbreak or escape is so small as to be negligible. Therefore, the LATS approximation
is an accurate representation of the embedded DTMC
near the initial state
for
. Furthermore, in Table , the probability of extinction converges faster (for smaller N) than the probability of outbreak. This means that realizations with the initial state
that lead to extinction are more likely to remain close to
than those that lead to outbreak. This is reasonable, since the initial state
is one transition in
from the subspace
associated with extinction, as evident from the first row of Table . Nevertheless, the fact that LATS approximation gives insight into the behaviour of
at such fine resolution is another benefit of the technique.
5. Locally deployed disease control
In this section, we consider 2 small communities coupled together by migration. This metapopulation experiences a disease outbreak in which infected individuals become fully susceptible immediately upon recovery. First, a deterministic SIS model in the form of a system of nonlinear ODEs is proposed and analysed, then a related CTMC is developed. Consider the following hypothetical: suppose that both patches are at risk of outbreak in the sense that their patch type reproduction numbers are greater than 1, with patch 2 at higher risk than patch 1. Suppose that patch 1 has the resources to deploy disease control to reduce the rate of infection by , but can only be deployed in one patch. We consider the strategies of deployment in patch 1 only, or patch 2 only, and show which strategy minimizes the basic reproduction number for a particular choice of parameters. LATS is used to determine the optimal strategy for control in the CTMC, taking into account outcome preferences of decision makers.
First we consider the following deterministic two-patch SIS model:
(19)
(19) where, in patch i,
is the number of susceptible individuals,
is the number of infected individuals,
is the total number of individuals,
is the rate of infection and
is the rate of recovery for i=1,2. The rate of migration between patches is d and
is the total number of individuals in the system. This model corresponds to the model studied in [Citation37] with n=2,
and
. When
, the system admits the disease-free steady state
. Following [Citation37], the basic reproduction number is
(20)
(20) The patch type reproduction number is given by
for i=1,2 and corresponds to the basic reproduction number in each patch in the absence of migration. Suppose that
and d=0.1. Then
,
and
. Now we modify system (Equation19
(19)
(19) ) to include parameters
and
related to the control. The new system is given by
(21)
(21) which corresponds to system (Equation19
(19)
(19) ) when
. The strategy of deploying disease control in patch 1 corresponds to
and the complementary strategy corresponds to
. The effect these strategies have on
and
for i=1,2 is found in Table . Clearly, the strategy of deploying control in patch 2 minimizes
as well as minimizing the sum of the patch-specific reproduction numbers,
. Regardless of which strategy is chosen,
and the disease persists [Citation27].
Table 4. Patch-specific and overall reproduction numbers for no control, control deployed in patch 1 only and control deployed in patch 2 only.
If d=0, then the system decouples and the basic reproduction number in a single patch is given by the patch type reproduction number , for i=1,2. For
sufficiently large, the probability of extinction following the introduction of a single infected individual is given by the GWbp approximation
, a decreasing function of
[Citation3,Citation51].
In order to investigate what happens at small population size we consider the CTMC with the infinitesimal transition probabilities
and associated rates
found in Table .
Table 5. State transitions and rates for the two-patch SIS CTMC,
Consider the two-patch SIS CTMC, with the parameters
and control strategy
. Since d=0 the two patches are decoupled and
for i=1,2. Suppose there are initially 10 individuals in patch 1 and 5 individuals in patch 2. Using LATS, we determine the probability of extinction
in patch i from the initial state
in patch 1 and
in patch 2 with and without control. As noted above, Whittle showed that in this case the GWbp approximation of the probability of extinction in patch i is the reciprocal of the patch reproduction number [Citation51]. The results of LATS approximation of the probability of extinction are reported alongside the patch reproduction numbers and the reciprocals of the patch reproduction numbers in Table . The results of the experiments reported in Table coincide with the hypothesis that the probability of extinction in a single patch is monotone in
for small populations as well.
Table 6. Patch i reproduction numbers () and GWbp probabilities of extinction () and LATS probabilities of extinction () from the initial state in patch i=1 and in patch i=2 with and without control.
Now let d=0.1 so that the two patches form a metapopulation. Let us return to the hypothetical that residents of patch 1 have resources available to deploy a control strategy that reduces the rates of infection in a single patch. The residents of patch 1 wish to deploy the control in the patch that yields the greatest benefit to themselves. To account for this preference, we want to calculate the probability of extinction in patch 1 only from the initial state . This is the state of the system if patch 1 is at its single patch quasistationary disease-free state
, patch 2 is at its single patch quasistationary endemic state
and a single infected individual migrates from endemic patch 2 to patch 1 as the rate of movement between patches, d, becomes positive. Recall that the state space S of
is the subset
with the property that
, i.e. that the total population is preserved. Let
be the subset of S associated with the extinction of the disease in patch 1 only and let
be the subset of S associated with total extinction of the disease. Then
. Define the probability of partial extinction in patch 1 to be the probability of hitting the set A. Since d>0, the event
for
is transient. However, we take it as an indicator of the disease risk in patch 1. Let
be the embedded DTMC. We use LATS as described in (A1) with V =A to approximate
and again with V =E to approximate
. Results in Table show that strategy
, corresponding to deployment in patch 1, optimizes patch 1 partial extinction,
. In contrast, the probability of total extinction,
, indicates deployment in patch 2 optimizes total extinction of the disease.
Table 7. Probability of partial extinction in patch 1 only and total extinction from initial state
Obviously, these are conflicting results. In order to make sense of them, we consider the classical setting in which a single infected individual appears in one patch or the other and calculate the probability of total extinction. The disease-free quasistationary distribution of the two-patch model is , which is not a state of the system. Therefore, we expect
to fluctuate between the states
and
when it is near the quasistationary distribution. We therefore consider the probability of extinction from the initial states
and
. These probabilities are reported in Table .
Table 8. The probability of extinction from initial state and .
The results in Table provide insight into the effect of the different control strategies. First, disease control measures deployed in a single patch promotes disease extinction in both patches. The probability of partial extinction in patch 1 given by reported in Table and
reported in Table reflects a bias towards patch 1, while
reflects a bias towards patch 2. From the perspective of a given patch, the optimal outcome is a result of deploying control measures in that patch, which may or may not coincide with minimizing
. The product of column
and column
can be viewed as giving a global perspective. From this perspective, it is still optimal to deploy control measures in a way that also minimizes
. Partial extinction probabilities, like
, may be useful tools for decision-making in the context of heterogeneous control in metapopulations. In addition to being a potentially useful indicator for heterogeneous control problems,
cannot be calculated using branching process approximation. The very fact that we have been able to calculate this probability using LATS illustrates another benefit of the technique, namely, that it is suited to approximating hitting problems in general.
6. Discussion
The LATS technique combines localization and collapsing of Markov chains to reduce a DTMC on a countably infinite state space to a finite absorbing Markov chain. It is a robust tool for approximating general hitting probabilities for typical chains when the local neighbourhood is sufficiently large. However, increasing the size of a neighbourhood comes at the cost of increasing computational expense, particularly if the degree of the induced graph is large. LATS is shown to be effective in some cases where branching process techniques are not suitable. This is due, in part, to the fact that LATS captures nonlinear behaviour of the Markov chain it seeks to approximate. In addition to solving the general hitting problem, LATS also gives information about the number of transitions in a path as well as the likelihood of long sojourns. Therefore, it is a valuable addition to the set of tools used to analyse stochastic models of real world phenomena.
In Section 5, partial extinction probabilities are shown to have the potential to help inform deployment of spatially heterogeneous disease control strategies. There are likely other interesting biological questions that can be formulated as general hitting problems. LATS is well suited to provide approximations for these problems.
In the context of heterogeneous control strategies, outcome preferences are important drivers of decision-making. Standard techniques to calculate probability of extinction may not be the ideal way to account for this. Formulating hitting problems that account for preference, such as partial extinction probabilities, may be useful to optimize decision-making subject to constrains.
Disclosure statement
No potential conflict of interest was reported by the author.
ORCID
Evan Milliken http://orcid.org/0000-0003-1268-9020
Additional information
Funding
References
- L.J.S. Allen, An Introduction to Stochastic Processes with Applications to Biology, Pearson, Upper Saddle River, NJ, 2003.
- L.J.S. Allen and A.M. Burgin, Comparison of deterministic and stochastic SIS and SIR models in discrete time, Math. Biosci. 163(1) (2000), pp. 1–33.
- L.J.S. Allen and G.E. Lahodny, Extinction thresholds in deterministic and stochastic epidemic models, J. Biol. Dyn. 6(2) (2012), pp. 590–611.
- L.J.S. Allen and E.J. Schwartz, Free-virus and cell-to-cell transmission in models of equine infectious anemia virus infection, Math. Biosci. 270 (2015), pp. 237–248.
- L.J.S. Allen and P. van den Driessche, Relations between deterministic and stochastic thresholds for disease extinction in continuous- and discrete-time infectious disease models, Math. Biosci. 243(1) (2013), pp. 99–108.
- J. Arino, Diseases in metapopulations, in Modeling and Dynamics of Infectious Diseases, Vol. 11, Z. Ma, Y. Zhou, and J. Wu, eds., World Scientific, New Jersey, 2009, pp. 65–123.
- J. Arino, Spatio-temporal spread of infectious pathogens of humans, Infect. Dis. Model. 2(2) (2017), pp. 218–228.
- J. Arino and S. Portet, Epidemiological implications of mobility between a large urban centre and smaller satellite cities, J. Math. Biol. 71(5) (2015), pp. 1243–1265.
- J. Arino and P. van den Driessche, A multi-city epidemic model, Math. Popul. Stud. 10(3) (2003), pp. 175–193.
- F. Arrigoni and A. Pugliese, Limits of a multi-patch SIS epidemic model, J. Math. Biol. 45(5) (2002), pp. 419–440.
- N.T.J. Bailey, The Mathematical Theory of Infectious Diseases and Its Applications, 2nd ed., Hafner, New York, 1975.
- F.G. Ball and P. Donnelly, Strong approximations for epidemic models, Stoch. Proc. Appl. 55(1) (1995), pp. 1–21.
- F. Ball, B. Tom, and L. Owen, Stochastic multitype epidemics in a community of households: Estimation and form of optimal vaccination schemes, Math. Biosci. 191(1) (2004), pp. 19–40.
- M. Behzad and G. Chartrand, Introduction to the Theory of Graphs, Allyn and Bacon, Inc., Boston, 1971.
- M. Bóna, A walk through combinatorics: An introduction to enumeration and graph theory, World Scientific, New Jersey, 2013.
- C.J. Burke and M. Rosenblatt, A Markovian function of a Markov chain, Ann. Math. Statist. 29(4) (1958), pp. 1112–1122.
- A. Dey and A. Mukherjea, Collapsing of non-homogeneous Markov chains, Statist. Probab. Lett. 84(1) (2014), pp. 140–148.
- T. Dhirasakdanon, H.R. Thieme, and P. Van Den Driessche, A sharp threshold for disease persistence in host metapopulations, J. Biol. Dyn. 1(4) (2007), pp. 363–378.
- O. Diekmann, J. Heesterbeek, and J. Metz, On the definition and computation of the basic reproduction ratio R0 in models of infectious disease in heterogeneous populations, J. Math. Biol. 28 (1990), pp. 365–382.
- R. Durrett, Essentials of Stochastic Processes, 2nd ed., Springer-Verlag, New York, 2012.
- K. Falk, E. Namork, E. Rimstad, S. Mjaaland, and B.H. Dannevig, Characterization of infectious salmon anemia virus, an orthomyxo-like virus isolated from Atlantic salmon (Salmo salar L.), J. Virol. 71(12) (1997), pp. 9016–23.
- I.I. Gikhman and A.V. Skorokhod, Introduction to the Theory of Random Processes, Dover, Mineola, NY, 1996.
- S.A. Gourley, H.R. Thieme, and P. van den Driessche, Stability and persistence in a model for bluetongue dynamics, SIAM J. Appl. Math. 71(4) (2011), pp. 1280–1306.
- A. Gray, D. Greenhalgh, L. Hu, X. Mao, and J. Pan, A stochastic differential equation SIS epidemic model, SIAM J. Appl. Math. 71(3) (2011), pp. 876–902.
- J. Hachigian, Collapsed Markov chains and the Chapman-Kolmogorov equation, Ann. Math. Statist. 34(1) (1963), pp. 233–237.
- T.E. Harris, The Theory of Branching Processes, Springer-Verlag, Berlin, 1963.
- A. Iggidr, G. Sallet, and B. Tsanou, Global stability analysis of a metapopulation SIS epidemic model, Math. Popul. Stud. 19(3) (2012), pp. 115–129.
- M. Jesse, R. Mazzucco, U. Dieckmann, H. Heesterbeek, and J.A.J. Metz, Invasion and persistence of infectious agents in fragmented host populations, PLoS ONE 6(9) (2011).
- S. Karlin and H.M. Taylor, A First Course in Stochastic Processes, 2nd ed., Academic Press, New York, 1975.
- M.J. Keeling, Metapopulation moments: Coupling, stochasticity and persistence, J. Anim. Ecol. 69(5) (2000), pp. 725–736.
- M.J. Keeling, C.A. Gilligan, and M.J. Keeling, Metapopulation dynamics of bubonic plague, Nature 407(6806) (2000), pp. 903–906.
- M.J. Keeling and J.V. Ross, On methods for studying stochastic disease dynamics, J. R. Soc. Interface 5(19) (2008), pp. 171–181.
- J.G. Kemeny and J.L. Snell, Finite Markov Chains, Springer-Verlag, New York, 1976.
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics – I, Proc. R. Soc. A 115(772) (1927), pp. 700–721.
- A. Khanafer and B. Tamer, An optimal control problem over infected networks, Proceedings of the International Conference of Control, Dynamic Systems, and Robotics, Ottawa, Ontario, Canada, 2014.
- A.L. Krause, L. Kurowski, K. Yawar, and R.A. Van Gorder, Stochastic epidemic metapopulation models on networks: SIS dynamics and control strategies, J. Theor. Biol. 449 (2018), pp. 35–52.
- G.E. Lahodny and L.J.S. Allen, Probability of a disease outbreak in stochastic multipatch epidemic models, Bull. Math. Biol. 75(7) (2013), pp. 1157–1180.
- E. Milliken, The probability of extinction of infectious salmon anemia virus in one and two patches, Bull. Math. Biol. 79 (2017), pp. 2887–2904.
- E. Milliken and S.S. Pilyugin, A model of infectious salmon anemia virus with viral diffusion between wild and farmed patches, DCDS-B 21(6) (2016), pp. 1869–1893.
- J.R. Norris, Markov Chains, Cambridge University Press, New York, 1997.
- M.A. Pinsky and S. Karlin, Introduction to Stochastic Modeling, Academic Press, Boston, 2011.
- M. Roseblatt, Functions of a Markov process that are Markovian, J. Math. Mech. 8(4) (1959), pp. 585–596.
- M. Rosenblatt, Random Processes, Oxford University Press, New York, 1962.
- R. Ross, An application of the theory of probabilities to the study of a priori pathometry. Part I, Proc. R. Soc. A 92(638) (1916), pp. 204–230.
- P. van den Driessche and J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci. 180 (2002), pp. 29–48.
- S. Vike, S. Nylund, and A. Nylund, ISA virus in Chile: Evidence of vertical transmission, Arch. Virol. 154(1) (2009), pp. 1–8.
- W. Wang and X.-Q. Zhao, An epidemic model in a patchy environment, Math. Biosci. 190(1) (2004), pp. 97–112.
- H.W. Watson and F. Galton, On the probability of extinction of families, J. Anthropol. Inst. GB Ireland 4 (1875), pp. 138–144.
- D.B. West, Introduction to Graph Theory, Prentice Hall, Upper Saddle River, NJ, 1996.
- R.W. West and J.R. Thompson, Models for the simple epidemic, Math. Biosci. 141 (1997), pp. 29–39.
- P. Whittle, The outcome of a stochastic epidemic – a note on Bailey's paper, Biometrika 42 (1955), pp. 116–122.