Abstract
The Digital Earth concept has attracted much attention recently and this approach uses a variety of earth observation data from the global to the local scale. Imaging techniques have made much progress technically and the methods used for automatic extraction of geo-ralated information are of importance in Digital Earth science. One of these methods, artificial neural networks (ANN) techniques, have been effectively used in classification of remotely sensed images. Generally image classification with ANN has been producing higher or equal mapping accuracies than parametric methods. Comparative studies have, in fact, shown that there is no discernible difference in classification accuracies between neural and conventional statistical approaches. Only well designed and trained neural networks can present a better performance than the standard statistical approaches. There are, as yet, no widely recognised standard methods to implement an optimum network. From this point of view it might be beneficial to quantify ANN's reliability in classification problems. To measure the reliability of the neural network might be a way of developing to determine suitable network structures. To date, the problem of confidence estimation of ANN has not been studied in remote sensing studies. A statistical method for quantifying the reliability of a neural network that can be used in image classification is investigated in this paper. For this purpose the method is to be based on a binomial experimentation concept to establish confidence intervals. This novel method can also be used for the selection of an appropriate network structure for the classification of multispectral imagery. Although the main focus of the research is to estimate confidence in ANN, the approach might also be applicable and relevant to Digital Earth technologies.
1. Introduction
All of today's key sciences—life sciences, nano sciences, information technology and environmental sciences depend heavily on imaging technologies of various kinds. Ever since the first images of our planet Earth became available, earth observation has contributed greatly to the development of the information society. The vigorous development of Earth observation technology is an indispensable basis for Digital Earth (DE), which is an internationally adopted concept (Chen and Guo Citation2000). DE, sometimes known as ‘Virtual Earth’, is a large open and complex system, and can fully utilise the huge amount of spatial and temporal information in areas of earth observation, natural resources, ecological environment, and social economy. It is designed as a virtual three-dimensional (3D) digital resources platform and information resources exploitation and utilisation environment by means of integrating and combining all kinds of data, information and knowledge. The DE approach uses a variety of earth observation data and the first phase of DE is to extract the relevant data from the earth observation imagery. The imagery and the metadata associated with it, form the input for the next phase, namely the extraction of meaningful information. Extracting relevant information from these huge data archives involves a number of technologies which are all undergoing rapid advancement (Shupeng and van Genderen Citation2008). These include, object-oriented image classification, graphical information analysis, geo-statistical analysis and data mining. In this respect soft computing techniques (fuzzy logic, neural networks, etc.) can contribute to the advancement of DE technology and be treated within this framework.
Much effort has been carried out into the automation of land cover mapping from remotely sensed information. The mapping of land cover by remote sensing is potentially one of the most important applications of modern satellite sensor technology. Various methods exist for distinguishing land cover types in imagery, ranging from simple image analysis measurements to more sophisticated structural definitions. One method which shows great potential in this area is that of neural networks. Artificial neural networks, computational systems inspired by the human brain, could be defined as a collection of interconnected simple computational units that work together cooperatively to solve linear and nonlinear problems. They have been used in many different application areas such as vector quantisation, speech recognition and pattern recognition. Unlike statistically based pattern recognition classifiers, ANNs require no assumption regarding the statistical distribution of the input pattern classes, and they are relatively noise tolerant and entail a massively parallel structure. ANNs are capable of handling non-normality, nonlinearity and collinearity in a system (Haykin Citation1994). The use of ANNs has become popular owing to their unique advantages of a non-parametric nature, arbitrary decision boundary capabilities and ability to handle noisy data. On the other hand, ANNs have some drawbacks, such as long training time requirements, determination of the most efficient network structure for a particular problem and inconsistent results due to the initial weights and learning parameters. An ANN is defined by an assemblage of ‘neurons’, a protocol for the way the neurons are networked, organised, weighted and connected, and a learning rule. An ANN is typically composed of an input layer, one output layer and one or more hidden layers. The system ‘learns’ by predicting output data from patterns learned from a set of input training data. By comparing the current output layer to a desired output response, the difference between the two can be obtained and used to adjust weights within the network. The goal is to achieve a set of weights that produce results that closely resemble the target output. This adaptive learning process is repeated until the difference between predicted and training values drop below a predetermined threshold of user-defined accuracy (Richard and Lippmann Citation1991, Jensen et al. Citation1999).
There are many examples of the use of ANNs in remote sensing, including many studies that illustrate the ability of ANNs to generalise. ANNs are particularly attractive for supervised classification. The use of ANNs to classify remotely sensed data has often resulted in a higher or equal mapping accuracy than that achieved with traditional classification methodologies (Benediktsson et al. Citation1990, Foody et al. Citation1995, Paola and Schowengerdt Citation1995, Arora and Foody Citation1997, Atkinson et al. Citation1997, Mills et al. Citation2006). More particularly, ANNs incorporating supervised training algorithms such as feed-forward back-propagation networks are capable of distinguishing interesting features from voluminous and noisy data sets having distorted patterns. One of the most commonly used ANNs in remote sensing is the multi-layer perceptron (MLP) trained via backpropagation (Rumelhart et al. Citation1986, Bishop Citation1995, Ripley Citation1996). Typically, each input neuron represents one band of imagery, and the number of output nodes corresponds to the number of information classes. The MLP is attractive for thematic mapping applications. There are, however, problems with the use of a MLP for supervised image classification (e.g. it is difficult to incorporate prior information and the MLP network can make unjustifiable extrapolations). Some of the problems with the MLP neural network may be reduced by pre- and post- classification processing analyses (Foody Citation1996, Foody Citation2001, Ingram Citation2005). ANN modelling has gained in popularity after the creation of the backpropagation (BP) training algorithm, by generalising the Widrow–Hoff learning rule to multiple-layer networks and nonlinear differentiable transfer functions. BP allows supervised mapping of input vectors and corresponding target vectors. Many BP variants have since been proposed to accelerate the updating of MLP weights and biases, while attempting to avoid convergence to a suboptimal local minimum (Rumelhart et al. Citation1986, Jang et al. Citation2006). The use of ANNs is complicated, basically due to problems encountered in their design and implementation. From the design perspective, the specification of the number and size of the hidden layer(s) is critical for the network's capability to learn and generalise. A further difficulty in the use of MLPs is the choice of appropriate values for network parameters that have a major influence on the performance of the learning algorithm. Finding an optimal network is therefore not an easy task, considering the uniqueness of each problem. The use of ANNs can be more complex than statistical classifiers, because of the problems related to their design and implementation. The performance of an ANN depends on its architecture and on the method of presenting the data and carrying out the training. Although an ANN correctly implemented generally presents a better performance than the standard statistical approaches, a network incorrectly designed or trained gives poorer results than standard methods such as the maximum likelihood method. Recent research indicated that there has been no real improvement in classification accuracy over the last decade, and that there is no discernible difference in classification accuracies between neural and non-neural approaches, considering classification results (Mas and Flores Citation2008). Furthermore, the superiority of the ANN approach is therefore not evident as expected and a deeper examination is required. Although much experience has been gained in the use of ANNs for remotely sensed imagery, trials oriented to the desired task are still needed before using them routinely. From this point of view it might be beneficial to assess the reliability of trained networks. When the reliability of a trained ANN is determined it might be possible to select appropriate network architure(s) from the other probable ones trained as extensive trial runs.
A reliable and practical measure of prediction confidence for neural networks is essential in real-world applications. In pattern recognition applications one is not only interested in the performance of a pattern classifier but also in the reliability of such a classifier. However, there is no systematic way of establishing reliability measure of a neural network a priori. Nonetheless, for an ANN to be useful in classification problems there might be a means of quantifying its reliability. An interesting point therefore is to define a reliability measure that still works in cases of sub-optimally trained networks. To measure the reliability of the neural network output is of importance. It is usually desirable that some form of confidence bound is placed on the output of a neural network. The problem of confidence bound estimation has been studied recently for prediction problems (Ruck et al. Citation1990, Kanaya and Miyake Citation1991, Chryssolouris et al. Citation1996, Rojas Citation1996, Shao et al. Citation1997, Hwang et al. Citation1997, De Veaux et al. Citation1998, Lawrence et al. Citation1998, Arslan Citation2001). The confidence estimation methods rely on a number of assumptions for accurate estimation, i.e. the network must be large enough and training must find a global minimum, infinite training data is required, and the a priori class probabilities of the test set must be correctly represented in the training set. Therefore it is difficult to choose the right method for a particular ANN application. The existing confidence estimation methods have surprisingly not been evaluated for image classification in remote sensing in the literature. Thus, a relatively simple algorithm based on statistical theory is developed to evaluate the performance of confidence estimation and to reveal the behaviours of the estimation in image classification in this study. The approach taken in the algorithm is to follow a binomial experimentation concept in order to establish confidence intervals on the accuracy of the ANN's approximations.
The main focus of the study is to develop an estimation scheme for reliability of ANNs and to find appropriate network structure(s) from the other trained networks on the basis of this ‘reliability information’ in multispectral imagery. The study does not aim to develop a method for designing an optimum ANN structure, but to improve a confidence estimation method to evaluate the reliability of trained networks in multispectral image classification. The outline of the paper is as follows. First the problem of confidence in neural networks will be introduced. The next section is dedicated to the concept of confidence intervals. In the following section the application of the proposed method for confidence estimation on an image classification is presented. The paper ends with conclusions and some remarks.
2. Confidence and confidence estimation
Feedforward neural networks are used widely in real-world regression and classification tasks. ANN predictions suffer uncertainty due to inaccuracies of the training data and to the limitations of the model. Truly reliable neural prediction systems require the prediction to be qualified by a confidence measure. So, a reliable and practical measure of prediction ‘confidence’ is essential in ANN applications. When a trained neural network classifies an unlabelled object, the operator would like to know what confidence one should have in the classification (Papadopoulos et al. Citation2001, Yang et al. Citation2002,). Much has been published about the overall error rate for a discriminant function, but here the aim is to estimate the probability that a certain classification is correct. The confidence of a classification can be estimated using different methods and in different layers of the network.
The confidence and its corresponding estimator should be introduced. Given a certain network the confidence can be defined as
2.1. Confidence bound estimation
The problem of confidence bound estimation has been studied recently for prediction problems. A few methods are now available and some theories have been developed. It is commonly assumed that the ANN satisfies the nonlinear regression model
From now on, we can estimate the confidence interval straightforwardly. The existing confidence bound (or confidence interval) estimation methods are asymptotically valid when the number of training points goes to infinite (Hwang et al. 1997). It is assumed that the model errors are independent and normally distributed with zero means, there is no observation error and the neural network is trained to convergence. In reality these assumptions are rarely satisfied. Neural network predictions suffer uncertainty due to inaccuracies in the training data and limitations of the model. The training set is typically noisy and incomplete. Moreover, the limitations of the model and the training algorithm introduce further uncertainty to the network's prediction. These two uncertainty sources are assumed to be independent and the total prediction variance is given by the sum of their variances. Confidence estimation must take into account both sources.
Additionally, a commonly encountered problem in feedforward neural network classification problems is related to the prior probabilities of the individual classes if the number of training examples that correspond to each class varies significantly between the classes, then it may be harder for the network to learn the rarer classes in some cases. Such practical experience does not match theoretical results which show that MLPs approximate Bayesian a posteriori probabilities (independent of the prior class probabilities) (Lawrence et al. Citation1998). As mentioned earlier, the behaviours of the estimated confidence bounds are not well understood when these assumptions are violated. It is therefore complicated for choosing the right method for a particular ANN application.
After introducing the general concept of estimating confidence for neural networks an easy to implement method should be developed for classification applications with ANN. From the above considerations there is a requirement for establishing a practical confidence estimation method for an ANN to be useful in multispectral image classification. Hence, this study investigated the suitability and potential of the new method for estimation. In view of the complicated features of existing confidence estimation methods a slightly different approach will be adopted in the study. Using the relatively simple method one is able to give an estimation of a confidence value for a classification process of remotely sensed images.
3. The proposed method
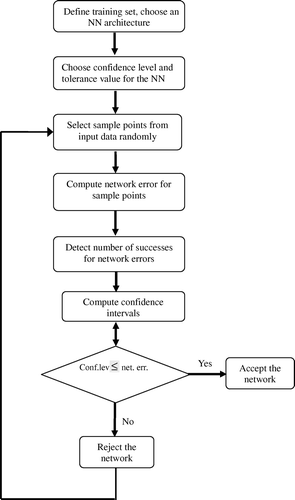
For an ANN to be used in classification of remotely sensed images, a method for quantifying the reliability of the trained neural network should be developed. To this end, a practical algorithm based on statistical theory is proposed and presented in this paper. The approach taken in the algorithm is to follow a binomial experimentation concept in order to establish confidence intervals on the accuracy of the ANN's classifications. Using the data in the training set an acceptable tolerance level for the approximation error can be defined and then network error at any point in the design space be compared with the specified tolerance level. Either the network error in the data is greater than the tolerance level or not. Here, a statistical approach (or algorithm) is recommended based on the binomial distribution.
Suppose that n trials have been carried out where for every trial the network error is simulated for each input point and the trial is considered a success if the network is greater than the tolerance level and failure if it is not. A (1–α) 100% confidence interval for the binomial parameter p (the probability of success) is approximately
Now with the aid of these theorems, a method is recommended to train feed forward neural networks for image classification with quantified degree of accuracy, given a confidence level. The algorithm can be summarised briefly as follows:
First, an initial training set (training sites in the image) is defined. Second a feedforward network architecture with a hidden layer is chosen. Then, the selected network is trained using appropriate network parameters until convergence is achieved. Recognising the fact that the initial values of the weights may influence the results significantly the NN structure is trained with different initial conditions (weights, learning parameters). As it is difficult to find the optimal topology the selected NN is trained with several runs. Once the network is well trained and verified, the method for confidence estimation proposed in this study should be applied: a confidence level α for the network accuracy and a desired tolerance for the network error is chosen. The tolerance value is the acceptable difference between the ANN's output and the corresponding exact value for the classification at any point. The exact values are obtained from known classes in the image. Next, a tolerance level for the probability of the network exceeding the desired error tolerance is specified. Then, n samples (or trials for binomial experiments) of the network error are taken by randomly choosing (n) points in the input space and computing the network error for each of the points. (Note that none of the n points should be in the initial training set.) After that, trial success as the network error exceeding the desired tolerance is defined and the number of successes (m) in the n trials above are counted. Then, the probability of success (sample proportion) is computed as
. End then, upper and lower limit of confidence level on the probability of the network error exceeding the desired tolerance can be computed from Equation (Equation9). If the tolerance level chosen before is greater than the computed confidence level, then the neural network will be accepted (as reliable). From then we might decide whether the designed network architecture is accepted or not. The procedure should be repeated on different network architectures (number of hidden layer and nodes in the hidden layers) until a suitable network is achieved ().
Figure 1. The flow chart of the method.
4. Application of the algorithm
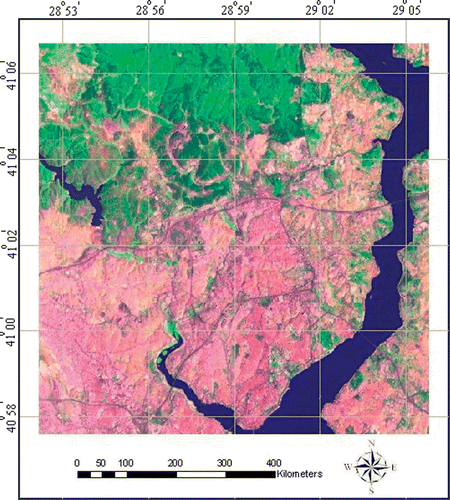
In this study, a multispectral data set (imagery) consisting of five bands with spectra ranging from 0.45 µm to 1.75 µm was used for automatic land-cover classification. To train the network, we picked points from the imagery itself, generating a training set consisting of seven categories. The image data consisted of the five bands of a Landsat TM scene of Istanbul acquired on 9 September 1992, with five bands at wavelengths 0.45–0.52, 0.52–0.60, 0.63–0.69, 0.76–0.90 and 1.55–1.75 µm. Ground resolution on the image is 30m pixels. The Landsat TM scene (512×512 pixels) was used as an example. Small image subareas of known classification have been selected as the training site needed by the ANNs ().
Figure 2. The image data used for ANN classification: Lansat TM scene of Istanbul.
The data set of the training site was divided into training data and validation data (separate datasets), consisting of 31 574 pixels and 15 787 pixels respectively for the classification. The purpose of the ANN application was to classify each pixel of the original image into one of the seven categories: forestry, woodland, bareland, road, sparse (urban) residential, dense residential and water. In the classification ground reference information for classes were taken into consideration. Map validation was also necessary to get an indication of how well the ANN was classifying land cover. Topographical maps (1:50 000 and 1:25 000 in scale), local knowledge and field excursions were used in combination to determine actual land cover types. Feedforward neural network structures were constructed in the study. The networks had an input unit for each of the selected wavebands of Landsat data and seven output units, one associated with each category. The number of output nodes is dependent upon the number of land-cover classes in the classification scheme. In this study, the output layer consisted of seven nodes, one for each class. Three bands (5, 4 and 1) were selected to reduce the size of the data set with minimum loss of original information in order to facilitate data handling and processing. Input into the neural network consisted of the three bands (i.e. 5, 4 and 1). Then entire image is fed into the network pixel-by-pixel. In this study, network architectures with one and two hidden layers were examined. In both of the cases described above, output layer consisting of seven neurons; that is, vectors of dimension 7 ().
Figure 3. Feedforward neural network structure used.
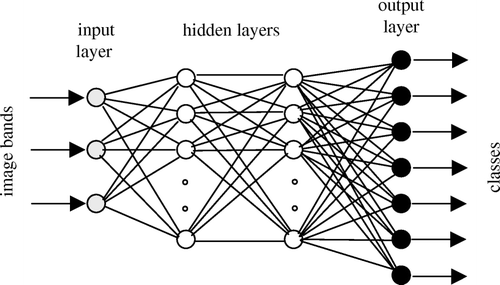
Feedforward neural networks with one and two hidden layers were designed to estimate confidence for land-cover classification. The number of hidden nodes were in the range from 3 to 30 in the network structures. The networks were initialised with three hidden nodes and increased one by one. It is worthwhile to note that increasing the number of hidden nodes increases the risk of overfitting. There is no universally practical rule concerning the optimum network structure. Most applications apply extensive and time-intensive trial and error tests to determine the optimal design (the number of hidden layers, the number of hidden neurons, etc.) for each study. There has been some recommendations on the number of hidden neurons in the literature but there is no guideline currently available to directly set up the ANN structure (Dunne and Campbell Citation1994, Miller et al. Citation1995, Atkinson et al. Citation1997, Kanellopoulos and Wilkinson Citation1997). As previously mentioned designing optimal network structure is not the main focus of the study. As it is difficult to find the optimal network topology for a particular problem a trial-and-error strategy was used. The Stuttgart Neural Network Simulator (SNNS), developed Stuttgart University, Germany, was chosen to implement the ANN models. Each of the neural networks was trained with a stochastic backpropagation algorithm. Generally, in setting the training processes, initial weights are set to a small range (e.g. −0.2 to 0.2), the learning rate is set to around 0.2, the momentum term is set to the range of (0.6 to 0.9). A validation data set was employed to determine the epoch at which the network can perform best generalisation capabilities. The activation function was the hyperbolic tangent function leading to quicker convergence. ANN parameter combinations were changed after a certain number of iterations during training implementation. It is worth noting that selected neural networks were trained with different random starting weights and learning parameters. Therefore several runs were employed for each NN structure. The ‘best’ NN structure which gives the optimal results is determined and retained for estimating of confidence intervals.
After the network structures trained and tested, the confidence estimation method proposed was carried out on these neural networks. The networks were designed to have a 95% confidence level that the probability of its approximation exceeding 5% error level would be no greater than 5%. Following our statistical approach some feasible test points were chosen randomly. Note that these points are used for binomial sampling and not for the standard ANN ‘training’ or ‘testing’. The term ‘test’ or ‘sample’ should not be mixed with the known standard terms for neural networks (e.g. validation set, test set). For each test point the output of the neural network was compared with the true output (known classes) values. Then confidence intervals were computed for the points related to the network architecture as explained above. This procedure was repeated for all network structures. Thus, according to the results obtained the designed network architecture was accepted or not. A section of the estimation results for the neural network architectures are given in .
Table 1. The computation of confidence intervals for the network structures chosen with a confidence level 95% and the network error level 0.05.
The first network structure is denoted by (3:4:7), which has an input layer of dimension (neurons) 3, a hidden layer of dimension 4 and an output layer of dimension 7 in this table. After the network(s) trained appropriately and its confidence level specified, the knowledge of image classification was derived. Finally, accuracy assessment for image classification was performed for the accepted (or found as reliable) network structures. Generally, in remote sensing the performance of image classification methods is analysed using error (or confusion) matrices and kappa statistics. The most important criterion for performance evaluation is the overall accuracy, which is defined as the ratio between the number of correctly assigned test data and their total number. In addition, the Kappa coefficient, which is another measure of agreement between reference and classified data, is used. Presently, the Kappa coefficient is expressed by the Khat statistic calculated from both correct and incorrect assignments (Congalton and Green Citation1999, Congalton Citation2001). The Khat statistic is typically scaled between 0, which indicates complete disagreement between assignment and reference data, and 1, which indicates complete agreement. Producer's accuracy measures omission error and it is computed as the number of pixels correctly identified for a class divided by column total in error matrix. User's accuracy measures commission error and it is computed as the number of pixels correctly identified for that class divided by row total. Among the architectures found reliable, accuracy assessment for the neural network structure (3:3:16:7) which is yielded the highest classification accuracy is shown in .
Table 2. Accuracy assessment of the neural network classification (for NN 3:3:16:7).
This architecture gave the overall accuracy of 94.4%. The classification revealed that in general good classification was achieved over the areas covered with water, bareland, forest and road. It can obviously be seen from the producer's accuracy values in the table. Examination of the table showed that a slightly lower accuracy was achieved for the regions with residential areas. The reason of this result might be attributed to relatively poor selection of the training areas. It should however be stated that the NN image better reflected the actual distribution of classes in the original image. Although several previous studies have used and adopted the ANN structure with single hidden layer, the networks with two hidden layers gave similar results in this study. This result is not surprising as it is known that a network with two hidden layers may solve some problems much more efficiently than a network with only one hidden layer. Although the majority of the ANNs are based on a single hidden layer MLP some authors have reported the use of network with two hidden layers in land cover classification (Civco Citation1993, Dreyer Citation1993, Jensen et al. Citation1999, Kontoes et al. Citation2000, Frizelle and Moody Citation2001, Paul et al. Citation2004, Aitkenhead and Aalders Citation2008). Examination of showed that the networks found to be reliable were those with two hidden layers. The accepted network structures are denoted as writing with bold type in the table. The network structures marked as bold can be considered as reliable and used for classification confidently. Thus a practical method was successfully applied to estimate confidence bounds for feedforward neural networks in image classification. This method should be viewed as a novel approach to assess the reliability of networks and an improvement way of specifying the suitable network structure(s) that could be used for multispectral imagery.
5. Conclusion
Because remotely sensed imagery is of crucial importance in DE, automation of image analysis methods can contribute to the development of the DE framework and related technologies. ANN technique should be viewed as such a computational method for automatic extraction of geo-related information needed in DE. The advent of such kinds of analysis methods can positively affect the operational phases of DE technology. The presented methodology in this paper might be regarded as an improvement for image-based analysis. Although the research described in the paper relate mainly to estimate confidence in ANN, the approach may also be relevant to DE technologies. The effectiveness of a statistical sampling-based confidence estimation method for ANNs is investigated for multispectral image classification. A relatively simple method is proposed to select network topology based on confidence estimation. The methodology presented in the paper addressed the confidence estimation problem in terms of allowing the design of neural networks to a specific level of accuracy, for a given statistical confidence level. Following the algorithm based on statistical sampling theory one can compute the confidence intervals for the trained neural networks efficiently in image classification. Using the reliability information the appropriate network structures can confidently be determined. This alternative approach may be considered as a reliable and practical method for estimating confidence in neural networks used for classification of remotely sensed images. The method proposed appears to have potential for future studies.
Notes on the contributor
Ozan Arslan graduated from Geodesy and Photogrammetry Engineering Department in Istanbul Technical University (ITU), Turkey, in 1990. From 1990 to 1993 he worked as a research assistant in the Photogrammetry Division. He received a MSc degree on Geographic Information Systems in the Institute of Science and Technology (ITU) in 1993. He received his PhD degree at the same institute on analysis of artificial neural networks in image classification. Since 2003 he has been Assistant Professor in Geodesy and Photogrammetry Engineering Department in Kocaeli University, Kocaeli. Currently his main research interests are photogrammetry, remote sensing, artificial neural networks, image processing, geographic information systems, parameter estimation and multivariate statistical analysis.
Related Research Data
References
- Agresti , A. and Coull , B.A. 1998 . Approximate is better than ‘exact’ for interval estimation of binomial proportions . The American Statistician , 52 ( 2 ) : 119 – 126 .
- Aitkenhead , M.J. and Aalders , I.H. 2008 . Classification of Landsat Thematic Mapper imagery for land cover using neural networks . International Journal of Remote Sensing , 29 ( 7 ) : 2075 – 2084 .
- Arora , M.K. and Foody , G.M. 1997 . Log-linear modelling for the evaluation of the variables affecting the accuracy of probabilistic, fuzzy and neural network classifications . International Journal of Remote Sensing , 18 : 785 – 798 .
- Arslan , O. , 2001 . Analysis and optimisation of artificial neural networks for image classification . Thesis (PhD) Istanbul Technical University , The Institute of Science and Technology Turkey . In Turkish .
- Atkinson , P.M. , Cutler , M.E.J. and Lewis , H.G. 1997 . Mapping sub-pixel proportional land cover with AVHRR imagery . International Journal of Remote Sensing , 18 : 917 – 935 .
- Atkinson , P. M. and Tatnall , A. R. L. 1997 . Introduction Neural networks in remote sensing . International Journal of Remote Sensing , 18 ( 4 ) : 699 – 709 .
- Benediktsson , J.A. , Swain , P.H. and Ersoy , O.K. 1990 . Neural network approaches versus statistical methods in classification of multisource remote sensing data . IEEE Transactions on Geosciences and Remote Sensing , 28 : 540 – 551 .
- Bishop , C.M. 1995 . Neural networks for pattern recognition , Oxford : Clarendon Press .
- Brown , L.D. , Cai , T.T. and Dasgupta , A. 2001 . Interval estimation for a binomial proportion . Statistical Science , 16 ( 2 ) : 101 – 133 .
- Chryssolouris , G. , Lee , M. and Ramsey , A. 1996 . Confidence intervals prediction for neural network models . IEEE Transactions on Neural Networks , 7 : 229 – 232 .
- Chen , S.P and Guo , H.D. 2000 . Digital Earth and Earth Observation . Acta geographica sinica , 55 : 9 – 14 .
- Civco , D.L. 1993 . Artificial neural networks for land-cover classification and mapping . International Journal of Geographical Information Systems , 7 : 173 – 186 .
- Congalton , R.G. and Green , K. 1999 . Assessing the Accuracy of Remotely Sensed Data: Principles and Practices , Washington : Lewis Publishers .
- Congalton , R.G. 2001 . Accuracy assessment and validation of remotely sensed and other spatial information . International Journal of Wildland Fire , 10 ( 4 ) : 321 – 328 .
- De Veaux , R.D. , Schumi , J. , Schweinsberg , J. and Ungar , L. H. 1998 . Prediction intervals for neural networks via nonlinear regression . Technometrics , 40 ( 4 ) : 273 – 282 .
- Dreyer , P. 1993 . Classification of land cover using optimized neural nets on SPOT data . Photogrammetric Engineering and Remote Sensing , 59 : 617 – 621 .
- Dunne , R.A. and Campbell , N.A. 1994 . Some practical aspects of pruning multi-layer perceptron models applied to remotely sensed data Technical Report 94/06 . Murdoch University
- Dybowski , R. and Roberts , S. 2001 . “ Confidence intervals and prediction intervals for feed-forward neural networks ” . In Clinical Applications of Artificial Neural Networks , Edited by: Dybowski , R. and Gant , V. 298 – 326 . Cambridge : Cambridge University Press .
- Foody , G.M. , Mcculloch , M.B. and Yates , W.B. 1995 . Classification of remotely sensed data by an artificial neural network: issues related to training data characteristics . Photogrammetric Engineering and Remote Sensing , 61 : 391 – 401 .
- Foody , G.M. 1996 . Relating the land-cover composition of mixed pixels to artificial neural network classification output . Photogrammetric Engineering and Remote Sensing , 62 ( 5 ) : 491 – 499 .
- Foody , G.M. 2001 . Thematic mapping from remotely sensed data with neural networks: MLP, RBF and PNN based approaches . Journal of Geographical Systems , 3 : 217 – 232 .
- Frizzelle , B.G. and Moody , A. 2001 . Mapping continuous distributions of land cover: a comparison of maximum-likelihood estimation and artificial neural networks . Photogrammetric Engineering and Remote Sensing , 67 : 693 – 705 .
- Haykin , S. 1994 . Neural networks: A comprehensive foundation , Upper Saddle River, NJ : Prentice Hall .
- Heskes , T. 1997 . Practical confidence and prediction intervals . Advances in Neural Information Processing Systems , 9 : 176 – 182 .
- Hoekstra , A. , Tholen , S.A. , and Duin , P.W. , 1996 . Estimating the Reliability of Neural Network Classifications . International Conference on Artificial Neural Networks (ICANN) Proceedings , 16–19 July, Bochum, Germany . Lecture Notes in Computer Science, Springer 53 58 .
- Hwang , J.T. and Ding , A.A. 1997 . Prediction intervals for artificial neural networks . Journal of the American Statistical Association , 92 : 748 – 757 .
- Ingram , J.C. , Dawson , T.P. and Whittaker , R.J. 2005 . Mapping tropical forest structure in southeastern Madagascar using remote sensing and artificial neural networks . Remote Sensing of Environment , 94 : 491 – 507 .
- Jang , J.D. , Viau , A.A. , Anctil , F. and Bartholome , E. 2006 . Neural network application for cloud detection in Spot vegetation images . International Journal of Remote Sensing , 27 ( 4 ) : 719 – 736 .
- Jensen , J. R. , Qiu , F. and Ji , M. H. 1999 . Predictive modelling of coniferous forest age using statistical and artificial neural network approaches applied to remote sensor data . International Journal of Remote Sensing , 20 : 2805 – 2822 .
- Kanaya , F. and Miyake , S. 1991 . Bayes statistical behavior and valid generalization of pattern classifying neural networks . IEEE Transactions on Neural Networks , 2 ( 1 ) : 471
- Kanellopoulos , I. and Wilkinson , G.G. 1997 . Strategies and best practice for neural network image classification . International Journal of Remote Sensing , 18 ( 4 ) : 711 – 725 .
- Kontoes , C.C. , Raptis , V. , Lautner , M. and Oberstadler , R. 2000 . The potential of kernel classification techniques for land use mapping in urban areas using 5m-spatial resolution IRS-1C imagery . International Journal of Remote Sensing , 21 : 3145 – 3151 .
- Lawrence , S. , Burns , I. , Back , A. , Tsoi , A.C. and Giles , C.L. 1998 . Neural network classification and prior class probabilities, neural networks: Tricks of the trade . Berlin/Heidelberg : Springer 1524 (ISNN:0302–9743), 299–314 .
- Mas , J.F. and Flores , J.J. 2008 . The application of artificial neural networks to the analysis of remotely sensed data . International Journal of Remote Sensing , 29 ( 3 ) : 617 – 663 .
- Miller , D.M. , Kaminsky , E.J. and Rana , S. 1995 . Neural network classification of remote sensing data . Computers & Geosciences , 21 ( 3 ) : 377 – 386 .
- Mills , H. , Cutler , M.E.J. and Fairbairn , D. 2006 . Artificial neural networks for mapping regional-scale upland vegetation from high spatial resolution imagery . International Journal of Remote Sensing , 27 ( 11 ) : 2177 – 2195 .
- Nix , D.A. and Weigend , A.S. , 1994 . Estimating the mean and variance of the target probability distribution . In: Proceedings of the IEEE International Conference on Neural Networks (IEEE-ICNN'94) , Orlando, FL, USA Piscataway, NJ IEEE Press , 55 – 60 .
- Paola , J.D. and Schowengerdt , R.A. 1995 . A detailed comparison of backpropagation neural network and maximum-likelihood classifiers for urban land use classification . IEEE Transactions on Geosciences and Remote Sensing , 33 : 981 – 996 .
- Papadopoulos , G. , Edwards , P.J. and Murray , A.F. 2001 . Confidence Estimation Methods for Neural Networks: A Practical Comparison . IEEE Transactions on Artificial Neural Networks , 12 ( 6 ) : 1278 – 1287 .
- Paul , F. , Huggel , C. and Ka , A. 2004 . Combining satellite multispectral image data and a digital elevation model for mapping debris-covered glaciers . Remote Sensing of Environment , 89 : 510 – 518 .
- Qazaz , C. , 1996 . Bayesian error bars for regression . Thesis (PhD), Aston University, UK .
- Richard , M.D. and Lippmann , R.P. 1991 . Neural network classifiers estimate Bayesian a posteriori probabilities . Neural Computation , 3 ( 4 ) : 461 – 483 .
- Ripley , B.D. 1996 . Pattern recognition and neural networks , Cambridge : Cambridge University Press .
- Rojas , R. 1996 . A short proof of the posterior probability property of classifier neural networks . Neural Computation , 8 : 41 – 43 .
- Ruck , D.W. , Rogers , S.K. , Kabrisky , K. , Oxley , M.E. and Suter , B.W. 1990 . The multilayer perceptron as an approximation to an optimal Bayes estimator . IEEE Transactions on Neural Networks , 1 ( 4 ) : 296 – 298 .
- Rumelhart , D.E. , Hinton , G.E. and Williams , R.J. 1986 . “ Learning internal representation by error propagation ” . In Parallel Distributed Processing: Explorations in the Microstructure of Cognition , 318 – 362 . Cambridge, MA : MIT Press .
- Shao , R. , Martin , E.B. , Zhang , J. and Morris , A. J. 1997 . Confidence bounds for neural network representations . Computers & Chemical Engineering , 21 : 1173 – 1178 .
- Shupeng , C. and van Genderen , J. , 2008 . Digital Earth in support of global change research . International Journal of Digital Earth , 1 (1) , March , 43 – 65 .
- Tibshirani , R. 1996 . A comparison of some error estimates for neural network models . Neural Computation , 8 : 152 – 163 .
- Yang , L. , Kavli , T. , Carlin , M. , Clausen , S. , and De Groot , P.M. , 2002 . An evaluation of confidence bound estimation methods for neural networks . In: H.-J. Zimmermann Advances in Computational Intelligence and Learning: Methods and Applications 71 84 , Kluwer Academic Publishers (Premier version in Proc. European Symp. Intelligent Techniques, 322–329, Aachen, Germany, Sept. 2000.)