
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The well known linear chain trick (LCT) allows modellers to derive mean field ODEs that assume gamma (Erlang) distributed passage times, by transitioning individuals sequentially through a chain of sub-states. The time spent in these sub-states is the sum of k exponentially distributed random variables, and is thus gamma distributed. The generalized linear chain trick (GLCT) extends this technique to the broader phase-type family of distributions, which includes exponential, Erlang, hypoexponential, and Coxian distributions. Phase-type distributions are the family of matrix exponential distributions on that represent the absorption time distributions for finite-state, continuous time Markov chains (CTMCs). Here we review CTMCs and phase-type distributions, then illustrate how to use the GLCT to efficiently build ODE models from underlying stochastic model assumptions. We introduce two novel model families by using the GLCT to generalize the Rosenzweig-MacArthur predator-prey model, and the SEIR model. We illustrate the kinds of complexity that can be captured by such models through multiple examples. We also show the benefits of using a GLCT-based model formulation to speed up the computation of numerical solutions to such models. These results highlight the intuitive nature, and utility, of using the GLCT to derive ODE models from first principles.
1. Introduction
Continuous time state transition models, often formulated as mean field ODE models, are widely used throughout the biological sciences and across multiple scales [Citation4,Citation9,Citation13,Citation25,Citation30,Citation31,Citation39,Citation53,Citation56,Citation57,Citation78,Citation79,Citation82,Citation103,Citation111]. Examples include models of multi-species interactions [Citation76,Citation81], infectious disease transmission [Citation7,Citation28,Citation35,Citation71], cell proliferation and cancer [Citation18,Citation26,Citation43,Citation65,Citation98,Citation113], and various other applications in which entities transition among a finite number of states. One criticism of mean field ODE models is that they often implicitly assume that the time individuals spend in the different states are exponentially distributed [Citation36,Citation110]. That is, an ODE model with a linear loss rate can be interpreted as implicitly assuming an underlying stochastic state transmission model with an exponentially distributed dwell-time in the focal state. For example, the simple model is consistent with assuming an underlying stochastic state transition model in which individuals spend an exponentially distributed amount of time with mean 1/d in the state corresponding to variable x.
Importantly, the timing of state transitions can meaningfully affect model dynamics and model outputs in an applied setting [Citation67,Citation68,Citation79,Citation80,Citation84,Citation96,Citation110]. One remedy to address this issue with ODE models is known as the linear chain trick (LCT) [Citation22,Citation23,Citation33,Citation51,Citation68–70,Citation73,Citation100,Citation107,Citation108], which allows modellers to instead assume gamma (ErlangFootnote1) distributed passage times (a.k.a., dwell times). This is accomplished by partitioning a state into a series of k sub-states, where individuals transition sequentially through this ‘linear chain’ of sub-states. The resulting time spent in this collection of sub-states is thus the sum of k exponentially distributed random variables, and therefore follows an Erlang distribution (if the each exponential has the same rate) or a generalized ErlangFootnote2 distribution (if the rates differ).
The generalized linear chain trick (GLCT) [Citation51] extends this technique to allow modellers to assume these passage times follow a much broader family of distributions that includes the phase-type family of distributions [Citation15,Citation44,Citation46,Citation66,Citation91]. These real-valued, matrix exponential distributions on are the family of all possible hitting time (or absorption time) distributions for finite-state, absorbing, continuous time Markov chains (CTMCs). See Equations (Equation4
(4c)
(4c) ) in Section 1.1.2 below for a more detailed definition, and for further details, see [Citation5,Citation15,Citation44–46,Citation91,Citation92,Citation102]. This broad family includes exponential, Erlang, hypoexponential, hyperexponential, and Coxian distributions [Citation15,Citation38,Citation46,Citation91]. The phase-type family is also closed under various operations including minimum, finite mixtures, and convolutions (sums) [Citation14]. Recently, phase-type distributions have been increasingly applied outside of queuing theory, where much of the theory and methods for phase-type distributions have been developed [Citation10,Citation46,Citation75,Citation77,Citation89]. For example, they are increasingly being used in biology and medicine [Citation1,Citation32,Citation40,Citation74,Citation104]. Importantly, the availability of statistical tools for estimating such distributions from data has been increasing (e.g.[Citation44–47]), allowing researchers to build approximate empirical distributions into ODE models using the GLCT.
In this article, we build upon the theoretical foundation laid out in [Citation51] and illustrate how to use the GLCT, in conjunction with concepts and techniques from CTMC theory, to build mean field ODE models using a much richer set of possible underlying stochastic model assumptions. We also demonstrate the potential computational benefits of using GLCT-based model formulations. The paper is organized as follows: First, we review CTMCs, phase-type distributions, and then the GLCT for phase-type distributions. Then, we generalize some simple biological state transition models by replacing their implicit assumption of exponentially distributed passage time assumptions with arbitrary phase-type distributions. We also illustrate how to implement a sub-state transition that does not affect the overall distribution of time spent in that state using the example of hospitalization without altering the infectious period distribution. Lastly, we investigate some of the costs and benefits of using this generalized model framework with regards to computing numerical solutions. These results highlight the efficient, intuitive nature of using this novel approach to derive mean field state transition models from explicitly stochastic assumptions framed in the context of Poisson processes and CTMCs.
1.1. Continuous time Markov chains & phase-type distributions
To provide proper context for an intuitive understanding of the generalized linear chain trick (GLCT), we briefly review continuous time Markov chains (CTMCs) with a focus on CTMCs that have a single absorbing state. Our focus will then be on the probability distributions that describe the time it takes to reach that absorbing state starting from one of the transient states. These absorption time distributions define the phase-type family of distributions [Citation15,Citation46,Citation66,Citation91]. The summaries below build upon the similar descriptions laid out in [Citation51].
1.1.1. Discrete & continuous time Markov chains
Discrete time Markov chains (DTMCs) describe the transition of an individual (or other distinct entity) among a set of n states [Citation11,Citation48,Citation94,Citation102]. For our purposes below, we will restrict our attention to Markov chains in which the first k = n−1 states are transient states and the last state is an absorbing state. That is, eventually, the system enters this last state and remains there on each subsequent time step with probability 1. The initial-state distribution vector is
where each value is non-negative and
. We will refer to the transient states component of this initial distribution vector with column vector
. The transition probabilities from the ith state to the jth state (
where
) are best organized using a transition probability matrix
, where
is value in the ith row and jth column of the matrix (
).
The transition probability matrix can be written in block form [Citation11,Citation94] according to these first k = n−1 transient states (we'll call this set of states X) and the last absorbing state as
(1)
(1) where
is a
matrix describing transition probabilities among transient states,
is the
vector of probabilities of transitioning from the ith transient state to the absorbing state, and
is a
vector of zeros.
In a continuous time Markov chain (CTMC), these transitions don't occur according to a fixed time step, but instead each transition occurs after an exponentially distributed amount of time [Citation11,Citation48,Citation94,Citation102]. If the individual is in the ith state, that exponential distribution has rate or equivalently has mean duration
. Let
be the vector of these rates
,
. Due to the memorylessness property of exponential distributions, transitions from state i to state i can effectively be ignored, thus we can formulate a new transition probability matrix that describes an equivalent Markov chain but where we only track transitions to new states. This reformulated Markov chain is known as the embedded jump process or embedded Markov chain [Citation48], and it is described with a transition probability matrix
where the diagonal entries are 0, and the off diagonal transition probabilities
. That is, these are just the off-diagonal entries of
with the diagonal set to 0, and the rows normalized so each row sums to 1. For our purposes, since a Markov chain with an absorbing state is not ergodic and therefore does not properly have an embedded jump process representation, the above procedure is only applied to k rows corresponding to transient states. Hence, the last row of
and
will be the same, so that the last state in the Markov chain remains an absorbing state.
In a CTMC context, the transition probability matrix and rate vector
are usually combined into a single matrix called the transition rate matrix
[Citation48,Citation99]. The entries of
can be thought of as the mean-field, per-individual loss rates from each state (along the diagonal) and the transition rates from the ith state into the jth state (the off diagonal entries). It has the block form
(2)
(2) where
is a
matrix describing the transition rates among transient states,
is the
vector of transition rates from the transient states to the absorbing state, and the bottom row is all zeros for the absorbing state.
Matrices and
are constructed from the entries of the transition probability matrix
and the vector of rates for the exponential distributed dwell-times
as follows. The ith diagonal entry of
is the loss rate
and the rest of the entries in the ith row are the product of the
and the transition probabilities
. That is, the ij off-diagonal entries of
are the per-individual transition rates from the ith state into the jth state, given by
. Since the rows of
sum to 1, the rows of
sum to 0, and it then follows that vector
is equal to the negative of the row sums of
. Thus, one can write
, where
is a column vector of k ones.
The above shows that, for CTMCs which have k transient states and 1 absorbing state, all of the information necessary to describe the CTMC is contained in the transition rate matrix for transient states, , and initial distribution vector
. As detailed next, these two quantities are also sufficient to parameterize the phase-type distribution corresponding to such a CTMC.
1.1.2. Phase-type distributions
With the above family of CTMCs in mind, let be defined as the duration of time that it takes to first reach the absorbing state, given the CTMC starts in the ith transient state. We call this an absorption time [Citation94]. More generally, let Y be the absorption time where the initial state is determined by the initial probability vector
(i.e. Y follows the mixture distribution of random variables
with mixing probabilities
).
Phase-type distributions are the family of absorption time distributions for all such Y described above. The most familiar examples are perhaps the exponential distributions and the Erlang distributions, i.e. those gamma distributions that have an integer shape parameter, k, and can therefore be thought of as the sum of k independent exponentially distributed random variables, each with rate r. Erlang distributions can be parameterized in terms of their mean μ and variance (or coefficient of variation
, the standard deviation over the mean), or parameters rate r and shape k, where
(3)
(3) More generally, as detailed in [Citation15,Citation91], phase-type distributions are parameterized by vector
and transient state rate matrix
, and have the probability density function
, cumulative density function
, and jth moment function
given by:
(4a)
(4a)
(4b)
(4b)
(4c)
(4c) Here
is a column vector of ones with the same number of rows as
and
. Note that
and
are not necessarily a unique parameterization of a given phase-type distribution, as there are often equivalent parameterizations using vector-matrix pairs of the same dimension as well as different dimensions [Citation85,Citation95]. Phase-type distributions can be classified as cyclic (transient states can be visited infinitely often) and acyclic (transient states can only be visited once), and all acyclic phase-type distributions have a Coxian representation [Citation21,Citation27,Citation85]. This family of distributions has been relatively well studied in the queuing theory literature, and for further details, readers are encouraged to consult [Citation5,Citation14,Citation15,Citation44,Citation45,Citation85–87,Citation91,Citation92] and related works.
Additionally, freely available computational tools such as BuTools for Matlab and Python [Citation46,Citation47] enable researchers to fit phase-type distributions to data or to approximate other distributions (see also [Citation66]). This fact, combined with the GLCT, allows for the construction of ODE models that incorporate empirically derived (or other) distributional assumptions for the time spent in a given state.
1.2. Generalized linear chain trick
The GLCT provides modellers with a direct way to use the matrix and vector parameterization of a given phase-type distribution to take an existing ODE model with exponentially distributed dwell times, and replace the ODE equation for that state by a set of ODEs that describe a set of sub-states that together incorporate an overall dwell-time distribution that obeys the given phase-type distribution [Citation49,Citation51]. This technique can also be used to implement the classic linear chain trick (LCT), as Erlang distributions are a subfamily of phase-type distributions.
The GLCT in its most general form [Citation51] extends the GLCT for phase-type distributions to the scenario where the rates and probabilities in the CTMC framework described above can vary with time. Here, we only provide a statement of the GLCT for phase-type distributions:
Theorem 1.1
GLCT for phase-type distributions [Corollary 2 in [Citation51]
] Assume individuals enter state X at rate and that the distribution of time spent in state X follows a continuous phase-type distribution given by the
initial probability vector
and the
matrix
, where k is a positive integer. Then state X can be partitioned into k sub-states and the mean field equations for the amounts in each sub-state at time t,
are given by
(5)
(5) where
, the rate of individuals leaving each of these sub-states of X is given by the vector
where ° is the Hadamard (element-wise) product of the two vectors, and thus the total rate of individuals leaving state X is given by the sum of those terms, i.e.
.
Note that, assuming an overall influx rate of at time t, this influx is distributed across the sub-states of X according to the initial distribution vector
, and the second term in Equation (Equation5
(5)
(5) ) describes both the movements among sub-states of X as well as the loss rate from the state X contributed from each sub-state.
The linear chain trick (LCT) has been known for decades [Citation22,Citation23,Citation33,Citation51,Citation69,Citation70,Citation73,Citation100,Citation107, Citation108], and is special case of the GLCT for phase-type distributions stated above [Citation51]. For completeness, below we provide a formal statement of the LCT, which assumes an Erlang distributed dwell time with shape k and rate r.
Corollary 1.2
Linear Chain Trick
Consider the GLCT above. Assume that the dwell-time distribution is an Erlang distribution with shape k and rate r or if written in terms of shape k and mean
then use rate
. Then the corresponding mean field ODE equations for the k sub-states of X are
(6)
(6) where the total loss rate from state X at time t is the loss rate from the final sub-state,
.
Proof.
The phase-type distribution formulation of the Erlang distribution with shape k and rate r is given by v and M below, and substituting these into Equation (Equation5(5)
(5) ) yields the desired result.
(7)
(7) See [Citation51] for a direct proof that uses a recursive relationship between Erlang density functions and their derivatives.
2. Results
In the sections below, we extend some well-known models using the GLCT by replacing the implicit exponentially distributed dwell time assumptions of these models with phase-type distribution assumptions. Importantly, these more general model formulations can also be used as a way to formulate models derived using the standard LCT (i.e.the assumption of Erlang distributed dwell times), as the phase-type formulation of such models can often be more practically and computationally advantageous to work with, and we show in section 2.4.
2.1. Rosenzweig-MacArthur predator-prey model
Maturation delays in population models can influence model outputs, however, such delays are not always incorporated into models used in applications [Citation96]. In this section, we illustrate how one can use the GLCT to incorporate phase-type maturation times into such population models, using the well known Rosenzweig-MacArthur model of predator-prey (consumer-resource) dynamics [Citation81,Citation97]:
(8a)
(8a)
(8b)
(8b)
In the absence of predators (P), the prey population (N) is subject to logistic growth, and predators consume prey following a Holling's type II functional response [Citation24,Citation41,Citation42,Citation81]. Predators live for an exponentially distributed lifetime with mean .
One can incorporate a maturation delay of duration τ by formulating a delay differential equation (DDE) extension of Equation (Equation8(8b)
(8b) ), as in [Citation112]:
(9a)
(9a)
(9b)
(9b)
This can be thought of as the limit of a distributed delay model, with mean delay time τ, for which the variance (or coefficient of variation) goes to zero to yield a delay distribution with point mass at τ (i.e. the distribution can be described with a Dirac delta function). The LCT has long been used to approximate such limiting cases in DDE models by assuming instead a delay distribution that is Erlang distributed with mean τ and a very small coefficient of variation (small variance), i.e. a large shape parameter [Citation51,Citation100]. Writing this approximating model, as in [Citation50], yields the Rosenzweig–MacArthur model with Erlang distributed maturation time in the predators:
(10a)
(10a)
(10b)
(10b)
(10c)
(10c)
(10d)
(10d)
The sub-states ,
, track the immature stages of the predators before they reach maturity.
Using the GLCT [Citation49,Citation51], the above model can be generalized in two ways. First, the Erlang distributed maturation time assumption that yields the sub-states can be replaced by the assumption of a more general phase-type distribution with matrix-vector parameterization
and
. Similarly, the exponentially distributed time duration that predators spend as adults can also be replaced with a more general phase-type distribution with parameter vector
and matrix
. According to the GLCT, these assumptions yield the more general model
(11a)
(11a)
(11b)
(11b)
(11c)
(11c) where
denotes the vector of maturing predator sub-states
,
is the vector of adult predator sub-states
, and where
.
Observe that Equations (Equation10(10d)
(10d) ) are the special case of Equations (Equation11
(11c)
(11c) ) where the phase-type distribution matrix-vector parameterization for an Erlang distribution with mean τ and shape parameter k is given by
(12)
(12) and for an exponential distribution with rate μ,
(13)
(13) Note that Equations (Equation10
(10d)
(10d) ) are a much more compact way of formulating such models without the need to specify the number of sub-states. As will be shown below, this formulation allows modellers to more efficiently write computer code for computing numerical solutions to such models, and also can be used with computer algebra systems generate ODEs like Equations (Equation10
(10d)
(10d) ) from first principles.
2.2. SEIR models
SIR-type models of infectious disease transmission are widely used in the study of infectious diseases, and help inform public health policy and related efforts to limit the spread of infectious diseases [Citation7,Citation17,Citation28,Citation34,Citation35,Citation54,Citation58–63,Citation70,Citation72,Citation109,Citation110]. For example, such models are being used at this time to model the ongoing SARS-CoV-2/COVID-19 pandemic [Citation12,Citation29,Citation83,Citation93].
It is known that including a latent period prior to the onset of symptoms and infectiousness, as well as incorporating non-exponential distributions for the time spent in the different infection states, can be important to include in such models when used in applications [Citation34,Citation69,Citation109,Citation110].
Here we use the GLCT to formulate a more general family of SEIR models, where we assume that the latent period (time spent in state E) and infectious period (time spent in state I) follow independent phase-type distributions. For simplicity, we assume the state variables have been scaled by the total population size so that S + E + I + R = 1, and that there are no births or deaths in the model.
To begin, consider the simple SEIR model below, Equations (14), where S is the fraction of susceptibles in the population, E the fraction of exposed individuals with latent infections, I the fraction of individuals with active infections, and R the fraction of recovered or removed individuals:
(14a)
(14a)
(14b)
(14b)
(14c)
(14c)
(14d)
(14d)
Next, assume the latent period distribution is phase-type with parameters and
, and the infectious period distribution is also phase-type but with parameters
and
. Let
and
be the column vectors of the fraction of individuals in each of the exposed and infectious sub-states, respectively, where
and
. Then by the GLCT we can write the mean field ODEs for the generalized SEIR model as follows:
(15a)
(15a)
(15b)
(15b)
(15c)
(15c)
(15d)
(15d)
As in the previous model, to assume (for example) an Erlang distributed latent period with mean and shape
, i.e.rate
and coefficient of variation
, then one would use
(16)
(16) Similarly, an Erlang infectious period distribution with mean
and shape parameter
(coefficient of variation
) would be parameterized by
(17)
(17) Simplifying the right hand side of Equations (Equation15
(15d)
(15d) ) using the matrices and vectors above yields the familiar sub-state equations for an SEIR model with Erlang distributed latent and infectious periods [Citation6,Citation55,Citation69,Citation72,Citation110]:
(18a)
(18a)
(18b)
(18b)
(18c)
(18c)
(18d)
(18d) where
,
, and
. By allowing different loss rates from each substate in Equation (Equation15
(15d)
(15d) ) (i.e. in each row of the matrix in Equation (Equation16
(16)
(16) )) one could similarly implement a generalized Erlang (or hypoexponential) distribution.
Other phase-type distributions can also be implemented using Equations (Equation15(15d)
(15d) ). For example, consider the Coxian distribution [Citation19,Citation20,Citation37,Citation38,Citation74,Citation75,Citation95,Citation104], which is a further generalization of the generalized Erlang distribution. These also have potentially distinct loss rates from each of the k sub-states, plus an additional k−1 proportions (
) that describe the fraction of those transitions leaving the ith state that go to the i + 1 state. The remaining fraction (
) go directly to the absorbing state (i.e. if all
the Coxian distribution simplifies to a generalized Erlang distribution).
In [Citation64], an SEIR model with a Coxian latent period is developed from first principles. However, we have shown above how it can be more straightforward to use the GLCT to develop such SEIR-type models. Using Equations (Equation15(15d)
(15d) ), it is straight forward to derive an SEIR model with Coxian latent and infectious period distributions once they are parameterized in the form of Equations (Equation4
(4c)
(4c) ), with matrix-vector parameters of the form
(19)
(19) This yields the Coxian SEIR model (see Figure )
(20a)
(20a)
(20b)
(20b)
(20c)
(20c)
(20d)
(20d)
Figure 1. Diagram for an SEIR-type model with an Erlang latent period and Coxian infectious period. A special case of Equations (Equation15(15d)
(15d) ) and Equations (Equation20
(20d)
(20d) ). See the main text for details (and compare to Figure in [Citation83]).
![Figure 1. Diagram for an SEIR-type model with an Erlang latent period and Coxian infectious period. A special case of Equations (Equation15(15d) dRdt=(−AI1)Ty⏞(15d) ) and Equations (Equation20(20d) dRdt=rIIkI+∑j=1kI−1(1−ρIj)λIjIj.(20d) ). See the main text for details (and compare to Figure 2 in [Citation83]).](/cms/asset/473ca429-da57-4c8f-82f5-e759f33c06ad/tjbd_a_1912418_f0001_ob.jpg)
Figure 2. SEIR-type model with heterogeneity in illness severity and hospitalizations that do not alter the infectious period. A special case of Equations (Equation21(21e)
(21e) ) (cf. Figure ). See the main text for details. Here the standard LCT has been applied to the exposed (E) state, and the GLCT is applied to the I states, using the competing Poisson process approach [Citation51] to model hospitalizations in a fraction of the I state individuals. This ensures that the time spent in I is independent of whether or not individuals transition to the hospital or not. Compare to [Citation35].
![Figure 2. SEIR-type model with heterogeneity in illness severity and hospitalizations that do not alter the infectious period. A special case of Equations (Equation21(21e) dRdt=(−AI01)Ty0+(−AIs1)Tys.(21e) ) (cf. Figure 3). See the main text for details. Here the standard LCT has been applied to the exposed (E) state, and the GLCT is applied to the I states, using the competing Poisson process approach [Citation51] to model hospitalizations in a fraction of the I state individuals. This ensures that the time spent in I is independent of whether or not individuals transition to the hospital or not. Compare to [Citation35].](/cms/asset/36cb12cb-feca-4db5-98db-5ad51def7d2d/tjbd_a_1912418_f0002_ob.jpg)
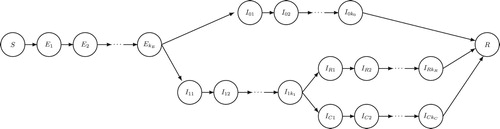
Figure 3. SEIR-type model with heterogeneity in illness severity in which a fraction of infected individuals experience severe illness, and a fraction of those require critical care. This is also a special case of Equations (Equation21(21e)
(21e) ) (see Figure ). See the main text for details.
Compare Equations (Equation20(20d)
(20d) ), which assume no births or deaths, to Equations (12) in [Citation64], which assume a simple birth-death process.
2.3. SEIR model with heterogeneity among infected individuals
The examples above illustrate how an existing ODE or DDE model can be generalized or approximated by assuming phase-type distributed dwell times in one or more states. Here we take the generalized SEIR model above and use the GLCT to further explore more complex model assumptions. We do this by considering two special cases of this generalized model (see Figures and ): one that models hospitalization in a manner that does not change the distribution of time in the infected class, and a second case that models heterogeneity in the severity and duration of disease. In each case, we assume that infected individuals will either experience mild or severe disease with the potential for distributional differences in the duration of infection.
For simplicity, we assume that the removed class R contains both recovered and deceased individuals, and that, upon transitioning from the class of individuals with latent infection (E) to the infectious class (I), a fraction ρ will go on to develop severe symptoms (in state I) that may require hospitalization, whereas the remaining fraction (
) do not develop severe disease and thus enter a different state of more mild disease (I
). Using the GLCT, the states I
and I
are partitioned into sub-states, where the numbers in each are described by vectors
and
, respectively, and their dynamics obey the following system of ODEs:
(21a)
(21a)
(21b)
(21b)
(21c)
(21c)
(21d)
(21d)
(21e)
(21e)
Equation (Equation21(21e)
(21e) ) can be viewed as a special case of Equation (Equation15
(15d)
(15d) ) defined in terms of a mixture of two phase-type distributions, where
, the vector
, and
is the block diagonal matrix
diag(
). The two cases below are described in the context of Equations (Equation21
(21e)
(21e) ).
2.3.1. Case 1: hospitalization independent of progress towards infection resolution
In this scenario, individuals progress towards recovery or death according to an Erlang distribution with rate λ and shape . Independently, they also move towards hospitalization according to an Erlang distributed hospitalization time with rate r and shape
(for an example of this structure used to model Ebola, but where
, see [Citation35]). Modeling this with Erlang latent and infectious period distributions (for simplicity) and according to the competing Poisson processes motif detailed in [Citation51] yields a sub-state structure as shown in Figure . The matrix-vector pairs
,
, and
,
are as described above for Erlang distributions.
The matrix-vector pair and
are defined as followsFootnote3. If we order these states starting at the
entry and work across each rows left to right before moving down to the next row (see Figure ), then the associated rate matrix has the following block form, with each column and row having
blocks of dimension
. This block structure corresponds to each row of the I
sub-states shown in the lower portion of Figure as a
grid of sub-states. This yields
(22)
(22) where the diagonal and superdiagonal blocks are
(23)
(23) and the bottom right diagonal entry is
(24)
(24) Together, the matrix
and the
initial distribution vector
complete the parameterization of model Equations (Equation21
(21e)
(21e) ) to yield the model structure illustrated in Figure .
Observe that matrix above has the same diagonal and superdiagonal blocks in all rows except for the bottom right block, for which the diagonal entries are
not
. Here the dwell time in each sub-state of I
(except for the bottom row of sub-states in Figure ) follows the minimum of two independent exponential distributions with rates λ and r, thus by the properties of exponential distributions, those dwell times are each exponentially distributed with rate
. Individuals leaving those sub-states then either move horizontally towards resolving their infections, with probability
, or move downwards towards hospitalization (the the bottom row of sub-states in Figure ) with probability
[Citation51]. In the bottom row of sub-states in Figure , individuals are hospitalized and can only move horizontally towards the resolution of their illness. This structure ensures that time transition to the hospital (the last row) does not impact their overall distribution of time spent in state I
.
2.3.2. Case 2: hospitalization with heterogeneous need for critical care
To further illustrate the flexibility of Equations (Equation15(15d)
(15d) ) and (Equation21
(21e)
(21e) ), we now consider the model structure illustrated in Figure . In this case, we make similar assumptions to the case above, except for the states that pertain to the fraction ρ of individuals who experience severe illness. Those individuals exhibit an Erlang distributed period of relatively mild illness, with rate
and shape parameter
. A fraction f of those individuals recover after an Erlang distributed period of time with rate
and shape
. The remaining fraction
become even more ill and require hospital care for an Erlang distributed duration of time, with rate
and shape
. As above, all individuals then enter a removed state R which, for our purposes here, makes no distinction between recovery and death.
Comparing Figures and , we see that this second scenario is also a special case of Equations (Equation21(21e)
(21e) ), and only differs from that case in the definition of matrix
and the length
initial distribution vector
. Ordering the substates of I
from I
to I
to I
to I
to I
to I
, then, by the assumptions above,
is given by
The two examples above illustrate the utility of deriving models from first principles using the GLCT and basic concepts from Markov chains. This approach can also be leveraged for the analytical study of such models (e.g. see [Citation52]), but as we show in the next section, it can also facilitate the process of computing numerical solutions to such systems of ODEs.
2.4. Benchmarking numerical solutions: LCT vs GLCT
Software like Matlab, Python, Julia, and R, have built-in ODE solvers that implement various numerical methods for obtaining numerical solutions to ODEs. In Figure , we summarize the time it takes, using the deSolve package in R [Citation90,Citation101], to compute a numerical solution to the generalized Rosenzweig-MacArthur model with Erlang distributed maturation time and time predators spend in the adult stage, either in the (LCT) form of Equations (Equation10(10d)
(10d) ) or in the (GLCT) form of Equation (Equation11
(11c)
(11c) ). In Figure we make a similar comparison with the SEIR model with Erlang (panel a) and Coxian (panel b) latent and infectious periods, comparing the time it takes to compute numerical solutions to that model in the form of Equation (Equation18
(18d)
(18d) ) or the equivalent model in the (GLCT-based) form of Equation (Equation15
(15d)
(15d) ). See the figure captions further computational details (or the R code that was used to create these figures, available in the Supplementary Materials).
Figure 4. Benchmark results for 140 iterations computing numerical solutions to Rosenzweig-MacArthur model with Erlang (gamma) distributed maturation times and time spent in the adult-stage, using either a direct (LCT; medium grey) or more general (GLCT; black) formulations of the model (the standard Rosenzweig-MacArthur model with no maturation delay and exponentially distributed time spent in the adult stage [light grey; Equations (Equation8(8b)
(8b) )] is also included as a baseline). The second and third cases are mathematically equivalent systems. For smaller shape parameters (lower dimension systems) the GLCT model formulation is relatively slower than explicitly writing out the 2M + 1 equations, whereas for larger shape parameters (higher dimension systems) the GLCT-based formulation becomes markedly faster. This is likely due to the efficiency of the matrix computations. The x-axis values M indicate the number of maturing predator sub-states (
) and adult predator sub-states (
), which yields a 2M + 1 dimensional model. Numerical solutions were computed using the ode() function in the deSolve package [Citation101] in R [Citation90], using method ode45 with atol=10-6, for time points 0 to 500 in increments of 1, and model parameters r = 1, K = 1000, a = 5, h = 500,
,
,
, with initial conditions
,
(
),
, and
(j>1).
![Figure 4. Benchmark results for 140 iterations computing numerical solutions to Rosenzweig-MacArthur model with Erlang (gamma) distributed maturation times and time spent in the adult-stage, using either a direct (LCT; medium grey) or more general (GLCT; black) formulations of the model (the standard Rosenzweig-MacArthur model with no maturation delay and exponentially distributed time spent in the adult stage [light grey; Equations (Equation8(8b) dPdt=χaNh+NP−μP(8b) )] is also included as a baseline). The second and third cases are mathematically equivalent systems. For smaller shape parameters (lower dimension systems) the GLCT model formulation is relatively slower than explicitly writing out the 2M + 1 equations, whereas for larger shape parameters (higher dimension systems) the GLCT-based formulation becomes markedly faster. This is likely due to the efficiency of the matrix computations. The x-axis values M indicate the number of maturing predator sub-states (kx=M) and adult predator sub-states (ky=M), which yields a 2M + 1 dimensional model. Numerical solutions were computed using the ode() function in the deSolve package [Citation101] in R [Citation90], using method ode45 with atol=10-6, for time points 0 to 500 in increments of 1, and model parameters r = 1, K = 1000, a = 5, h = 500, χ=0.5, μx=0.5, μy=1, with initial conditions N(0)=1000, xi(0)=0 (i≥1), y1(0)=10, and yj(0)=0 (j>1).](/cms/asset/4e72f71e-3278-4a76-a7a2-147a7b514578/tjbd_a_1912418_f0004_ob.jpg)
Figure 5. Benchmark results for 500 iterations computing numerical solutions to an SEIR model with latent and infectious period distributions that are either Erlang (panel a; Equation (Equation18(18d)
(18d) )) or Coxian (panel b; Equation (Equation20
(20d)
(20d) )), using either a direct equation-by-equation formulation (LCT; medium grey) or more general matrix-vector formulation (GLCT; black) of the model (SEIR with exponentially distributed latent and infectious periods [light grey; Equation (14)] also included as a baseline). The second and third cases are mathematically equivalent systems. For smaller shape parameters (lower dimension systems) the GLCT model formulation is relatively slower than explicitly writing out the 2N + 2 equations, whereas for larger shape parameters (higher dimension systems) the GLCT-based formulation becomes faster, presumably due to the efficiency of the matrix computations. The x-axis values N indicate the number of sub-states in each of E (
) and I (
), which yields a 2N + 2 dimensional model. Numerical solutions were computed using the ode() function in the deSolve package [Citation101] in R [Citation90], using method ode45 with atol=10-6, for time points 0 to 100 in increments of 0.5, and model parameters
,
,
, where all
, with initial conditions
,
,
(i>1),
,
(i>1), and
. See Supplementary Materials for more details.
![Figure 5. Benchmark results for 500 iterations computing numerical solutions to an SEIR model with latent and infectious period distributions that are either Erlang (panel a; Equation (Equation18(18d) dRdt=kIτIIkI(18d) )) or Coxian (panel b; Equation (Equation20(20d) dRdt=rIIkI+∑j=1kI−1(1−ρIj)λIjIj.(20d) )), using either a direct equation-by-equation formulation (LCT; medium grey) or more general matrix-vector formulation (GLCT; black) of the model (SEIR with exponentially distributed latent and infectious periods [light grey; Equation (14)] also included as a baseline). The second and third cases are mathematically equivalent systems. For smaller shape parameters (lower dimension systems) the GLCT model formulation is relatively slower than explicitly writing out the 2N + 2 equations, whereas for larger shape parameters (higher dimension systems) the GLCT-based formulation becomes faster, presumably due to the efficiency of the matrix computations. The x-axis values N indicate the number of sub-states in each of E (kE=N) and I (kI=N), which yields a 2N + 2 dimensional model. Numerical solutions were computed using the ode() function in the deSolve package [Citation101] in R [Citation90], using method ode45 with atol=10-6, for time points 0 to 100 in increments of 0.5, and model parameters β=1, μE=4, μI=7, where all ρE=ρI=0.99, with initial conditions S(0)=0.9999, E1(0)=0.0001, Ei(0)=0 (i>1), I1(0)=0, Ii(0)=0 (i>1), and R(0)=0. See Supplementary Materials for more details.](/cms/asset/19b61798-ac82-4f47-b3a1-1182a64ca2c1/tjbd_a_1912418_f0005_ob.jpg)
To summarize these results, neither approach performs uniformly better than the other. In both comparisons, low dimensional models (i.e. smaller shape parameters and thus larger coefficients of variation), coded using the more common equation-by-equation (LCT) model formulation like Equations (Equation10(10d)
(10d) ), (Equation18
(18d)
(18d) ), and (Equation20
(20d)
(20d) ), yielded numerical solutions at the same speed as, or faster than, mathematically equivalent models coded using the more general phase-type (GLCT) formulation like Equations (Equation11
(11c)
(11c) ) and (Equation15
(15d)
(15d) ) (see Supplementary Materials for details).
However, for higher dimensional models, the phase-type (GLCT) formulation of these models outperformed their LCT-type counterparts. For a given model family, it is worth noting that these computing speed gains for higher dimensional models are substantially larger than the speed costs associated with low dimensional models. In some cases (see Figure ), the computing speeds for higher dimensional GLCT-based models were more than twice as fast. These gains are very likely the result of the matrix calculations used in the phase-type (GLCT) formulation of the models being more computationally efficient, and together suggest that the (GLCT-based) matrix-vector model formulations might be preferable in some applications.
Additionally, it is worth noting that the GLCT-based statement of the ODE function only needs to be coded once, as it is agnostic of the number of sub-state variables. For details, see the R code used to create these figures in the Supplementary Materials. In contrast, researchers typically hard-code the number of sub-states for such computations, and thus must write multiple ODE functions to consider models using different shape parameters for the assumed Erlang (or other phase-type) distributions. Thus, taking the time spent writing computer code into consideration, the (GLCT-based) matrix-vector model formulations might again be preferred in many applications.
In summary, these results suggest that the GLCT-based model formulations may allow for significant computing speed improvements, and may simplify the process of writing computer code for use with ODE solvers in R (and similar languages) since a single instance of the model can be used to simulate ODE models of arbitrary number of dimensions.
3. Discussion
ODE models are widely used in the biological sciences, and can often be viewed as mean field models for some (often unspecified) stochastic state transition model [Citation2–4,Citation8,Citation16,Citation35,Citation50]. Such ODE models are sometimes rightfully criticized for their implicit assumption of exponentially distributed dwell times (e.g.exponentially distributed lifetimes of organisms) and their frequent lack of age or stage structure to capture important time lags in the system being modelled, such as the maturation times of organisms or latent periods in disease transmission models [Citation35,Citation36,Citation67,Citation79,Citation80,Citation84,Citation96,Citation110].
In this article, we have provided an overview of the generalized linear chain trick (GLCT) [Citation51], a relatively new tool modellers can use to improve upon existing ODE models to address these shortcomings. We also give an overview of related concepts from Markov chain theory, and have illustrated the utility of the GLCT with some novel applications.
The GLCT [Citation51] extends the well known linear chain trick (LCT) [Citation22,Citation23,Citation33,Citation51,Citation69,Citation70,Citation73, Citation100,Citation107,Citation108]) to a broad family of probability distributions that includes the phase-type distributions, which are the absorption time distributions for continuous time Markov chains (CTMCs) [Citation15,Citation40,Citation44,Citation66,Citation91]. As such, the GLCT helps to clarify how mean field ODEs reflect underlying stochastic model assumptions when viewed from the perspective of CTMCs [Citation50,Citation52]. The phase-type family of probability distributions includes a number of named probability distributions including exponential, hyperexponential, Erlang (gamma with an integer shape parameter), hypoexponential (generalized Erlang), and Coxian distributions. Importantly, freely available statistical tools exist for fitting phase-type distributions to data, or to other distributions [Citation46,Citation47,Citation77,Citation88]. This enables modellers to build approximate empirical (or other) dwell time distributions into ODE models using the GLCT.
In the Results section above, we derived multiple novel models using the GLCT to illustrate its utility, and we demonstrated some of the computational benefits of using GLCT-based model formulations. Specifically, the GLCT was used to derive extensions of two familiar models: the Rosenzweig-MacArthur predator-prey model, and the SEIR model of infectious disease transmission. We showed how special cases of that generalized SEIR model can be constructed to accommodate additional heterogeneity among infected individuals: the first case models a hospitalization scenario in which the transition to the hospitalized state has no impact on the distribution of the overall time individuals spend sick [cf. [Citation35]], and the second case models heterogeneity in the progression of more severe cases. These examples illustrate how the GLCT can be used to refine model assumptions in a rigorous manner, but without the need to explicitly derive mean field ODEs from stochastic model equations or mean field integral equations.
We also showed some computational benefits of using a GLCT-based approach to ODE model formulation by comparing the time it takes to compute numerical solutions of ODEs using the standard equation-by-equation model formulation or using a GLCT-based approach that entails writing models in a matrix-vector form.
Practically, the first benefit of the GLCT-based approach is that computer code for only one ODE model function definition needs to be written, since it is agnostic of the model dimension (see Supplementary Materials). In contrast, models that have been derived using the standard LCT typically have the number of sub-states hard-coded (since model dimension depends on the shape parameter for the Erlang distributions), and therefore multiple model functions must be coded to explore different shape parameter values. This may be quite beneficial in some applications.
Second, our results show that for low dimensional models the GLCT-based computations are as fast as, or a little slower than, their more traditionally coded counterparts, however for higher dimensional models the GLCT-based model formulations performed best (see Figures and ). In Figure , the GLCT-based approach was more than twice as fast as the traditional approach. We have only demonstrated these benefits for specific examples implemented using the R programming language [Citation90], however, we expect that using other software such as python or Matlab would yield similar results since this improvement in computing time is presumably the result of the computational efficiency of doing matrix and vector based computations. Exploring these computational comparisons in greater detail, with other models and using other computing platforms, would be a useful follow-up to these results. Future work on leveraging the theory of Markov chains and phase-type distributions during analytical investigations of GLCT-based ODE models, as in [Citation52], may also prove to be useful.
This GLCT-based approach to the derivation and application of mean field models does have limitations. While phase-type distributions are dense in the space of univariate probability distributions on , it may not be possible to accurately approximate a given distribution with a phase-type distribution unless a very large number of sub-states are used. For example, distributions with finite support (such as a uniform distribution), or that are heavy-tailed, may not be adequately approximated by a phase-type distribution with only a small number sub-states (or ‘phases’), depending on the application [Citation5,Citation66,Citation105,Citation106].
In conclusion, we hope this work helps other researchers to better understand underlying model assumptions when deriving and evaluating mean field ODE models. We also hope this work demonstrates the relative ease with which some basic intuition from Markov chain theory can be used to specify clear model assumptions from first principles, which can then be very quickly realized as one or more mean field ODE models using the GLCT [Citation49,Citation51].
Acknowledgments
The authors thank Dr. Deena Schmidt, Jillian Kiefer, and the rest of the Mathematical Biology Lab Group at UNR for conversations and comments that improved this manuscript. We also thank two anonymous reviewers for their feedback, and the editors of this issue for their generous accommodation to provide additional time to submit this work during the ongoing SARS-CoV-2/COVID-19 pandemic.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Gamma distributions with integer-valued shape parameters are those that can be thought of as the sum of independent and identically distributed exponential random variables, and are known as Erlang distributions.
2 The sum of independent exponentially distributed random variables with different rates is known as a generalized Erlang or hypoexponential distribution.
3 Compare to the matrix-vector parameterization of the minimum of two Erlang distributions (the minimum of two phase-type distributions is itself phase-type) using the formulas given in [Citation15].
References
- O.O. Aalen, Phase type distributions in survival analysis, Scand. J. Stat. 22 (1995), pp. 447–463. Available at http://www.jstor.org/stable/4616373.
- L.J.S. Allen, An Introduction to Stochastic Processes with Applications to Biology, 2nd ed., Chapman and Hall/CRC, 2010.
- L.J. Allen, A primer on stochastic epidemic models: formulation, numerical simulation, and analysis, Infect. Dis. Model. 2 (2017), pp. 128–142.
- L. Allen, An Introduction to Mathematical Biology, Pearson/Prentice Hall, Upper Saddle River, NJ, 2007.
- T. Altiok, On the phase-type approximations of general distributions, IIE Trans. 17 (1985), pp. 110–116.
- D. Anderson and R. Watson, On the spread of a disease with gamma distributed latent and infectious periods, Biometrika 67 (1980), pp. 191–198.
- R.M. Anderson, R.M. May, Infectious Diseases of Humans: Dynamics and Control, Oxford University Press, New York, 1992.
- B. Armbruster and E. Beck, Elementary proof of convergence to the mean-field model for the SIR process, J. Math. Biol. 75 (2017), pp. 327–339.
- D.K. Arrowsmith, C.M. Place, An Introduction to Dynamical Systems, Cambridge University Press, New York, 1990.
- M.C. Ausin, M.P. Wiper, and R.E. Lillo, Bayesian estimation of finite time ruin probabilities, Appl. Stoch. Models Bus. Ind. 25 (2009), pp. 787–805.
- N.T.J. Bailey, The Elements of Stochastic Processes with Applications to the Natural Sciences, John Wiley & Sons, New York, 1990.
- A.L. Bertozzi, E. Franco, G. Mohler, M.B. Short, and D. Sledge, The Challenges of Modeling and Forecasting the Spread of COVID-19, Proceedings of the National Academy of Sciences Vol. 117, 2020, pp. 16732–16738
- A. Beuter, L. Glass, M.C. Mackey, and M.S. Titcombe, eds., Nonlinear Dynamics in Physiology and Medicine, Interdisciplinary Applied Mathematics (Book 25), Springer, 2003.
- M. Bladt, B.F. Nielsen, Matrix-Exponential Distributions in Applied Probability, Springer, New York, 2017.
- M. Bladt and B.F. Nielsen, Phase-Type Distributions, in Matrix-Exponential Distributions in Applied Probability, USA, Springer, 2017, pp. 125–197
- D. Champredon, J. Dushoff, and D.J.D. Earn, Equivalence of the Erlang-distributed SEIR epidemic model and the renewal equation, SIAM J. Appl. Math. 78 (2018), pp. 3258–3278.
- G. Chowell, J.M. Hyman, L.M.A. Bettencourt, and C. Castillo-Chavez, eds., Mathematical and Statistical Estimation Approaches in Epidemiology, Springer, Netherlands, 2009.
- G. Clapp and D. Levy, A review of mathematical models for leukemia and lymphoma, Drug Dis. Today: Dis. Models 16 (2015), pp. 1–6.
- D.R. Cox, The analysis of non-markovian stochastic processes by the inclusion of supplementary variables, Math. Proc. Cambridge Philos. Soc. 51 (1955), pp. 433–441.
- D.R. Cox, A use of complex probabilities in the theory of stochastic processes, Math. Proc. Cambridge Philos. Soc. 51 (1955), pp. 313–319.
- A. Cumani, On the canonical representation of homogeneous markov processes modelling failure -- time distributions, Microelectron. Reliab. 22 (1982), pp. 583–602.
- J.M. Cushing, An Introduction to Structured Population Dynamics, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1998.
- J.M. Cushing, Integrodifferential Equations and Delay Models in Population Dynamics, Springer, Berlin Heidelberg, 1977.
- J. Dawes and M. Souza, A derivation of holling's type i, II and III functional responses in predator–prey systems, J. Theor. Biol. 327 (2013), pp. 11–22.
- P. Dayan and L.F. Abbott, Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems, Computational Neuroscience, The MIT Press, 2005.
- L. de Pillis, K.R. Fister, W. Gu, C. Collins, M. Daub, D. Gross, J. Moore, and B. Preskill, Mathematical model creation for cancer chemo-immunotherapy, Comput. Math. Methods Med. 10 (2009), pp. 165–184.
- M. Dehon and G. Latouche, A geometric interpretation of the relations between the exponential and generalized Erlang distributions, Adv. Appl. Probabil. 14 (1982), pp. 885–897.
- O. Diekmann and J. Heesterbeek, Mathematical Epidemiology of Infectious Diseases: Model Building, Analysis and Interpretation, Wiley Series in Mathematical and Computational Biology, John Wiley & Sons, LTD, New York, 2000.
- J. Drake, A. Handel, E. O'Dea, and A. Tredennick, A Stochastic Model for the Transmission of SARS-CoV-2 in Georgia, USA, 2020. Available at https://www.covid19.uga.edu/stochastic-fitting-georgia-suplement.html. Accessed: 2020-01-20
- L. Edelstein-Keshet, Mathematical Models in Biology, Classics in Applied Mathematics (Book 46), Society for Industrial and Applied Mathematics, 2005.
- S.P. Ellner, J. Guckenheimer, Dynamic Models in Biology, Princeton University Press, Princeton, NJ, 2006.
- M. Fackrell, Modelling healthcare systems with phase-type distributions, Health Care Manage. Sci.12 (2008), pp. 11–26.
- D. Fargue, Réductibilité des systèmes héréditaires à des systèmes dynamiques (régis par des équations différentielles ou aux dérivées partielles), C. R. Acad. Sci. Paris Sér. A-B 277 (1973), pp. B471–B473MR 0333630
- Z. Feng, D. Xu, and H. Zhao, Epidemiological models with non-exponentially distributed disease stages and applications to disease control, Bull. Math. Biol. 69 (2007), pp. 1511–1536.
- Z. Feng, Y. Zheng, N. Hernandez-Ceron, H. Zhao, J.W. Glasser, and A.N. Hill, Mathematical models of Ebola-Consequences of underlying assumptions, Math. Biosci. 277 (2016), pp. 89–107.
- W.M. Getz, C.R. Marshall, C.J. Carlson, L. Giuggioli, S.J. Ryan, S.S. Romañach, C. Boettiger, S.D. Chamberlain, L. Larsen, P. D'Odorico, and D. O'Sullivan, Making ecological models adequate, Ecol. Lett. 21 (2018), pp. 153–166.
- Q.M. He and H. Zhang, PH-invariant polytopes and coxian representations of phase type distributions, Stoch. Models 22 (2006), pp. 383–409.
- Q.M. He and H. Zhang, Coxian approximations of matrix-exponential distributions, Calcolo 44 (2007), pp. 235–264.
- M.W. Hirsch, S. Smale, and R.L. Devaney, Differential Equations, Dynamical Systems, and an Introduction to Chaos, 3rd ed., Elsevier, 2013.
- A. Hobolth, A. Siri-Jégousse, and M. Bladt, Phase-type distributions in population genetics, Theor. Popul. Biol. 127 (2019), pp. 16–32.
- C.S. Holling, The components of predation as revealed by a study of small-mammal predation of the european pine sawfly, Can. Entomol. 91 (1959), pp. 293–320.
- C.S. Holling, Some characteristics of simple types of predation and parasitism, Can. Entomol. 91 (1959), pp. 385–398.
- S. Hoops, R. Hontecillas, V. Abedi, A. Leber, C. Philipson, A. Carbo, J. Bassaganya-Riera, Ordinary Differential Equations (ODEs) Based Modeling, in Computational Immunology, Josep Bassaganya-Riera, eds., Elsevier, San Diego, CA, 2016. pp. 63–78.
- A. Horváth, M. Scarpa, and M. Telek, Phase Type and Matrix Exponential Distributions in Stochastic Modeling, in Principles of Performance and Reliability Modeling and Evaluation: Essays in Honor of Kishor Trivedi on his 70th Birthday, L. Fiondella and A. Puliafito, eds., Springer International Publishing, Cham, 2016, pp. 3–25
- G. Horváth, P. Reinecke, M. Telek, and K. Wolter, Efficient Generation of PH-Distributed Random Variates, in Proceedings of the 19th international conference on Analytical and Stochastic Modeling Techniques and Applications, K. Al-Begain, D. Fiems, and J.M. Vincent, eds., Berlin, Heidelberg, Springer, 2012, pp. 271–285.
- G. Horváth and M. Telek, BuTools 2: A Rich Toolbox for Markovian Performance Evaluation, in ValueTools 2016 -- 10th EAI International Conference on Performance Evaluation Methodologies and Tools, 1. Association for Computing Machinery, 2017, pp. 137–142
- G. Horváth and M. Telek, Butools v2.0. Available at http://webspn.hit.bme.hu/%7Etelek/tools/butools/doc/index.html (2020). Accessed: 2020-05-15
- S.K. Howard and M. Taylor, An Introduction to Stochastic Modeling, 3rd ed., Academic Press, 1998.
- P. Hurtado and C. Richards, A procedure for deriving new ODE models: using the generalized linear chain trick to incorporate phase-type distributed delay and dwell time assumptions, Math. Appl. Sci. Eng. 9999 (2020), pp. 1–14.
- P.J. Hurtado, Building New Models: Rethinking and Revising ODE Model Assumptions, in Foundations for Undergraduate Research in Mathematics, Hannah Callender Highlander, Alex Capaldi, Carrie Diaz Eaton, ed., Springer International Publishing, Birkhäuser, Cham, 2020. pp. 1–86.
- P.J. Hurtado and A.S. Kirosingh, Generalizations of the ‘linear chain trick’: incorporating more flexible dwell time distributions into mean field ODE models, J. Math. Bio. 79 (2019), pp. 1831–1883.
- P.J. Hurtado and C. Richards, Finding reproduction numbers for epidemic models & predator-prey models of arbitrary finite dimension using the generalized linear chain trick (2020). arXiv:2008.06768
- E.M. Izhikevich, Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting, Computational Neuroscience, MIT Press, 2010.
- M.J. Keeling and B.T. Grenfell, Disease extinction and community size: modeling the persistence of measles, Science 275 (1997), pp. 65–67.
- M.J. Keeling and B.T. Grenfell, Understanding the persistence of measles: reconciling theory, simulation and observation, Proc. R. Soc. Lond. Ser. B: Biol. Sci. 269 (2002), pp. 335–343.
- J. Keener and J. Sneyd, Mathematical Physiology I: Cellular Physiology, 2nd ed., Springer, 2008.
- J. Keener and J. Sneyd, Mathematical Physiology II: Systems Physiology, 2nd ed., Springer, 2008.
- W.O. Kermack and A.G. McKendrick, A contribution to the mathematical theory of epidemics, Proc. R. Soc. Lond. Ser. A, Containing Papers Math. Phys. Charact. 115 (1927), pp. 700–721.
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics. II. The problem of endemicity, Proc. R. Soc. Lond. Ser. A, Containing Papers Math. Phys. Character 138 (1932), pp. 55–83.
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics. III. Further studies of the problem of endemicity, Proc. R. Soc. Lond. Ser. A, Containing Papers Math. Phys. Character 141 (1933), pp. 94–122Available at http://www.jstor.org/stable/96207
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics – i, Bull. Math. Biol. 53 (1991), pp. 33–55.
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics – II. the problem of endemicity, Bull. Math. Biol. 53 (1991), pp. 57–87.
- W.O. Kermack and A.G. McKendrick, Contributions to the mathematical theory of epidemics – III. further studies of the problem of endemicity, Bull. Math. Biol. 53 (1991), pp. 89–118.
- S. Kim, J.H. Byun, and I.H. Jung, Global stability of an SEIR epidemic model where empirical distribution of incubation period is approximated by Coxian distribution, Adv. Diff. Equ. 2019 (2019).
- D. Kirschner and J.C. Panetta, Modeling immunotherapy of the tumor -- immune interaction, J. Math. Biol. 37 (1998), pp. 235–252.
- Z. Komárková, Phase-type approximation techniques, Bachelor's Thesis, Masaryk University, 2012. Available at https://is.muni.cz/th/ysfsq/
- O. Krylova and D.J.D. Earn, Effects of the infectious period distribution on predicted transitions in childhood disease dynamics, J. R. Soc. Interface 10 (2013).
- A.L. Lloyd, The dependence of viral parameter estimates on the assumed viral life cycle: limitations of studies of viral load data, Proc. R. Soc. Lond. B: Biol. Sci. 268 (2001), pp. 847–854.
- A.L. Lloyd, Destabilization of epidemic models with the inclusion of realistic distributions of infectious periods, Proc. R. Soc. Lond. B: Biol. Sci. 268 (2001), pp. 985–993.
- A.L. Lloyd, Realistic distributions of infectious periods in epidemic models: changing patterns of persistence and dynamics, Theor. Popul. Biol. 60 (2001), pp. 59–71.
- A.L. Lloyd, Sensitivity of Model-Based Epidemiological Parameter Estimation to Model Assumptions, in Mathematical and Statistical Estimation Approaches in Epidemiology, G. Chowell, J.M. Hyman, L.M.A. Bettencourt, and C. Castillo-Chavez, eds., Springer, Netherlands, Dordrecht, 2009, pp. 123–141
- J. Ma and D.J.D. Earn, Generality of the final size formula for an epidemic of a newly invading infectious disease, Bull. Math. Biol. 68 (2006), pp. 679–702.
- N. MacDonald, Time Lags in Biological Models, Lecture Notes in Biomathematics, Vol. 27, Springer, Verlag Berlin Heidelberg, 1978.
- A.H. Marshall and S.I. McClean, Using coxian phase-Type distributions to identify patient characteristics for duration of stay in hospital, Health Care Manage. Sci. 7 (2004), pp. 285–289.
- A.H. Marshall and M. Zenga, Experimenting with the coxian phase-Type distribution to uncover suitable fits, Methodol. Comput. Appl. Probab. 14 (2010), pp. 71–86.
- K.S. McCann, Food Webs, Monographs in Population Biology (Book 57), Princeton University Press, 2011.
- C. McGrory, A. Pettitt, and M. Faddy, A fully Bayesian approach to inference for Coxian phase-type distributions with covariate dependent mean, Comput. Stat. Data Anal. 53 (2009), pp. 4311–4321.
- J.D. Meiss, Differential Dynamical Systems, Revised ed., Society for Industrial and Applied Mathematics, Philadelphia, PA, 2017.
- J.A.J. Metz and O. Diekmann, eds., The Dynamics of Physiologically Structured Populations, Lecture Notes in Biomathematics, Vol. 68, Springer, Berlin, Heidelberg, 1986.
- J. Metz and O. Diekmann, Exact finite dimensional representations of models for physiologically structured populations. I: The abstract formulation of linear chain trickery, in Proceedings of Differential Equations With Applications in Biology, Physics, and Engineering 1989, J.A. Goldstein, F. Kappel, and W. Schappacher, eds., Vol. 133, 1991, pp. 269–289
- W.W. Murdoch, C.J. Briggs, and R.M. Nisbet, Consumer–Resource Dynamics, Monographs in Population Biology , Vol. 36, Princeton University Press, Princeton, USA, 2003.
- J.D. Murray, Mathematical Biology: I. An Introduction, Interdisciplinary Applied Mathematics (Book 17), Springer, 2007.
- A. Nande, B. Adlam, J. Sheen, M.Z. Levy, and A.L. Hill, Dynamics of COVID-19 under social distancing measures are driven by transmission network structure, PLOS Comput. Biol. 17 (2021), p. e1008684.
- R.M. Nisbet, W.S.C. Gurney, and J.A.J. Metz, Stage Structure Models Applied in Evolutionary Ecology, in Applied Mathematical Ecology, S.A. Levin, T.G. Hallam, and L.J. Gross, eds., Springer, Berlin, Heidelberg, 1989, pp. 428–449
- C.A. O'Cinneide, On non-uniqueness of representations of phase-type distributions, Commun. Stat. Stoch. Models 5 (1989), pp. 247–259.
- C.A. O'Cinneide, Characterization of phase-type distributions, Commun. Stat. Stoch. Models 6 (1990), pp. 1–57.
- C.A. O'Cinneide, Phase-type distributions: open problems and a few properties, Commun. Stat. Stoch. Models 15 (1999), pp. 731–757.
- H. Okamura and T. Dohi, Mapfit: An R-Based Tool for PH/MAP Parameter Estimation, in Proceedings of the 12th International Conference on Quantitative Evaluation of Systems, J. Campos and B.R. Haverkort, eds., QEST 2015 Vol. 9259, New York, NY, USA. Springer-Verlag, New York, Inc., 2015, pp. 105–112
- T. Osogami and M. Harchol-Balter, Closed form solutions for mapping general distributions to quasi-minimal PH distributions, Perform. Eval. 63 (2006), pp. 524–552.
- R Core Team, A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria , 2020. Available at https://www.R-project.org/.
- P. Reinecke, L. Bodrog, and A. Danilkina, Phase-Type Distributions, in Resilience Assessment and Evaluation of Computing Systems, K. Wolter, A. Avritzer, M. Vieira, and A. van Moorsel, eds., Springer, Berlin, Heidelberg, 2012, pp. 85–113
- P. Reinecke, T. Krauß, and K. Wolter, Cluster-based fitting of phase-type distributions to empirical data, Comput. Math. Appl. 64 (2012), pp. 3840–3851.
- M. Renardy, M. Eisenberg, and D. Kirschner, Predicting the second wave of COVID-19 in washtenaw county, MI, J. Theor. Biol. 507 (2020), p. 110461.
- S.I. Resnick, Adventures in Stochastic Processes, Birkhäuser, Boston, 2002.
- J. Rizk, K. Burke, and C. Walsh, On the Non-uniqueness of Representations of Coxian Phase-Type Distributions (2019). arXiv:1901.03849v2
- S.L. Robertson, S.M. Henson, T. Robertson, and J.M. Cushing, A matter of maturity: to delay or not to delay? continuous-time compartmental models of structured populations in the literature 2000-2016, Nat. Resour. Model. 31 (2018), pp. e12160.
- M.L. Rosenzweig and R.H. MacArthur, Graphical representation and stability conditions of predator-prey interactions, Am. Nat. 97 (1963), pp. 209–223.
- R. Sachs, L. Hlatky, and P. Hahnfeldt, Simple ode models of tumor growth and anti-angiogenic or radiation treatment, Math. Comput. Model. 33 (2001), pp. 1297–1305.
- H.M.T. Samuel Karlin, A First Course in Stochastic Processes, 2nd ed., Academic Press, 1975.
- H. Smith, An Introduction to Delay Differential Equations with Applications to the Life Sciences, Vol. 57, Springer Science & Business Media, 2010.
- K. Soetaert, T. Petzoldt, and R.W. Setzer, Solving differential equations in R: package deSolve, J. Stat. Softw. 33 (2010), pp. 1–25Available at http://www.jstatsoft.org/v33/i09
- W.J. Stewart, Introduction to the Numerical Solution of Markov Chains, Princeton University Press, Princeton, NJ, 1994.
- S.H. Strogatz, Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering, Studies in Nonlinearity, 2nd ed., Westview Press, 2014.
- X. Tang, Z. Luo, and J.C. Gardiner, Modeling hospital length of stay by Coxian phase-type regression with heterogeneity, Stat. Med. 31 (2012), pp. 1502–1516.
- E. Vatamidou, I. Adan, M. Vlasiou, and B. Zwart, On the accuracy of phase-type approximations of heavy-tailed risk models, Scand. Actuar. J. 2014 (2012), pp. 510–534.
- S. Venturini, F. Dominici, and G. Parmigiani, Gamma shape mixtures for heavy-tailed distributions, Ann. Appl. Stat. 2 (2008), pp. 756–776.
- T. Vogel, Systèmes déferlants, systèmes héréditaires, systèmes dynamiques, in Proceedings of the International Symposium Nonlinear Vibrations, IUTAM, Kiev, 1961, pp. 123–130
- T. Vogel, Théorie des Systèmes Évolutifs, no. 22 in Traité de physique théorique et de physique mathématique, Gauthier-Villars, Paris, 1965
- X. Wang, Y. Shi, Z. Feng, and J. Cui, Evaluations of interventions using mathematical models with exponential and non-exponential distributions for disease stages: the case of ebola, Bull. Math. Biol. 79 (2017), pp. 2149–2173.
- H.J. Wearing, P. Rohani, and M.J. Keeling, Appropriate models for the management of infectious diseases, PLOS Med. 2 (2005).
- S. Wiggins, Introduction to Applied Nonlinear Dynamical Systems and Chaos, 2nd ed., Texts in Applied Mathematics, Vol. 2, Springer-Verlag, New York, 2003.
- J. Xia, Z. Liu, R. Yuan, and S. Ruan, The effects of harvesting and time delay on predator-prey systems with holling type II functional response, SIAM J. Appl. Math. 70 (2009), pp. 1178–1200.
- C.A. Yates, M.J. Ford, and R.L. Mort, A multi-stage representation of cell proliferation as a Markov process, Bull. Math. Biol. 79 (2017), pp. 2905–2928.